《SRE:Google 运维解密》读书笔记08: Google 的自动化系统的演进 - 当“琐事”遇上“自动化”
本文摘要:Google SRE方法论强调自动化是减少琐事的核心解决方案,但其本质是"元软件"而非万能药。自动化演进路径分为五个阶段:从手工操作到系统自治,最终目标是实现无需人工干预的自治系统。自动化具有五大价值:一致性、平台性、快速修复、加速行动和节省时间。衡量自动化质量的三个维度是能力、延迟和相关性。实践中需警惕"专业化倾向",即自动化代码需要持续维护。安
作者: andylin02
学习章节:第7章 Google 的自动化系统的演进
关键词:自动化、系统自治、演进路径、Admin 服务器、力量倍增器、专业化倾向
一、引言:当“琐事”遇上“自动化”
前几章我们先后学习了“拥抱风险管理”“服务质量目标”“减少琐事”和“监控分布式系统”。如果把 SRE 方法论比作一座大厦,第5章的“琐事”就是地基下沉的裂缝,而第6章的“监控”就是墙上的烟雾探测器——前者提醒你有问题,后者帮助你发现问题的位置。
本章回答的问题正是:如何从根本上解决琐事?
答案就是自动化。但 Google 告诉我们的不是简单地“写几个脚本就算自动化了”,而是一整套关于自动化演进的系统方法论:自动化应该遵循怎样的演进路径?在什么阶段采用什么层次的自动化?如何避免自动化带来的新问题?以及自动化的终极目标是什么?
核心观点:对于 SRE 而言,自动化是一种力量倍增器,而不是灵丹妙药。对力量的倍增并不能改变力量用在哪的准确性,草率地进行自动化可能在解决问题的同时产生出同样多的问题。
二、核心观点速览
| 维度 | 核心要点 |
|---|---|
| 自动化的定义 | 自动化是“元软件”——操作其他软件的软件 |
| 自动化的价值 | 一致性、平台性、修复速度更快、行动速度更快、节省时间 |
| 演进路径 | 无自动化 → 外部维护特定 → 外部维护通用 → 内部维护 → 自治系统 |
| 自动化≠万能药 | 盲目自动化可能产生新问题;自治系统才是最终目标 |
| 安全演进 | 从 SSH + 脚本 → Admin 服务器 + RPC + ACL + 审计 |
| 终极目标 | 从“手动操作”和“软件自动化”进阶为“系统自治” |
三、详细内容拆解
3.1 为什么 Google 坚定选择自动化?
Google 的产品和服务是全球部署的,通常没有时间和其他组织一样手动维护系统。尽管 Google 在思想上倾向于尽可能使用机器管理机器,但实际情况需要一定的变通。
但 Google 也清醒地认识到:并不是实际情况下任何组件都是需要进行自动化的。比如某些 Demo 和一些快速原型并不需要长久运行,这些生命周期短暂的应用也并没有应对自动化做出相应的设计。
自动化的根本动因
-
规模倒逼:Google 的服务器以百万计,人工操作从物理上就不可能实现
-
琐事驱逐:如果 SRE 把时间花在重复性工作上,就无法投入到有长期价值的工程工作中
-
人为错误:没有人能像机器一样永远保持一致,手动执行数百次动作时,不可避免地会产生疏漏
-
SRE 50% 开发规则:SRE 团队必须将 50% 的精力花在真实的开发工作上,而自动化正是这个“开发工作”的核心组成部分
3.2 自动化的五大价值
书中详细阐述了自动化对 SRE 的价值,总结为以下五点:
价值①:一致性
一致性地执行范围明确、步骤已知的程序,是自动化的首要价值。传统系统管理员手动执行任务时,不可能保证每次都用同样的方式进行。这种不一致性会导致错误、疏漏、数据质量问题和可靠性问题。
实例:批量执行配置变更。人工在 1000 台机器上执行相同的命令,很难保证每台机器的执行顺序、时机和结果完全一致;而自动化工具可以精确地、幂等地完成这些操作。
价值②:平台性
自动化不仅仅提供一致性。通过正确地设计和实现,自动化系统可以提供一个可扩展的、广泛适用的平台。平台可以暴露自身的性能指标,也可以帮助你发现流程中以前所不知道的细节。
实例:一个自动化运维平台不仅能够执行运维任务,还能记录每次操作的结果、耗时、成功率等元数据,为后续的优化提供数据基础。
价值③:修复速度更快
在产品生命周期中一个问题越晚被发现,修复代价越高。自动化的自我修复能力可以极大缩短从故障发生到恢复的时间。
实例:MySQL 自动故障切换。传统场景中,DBA 收到告警后手动进行主从切换可能需要 10-30 分钟;自动化系统可以在几秒到一分钟内完成切换。
价值④:行动速度更快
自动化可以让人从重复无意义的事情中解脱出来,从而加速整体行动速度。自动化部署发布、自动运维拉起进程等都是典型例子。
价值⑤:节省时间
“如果我们持续产生不可自动化的流程和解决方案,我们就继续需要人来进行系统维护。如果我们要雇佣人来做这项工作,就像是在用人类的鲜血、汗水和眼泪养活机器。这就像是一个没有特效但是充满了愤怒的系统管理员的 Matrix 世界。”
实例:自动扩缩容、自动化中间件部署。将 SRE 从重复工作中解放,从而有更多精力去做更有价值的事情,如设计更可靠的架构、优化系统性能。
3.3 自动化演进路径:从手工操作到系统自治
这是本章最核心的内容。Google 将自动化演进划分为清晰的五个阶段:

阶段一:没有自动化
完全依赖人工手动操作。例如:运维人员在收到告警后,手动将数据库主进程在多个位置之间转移。
阶段二:外部维护的系统特定的自动化系统
SRE 在个人主目录中保存一份故障转移脚本,依赖脚本执行故障转移。
阶段三:外部维护的通用的自动化系统
将数据库支持添加到“通用故障转移”脚本中,团队中所有人都可以使用。
阶段四:内部维护的系统特定的自动化
自动化能力被内置到系统中。例如,数据库自己发布故障转移脚本,不依赖外部维护。
阶段五:不需要任何自动化的自治系统
这是终极目标。系统能够在注意到问题发生的情况下,在无须人工干预的情况下自动完成故障转移。
关键洞察:手动操作和软件自动化均非最优解,自治系统才是最终目标。自治系统并非“后期加自动化脚本”,而是在系统设计初期就融入“运维思维”。从手动到程序自动,从基础自动化到系统自治,反映出 SRE 的追求不止于“工具优化”,更在于“系统本质的升级”。
3.4 自动化程序的三个度量维度
自动化程序的质量可以从以下三个维度来衡量:
| 维度 | 含义 | 重要性 |
|---|---|---|
| 能力 | 自动化执行任务的准确性 | 决定自动化是否可靠 |
| 延迟 | 开始执行后,执行所有步骤所需的时间 | 决定故障恢复速度 |
| 相关性 | 自动化所涵盖的实际流程比例 | 决定自动化是否“够用” |
这三个维度相互关联。一个自动化程序可能在准确性上很好,但覆盖范围太小(相关性不足),无法真正减少人工干预;或者覆盖面广但延迟太高,在紧急场景下不实用。好的自动化需要在三者之间找到平衡。
3.5 自动化实践案例:MySQL 迁移到 Borg
书中以 MySQL 迁移到 Google 集群调度系统 Borg 为例,展示了自动化在实际工程中的应用:
-
启动阶段:将标准副本替换流程的常规工作最糟糕的部分自动化,但没有全部自动化
-
发现问题:将 MySQL 迁移到 Borg 下部署原型实例后,发现需要手动故障转移,无法满足高可用需求
-
深化自动化:开发了自动故障切换后台程序——“决策者”,实现快速的数据库故障转移流程
-
提升健壮性:在应用程序中增加大量错误处理逻辑
这个案例揭示了自动化演进的典型模式:从局部自动化到全覆盖自动化,从被动故障处理到主动故障预防。
3.6 案例:将自动化应用到集群上线
集群上线的痛点
一些服务有超过一百个不同的组件子系统,每一个都具有复杂的网状依赖。某个子系统的配置失败,或者没有按照其他集群来配置一个系统或组件,都会造成潜在的故障发生。
为了加速集群交付,大量采用 SSH 执行 Shell 脚本应对繁琐的包分发和服务初始化,但这些格式自由的 Shell 脚本会逐渐形成技术债务。
解决方案
Google 采用了以下策略:
-
使用 Prodtest(生产测试)检测不一致情况:类似单元测试,能指出哪些测试失败
-
幂等地解决不一致情况:修复程序可以周期性执行,而不会对集群配置造成损害
3.7 专业化倾向:自动化也需要维护
“自动化代码和单元测试代码一样,当维护团队不再关心它与覆盖的代码仓库同步的时候就会逐渐失效。”
这是一个非常重要的警示。自动化不是一劳永逸的:
-
系统不断演化,自动化代码需要随之更新
-
当团队频繁变动,自动化脚本可能无人维护
-
“专业化倾向”指的是:当自动化工具/代码的维护责任被移除出核心团队职责时,它就会逐渐失效
启发:任何自动化都应该有明确的“所有者”和定期维护机制,否则它会逐渐变成“另一种技术债务”。
3.8 从 SSH 到 Admin 服务器:安全自动化的演进
许多分布式自动化依赖于 SSH。从安全角度来看,这是笨拙的,因为人们必须拥有机器的 root 权限才能运行大多数命令。Google 用一个支持认证、ACL 驱动,以及基于 RPC 的本地管理进程来取代 sshd,这被称为 Admin 服务器,它拥有本地执行更改的权限。
Admin 服务器的核心价值:
-
最小权限原则:没有人可以绕过审计跟踪来安装或修改服务器
-
代码评审把关:对 Admin 服务器代码和 Package 仓库的修改通过代码评审来把关,越权操作非常困难
-
完整审计:Admin 服务器会记录 RPC 请求者、全部参数以及所有 RPC 的结果,以提高调试和安全审计功能
启示:从 SRE 在自己的主目录里维护 Shell 脚本,到构建评审过的 RPC 服务器与细粒度的 ACL 上,实现了最小权限的 SRE,以及完整的审计过程。这也是从“个人脚本”(阶段二)到“平台化自动化”(阶段四)的典型安全演进路径。
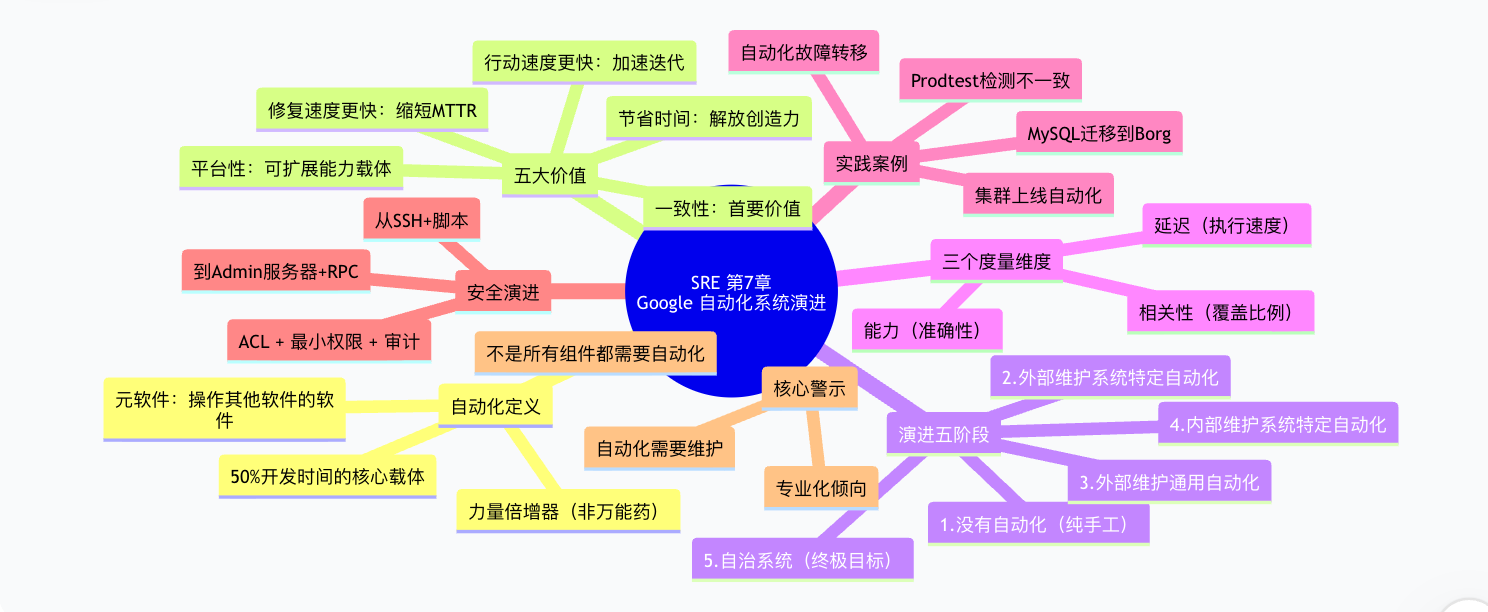
四、第7章知识点脑图总结
五、总结:一句话记住本章
自动化是 SRE 从琐事中解放出来的力量倍增器,但不是万能药;从手动脚本到系统自治的演进是自动化的终极路径,而安全、可维护和专业化倾向是必须始终警惕的三个维度。
| 关键点 | 一句话概括 |
|---|---|
| 自动化本质 | 自动化是操作其他软件的“元软件”,是 SRE 50% 开发时间的核心产出 |
| 五大价值 | 一致性、平台性、修复速度更快、行动速度更快、节省时间 |
| 演进路径 | 无自动化 → 外部维护特定 → 外部维护通用 → 内部维护 → 自治系统(共五阶段) |
| 终极目标 | “手动操作”和“软件自动化”均非最优解,“自治系统”才是最终目标 |
| 安全演进 | 从 SSH + 脚本到 Admin 服务器 + RPC + ACL + 完整审计 |
| 核心警示 | 自动化需要持续维护,专业化倾向会让自动化逐渐失效 |
| 三大维度 | 衡量自动化的质量:能力(准确性)、延迟(执行速度)、相关性(覆盖比例) |
行动建议:
-
本周内完成:审视团队现有的自动化工具/脚本,对照五个演进阶段评估它们目前处于哪个阶段
-
一个月内完成:识别团队中最耗时的琐事,制定自动化的演进路线图,从阶段二/三向阶段四/五推进
-
一个季度内完成:建立自动化代码的维护机制,明确所有者;检查是否存在“专业化倾向”导致的僵尸自动化
-
长期坚持:持续推动从“软件自动化”到“系统自治”的演进,在系统设计初期就融入“运维思维”;审视安全实践,从 SSH 向 Admin 服务器模式演进
六、高频考点自测
问题1:Google 自动化演进分为哪五个阶段?请简要描述。
参考答案:
-
没有自动化:完全依赖人工手动操作,如手动转移数据库主进程
-
外部维护的系统特定的自动化系统:SRE 在个人主目录中保存故障转移脚本
-
外部维护的通用的自动化系统:将特定系统支持添加到通用脚本中,团队共享使用
-
内部维护的系统特定的自动化:自动化能力被内置到系统中(如数据库自己发布故障转移脚本)
-
不需要任何自动化的系统(自治系统):系统在无需人工干预的情况下自动完成故障转移
从阶段一到阶段五,人工介入程度逐级递减,系统自主能力逐级增强。手动操作和软件自动化均非最优解,自治系统才是最终目标。
问题2:自动化对 SRE 的五大价值分别是什么?请举例说明。
参考答案:
-
一致性:自动化可以一致性地执行范围明确、步骤已知的程序。例如批量配置变更在 1000 台机器上精确执行
-
平台性:自动化系统可以搭建可扩展的平台,暴露自身性能指标。例如运维平台记录每次操作的成功率和耗时
-
修复速度更快:自动化自我修复缩短故障恢复时间。例如 MySQL 自动主从切换从 10-30 分钟降到几秒
-
行动速度更快:自动化部署发布、自动运维拉起进程,加速业务迭代
-
节省时间:将 SRE 从重复工作中解放,有更多精力做架构设计、性能优化等更有价值的工作
问题3:什么是“专业化倾向”?为什么它是自动化的一个挑战?
参考答案:“专业化倾向”指的是自动化代码和单元测试代码一样,当维护团队不再关心它与覆盖的代码仓库同步的时候就会逐渐失效。
这是因为:系统不断演化,自动化代码需要随之更新;当团队频繁变动或自动化工具的维护责任被移除出核心团队职责时,自动化就会逐渐成为“另一种技术债务”。任何自动化都应该有明确的“所有者”和定期维护机制,否则它会在不知不觉中失效。
问题4:Google 为什么要从 SSH 迁移到 Admin 服务器?Admin 服务器带来了哪些安全改进?
参考答案:因为许多分布式自动化依赖 SSH,人们必须拥有机器的 root 权限才能运行大多数命令,这带来了安全风险。
Admin 服务器的安全改进:
-
最小权限原则:没有人可以绕过审计跟踪来安装或修改服务器
-
代码评审把关:对 Admin 服务器代码和 Package 仓库的修改通过代码评审,越权操作非常困难
-
完整审计跟踪:记录 RPC 请求者、全部参数及所有 RPC 结果,提高调试和安全审计功能
-
职责分离:赋予别人安装软件包的权限不会允许他们查看日志
问题5:自动化程序的三个度量维度是什么?为什么重要?
参考答案:三个维度是:
-
能力:自动化执行任务的准确性
-
延迟:开始执行后,执行所有步骤所需的时间
-
相关性:自动化所涵盖的实际流程比例
这三个维度相互关联。一个自动化程序可能在准确性上很好,但覆盖范围太小(相关性不足),无法真正减少人工干预;或者覆盖面广但延迟太高,在紧急场景下不实用。好的自动化需要在三者之间找到平衡。
七、延伸阅读推荐
-
《Google SRE 工作手册》第 7 章:更深入的自动化实践指南
-
《Google SRE 二十年的经验教训》:https://dbaplus.cn/news-21-5456-1.html
-
《Automation at Google》:Google 官方技术博客关于自动化的系列文章
-
《The Evolution of SRE at Google》:USENIX 年度会议主题演讲
-
SRE 中文社区:https://www.srenow.cn
-
Borg:Google 集群管理系统(本书第 29 章有详细介绍)
学习下一章预告:第 8 章“发布工程” —— 如何通过自动化构建、测试和部署流程,实现安全可靠的持续交付。
本文为个人学习笔记,仅用于知识分享。如有错误,欢迎指正。
👍🏻 点赞 + 收藏 + 分享,让更多开发者看到这篇深度解析!❤️ 如果觉得有用,请给个赞支持一下作者!

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 14
14 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)