MySQL进阶篇详解
在该层,服务器会解 析查询并创建相应的内部解析树,并对其完成相应的优化如确定表的查询的顺序,是否利用索引等, 最后生成相应的执行操作。如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操。不同的存储引擎具有不同的功能,这样我们可以根据自己的需要,来选取合适的存储引擎。的,而不是 基于库的,所以存储引擎也可被称为表类型。语句,服务器
一、体系结构
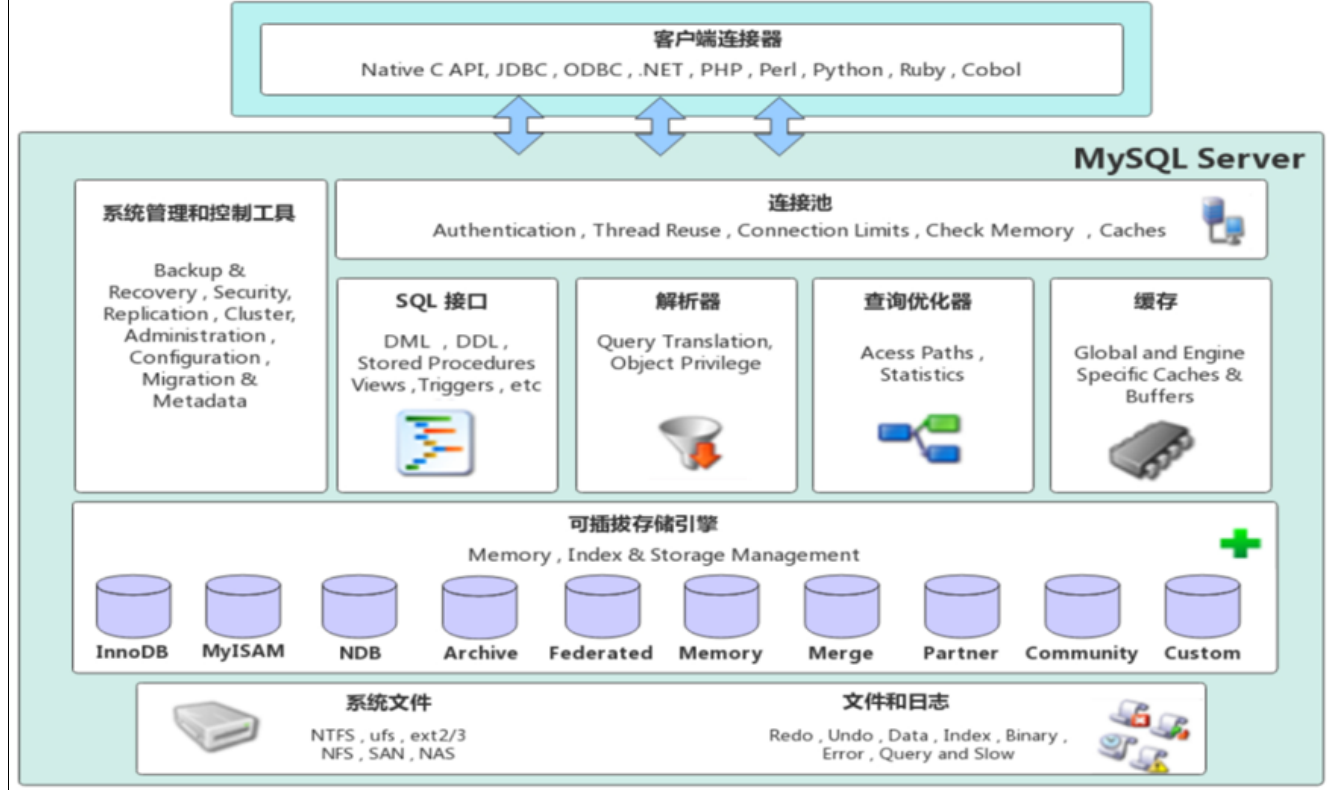
1). 连接层
最上层是客户端和链接服务,包含本地 sock 通信和基于客户端 / 服务端的 TCP/IP 通信。主要完成:连接处理、授权认证、安全方案。引入线程池为安全接入的客户端提供线程,支持 SSL 安全链接,同时验证客户端操作权限。
2). 服务层
第二层完成核心服务功能:SQL 接口、缓存查询、SQL 分析与优化、内置函数执行。所有跨存储引擎的功能(过程、函数等)均在此层实现。服务器会解析查询、创建解析树、优化执行计划(查询顺序、索引使用等)。查询语句会优先命中内部缓存,提升大量读操作场景下的系统性能。
3). 引擎层
存储引擎层,真正负责 MySQL 中数据的存储与提取,服务器通过 API 与存储引擎通信。不同存储引擎具备不同功能,可按需选择。数据库索引在存储引擎层实现。
4). 存储层
数据存储层,将 redolog、undolog、数据、索引、二进制日志、错误日志、查询日志、慢查询日志等存储在文件系统之上,并与存储引擎完成交互。MySQL 插件式存储引擎架构,将查询处理与数据存储分离,可根据业务选择合适引擎。
二、存储引擎
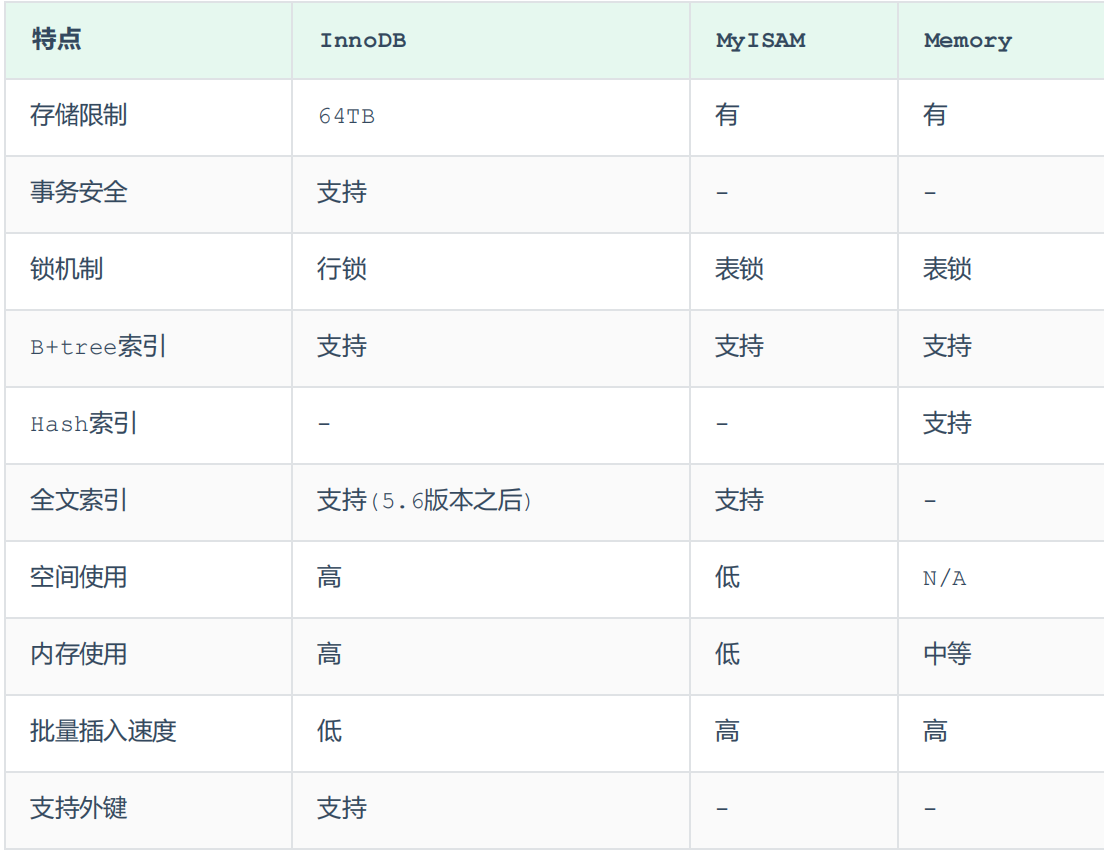
存储引擎是存储数据、建立索引、更新 / 查询数据的技术实现方式。存储引擎基于表,而非基于库,也可称为表类型。创建表时可指定存储引擎,未指定则使用默认引擎。
面试题:InnoDB 与 MyISAM 区别
- InnoDB 支持事务,MyISAM 不支持
- InnoDB 支持行锁 + 表锁,MyISAM 仅支持表锁
- InnoDB 支持外键,MyISAM 不支持
引擎选择
- InnoDB:MySQL 默认引擎,支持事务、外键。适合对事务完整性、并发一致性要求高,存在大量更新、删除的业务。
- MyISAM:以读和插入为主,更新删除少,对事务、并发要求不高的场景。
- MEMORY:数据全存放内存,访问快,用于临时表与缓存;表大小受限,数据安全性低。
三、索引
索引是帮助 MySQL 高效获取数据的有序数据结构。数据库在数据之外,维护满足查找算法的数据结构,实现快速查询。
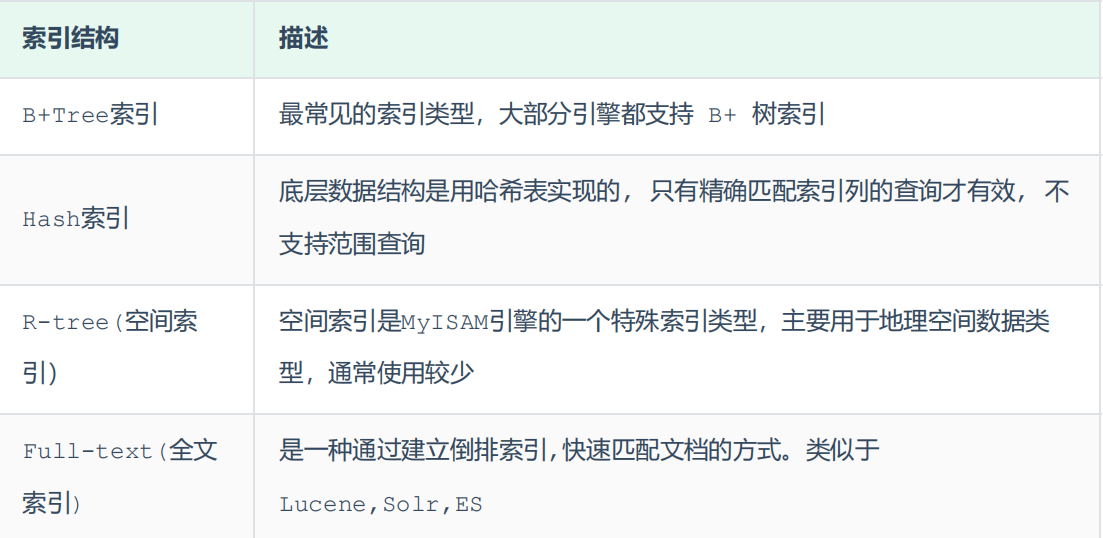
B 树和 B+ 树
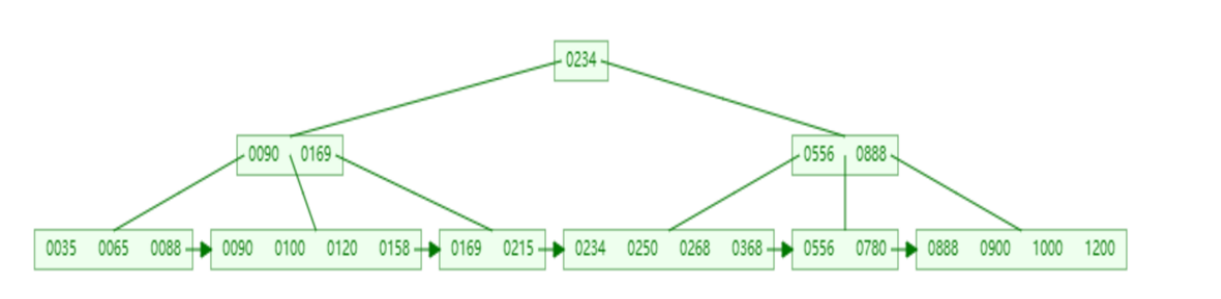
B 树
多叉平衡查找树,节点可拥有多个分支。以 5 阶 B 树为例:
- 每个节点最多存储 4 个 key,对应 5 个指针
- key 数量达到上限会裂变,中间元素向上分裂
- 非叶子节点和叶子节点都会存放数据
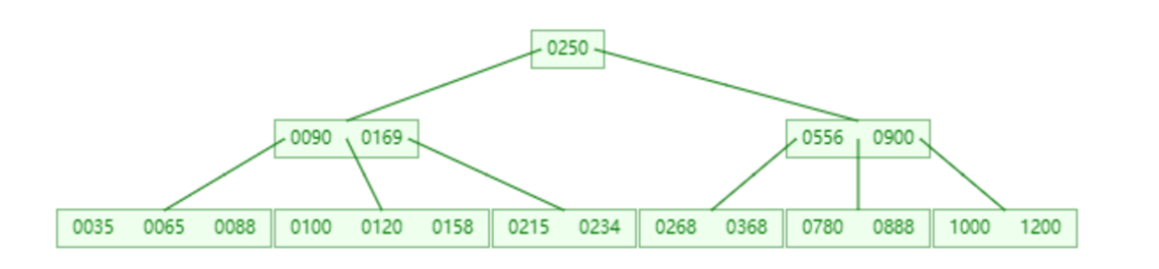
B+ 树
与 B 树核心区别:
- 所有数据都存放在叶子节点
- 叶子节点形成单向链表
- 非叶子节点仅作为索引,不存实际数据
为什么使用 B+ 树
- 哈希表:等值查询 O (1),但不支持高效范围查询
- 二叉树:数据量大时树层级高,磁盘 IO 多
- B 树:非叶子节点存索引 + 数据,空间利用率低,树更高,IO 多
- B+ 树:非叶子节点只存索引,分支因子大、树高度低、IO 少;叶子节点链表结构支持高效范围查询
索引分类
- 基础类型:主键索引、唯一索引、常规索引、全文索引
- InnoDB 存储形式:
- 聚集索引:主键索引;无主键则使用第一个非空唯一索引
- 二级索引:非主键索引

聚集索引叶子节点:索引数据 + 整行记录二级索引叶子节点:索引数据 + 主键值
四、SQL 性能分析
- SQL 执行频率
- 慢查询日志:记录执行时间超过
long_query_time(默认 10 秒)的 SQL - profile 详情
- Explain 执行计划(查看各字段含义)

五、索引使用
最左前缀法则
查询从索引最左列开始,不跳过索引列;跳过则索引部分失效。原因:联合索引树按左侧字段排序,缺少左列则无法按索引树查找。
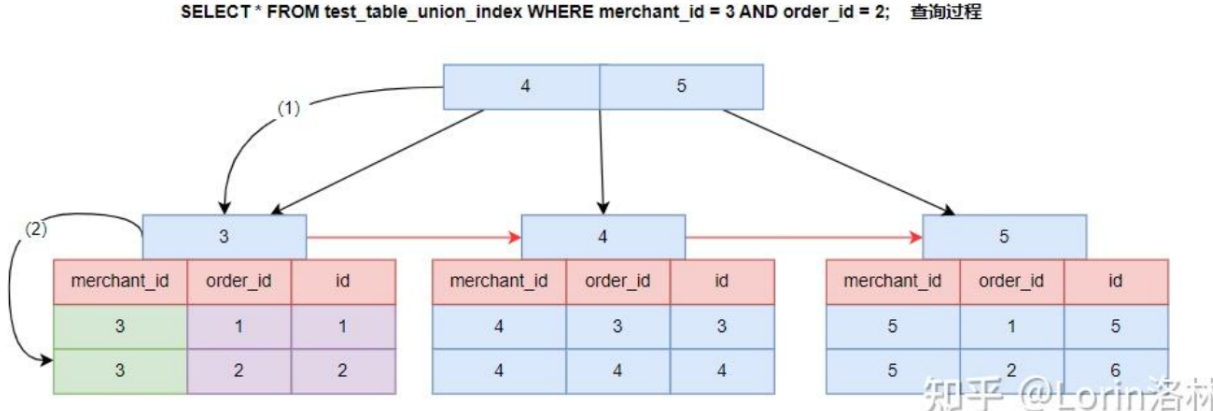
范围查询
联合索引中,>、< 范围查询会导致右侧列索引失效。业务允许时优先使用 >=、<=。
索引失效场景
- 违反最左前缀、范围查询右侧失效
- 索引列参与运算或使用函数
- 字符串不加引号
- 模糊查询不当
- OR 连接条件
六、索引覆盖和回表
- 覆盖索引:查询使用的索引包含所有需要返回的列
- 回表:使用二级索引查询时,先获取主键,再回到主键索引树查询完整数据回表会降低性能,应尽量避免。
七、SQL 优化
优化流程
慢 SQL 定位 → 分析问题 → 解决方案
慢 SQL 定位
开启慢查询日志,记录超时 SQL。
慢 SQL 原因
- 数据量太大
- 并发量太高
- 索引未使用 / 使用不当
- SQL 书写不当
- 表结构设计不合理
- 业务设计不合理
- 服务器性能配置低
七、锁
3.1 锁分类
- 全局锁:锁定整个数据库实例,库只读,用于全库备份
- 表级锁:锁定整张表,粒度大、并发低
- 行级锁:锁定单行数据,粒度小、并发高,仅 InnoDB 支持
3.2 表级锁
- 元数据锁 MDL:系统自动添加,保证表结构一致;DML 加读锁,DDL 加写锁
- 意向锁:协调表锁与行锁,分为意向共享锁(IS)、意向排他锁(IX)
3.3 行级锁
- 记录锁:锁定单行记录
- 间隙锁:锁定索引间隙,防止幻读
- 临键锁:记录锁 + 间隙锁,InnoDB 默认行锁算法
八、InnoDB 引擎详解
4.1 逻辑存储结构
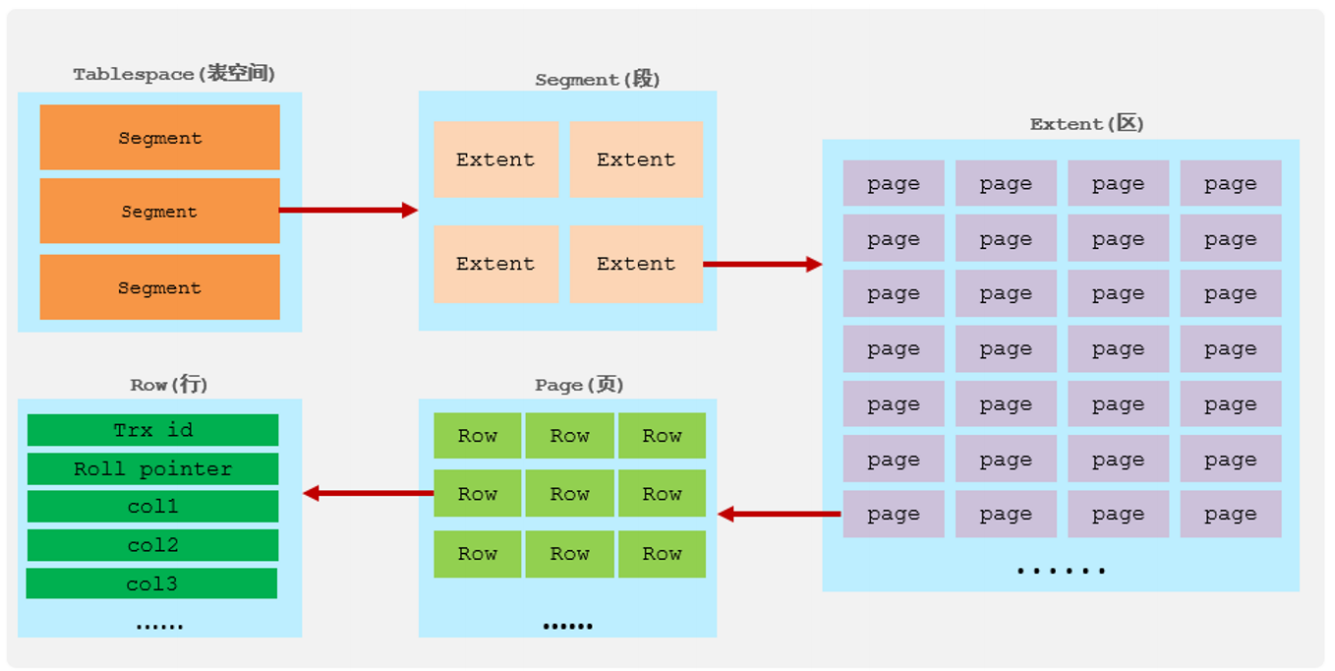
- 表空间:对应
.ibd文件,存储数据与索引 - 段:数据段、索引段、回滚段
- 区:固定 1M,包含 64 个连续页
- 页:默认 16KB,磁盘 IO 最小单元
- 行:数据按行存储,包含隐藏字段
4.2 核心架构
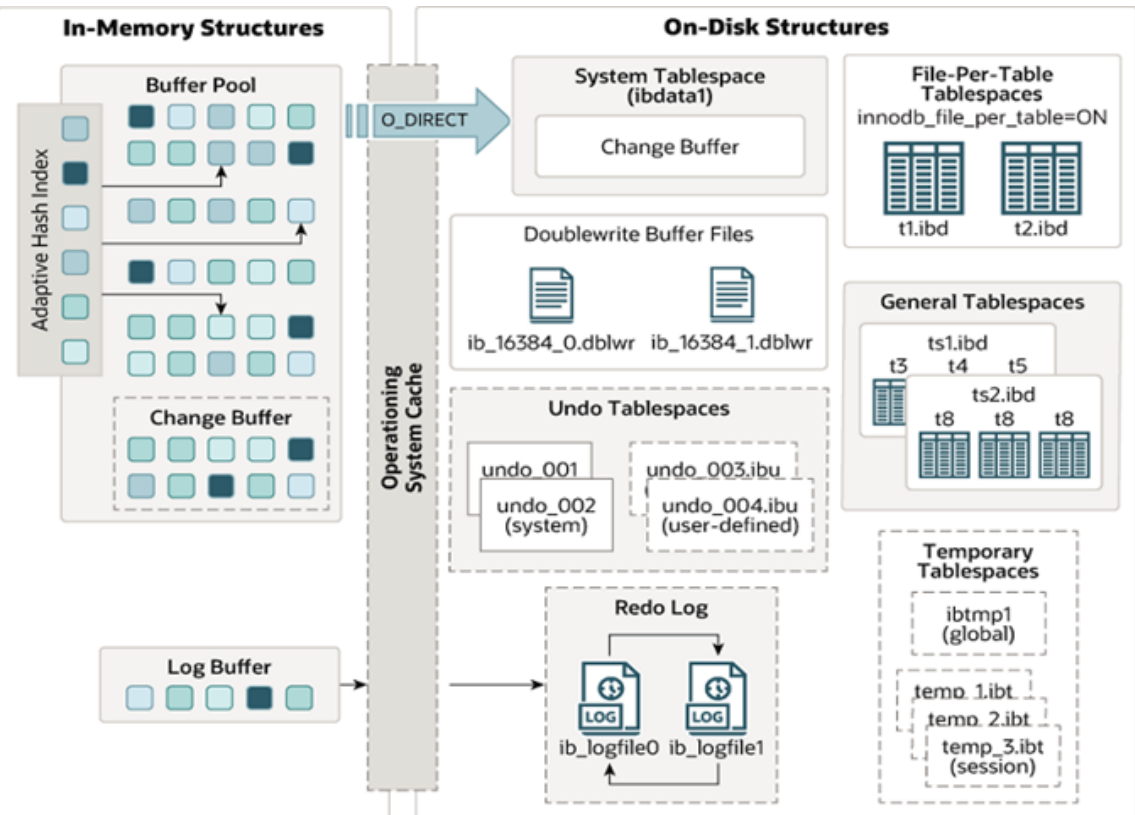
- Buffer Pool:缓冲池,缓存数据页、索引页,减少磁盘 IO
- Change Buffer:变更缓冲,优化非唯一二级索引写入
- Log Buffer:日志缓冲,缓存 redo/undo 日志
- 磁盘结构:系统表空间、独立表空间、redo log、undo log 等
4.3 事务与 ACID
- 原子性:由 undo log 保证
- 持久性:由 redo log 保证
- 一致性:redo log + undo log + 锁 + MVCC 共同保证
- 隔离性:由锁与 MVCC 保证
4.4 MVCC 多版本并发控制
4.4.1 核心概念
- 当前读:读取最新数据并加锁,如
select for update、update、delete - 快照读:不加锁读取历史版本,普通 select 即快照读(MVCC)
4.4.2 实现组件
-
隐藏字段
- DB_TRX_ID:最近修改记录的事务 ID
- DB_ROLL_PTR:回滚指针,指向 undo log 版本
- DB_ROW_ID:无主键时自动生成的隐藏主键
-
ReadView 核心字段
- m_ids:当前活跃事务 ID 集合
- min_trx_id:最小活跃事务 ID
- max_trx_id:预分配下一个事务 ID
- creator_trx_id:当前事务 ID
- .Undolog 版本链
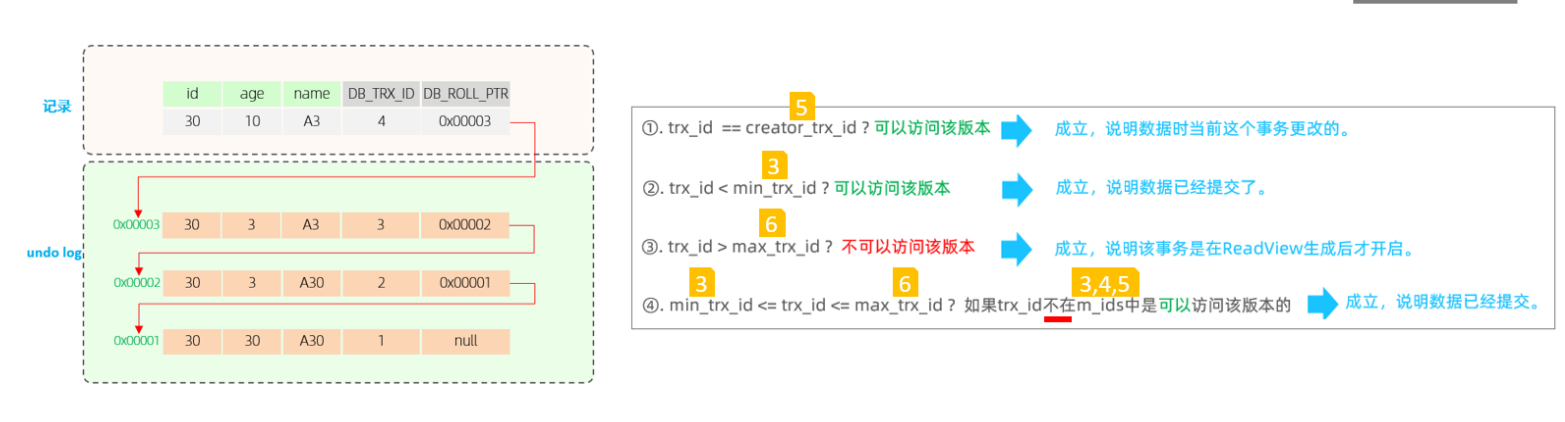
4.4.3 可见性规则
- 事务 ID = 当前事务 ID → 可见
- 事务 ID < 最小活跃 ID → 可见
- 事务 ID > 最大活跃 ID → 不可见
- 事务 ID 不在活跃集合 → 可见
4.4.4 隔离级别差异
- RC(读已提交):每次快照读生成新 ReadView
- RR(可重复读):仅第一次生成 ReadView,后续复用
4.4.5 总结
MVCC 通过隐藏字段 + undo 版本链 + ReadView,实现无锁并发读、读写不冲突,极大提升 InnoDB 并发性能。
MVCC无法解决幻读,通过MVCC加锁才能解决幻读问题。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)