服务器双卡5090 配置深度学习环境
主要记录一下安装过程,后面会不断的更新
文章目录
安装过程
1、验证
验证:运行 nvidia-smi,确认驱动版本和两块RTX 5090都已正确识别。
需要注意,驱动版本大于一定的版本
2、安装cuda
下载安装:从NVIDIA CUDA Toolkit下载 下载地址
- 从这里面下载合适你的就可以,我们通常说安装CUDA 就是安装CUDA Toolkit
- 注意:在安装界面,务必用空格键取消选中 [X] Driver 选项,仅安装CUDA Toolkit(如果你的系统满足驱动版本)。
CUDA Installer
[ ] Driver
[X] CUDA Toolkit 12.4
[X] CUDA Demo Suite 12.4
[X] CUDA Documentation 12.4
Options
Install
↓
安装好cuda以后,需要把路径写到全局路径当中
echo 'export PATH=/usr/local/cuda-12.8/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-12.8/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
2、安装minconda
# 下载并安装 Miniconda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
# 按照提示安装,选择 yes 添加到 PATH
source ~/.bashrc(安装 Miniconda 时,安装程序会自动在你的 ~/.bashrc 文件末尾添加几行配置)
3、关于CUDANN
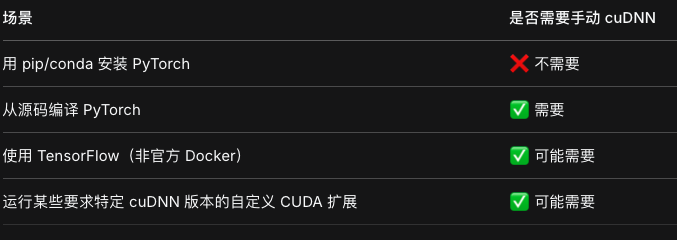
- 当你通过 pip install torch(包括指定 --index-url 的 CUDA 版本)安装 PyTorch时,安装包里面已经内置了预编译好的 cuDNN 库。换句话说:PyTorch 不依赖系统全局安装的 cuDNN,它自己“打包”了一份。所以即使你不手动安装 cuDNN,torch.backends.cudnn.version() 仍然能正常工作。
4、环境导入
以其版本,比如readme里面的环境都比较老了,导入肯定会报错,建议直接第一步 pip install torch 剩下的环境缺啥补啥
双卡联动训练模型
对于yolo来说
想用双卡跑你的训练脚本,最简单的办法是修改model.train()中的 device 参数,将其设置为一个包含两个GPU ID的列表。
from ultralytics import YOLO //这个是下载的代码部分中去找,双卡就不从你的代码里面去找
# 加载模型
model = YOLO('/home/hello/下载/ultralytics-main/YOLOcheckpoint/yolov8n.pt') //
# 训练
model.train(
data='/home/hello/下载/ultralytics-main/ultralytics/cfg/datasets/quexian.yaml',
cfg='/home/hello/下载/ultralytics-main/ultralytics/cfg/aug.yaml',
imgsz=1280,
epochs=100,
batch=8, # 这是 每张卡 的batch size还是 total batch size?
device=[0, 1], # ✅ 就在这里,将0改为[0, 1]
workers=8
)
当你使用多卡训练时,对batch参数的理解至关重要。你需要确认代码的运行逻辑属于哪种情况:
- 情况A:Ultralytics YOLOv8 的标准行为 (最常见) 当你传入 batch=8 并使用多卡时,这个 8
指的是每张卡上的批次大小(per-GPU batch size)。因此,你的总批次大小(Total batch size) 会是 8 * 2 = 16。这意味着模型每处理16张图片,才会更新一次参数。 - 情况B:旧版或某些特定库的行为 在某些实现中,batch代表总的批次大小。这种情况下,库会自动将其均分到每张卡上(即每张卡处理4张图片)。
注意:
单卡启动的进程是从你下载的代码部分中去找,双卡就不从你的代码里面去找,去你安装的虚拟环境里面去找ultralytics安装包里面去找
在 Ultralytics YOLO 的 train() 方法中,当指定 device=[0,1] 使用多 GPU 分布式训练(DDP)时,参数 batch=8 的含义是 每个 GPU 上的 batch size。因此两张卡的总有效 batch size 为:8 (每卡)×2(卡数)=16,这是 Ultralytics 框架的标准行为。你可以通过训练启动时的日志输出确认,通常会显示类似 Batch size: 8 (per GPU) 或总批次大小的信息。
torchrun的用法
为什么需要torchrun --nproc_per_node=2 train_ddp.py 才能启动,而python train_ddp.py 就会保错
--nproc_per_node 是 torchrun 中用于指定每个节点上运行的进程数量的参数。在分布式训练中,
通常每个进程绑定一个 GPU,所以这个值一般设为当前节点的 GPU 数量(例如 2 表示使用该节点上的 2 块 GPU 启动 2 个进程)。
直接用 python 启动会报错,根本原因在于 torchrun 负责建立 DDP 所需的基础环境,而这些是 python 命令无法提供的。要理解这个区别,你需要知道 DDP 成功运行的前提,以及 torchrun 到底帮我们做了什么。 DDP 运行的前提:四大关键变量 DDP 要求每个参与训练的进程都知道自己的身份和同伴的信息,这通过四个环境变量来传递:
- RANK (全局排名): 进程在所有进程中的唯一编号(如 0, 1, 2, 3)。
- WORLD_SIZE (世界大小): 参与训练的进程总数。
- LOCAL_RANK (本地排名): 进程在当前机器上的编号(用于指定使用的 GPU 卡)。
- MASTER_ADDR:MASTER_PORT (主节点地址): 用于进程间协调和通信的“会议室”。
为什么 python 命令做不到?
- 当执行 python train_ddp.py 时,你只是启动了一个单一的、隔离的 Python 进程。这个新进程对 DDP 所需的环境变量一无所知,如同一个没有“身份”和“同伴”的孤岛,自然无法与其他进程协同。因此,当代码中调用 去拉取这些必需信息时会立刻报错。
其他的模型训练是否也可以这样用
- torchrun 本身就是 PyTorch 为 DDP 设计的官方工具,因此几乎所有基于 PyTorch的训练脚本或上层库,你都可以用它来启动,或者有一套围绕它构建的工具。
怎么看双卡是两倍的batch,还是每一个卡就是一半的batch
- 如果没有明确文字,就去看数据加载器的实际输出:打印一个 iteration 输入的图片张量大小,比如 inputs.shape = [8,
3, 1280, 1280],若 8 对应 batch 维度,且你有 2 张卡,那么这个 8 是这张卡上的 batch(即每卡 8),总
batch 就是 16。
DDP是怎么做的,是把模型复制一份到另外一张卡吗
- 如果模型能完整放进一张卡,就为每张卡复制一份,然后将一批数据拆开,让每张卡处理各自的一部分。这能极大提升训练速度,因为你相当于雇佣了多个工人,每人拿着完整的图纸(模型),同时处理不同的零件(数据)。
双卡下如何为cuda指定设备
1、默认的
一般来说,可以指定device=[0,1],像上面的yolo
2、可以通过CUDA_VISIBLE_DEVICES=0,1
CUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node=2 train.py
如何判定启动了双卡训练
系统监控这是最直观的方法,能直接看到多张显卡是否被调用。
- nvidia-smi命令:这是最核心的命令。在终端输入 nvidia-smi
查看实时状态。在Processes下方,你会看到有多个(超过1个)GPU被你的训练进程(PID)列出。在VolatileGPU-Util列,这几张GPU的利用率都显著高于0%。 - 进阶用法:可以用 watch -n 1 nvidia-smi 每隔一秒刷新一次来动态观察,或者在代码开始训练后立刻执行 nvidia-smi 看显存占用。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐


 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)