如何设计 Google Docs
本文概述了如何设计一个类似Google Docs的实时协同文档编辑系统。系统核心挑战在于处理高并发写入时的数据一致性,需支持多人实时编辑、权限管理、版本历史等功能。架构设计包含WebSocket网关、协同编辑服务、Kafka消息队列和Redis缓存,采用Operational Transformation算法解决冲突合并问题。估算表明系统需处理870 ops/s的峰值写入和8,700 req/s的
如何设计 Google Docs
📌 一、题目解读与需求澄清
本质问题:设计一个支持多人实时协同编辑的在线文档系统,核心挑战在于如何在高并发写入场景下保证多端数据的一致性与操作的正确合并。
功能性需求(Functional Requirements)
- 文档 CRUD:用户可以创建、读取、编辑、删除文档
- 实时协同编辑:多个用户可以同时编辑同一文档,变更毫秒级同步
- 权限管理:文档支持 Owner / Editor / Commenter / Viewer 四种角色
- 版本历史:支持查看历史版本,并能回滚到任意历史节点
- 评论与建议:支持行内评论、@提及、建议编辑模式
非功能性需求(Non-Functional Requirements)
- 低延迟:本地操作立即响应(<50ms),协同更新延迟 <300ms
- 高可用:99.99% 可用性,不接受单点故障
- 最终一致性:允许短暂冲突,通过 OT/CRDT 算法自动合并
- 数据持久性:任何已确认的写入不丢失(持久化 + 多副本)
- 可扩展性:支持亿级文档、数千万 DAU
容易被忽略的隐藏需求
- 离线编辑:用户断网后继续编辑,重连后自动同步(操作队列 + 冲突合并)
- 大文档性能:百万字符的文档如何高效加载(分块、懒加载)
- 光标/选区同步:协作者的光标位置需要实时广播,但这不能影响核心编辑
- 操作的幂等性:网络重试时重复提交的操作不能被二次执行
- 移动端适配:触控环境下的协同编辑体验(选区、输入法 IME 事件差异)
📐 二、规模估算
关键假设
| 参数 | 假设值 | 说明 |
|---|---|---|
| DAU | 5000 万 | 参考 Google Workspace 规模 |
| 人均文档数 | 200 | 含共享文档 |
| 总文档数 | 100 亿 | 5000万 × 200 |
| 每人每天编辑时长 | 30 分钟 | 含浏览 |
| 协同编辑比例 | 20% | 即 1000 万会话/天有协作者 |
| 单条 Operation 大小 | ~200 Bytes | 含 Op 类型、位置、内容、版本号 |
QPS 估算
活跃编辑会话:5000万 DAU × 30% 活跃编辑 = 1500万 session/天
峰值并发 session(1/5 集中在4h内)≈ 375万
写 QPS(每个 session 每秒约 1次 op):
平均写 QPS = 5000万 × 0.3 / 86400 ≈ 174 ops/s
峰值写 QPS ≈ 174 × 5 ≈ 870 ops/s (较低,因为编辑行为非连续)
读 QPS(文档加载:读/写 ≈ 10:1):
峰值读 QPS ≈ 870 × 10 ≈ 8700 req/s
结论:这是一个读多写少的系统,但写操作对延迟极度敏感
存储估算
文档内容:
平均文档大小 = 50 KB (含格式信息)
总文档内容 = 100亿 × 50KB = 500 TB
Operation Log(协同核心):
每次编辑 session 产生约 1000 条 op
1500万 session/天 × 1000 × 200B ≈ 3 TB/天
版本快照(每100次op做一次快照):
1500万 × 10次快照 × 50KB ≈ 7.5 TB/天
(实际只存 diff,压缩后约 ~500 GB/天)
年存储增量 ≈ (3TB + 0.5TB) × 365 ≈ 1.3 PB/年
带宽估算
实时协同广播(每条 op 广播给同文档所有协作者,平均3人):
870 ops/s × 200B × 3 ≈ 520 KB/s(可忽略)
文档初始加载(读 QPS 8700 × 平均传输 20KB):
≈ 174 MB/s 出站带宽
🏗️ 三、高层架构设计
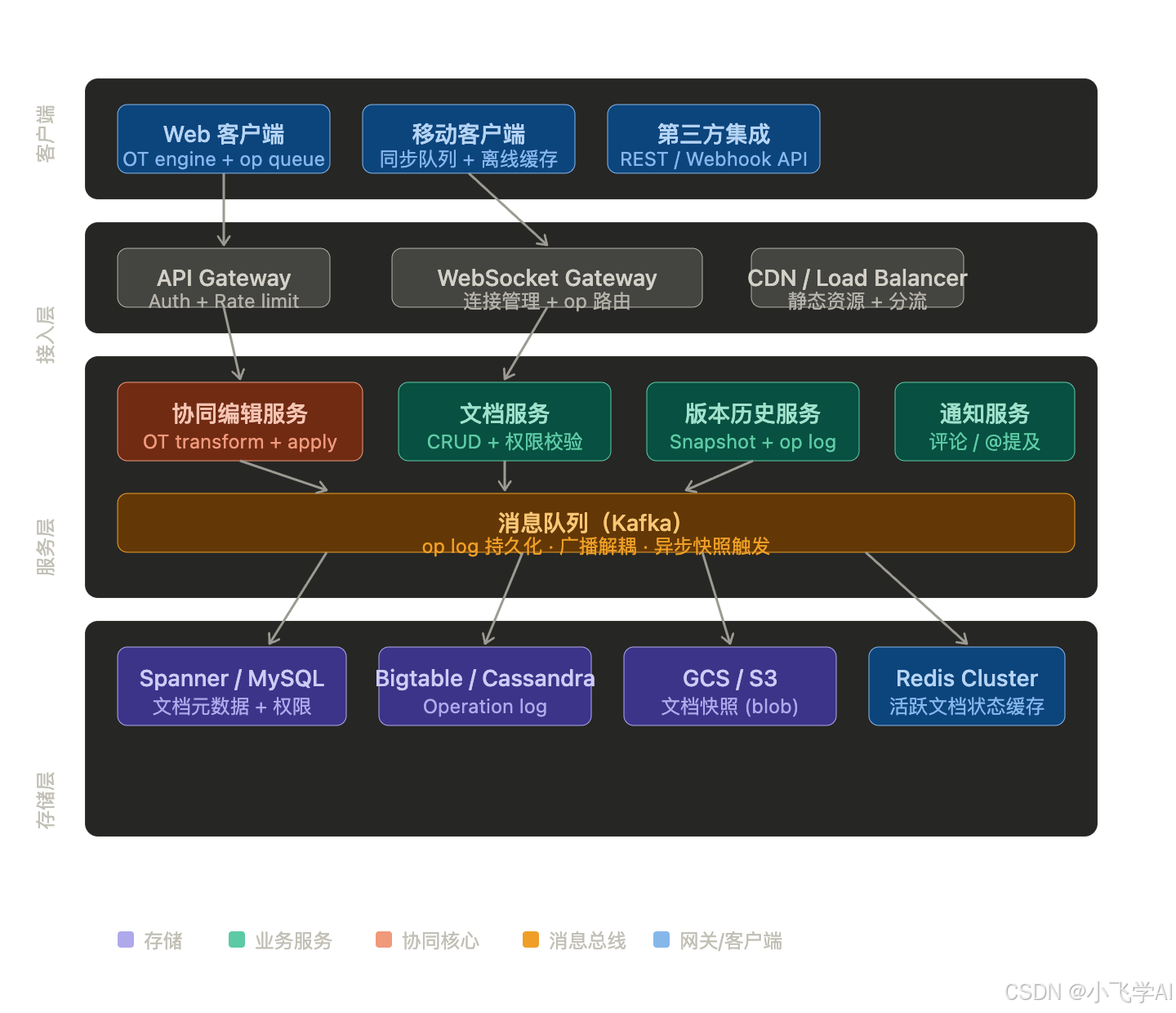
核心组件职责
WebSocket Gateway:维护用户与文档 session 的长连接映射,将客户端发来的 op 路由到对应的协同编辑服务实例,并将广播结果推回给同文档的其他在线用户。
协同编辑服务:系统的核心大脑。接收 op,执行 Operational Transformation(OT)算法进行转换,更新文档的内存状态,再将转换后的 op 写入 Kafka 和缓存。
Kafka:作为 op log 的持久化缓冲区,解耦写入与广播。下游的快照服务、版本历史服务消费这个 topic,异步完成持久化和快照生成,不阻塞主编辑链路。
Redis Cluster:缓存活跃文档的当前状态(最新版本的 op sequence 和文档内容),避免每次广播都查数据库。文档无活跃用户后,状态 TTL 过期自动清除。
核心数据库表结构
-- 文档元数据(MySQL / Spanner)
CREATE TABLE documents (
doc_id VARCHAR(36) PRIMARY KEY,
owner_id VARCHAR(36) NOT NULL,
title VARCHAR(500),
created_at TIMESTAMP,
updated_at TIMESTAMP,
current_rev BIGINT DEFAULT 0, -- 当前最新 revision
snapshot_rev BIGINT DEFAULT 0, -- 最近一次快照的 revision
INDEX idx_owner (owner_id),
INDEX idx_updated (updated_at)
);
-- 权限表
CREATE TABLE doc_permissions (
doc_id VARCHAR(36),
user_id VARCHAR(36),
role ENUM('owner','editor','commenter','viewer'),
PRIMARY KEY (doc_id, user_id)
);
-- Operation Log(Bigtable / Cassandra)
-- Row key: doc_id + rev(保证按文档分区、按版本排序)
CREATE TABLE op_log (
doc_id VARCHAR(36),
rev BIGINT, -- 单调递增,全局 revision
user_id VARCHAR(36),
op_type VARCHAR(20), -- 'insert' | 'delete' | 'retain' | 'format'
position INT,
content TEXT, -- 插入内容(删除时为空)
length INT, -- 影响的字符长度
client_rev BIGINT, -- 客户端发送时的本地 rev(OT 用)
created_at TIMESTAMP,
PRIMARY KEY (doc_id, rev)
);
🔬 四、深入细节
子问题 1:Operational Transformation(OT)——多人冲突合并
问题描述:Alice 在位置 5 插入了字符 “X”,同一时刻 Bob 在位置 5 删除了字符 “Y”。两个操作在各自客户端并发发生,如果直接应用会导致数据不一致。
解决方案分析:
OT 的核心思路是:当服务器收到一个 op 时,如果该 op 基于的 revision 已经"过时"(其他操作已经先被应用),需要把这个 op 转换(Transform)成相对于最新状态仍然语义正确的版本。
初始文档: "Hello" (rev=0)
客户端A(基于rev=0): Insert("X", pos=5) → "HelloX"
客户端B(基于rev=0): Delete(pos=3, len=2) → "Hel"
服务器先收到A的op,文档变为 "HelloX"(rev=1)
服务器再收到B的op,但B的op是基于rev=0发出的
OT transform:
B_op: Delete(pos=3, len=2)
A_op(已提交): Insert(pos=5, len=1)
由于A在pos=5插入,而B删除的是pos=3~4,A的插入不影响B的删除范围
→ 转换后B_op保持不变: Delete(pos=3, len=2)
→ 最终文档: "HelX"(正确合并两人意图)
推荐方案:服务器端维护 Op History,对每个新到的 op 使用 transform(op, concurrent_ops) 逐一转换,最终得到可以安全应用的新 op。客户端也维护 pending queue,服务器确认后清空。
class OTEngine:
def transform(self, op: Op, other: Op) -> Op:
"""
将 op 针对已提交的 other op 进行转换
保持 op 的原始语义意图
"""
if op.type == 'insert' and other.type == 'insert':
# 如果 other 在 op 之前插入,op 的位置需要右移
if other.pos <= op.pos:
return Op('insert', op.pos + len(other.content), op.content)
return op
if op.type == 'insert' and other.type == 'delete':
if other.pos < op.pos:
# other 删除了 op 位置之前的内容,op 位置左移
return Op('insert', op.pos - other.length, op.content)
return op
if op.type == 'delete' and other.type == 'insert':
if other.pos <= op.pos:
return Op('delete', op.pos + len(other.content), op.length)
return op
if op.type == 'delete' and other.type == 'delete':
if other.pos + other.length <= op.pos:
return Op('delete', op.pos - other.length, op.length)
elif other.pos >= op.pos + op.length:
return op
else:
# 两个删除范围有交叠,需要裁剪
overlap_start = max(op.pos, other.pos)
overlap_end = min(op.pos + op.length, other.pos + other.length)
overlap = overlap_end - overlap_start
new_length = max(0, op.length - overlap)
new_pos = min(op.pos, other.pos)
return Op('delete', new_pos, new_length)
def apply_ops(self, doc_state: str, ops: list[Op]) -> str:
"""将一组 op 顺序应用到文档"""
for op in ops:
if op.type == 'insert':
doc_state = doc_state[:op.pos] + op.content + doc_state[op.pos:]
elif op.type == 'delete':
doc_state = doc_state[:op.pos] + doc_state[op.pos + op.length:]
return doc_state
def server_receive(self, incoming_op: Op, history: list[Op], client_rev: int) -> Op:
"""服务端:将 incoming_op 转换为针对最新状态的 op"""
concurrent_ops = history[client_rev:] # 客户端发出后,服务端已应用的 ops
transformed = incoming_op
for applied_op in concurrent_ops:
transformed = self.transform(transformed, applied_op)
return transformed
子问题 2:实时协同的连接管理与广播
问题描述:数百万个 WebSocket 长连接如何高效管理?同一文档的 op 如何广播给所有协作者?单机 WebSocket 服务无法存储所有连接,如何做水平扩展?
解决方案:Pub/Sub + 连接注册表
每个 WebSocket Gateway 节点只维护连接到自己的会话
Redis 中存储:doc_id → [gateway_node_id, ...](哪些节点上有该文档的在线用户)
op 到来时广播路径:
客户端A → WS Gateway Node-1
→ 协同编辑服务(处理 op)
→ 查 Redis: doc_123 的在线节点 = [Node-1, Node-3]
→ 向 Node-1 和 Node-3 发布消息(通过 Redis Pub/Sub 或内部 gRPC)
→ Node-1 和 Node-3 各自推送给本地的连接用户
class CollaborationBroadcaster:
def __init__(self, redis_client, own_node_id: str):
self.redis = redis_client
self.node_id = own_node_id
# 本地连接表: user_id -> websocket_connection
self.local_connections: dict = {}
def on_user_connect(self, user_id: str, doc_id: str, ws_conn):
"""用户建立 WebSocket 连接时注册"""
self.local_connections[user_id] = ws_conn
# 将本节点注册到 Redis 的文档-节点映射
self.redis.sadd(f"doc:nodes:{doc_id}", self.node_id)
# 同时记录 user->node 的反向映射,用于断连时清理
self.redis.set(f"user:node:{user_id}", self.node_id, ex=3600)
def broadcast_op(self, doc_id: str, op: dict, exclude_user: str):
"""将 op 广播给文档的所有在线协作者"""
nodes = self.redis.smembers(f"doc:nodes:{doc_id}")
message = json.dumps({"doc_id": doc_id, "op": op, "exclude": exclude_user})
for node_id in nodes:
if node_id == self.node_id:
# 本节点直接推送
self._local_push(doc_id, op, exclude_user)
else:
# 跨节点通过 Redis Pub/Sub 或 MQ 转发
self.redis.publish(f"node:msgs:{node_id}", message)
def _local_push(self, doc_id: str, op: dict, exclude_user: str):
doc_users = self.redis.smembers(f"doc:users:{doc_id}")
for user_id in doc_users:
if user_id != exclude_user and user_id in self.local_connections:
self.local_connections[user_id].send_json(op)
子问题 3:版本历史与快照策略
问题描述:如果每次查看历史都重放所有 op(可能几十万条),延迟不可接受。如何设计高效的版本查询?
解决方案:定期快照 + op log 增量重放
核心思路类似数据库的 WAL(Write-Ahead Log)+ Checkpoint:每隔 N 条 op(或一定时间),生成一次文档的完整快照并存入对象存储(GCS/S3)。查询历史版本时,找到最近的快照,再重放快照之后的增量 op。
class VersionHistoryService:
SNAPSHOT_INTERVAL = 100 # 每100个op做一次快照
def create_snapshot_if_needed(self, doc_id: str, current_rev: int, doc_content: str):
"""由 Kafka consumer 异步调用,决定是否生成快照"""
if current_rev % self.SNAPSHOT_INTERVAL == 0:
snapshot_key = f"snapshots/{doc_id}/rev_{current_rev}.gz"
compressed = gzip.compress(doc_content.encode())
self.object_storage.put(snapshot_key, compressed)
# 更新 metadata 表中 snapshot_rev
self.db.execute(
"UPDATE documents SET snapshot_rev=? WHERE doc_id=?",
(current_rev, doc_id)
)
def get_doc_at_revision(self, doc_id: str, target_rev: int) -> str:
"""获取文档在某个历史 revision 时的内容"""
# 1. 找到 <= target_rev 且最近的快照
meta = self.db.query(
"SELECT snapshot_rev FROM documents WHERE doc_id=?", (doc_id,)
)
snapshot_rev = (target_rev // self.SNAPSHOT_INTERVAL) * self.SNAPSHOT_INTERVAL
# 2. 从对象存储加载快照
snapshot_key = f"snapshots/{doc_id}/rev_{snapshot_rev}.gz"
doc_content = gzip.decompress(
self.object_storage.get(snapshot_key)
).decode()
# 3. 从 op_log 增量重放 snapshot_rev → target_rev
ops = self.db.query(
"SELECT * FROM op_log WHERE doc_id=? AND rev>? AND rev<=? ORDER BY rev",
(doc_id, snapshot_rev, target_rev)
)
ot_engine = OTEngine()
return ot_engine.apply_ops(doc_content, [Op.from_row(r) for r in ops])
子问题 4:文档分片与大文档性能
问题描述:一篇 100 万字的文档,如果全量加载、全量发送 op,客户端会卡死。
解决方案:逻辑分块(Chunk)加载 + 视口感知渲染
将文档逻辑上分为固定大小的 chunk(如每块 10,000 字符),只加载当前视口附近的 chunk。op 的位置转换需要带上 chunk 信息。
文档结构:
doc_id: "abc"
chunks: [
{ chunk_id: 0, rev: 45, start_char: 0, end_char: 10000 },
{ chunk_id: 1, rev: 12, start_char: 10000, end_char: 20000 },
{ chunk_id: 2, rev: 3, start_char: 20000, end_char: 30000 },
]
加载策略:
- 打开文档:加载 chunk_0(首屏内容)+ 预加载 chunk_1
- 滚动到 chunk_1 时:后台预加载 chunk_2
- op 只需携带 chunk_id + 块内偏移,减少 OT 计算范围
子问题 5:光标与协作者感知
问题描述:协作者的实时光标位置需要广播,但这类消息频率极高(每次鼠标移动都触发),会淹没编辑 op。
解决方案:光标消息与编辑 op 走不同通道,独立限流
class CursorBroadcaster:
def __init__(self, ws_gateway):
self.ws_gateway = ws_gateway
# 每个用户的光标更新限速:最多10次/秒
self.throttle_cache: dict = {}
def update_cursor(self, user_id: str, doc_id: str, position: int, color: str):
now = time.time()
last_sent = self.throttle_cache.get(user_id, 0)
if now - last_sent < 0.1: # 100ms 节流
return # 丢弃高频光标更新
self.throttle_cache[user_id] = now
cursor_msg = {
"type": "cursor", # 区别于编辑 op
"user_id": user_id,
"position": position,
"color": color, # 每个协作者分配一个固定颜色
}
# 走独立的 cursor channel(优先级低于 op channel)
self.ws_gateway.broadcast_cursor(doc_id, cursor_msg, exclude=user_id)
⚖️ 五、技术选型与 Trade-off 讨论
| 决策点 | 选项A | 选项B | 本题推荐 |
|---|---|---|---|
| 冲突合并算法 | OT(Operational Transformation) | CRDT(Conflict-free Replicated Data Type) | OT(服务端集中式,实现成熟,Google Docs 实际采用) |
| 实时传输协议 | WebSocket | SSE(Server-Sent Events)+ HTTP轮询 | WebSocket(双向实时,协同场景必需) |
| Op 存储 | MySQL/PostgreSQL(关系型) | Bigtable/Cassandra(宽列) | 宽列存储(按 doc_id+rev 分区,写吞吐远高于关系型) |
| 一致性模型 | 强一致性(同步写多副本) | 最终一致性(Kafka 异步持久化) | 最终一致性(编辑 op 接受毫秒级延迟,用户无感知) |
| 文档元数据存储 | Spanner(全球分布式SQL) | MySQL(单地域) | Spanner(全球用户场景,跨地域事务能力关键) |
OT vs CRDT 详细讨论:
CRDT 的优势是去中心化,天然支持离线合并,无需服务器协调。但代价是数据结构膨胀(每个字符需要携带唯一 ID 和因果关系),内存和网络开销大 3~5 倍。Google Docs 规模下,OT 在服务端中心化协调,实现更简洁、性能更好。Figma、Notion 等较新的产品则选择 CRDT,因为其更好的离线支持和 P2P 扩展性。
❓ 六、常见面试追问点
Q1:如果服务端协同编辑服务崩溃了,正在编辑的用户数据会丢失吗?
服务端在接受 op 时,先写 Kafka(持久化),再更新内存状态。只要 Kafka ACK 返回,op 就不会丢失。崩溃重启后,新实例从 Kafka 重放 op 恢复状态。客户端维护 pending op queue,未收到 ACK 的 op 会在重连后重试。
Q2:一个热门文档同时有 10 万人在线,广播会不会成为瓶颈?
实际上真正活跃编辑的人通常是少数,其余是只读查看者。对于只读用户,可以降级为定时拉取(polling)而非实时推送。真实的协同编辑(同时有多人疯狂打字)几乎只发生在小团队(<20人)。10 万人"在线"的文档,可以考虑将广播降级为 SSE 推送,并在 WebSocket Gateway 层加限速。
Q3:OT 算法在多个操作并发时是否仍然保证正确性?
标准 OT 需要满足 TP1(transform 后效果与顺序无关)和 TP2(复合 transform 的交换律)才能在多操作并发时保证收敛。Google Wave 论文指出,满足 TP2 的算法实现极难。实践中通常通过"服务器序列化所有 op"来规避 TP2 问题——所有操作经过服务端定序,客户端只需做服务端视角的单向 transform,避免了客户端-客户端之间的双向 transform。
Q4:如何防止恶意用户发送超大 op 破坏文档?
在 API Gateway 层对单条 op 的 content 字段设置大小限制(如 1MB),对单个用户的 op 频率限流(如 100 ops/s),对写操作在服务端校验 position 范围是否合法(不超过当前文档长度)。Kafka 消费前也可加一道格式校验。
Q5:版本历史查询慢如何优化?
除了快照+增量重放外,还可以对「查看最近 N 次修改」这种高频场景专门维护一张轻量的 revision_summary 表,只记录 rev、时间戳、user_id、改动摘要(如"插入了 200 字"),不存储完整 op。完整内容只有用户真正点击"恢复到此版本"时才触发重放。
Q6:多地域部署时,同一文档的用户可能在不同 region,OT 如何处理?
推荐为每个文档指定一个主 region(基于 owner 所在地),所有 op 路由到主 region 的协同编辑服务做定序。其他 region 的用户连接到本地 WebSocket Gateway,op 转发到主 region,结果广播回来。可接受额外的跨地域延迟(约 50~150ms),换取强一致的 op 定序。
Q7:如何设计"建议编辑"模式(Suggesting mode)?
Suggesting mode 的操作不直接修改文档内容,而是以"pending op"形式存储,带有 suggested_by、state(pending/accepted/rejected)字段。文档渲染时叠加显示。接受建议时,将 pending op 变为正式 op 应用到文档;拒绝时直接删除 pending op。底层仍复用 op log 表,只是加了 op_status 字段。
Q8:如何估算协同编辑服务需要多少台机器?
每个协同编辑服务实例处理一批活跃文档,一个实例在内存中维护活跃文档状态(平均每文档约 500KB Redis 缓存)。假设单实例维护 1000 个活跃文档,峰值活跃文档数约 100 万(5000万 × 2%),需要约 1000 个实例。文档→服务节点的映射通过 Consistent Hashing 实现,保证同一文档的 op 路由到同一节点。
Q9:客户端如何处理离线后再上线的场景?
客户端维护一个本地 op queue(可持久化到 IndexedDB)。离线时继续本地编辑,所有操作入队。重新上线后,将 queue 中的 op 批量发送给服务端,携带断网时的最后已知 rev。服务端对每条 op 执行标准 OT transform(针对断网期间其他用户的 ops 做转换),然后顺序应用。这本质上就是 OT 算法处理长时间并发的自然扩展。
Q10:评论系统中,评论绑定的是文本范围,如果被评论的文本被删除了怎么办?
评论在创建时记录锚点:被评论文本的起始位置 + 内容哈希。每当文档有 op 发生时,系统需要维护所有评论的锚点位置(类似 OT transform 对位置的更新)。如果被评论的文字被完全删除,将该评论标记为 “resolved”(无效锚点),在 UI 上显示为灰色,但内容仍保留在评论 history 中,不丢弃。
🗺️ 七、学习路线图
延伸阅读
必读论文:Google Wave OT 论文「Operational Transformation in Real-Time Group Editors」,以及 Joseph Gentle 的「I was wrong. CRDTs are the future」,后者从工程角度对比了 OT 与 CRDT 的现实选择。
开源参考:ShareDB(Google Docs 同款 OT 的 Node.js 实现)、Yjs(CRDT 实现,Notion 离线协同的基础)、Automerge(另一成熟 CRDT 库)。
深度文章:Figma 官方技术博客「How Figma’s multiplayer technology works」,清晰讲解了他们在实际产品中选择 OT 还是 CRDT 的工程权衡。
知识复用地图
Google Docs
├── WebSocket 连接管理 → 设计聊天系统(Slack/WhatsApp)
├── Kafka op log 持久化 → 设计 Event Sourcing 系统 / 设计消息队列本身
├── 版本历史快照策略 → 设计 Git / 数据库 Undo 功能
├── OT/CRDT 冲突合并 → 设计分布式数据库的 MVCC 冲突处理
├── 权限 & 共享系统 → 设计 Dropbox / Google Drive 文件系统
└── 大文档分块加载 → 设计 YouTube(视频分块流式传输)

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)