Gemma-4 模型部署全记录:从下载到对话(2B/4B)
本文详细记录了在本地服务器上部署Google Gemma-4系列模型(2B/4B参数版本)的全过程。主要内容包括:通过ModelScope下载模型文件、配置Python环境(PyTorch、Transformers等)、编写交互式对话脚本,并支持思考模式展示推理过程。文章提供了完整的代码示例和运行参数说明,同时总结了常见问题的解决方案。通过分步指导,帮助开发者在本地快速部署和测试Gemma-4模型
Gemma-4 模型部署全记录:从下载到对话(2B/4B)
本博客全部操作流程均由 DeepSeek V4 全程辅助完成
对话链接:https://chat.deepseek.com/share/xqyyj3p0og9mibsu6n
b站视频:https://www.bilibili.com/video/BV1JSooBvEJj/
Google 发布的 Gemma 4 系列模型(2B、4B 等)凭借其优秀的推理能力和“思考模式”(enable_thinking)获得了广泛关注。本文记录在本地服务器上通过 ModelScope 下载并部署 Gemma-4-2B-it 和 Gemma-4-4B-it 的全过程,提供可直接复用的 Python 脚本,并分享踩坑经验。
📦 一、模型下载(通过 ModelScope)
ModelScope(魔塔社区)提供了便捷的模型下载接口。我们选择两个适合本地运行的 IT(指令调优)模型:
google/gemma-4-E2B-it—— 约 2B 参数,速度快,适合资源有限的环境google/gemma-4-E4B-it—— 约 4B 参数,效果更好,需更多显存
https://www.modelscope.cn/collections/google/Gemma-4
https://www.modelscope.cn/models/google/gemma-4-E2B-it
下载脚本
# download_models.py
from modelscope import snapshot_download
# 指定缓存根目录(可修改)
cache_dir = '/home/shared/winston/model'
# 下载 2B 模型
model_dir_2b = snapshot_download('google/gemma-4-E2B-it', cache_dir=cache_dir)
print(f"2B 模型已下载到: {model_dir_2b}")
# 下载 4B 模型
model_dir_4b = snapshot_download('google/gemma-4-E4B-it', cache_dir=cache_dir)
print(f"4B 模型已下载到: {model_dir_4b}")
执行后,模型文件会保存在 cache_dir 下的镜像目录中。建议记录下最终路径(例如 /home/shared/winston/model/google/gemma-4-E2B-it),后续脚本会用到。
如果下载速度慢,可以设置
export MODELSCOPE_CACHE=/your/path或使用魔塔提供的加速方案(如source /etc/network_turbo)。
🛠️ 二、环境配置
为了避免依赖冲突,新建一个干净的 Conda 环境。
conda create -n gemma4 python=3.12 -y
conda activate gemma4
2.1 安装 PyTorch(CUDA 12.4)
使用阿里云镜像快速安装:
pip install torch torchvision torchaudio -f https://mirrors.aliyun.com/pytorch-wheels/cu124/
2.2 安装 Transformers 与 Accelerate
pip install transformers accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple
2.3 安装 ModelScope(用于加载模型)
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
🐍 三、交互脚本(支持思考模式)
以下脚本 gemma_chat.py 实现了命令行对话,支持 --enable-thinking 参数,并可通过 --model-path 指定使用 2B 或 4B 模型。
#!/usr/bin/env python3
"""
Gemma 4 模型交互脚本(支持 2B / 4B)
用法示例:
python gemma_chat.py # 使用默认路径(2B)
python gemma_chat.py --model-path /path/to/4B # 指定 4B 模型
python gemma_chat.py --enable-thinking # 开启思考模式
"""
import argparse
from modelscope import AutoProcessor, AutoModelForCausalLM
# 默认模型路径(请根据实际下载位置修改)
DEFAULT_MODEL_PATH = "/home/shared/winston/model/google/gemma-4-E2B-it"
def load_model(model_path):
"""加载模型和处理器"""
print(f"正在加载模型: {model_path}")
processor = AutoProcessor.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
dtype="auto",
device_map="auto"
)
print("模型加载完成!")
return processor, model
def generate_response(processor, model, user_input, enable_thinking=False):
"""生成模型回复"""
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": user_input},
]
text = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=enable_thinking
)
inputs = processor(text=text, return_tensors="pt").to(model.device)
input_len = inputs["input_ids"].shape[-1]
outputs = model.generate(**inputs, max_new_tokens=1024)
response = processor.decode(outputs[0][input_len:], skip_special_tokens=False)
parsed = processor.parse_response(response)
return parsed
def main():
parser = argparse.ArgumentParser(description="Gemma 4 模型对话脚本")
parser.add_argument("--model-path", type=str, default=DEFAULT_MODEL_PATH,
help="本地模型路径(支持 2B 或 4B)")
parser.add_argument("--enable-thinking", action="store_true",
help="开启思考模式(显示推理过程)")
args = parser.parse_args()
processor, model = load_model(args.model_path)
print("\n" + "=" * 50)
print("Gemma 4 模型已就绪")
if args.enable_thinking:
print("🧠 思考模式已开启")
print('输入 "quit" 或 "exit" 退出程序')
print("=" * 50 + "\n")
while True:
try:
user_input = input("\n请输入问题: ").strip()
if user_input.lower() in ["quit", "exit"]:
print("再见!")
break
if not user_input:
continue
response = generate_response(processor, model, user_input, args.enable_thinking)
print(f"\n模型回复:\n{response}")
except KeyboardInterrupt:
print("\n\n再见!")
break
except Exception as e:
print(f"\n发生错误: {e}")
if __name__ == "__main__":
main()
🚀 四、运行测试
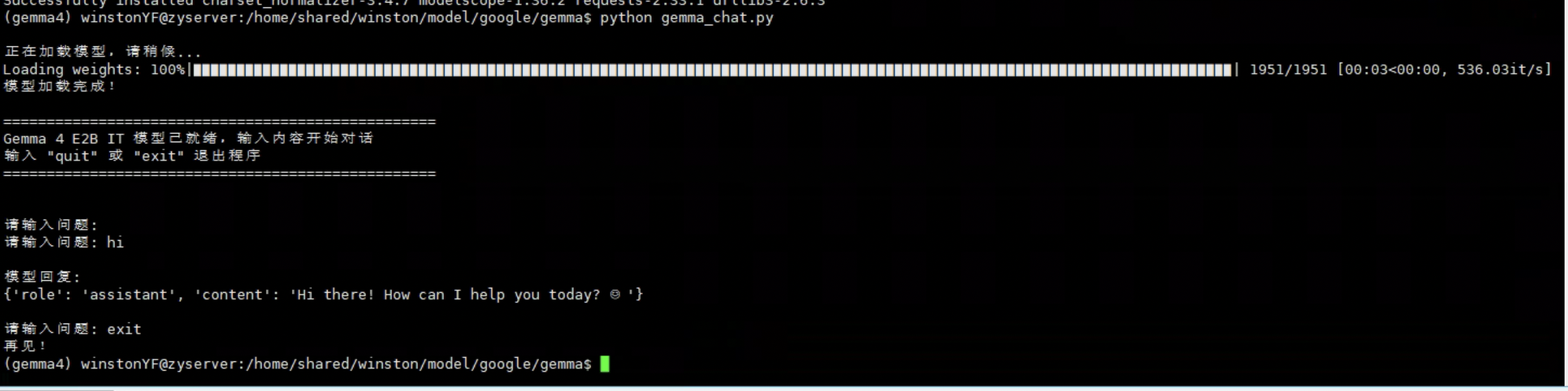
4.1 基本对话(2B 模型)
python gemma_chat.py
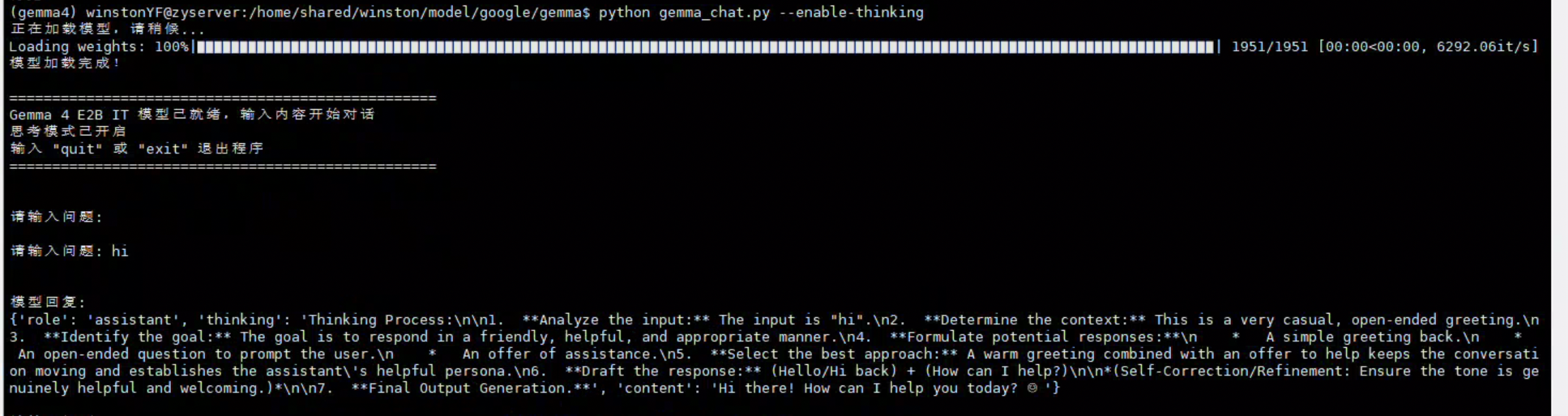
4.2 开启思考模式(4B 模型)
python gemma_chat.py --model-path /home/shared/winston/model/google/gemma-4-E4B-it --enable-thinking
模型会先输出一步一步的推理过程,再给出最终答案。
⚠️ 五、常见问题与解决方案
| 问题 | 可能原因 | 解决方法 |
|---|---|---|
Unrecognized processing class |
本地模型缺少 processor 配置文件 | 重新用 snapshot_download 下载完整模型;或改用 HuggingFace transformers 直接加载 |
| CUDA 版本错误 / import 崩溃 | PyTorch 与 torchvision 的 CUDA 版本不匹配 | 使用阿里云镜像重新安装(如上文) |
| 显存不足(OOM) | 4B 模型需要约 8-10GB 显存 | 添加 torch_dtype=torch.float16 半精度加载;或使用 2B 模型 |
| 生成内容乱码或重复 | 模型输出未正确解析 | 升级 transformers/modelscope 到最新版;调整 max_new_tokens 或 temperature |
| 下载速度极慢 | 网络限制 | 使用魔塔加速(source /etc/network_turbo)或手动下载后放到对应目录 |
📝 六、总结
通过本文的步骤,你可以:
- 使用 ModelScope 一键下载 Gemma 4 的 2B 和 4B 模型;
- 搭建独立的 Conda 环境并安装必要依赖;
- 运行交互式脚本,体验模型的“思考模式”;
- 根据显存大小灵活切换模型版本。
Gemma 4 系列模型在保持轻量的同时,展现了强大的推理能力和透明的思考过程,非常适合学术研究、教学演示以及需要可解释 AI 的落地场景。
🎉 特别感谢 DeepSeek V4 在脚本编写、排错建议和博客润色上提供的全程智能支持!
🔗 七、参考链接

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)