天机学堂DAY01-08
DAY01
项目搭建
环境搭建
企业开发模式

目前项目开发状态1.0
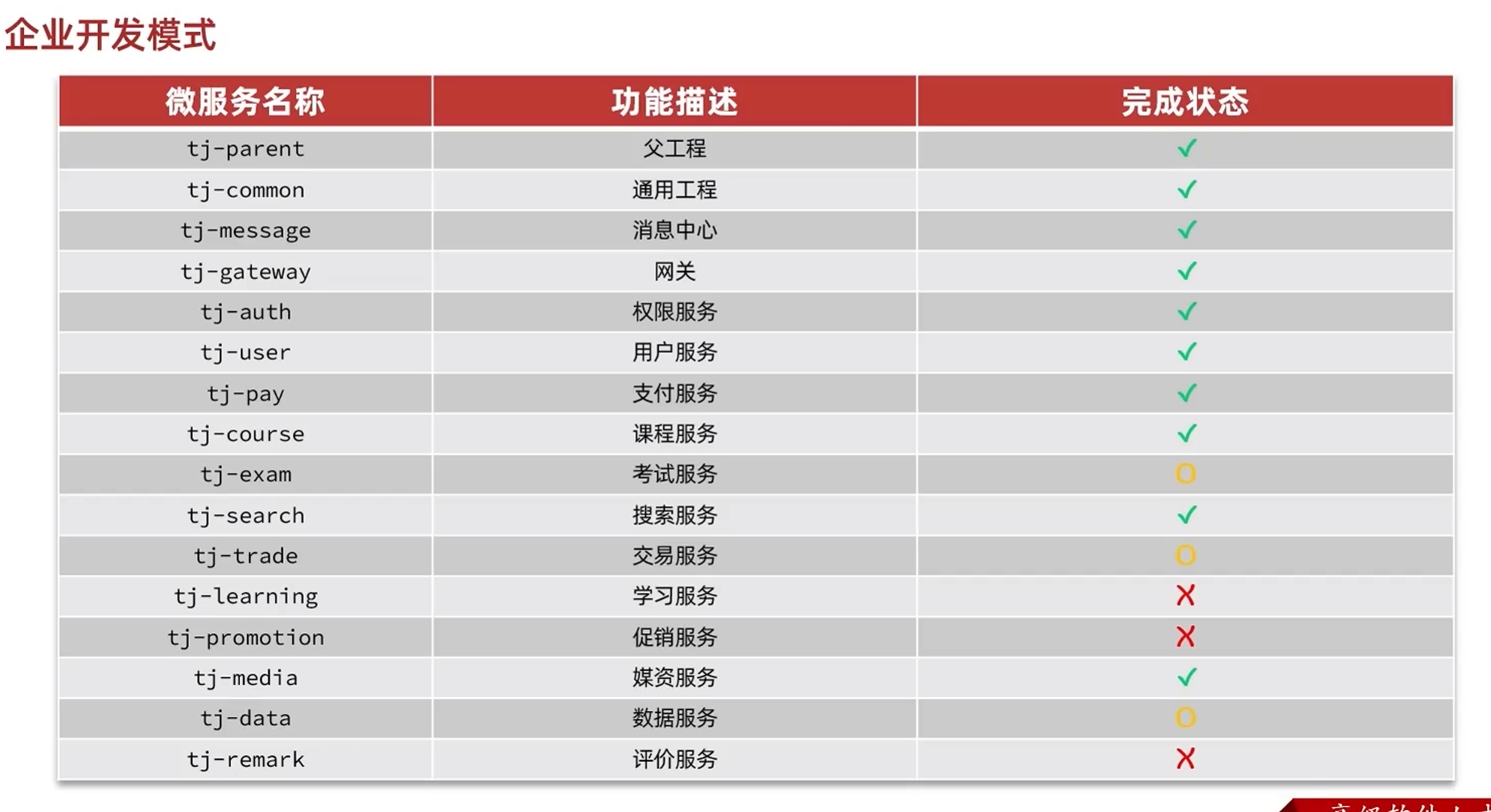
在公司中碰到的项目大多都是这样开发了部分项目的情况

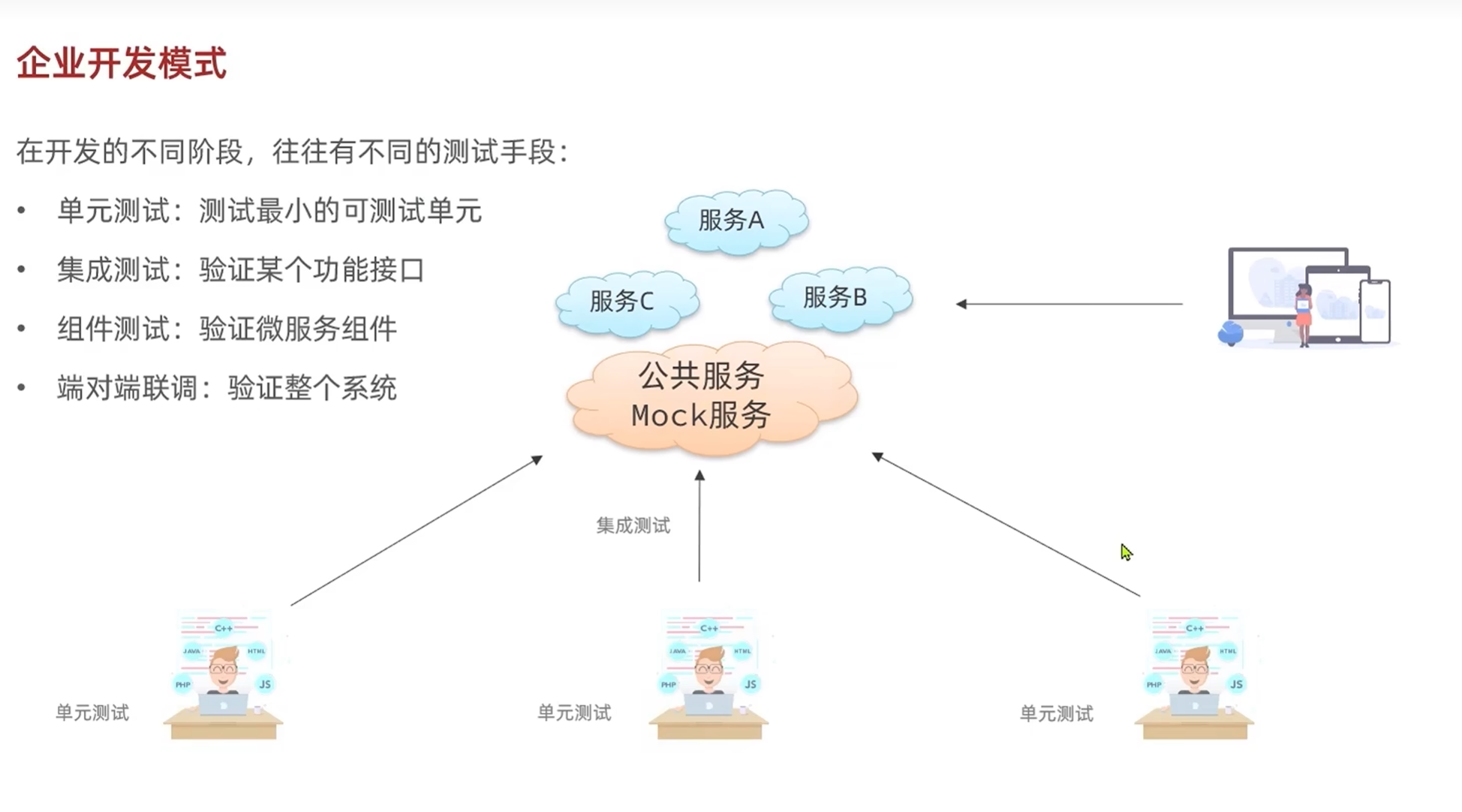
在开发的不同阶段有不同的测试手段
单元测试,程序员在自己的电脑上编写单元测试开始测试代码
集成测试,程序员在公共服务器上自己编写测试语句,自己编写请求来验证某个接口
组件测试,负责不同的服务的程序员把自己的服务上传到公共服务上进行测试
端对端连调,大型的前后端联调
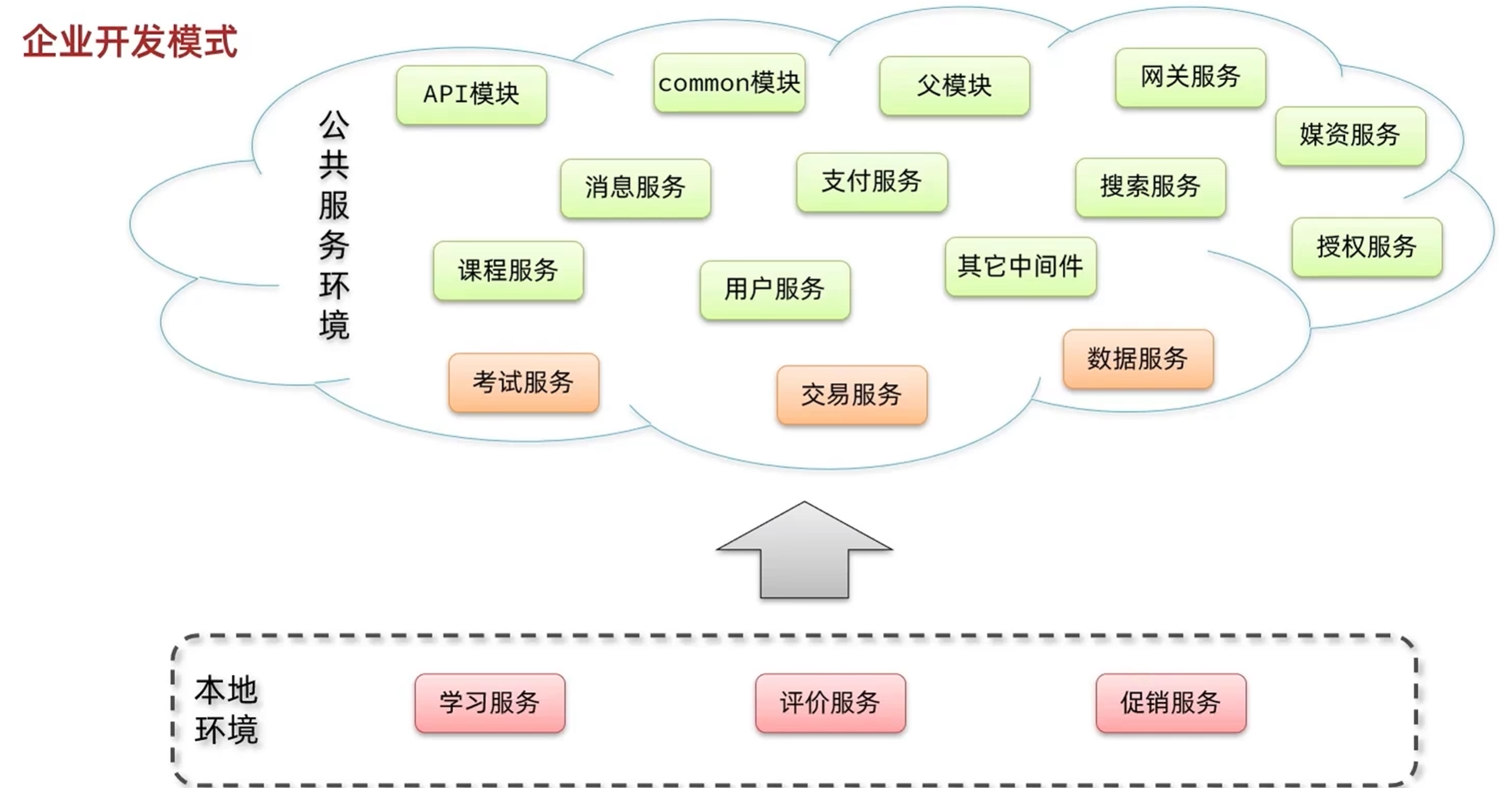
模拟企业环境

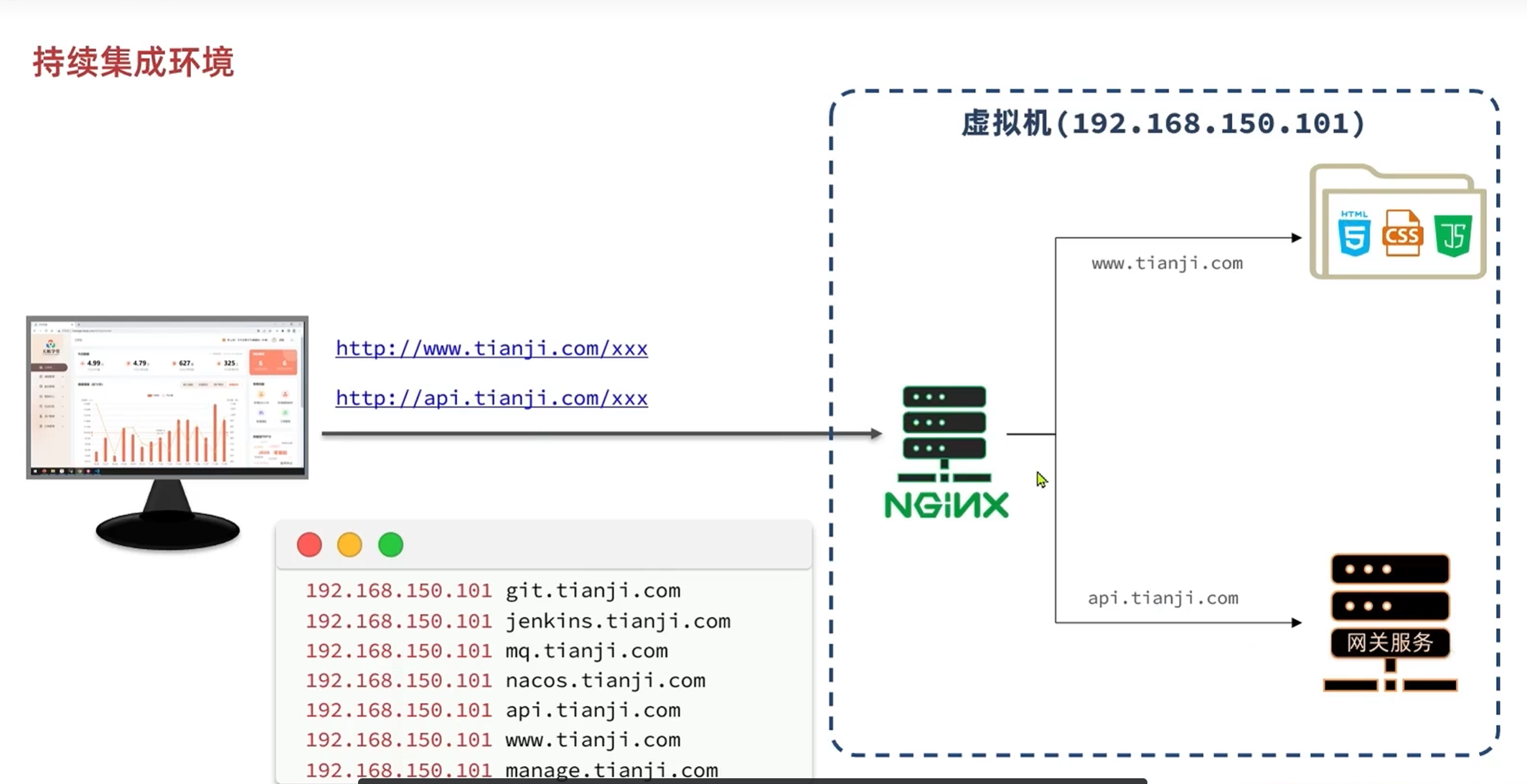
因为软件太多,端口号也太多,容易记混,所以在本地配置域名
在本地的下面这个个地址访问hosts文件
C:\Windows\System32\drivers\etc
这个host文件是在System文件夹下的,没有权限去修改,直接修改会很麻烦
一般使用Swithhosts来修改
不用Switchhosts修改的方法如下
修改 hosts 文件
用记事本管理员方式打开(最稳)
-
按下
Win键,搜索 记事本 -
右键记事本 → 以管理员身份运行
-
打开记事本后,点击左上角「文件」→「打开」
-
在地址栏输入路径:
plaintext
C:\Windows\System32\drivers\etc\hosts -
右下角文件类型选择 所有文件,就能看到
hosts文件了 -
选中
hosts文件,点击「打开」
添加域名解析规则
在 hosts 文件的最后一行,添加下面的内容(把 IP 换成你的虚拟机 IP):
192.168.150.101 jenkins.tianji.com
保存文件(Ctrl+S),关闭记事本。
验证是否生效
-
按下
Win + R,输入cmd打开命令提示符 -
输入命令刷新 DNS 缓存:
ipconfig /flushdns -
测试解析是否成功:
ping jenkins.tianji.com如果能解析到你设置的 IP,说明配置成功 ✅
五、访问你的服务
现在打开浏览器,访问:
http://jenkins.tianji.com:端口号
(端口号是你服务实际监听的端口,比如 Jenkins 默认 8080,或者 Nginx 的 8080)
要添加的域名如下
192.168.150.101 git.tianji.com
192.168.150.101 jenkins.tianji.com
192.168.150.101 mq.tianji.com
192.168.150.101 nacos.tianji.com
192.168.150.101 xxljob.tianji.com
192.168.150.101 es.tianji.com
192.168.150.101 api.tianji.com
192.168.150.101 www.tianji.com
192.168.150.101 manage.tianji.com
192.168.150.101 cpolar.tianji.com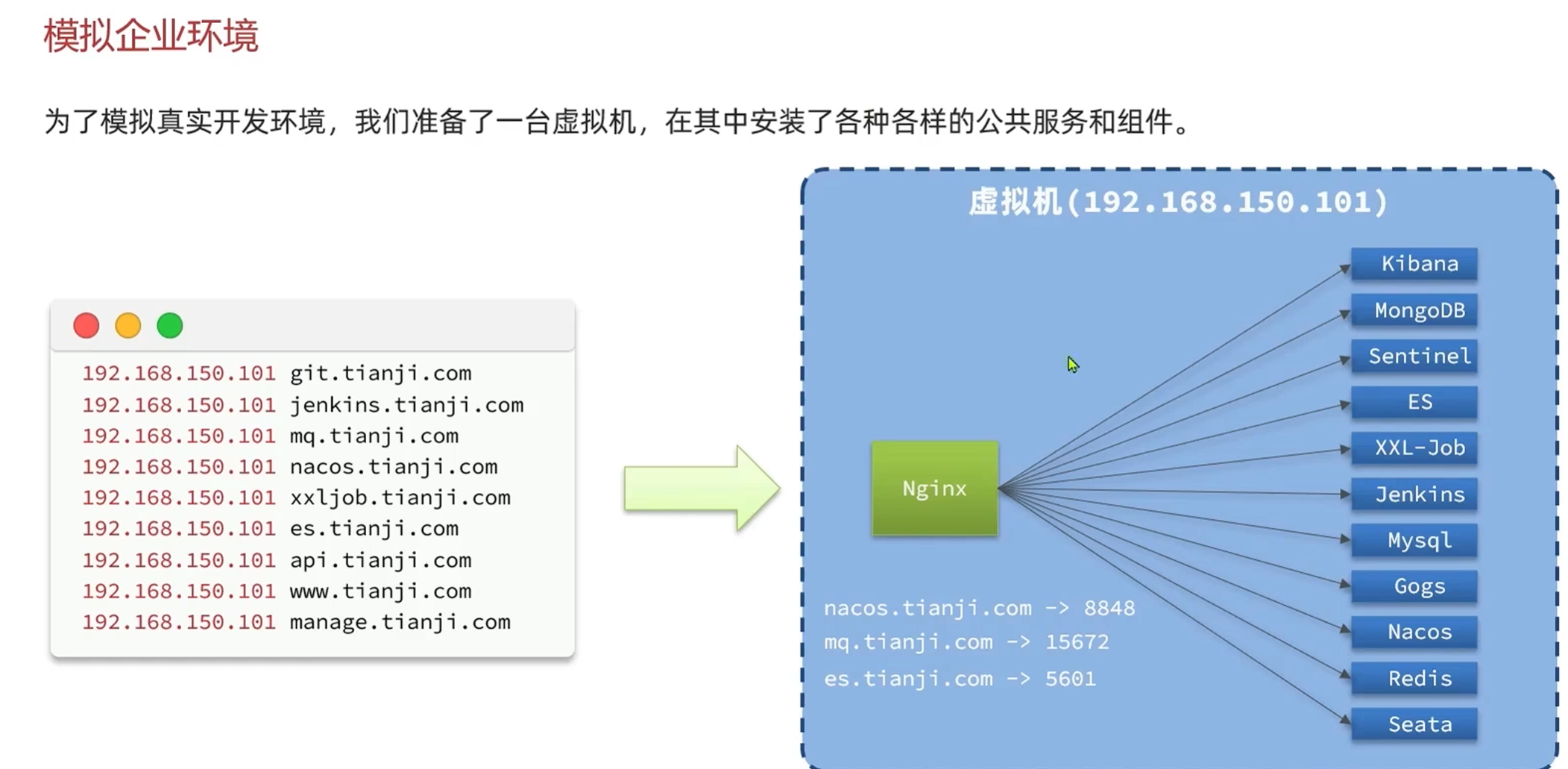
在浏览器中输入这些域名的时候,一定会指向虚拟机
不写端口,默认访问到80端口,也就是nginx
用nginx对这些端口做监听和反向代理,在访问到80端口之后,由nginx反向代理到指定的端口号
域名对应的服务列表:
|
名称 |
域名 |
账号 |
端口 |
|---|---|---|---|
|
Git私服 |
git.tianji.com |
tjxt/123321 |
10880 |
|
Jenkins持续集成 |
jenkins.tianji.com |
root/123 |
18080 |
|
RabbitMQ |
mq.tianji.com |
tjxt/123321 |
15672 |
|
Nacos控制台 |
nacos.tianji.com |
nacos/nacos |
8848 |
|
xxl-job控制台 |
xxljob.tianji.com |
admin/123456 |
8880 |
|
ES的Kibana控制台 |
es.tianji.com |
- |
5601 |
|
微服务网关 |
api.tianji.com |
- |
10010 |
|
用户端入口 |
www.tianji.com |
- |
18081 |
|
管理端入口 |
manage.tianji.com |
- |
18082 |
持续集成环境
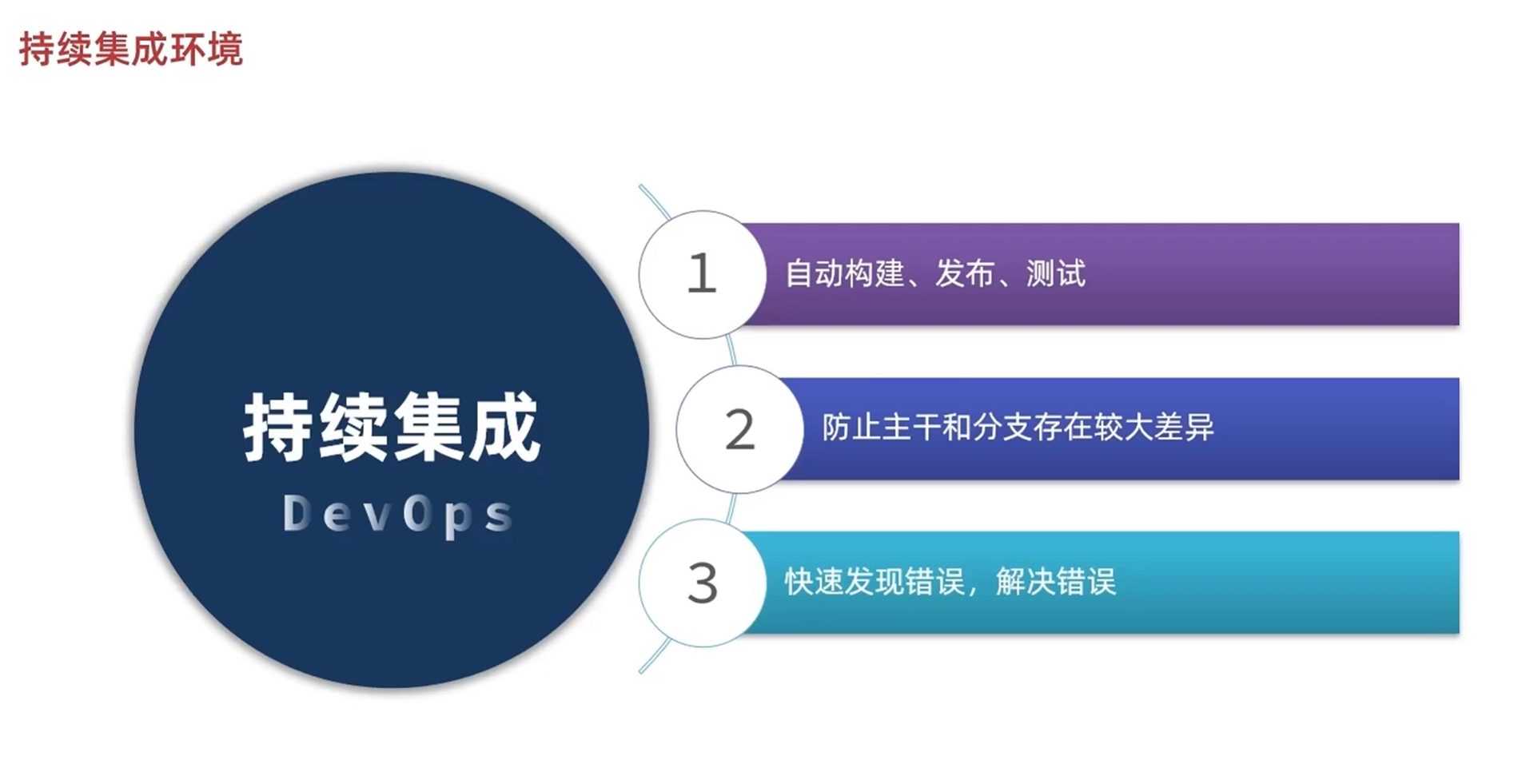
以前是所有开发完成了在合并测试,万一测试的时候写了没有被发现的bug,时间长了攒了很多bug的时候改起来非常困难
现在是程序员开发完一个接口就可以自动构建并部署进行测试,可以快速发现错误,解决错误
jenkins帮助我们获取,编译,构建,部署代码,是持续集成环境的核心
在写完代码之后,代码会直接推送到gogs账号
jenkins会直接拉取gogs账号里面的代码,把代码拉取下来之后再做代码的编译,构建和打包
jenkins打包代码是指打包成docker镜像
在docker上完成容器部署
具体流程是
当代码提交到gogs的时候,由于web钩子的存在,gogs就会向jenkins发送请求
请求的时候,jenkins会自动执行,做项目的编译构建部署
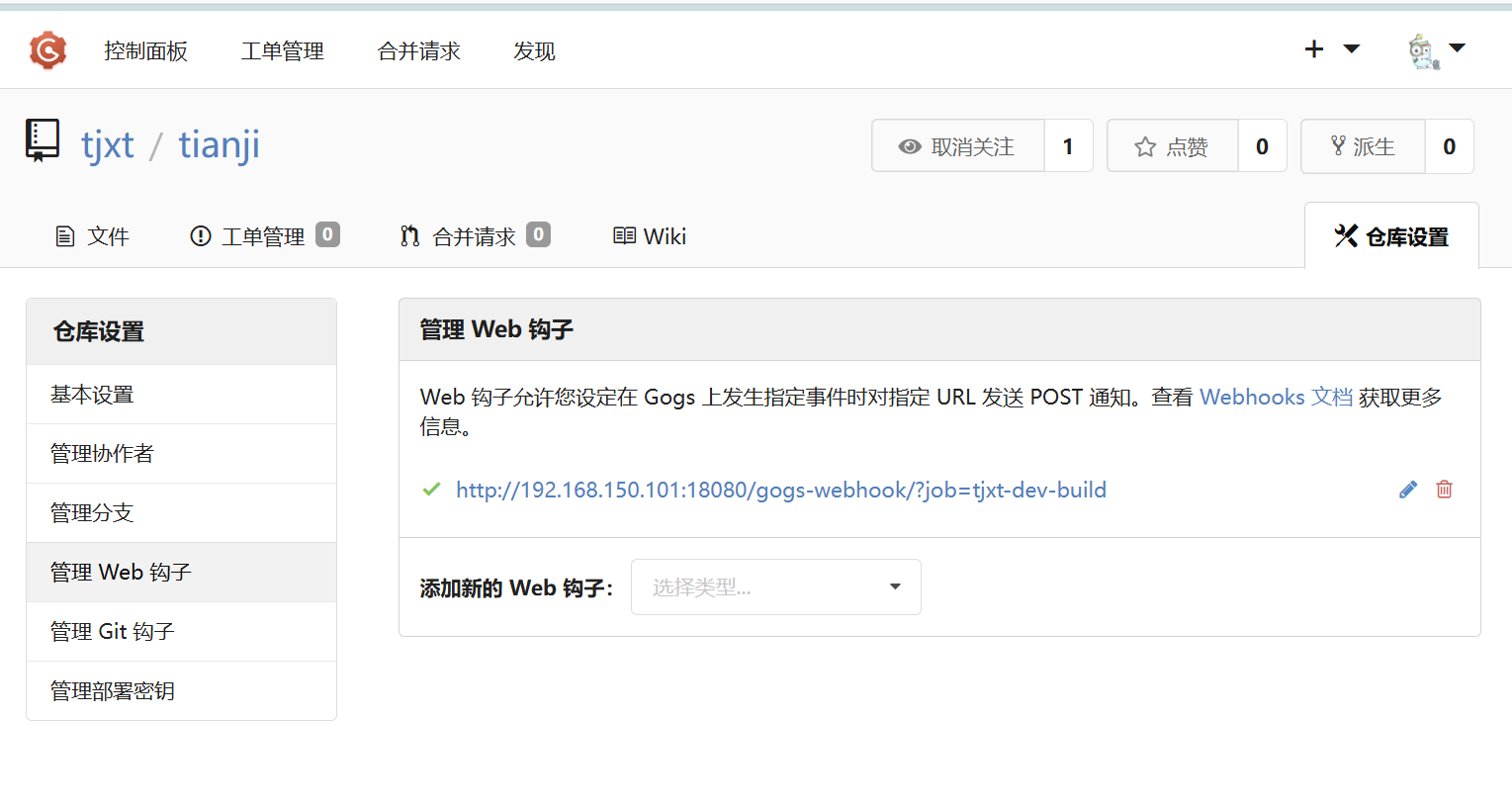
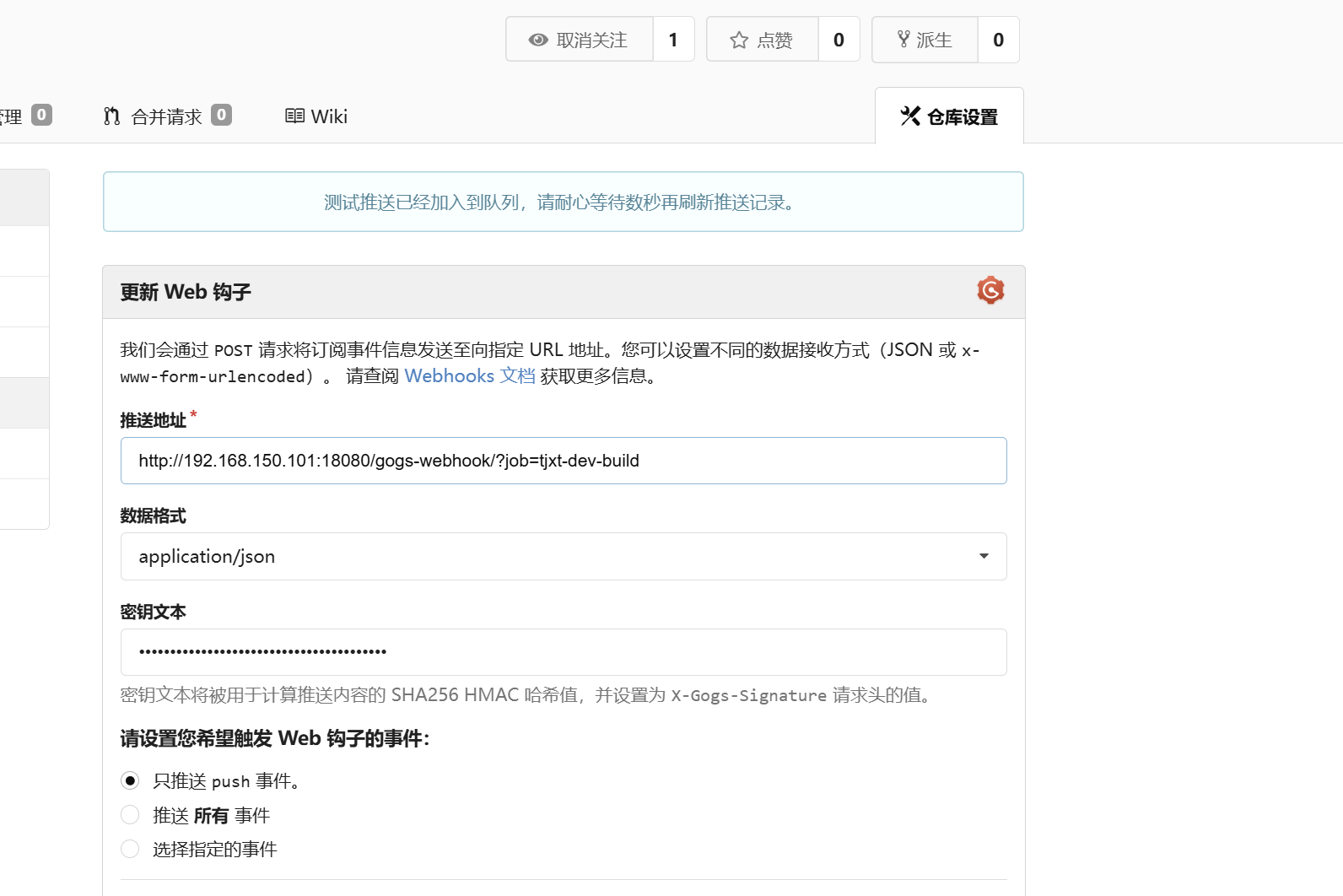
测试部署的微服务
本地部署开发方式

应该先把代码从Gogs上面拉取下来
在实际开发过程中可能需要获取权限才能拉取代码
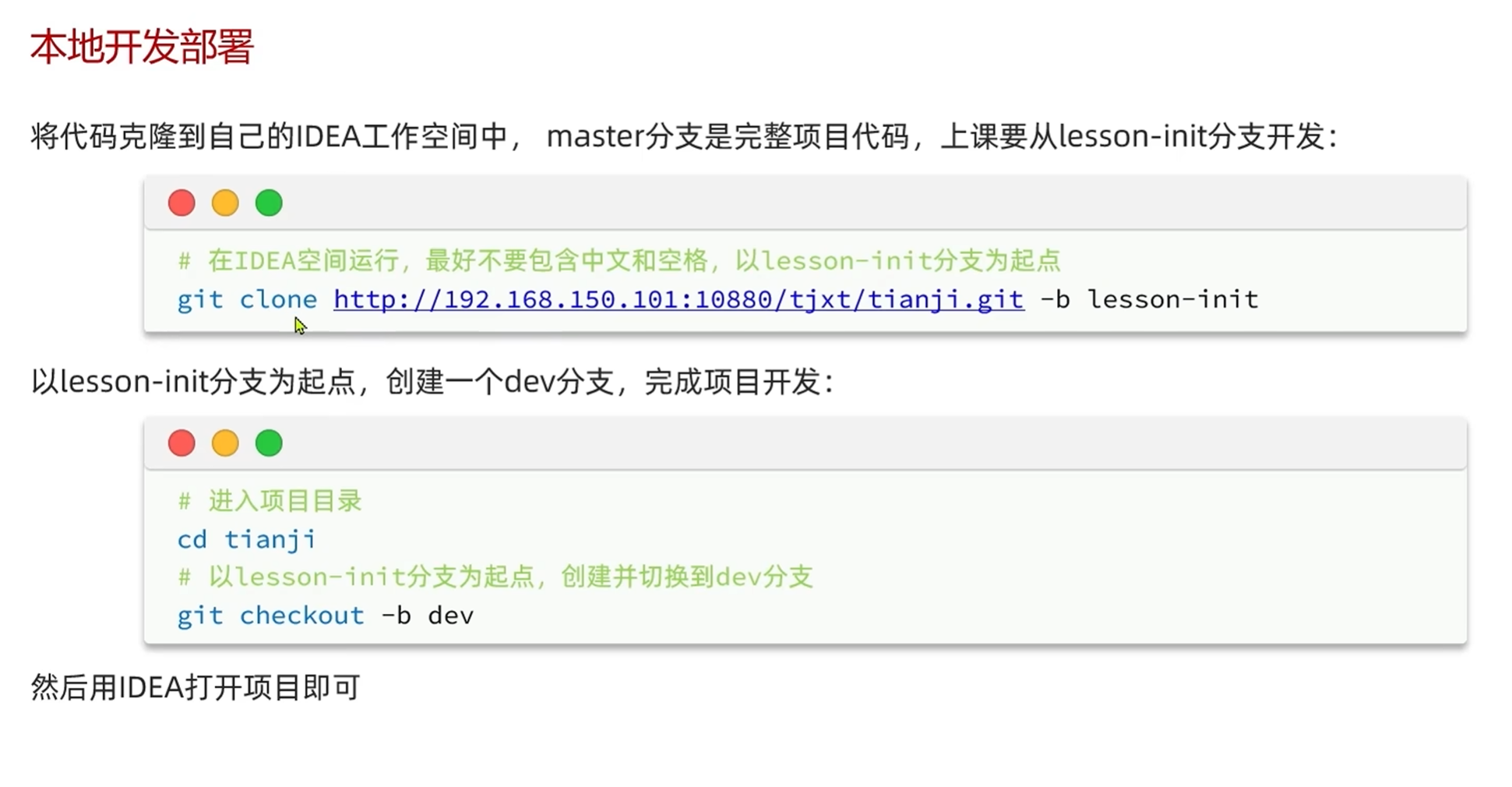
具体拉取方式
创建一个没有中文的文件夹
用终端打开输入命令
完成后用idea打开
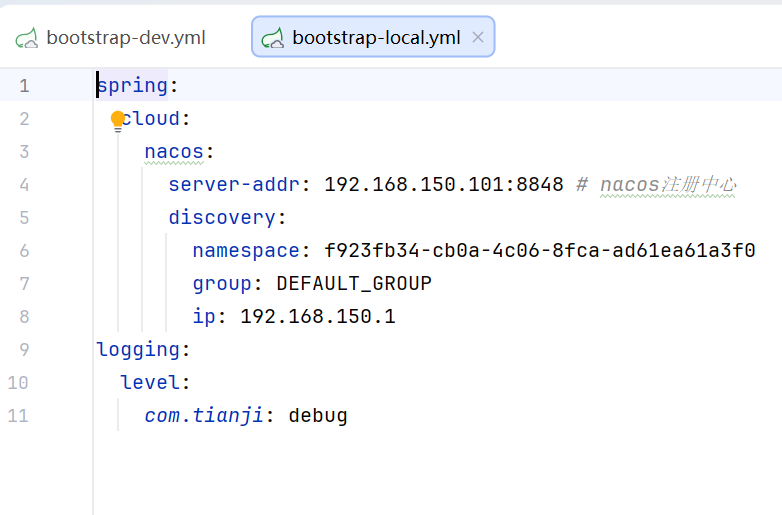
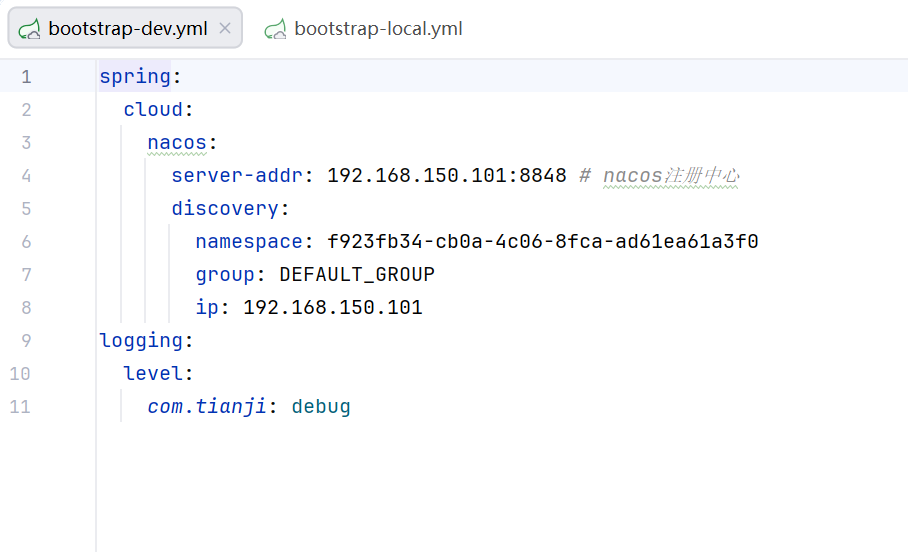
在本地部署和在虚拟机上部署的唯一的区别是ip地址不同
在本地部署和在虚拟机上面部署用的nacos是同一个,这是因为不管是在本地还是在虚拟机上面部署都需要远程调用访问其他的微服务,这时候都需要在nacos注册中心来注册
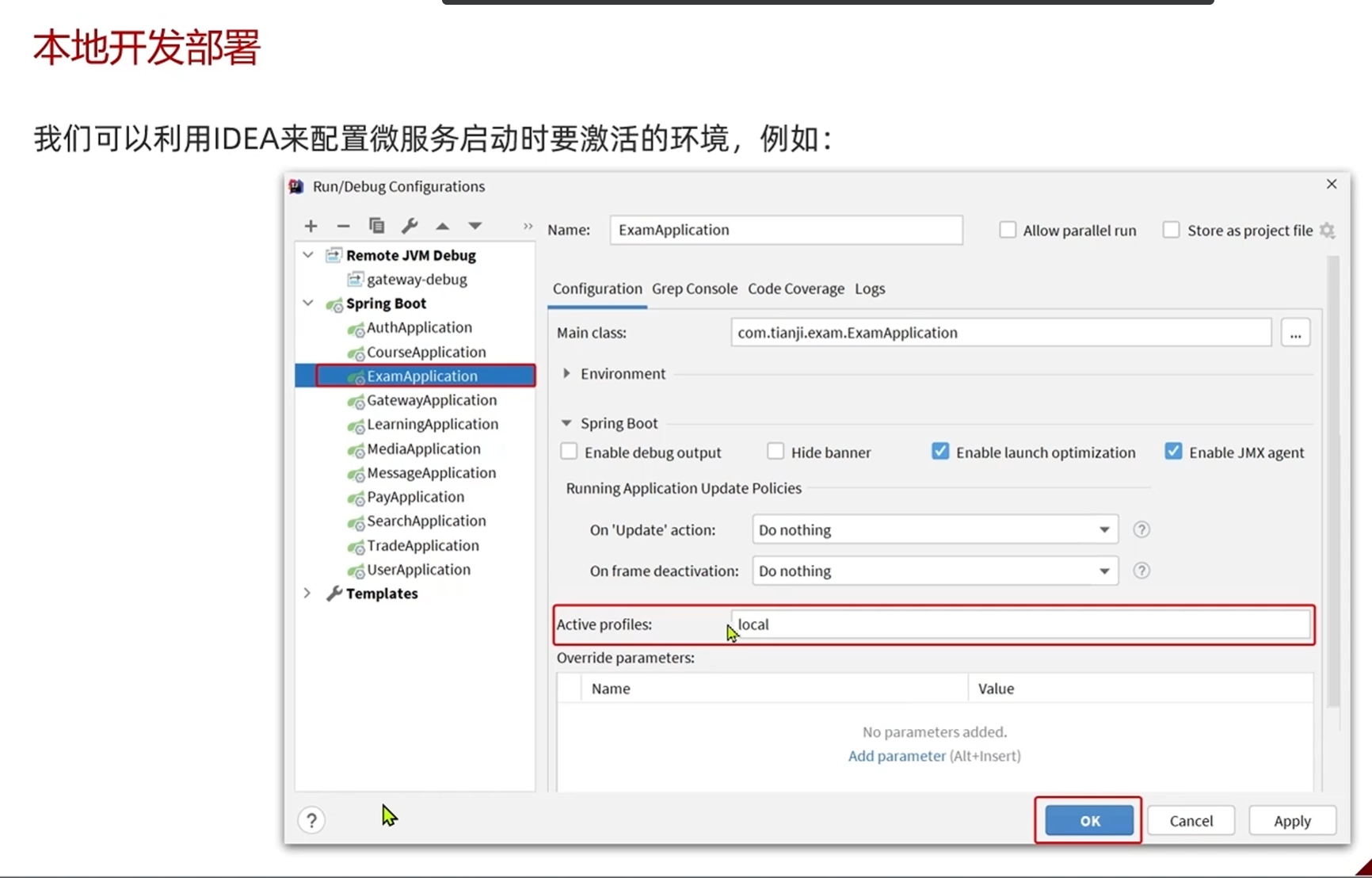
要指定部署方式的方法是去启动类里面把Active profiles改成local这个比配置文件优先级高,在切换不同部署方式的时候就不用修改配置文件了
每一次运行服务器都会把自己的服务注册到nacos上面,这样在合作中会让一个服务创建多个实例,在调用的时候可能就会调用的不是自己本地的服务实例,所以在本地要修改yaml配置
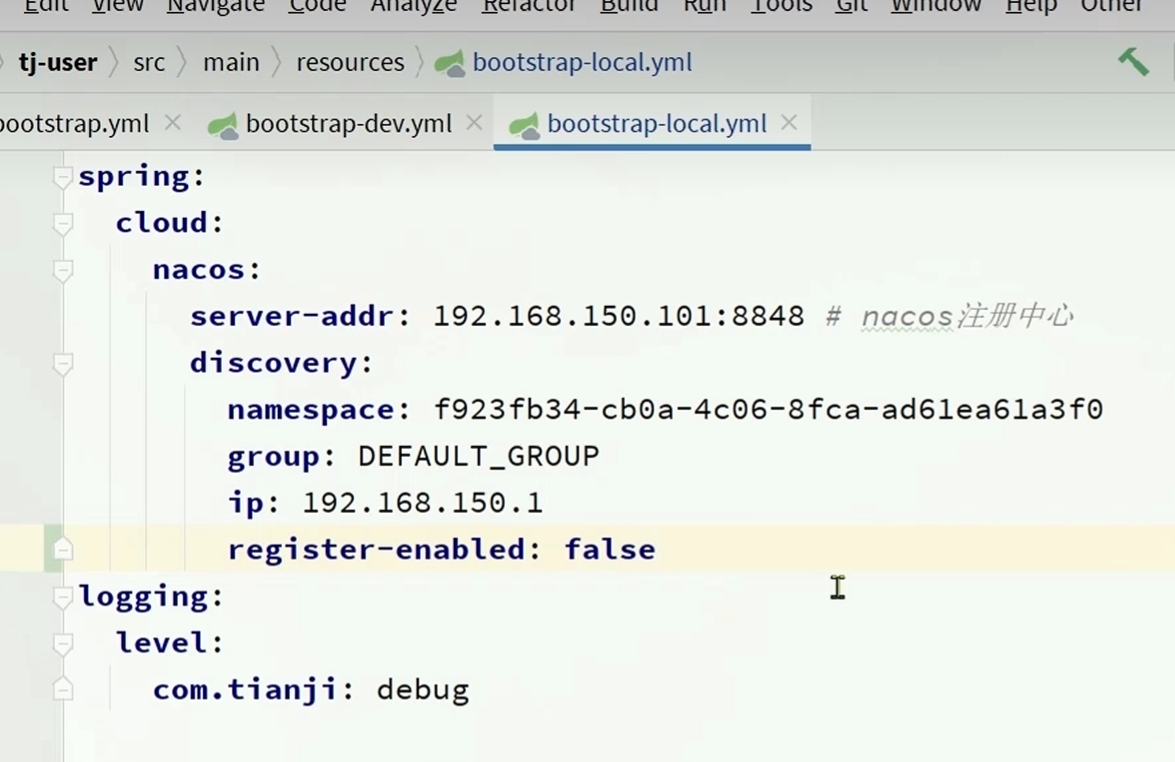
修改register-enabled为false
因为nacos实际上就做两件事,一件事是拉取别的服务,一件事是把服务注册到nacos上面
修改这个配置之后不会把本地的服务注册到nacos上面了,防止出现多个实例的问题
修复BUG
熟悉项目



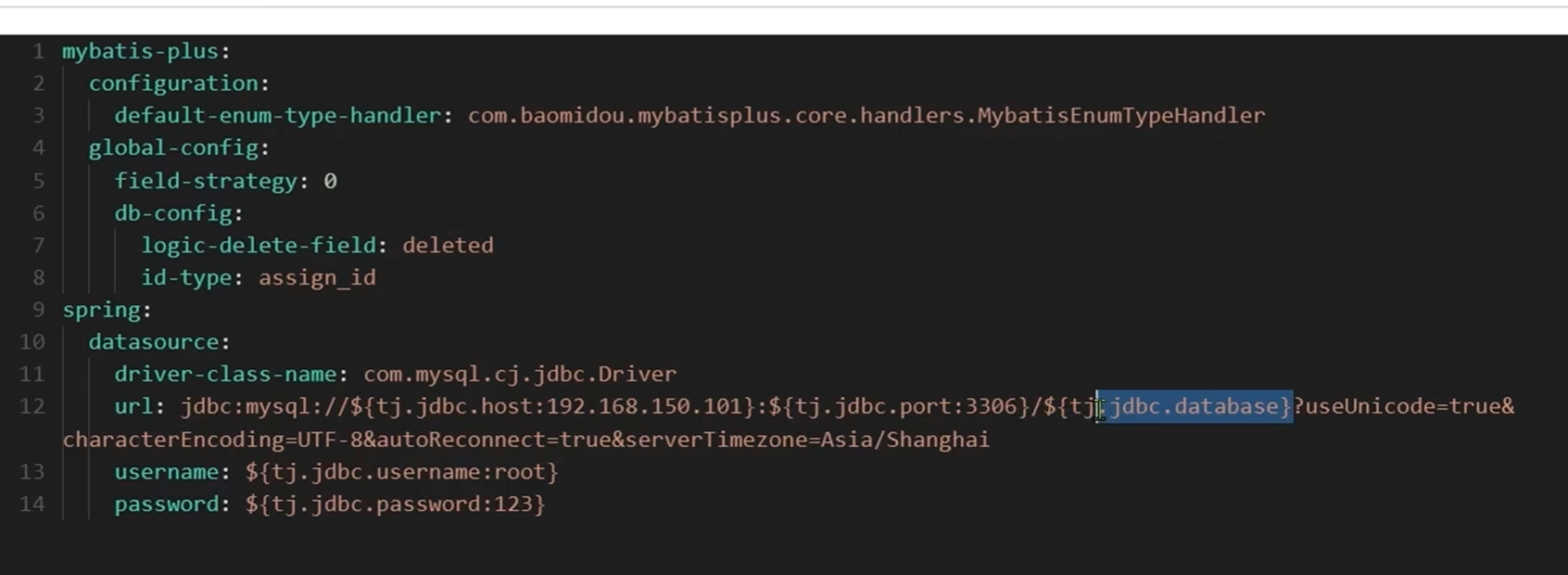
nacos上面还有共享配置,配置的语法是${ :}冒号前面是要读取的配置,冒号后面是默认值
由于是在虚拟机上面配置的,所以默认为192.168.150.101
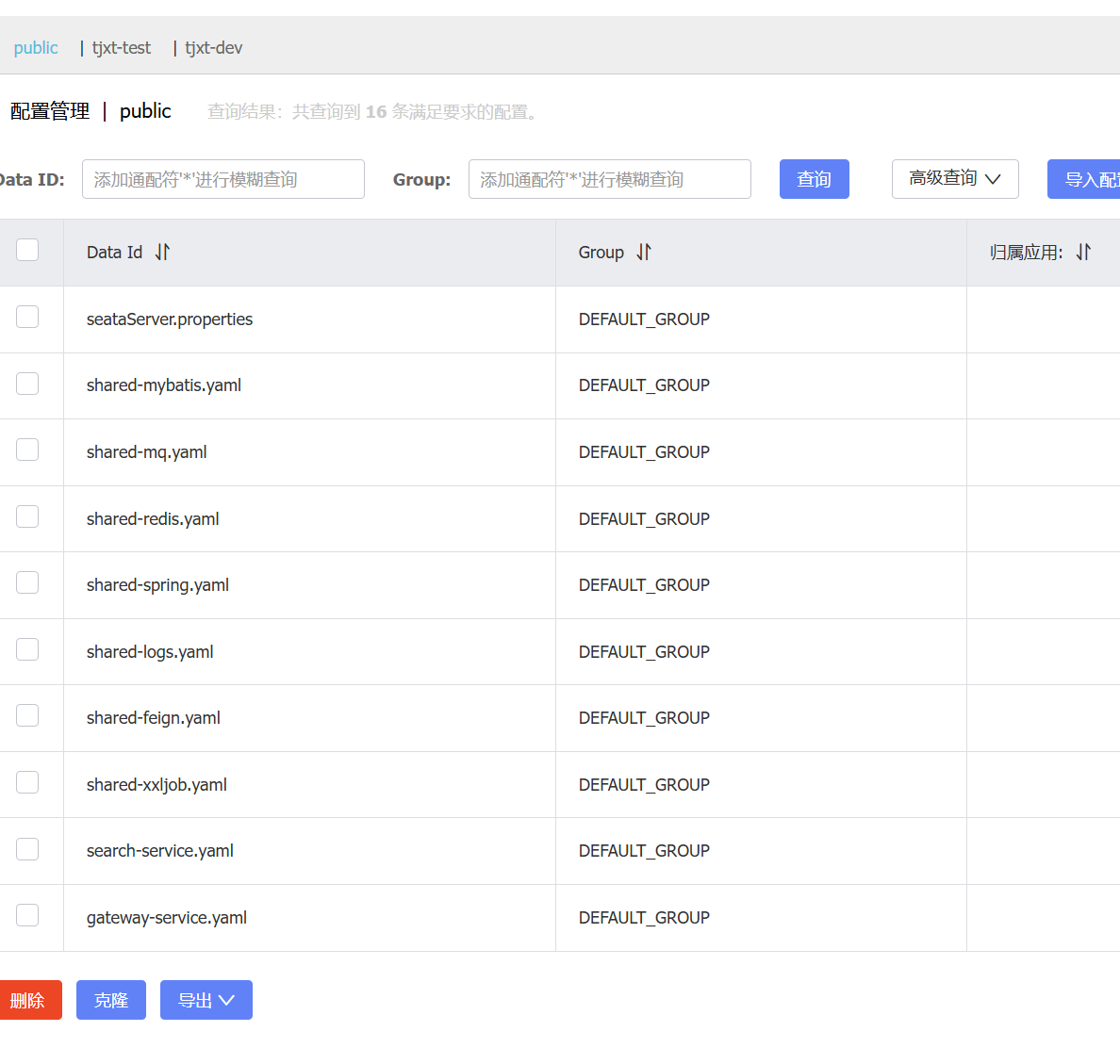
配置是按功能拆分的,基本上都可以拿来直接用
阅读源码
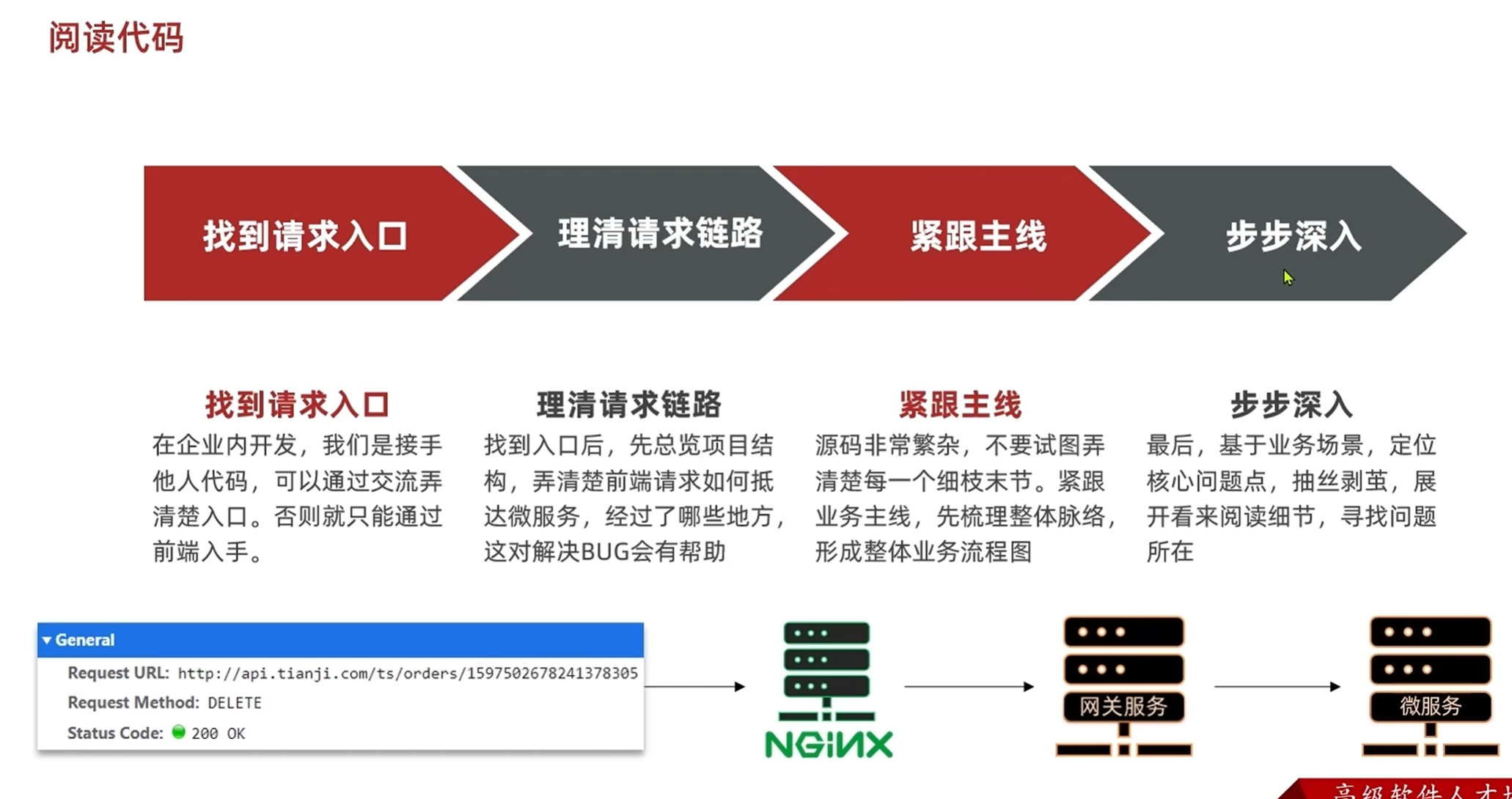
如果有完整的接口文档可以看接口文档
如果没有接口文档可以看前端的发送的请求来定位
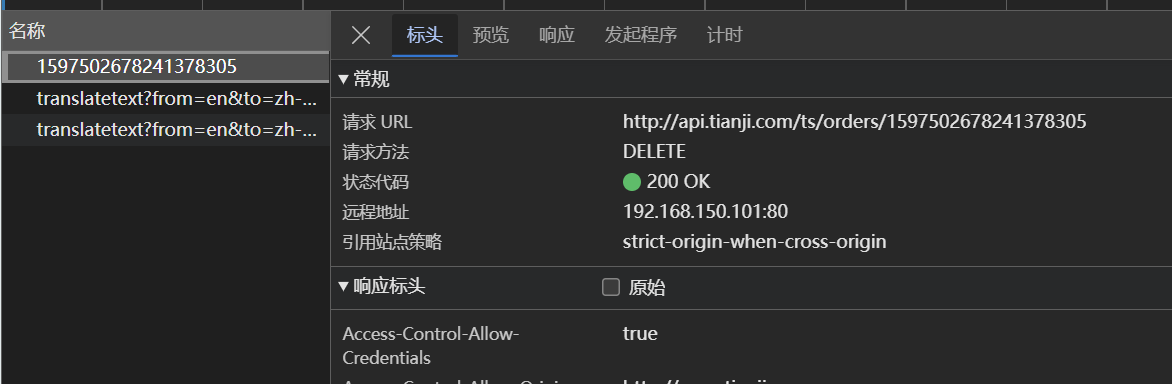
请求到达nginx
nginx对域名进行反向代理,api.tianji.com这是向网端发送请求的域名,可以在nginx的conf文件夹下查看
请求由nginx发送向网关之后,网关解析请求并路由,具体信息在网关的配置文件里面可以看
/ts是发送向微服务trade-service的请求
/order是指trade-service里的order服务

分析和解决
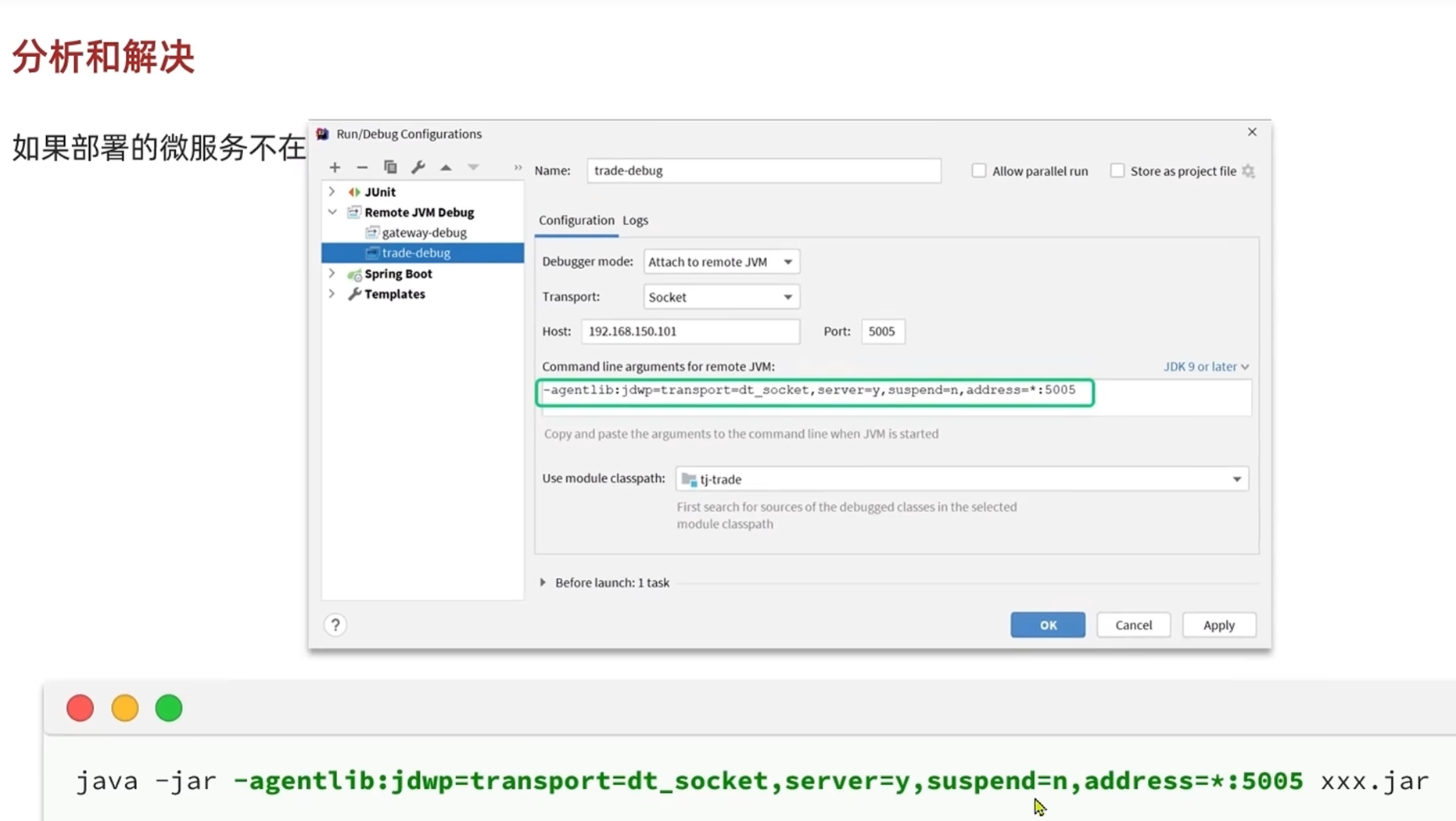
当部署的微服务不在本地的时候,可以远程修改
首先是
获取这一行代码
-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=*:5005然后把这段参数加在运行微服务的命令上面
现在是jenkins启动微服务的
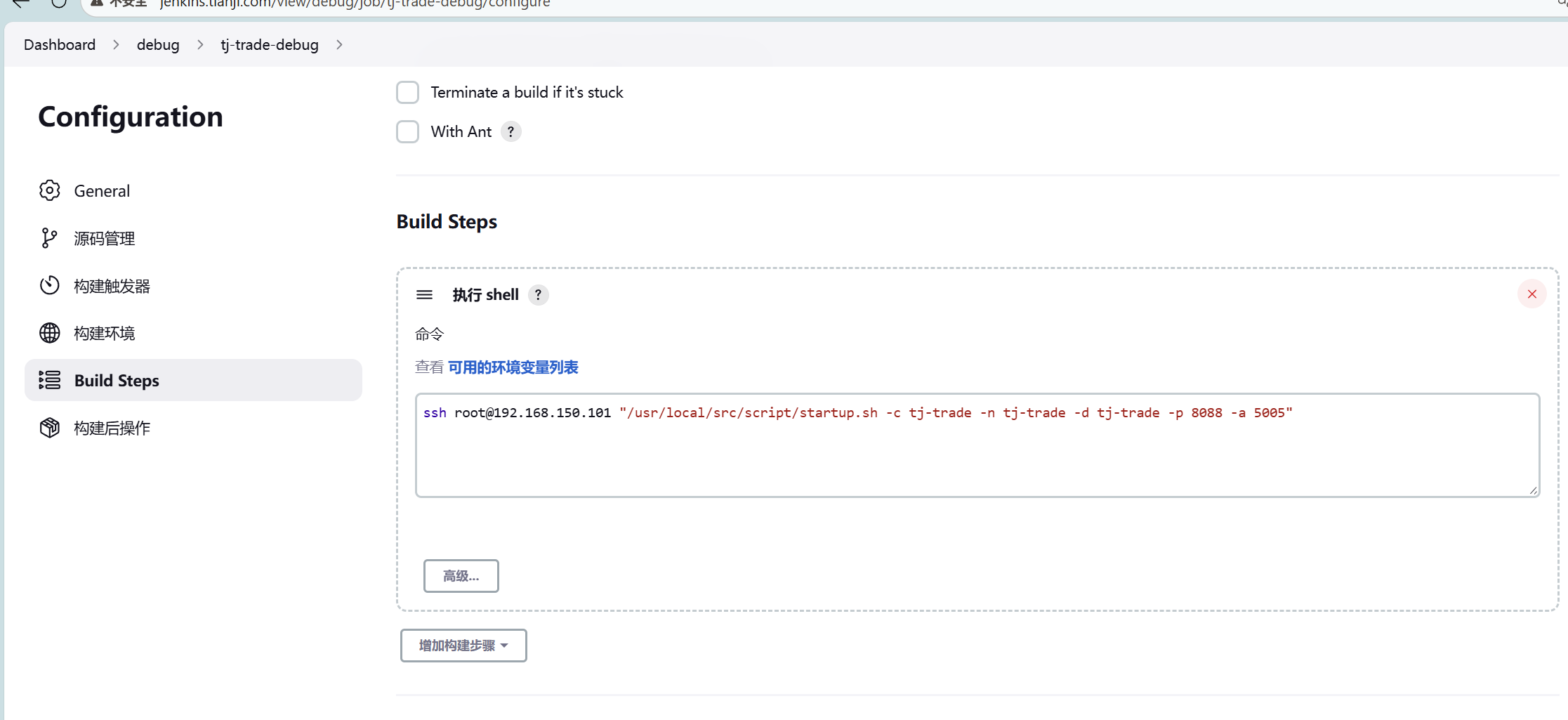
ssh root@192.168.150.101 "/usr/local/src/script/startup.sh -c tj-trade -n tj-trade -d tj-trade -p 8088 -a 5005"配置信息里面有一个很重要的文件startup.sh 所有的参数都写在这个里面,启动的时候会把这个当作启动脚本来启动
这个文件中配置有上面所说的那一行代码
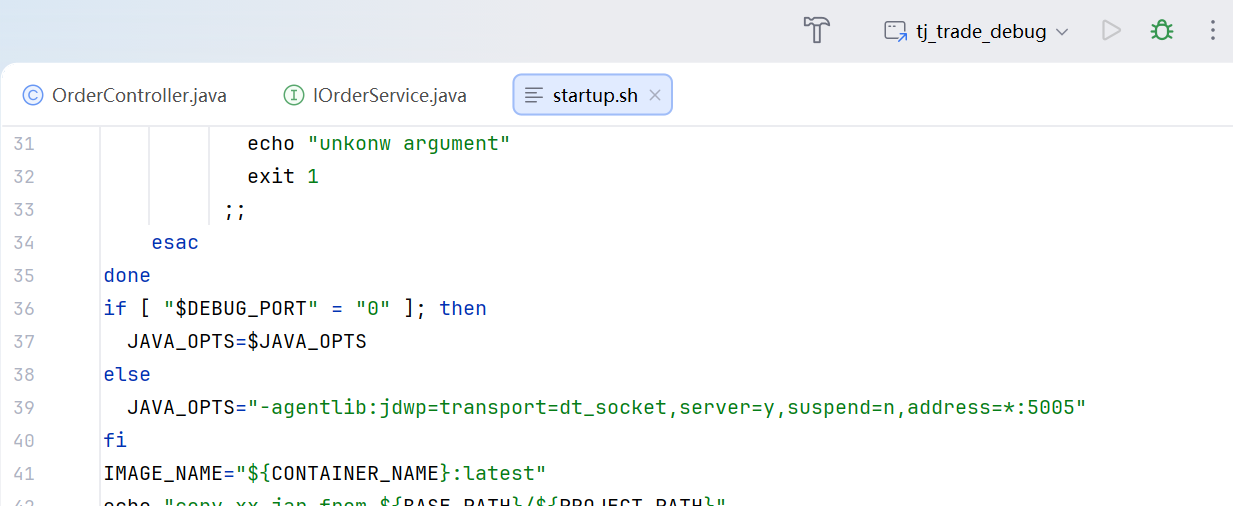
在微服务启动成功之后,虚拟机中会生成这个镜像并启动
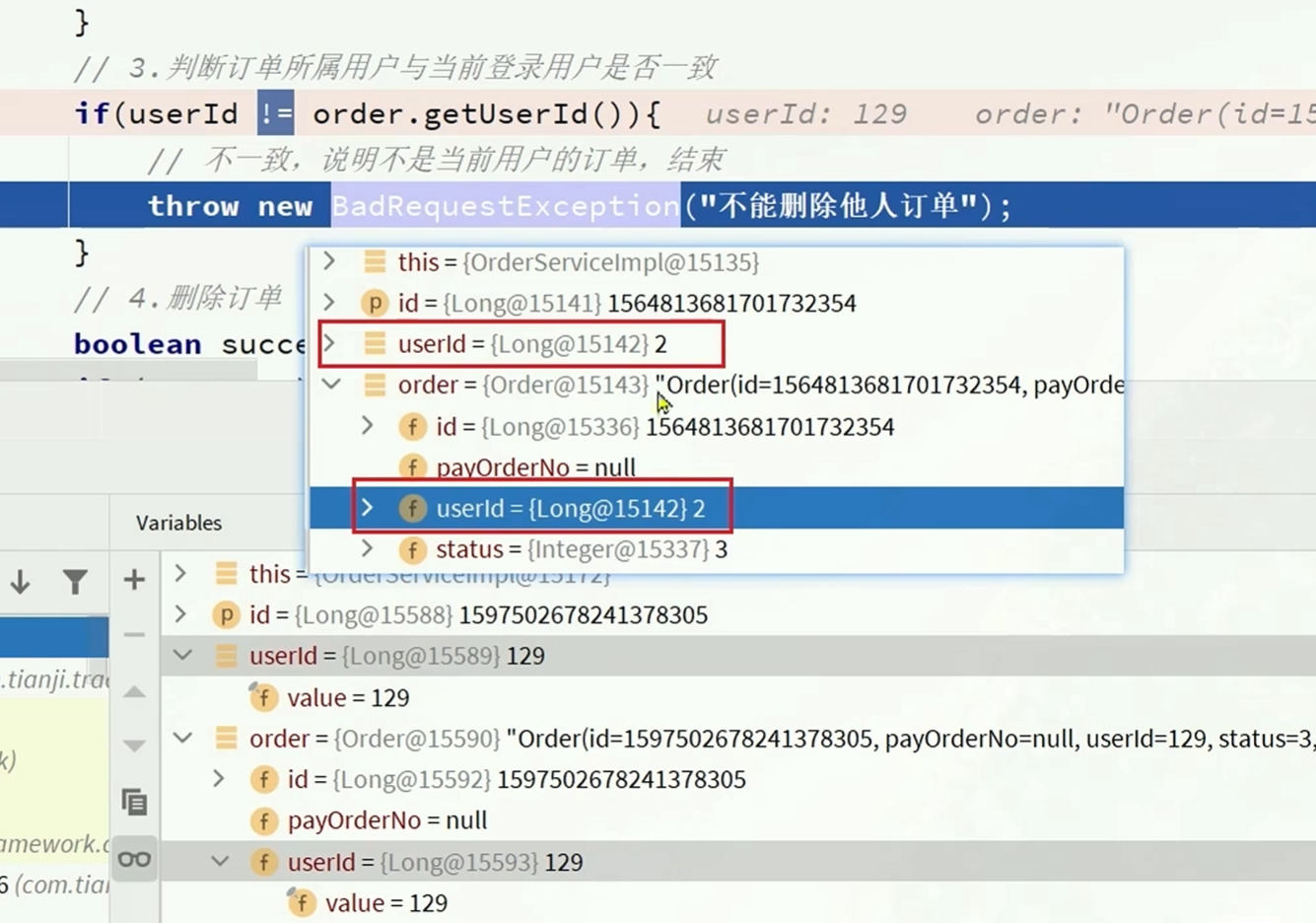
!=和==的逻辑相似,在比较基本类型是否相同的时候会自动比较大小,在比较对象等引用数据类型的时候就会比较地址
因为在源码中可以发现
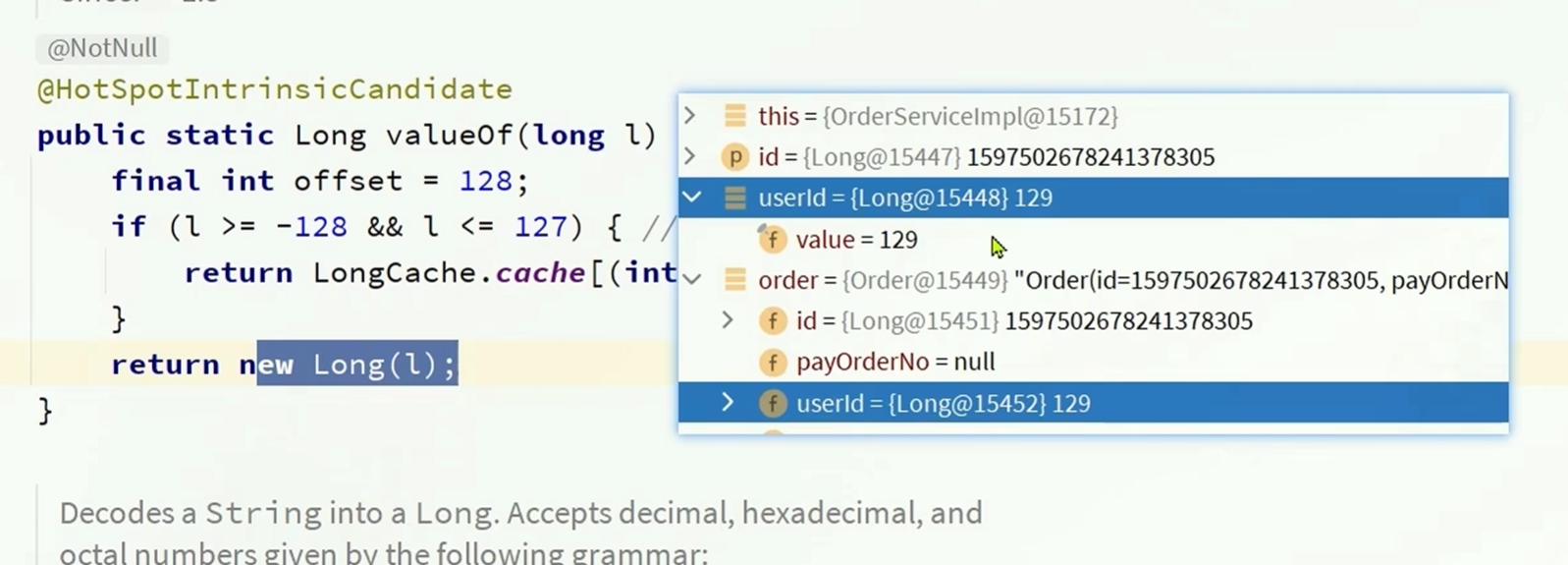

在输入的id超出一定范围的时候会new一个对象出来,
jack的没有超出范围是返回的一个
而rose的超出了范围,是new出来的对象,第一次是new出来的登陆的id,第二次是new出来的order的id
所以说虽然数值大小是相同的,但是地址不同,不是一个对象
测试部署
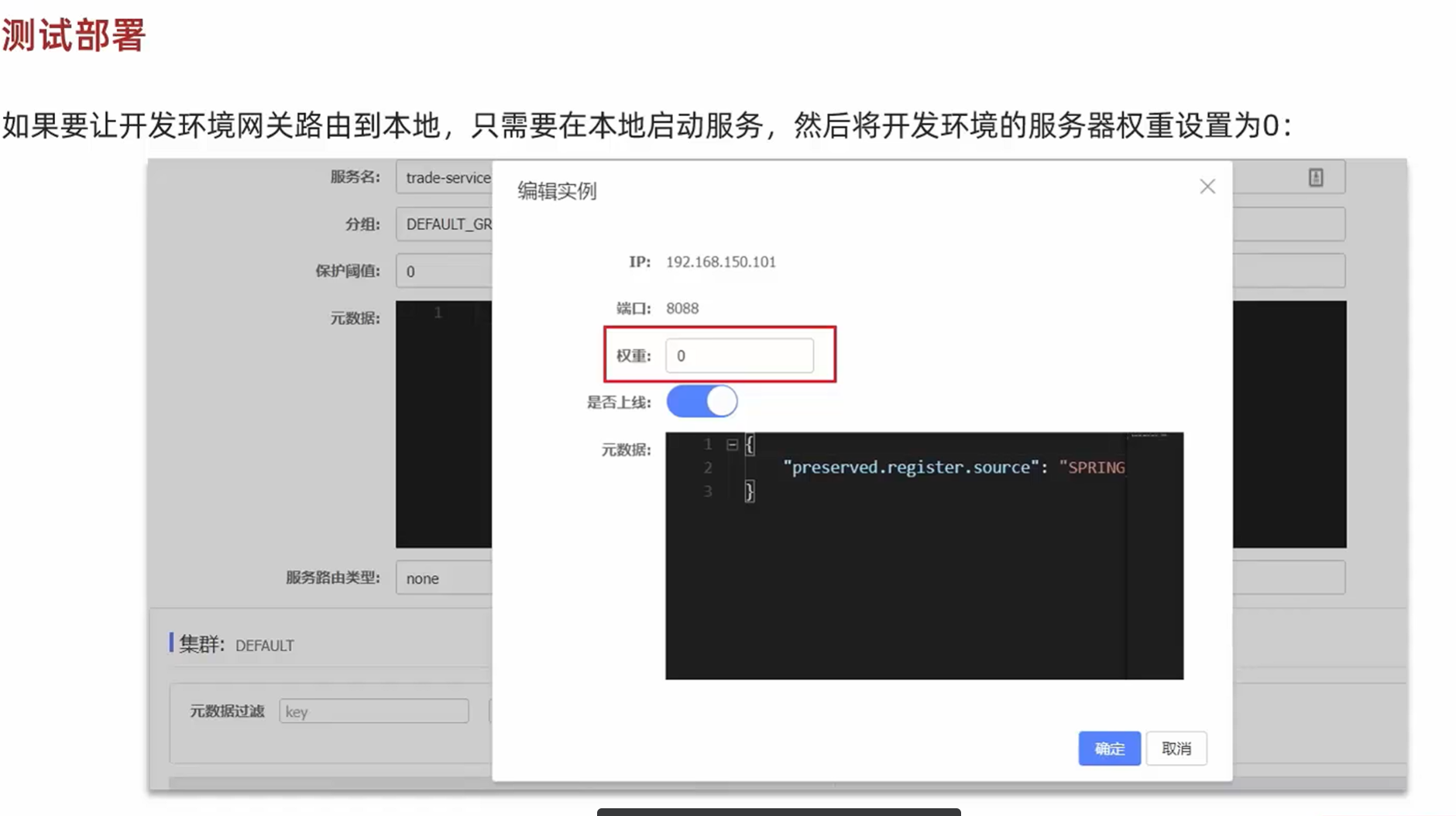
可以更改权重,将开发环境的服务器权重设置为0,确保只在本地启动该服务
也可以直接省事一点,在虚拟机里面直接停掉tj-trade
停掉虚拟机的服务之后直接去前端的页面进行测试
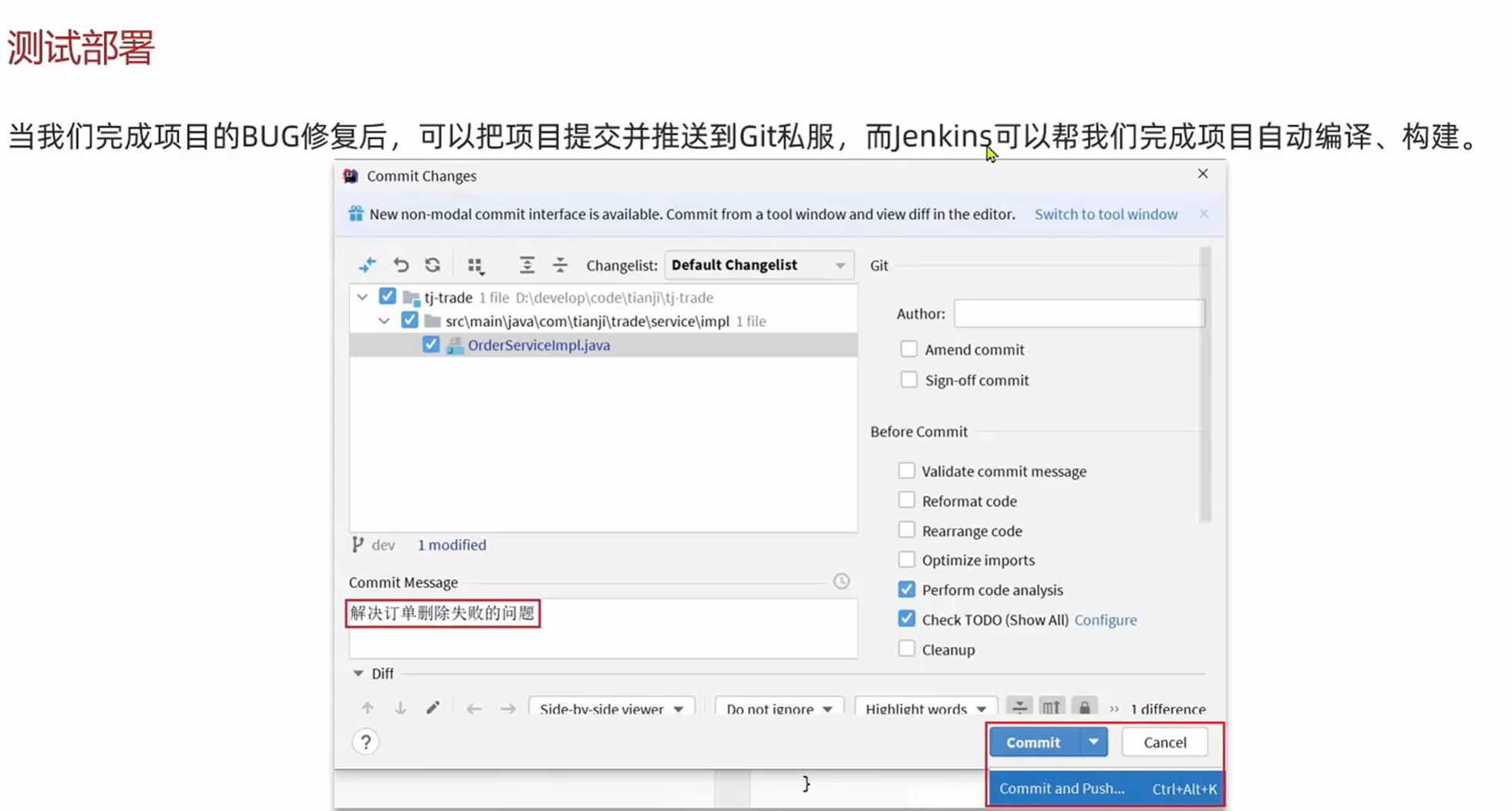
最后一步是将项目部署到开发环境,做前后端联调,然后做测试环境,预发布环境联调
将项目部署到开发环境:把项目提交并推送给Git私服Gogs,然后通过Web钩子,jenkins自动编译,构建,部署
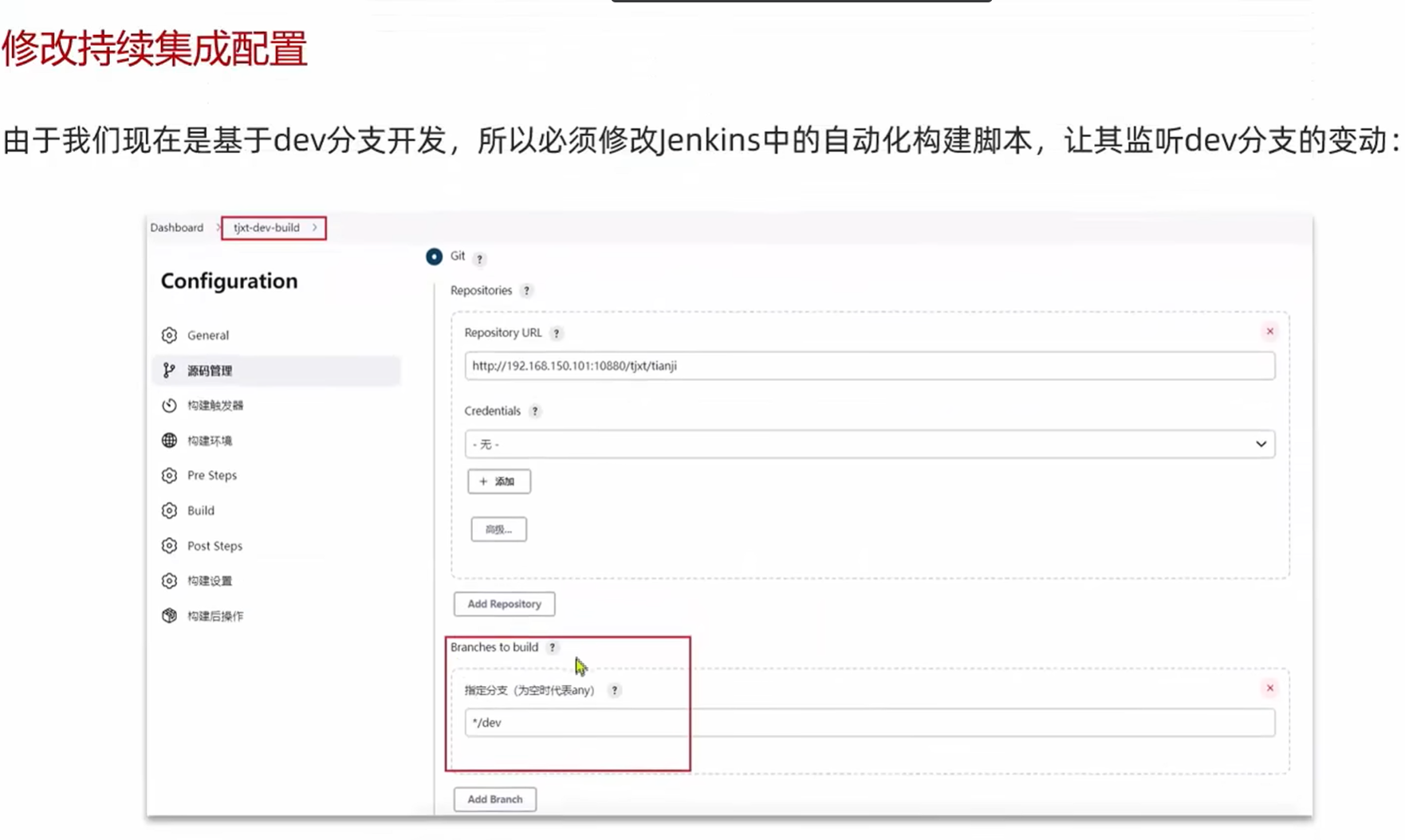
jenkins进行代码构建的时候要确定是基于哪个分支来构建,而且要加上分支过滤器,如果不加分支过滤器,以后只要是分支代码推送过来,不管是哪个分支的代码都会构建
构建分支修改如下:
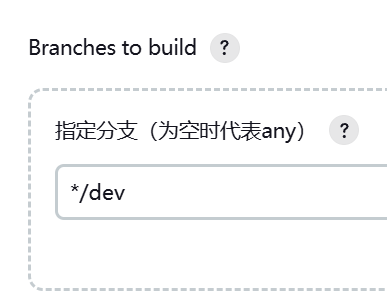
修改分支过滤如下
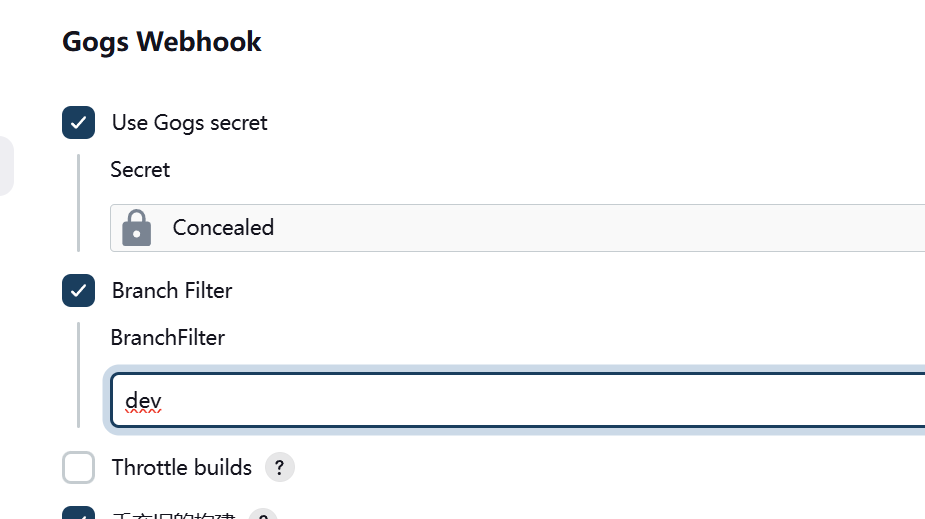
【分支】
只有主分支的代码是最终代码
其他小分支的代码相当于是修代码的维修车间,在代码完全没有nug之后合并进主分支
DAY02
分析产品原型

业务流程分析

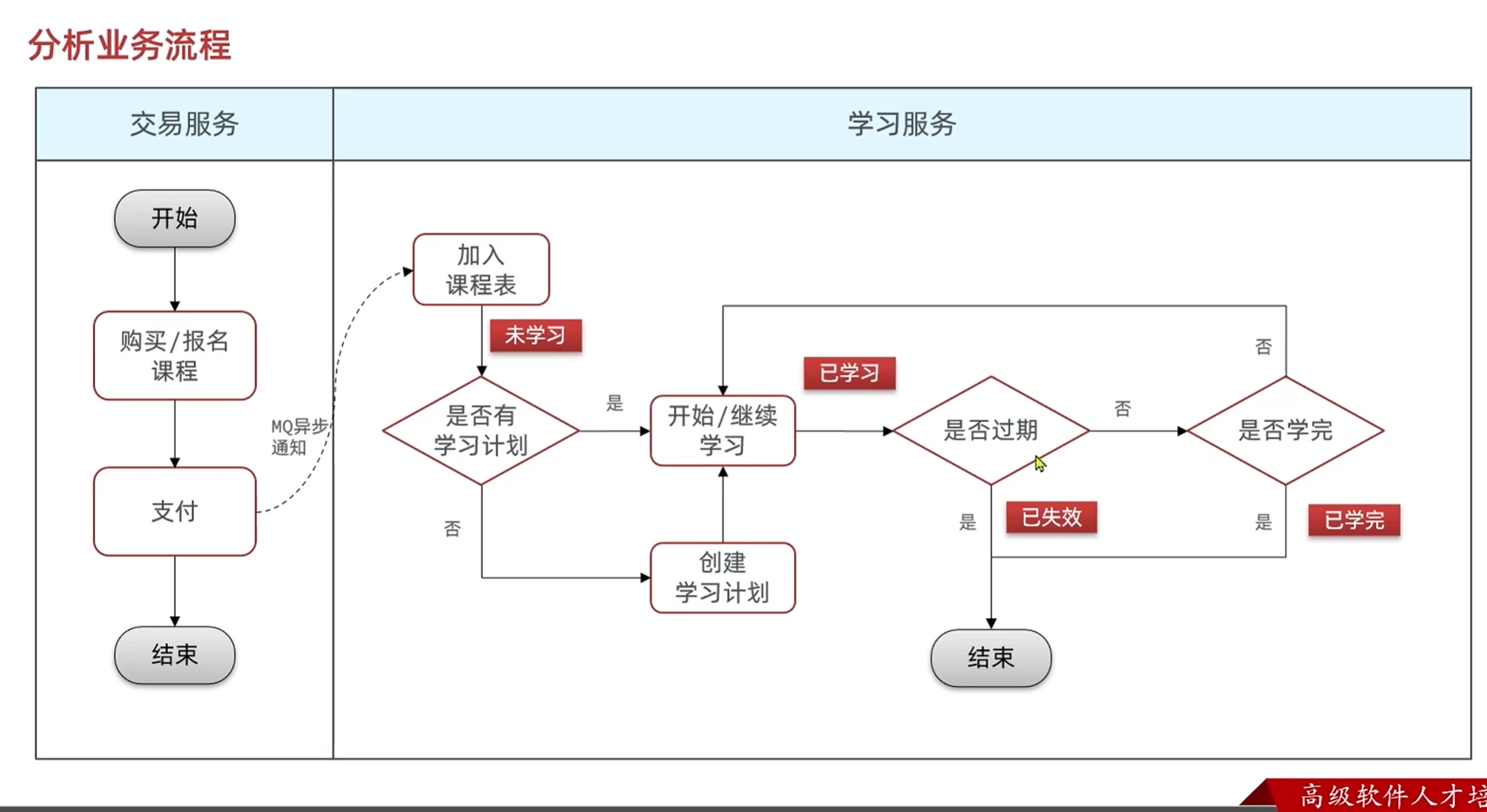
设计业务接口
设计接口的几个要素
请求地址
请求参数
返回的状态码以及返回的数据
请求路径的编写方法
按照reatful的风格
请求方式 /微服务名/资源名称/路径参数等
在做用户相关操作,资源就是用户

封装返回对象
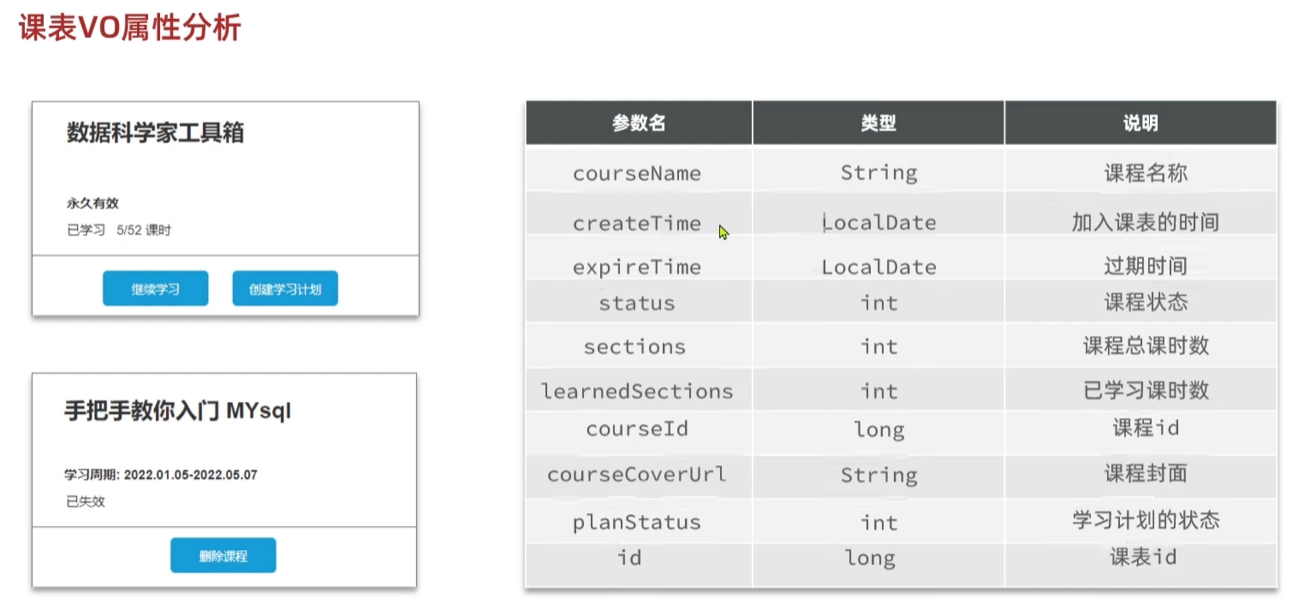
统计我的课程相关接口
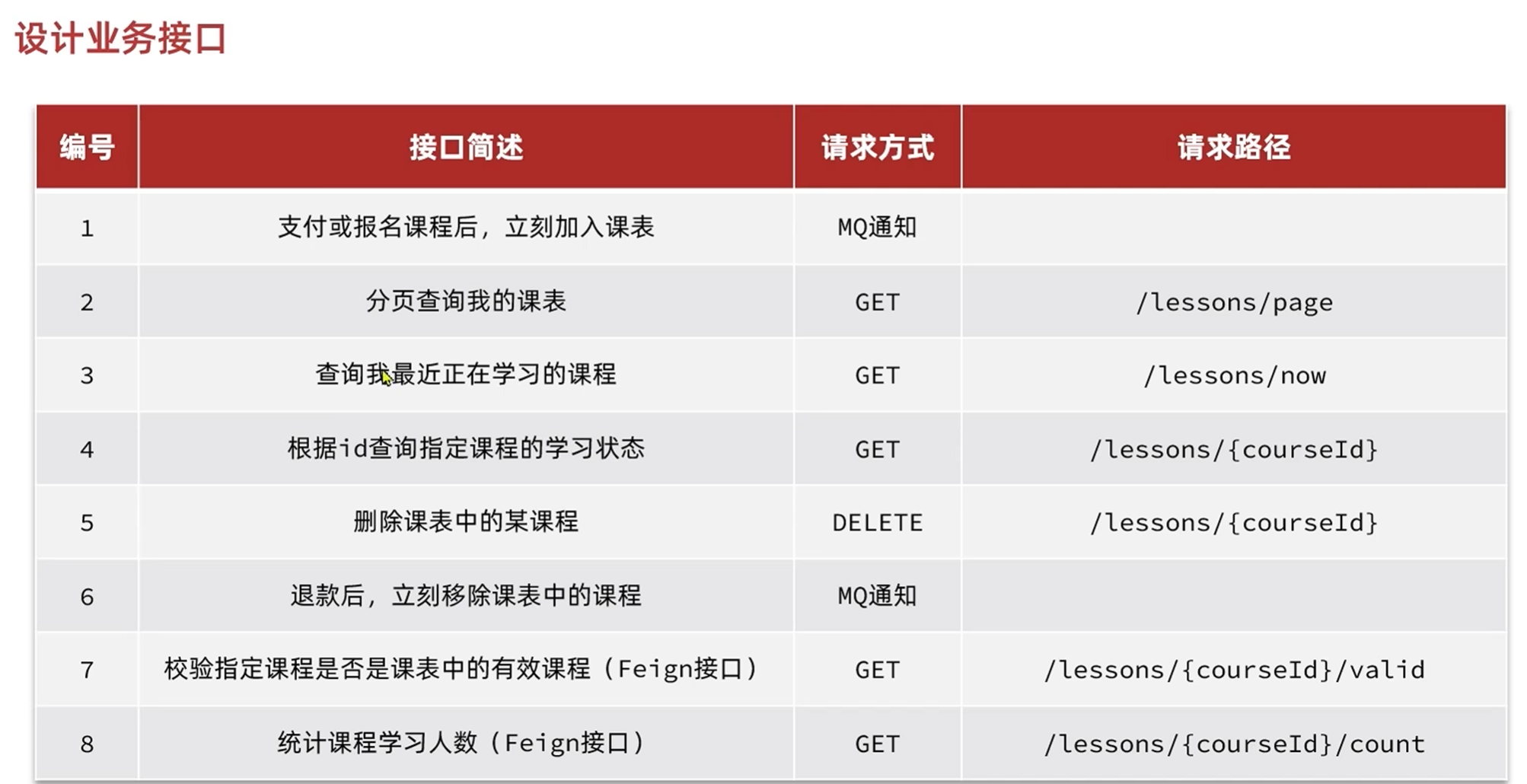
设计添加课程到我的课程的接口
要知道交易服务发过来的mq的信息格式,就要在交易完成之后,找到添加课程的请求
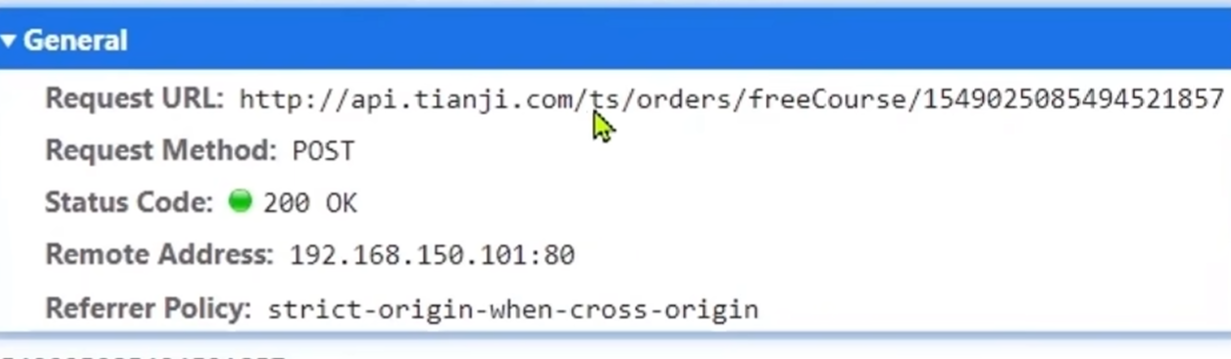
根据请求链路找到网关路由->微服务->方法
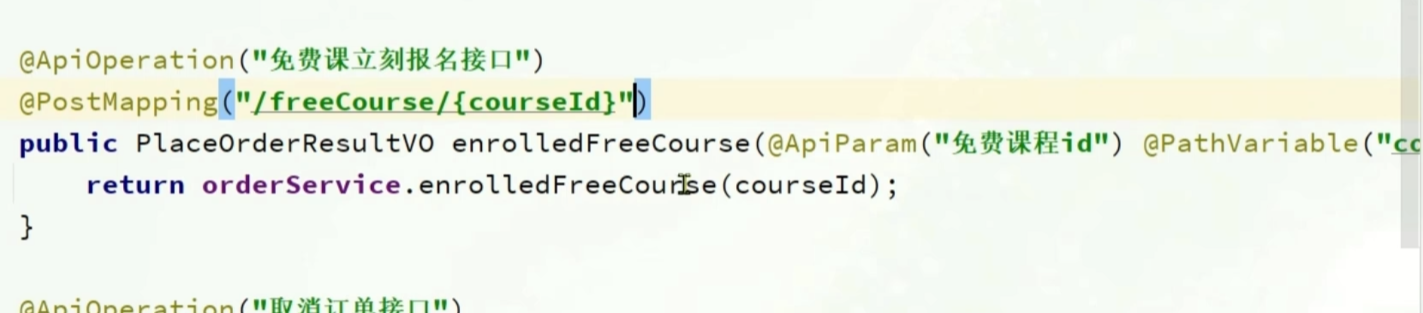
找到该方法的实现类

通的是一个构造体的模式,构造的对象是
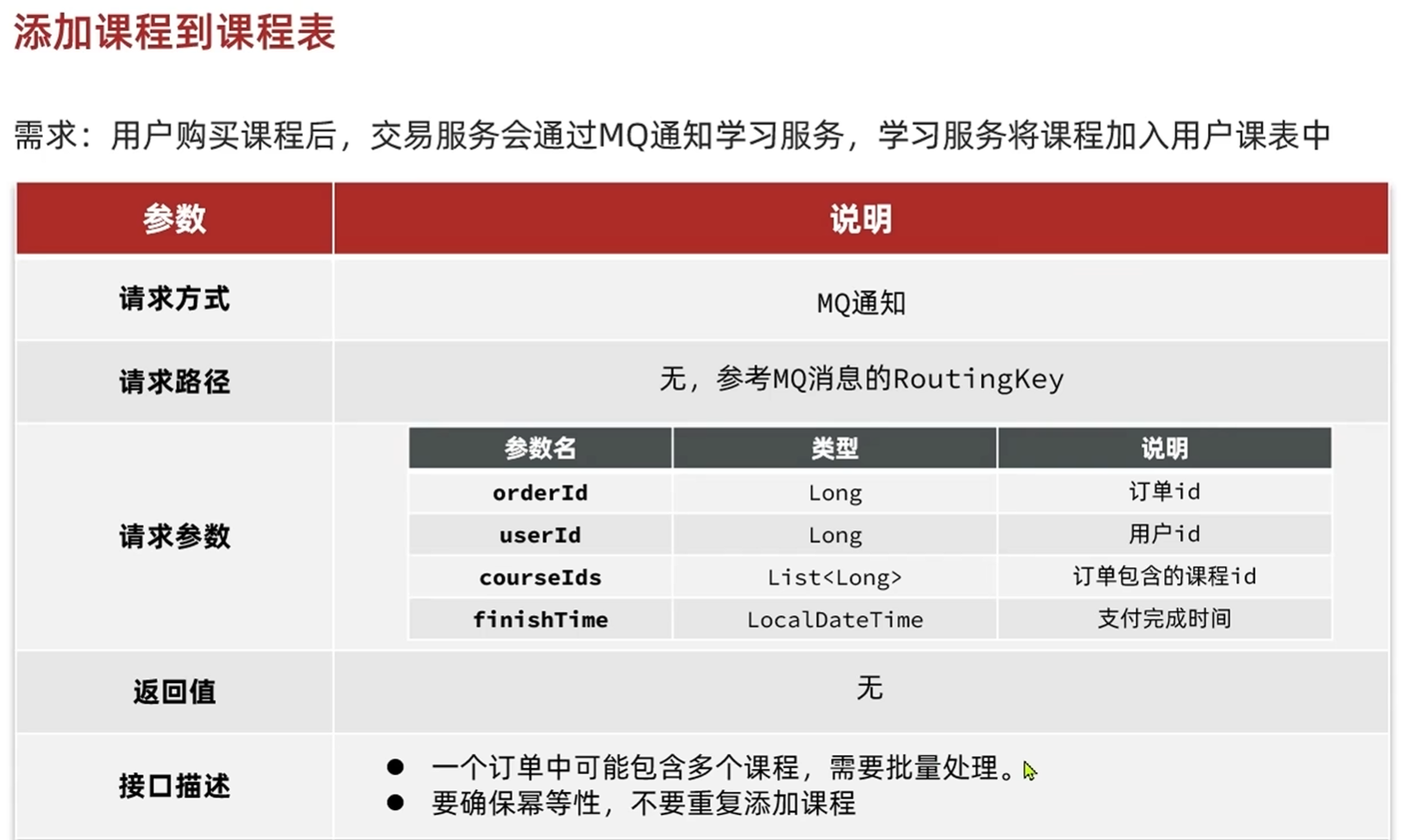
设计查询最近学习的课程接口
根据id查询指定课程的学习状态
详情页中,如过没有购买就会显示购买的图标
如果购买了就会显示立即学习的图标,且显示已经学习的课程数
其他要返回的数据和最近课程查询,我的课程查询要返回的差不多
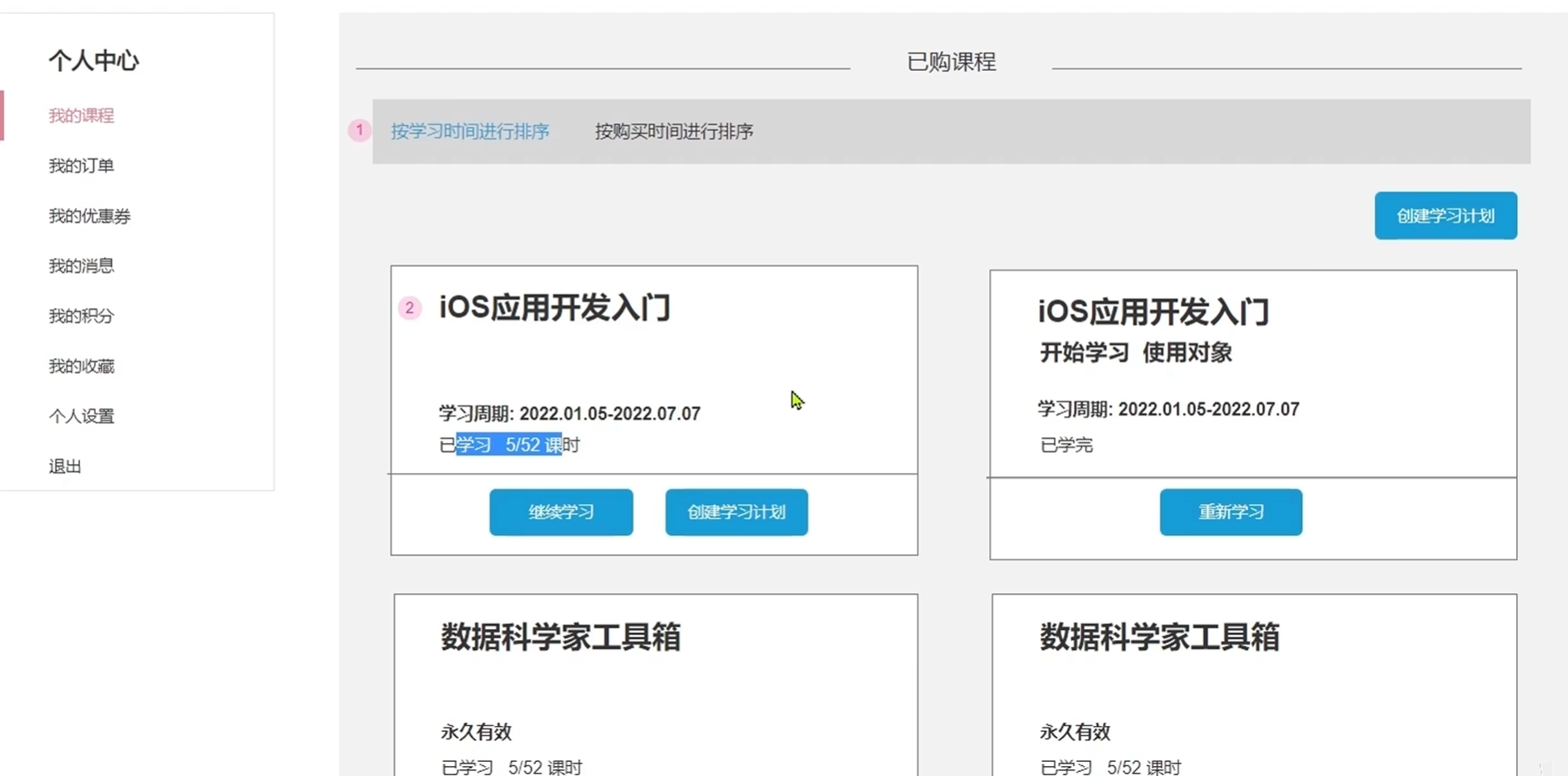
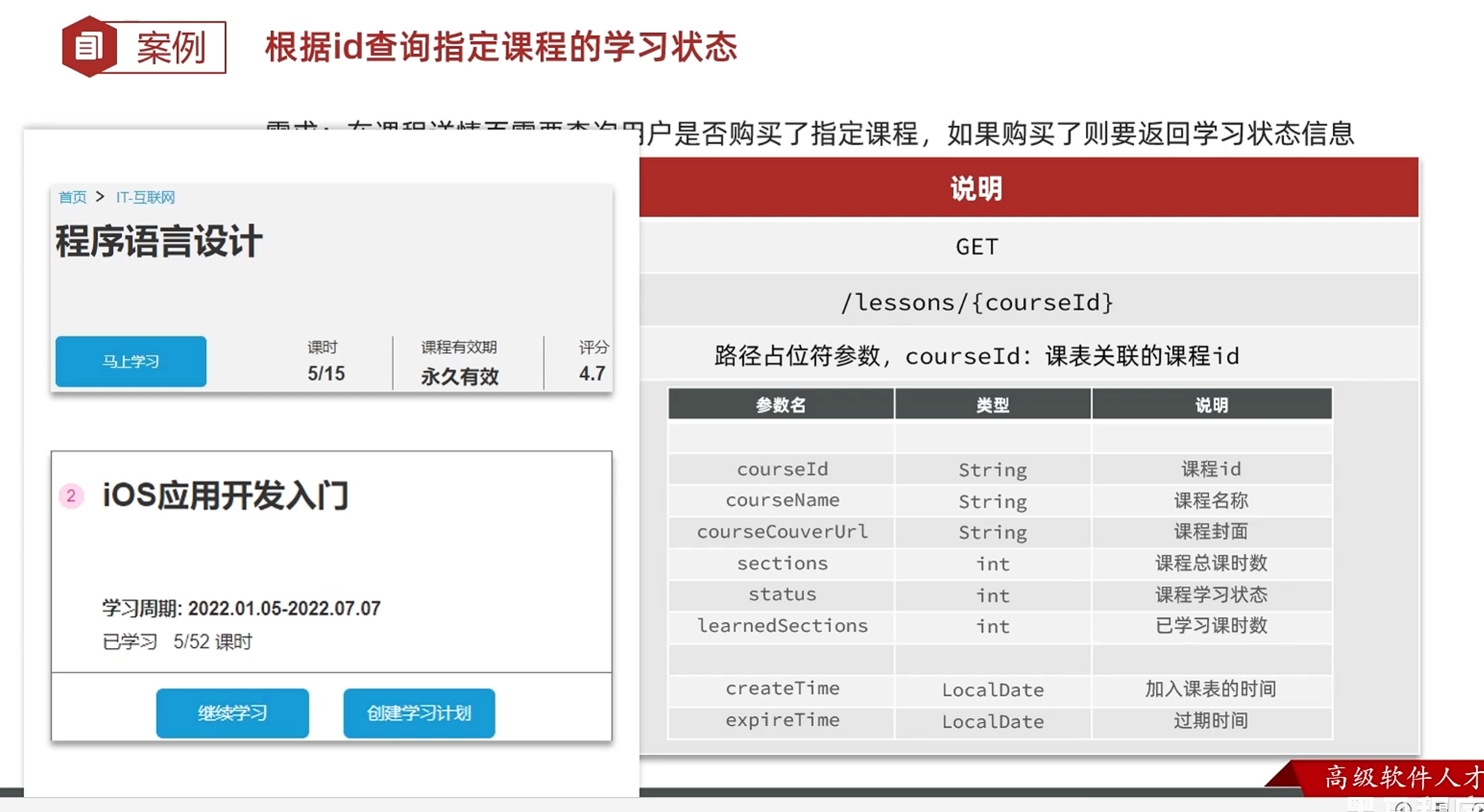
由于三个接口的返回对象十分相似,所以拉取三个对象里面共有的属性封装成一个对象,防止重复封装多个返回对象
抽取QUERY、DTO、VO实体
query
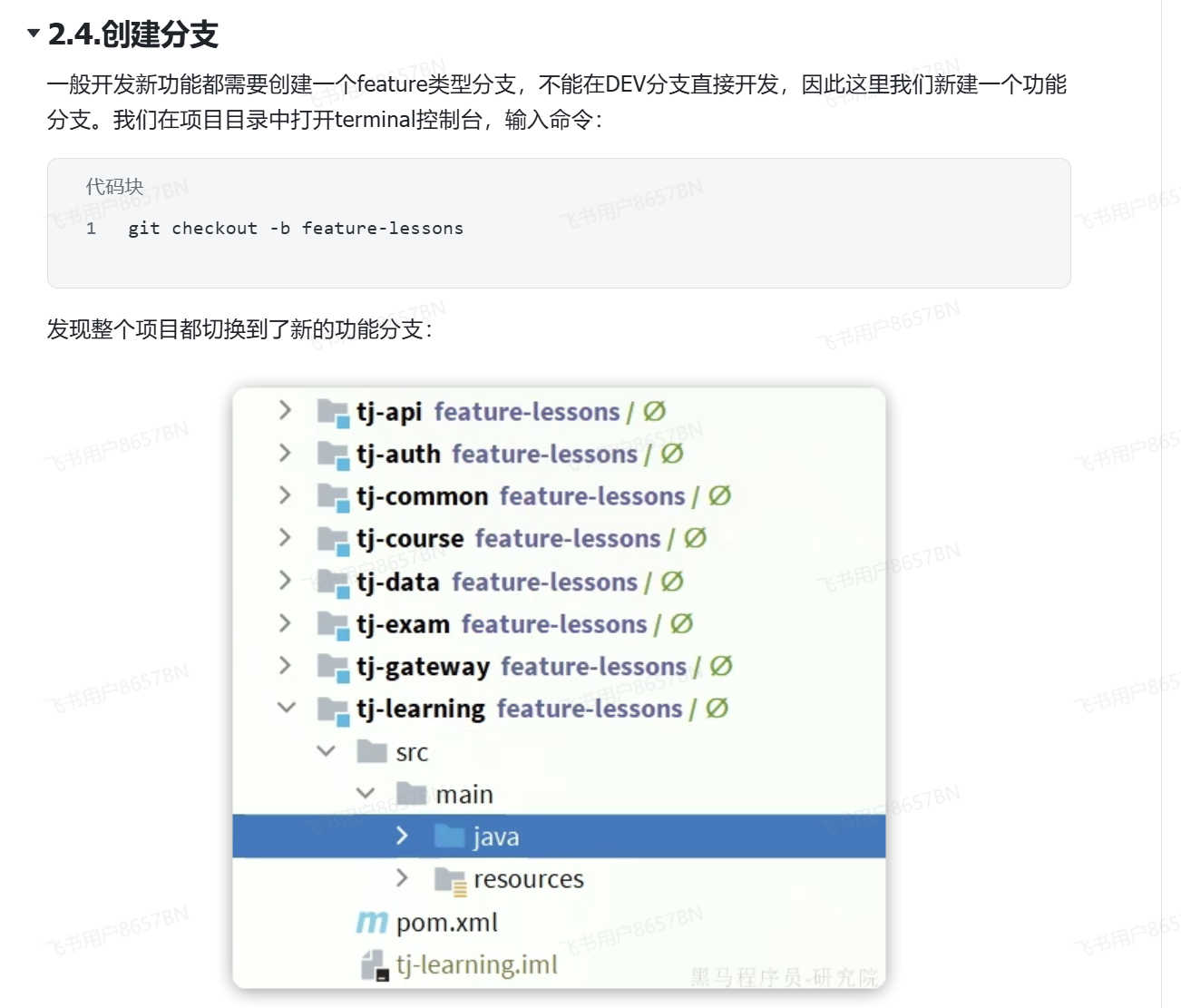
创建新的分支
在编写代码的时候不能直接修改dev总分支里的代码,要创建新的分支
导入类
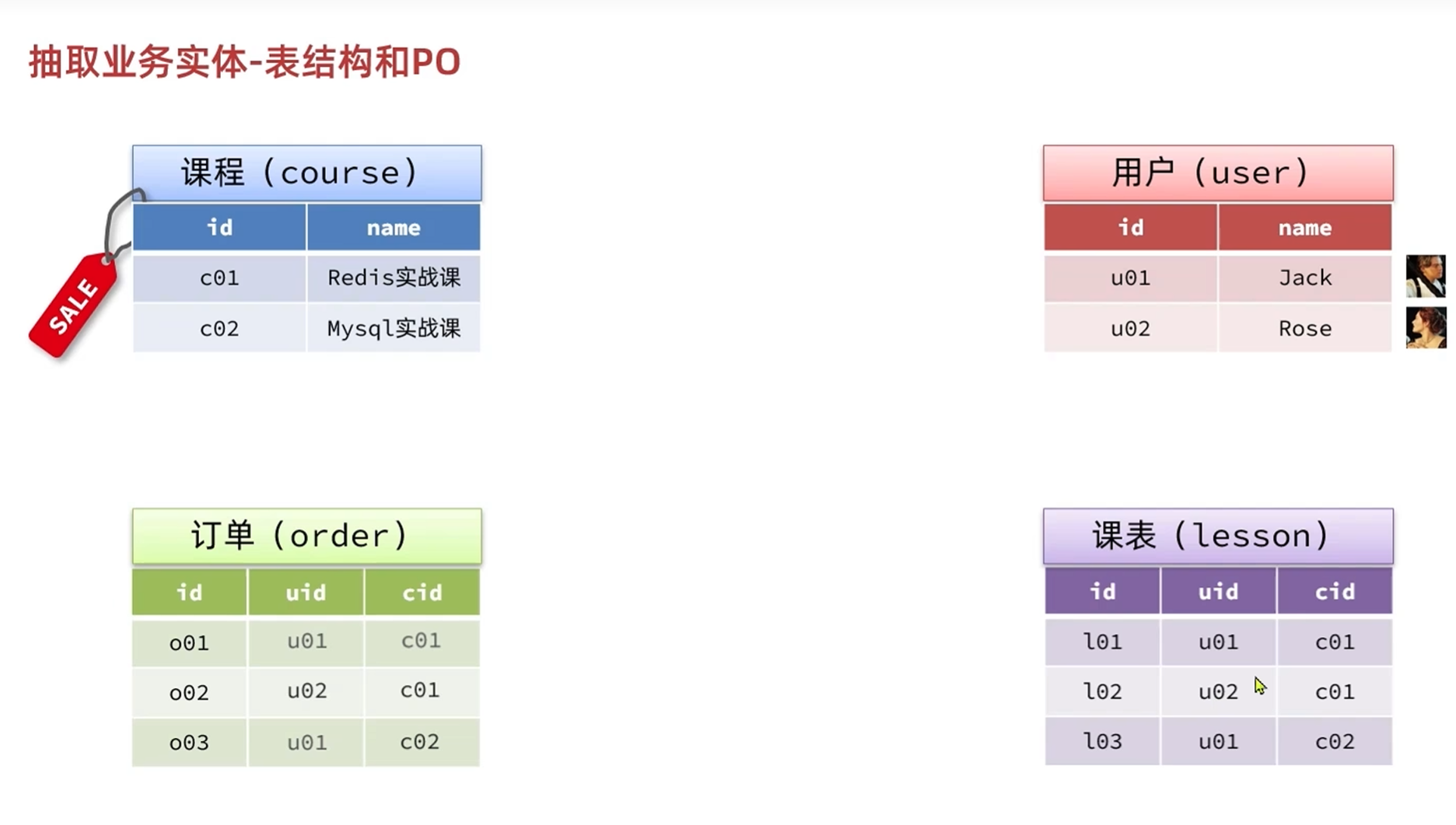
数据库结构和po
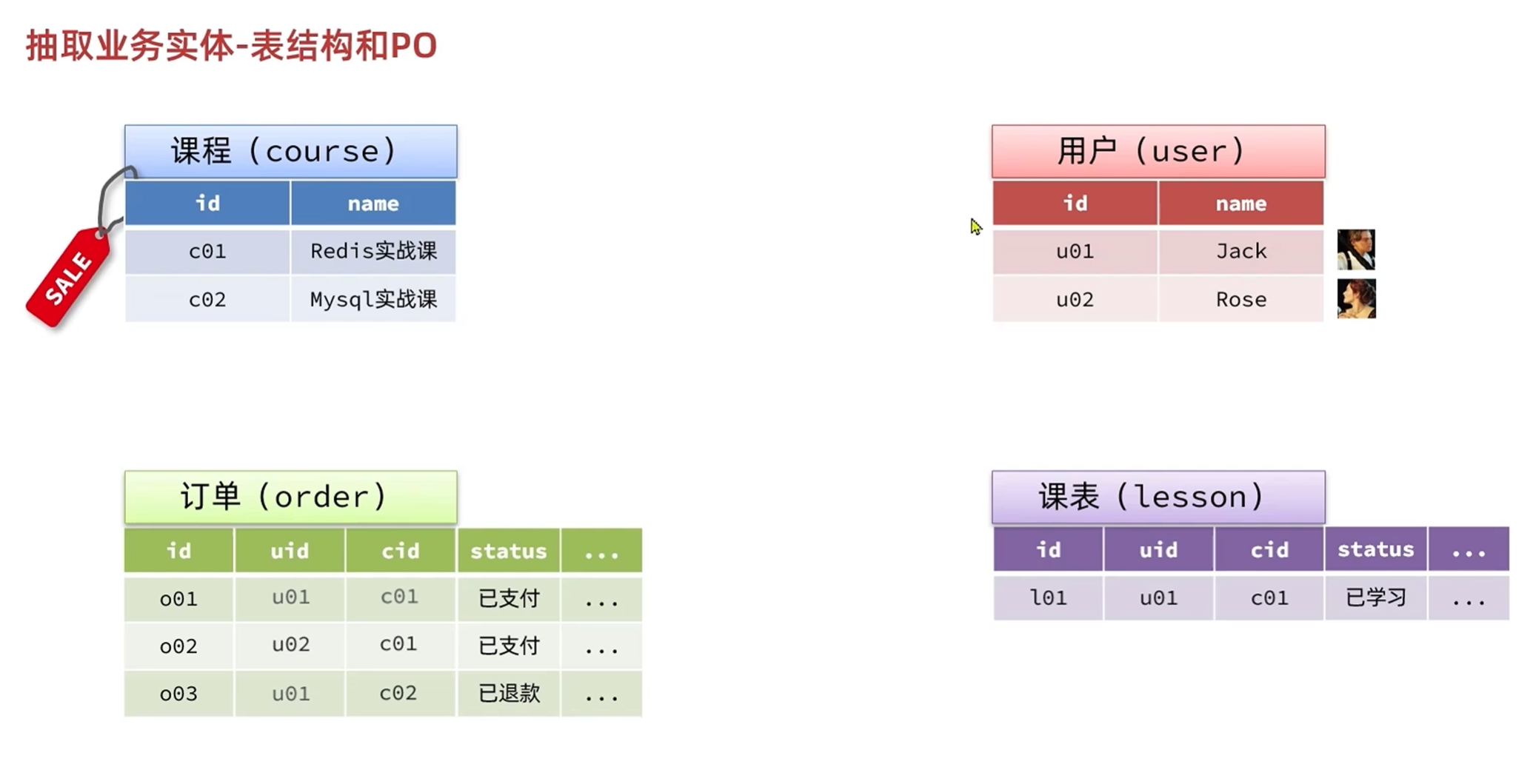
订单表和课表的内容不一样
订单取消之后,该课程在订单表中会保留,但是在课表中不会保留
先根据页面原型分析出VO,再根据VO分析PO
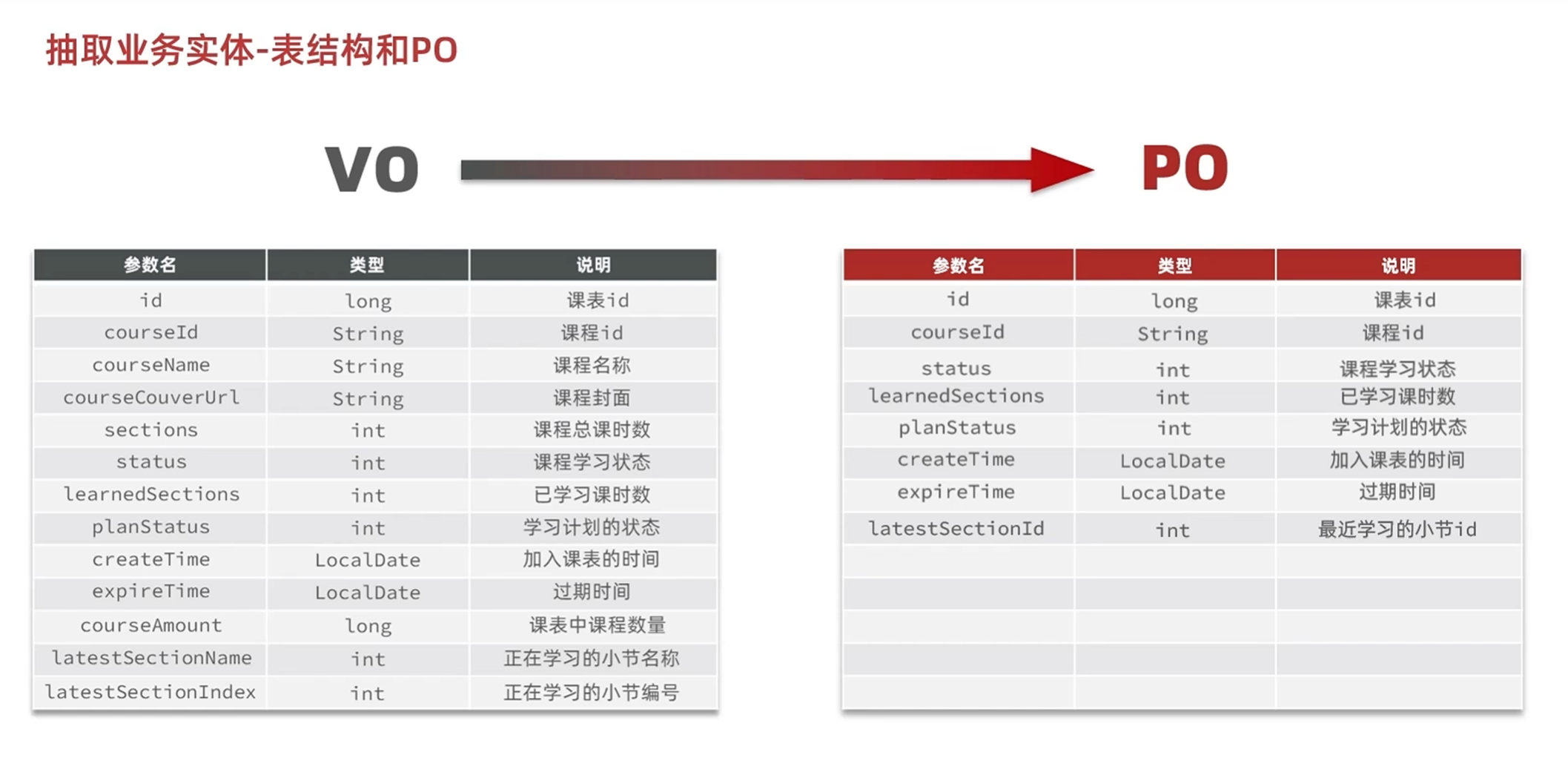
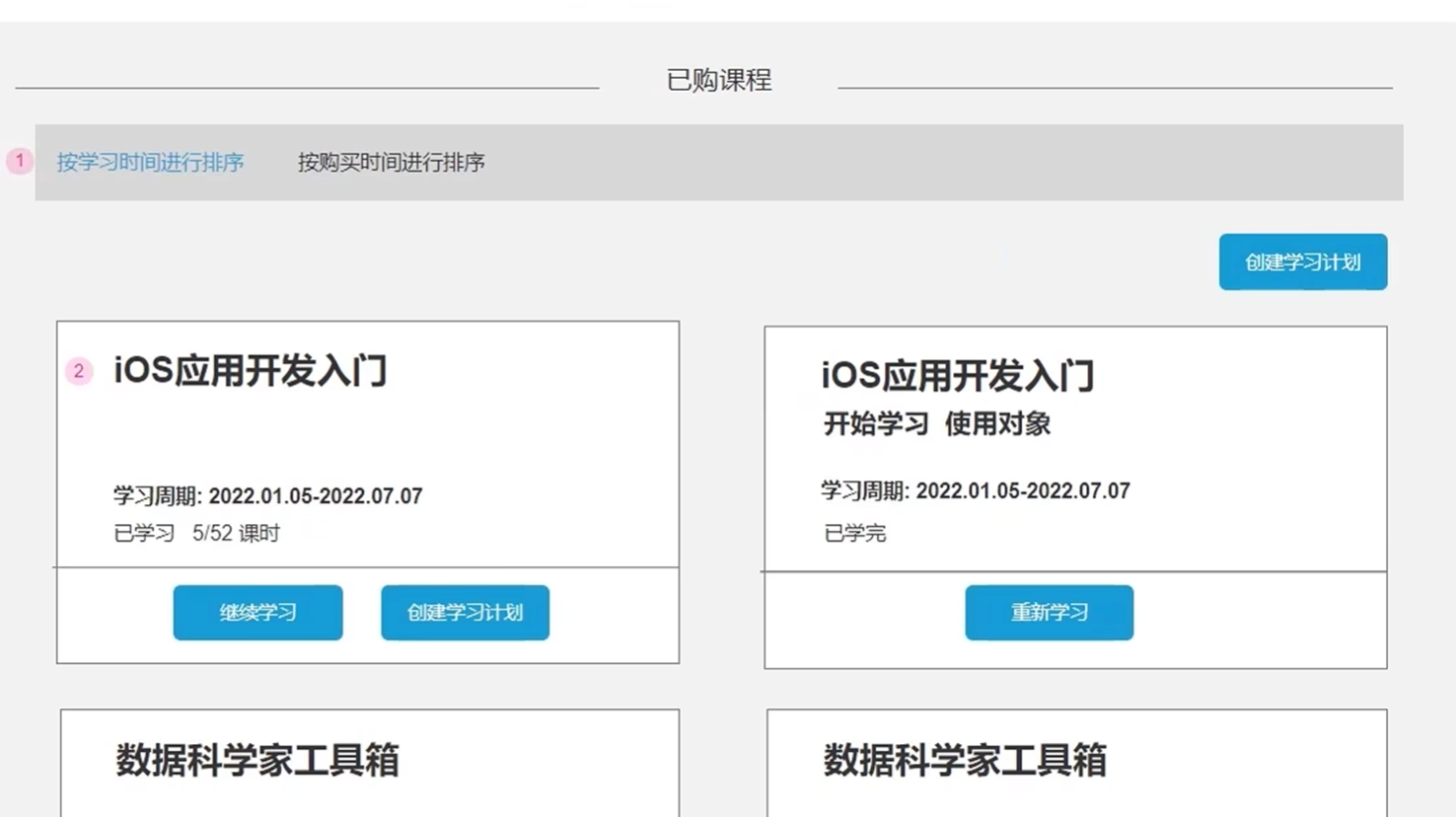
根据页面原型可以知道,要通过学习时间排序,所以要记录最近一次的学习时间
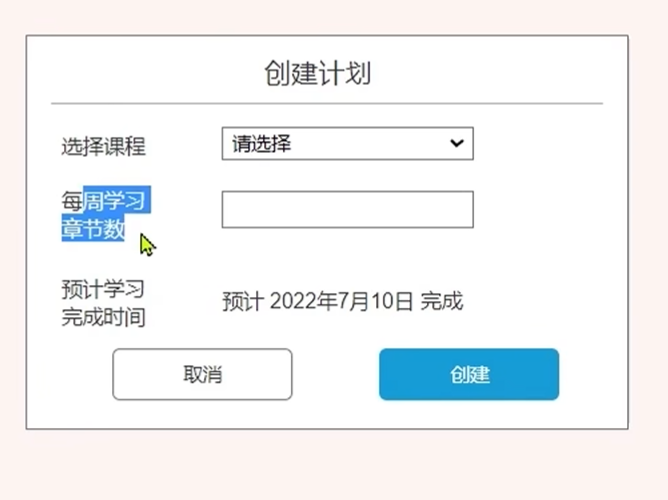
创建学习计划的时候要填课程的每周学习的章节数,实体表中可以加入这个字段
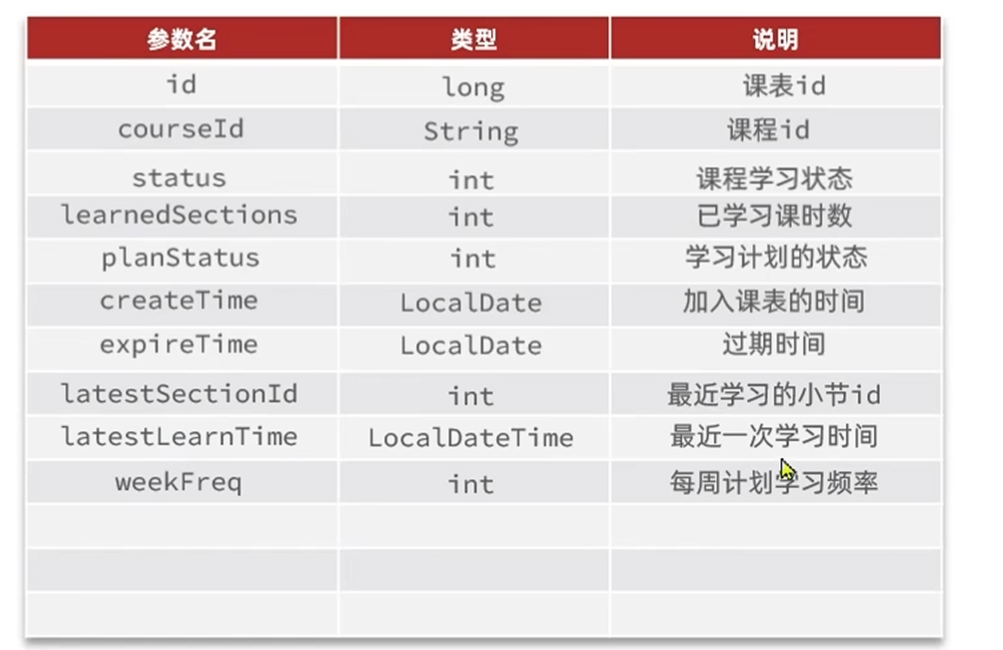
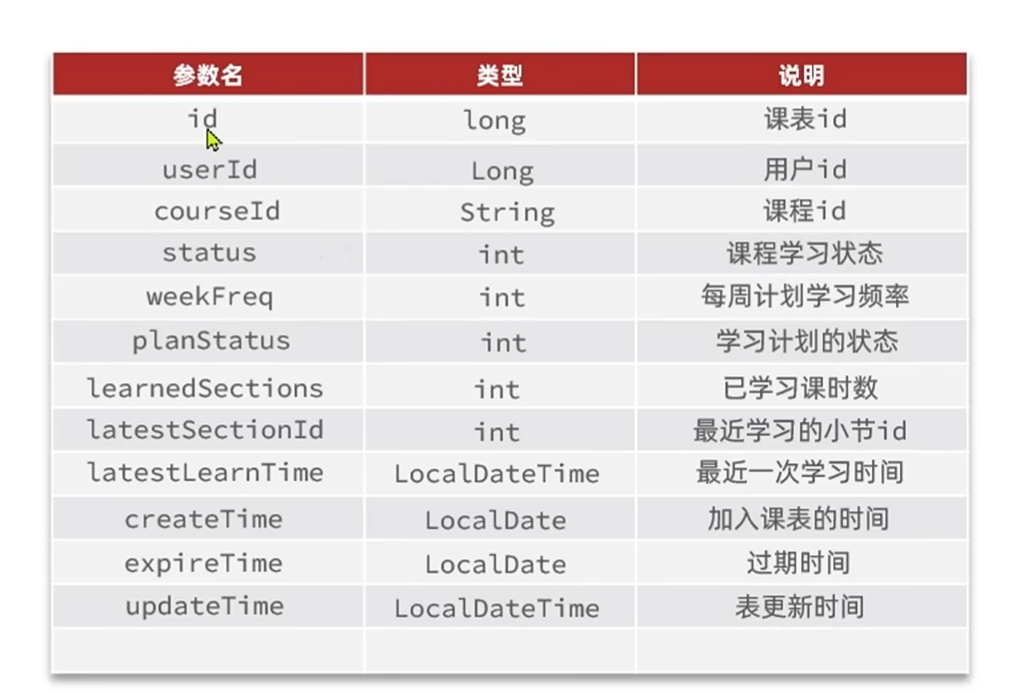
梳理后的po为
下载插件Mybatis Plus,用它的功能代码生成器生成代码
代码生成器
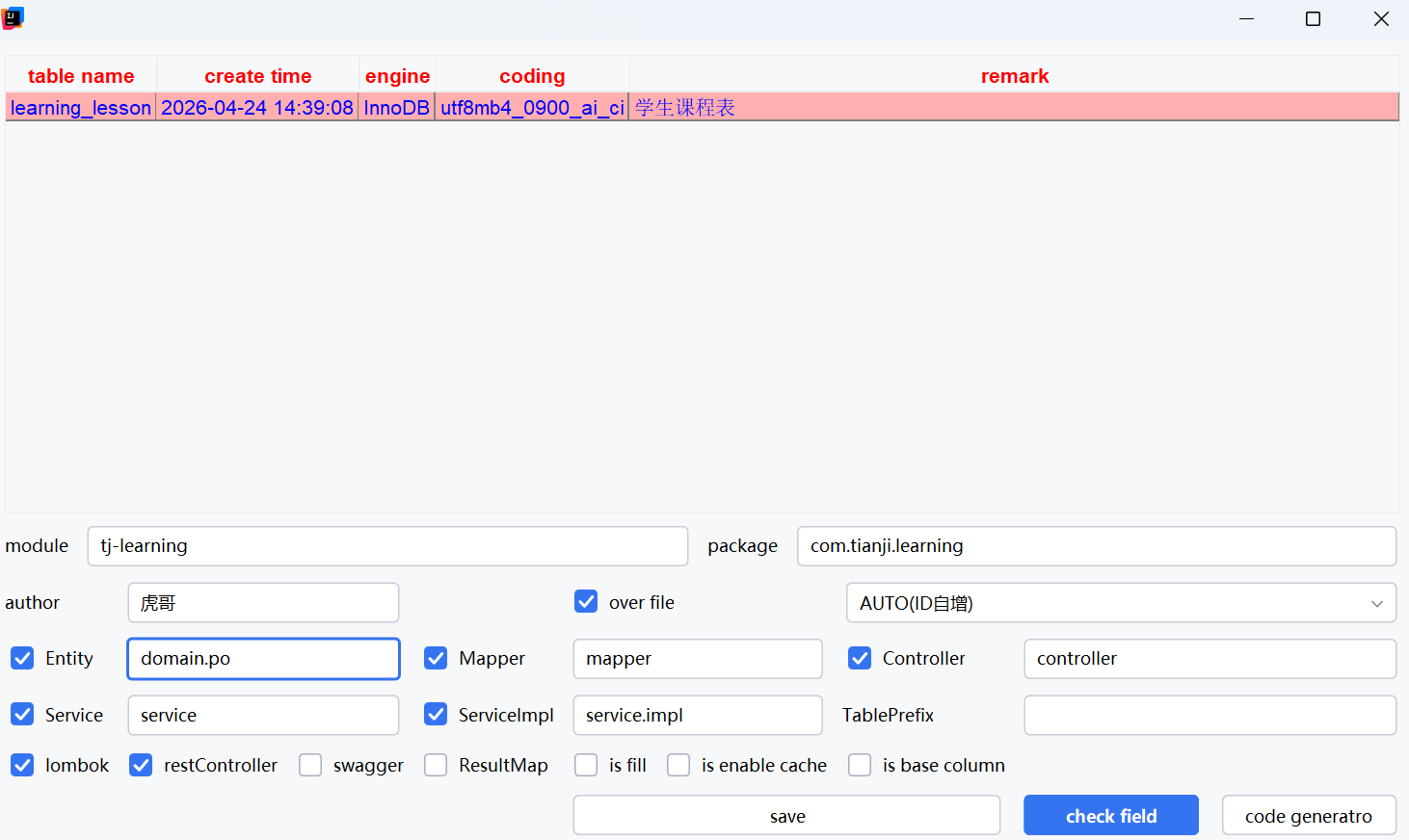
生成后结果如下
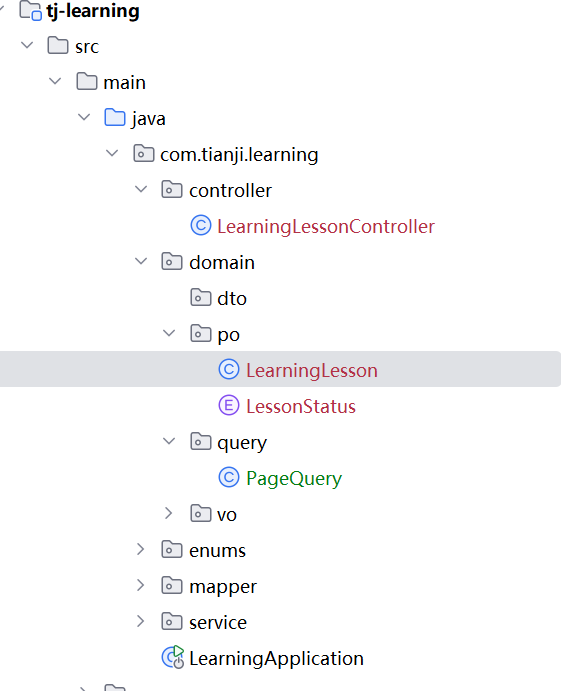
开发接口功能
-添加课程到课表
-思路分析

-代码实现
@Slf4j
@Component
@RequiredArgsConstructor//自动函数式注入的注解
public class LessonsChangesListener {
private final ILearningLessonService iLearningLessonService;
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = "learning.lesson.pay.queue",durable = "true"),
exchange = @Exchange(name = MqConstants.Exchange.ORDER_EXCHANGE,
type = ExchangeTypes.TOPIC),
key =MqConstants.Key.ORDER_PAY_KEY
)
)
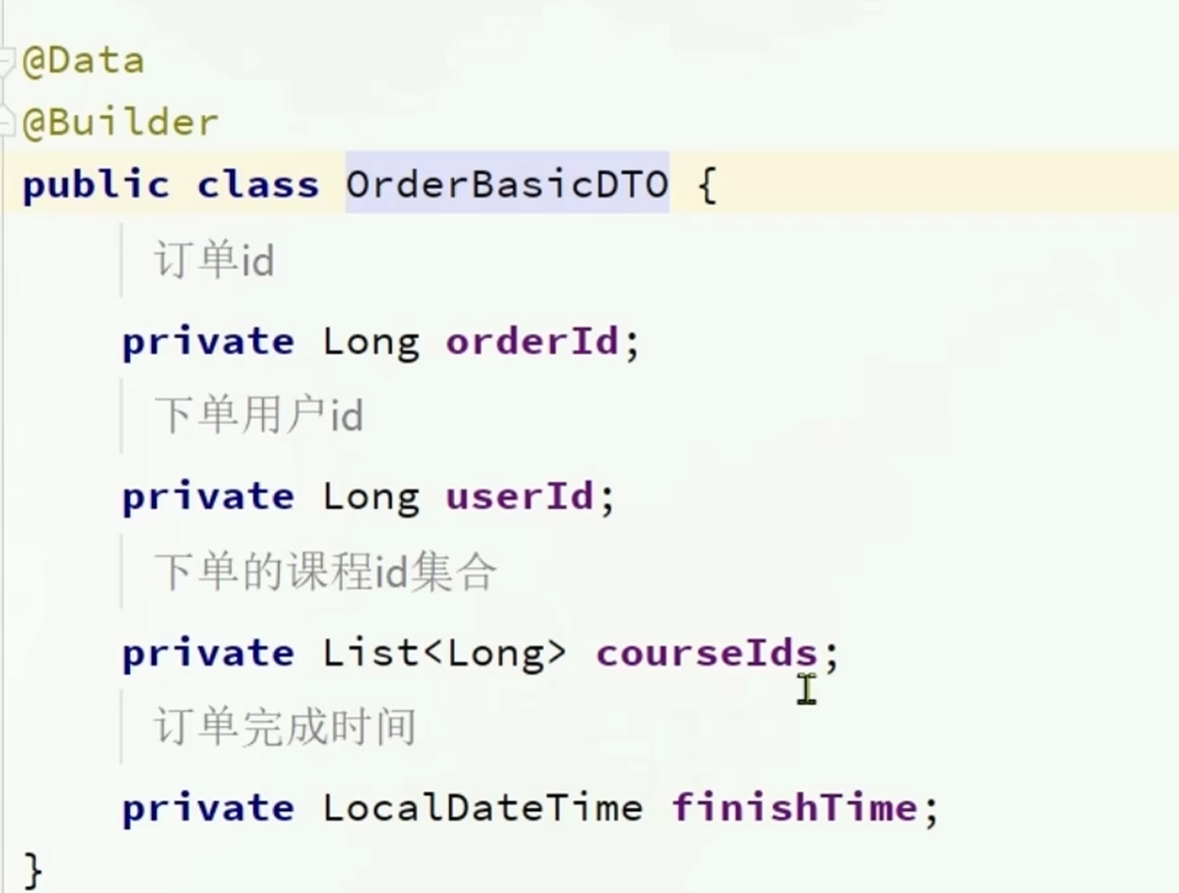
public void processMessage(OrderBasicDTO orderBasicDTO) {
//在方法被调用之前就已经接收到了数据
//1.健壮性测试
if(orderBasicDTO.getOrderId()==null||orderBasicDTO.getUserId()==0){
log.error("监听到的消息中用户id或订单id有误");
}
//2.将接收到的对象传递给接口
iLearningLessonService.addUserLessons(orderBasicDTO.getUserId(),orderBasicDTO.getCourseIds());
}
}监听消息的服务器只需要说明绑定的队列,交换机,key就行,其中队列的名字可以乱起,交换机和key的值必须和发送消息的publisher相同
基于注解编写的绑定,如果不存在会自动创建
@Slf4j
@Service
@Transactional(rollbackFor = Exception.class)
@RequiredArgsConstructor
public class LearningLessonServiceImpl extends ServiceImpl<LearningLessonMapper, LearningLesson> implements ILearningLessonService {
private final CourseClient courseClient;
@Override
public void addUserLessons(Long userId, List<Long> courseIds) {
//接收到消息之后就可以开始填充类了
//1.根据id查询课程的有效期
List<CourseSimpleInfoDTO> courseInfoList = courseClient.getSimpleInfoList(courseIds);
//2.根据查询到的有效期填充字段
//2.1先确认课程不为空来提升代码的健壮性
if(CollUtil.isEmpty(courseInfoList)){
log.error("课程为空");
return;
}
List<LearningLesson> learningLessonList = new ArrayList<>();
for (CourseSimpleInfoDTO course : courseInfoList) {
LearningLesson learningLesson = new LearningLesson();
//填充课程失效日期字段
Integer validDuration = course.getValidDuration();
if(validDuration!=null && validDuration > 0){
LocalDateTime now = LocalDateTime.now();
LocalDateTime validEndTime = now.plusMonths(validDuration);
learningLesson.setExpireTime(validEndTime);
}
learningLesson.setUserId(userId);
learningLesson.setCourseId(course.getId());
learningLessonList.add(learningLesson);
}
//批量插入课程
saveBatch(learningLessonList);
}
}方法中在获取对象以及数据之后都会做健壮性测试,防止为空或者数据没用导致bug,测试不为空和数据没用时候与不少的方法,要注意一一匹配,分清楚什么情况下用哪个
判断包装类不相等要用.equals()否则会比较两者的地址
判断集合是否为空要用CollUtil.isEmpty();
因为调用的方法都是MabatisPlus里的方法,所以对参数的格式有要求,必须是当时代码生成器里指定的表对应的实体类
MybatisPlus最大的用处就是实现了实体类/数据库的mapper方法并生成了接口和实现类用以继承
用的时候只需要写出方法名,给出参数就行
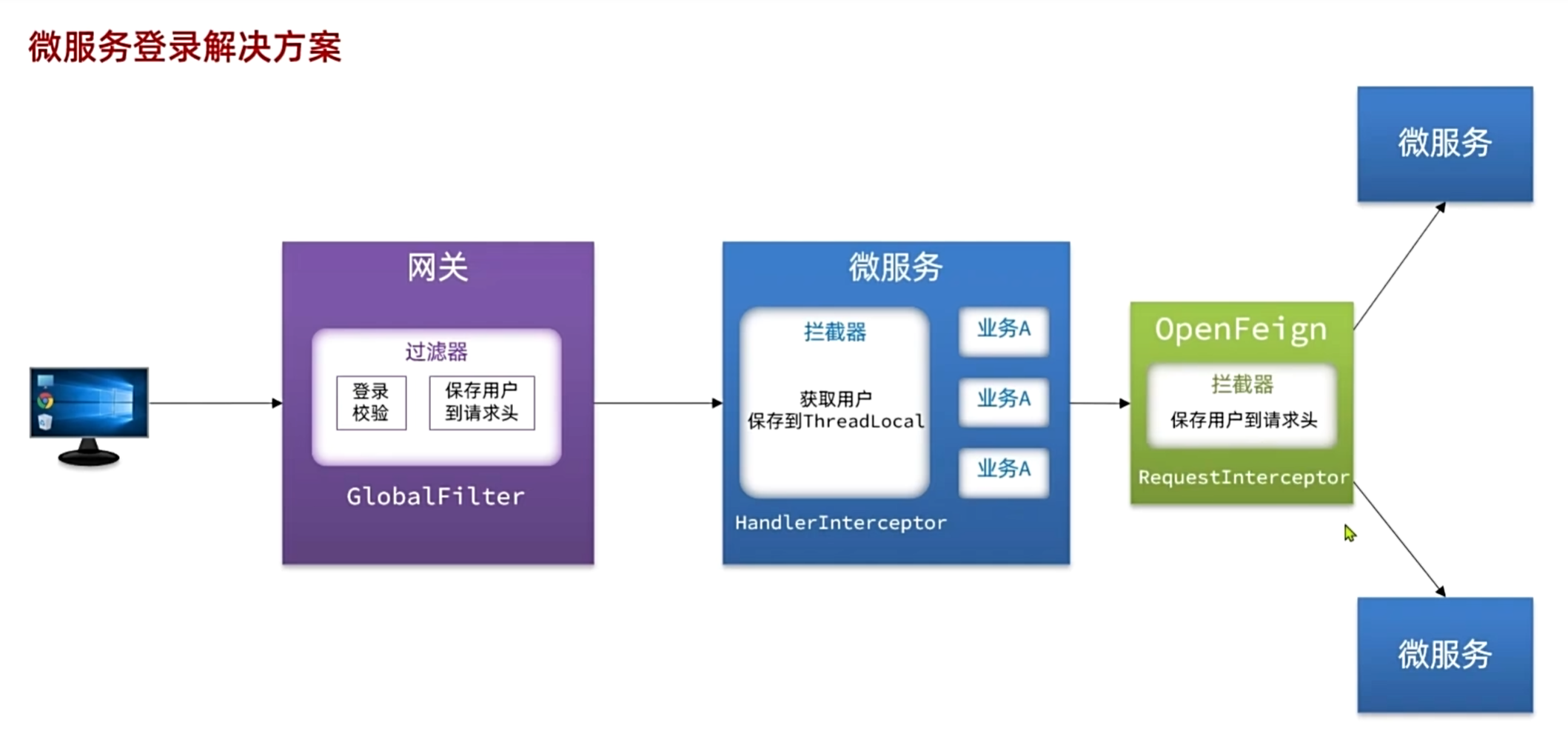
-分析登录用户传递流程
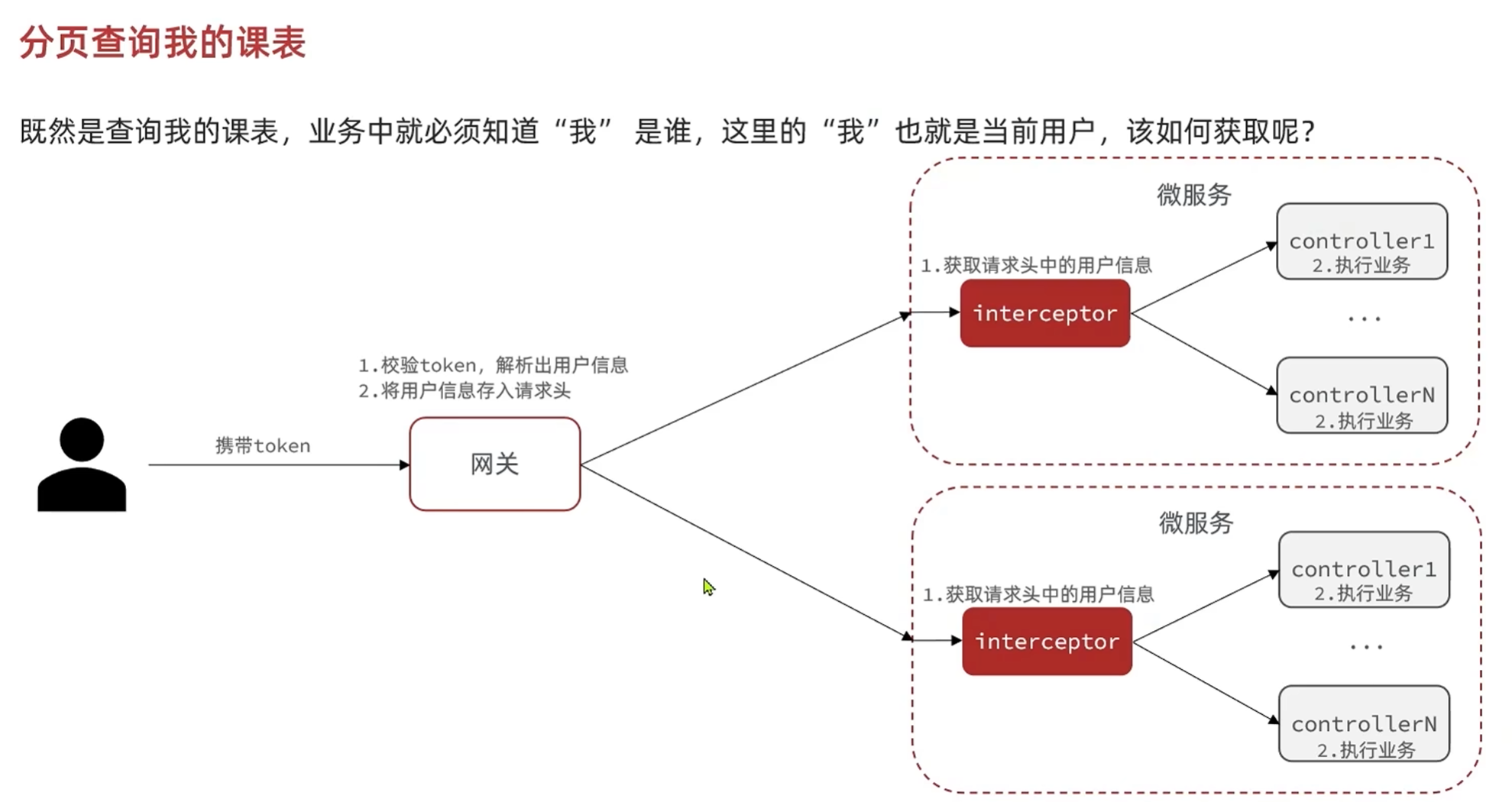
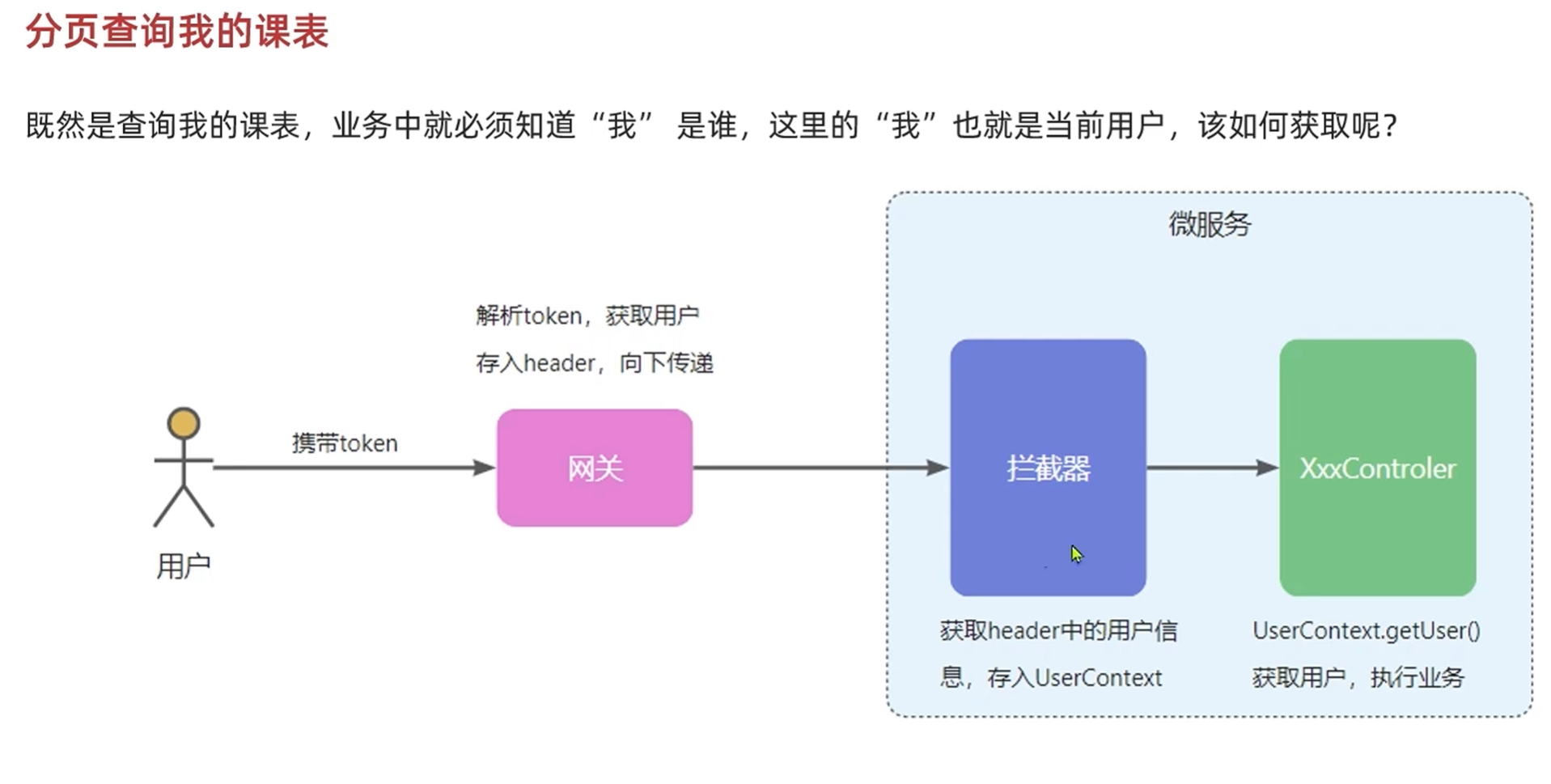
@Slf4j
@Service
@Transactional(rollbackFor = Exception.class)
@RequiredArgsConstructor
public class LearningLessonServiceImpl extends ServiceImpl<LearningLessonMapper, LearningLesson> implements ILearningLessonService {
private final CourseClient courseClient;
@Override
public void addUserLessons(Long userId, List<Long> courseIds) {
//接收到消息之后就可以开始填充类了
//1.根据id查询课程的有效期
List<CourseSimpleInfoDTO> courseInfoList = courseClient.getSimpleInfoList(courseIds);
//2.根据查询到的有效期填充字段
//2.1先确认课程不为空来提升代码的健壮性
if(CollUtil.isEmpty(courseInfoList)){
log.error("课程为空");
return;
}
List<LearningLesson> learningLessonList = new ArrayList<>();
for (CourseSimpleInfoDTO course : courseInfoList) {
LearningLesson learningLesson = new LearningLesson();
//填充课程失效日期字段
Integer validDuration = course.getValidDuration();
if(validDuration!=null && validDuration > 0){
LocalDateTime now = LocalDateTime.now();
LocalDateTime validEndTime = now.plusMonths(validDuration);
learningLesson.setExpireTime(validEndTime);
}
learningLesson.setUserId(userId);
learningLesson.setCourseId(course.getId());
learningLessonList.add(learningLesson);
}
//批量插入课程
saveBatch(learningLessonList);
}
@Override
public PageDTO<LearningLessonVO> queryMyLessons(PageQuery query) {
//查询课表相关信息
//获取当前用户的id
Long userId = UserContext.getUser();
//根据id查询需要的信息
//调用本类的分页查询获取page结果,包括page,pageSize,List<LearningLesson>
//这块是设置查询条件和分页查询的顺序
Page<LearningLesson> page = lambdaQuery()
.eq(LearningLesson::getUserId, userId)
.page(query.toMpPage("latest-learn-time",false));
List<LearningLesson> records = page.getRecords();
//如果课程为空则直接返回
if(records == null || records.isEmpty()){
return PageDTO.empty(page);
}
//查询课程相关信息
//根据课程id的集合去课程的表里查询相关信息
Set<Long> cIds = records.stream()
.map(LearningLesson::getCourseId).collect(Collectors.toSet());
List<CourseSimpleInfoDTO> cInfoList = courseClient.getSimpleInfoList(cIds);
//每次查出结果来都要进行防止空指针和数据不合理出此案,增强健壮性
if(CollUtil.isEmpty(cInfoList)){
throw new RuntimeException("查找到的课程相关数据不合理");
}
//查出来的结果和分页查询出来的结果没办法一一对应
//把结果封装为Map集合,加个标签,遮阳根据主键查询就能找到对应的课程信息然后一起封装了
Map<Long, CourseSimpleInfoDTO> cMap = cInfoList.stream()
.collect(Collectors.toMap(CourseSimpleInfoDTO::getId, c -> c));
//把page的List<LearningLesson>的信息取出再加入课程相关信息,封装为List<LearngingLessonVO>
List<LearningLessonVO> learningLessonVOList = new ArrayList<>();
for(LearningLesson r : records){
LearningLessonVO learningLessonVO = new LearningLessonVO();
BeanUtils.copyProperties(r,learningLessonVO);
//根据当前的课程id查询到cMap里面的课程对象
CourseSimpleInfoDTO courseSimpleInfoDTO = cMap.get(r.getCourseId());
learningLessonVO.setCourseName(courseSimpleInfoDTO.getName());
learningLessonVO.setCourseCoverUrl(courseSimpleInfoDTO.getCoverUrl());
learningLessonVO.setSections(courseSimpleInfoDTO.getSectionNum());
//把当前对象加到list集合里面
learningLessonVOList.add(learningLessonVO);
}
//封装返回
return PageDTO.of(page,learningLessonVOList);
}
//课程相关信息可以单独封装成一个方法
}代码提交和分支合并
常用知识点
Stream
Java 业务开发 最常用 8 种 Stream 流(直接背会,写业务天天用)
我给你整理最实用、业务代码 90% 都会用到的 Stream 写法,全部配真实业务例子,一看就会、一用就爽。
一、先记住:Stream 固定套路
集合.stream() // 把集合变成流
.中间操作() // 过滤、转换、排序...
.终结操作() // 收集成 List/Set/Map、统计、遍历
二、业务开发 最常用 8 大 Stream 用法
1)filter 过滤(最常用!)
作用:筛选出符合条件的数据
// 筛选出 年龄 > 18 的用户
List<User> adults = userList.stream()
.filter(user -> user.getAge() > 18)
.toList();
业务场景
-
筛选状态正常的数据
-
过滤 null、空值
-
筛选指定类型 / 指定范围
2)map 类型转换(你刚才用的!)
作用:把一个对象 转成 另一个对象 / 字段
// 提取所有用户ID
List<Long> ids = userList.stream()
.map(User::getId)
.toList();
// 对象转 VO
List<UserVO> voList = userList.stream()
.map(user -> new UserVO(user.getId(), user.getName()))
.toList();
业务场景
-
提取 ID 集合
-
DO 转 VO / DTO
-
取某个字段做后续操作
3)collect(Collectors.toList()) / toSet()
作用:把流转回集合
List<Long> idList = list.stream().map(User::getId).toList();
Set<Long> idSet = list.stream().map(User::getId).collect(Collectors.toSet());
toSet () 自动去重!
4)collect (Collectors.toMap ()) 转 Map(超级常用)
作用:List 快速转 Map,方便根据 ID 取值
// key = userId, value = user
Map<Long, User> userMap = userList.stream()
.collect(Collectors.toMap(
User::getId, // key
user -> user, // value
(oldValue, newValue) -> oldValue // 重复 key 保留旧的
));
业务场景
-
根据 ID 批量查对象,避免循环查库
-
关联查询时做匹配
5)forEach 遍历
作用:循环处理每一条数据
userList.stream().forEach(user -> {
System.out.println(user.getName());
});
6)sorted 排序
作用:按字段升序 / 降序
// 按年龄升序
List<User> sortedList = userList.stream()
.sorted(Comparator.comparingInt(User::getAge))
.toList();
// 按年龄降序
.sorted(Comparator.comparingInt(User::getAge).reversed())
7)distinct 去重
List<Long> uniqueIds = idList.stream()
.distinct()
.toList();
8)anyMatch /allMatch/noneMatch 判断
作用:快速判断集合中是否存在符合条件的数据
// 是否存在成年人
boolean hasAdult = userList.stream()
.anyMatch(user -> user.getAge() > 18);
-
anyMatch:任意一个匹配就返回 true
-
allMatch:全部匹配才返回 true
-
noneMatch:全都不匹配才返回 true
三、最常用 Stream 语法(速查表)
1. 流创建
list.stream()
2. 中间操作(可叠加)
.filter() 过滤
.map() 转换
.sorted() 排序
.distinct() 去重
.limit() 限制条数
3. 终结操作(必须有)
.toList()
.collect(Collectors.toSet())
.collect(Collectors.toMap())
.forEach()
.anyMatch()
.count()
四、你业务代码里最常见的组合(必背)
组合 1:过滤 + 提取 ID
Set<Long> cIds = records.stream()
.filter(Objects::nonNull)
.map(LearningLesson::getCourseId)
.collect(Collectors.toSet());
组合 2:List 转 Map 批量匹配
Map<Long, Course> courseMap = courseList.stream()
.collect(Collectors.toMap(Course::getId, c -> c));
组合 3:过滤 + 排序 + 转 VO
List<UserVO> voList = userList.stream()
.filter(u -> u.getStatus() == 1)
.sorted(Comparator.comparing(User::getCreateTime).reversed())
.map(u -> new UserVO(u.getId(), u.getName()))
.toList();
五、一句话总结 Stream
Stream = 对集合做:筛选 → 转换 → 排序 → 收集,一行搞定,不用写 for 循环。
调试运行相关问题
一、为本地请求不用 /ls 也能访问,本地请求不通过网关
你本地请求路径是 localhost:8090/lesson/page,而不是 localhost:8090/ls/lesson/page,能正常返回数据,核心原因只有一个:/ls 是网关层的路径前缀,你现在是直接访问服务端口,不走网关!
-
你当前的请求链路
浏览器/Postman → localhost:8090 → tj-learning服务(端口8090)这个链路里,请求直接打到了
tj-learning服务的 Tomcat,没有经过任何网关转发。 -
网关的作用是什么?网关(比如
tj-gateway)的核心作用是反向代理,配置类似这样:spring: cloud: gateway: routes: - id: learning-service uri: lb://tj-learning predicates: - Path=/ls/**它的逻辑是:
-
当你访问
localhost:8080/ls/lesson/page时,网关会把请求转发到tj-learning服务的http://tj-learning/lesson/page -
所以
/ls只是网关层的路径前缀,服务本身的接口是不带/ls的
-
在本地调用的时候体现不出网关的作用来,网关其实只有两个作用:
对发送过来的请求做过滤,筛选掉没有认证的,
对筛选后剩下的请求做一些路由
本地发的请求直接发送到服务里面,没有经过网关
但是实际情况下项目上线以后,只会在同一个网站发请求,不会出现这种情况
二、本地请求不会经过虚拟机的 Nginx
不会!完全不会!
原因:网络隔离
-
你本地电脑的
localhost是127.0.0.1,请求只会在你的电脑内部流转,不会发送到局域网 / 互联网 -
虚拟机里的 Nginx 是独立的服务,监听的是虚拟机的 IP(比如
192.168.100.10:80),和你本地的localhost:8090完全是两个不同的网络地址
什么时候才会经过虚拟机的 Nginx?
只有当你这样请求时,才会经过:
http://192.168.100.10/ls/lesson/page
此时请求会先到虚拟机的 Nginx,再由 Nginx 转发到网关,最后到 tj-learning 服务。
三、给你总结一下本地 vs 虚拟机的请求链路
表格
|
请求场景 |
请求路径 |
链路 |
是否经过网关 / Nginx |
|---|---|---|---|
|
本地直连服务 |
|
浏览器 → |
❌ 不经过网关、Nginx |
|
本地访问网关 |
|
浏览器 → |
✅ 经过网关,不经过 Nginx |
|
虚拟机访问 Nginx |
|
浏览器 → 虚拟机 Nginx → 网关 → |
✅ 经过 Nginx、网关 |
四、你现在这个接口成功,是因为这两个关键条件:
-
直接访问服务端口,跳过了网关层的路径前缀
/ls -
user-info请求头传了纯数字2,通过了UserInfoInterceptor的认证 -
course-service也正常启动了,远程调用没有报错
部署流程
企业级微服务 本地开发 → Git 私服 → Jenkins 构建 → 虚拟机部署 完整标准流程清单
(结合你项目:tianji + Nacos + 微服务 + 网关 + MySQL + Redis + Git 私服 + Jenkins)我给你整理成企业最标准、最通用、你每天都要照着做的一套完整清单。
一、开发前:本地环境启动清单
你每次打开 IDEA 开发,必须按这个顺序启动,否则一定会报错!
1. 启动本地中间件(顺序不能乱)
-
启动 Nacos(注册中心 + 配置中心)
-
访问:
localhost:8848/nacos -
作用:所有微服务必须注册到这里才能互相调用
-
-
启动 MySQL(本地库)
-
启动 Redis
2. 启动基础微服务(顺序不能乱)
-
启动网关服务 tj-gateway
-
端口:8080
-
-
启动用户认证服务 tj-auth
-
启动课程服务 tj-course(你接口依赖的服务)
-
端口:80xx
-
-
最后启动你开发的服务 tj-learning
-
端口:8090
-
✅ 启动完成检查
打开 Nacos → 服务列表 → 能看到:
-
tj-gateway
-
tj-auth
-
tj-course
-
tj-learning
二、本地开发 + 测试流程清单(你每天都做)
1. 写代码
-
Controller → Service → Mapper
-
Feign 远程调用(course-service)
2. 本地接口测试(2 种方式)
方式 1:直连服务(不走网关,开发最快)
-
地址:
localhost:8090/lesson/page -
请求头:
user-info: 2 -
不走网关、不走 Nginx、不经过虚拟机
方式 2:走网关(模拟真实环境)
-
地址:
localhost:8080/ls/lesson/page -
请求头:
user-info:2 -
经过网关,但不经过 Nginx、不经过虚拟机
3. 本地测试通过标准
-
接口返回 200
-
远程调用不报错
-
数据库数据正常
-
无 401、无 404、无 UnknownHostException
三、代码提交到 Git 私服 流程清单(企业标准)
1. 开发完成后执行
git add .
git commit -m "【功能】学习课表列表接口开发完成"
2. 推送到 Git 私服(GitLab/Gitee)
git push origin 你的分支
3. 提交合并请求(Merge Request)
-
从
dev/xxx合并到develop分支 -
组长 / 架构师审核
四、Jenkins 自动化构建部署清单(企业级标准)
1. 开发提交代码 → Git 私服触发 Jenkins
2. Jenkins 自动执行流程(你不用管)
-
拉取最新代码
-
从 Git 私服 拉取 develop 分支代码
-
-
Maven 构建
-
mvn clean package -Dmaven.test.skip=true
-
-
单元测试
-
代码质量检查(SonarQube)
-
生成 jar 包
-
tj-learning.jar
-
3. Jenkins 自动部署到 测试虚拟机
-
停止虚拟机上旧的服务
-
上传新 jar 到虚拟机
/opt/tianji/ -
启动新 jar
-
健康检查
4. 部署完成
-
虚拟机服务自动注册到虚拟机 Nacos
-
测试环境可访问
五、虚拟机(Linux)环境部署流程清单
1. 虚拟机环境必须启动
-
Nacos(虚拟机版)
-
MySQL
-
Redis
-
Nginx
2. 虚拟机服务启动顺序
-
tj-gateway
-
tj-auth
-
tj-course
-
tj-learning
3. 访问方式(经过 Nginx + 网关)
http://虚拟机IP/ls/lesson/page
浏览器 → Nginx → 网关 → 微服务
六、本地 / Git 私服 / Jenkins / 虚拟机 四者关系图(最关键)
1. 本地开发
IDEA → 本地服务 → 本地Nacos → 本地MySQL
不走 Jenkins、不走虚拟机、不走 Nginx
2. 提交代码
本地 → Git私服
3. Jenkins 自动化
Git私服 → Jenkins打包 → 虚拟机部署
4. 测试环境
用户 → Nginx → 网关 → 微服务(虚拟机)
七、你项目的 最简黄金工作流(背下来,企业通用)
日常开发(本地)
-
启动 Nacos
-
启动依赖服务
-
启动自己服务
-
直连服务测试:
localhost:8090
开发完成
-
commit → push 到 Git 私服
-
提交合并请求
-
Jenkins 自动构建部署到虚拟机
-
测试环境访问:
虚拟机IP/ls/xxx
八、我再给你一句最经典总结
** 本地开发直连服务,不走网关不走虚拟机;
提交代码走 Git,构建部署用 Jenkins;测试环境走 Nginx + 网关,访问前缀带 /ls。**
虚拟机上的镜像的工作原理
✅ 虚拟机 Docker 里的 Nacos、MySQL、Redis,完全可以被你本地电脑直接连接、直接调用、直接使用✅ 就像你本地 Navicat 连虚拟机 Docker 的 MySQL 一模一样,不用钻进虚拟机系统内部、不用虚拟机里的服务才能访问
一、核心原理:Docker 容器 + 虚拟机端口映射
你现在架构:
-
虚拟机(CentOS)
-
虚拟机里装 Docker
-
Docker 跑:Nacos、MySQL、Redis 容器
关键配置:端口映射(port映射)
Docker 启动容器时一定会加参数:
bash
运行
# 示例:Nacos docker启动命令
docker run -d \
-p 8848:8848 \
-p 9848:9848 \
--name nacos \
nacos/nacos-server
-
左边
8848:虚拟机宿主机端口 -
右边
8848:Docker 容器内部端口
👉 含义:访问 虚拟机 IP:8848 → 自动转发到 Docker 里的 Nacos 容器:8848
二、所以:本地电脑 完全跨网络访问虚拟机 Docker 中间件
1. 网络链路(极简)
plaintext
你本地电脑(Windows)
↓ 局域网互通
虚拟机IP(例如:192.168.122.100)
↓ 端口映射
Docker 内部 Nacos / MySQL / Redis 容器
2. 和你 Navicat 连虚拟机 MySQL 完全一模一样
你平时:
-
Navicat 连接:
虚拟机IP:3306 -
直接操作虚拟机 Docker 里的 MySQL
同理:
-
IDEA 项目 连接:
虚拟机IP:8848→ 操作 Docker Nacos -
本地浏览器访问:
http://虚拟机IP:8848/nacos -
本地微服务 注册到 虚拟机 Docker Nacos
三、本地微服务 直接注册「虚拟机 Docker Nacos」可行吗?
✅ 100% 可行,企业开发常态
你的项目直接改配置就能用
yaml
spring:
cloud:
nacos:
discovery:
server-addr: 192.168.122.100:8848 # 你的虚拟机IP
config:
server-addr: 192.168.122.100:8848
-
你本地的
tj-learning、tj-course、gateway -
全部注册到 虚拟机 Docker 的 Nacos
-
本地服务之间照样互相调用、Feign 远程调用完全正常
四、两种开发模式(企业全都在用,你自由切换)
模式①:全本地中间件(你之前的用法)
-
本地 Windows 启动 Nacos、MySQL、Redis
-
服务注册:
127.0.0.1:8848 -
优点:断网也能写代码
-
缺点:本机臃肿、环境不一致
模式②:本地服务 + 虚拟机 Docker 中间件(企业主流推荐)
-
中间件全部统一放在虚拟机 Docker(Nacos/MySQL/Redis/RabbitMQ)
-
你本地只写代码、启动微服务
-
本地服务连 虚拟机 IP 中间件
-
优点:
-
所有人环境统一
-
本机干净不装乱七八糟软件
-
测试环境、线上环境中间件完全一致
-
Jenkins 打包、虚拟机部署无缝衔接
-
五、你最关心的几个问题,逐个回答
1. 本地不进虚拟机,能连 Docker 的 Nacos 吗?
能。只要虚拟机防火墙放行端口、Docker 做了端口映射。
2. 本地服务 和 虚拟机里的服务 能互相注册、互相调用吗?
能。只要都连同一个 Nacos(虚拟机 Docker)
-
本地服务 ↔ 虚拟机服务
-
跨机器、跨环境 Feign 远程调用完全通
3. 必须虚拟机内部启动业务服务才能用 Nacos 吗?
❌ 完全不用。谁配置了 Nacos 地址,谁就能注册你本地代码配置虚拟机 Nacos,本地就注册进去。
4. 和 Nginx 有关系吗?
毫无关系。
-
Nginx 是最外层反向代理(给前端 / 测试人员用)
-
服务注册、发现、Feign 调用 只走 Nacos,不走 Nginx
六、一键检查你能不能连通(你现在就能测)
-
虚拟机 IP 举例:
192.168.122.100 -
本地浏览器输入:
plaintext
http://192.168.122.100:8848/nacos
能打开 Nacos 控制台 = 完全打通打不开 = 虚拟机防火墙没开端口
七、终极总结(背下来,面试 + 开发都能用)
-
Docker 容器只要做了端口映射,就是暴露给局域网的
-
虚拟机 Docker 里的 Nacos/MySQL/Redis,和本地软件无区别,局域网内所有机器都能连
-
本地微服务可以直接注册到虚拟机 Nacos,跨机器服务调用完全支持
-
Nginx 是入口代理,和微服务注册、内部调用无关
-
企业标准做法:开发机只写代码,中间件全部统一 Docker 部署在虚拟机 / 服务器
Nacos的工作原理
要远程调用其他服务的时候要用nacos,但是这个时候必须是虚拟机部署的服务吗
远程调用的服务,可以是本地启动的、也可以是虚拟机启动的,只要:所有服务 连接同一个 Nacos**,就能互相发现、互相 Feign 调用。**
一、Nacos 本质是什么
-
服务注册:所有微服务启动时,把「服务名 + 当前 IP + 端口」上报给 Nacos
-
服务发现:A 服务要调用 B 服务 → 问 Nacos 要 B 服务的 IP 和端口
✅ Nacos 不限制 IP 是谁
-
你的电脑本地 IP
-
虚拟机 LinuxIP
-
公司服务器 IP全都能注册、混合调用
二、三种企业真实混合部署场景(全都能互相调用)
场景 1:全本地开发(你之前)
-
Nacos:本地 localhost:8848
-
learning、course、gateway:全都本地启动
-
互相调用:正常
场景 2:本地代码 + 虚拟机中间件(企业最常用⭐)
-
Nacos / MySQL / Redis:虚拟机 Docker 容器
-
你的业务服务:全部在你电脑本地 IDEA 启动
-
所有服务配置:
nacos地址=虚拟机IP:8848👉 结果:本地 learning ↔ 本地 course 正常 Feign 远程调用
场景 3:混合环境(面试常问、工作天天用)
-
服务 A(course):部署在 虚拟机
-
服务 B(learning):运行在 你本地电脑
-
共用同一个虚拟机 Nacos👉 结果:本地服务 完美调用 虚拟机服务虚拟机服务 也能调用 本地服务
三、结合你的项目 举实例
前提
Nacos 地址:192.168.xxx.xxx:8848(虚拟机 Docker)
-
你本地 IDEA 启动:
-
tj-learning(本地 IP:192.168.1.50:8090)
-
-
同事 / 测试机 启动:
-
tj-course(虚拟机 IP:192.168.1.100:8081)
-
流程
-
两个服务启动,都注册到 同一个虚拟机 Nacos
-
learning 发起 Feign 调用
@FeignClient("course-service") -
去 Nacos 拉取 course-service 列表,拿到虚拟机 IP
-
直接 HTTP 请求虚拟机的 course 接口✅ 调用成功,完全没问题
四、纠正你一个关键误区
误区:微服务远程调用,必须都部署在虚拟机 / 服务器❌ 错!
-
虚拟机只是用来统一存放中间件、测试环境、生产环境
-
开发阶段:业务服务 100% 本地跑,只连虚拟机中间件,是企业标准写法
-
Nginx、虚拟机环境,只负责「前端正式访问、外网入口」
-
服务内部 Feign 调用,和 Nginx、网关、虚拟机环境 毫无绑定关系
五、什么时候才必须把服务部署到虚拟机?
只有这 3 种情况:
-
功能开发完成,提交 Git、Jenkins 自动打包,交付测试
-
测试人员要通过 Nginx + 网关 统一入口测完整流程
-
上线生产环境
👉 日常开发、调试、写代码:永远本地跑服务,不用部署虚拟机
六、给你一套最简开发规范(你以后就这么用)
-
中间件全部用虚拟机 Docker:Nacos、MySQL、Redis、RabbitMQ
-
你的所有微服务:IDEA 本地启动
-
所有服务配置文件统一:
yaml
spring: cloud: nacos: server-addr: 虚拟机IP:8848 # 数据库、redis 全部连虚拟机 -
本地直连调试接口:
localhost:8090/xxx -
写完代码提交 Git 私服 → Jenkins 自动发到虚拟机测试环境
七、终极总结(背住)
-
Nacos 只管理「服务名 + IP + 端口」,不分本地 / 虚拟机
-
只要连同一个 Nacos,本地、虚拟机服务可以任意混合调用
-
开发期:业务服务本地跑,中间件虚拟机 Docker 跑,最高效
-
测试 / 生产期:全服务部署虚拟机 / 服务器,走 Nginx 统一入口
-
Feign 远程调用只依赖 Nacos,和虚拟机、Nginx 无强制绑定
DAY03
页面原型
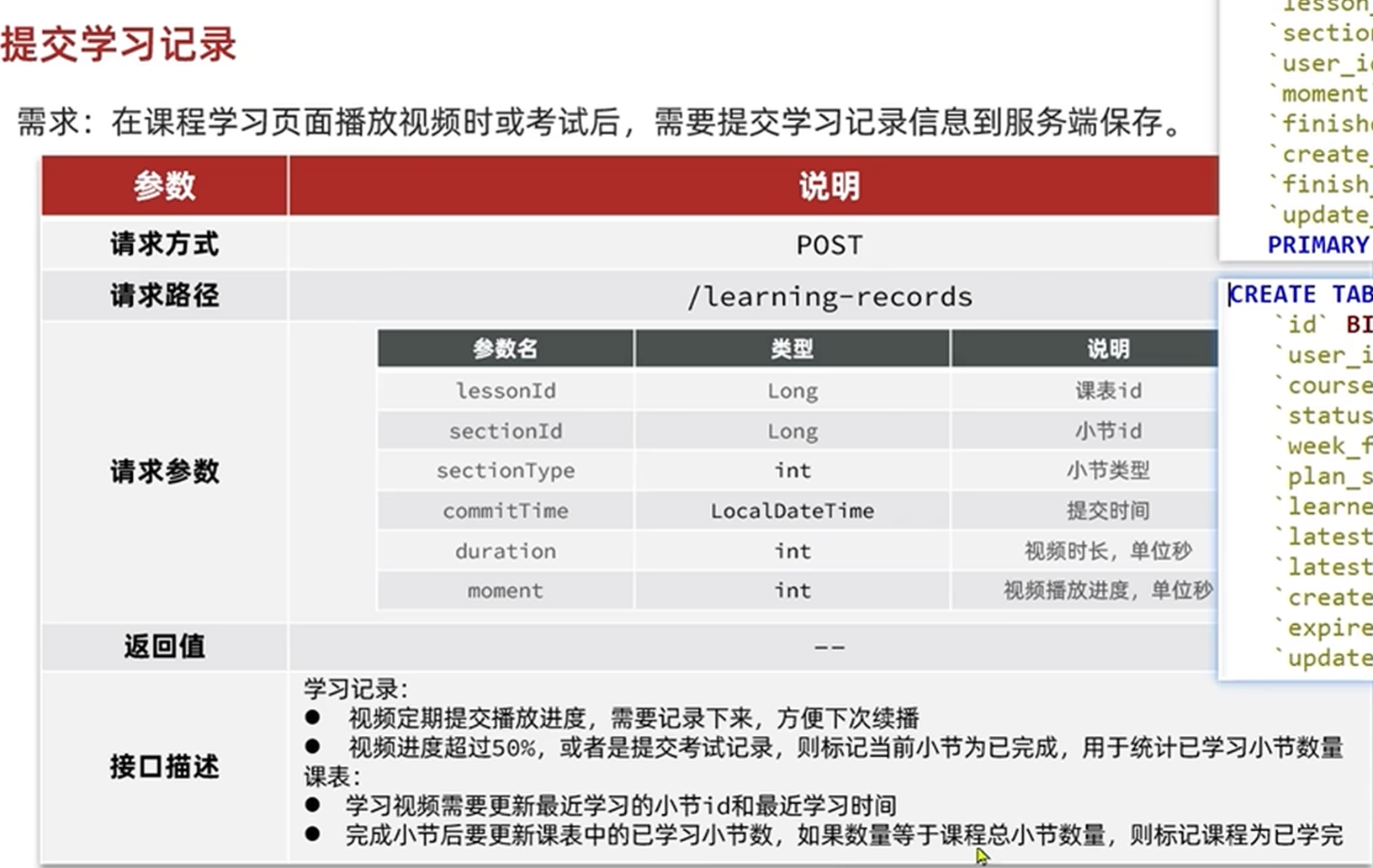
设计提交学习记录的接口
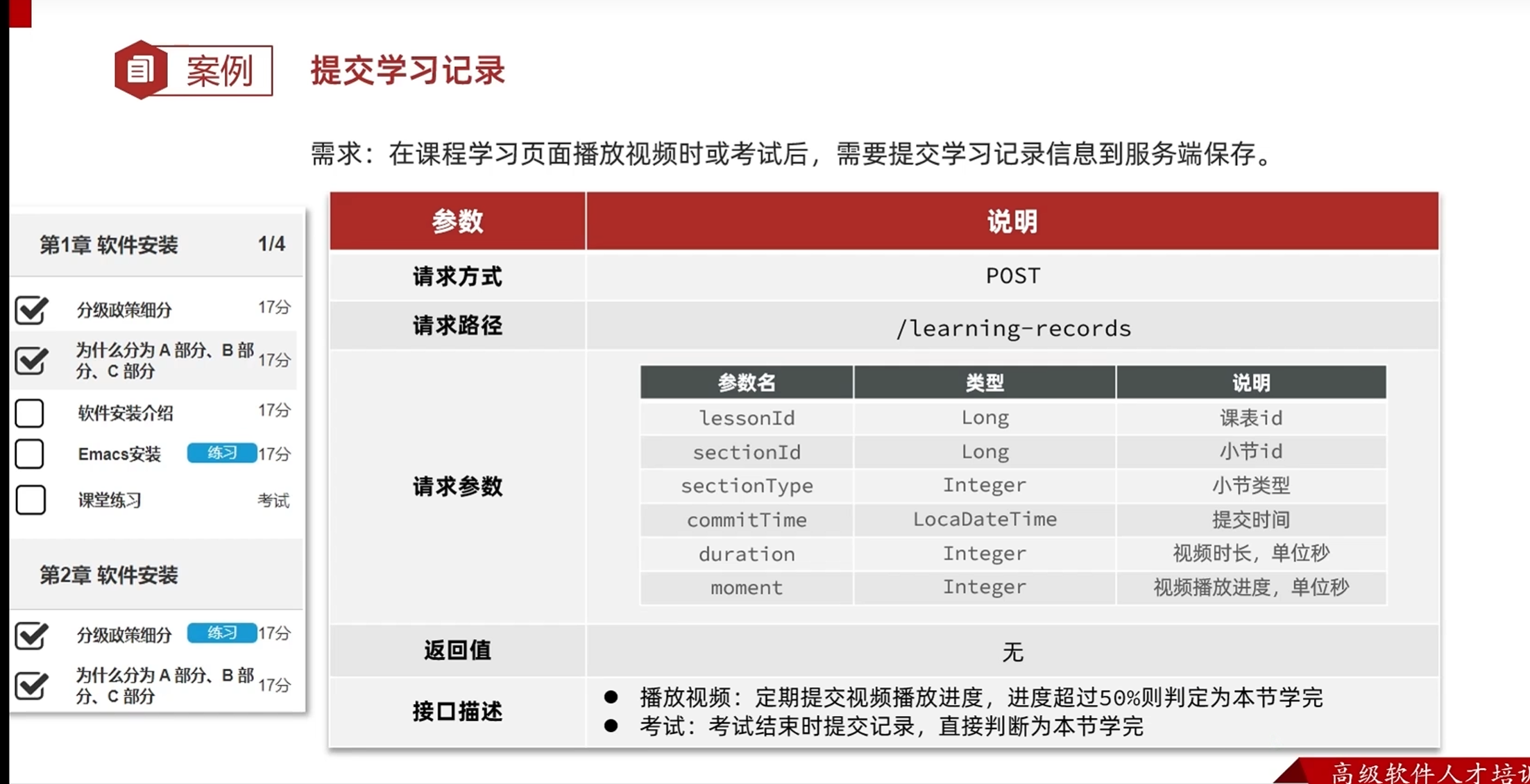
请求数据的时候,可以前端一次发两个请求,这样会增加服务器的压力
也可以前端只发送一次请求给后端,后端调用微服务,这样会增加占用微服务带宽,但可以减轻服务器的压力
所以综上所述,一般前端只发送一次请求
设计查询学习记录的接口
点击继续学习的时候,后端要根据课程id查找最近在学习的章节
该页面提交学习记录的时候需要返回课程的id

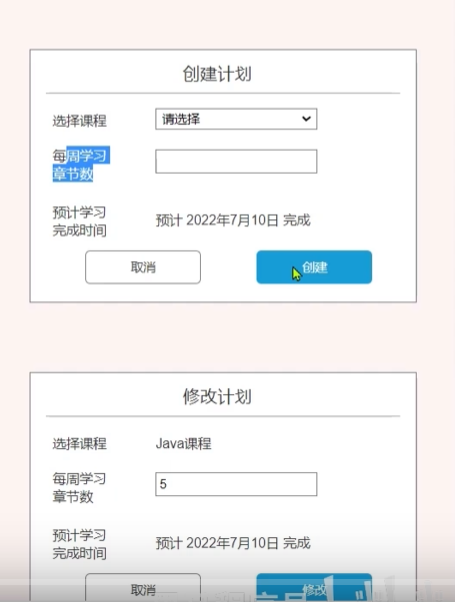
设计学习计划相关接口
每一个课程点击创建学习计划的时候都会跳转到一下页面
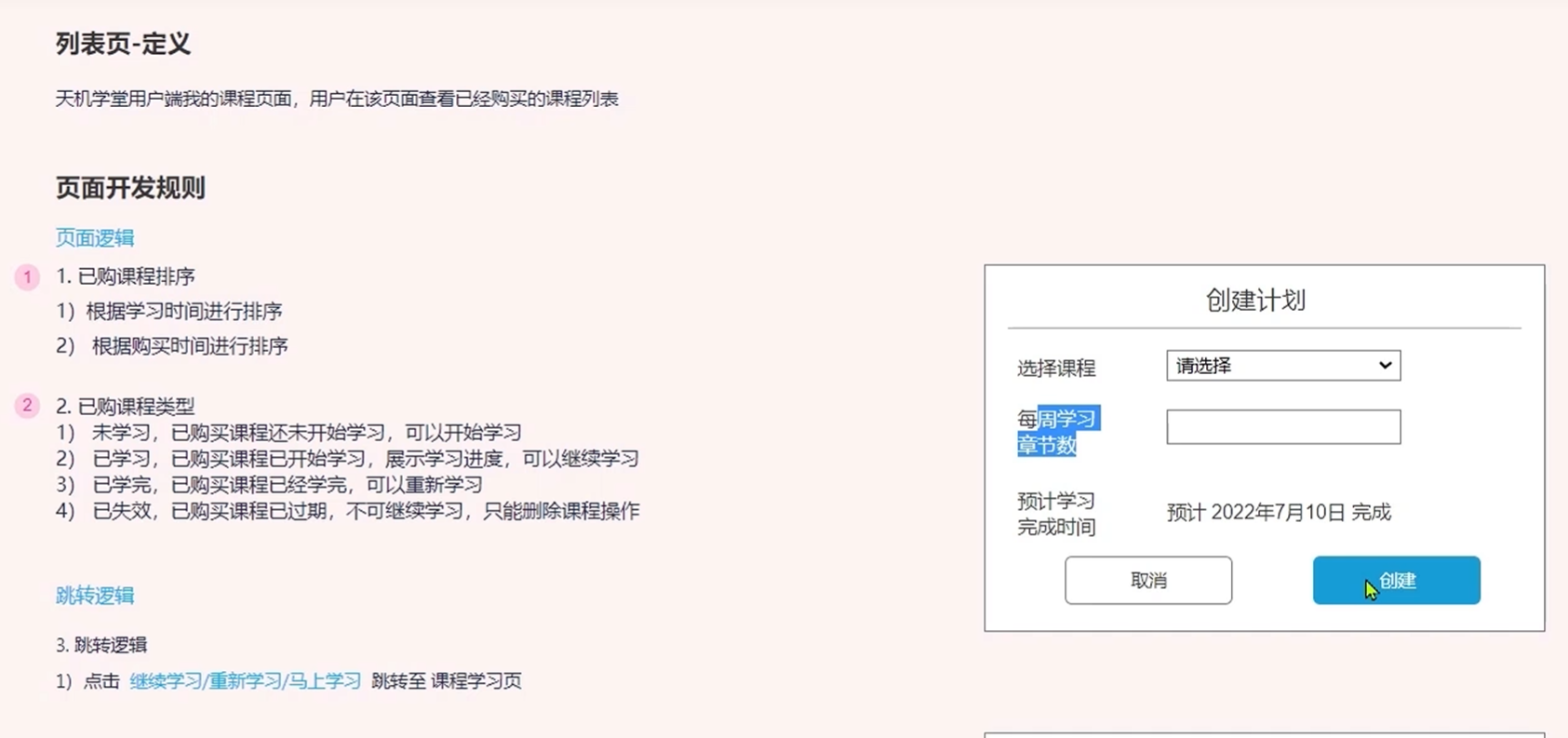
查询最近正在学习的课程的学习计划
设计数据库的表结构

发开的流程:看页面原型->设计接口->设计数据库的表结构->开始开发
详细步骤:
->创建新的分支->根据代码生成器生成代码->修改id为雪花算法
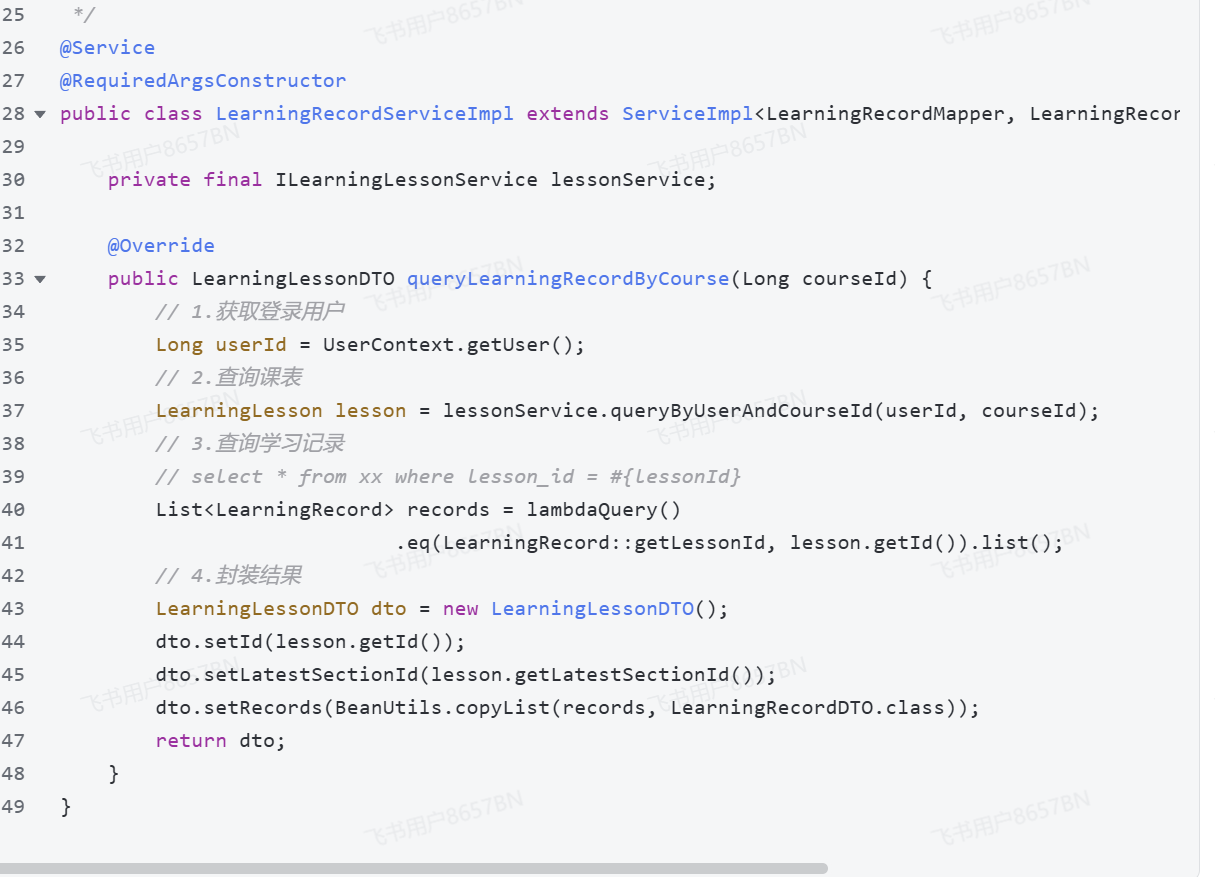
开发接口-查询指定课程学习记录
开发接口-提交学习记录的流程分析
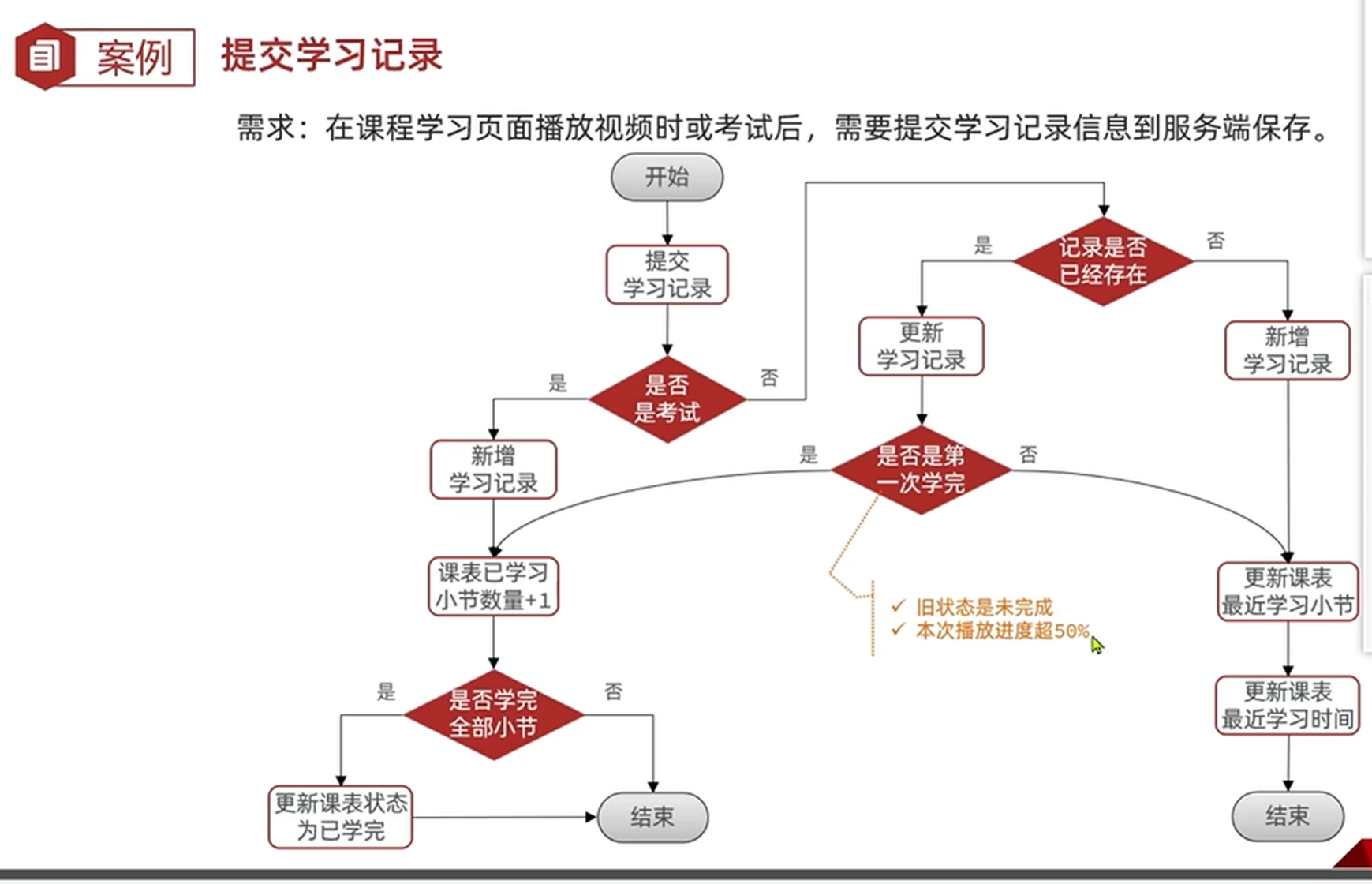
开发接口-提交学习记录
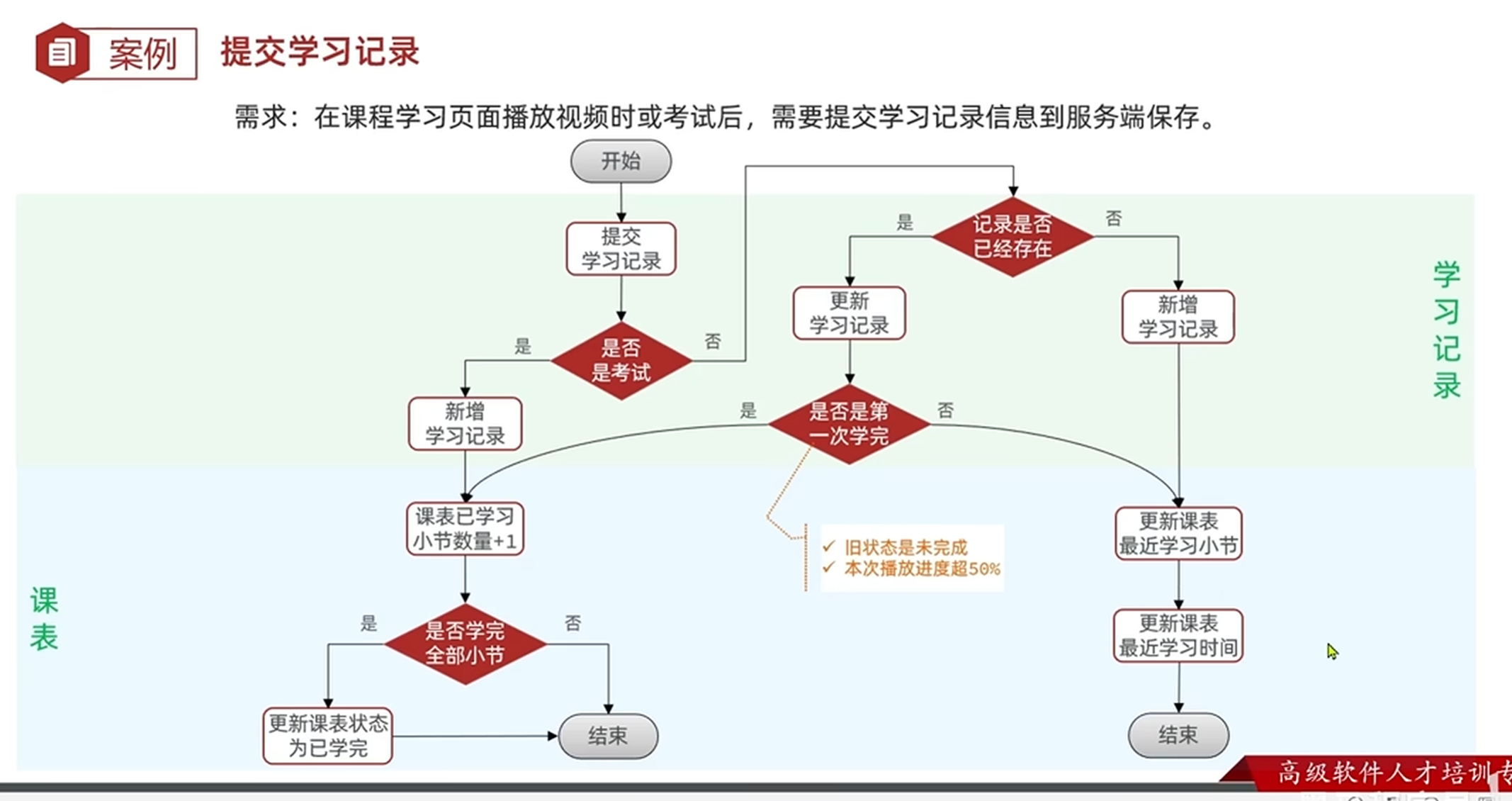
从结构上来说,这个代码可以分成三个部分
1.提交学习记录之后分成考试和视频分别处理
2.处理新增和更新学习记录,并给出返回值
3.根据返回值处理和更新课表(这部分因为处理逻辑相同就放在一块处理了)
@Override
public void addLearningRecords(@MonotonicNonNull LearningRecordFormDTO learningRecordFormDTO) {
//获取当前用户的id
Long userId = UserContext.getUser();
//根据表单信息修改学习记录
Boolean flag =false;
//考试
if (learningRecordFormDTO.getMoment() == SectionType.EXAM.getValue()) {
flag = handleExamRecord(userId, learningRecordFormDTO);
} else{ //视频
flag = handleVideoRecord(userId, learningRecordFormDTO);
}
//根据表单修改课表状态
handleLearningLessonChanges(flag,learningRecordFormDTO);
}
Boolean handleExamRecord(Long userId,LearningRecordFormDTO learningRecordFormDTO){
//直接新增一条学习记录
//转成实体类
LearningRecord learningRecord = BeanUtils
.copyProperties(learningRecordFormDTO, LearningRecord.class);
learningRecord.setUserId(userId);
learningRecord.setFinished(true);
learningRecord.setFinishTime(learningRecordFormDTO.getCommitTime());
//添加数据
boolean save = save(learningRecord);
if (!save) {
throw new DbRuntimeException("新增学习记录失败");
}
return true;
}
Boolean handleVideoRecord(Long userId, LearningRecordFormDTO learningRecordFormDTO) {
//查看记录是否已经存在
LearningRecord record = lambdaQuery()
.eq(LearningRecord::getLessonId, learningRecordFormDTO.getLessonId())
.one();
//不存在则新增学习记录
if(record == null) {
LearningRecord learningRecord = BeanUtils
.copyProperties(learningRecordFormDTO, LearningRecord.class);
learningRecord.setUserId(userId);
learningRecord.setFinished(true);
learningRecord.setFinishTime(learningRecordFormDTO.getCommitTime());
//添加数据
boolean save = save(learningRecord);
if (!save) {
throw new DbRuntimeException("新增学习记录失败");
}
return false;
}
//存在则更新学习记录
// 判断是否是第一次完成
boolean finished = !record.getFinished() && learningRecordFormDTO.getMoment() * 2 >= learningRecordFormDTO.getDuration();
//更新数据
boolean success = lambdaUpdate()
.set(LearningRecord::getMoment, learningRecordFormDTO.getMoment())
.set(finished, LearningRecord::getFinished, true)
.set(finished, LearningRecord::getFinishTime, learningRecordFormDTO.getCommitTime())
.eq(LearningRecord::getId, record.getId())
.update();
if(!success){
throw new DbException("更新学习记录失败!");
}
return finished ;
}
void handleLearningLessonChanges(Boolean flag,LearningRecordFormDTO learningRecordFormDTO){
//只有更新学习记录的才需要判断是否为第一次学完
//查询课表
LearningLesson lesson =learningLessonServiceImpl
.getById(learningRecordFormDTO.getLessonId());
if (lesson == null) {
throw new BizIllegalException("课程不存在,无法更新数据");
}
//判断是否有新完成的小节
boolean allLearned =false;
if(flag){
//如果有新完成的小节,则需要查询课程数据
CourseFullInfoDTO courseInfoById = courseClient.getCourseInfoById(lesson.getCourseId(), false, false);
if(courseInfoById==null){
throw new BizIllegalException("课程不存在,无法查询数据");
}
allLearned = lesson.getLearnedSections()+1>=courseInfoById.getSectionNum();
}
//更新数据
lessonService.lambdaUpdate()
.set(lesson.getLearnedSections() == 0, LearningLesson::getStatus, LessonStatus.LEARNING.getValue())
.set(allLearned, LearningLesson::getStatus, LessonStatus.FINISHED.getValue())
.set(!flag , LearningLesson::getLatestSectionId, learningRecordFormDTO.getSectionId())
.set(!flag, LearningLesson::getLatestLearnTime, learningRecordFormDTO.getCommitTime())
.setSql(flag, "learned_sections = learned_sections + 1")
.eq(LearningLesson::getId, lesson.getId())
.update();
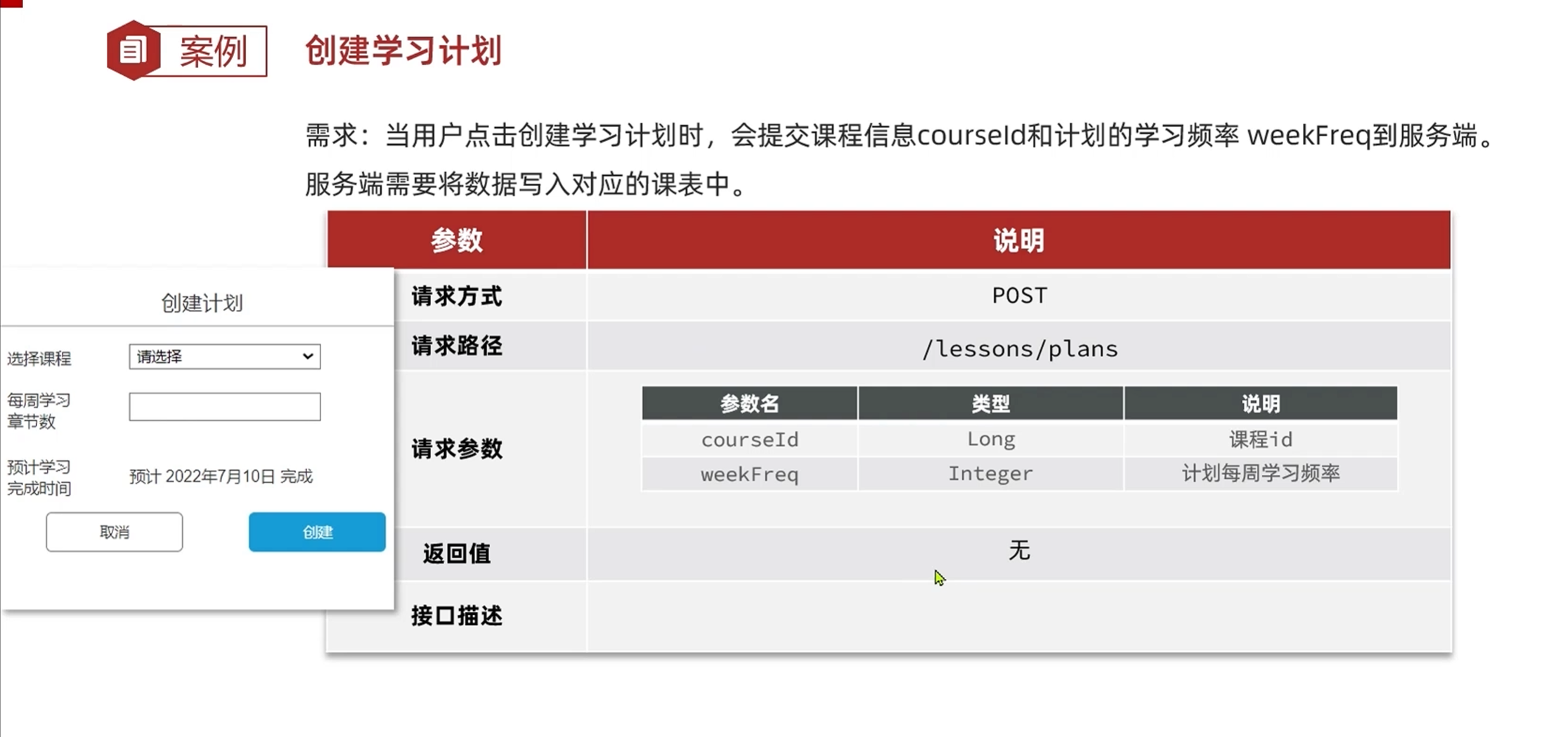
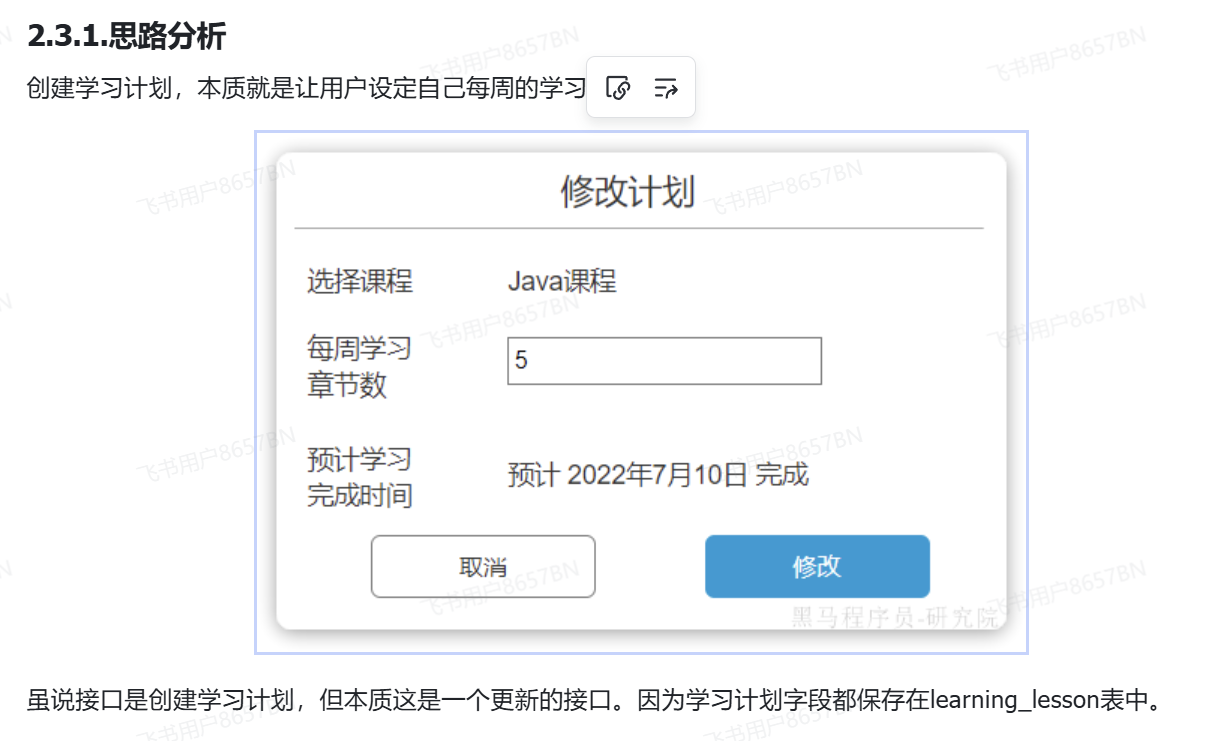
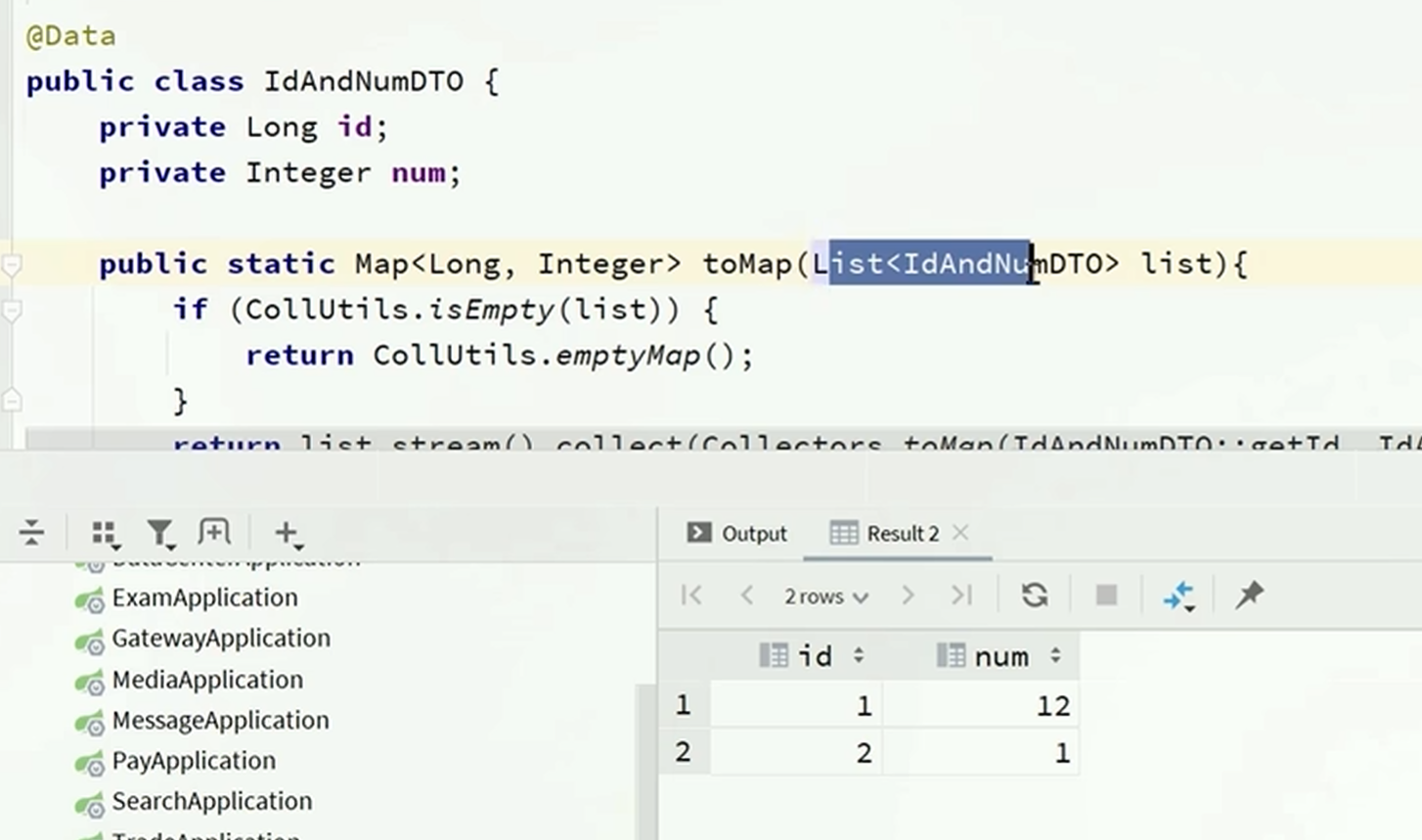
}开发接口-创建学习计划
LearningPlanDTO

上面有注解校验从前端传递过来的数据,如果超过注解限定的范围则会校验失败

controller

@Override
public void createLearningPlan(Long courseId, Integer freq) {
//获取当前的登录用户id
Long userId = UserContext.getUser();
//查询当前课表,如果课表不存在则抛出异常
LearningLesson learningLesson = queryByUserAndCourseId(userId, courseId);
AssertUtils.isNotNull(learningLesson,"课程不存在!");
//更新计划信息
lambdaUpdate()
.eq(LearningLesson::getCourseId,courseId)
.eq(LearningLesson::getUserId,userId)
.set(LearningLesson::getWeekFreq,freq)
.set(LearningLesson::getPlanStatus, PlanStatus.PLAN_RUNNING);
}
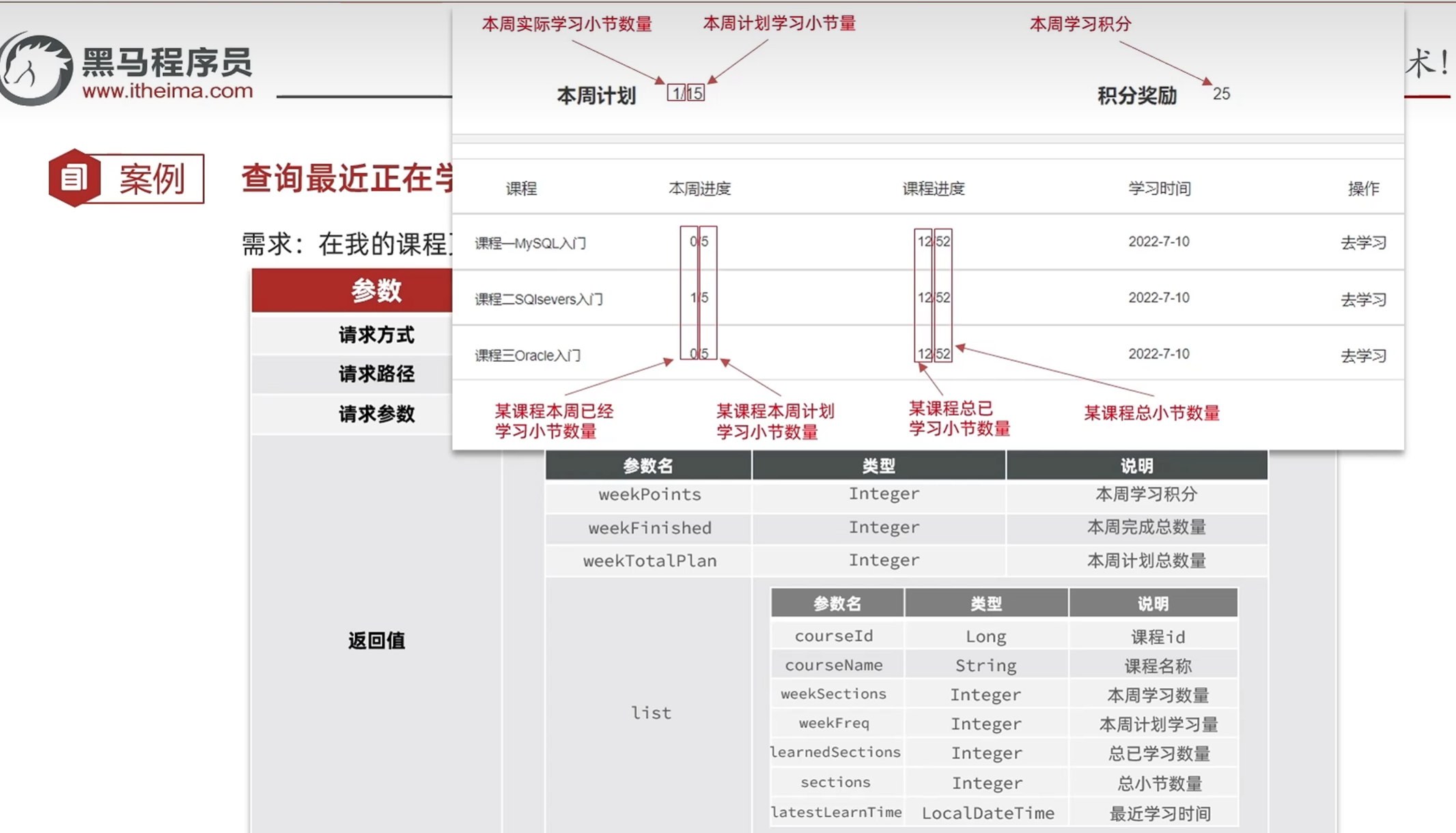
开发接口-查询学习计划

该接口主要麻烦的点在数据需要去统计,数据限定在本周的几天,所以需要去record表里面统计本周的已经学习的小节数量
LearningPlanPageVO继承了PageDTO
<>里的存储的是泛型的类型

也就是PageDTO里的List<>里的元素的类型
LearningPlanVO

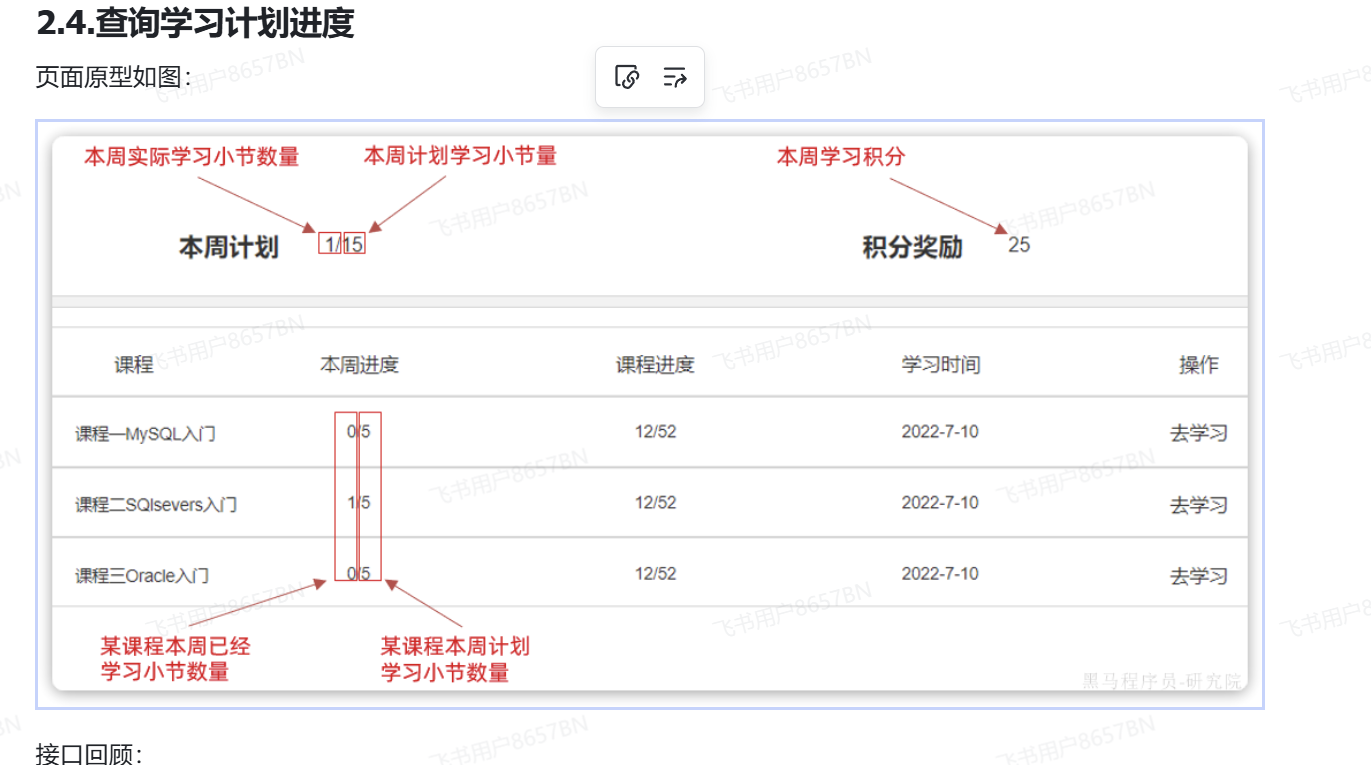
查询流程
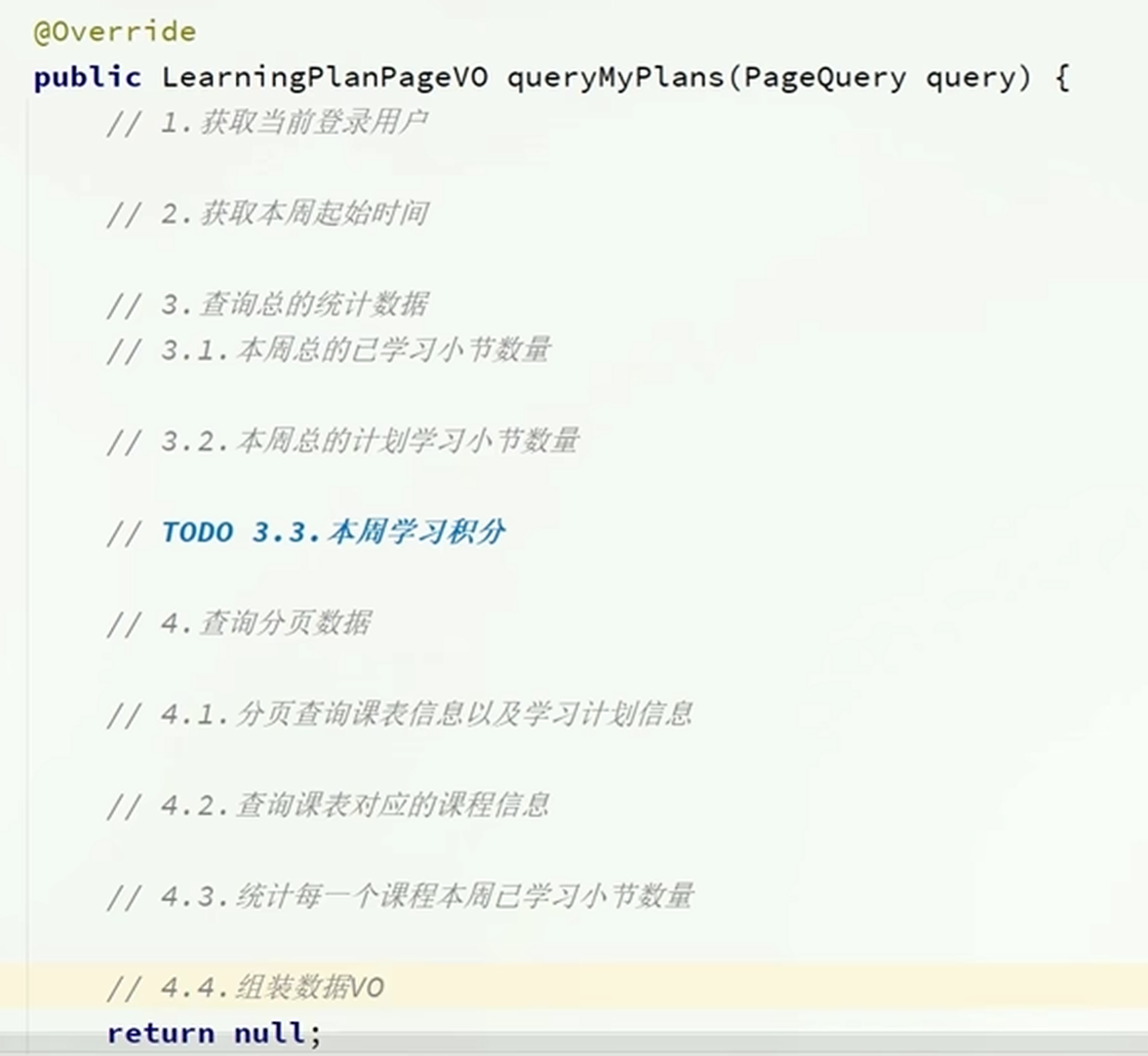
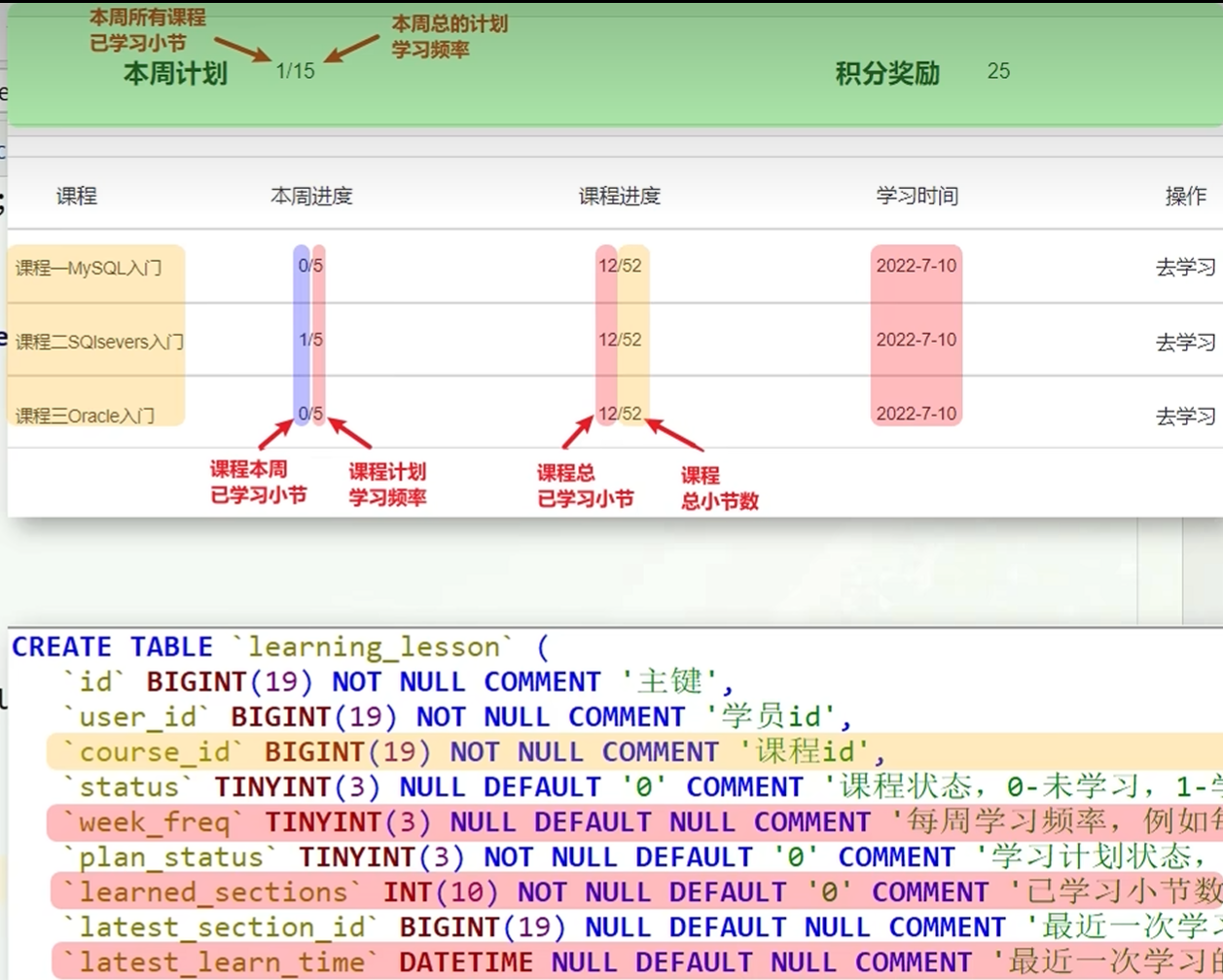
总的查询数据:
根据学习记录表:本周所有课程的已经学习小结
根据课表:本周总的计划学习频率
分页查询每一个课程:
根据课程表要搜索的数据为:课程的名称,课程的总节数
要根据学习记录表搜索的数据为:本周学习的节数,这个课程的总的学习节数,最新的学习时间
总查询如下
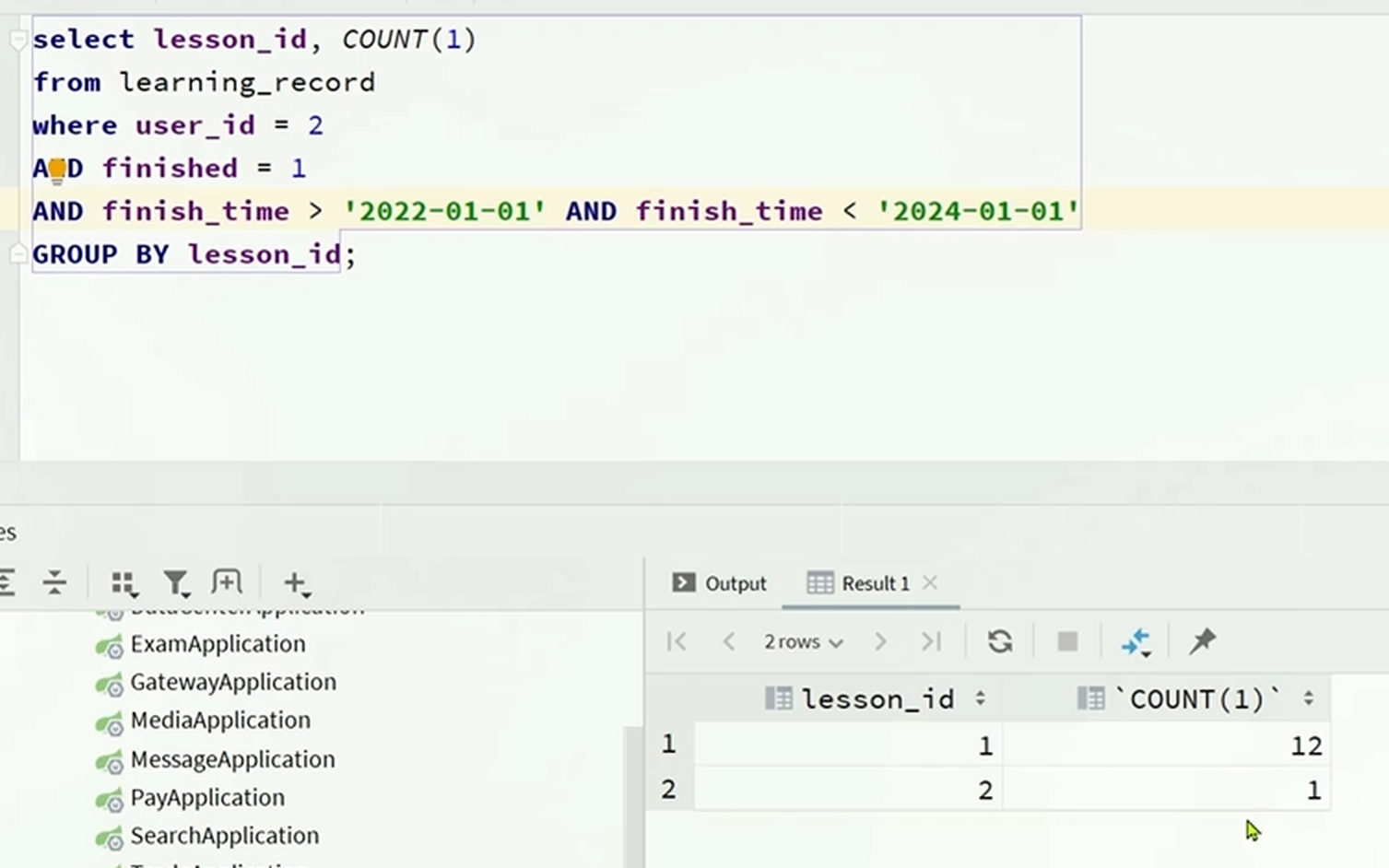
总的查询数据:
根据学习记录表:本周所有课程的已经学习小结
根据课表:本周总的计划学习频率
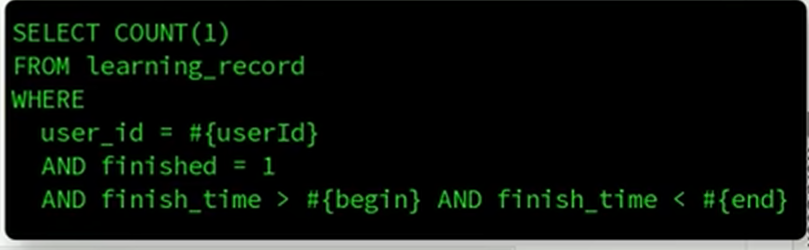
根据sql语句编写表达式
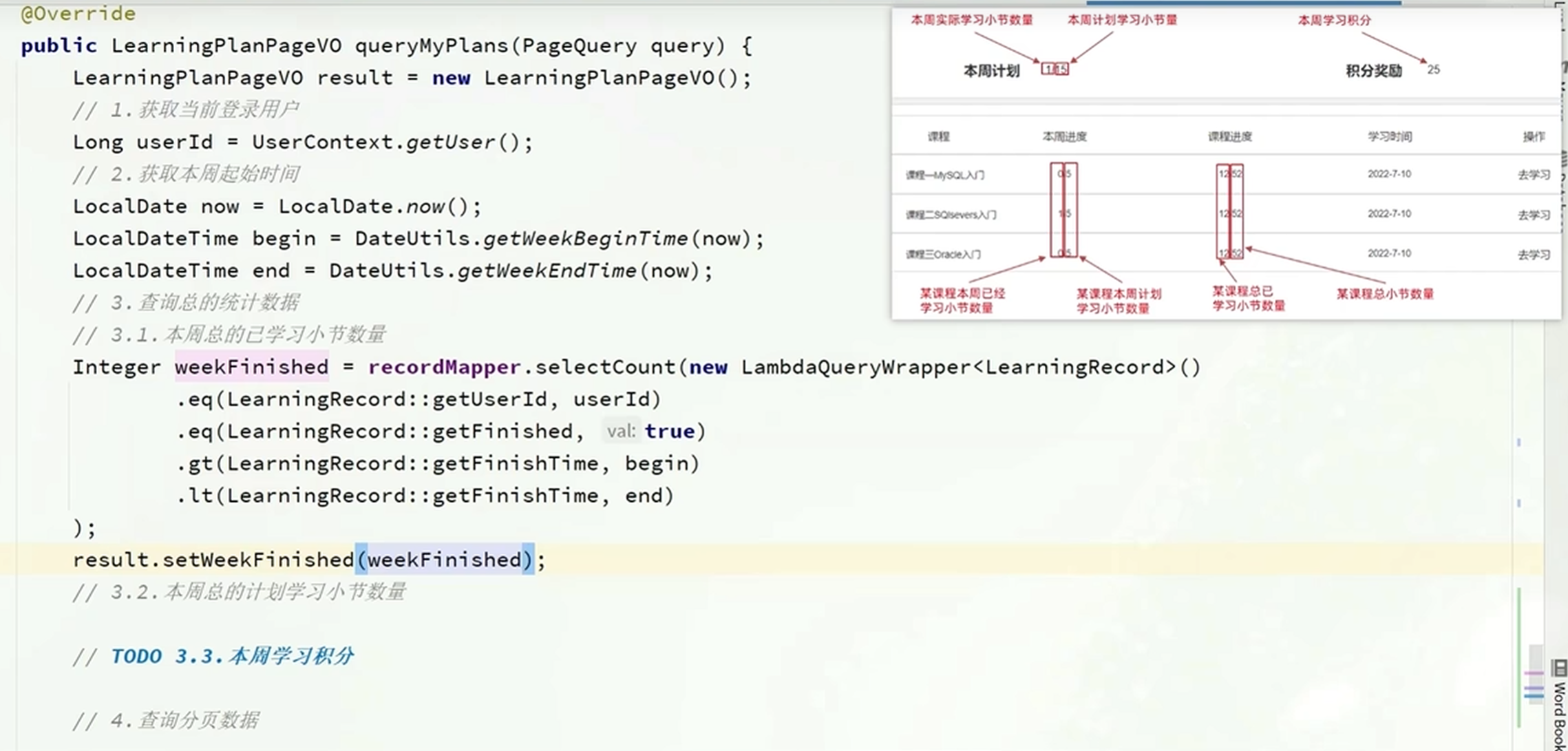
分页查询如下
分页查询每一个课程:
根据课程表要搜索的数据为:课程的名称,课程的总节数
(条件为:有学习计划,学习状态为学习中,隐藏条件为:登陆用户的课表)
要根据学习记录表搜索的数据为:本周学习的节数,这个课程的总的学习节数,最新的学习时间
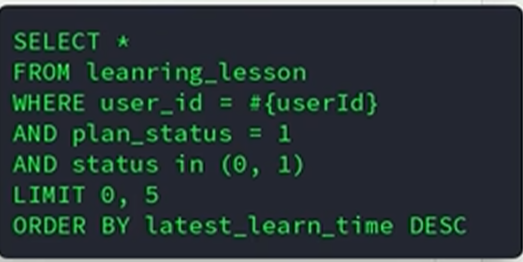
/**
*
* @param query
* @return
*/
@Override
public LearningPlanPageVO queryMyPlans(PageQuery query) {
LearningPlanPageVO result = new LearningPlanPageVO();
//获取当前用户
Long userId = UserContext.getUser();
//获取本周起始时间--自定义的类DateUtil
LocalDateTime now = LocalDateTime.now();
LocalDateTime begin = DateUtils.getDayEndTime(now);
LocalDateTime end = DateUtils.getDayEndTime(now);
//获取总的信息
//查询本周的实际学习小节数量--查询学习记录表
//因为学习记录的实现类当中已经引入了课表的实现类,为了防止循环引入,只能引入学习记录的mapper
//查询学习记录表--用户id为登录用户id,学习状态为已完成,时间为本周内
Integer totalRecord = recordMapper.selectCount(new LambdaQueryWrapper<LearningRecord>()
.eq(LearningRecord::getUserId, userId)
.eq(LearningRecord::getFinished, true)
.ge(LearningRecord::getFinishTime, begin)
.lt(LearningRecord::getFinished, end));
//查询本周计划学习的小节数量--查询课表--累加课表内每一个课程的本周的计划学习频率
//mabatisplus中没有这种方法
//用户id为当前登录id,课程状态为未学习或者已学习(固定的)
Integer weekTotalPlan = getBaseMapper().queryTotalPlan(userId);
result.setWeekTotalPlan(weekTotalPlan);
//获取分页查询的信息
//查询每个课程的信息
Page<LearningLesson> p = lambdaQuery()
.eq(LearningLesson::getUserId, userId)
.eq(LearningLesson::getPlanStatus, PlanStatus.PLAN_RUNNING)
.in(LearningLesson::getStatus, LessonStatus.NOT_BEGIN, LessonStatus.LEARNING)
.page(query.toMpPage("latest_learning_time", false));
List<LearningLesson> records = p.getRecords();
if(CollUtil.isEmpty(records)){
return result;
}
//查询课程相关的信息
Map<Long, CourseSimpleInfoDTO> cMap = getSimpleInfoList(records);
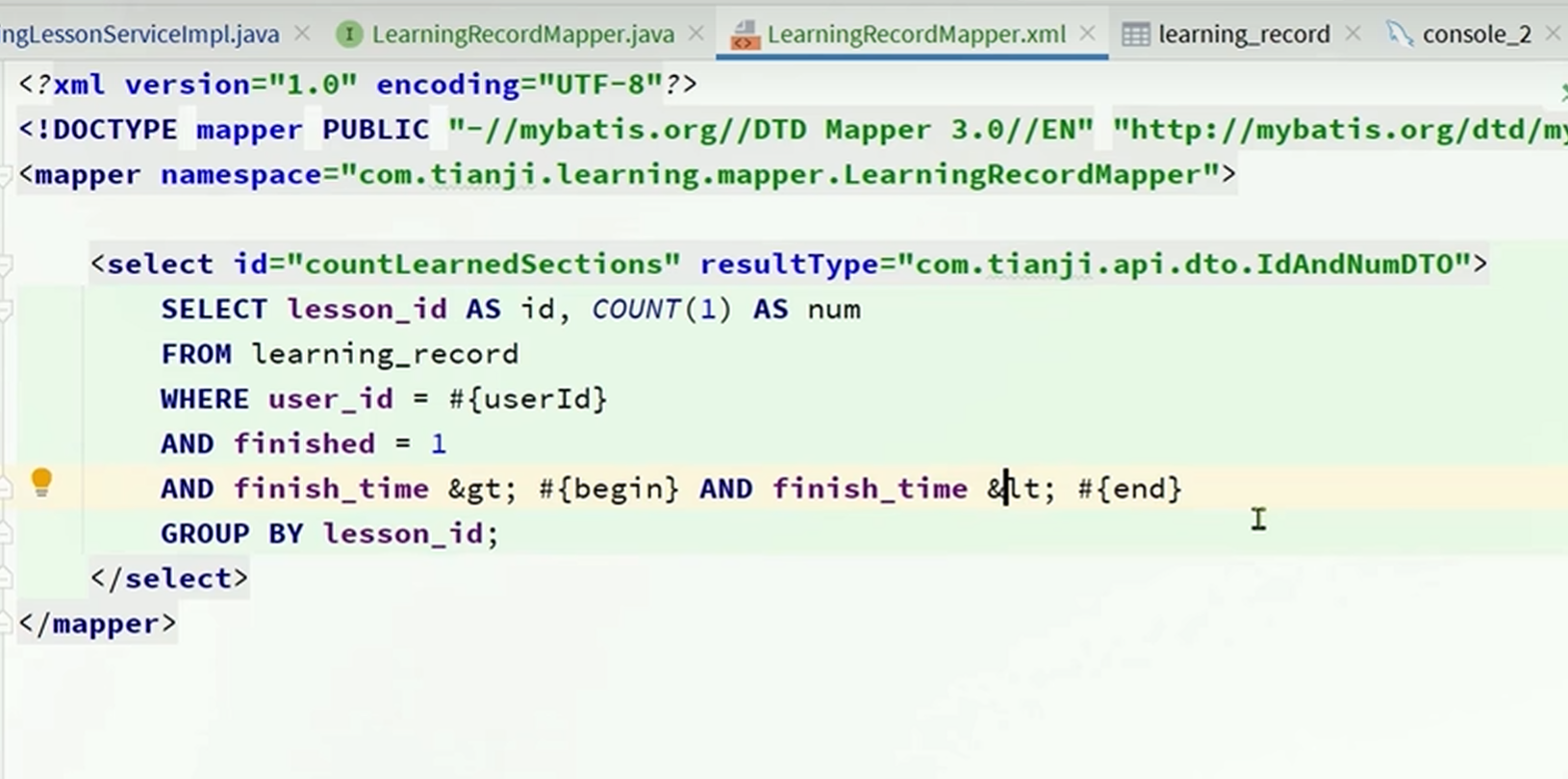
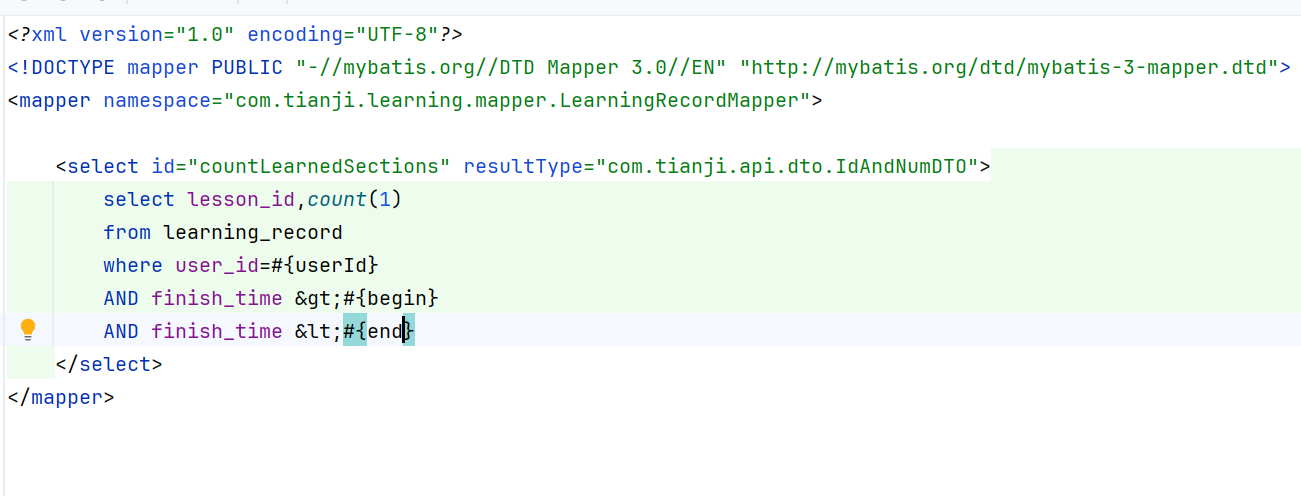
//查询每一个课程本周的已学习小节数量
List<IdAndNumDTO> idAndNumDTOList = recordMapper.countLearnedSections(userId, begin, end);
Map<Long, Integer> rMap = IdAndNumDTO.toMap(idAndNumDTOList);
//组装数据
List<LearningPlanVO> voList = new ArrayList<>(records.size());
for(LearningLesson r : records){
//拷贝基础属性到vo
LearningPlanVO vo = new LearningPlanVO();
BeanUtils.copyProperties(r, vo);
//填充课程信息
CourseSimpleInfoDTO cInfo = cMap.get(r.getCourseId());
if (cInfo != null) {
vo.setCourseName(cInfo.getName());
vo.setSections(cInfo.getSectionNum());
}
//每个课程的本周已学习小节数量
vo.setWeekLearnedSections(rMap.getOrDefault(r.getId(), 0));
voList.add(vo);
}
return result.pageInfo(p.getTotal(), p.getPages(), voList);
}
Map<Long, CourseSimpleInfoDTO> getSimpleInfoList(List<LearningLesson> records){
Set<Long> cIds = records.stream()
.map(LearningLesson::getCourseId).collect(Collectors.toSet());
List<CourseSimpleInfoDTO> cInfoList = courseClient.getSimpleInfoList(cIds);
//每次查出结果来都要进行防止空指针和数据不合理出此案,增强健壮性
if(CollUtil.isEmpty(cInfoList)){
throw new RuntimeException("查找到的课程相关数据不合理");
}
//查出来的结果和分页查询出来的结果没办法一一对应
//把结果封装为Map集合,加个标签,这样根据主键查询就能找到对应的课程信息然后一起封装了
Map<Long, CourseSimpleInfoDTO> cMap = cInfoList.stream()
.collect(Collectors.toMap(CourseSimpleInfoDTO::getId, c -> c));
return cMap;
}
DAY04进度优化分析
方案分析-高并发优化方案分析
DAY05互动问答
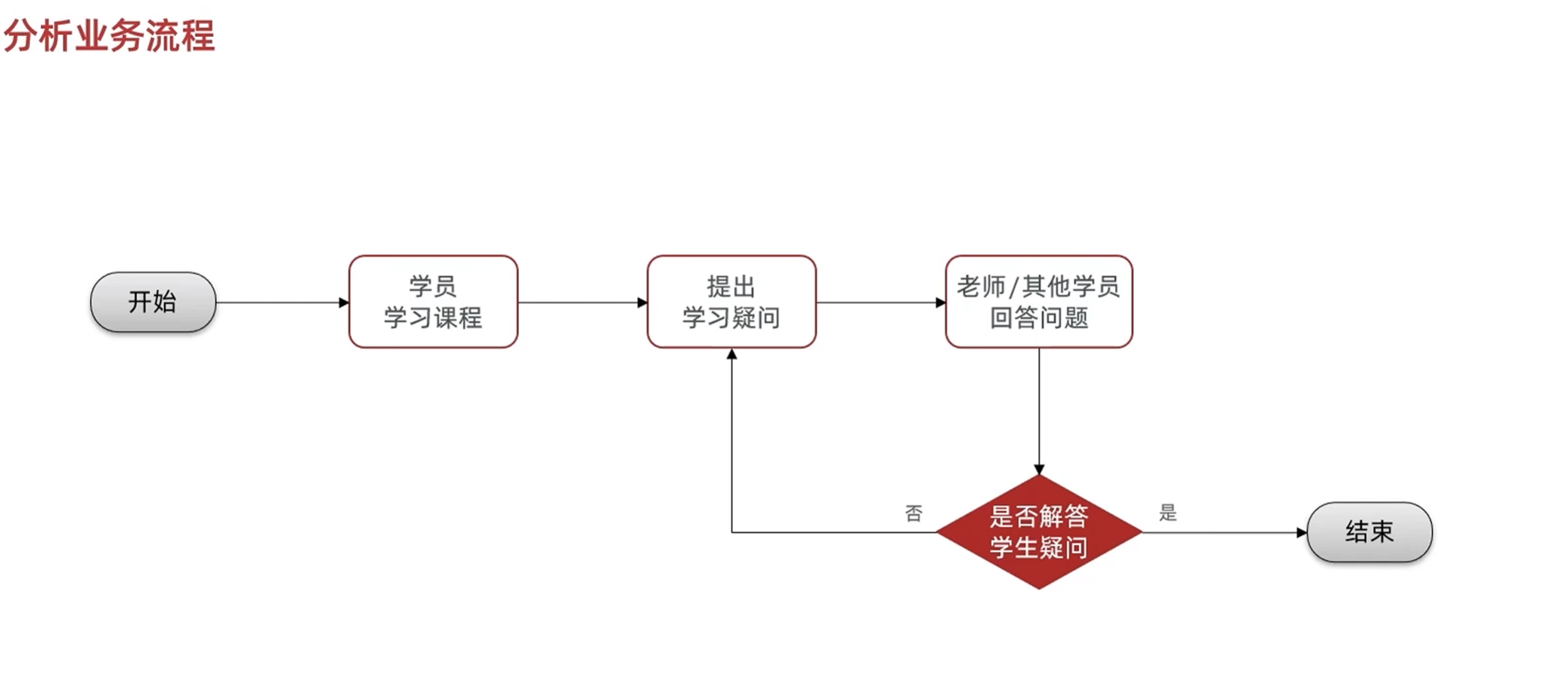
分析产品原型-业务流程分析和接口统计
课程学习页有问答的功能
课程详情页也有问答功能,可以点击对应节数来访问
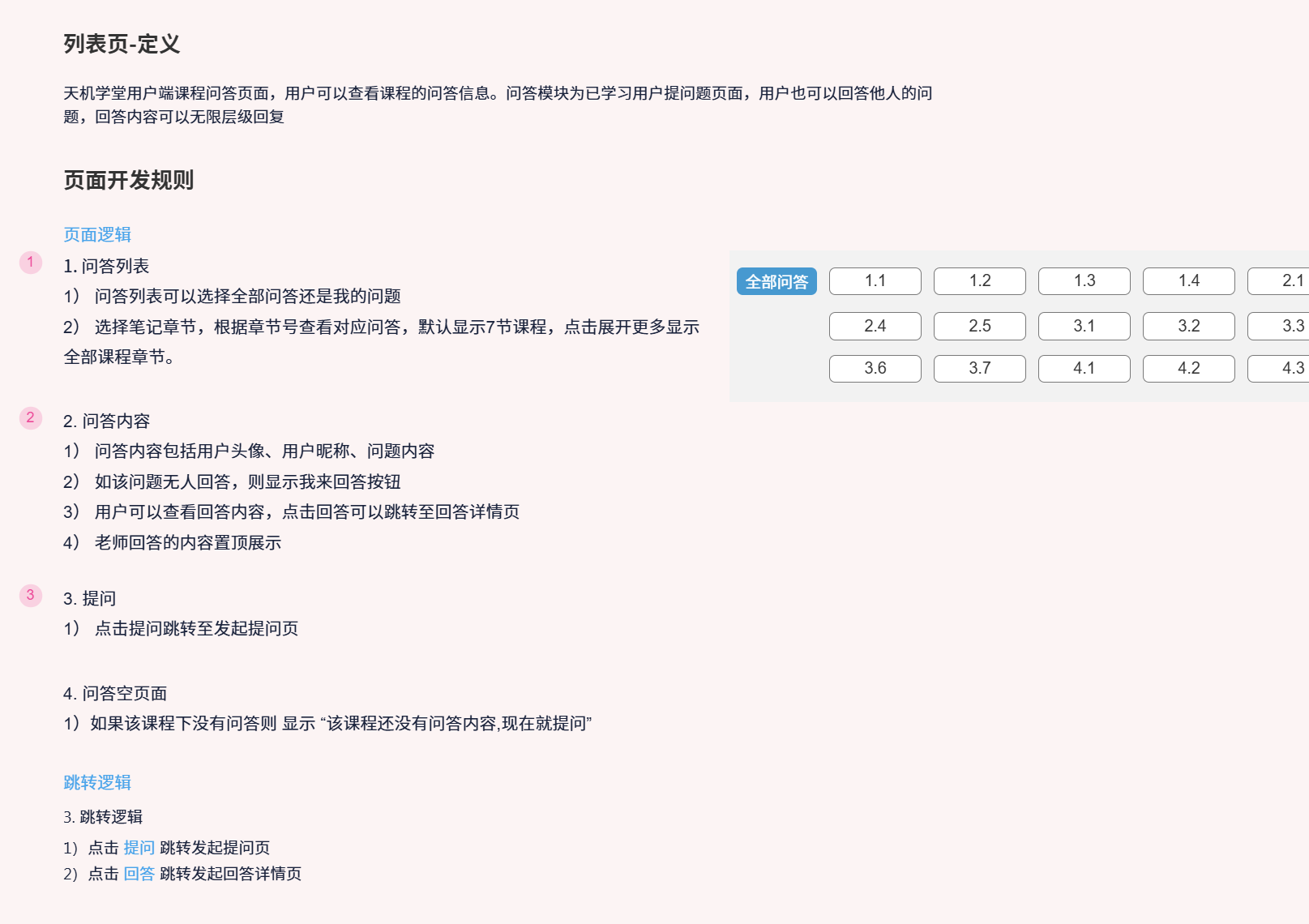
可以点击提问按钮来发出问题
也可以点击回答来回答别人的问题
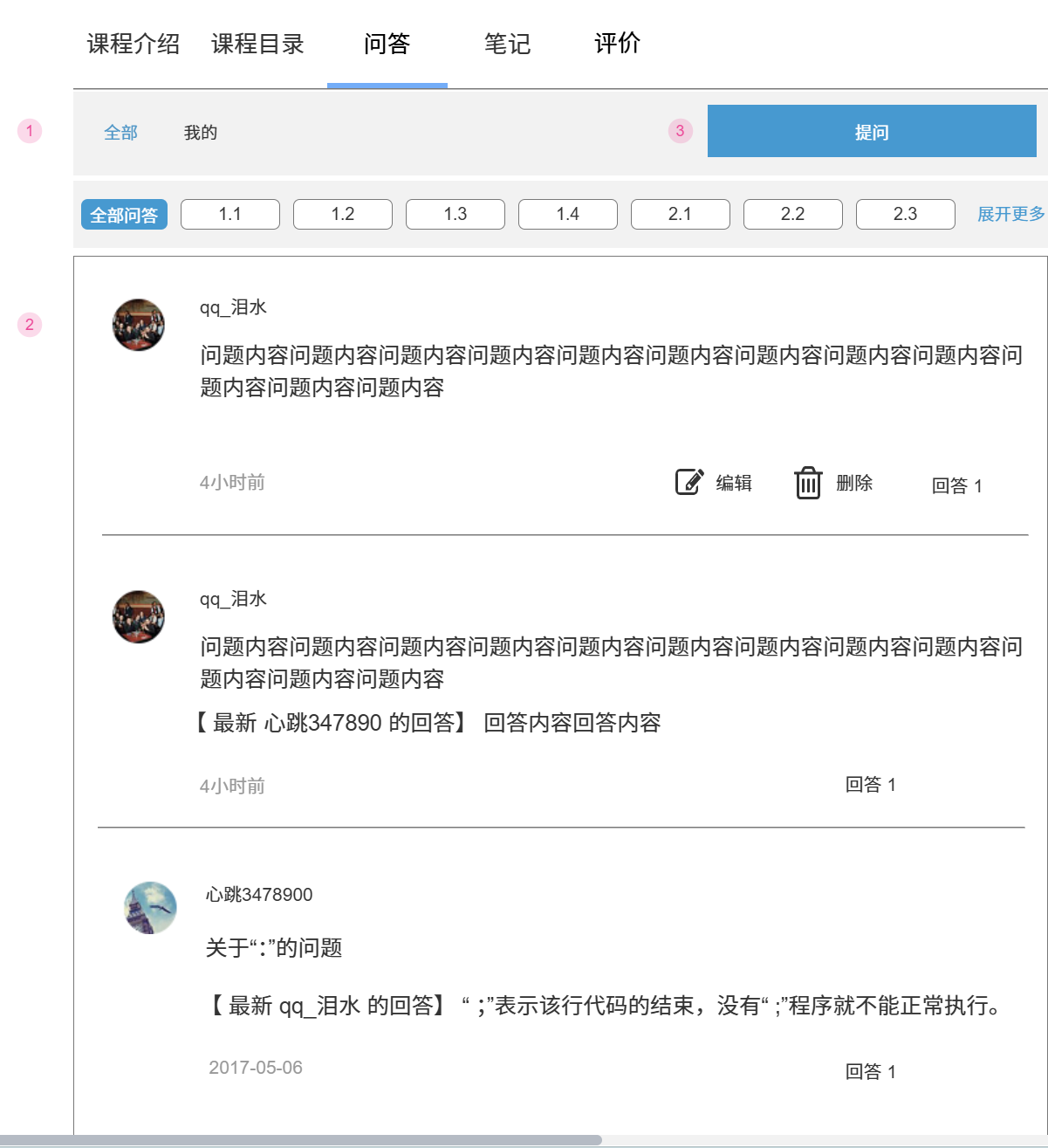
可以编辑或者删除自己的问题
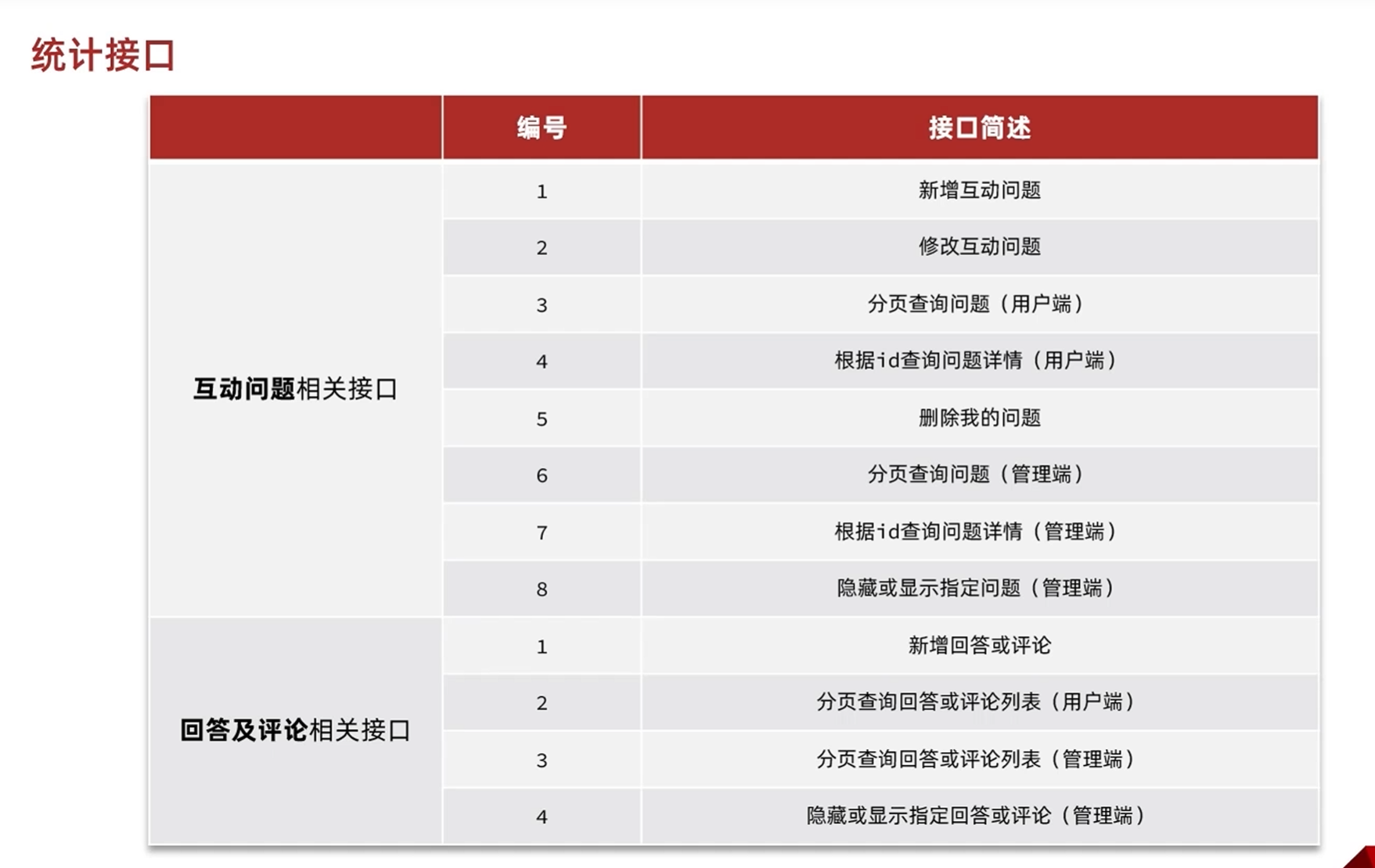
与问题有关的接口

与评论有关的接口

分析产品原型-新增、修改、删除问题的接口设计
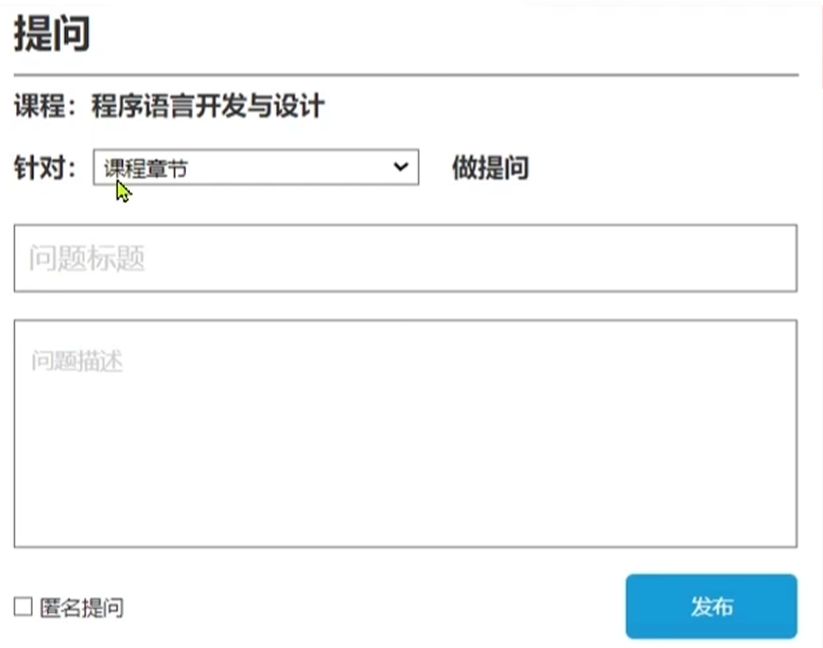
不需要用户给出课程id,因为本来就是从以下两个页面进入的,课程id是已知的
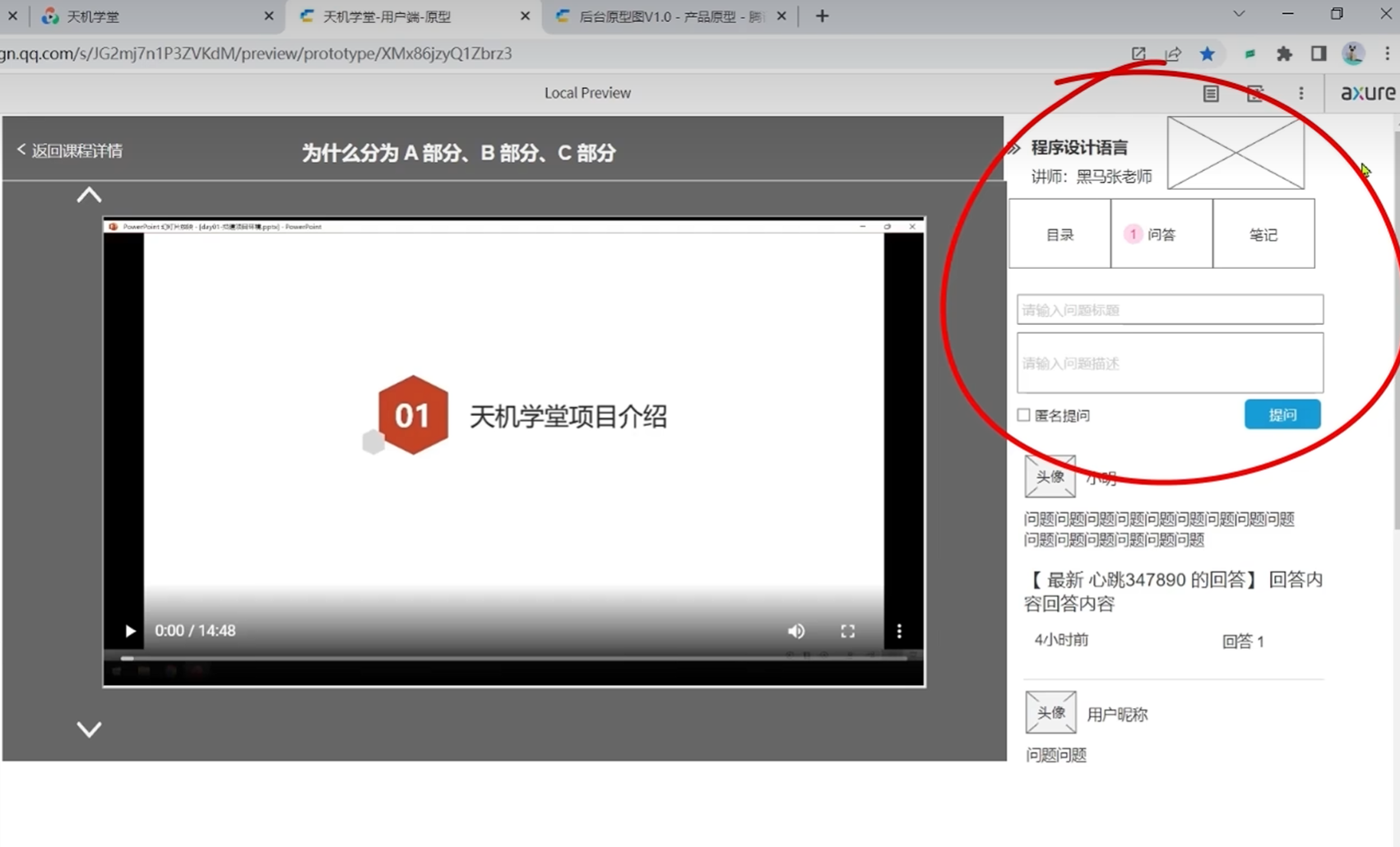
但是前端肯定会把这个课程id交给后端
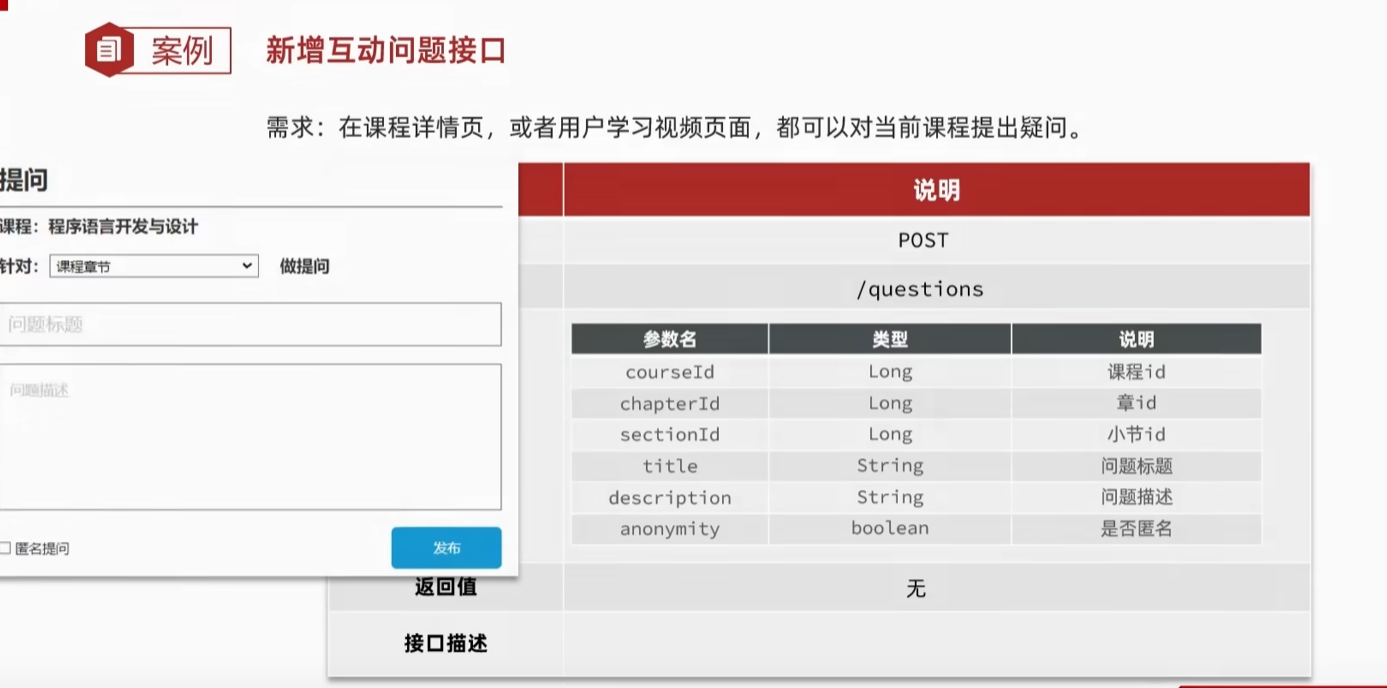
编辑互动接口的时候基于问题的id进行修改问题
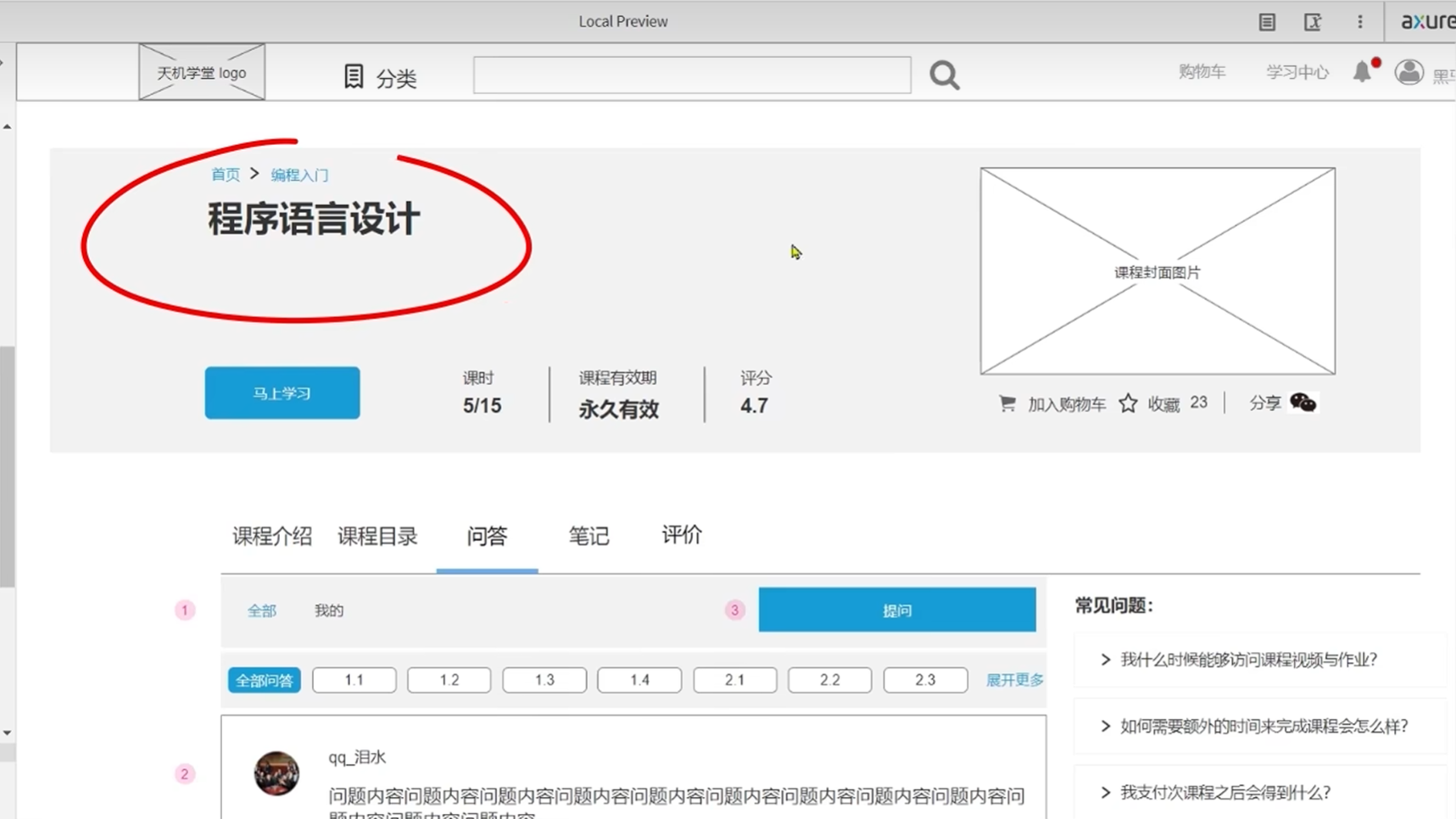
分析产品原型-分页查询问题和根据id查询问题接口设计
 请求路径:用资源做名称,page做标记,标记这是一个分页查询
请求路径:用资源做名称,page做标记,标记这是一个分页查询
分页查询的请求参数
包括固定的页码,每页大小字段以外,还有筛选条件和排序字段
分页查询结果的构成是
先用page接收分页查询的结果
如:记录分页页数,记录分页的总条数和分页查到的数据
然后准备一个继承了pageDTO的类,把上面准备的分页数据填进去,包括分页页数,分页总条数,和分页数据
再把pageDTO里的其他需要填入的字段也填进去
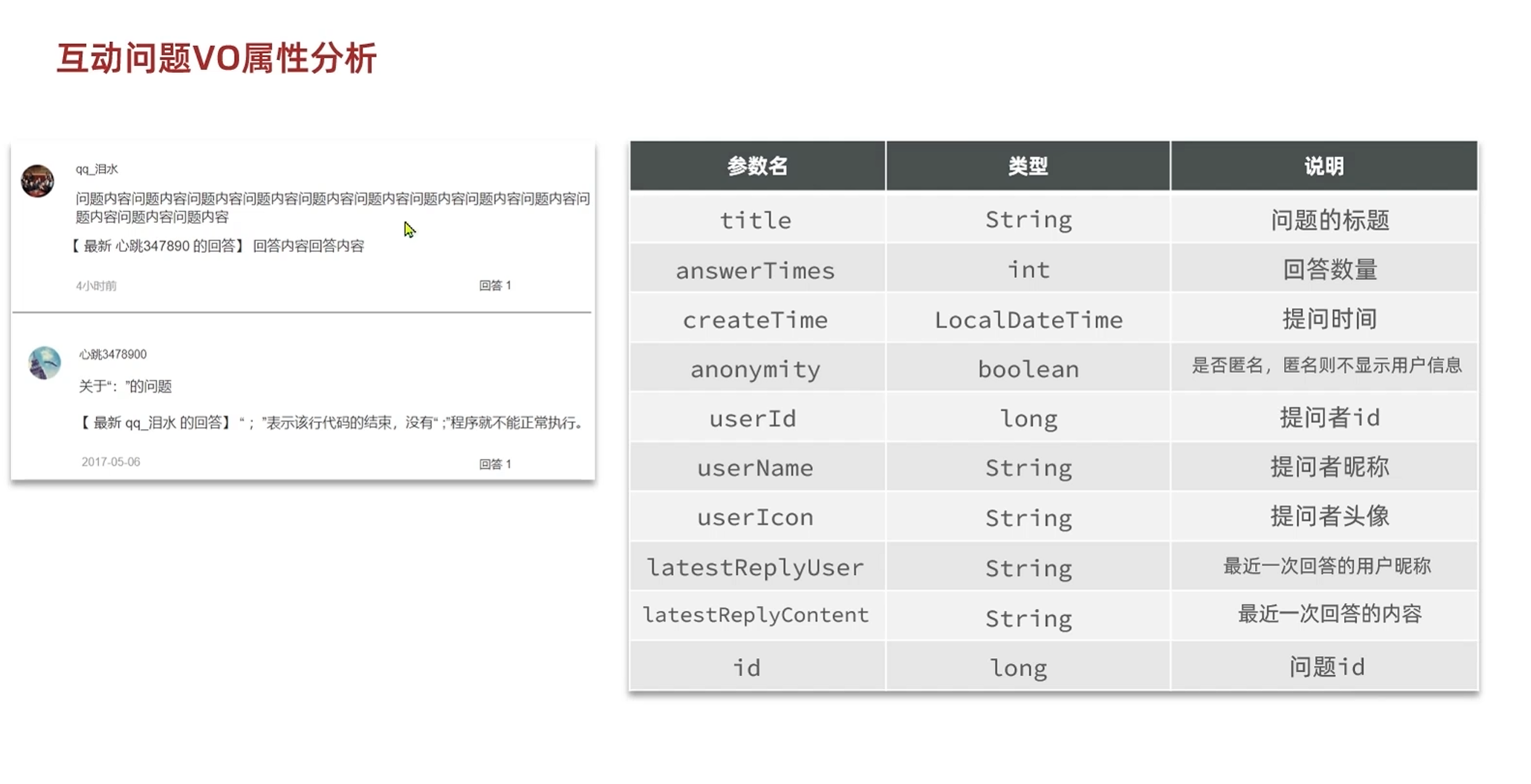
这个问题是一个带有过滤条件的简单分页问题
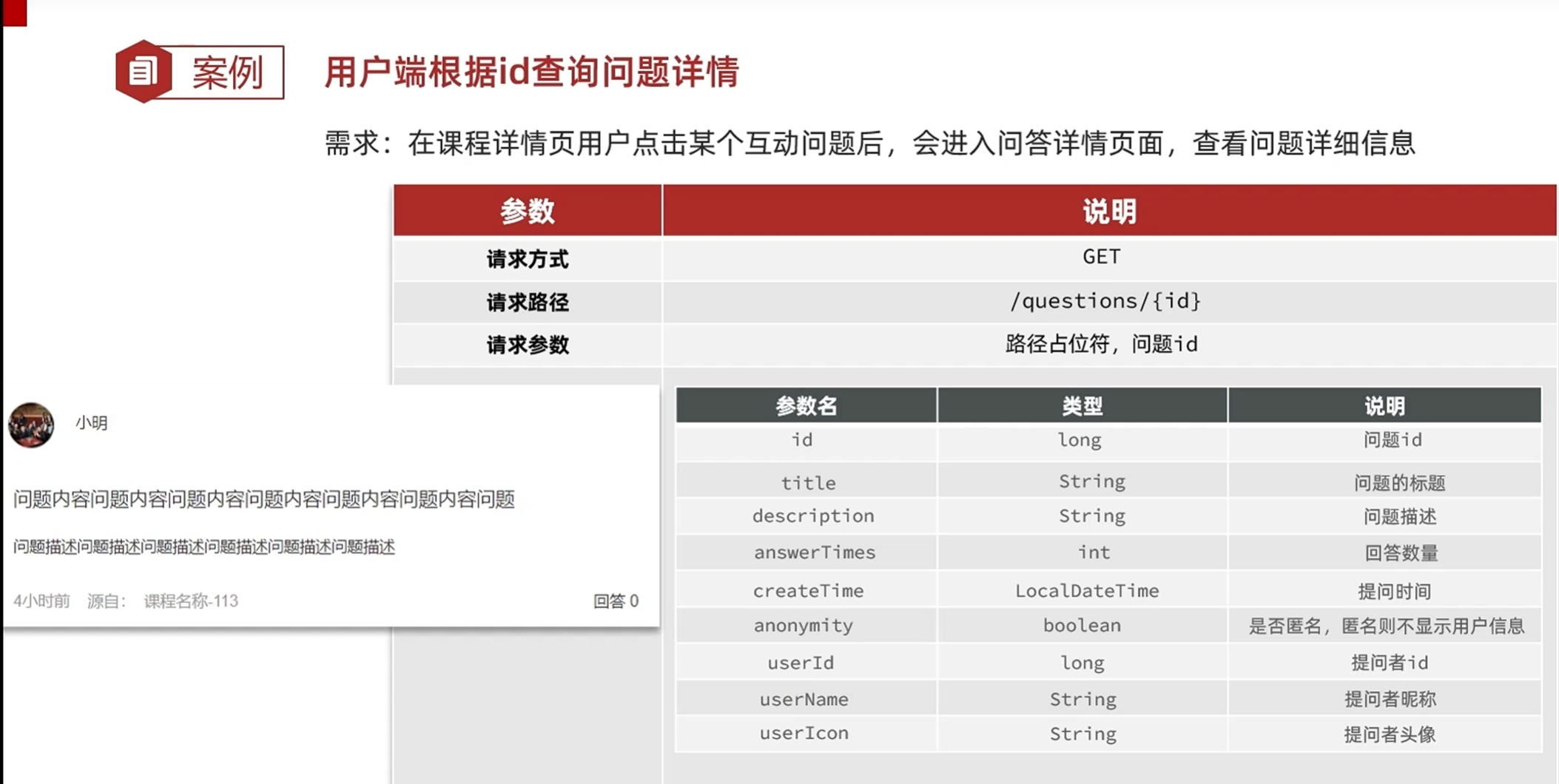
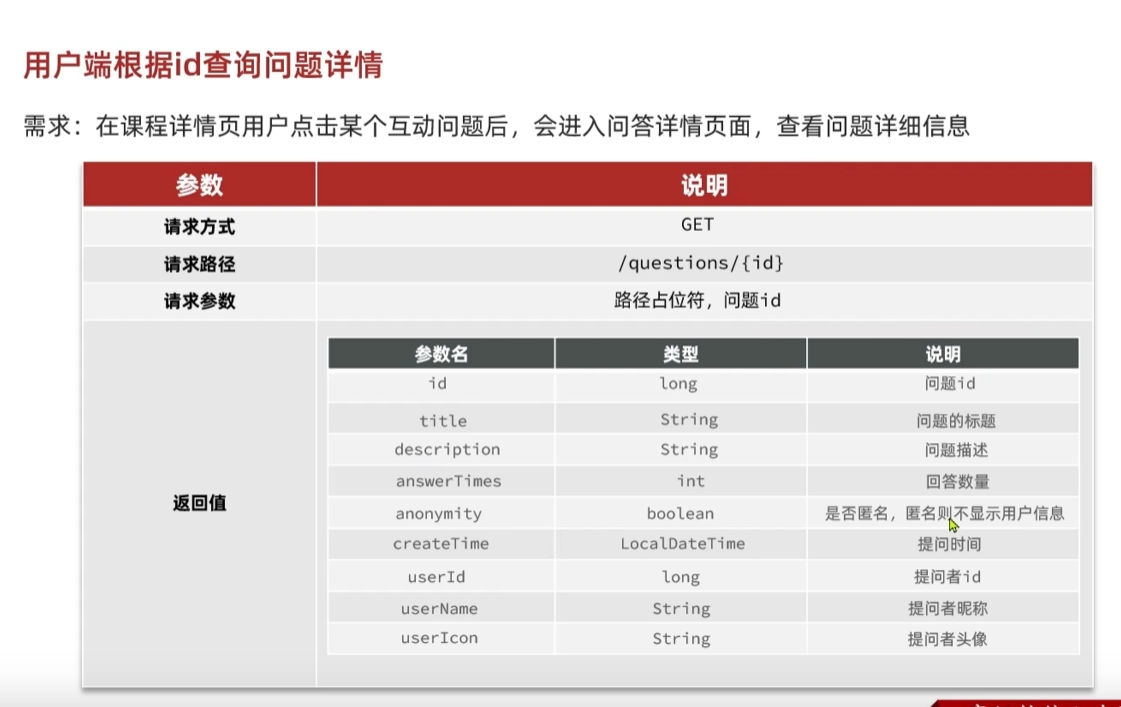
根据id查询问题详情
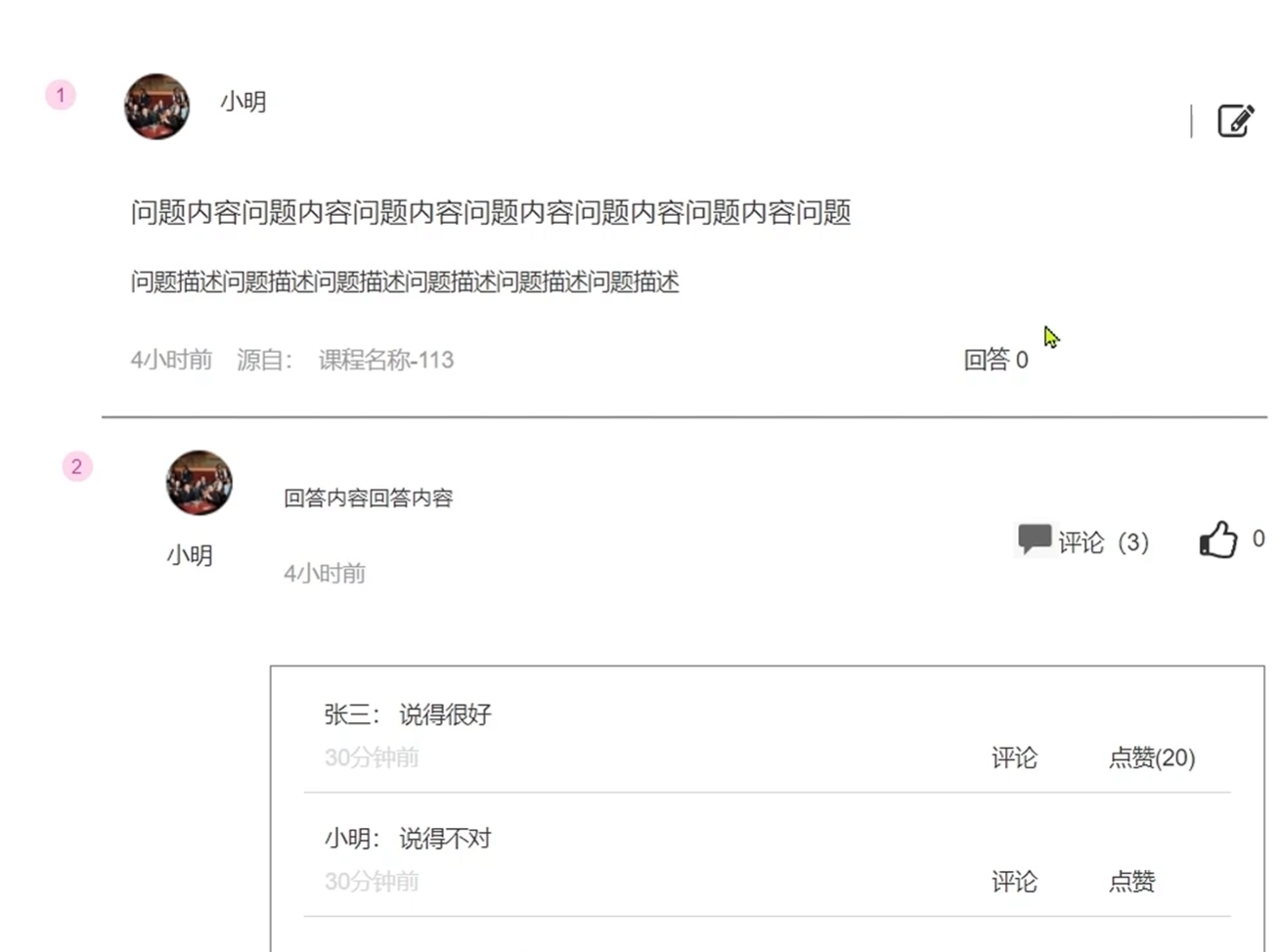
在点击问题查看详情之后会进入问题详情页,如下
分析产品原型-管理端问题相关接口的设计

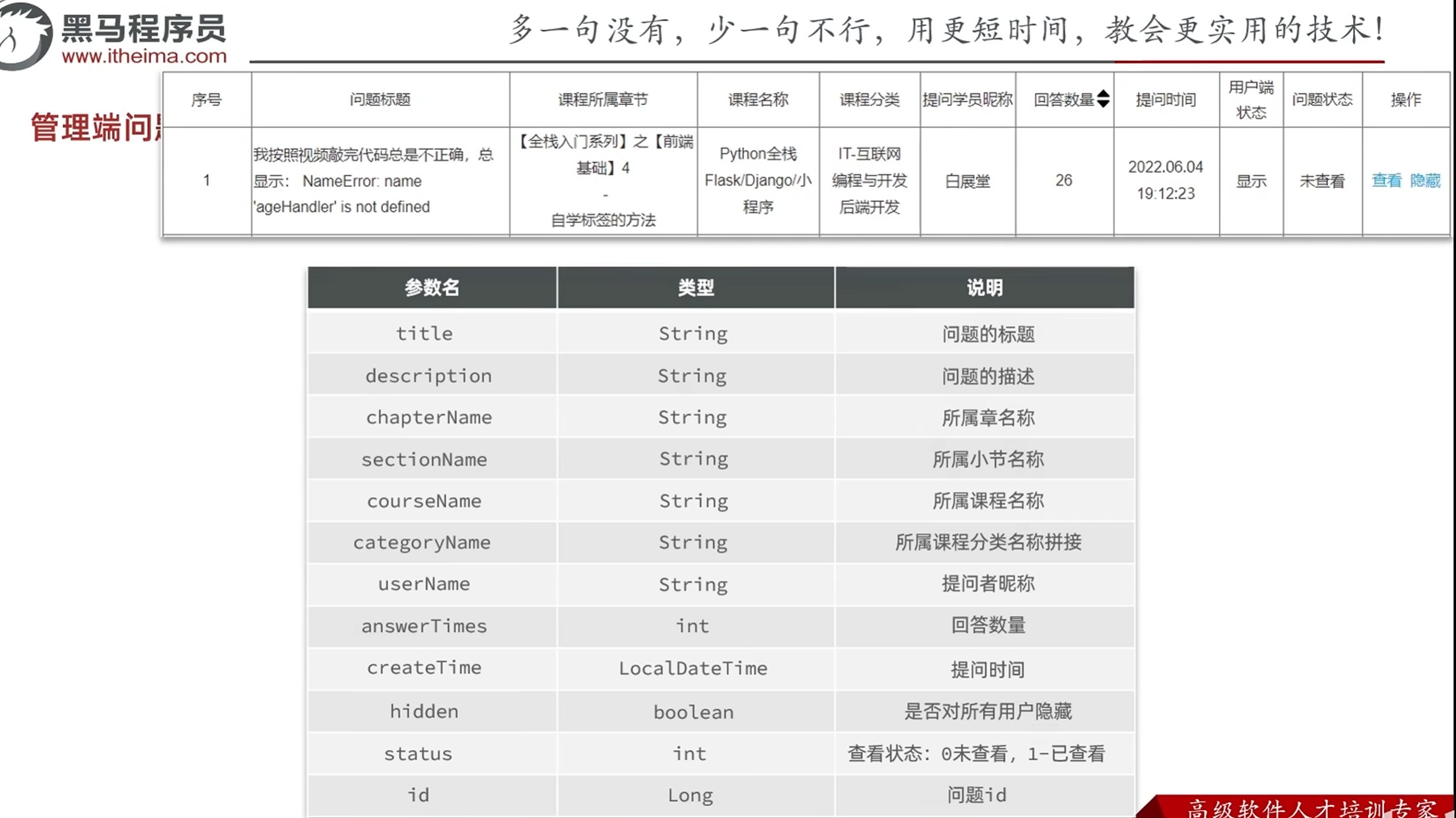
课程分类有三级分类
后续要对问题进行查看和隐藏操作,所以还要返回问题的id
分析产品原型-新增回答或评论的接口设计
回答和评论:第一级是评论,第二级是回答,不管是在楼内还是楼外,都一样,所以可以放在一块解决
问题和课程有关联,回答和问题有关联,评论和回答有关联。

分析产品原型-分页查询回答或评论的接口设计


分析产品原型-设计业务实体及数据库表结构
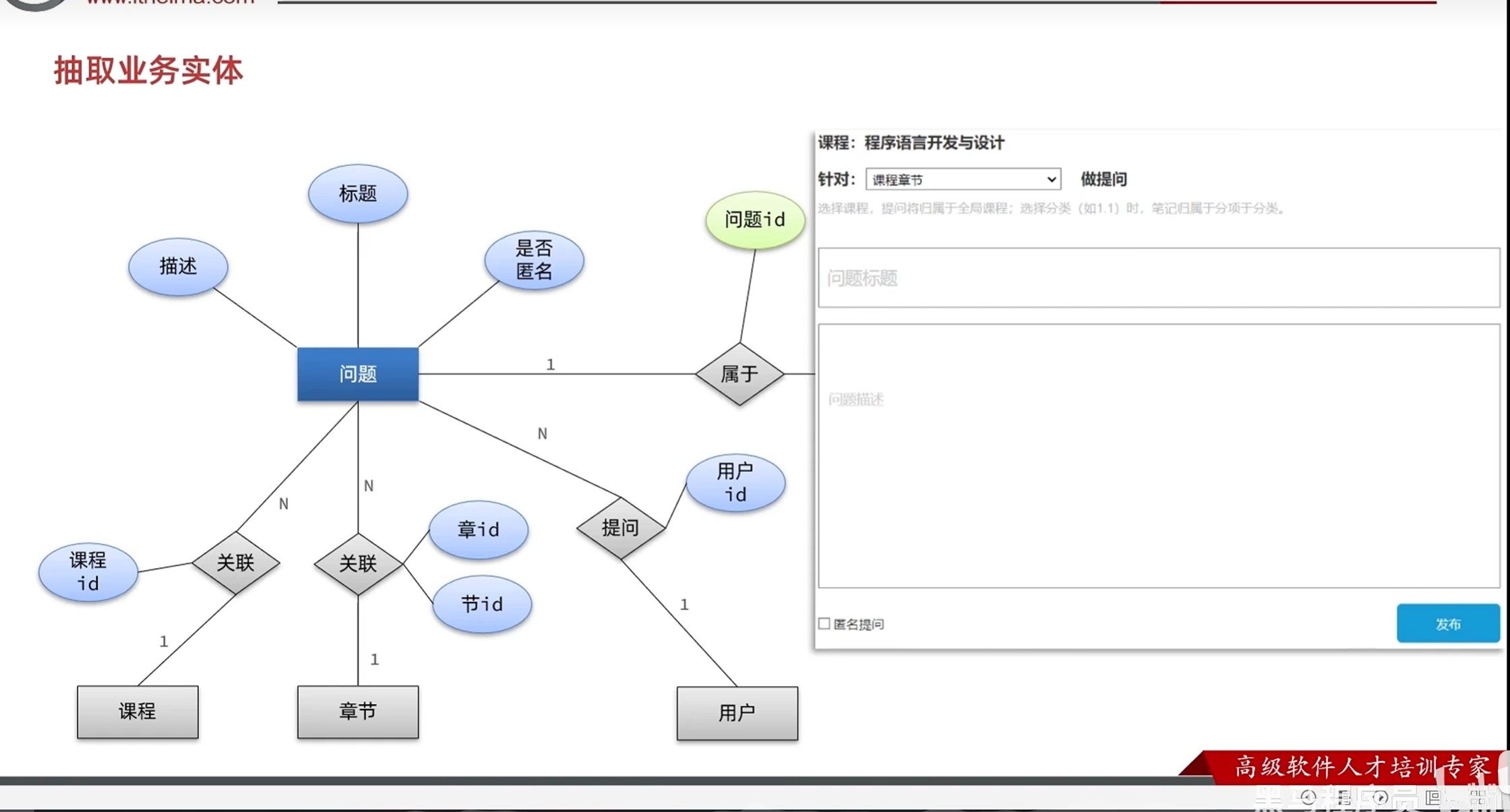
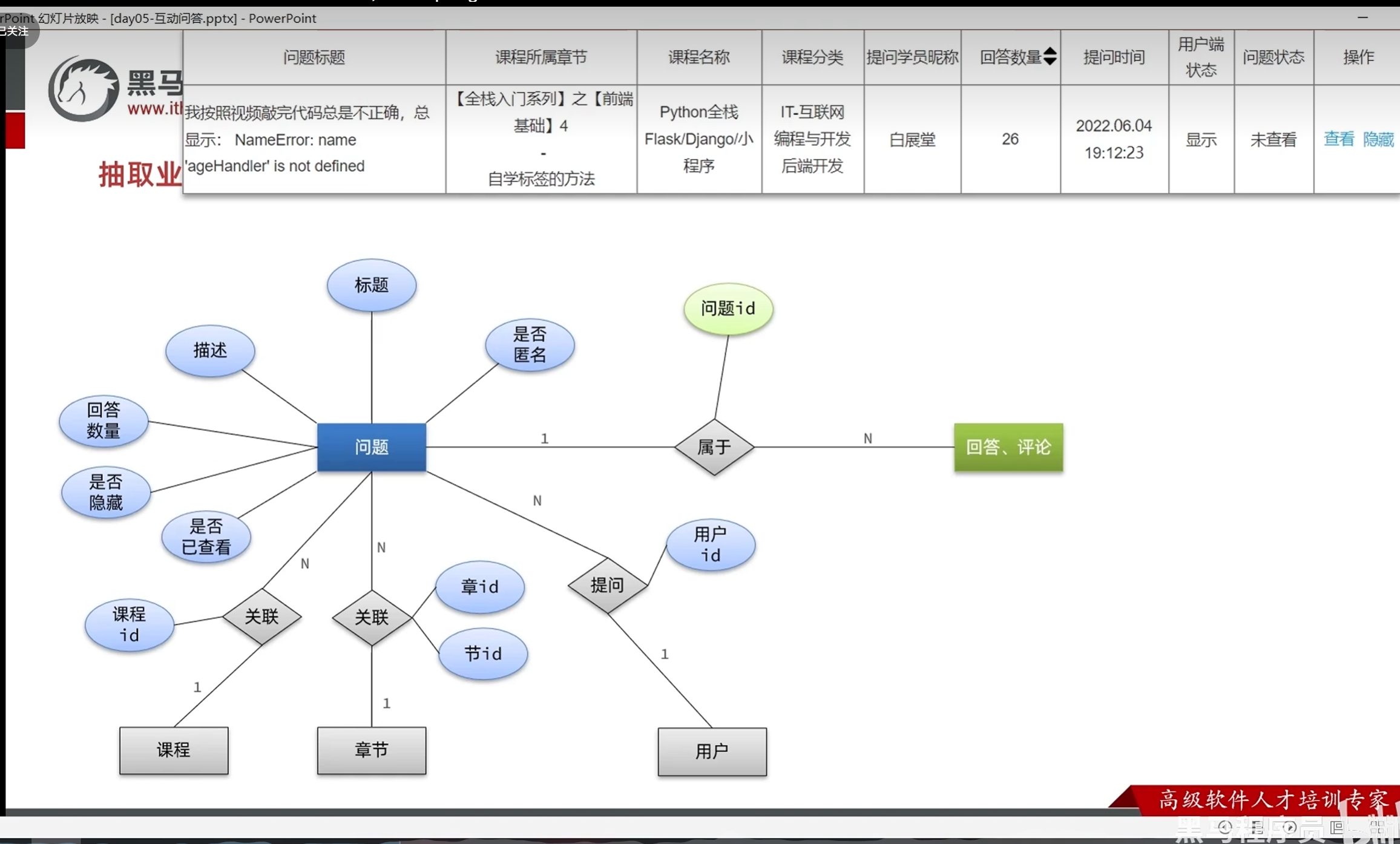
查询问题时候的最新回答:
每次查看都去回答里面查找时间最新的回答会对数据库造成很大的压力,
所以干脆新建一个字段,关联回答,在每一次有新的回答的时候更新问题的数据库,
以后查询的时候对数据库的压力就会很小
评论是用户对于提问者的问题进行回复,评论是对对于回复的评论,
所以评论要记录目标评论id和目标用户id
恢复只需要记录上级回答的id就行
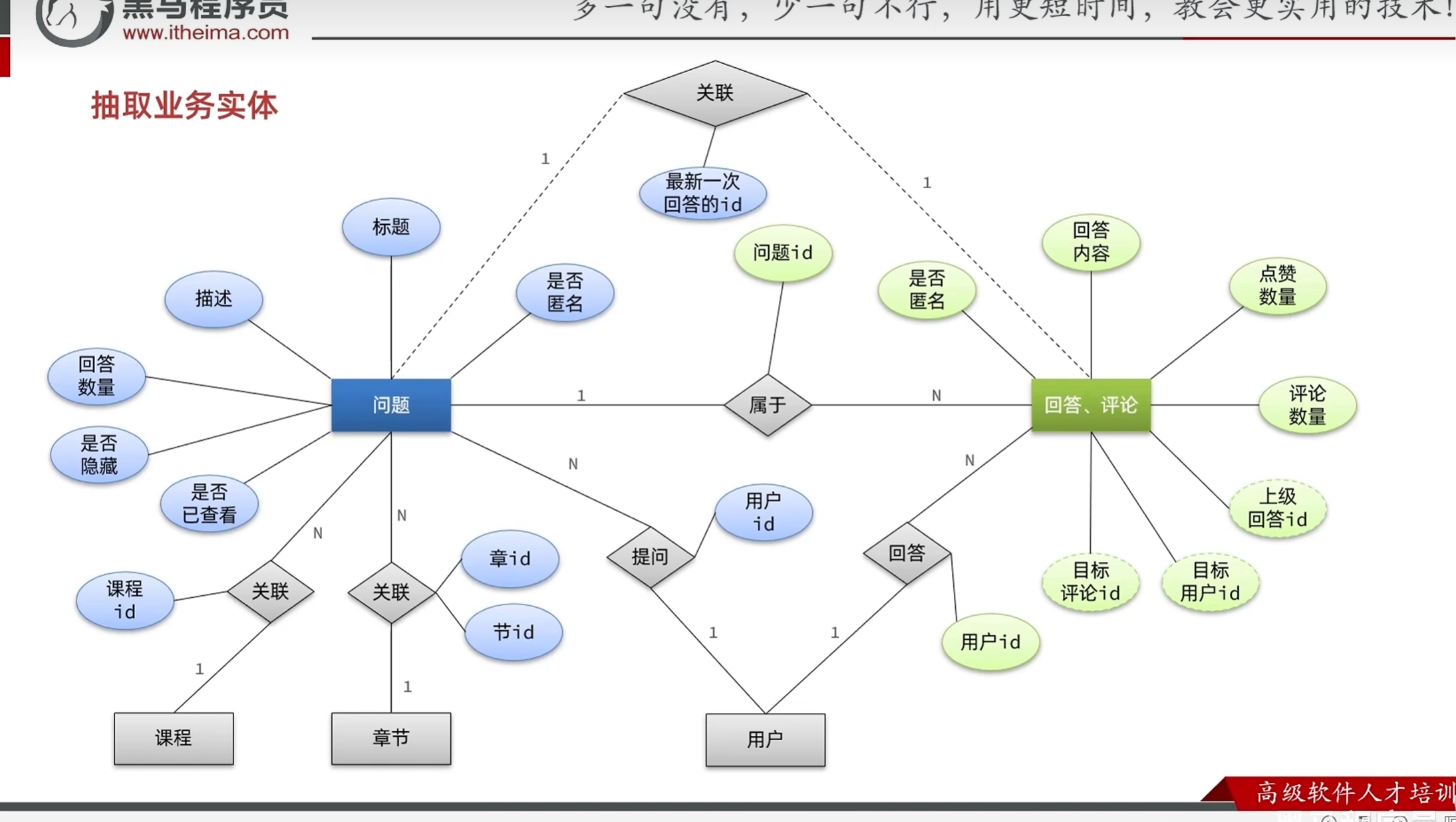
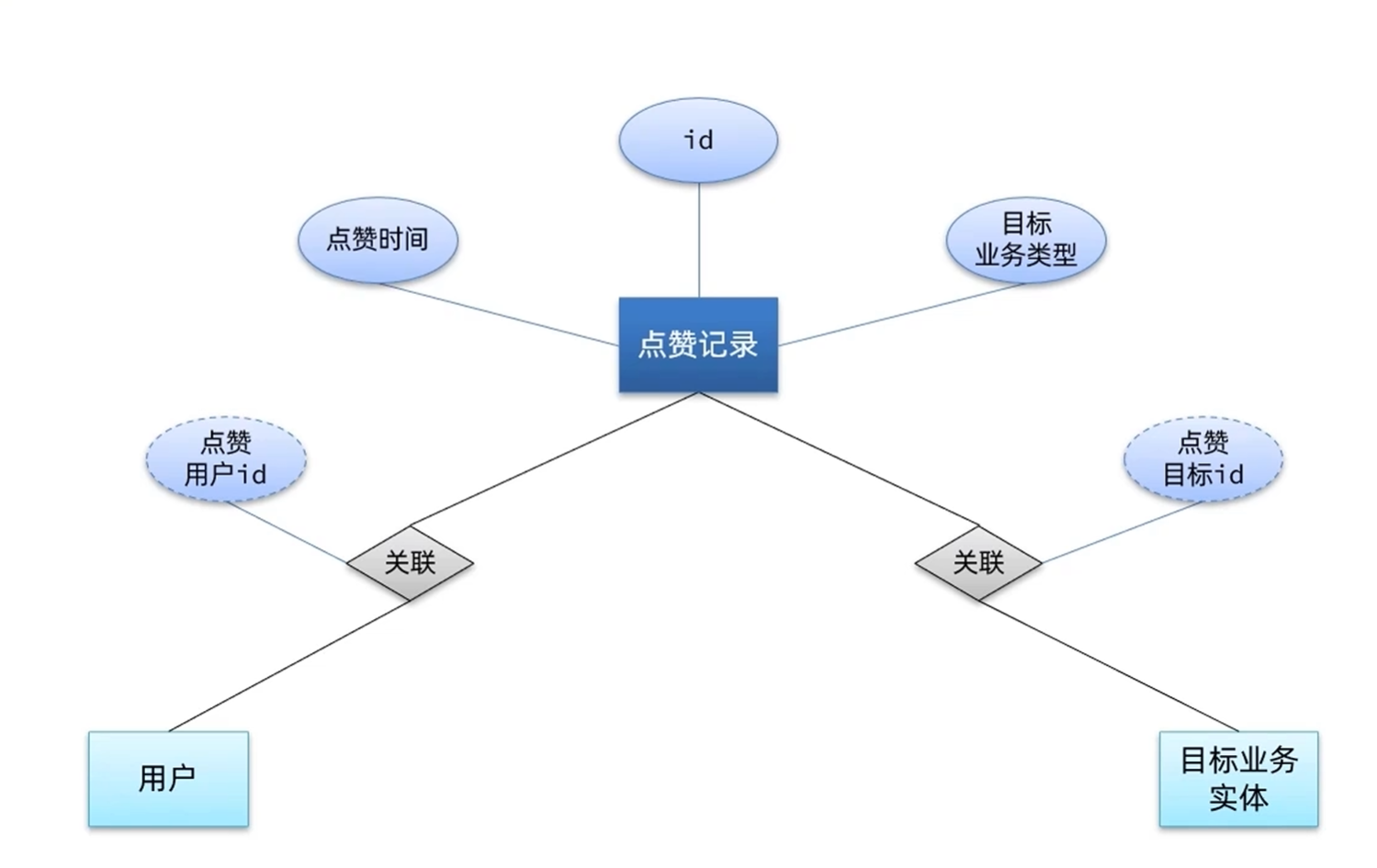
问题的业务实体
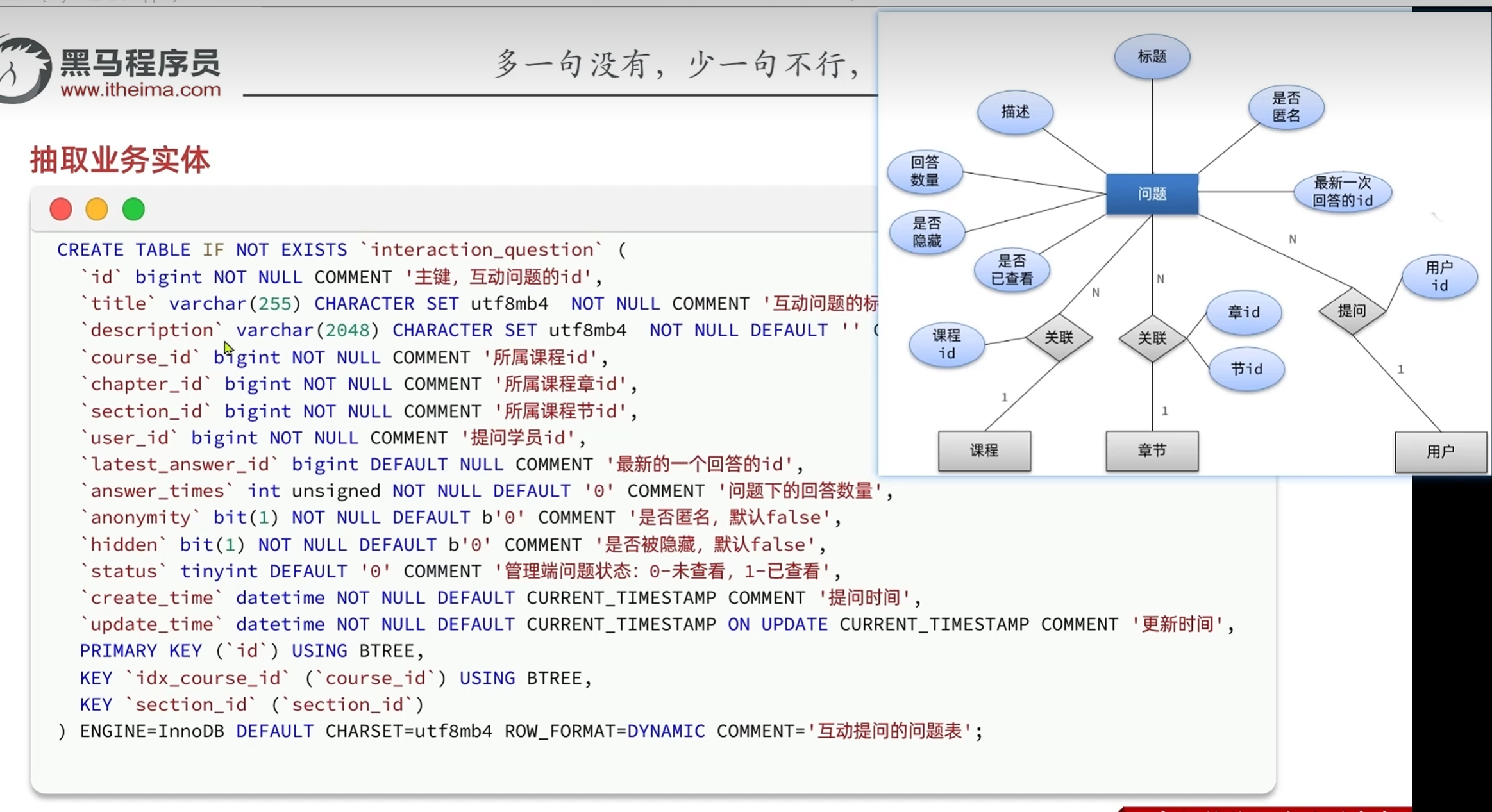
评论的业务实体
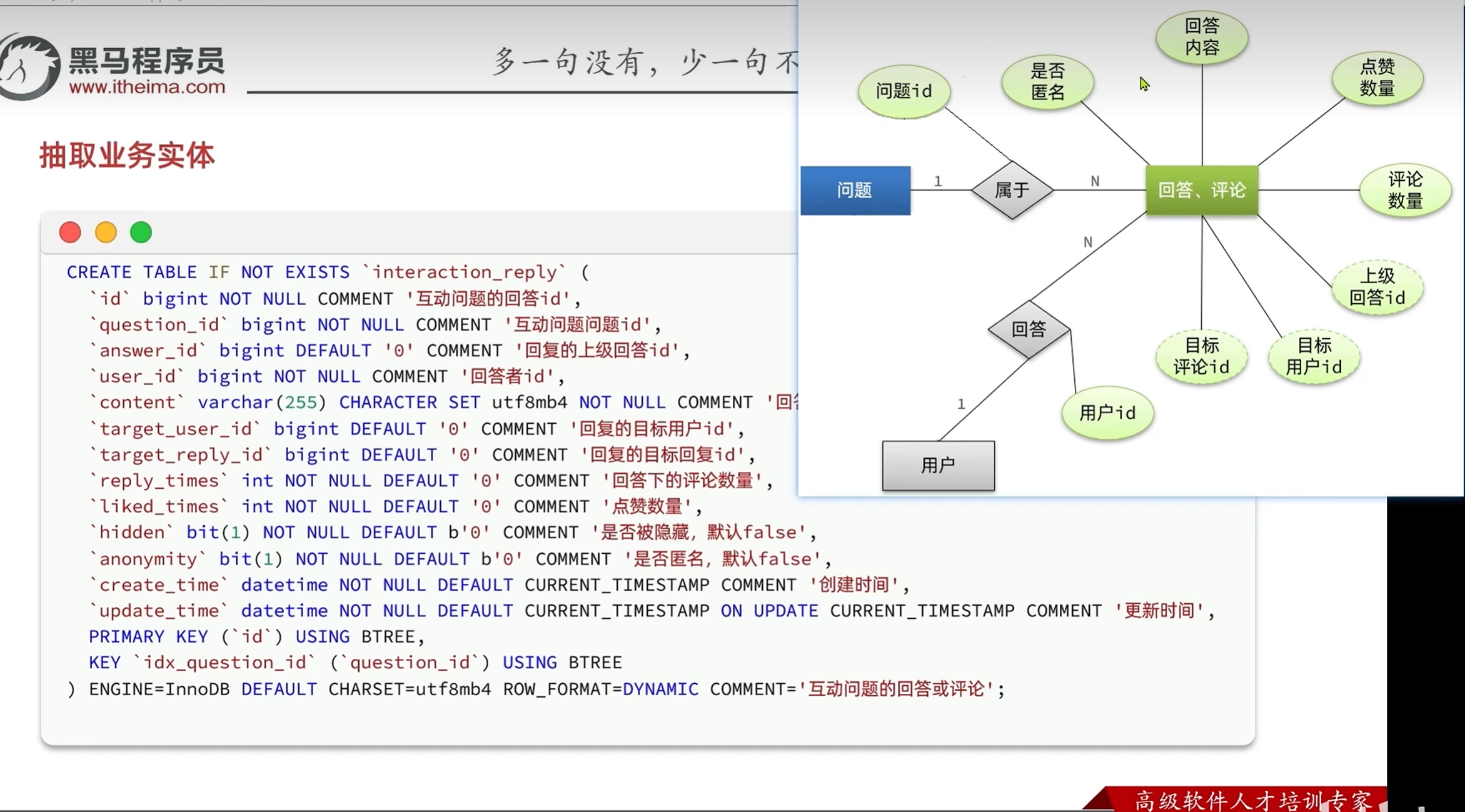
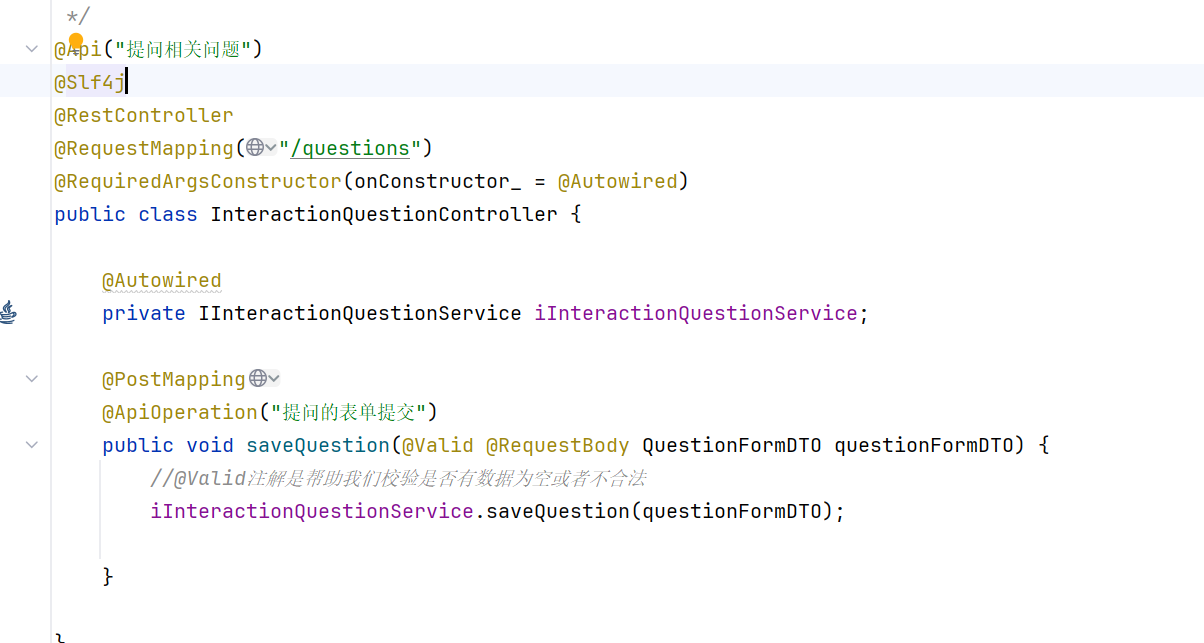
开发接口-新增问题接口
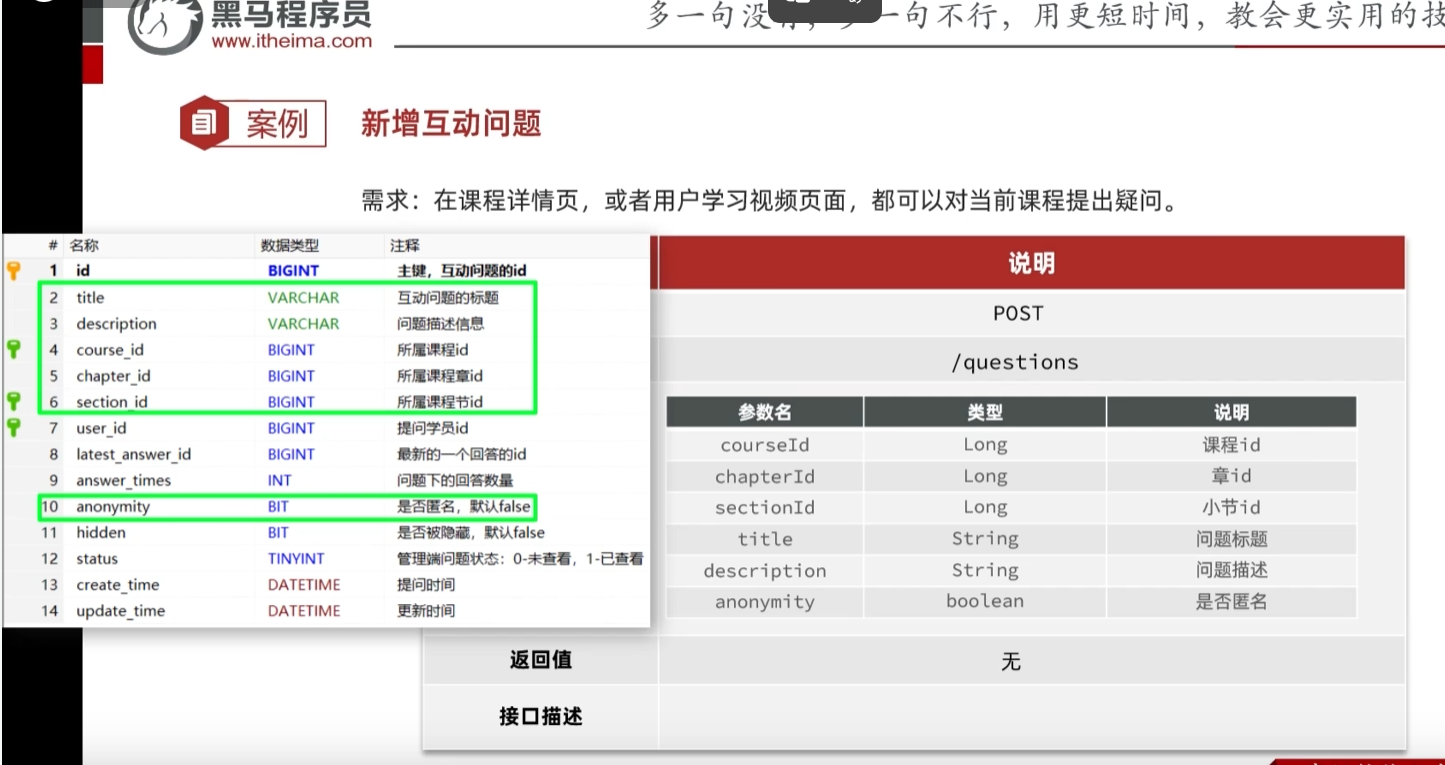

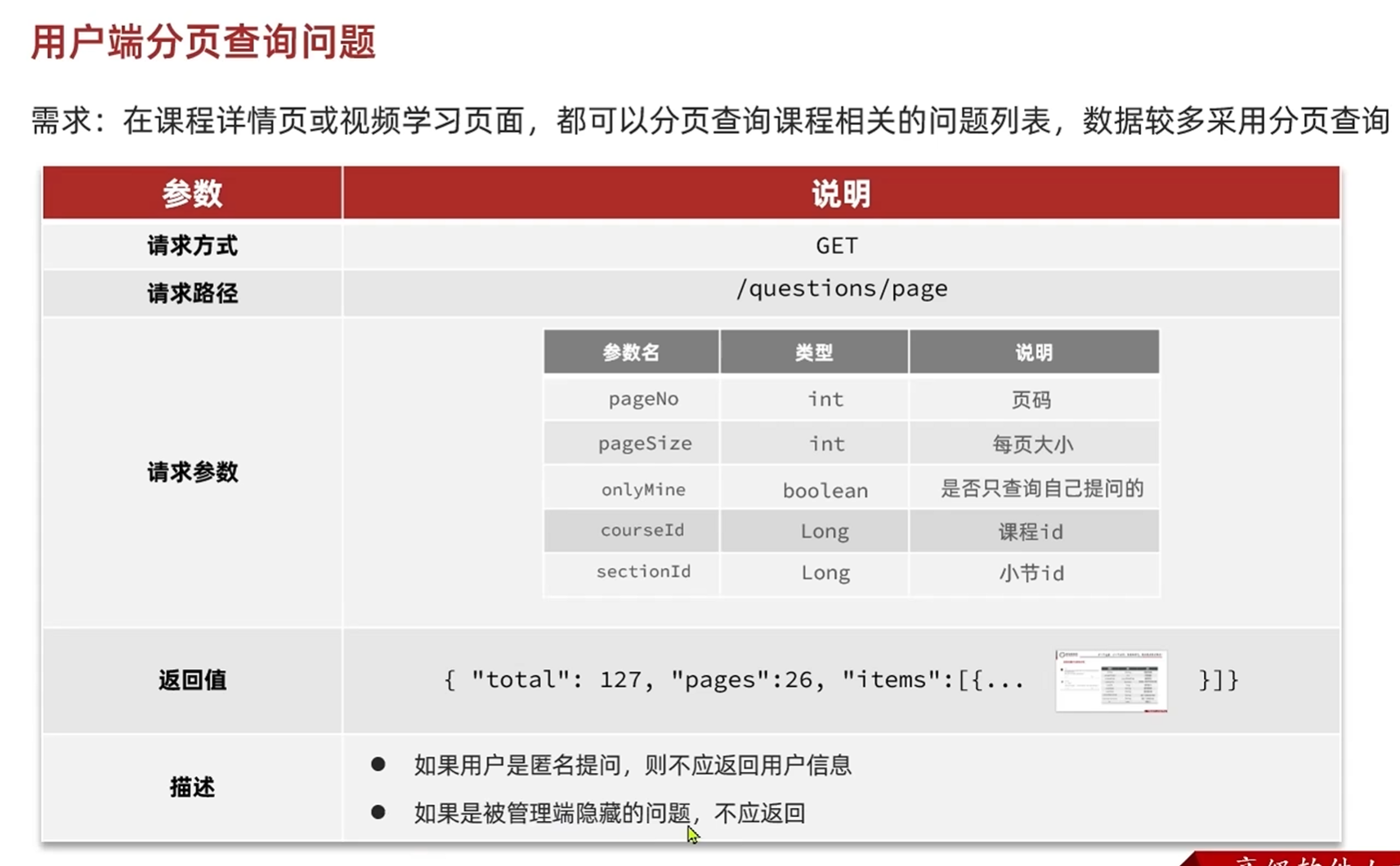
开发接口-用户端分页查询问题
分析接口

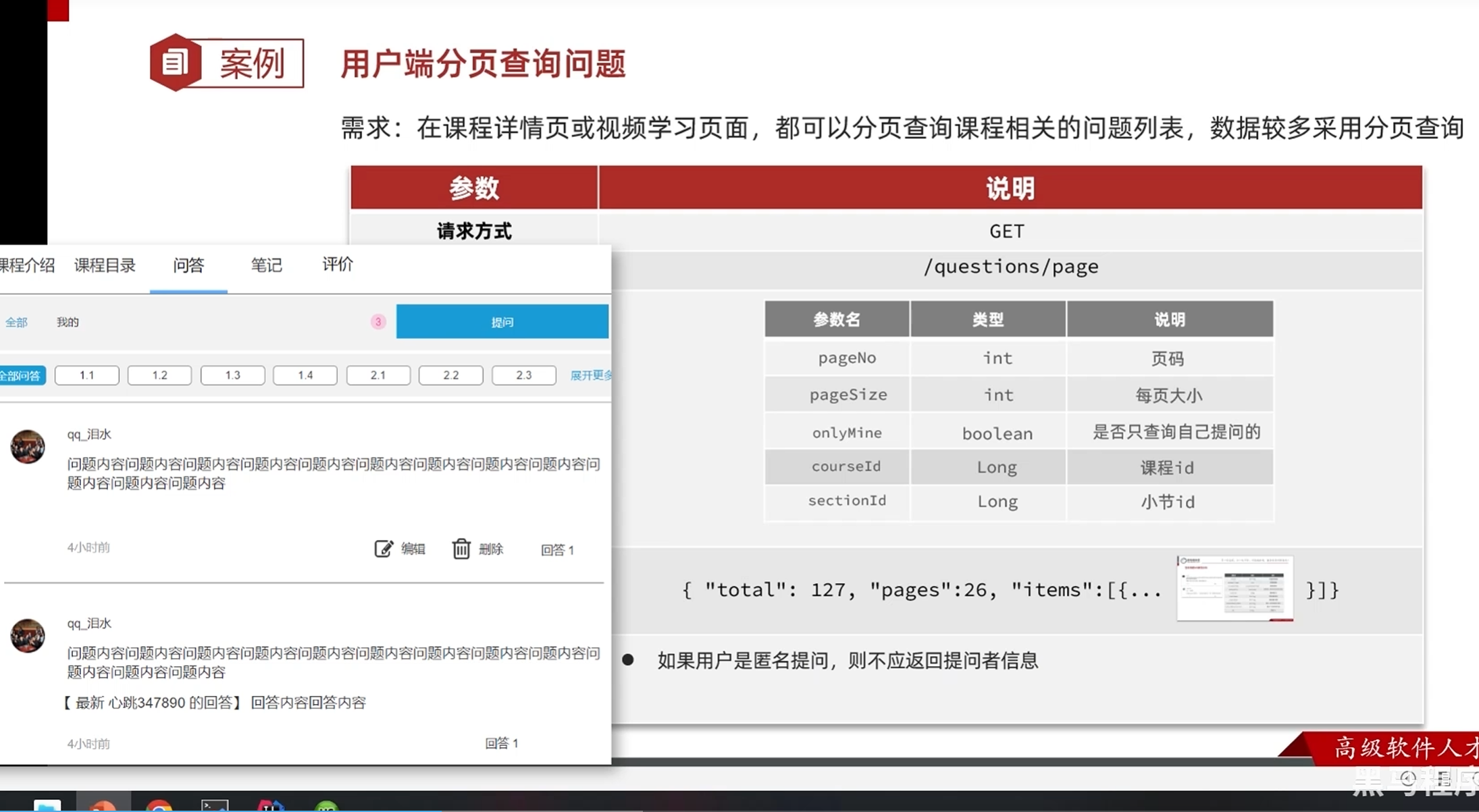
课程id和小节id两个参数只要有一个存在就行,因为小节数据都是在一个表中存储的,通过表中有一个课程id来定位是哪一个课程的,小节的id是他的唯一身份凭证
还有一个隐形的过滤条件:hidden,如果选择了匿名回答则不给前端返回该用户的相关数据


左侧数据库的内容和右侧VO的内容还是有不同点的
数据库只保留了问题的必要的核心的信息,比如用户只保留了用户id但是VO当中要求返回的还有用户的头像和昵称
数据库:最近一个回答的id VO:最近一次回答的用户昵称和内容
这些都是我们需要在后续开发接口时注意查询填充的
QuestionPageQuery--继承于PageQuery
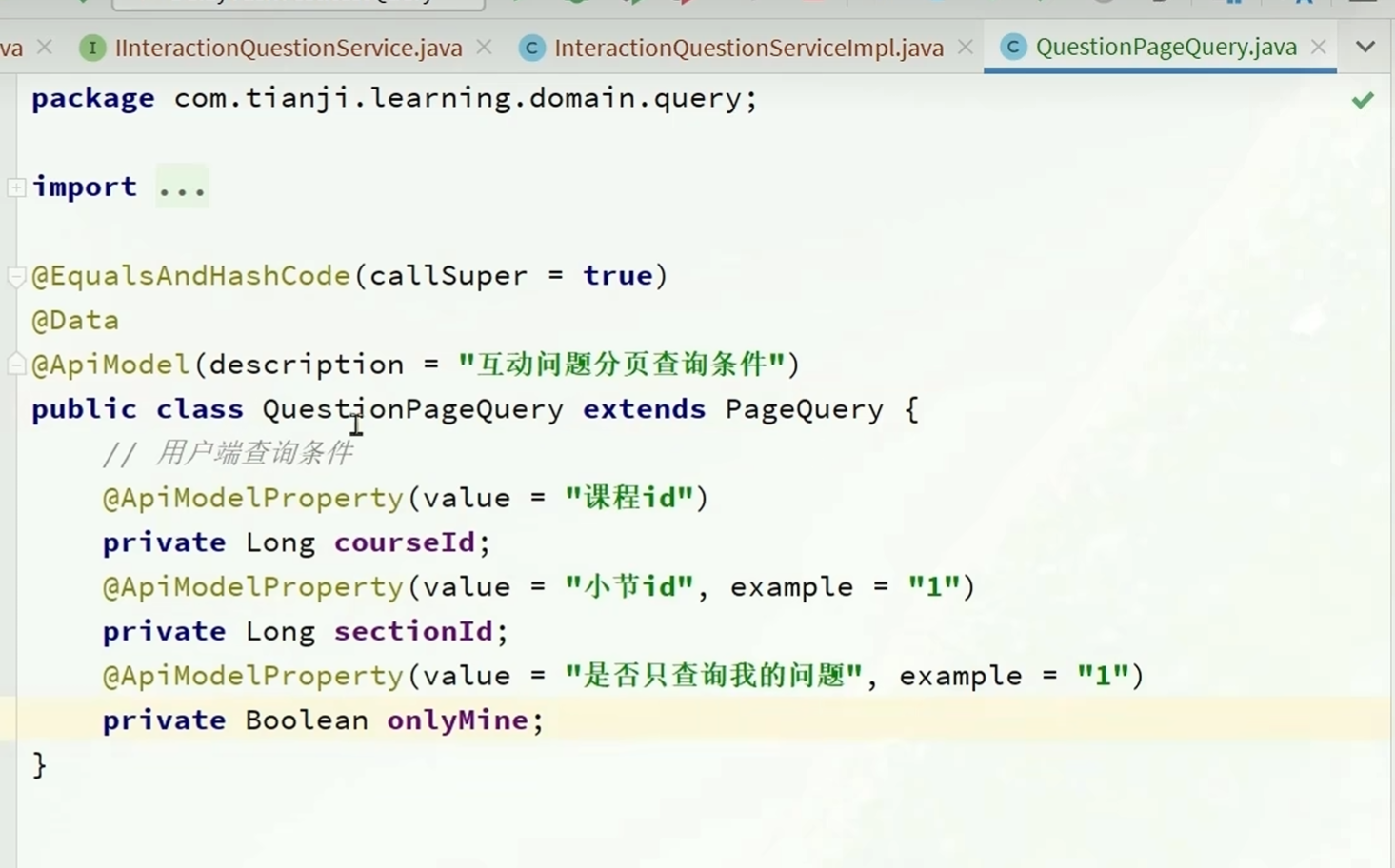
QuestionPageQuery继承了PageQuery,
PageQuery内的基本分页参数以及里面的方法就可以被QuestionPageQuery继承并使用
相当于给PageQuery增加了几个成员变量
参数校验-防止有人一次把数据库内的信息都查询出来

分页查询--根据过滤条件进行查询

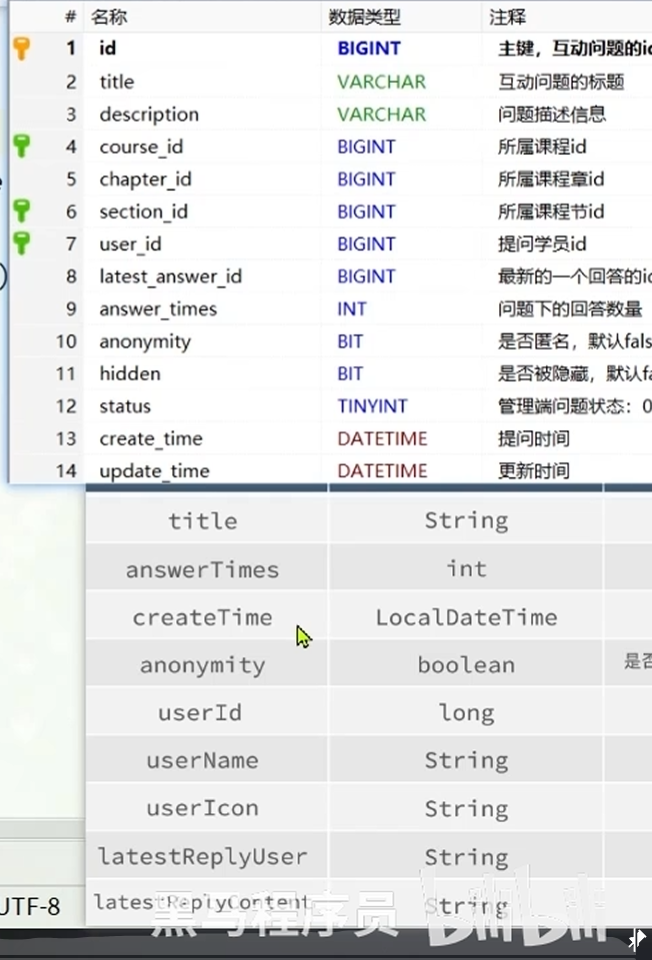
分页查询中:lambdaQuery这种mabatisplus提供的方法查询和接收的参数都是实体类(也就是和数据库表一样的结构)
经过对比可以得出实体类返回了VO所部需要的字段:description这个字段,这个字段很长且是不需要的字段,查询出来的话太占数据库资源,所以不返回这个字段
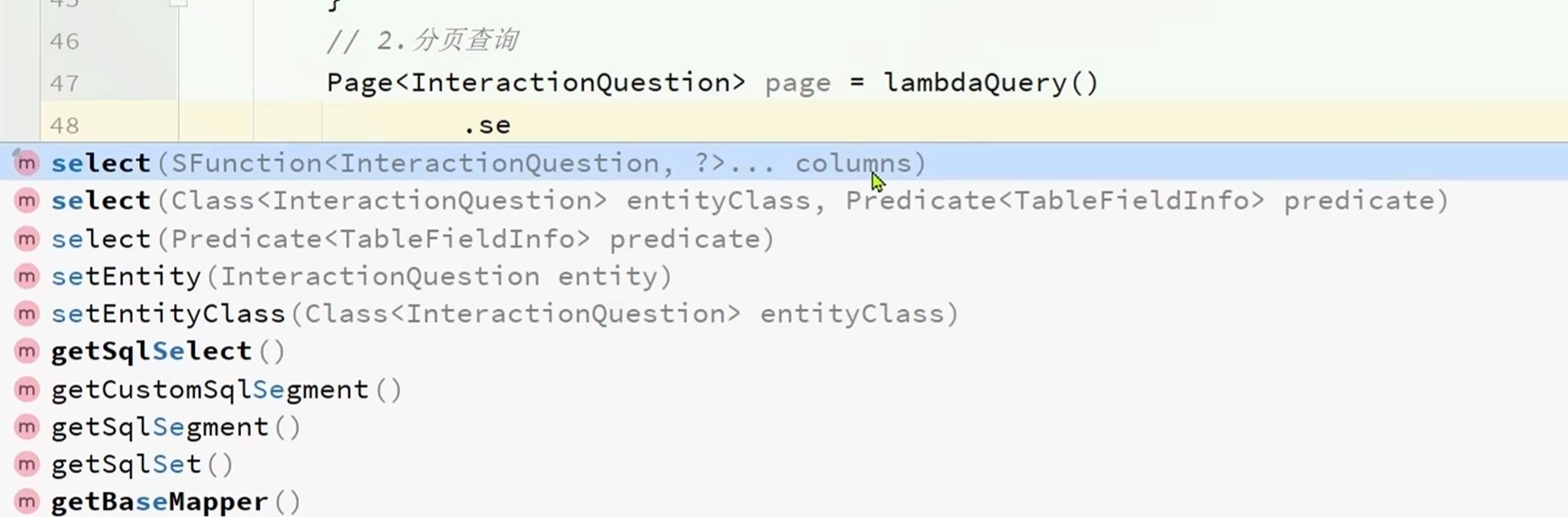

select里面提供了两种方法:
1.列举要返回的字段
2.去除不返回的字段:给字段取名为info,取出字段名,只要是字段名不为description的字段就返回

到现在已经把这个四个字段都查询出来了
还差这几个字段
/**
*
* @param questionPageQuery
* @return
*/
@Override
public PageDTO<QuestionVO> pageQuery(QuestionPageQuery questionPageQuery) {
//参数的校验--防止数据库信息都被查出
Long courseId =questionPageQuery.getCourseId();
Long sectionId = questionPageQuery.getSectionId();
if(courseId==null &§ionId==null){
throw new BadRequestException("课程id和小节id不能同时为空");
}
//获取当前用户的id
Long userId = UserContext.getUser();
//分页查询基本信息
Page<InteractionQuestion> page = lambdaQuery()
.select(InteractionQuestion.class,tableFieldInfo -> !tableFieldInfo.getProperty().equals("description"))
//判断仅查看自己的问题的boolean值是否为true,是true则这个查询条件起效
.eq(questionPageQuery.getOnlyMine(), InteractionQuestion::getUserId, UserContext.getUser())
//如果course不为空则纳入过滤条件
.eq(courseId != null, InteractionQuestion::getCourseId, questionPageQuery.getCourseId())
.eq(sectionId != null, InteractionQuestion::getSectionId, questionPageQuery.getSectionId())
.eq(InteractionQuestion::getAnonymity, false)
.page(questionPageQuery.toMpPageDefaultSortByCreateTimeDesc());
List<InteractionQuestion> records = page.getRecords();
if (CollUtils.isEmpty(records)) {
return PageDTO.empty(page);
}
//查询相关信息
//1.查询用户相关信息
//1.1获取要查询的用户的id集合
//因为发出提问的用户可能会是同一个用户,所以用set去重
//因为有的问题的体温这可能设置了匿名提问,所以需要去掉这一部分的用户
Set<Long> userIds = new HashSet<>();
Set<Long> answerIds = new HashSet<>();
for (InteractionQuestion p : records) {
if(p.getAnonymity()){
userIds.add(p.getUserId());
}
answerIds.add(p.getLatestAnswerId());
}
//1.2查询用户信息
List<UserDTO> userDTOS = userClient.queryUserByIds(userIds);
//把查询出来的userDTOs加上搜索的索引
Map<Long,UserDTO> userMap =new HashMap<>(userDTOS.size());
for (UserDTO user : userDTOS) {
userMap.put(user.getId(),user);
}
//2查询问题的最近一次回答
//2.1获取问题的最近一次回答的id--上面实现了
//因为有的问题没有被回答,所以可能为null
answerIds.remove(null);
Map<Long, InteractionReply> replyMap = new HashMap<>(answerIds.size());
//2.2查询·最新的回复
if(!answerIds.isEmpty()){
List<InteractionReply> latestReplies = replyMapper.selectBatchIds(answerIds);
for (InteractionReply reply : latestReplies) {
replyMap.put(reply.getUserId(),reply);
if(!reply.getAnonymity()){ // 匿名用户不做查询
//获取回答者中不为匿名的回答者的id放到要查询的id集合里面等待查询
userIds.add(reply.getUserId());
}
}
}
//封装VO
List<QuestionVO> voList = new ArrayList<>(records.size());
for (InteractionQuestion r : records) {
QuestionVO vo = BeanUtils.copyProperties(r, QuestionVO.class);
vo.setUserId(null);
voList.add(vo);
// 4.2.封装提问者信息
if (!r.getAnonymity()) {
UserDTO userDTO = userMap.get(r.getUserId());
if (userDTO != null) {
vo.setUserId(userDTO.getId());
vo.setUserName(userDTO.getName());
vo.setUserIcon(userDTO.getIcon());
}
}
// 4.3.封装最近一次回答的信息
InteractionReply reply = replyMap.get(r.getLatestAnswerId());
if (reply != null) {
vo.setLatestReplyContent(reply.getContent());
if (!reply.getAnonymity()) {// 匿名用户直接忽略
//获取回答者的信息并封装
UserDTO user = userMap.get(reply.getUserId());
vo.setLatestReplyUser(user.getName());
}
}
}
return PageDTO.of(page,voList);
}开发接口-用户端根据id查询问题详情
开发接口-管理端分页查询问题
分析分页参数

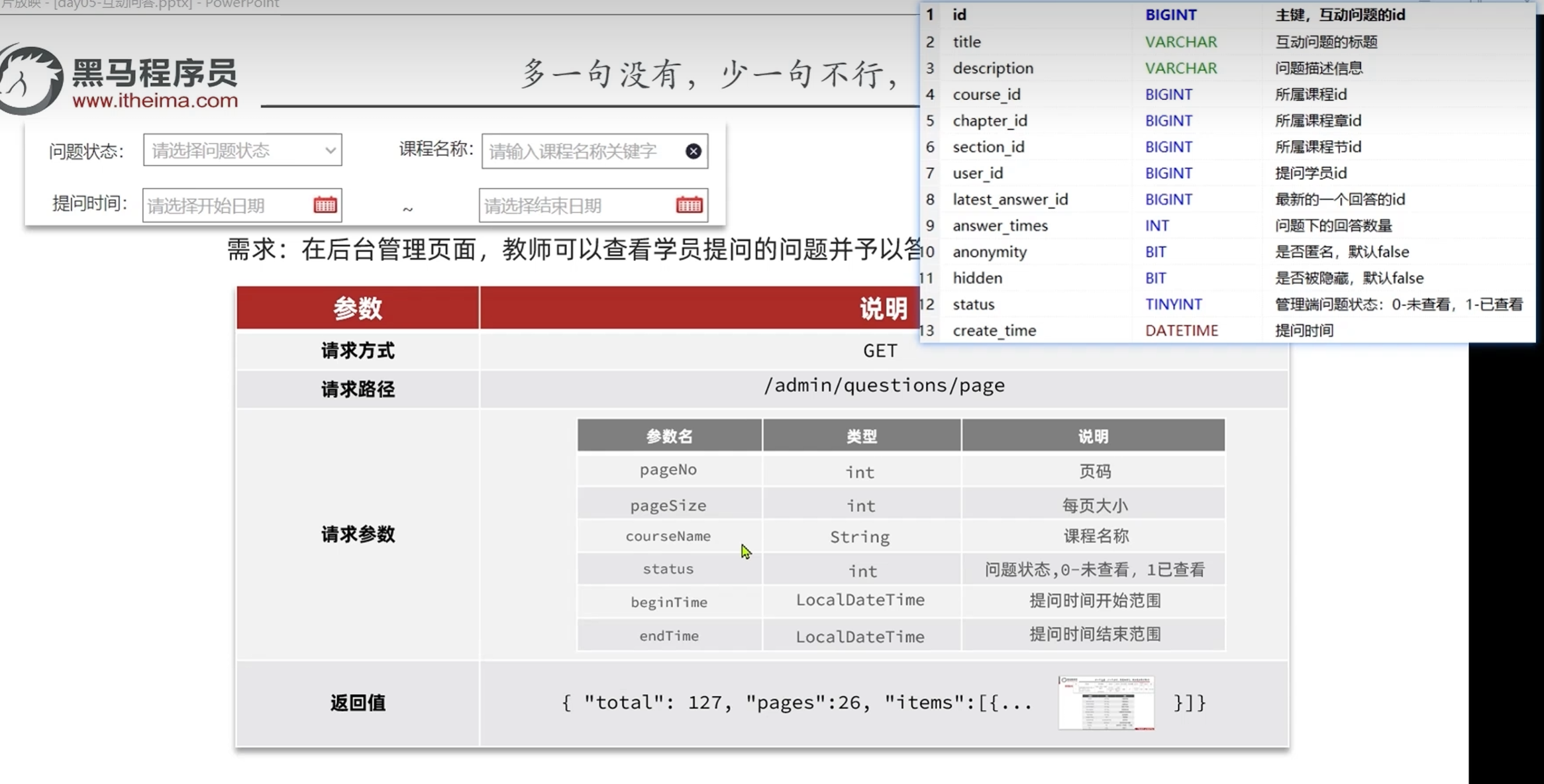
根据页面原型可以知道前端传递过来的表单参数里面传递的是课程的名称而不是课程的id
所以在后端想要课程的id和章节id查询到问题的详细信息的时候就需要根据课程名称进行模糊搜索找到课程的id
模糊搜索在sql中效率不高,所以放在els中完成
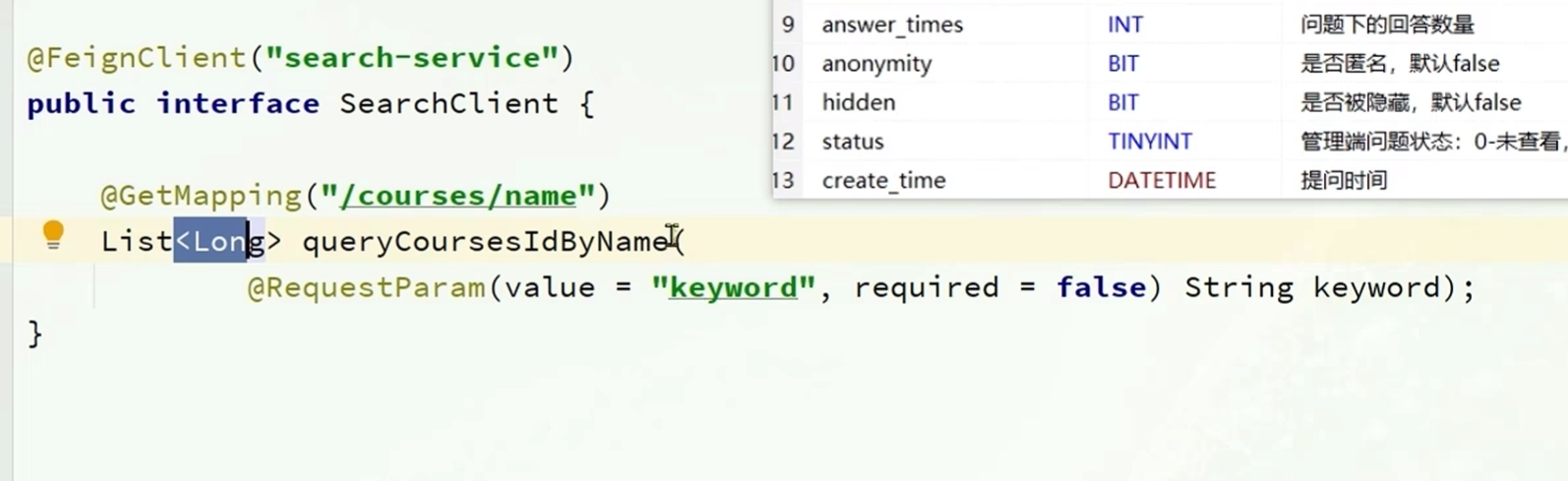
在tj-search中就实现了这样的方法
在tj-api中有tj-search的服务
分析要返回的数据
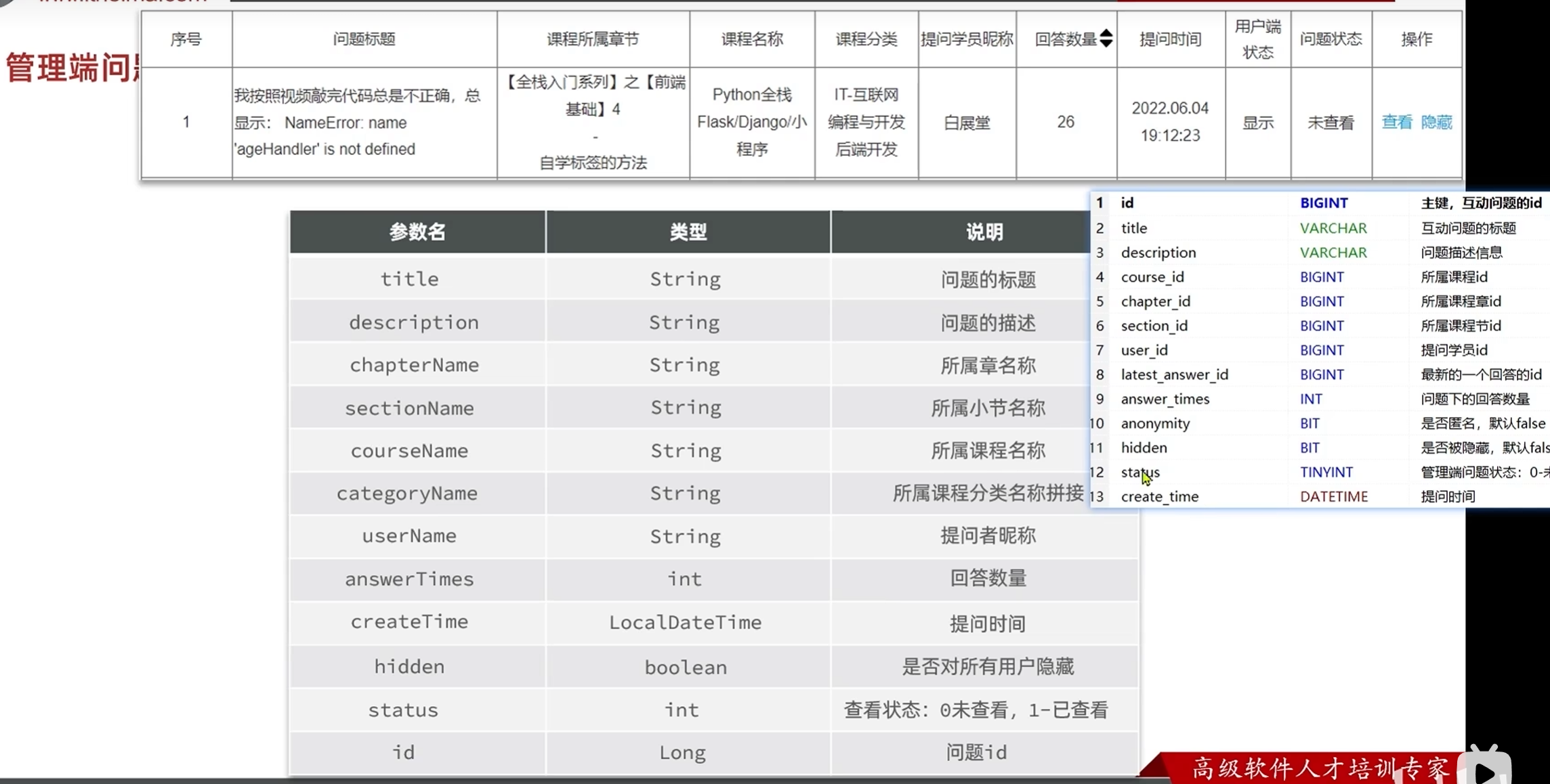
后端要返回给前端的参数里面:
不包含的参数:所属章节的名称--查询章节表
所属课程名称--查询课程表
其他参数--查询问题表
所属课程分类名称拼接--在课程表中并不直接存在,但是有关联的分类id
用于在主页进行分类查询的时候查找到课程
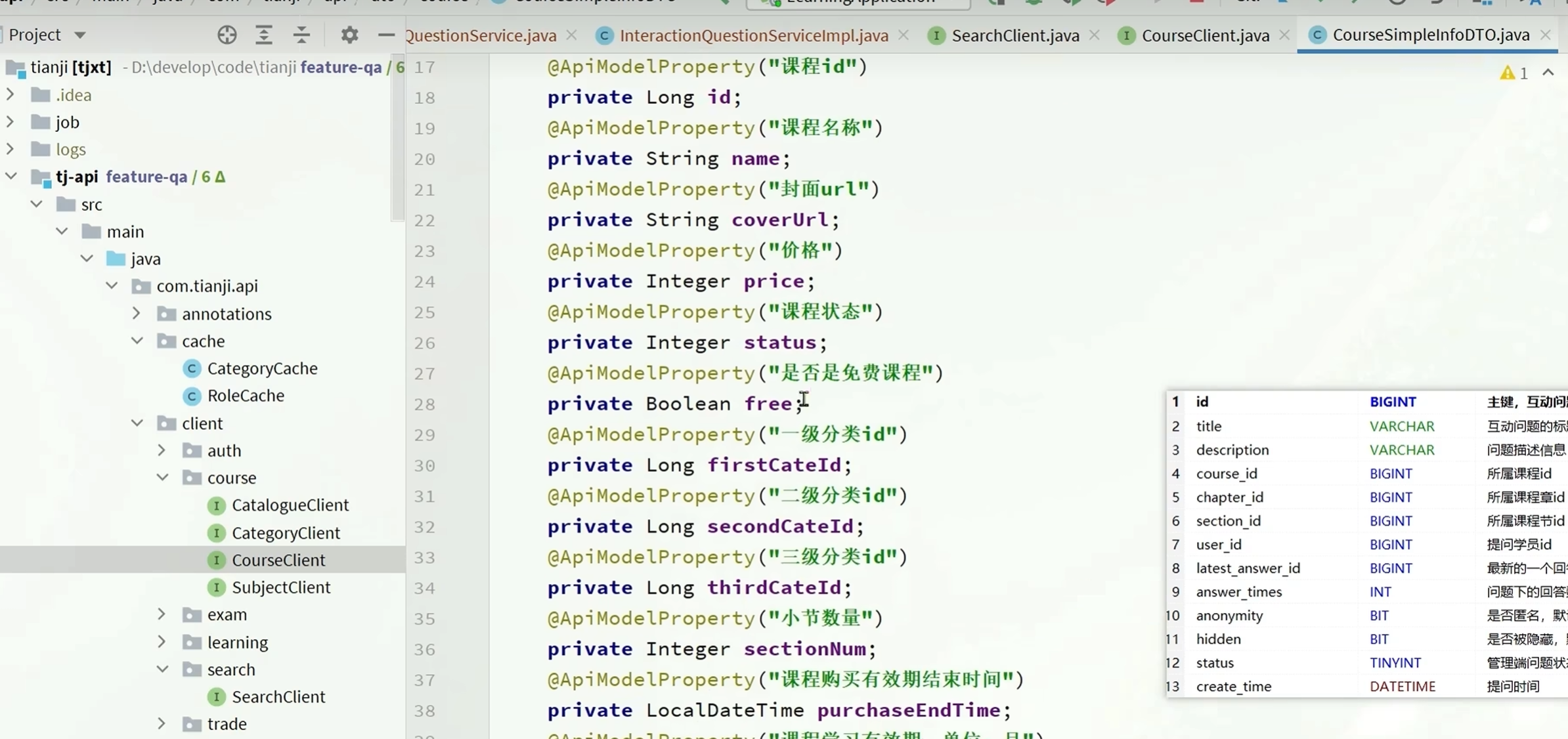
课程里面包含了三级分类各自的id以及三级分类的拼接id
根据id查询到课程之后,再根据id查询分类服务获得三级分类的名称
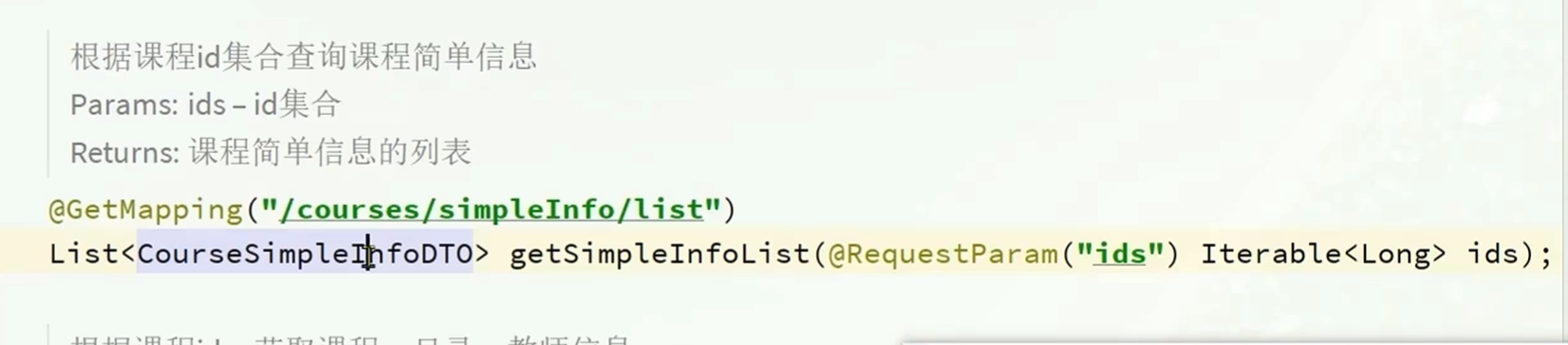
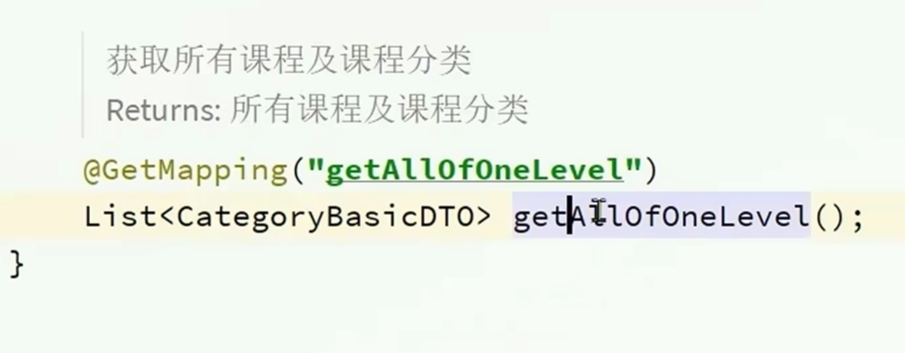
开发接口
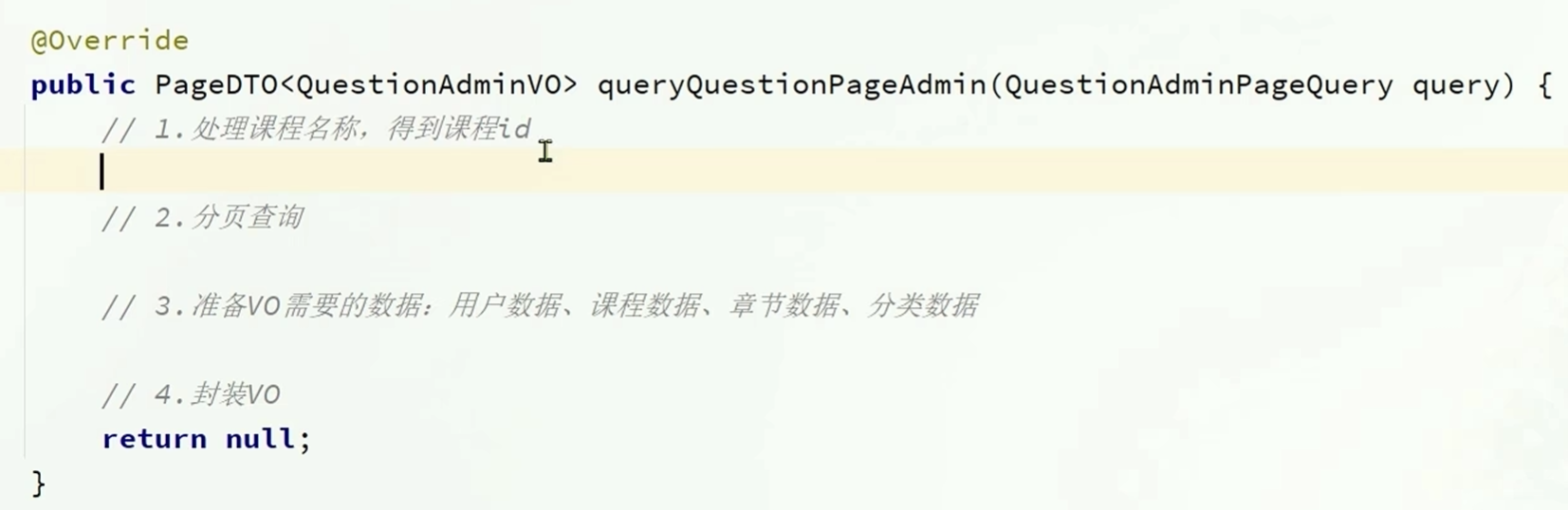
基本逻辑是:先处理课程名称得到课程id(处理分页数据)之后进行分页查询
得到分页查询的数据之后
查询其他的VO需要的数据
封装VO
分类数据
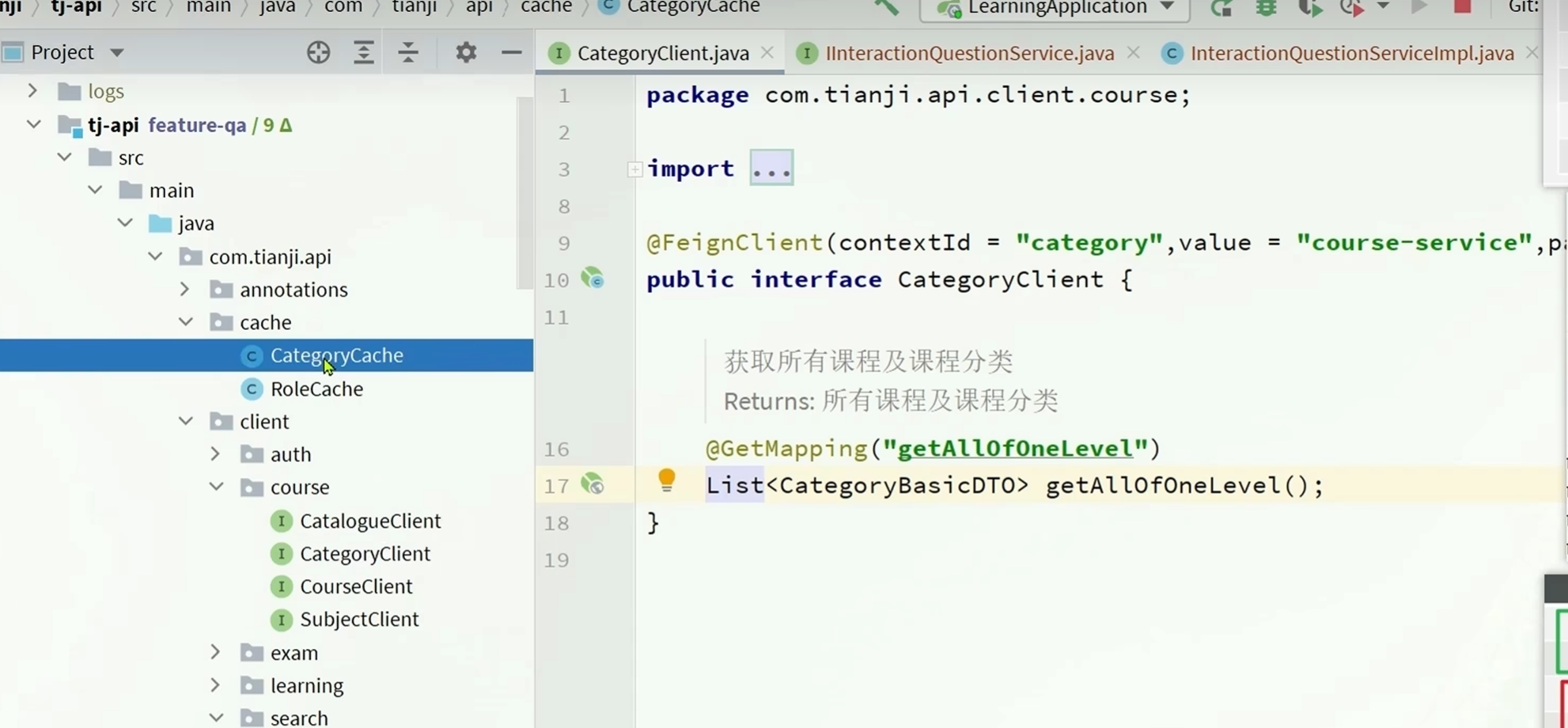
根据观察可以知道查询分类的时候并没有提供根据id查询的方法,而是返回所有的课程以及课程分类
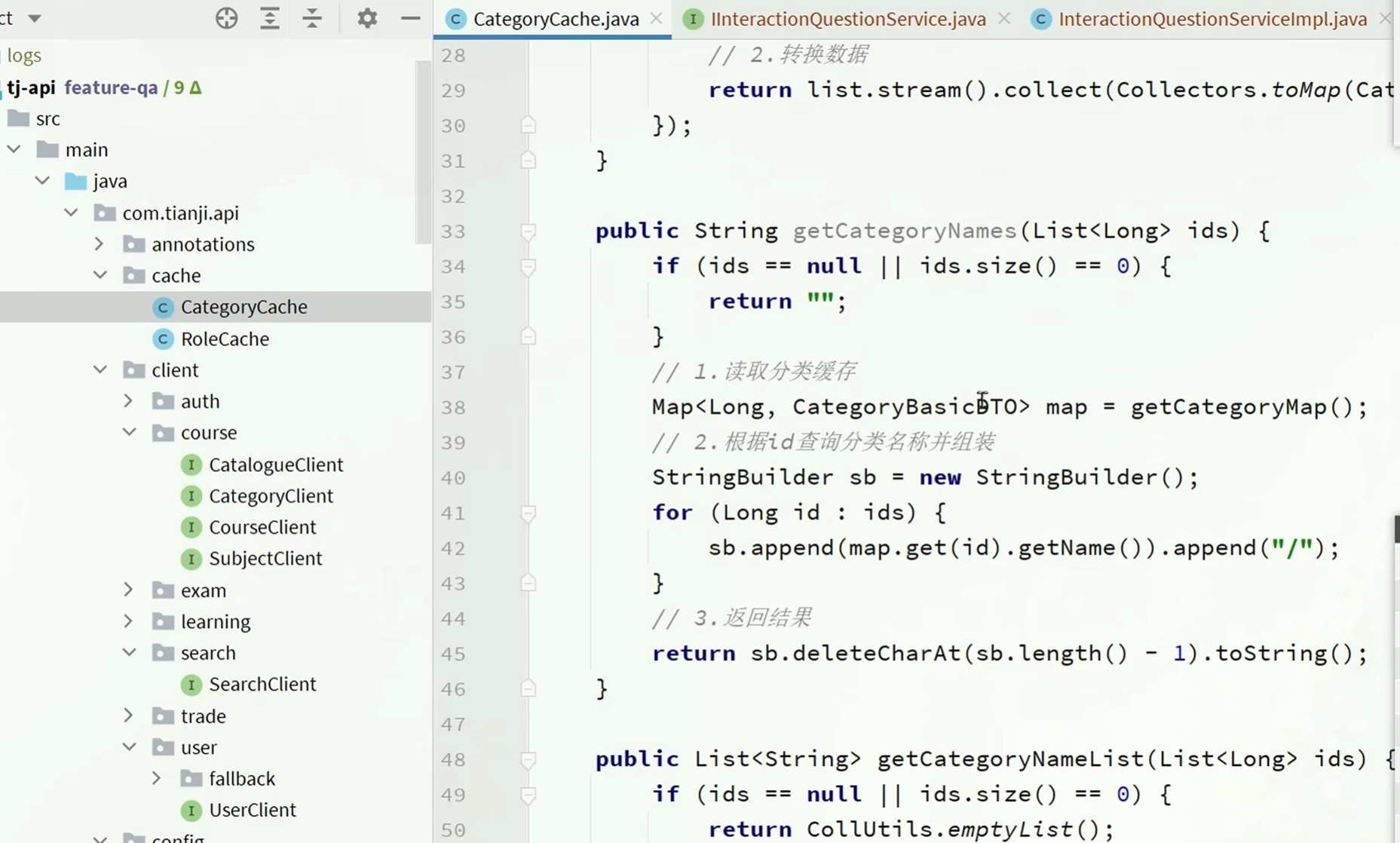
在CategoryCache里面提供了相关方法
管理端根据id查询问题详情的业务分析
DAY06
点赞业务分析
课程导入
可以对别人的问答,笔记进行点赞
点赞系统可以迁移到转发系统等,都可以用
需求和思路分析
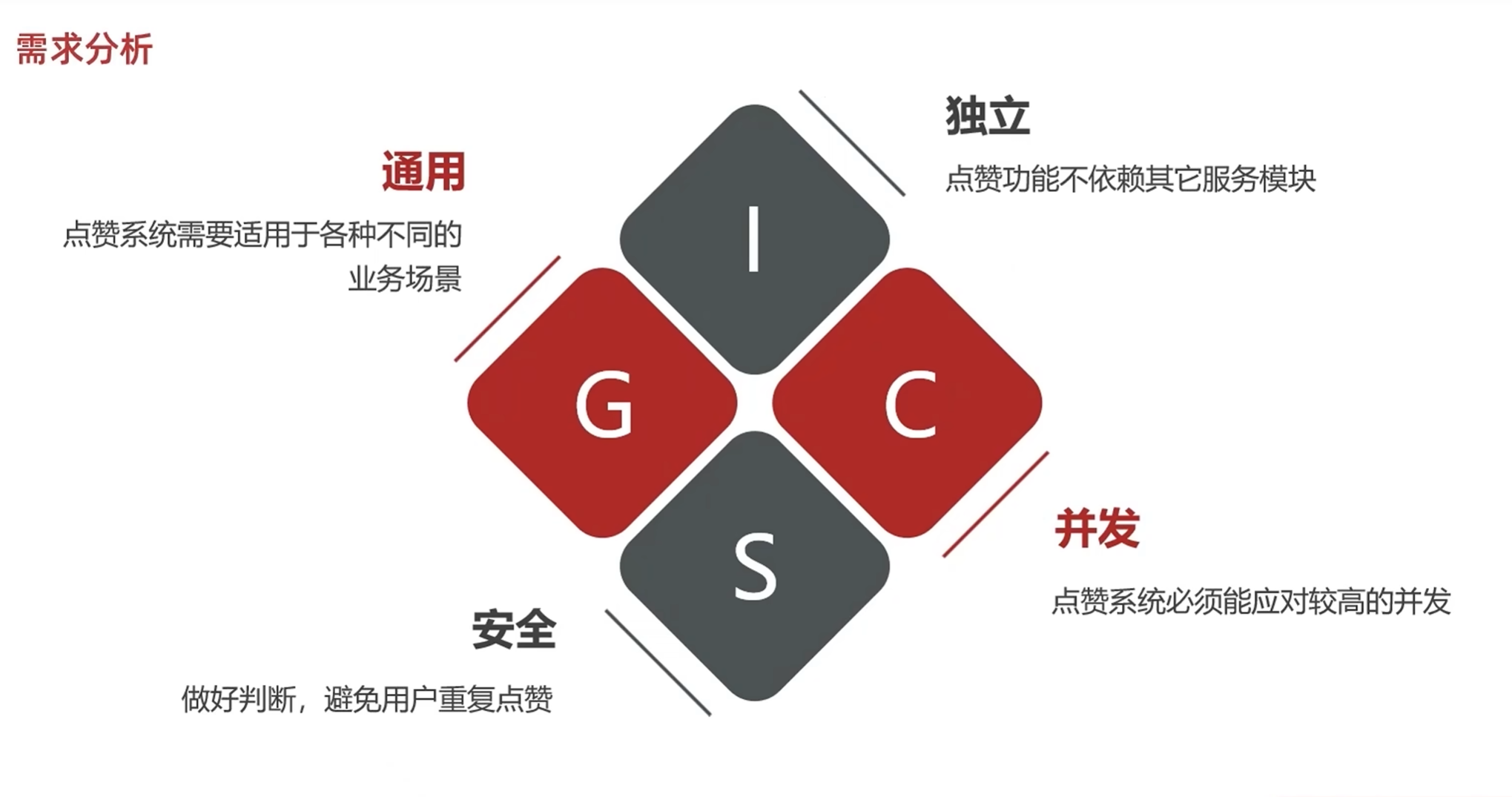
点赞系统的应用是很广泛的,在很多地方都会用到
因此要确保一个点赞系统的通用性,也就是在任何服务里面都能运行,就要保证他的独立性
不与其它服务产生耦合
在展示回答列表的时候会展示点赞数量,在排序的时候也会根据点赞的数量进行排序
要进行复杂的操作,比如根据点赞的数量进行排序,且在点赞量相同的时候按照时间倒序排序这种,就只能把点赞数量保存在其他业务上面
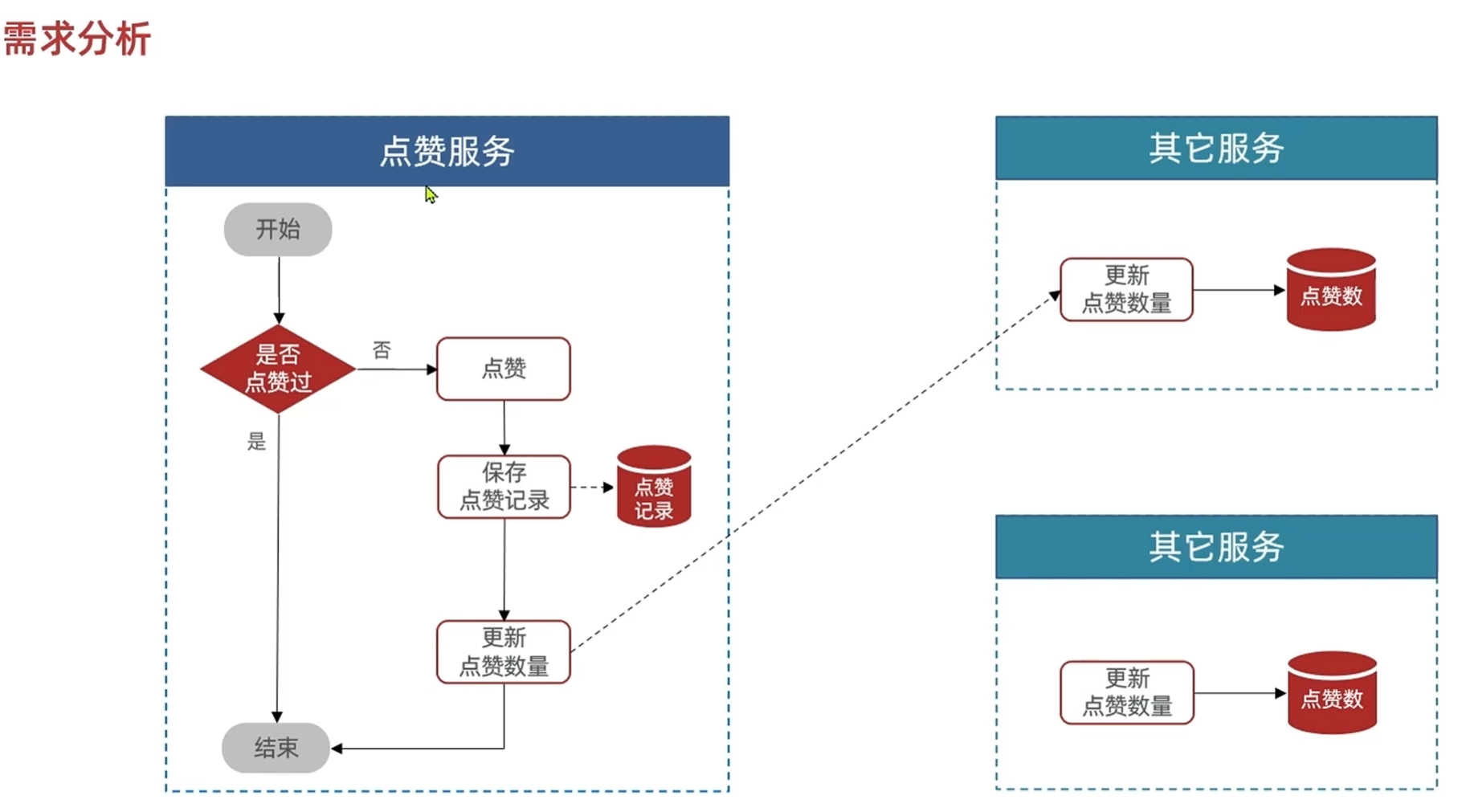
如果远程调用其他接口的话,会与其他业务产生强耦合
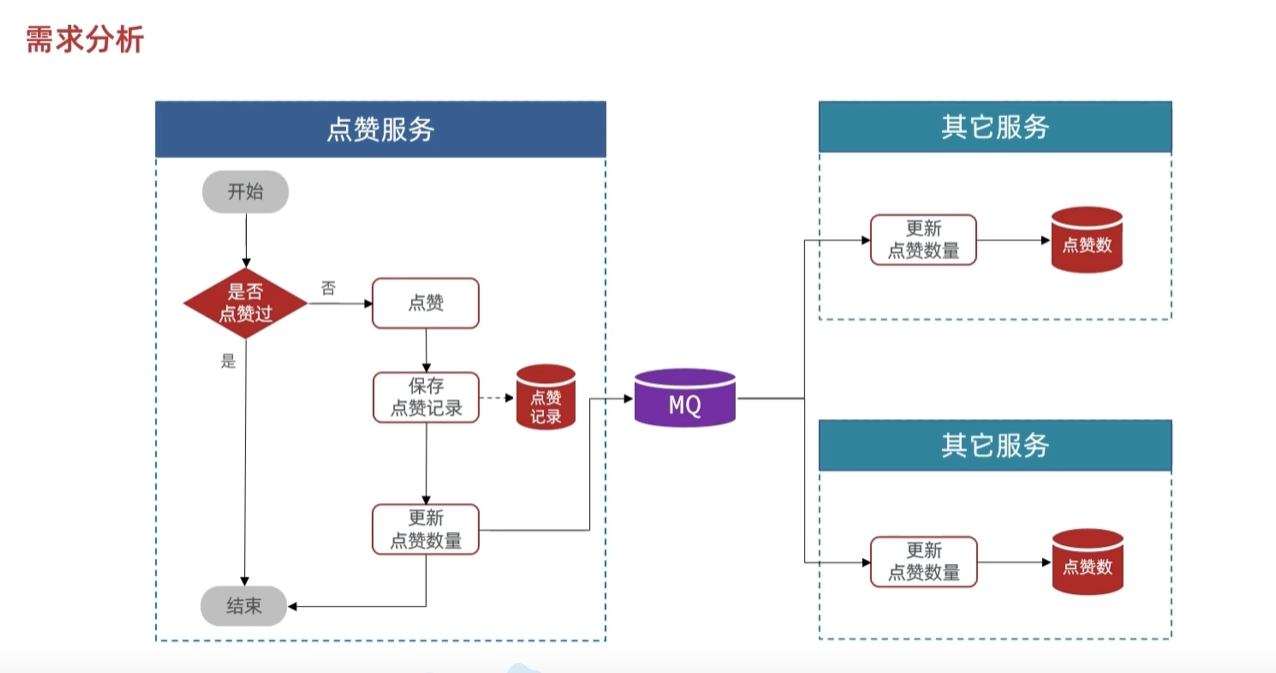
所以要用消息队列
数据表结构设计

准备业务实体
因为点赞服务要是一个独立的服务,所以要把点赞服务放在一个独立的模块里面
server:
port: 8091 #端口
tomcat:
uri-encoding: UTF-8 #服务编码
spring:
profiles:
active: dev
application:
name: remark-service
cloud:
nacos:
config:
file-extension: yaml
shared-configs: # 共享配置
- data-id: shared-spring.yaml # 共享spring配置
refresh: false
- data-id: shared-redis.yaml # 共享redis配置
refresh: false
- data-id: shared-mybatis.yaml # 共享mybatis配置
refresh: false
- data-id: shared-logs.yaml # 共享日志配置
refresh: false
- data-id: shared-feign.yaml # 共享feign配置
refresh: false
- data-id: shared-mq.yaml # 共享mq配置
refresh: false
tj:
swagger:
enable: true
enableResponseWrap: true
package-path: com.tianji.remark.controller
title: 天机学堂 - 评价中心接口文档
description: 该服务包含用户评价,点赞等的各种辅助功能
contact-name: 传智教育·研究院
contact-url: http://www.itcast.cn/
contact-email: zhanghuyi@itcast.cn
version: v1.0
jdbc:
database: tj_remark
auth:
resource:
enable: true # 登录拦截功能我们在nacos里面配置了很多共享配置,一旦引入之后就不需要重复的编写相关的配置了
tj的swagger配置,只需要给出扫描包就能给该包添加一个swagger文档
jdbc数据库的配置时动态变量的配置方法,所以只需要给出数据库的名字就行
auth是配置是否需要登录拦截
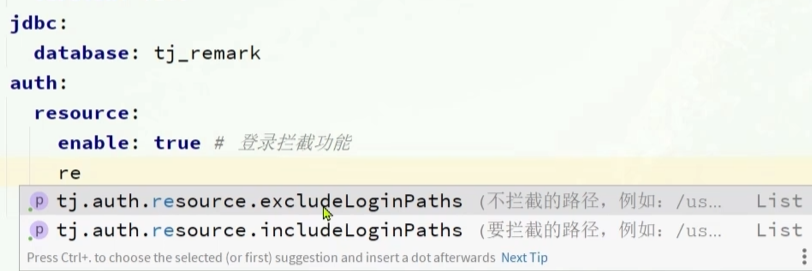
也可以配置比较复杂的条件,比如指定要拦截的路径和不拦截的路径
实现点赞功能
-点赞或取消点赞接口设计
点赞或者取消点赞
在点赞的时候,如果已经点过赞,再次点击点赞就会取消点赞,如果没有点过赞,点击点赞会点赞
点击点赞的时候,可能会触发点赞或者取消点赞
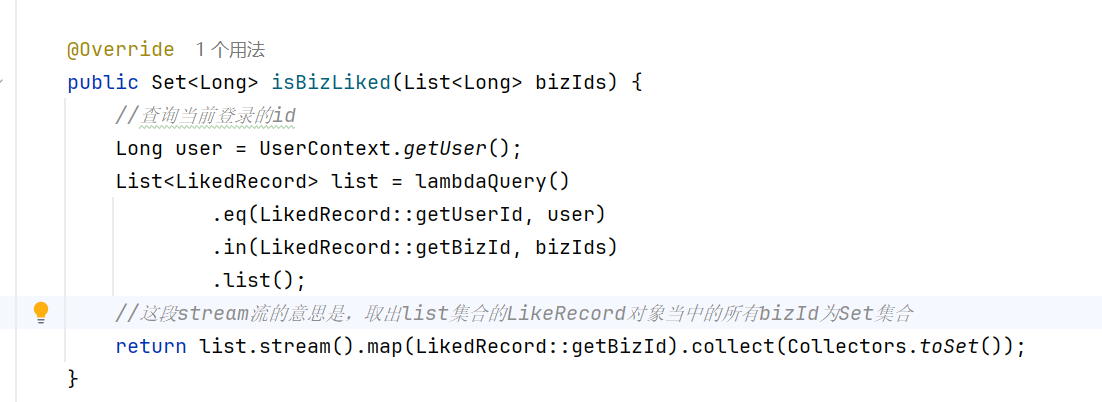
查询点赞状态
而且当前页面上所有的点过赞的手都是红色的,所以在页面展示的最后一刻,我们需要知道该回答有没有被点赞

点赞或者取消点赞
有两种方案:1.在点赞的时候给后端插入有一条数据,在取消点赞的时候删除这条数据
2.在表中用一个字段来标识有没有点过赞,
当用户点赞的时候,先看一下这条数据是否存在,如果不存在则插入,如果存在,则看状态是点赞还是未点赞,如果是未点赞则该成已点赞
当用户取消点赞的时候,先看一下这条数据是否存在,如果不存在或者存在了但是状态是为点赞则不用管,如果存在但是已点赞则把状态改为未点赞
第二种方法由于要把未点赞的数据也放在数据库里面,造成了数据库的浪费
所以采用第一种方案
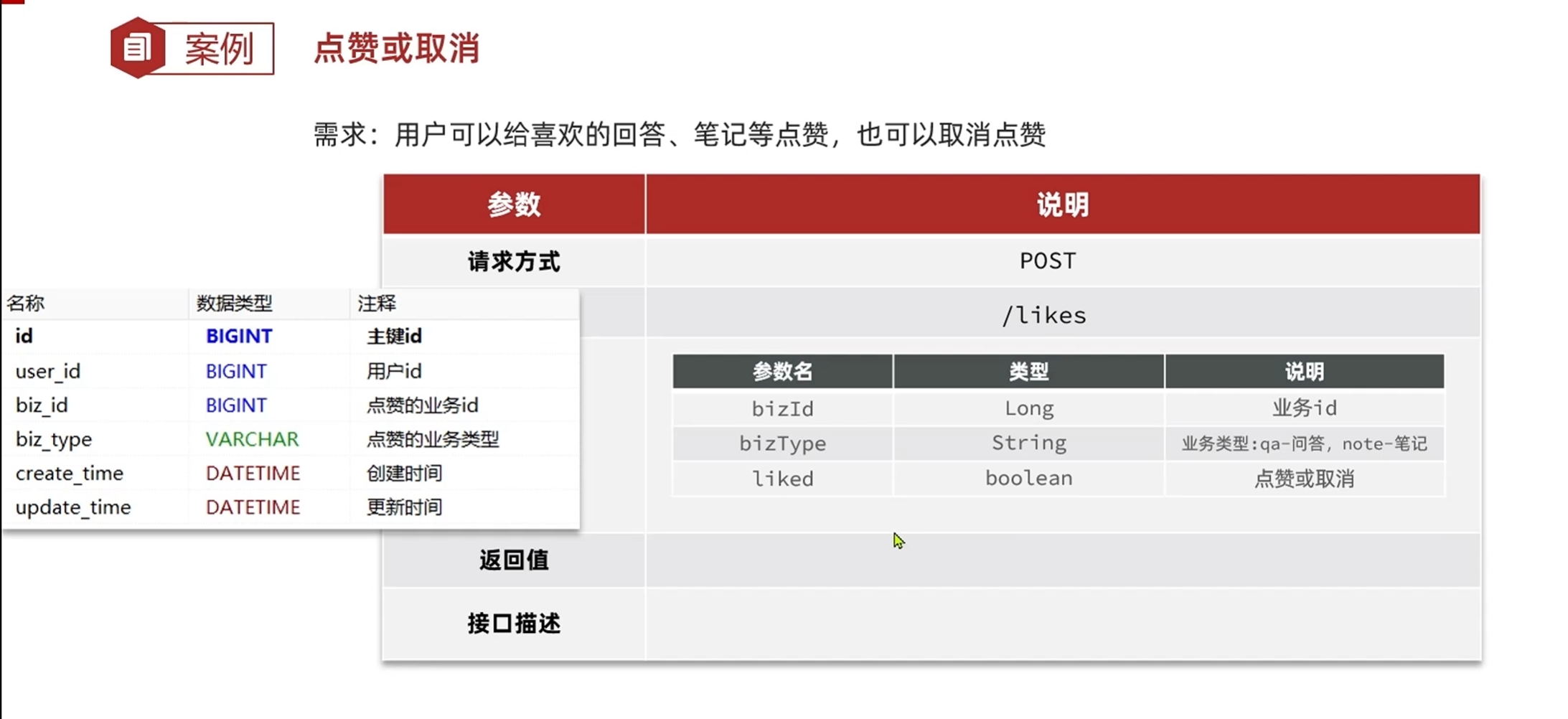
前端只需要传递业务id,业务类型,点赞或取消
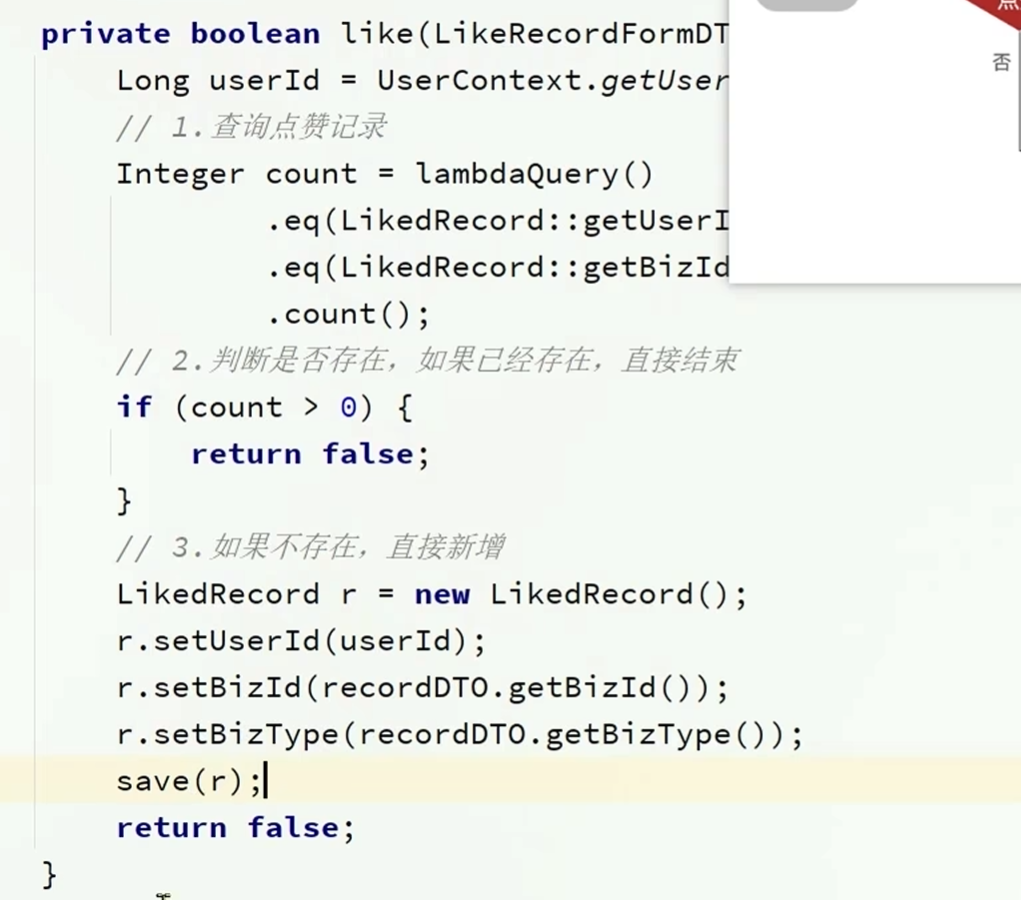
实现点赞或取消点赞接口
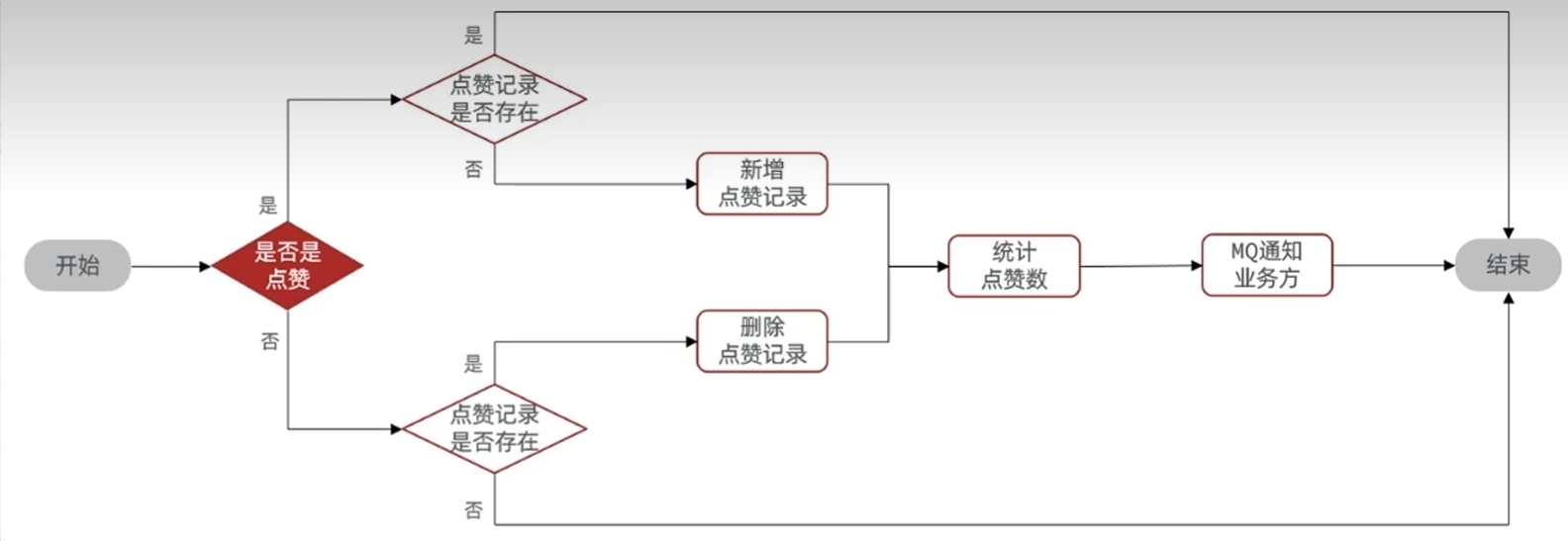
在看点赞记录是否存在的时候,点赞和取消点赞的业务逻辑并不相同
点赞的话,如果存在则返回false
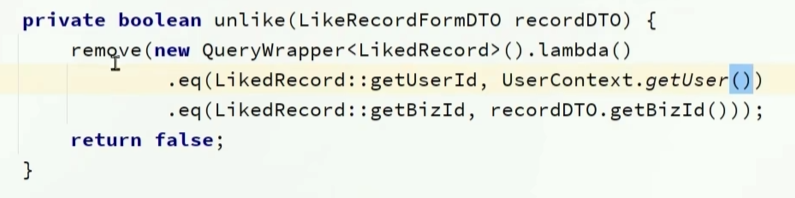
取消点赞的话,如果不存在则返回false
或者直接删除,看删除是否成功,成功则返回true,不成功则返回false
lambdaQuery里面有计数的方法,但是没有列求和的方法
mq发送消息的时候,虽然想要得到这个消息的服务很多,但是每个服务想要得到的内容不一样,所以要用topic或者别的
要用这种publisher就得有不同的rountingkey,这个key根据前端传递过来的参数业务类型来
一般还会加上前缀或者后缀,让他们的形式变得一样
在common模块中有常量,见名知意,可以直接拿来使用
包括exchange交换机和routingkey
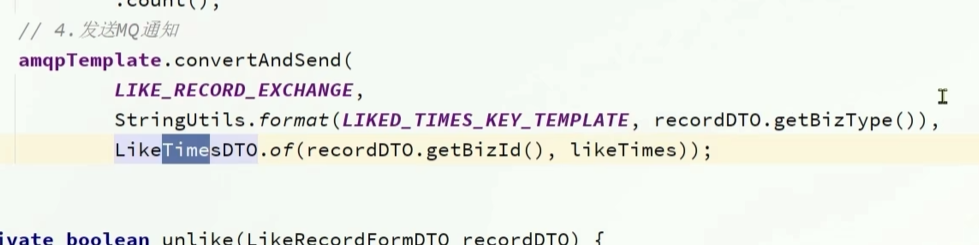
发送消息的时候,定义一个类,包括点赞数,对应id
发送点赞次数的类是方法里面的,应该放到api下
工具类,应该放到common下,方法则放到api下

加入一个构造方法of方便构造这个类
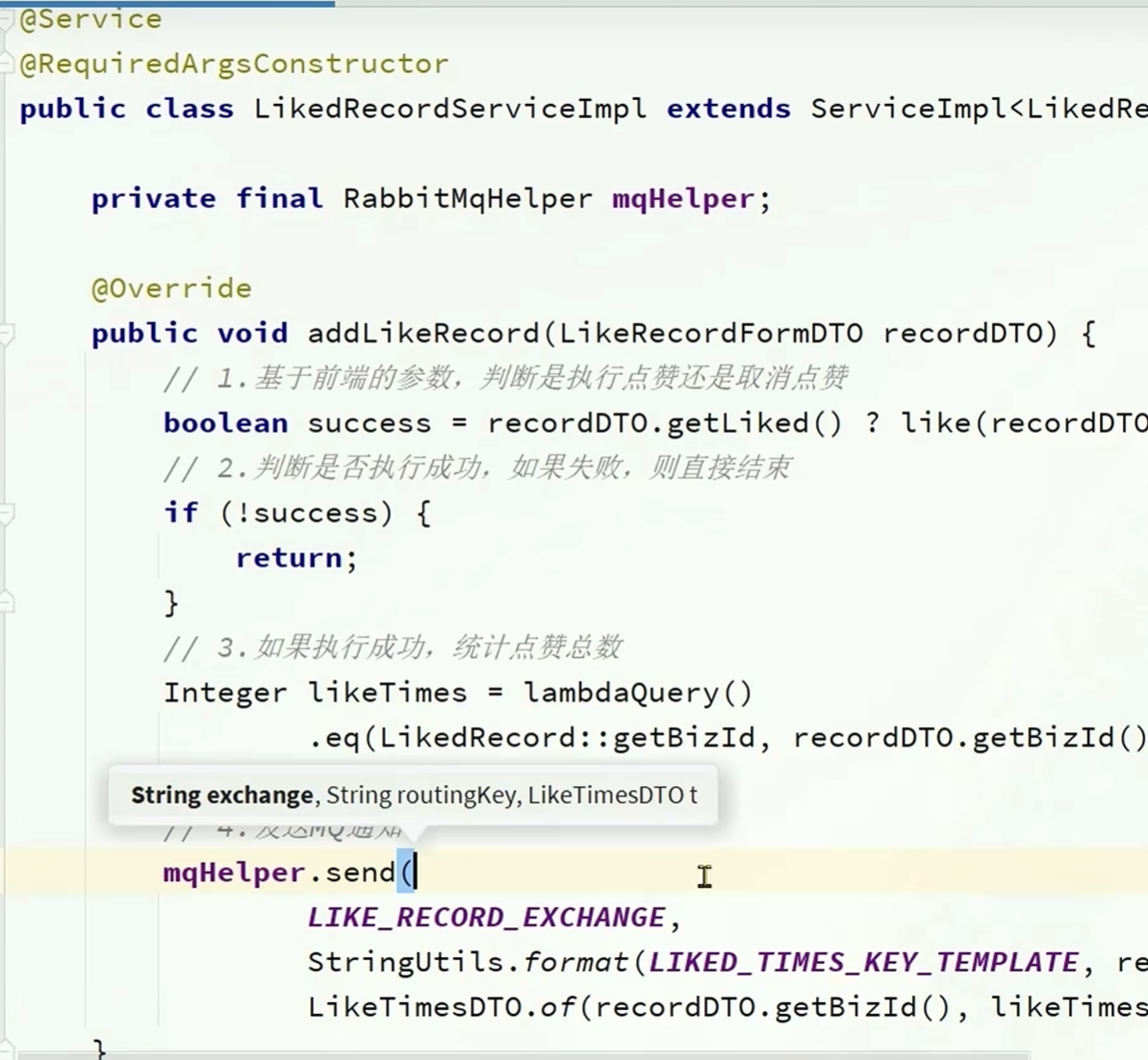
可以使用RabbirMqHelper这种类
这个类提供了很多不同的方法
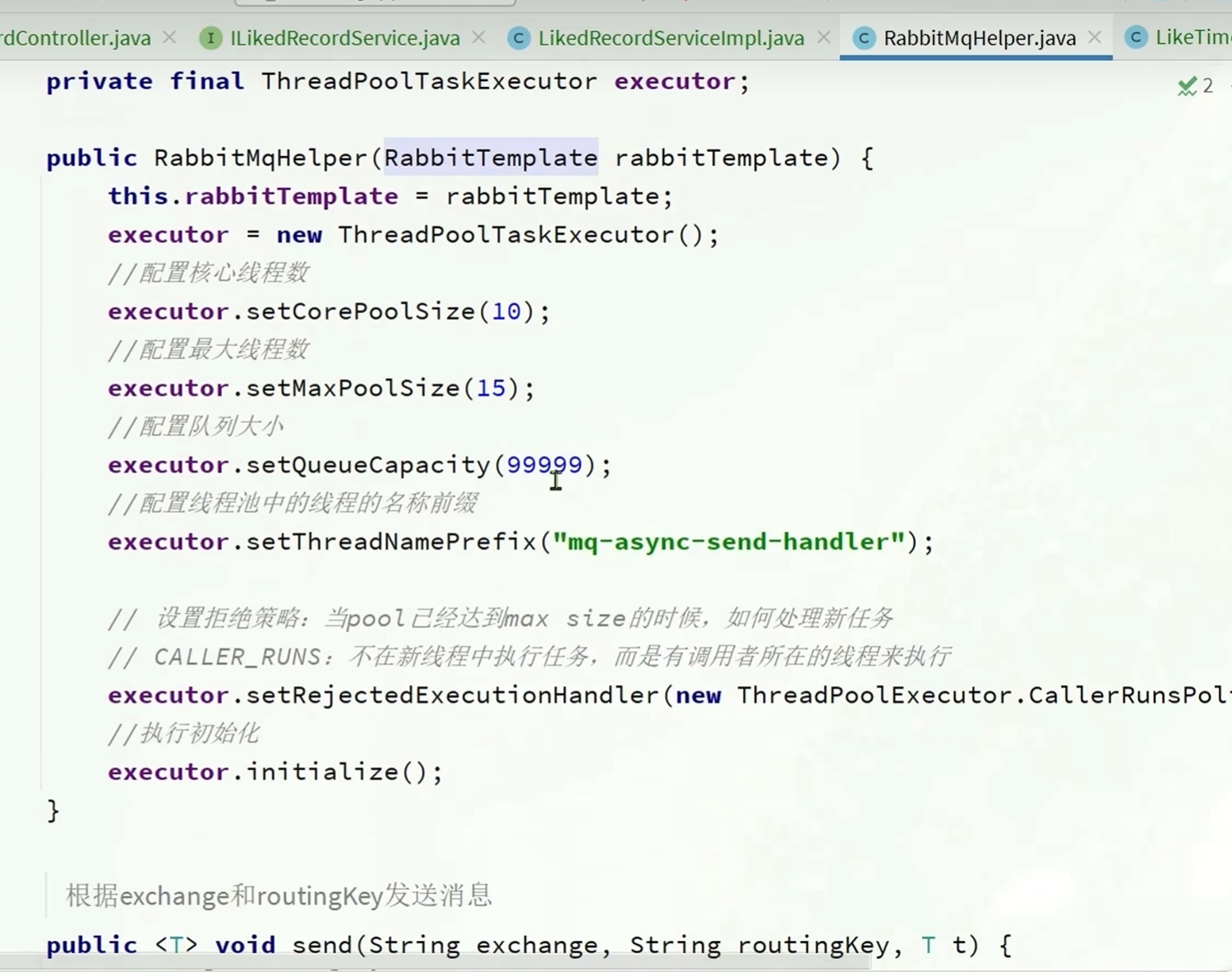
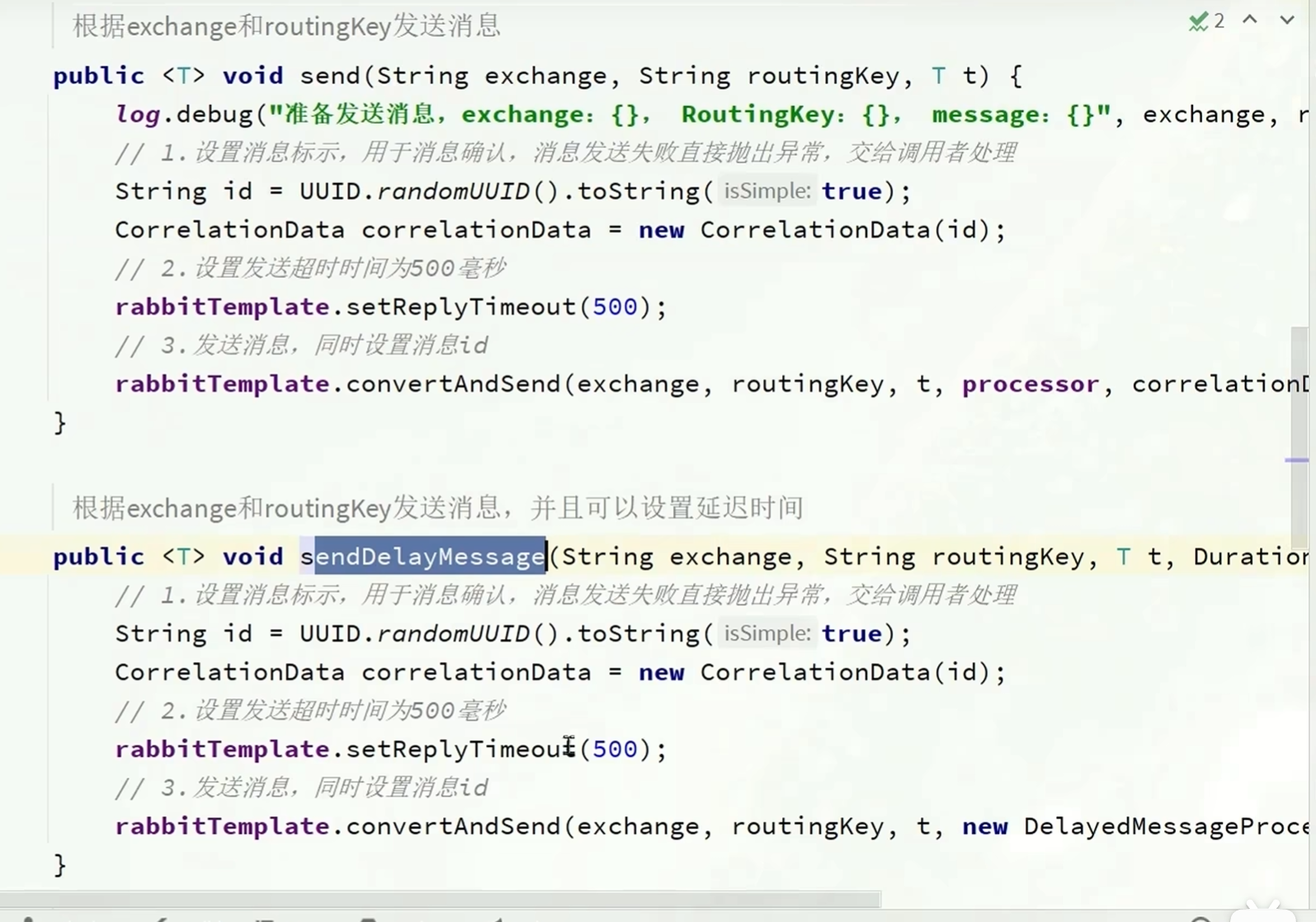
支持消息发送失败交给调用者处理,或者使用延迟发送
@Data
@NoArgsConstructor
@AllArgsConstructor(staticName = "of")
public class LikedTimesDTO {
/**
* 点赞的业务id
*/
private Long bizId;
/**
* 总的点赞次数
*/
private Integer likedTimes;
}
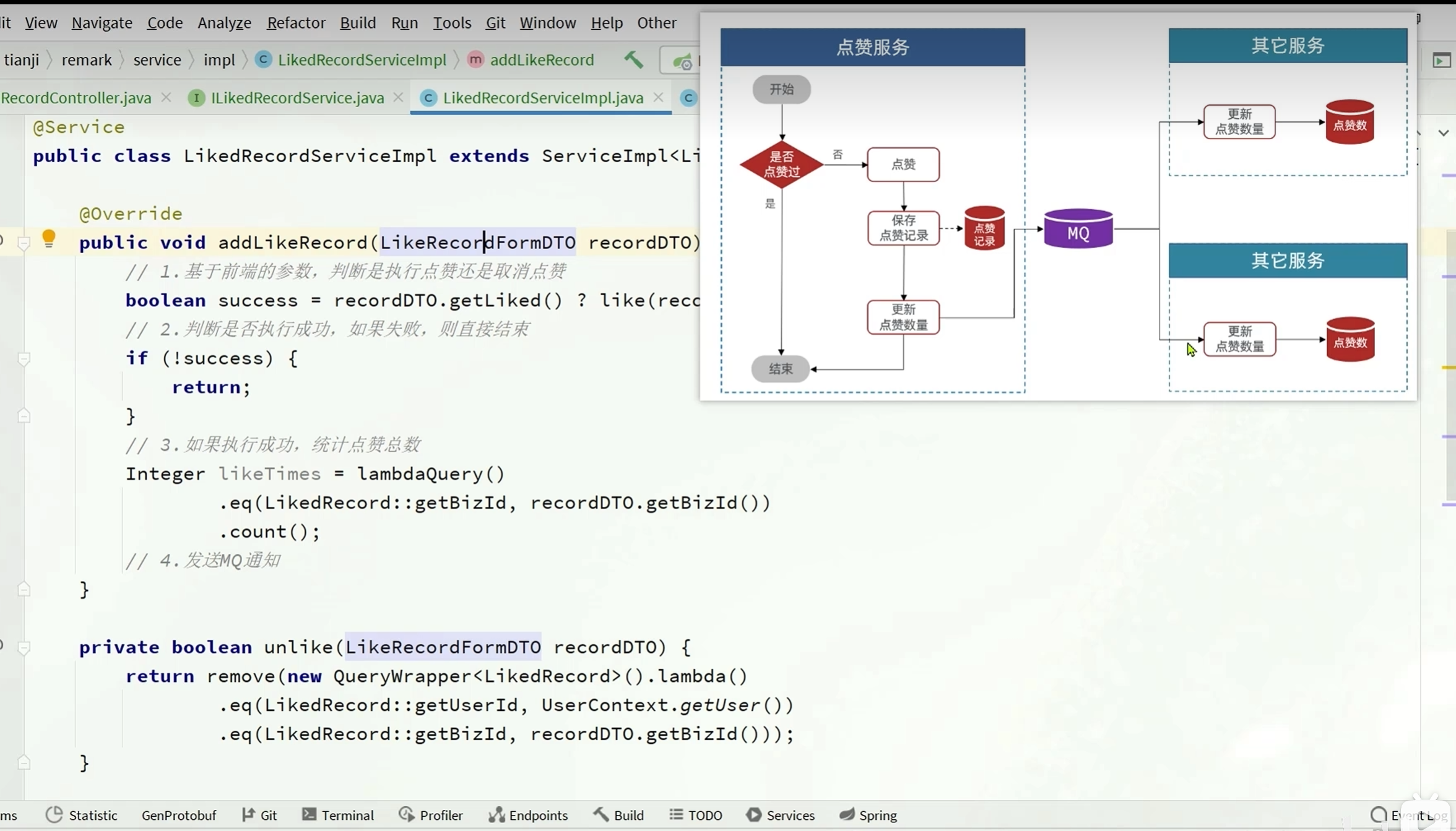
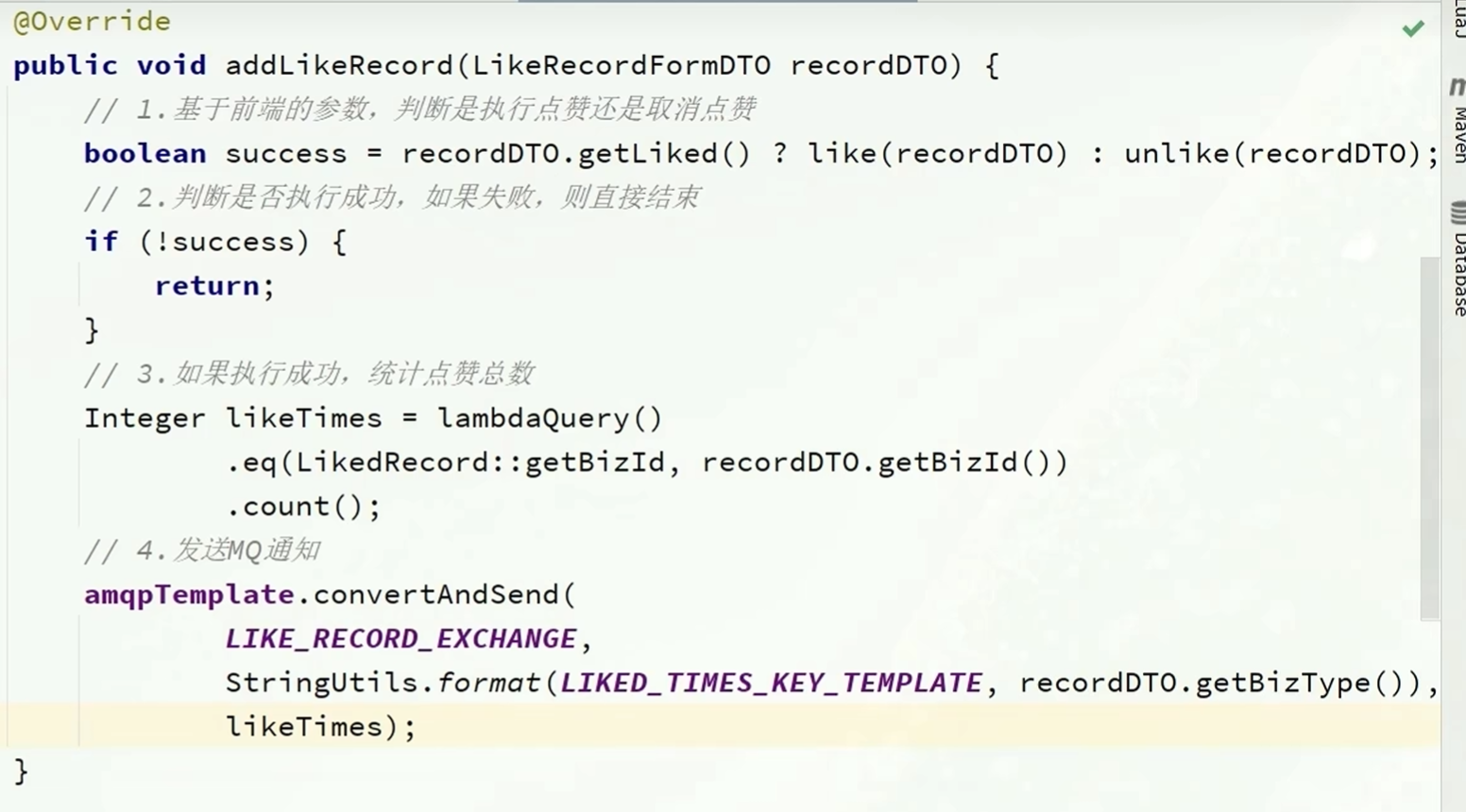
@Override
public void addLikeRecord(LikeRecordFormDTO likedRecord) {
//在执行统计次数前先判断要不要直接退出服务
Boolean flag = false;
if(likedRecord.getLiked()) {
flag = like(likedRecord);
}else {
flag = unlike(likedRecord);
}
if(!flag){
return;
}
//统计点赞次数
Integer count = lambdaQuery()
.eq(LikedRecord::getBizId, likedRecord.getBizId())
.count();
//发送消息
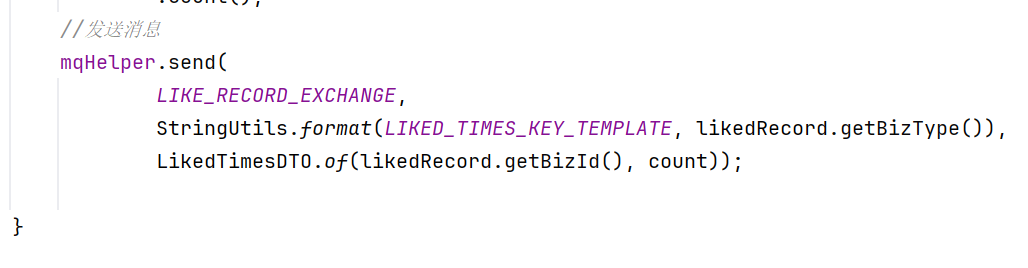
mqHelper.send(
LIKE_RECORD_EXCHANGE,
StringUtils.format(LIKED_TIMES_KEY_TEMPLATE, likedRecord.getBizType()),
LikedTimesDTO.of(likedRecord.getBizId(), count));
}
private Boolean like(LikeRecordFormDTO likedRecord) {
//查看有没有这一条数据
Integer count = lambdaQuery()
.eq(LikedRecord::getUserId, UserContext.getUser())
.eq(LikedRecord::getBizId, likedRecord.getBizId())
.count();
//判断是否已经存在,如果已经存在则退出
if(count > 0){
return false;
}
//如果不存在,则直接添加
LikedRecord record = new LikedRecord();
record.setUserId(UserContext.getUser());
record.setBizId(likedRecord.getBizId());
record.setBizType(likedRecord.getBizType());
save(record);
return true;
}
private Boolean unlike(LikeRecordFormDTO likedRecord) {
return remove(new QueryWrapper<LikedRecord>().lambda()
.eq(LikedRecord::getUserId, UserContext.getUser())
.eq(LikedRecord::getBizId, likedRecord.getBizId()));
}
实现查询点赞状态接口

只返回前端传递过来的参数中被点赞了的部分
编写到Client里面

fallback里面
fallback就是当Client接口中的方法产生错误之后会做的事
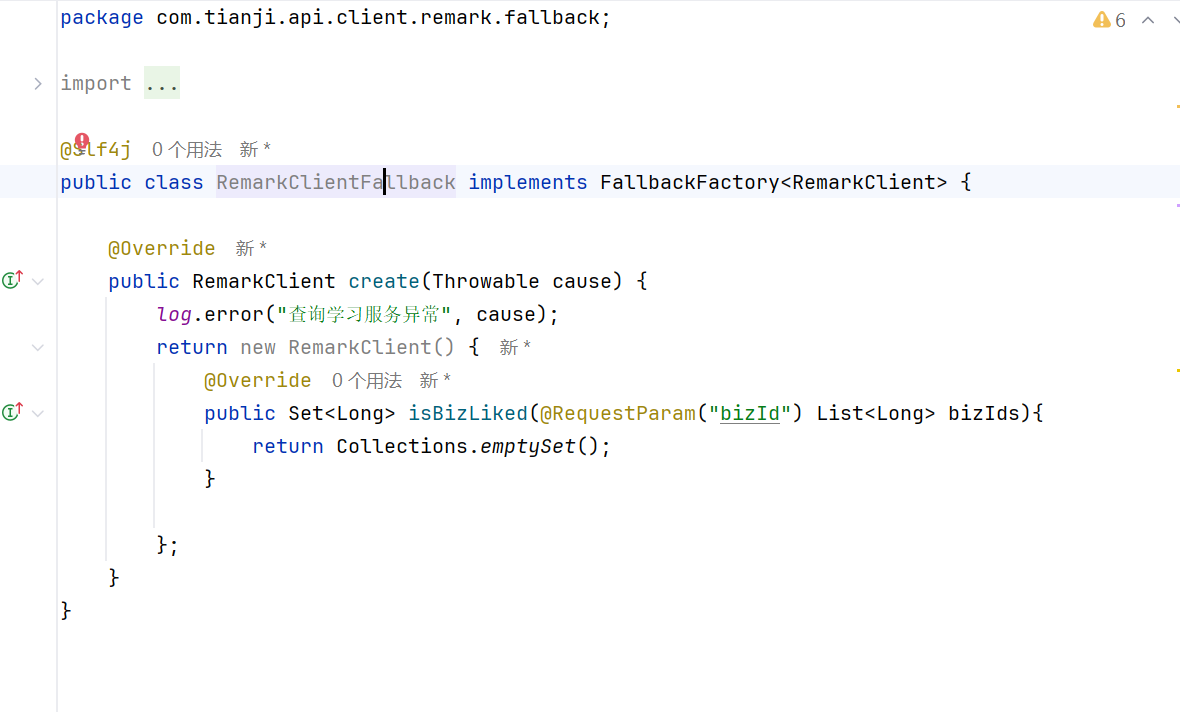
最后要做的事是把fallback里面的类注入到Spring里面,让Spring统一管理
Component扫描包的方式肯定不行,因为两个位置不同,扫不到
所以使用Spring的自动装配原理
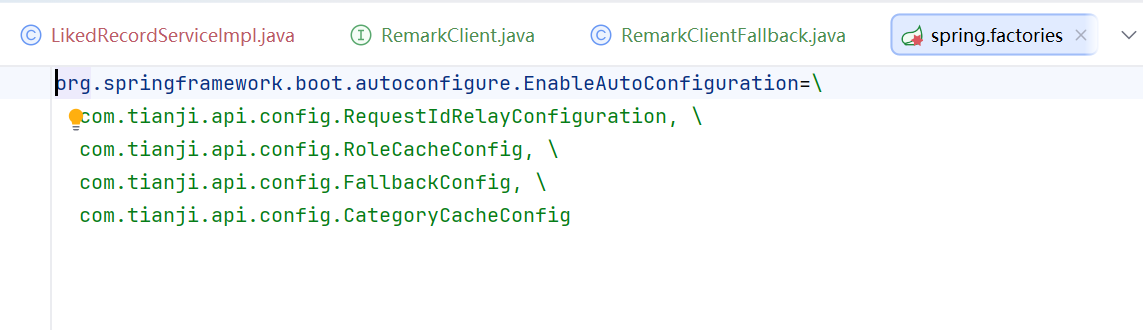
定义spring.factories,同时里面定义有很多的有配置类
有fallback的Config类,里面是特定来注册类的
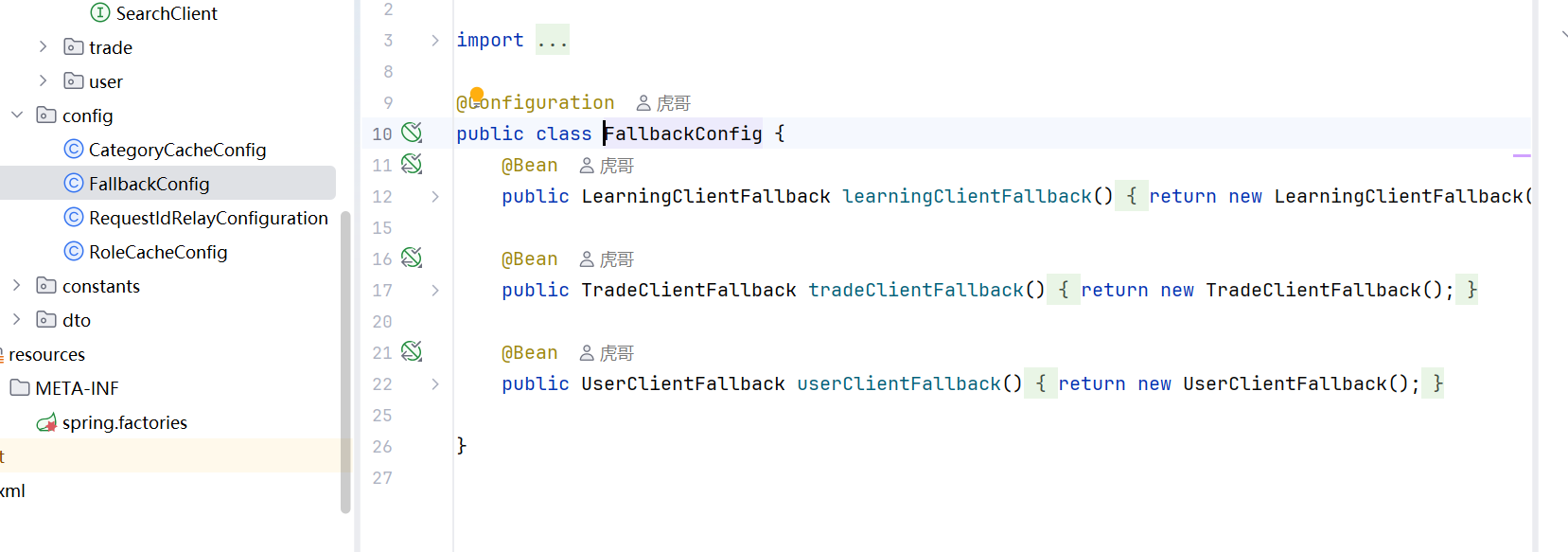
修改为
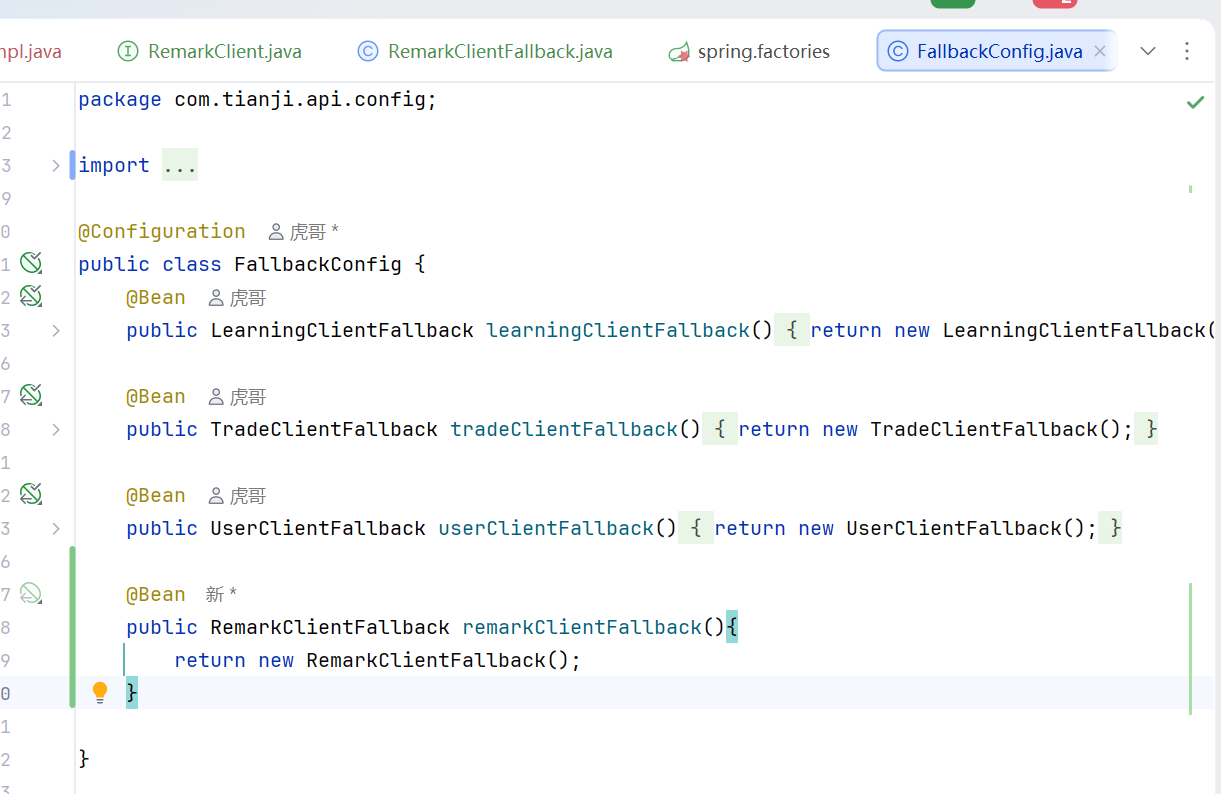
同时Client里面加上这一行
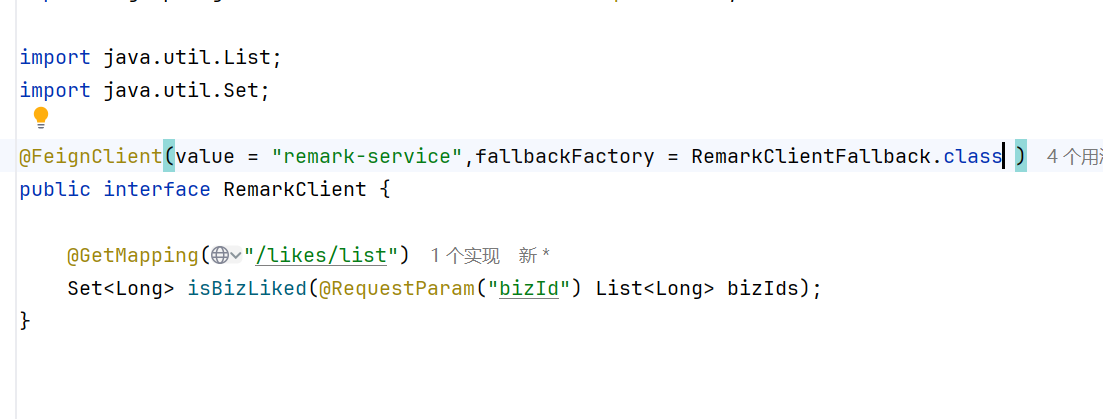
为什么不用Component
为什么 API 模块默认不被扫描?为什么不统一装配?
这是微服务架构的设计原则,核心原因是职责分离 + 避免耦合。
1. API 模块的定位:只做 “契约定义”
你的 tianji-api 模块,本质上是一个公共依赖包,里面只有接口(FeignClient)、DTO、常量、降级类这些纯定义,不应该包含任何 Spring 管理的 Bean。
-
它会被多个服务(学习服务、评论服务等)依赖。
-
如果它自己带了
@Component等注解,被 Spring 扫描装配,就会导致所有依赖它的服务都自动创建这些 Bean,容易出现:-
单例冲突、重复创建
-
依赖循环
-
配置混乱,难以维护
-
2. 启动类的组件扫描范围,默认只扫自己
Spring Boot 的 @SpringBootApplication 注解,默认的组件扫描范围是:
启动类所在包及其所有子包
比如你的启动类在 com.tianji.remark,那它只会扫描 com.tianji.remark 包下的类。
-
tianji-api里的类在com.tianji.api,不在扫描范围内,所以默认扫不到。 -
这么设计是为了保证每个服务的 Bean 都是自己可控的,避免引入外部依赖里的未知 Bean。
3. 为什么不统一扫描 API 模块?
如果强行让所有服务都扫描 tianji-api,会有几个严重问题:
-
破坏依赖隔离:API 模块一旦修改,所有依赖它的服务都会受影响,不符合 “开闭原则”。
-
难以排查问题:如果 API 里的 Bean 出了问题,你不知道是哪个服务创建的,也不知道配置是哪个服务注入的。
-
违背微服务 “自治” 原则:每个服务应该对自己的依赖和 Bean 完全可控,而不是被公共依赖 “偷偷” 注入 Bean。
FallBack
Fallback = 服务挂了时的 “备胎方案”
我给你讲微服务大白话,一听就懂👇
1. 什么场景会用到?
你现在写的是 微服务调用:
-
A 服务 → 调用 → B 服务
-
比如:学习服务 → 调用 → 点赞服务
但万一:
-
B 服务宕机了
-
网络断了
-
B 服务超时卡死
-
被限流、被熔断
那 A 服务会怎样?
直接报错、全线崩溃、用户页面 500!
2. Fallback 是干嘛的?
Fallback = 出故障时的 “保底方案”
一句话:
调用失败 → 不报错 → 直接返回一个默认值
让系统不死、不崩、用户无感知。
3. 你现在写的这个 RemarkClientFallback 作用是什么?
@Override
public Set<Long> isBizLiked(List<Long> bizIds) {
return Collections.emptySet(); // 👈 这就是备胎
}
意思是:
点赞服务挂了 → 查不到点赞记录 → 直接返回空集合
-
不抛异常
-
不卡死
-
不影响主流程
-
页面还能正常显示
4. 超级形象比喻
你(服务 A)打电话给朋友(服务 B)
朋友不接、关机、欠费
没有 fallback:
你直接崩溃、原地爆炸、程序报错
有 fallback:
你不慌不忙,自己给自己一个默认答案→ 继续正常运行
5. 微服务里的专业叫法(你必须懂)
-
Fallback = 降级
-
FallbackFactory = 带异常日志的降级
-
作用 = 服务雪崩防护
-
目的 = 一个服务挂了,不拖死整个系统
6. 最终总结(最关键)
**Fallback 不是业务逻辑!
它是微服务的 “安全兜底、保险丝、备胎、救命方案”!**
你只需要记住 3 句:
-
正常情况 → 不用 Fallback
-
远程调用失败 → 自动走 Fallback
-
作用 → 系统不崩、返回默认值、继续运行
实现点赞数变更的消息监听器
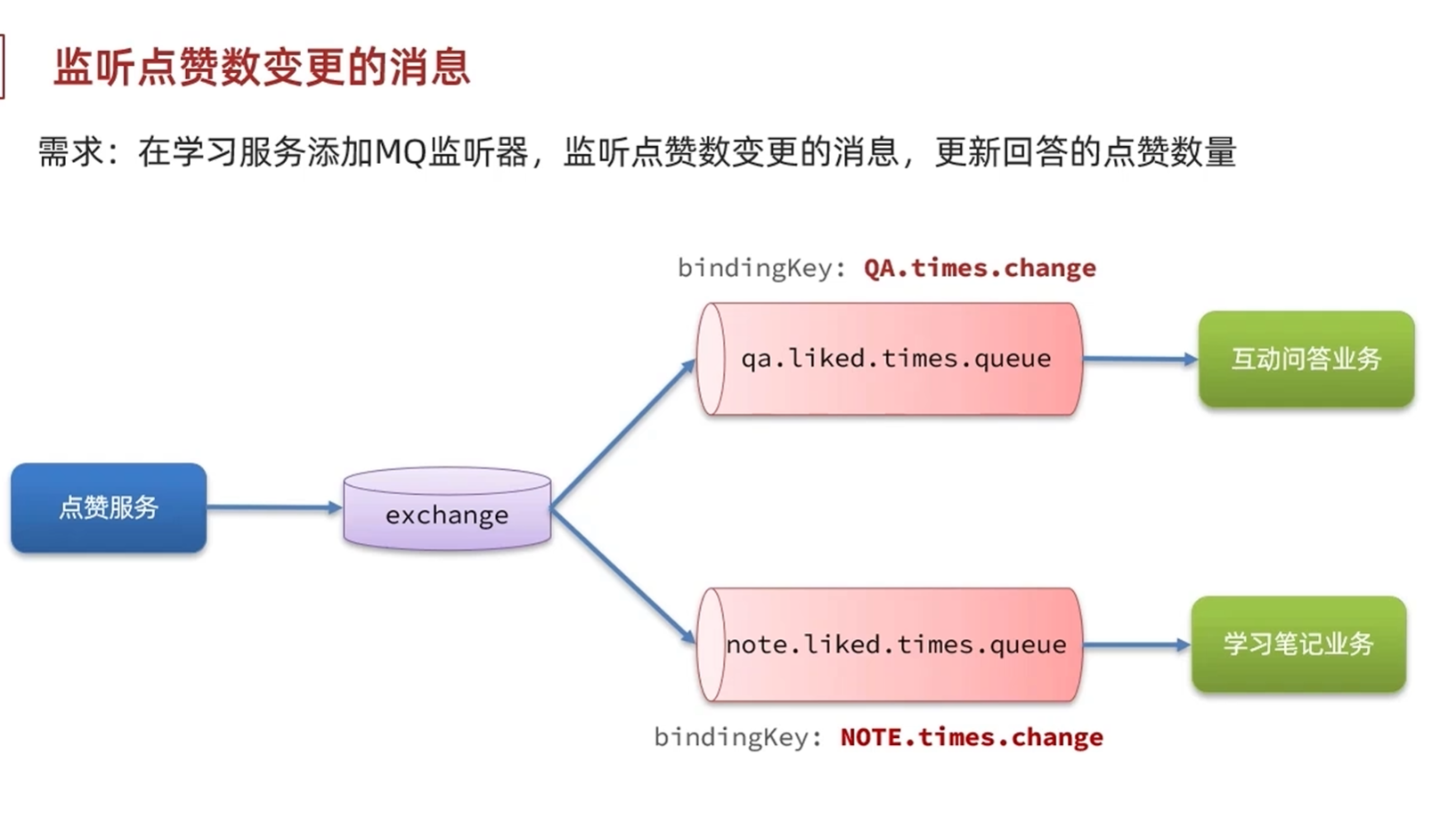

这里使用了StringUtils提供的format拼接方法,把bizType和routingKey拼接起来,形成了动态routingkey
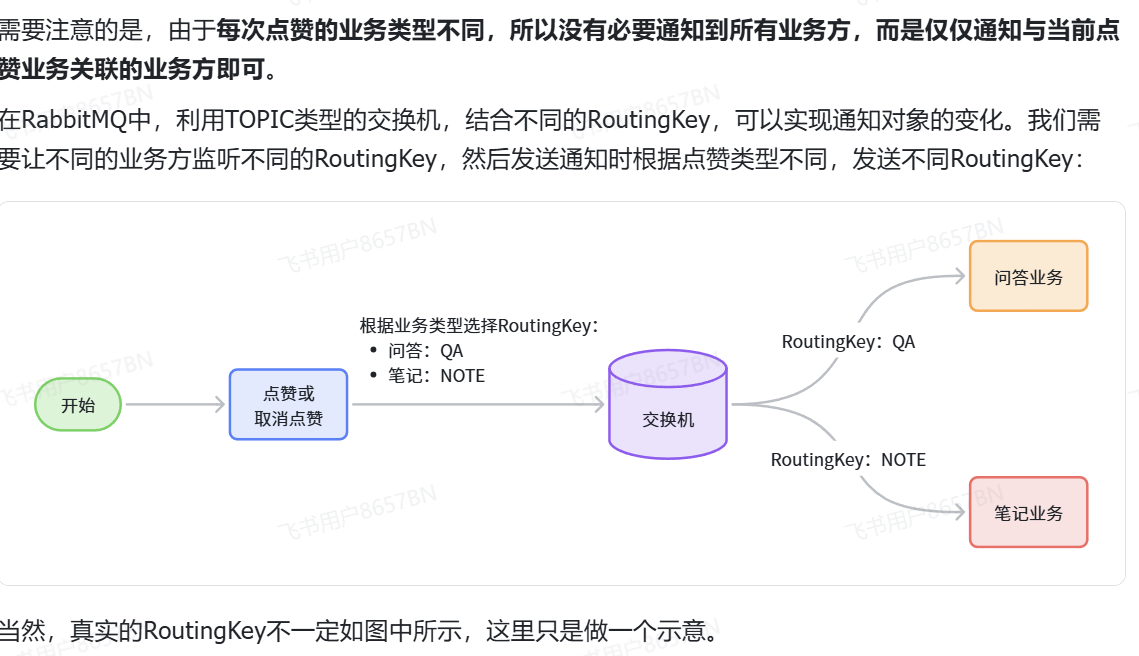
使用的交换机相同但是使用的routingKey不同,因为每次通知的时候不需要通知到所有业务方
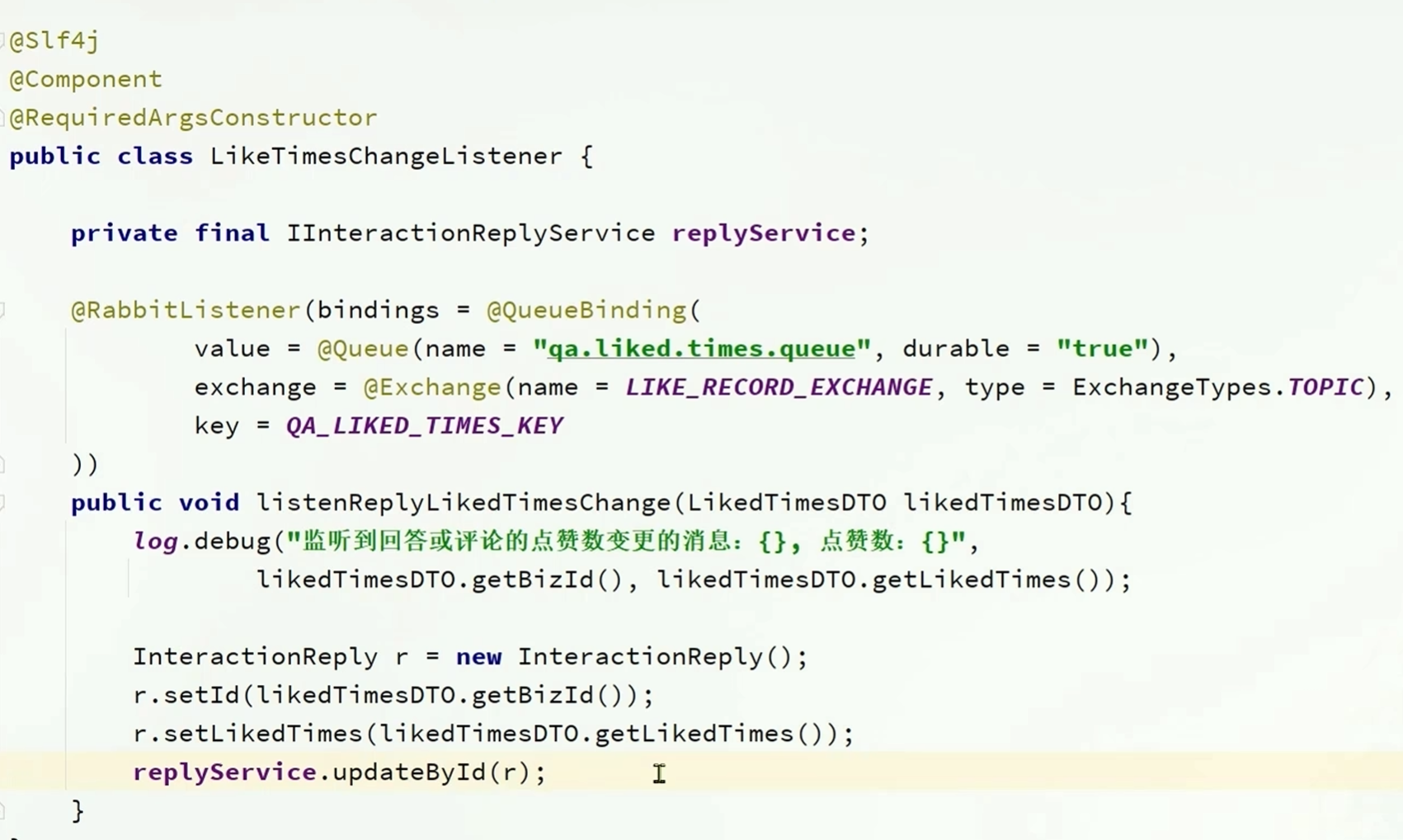
@Slf4j
@Component
@RequiredArgsConstructor
public class LikeTimesChangeListener {
private final ILearningLessonService iLearningLessonService;
private final IInteractionReplyService iInteractionReplyService;
//创建对应的listen方法,并配置bindings
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name ="qa.liked.times.queue" ,durable = "true"),
exchange = @Exchange(name =LIKE_RECORD_EXCHANGE ,type = ExchangeTypes.TOPIC),
key =QA_LIKED_TIMES_KEY
))
public void listenLikeTimesChangeListener(LikedTimesDTO likedTimesDTO) {
//接收到监听到的类之后
log.info("接收到的参数为{}{}", likedTimesDTO.getBizId(), likedTimesDTO.getBizId());
InteractionReply r = new InteractionReply();
r.setLikedTimes(likedTimesDTO.getLikedTimes());
r.setId(likedTimesDTO.getBizId());
iInteractionReplyService.updateById(r);
}DAY07--积分系统
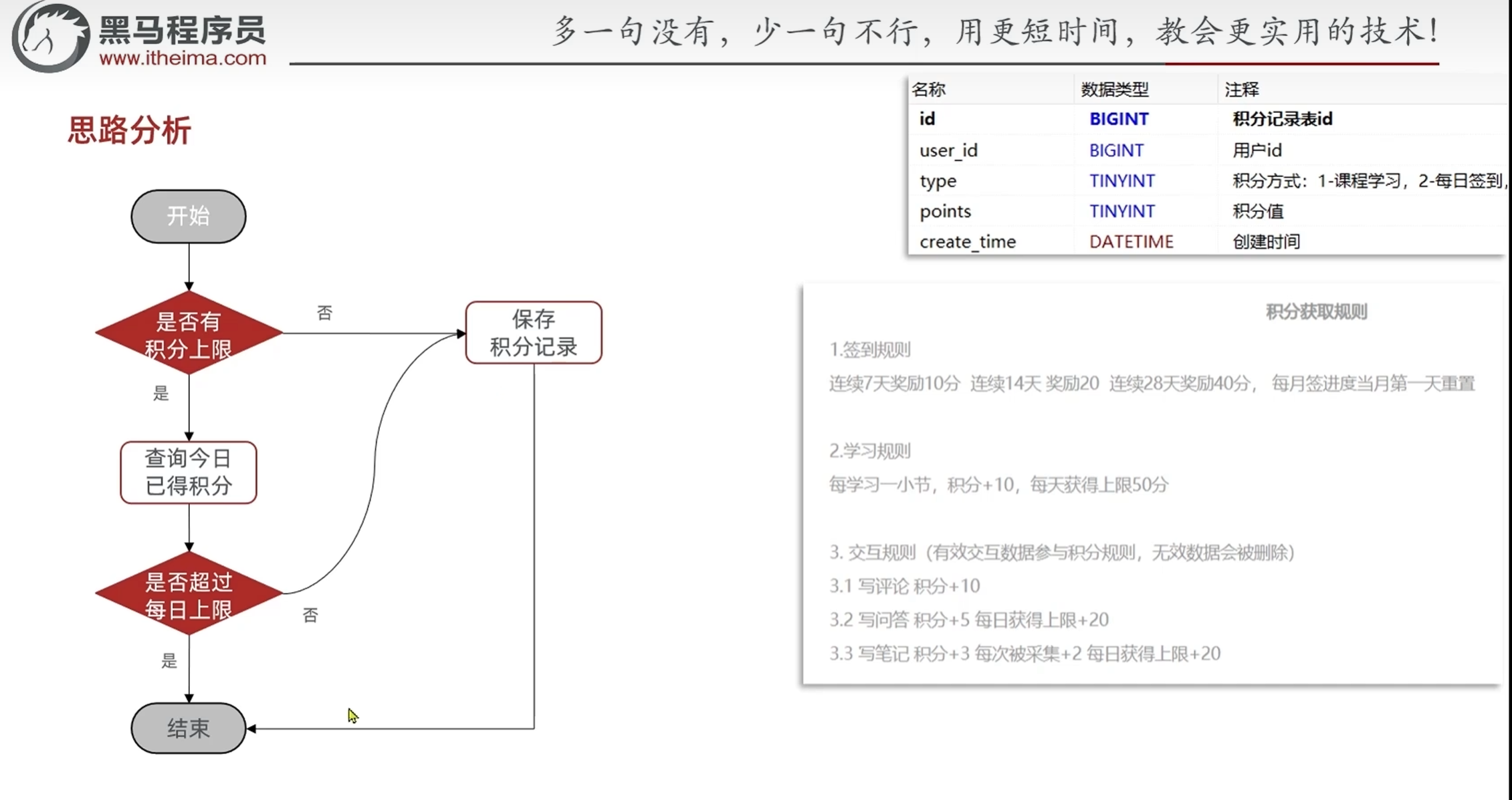
分析产品原型
-分析业务并统计接口
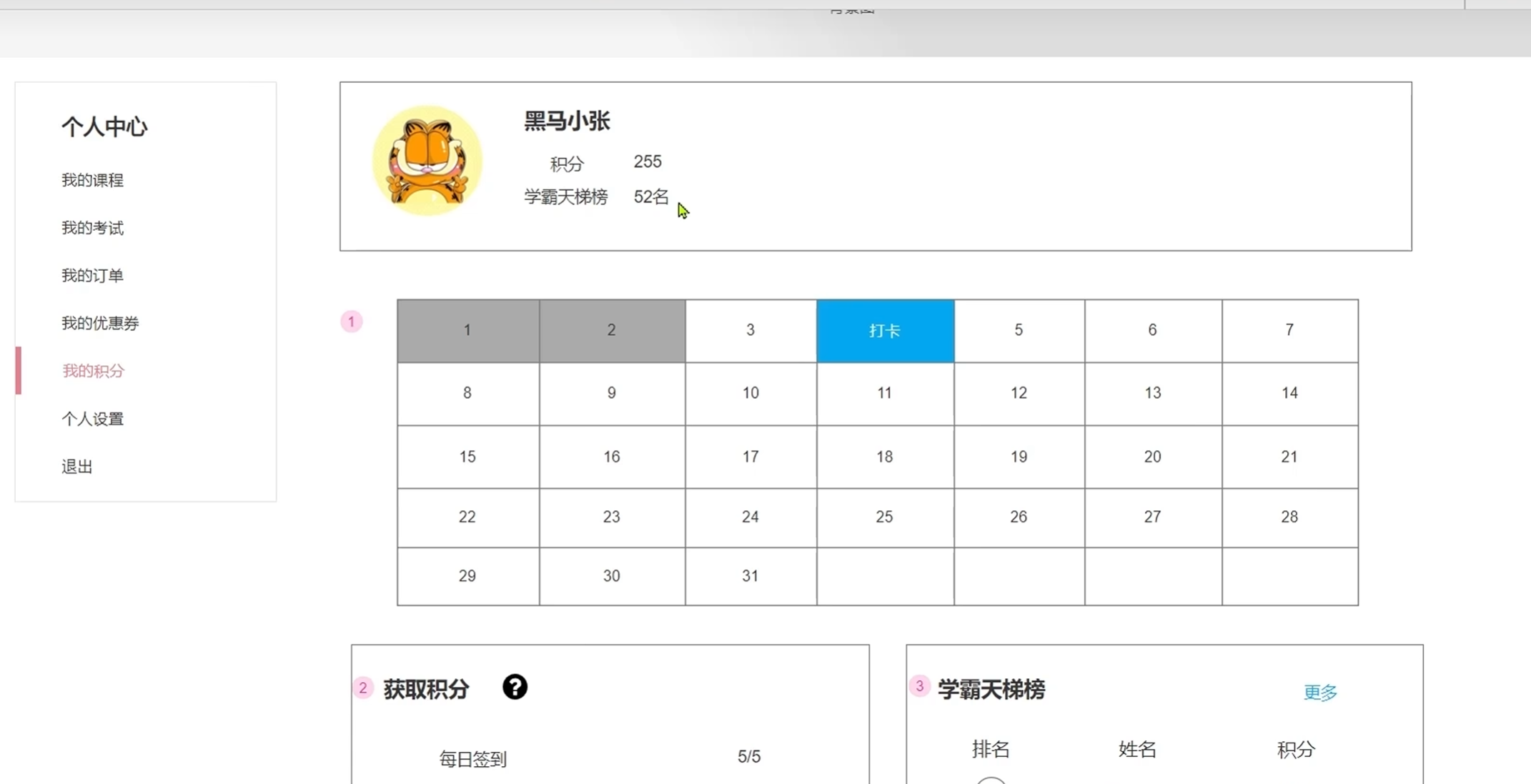
个人中心进入我的积分界面之后,
顶部会显示当前用户的id,头像,积分和在学霸天体榜中的排名
1.根据当前用户id返回数据
页面底部有一个完整的榜单,上面有本月的姓名和积分(按照积分倒序排列)
2.获取本月的榜单
点击更多
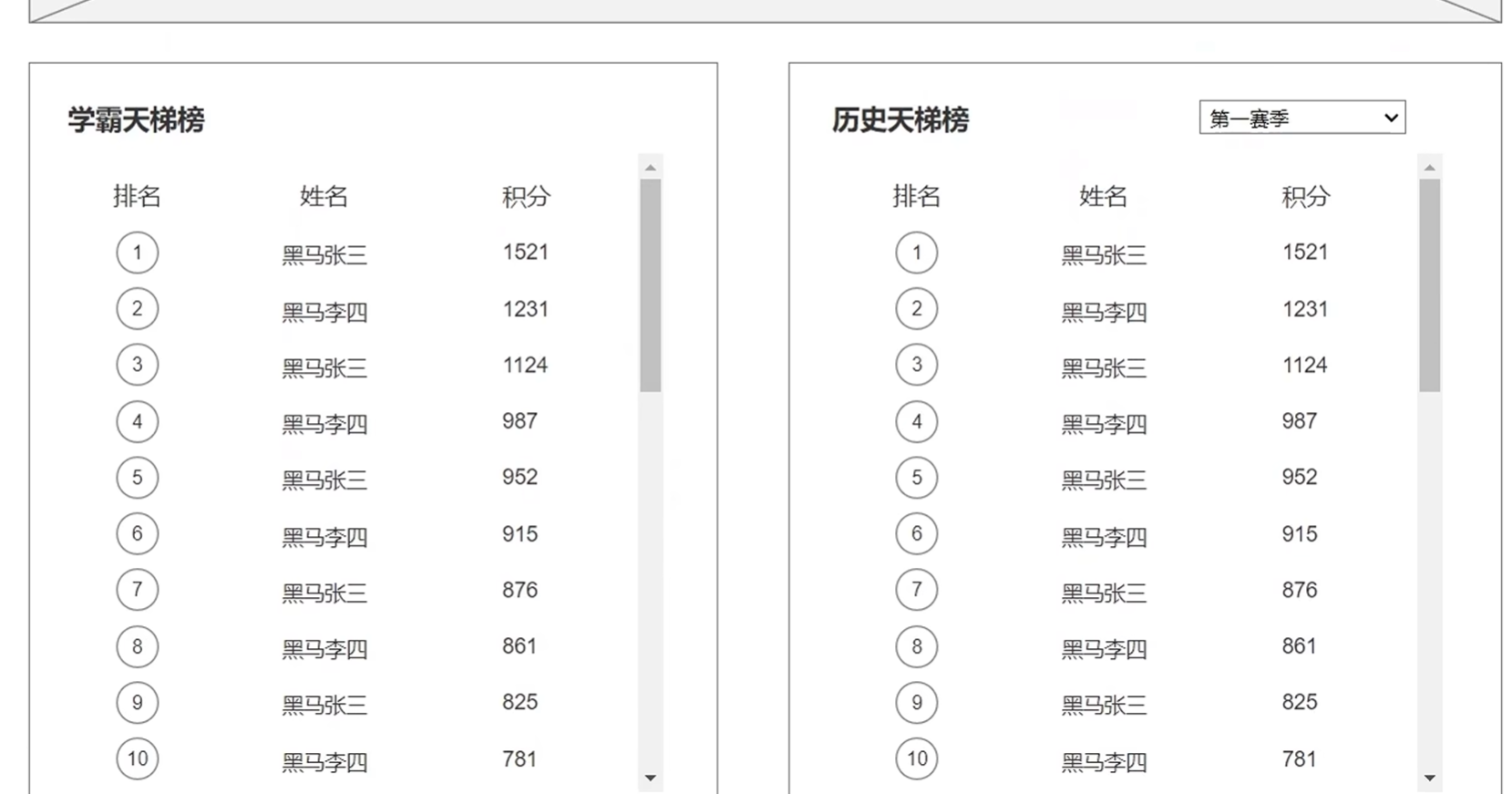
会显示当前赛季和选中的某一个赛季的历史天体榜单
3.根据时间查询历史榜单
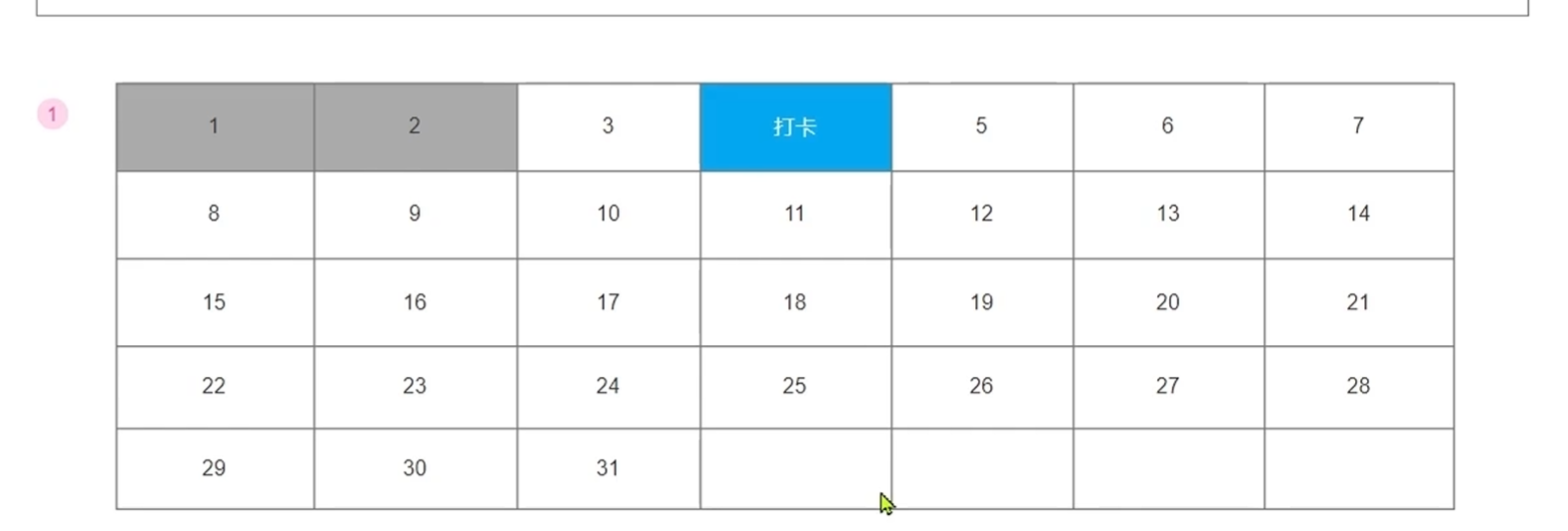
页面正中央有一个签到的日历,签到获取积分
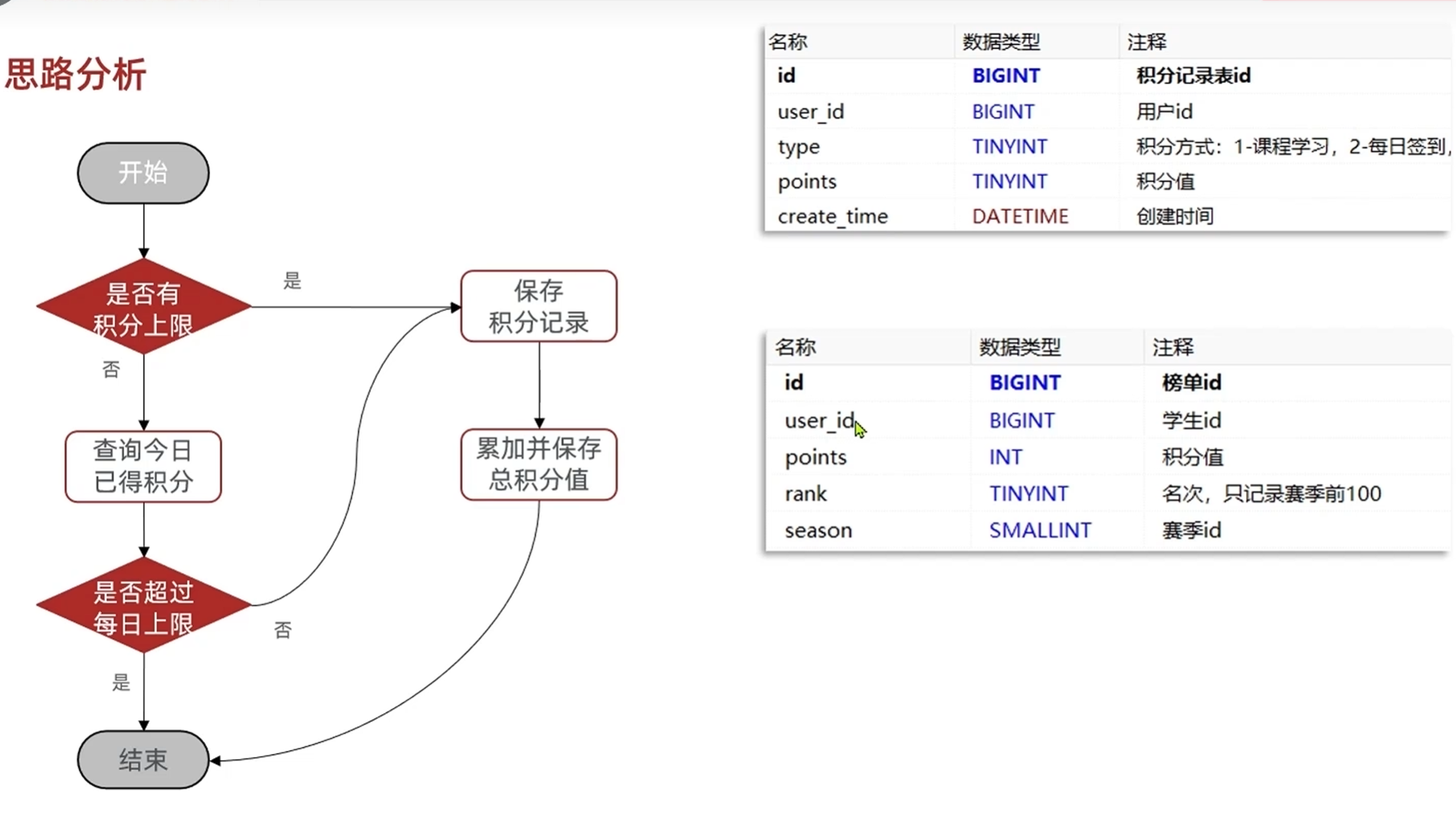
4.打卡接口,记录打卡信息,之后根据打卡信息判断积分
5.获取历史打卡信息,打卡的和未打卡的区别开
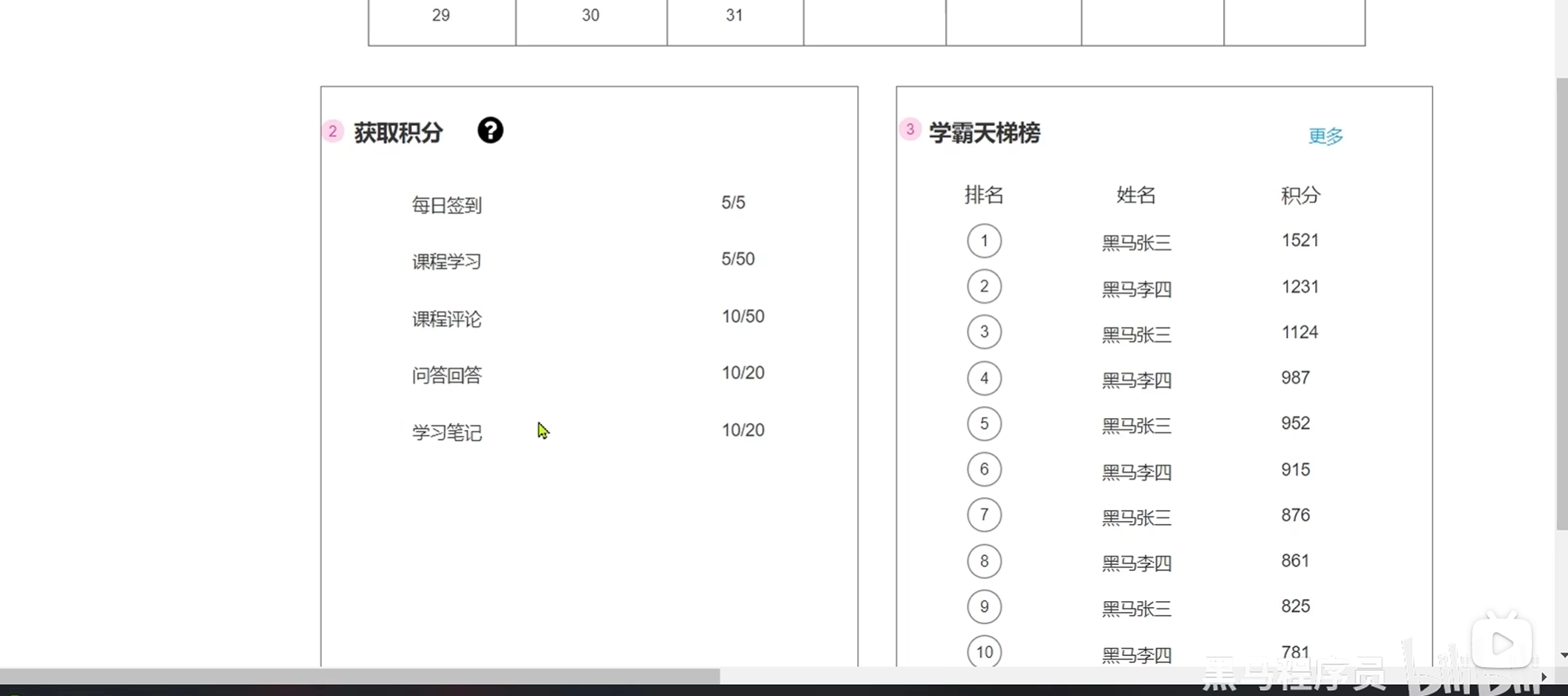
底部左侧会显示获取积分的途径以及完成情况
不同的方式获取积分有不同的上限
每次添加积分的时候都要判断是否达到上限
这就要求我们把每次获取积分的方式(看当前方式的积分有没有达到上限),时间(在本月内),分数(添加之后是否达到上限),次数(返回给前端)都记下来
6.保存用户积分记录
7.查看当前积分情况
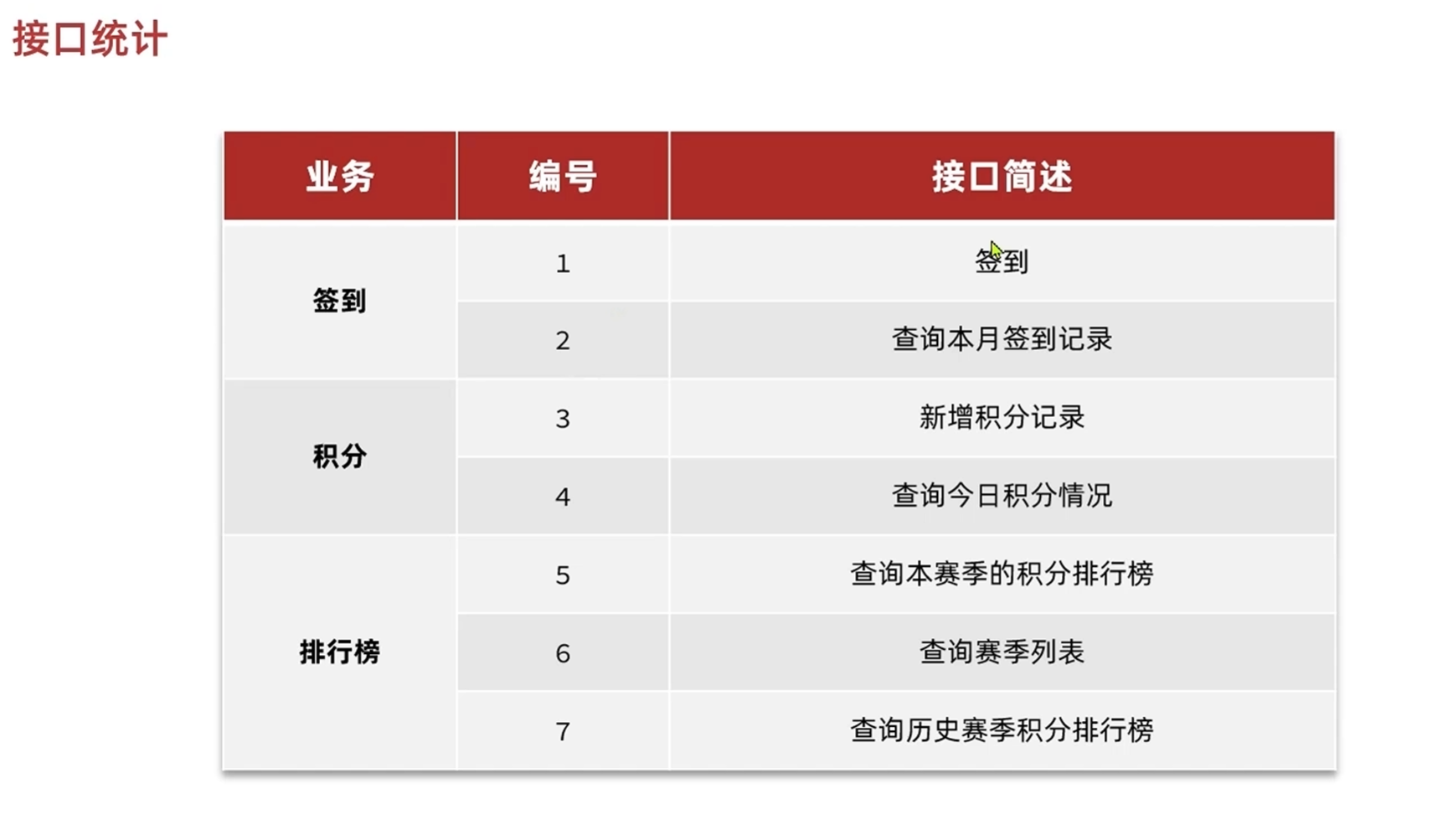
-数据库结构设计和代码生成
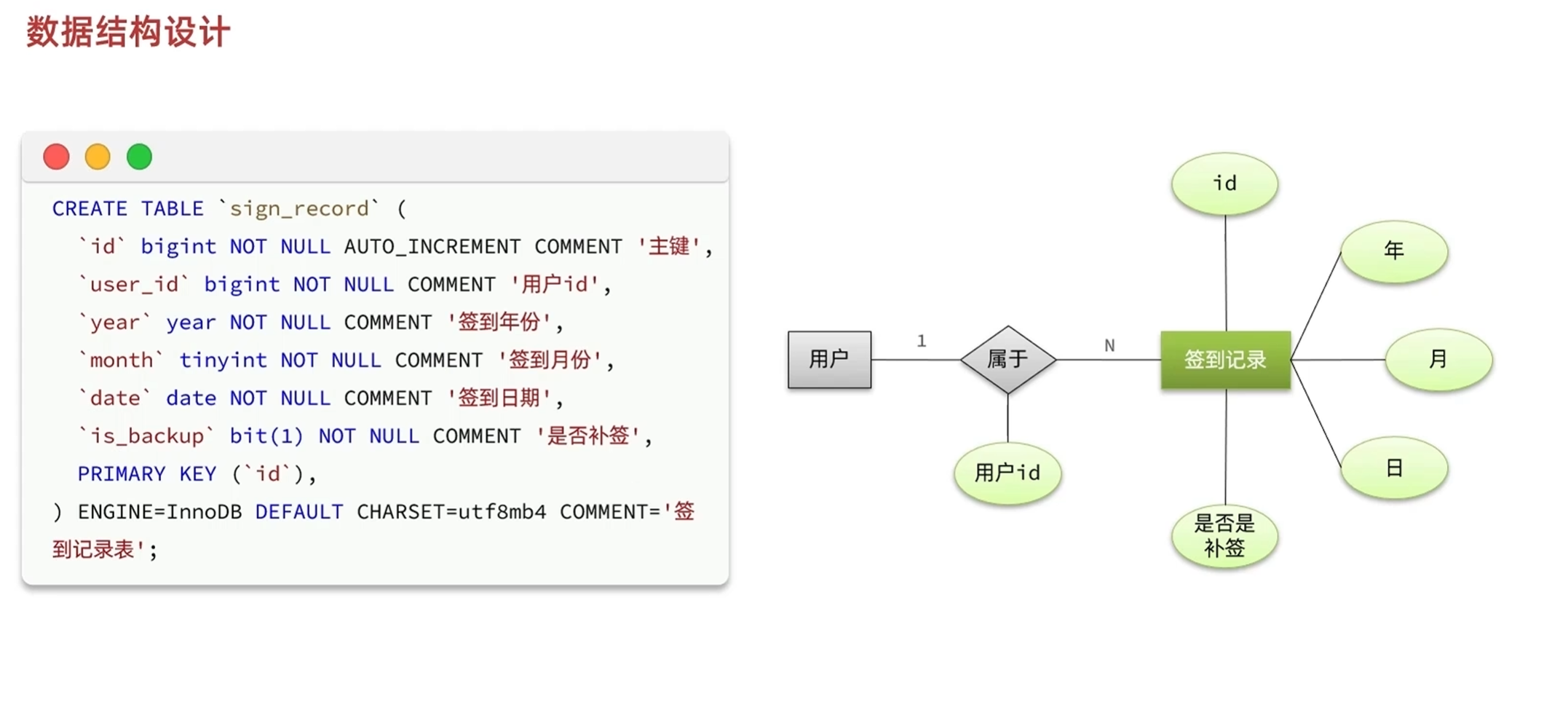
签到记录用年月日三个字段分别储存,这样便于查找在特定范围内的签到记录
签到功能
-签到思路分析

一个平台的用户如果有一千万,每个人平均每年签到十次都会有一亿次的签到记录,对数据库的压力会很大,
每条数据占用22个字节,二十二亿字节对于数据库来说也是很庞大的
可以用一个字段记录一年的签到情况
用户签到要么签到了要么没签到,就相当于0或者1


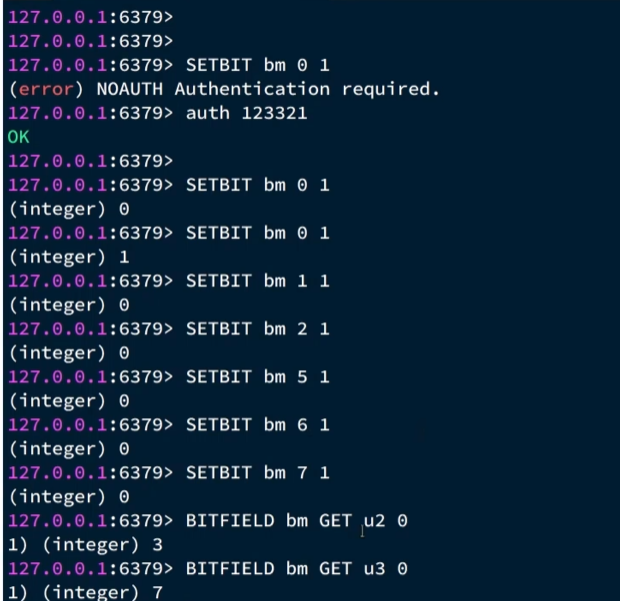
BITFIELD bm GET u2 0 前一个是偏移量,第二个是从哪一位开始
实现记录签到的信息


前端给后端传递参数的时候,后端自己能获取的参数前端就不要传递,为了安全考虑
细节上的信息:用户每天只能签到一次
SignResultVO

把总积分分成了两个字段:基本的签到得分和连续签到七天以上的奖励分数
redis的key设计
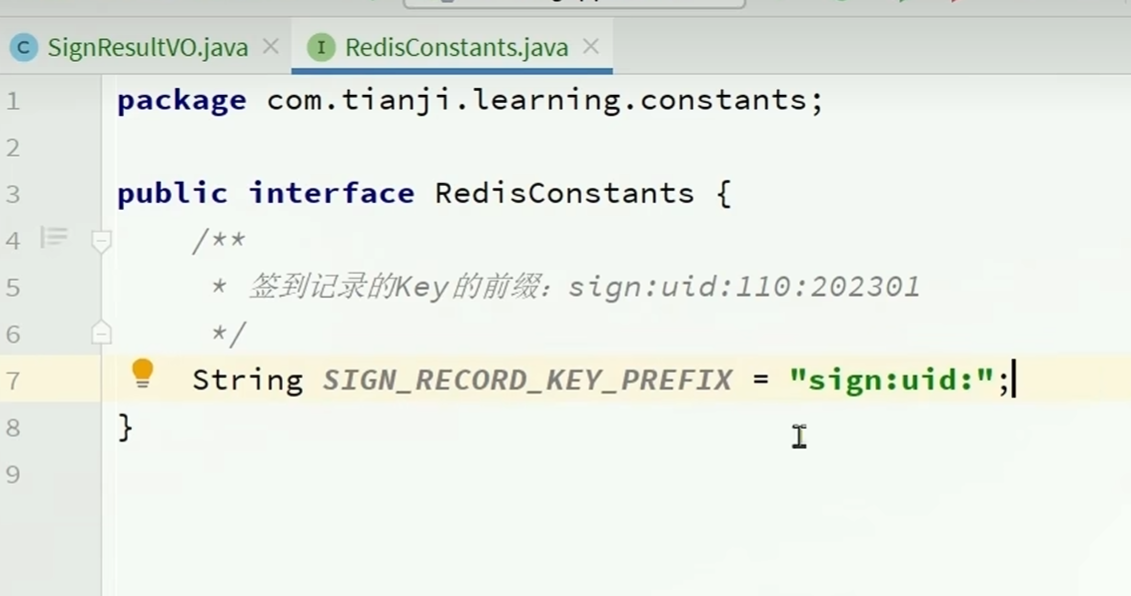
redis里面的key就像mysql里面的id一样,唯一固定一条数据,
key固定部分是sign:uid: 拼接上后面的动态部分用户id和当前年月
就表示是签到表的某一用户的某月的签到记录
业务逻辑

签到得分也是积分得分的一部分,都要存储在记分表里面

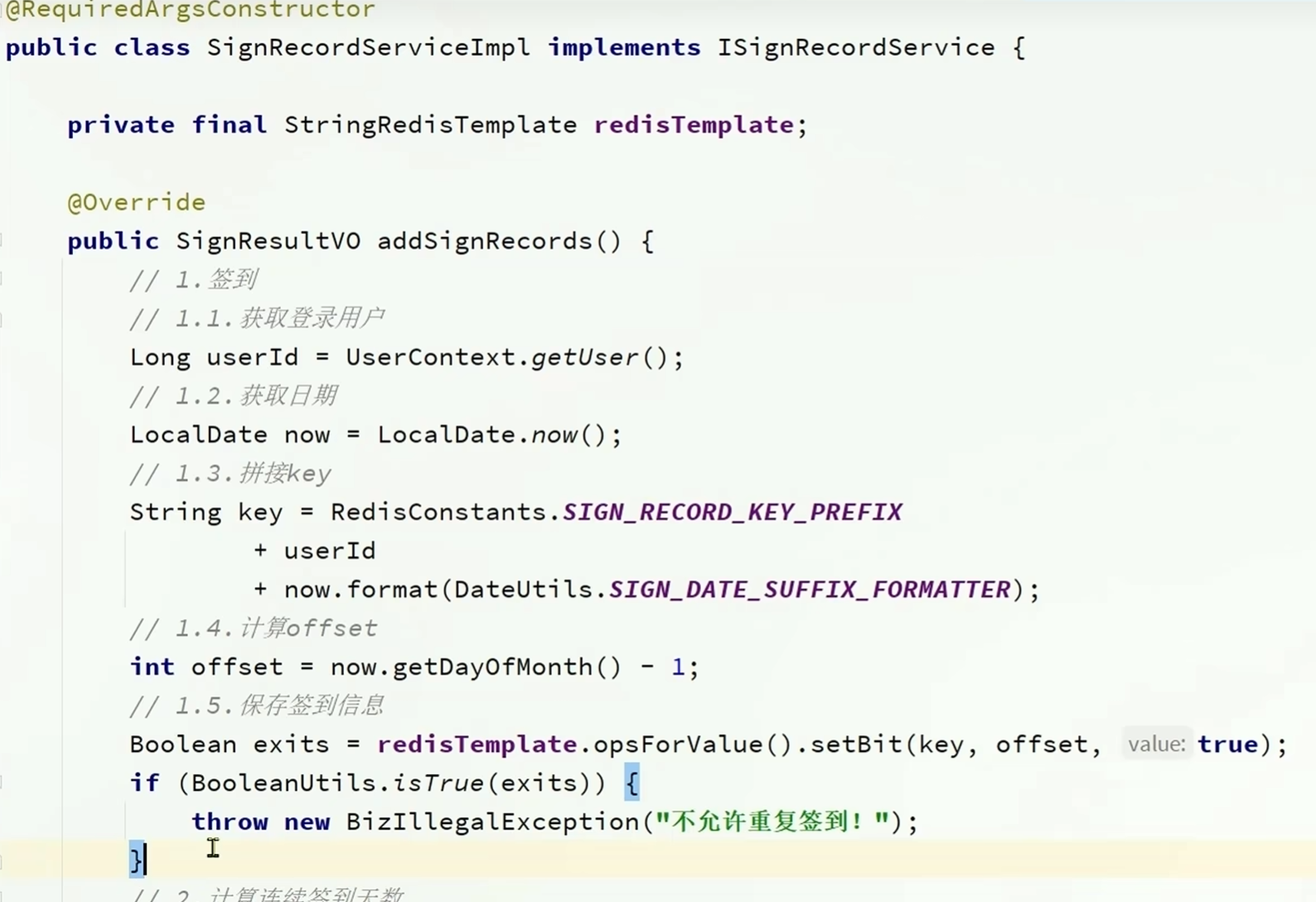
签到
签到的本质向redis里面存储一条数据,包括key,offset和值,表示某个用户在某年某月某天签到
key表示某个用户在某年的某月签到,包括常量,用户的id和当前的年月
offset表示在该月的某天签到,是当前日期的天数-1
value表示签到,为true
再把这些信息拼接,处理好传递进redistemplate里面之后就相当于存储了一条签到记录,也就是完成了签到这个动作
判断是否为重复签到
根据redistemplate返回的数据来看
redis会返回原有的数字,也就是说如果是重复签到的话会返回true,不是重复签到的话会返回false
连续签到天数统计

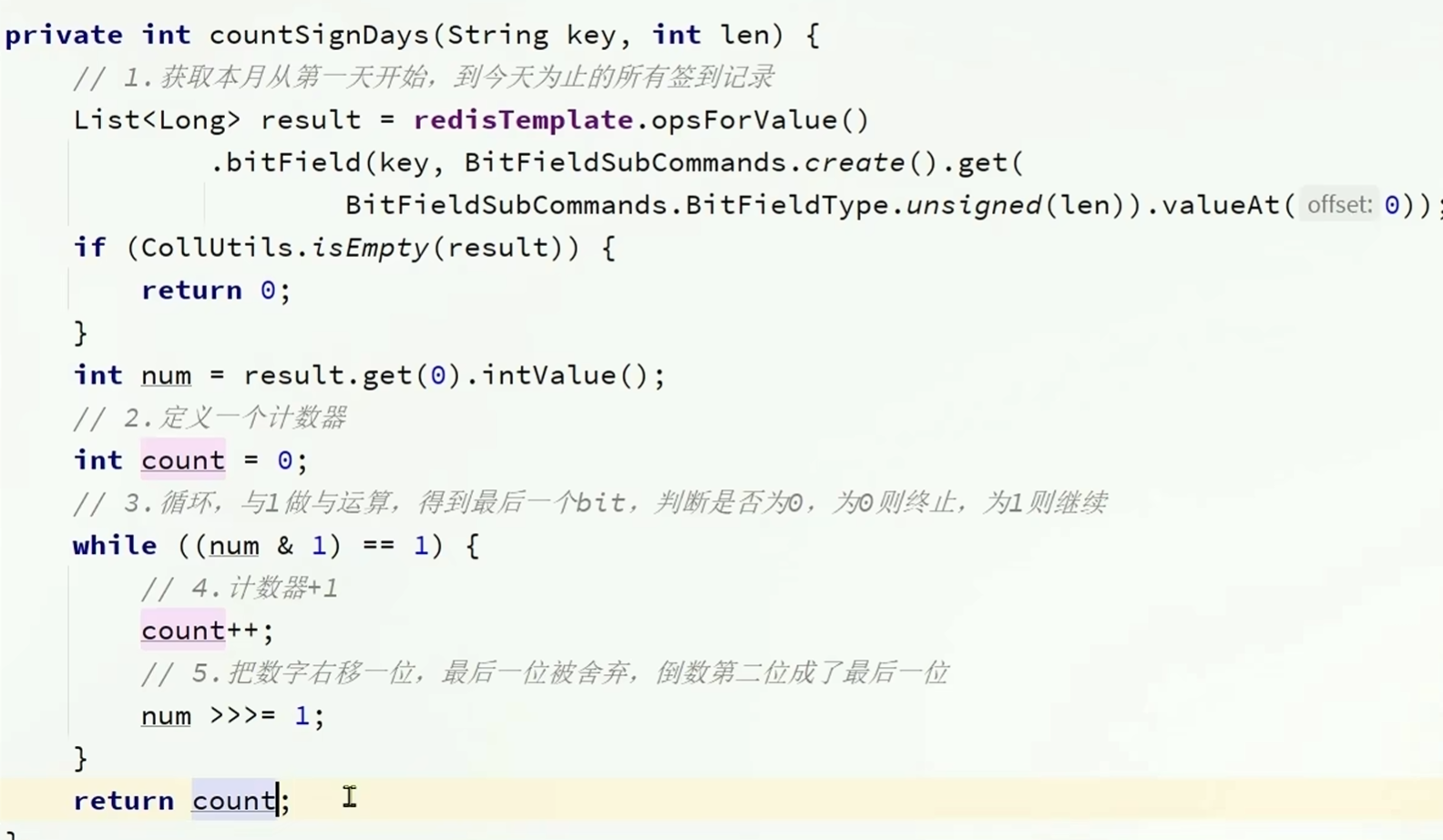
查询签到记录的思路分析
REDIS
一、微服务里 Redis 核心地位
微服务必用 Redis 做:
-
缓存热点数据
-
分布式锁(多服务并发抢资源)
-
分布式全局会话 / 登录用户缓存
-
接口限流、防重
-
计数器、点赞 / 浏览量
-
黑名单、白名单
-
延迟队列简单实现
二、SpringBoot 微服务标配依赖(直接拷 pom)
<!-- Redis 启动器 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
三、配置 yml(微服务统一配)
spring:
redis:
host: 192.168.150.101
port: 6379
password: 123456
database: 0
lettuce:
pool:
max-active: 8
max-idle: 8
min-idle: 2
四、IDEA 微服务必用模板:注入 RedisTemplate
1. 直接注入(所有微服务通用)
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Autowired
private StringRedisTemplate stringRedisTemplate;
-
StringRedisTemplate:只存字符串,日常配置、验证码、key 缓存最常用
-
RedisTemplate:可存对象、序列化实体类
2. 微服务标准序列化配置(直接建配置类)
解决乱码、序列化问题,微服务统一用这个:
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(factory);
// key 字符串序列化
StringRedisSerializer keySerializer = new StringRedisSerializer();
// value JSON 序列化
GenericJackson2JsonRedisSerializer valSerializer = new GenericJackson2JsonRedisSerializer();
template.setKeySerializer(keySerializer);
template.setHashKeySerializer(keySerializer);
template.setValueSerializer(valSerializer);
template.setHashValueSerializer(valSerializer);
return template;
}
}
五、微服务高频常用 API(开发天天写)
1. 普通存取值
// 存
stringRedisTemplate.opsForValue().set("login:user:24018", "admin");
// 取
String val = stringRedisTemplate.opsForValue().get("login:user:24018");
// 设过期时间(秒)
stringRedisTemplate.opsForValue().set("code:123456", "888888", 300, TimeUnit.SECONDS);
2. Hash 存对象(微服务存用户、配置)
// 存单个字段
stringRedisTemplate.opsForHash().put("user:info:1001", "nickName", "张三");
// 取单个字段
String name = (String) stringRedisTemplate.opsForHash().get("user:info:1001", "nickName");
3. 自增计数器(点赞、浏览量)
// +1
Long count = stringRedisTemplate.opsForValue().increment("biz:like:110");
4. 删除 key
stringRedisTemplate.delete("biz:like:110");
5. 判断 key 是否存在
boolean hasKey = Boolean.TRUE.equals(stringRedisTemplate.hasKey("code:123456"));
六、微服务最关键:Redis 分布式锁(必背必用)
微服务多实例部署,防止重复操作(重复点赞、重复下单)
简易加锁 / 释放锁
// 加锁 setNx:不存在才设置,过期防死锁
Boolean lock = stringRedisTemplate.opsForValue()
.setIfAbsent("lock:like:110", "locked", 10, TimeUnit.SECONDS);
if (Boolean.TRUE.equals(lock)) {
try {
// 执行业务
} finally {
// 释放锁
stringRedisTemplate.delete("lock:like:110");
}
}
七、微服务里 Redis 规范(项目统一遵守)
-
key 统一分层命名
业务:模块:标识:id例:-
login:token:userId -
biz:like:article:110 -
limit:ip:192.168.x.x
-
-
所有缓存必须设过期时间,避免 Redis 爆内存
-
用户 ID 后端从上下文拿,拼到 Redis key 里,不让前端传
-
热点数据、接口查询优先查 Redis,再查 MySQL
八、IDEA 开发小技巧
-
装 Redis Viewer 插件,IDEA 内直接看 Redis 数据,不用切虚拟机
-
常用 Redis 操作封装成 RedisUtil 工具类,全局复用
-
微服务统一把 RedisConfig 放到 common 公共模块,所有服务依赖直接复用
序列化和反序列化的原因
Redis 底层只存「字节数组 byte []」,只能存二进制,不能直接存 Java 对象所以:Java 对象 → 序列化 → 字节数组 → 存进 Redis取出来:字节数组 → 反序列化 → Java 对象
1. 为什么必须序列化?
① Redis 根本不认识 Java 对象
Redis 是独立中间件,跟 Java 没关系它只接受:字符串、字节流你直接传一个 User、LikedRecord 对象给 Redis,它看不懂,存不了。
② 网络传输只能传二进制
微服务之间、程序和 Redis 之间走网络网络只能传字节流复杂对象必须转成字节才能发出去。
③ 把对象变成可存储的格式
序列化就是:把 Java 复杂对象 → 转成 JSON / 二进制字节存到 Redis 字符串 / Hash 里。
2. 序列化常见两种方式
1)JDK 原生序列化
-
实现
Serializable -
缺点:乱码、可读性差、跨语言不能用
2)JSON 序列化(微服务标配)
把对象转 JSON 字符串存 Redis取出来再把 JSON 转回对象
-
可读性高
-
前端、Go、Python 都能读
-
微服务统一用这种
3. 不配置序列化会怎样?(你项目里必遇到)
如果不手动配置 RedisTemplate 序列化:
-
key 变成一堆乱码
\xAC\xED\x00\x05t\x00 -
value 乱码
-
看着难受,还没法手动在 Redis 客户端查数据
-
无法正常存对象、取对象
所以微服务都要手动配:key 用字符串序列化value 用 JSON 序列化
4. 序列化、反序列化完整流程
存数据:Java 对象 👉 JSON 序列化 👉 字符串 / 字节 👉 Redis 存储
取数据:Redis 读出字节 👉 JSON 反序列化 👉 还原成 Java 对象
5. 微服务里为什么格外强调序列化?
-
多服务共享 Redis,必须统一序列化格式(都用 JSON)
-
服务实例多、集群部署,对象要网络传输
-
方便运维直接看 Redis 里的 value,不是乱码
-
缓存对象、Hash 结构必须依赖序列化
序列化和反序列化生效的过程
一句话讲透:Redis 配置类里的序列化 Bean,到底怎么全程生效的
我给你从原理→配置→底层流程→实际作用,一口气讲明白,超好懂。
1. 先记住核心
你在 RedisConfig 里 **@Bean 注册了一个 RedisTemplate**并且手动指定了:
-
key 序列化器:
StringRedisSerializer -
value 序列化器:
GenericJackson2JsonRedisSerializer
一旦这个 Bean 放入 Spring 容器,之后你项目里所有:
@Autowired
private RedisTemplate<String,Object> redisTemplate;
都会直接用你配置好的序列化规则,全程自动帮你序列化、反序列化,不用你手动转 JSON。
2. 底层完整工作流程(关键)
存数据时
-
你代码:
redisTemplate.opsForValue().set("user:1001", userObj);
-
Spring 自动走你配置的序列化器
-
把
userObj自动序列化为 JSON 字节数组
-
-
发给 Redis 存起来
取数据时
-
你代码:
User u = (User) redisTemplate.opsForValue().get("user:1001");
-
Spring 自动用配置的反序列化器
-
从 Redis 读出 JSON 字节
-
自动转成 Java Bean 对象还给你
-
👉 全程你不用写任何 JSON 转换代码,配置类的 Bean 已经替你包办了。
3. 配置类里的代码到底在干嘛?
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(factory);
// 指定序列化规则
StringRedisSerializer keySer = new StringRedisSerializer();
GenericJackson2JsonRedisSerializer valSer = new GenericJackson2JsonRedisSerializer();
template.setKeySerializer(keySer);
template.setValueSerializer(valSer);
return template;
}
作用:
-
手动创建 RedisTemplate 实例
-
提前给它装上固定的序列化器
-
把这个定制好的模板交给 Spring 容器
以后项目中自动注入的 RedisTemplate 都是这一个带序列化配置的实例。
4. 如果不配置这个 Bean 会怎样?
Spring 会给你默认原生 RedisTemplate:
-
用 JDK 原生序列化
-
key、value 全是乱码
\xAC\xED... -
存对象无法阅读、跨服务无法解析
-
根本没法在微服务里用
所以必须自己 @Bean 覆盖默认的。
5. 用最直白的比喻
-
你写的 RedisConfig 里的 @Bean相当于给 RedisTemplate 提前装好翻译官
-
存对象时:翻译官自动把 Java 对象翻译成 JSON 字节
-
取数据时:翻译官自动把 JSON 字节翻译回 Java Bean
-
你业务代码只管存对象、取对象,不用管转换细节
实现积分功能
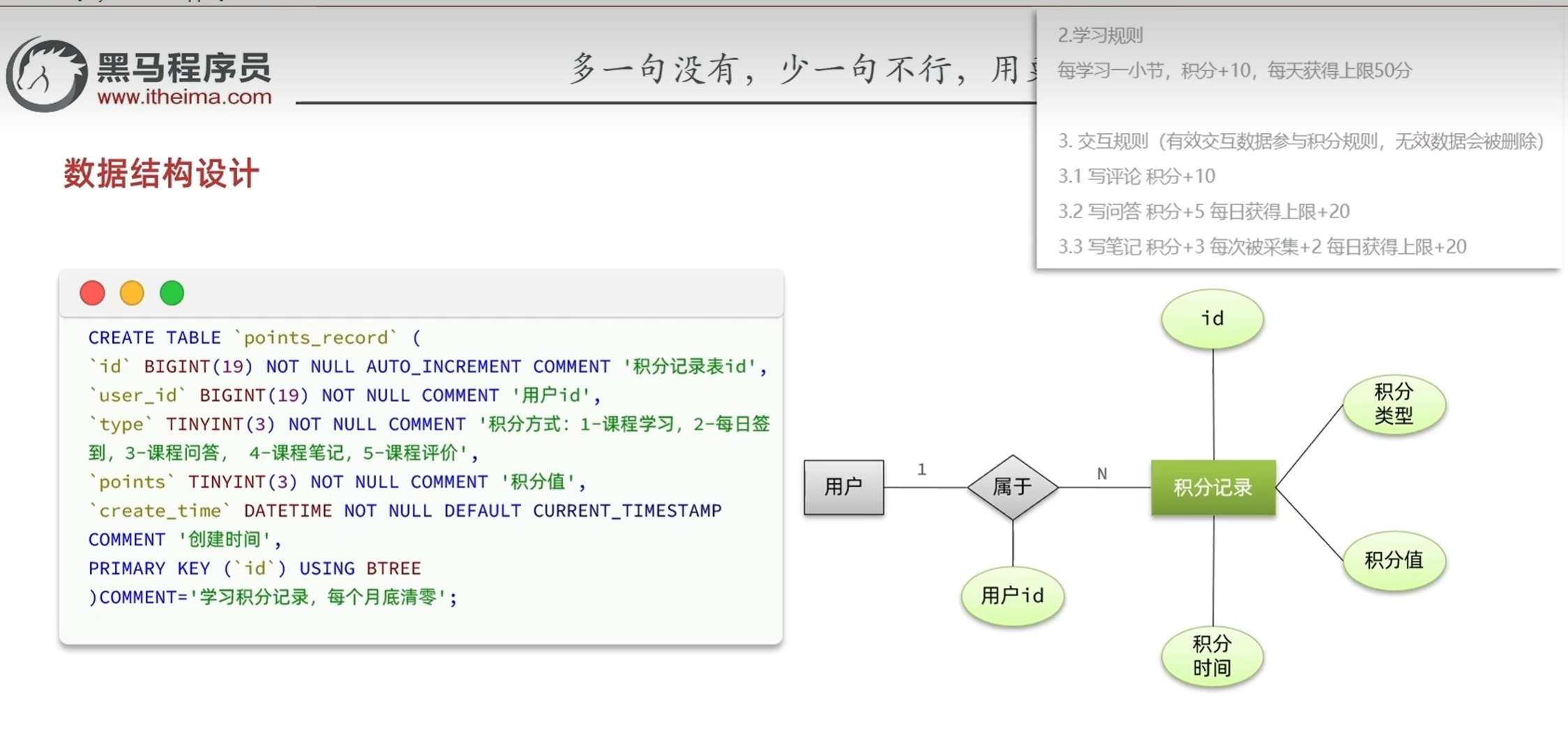
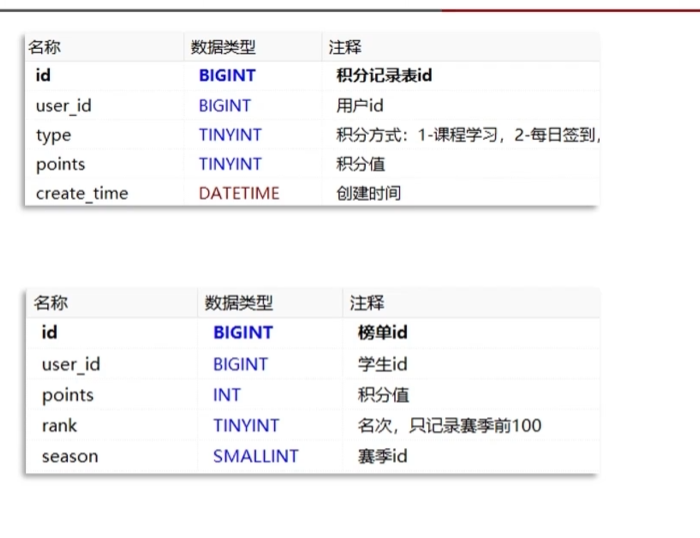
保存积分明细
积分表是当月有效,月底清零,而积分总表保存了从第一赛季以来所有的积分榜单信息
也就是积分明细表和积分总表是不同的表
 积分的获取方式有五种:
积分的获取方式有五种:
签到
观看学习视频
给课程写评论
写问答
写笔记,笔记被采集有额外得分
积分功能并不能作为独立的http请求暴露在外面,
因为如果是http请求的话,在每次观看完视频,签完到等情况下都要调用积分功能的请求,
一是万一积分功能出问题了,这些接口都得出问题(比如积分功能出问题了,参与回滚),
二是积分功能耗时比较长,同步调用会降低性能
这就是耦合度太高的弊端
要降低耦合度,就要确保一个服务里面只编写核心业务,对于这种附属业务就用mq(异步调用)来完成
编写mq的流程
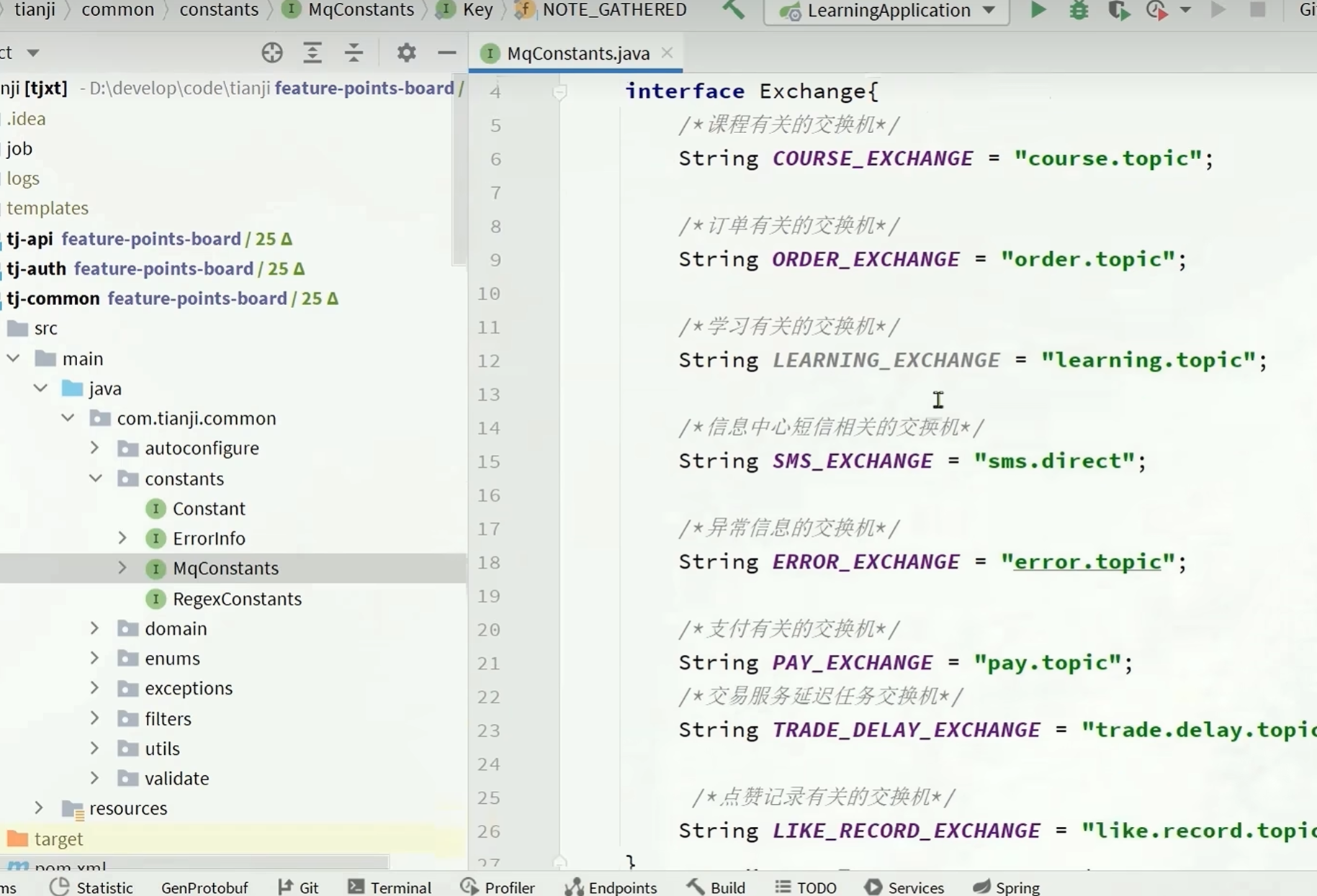
在MqConstants里面挑选合适的交换机,routingkey
确定要传递的参数
新增数据要传递什么参数往往取决于数据库里面需要什么参数
userId不一定是当前登录用户的id,
有一个特殊的地方:当当前用户采集他人的笔记时,被采集的用户要加积分
此时userId不为当前登录用户的id
编写listener
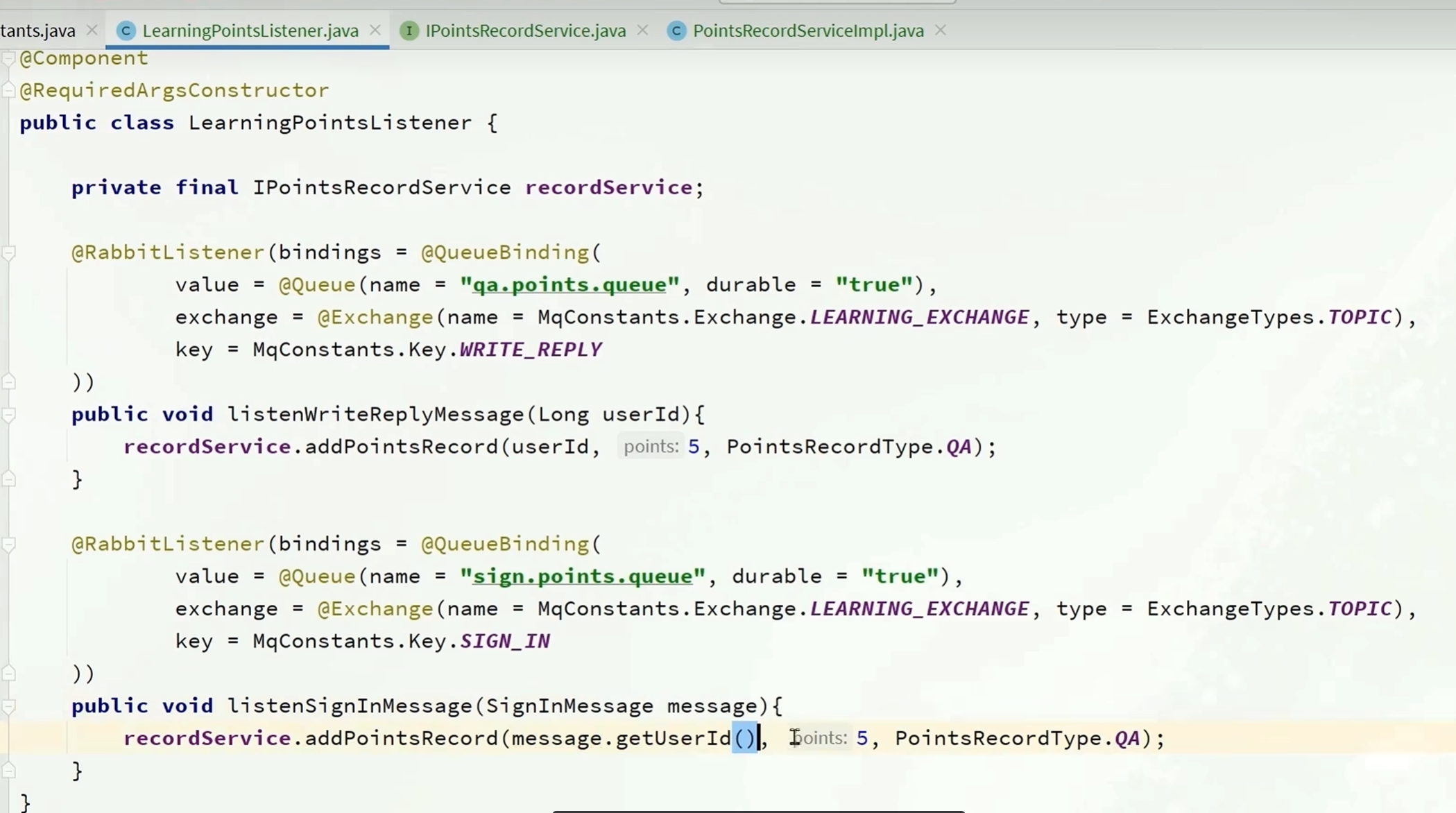
签到监听器和学习问答监听器不一样的点是:
学习问答监听器只需要传递用户id就行,积分是固定的
签到监听器的积分是动态的,需要签到接口返回给我们,所以用对象来接受
传递到记录积分明细表的信息有:用户id,积分数,积分类型
实现保存积分明细表的业务逻辑
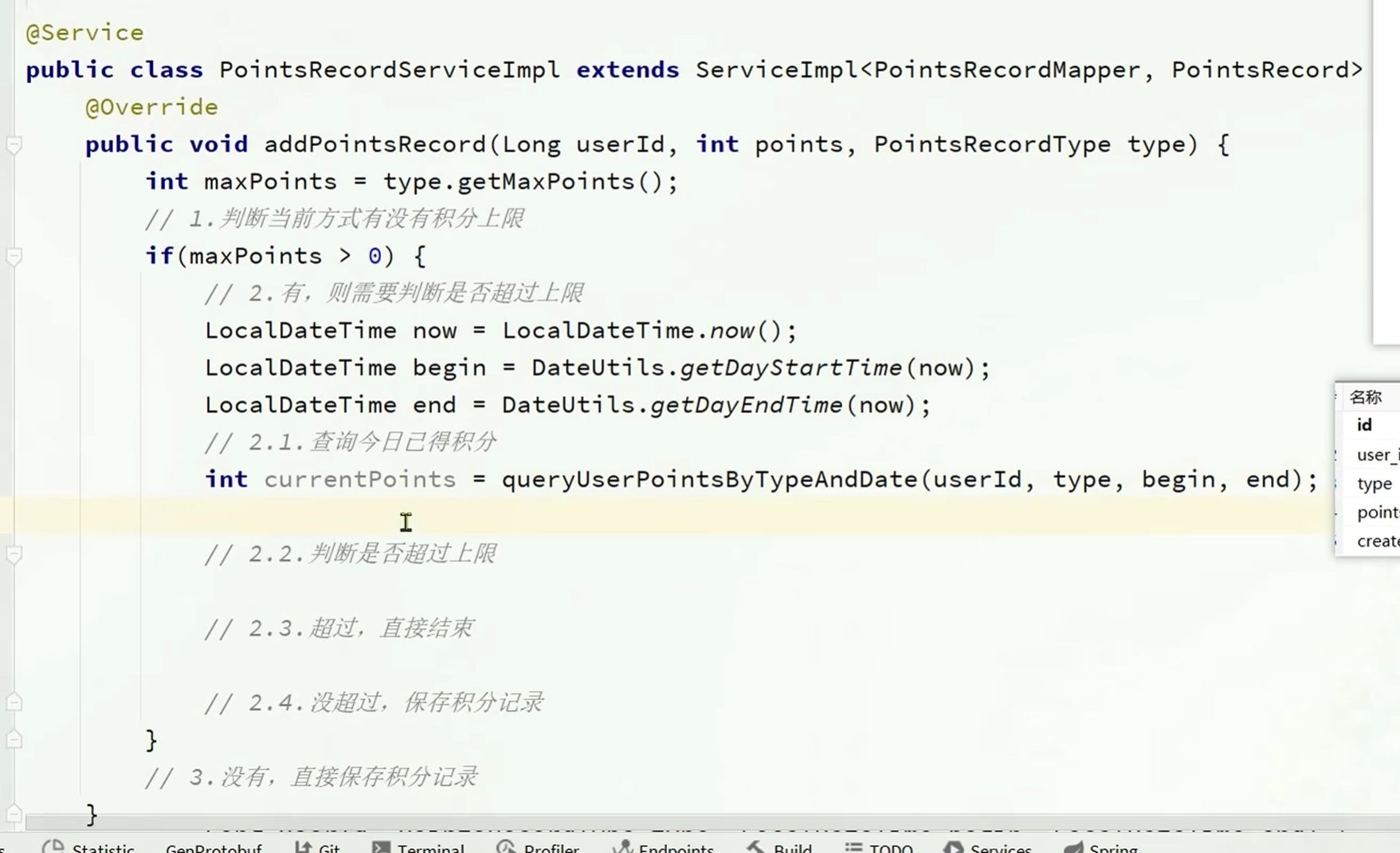
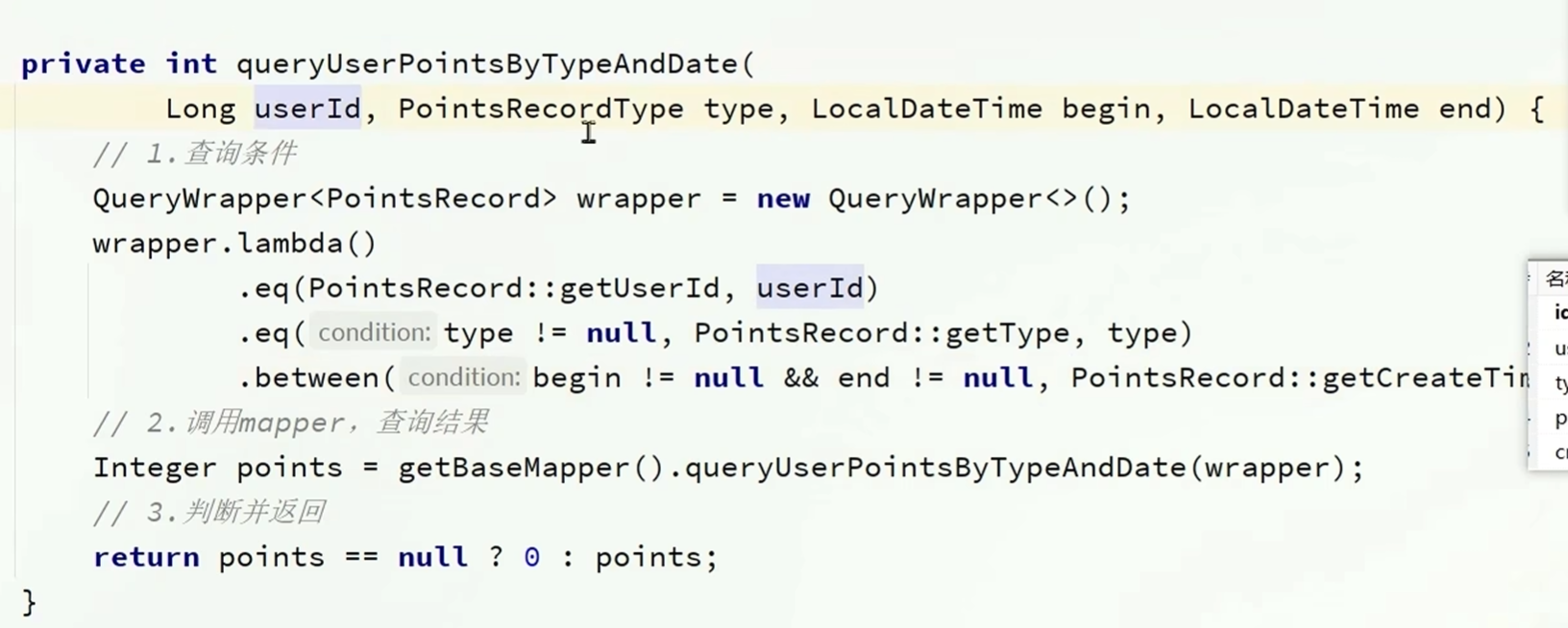
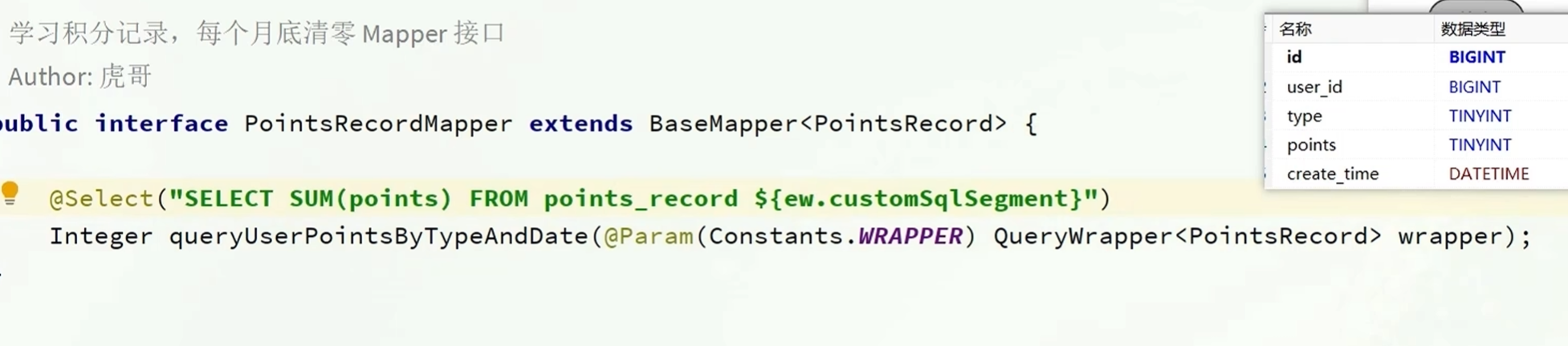
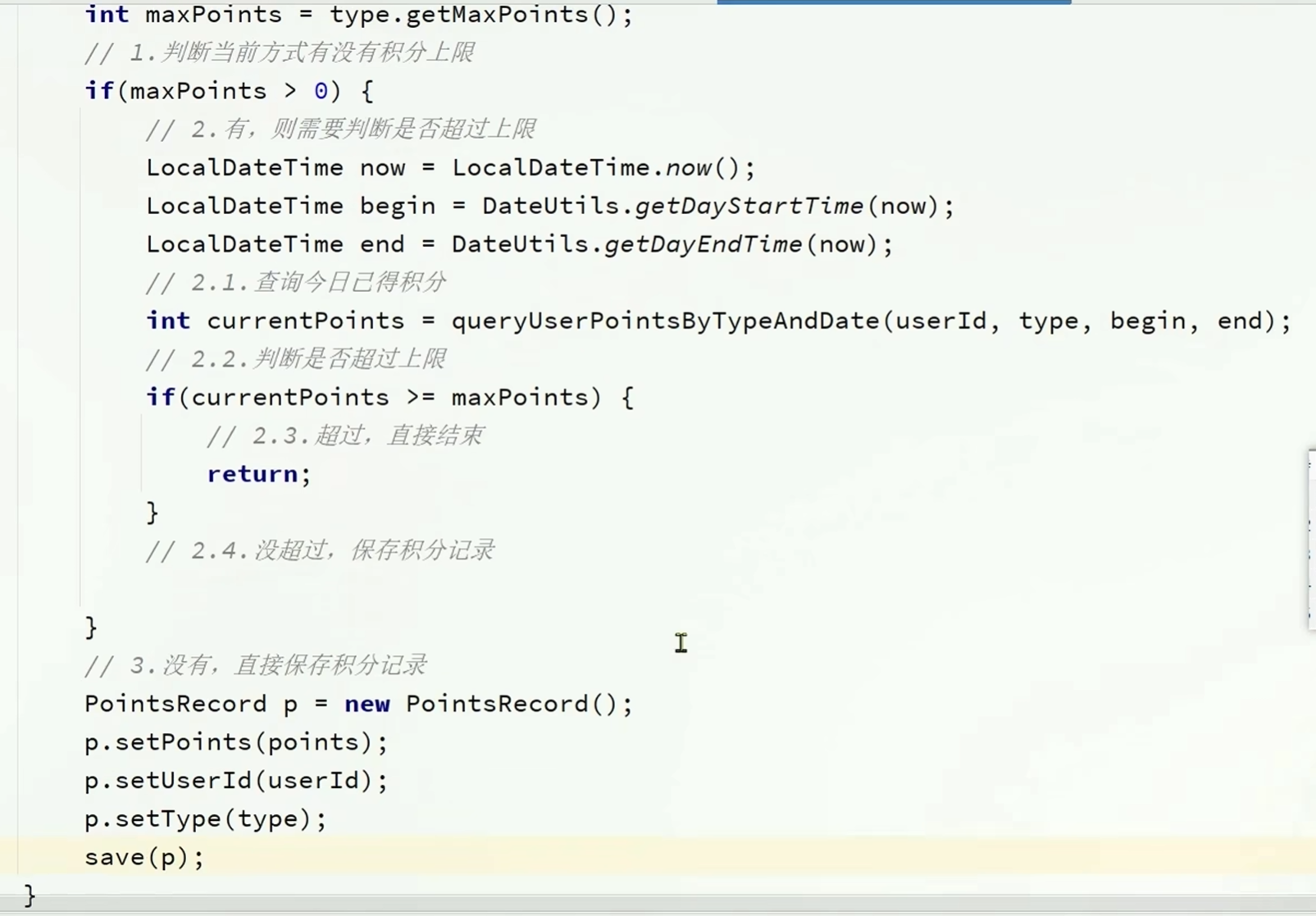
有个小问题,在没超出上积分上限的时候存储入积分后可能会超过积分上限
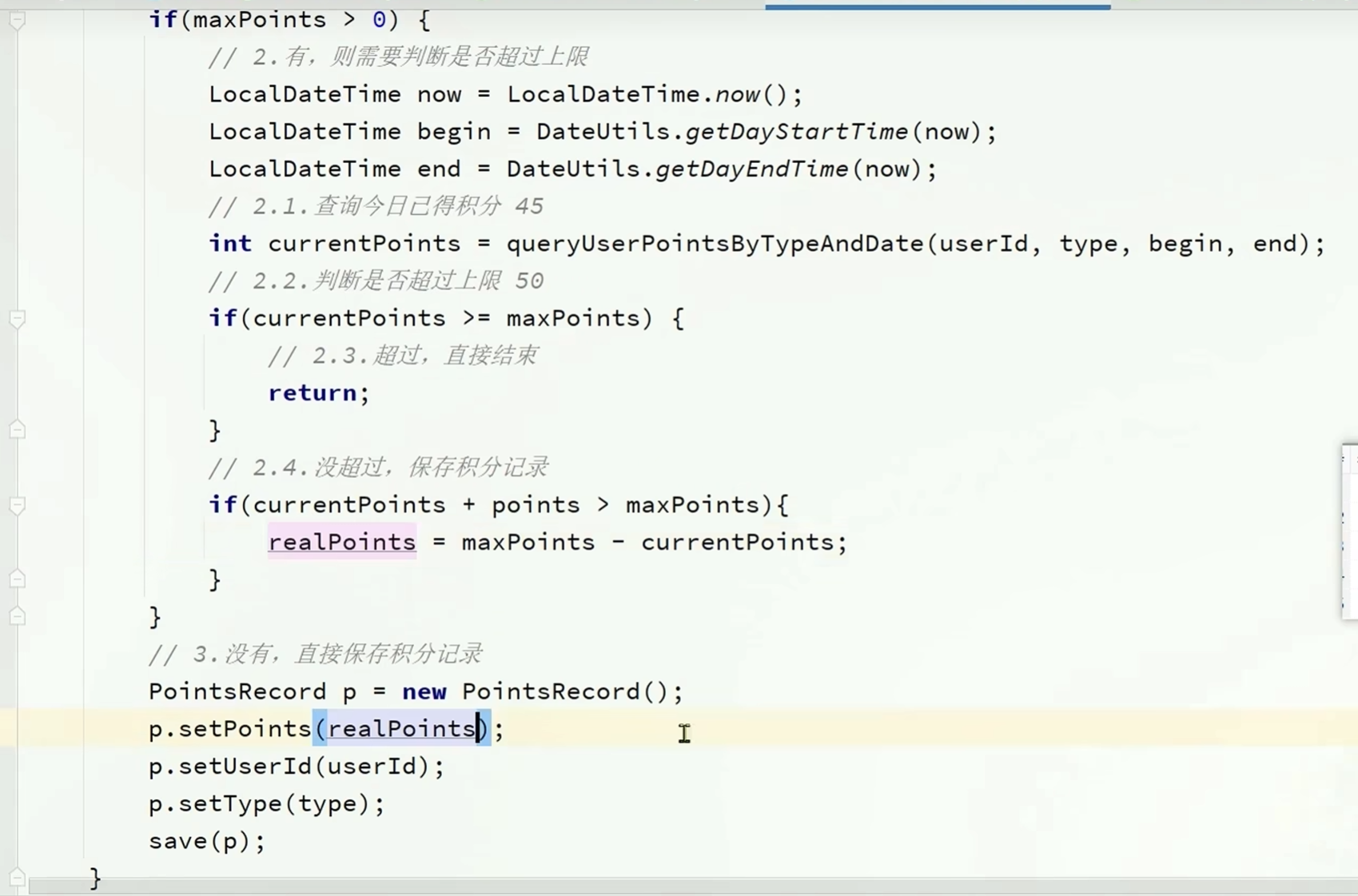
只存入未超出积分上限的部分
查询我的今日积分
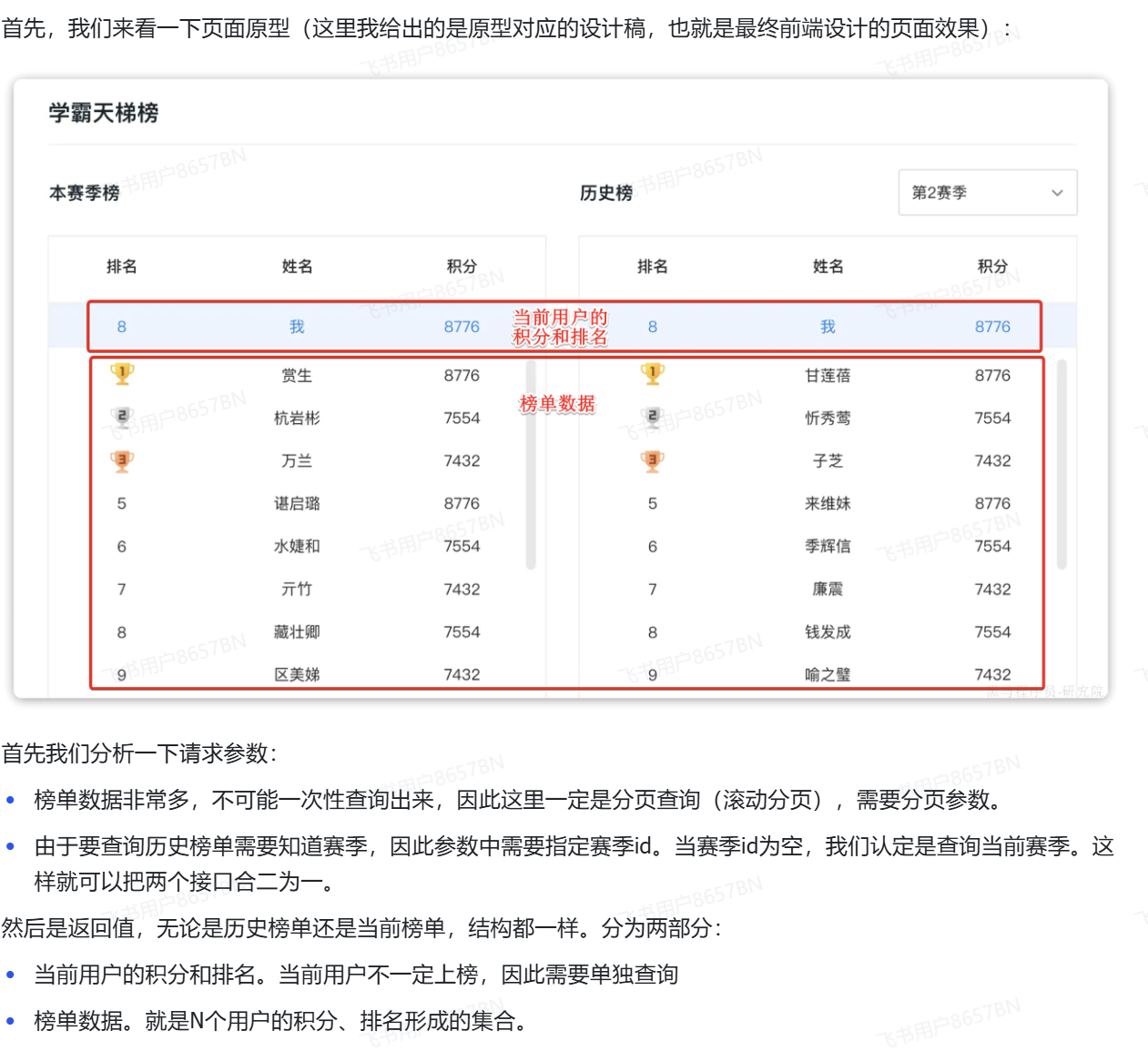
DAY08排行榜
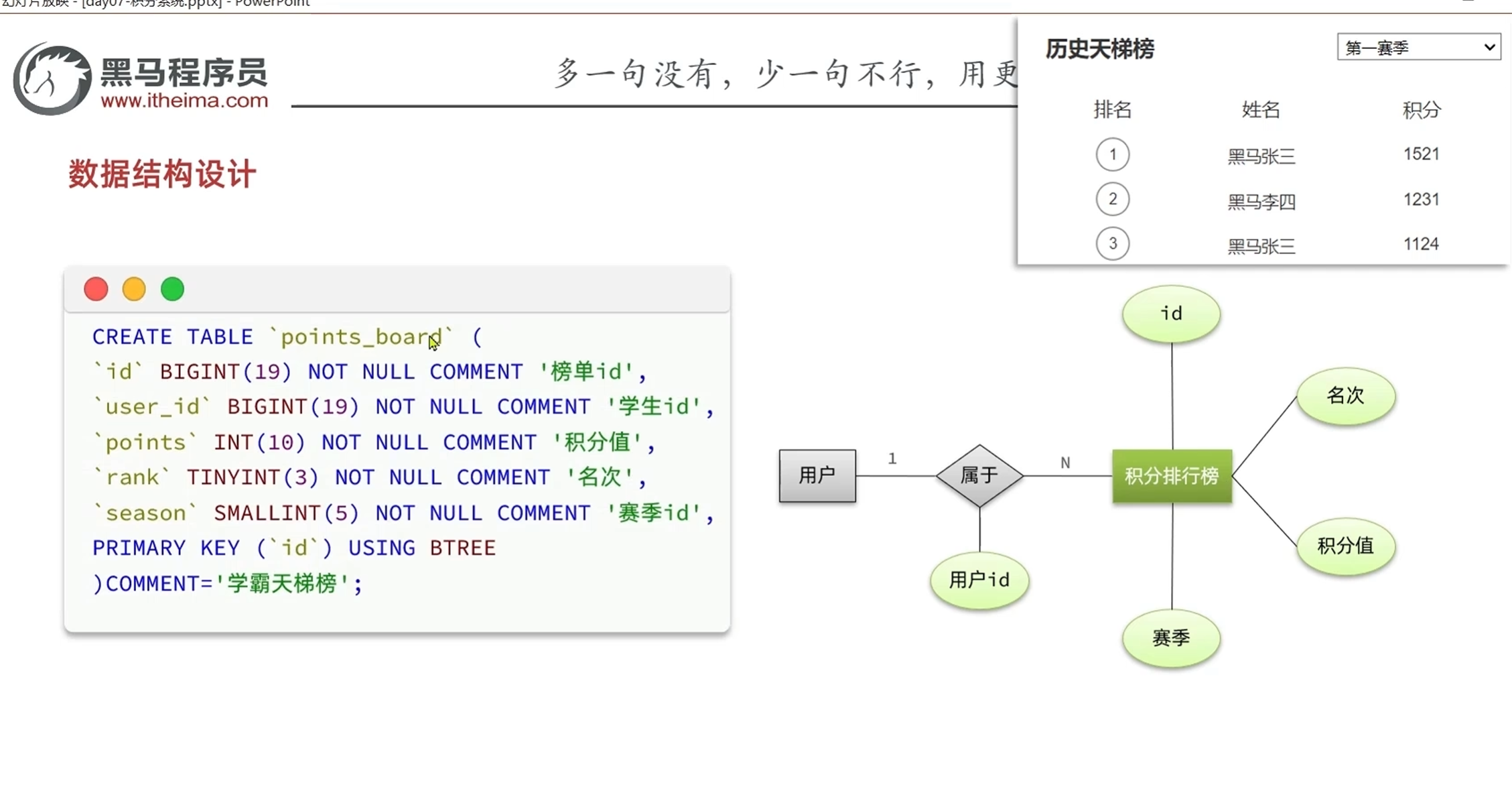
实时排行榜
排行榜思路分析
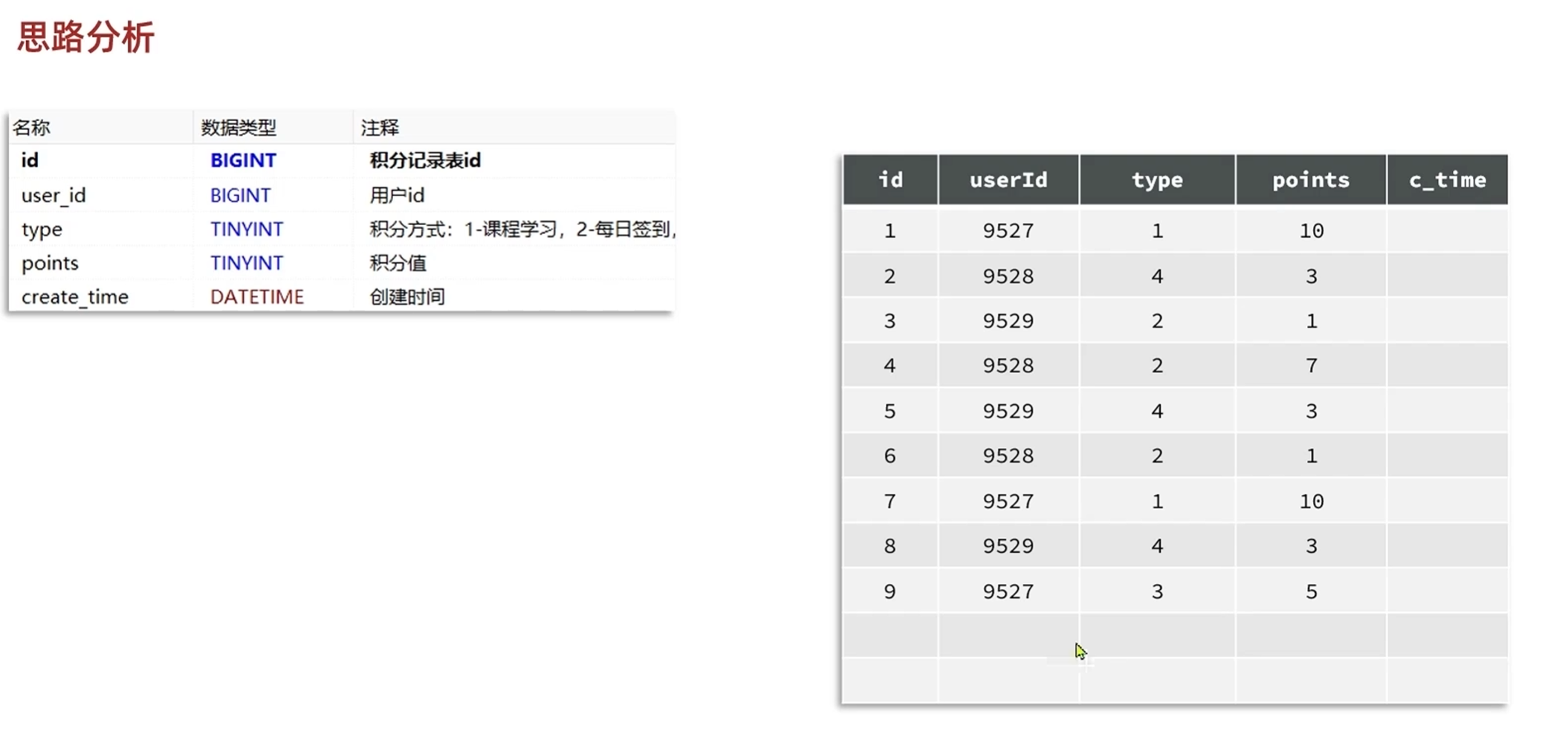
散乱的数据肯定不行,要转变为按照积分总数倒序排序的形式
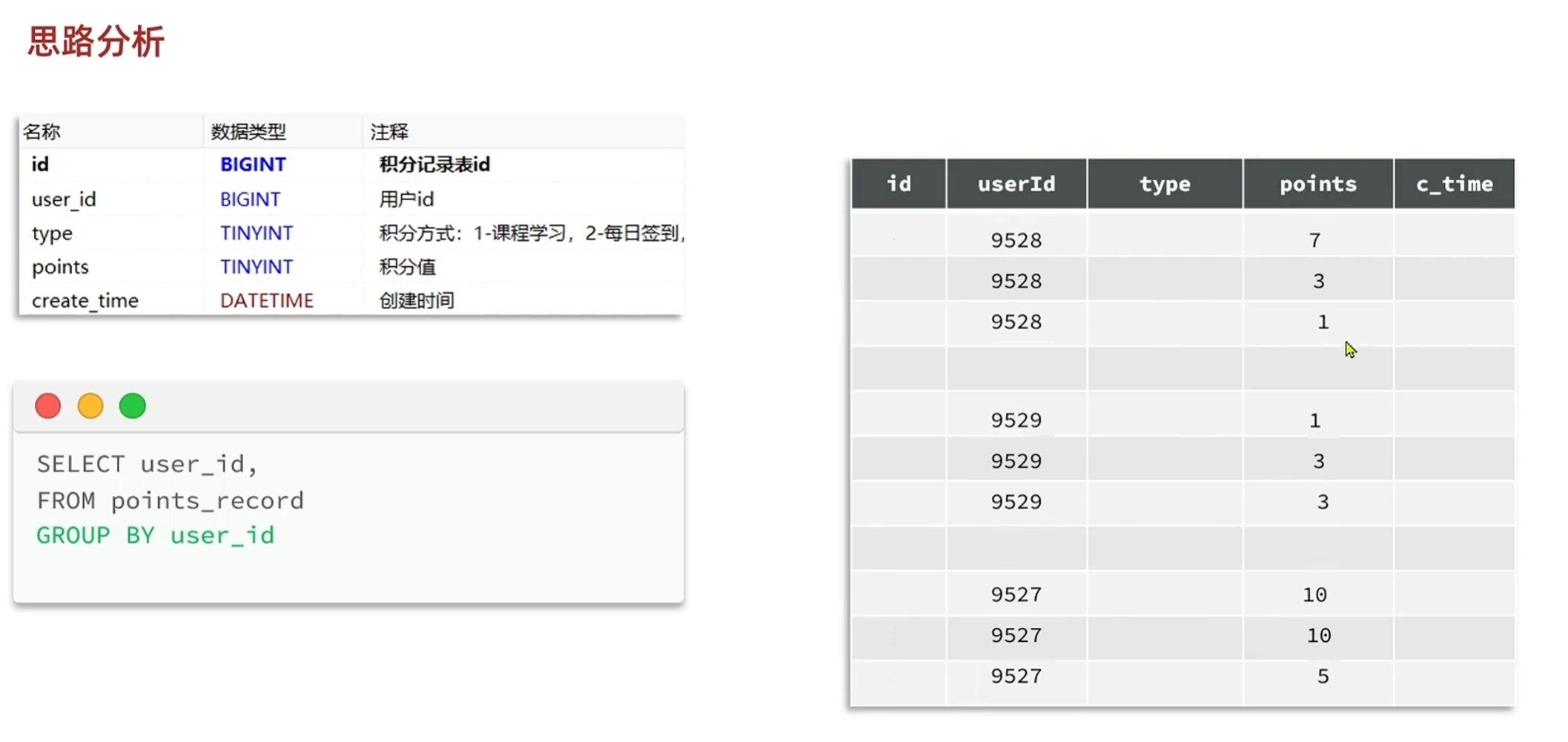
1.先把数据按照userId分组
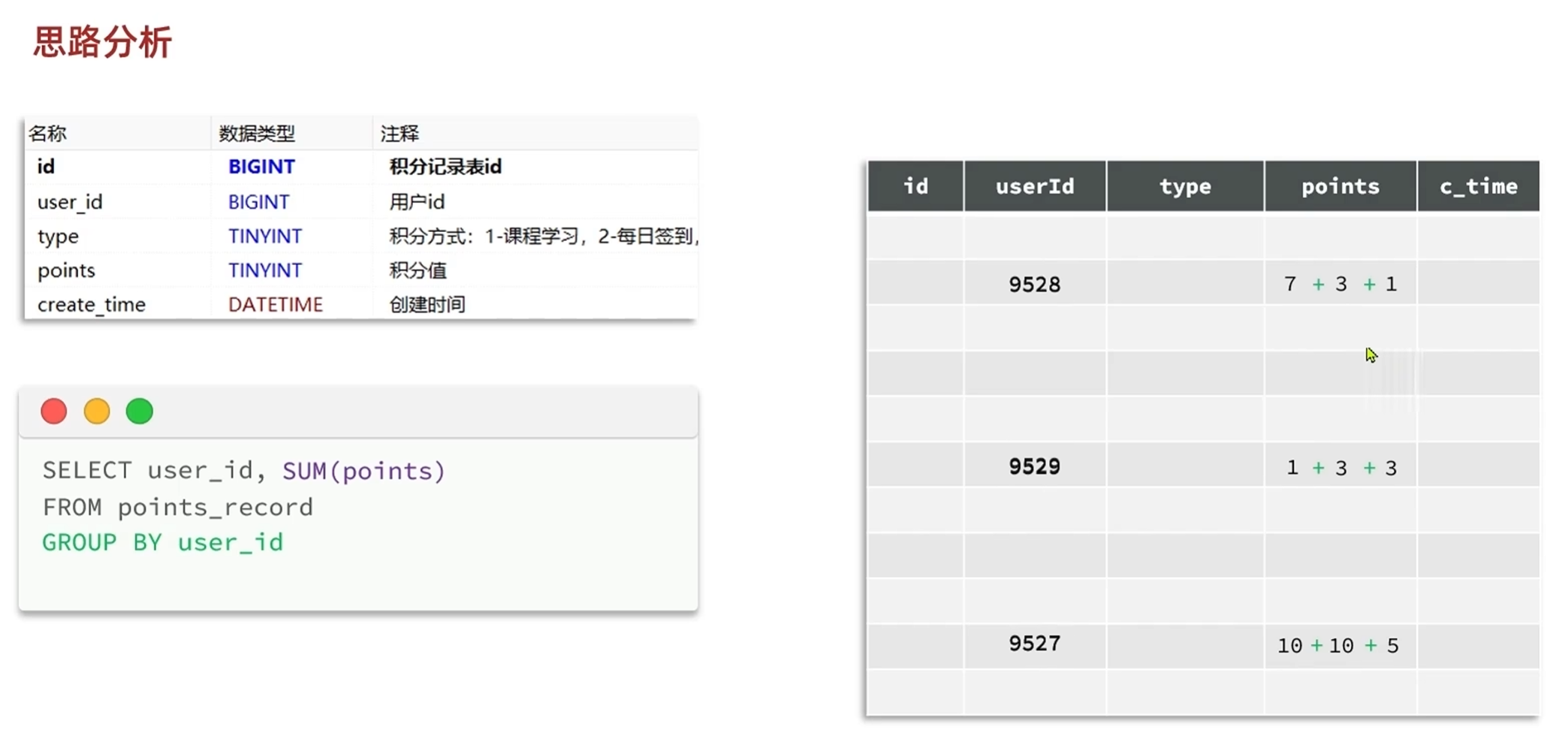
2.根据不同的分组字段进行求和
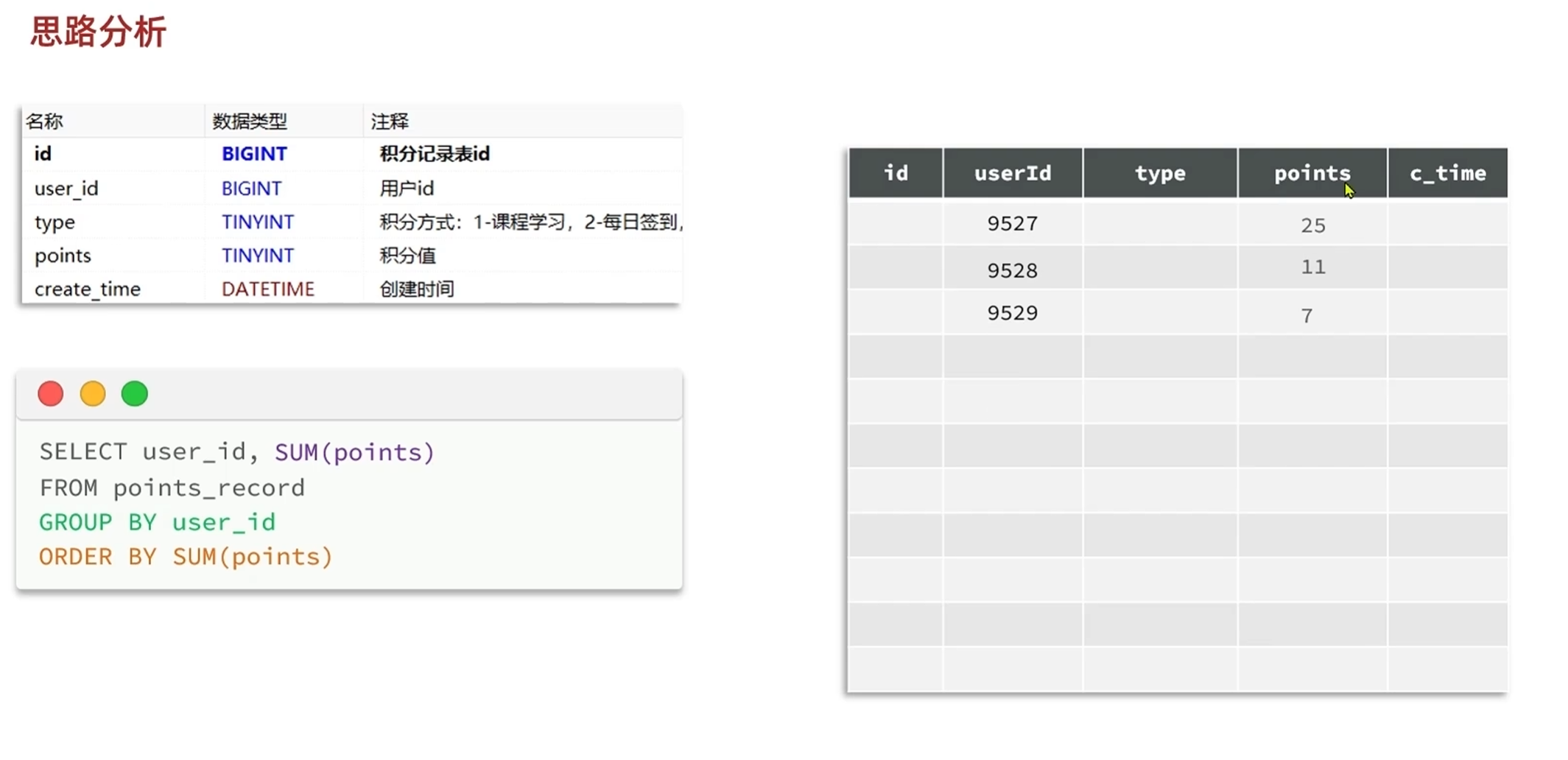
3.得到求和结果之后按照积分大小倒序排列
对应的sql语句如下:
在每次查询的时候都需要进行分类,分组求和的操作,效率低下,
新办法,让数据一开始就是分类好的
如果我们不想在每次查询榜单的时候都进行一系列的分类,分组求和操作的话,
就要利用上积分排行榜表,在每一次保存积分明细的时候,都来更新积分排行榜表的总积分值
当数据规模比较大,比如说几万几十万的情况下
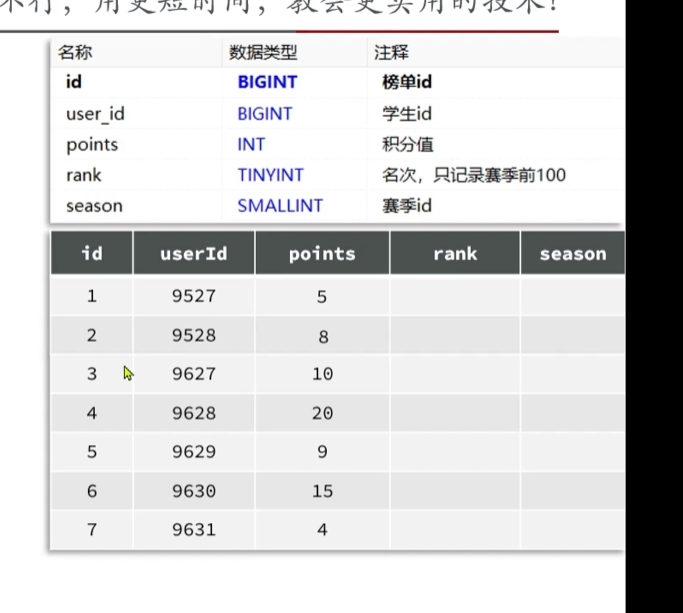
查询用户的排名就会变得的困难,
比如查询当前登录用户的排名就需要把积分比当前用户低的用户全部统计出来,如果这个用户是第几万名的话,查询就会变得很耗时
所以这种方法还是不够完美
我们想要使用一种,不用每次查询的时候都需要全表查询的方式
Redis的sorted set就可以办到每次数据更新的时候自动进行排序
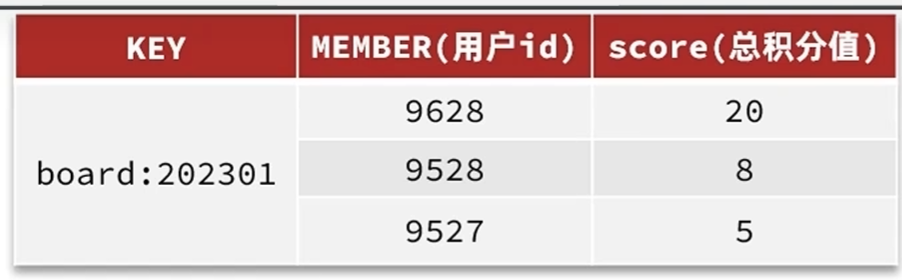
性能相对于mysql数据库有了非常大的提升
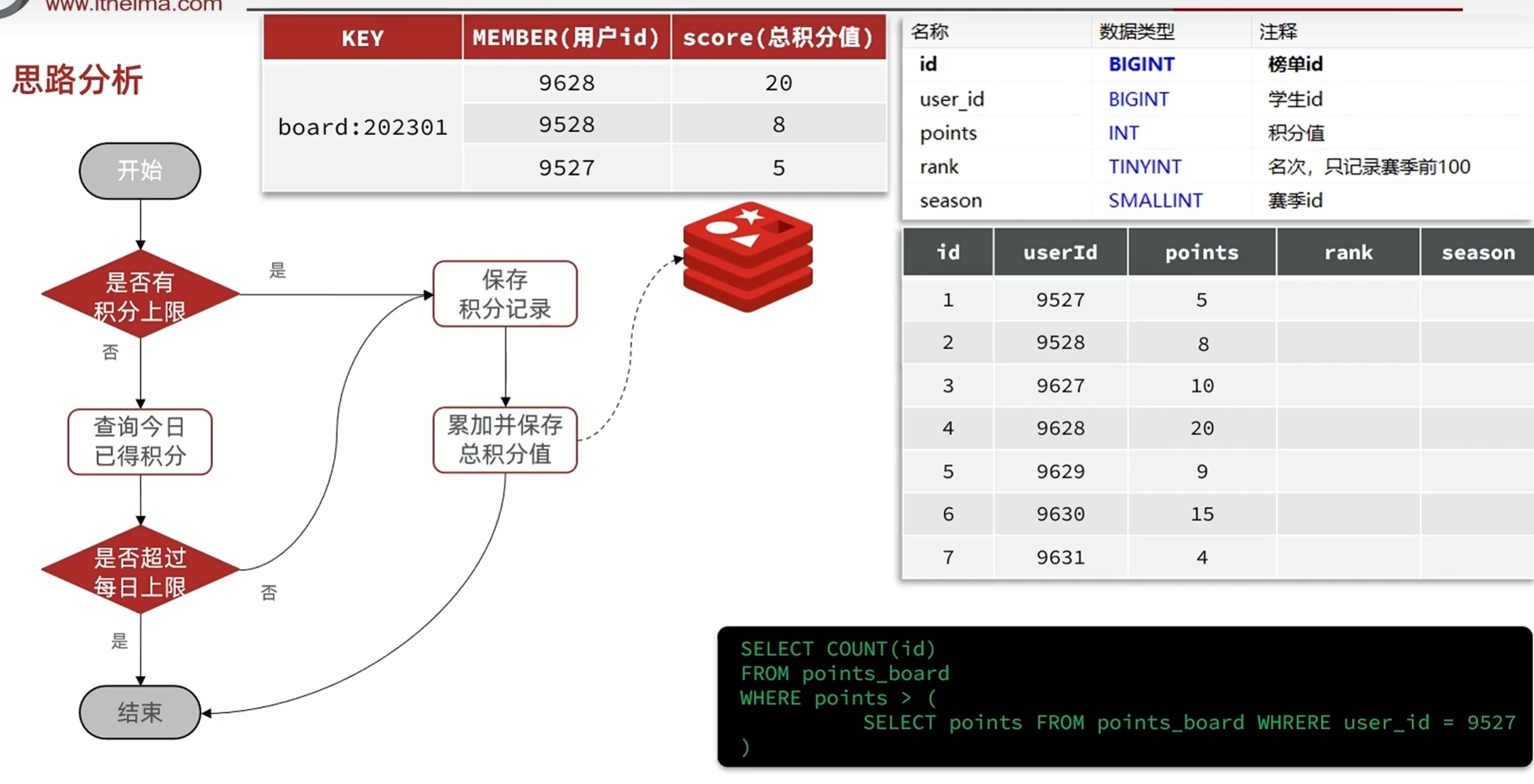
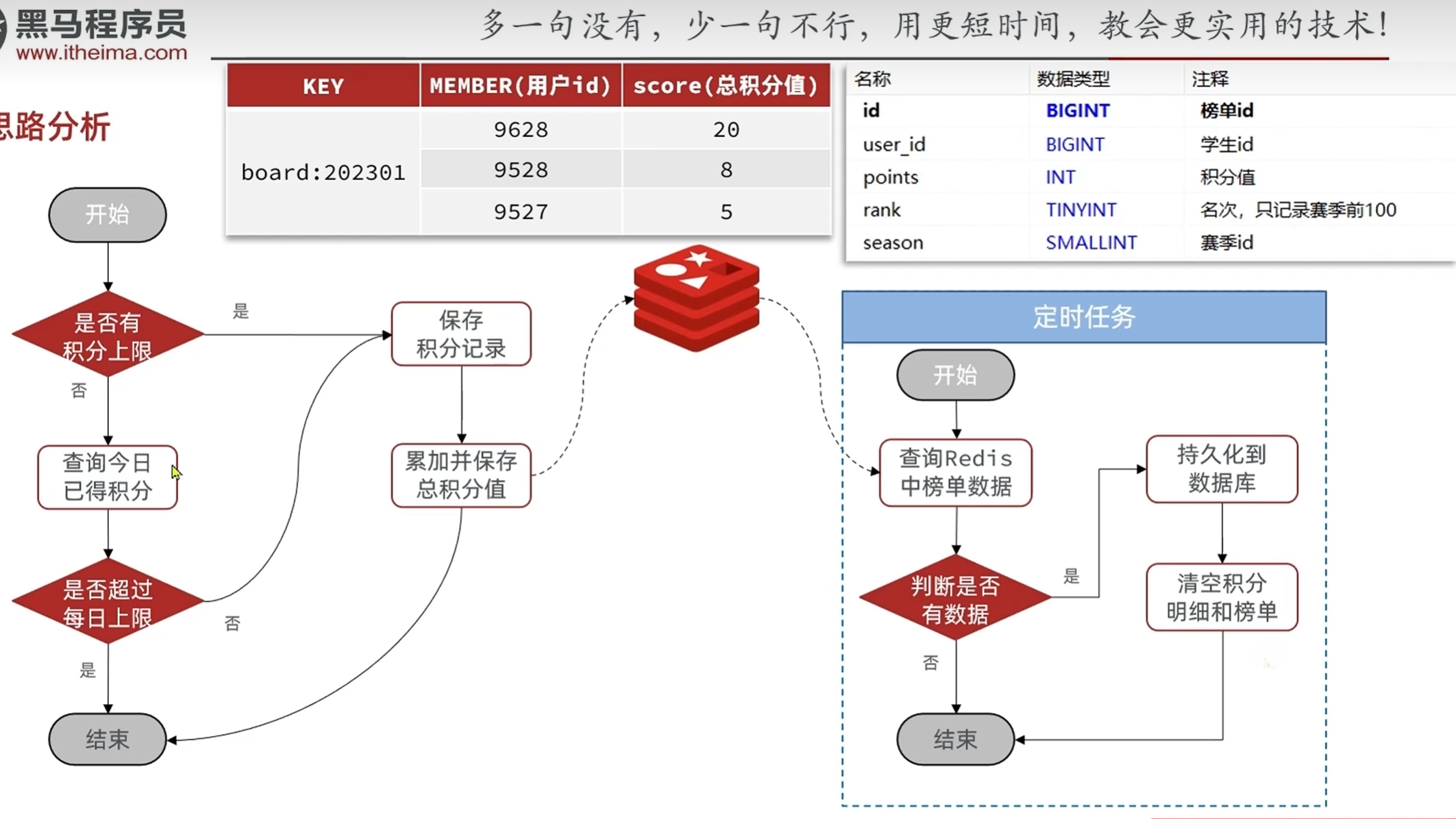
在实时排行榜新增和更新的过程中放到redis里面,用redis里面的salted set的自动排序,让查询的时候不用查询整表来给数据排序
在本月结束之后持久化到数据库里面
-利用Redis生成实时排行榜
redis常用命令
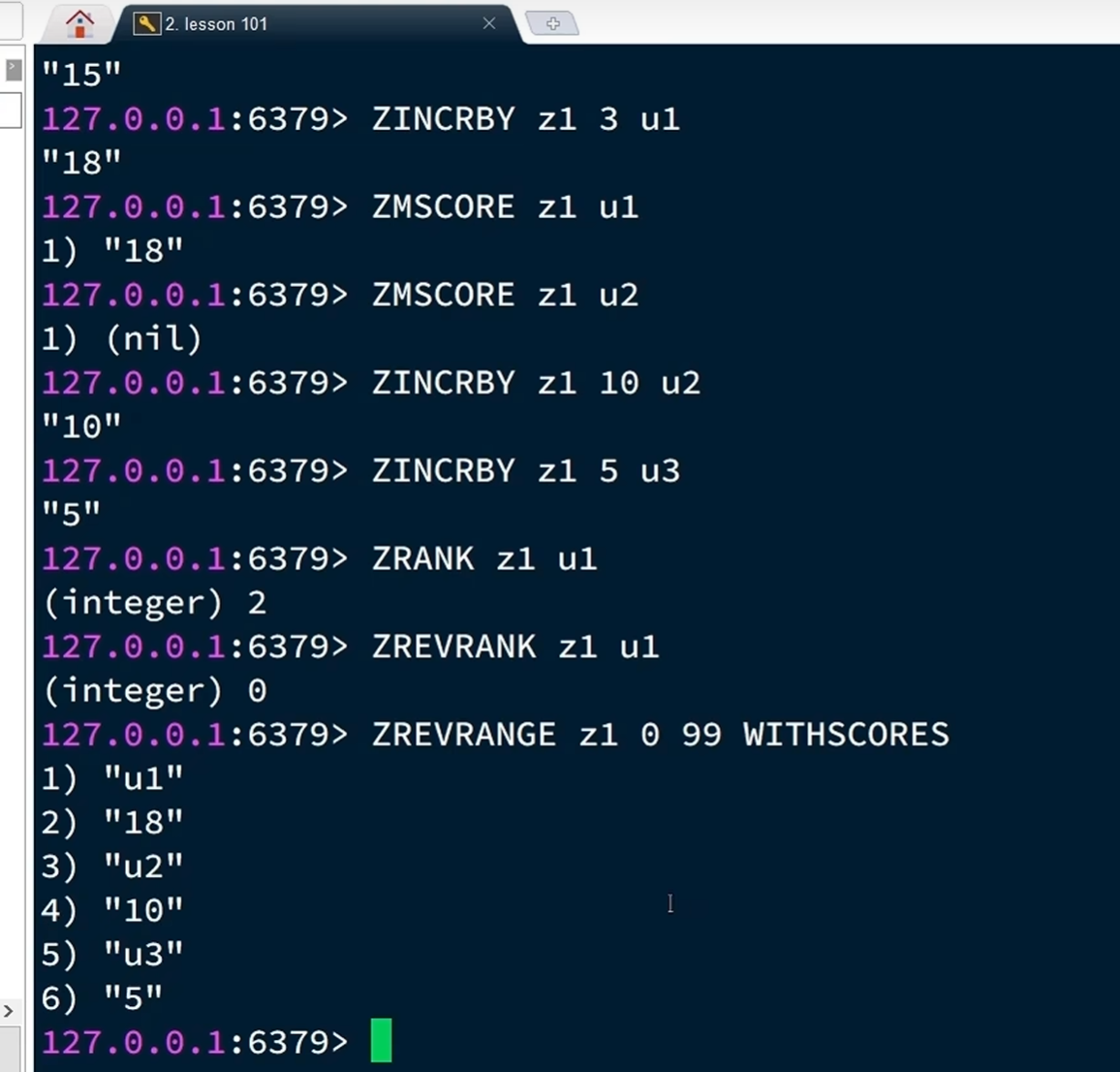
ZINCRBY:在原有的基础上增加
ZRANK:查看查看某个用户的排名(升序)
ZREVRANK:查看某个用户的排名(倒序)
ZRANGE:查看范围内的排行榜(升序)
ZREVRANGE:查看范围内的排行榜(倒序)

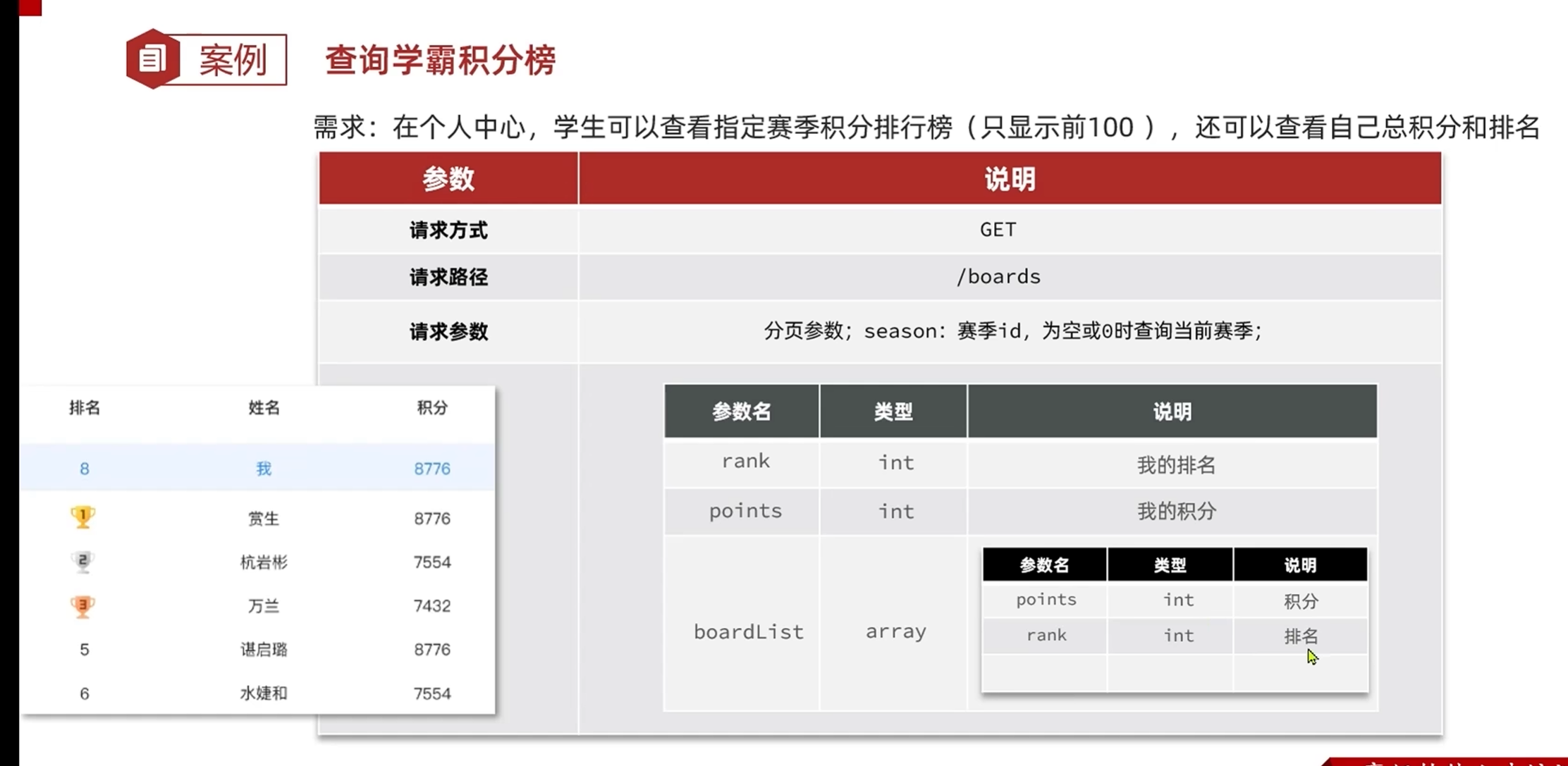
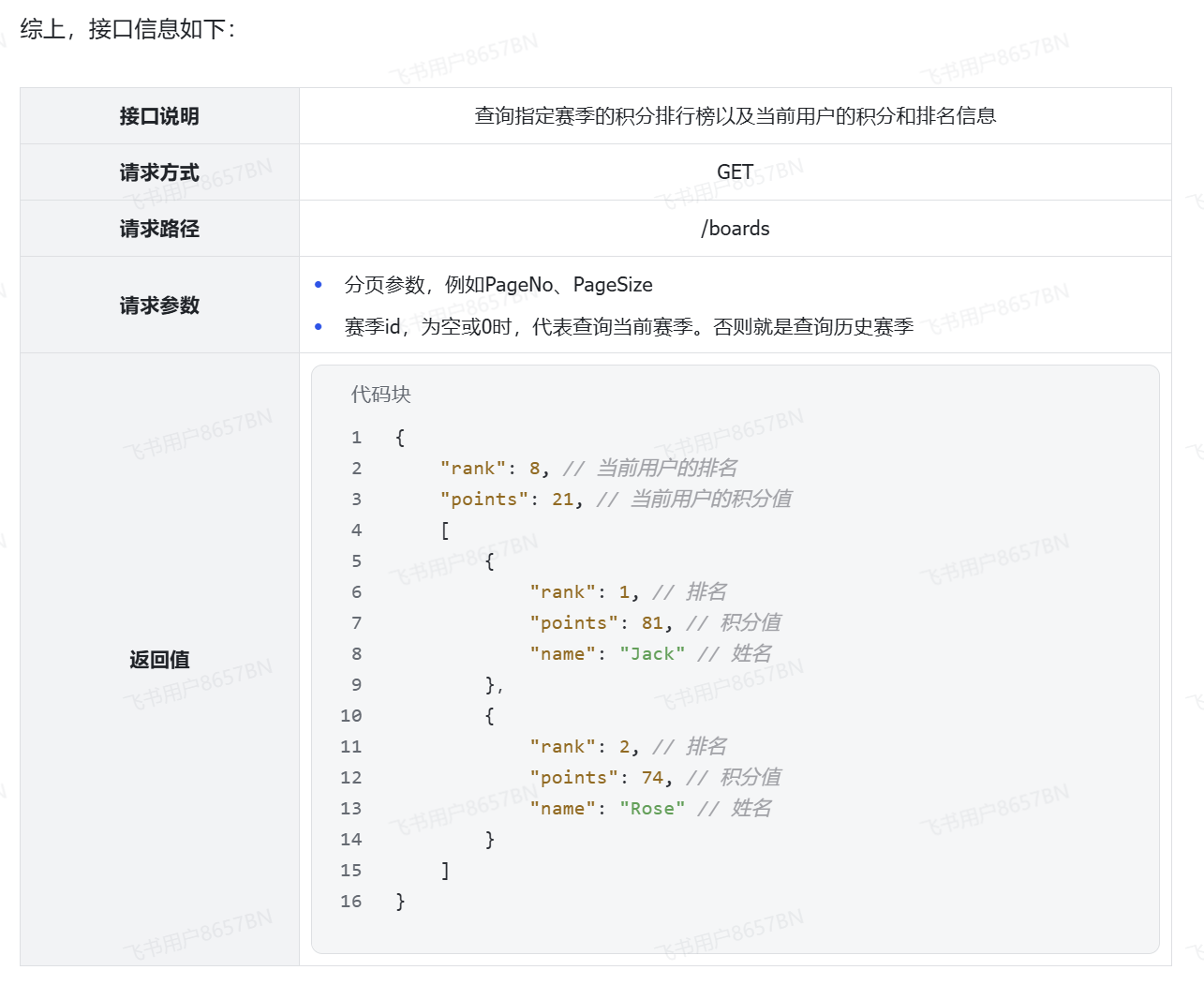
-查询学霸积分榜的接口声明

两个接口是分开的,因为查询学霸积分排行榜只展示前一百名
但是查询当前用户的积分和排名时,当前用户可能并不在前一百名,所以这是两个不同的查询
定义redis的key前缀
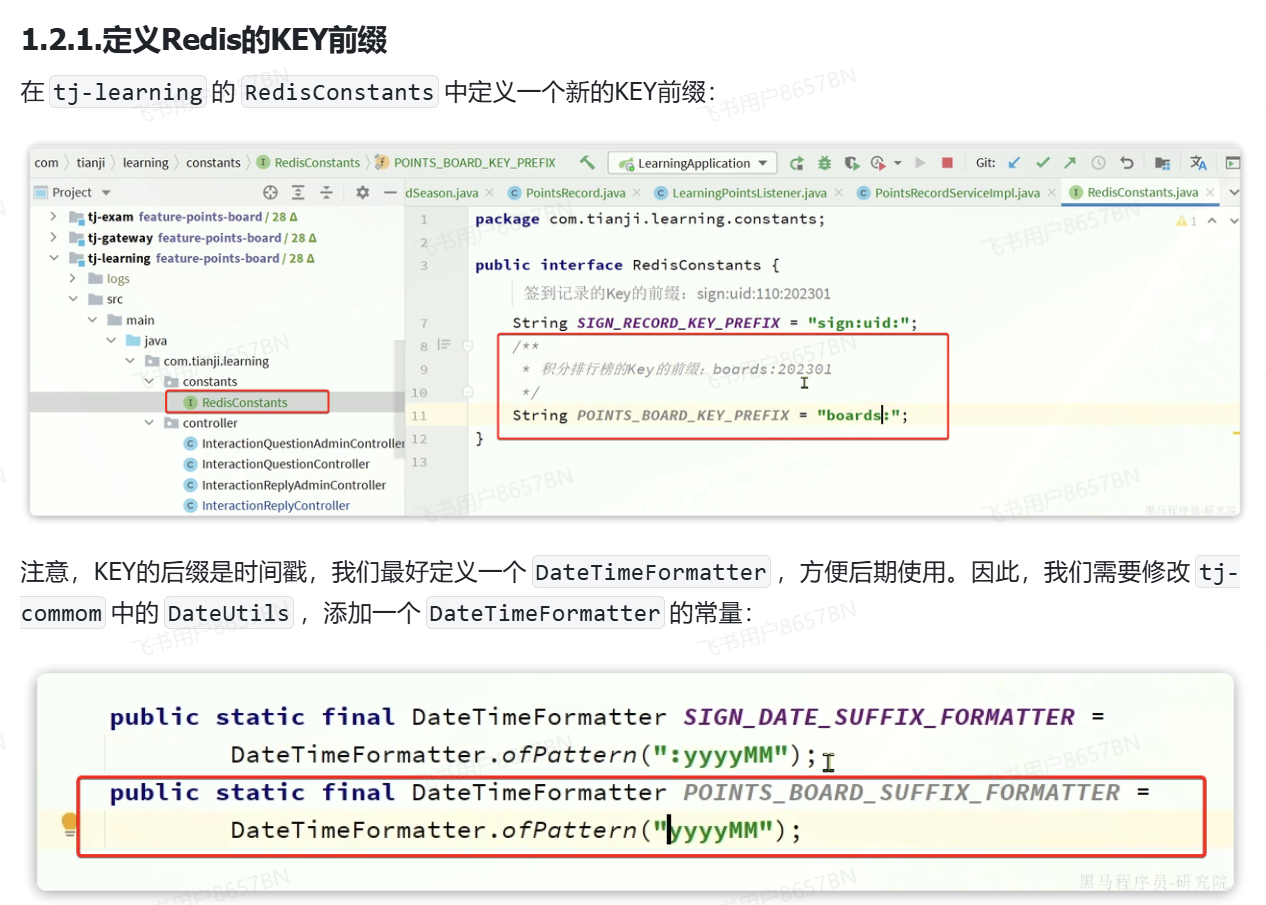

now.format()
是给now这个时间做格式化的存储,括号内的格式就是格式化的形式
实现查询学霸积分榜
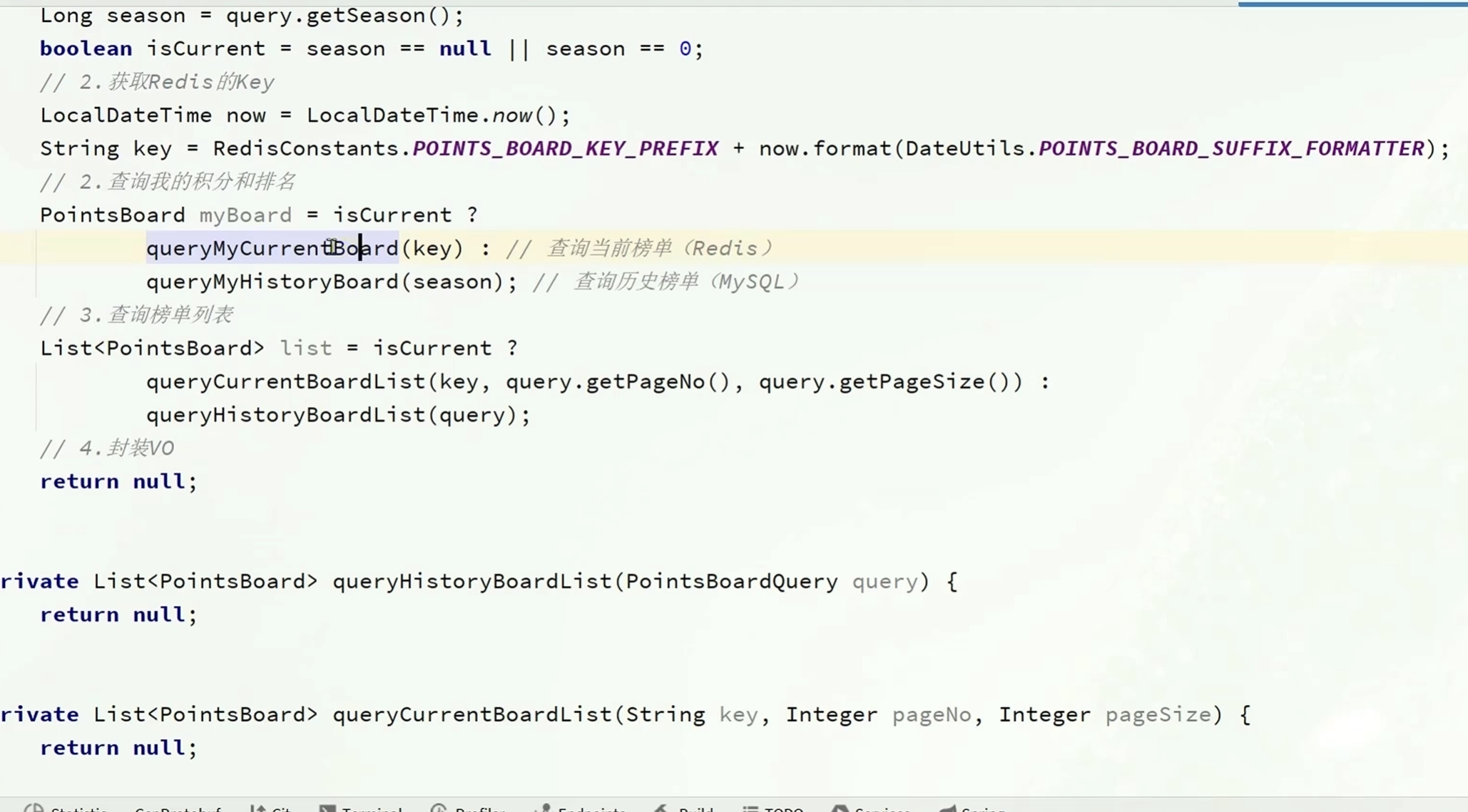
根据接口中赛季的不同,可以分为两部分来查询
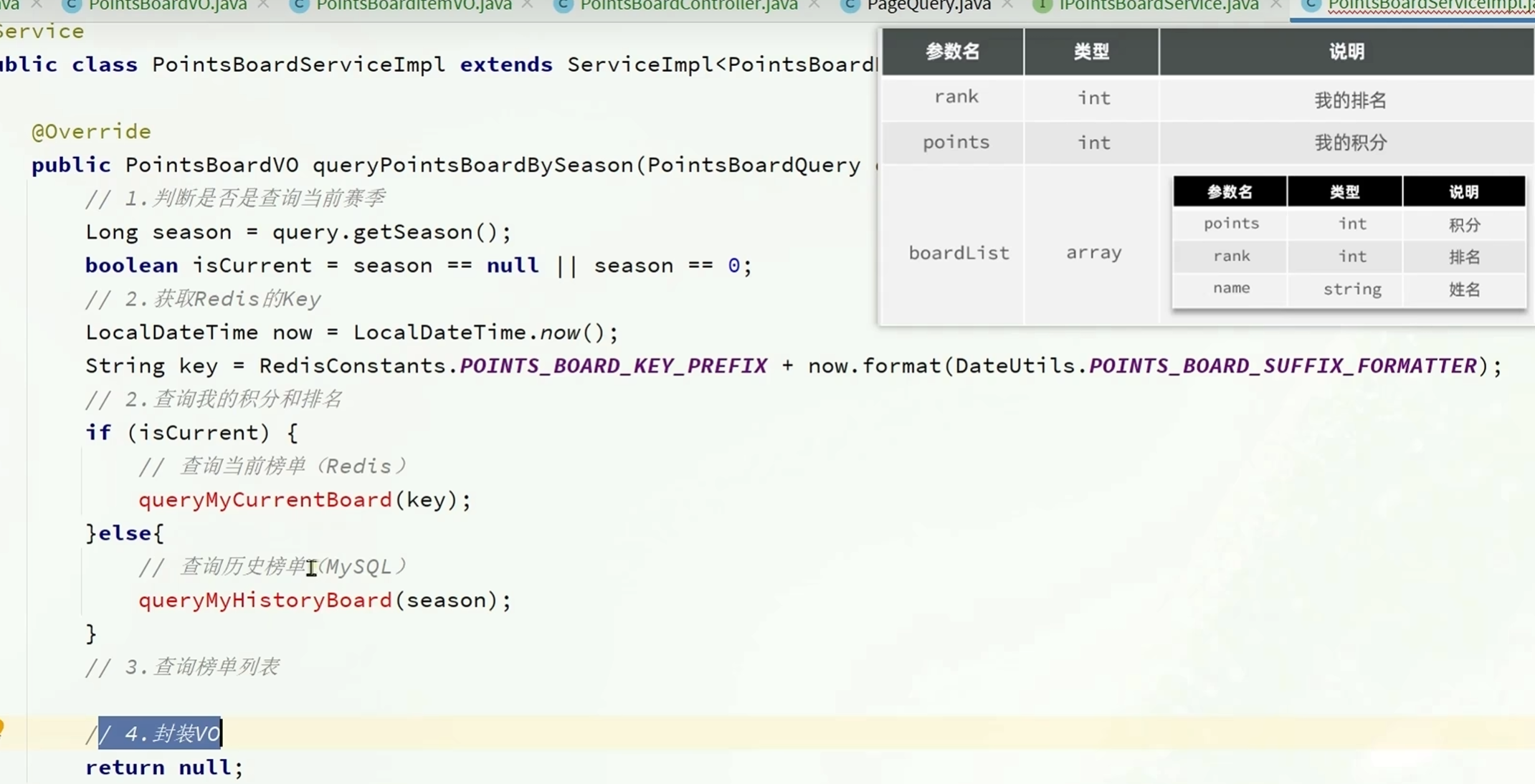
用三目运算符
判断条件?是:不是
有四个函数:
查询我的当前积分,历史积分
查询实时排行榜,历史排行榜
查询当前登录用户的积分排行

查询当前积分排行榜单
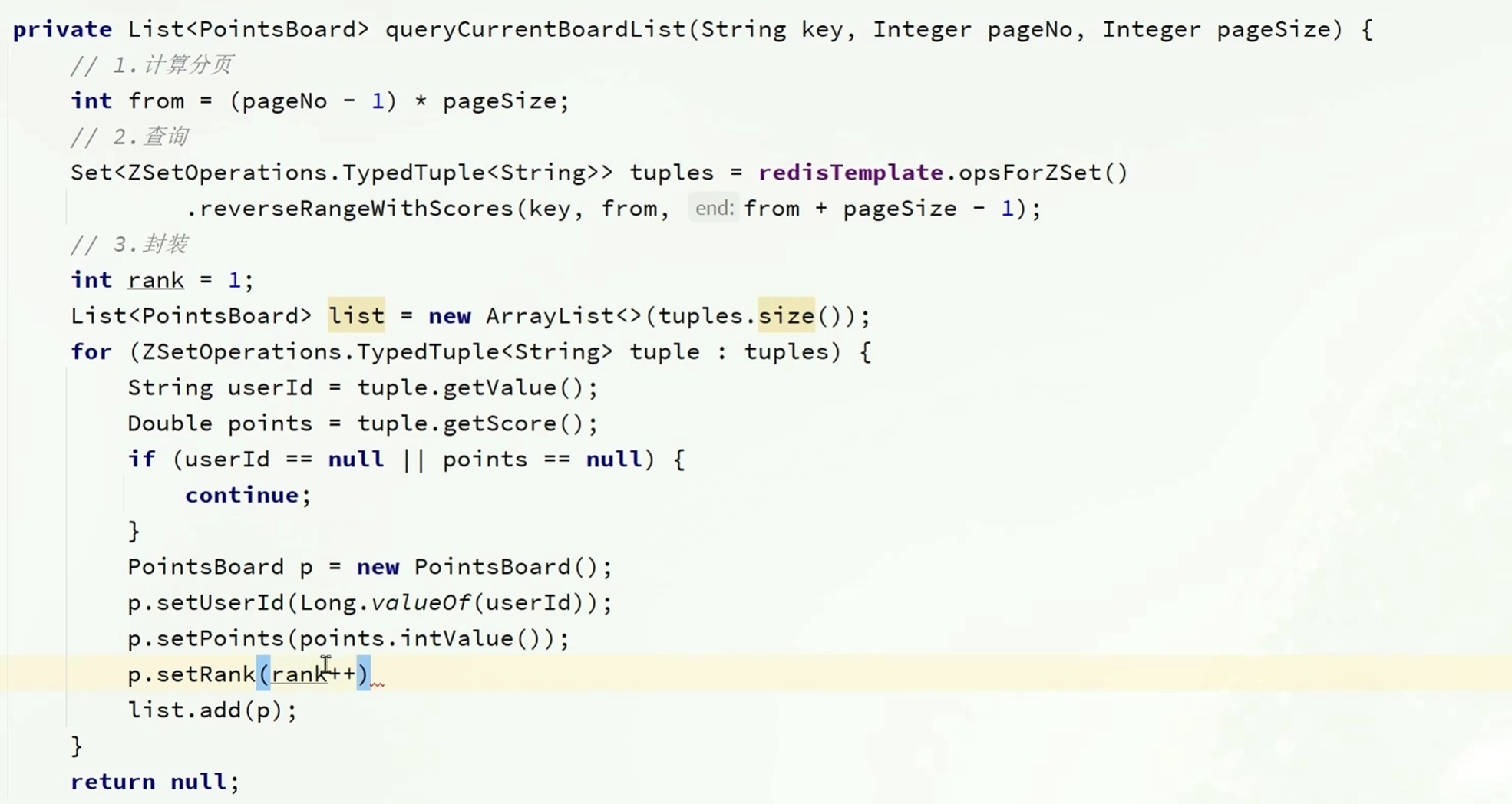
代码实现如下
/**
* <p>
* 学霸天梯榜 服务实现类
* </p>
*
* @author 虎哥
* @since 2026-05-01
*/
@Service
@RequiredArgsConstructor
public class PointsBoardServiceImpl extends ServiceImpl<PointsBoardMapper, PointsBoard> implements IPointsBoardService {
private StringRedisTemplate stringRedisTemplate;
private UserClient userClient;
@Override
public PointsBoardVO getAllPointsBoards(PointsBoardQuery pointsBoardQuery) {
//1.判断赛季是否为空或者为0
Long season = pointsBoardQuery.getSeason();
boolean isCurrent =pointsBoardQuery.getSeason() ==null||pointsBoardQuery.getSeason()==0;
LocalDateTime now = LocalDateTime.now();
String key = RedisConstants.POINT_BOARD_KEY_SUFFIX + now.format(DateUtils.POINT_BOARD_SUFFIX_FORMATTER);
//如果是为空或者为零(也就是boolean为true的时候进行当前的排行榜查询)
//2.1查询我的积分排名,需要的参数为key和当前用户的id
PointsBoard pointsBoard = isCurrent ?
queryMyCurrentBoard(key):
queryMyHistoryBoard(season);
//2.2查询积分榜单
//因为榜单数据很多,不能一次性都查出来,所以要分页一次一次查询
//需要的参数为:页数,每页查询多少数据,key
List<PointsBoard> pointsBoardList = isCurrent?
queryCurrentBoard(key,pointsBoardQuery.getPageNo(),pointsBoardQuery.getPageSize()):
queryHistoryBoard(season,pointsBoardQuery.getPageNo(),pointsBoardQuery.getPageSize());
//封装得到的结果并返回
//2封装我的积分部分
PointsBoardVO pointsBoardVO = new PointsBoardVO();
if(pointsBoard!=null){
pointsBoardVO.setPoints(pointsBoard.getPoints());
pointsBoardVO.setRank(pointsBoard.getRank());
}
if(CollectionUtils.isNotEmpty(pointsBoardList)){
return pointsBoardVO;
}
//3.封装积分排行榜的部分
//返回值pointBoardVO里面存储的都是用户的用户名,要去userService里面查询
//3.1取出用户id的集合
Set<Long> userIdList =new HashSet<>(pointsBoardList.size());
userIdList = pointsBoardList.stream().map(PointsBoard::getUserId).collect(Collectors.toSet());
//3.2查询
List<UserDTO> userDTOS = userClient.queryUserByIds(userIdList);
//3.3封装成map
Map<Long,String> userMap =new HashMap<>(userDTOS.size());
if(CollectionUtils.isNotEmpty(userDTOS)){
userMap = userDTOS.stream().collect(Collectors.toMap( UserDTO::getId, UserDTO::getName));
}
//3.4开始封装
int begin = (pointsBoardQuery.getPageNo()-1)*pointsBoardQuery.getPageSize();
List<PointsBoardItemVO> pointsBoardItemVOList =new ArrayList<>(pointsBoardList.size());
for(PointsBoard r :pointsBoardList){
PointsBoardItemVO pointsBoardItemVO = new PointsBoardItemVO();
pointsBoardItemVO.setPoints(r.getPoints());
pointsBoardItemVO.setRank(r.getRank());
pointsBoardItemVO.setName(userMap.get(r.getUserId()));
pointsBoardItemVOList.add(pointsBoardItemVO);
}
pointsBoardVO.setBoardList(pointsBoardItemVOList);
//4.返回
return pointsBoardVO;
}
private List<PointsBoard> queryHistoryBoard(Long season, @Min(value = 1, message = "页码不能小于1") Integer pageNo, @Min(value = 1, message = "每页查询数量不能小于1") Integer pageSize) {
return null;
}
private List<PointsBoard> queryCurrentBoard(String key, @Min(value = 1, message = "页码不能小于1") Integer pageNo, @Min(value = 1, message = "每页查询数量不能小于1") Integer pageSize) {
//查询当前的榜单,因为当前的榜单都是存储在redis里面的
//要传入redis里面的是key,起始排名,结尾排名
int begin = (pageNo-1)*pageSize;
//stringRedisTemplate里面封装了get,set方法,所以不用管返回的值不认识,只需要get,set就行
Set<ZSetOperations.TypedTuple<String>> tuples = stringRedisTemplate
.opsForZSet()
.reverseRangeWithScores(key, begin, begin + pageSize - 1);
if(CollectionUtils.isEmpty(tuples)){
return Collections.emptyList();
}
//获得的数据为分数和用户id,没有排名
int rank = begin + 1;
List<PointsBoard> list = new ArrayList<>(tuples.size());
for (ZSetOperations.TypedTuple<String> tuple : tuples) {
String userId = tuple.getValue();
Double points = tuple.getScore();
if (userId == null || points == null) {
continue;
}
PointsBoard p = new PointsBoard();
p.setUserId(Long.valueOf(userId));
p.setPoints(points.intValue());
p.setRank(rank++);
list.add(p);
}
return list;
}
private PointsBoard queryMyHistoryBoard(Long season) {
return null;
}
private PointsBoard queryMyCurrentBoard(String key) {
//因为要查的是多个数据,所以绑定key之后再查询
BoundZSetOperations<String, String> ops = stringRedisTemplate.boundZSetOps(key);
//查询当前用户的排名,积分
Long user = UserContext.getUser();
Long rank = ops.reverseRank(user);
Double score = ops.score(user);
//封装成PointBoard对象返回
PointsBoard pointsBoard = new PointsBoard();
if (score != null) {
pointsBoard.setPoints(score.intValue());
}
if (rank != null) {
pointsBoard.setRank(rank.intValue());
}
pointsBoard.setUserId(user);
return pointsBoard;
}
}
历史排行榜
-数据库的分区和分表
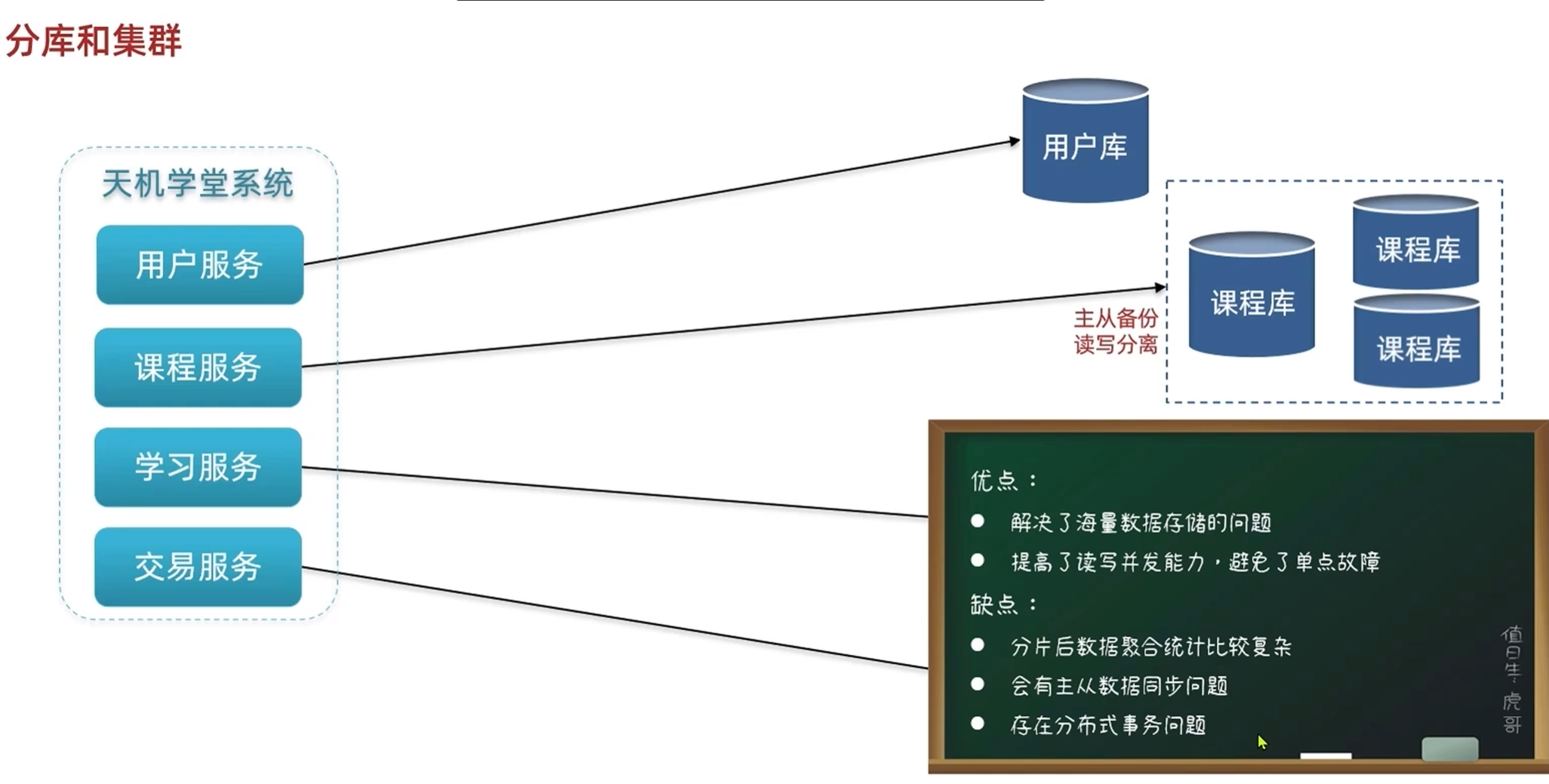
水平拆分
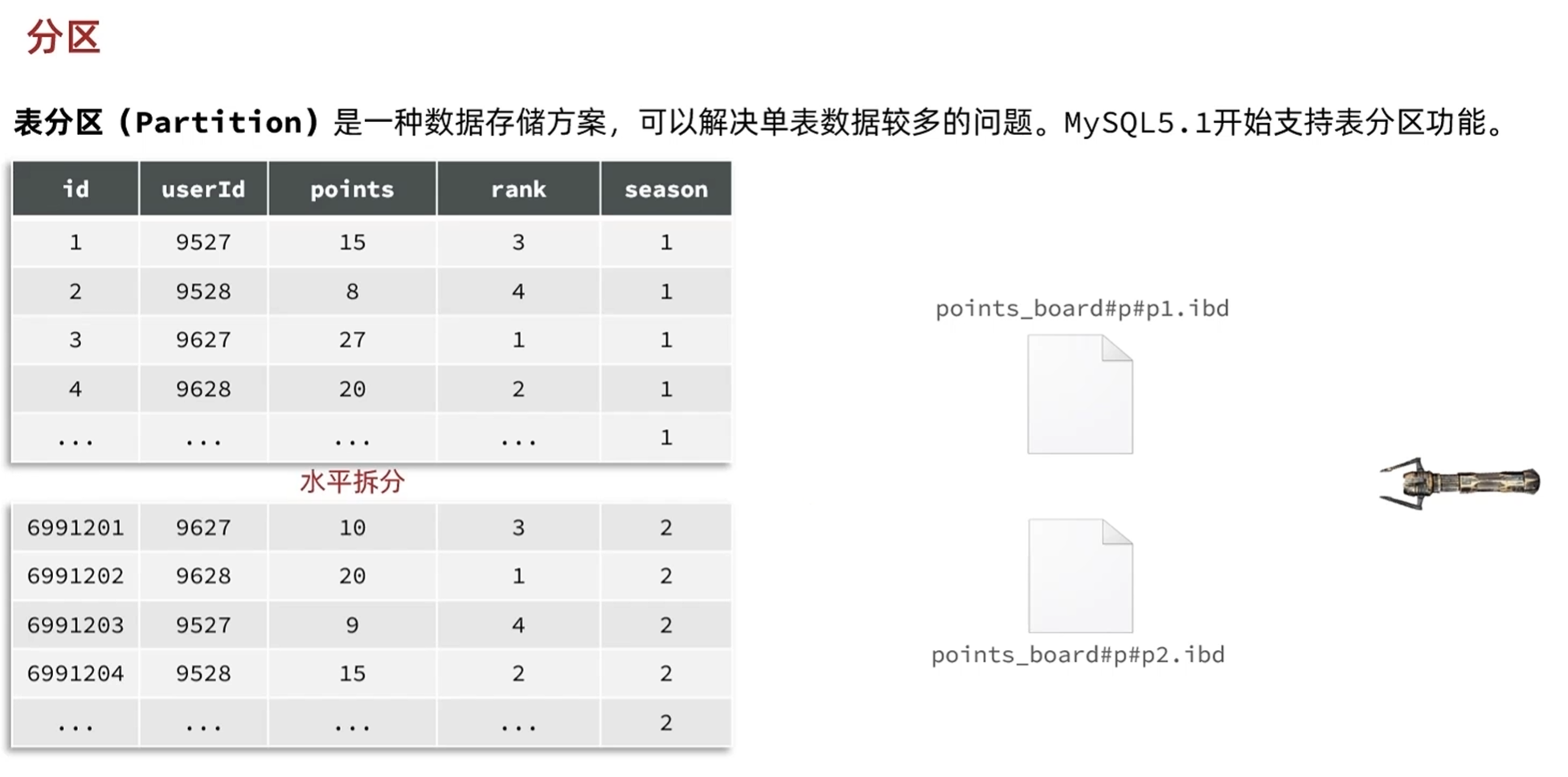
优点
1.提高数据检索性能:根据赛季分成了不同的表,在查询的时候可以分不同的表进行查询
2.提升求和性能:多线程求和
3.打破磁盘容量限制:防止单个文件过大,磁盘放不下
4.根据分区清理效率高:长时间没人看的第一赛季的数据可以直接删除,不用写sql语句来删除,直接删表
5.表虽然是在物理上拆分,但是写代码的时候基本不用改
缺点:比较死板,支持水平分区
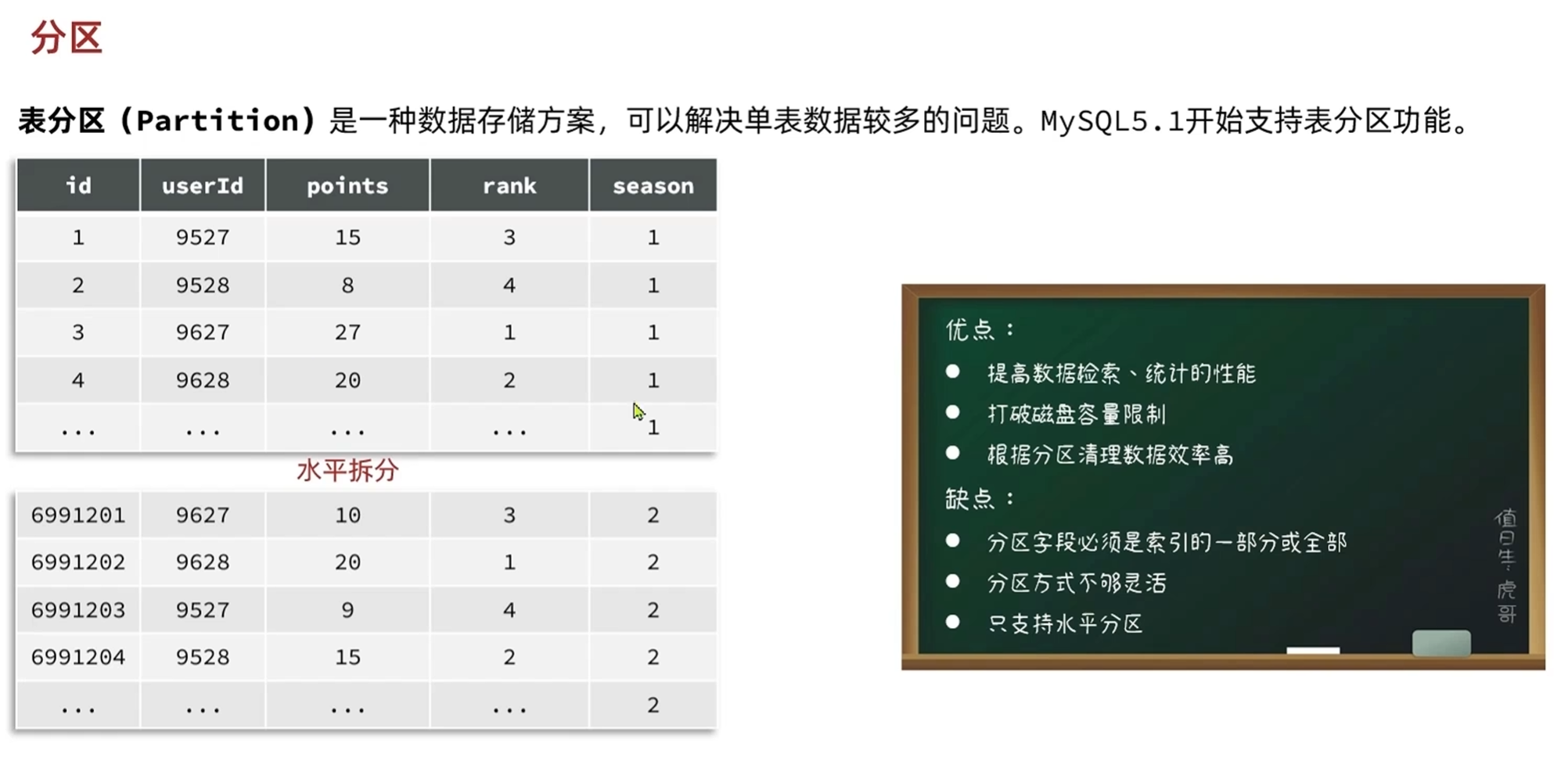
分区是数据库自主完成的,本质上是一张表,分表是表在设计的时候就分开了,本质上是不同的表
一般会使用分表存储
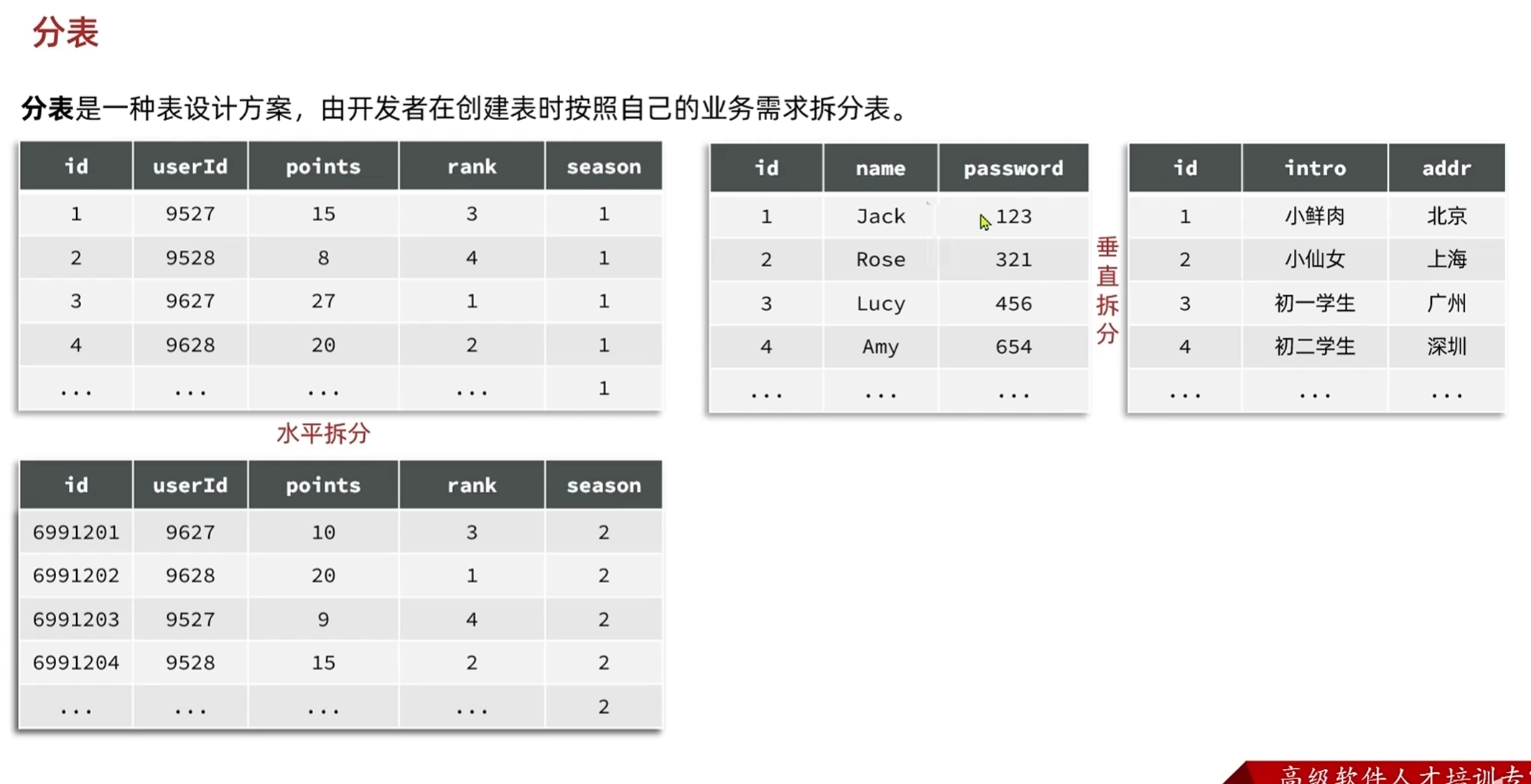
垂直拆分是通过id相同进行关联,把字段分开了
垂直拆分是把表的数据分开了,表结构完全相同
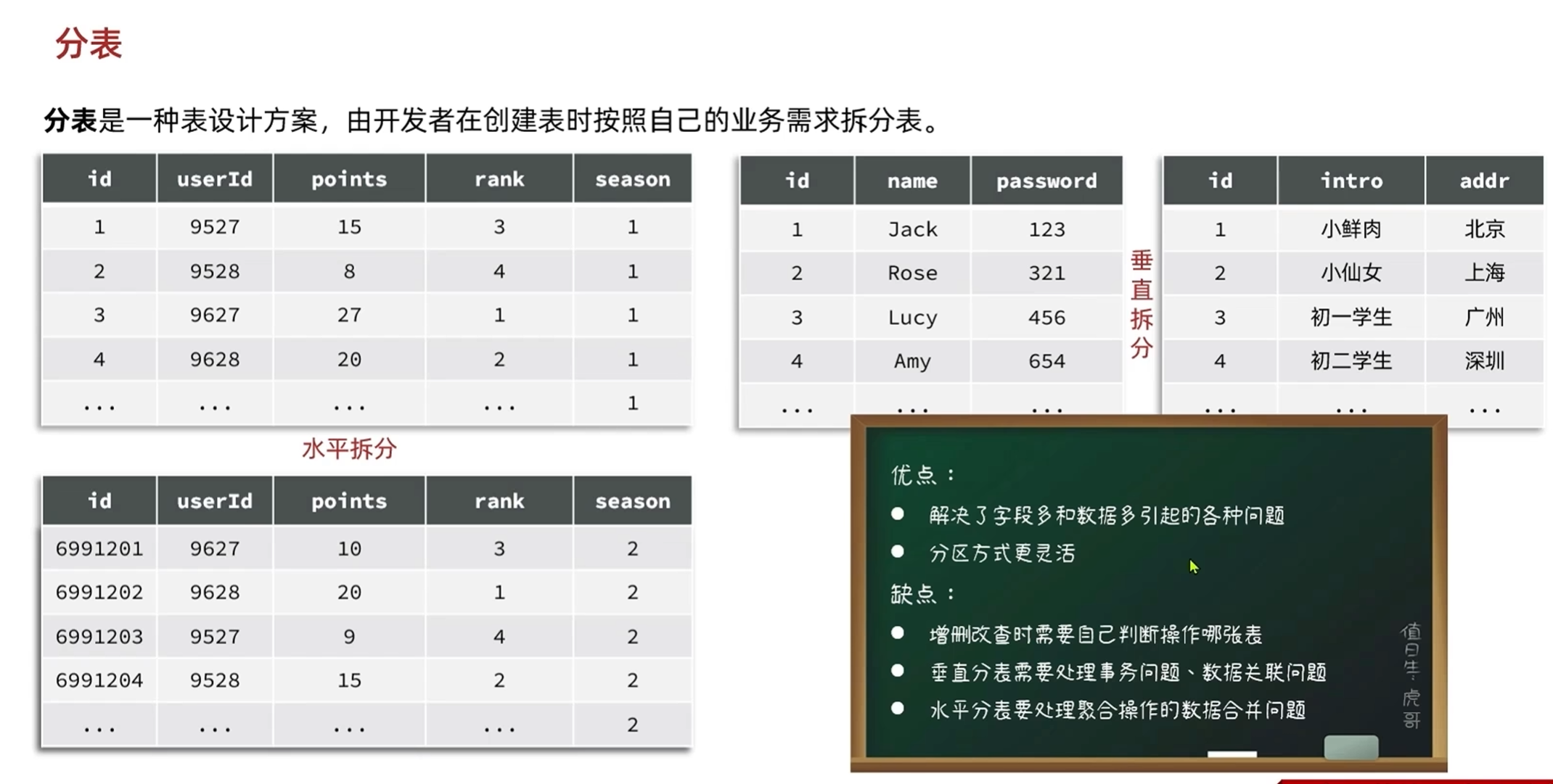
垂直拆分需要处理事务问题,数据关联问题,业务逻辑比较复杂
-分库和集群方案
单个数据库能够抗住的并发,缓存都是有限的,在数据过多的时候只能分库了
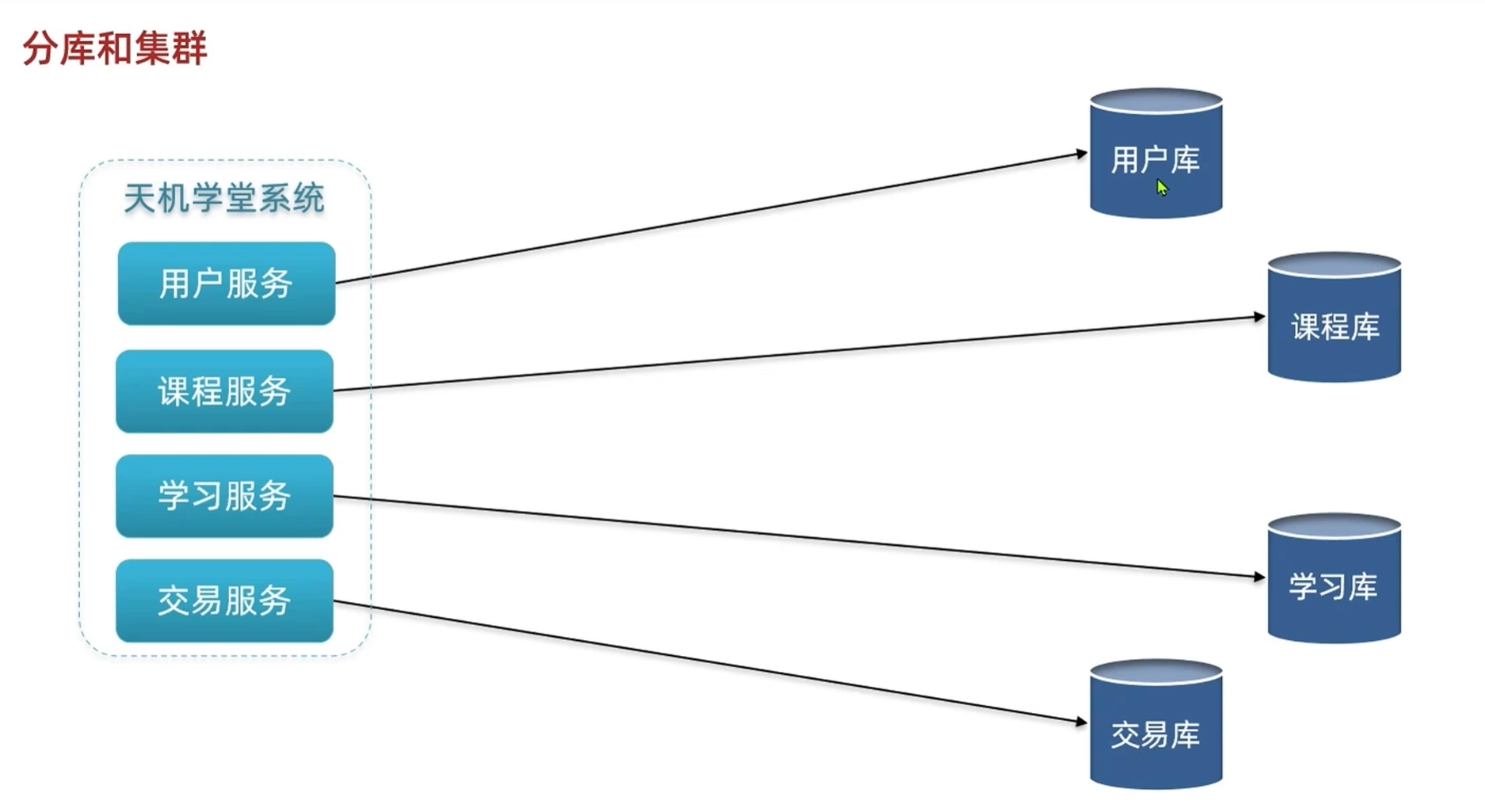
某一个库被访问的贴别多的时候,就很容易崩,这个服务只对应这一个库的时候就会单点崩溃
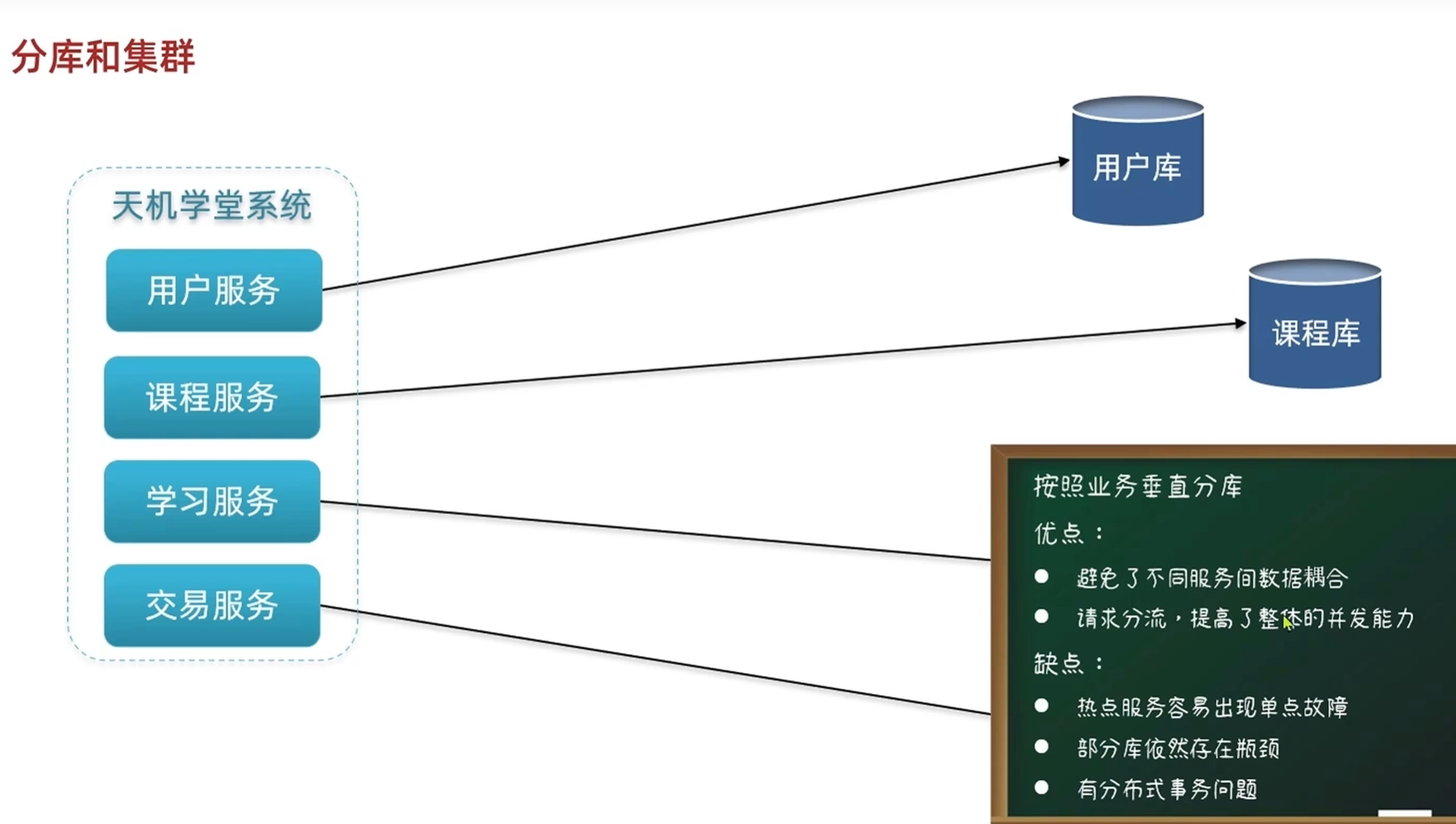
某一个服务要访问多个库的时候会涉及分布式事务问题,但也有对应的事务方法,只是在业务上比较复杂
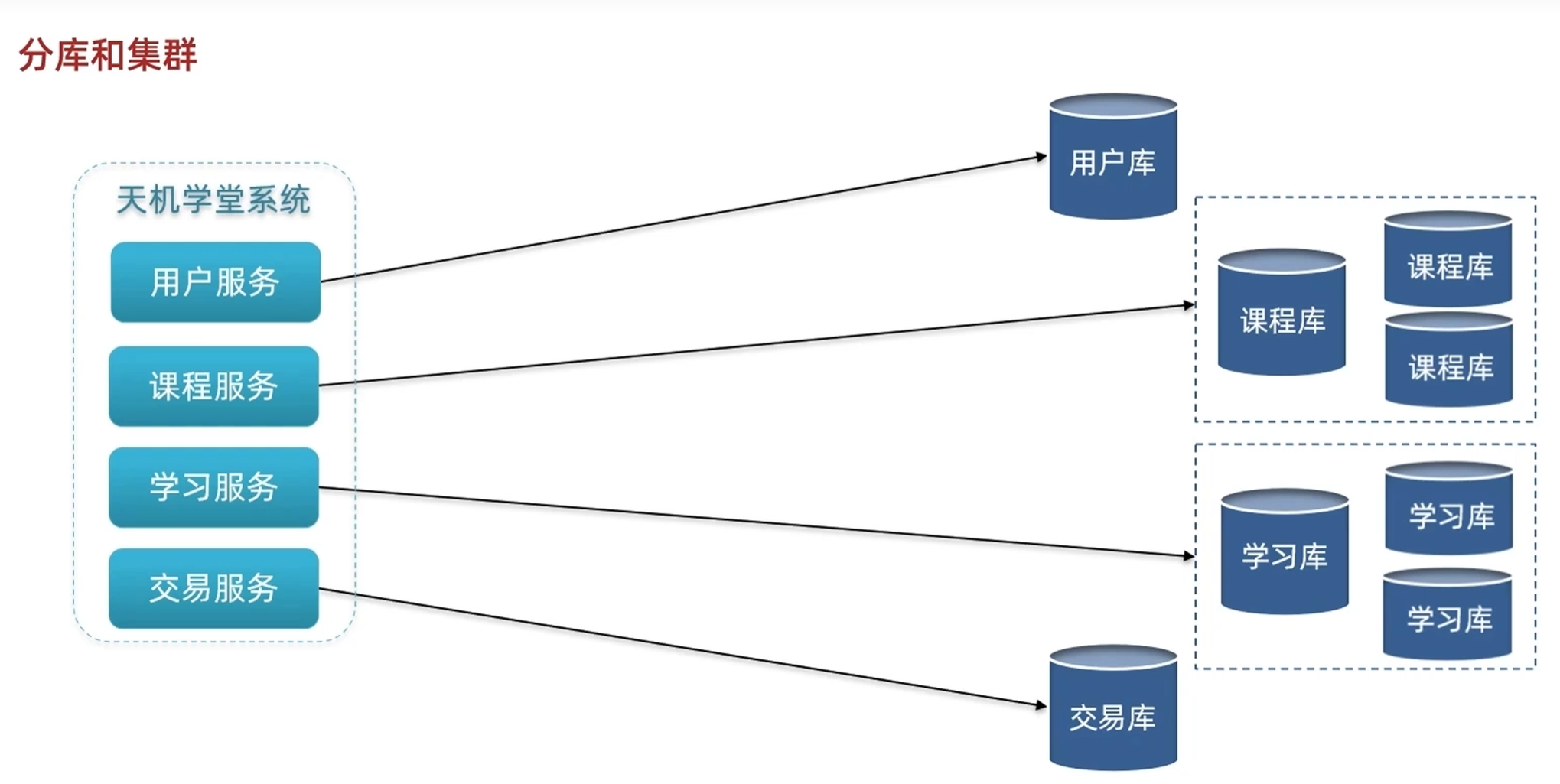
1.水平拓展:在访问的较多的库,复制成三个库,万一有库挂了就去访问其他一摸一样的库,防止单体故障,提高安全性
2.把库分成三个库,提高性能
课程库这种对于读的要求比较高的,可以复制三个库
学习库这种对于写的要求比较高的,可以分成三个库

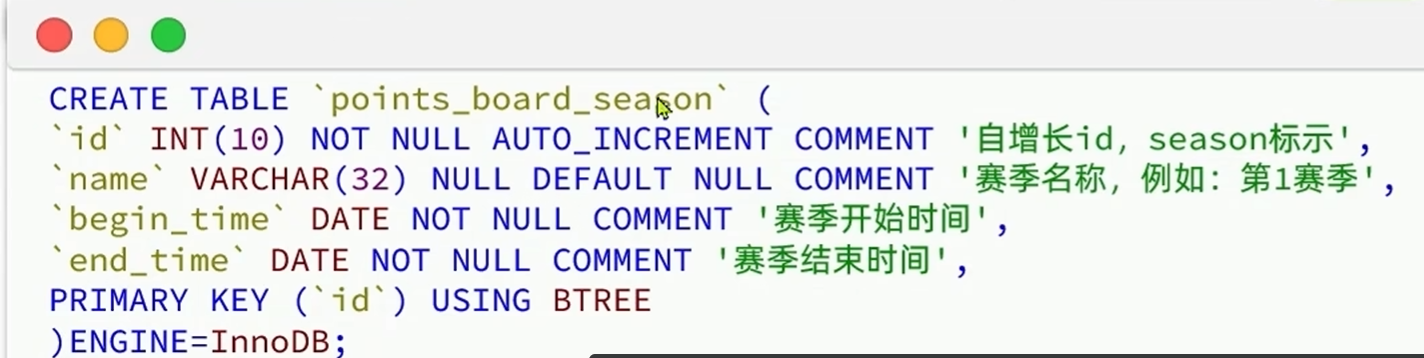
-历史榜单分表策略
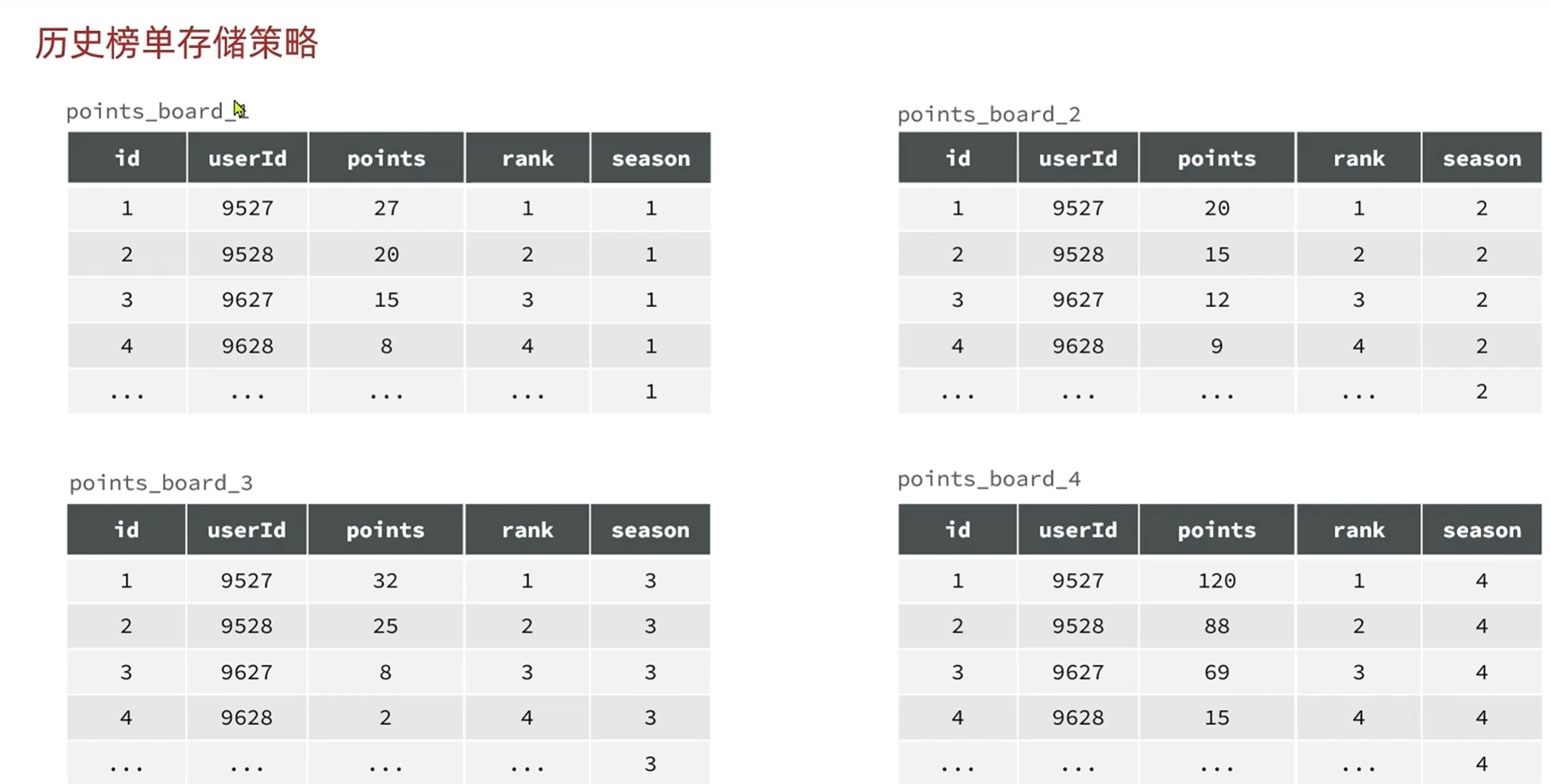
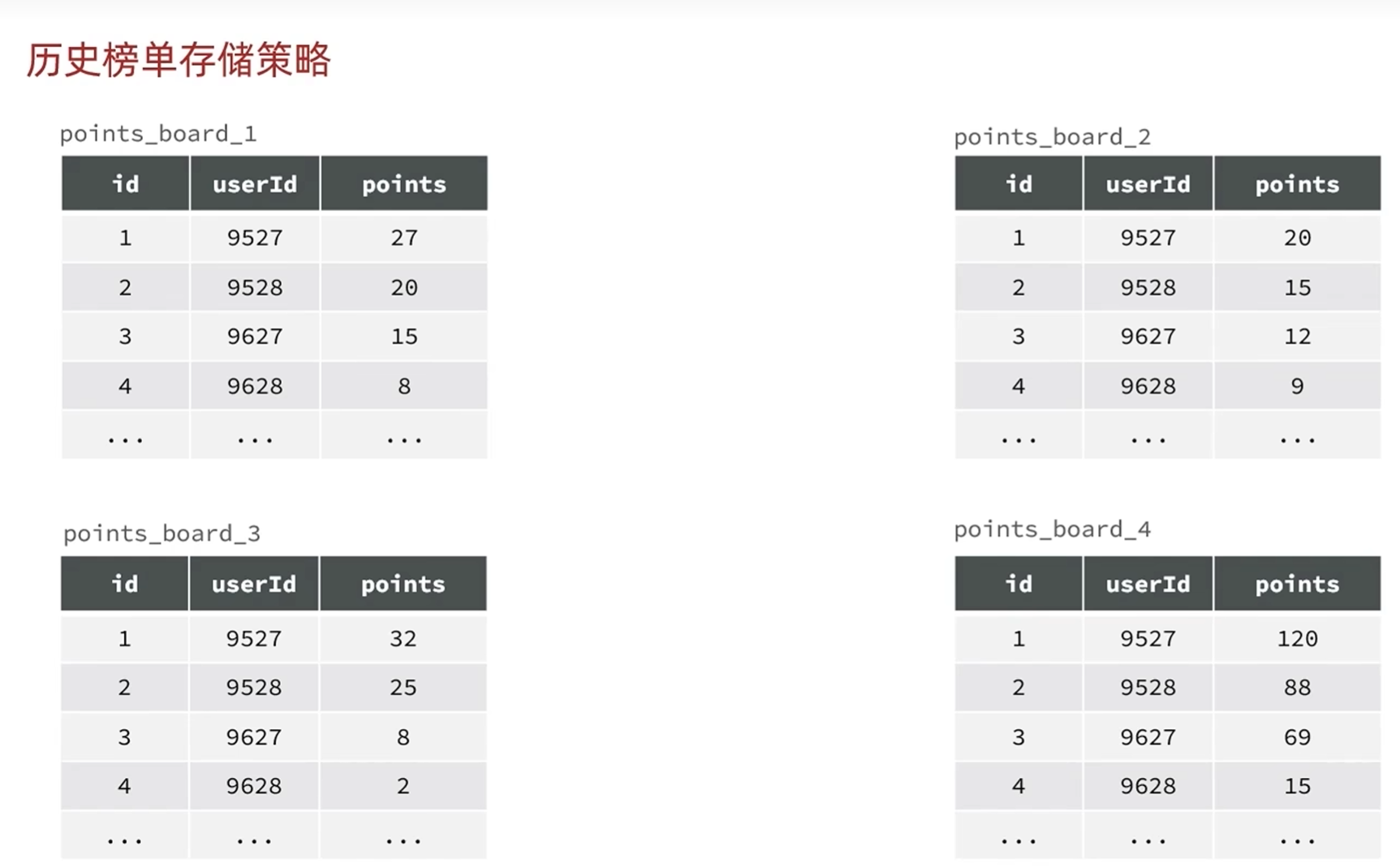
根据表id自增长的策略,合并id和rank,因为排列的时候是按照积分大小从大到小排列的
根据表名拼接赛季来区分不同的赛季,去掉赛季这个字段
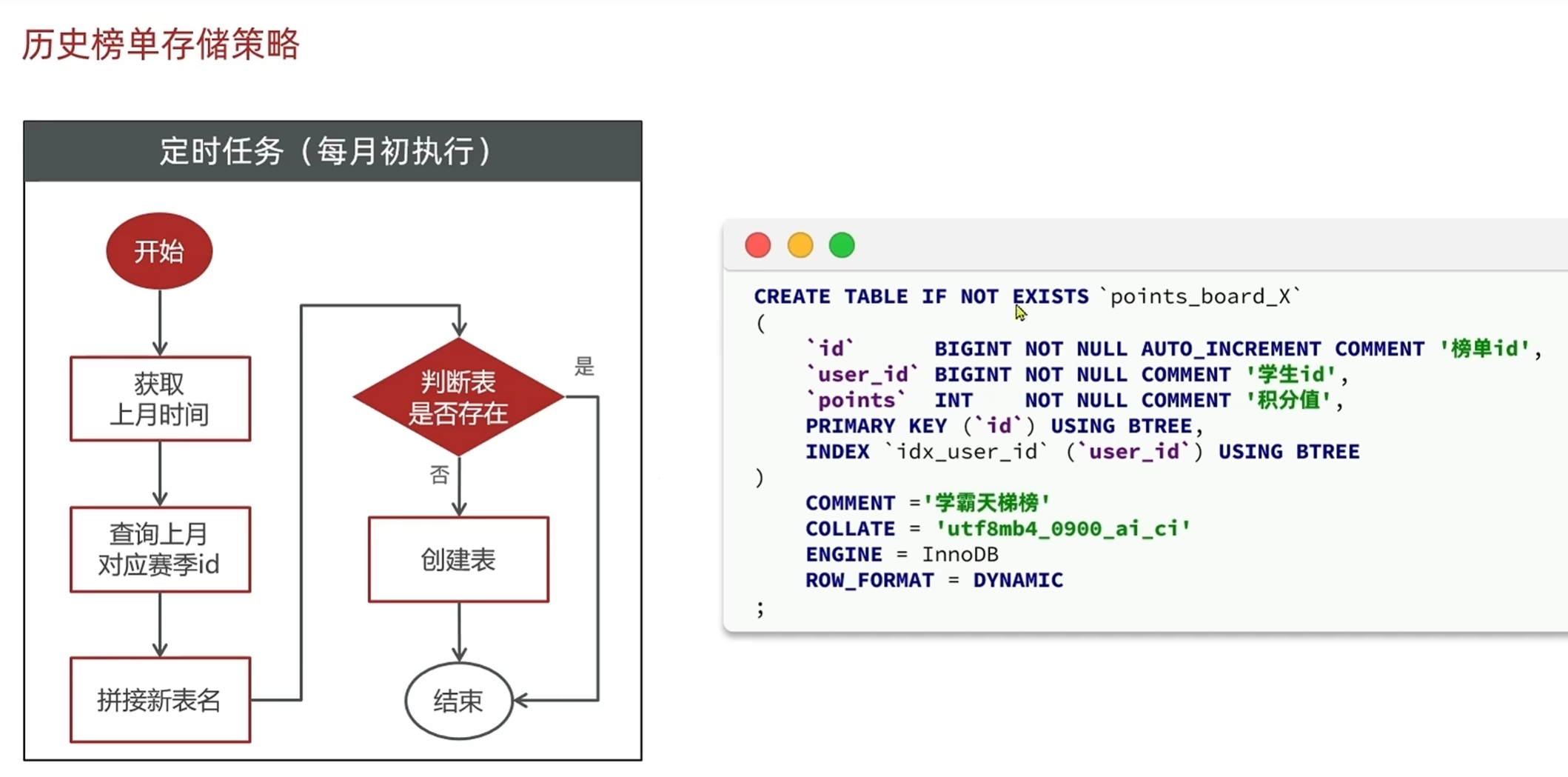
-定时生成历史榜单表
先创建一个定时实现的类
交给IOC容器管理
定时类要有一个注解@Schedule

获取上月时间:当月时间减去上个月的时间

在mapper中实现方法

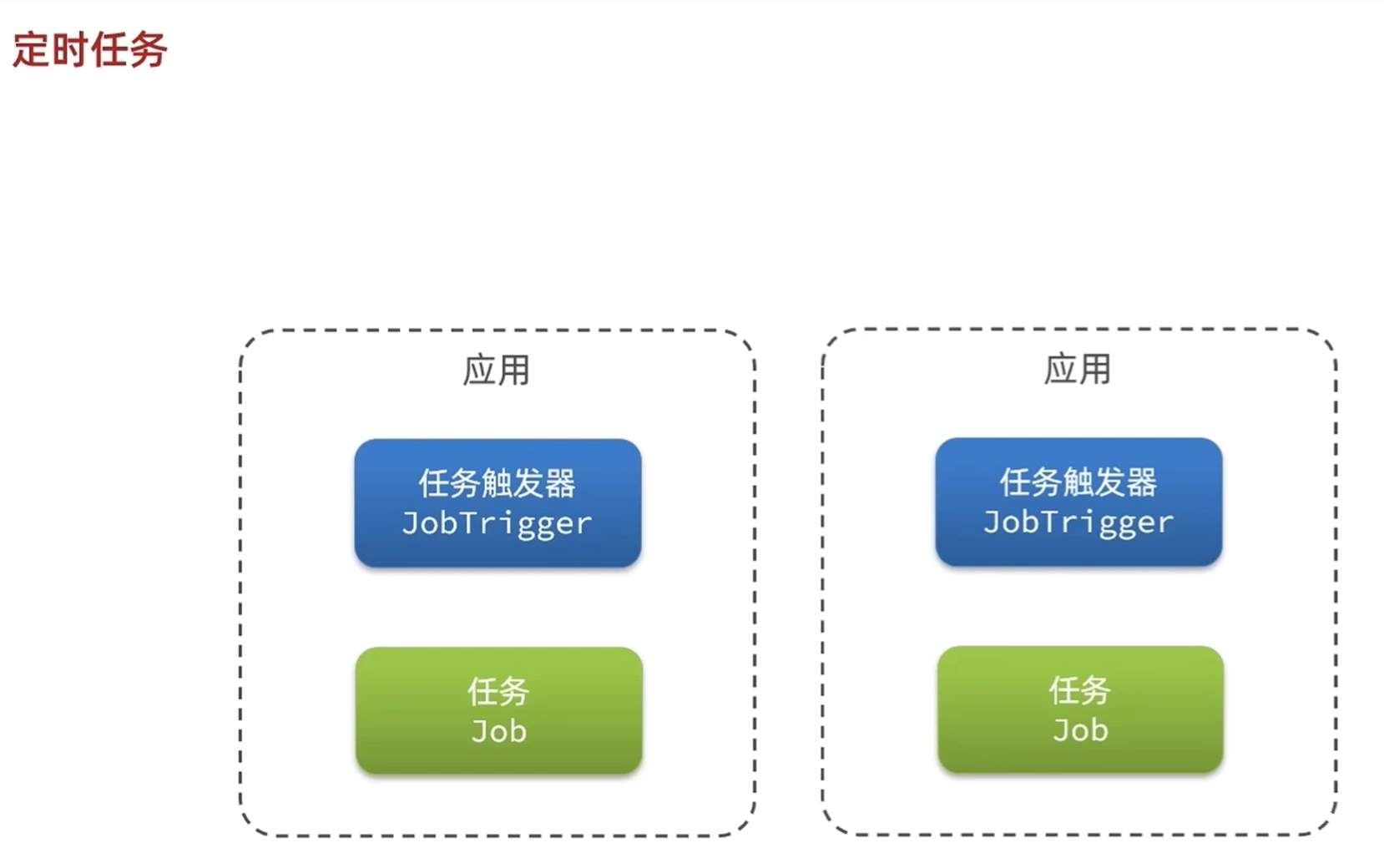
单体项目中,每有一个实例就有一个任务触发器,在微服务中一个服务可能会产生多个实例,就会有多个任务触发器,但是只想要一个任务触发器,就要把任务触发器提取出来
提取任务触发器--判断有没有任务要执行
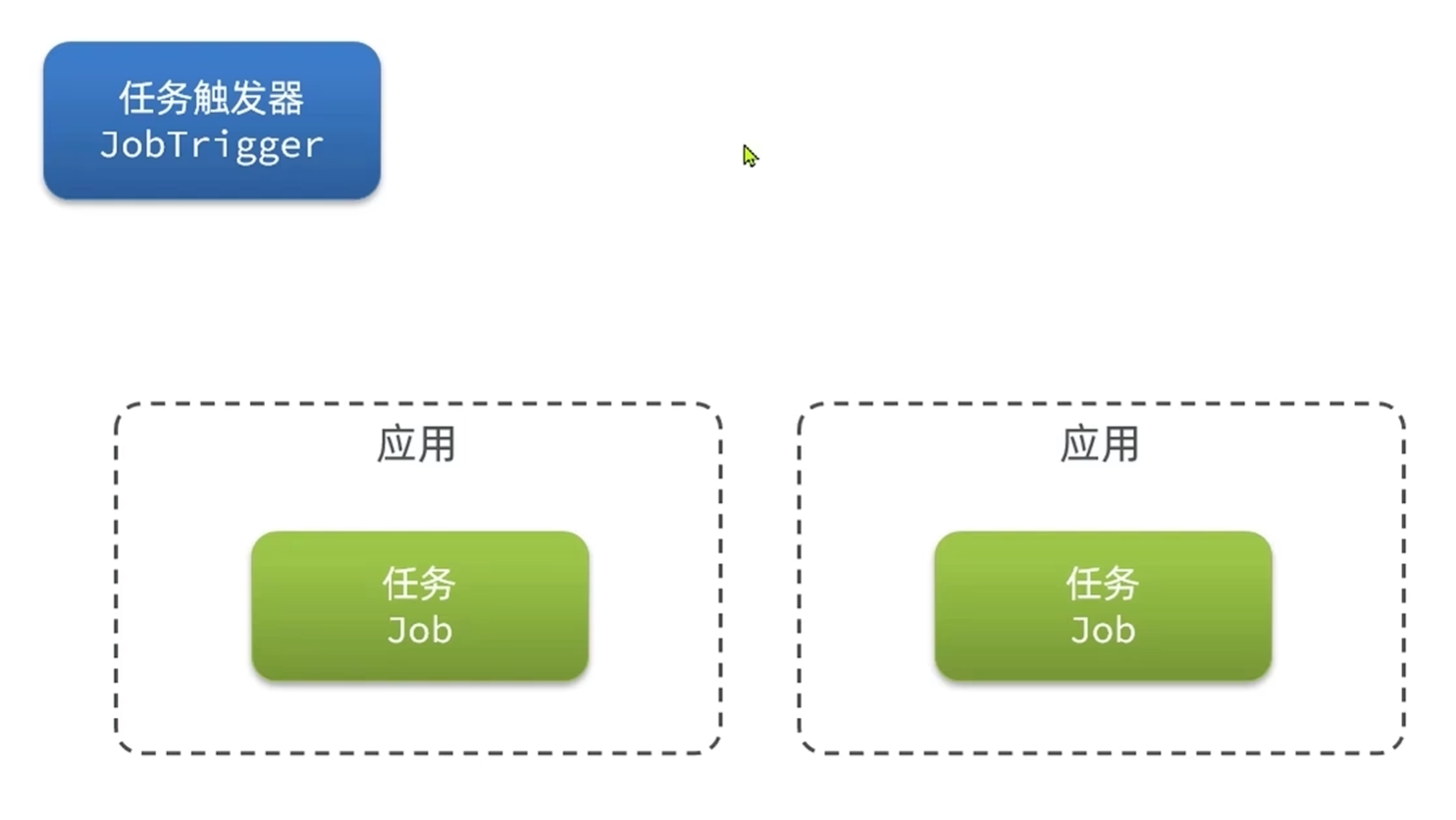
任务调度器--任务到期了如何去执行
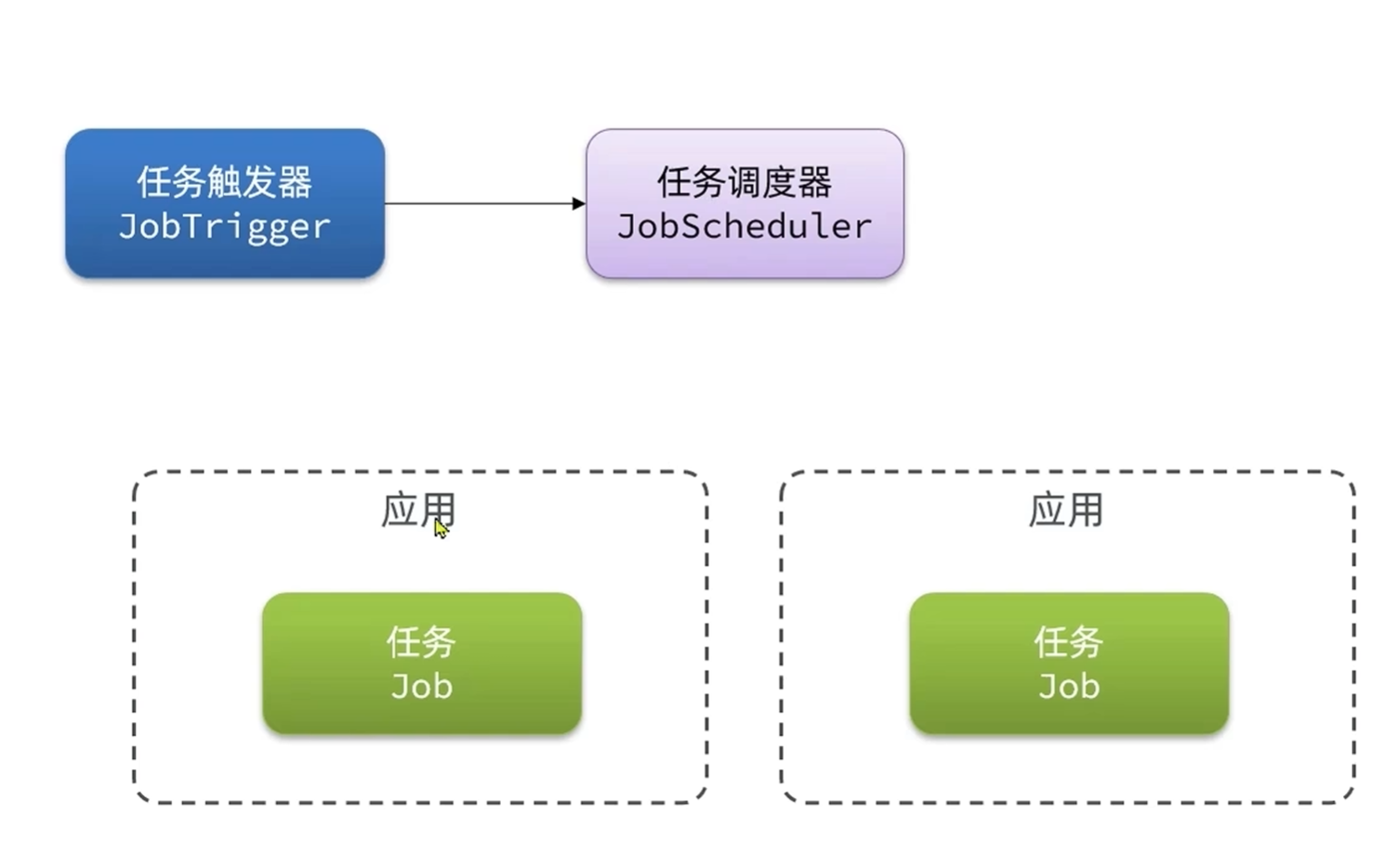
在任务到期了要去执行的时候发现有多个应用都可以执行任务,这个时候任务调度器就会根据提前定义好的规则来执行,判断要让一个任务去执行还是两个任务去执行
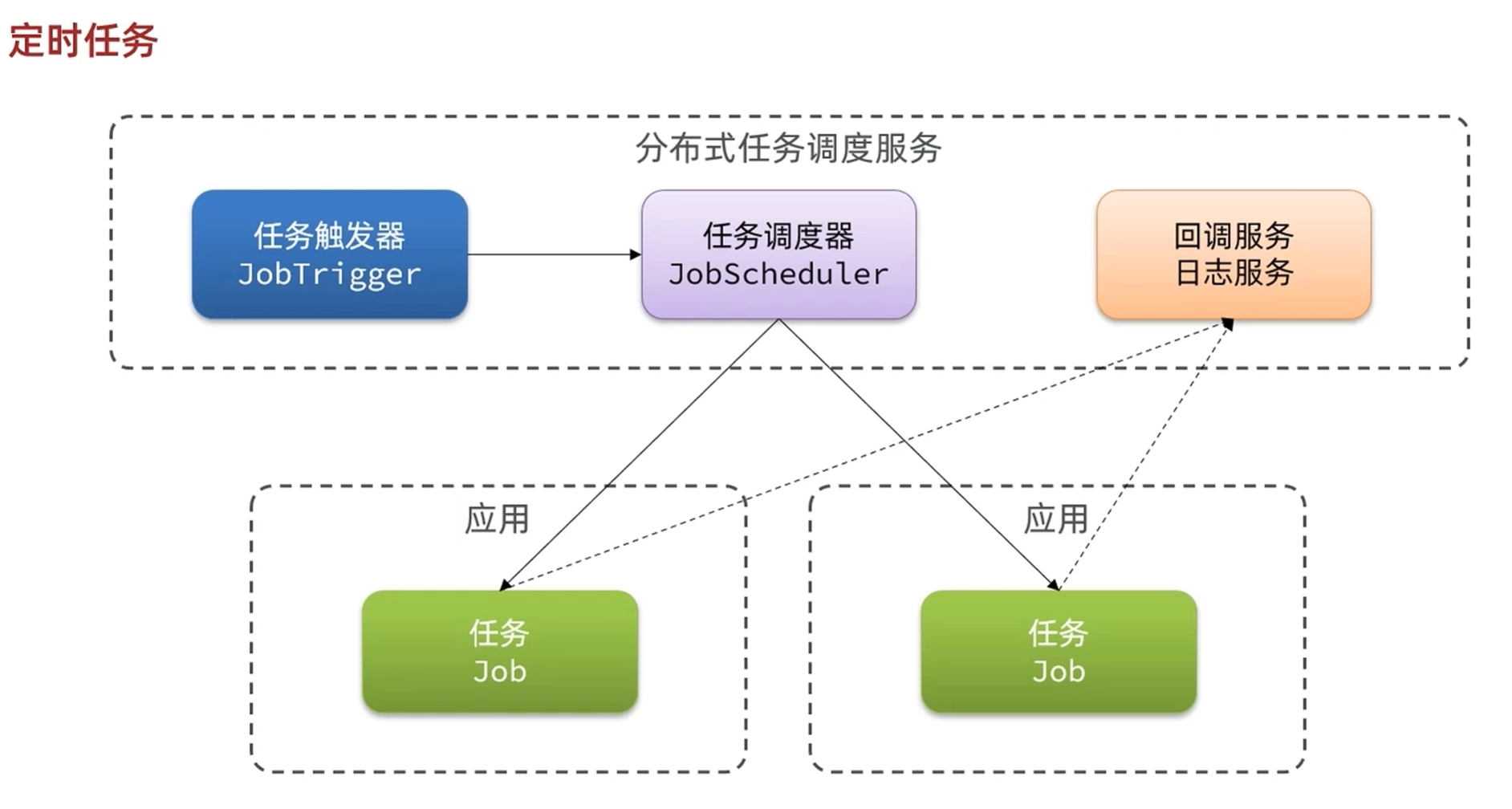
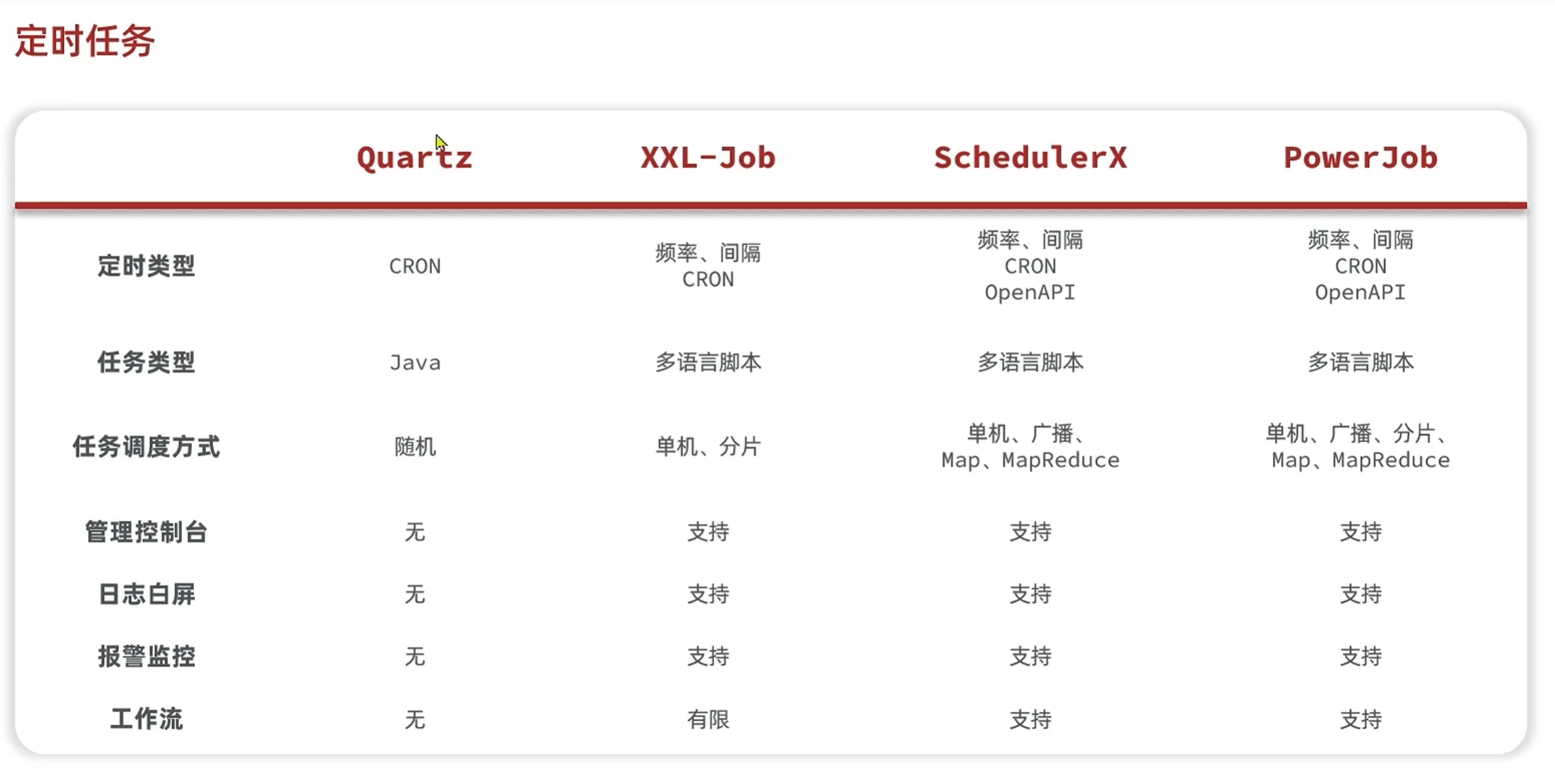
XXL Job快速入门
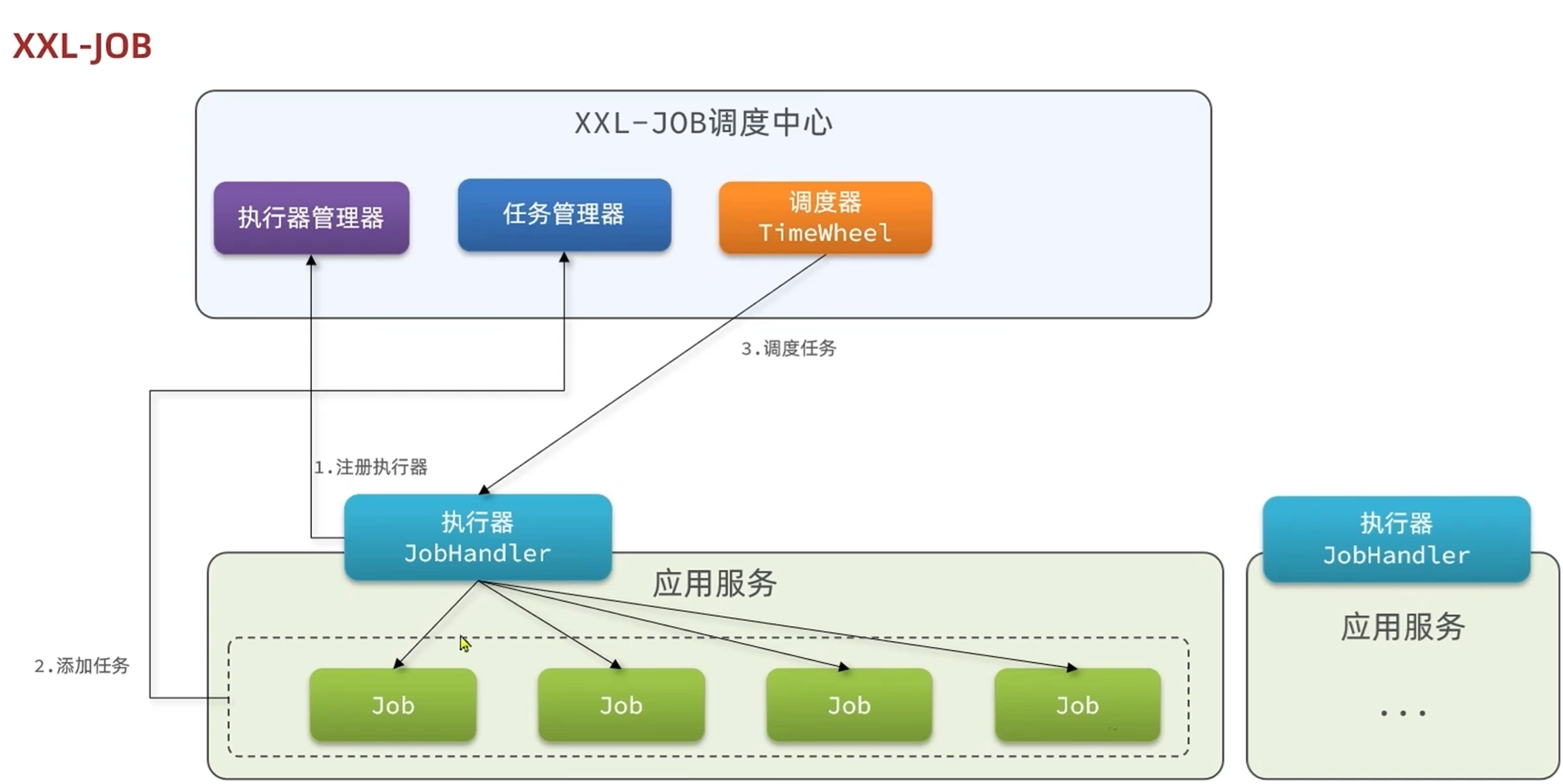
执行器管理器:管理执行器,执行器创建哈之后自动注册到执行器管理器
任务管理器:把任务添加到执行器里面,执行器和任务有绑定关系
调度器:调度器在发现定时到期的时候回去执行执行器
执行器:每个执行器对应多个服务
同一个服务产生多个实例的时候,执行器也会产生多个实例,这时候由调度器来决定是随机,轮询,一致性或者其他
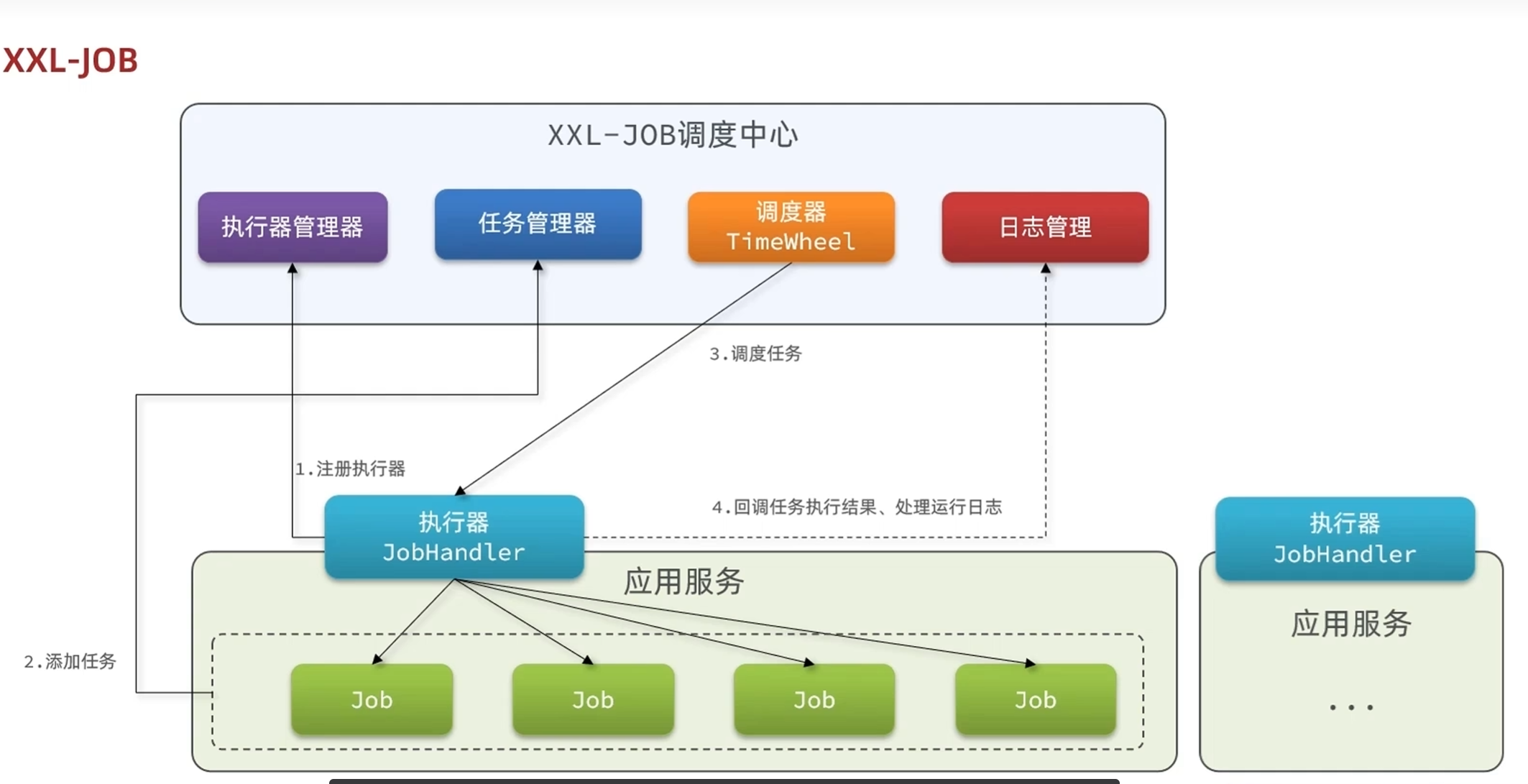
1.启动独立服务XXL-JOB调度中心
2.在应用服务中引入执行器
3.编写需要执行的任务,设置执行时间,周期
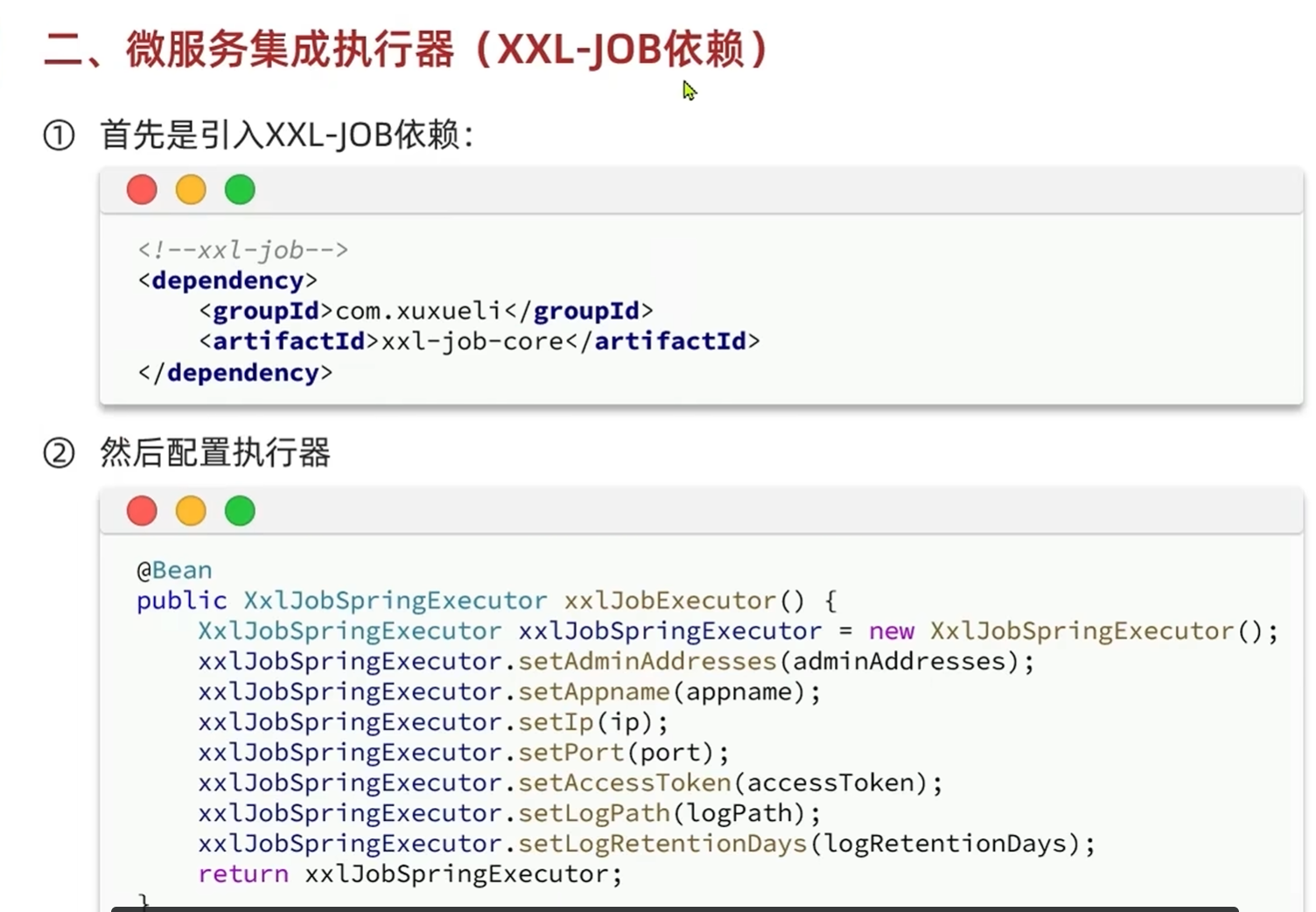
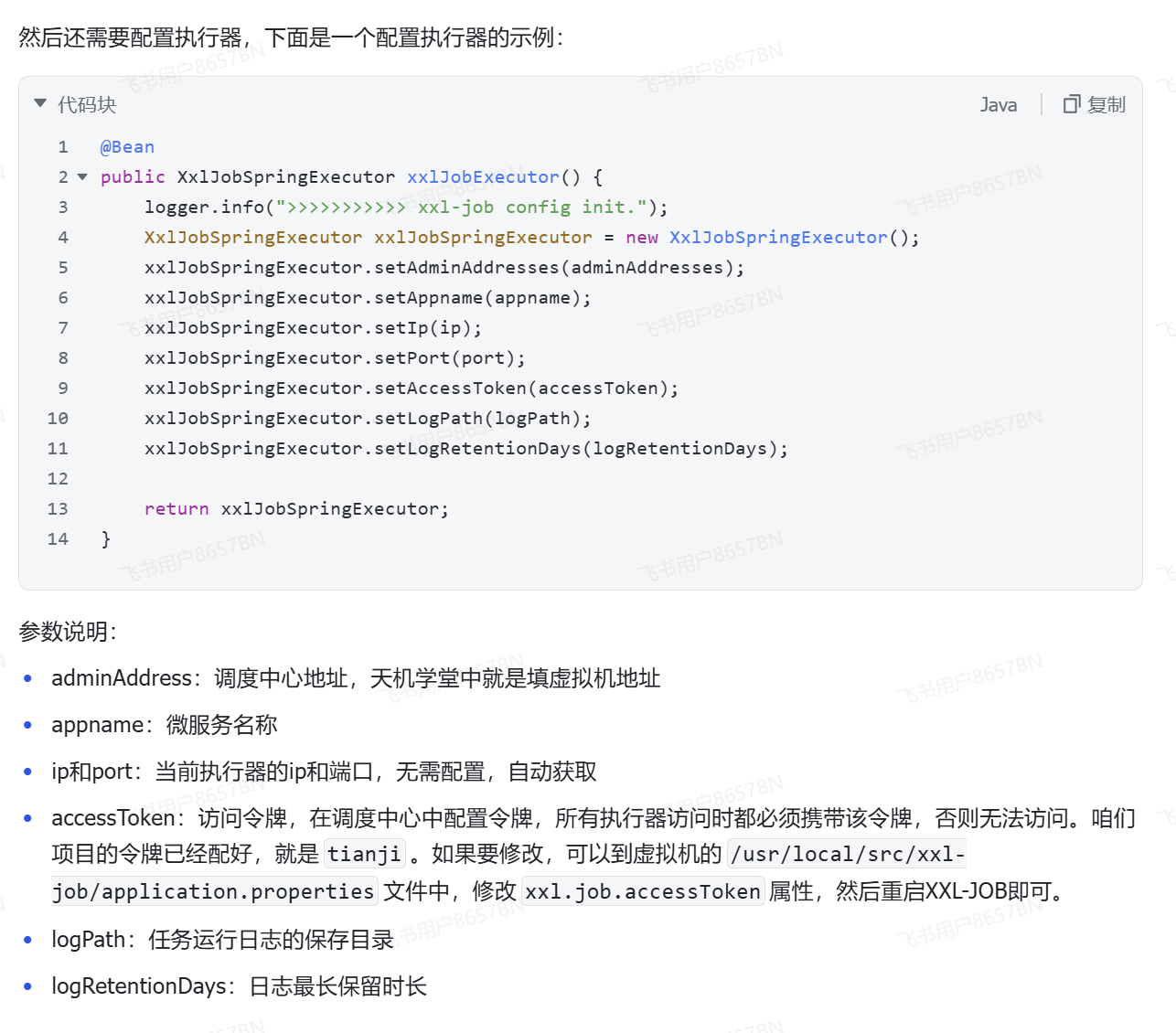
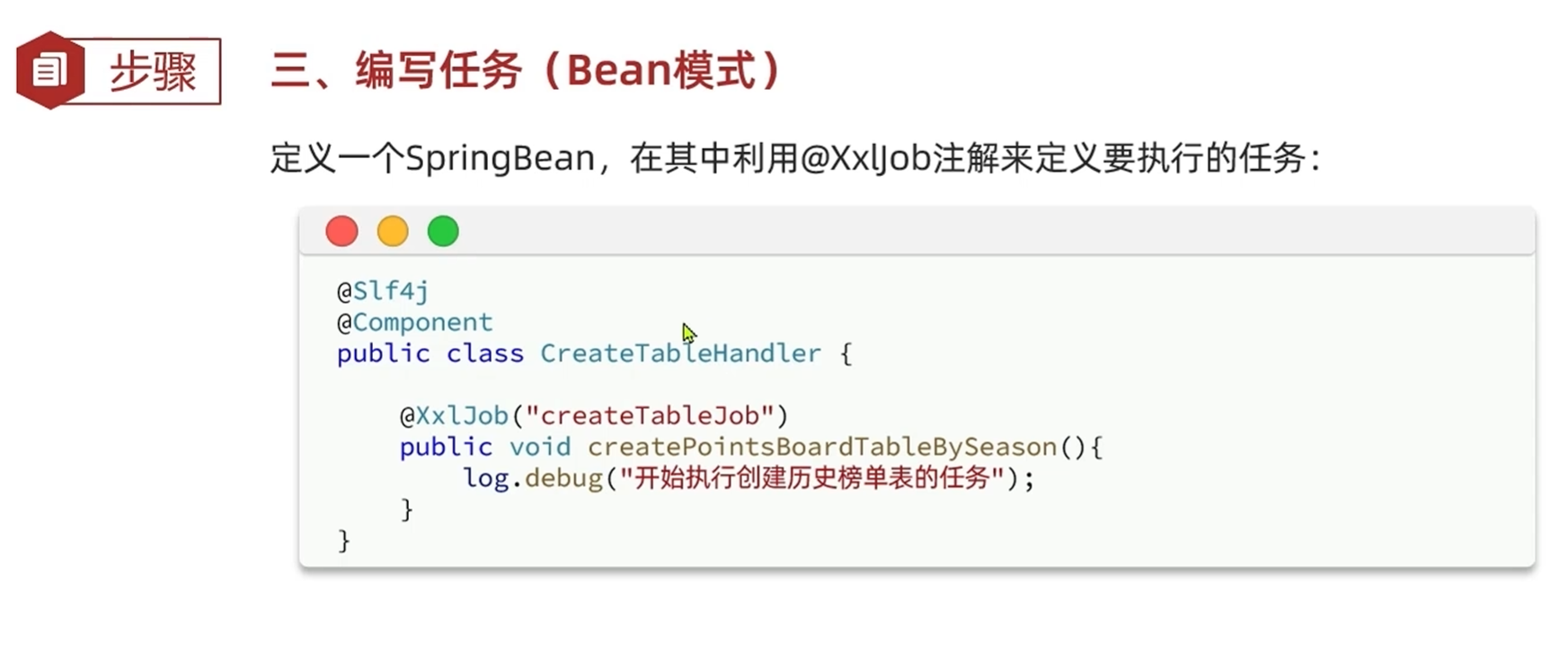
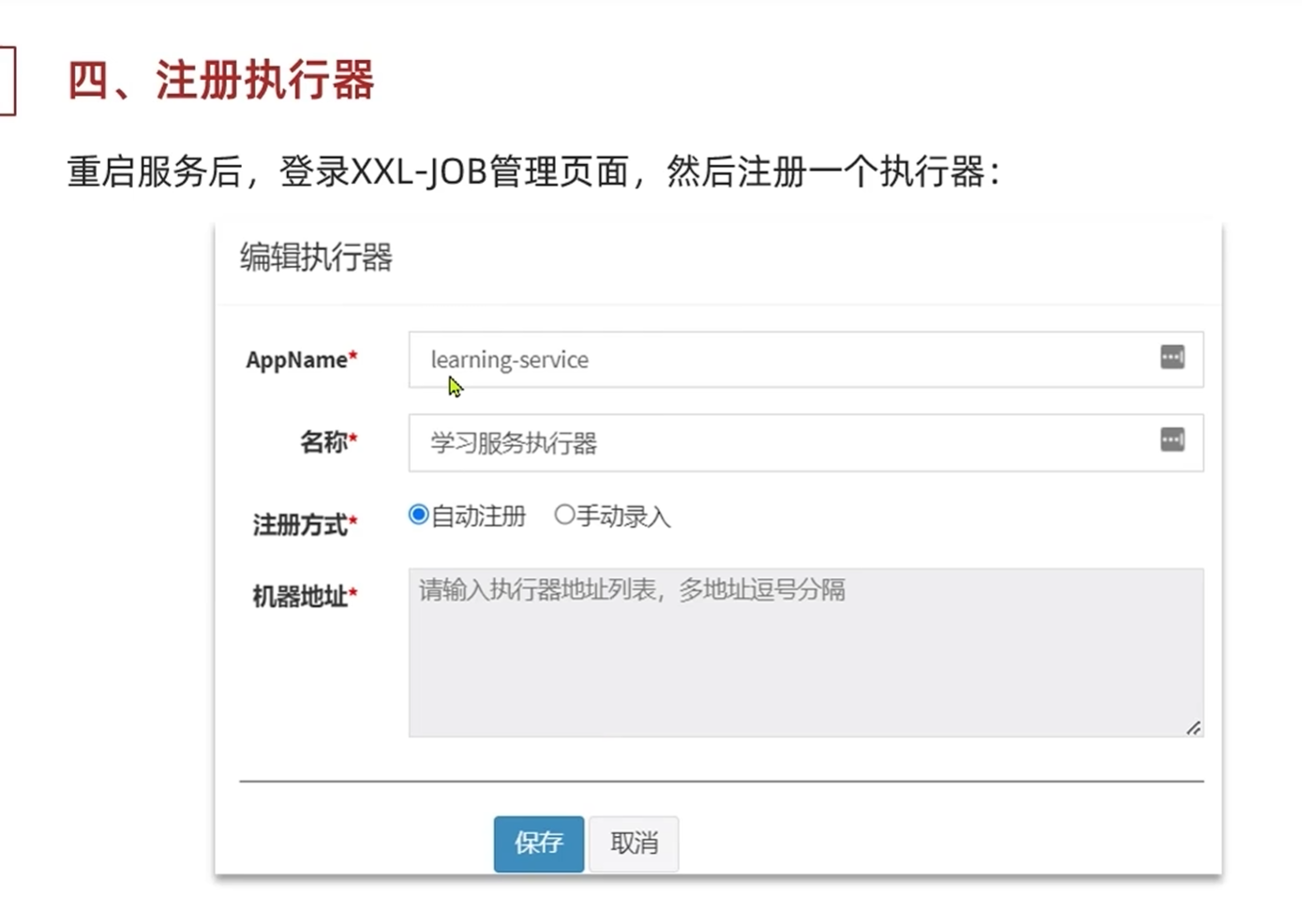
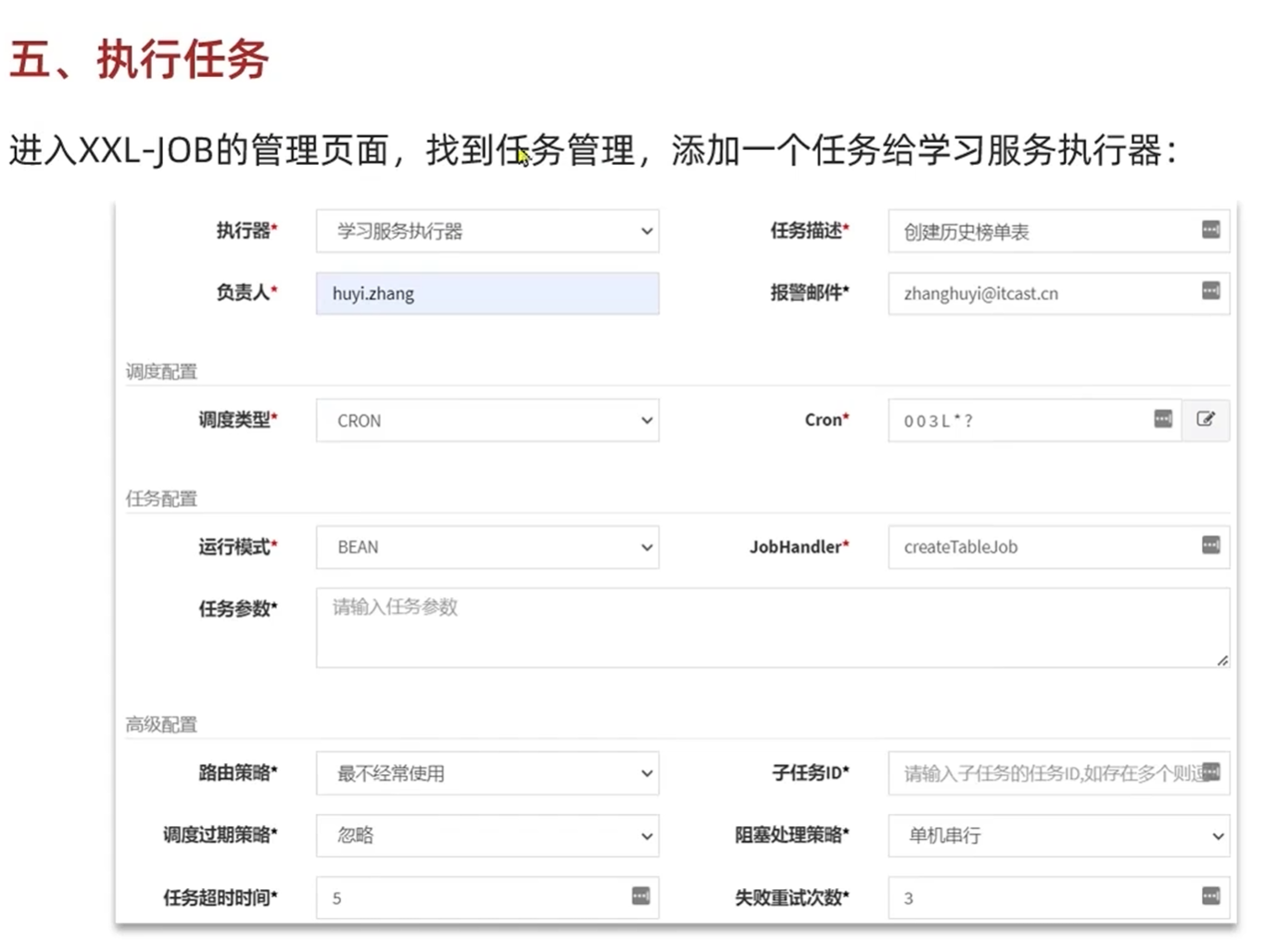
-MybatisPlus的动态表名插件
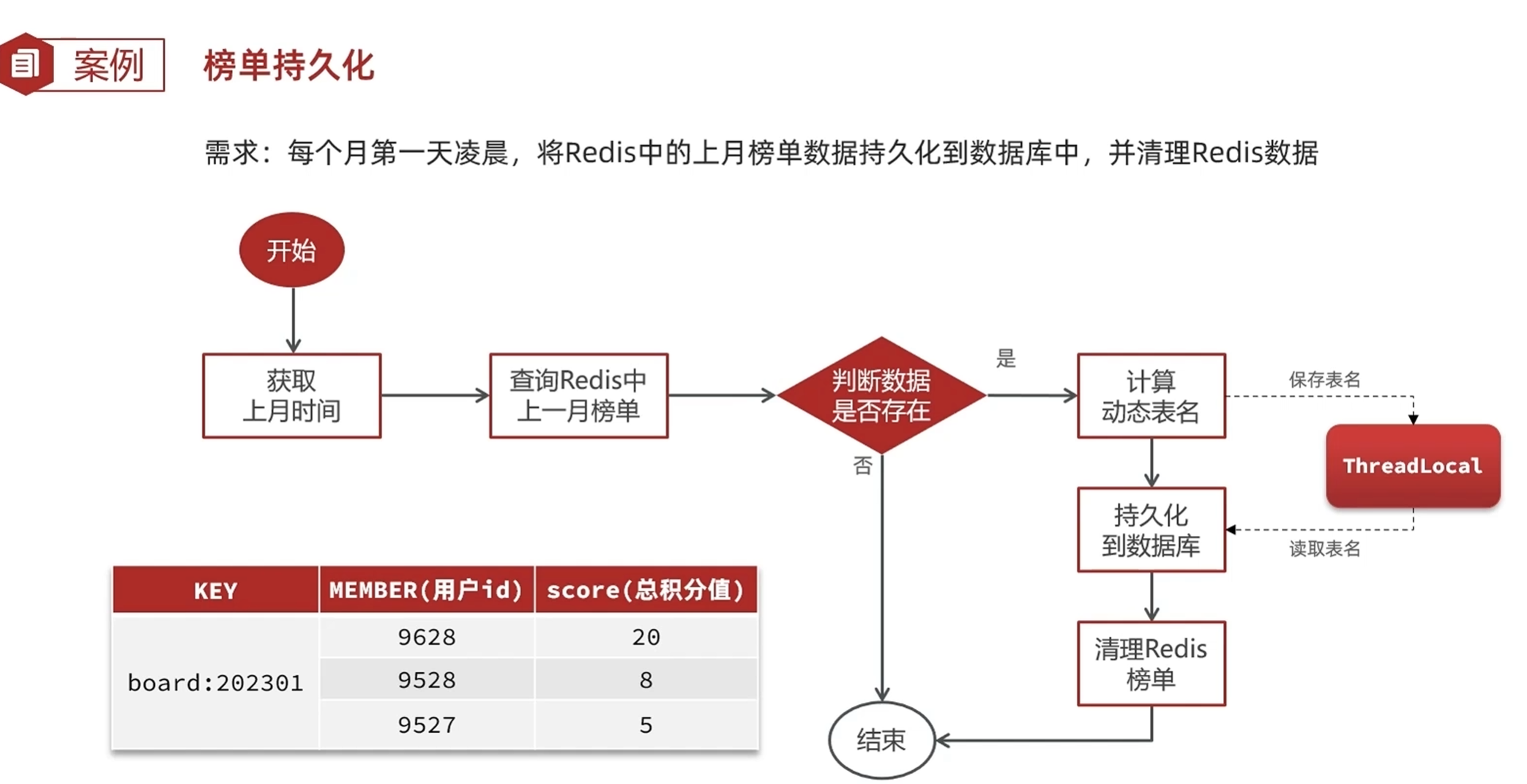
计算动态表名保存在线程中等待使用,使用完之后移除
@Slf4j
@RequiredArgsConstructor
public class PointsBoardPersistentHandler {
private final IPointsBoardSeasonService seasonService;
private final PointsBoardMapper pointsBoardMapper;
private final IPointsBoardService pointsBoardService;
//添加一个定时任务
@Scheduled(cron = "0 0 0 1 * ?")
public void savePointsBoard() {
//每月一日创建历史积分排行榜表
//1.拼接动态表名
//1.1获取上一个月的时间//现在的时间减去一个月
LocalDateTime time = LocalDateTime.now().minusMonths(1);
//1.2获取上一个月的赛季id
Integer seasonId = seasonService.querySeasonByTime(time);
//1.3动态拼接表名
String tableName = "points_board"+seasonId;
//2.创建历史积分排行榜表
pointsBoardMapper.createPointsBoardTable(tableName);
}
@XxlJob("savePointsBoard2DB")
public void savePointsBoard2DB(){
// 1.获取上月时间
LocalDateTime time = LocalDateTime.now().minusMonths(1);
// 2.计算动态表名
// 2.1.查询赛季信息
Integer season = seasonService.querySeasonByTime(time);
// 2.2.将表名存入ThreadLocal
TableInfoContext.setInfo(POINTS_BOARD_TABLE_PREFIX + season);
// 3.查询榜单数据
// 3.1.拼接KEY
String key = RedisConstants.POINTS_BOARD_KEY_PREFIX + time.format(DateUtils.POINT_BOARD_SUFFIX_FORMATTER);
// 3.2.查询数据
int pageNo = 1;
int pageSize = 1000;
while (true) {
List<PointsBoard> boardList = pointsBoardService.queryCurrentBoardList(key, pageNo, pageSize);
if (CollUtils.isEmpty(boardList)) {
break;
}
// 4.持久化到数据库
// 4.1.把排名信息写入id
boardList.forEach(b -> {
b.setId(b.getRank().longValue());
b.setRank(null);
});
// 4.2.持久化
pointsBoardService.saveBatch(boardList);
// 5.翻页
pageNo++;
}
// 任务结束,移除动态表名
TableInfoContext.remove();
}
配置类的原理
一、配置类 是干什么的?(作用)
一句话:配置类 = 告诉 Spring 要启用哪些功能、怎么运行这些功能。
对应你图片里的 MyBatis 插件配置类,作用更具体:
-
把插件注册给 MyBatis(让 MyBatis 知道有这个插件)
-
定义插件的规则(比如动态表名怎么改、分页怎么拼 SQL)
-
让插件生效(Spring 一启动,插件就开始工作)
二、配置类 底层原理是什么?(超级通俗)
我用生活例子讲,你一下就懂:
1. 配置类 = 插件的 “安装说明书”
-
你写的配置类
-
就是告诉 Spring:→ 我要装这个插件→ 插件怎么工作→ 给插件准备规则
Spring 启动时,会自动读取这个配置,把插件装到 MyBatis 里。
2. 插件本质 = 拦截器(Interceptor)
所有 MyBatis 插件,底层都是一个东西:拦截器。
工作流程:
-
你的程序执行 SQL
-
拦截器先截住
-
拦截器按配置规则修改 SQL / 参数 / 结果
-
再把修改后的 SQL 交给数据库执行
你图片里的 动态表名插件 就是:
-
拦截 SQL
-
把
points_board→ 改成points_board_202505 -
再执行
3. 配置类原理 = 注册 + 定义规则
java
运行
@Configuration
public class MyBatisConfig {
@Bean
public DynamicTableNameInnerInterceptor dynamicTableNameInnerInterceptor() {
// 1. 创建插件对象
DynamicTableNameInnerInterceptor interceptor = new DynamicTableNameInnerInterceptor();
// 2. 定义规则:points_board 表要动态改名
Map<String, TableNameHandler> map = new HashMap<>();
map.put("points_board", (sql, tableName) -> {
return tableName + "_" + season;
});
// 3. 把规则交给插件
interceptor.setTableNameHandlerMap(map);
// 4. 返回插件 → 交给Spring管理
return interceptor;
}
}
原理拆解:
-
@Configuration告诉 Spring:→ 我是配置类,启动时来读我
-
@Bean告诉 Spring:→ 把这个插件创建出来,放进容器里
-
MyBatis 自动识别MyBatis 启动时会自动从 Spring 容器中找到所有插件→ 自动加入拦截链
-
插件开始工作以后执行 SQL 都会经过插件处理
三、最终极总结(背会就能理解所有插件)
配置类的作用:
注册插件 + 定义规则 + 让插件生效
配置类的原理:
-
Spring 启动
-
加载配置类
-
创建插件对象
-
把插件交给 MyBatis
-
MyBatis 将插件加入拦截链
-
执行 SQL 时被插件拦截、处理
四、你图片里的动态表名插件
作用:
自动把表名 points_board变成points_board_赛季号
原理:
拦截 SQL → 改表名 → 执行新 SQL
所有的插件都是对象
1. 一句话结论
不管是 MyBatis 插件、Spring 插件、还是你图片里的分页 / 分表插件,本质全都是:一个 Java 类 → new 出来的 → 对象!
没有任何神秘的东西。
2. 为什么配置类里要写 @Bean?
因为:Spring 只认对象,不认 “功能”。
你想让插件生效,必须:
-
写一个类(比如
DynamicTableNameInnerInterceptor) -
把它 new 出来 → 变成对象
-
把对象交给 Spring 管理
所以配置类干的事就是:
java
运行
@Bean
public 插件对象 方法名() {
// 1. 创建插件对象
插件 plugin = new 插件();
// 2. 配置插件规则
plugin.setXxx(...);
// 3. 返回对象 → 交给Spring
return plugin;
}
插件 = 对象配置 = 给对象设置规则
3. 所有插件都是对象,包括这些:
plaintext
MybatisPlusInterceptor → 对象
PaginationInnerInterceptor → 对象
DynamicTableNameInnerInterceptor → 对象
MetaObjectHandler(自动填充) → 对象
它们全部是 Java 实例(对象)。
4. 插件工作原理(最本质版本)
-
插件是一个对象
-
这个对象实现了 Interceptor 接口
-
MyBatis 启动时会把所有插件对象放进一个列表
-
执行 SQL 时,MyBatis 会依次调用这些插件对象
-
每个插件对象做自己的逻辑(改表名、分页、填充字段…)
一句话:插件 = 拦截器对象
5. 超级好记的总结(背会这三句)
-
所有插件都是对象
-
配置类就是创建插件对象
-
Spring 管理这些插件对象
6. 你图片里的插件,也是对象!
java
运行
DynamicTableNameInnerInterceptor a = new DynamicTableNameInnerInterceptor();
这行代码就是:创建一个动态表名插件对象!
配置类就是创建并配置这些插件对象
核心知识点回顾
-
所有插件的本质,都是一个 Java 对象不管是动态表名、分页插件,还是自动填充,它们全都是实现了特定接口的类实例,和你自己写的普通
new Object()没有本质区别。 -
配置类的作用,就是创建并配置这些插件对象
-
@Configuration:告诉 Spring 这是一个配置类,启动时会扫描并加载它。 -
@Bean:方法里new出插件对象,设置好规则,然后交给 Spring 容器管理。 -
插件对象被 Spring 管理后,MyBatis 会自动识别并把它加入到 SQL 执行的拦截链中。
-
-
插件的工作流程:拦截 → 处理 → 放行当你的业务代码执行 SQL 时,MyBatis 会把这条 SQL 依次交给拦截链上的所有插件对象。每个插件对象根据你配置的规则(比如 “遇到
points_board就改表名”)处理完 SQL 后,再交给下一个插件,最终执行修改后的 SQL。
💡 一句话总结
配置类就是插件的 “出生证和安装说明书”,插件本身就是个等待被 Spring 调用的对象。
-数据跑批业务和XXL Job的分片广播

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)