Linux:模拟实现Shell命令行解释器
在学习过前面的关于进程控制的所有知识之后,我们就可以自主模拟实现一个shell命令行解释器。因为我们在 Xshell 上输出指令,然后由操作系统内核读取到指令再运行。这一过程当中输入的指令,本质上就是在输入字符串。并且因为命令行解释器会不断地读取我们输入的字符串,也就是说命令行解释器本质上是一个死循环的可执行程序文件。
1. 命令行提示符
在学习过前面的关于进程控制的所有知识之后,我们就可以自主模拟实现一个shell命令行解释器。因为我们在 Xshell 上输出指令,然后由操作系统内核读取到指令再运行。这一过程当中输入的指令,本质上就是在输入字符串。并且因为命令行解释器会不断地读取我们输入的字符串,也就是说命令行解释器本质上是一个死循环的可执行程序文件。
首先第一步,我们要把 Linux Shell 命令行提示符 先给打印出来,就是这个东西:

这分别表示用户名、主机名和当前工作目录,对于操作系统来说,是直接通过系统调用的方式获取到的这三个信息,考虑到我们是自主模拟实现,就没必要这么复杂了,因为如果我们要自己去进行函数调用的话步骤会是这样的:自己从内核拿原始数据 → 自己查表 → 自己转字符串 → 自己管理缓冲区 → 自己处理错误。这比较繁琐。
因为用户名、主机名和当前工作目录都是存储在环境变量列表里面的,所以我们可以直接封装一个函数,然后读取环境列表中对应的信息再返回即可:
1 #include <stdio.h>
2 #include <unistd.h>
3 #include <stdlib.h>
4
5 const char *GetUserName()
6 {
7 char *name = getenv("USER");
8 if(name == NULL)
9 {
10 return "None";
11 }
12 return name;
13 }
14
15 const char *GetHostName()
16 {
17 char *hostname = getenv("HOSTNAME");
18 if(hostname == NULL)
19 {
20 return "None";
21 }
22 return hostname;
23 }
24
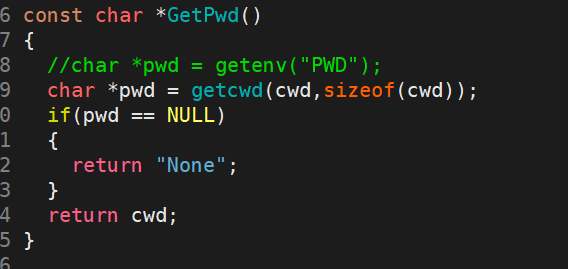
25 const char *GetPwd()
26 {
27 char *pwd = getenv("PWD");
28 if(pwd == NULL)
29 {
30 return "None";
31 }
32 return pwd;
33 }
34
35 void PrintCommandLine()
36 {
37 printf("[%s@%s %s]$ ",GetUserName(),GetHostName(),GetPwd());
38 fflush(stdout);
39 }
40
41
42 int main()
43 {
44 while(1)
45 {
46 PrintCommandLine();
47 sleep(1);
48 }
49 return 0;
50 } 并且我们输入指令时,是在用户名、主机名和当前工作目录后面输入指令的,所以这里我们将这三个信息打印出来的时候,并没有用 \n 的方式去刷新缓冲区,而是使用了 fflush 的方式,否则输入指令将会在用户名、主机名和当前工作目录这三个信息下面输入。
得到的效果是这样的:

2. 获取用户输入
但是这样的操作是有问题的,因为这里打印了很多次,而我们是希望命令提示符打印出来一次之后就停在这里,等待我们输入命令,直到下一条指令再打印出来一次,这样进行循环。
所以我们得控制命令行提示符的停止的同时,去读取从键盘获取的信息。大家首先想到,从键盘读取信息,用C语言写的话肯定是 scanf 喽,但是 scanf 会以空格键为分隔符,但是我们平时输入的命令,只是以空格做隔开,本质上还是一个整体,所以我们就需要调用一个函数:fgets。
char *str:存储读取内容的字符数组首地址,作为数据写入目标。int num:最大读取字符数上限,函数最多读取num-1个字符,并自动在末尾补充\0结束符,防止数组越界。FILE *stream:输入数据源文件流,传入stdin代表从键盘标准输入读取数据。
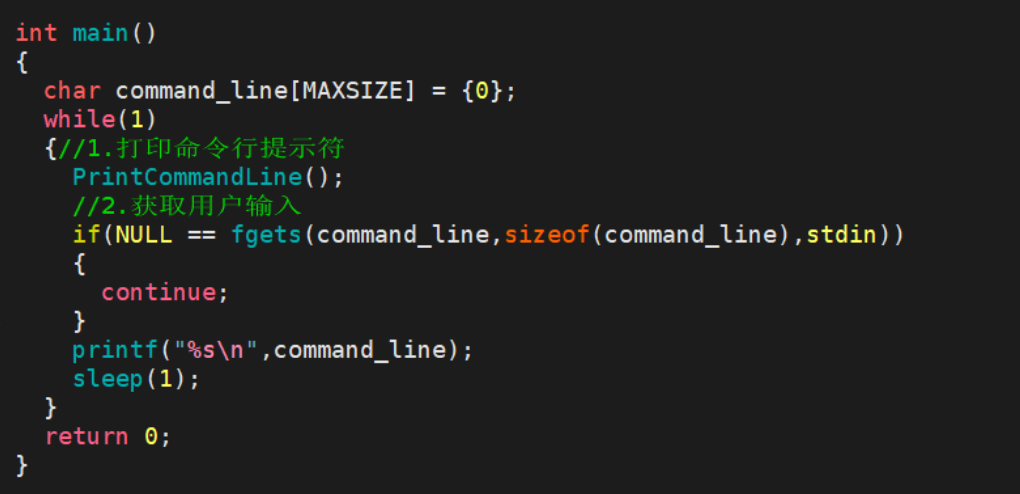
fgets 就是 从输入流里 “读一行字符串” 的函数。这里用的是 stdin(标准输入),stdin 就是键盘。所以系统就等着用户从键盘敲字符,直到按下回车,把这一整行读到数组里。command_line就是我们要将从键盘中读取到的信息要存储的位置。并且会是这个逻辑:读到内容了→ 返回数组地址(非 NULL);没读到内容(读到 EOF / 出错)→ 返回 NULL。
如果没有读取到内容,进入if条件语句当中,执行 continue ,直接跳过本次循环后面所有代码(printf、sleep全部不执行),再次打印命令行提示符。

但是我们执行的结果好像有点偏差,输入ls -al之后,确实打印出来了,但后面还跟着一行空格。这说明执行了两次换行,我们代码里面的printf函数里带了一个 \n ,那另一个 \n 是从哪来的呢?这其实是fgets函数的一个坑:当我们写完 ls -al 的指令之后,需要按下回车表示当前命令已经输入结束,开始执行。但是 fgets 会把你按下回车输入的 \n 换行符,一并读入数组,也就是说,你敲回车结束输入,\n 会被当成普通字符存进 command_line,然后打印出来。
举个例子:
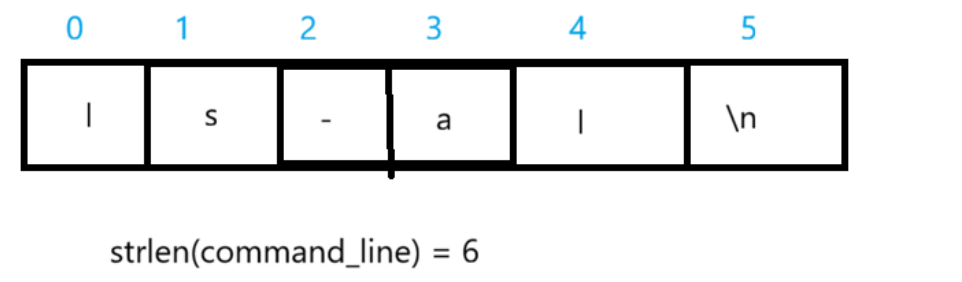
当我们输入 ls -al 的时候,算上空格其实有6个字符,再加上 \n 实际上是 7 个字符,所以我们要做的就是将数组里的最后一位给置空,也就是将 \n 设置成 \0 即可:
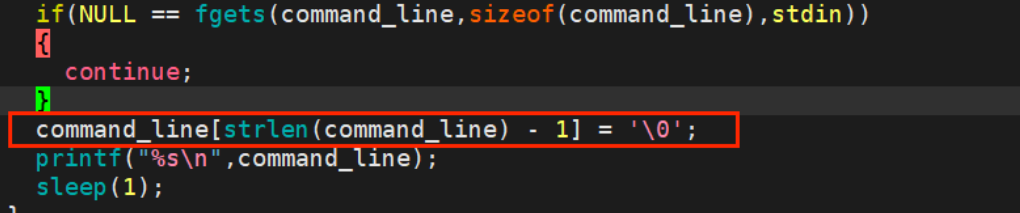
并且在用户输入的时候,就算什么都不输入,也要按下一个回车键表示结束,那在数组中对应的就是一个 \n ,所以数组的大小就是 1 ,那也就不用担心数组越界的问题。
然后我们将命令行提示的获取字符并判断是否为空字符的逻辑封装成一个函数,便于后续管理维护代码:
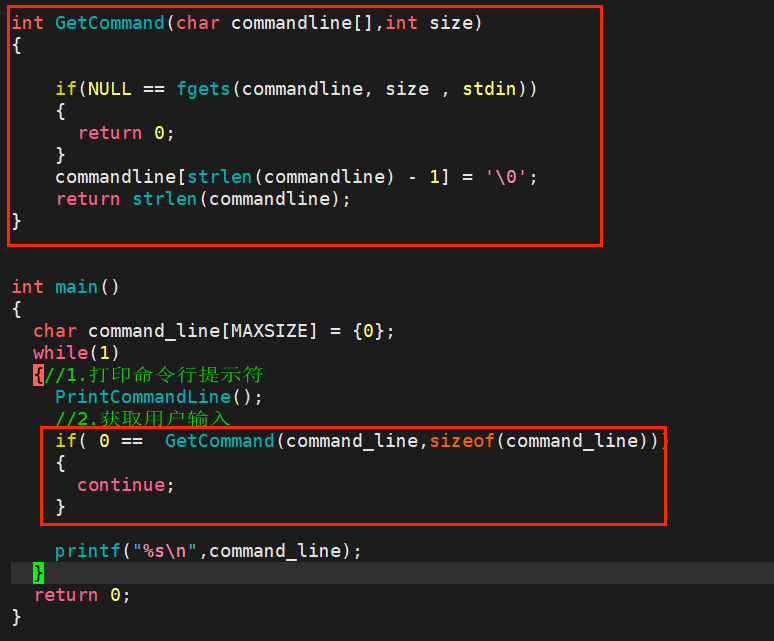

得到的效果就如上图所示。
3. 解析字符串
我们刚才只是从键盘当中获取到了用户的输入,但真正的命令行解释器还要对用户输入进行解析并执行操作。因此我们可以用到前面学习过的程序替换函数来实现操作,那么首先就需要一个命令行参数列表。
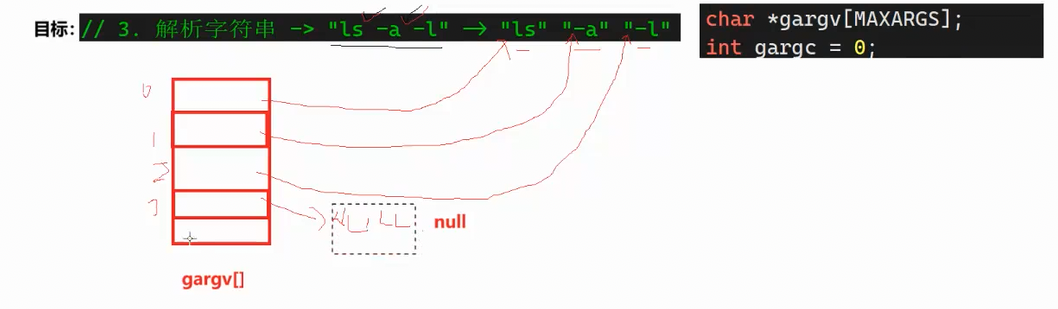
我们的目的就是让这个命令行参数列表先去存储获得的字符串,并在最后以NULL结尾。我们就需要strtok这个函数。
char *strtok(char *str, const char *delim);- str:要切割的字符串
- delim:分隔符(比如
" "空格、"\n"换行)
这里所谓的“要切割的字符串“,并不是传参的时候就传一个字符串,要记住 strtok 函数第一个参数只能传数组,因为strtok函数会修改原字符串!它会把分隔符的位置替换成 \0 。所以就直接传我们的command_line数组。另外,这个函数如果想要连续切割字符串,第二次必须传 NULL,传 NULL 代表:继续切上一次剩下的字符串。但是传NULL的话,strtok是怎么知道该切割哪一个字符串的呢?这是因为,strtok 内部有一个静态变量 static char :它会永久记住你第一次传进来的字符串位置。所以第一次传数组代表你告诉它切谁,后面它自己知道切谁。 这就是strtok函数的设计:
- 非 NULL = 重新开始切一个新字符串
- NULL = 继续切上一个字符串
另外,分隔符为了方便维护和安全性,我们直接定义成一个变量:char *gsep = " ";
所以我们可以这样去写函数:
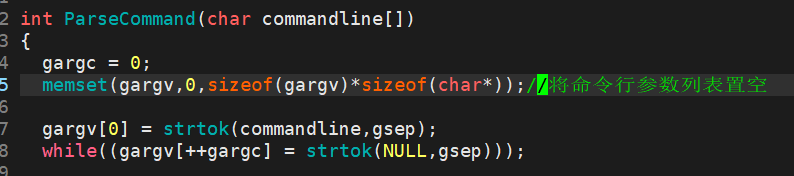 因为我们的命令行参数列表定义的是全局变量,所以在每一次进行切割新的字符串的时候要先置空。另外,第一次让命令行参数列表的第一个位置存储切割出来的第一个内容,后续直接使用while循环去切,这里的逻辑是:
因为我们的命令行参数列表定义的是全局变量,所以在每一次进行切割新的字符串的时候要先置空。另外,第一次让命令行参数列表的第一个位置存储切割出来的第一个内容,后续直接使用while循环去切,这里的逻辑是:
在 C 语言中,赋值操作具有返回值,该值即为赋值运算符右侧表达式的计算结果。因此,gargv[++gargc] = strtok(NULL, gsep) 这一表达式会先完成字符串切割与数组赋值操作,再将strtok 的返回值作为整个表达式的结果,供 while 循环进行真假判断。当 strtok 返回有效参数地址时,表达式结果为真,循环继续;当返回 NULL 时,结果为假,循环终止。
也就是说,while只是一个默默干活的驴,它只是判断这个条件判断的结果正不正确,只要正确它就要再判断一次,直到条件判断的结果是错误的,它才会停下来。因此在不知不觉中,往gargv[ ]这个列表里存储内容的操作就完成了。
4. 执行命令
得到从键盘中获取的字符串后,就要开始执行命令,首先我们要搞清楚是哪一个进程去做执行命令的工作。我们先创建一个 ExecutCommand 函数,那么在函数运行时就会有一个父进程,如果在这个函数内部直接让父进程去做执行命令的工作,那在执行命令结束后,这个父进程就结束了,那就无法进行循环读取键盘并执行命令的操作了。所以我们需要创建一个子进程,然后让父子进程分流做任务。
那么对于要做执行任务的子进程来说,需要用一个程序替换函数,去直接使用系统提供的系统调用函数,这样我们就不用自己去编写代码,一个是因为根本写不出来,代码量太多;另一个是因为太繁琐,我们只是单纯的模拟。
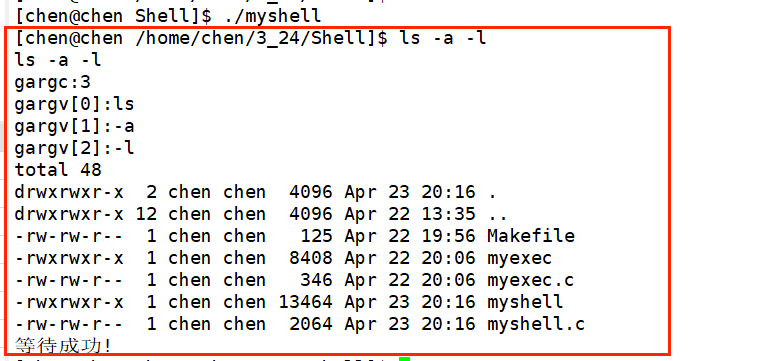
既然如此,我们就要选择一个程序替换函数。因为我们是将字符串存储到了 gargv 这个命令行参数列表里面的,所以使用 execvp 这个替换函数最好:

一方面,该函数支持以数组形式传入参数,与命令解析得到的gargv参数数组完美兼容,无需二次处理参数;另一方面,函数自带PATH环境变量路径检索能力,无需手动填写命令程序绝对路径,相比execv使用更便捷。同时其可直接继承父进程环境变量,相比额外携带环境变量传参接口的execvpe,代码实现更精简、运行更稳定,无多余冗余功能。
因此我们的代码可以这样去编写:
81 int ExecutCommand()
82 {
83 pid_t id = fork();
84 if(id < 0)
85 return -1;
86 else if(id == 0)//让子进程做执行命令的操作
87 {
88 execvp(gargv[0],gargv);
89 exit(1);
90 }
91 else //父进程
92 {
93 int status = 0;
94 pid_t rid = waitpid(id,&status,0);
95 if(rid > 0)
96 {
97 printf("等待成功!\n");
98 }
99 }
100 return 0;
5. 内建命令
但是我们目前编写的这个代码还是不完善的,因为这里的Shell只能执行系统调用里面的部分命令,但还有一些指令不是系统调用。并且我们发现这样一个现象:
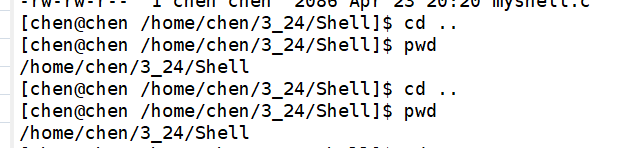
当我想要回退到上一工作路径的时候,对于我们自己模拟实现的Shell来说,并没有做任何改变?这是什么原因?那么对于 cd .. 这个命令来说,移动工作路径移动的到底是谁的路径?
我们现在的代码逻辑,和原生系统 Shell 完全一样,执行流程是:
- 输入
cd .. -
ParseCommand函数解析:gargv[0] = "cd",完成参数解析 ExecutCommand函数fork()新建子进程- 子进程内部调用
execvp(gargv[0], gargv),去执行系统原生的cd程序 - 子进程执行
cd ..:成功修改了这个子进程自己的工作目录 - 子进程执行完毕直接
exit退出、销毁 - 父进程( myshell 主程序本身)全程没有任何操作,它自己的工作目录一丝一毫都没有改变
- 下一轮循环你
pwd,打印的永远是 父进程(myshell)的当前路径,所以看起来路径完全没动。
这是因为:cd 命令修改的,永远是「调用执行 cd 命令的那个进程自身」的工作目录。
Linux 系统中,每一个进程 PCB 里,都有自己独立的、专属的当前工作目录(cwd)。父子进程的工作目录天生相互独立,子进程只会初始继承父进程的路径,后续各自修改互不影响。之前 fork 出的子进程:子进程执行 cd ..,只修改了这个临时子进程自己的工作目录。子进程跑完直接销毁,它的路径修改随着进程一起消失,完全不会回传给父进程。而我们的父进程( myshell 外壳程序):自始至终,工作目录从来没有被修改过。后续所有pwd、ls命令,全部都是父进程的路径,所以看起来cd完全失效。
用通俗易懂的话去说就是:父子进程各自有自己的路径,谁调用的cd命令,修改的就是谁的路径,因为我们的代码中是子进程去cd,但是打印命令行提示符的函数里打印的是父进程的路径,所以说看上去没有移动路径。
因此,cd 命令不能交给子进程执行,必须让父进程自己执行,才能真正改变 Shell 的路径。
而这种 不需要创建子进程、不需要程序替换,直接由父进程(Shell 自己)执行的命令,就是内建命令!
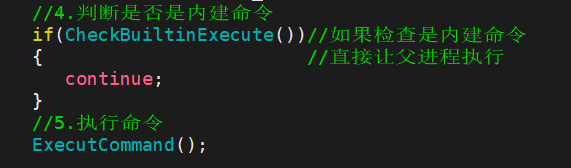
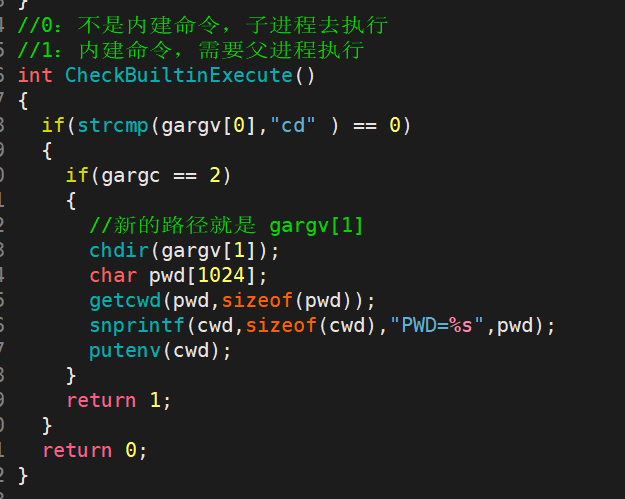
因为我们需要判断一个命令是否是内建命令,就需要去做if判断语句,因为我们没有办法直接获取字符串然后去进行比较,所以我们需要手动加内建命令:
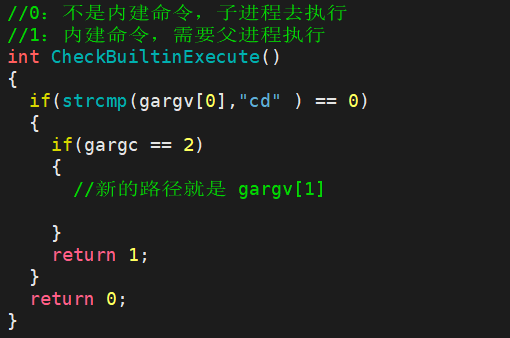
以 cd 命令举例,首先要判断是不是 cd ,如果是的情况下,再判断这个cd是不是合法的,如果是合法的,那么肯定是这个格式: cd 目标路径 ,因此gargc的数据就必定是 2 ,那么我们的目标路径就是 gargv[ 1 ] 。此时要修改路径的话,就要调用这个函数:
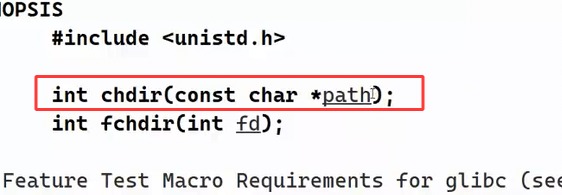
它的作用就是,谁调用函数,就将谁的工作路径改为参数路径。
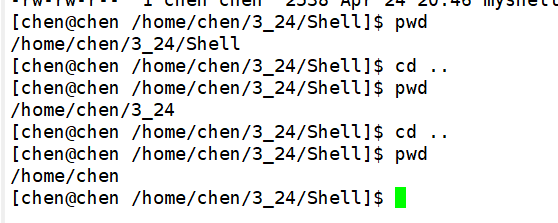
至此,我们就可以修改父进程的工作路径。不过它还需要一些修改,因为我们现在修改完成之后,后续的命令行提示符没有跟着修改,但是对于标准的Shell来说,命令行提示符的工作路径是会随着当前工作路径的修改而修改的。因为我们关于命令行提示符里的信息,都是直接读取的环境变量的信息,因此之所以出现这种情况,肯定是因为当前进程的环境变量没有更新。
所以我们需要手动更改环境变量。第一种方法就是调用 getcwd 函数:

其中第一个参数 *buf 用来存放当前工作目录路径的缓冲区(数组 / 内存空间),第二个参数告诉系统 buf 缓冲区有多大(多少字节)。
我们摒弃从环境变量中获取工作路径的方式,直接使用系统调用,获取当前工作路径,然后放到命令行提示符里,这里我们先创建了一个变量 char cwd[MAXSIZE] :
至此,命令行提示符里的当前工作路径一栏就可以根据实际工作目录的改变而改变了。这里 getcwd的实际作用就是: 把当前进程(你的 Shell 父进程)的工作目录路径字符串,全部存放到 cwd 这个数组里。同时用指针 pwd 指向这个存放路径的数组,如果成功了就返回 pwd 数组的地址,失败了就返回 NULL。
第二种方法就是直接更改环境变量的参数,这样对于 GetPwd的源代码就不用改变。我们需要调用 snprintf 函数:

snprintf 是一个安全的字符串格式化函数,能够将指定格式的内容写入字符数组。第一个参数表示存储结果的缓冲区,第二个参数表示缓冲区大小以防止越界,第三个参数是格式化字符串。该函数会自动在末尾添加字符串结束符。
也就是说snprintf的作用是把第三个参数的这个格式化后的字符串,存储到第一个参数代表的字符数组中,第二个参数表示存储的数量。如果格式化的字符串的长度,大于第二个参数给的数值,它也只写 size - 1 个字符,然后强制在最后加 \0 结束,剩下的全部截断丢掉:
snprintf 将路径拼接为 PWD=路径 的环境变量格式字符串,并安全存储到 cwd 缓冲区。 putenv 将该字符串添加到当前进程的环境变量列表中,更新 PWD 环境变量,使后续程序能正确获取当前工作目录。
这样也能达成目的。
不过我们最终想要的效果是只在命令行提示符上输出相对路径,但是我们目前写的代码输出的是绝对路径,所以需要调整,我们的思路是去在获取到的工作路径里面做分割,只要相对路径。首先我们来创建一个分割函数:
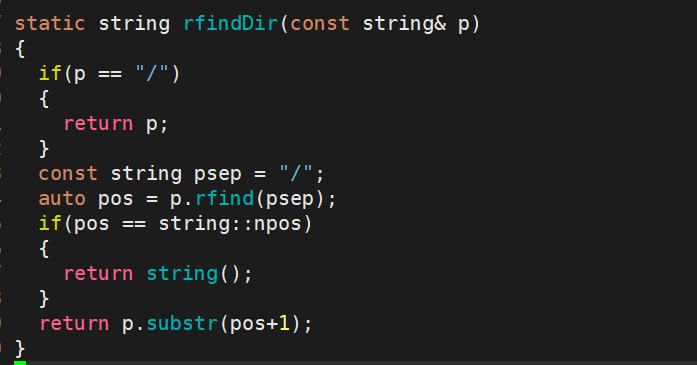
这段代码的逻辑是:如果传入的路径是根目录 /,就直接返回 /;
如果不是根目录,就从路径的末尾向前查找最后一个 / 符号。
如果找不到 /,说明路径不合法或没有目录结构,就返回空字符串;
如果找到了 /,就截取 / 后面的内容并返回,这部分内容就是路径的最后一段名称。
然后在这里做一下修改:

这是将GetPwd的值传入rfindDir之后,再把结果以c语言字符串的形式返回。这是因为:printf 是 C 语言函数,它的 %s 占位符要求的是 const char* 类型(C 风格字符串)。而rfindDir(GetPwd()) 返回的是 C++ 的 std::string 对象。
所以 .c_str() 可以把 C++ 的 std::string,转换成 C 语言能直接用的 const char* 字符串指针。
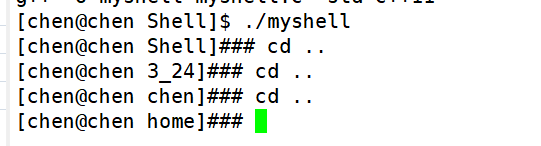
这样命令行提示符的修改就完成了, 为了便于区分是我们自己写的Shell还是系统的Shell,我将原来代码里的 $ 改成了 ### 以便于区分。
6. 退出码问题
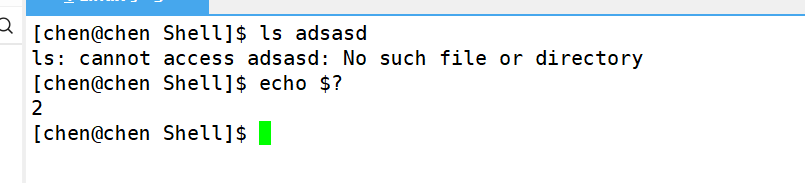
在系统的Shell中,当一个进程出错的时候,会返回一个错误码,通过 echo $? 的方式可以获取到。但是在我们自己模拟的Shell里就没有这个效果,那这到底要怎么实现呢?

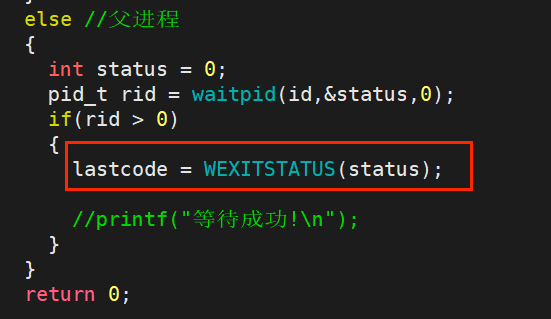
首先要做的是先创建一个变量用于存储退出码,然后我们只需要在父进程里面保存退出码:
然后去设计 echo 内建命令的逻辑:
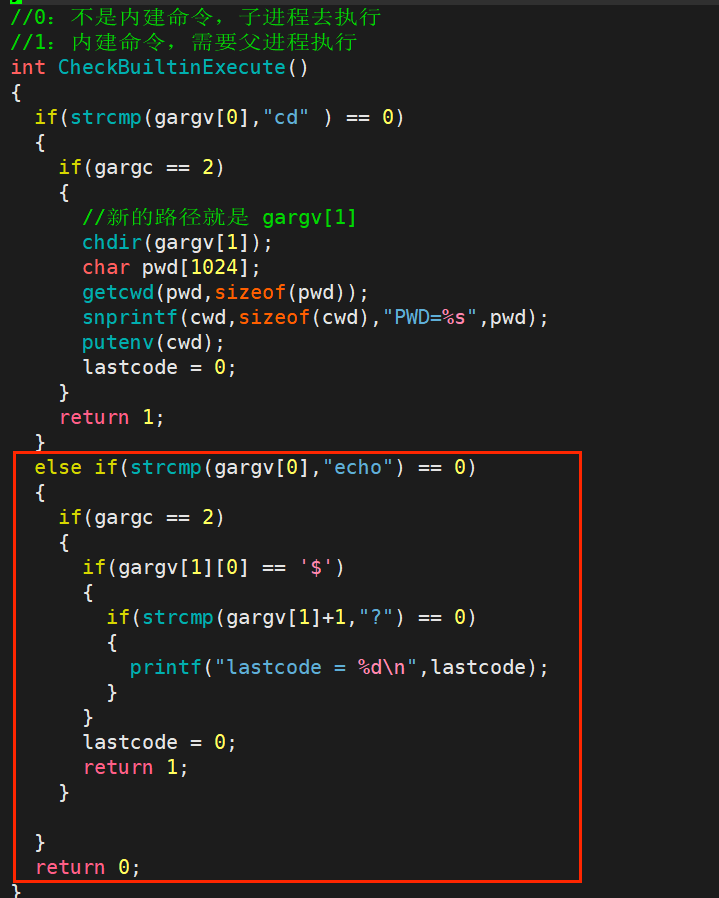
主要是要看懂 gargv[1][0] == ‘$’ 这一行代码,这里的逻辑是这样的:
gargv[1]:取出第二个参数字符串(比如"$?")gargv[1][0]:取出这个字符串的第 0 个字符(也就是第一个字符)== '$':判断这个字符是不是美元符号$
因为我们如果要查看退出码,那么写法是这样的:echo $? ,所以这一行的作用是判断 echo 命令的第二个参数,也就是 $? ,是不是一个以 $ 开头的环境变量。

本文到此结束,感谢各位读者的阅读,如果有讲解的不到位或者错误的地方,欢迎各位读者批评或指正。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)