ClickHouse 内存只涨不降之谜:MemoryTracking 20G 但 MemoryResident 才 2.5G,内存到底跑哪去了?
一道我自己没完全解开的题,求老司机指路。
ClickHouse 内存连涨 5 天,TRUNCATE 系统日志没用、配 TTL 没用、OPTIMIZE FINAL 没用,
SYSTEM JEMALLOC PURGE也没用。最后只能重启大法——但下次它还会涨。最迷的是:CK 自己说占了 20G+,OS 看进程 RSS 才 2.5G。这两个对不上的内存到底在哪?
本文把完整排查路径 + 一份能落地的**"缓解型"方案(监控 + 定时重启)** 一起交给你;根因我也还在找。
一、背景
线上一台 ClickHouse 单机节点,跑了一段时间后,内存监控曲线像股神看走眼那天的 K 线——只涨不跌。
近 5 天的内存占用是一条优雅的、毫不犹豫的上升直线。
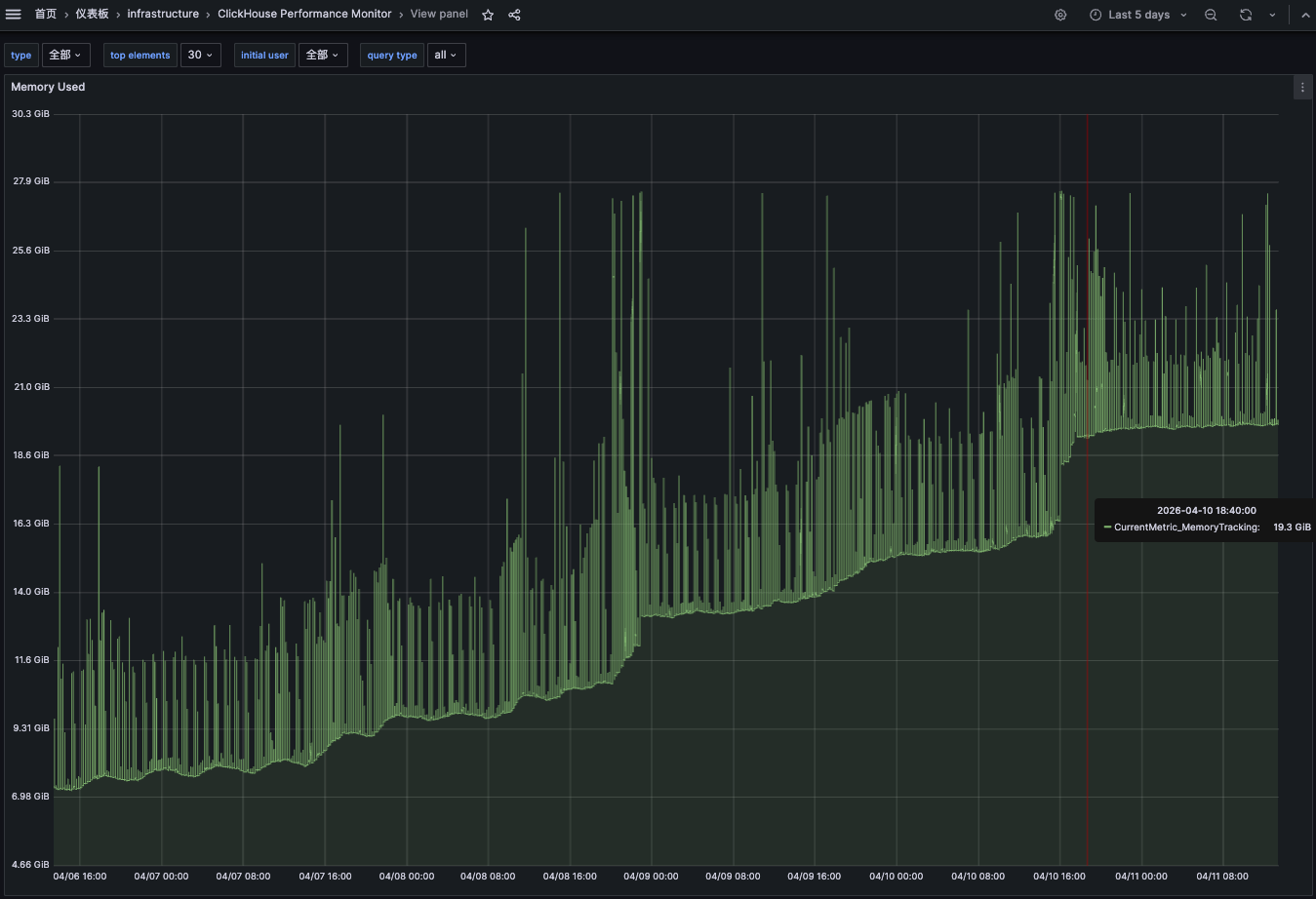
机器总内存约 30GB,CK(ClickHouse,下文简称 CK)一路吃到接近 22GB 才开始触发我们的告警。
注:本文里所有表名、数字都做了脱敏处理。重点不在具体数字,而在排查路径和那个迷之矛盾。
二、第一回合:常规排查
按 ClickHouse 内存问题的标准套路,先把"嫌疑人名单"过一遍。
2.1 看各类内存指标分布
SELECT
metric,
formatReadableSize(value) AS size
FROM system.metrics
WHERE metric LIKE '%Memory%' OR metric LIKE '%Cache%'
ORDER BY value DESC;
| metric | size |
|---|---|
| MemoryTracking | 18.4 GiB |
| MemoryTrackingUncorrected | 16.16 MiB |
| MergesMutationsMemoryTracking | -448.00 B |
| 其他 Cache 相关 | 几乎全是 0.00 B |
MemoryTracking 是 ClickHouse 自己跟踪的内存总量,排查开始时是 18.4 GiB(后面会看到它还在继续涨)。
但奇怪的是其他细分指标几乎全是 0。各种 Cache 都没用,这 18 个 G 到底是谁吃的?
2.2 看是否有残留的 Memory 引擎临时表
Memory 引擎的表是常见"内存泄露源"——数据全在内存里,不主动 DROP 就不会释放。
SELECT `database`, name, `engine`,
formatReadableSize(total_bytes) AS size,
metadata_modification_time
FROM system.tables
WHERE `engine` = 'Memory';
| database | name | engine | size |
|---|---|---|---|
| tmp | tmp_pair_first_pay | Memory | 0.00 B |
| tmp | tmp_pair_messages | Memory | 0.00 B |
两张临时表都是空的。排除。
2.3 看各表内存占用(含主键 + 压缩 + 未压缩)
SELECT
database, table,
formatReadableSize(sum(primary_key_bytes_in_memory)) AS pk_memory,
formatReadableSize(sum(data_compressed_bytes)) AS compressed,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed,
sum(rows) AS total_rows,
count() AS parts_count
FROM system.parts
WHERE active
GROUP BY database, table
ORDER BY sum(primary_key_bytes_in_memory) DESC
LIMIT 10;
| database | table | pk_memory | compressed | uncompressed | rows | parts |
|---|---|---|---|---|---|---|
| ods | ods_event_log | 2.83 MiB | 121.76 GiB | 698.95 GiB | 9.2 亿 | 402 |
| ods | ods_im_message_ext | 2.45 MiB | 52.21 GiB | 207.75 GiB | 5.5 亿 | 64 |
| dws | dws_user_activity_hour | 1.31 MiB | 352.21 MiB | 9.26 GiB | 4.3 亿 | 7 |
| ods | ods_tb_user_extra_info | 930.49 KiB | 1.10 GiB | 2.56 GiB | 1098 万 | 246 |
| … | … | … | … | … | … | … |
| system | trace_log | 128.47 KiB | 24.67 GiB | 269.15 GiB | 7.6 亿 | 32 |
注意最后一行:system.trace_log 24.67 GiB 压缩、269 GiB 未压缩、7.6 亿行。
trace_log 是 ClickHouse 内部的性能采样日志,默认保留时间很长。一旦没配 TTL,它能涨到吓人。这是头号嫌疑。
2.4 看未合并的 parts 数量
SELECT database, table,
count() AS parts,
sum(rows) AS total_rows,
formatReadableSize(sum(bytes_on_disk)) AS disk_size
FROM system.parts
WHERE active
GROUP BY database, table
HAVING parts > 50
ORDER BY parts DESC;
| database | table | parts | rows | disk |
|---|---|---|---|---|
| ods | ods_tb_user_action_record | 589 | 4.2 亿 | 8.20 GiB |
| dwd | dwd_log_track_user | 432 | 7700 万 | 2.46 GiB |
| ods | ods_event_log | 399 | 9.2 亿 | 121.78 GiB |
| ods | ods_mongo_trace_logs | 324 | 8.9 亿 | 46.30 GiB |
| … | … | … | … | … |
parts 数 500+ 是另一个警钟——后台 merge 跟不上写入。parts 多了不仅查询慢,每个 part 的元数据也都吃内存。
2.5 看 mark cache 和解压缓存
SELECT name, formatReadableSize(value) AS size
FROM system.asynchronous_metrics
WHERE name IN ('MarkCacheBytes', 'MarkCacheFiles',
'UncompressedCacheBytes', 'UncompressedCacheCells');
| name | size |
|---|---|
| MarkCacheBytes | 40.57 MiB |
| UncompressedCacheBytes | 0.00 B |
| MarkCacheFiles | 38.90 KiB |
| UncompressedCacheCells | 0.00 B |
Mark cache 才 40 MB,解压缓存压根没用。也不是缓存的锅。
三、第一回合处理
线索基本清晰:trace_log 等 system 日志表 + 高碎片业务表两座大山。先动手清。
3.1 TRUNCATE 体积最大的 system 日志表
TRUNCATE TABLE system.trace_log;
TRUNCATE TABLE system.text_log;
TRUNCATE TABLE system.processors_profile_log;
TRUNCATE TABLE system.asynchronous_metric_log;
-- query_log / metric_log 留着,按时间删
ALTER TABLE system.query_log DELETE WHERE event_date < today() - 3;
ALTER TABLE system.metric_log DELETE WHERE event_date < today() - 3;
3.2 配置 TTL 防复发
<!-- /etc/clickhouse-server/config.d/log_tables_ttl.xml -->
<clickhouse>
<query_log> <ttl>event_date + INTERVAL 7 DAY DELETE</ttl></query_log>
<trace_log> <ttl>event_date + INTERVAL 3 DAY DELETE</ttl></trace_log>
<text_log> <ttl>event_date + INTERVAL 3 DAY DELETE</ttl></text_log>
<metric_log> <ttl>event_date + INTERVAL 7 DAY DELETE</ttl></metric_log>
<asynchronous_metric_log><ttl>event_date + INTERVAL 3 DAY DELETE</ttl></asynchronous_metric_log>
<processors_profile_log> <ttl>event_date + INTERVAL 3 DAY DELETE</ttl></processors_profile_log>
</clickhouse>
3.3 低峰期 OPTIMIZE 高碎片业务表
-- 3 分多
OPTIMIZE TABLE ods.ods_tb_user_action_record FINAL;
-- 1 分多
OPTIMIZE TABLE dwd.dwd_log_track_user FINAL;
-- 44 分钟(这张表确实大)
OPTIMIZE TABLE ods.ods_event_log FINAL;
⚠️
OPTIMIZE FINAL自身会消耗大量内存,建议低峰期串行执行,不要并行。
四、然而……内存没降
按理说,TRUNCATE 几张几十 G 的 system 日志表 + OPTIMIZE 高碎片业务表,内存应该有个明显回落。
实际情况是——几乎没动。监控图依旧是那条优雅的上升直线。
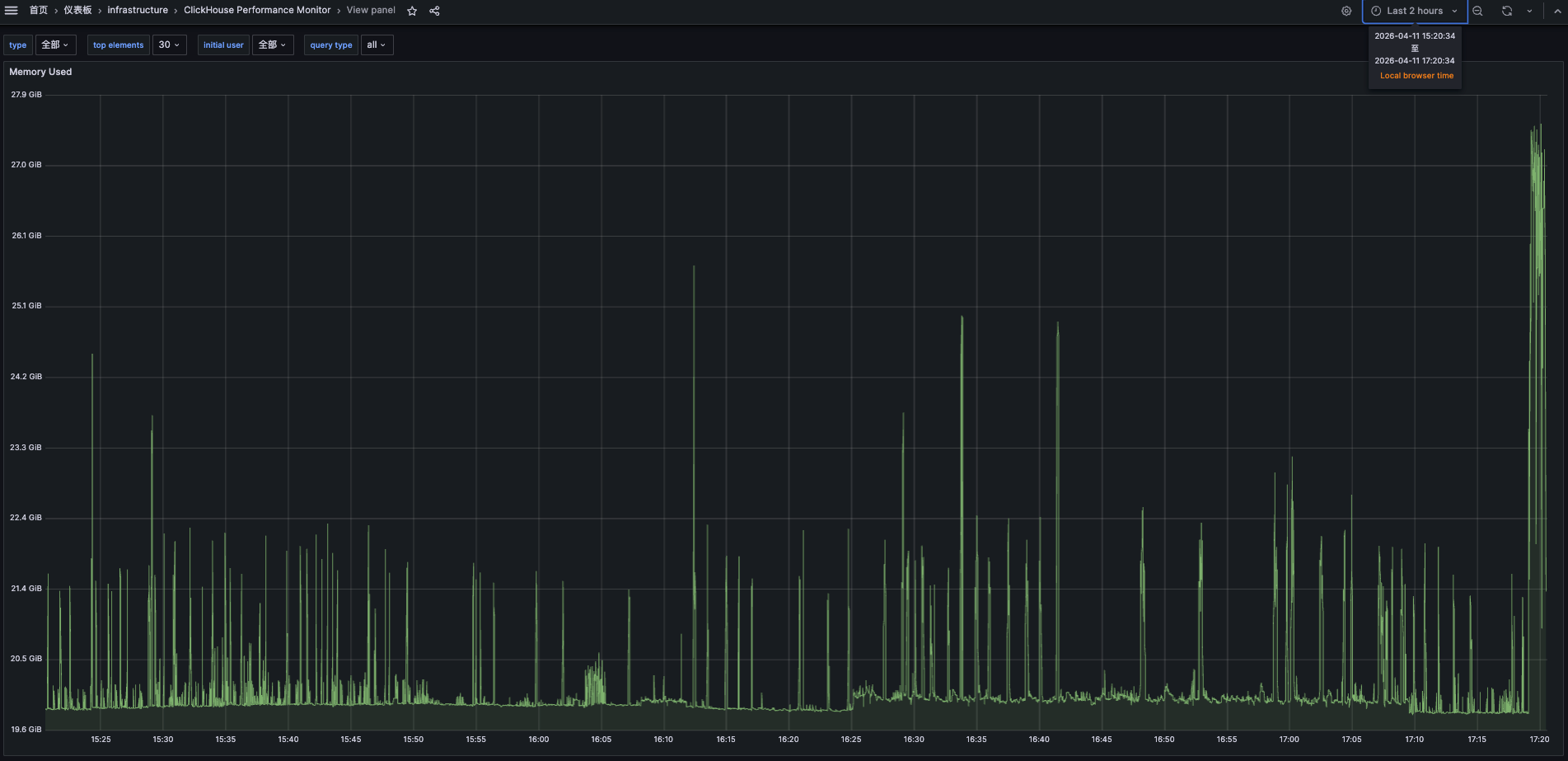
我的内心活动:
我:trace_log 24G 都干掉了,怎么不降?
ClickHouse:你猜啊。
只能继续往里挖。
五、第二回合:深入排查
注意:排查过程中 CK 还在持续运行,
MemoryTracking已经从第一回合的 18.4 GiB 涨到了 20.6 GiB——它不等人。
5.1 正在运行的查询
SELECT query_id, user,
formatReadableSize(memory_usage) AS memory,
elapsed, substring(query, 1, 120) AS query_short
FROM system.processes
ORDER BY memory_usage DESC;
结果只有我自己跑的这条查询本身。没有任何用户查询在占内存。
5.2 后台 merge
SELECT database, table,
formatReadableSize(memory_usage) AS memory,
elapsed, progress, num_parts
FROM system.merges
ORDER BY memory_usage DESC;
| database | table | memory | progress |
|---|---|---|---|
| system | asynchronous_metric_log | 17.06 MiB | 56% |
只有一个 17MB 的小 merge,也不是它。
5.3 各 db 的 parts 元数据
SELECT database,
count() AS parts_count,
formatReadableSize(sum(primary_key_bytes_in_memory)) AS pk_in_memory,
formatReadableSize(sum(primary_key_bytes_in_memory_allocated)) AS pk_allocated
FROM system.parts
WHERE active
GROUP BY database
ORDER BY sum(primary_key_bytes_in_memory_allocated) DESC;
| database | parts_count | pk_in_memory | pk_allocated |
|---|---|---|---|
| ods | 3,964 | 9.39 MiB | 10.45 MiB |
| dws | 206 | 1.31 MiB | 1.33 MiB |
| dwd | 384 | 729.37 KiB | 1.20 MiB |
| system | 206 | 154.96 KiB | 194.93 KiB |
| … | … | … | … |
全部加起来才 13 MB 不到。和 20 GiB 差着 1500 倍,根本不是一个量级。
5.4 ⭐ 最关键的一查:CK 内部各组件内存分配
SELECT metric, formatReadableSize(value) AS size
FROM system.asynchronous_metrics
WHERE lower(metric) LIKE '%cache%'
OR lower(metric) LIKE '%memory%'
OR lower(metric) LIKE '%rss%'
OR lower(metric) LIKE '%pool%'
ORDER BY value DESC
LIMIT 30;
| metric | size |
|---|---|
| MemoryVirtual | 59.83 GiB |
| MemoryDataAndStack | 58.87 GiB |
| OSMemoryTotal | 30.64 GiB |
| OSMemoryAvailable | 26.00 GiB |
| CGroupMemoryUsed | 25.45 GiB |
| OSMemoryFreePlusCached | 25.41 GiB |
| MemoryResidentMax | 23.33 GiB |
| OSMemoryCached | 22.17 GiB |
| OSMemoryFreeWithoutCached | 3.24 GiB |
| MemoryResidentWithoutPageCache | 2.58 GiB |
| MemoryResident | 2.58 GiB |
| MemoryCode | 319.02 MiB |
| MemoryShared | 74.79 MiB |
| MarkCacheBytes | 30.52 MiB |
| TotalPrimaryKeyBytesInMemoryAllocated | 13.39 MiB |
| … | … |
这一查直接让我懵了。
| 视角 | 数值 | 含义 |
|---|---|---|
MemoryTracking(CK 视角) |
20.6 GiB | CK 自己跟踪的内存使用量 |
MemoryResident(OS 视角) |
2.58 GiB | OS 看到的进程 RSS(实际物理内存) |
差了将近 8 倍。
CK 在喊"我用了 20G!“,操作系统在说"你才用了 2.5G 啊兄弟”。到底听谁的?
按道理 MemoryResident(RSS)才是真实物理内存占用。可既然 RSS 才 2.5G,监控曲线为什么还在涨、内存为什么吃得越来越紧?
5.5 inactive parts 是不是没物理清理
SELECT database, table,
count() AS inactive_parts,
formatReadableSize(sum(bytes_on_disk)) AS disk_size
FROM system.parts
WHERE NOT active AND database = 'system'
GROUP BY database, table
ORDER BY sum(bytes_on_disk) DESC;
| table | inactive_parts | disk_size |
|---|---|---|
| metric_log | 76 | 340.76 MiB |
| query_views_log | 128 | 103.99 MiB |
| asynchronous_metric_log | 138 | 63.40 MiB |
| … | … | … |
确实有几百 MB 的 inactive parts 没回收,但也就 600 MB 量级,不至于撑起 20G 的差值。
六、第三回合:继续追凶
到这里还没找到凶手,再排除几个冷门嫌疑。
6.1 allocator 层内存
SELECT metric, formatReadableSize(value) AS size
FROM system.metrics
WHERE metric LIKE '%Memory%'
ORDER BY value DESC;
| metric | size |
|---|---|
| MemoryTracking | 20.6 GiB |
| MemoryTrackingUncorrected | 16.16 MiB |
| MergesMutationsMemoryTracking | -448.00 B |
MergesMutationsMemoryTracking 居然是负值。这通常是统计误差——但负值本身就说明内存计数器有 bug。这个细节先记下来。
6.2 其他嫌疑一次性排除
| 嫌疑 | 查询 | 结果 |
|---|---|---|
| Lightweight delete 残留 | has_lightweight_delete 列 |
全是 0,排除 |
| 后台 mutation 未完成 | system.mutations WHERE is_done != 1 |
空,排除 |
| 外部 dictionary | system.dictionaries |
空,没用 |
| stack trace 分配 | sum(size) FROM system.stack_trace |
量级不对 |
常规嫌疑人名单全过完了,主谋还没找到。
七、尝试解决
7.1 方案 1:强制 jemalloc 释放(无效)
ClickHouse 用 jemalloc 做内存分配。理论上,应用层"释放"了内存后,jemalloc 可能还把页面缓存在自己手里没还给 OS。SYSTEM JEMALLOC PURGE 就是强制 jemalloc 把这些页面归还。
SYSTEM JEMALLOC PURGE;
-- Updated Rows: -1
-- Execute time: 43s
执行了 43 秒,看起来很认真在干活。然后查内存:
SELECT formatReadableSize(value) FROM system.metrics WHERE metric = 'MemoryTracking';
结果:还是 20G 左右。
jemalloc:你说释放就释放,那我面子往哪儿搁?
7.2 方案 2:重启 CK(有效,但不优雅)
最后只能祭出"重启大法"。先确认没在跑重要的东西:
-- 没有用户查询
SELECT count() FROM system.processes WHERE query NOT LIKE '%system.processes%';
-- 没有进行中的 merge
SELECT count() FROM system.merges;
两个都是 0,可以重启:
# systemd
systemctl restart clickhouse-server
# Docker
docker restart <clickhouse-container>
重启后再看:
SELECT formatReadableSize(value) FROM system.metrics WHERE metric = 'MemoryTracking';
-- 920 MiB
从 20G 直接降到不到 1G。 重启大法好。
但下次再涨上去,难道还得重启?不能每次都靠半夜爬起来执行 docker restart。
八、核心谜题:MemoryTracking vs MemoryResident,相信谁?
整个排查到这里,所有"常规嫌疑人"都查了:
| 嫌疑 | 状态 |
|---|---|
| Memory 引擎临时表 | 排除(空) |
| 各表主键内存 | 排除(13 MB,量级不对) |
| Mark / Uncompressed Cache | 排除(< 50 MB) |
| 正在运行的查询 | 排除(无) |
| 后台 merge 占用 | 排除(17 MB) |
| 后台 mutation | 排除(无) |
| 外部 dictionary | 排除(无) |
| Lightweight delete 残留 | 排除(无) |
| Inactive parts 没回收 | 部分中招(600 MB),但量级不够 |
| jemalloc 缓存未归还 | 尝试 PURGE 无效 |
最终的核心矛盾:
MemoryTracking = 20.6 GiB (CK 自己跟踪)
MemoryResident = 2.58 GiB (OS 看到的 RSS)
MemoryResidentMax = 23.33 GiB (历史峰值 RSS)
CGroupMemoryUsed = 25.45 GiB (cgroup 视角)
几个我目前的猜想方向(都不确定,如有大佬指点感激不尽):
猜想 1:MemoryTracking 计数器漂移
ClickHouse 的 MemoryTracking 是应用层手动维护的计数器,每次分配/释放都靠代码主动更新。如果某个路径只 +=、不 -=(或者反过来),就会漂移。
MergesMutationsMemoryTracking = -448 B 这个负值就是漂移的证据——统计逻辑确实有 bug。
但这又解释不了为什么 OS 视角看到的 MemoryResidentMax 也到了 23 GiB——OS 不会撒谎。
猜想 2:cgroup 把 page cache 也算进去了
CGroupMemoryUsed = 25 GiB,但单看 CK 进程 RSS 只有 2.5 GiB。
OSMemoryCached = 22 GiB 这个数非常可疑——大概率是 page cache(大量顺序扫表产生的文件缓存)拉高了 cgroup 占用。这就是"假性内存高"——但 page cache 是可回收的,不应该让监控持续涨、涨到触发告警。
猜想 3:某种我没查到的内部缓存
CK 内部组件的所有 Cache 我都查过,加起来不到 100 MB。但 ClickHouse 的内部组件多到我未必都数得过来——是否还有某个未暴露给 system.metrics 的隐藏缓存在涨?
猜想 4:jemalloc 的 dirty pages 没被释放
SYSTEM JEMALLOC PURGE 据说是强制清理 dirty pages,但我执行后没看到任何变化。是命令没生效,还是 dirty pages 不是元凶?
(欢迎懂的朋友在评论区给我科普。)
不过,根因归根因,线上不能裸奔。下面先给一份能落地的缓解方案——至少让下次"它又涨上去了"这件事变得可预测、可自动化。
九、根因没定位,先给一份能落地的缓解方案
重启能解决一次,但不能解决永远。既然根因一时找不到,至少先把"下次它再涨上来"这件事变得可预测、可自动化。
两件事:
- 监控:给
MemoryTracking配 Grafana 告警,早发现早响应 - 兜底:加定时任务,超阈值(或每天固定时间)自动重启
9.1 Grafana 监控看板
指标选择:用 system.metrics.MemoryTracking(CK 进程自身跟踪的内存),不要用 CGroupMemoryUsed(含 page cache 虚高,前面猜想 2 说过)。
历史数据:system.metric_log 自动记录 CurrentMetric_MemoryTracking 的历史值,不需要额外 exporter。
-- Grafana 官方插件语法
SELECT
event_time AS time,
CurrentMetric_MemoryTracking / 1073741824 AS memory_gib
FROM system.metric_log
WHERE event_time >= toDateTime64($__from / 1000, 3, 'Asia/Shanghai')
AND event_time < toDateTime64($__to / 1000, 3, 'Asia/Shanghai')
ORDER BY event_time
9.2 告警规则:连续 4 小时超阈值
Grafana 的 Alerting → New alert rule:
Query A:按小时聚合取 max
SELECT
toStartOfHour(event_time) AS t,
min(CurrentMetric_MemoryTracking) / 1073741824 AS memory_gib
FROM system.metric_log
WHERE event_time >= now() - INTERVAL 4 HOUR
GROUP BY t
ORDER BY t
Expression 配置:
- Expression B(Reduce):Function = Min,Input = A —— 对 4 小时的 max 值取 min;最低值都超标,才算"持续超标"
- Expression C(Threshold):Input = B,Condition = IS ABOVE 15.32 —— 容器 30.64 GiB 的 50%
- Alert condition 选 C
Evaluation:
- Evaluate every
5m - Pending period
0s(SQL 已用 4 小时窗口,无需再等)
阈值计算表:
| 容器总内存 | 报警阈值(50%) | 修改位置 |
|---|---|---|
| 30.64 GiB(升级前) | 15.32 GiB | Expression C 的 IS ABOVE |
| 64 GiB(升级后) | 32 GiB | 同上,扩容后记得同步调整 |
容器扩容就按新总内存的 50% 调整。
9.3 兜底:定时重启
方案 A:每天固定重启(简单直接)
crontab -e
# 每天凌晨 4 点重启 CK(业务低峰期)
0 4 * * * docker restart clickhouse-server >> /var/log/ck-restart.log 2>&1
方案 B:超阈值才重启(更稳妥)
写个检查脚本,超过 15 GiB 才重启:
cat > /home/ec2-user/ck_memory_check.sh << 'EOF'
#!/bin/bash
THRESHOLD_GB=15
CONTAINER=clickhouse-server
MEMORY_BYTES=$(docker exec $CONTAINER clickhouse-client \
--user=admin --password='xxx' \
-q "SELECT value FROM system.metrics WHERE metric = 'MemoryTracking'" 2>/dev/null)
if [ -z "$MEMORY_BYTES" ]; then
echo "$(date) 查询失败,跳过" >> /var/log/ck-restart.log
exit 1
fi
MEMORY_GB=$(echo "$MEMORY_BYTES / 1073741824" | bc)
if [ "$MEMORY_GB" -ge "$THRESHOLD_GB" ]; then
echo "$(date) MemoryTracking=${MEMORY_GB}GiB >= ${THRESHOLD_GB}GiB,重启 CK" >> /var/log/ck-restart.log
docker restart $CONTAINER >> /var/log/ck-restart.log 2>&1
else
echo "$(date) MemoryTracking=${MEMORY_GB}GiB,正常" >> /var/log/ck-restart.log
fi
EOF
chmod +x /home/ec2-user/ck_memory_check.sh
crontab -e
# 每 4 小时检查一次
0 */4 * * * /home/ec2-user/ck_memory_check.sh
选型建议:业务对可用性敏感的选 方案 B,不敏感的选 方案 A——固定时间重启更可预测。
9.4 触发报警后的手工处理流程
在定时任务兜底之前,如果值班收到报警:
-- 1. 看一眼当前 MemoryTracking
SELECT formatReadableSize(value) FROM system.metrics WHERE metric = 'MemoryTracking';
-- 2. 试试 jemalloc purge(大概率无效,但 30 秒搞定)
SYSTEM JEMALLOC PURGE;
-- 3. 没降再确认能否重启
SELECT count() FROM system.processes WHERE query NOT LIKE '%system.processes%';
SELECT count() FROM system.merges;
-- 4. docker restart clickhouse-server
9.5 终极方案:升级机器内存(已实施)
前面的监控 + 定时重启都是"治标",跑了一段时间后发现:MemoryTracking 漂移速度快于预期,定时重启的间隔越缩越短,影响数仓调度任务的连续性。
最终决定直接升级机器配置:
| 升级前 | 升级后 | |
|---|---|---|
| CPU | 4C | 4C(不变) |
| 内存 | 32 GB | 64 GB |
为什么选择加内存而不是继续治标:
- 根因未定位——
MemoryTracking计数器漂移是 ClickHouse 内部行为,短期内无法从应用层修复 - 32G 的容错空间太小——CK 正常运行 ~10G、
MemoryTracking漂移每天 ~2-3G,32G 的机器只能撑 7-10 天就要重启 - 64G 给了足够的漂移缓冲——即使漂移速度不变,也能撑 20+ 天,配合每周一次的定时重启完全够用
- 成本可控——云服务器升内存的增量费用远低于持续排查 + 人工重启的人力成本
这不是最优雅的方案,但确实是当前最务实的方案。根因没定位之前,花钱买时间是合理的——"重启保平安"从每天一次变成每周一次,DBA 的睡眠质量也是生产力。
十、求助:欢迎大家给根因提供线索
前面这套方案是"压住症状"——根因没解决。
如果你也踩过类似的坑、或者对 CK 内存管理有更深理解,欢迎在评论区告诉我:
MemoryTracking远大于MemoryResident这种现象你见过吗?原因是什么?SYSTEM JEMALLOC PURGE在你那有效过吗?有没有更激进的释放方式(比如MALLOC_CONF里的dirty_decay_ms/muzzy_decay_ms)?- 除了
SYSTEM DROP MARK CACHE/SYSTEM DROP UNCOMPRESSED CACHE/SYSTEM DROP COMPILED EXPRESSION CACHE,有没有不重启就能强制释放的姿势? system.trace_log这类内部表"已 TRUNCATE 但内存映射没释放"是不是已知问题?- 是不是某些 CK 版本的内存计数器有已知 bug?
本文所有排查 SQL 都能复制粘贴运行,除了第三节的 TRUNCATE / OPTIMIZE,其他都是只读。
十一、本文会持续更新
这是一篇根因未结案的文章,如果后续定位到真正的元凶,我会回来把答案补上。
| 时间 | 进展 |
|---|---|
| v1 | 排查路径整理完毕,重启暂时缓解,根因未定位 |
| v2 | 补充 Grafana 监控报警 + 定时重启缓解方案 |
| v3 | 升级机器 4C32G → 4C64G,以空间换时间 |
| 待更新 | 找到根因后回来更新这里 |
订阅作者,蹲一个续集 🙏
附录:本文用到的全部排查 SQL 速查
为了方便你直接复现,把全部只读 SQL 整理在这里:
-- 1. 看各类内存指标分布
SELECT metric, formatReadableSize(value) AS size
FROM system.metrics
WHERE metric LIKE '%Memory%' OR metric LIKE '%Cache%'
ORDER BY value DESC;
-- 2. 看 Memory 引擎的临时表
SELECT `database`, name, `engine`,
formatReadableSize(total_bytes) AS size,
metadata_modification_time
FROM system.tables
WHERE `engine` = 'Memory'
ORDER BY total_bytes DESC;
-- 3. 看各表内存占用(含主键 + 压缩 + 未压缩)
SELECT database, table,
formatReadableSize(sum(primary_key_bytes_in_memory)) AS pk_memory,
formatReadableSize(sum(data_compressed_bytes)) AS compressed,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed,
sum(rows) AS total_rows,
count() AS parts_count
FROM system.parts
WHERE active
GROUP BY database, table
ORDER BY sum(primary_key_bytes_in_memory) DESC
LIMIT 20;
-- 4. 看未合并的 parts 数量
SELECT database, table,
count() AS parts,
sum(rows) AS total_rows,
formatReadableSize(sum(bytes_on_disk)) AS disk_size
FROM system.parts
WHERE active
GROUP BY database, table
HAVING parts > 50
ORDER BY parts DESC;
-- 5. 看 mark / uncompressed cache
SELECT name, formatReadableSize(value) AS size
FROM system.asynchronous_metrics
WHERE name IN ('MarkCacheBytes', 'MarkCacheFiles',
'UncompressedCacheBytes', 'UncompressedCacheCells');
-- 6. 看正在运行的查询
SELECT query_id, user,
formatReadableSize(memory_usage) AS memory,
elapsed, substring(query, 1, 120) AS query_short
FROM system.processes
ORDER BY memory_usage DESC;
-- 7. 看后台 merge
SELECT database, table,
formatReadableSize(memory_usage) AS memory,
elapsed, progress, num_parts,
formatReadableSize(total_size_bytes_compressed) AS merge_size
FROM system.merges
ORDER BY memory_usage DESC;
-- 8. ⭐ 看 CK 内部组件内存(最关键)
SELECT metric, formatReadableSize(value) AS size
FROM system.asynchronous_metrics
WHERE lower(metric) LIKE '%cache%'
OR lower(metric) LIKE '%memory%'
OR lower(metric) LIKE '%rss%'
OR lower(metric) LIKE '%pool%'
ORDER BY value DESC
LIMIT 30;
-- 9. 看 inactive parts
SELECT database, table,
count() AS inactive_parts,
formatReadableSize(sum(bytes_on_disk)) AS disk_size
FROM system.parts
WHERE NOT active
GROUP BY database, table
ORDER BY sum(bytes_on_disk) DESC;
-- 10. 看后台 mutation
SELECT database, table, mutation_id, command, create_time,
is_done, latest_fail_reason
FROM system.mutations
WHERE is_done != 1
ORDER BY create_time;
-- 11. 看 dictionary
SELECT name, formatReadableSize(bytes_allocated) AS memory, element_count
FROM system.dictionaries
ORDER BY bytes_allocated DESC;
-- 12. Grafana 看板:MemoryTracking 历史曲线
SELECT event_time AS time,
CurrentMetric_MemoryTracking / 1073741824 AS memory_gib
FROM system.metric_log
WHERE event_time >= toDateTime64($__from / 1000, 3, 'Asia/Shanghai')
AND event_time < toDateTime64($__to / 1000, 3, 'Asia/Shanghai')
ORDER BY event_time;
-- 13. 告警查询:近 4 小时按小时 max
SELECT toStartOfHour(event_time) AS t,
min(CurrentMetric_MemoryTracking) / 1073741824 AS memory_gib
FROM system.metric_log
WHERE event_time >= now() - INTERVAL 4 HOUR
GROUP BY t
ORDER BY t;
-- 14. 强制 jemalloc 释放(大概率无效,但无副作用)
SYSTEM JEMALLOC PURGE;
-- 15. 重启前确认安全
SELECT count() FROM system.processes
WHERE query NOT LIKE '%system.processes%';
SELECT count() FROM system.merges;
根因未结案,欢迎一切线索 🙇 评论区见。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)