从硬件到软件:一文搞懂冯·诺依曼体系、操作系统与进程管理
冯·诺伊曼体系结构是现代计算机的基石,其核心思想是将计算机系统分为输入设备、输出设备、存储器、运算器和控制器五大部件。该体系结构通过内存作为数据中转枢纽,CPU作为处理中心,外设作为输入输出通道,形成了高效的数据流动机制。操作系统在此基础上通过进程管理(PCB控制块)、系统调用和库函数实现对硬件资源的安全访问。进程创建采用fork()函数实现写时复制,父子进程共享代码但拥有独立数据空间。这种分层管
一、冯·诺伊曼体系结构:现代计算机的基石
1. 1 概念
冯·诺伊曼体系结构是现代计算机设计的基础模型,由著名数学家冯·诺伊曼在1945年提出。该体系结构将计算机系统划分为五大核心组成部分:输入设备、输出设备、存储器、运算器和控制器。
这五大部分既有独立性,又通过总线相互连接,共同完成数据的存储、处理和流动。
1.1.1 设备是独立的
在冯·诺伊曼结构中,各类设备功能明确:
-
输入设备:键盘、鼠标、话筒、网卡、磁盘、摄像头等
-
输出设备:显示器、声卡、显卡、网卡、磁盘、打印机等
在这些设备中,有的只能做输入(键盘、鼠标),有的只能做输出(显示器),而像网卡、磁盘则可以同时承担输入和输出两种角色。这些设备统称为外设。磁盘也叫外存,需要特别注意和内存区分开。
这里可以自然引出 I/O(Input/Output) 的概念。如果站在内存的角度来看:
-
外设把数据交给内存 → 输入(I)
-
内存把数据交给外设 → 输出(O)
这个视角,是理解计算机系统中数据流动的关键。
1.1.2 设备是连接的
设备之间通过总线连接,并集成在主板上。连接的最终目的是实现设备之间的数据流动。而数据流动的本质,就是数据在不同设备之间进行拷贝。
数据拷贝的整体效率,决定了冯·诺伊曼体系结构的效率,也就是决定计算机整体性能的关键指标之一。
1.1.3 运算器与存储器的关系
计算机的硬件并非杂乱无章地堆砌在一起,而是按照一定的规律,形成了一个经典的体系结构——这就是冯·诺伊曼体系结构。
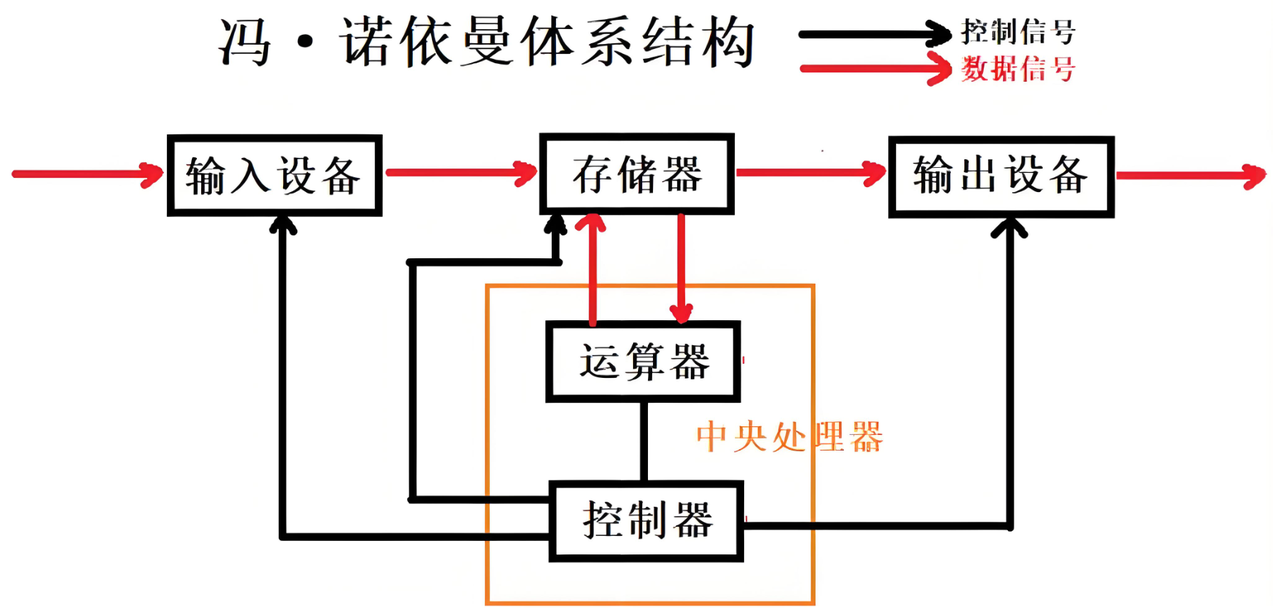
-
运算器 + 控制器 = CPU(中央处理器)
-
存储器 = 内存(注意不是硬盘)
CPU负责处理数据,内存负责临时存储正在运行的程序和数据。
1.1.4 现代计算机的特性
普遍流行的计算机(如个人PC、服务器)通常具备以下特点:
-
稳定性较好
-
效率较高
-
价格相对便宜
这正是冯·诺伊曼体系能够在几十年间成为主流的重要原因。冯·诺伊曼体系结构不仅奠定了现代计算机的理论基础,也深刻影响了我们日常使用的每一台设备。理解它的组成与工作方式,是学习计算机科学的第一步。
1.2 数据信息流动过程
一、计算机的存储金字塔
在冯·诺伊曼体系结构中,存储设备按照距离 CPU 的远近,形成了金字塔结构: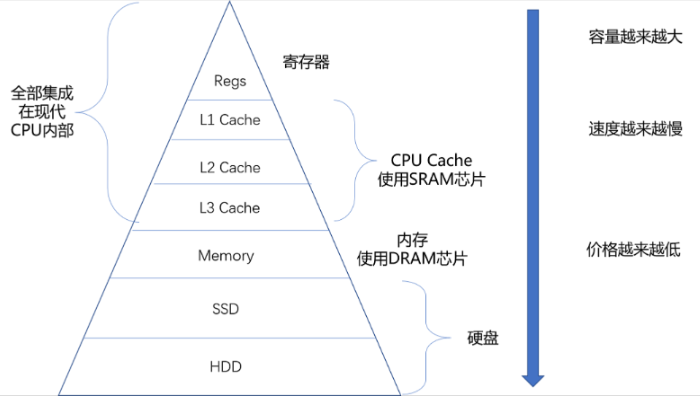
-
距离 CPU 越近的存储单元,访问效率越高,但单体容量小,造价昂贵(如寄存器、缓存)
-
距离 CPU 越远的存储单元,访问效率越低,但单体容量大,造价便宜(如内存、磁盘)
二、为什么体系结构中必须存在内存?
如果体系结构中没有内存,根据木桶原理(短板效应),计算机的整体效率将被最慢的环节决定——也就是外设(如磁盘)的访问效率。而外设(尤其是磁盘)的访问速度远低于内存。有了内存之后,计算机的整体效率就以内存的访问效率为主,这比直接访问磁盘要快得多。
内存的引入,本质上是把效率问题转化为了软件问题:
-
硬件提供了一套相对快速且成本可接受的中间存储
-
软件(操作系统、编译器、程序员)负责合理管理内存
-
最终结果是:计算机效率不错,且价格便宜,普通人也能买得起
三、一个核心规则
所有设备只能直接和内存打交道
更精确地说:
-
CPU 只能直接读写内存,不能直接访问外设(如磁盘、网卡、键盘、显示器)
-
外设也只能将数据写入内存,或从内存中读取数据
这就意味着:任何一次数据流动,内存都是必经的中转站。
1.3 数据信息流动的应用场景
程序运行前存储在磁盘中,为什么要加载到内存?
这是冯·诺伊曼体系结构的基本规定。
程序本质上是一个二进制的可执行文件,存储在磁盘(外设)中。
由于 CPU 只能直接访问内存,因此程序必须先被加载到内存中,CPU 才能从内存中逐条读取指令、访问数据,从而执行程序。
场景 a:登录 QQ 与朋友聊天时的数据流动
你发送消息:
键盘(输入) → 内存 → CPU(处理/编码) → 内存 → 网卡(输出)
网友回复消息:
网卡(输入) → 内存 → CPU(处理/解码) → 内存 → 显示器(输出)
可以看出:内存始终是数据的“中转枢纽”,CPU 是“加工厂”,外设是“出入口”。
场景 b:在 QQ 上发送文件时的数据流动
发送一个本地文件给好友
数据路径:
磁盘(外存,输入) → 内存 → CPU(可能做分片、校验等) → 内存 → 网卡(输出)
与聊天场景相比,唯一的区别只是输入源从键盘换成了磁盘,整体流动模式完全一致。
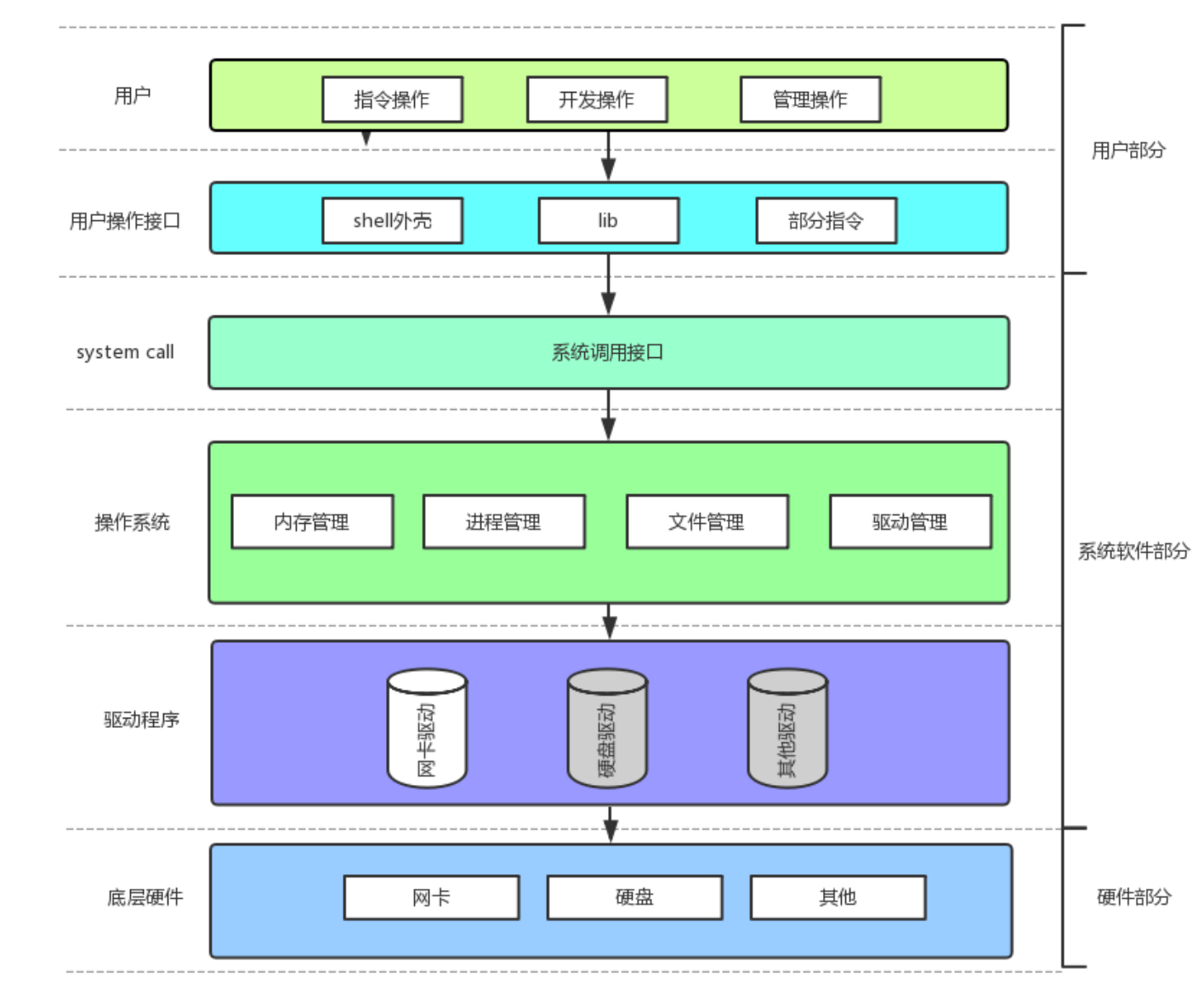
二、操作系统(Operator System/OS)
2.1 操作系统概念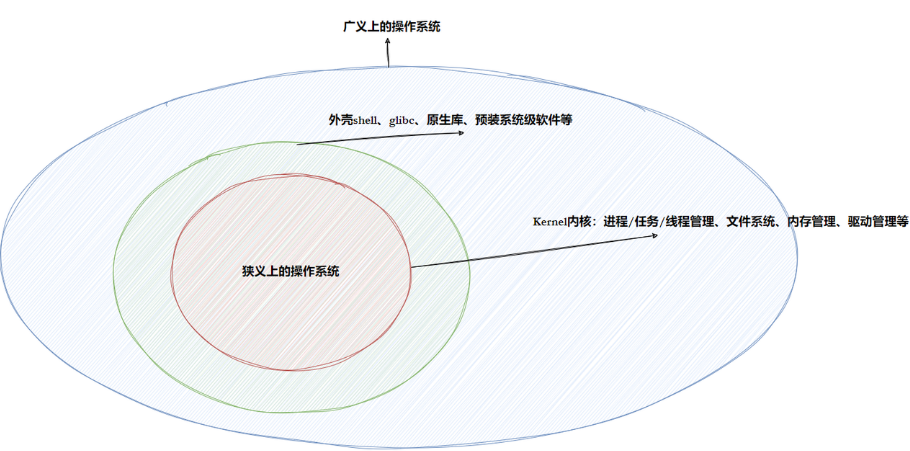
操作系统是一个进行软硬件资源管理的软件。更完整的定义:
操作系统是计算机系统中第一个被加载到内存的软件,它负责管理所有硬件和软件资源,并为上层应用程序提供运行环境和支持。
操作系统的两大职责:
-
数据方面:管理数据的存储、流动、访问权限
-
技术方面:提供系统调用接口,简化应用程序开发
2.2 管理——从生活到计算机的类比
一、以校园生活理解“管理”
在生活与工作中,角色大致可分为三类:
| 角色 | 职责 | 校园类比 |
|---|---|---|
| 只做决策 | 管理者 | 校长 |
| 只做执行 | 被管理者 | 学生 |
| 既执行又决策 | 中层管理者 | 辅导员(保证决策落地) |
核心洞察:
管理的本质不是对人做管理,而是对人的属性信息(数据)做管理。
管理者和被管理者无需见面。例如:从入学到毕业,你可能从未见过校长,但你的四年学业课程却被安排得“明明白白”。这说明管理一个人的本质不在于见面,而在于管理这个人的相关信息。
管理者的核心工作是做决策——根据被管理者的数据来做决策。那么问题来了:管理者如何拿到被管理者的数据?答案:通过中层管理者(如辅导员)来收集信息、保证决策落地。
二、当数据量很大时,如何管理?
计算机的解决方案:
使用结构体、类来封装一组类型不同但相关的数据,以及操作这些数据的方法。
举例:所有学生在特定场景下具有相同的属性信息,如姓名、年龄、学号、年级等。我们可以:
-
定义一个
struct student来描述学生的属性信息(描述) -
创建多个结构体变量(实例化)
-
将这些变量放入特定的数据结构(如链表)中(组织)
把对学生的管理工作,转化为对链表的增删查改。
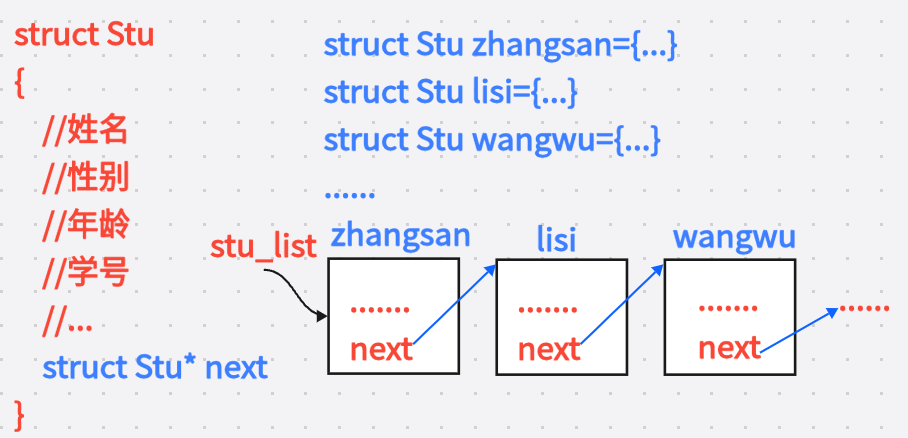
例如:“找到年龄最小的学生并删除”
-
以学生年龄属性作为比较基准
-
遍历链表
-
找到目标节点并删除
核心方法论:
对管理的计算机建模过程 = 先描述,再组织
计算机级别的建模:将具体问题或现象,转化为计算机能够认识和处理的形式。
三、从 C 语言到面向对象
历史回顾:
-
先描述(面向对象的过程):
class、struct -
再组织(数据结构):STL 容器,如
vector、list、stack、map、set、unordered系列
类中有对象的属性(数据)和方法(行为),再把用该类创建的对象放入容器中。
C 语言小项目示例(通讯录):
// 描述:一个人的信息
struct Person {
string name;
int number;
};
// 组织:通讯录的结构
struct Contact {
int num;
struct Person p[1000];
};以后只要是进行“管理”,都要做两件事:
先描述(
class、struct)再组织(STL容器、数据结构)
这就是将具体问题进行计算机级别的建模,转化为计算机能够认识的问题。
数据结构的本质,就是对数据进行管理。
一句话总结:把对数据的管理场景,转化为对特定数据结构的增删查改。
2.3 设计操作系统的目的
为什么要存在操作系统?
对下:进行软硬件资源管理(手段)
对上:提供一个良好的运行环境(目的)
为什么要存在系统调用接口?
a. 安全保护和资源管理
-
通过系统调用,操作系统可以确保用户程序不会直接访问或修改内核数据,防止潜在的安全风险
-
系统调用接口是用户与内核进行交互的唯一途径
-
有助于操作系统有效管理资源,确保用户程序在受控、安全的环境下访问和使用系统资源
b. 简化操作
-
系统调用为用户程序提供了高级、易用的接口,以访问操作系统提供的各种服务和功能
-
程序员无需深入了解底层硬件和操作系统细节,就可以编写出高效且可靠的应用程序
2.4 系统调用与库函数
一、系统调用(System Call)
访问操作系统,必须使用系统调用,系统调用是操作系统提供给用户和内核进行交互的一组接口。因为 Linux 大部分代码是用 C 语言编写的,所以 system call 本质上是用 C 语言设计的函数。
生活类比:
去银行取钱时,银行会有一个窗口将你“挡在外面”,你只能通过银行内部人员完成取款。
银行窗口 ≈ 系统调用接口
核心规则:用户不能绕过操作系统直接访问硬件资源(否则会出现数据损害、资源冲突、系统崩溃等安全隐患)。一般情况下,任何人不能直接访问操作系统内核,必须通过系统调用接口。
系统调用的价值:在确保操作系统安全性的前提下,为用户程序提供对底层硬件访问、系统级任务执行的能力。
二、库函数(Library Function)
库函数是由编译器或操作系统预先写好的函数,被存放在“库”中,供用户调用。
例如:printf、scanf 存放在 C 标准库中。
为什么需要库函数?
系统调用接口是系统级别的,要求使用者对操作系统有一定了解。然而大多数用户并不了解操作系统底层细节。因此,用户提供了类似于 printf、scanf 级别的库函数,两者都可以让用户完成对硬件资源的使用,但库函数更友好。
生活类比:
对于不识字的老爷爷来说,直接使用银行的自助服务系统非常困难。此时银行会提供一个服务人员来帮助他完成任务。
服务人员 ≈ 用户操作接口(库函数)
三、printf / scanf 的重新理解
-
printf向显示器打印 → 需要访问硬件设备(显示器) -
scanf从键盘读取 → 需要访问硬件设备(键盘)对硬件设备的访问,必须通过操作系统;而对操作系统的访问,必须通过系统调用接口。
我们的程序,只要它访问了硬件,那么它必须贯穿整个软硬件体系结构,因此:printf、scanf 底层封装了系统调用。
四、C 标准库的跨平台性
C 标准库具有跨平台性、可移植性。原因之一是:C 库函数中调用的 system call 由当前操作系统决定。
举例:
-
Windows 下,
printf封装的 system call 是代码 A -
Linux 下,
printf封装的 system call 是代码 B
C 标准库在实现 printf 时并没有指定使用代码 A 还是代码 B,具体情况取决于编译和运行时的操作系统。
五、库函数 vs 系统调用(上下层关系)

库函数在上,系统调用在下。库函数内部封装了系统调用。
三、进程
3.1 引言
回顾前文:可执行程序是二进制文件,存放在磁盘(外设)中,运行前必须被加载到内存中。
现在提出新问题:
-
我们可以同时启动多个程序吗? → 可以。
-
那么多个可执行程序都必须加载到内存中吗? → 是的。
于是引出下一个问题:操作系统需要管理多个被加载到内存的程序吗?
答案显而易见:需要。
那么核心问题来了:操作系统如何管理多个被加载到内存的程序?
答案就是我们之前总结的计算机管理方法论:先描述,再组织。
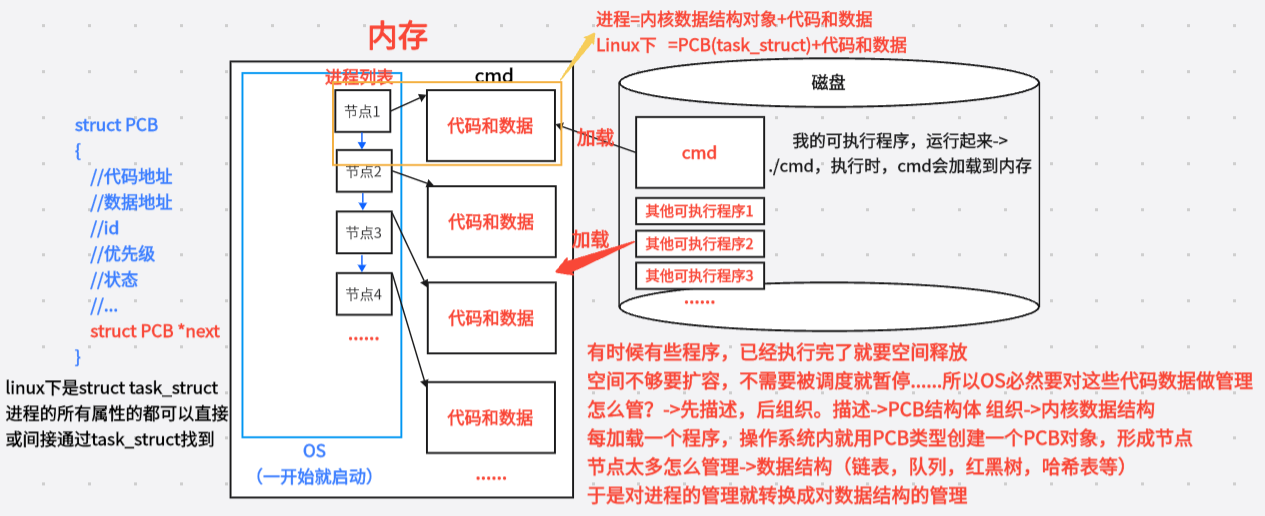
3.2 进程的概念
基本定义
进程 = PCB对象 + 可执行程序 = 内核数据结构 + 可执行程序
教材中常见的定义方式:
-
进程是正在运行的程序
-
进程是被加载到内存的程序
-
进程可以排队等待CPU资源
核心问题:为什么要为每个进程创建PCB对象?
因为操作系统要对进程进行管理,而管理的方法就是先描述、再组织。
-
PCB(Process Control Block,进程控制块) 是用于描述进程所有属性信息的数据结构
-
多个PCB被放入各种数据结构中,实现组织
管理的本质就是对数据结构的对象进行管理。
我们可以做一个重要类比:
之前学习的所有数据结构(链表、队列、树等)及其操作方法(增删查改),本质上都是在模拟操作系统对进程的管理工作。
结论:
操作系统与数据结构的关联度极高。对数据结构掌握得越好,理解操作系统就越容易。
一个重要的认知转折
未来所有对进程的操作和控制,都只与进程的PCB有关,与进程的可执行程序无关。
这意味着:
-
进程的PCB(相当于链表中的一个节点)可以被放入任意多个数据结构中
-
同一个进程可以同时出现在运行队列、等待队列、挂起队列等不同队列中
举例说明:
CPU资源是有限的,多个进程在运行时需要竞争CPU。
进程的PCB会被放入一个队列中,准备被CPU调度,这个队列称为运行队列(run queue)。
tips:
几乎所有的独立指令(即可执行程序),当它们被运行起来,都要变成进程。
你双击一个图标、在终端输入一个命令,背后都是在创建进程。
3.3 PCB(进程控制块)
基本概念
PCB是操作系统为了管理进程而设置的一个数据结构,存放着操作系统用于描述进程的所有属性信息,是进程存在的唯一标识。
| 术语 | 说明 |
|---|---|
| PCB | 操作系统学科中的通用叫法 |
| task_struct | Linux操作系统下PCB的具体名称 |
PCB中需要包含哪些信息?(简要列举)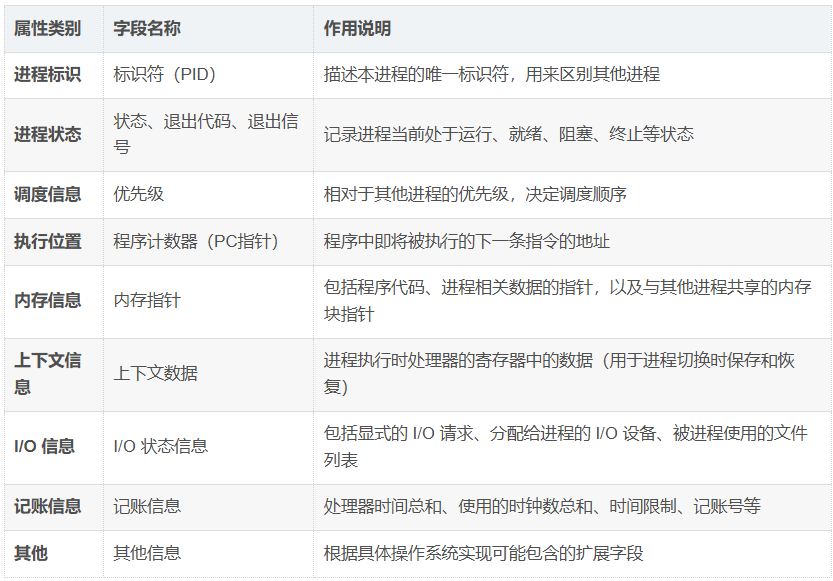
重点:程序计数器(PC指针 / eip寄存器)
在操作系统中,每个进程都有唯一的程序计数器,用于存储下一条将要执行的指令的地址。
PC指针的重要性:
PC指针指向哪个进程的代码,就表示哪个进程正在被CPU调度运行。
tips:
PCB(Node)可以被放入多个数据结构中,这体现了操作系统管理的灵活性。
一个进程可以同时出现在运行队列、等待I/O的队列、挂起队列等不同队列中。
3.4 查看进程
3.4.1 ps 命令 —— 查看进程的快照
基本概念
ps(process status)命令用于显示当前系统中的进程快照(某一瞬间的状态)。
常用选项组合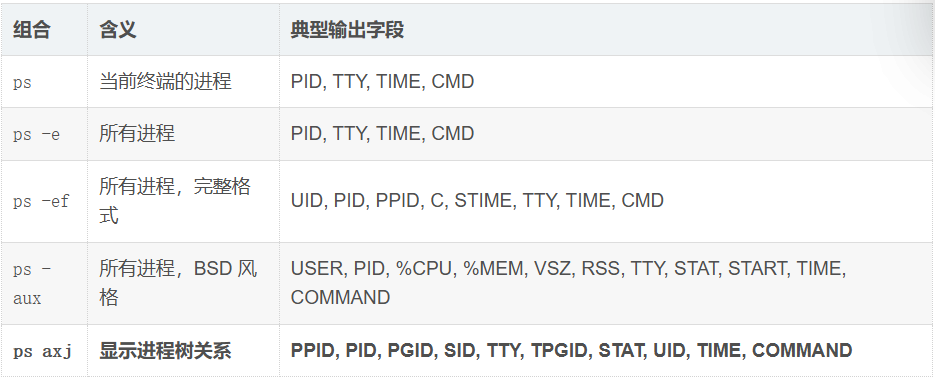
示例演示

配合 /proc 理解
ps 命令的本质:读取 /proc 目录下各 PID 子目录中的信息,格式化输出
3.4.2 /proc 文件系统(更底层)
一、基本概念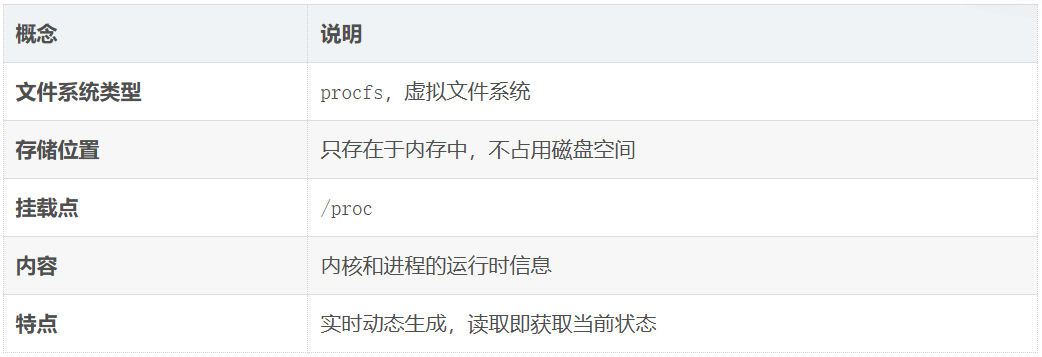
二、/proc 的核心内容
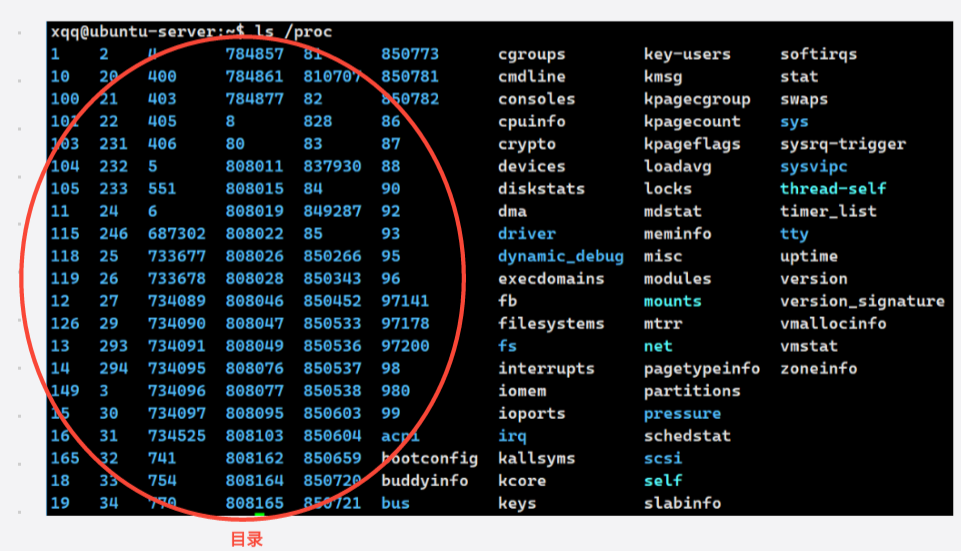
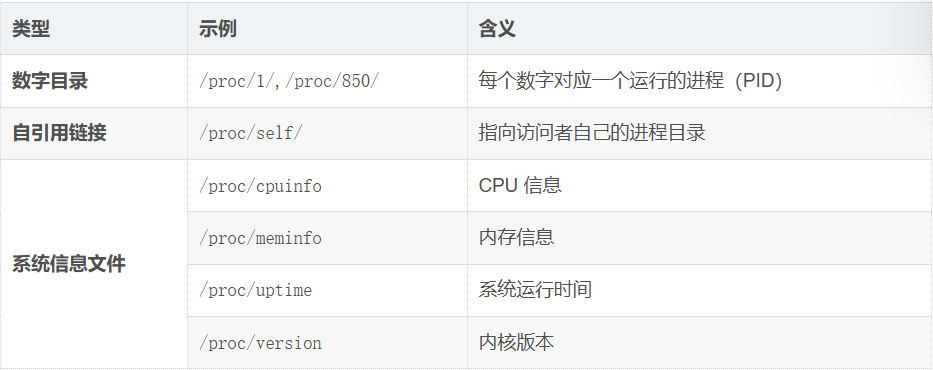
三、进程目录内部结构
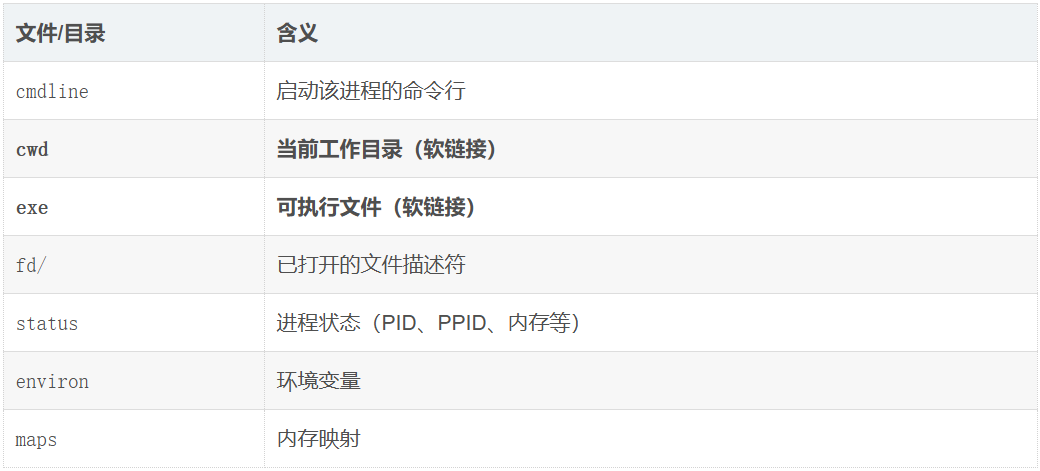
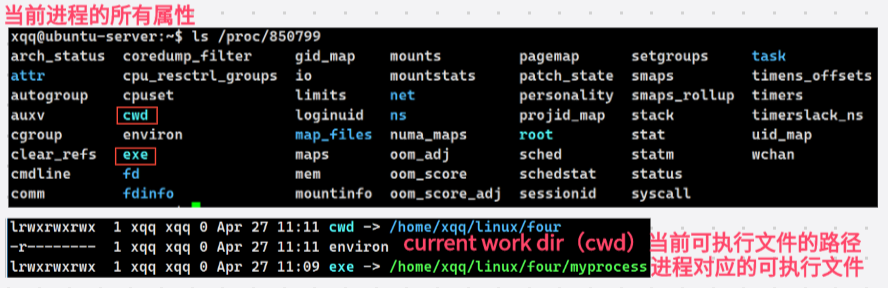
/proc/PID/cwd 是进程当前工作目录的内核视图,可以通过 int chdir(const char*path) 系统调用修改,修改只影响当前进程本身。
此时如果将exe也就是可执行文件删除,进程依旧会继续跑,因为所删除的exe文件是在硬盘上的,而进程启动时已经将这个文件拷贝到内存里面了,如果再继续查看进程属性就看不到exe了
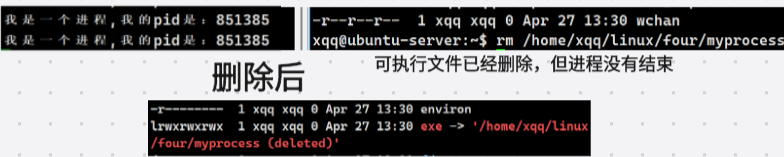
四、动态变化特性
知识补充:
Ctrl+C 只能杀前台进程(SIGINT),kill -9 可以杀任意进程(SIGKILL),是强制终止的最后手段。
实验中,
kill -9 850765之后显示了Killed,这是 shell 告诉你进程被杀了。有趣的是,kill -9 的进程无法执行任何清理工作(比如关闭文件、释放资源),所以一般建议:
优先用
kill PID(SIGTERM)如果进程不响应,再用
kill -9 PID



核心理解:
进程目录随进程创建而生成,随进程退出而消失 ——
/proc是一面实时反映内核状态的镜子。/proc就是把内核中抽象的进程数据结构,具象化为用户可见、可操作的目录和文件。这正是 linux下"一切皆文件" 哲学的最好体现。
3.4.3其他查看命令(补充)
一、top / htop —— 动态实时监控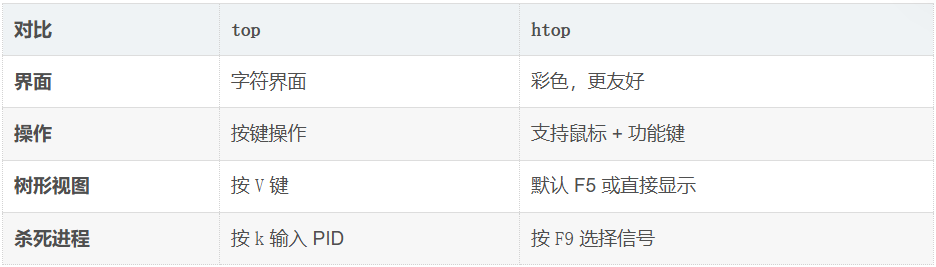
top 常用交互命令
| 按键 | 功能 |
|---|---|
1 |
展开/折叠 CPU 核心 |
M |
按内存使用排序 |
P |
按 CPU 使用排序 |
k |
杀死进程(输入 PID) |
q |
退出 |
htop 的优势
-
默认显示进程树(父子关系)→ 直观看到 PID / PPID 关系
-
支持鼠标点击
-
可以横向/纵向滚动
-
颜色区分不同类型信息
二、pgrep / pidof —— 按名称查 PID
2.1 pidof —— 根据程序名查 PID
# 基本用法
pidof bash
# 输出:851254 852100 852101(所有 bash 进程的 PID)
pidof myprocess
# 输出:851977
# 只返回一个 PID
pidof -s myprocess
2.2 pgrep —— 更强大的进程查找
# 基本用法
pgrep bash
# 输出:851254
pgrep myprocess
# 输出:851977
# 只返回数量
pgrep -c bash
# 显示完整命令行
pgrep -a myprocess
# 输出:851977 ./myprocess -arg1
# 查找某个用户的进程
pgrep -u xqq bash
# 查找 PPID 是某个值的进程
pgrep -P 851254 # 找出所有父进程是 851254 的子进程| 选项 | 含义 |
|---|---|
-a |
显示完整命令行 |
-c |
只计数,不显示 PID |
-P PPID |
根据父进程 PID 查找 |
-u 用户名 |
根据用户查找 |
-x |
精确匹配进程名 |
总结: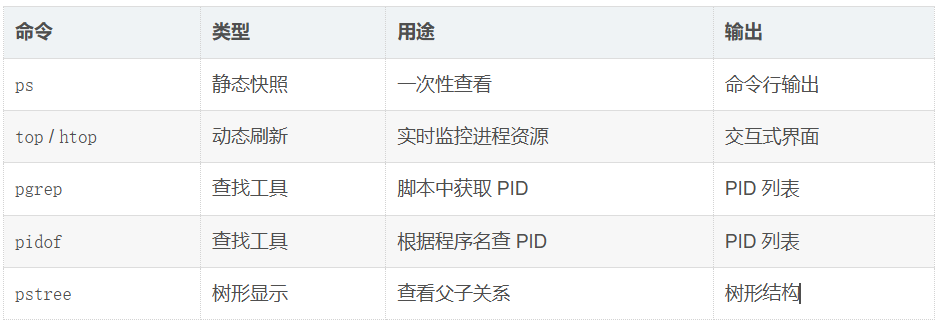
3.5 获取进程标识符 getpid() / getppid()
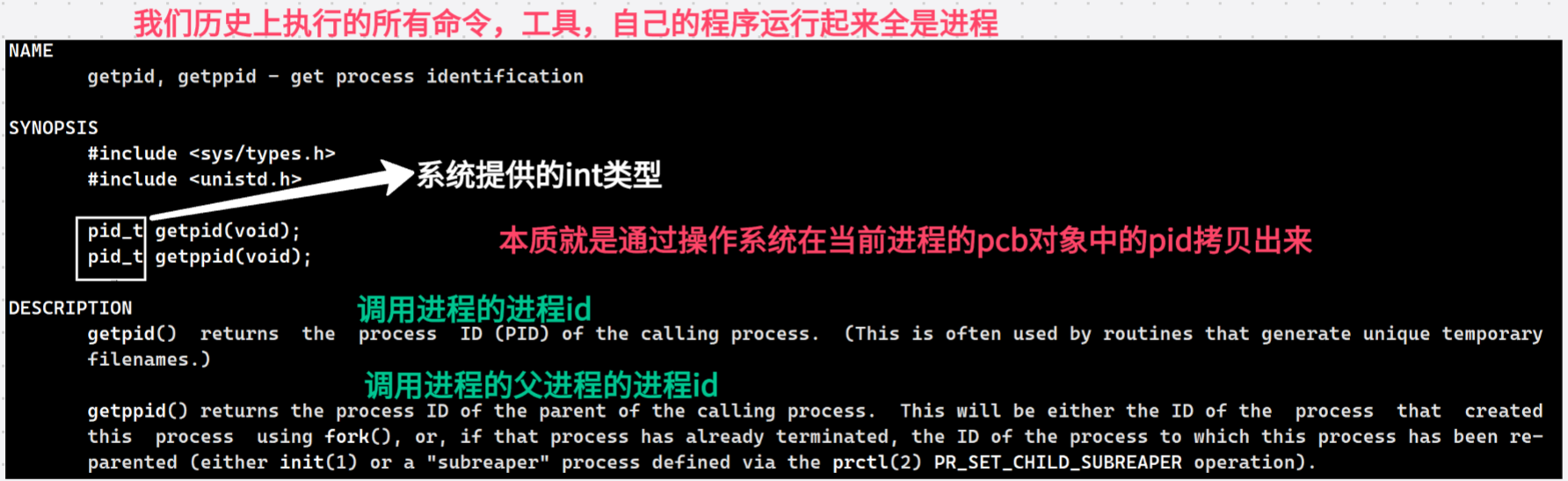
getpid()的本质,就是从当前进程的 PCB 对象(struct task_struct)中,把pid字段的值拷贝出来返回给用户。
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("PID: %d\n", getpid()); // 我是谁
printf("PPID: %d\n", getppid()); // 谁生了我
return 0;
}xqq@ubuntu-server:~/linux/four$ ./myprocess
我是一个进程,我的pid是:851977;我的父进程id是:851254
^C
xqq@ubuntu-server:~/linux/four$ ./myprocess
我是一个进程,我的pid是:851978;我的父进程id是:851254
^C
xqq@ubuntu-server:~/linux/four$ ./myprocess
我是一个进程,我的pid是:851979;我的父进程id是:851254
^C
xqq@ubuntu-server:~/linux/four$ echo $$ # 查看当前 shell 的 PID
851254
关键发现
-
PID 每次都在增加:851977 → 851978 → 851979
-
PPID 始终不变:都是 851254
-
每次运行都是新进程:不是同一个进程在重复
我们通过ps显示当前系统中851254这个父进程的消息,于是我们通过下面发现,父进程其实就是命令行解释器(bash),也就是说在命令行中运行的每一个程序,都是当前 Shell 进程的"孩子"。
xqq@ubuntu-server:~/linux/four$ ps axj | head -1;ps axj | grep 851254 | grep -v grep
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
851253 851254 851254 851254 pts/1 852009 Ss 1001 0:00 -bash
851254 852009 852009 851254 pts/1 852009 R+ 1001 0:00 ps axj
-
Shell 是所有命令的父进程
-
ps 自己也是一个进程,会被 ps 的输出列出来
-
进程树中的父子关系清晰可见
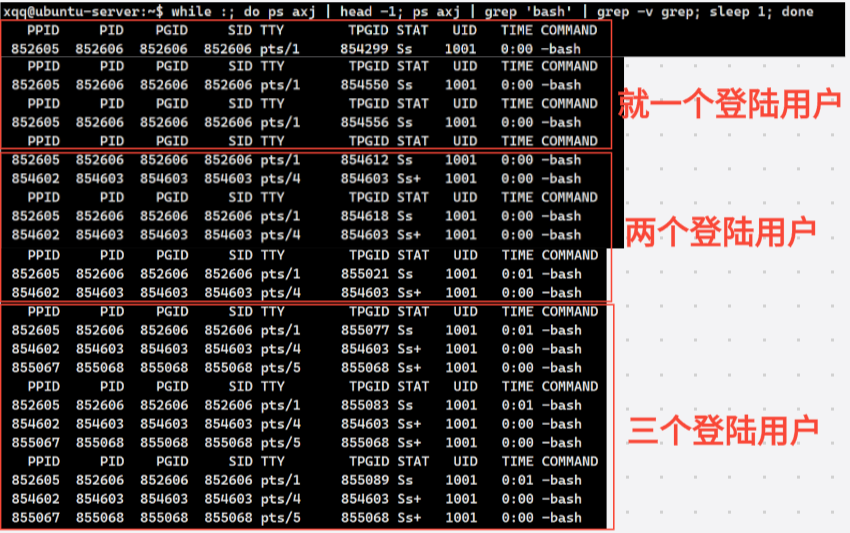
知识点:os会给每一个登陆用户分配一个bash,也就是说每登录一个用户,就分配一个bash,下面进行演示:
所以我们的命令行本质就是bash打印出来的一个字符串,打印完就卡在这()等用户输入命令,就类似c语言的scanf
3.6 进程的创建
3.6.1 fork函数
一、核心功能:创建一个子进程。

二、fork() 前后的变化
2.1 代码共享
关键理解:
-
代码共享:子进程和父进程执行的代码是同一份(只读)
-
数据独有:子进程会复制父进程的数据(写时拷贝优化)
fork() 创建子进程时,内核会拷贝父进程的 PCB 给子进程(修改其中的 PID、PPID 等字段),但最初并不拷贝代码和数据,而是让父子进程指向同一份物理内存。
这就像复印了一份简历,名字改成了新的 PID,但简历中写的“家庭住址”(指向代码/数据的指针)暂时没变,还是指向同一个地方。
只有当子进程或父进程真正要修改数据时,内核才会把要修改的那一页内存拷贝一份给该进程 —— 这叫写时拷贝(Copy-on-Write)。后面我会继续更新,深度剖析过程
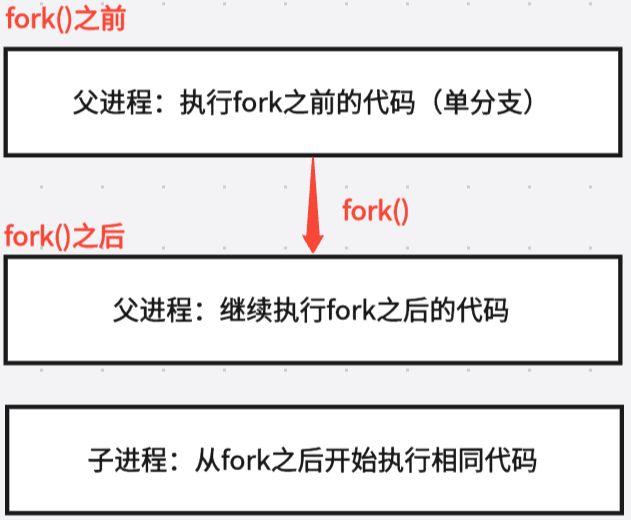
2.2 从"一个分支"变为"两个分支"
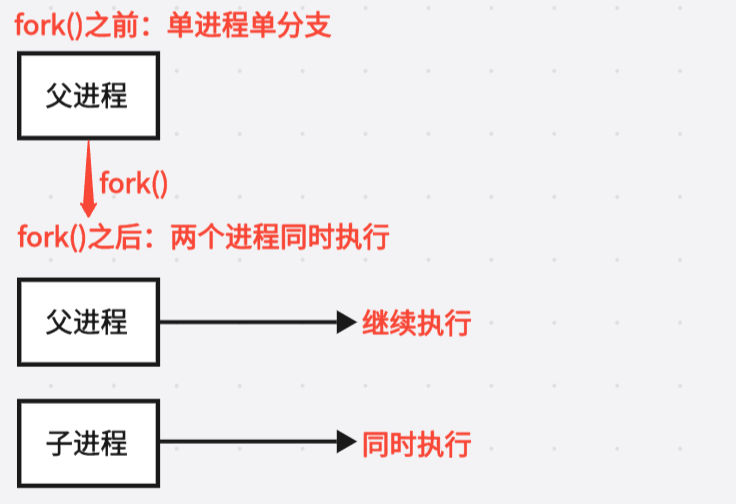
子进程从
fork()返回处开始执行,不是从头。它"看得见"前面的代码(因为共享),但"不会执行"(因为 PC 不指向那里)
核心规则:
fork() 之后的代码,父子进程同时执行,无法预知谁先执行(取决于调度器)。
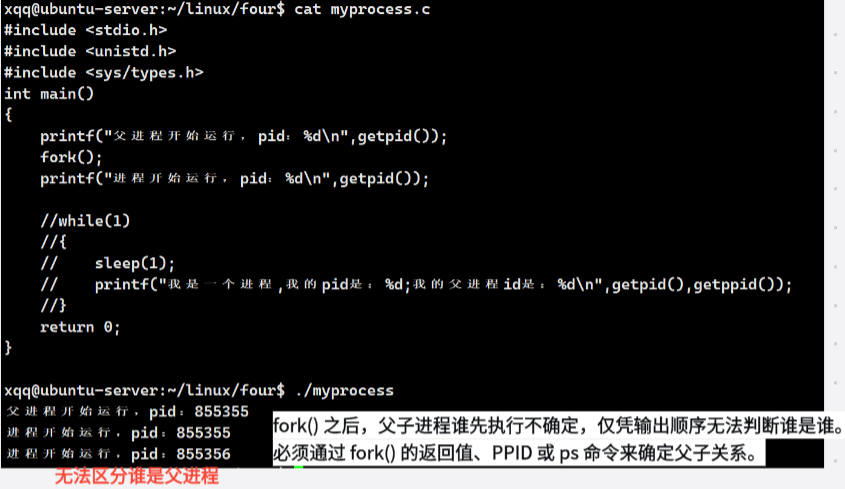
三、fork()返回值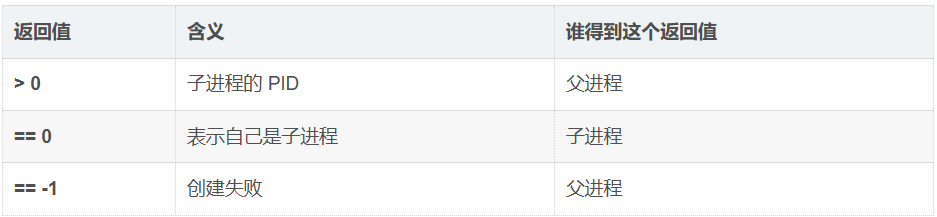
图解:
fork()
│
┌─────────┴─────────┐
│ │
▼ ▼
父进程 子进程
返回:子进程PID 返回:0
(例如 851977) 示例代码:
#include <stdio.h>
#include <unistd.h>
int main()
{
pid_t pid = fork();
if (pid == -1)
{
// fork 失败
perror("fork");
return 1;
}
else if (pid == 0)
{
// 子进程:返回 0
printf("我是子进程,PID=%d,PPID=%d\n", getpid(), getppid());
}
else
{
// 父进程:返回子进程的 PID
printf("我是父进程,PID=%d,子进程的PID=%d\n", getpid(), pid);
}
return 0;
}运行结果:
我是父进程,PID=855413,子进程的PID=855414
我是子进程,PID=855414,PPID=855413关系链:bash (PID) → 855413 → 855414
我们发现else if和else分支同时执行,也就是说一个变量id 有两个值,这是我们之前编写C/C++从来没有见过的。问题:
q1.为什么fork给父子返回各不相同的返回值,也就是为什么给子返回0,给父返回子pid?
答:因为子进程:父进程=1:n也就是说任何一个父进程可以有0或者多个孩子,而任何一个子进程只有一个父亲,由于父进程要通过不同的子进程pid来区分子进程,而子进程不用获取父进程的pid因为已经可以直接获得(getppid)
q2.为什么一个函数会返回两次?
一个函数如果执行到return时,主体逻辑(核心功能)已经完成了,也就是说当fork开始return时,fork的创建子进程的核心功能就完成了
所以return 语句就被执行了两次
q3.为什么一个变量,即已经==0了为什么又>0,导致if else同时成立?
要理解这个先要理解进程具有独立性:也就是说一个进程结束不会影响其他进程,即使父进程结束也不会影响子进程。
所以其实不是"一个变量既等于0又大于0",而是"两个独立的进程,各自有一个
id变量,父进程的id= 子进程PID(>0),子进程的id= 0"。if和else if分别在两个进程中成立,而不是同一个进程中同时成立。xqq@ubuntu-server:~/linux/four$ cat test.c #include <stdio.h> #include <unistd.h> int main() { pid_t id = fork(); printf("id = %d, &id = %p, 我是 %s\n", id, &id, id == 0 ? "子进程" : "父进程"); return 0; } xqq@ubuntu-server:~/linux/four$ ./test id = 855566, &id = 0x7ffd1b2779e4, 我是 父进程 id = 0, &id = 0x7ffd1b2779e4, 我是 子进程
两个进程打印的
&id地址相同(虚拟地址,这个我们后面了解)但这两个虚拟地址映射到不同的物理内存页,所以值不同,互不影响
这正是
fork()的神奇之处:一次调用,两个返回,两个进程,两个结果。


四、fork() 的特点
子进程是父进程的"副本"
| 继承的内容 | 说明 |
|---|---|
| 代码段 | 共享,只读 |
| 数据段 | 复制一份(写时拷贝) |
| 堆/栈 | 复制一份 |
| 文件描述符 | 指向同一张文件表 |
| 环境变量 | 完全复制 |
| 工作目录 | 继承 cwd |
| 信号处理方式 | 继承 |
五、为什么要用 if...else 分流?
问题: fork() 之后父子进程执行相同的代码,如何区分?
解决方案: 根据 fork() 的返回值进行分流。
为什么必须这样做?
-
父子进程想做的事情通常不同
-
父进程可能需要等待子进程,子进程可能去执行其他程序(exec)
-
没有分流,父子进程就会执行完全相同的逻辑
六、完整示例程序
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int main()
{
int x = 100; // 变量在 fork 前后会被复制
printf("fork 之前,x = %d\n", x);
pid_t pid = fork();
if (pid == -1)
{
perror("fork");
return 1;
}
else if (pid == 0)
{
// 子进程
printf("子进程:PID=%d, PPID=%d\n", getpid(), getppid());
x = 200; // 修改 x,只影响子进程的副本
printf("子进程:修改后 x = %d\n", x);
}
else
{
// 父进程
printf("父进程:PID=%d, 子进程PID=%d\n", getpid(), pid);
wait(NULL); // 等待子进程结束
printf("父进程:x = %d(未受影响)\n", x);
}
return 0;
}输出:
父进程:PID=851254, 子进程PID=851977
子进程:PID=851977, PPID=851254
子进程:修改后 x = 200
父进程:x = 100(未受影响)
七、核心要点总结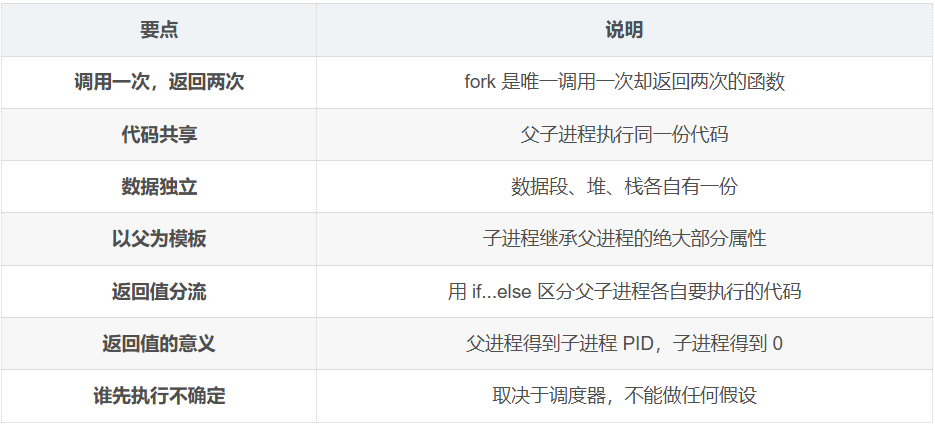
八、常见问题
Q1:子进程是否拷贝了整个父进程的内存?
A:不是立刻拷贝。 采用写时拷贝(Copy-on-Write, COW)技术,只有谁修改了数据,才会真正复制。
Q2:fork() 失败的原因?
A: 进程数达到系统上限、内存不足等。
Q3:子进程继承了什么?
A: 几乎全部:代码、数据、文件描述符、环境变量、信号处理等。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 31
31 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)