Linux操作系统与IO编程拟面试题
常用文件:~/.bashrc 或 ~/.profile(最常用的是 ~/.bashrc)。如果当前目录下有一个叫 clean 的文件,make clean 会认为目标文件已经存在且无需更新,就不会执行 clean 里的命令。目标(target):要生成的文件(比如可执行文件、.o 文件),也可以是伪目标(比如 clean)软连接:文件的 “快捷方式”,记录路径,可跨分区 / 链接目录,原文件删除后
一、指令部分
二、Linux路径下内容
| 目录名称 | 功能描述 |
|---|---|
| /bin | 存放基本二进制可执行文件,如常用命令 ls、cp 等,所有用户均可执行 |
| /etc | 存储系统级配置文件,如网络配置、用户信息(/etc/passwd)、服务启动脚本等 |
| /dev | 包含硬件设备文件(如 /dev/sda 表示硬盘,/dev/tty 表示终端),用于硬件交互 |
| /home | 普通用户的主目录,每个用户有独立子目录(如 /home/ 用户名),存放个人文件和配置 |
| /lib | 保存系统运行必需的共享库文件(如 C 标准库 libc.so)及内核模块,支撑程序运行 |
| /usr | 存储用户程序和数据,如应用程序、开发工具、库文件、文档等,类似集中的 “程序资源库” |
| /root | 超级用户(root)的主目录,存放其专属文件、配置及管理工具 |
| /tmp | 临时文件存储目录,用于存放系统和应用运行时产生的临时数据,系统重启时内容通常会被清空 |
| /mnt | 临时挂载点目录,用于手动挂载外部存储设备(如 U 盘、光盘)或其他文件系统 |
| /opt | 第三方软件或附加应用程序的存放目录,便于集中管理,如 /opt/ 软件名称 |
三、硬软连接区别
1. 硬链接
创建方式:ln 原文件 硬链接名(默认不带 -s)
特点: 所有硬链接地位平等,没有 “主文件 / 副本” 之分,删除任意一个都不影响其他链接。 只有当所有硬链接都被删除,且没有进程打开文件时,文件数据才会被系统回收。 无法跨文件系统创建,也不能链接目录(普通用户)。
2. 软连接
创建方式:ln -s 原文件/目录 软连接名(必须带 -s 参数)
特点: 是独立的文件,存储的是目标的路径信息,删除软连接不会影响原文件。
原文件被移动、重命名或删除后,软连接会失效,变成红色的 “死链接”。
支持跨分区、跨文件系统,也可以链接目录,使用更灵活。
一句话总结
硬链接:文件的 “别名”,共享数据块,防误删,不能跨分区 / 链接目录。
软连接:文件的 “快捷方式”,记录路径,可跨分区 / 链接目录,原文件删除后失效。
四、环境变量的配置
1.临时配置(仅当前终端有效)
如果你只是临时想测试一下某个路径,或者不想修改系统文件,可以使用 export 命令。
命令格式:export 变量名=变量值
示例(添加 PATH):
export PATH=$PATH:/opt/my_new_tool/bin
export
声明为全局环境变量,子进程、终端都能生效
PATH
系统命令查找路径变量
=
赋值
$PATH $\ = 引用变量
👉 保留**原来所有的旧路径 **,不覆盖
:
Linux 路径分隔符,用来隔开多个路径
/opt/my_new_tool/bin
你要新增的自定义命令路径
把 /opt/my_new_tool/bin 追加到 原有 PATH 后面
✅ 不会删掉系统原本的命令路径
✅ 以后可以直接执行这个目录里的程序,不用 ./(注意:$PATH 表示保留原本的路径,后面追加新的路径。如果直接写 PATH=/xxx,原本的系统命令(如 ls, cd)可能会找不到)
生效范围:只在当前 Shell 会话中有效,关闭终端或重启后失效。
2.永久配置
永久配置(写入配置文件) 要让环境变量永久生效,需要将 export 命令写入到特定的配置文件中。
根据作用范围不同,分为用户级和系统级。
用户级配置(推荐) 适用场景:只针对当前登录的用户生效,不影响其他用户。 常用文件:~/.bashrc 或 ~/.profile(最常用的是 ~/.bashrc)。
操作步骤:
(1)打开文件:vim ~/.bashrc
(2)在文件末尾添加:
export MY_VAR="hello"
export PATH=$PATH:/your/custom/path(3)保存退出。
(4)立即生效:执行 source ~/.bashrc。
3.系统级配置(全局)
适用场景:对所有用户都生效(需要 root 权限)。
常用文件:/etc/profile 或 /etc/environment。
操作步骤:
(1)打开文件:sudo vim /etc/profile
(2)在文件末尾添加:
export JAVA_HOME=/usr/local/java
export PATH=$PATH:$JAVA_HOME/bin(3)保存退出。
(4)立即生效:执行 source /etc/profile。
4.环境变量的作用
1、指定系统或软件配置
2、告诉程序去找依赖
3、传递敏感信息
4、C语言编译参数

5.常见的环境变量及用途
| 变量名 | 用途说明 |
|---|---|
| PATH | 最常用。指定命令的搜索路径。当你输入 ls 时,系统会去 PATH 里的目录找这个可执行文件。 |
| HOME | 当前用户的主目录路径(如 /home/user)。 |
| SHELL | 当前使用的 Shell 解释器(如 /bin/bash)。 |
| LANG | 系统语言和字符集(如 en_US.UTF-8 或 zh_CN.UTF-8)。 |
| LD_LIBRARY_PATH | 程序运行时查找动态链接库(.so 文件)的路径。 |
| PKG_CONFIG_PATH | 编译器查找 .pc 文件的路径,用于定位库的头文件和库文件位置。 |
验证配置是否成功
配置完成后,可以使用以下命令查看变量是否已生效:
查看特定变量:
echo $PATH
echo $JAVA_HOME查看所有
env五、makefile
1.Makefile 是什么?
Makefile 是 GNU Make 工具的配置文件,用来自动化编译项目。
核心解决什么问题?
项目文件多、依赖复杂,手动敲 gcc 命令容易出错、效率低
自动判断:哪些文件被修改过,只重新编译修改过的文件,大幅提升编译效率
一键执行编译、清理、安装等操作,不用记复杂命令
2.Makefile 最基础语法(万能模板)
目标: 依赖文件列表
命令1
命令2⚠️ 关键细节:命令前面必须是一个 Tab 键,不能用空格!
核心概念
目标(target):要生成的文件(比如可执行文件、.o 文件),也可以是伪目标(比如 clean)
依赖(prerequisites):生成目标需要的文件 / 条件
命令(recipe):依赖更新后,执行的编译 / 操作命令
# 最终目标:生成可执行文件 calc
# 依赖:三个 .o 目标文件(必须先生成这三个)
calc: main.o add.o sub.o
gcc main.o add.o sub.o -o calc # 把三个 .o 链接成可执行文件 calc
# 目标:生成 main.o
# 依赖:main.c + add.h + sub.h(头文件变了也要重新编译)
main.o: main.c add.h sub.h
gcc -c main.c -o main.o # -c:只编译,不链接,生成 main.o
# 目标:生成 add.o
# 依赖:add.c + add.h
add.o: add.c add.h
gcc -c add.c -o add.o # -c:只编译,生成 add.o
#当 add.c 或 add.h 发生变化时,执行 gcc -c add.c -o add.o,重新生成 add.o 目标文件
# 目标:生成 sub.o
# 依赖:sub.c + sub.h
sub.o: sub.c sub.h
gcc -c sub.c -o sub.o # -c:只编译,生成 sub.o
# 伪目标:清理编译产生的文件
clean:
rm -rf *.o calc # 删除所有 .o 文件 + 可执行文件 calc3.Makefile 核心符号详解
| 符号 | 含义 | 例子 |
|---|---|---|
= |
直接赋值(会被后面的赋值覆盖) | CC = gcc |
:= |
立即赋值(定义时就计算好,不会被覆盖) | SRC := $(wildcard *.c) |
?= |
条件赋值:变量未定义时才赋值 | CC ?= gcc |
+= |
追加赋值 | CFLAGS += -O2 |
$< |
第一个依赖文件 | 模式规则中代表 %.c |
$@ |
当前目标文件 | 模式规则中代表 %.o |
$^ |
所有依赖文件(去重) | $(CC) $^ -o $@ |
$* |
不包含扩展名的目标文件名 | 比如 main.o → main |
@ |
执行命令时,不在终端打印命令本身 | @echo "编译完成" |
% |
通配符,用于模式匹配 | %.o: %.c |
1. $<:第一个依赖文件
# 模式规则:所有 .o 文件都由对应的 .c 文件生成
%.o: %.c
# $< 代表第一个依赖文件,这里就是 %.c
gcc -c $< -o $@ 当处理 main.o 时,$< 会自动替换成 main.c
等价于:gcc -c main.c -o main.o
2. $@:当前目标文件
# 最终目标:生成 calc
calc: main.o add.o sub.o
# $@ 代表当前目标文件,这里就是 calc
gcc main.o add.o sub.o -o $@ 等价于:gcc main.o add.o sub.o -o calc
# 也可以用在模式规则里
%.o: %.c
gcc -c $< -o $@处理 main.o 时,$@ 就是 main.o
3. $^:所有依赖文件(去重)
calc: main.o add.o sub.o
# $^ 代表所有依赖文件:main.o add.o sub.o(自动去重)
gcc $^ -o $@ 等价于:gcc main.o add.o sub.o -o calc
如果依赖里有重复的文件,$^ 会自动去掉重复项,只保留一份
4. $*:不包含扩展名的目标文件名
# 比如目标是 main.o,$* 就是 main
%.o: %.c
gcc -c $< -o $@
# $* 可以用来生成不带扩展名的中间文件
echo "编译了 $*.c,生成了 $*.o" 运行 make main.o 时,会输出:编译了 main.c,生成了 main.o
5. @:执行命令时不打印命令本身
clean:
# 不加 @:终端会打印 rm -rf *.o calc
rm -rf *.o calc
# 加 @:只打印“清理完成”,不打印 echo 命令
@echo "清理完成" 效果对比:
不加 @:终端会显示 echo "清理完成",再显示文字
加 @:终端只显示 清理完成,不会显示 echo 命令本身
6.%:通配符,用于模式匹配
# 模式规则:所有 .o 文件,都由同名的 .c 文件生成
%.o: %.c
gcc -c $< -o $@这里的 %.o 和 %.c 是一对通配符
当你执行 make main.o 时,Make 会自动匹配 main.c,并执行规则里的命令
不用再一个个写 main.o: main.c、add.o: add.c 了
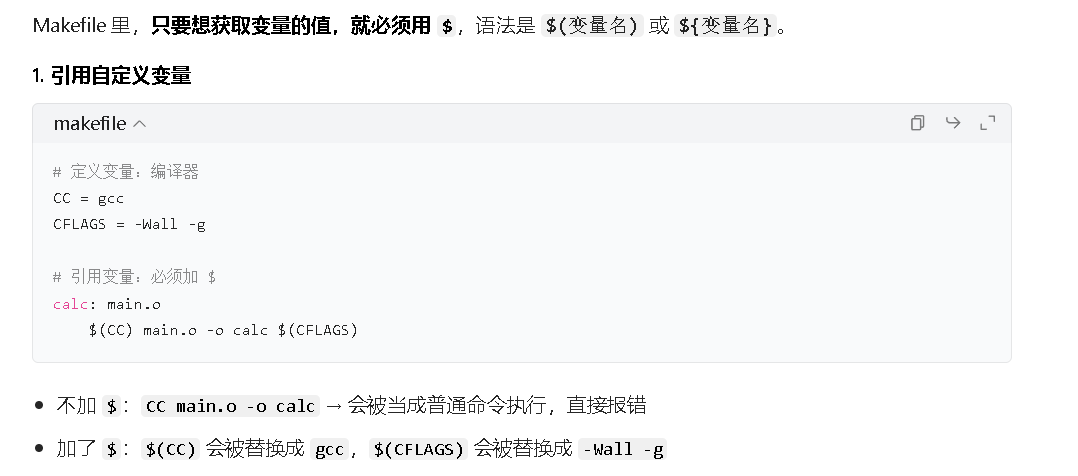
7.完整示例
# 编译器
CC = gcc
# 编译选项
CFLAGS = -Wall -g
# 目标文件列表
OBJS = main.o add.o sub.o
# 最终可执行文件
TARGET = calc
# 最终目标:链接所有 .o 文件
$(TARGET): $(OBJS)
# $^:所有依赖文件;$@:当前目标文件
$(CC) $^ -o $@
# @:不打印 echo 命令本身
@echo "链接完成,生成可执行文件:$@"
# 模式规则:自动编译所有 .c 文件为 .o 文件
%.o: %.c
# $<:第一个依赖文件;$@:当前目标文件
$(CC) $(CFLAGS) -c $< -o $@
@echo "编译完成:$*.c → $*.o"
# 伪目标:清理
.PHONY: clean
clean:
rm -rf $(OBJS) $(TARGET)
@echo "清理完成"运行结果
1.执行 make:
会自动编译 main.c add.c sub.c 为 .o 文件
再链接生成 calc
终端只会显示 编译完成:main.c → main.o 这类信息,不会打印 gcc 命令本身
2.执行 make clean:
会删除所有 .o 文件和 calc,并打印 清理完成
# 添加自定义变量 -> makefile中注释前 使用 #
# 使用函数搜索当前目录下的源文件 .c
src=$(wildcard *.c)
# 将源文件的后缀替换为 .o
obj=$(patsubst %.c, %.o, $(src))
target=calc
$(target):$(obj)
gcc $(obj) -o $(target)
%.o:%.c
gcc $< -c
# 添加规则, 删除生成文件 *.o 可执行程序
# 声明clean为伪文件
.PHONY:clean
clean:
# shell命令前的 - 表示强制这个指令执行, 如果执行失败也不会终止
-rm $(obj) $(target)
echo "hello, 我是测试字符串"
作者: 苏丙榅
链接: https://subingwen.cn/linux/makefile/#6-5-%E7%89%88%E6%9C%AC5
来源: 爱编程的大丙
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。4.伪目标(.PHONY)详解
伪目标不是一个真实的文件,只是一个操作命令的名字,比如 clean、install。
为什么要加 .PHONY?
如果当前目录下有一个叫 clean 的文件,make clean 会认为目标文件已经存在且无需更新,就不会执行 clean 里的命令。
用 .PHONY: clean 声明后,Make 就会把它当成伪目标,不管有没有同名文件,都会执行命令。
-MMD = 自动帮你生成「头文件依赖清单」,让 Makefile 知道:改了 .h 必须重新编译 .c
它是 gcc 编译器的参数,不是 Makefile 的语法。
-MMD:只追踪 你自己写的头文件(a.h、common.h)
-MD:连系统头文件一起追踪(stdio.h、stdlib.h)
-MMD = 自动生成 .d 依赖文件,让 Make 能识别头文件,改 .h 自动重新编译 .c
它其实是两个功能合体:
-MM:列出当前 .c 依赖的所有头文件
-D:把这些依赖写入一个 .d 文件(dependency file)
所以:
-MMD = 自动生成依赖文件 .d
.d 文件是依赖描述文件,里面记录了:
a.o 依赖 a.c + a.h + common.h 等
在 Makefile 中,变量命名虽然没有强制的语法限制,但在长期的工程实践中,已经形成了一套约定俗成的惯例。遵循这些惯例能极大地提升 Makefile 的可读性和可维护性。
1. 常用内置变量(预定义变量)
Make 自带了许多默认变量,通常使用全大写字母来命名。在编写 Makefile 时,我们经常会覆盖或修改这些变量的默认值:
CC:指定 C 语言编译器,默认通常是gcc。CXX:指定 C++ 编译器,默认通常是g++。CFLAGS:C 编译器的编译选项(例如:-Wall -g -O2)。CXXFLAGS:C++ 编译器的编译选项。CPPFLAGS:C 预处理器的选项(例如:指定头文件路径-I./include)。LDFLAGS:链接器的选项(例如:指定库文件路径-L./lib)。LIBS或LDLIBS:需要链接的库文件列表(例如:-lm -lpthread)。AR:归档器,用于创建静态库,默认为ar。RM:删除命令,默认为rm -f。
2. 自定义变量的命名风格
对于开发者自己定义的变量,虽然没有强制要求,但为了代码清晰,通常建议遵循以下风格:
- 全局配置参数(推荐全大写):
为了和内置变量保持一致,并突出其作为“全局配置”的作用,自定义的全局变量(如目标文件名、源码目录等)通常也使用全大写。- 例如:
TARGET := myapp、SRC_DIR := ./src、INCLUDE_PATH := ./include。
- 例如:
- 内部辅助变量(可使用小写):
如果在 Makefile 的局部逻辑或函数中定义一些临时使用的辅助变量,可以使用小写字母,以区分于全局配置。- 例如:
temp_files := $(wildcard *.tmp)。
- 例如:
3. 核心自动变量
这些是 Make 在执行规则时自动填充的特殊变量,它们通常由单字符的符号组成,只能在规则的命令部分使用:
$@:代表当前规则的目标文件(Target)。$^:代表当前规则的所有依赖文件(Prerequisites),以空格分隔且去重。$<:代表当前规则的第一个依赖文件。$?:代表所有比目标文件更新的依赖文件。$*:在模式规则(如%.o: %.c)中,代表匹配到的文件名主干(不含后缀)。- $+ :表示所有的依赖文件,这些依赖文件之间以空格分开,按照出现的先后为顺序,其中可能 包含重复的依赖文件
4. 为什么要遵循这些惯例?
- 一目了然:看到全大写的
CC或CFLAGS,开发者立刻就知道这是可以修改的编译配置。 - 避免冲突:许多外部工具链(如 Autotools、CMake)默认识别大写变量,遵循惯例能更好地与它们兼容。
- 提升协作效率:统一的命名风格(如全局大写、局部小写)能让团队成员在阅读和维护 Makefile 时更加顺畅,减少理解成本。
$(info ...) 是 Makefile 自己的命令
HEADERS := $(wildcard *.h)
$(info HEADERS = $(HEADERS))
echo 是 Linux 系统的命令
HEADERS := $(wildcard *.h)
all:
echo HEADERS = $(HEADERS) # 必须加 Tab5.Makefile 工作流程(理解它的核心逻辑)
a.执行 make 时,默认找第一个目标(比如 calc)
b.检查 calc 的依赖文件(main.o add.o sub.o)是否存在、是否被修改过
c.递归检查每个依赖的依赖(比如 main.o 依赖 main.c add.h)
d.如果 .c 文件比 .o 文件新,就重新编译生成 .o
e.所有 .o 文件更新完成后,执行链接命令生成最终目标
patsubst 是模式替换函数,可将 %.c 替换为 %.o,例如 $(patsubst %.c,%.o,main.c func.c);wildcard 用于获取文件列表,info 用于打印信息,subst 非 Makefile 标准函数
6.极简背诵版
核心格式:目标: 依赖,命令前必须是 Tab
变量用 = 定义,$(变量名) 引用
模式规则 %.o: %.c,配合 $< $@ 简化代码
伪目标用 .PHONY 声明,避免和文件重名
make 只编译修改过的文件,提升效率
六、GDB调试流程
*编译生成带调试信息的可执行文件:
gcc -g 源文件.c -o 可执行文件
(例:gcc -g main.c -o main)
启动gdb调试程序:
gdb 可执行文件名
(例:gdb main)
常用调试操作:
l 查看源码
b 行号 设置断点
r 运行程序
n 单步跳过
s 单步进入
p 变量名 打印变量
c 继续运行
q 退出gdb
bt 查看程序栈gcc -g开启调试
r:继续运行
b:打断点
n:单步跳过
s:单步进入
bt:查看程序栈
p:看变量的值
gcc 是什么?
GNU C Compiler → C 语言编译器
作用:把 .c 源代码 → 变成 可执行文件
gcc 文件名.c → 生成 a.out
-o 名字 → 指定可执行文件名
-c → 只编译,生成 .o
-g → 加调试信息,给 gdb 用
| 参数 | 含义(中文) | 作用 |
|---|---|---|
-c |
只编译,不链接 | 生成 .o 目标文件 |
-o |
指定输出文件名 | 不生成默认 a.out |
-g |
生成调试信息 | 给 gdb 调试 用 |
-Wall |
显示所有警告 | 帮你找代码错误 |
-I |
指定头文件路径 | 找 .h 文件 |
-L |
指定库文件路径 | 找 .so/.a 库 |
-l |
链接库 | 链接系统库,如 -lpthread |
七、标准IO的缓存机制和刷新条件
缓冲机制
1. 全缓冲(Full Buffering)默认4096字节(4KB)
规则:只有当缓冲区被写满,或调用fflush强制刷新时,数据才会写入内核。
适用场景:文件流(fopen打开的文件,默认全缓冲)。(普通文件
特点:效率最高,系统调用次数最少。
2. 行缓冲(Line Buffering)默认1024字节(1KB)
规则:遇到换行符\n、缓冲区写满、调用fflush或程序正常退出时,数据会被刷新。
适用场景:标准输入stdin、标准输出stdout(终端设备默认行缓冲)
例子:printf("hello");不会立即输出,直到遇到\n或程序结束。
3. 无缓冲(Unbuffered)默认0字节
规则:数据不经过用户缓冲区,直接调用系统调用写入内核。
适用场景:标准错误stderr(默认无缓冲,错误信息会立即输出,方便调试)
特点:效率最低,但实时性最强,错误信息不会被缓冲延迟。
#include <stdio.h>
int main()
{
// 1. stdout 标准输出:正常信息,行缓冲
printf("我是普通输出 stdout:");
// 2. stderr 标准错误:报错信息,无缓冲
fprintf(stderr, "【错误】我是 stderr 立刻打印\n");
// 3. stdin 标准输入:从键盘读
char buf[100];
printf("请输入内容:");
fgets(buf, sizeof(buf), stdin);
return 0;
}缓存区刷新条件
1.缓冲区写满
2.调用 fflush(fp) 强制刷新
3.程序正常结束
4.调用 fclose(fp) 关闭文件
5.终端流遇到换行符
6.遇到换行符'\n'(仅行缓冲中)

八、动静态库的区别
| 对比项 | 静态库(.a) |
动态库(.so) |
|---|---|---|
| 链接时机 | 编译链接时 | 程序运行时 |
| 打包方式 | 直接打包进可执行文件 | 仅留引用,不打包 |
| 可执行文件大小 | 大 | 小 |
| 运行依赖 | 无 | 必须依赖库文件 |
| 更新方式 | 需重新编译程序 | 直接替换库文件 |
| 制作命令 | ar cr libxxx.a x.o |
gcc -shared -fPIC -o libxxx.so x.o |
九、标准IO创建文件的权限用文件IO创建如何编写
1.标准IO(fopen)
没有权限参数,创建文件默认权限:0666,受 umask 修正。
// w 模式:不存在则创建,存在则清空
FILE *fp = fopen("test.txt", "w");2.文件 IO(open):
必须在 O_CREAT 时指定 mode 参数,实际权限 = mode & ~umask
open("test.txt", O_RDWR | O_CREAT | O_TRUNC, 0664);#include <stdio.h>
int main()
{
// 不存在就创建,存在就清空
FILE *fp = fopen("test.txt", "w");
if(NULL == fp)
{
perror("fopen");
return -1;
}
fclose(fp);
return 0;
}#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main()
{
// 和 fopen "w" 完全等价
// O_WRONLY :只写
// O_CREAT :文件不存在则创建
// O_TRUNC :文件存在则清空
// 0666 :创建默认权限
int fd = open("test.txt", O_WRONLY|O_CREAT|O_TRUNC, 0666);
if(-1 == fd)
{
perror("open");
return -1;
}
close(fd);
return 0;
}十、IO实现拷贝(文件和标准IO)
1.文件IO实现拷贝
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main(int argc, const char *argv[])
{
// 1.对输入参数的参数个数进行检查 argc
if (argc != 3)
{
printf("输入的参数个数有误\n");
printf("usage: ./a.out src_file dest_file\n");
return -1;
}
// 2.以只读的方式打开源文件 以只写的方式打开目标文件 open
// argv[1] 源文件的路径
// argv[2] 目标文件的路径
int src_fd = 0; //源文件的文件描述符
//O_RDONLY如果文件不存在则会进行报错,打开文件就会失败
if(-1 == (src_fd = open(argv[1],O_RDONLY)))
{
perror("打开源文件失败");
return -1;
}
printf("打开源文件成功,src_fd=%d\n",src_fd);
int dest_fd = 0; //目标文件的文件描述符
//O_WRONLY如果文件不存在则会进行报错.打开文件失败
//以只写的方式打开文件,如果文件不存在则创建新文件
//如果文件存在则将文件中原有的内容进行清空操作
if(-1 == (dest_fd = open(argv[2],O_WRONLY|O_CREAT|O_TRUNC,0666)))
{
perror("打开目标文件失败");
return -1;
}
printf("打开目标文件成功,dest_fd=%d\n",dest_fd);
// 3.循环读取和写入 read 和 write
char buf[1024] = {0};
ssize_t ret_read = 0; //用来接收read函数的返回值
ssize_t ret_write = 0; //用来接收write函数的返回值
while((ret_read = read(src_fd,buf,sizeof(buf)))>0)
{
//循环写入操作
ret_write = write(dest_fd,buf,ret_read);
if(ret_write == -1)
{
perror("写入目标文件失败");
return -1;
}
//检查写入的字节数与读取的字节数是否一致
if(ret_read != ret_write)
{
printf("写入的字节数与读取的字节数不一致\n");
return -1;
}
}
// 4.关闭文件 close
close(src_fd);
close(dest_fd);
return 0;
}2.标准IO实现拷贝
#include <stdio.h>
#define BUF_SIZE 1024 // 缓冲区大小
int main(int argc, const char *argv[])
{
// 参数校验:./a.out 源文件 目标文件
if (argc != 3)
{
printf("参数错误!\n");
printf("用法:%s src_file dest_file\n", argv[0]);
return 1;
}
FILE *fp_src = fopen(argv[1], "r");
FILE *fp_dest = fopen(argv[2], "w");
if (fp_src == NULL || fp_dest == NULL)
{
perror("文件打开失败");
return 1;
}
char buf[BUF_SIZE] = {0};
size_t ret;
// 循环块读取 + 块写入
while ((ret = fread(buf, 1, BUF_SIZE, fp_src)) > 0)
{
// 只写入实际读到的字节数
fwrite(buf, 1, ret, fp_dest);
}
// 关闭流
fclose(fp_src);
fclose(fp_dest);
printf("文件拷贝完成\n");
return 0;
}十一、标准IO和文件IO的区别
文件 IO:Linux 系统调用,无用户态缓冲区,直接操作内核
标准 IO:C 标准库函数,带用户态缓冲区,效率更高,跨平台
| 对比项 | 文件 IO(系统调用) | 标准 IO(C 库函数) |
|---|---|---|
| 所属层次 | 系统调用,内核提供 | C 标准库,用户态封装 |
| 头文件 | <unistd.h> <fcntl.h> |
<stdio.h> |
| 操作对象 | 文件描述符 int fd |
文件指针 FILE* fp |
| 是否带缓冲区 | ❌ 无用户态缓冲区 | ✅ 带用户态缓冲区(全缓冲 / 行缓冲 / 无缓冲) |
| 效率 | 低(频繁陷入内核) | 高(减少系统调用次数) |
| 移植性 | 弱(仅 Linux/Unix) | 强(Windows/Linux 通用) |
| 常用函数 | open/read/write/lseek/close |
fopen/fread/fwrite/fseek/fclose |
| 适用场景 | 设备文件、网络、驱动、底层操作 | 普通文件读写、日志、跨平台程序 |
十二、段错误一般由什么情况引起
访问非法内存:访问操作系统禁止读写的内存地址,如内核空间、未分配内存。
野指针、空指针操作:指针未初始化、指针为 NULL,直接解引用、赋值、读写。
数组越界:访问数组下标超出定义范围,破坏栈内存。
修改只读内存:例如:字符串常量不可修改,char *p="abc"; p[0]='1';
栈溢出:局部数组过大、递归层数过多,耗尽栈空间。
重复释放 / 多次 free:同一块堆内存重复释放,破坏内存管理结构。
释放后继续使用内存:free 销毁空间后,继续操作该指针。
总结:空指针 / 野指针解引用、数组越界、修改常量字符串、栈溢出、非法访问内存、重复释放内存、释放后继续使用。
缓冲区的区别(最容易考)
文件 IO:每次 read/write 都直接发起系统调用,频繁读写会非常慢
标准 IO:数据先写到用户态缓冲区,缓冲区满 / 刷新时才一次性调用系统写入内核,大大减少系统调用次数
对应关系:
| 功能 | 文件 IO | 标准 IO |
|---|---|---|
| 打开文件 | open() |
fopen() |
| 读文件 | read() |
fread() / fscanf() / getchar() |
| 写文件 | write() |
fwrite() / fprintf() / putchar() |
| 定位文件 | lseek() |
fseek() |
| 关闭文件 | close() |
fclose() |
用 标准 IO:写日志、配置文件、普通文本处理(带缓存,效率高)
用 文件 IO:设备驱动、网络套接字、实时数据传输(无缓存,直接操作)
stdin、stdout、stderr
1. 含义
stdin 标准输入 键盘
stdout 标准输出 终端屏幕
stderr 标准错误 终端屏幕
2. 文件描述符(文件 IO)
0 → 标准输入 stdin
1 → 标准输出 stdout
2 → 标准错误 stderr
3.标准IO对应
FILE *stdin;
FILE *stdout;
FILE *stderr;4.例子
// 往标准输出打印
fprintf(stdout,"hello\n");
// 往标准错误打印
fprintf(stderr,"出错了!\n");软硬链接什么时候用:
| 特性 | 硬链接 | 软链接(符号链接) |
|---|---|---|
| 本质 | 多个文件名指向同一个 inode | 一个文件指向另一个文件的路径 |
| 跨分区 | ❌ 不能跨分区 | ✅ 可以跨分区 |
| 链接目录 | ❌ 不能链接目录 | ✅ 可以链接目录 |
| 原文件删除 | 链接依然有效,inode 计数没到 0 就不会删 | 链接失效,变成 “断链” |
| 大小 | 和原文件一样 | 很小,只存路径字符串 |
1.硬链接:什么时候用?
✅ 场景 1:需要多个文件名指向同一个文件,且不希望文件被误删
比如:你有一个重要配置文件,想在多个地方都能访问,又怕不小心删了其中一个导致文件丢失。
用法:
ln /etc/nginx/nginx.conf /home/user/nginx.conf.link效果:删 /home/user/nginx.conf.link,原文件 /etc/nginx/nginx.conf 完全不受影响。
场景 2:做文件备份 / 防误删(同分区内)
原理:硬链接本质是同一个文件,修改任何一个链接,所有链接都会同步变化。
比如:重要日志文件,建一个硬链接,就算原文件被程序删除(inode 计数没到 0,进程还开着),硬链接依然能看到完整数据。
2.❌ 硬链接绝对不能用的情况
跨不同磁盘 / 分区(比如把 /home 下的文件链接到 /tmp 下)
链接目录(系统默认不允许,防止循环链接)
链接不存在的文件(硬链接必须基于已存在的 inode)
3.软链接:什么时候用?(日常开发 90% 的场景都用它)
✅ 场景 1:简化路径,快速访问深层目录 / 文件
比如:你经常要进 /opt/software/nginx-1.24.0/conf/,每次输路径太麻烦。
用法:
ln -s /opt/software/nginx-1.24.0/conf/ ~/nginx-conf效果:直接 cd ~/nginx-conf 就能进去,不用输长路径。
✅ 场景 2:软件版本切换(比如 Python、JDK)
比如:你同时装了 Python3.8 和 Python3.10,想随时切换默认版本。
用法:
ln -s /usr/bin/python3.10 /usr/bin/python想切回 3.8 时,删掉旧链接重新建就行,不用改环境变量。
✅ 场景 3:跨分区 / 跨磁盘链接文件
比如:你在系统盘装了程序,数据存在数据盘,用软链接把数据盘的目录链接到程序的默认路径下。
硬链接做不到,但软链接可以。
✅ 场景 4:给编译后的可执行文件创建快捷方式
比如:你自己编译了一个 myapp,想直接在终端输入 myapp 就能运行,不用写 ./myapp 或者绝对路径。
用法:
ln -s /home/user/myapp/bin/myapp /usr/local/bin/myapp软链接的坑:原文件 / 目录删除 / 移动后,链接会失效
比如:你把原文件 nginx.conf 删了,软链接就变成了无效的 “红名文件”,打开会报错。
怎么选?
同分区、想防误删、多入口访问同一份数据 → 用硬链接
跨分区、简化路径、版本切换、快捷方式 → 用软链接(绝大多数场景都用它)

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐



 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)