C语言的指针
在编程中,指针与地址是同一个概念,因此可以先从地址的角度理解指针。编程中的地址可以说是对实际生活中地址的抽象,比如在收发快递时,快递员通过提供的地址,就可以准确的定位到你家的位置。对应到编程中,可以说操作系统对每字节的内存空间都进行了编号,通过这个编号,就可以准确定位到每字节的内存空间,这个编号,就是所谓的指针,并且我们在大多数情况下并不关注指针本身,而是关注通过这个指针能够找到的资源数据。然后很
相信对大多数人来说,指针是学习C语言的第一道坎,本人在初学编程时被这个东西折磨的不轻,因此写下这篇博客进行进行一些总结与归纳,希望能让读者有所收获。(注:1.本文会穿插一丢丢C++的知识,不感兴趣的可以跳过这些部分 2.本文的部分代码在不同位数的操作系统下运行的结果可能不同)
1.指针的简单介绍和用法
1.1什么是指针
在编程中,指针与地址是同一个概念,因此可以先从地址的角度理解指针。编程中的地址可以说是对实际生活中地址的抽象,比如在收发快递时,快递员通过提供的地址,就可以准确的定位到你家的位置。对应到编程中,可以说操作系统对每字节的内存空间都进行了编号,通过这个编号,就可以准确定位到每字节的内存空间,这个编号,就是所谓的指针,并且我们在大多数情况下并不关注指针本身,而是关注通过这个指针能够找到的资源数据。
 然后很自然的会产生一个问题:操作系统是怎么产生这些编号的?这个问题与电脑的位数有关(就是常说的32位或64位操作系统),此处的位数是bit位,bit是计算机内存的最小单位,一个bit的空间只能存储一个0或一个1,0对应低电平,1对应高电平,32位系统可以用32个bit位存储的数据表示地址,显然可以产生2^32个编号,每个编号由32个0或1组合出来,同理64位系统可以产生2^64个编号,每个编号由64个0或1组合出来,也因此64位系统相比32位系统可以管理更多内存资源(指针的大小就由此决定,具体介绍请看下文)。
然后很自然的会产生一个问题:操作系统是怎么产生这些编号的?这个问题与电脑的位数有关(就是常说的32位或64位操作系统),此处的位数是bit位,bit是计算机内存的最小单位,一个bit的空间只能存储一个0或一个1,0对应低电平,1对应高电平,32位系统可以用32个bit位存储的数据表示地址,显然可以产生2^32个编号,每个编号由32个0或1组合出来,同理64位系统可以产生2^64个编号,每个编号由64个0或1组合出来,也因此64位系统相比32位系统可以管理更多内存资源(指针的大小就由此决定,具体介绍请看下文)。
1.2指针的简单语法
C语言中在已定义的变量前方用&(取地址)操作符就可以取出指向该变量内存资源的指针,并且接收指针时要在类型的后面加上*符号,同时*符号也用于对指针进行解引用(通过指针找到指针所指向的资源),所谓的内存资源就是程序员在内存中存储的有效数据。
int main()
{
int a = 10;
char c = 'o';
short d = 5;
int* pa = &a; //取出a的地址给指针pa
char* pc = &c;
short* pd = &d;
printf("%d\n", *pa); //对指针pa解引用,找到变量a,打印出10
printf("%c\n", *pc);
printf("%d\n", *pd);
return 0;
} 
对于其它简单类型也是如此,这里不再赘述。
1.3指针的类型
就像数据有不同的类型,指针同样也有不同的类型,(准确的说应该是指针变量有不同的类型,指针变量是用于储存指针的变量,但是在习惯上会认为指针和指针变量都指指针变量)
int main()
{
int a = 0;
float b = 1.2f;
short c = 3;
//.....
int* pa = &a; //指向整形数据a的指针,指针pa的类型是int*
float* pb = &b; //指向浮点型数据b的指针,指针pb的类型是float*
short* pc = &c; //指向短整型数据c的指针,指针pc的类型是short*
//.....
return 0;
}显而易见:对于简单类型的指针,其指针类型就是在数据类型后面加个*(复杂的指针类型不是,后文会进行详细的讲解)。在这里尤其要注意的是,指针本身也会占用内存空间,但是与不同的数据类型会占用不同大小的内存空间不同,任何指针占用的内存大小只取决于操作系统的位数(包括数组指针和函数指针),32位系统的一个指针由32个bit位生成,因此占用4字节空间,在64位系统下,一个指针由64个bit位生成,因此占用8字节空间(8bit=1字节),就像是别墅和平房,难道房子越大,地址就会越长吗?总之:指针的大小与其指向内存资源的大小无关,与指针的类型也无关,只取决于操作系统的位数,并且对于占用多字节内存的数据,其指针是其首字节的地址(比如int类型的数据占用4字节,那么一个int*类型的指针就会保存其首字节的地址)
1.4指针的类型的意义
1.不同的指针类型决定了指针变量在解引用时能访问多少个字节。
2.指针的类型决定了指针的步长。
先来解释一下1,前文已经提到:对于占用多字节内存的数据,指针是其首字节的地址,那么在指针解引用时能访问多少字节的数据就非常重要了。比如一个char类型的数据会占用一字节的内存空间,那么一个char*类型的指针在解引用后就能往后访问到1字节的空间,同理,一个int类型占用4字节的空间,那么一个int*类型的指针在解引用后就可以往后访问4字节的空间,其它简单类型也是如此。因此如果用指针接收了不同类型的数据,就会出现一些问题:
int main()
{
int a = 100;
char* pa = &a;
int b = 1000000;
char* pb = &b;
printf("%d", *pa);
printf("%d", *pb);
return 0;
}

可以看到,*pa打印出了正确的结果,但是*pb打印出了一个奇怪的东西,其原因就是指针char*在解引用后只能往后访问1字节的内存,而100是可以用1字节进行完整储存的,但是1000000无法只使用1字节进行存储,因此指针pb把1000000在内存中存储的值进行了截断,只取了1字节,所以打印出了64。要注意的是,上方的代码只能在c的编译环境下运行,在c++的编译环境下,上方的代码会报编译错误(因为c++做了更加严格的类型检查)。因此在使用指针时一定要让指针的类型和数据的类型匹配上。
然后再来看看2,所谓指针的类型决定了指针的步长,就是在我们对指针进行+和-操作时,指针会往后走几个字节,来看看以下代码:
int main()
{
int a = 10;
char c = '1';
int* pa = &a;
pa++;
pa+=10;
char* pc = &c;
pc++;
pc+=10;
return 0;
}在上方代码中,pa是int*类型的指针,那么我们如果对其++,pa就会往后走4个字节,对其+=10,那么pa就会往后走40个字节,同理,我们对char*类型的指针pc进行++后,它会往后走1字节。对其+=10后,它会往后走10字节,对于其它简单类型也是同理,指针类型的步长与其解引用后能够访问的字节数是相同的(即:指针的步长 = 指针指向的目标类型的大小),这个特性在实现指定访问数组中的某一个元素时起到了重要的作用。
1.5野指针
在C语言中,野指针是一个非常可怕的东西,它是一个有问题的指针,该指针指向的位置不可知(随机的,不正确的,没有明确限制的),也就是说,如果对野指针进行解引用,那么就可以访问到一块不属于你的空间,该空间中储存的可能是随机值,也可能是某些重要的数据,如果是随机值还好说,但是如果这片空间中储存着重要的数据,而你又通过了野指针找到了这片空间并且通过解引用操作其值进行了修改,那你可能就要有大麻烦了。试想一下,你是微信开发团队中的一员,在某天你不小心使用了野指针把一个值从0修改成了10000000,而这个值又正好对应着某个微信用户零钱的数额,那你可能就要喜提几年牢饭了。
显然,我们必须避免野指针的产生,那么首先就要先理解野指针是怎么产生的,先来看看几个简单的场景:
1.变量没有初始化
int mian()
{
int* p; //p没有初始化(没有明确的指向),一个局部变量不初始化的话,会放入随机值
*p = 10; //非法访问内存,此处的p就是野指针
return 0;
}
在这种情况下,程序员也无法确定p会指向哪里,p显然就是一个野指针,但是这种情况还好,编译器会检查出来,恐怖的是编译器检查不出来的野指针。
2.越界访问
int main()
{
int arr[5] = { 0, 1, 2, 3 };
arr[100] = -10000000000;
return 0;
}
如上方代码,我们显然进行了对数组arr进行了越界访问,此时没有人知道arr[100]的位置会是什么东西,并且编译器还没有报错,这是一件多么可怕的事啊,如果arr[100]原本储存的是某个人银行卡中的数额呢?那这个幸运儿就要变成世界首负了。那么这么明显的错误编译器为什么没有报出呢,这波全是编译器的锅。其实编译器也是有苦说不出啊,编译器对于数组的越界采取的是抽查的行为,一般只会对一个数组越界的后面几位进行检查,并且只会检查越界写,不会检查越界读。因为编译器也不知道程序员越界会越到哪里去,毕竟程序员是自由的,如果是arr[1000]呢?总不可能对每个内存块都进行检查吧,那原本0.1秒能编译好的代码就可能要编译1个小时了,你打开个原神就要开1天,那这还玩个毛啊,所以编译器只能采用抽查的方案,并且在C++中对于数组越界的检查也是抽查(不过在C++利用vector代替数组可以解决这个问题),因此为了避免这种情况,就只能靠程序员的火眼金睛了。
3.当变量被销毁,但是指向变量的指针被保留也会产生野指针
int* fun()
{
int a = 10;
return &a;
}
int main()
{
int* pa = fun();
return 0;
}

如上方代码,a是fun函数的局部变量,在函数fun调用结束后a就会被销毁,但是逆天的是这个函数返回了变量a的地址,并且这个程序还可以正常运行,编译器仅仅是报了一个警告(有时候连警告都不会有),那么显然,pa又是一个野指针。从这里我们也可以发现,编译器对于野指针在大部分情况下都是不会报错的,所以才说野指针是一个非常可怕的东西,如果你不想编代码编到监狱去,那就保持对野指针的高度警惕并养成使用指针的好习惯吧。
使用指针的好习惯:
1.对指针进行初始化
2.小心指针越界
3.不知道为指针赋什么值时就用NULL
4.避免返回局部变量的地址
5.使用指针前检测其有效性
在这里要进行说明的是第3条:NULL是一个空指针,其值是0,你可以把野指针当作一条野狗,野狗不拴起来就会到处咬人,而NULL就是一颗固定的树,只要你把野狗栓到这棵树上,那野狗就咬不到人了(此时被拴起来的指针叫空指针)。
int main()
{
int* pa;
int* pb = NULL;
return 0;
}如上方代码,pa是一个野指针,pb是一个空指针,相当于野狗pa完全是野的,而野狗pb被NULL栓起来了,相比之下,显然是pb要更加安全,需要注意的是不能对空指针进行解引用,会报运行错误。
1.6指针运算
上文已经提过,指针有不同的类型,并且不同类型的指针的步长不同,而在指针的运算中,这个性质就起到了重要作用。
1:指针的+-运算
这种运算在讲解指针步长时已经提到过,不同类型的指针的+-操作所走的距离是不同的,比如int*类型的指针的+-操作就会走过4字节的空间,其它类型也是同理,利用这个特性,就可以实现使用数组下标进行指定元素的访问:
int main()
{
int arr[10] = { 1, 2, 3, 4, 5, 6, 7 };
printf("%d\n", arr[3]);
printf("%d\n", *(arr + 3));
return 0;
}
如果上方代码,相信不少人在初学数组时都感觉[]是一个超牛逼的操作,但是当我们脱下[]光鲜亮丽的外壳后就会发现,数组的[]操作其实就算利用指针的+-运算操作完成的,因此arr[3]和*(arr+3)实际上是等价的(数组名在大部分情况下都表示数组首元素的地址,具体细节会在后文进行说明)。
2:指针-指针
这个运算同样是利用不同类型的指针有不同步长的性质,当在内存中的连续空间中储存了同一种类型的数据时,利用这个运算就可以算出储存的数据的个数(不能算出指针直接相差的字节数)。
int main()
{
int arr[10];
int* p = arr + 10;
printf("%d", p - arr);
return 0;
}
在这个运算中需要注意的是在大部分情况下,都是使用相同类型的指针进行相减(不过有时候用不同类型的指针相减可以实现一些神奇的操作),并且只有对连续储存的内存空间的指针进行相减才是有意义的。
3:指针的关系运算
这个运算就是对指针进行> = <的一些逻辑运算:
int main()
{
int arr[10];
int* p = &arr[9];
if (p > arr)
{
printf("true");
}
return 0;
}
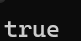
如上方代码,指针的关系运算非常的简单,并且有不少的应用场景:比如在链表中判断两个节点的指针是否相同,这里不再多说。
这时有人就会提出问题了:为什么指针就只有这些运算,怎么没有指针乘法和指针除法呢?在这里要进行说明的是:一个运算是否被实现,并不是取决于这个运算能不能被实现,而是取决于这个运算有没有实际的意义(在C++中重载运算符时就要尤其注意这点)。显然,指针乘法和指针除法虽然可以实现,但是其并没有任何意义,因此也就没有指针乘法和指针除法的概念了。
上篇都是一些基本的有关指针的介绍,那么现在让我们来看看指针的一些更牛逼的用法吧。
2.指针高级一些的用法
指针是把双刃剑,用的好就会非常的牛逼,但是指针一但出了错误,就会非常的恶心。
2.1const指针
先简单的介绍一下const,const是C语言的一个关键字,它可以修饰变量,被const修饰的变量变为常变量,常变量不可被修改 。
int main()
{
int a = 10;
a = 100;
const int b = 10;
b = 100;
return 0;
}如上方代码,a是一个正常的变量,是可以被修改的,但是b变量被const修饰,变为了常变量,因此b就不能被修改了。然后就来看看指针与const的结合吧。
int main()
{
int a = 10;
const int* pa1 = &a; //1
// const* int pa2 = &a; //2
int const* pa3 = &a; //3
int* const pa4 = &a; //4
return 0;
}
上方的4个const指针中第二个是错误的使用方法,会报编译错误,需要记住:在const和指针类型搭配时,*必须在类型的右方。再来看看下面的代码:
int main()
{
int a = 10;
const int* pa1 = &a;
int const* pa2 = &a;
int* const pa3 = &a;
pa1++; //1
pa2++; //2
pa3++; //3
(*pa1)++; //4
(*pa2)++; //5
(*pa3)++; //6
return 0;
}
首先,三个使用const的地方都是正确的用法,但是当const的位置不同时,所起到的效果也是不同的,要先明确的是:一个指针类型的变量由两部分组成,一部分是指针变量本身,一部分是指针变量指向的内容,而const对这两部分都可以进行修饰,当const在*的左边时,const修饰的就是指针指向的内容,即此时不能再通过该指针修改其指向的内容了,但是指针本身可以修改;当const在*的右边时,const修饰的是指针本身,即此时可以通过指针修改其指向的内容,但是不能对指针本身进行修改。根据这个规则,很容易就可以看出3,4,5处会报错,实际上也确实如此:

那么也容易推断出,const和指针还有这种搭配:
int main()
{
int a = 10;
const int* const pa = &a;
return 0;
}此时,const同时修饰了指针本身和指针指向的内容,pa本身不能修改,*pa也不能修改。
并且在C++中使用const指针时还会涉及到权限的问题,在这里进行一些简单的说明,先看看下方的代码:
int main()
{
int a = 10;
const int* pa1 = &a;
int* pa2 = pa1; //权限放大
(*pa2) = 100;
printf("%d", a);
return 0;
}
在C语言的环境下,上方的代码可以正常运行,并且也成功的通过指针pa2将a的值修改成了100,再来看看在C++中这段程序运行的结果:

可以看到,同样的程序在C++中就报错了,这里就涉及到了C++中提出的权限的概念,简单来说就是:我自己都不能修改的东西,我给别人后,当然也不能让别人修改。其实还是挺合理的,而在这段代码中,const修饰了pa1指向的内容,因此不能通过pa1修改a,在后面将pa1的值赋值给了pa2,那么pa2就同样需要不能修改a的值,所以在C++中需要这样写:
int main()
{
int a = 10;
const int* pa1 = &a;
const int* pa2 = pa1;
(*pa2) = 100;
printf("%d", a);
return 0;
}这样就同样不能通过pa2修改a的值了,不过在C++中有关指针权限问题还有一点需要注意:
int main()
{
int a = 10;
int* pa1 = &a;
const int* pa2 = pa1; //权限缩小
return 0;
}上方的代码在C++中是可行的,可以说相较于pa1,pa2的权限被缩小了,因此总结一下就可以得出:在C++中权限可以缩小,但是不能放大。(C++中的引用同样会涉及到权限问题)这条规则非常的简单,但是一但套在复杂的情况下,就会变得非常的恶心,可以看出,C++中对指针的使用提出了更高的要求(这也是因为指针这个东西太不好操控了)。
2.2多级指针
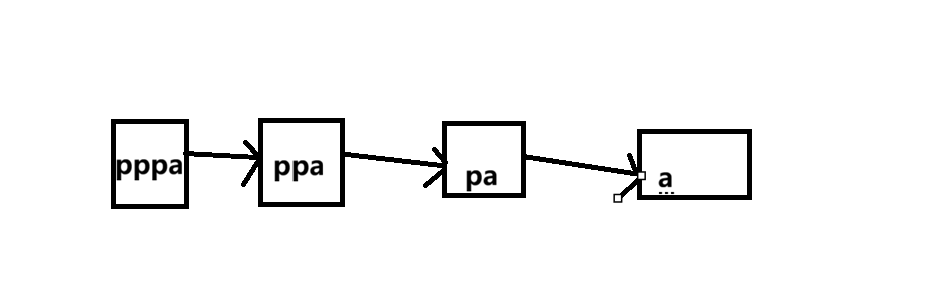
先明确一点,在内存中存放的所有数据都是要有地址的,而指针同样是存储在内存中的数据,那么指针的地址是什么呢?答案很简单:指针的地址是二级指针,那么二级指针的地址是什么呢?答案是三级指针,那么三级指针的地址是什么呢........(子子孙孙无穷尽也)。所以指针是可以无限套娃的,具体来看看下面的图片和代码:
int main()
{
int a = 10;
int* pa = &a;
int** ppa = &pa;
int*** pppa = &ppa;
*pa = 10;
**ppa = 20;
***pppa = 30;
printf("%d", a);
return 0;
} 
哦,这一看就非常的恶心,但是不用慌,后面还有更恶心的,那么就如上方说明过的,直接指向资源a的pa是指针(一级指针),指向一级指针pa的指针ppa是二级指针,而指向二级指针ppa的指针pppa当然就是三级指针了,并且在解引用时,对一级指针解一次引用就可以直接找到资源,而对二级指针来说,解一次引用会找到一级指针,再解一次引用才可以找到资源,三级指针也是同理。总结一下规律:在定义指针变量时用了几个*,那么在解引用时就需要同样多的*来进行解引用才能找到相应的资源。要注意的是,若非必要,在编程时不推荐使用多级指针,情况简单还好,一但情况变得稍微复杂一点,那么你就会嘴喷*****了。
上文已经提到过,指针是存在步长的概念的,并且不同指针类型的步长是不同的,那么多级指针的步长是什么呢?我们可以根据这条公式进行推断:指针的步长 = 指针指向的目标类型的大小,多级指针指向的一定是指针,而指针的大小是取决于操作系统的位数的,在32位系统下指针的大小是4字节,在64位系统下,指针的大小是8字节,因此我们可以推断:多级指针的步长要么是4字节,要么是8字节。并且要注意的是,多级指针同样也是指针,其大小同样取决于操作系统的位数,下面来进行证明:
int main()
{
int a = 10;
char c = '2';
int* pa = &a;
char* pc = &c;
int** ppa1 = &pa;
char** ppc1 = &pc;
int** ppa2 = ppa1 + 1;
int** ppc2 = ppc1 + 1;
printf("%d\n", (long long)ppa2 - (long long)ppa1); //不能直接ppa2-ppa1
printf("%d", (long long)ppc2 - (long long)ppc1);
return 0;
}


64位系统 32位系统
如上方代码,可以看到char和int的多级指针的步长是相同的,而且确实只取决于操作系统的位数,要注意的是我们不能直接让二级指针进行相减,因为指针-指针会得出两指针之间元素的个数,无法得出指针具体的步长是多少字节,如果直接让两个二级指针相减的话得出的就是这两个二级指针之间差了多少个一级指针,因此这里必须进行强制类型转换。
2.3void*指针
我们都知道,在C语言中对于不用返回具体类型的函数,会使用void(空类型)来作为函数的返回类型,即:
void fun()
{}那么空类型作为一种类型,它当然也是有相应的指针变量类型的,这个指针变量类型就是void*,在上文已经提过,指针类型的大小由计算机具体的位数决定,与其具体的类型无关,既然指针的大小是由计算机位数决定的,那么就可以利用这个特性,实现一个能够接受所有指针类型的指针类型,而这个类型就是void*,也就是说可以实现这样的操作:
int main()
{
int a = 10;
float b = 10.2f;
double c = 1.3;
//.......
void* pa = &a;
void* pb = &b;
void* pc = &c;
//.......
return 0;
}可以看到,void*类型的指针可以接收所有类型的指针,不过这么牛逼是要付出代价的,而void*付出的代价就是:由于void*不知道指向数据具体的大小,所以对它直接解引用会报错。我去,我用指针的最终目的就是为了通过指针找到其指向的资源,void*类型的指针连解引用都解不了,这有个毛用啊!那么先别急,要清楚,存在就会有意义,无论看起来多么离谱的语法都会有它的作用。void*类型的指针是无法直接解引用,但是它可以先进行类型转换,再解引用,它主要的意义是实现了一个泛型的接口(泛型在是一种非常厉害的思路,在C++中有更多的泛型操作)。我们在自己编写代码时是可以直接确定变量的类型的,因此也可以使用相对应的指针,但是如果你现在要实现一个通用指针类型函数给别人使用呢?你难道可以乘坐时光机去看看未来使用这个函数的人会传入什么类型的指针变量吗?因此在这种情况下,可以接受所有指针类型的void*就排上用场了,比如库中的memcpy函数就是利用了这种方法实现的:
void* my_memcpy(void* dest, const void* src, size_t n)
{
char* s = (char*)src;
char* d = (char*)dest;
for(size_t i = 0; i<n; i++)
{
*(d+i) = *(s+i);
}
return dest;
} 如上方代码就巧妙的利用了void*指针,因为char*指针的步长为1,所有只要调用方指定了要拷贝的字节数,那么该函数就可以实现任意类型的拷贝,并且C的动态申请内存也是利用void*的这个特性实现的,具体如下方代码
int main()
{
int* pa = (int*)malloc(sizeof(int)*10);
char* pc = (char*)malloc(sizeof(char)*10);
return 0;
}我们在用malloc动态申请内存时,都会对malloc返回的类型进行强制类型转换,原因就是 : malloc的返回类型是void*,因为malloc作为通用的动态内存申请函数,编写它的人肯定是无法确定用户用malloc会具体申请什么类型的数据。但是用户是肯定知道自己需要的是什么类型,因此使用void*作为返回值就完美的解决了这个问题。把选择权交给用户,出了问题也不是程序员的锅。
2.4指针类型作为函数参数和返回值
我们现在已经知道,通过对指针解引用就可以间接的修改或访问其指向的对象,利用这个性质,我们就可以让指针类型作为函数的参数,来实现在函数内部直接修改函数外部的变量,来看看下方的示例:
void fun1(int b)
{
a = 100;
}
void fun2(int* pa)
{
*pa = 100;
}
int main()
{
int a = 0;
fun1(a);
printf("%d\n", a);
fun1(&a);
printf("%d\n", a);
fun2(&a);
printf("%d", a);
return 0;
}
在上方代码中,fun1和fun2非常的相似,但它们的效果却截然不同,fun1的参数就是正常的传值传参,会把实参a的值拷贝给b,在之后实参a就和fun1没什么关系了,在fun1中的a和main中的实参a完全就是两个变量,仅仅是名称相同而已(在不同的作用域中可以定义同名变量),因此在fun1中修改a不会影响到main中的a(就算传了&a也没用,因为fun1的参数并不是指针类型),但是在fun2中,成功的在函数中修改了main中的a,其中的原理非常简单,首先传入的是a的地址,并且fun2的参数是指针类型,可以正确的接收,相当于int* pa = &a,那么pa就是main函数中变量a的指针,由于指针具有唯一性,不可能有两个不同的变量拥有相同的指针,因此就可以对pa解引用来准确的找到main函数中的变量a并对其进行修改。这是指针非常常用的用法,即当你想要在函数内部直接改变函数外部的变量时,可以传入该变量的地址,之后在函数中解引用就可以成功访问或改变这个变量(指针变量也一样),这也叫做函数的传址调用,并且除了可以实现修改外部变量的用处外,传址调用还可以提高程序的效率,来看看下方的代码:
struct A
{
int arr[100];
char crr[100];
double drr[100];
};
void fun1(struct A n)
{}
void fun2(struct A* pa)
{}
int main()
{
struct A a;
fun1(a);
fun2(&a);
return 0;
}
如上方代码,函数fun1和fun2的效率就会有巨大的差别,上文已经提过,fun1是传值传参,形参会是实参的一份临时拷贝,但是参数是一个结构体类型,并且这个结构体还非常的大,是:4*100+1*100+8*100=1300字节,这个拷贝的代价就非常的恐怖了,要足足拷贝1300字节的内存。再来看看fun2,出现了一个新的东西,结构体类型的指针,这里简单的说明一下,结构体作为自定义的类型,也是可以进行指针操作的,操作的具体方法和普通类型的指针相似(具体细节会在后文进行介绍)。fun2的参数就是一个结构体的指针,只要是指针,其大小就只取决于操作系统的位数,32位系统下是4字节,64位系统下是8字节,也就是说,此时fun2的形参最多也就只需要拷贝8字节,之后再在fun2中对pa进行解引用,同样可以访问到结构体中的数据。8和1300的差距还是非常的明显的,因此可以说,对于自定义的结构体类型,只要情况不是必须在函数中修改形参的值并且又不想影响到外部的实参,那么优先考虑使用传址传参。
函数的参数既然可以是指针类型,那么显然函数返回值也可以是指针类型,但是此时非常容易诞生难以发现的野指针,来看看下方的代码:
int* fun()
{
int a = 10;
return &a;
}
int main()
{
int* pa = fun();
printf("%d", *pa);
return 0;
}
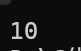
上方的看起来没什么问题,就连打印出来的结果好像也没什么问题,但是野指针其实已经诞生了,下面来证明一下:
int* fun1()
{
int a = 10;
return &a;
}
int* fun2()
{
int b = 10000;
return &b;
}
int main()
{
int* pa = fun1();
fun2();
printf("%d", *pa);
return 0;
}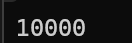
我去,我们好像使用fun2中的b修改了fun1中a,这是个什么原理,难不成fun2中的b和fun1中的a谈恋爱了吗?还是异地恋,其实这就是因为产生了野指针。
首先明确一点,函数中的局部变量在函数调用结束后就会被销毁,在fun1中,a显然是其中的一个局部变量,那么在调用完fun1函数后,a就会被销毁,但是fun1却返回了局部变量a的指针(编译器没有报错是因为这在语法层面上没有任何问题),因此在main函数中pa就是一个野指针。
下一个问题是为什么fun2中的b影响到了fun1中的被销毁的a,难道b把a救了出来吗?真是一段可歌可泣的爱情故事。真实答案当然不是因为什么爱情,在编程的世界中是不会存在这种浪漫的东西的,下面来进行回答:
首先,变量被销毁是什么意思呢?难道是变量被操作系统炸掉了吗,变量被销毁后变量占用的内存就不能使用了吗?答案当然是否定的,所谓的变量被销毁其实就是将变量所占用的内存空间还给了操作系统,操作系统之后还可以继续对这段空间进行分配,但是局部变量在销毁后,操作系统具体会不会刷新其内存空间处的值是不一定的(不同操作系统的行为不同,并且编译器也会对具体的行为造成影响),本人在VS2022中跑的代码,从上方的上方的代码中可以发现,fun中的a被销毁后,其值并没有被刷新,因此打印出了10,而在上方的代码中,由于fun2的函数结构和fun1的一模一样,因此操作系统在fun1调用结束后分配fun2的内存时(开辟函数栈帧),就正好分配到了同一块内存空间,而变量b又恰好覆盖掉了fun1中变量a原本所处的位置,因此在fun2中对b的修改就好像是影响到了fun1中的变量a。
像这种代码是非常危险的,尽管可以正常运行,但是我们无法确定其结果,而且还出现了野指针,毕竟不同于充满巧合与不确定性的爱情,编程是严谨的,对于这种充满不确定性的“浪漫”代码我们是要坚决抵制的。
2.5数组与指针
在上文已经提到过,在大部分情况下,数组名是数组首元素的地址,而这只是一种非常简单的情况,还会有不少特殊的情况,下面就对其进行详细的介绍。
2.5.1当数组名是首元素指针时
我们已经知道,在大部分情况下,数组名是数组首元素的地址,此时可以认为数组名是一个指向数组首元素的指针(这么理解比较方便,但是实际上不是),下面来证明一下:
int main()
{
int arr[10] = { 1, 2, 3, 4, 5 };
printf("%d", *arr);
return 0;
}

答案符合预期,arr确实指向了数组中的1,那么提出一个疑问,此时数组名可以改变指向到数组外部吗?问题比较抽象,来看看实际的代码:
int main()
{
int arr[10] = { 1, 2, 3, 4, 5 };
int b = 10;
arr = &b;
return 0;
}如果此时数组名就是一个纯粹的指向数组首元素的指针,那么数组名就是一个int*类型的指针,应该是可以进行这样的操作的,下面来看看实际情况:

结果报错了,而且报出的错误比较奇怪(左值的概念比较复杂,简单来说就是可以被改变的值,相对的还有一个右值,本人会在之后对引用的介绍的文章中进行详细的讲解,这里不多说),那么先抛开这个错误信息,用我们能够理解的方式解释一下,首先,如果arr=&b成功的改变了arr指向的位置的话,那么就意味着原本arr数组中的数据就丢失了,因此从使用的角度看,数组名不应该能指向数组之外的数据(此时不会出现内存泄漏,栈区的内存编译器会自动回收),而从语法的角度来看,可以认为数组名是一个常量指针(代表数组首元素地址),其值是不可改变的(相当于被const修饰了)。不能给一个常量赋值,也就是说下面的这些写法都是错误的:
int main()
{
int arr[10] = { 1, 2, 3, 4, 5, 6 };
int brr[10] = { 1, 2, 3, 4, 5, 6 };
arr++;
arr = &arr[0];
arr = brr;
return 0;
} 
在上方的代码中,都试图修改arr,而arr本身是不可被修改的,因此全都是错误的,至少在行为上,数组名arr的类型和int* const 类型的是相似的(数组名本身不可修改,但是可以通过它改变其指向的内容),那么arr到底是什么类型的呢?可以使用C++中的typeid().name()了看看编译器是怎么规定的:
int main()
{
int arr[10];
cout << typeid(arr).name() << endl;
return 0;
}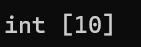
这个类型的样子比较奇怪,但是看起来arr和const没有半毛钱关系,往复杂的说,arr的实际类型int [10]是代表整个数组的,但是整个数组这个概念比较抽象,也比较难理解,因此笔者建议,除了在两种特殊情况下必须把数组名视为整个数组时(在下文会进行讲解),在其它情况下,把arr视为指向数组首元素的int* const类型的指针是比较方便理解的(但是要记住,这只是为了理解,arr的实际类型依旧是int [10])当然,这只是笔者的方法,具体情况还是以读者准。
下面来看看当数组被定义在结构体中的情况:
struct test
{
int arr[10];
char brr[20];
};
int main()
{
struct test i = { {1, 2, 3, 4, 5}, "abcde" };
printf("%d, %c", *(i.arr), *(i.brr));
return 0;
} 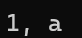
显然,定义在结构体中的数组和定义在其它地方的数组是差不多的,此时数组名可以视为首元素的地址,非常的简单,然后来看看下面的代码:
struct test
{
int arr[10];
char brr[20];
};
int main()
{
struct test i = { {1, 2, 3, 4, 5}, "abcde" };
i.arr = { 2, 3, 4, 5, 6 };
i.brr = "bcdef";
return 0;
} 
上面的代码看起来似乎没什么问题,就是给数组arr和brr赋值嘛,但是却报错了(本人在初学时就经常犯这样的错误),其实有了上面知识的铺垫,这里的错误原因还是可以轻松分析出来的,首先,i.arr和i.brr是结构体中的数组名,此时数组名是指向数组首元素的指针,arr就相当于int* const类型,brr就相当于char* const类型,它们本身都是不能被修改的,因此会报错,上方的写法还是可以容易的判断出来的,下面来看看另一种更具有迷惑性的写法:
struct test
{
int a;
char b;
double d[10];
}t;
int main()
{
t.a = 10;
t.b = '1';
t.d = { 1.1, 1.2 };
return 0;
}

上方的代码还是不容易发现错误的,而且报错的信息非常奇怪,真实的错误肯定不是什么{的问题,在这里也要说明一下,编译器的错误提示不一定是完全准确的(特别是在C++的模板中),其最多只能当成一个参考,回到上方的代码,要弄清楚上面的错误,首先就要分清楚初始化和赋值的区别,简单来说,要进行初始化的对象在初始化前是没有占用实际物理内存的,就是一个声明,而赋值是改变已经占用实际物理内存对象的值,来看看下方的代码:
int c;
struct test
{
int b;
};
int main()
{
int a;
printf("%zu\n", sizeof(a));
a = 10;
return 0;
} 
首先,在main函数中的a=10是一个赋值操作,因为a原本就有占用物理内存,只不过其中存储是是一个随机值,然后看看b和c,其中b是被定义在结构体中的,是一个声明,b本身不占用实际物理内存,相当于是告诉编译器在struct test中有一个int类型的变量,而c的情况和a类似,也会占用实际物理内存,对此可以这么理解,结构体是自定义类型,而类型本身一定是不会占用物理内存的,其就像是一个标识一样,就像int, char.....难道会占用内存吗?当然是不会的,而结构体作为自定义类型同样也是类型,其本身当然也是不会占用物理内存的,只有用类型定义出来的对象才会占用实际物理内存(在C++中定义的类也是如此),然后让我们回到最开始的问题:
struct test
{
int a;
char b;
double d[10];
}t;
int main()
{
t.a = 10;
t.b = '1';
t.d = { 1.1, 1.2 };
return 0;
}上方的代码为什么会报错,在理解了初始化和赋值的区别后,还需要对结构体本身的语法有一定的了解,但是讲结构体就有点离题太远了,这里不多说,首先,定义在结构体struct test末尾的t就是一个结构体对象(相当于在main函数写struct test t),既然t已经是一个类型实例化出的对象了,那么在main函数中对t中元素的操作就都是赋值操作了,而对于t.d来说,d是一个数组名,相当于是double* const类型,显然d是不能被修改的,那么对t.d进行赋值操作当然就会报错了。
2.5.2数组指针
数组指针的全名是:指向数组的指针。上文已经多次强调,数组名在大部分情况下都可以视为首元素的地址(相当于一个数组中元素类型的指针,并且指向数组首元素),那么现在就来介绍数组名不能被视为首元素地址的情况:
1.sizeof(数组名)
2.&数组名
只有在这两种情况下,数组名不能视为首元素的地址,而是要把其视为数组指针,数组指针是指向整个数组的指针(重要的是把整个数组视为一个整体),是一个具体的指针类型,我们已经熟悉: 整形指针变量存放的是整形变量的地址,是能够指向整形数据的指针。浮点型指针变量存放浮点型变量的地址,是能够指向浮点型数据的指针。那么数组指针变量就应该是:存放的是数组的地址,能够指向数组的指针变量。先来看看下方的代码:
int* pa1[10];
int (*pa2)[10];
//*与数组名结合表示这是一个数组指针
//前面的int表示这个数组指针指向的数组中存放的是int类型的数据
//最后的[10]表示这个数组指针指向的数组中存放了10个数据根据上文对指针数组的讲解可知,pa1是指针数组,而与pa1长得非常相似的pa2就是所谓的数组指针,区分它们的关键就是*是与谁结合的,对于pa1,*与其前方的int结合变为了int*,而对于一个数组来说,数组名前方的类型就是数组中存放数据的类型,因此pa1是一个存放int*指针类型的指针数组,而对于pa2,由于*与pa2用()括起来了,因此*显然是与pa2结合的,当*与数组名结合时,就会产生数组指针,而int (*pa2)[10]的整体含义就是:这是一个指向了存放了10个int类型的数组的指针。要注意区分指向的是首元素还是整个数组。那么要如何产生数组指针呢?具体来看看下方的代码:
int main()
{
int (*p)[10];
int arr[10];
int (*pa)[10] = &arr;
return 0;
}
可以看到p和pa是相同的类型,由于我们已知p是数组指针,因此可知pa也是数组指针,那么就可以确定了,&数组名取出的确实是整个数组的地址,而不是首元素的地址。所谓整个数组的地址的关键就是将数组视为一个整体。那么对数组指针解引用会发生什么呢?来看看下方的示例:
int main()
{
int arr[3] = { 1, 2, 3 };
int (*parr)[3] = &arr;
printf("%p\n", arr); //1
printf("%p\n", &arr[0]); //2
printf("%p", *parr); //3
return 0;
}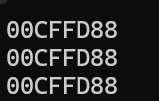
可以看到,三处printf打印出了相同的结果,我们已经知道,数组名在这种情况下代表首元素的地址,因此arr打印出来的就是数组arr首元素1的地址,所以1处和2处的结果是等价的(&arr[0]就是首元素的地址),关键的是3处,*parr也打印出了相同的结果,根据多级指针的知识来判断,难道所谓的数组指针是一个指向数组首元素指针的二级指针吗?答案是否定的,这就是数组指针一个恶心的地方,虽然看似好像与二级指针的行为相同,但它却不是二级指针,下面来进行证明:
int main()
{
int arr[3] = { 1, 2, 3 };
int* pa = &arr[0]; //首元素指针
int** ppa = &pa; //首元素的二级指针
int (*parr)[3] = &arr; //数组指针
printf("%p\n", *ppa);
printf("%p\n\n", *parr);
printf("%p\n", *(ppa + 1));
printf("%p", *(parr + 1));
return 0;
}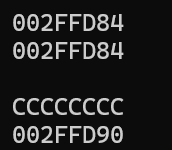
如上方代码,首元素的二级指针和数组指针解引用后得出了相同的结果(首元素的地址),但是如果数组指针就是首元素的二级指针的话,那么ppa+1和parr+1解引用的结果就应该会是相同的,但是显然打印出了不同的结果,因此数组指针并不是首元素的二级指针,关键的区别就在于数组指针的步长是整个数组,也就是说parr+1会跳过整个arr数组,下面来对这一点进行证明:
int main()
{
int arr[3] = { 1, 2, 3 };
int (*parr)[3] = &arr;
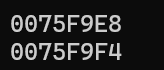
printf("%p\n", parr);
parr += 1;
printf("%p\n", parr);
return 0;
}
如果你刚接触编程没多久,那多半是看不懂这个奇怪的结果的,在这里进行简单的说明:在编程中,地址一般都采用16进制来表示,如果你想深入的学习编程,那么多种进制的运算是必须掌握的(比如2进制,8进制,16进制就用的比较多),这里简单的介绍一下16进制的规则:类比于十进制中有10个单位数(0,1,2,3,4,5,6,7,8,9),16进制同样有16个单位数:0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F其中A,B,C,D,E,F就代表着十进制中的 10,11,12,13,14,15,类比于10进制中的满10进1,16进制中同样会满16进1,因此在16进制中,10这个数就表示16。一个简单的16进制转10进制的方法就是先将16进制数从右至左将每一个数字提出来,然后让提出来的数乘以:16^该位置的权重,最后求和,说起来比较抽象,但实际操作起来是非常简单的,来看看具体的例子:
B02 //16进制数
2*16^0+0*16^1+11*16^2 = 2818 //转十进制
//从右到左第一个数是2,并且第一个数的位置的权重是0,因此是2*16^0
//第二个数是0,并且第二个数的位置的权重是1,因此是0*16^1
//第三个数是B(表示11),并且第三个数的位置的权重是2,因此11*16^2
值得一提的是该方法对于所有进制都是通用的,只需要把:数字^权重中的数字改为对应进制的数就可以了,(这里只是简单的介绍,想了解更多的可以去问问AI)根据这个规则,我们就可以先把上方地址的结果转为十进制数,再进行计算,即计算F4-E8(因为前面的数是一样的)转为十进制:(4+15*16)-(8+14*16),得出结果12,而数组arr中有三个int类型的元素,每个int类型的大小是4字节,正好就是12字节,因此可以证明数组指针的步长确实是整个数组。当然如果你觉得上方的证明太过于麻烦,那么可以直接看看下方代码的结果:
int main()
{
int arr[3] = { 1, 2, 3 };
int (*parr)[3] = &arr;
int (*pbrr)[3] = &arr + 1;
printf("%d\n", (int)pbrr-(int)parr);
return 0;
}
可以看到确实是12,至于为什么要类型转换在上文类似的情况中已经提过,这里不再赘述。
现在我们已经讨论了&数组名的情况并证明了在这种情况下,数组名确实表示整个数组,下面就来讨论一下sizeof(数组名)的情况:
int main()
{
int arr[10];
printf("%zu", sizeof(arr));
return 0;
}我们先来简单的分析一下,如果此时数组名代表着数组首元素地址的话,那么其大小就取决于操作系统的位数(32位时指针大小是4字节,64位时是8字节),如果此时数组名代表整个数组的话,那么就会求出整个数组的大小,而arr数组中有10个int类型的元素,因此数组的总大小应该是40字节,下面就来看看具体的结果:

打印出了40,因此可以证明,sizeof(数组名)中的数组名确实代表了整个数组,对于其它类型的数组也是如此,不过要注意的是:
int main()
{
int arr[0];
return 0;
}
我们不能在数组的[]中给0,报错已经说的很明确了,这里不多解释,再来看看下面的代码:
int main()
{
char crr1[] = "";
// char crr2[] = {};
char crr3[] = "123";
char crr4[3] = "123";
printf("%zu\n", sizeof(crr1));
// printf("%zu\n", sizeof(crr2));
printf("%zu\n", sizeof(crr3));
printf("%zu\n", sizeof(crr4));
return 0;
} 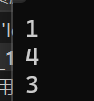
在上方的代码中,crr2是错误的,原因是在没有指定数组[]中的数时,编译器会根据{}中的元素个数进行推断,{}中什么都没有就意味着在[]中填入了0,因此会报错,对于crr1,虽然看似其中什么都没有,但是其大小确有1字节,原因是对于字符数组,在使用""创建时,当没有指定[]中的数或是指定的数的个数大于{}中元素的个数时,无论程序员没有手动填入\0字符作为结束标志,编译器会自动在有效字符的末尾填一个字符\0,因此数组crr1的大小是1,同理,crr3没有在[]中填入数字,编译器就默认多填了一个/0,因此crr3的大小是4,而crr4中指定了[]中的数字,此时编译器就无法再自动填入/0了,因此crr4的大小是4(注意:对于用{}创建的字符数组,编译器不会有自动填入\0的功能)。
根据数组指针的知识,我们就可以了解一些二维数组底层细节了,先来看看下面的代码:
int main()
{
int arr[3][3] = { {1, 2, 3}, {4, 5, 6}, {7, 8, 9} };
printf("%zu\n", sizeof(&arr[0]));
printf("%zu\n", sizeof(arr[0]));
printf("%zu\n", sizeof(arr));
printf("%d", (*(arr + 1))[0]);
return 0;
}
想必这个结果还是有一些出人意料的,二维数组看似简单,但其中有非常多的细节需要注意,想要真正的理解二维数组,那么就必须对数组指针有一个清晰的认识,下面就对上方的代码进行具体的分析:
先来看看第一个printf,首先arr[0]是二维数组的首元素,然后就出现了一个问题:二维数组的首元素是什么呢?看起来应该是二维数组中存放的第一个数组,而什么可以表示一个数组呢?答案是数组名(这样理解最方便),因此二维数组的首元素是二维数组中存放的第一个数组的数组名,所以在第一个printf中,arr[0]就是一个数组名,又由上文的讲解,&数组名会取出一个数组指针,而只要是指针,其大小就只取决于操作系统的位数,本人在32位系统下运行的代码,因此结果是4(要注意区分是sizeof(数组名),还是sizeof(数组指针))
然后再来看看第二个printf,这个结果同样也证明了二维数组的首元素是二维数组中存放的第一个数组的数组名,上文已经提过sizeof(数组名)会计算出整个数组的大小,因此打印出了12
然后是第三个printf,首先要注意区分arr是二维数组的数组名,arr[0]是二维数组arr中存放的第一个数组的数组名,而sizeof(数组名)会计算出整个数组的大小,因此sizeof(arr)计算出的就是整个二维数组的大小,因此打印出了36
最后一个printf, 先看*(arr+1),arr是二维数组的数组名,并且在这种情况下数组名是首元素地址,而二维数组的首元素是其中存放的第一个数组的数组名,那么首元素的地址就相当于是:&第一个数组的数组名,取出来的是一个数组指针,因此二维数组的数组名就是指向其中存放的第一个数组的指针,是一个数组指针,在上文已经提过,数组指针的步长是整个数组,所以arr+1就跳过了第一个数组,指向了arr中存放的第二个数组,而第二个数组的首元素是4,因此就打印出了4。对于二维数组还会有不少更复杂的情况,但是万变不离其宗,一定要对数组指针有清晰的认识。
2.5.3指针数组
指针数组的全称是:存放指针的数组。我们都知道,数组的本质是一组相同类型元素的集合,而指针同样有其具体的类型,那么自然就会诞生指针数组这种东西,下面来看看具体的代码:
int main()
{
int a = 1;
int b = 2;
int c = 3;
int* pa = &a;
int* pb = &b;
int* pc = &c;
int* parr[3] = { pa, pb, pc };
printf("%d\n", *parr[0]);
printf("%d\n", *parr[1]);
printf("%d\n", *parr[2]);
return 0;
}

如上方代码,parr就是所谓的数组指针,其中存放的是int*类型的指针,那么parr[0]取出的就是pa,而对pa进行解引用就可以访问到其指向的a,因此可以使用*parr[0]的方式访问到a。要注意的是,就如上文所述,数组名在大部分情况下都表示首元素的地址,而这种情况并不例外,数组名同样也是首元素的地址,但是数组parr的首元素是一个指针(一级指针),那么由多级指针的知识就可以得出,数组名parr是指向一级指针pa的指针,那么parr就是一个二级指针。感觉难理解的可以看看下方的示意图:
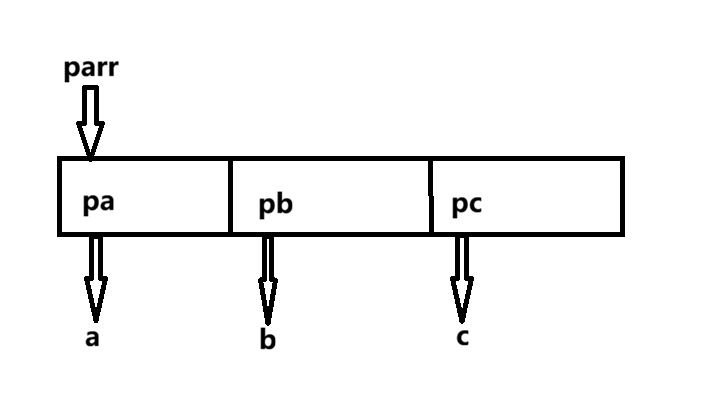
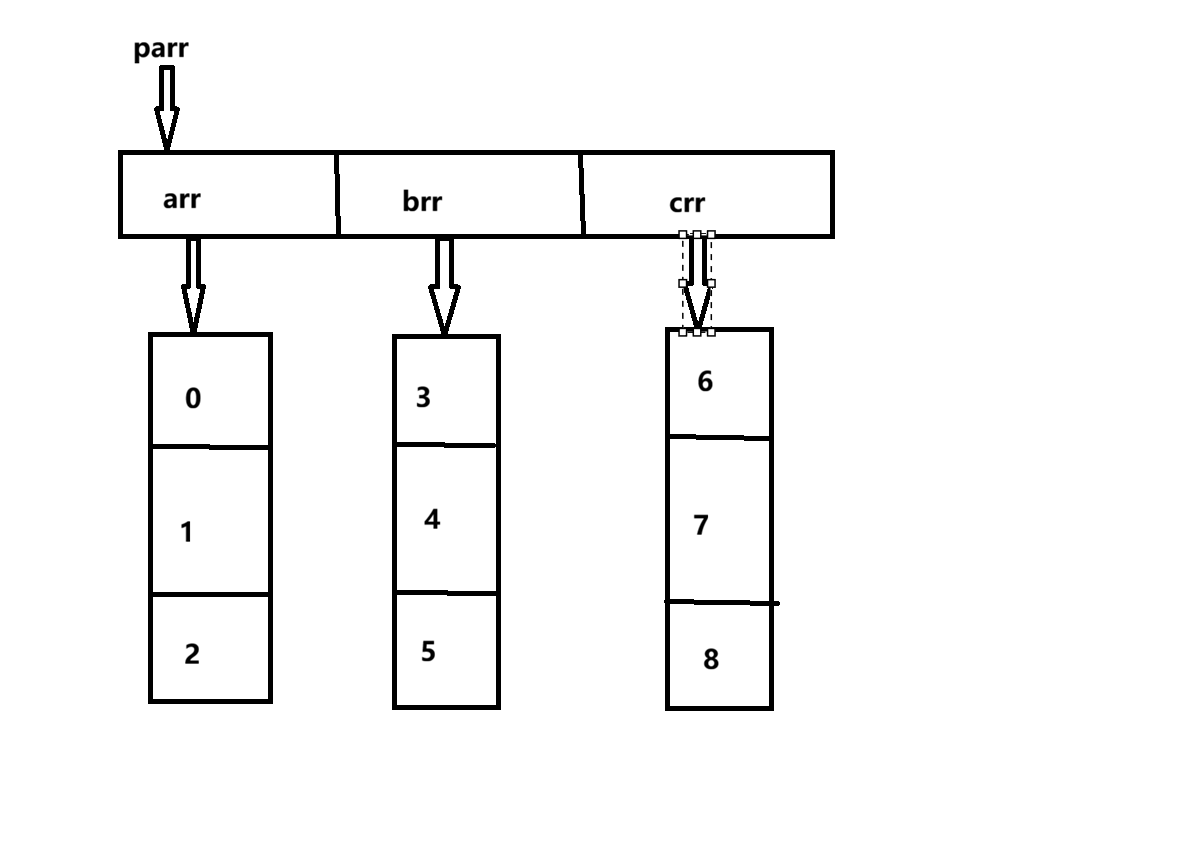
利用指针数组,我们可以实现不少骚操作,比如用一维指针数组来模拟实现二维数组:
int main()
{
int arr[3] = { 0, 1, 2 };
int brr[3] = { 3, 4, 5 };
int crr[3] = { 6, 7, 8 };
int* parr[3] = { arr, brr, crr };
printf("%d\n", parr[0][1]); //等价于*((*(parr+0))+1)
printf("%d\n", parr[1][2]);
return 0;
}

如上方代码,一维指针数组parr就模拟出了二维数组的效果,其原理非常简单,简单来说就是在这种情况下,数组名是数组首元素的地址。而parr的首元素是arr, arr本身又是普通数组的数组名,那么我们先进行parr[0]的操作就可以访问到其首元素arr,因此可以理解为parr[0]等同于arr,而arr本身也可以进行解引用操作,即arr[1]可以访问到数组arr的第一个元素1,既然parr[0]等同于arr,那么由此可得parr[0][1]同样可以访问到数组arr的第一个元素1。为了便于理解,可以将parr[][]操作分为两步,第一步进行parr[]操作访问parr数组中的元素,第二步再将parr[]本身视为一个整体,对这个整体进行解引用操作,即parr[][]。还觉得不理解的话可以看看下方的示意图:
2.5.3将数组名作为实参进行传参的本质
既然函数可以用指针类型作为参数,而数组名在多数情况下都是首元素地址,那么由此就可以得出:将数组名作为实参进行传参,实际上传入的就是数组首元素的地址,具体来看看下方的代码:
int fun1(int pa[])
{
return pa[3];
}
int fun2(int* pa)
{
return *(pa+3);
}
int fun3(int* pa)
{
return pa[3];
}
int main()
{
int arr[5] = { 1, 2, 3, 4, 5 };
int a = fun1(arr);
int b = fun2(arr);
int c = fun3(arr);
int d = fun1(arr + 1);
printf("a = %d, b = %d, c = %d, d = %d", a, b, c, d);
return 0;
}
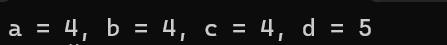
结果如我们所料,三个函数都返回了相同的值,在上文已经提过,pa[3]本质上就是*(pa+3),那么反过来对于指针类型也是可以使用[]操作符的,并且由于在数组名作为实参传递时也同样可以被视为首元素的地址,因此在函数进行传参时,传入的就是数组首元素的地址,而在形参处的int pa[]和int* pa实际上是等价的,只不过int pa[]看起来更顺眼罢了,因此a,b,c相等;对于a, b, c没什么好说的了,但是d的情况还是比较迷惑人的,下面来解释一下,在d处,往fun1中传入了arr+1,既然数组名arr的数组首元素的地址,那么arr+1显然就是数组的第二个元素的地址了,由于在形参处int pa[]和int* pa是等价的,因此可以理解成这样:int* pa = arr+1即用一个int*指针接收了数组第二个元素的地址,又因为pa[3]和*(pa+3)是等价的,那么先把pa[3]变为*(pa+3),再将pa替换为arr+1,就得出了*(arr+1+3),是数组下标为4的元素,正好就是5,一维数组还是比较简单的,下面来看看二维数组的情况:
int fun(int pa[][])
{
return pa[0][0];
}
int main()
{
int arr[3][5] = { {1, 2, 3, 4, 5}, {6, 7, 8, 9, 10}, {11, 12, 13, 14, 15} };
int a = fun(arr);
return 0;
}
如果可以的话,我们当然希望二维数组可以这样传参,可读性非常的好,但是非常可惜,二维数组不支持这样传参,因此我们只能另辟蹊径了,上文已经提到过,二维数组的首元素是其首元素的指针,是一个数组指针,那么就可以使用数组指针类型作为函数参数来实现二维数组的数组名传参:
int fun1(int (*pa)[5])
{
return pa[1][2];
}
int fun2(int (*pb)[3])
{
return pb[1][2];
}
int main()
{
int arr[3][5] = { {1, 2, 3, 4, 5}, {6, 7, 8, 9, 10}, {11, 12, 13, 14, 15} };
int a = fun1(arr);
int b = fun2(arr);
printf("a = %d, b = %d", a, b);
return 0;
}
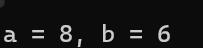
如上方代码,二维数组arr的首元素是一个存有5个元素的一维数组,因此二维数组的数组名就是一个指向存有5个元素的一维数组的数组指针,因此在函数的形参处可以使用数组指针进行接收,需要注意的是,形参处的[]必须填入正确的数字,即二维数组的列数(也就是二维数组中的一维数组元素个数),这样才可以访问到想访问的值,如果在形参处往[]填入了不匹配的数,那么尽管程序可以正常运行,但是却无法返回我们想要的值,其本质是因为[]中的数决定了指针的步长。
下面以函数fun2为例,解释一些其为什么返回了6:fun2在[]中填入了3,那么其形参pb就是一个指向元素数为3的数组指针,pb的步长就是3个int,我们将pb[1][2]拆分为两部分,先看看第一部分的pb[1],可以将其等价为*(pb+1),那么pb+1就走过了3个int,走到了二维数组arr中元素4的位置(从元素1开始,往后走3个int),即此时pb指向了二维数组arr中元素4的位置,然后再对pb+1进行解引用,因为pb是一个数组指针,而+1显然不会影响其类型,因此*(pb+1)就相当于访问到了一个可以储存3个元素的一维数组,然后可以将*(pb+1)抽象为一个一维数组名,再加上后面的[2],即抽象为:数组名[2],由于此时这个一维数组名是数组首元素地址,而该数组的首元素就是二维数组arr中的元素4,再将数组名[2]变为*(数组名+2),相当于pb往后走了两个int,正好就走到了二维数组arr中元素6的位置,总结一下就是pb[1][2]第一步[1]往后走了3个int(数组指针步长),第二步[2]往后走了2个int(int*指针步长),因此就返回了6。可以看到,二维数组名传参的关键是二维数组的列数(即二维数组中一维数组的元素数),因此下面这种形参也是可以的:
void fun(int pa[][5])
{}
int main()
{
int arr[3][5] = { {1, 2, 3, 4, 5}, {6, 7, 8, 9, 10}, {11, 12, 13, 14, 15} };
return 0;
}需要指定二维数组的列数,和int(*pa)[5]在本质上是一样的,可以发现,二维数组传参是比较恶心的,而且参数的列数还会被限制,但是在C99及以上加入了新语法,让列数可以由调用方指定,下来看看具体的代码:
int fun(int row, int col, int pa[][col])
{
return pa[row][col];
}
int main()
{
int arr[3][5] = { {1, 2, 3, 4, 5}, {6, 7, 8, 9, 10}, {11, 12, 13, 14, 15} };
return 0;
}本质上就是将形参处二维数组的列数也作为参数,但是这种语法在许多编译器上都没有支持,并不推荐使用。
2.6函数与指针
C语言作为一个面向过程的语言,函数就是它最重要的一部分,我们通常都是这样使用函数:
void fun()
{}
int main()
{
fun();
return 0;
}那么不知道你有没有想过:编译器是怎么通过找到函数名找到要调用的函数的,毕竟编译器不是人,它可认不出函数的名字。由此就引出了这一节的主题:函数指针,函数指针是一个指向函数的指针,其一般指向的函数中第一句指令的地址,编译器在调用函数时,就是根据函数指针来找到相应的函数的(底层还涉及到符号表与链接的知识,水比较深,这里不多介绍),先来证明一下函数指针是否真的存在:
void test()
{}
int main()
{
printf("%p\n", &test);
printf("%p", test);
return 0;
}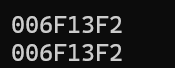
上方的代码显示出了不少信息,首先函数指针是真实存在的,并且从结果上来看,函数名的值就是函数指针的值,并且就算是函数中什么都没有,编译器也会给函数分配地址,下面再来看看函数指针具体是长什么样子的:
void test1(int a)
{
printf("%d\n", a);
}
int test2(char a, double b)
{
return 10;
}
int main()
{
void (*ptest1)(int) = &test1; //ptest1就是指向函数test1的函数指针
int (*ptest2)(char, double) = &test2; //ptest2就是指向test2的函数指针
return 0;
}首先可以发现,函数指针非常的丑陋且麻烦,与数组指针不相上下(因此在C++中使用了仿函数代替了函数指针),这里简单的对函数指针进行一些解释,总结一下可以发现函数指针由三部分组成:类型 (*名称) (类型),第一部分的类型是函数的返回类型,第二部分必须使用()让*与名称进行结合(名称是随意取的),第三部分是函数的参数类型(有几个参数,就要写几个类型,必须与实际的函数相匹配),下面来看看函数指针的一些用法:
int add(int a, int b)
{
return a + b;
}
int main()
{
int (*padd)(int, int) = &add;
int sum1 = padd(10, 20);
int sum2 = (*padd)(1, 2);
printf("%p\n", padd);
printf("%p\n", *padd);
printf("%d\n", sum1);
printf("%d", sum2);
return 0;
}
上方的代码使用函数指针调用了函数,可以发现函数指针本身可以调用函数,函数指针的解引用也可以调用函数,并且函数指针padd和padd的解引用是相同的(因为函数名和&函数名就是相同的),虽然这个操作看起来非常的弱智,但是只需要一点点巧妙的构思,这个用法就可以打出非常骚的操作(在下面的函数指针数组中会进行演示)。下面先看看两段有趣(恶心)的代码(出自《C陷阱和缺陷》)
int main()
{
(*(void(*)())0)(); //1
void (*signal(int, void(*)(int)))(int); //2
}你可以具体的解释一下上方两句代码的含义吗?如果你觉得非常的轻松,那么你的函数指针就算是掌握的不错了,下面本人来进行一下简单的说明:
先看1:先进行代码的拆分,void(*)()是一个函数指针类型,数字0是一个int类型的常量,那么把这两部分进行结合:(void(*)())0,抽象一下就可以变为(类型)常量,可以发现是一个类型转换,即把0转换为函数指针类型void(*)(),然后再套上外层的 (*)()变为(*(void(*)())0)(),现在已知里面的(void(*)())0整体是一个函数指针,那么抽象一下就可以得到:(*函数指针)(),现在就非常的简单了,显然是对函数指针进行解引用,然后再调用这个函数指针指向的函数,也就是说1处的代码整体上是一个函数的调用。
然后再看看2:先说结论,2处的代码整体上是一个函数声明(本人初见这两句代码时只分析对了1处的代码),先来看看我当时的错误分析:将int和void(*)(int)当作signal函数的参数传入,再将返回的值当作一个函数指针,该指针指向一个参数为int类型,无返回的函数。现在看来,一处明显的错误就是signal(int, void(*)(int))并不是函数调用,怎么可能有返回值呢?当年确实是蠢的可以,这分析真是狗屁不通。然后再进行正确的解读:同样先进行代码的拆分,先看signal(int, void(*)(int)),这里其实还是非常简单的,抽象一下就可以变为:函数名(int类型,函数指针类型),已经可以发现非常的像函数声明了,迷惑人的是外面的壳:先去掉里面的signal(int, void(*)(int)),剩下void(*)(int),可以发现是一个函数指针类型,然后再抽象一下就可以得到:类型 函数名(类型, 类型),答案已经非常明确了,void (*signal(int, void(*)(int)))(int)是一个参数类型为int和void(*)(int),返回类型为void(*)(int)的函数声明,不知道你想对了吗?
2.7函数指针数组
函数指针被搞出来肯定不是为了恶心人的,它一定有它的用处,而函数指针数组就是函数指针的一个使用场景,先解释一下:函数指针数组是存放函数指针的数组,也就是该数组的元素是函数指针,先来看看它长什么样子:
int *p1[3]();
int (*)() p2[3];
int (*p3[3]) ();上方的三条代码中,只有p3是正确的函数指针数组的定义,强行解释一下(其实我觉得p2的可读性更好,但是C的祖师爷是这样设计的,我们也没办法):对于p3,[]先和p3结合,表明p3是一个数组,而p3的"外壳":int(*)()就是p3中元素的类型。再来看看具体用法:
int add(int a, int b)
{
return a + b;
}
int sub(int a, int b)
{
return a - b;
}
int mult(int a, int b)
{
return a * b;
}
int divide(int a, int b)
{
return a / b;
}
int main()
{
int(*padd)(int, int) = &add;
int(*psub)(int, int) = ⊂
int(*mult)(int, int) = &mult;
int(*divide)(int, int) = ÷
int (*pall[4])(int, int) = { padd, psub, mult, divide };
return 0;
}
pall就是一个函数指针数组,并且存放的类型是int(*)(int, int),其实已经可以看出函数指针数组有不少的限制。比如对于除法函数divide,应该使用浮点类型float作为函数的参数类型和返回值更好,但是这样就由于类型不同而不能把divide加入数组了(在C++中几乎不会用这个东西),利用函数指针数组,可以实现一个叫转移表的东西(程序员总喜欢取一些高大上的名字,但其原理往往都非常简单,当年刚接触编程的时候就被不少牛逼的名词吓到了),来看看具体的实现:
int add(int a, int b)
{
return a + b;
}
int sub(int a, int b)
{
return a - b;
}
int mult(int a, int b)
{
return a * b;
}
int divide(int a, int b)
{
return a / b;
}
int main()
{
int(*padd)(int, int) = &add;
int(*psub)(int, int) = ⊂
int(*mult)(int, int) = &mult;
int(*divide)(int, int) = ÷
int (*pall[4])(int, int) = { padd, psub, mult, divide };
int a = (*pall[0])(1, 3);
int b = (*pall[1])(10, 3);
printf("%d\n", a);
printf("%d", b);
return 0;
}
没错,所谓的转移表其实就是函数指针数组,在这里需要注意的就只有在使用函数指针数组调用相应的函数时的操作,比如(*pall[0])(1, 3),先指定[]中的数字来指定要访问数组中的哪一个函数指针,再对取出来的函数指针进行解引用找到相对应的函数(*pall[0]),最后再在后面的括号中传入参数,非常的简单,这里不再赘述,函数指针还有不少其它用途,比如回调函数,这个要更加实用,来具体看看:
int add(int a, int b)
{
return a + b;
}
int sub(int a, int b)
{
return a - b;
}
int add_or_sub(int a, int b, int(*fun)(int, int))
{
return fun(a, b);
}
int main()
{
int a = add_or_sub(1, 3, &add);
int b = add_or_sub(4, 1, sub);
printf("%d\n", a);
printf("%d", b);
return 0;
}
这个操作还是非常实用的,回调函数的原理非常简单,就是将函数指针类型作为函数参数的类型,在函数中利用函数指针传入不同函数,来实现同一函数的不同行为,其实这就很像是多态了,在C++中使用仿函数,模板,继承......等语法,泛化了多态,可以看到C++中的不少概念其实都是从C中来的,其实就连类这个东西都可以说是C中结构体的升级版,如果读者是直接学C++的或是直接学其它高级语言,仅仅对C有一点了解,那么笔者强烈建议先去好好学一下C语言,C语言可以说是这些高级语言的祖宗,学好了C语言后对于那些高级语言中看似莫名其妙的语法才能有更好的理解,笔者是在学完C和C++后再来写这篇文章的,这种感觉便尤为强烈,当然这仅仅只是笔者的一些学习编程的建议,具体还是以读者的实际情况为重。
2.8结构体指针
指针作为内存资源的唯一标识,在C语言中可以说是无处不在的,内置类型都有其相应的指针,就连数组和函数都有指针,那么显然自定义类型结构体也是有指针的,下面就来看看其具体的语法:
struct obj
{
int a;
int b;
int c;
int d;
};
int main()
{
struct obj o = { 1, 2, 3, 4 };
struct obj* po = &o;
return 0;
}相比于数组指针和函数指针,结构体指针可以算是和蔼可亲了,语法非常的简单,似乎也没什么好讲的,本人把这个东西放在这里进行讲解也不是为了介绍它的语法的,而是为了介绍内存更加具体的模样,因此在这里抛出一个问题:结构体的指针指向结构体中的哪一个字节?
2.8.1内存地址的高低
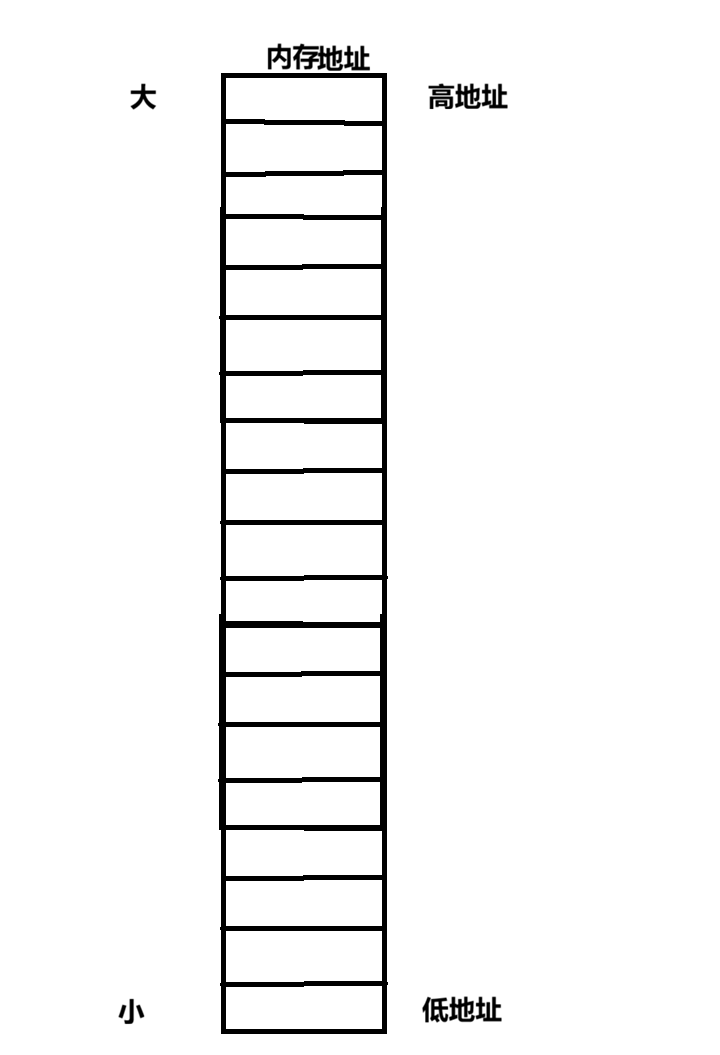
为了回答上面的问题,首先就要对内存中的地址有更加深刻的认识,在文章的开头就提过:内存中的地址是有0和1组合出来的,每一个地址都是由多个二进制数字组合出来的值,既然是数字值,那么一定就有大小之分,因此在计算机中规定,地址小的那边叫低地址,地址大的那边叫高地址:
地址高低的规定非常的简单,既然地址已经准备好了,那么现在重要的就是怎么把数据储存在内存空间并利用地址的高低进行管理了。
2.8.2数据在内存中的存储
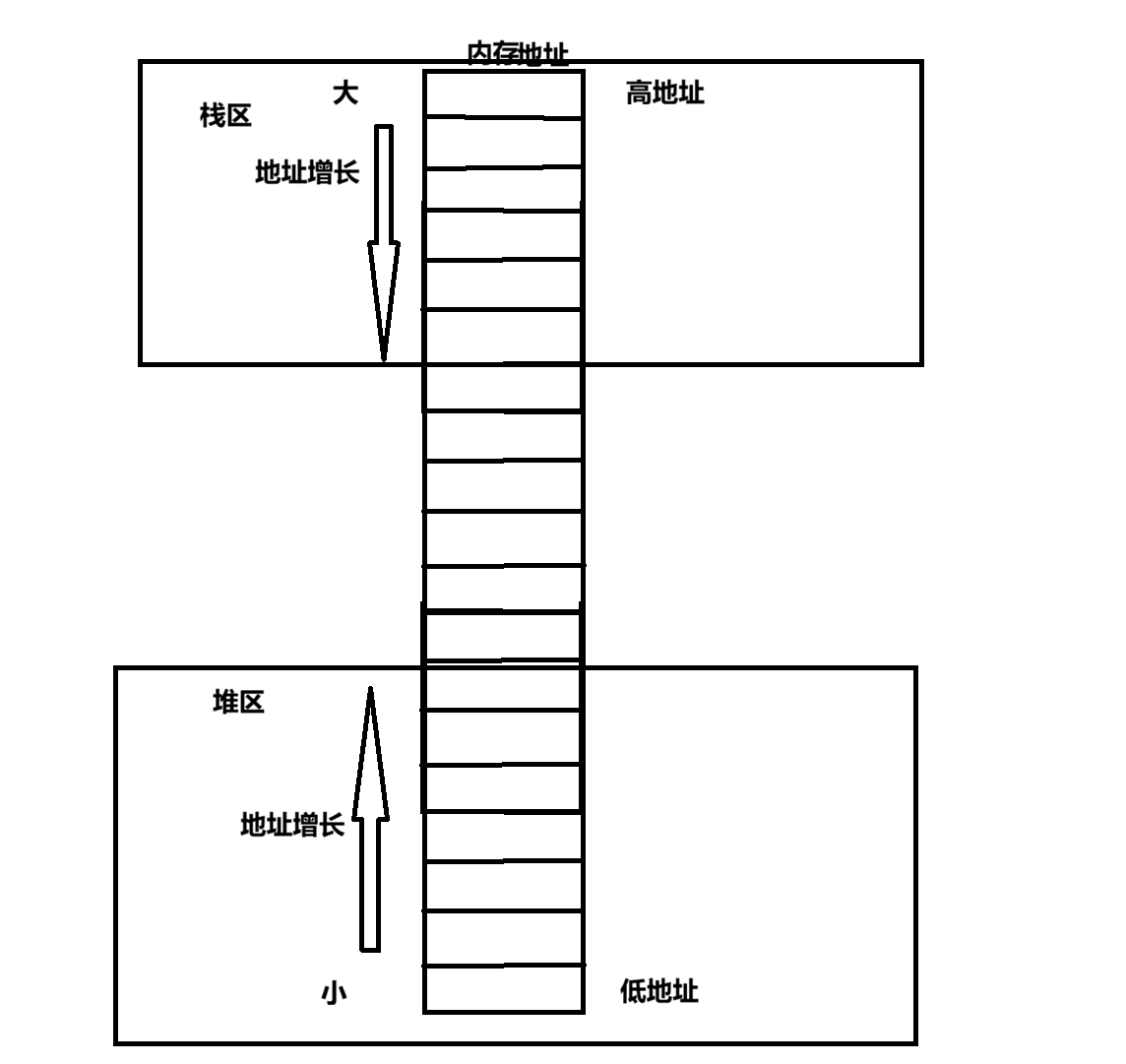
为了便于管理内存中的数据,肯定是要对数据在内存中的存储方式进行规定了,在大方向上,会对内存进行整体的划分,具体会分为:栈区,静态区,常量区,堆区.......。这里重点关注内存中的栈区和堆区,我们编写的大部分代码在加载到内存后都是处于栈区的,因为函数就是在栈区创建的,而我们在代码中动态申请的内存就是位于堆区的内存,这两个区域在实际编程中用到的是最多的,对于栈区,其对内存的使用是从高地址向低地址增长,而堆区对内存的使用一般是从低地址向高地址增长,并且堆区通常更加靠近低地址处,而栈区更加靠近高地址处:
下面用代码来实际说明一下:
void test1() //测试栈地址的增长方向
{
int a1;
int b1;
int c1;
printf("a1的地址:%p b1的地址:%p c1的地址:%p\n\n\n", &a1, &b1, &c1);
}
void test2() //测试栈地址的增长方向
{
int arr[10];
printf("arr的地址:%p arr+5的地址:%p\n\n\n", arr, arr + 5);
}
void test3() //测试堆地址的增长方向
{
int* a2 = (int*)malloc(sizeof(int));
int* b2 = (int*)malloc(sizeof(int));
int* c2 = (int*)malloc(sizeof(int));
printf("a2的地址:%p b2的地址:%p c2的地址:%p\n\n\n", a2, b2, c2);
}
void test4() //测试堆地址的增长方向
{
int* brr = (int*)malloc(sizeof(int) * 10);
printf("brr的地址:%p brr+5的地址:%p\n", brr, brr + 5);
}
int main()
{
test1();
test2();
test3();
test4();
return 0;
}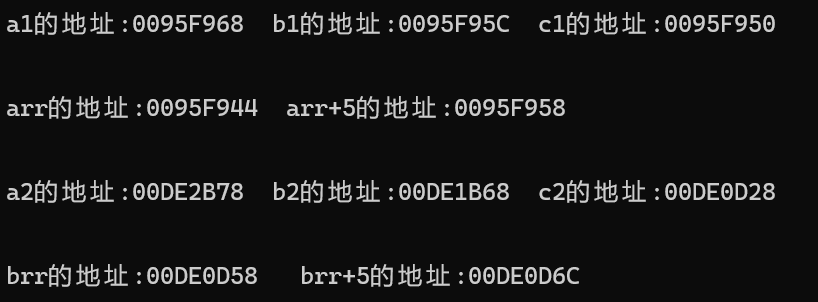
test1中没有动态申请内存,因此变量a,b,c都是位于栈区的,比较变量地址的后两位即:68, 5C, 50转为十进制后是(68)6*16+8,(5C)5*16+12,(50)5*16+0, 可以看到,最先定义的变量a的地址是最大的,并且越晚定义的变量的地址越小,对于单独定义的变量,其地址的增长确实是从高到低。
对于test2可以发现其同样是在栈区定义的,但是其地址却显然是从低往高增长的,因此在这里要进行说明的是:在栈区分开定义的多个变量,其整体地址是从高往低的,但是如果一个变量中包含了多个变量,比如数组和结构体,这种变量中的单个小变量的地址是从低地址往高地址增长的,也就是说在这种整体变量中越先定义的变量的地址越小。
test3测试的是堆区的分开定义的变量的地址的变化,一般来说,因为堆区地址的增长情况是从低地址到高地址,因此越后定义的变量的地址会越大,但是测试的情况却不是这样的,在测试中,是a2>b2>c2,似乎反过来了,而且地址的跨度非常的大,其原因是我们在堆区是动态申请内存的,而动态申请就可能会出现申请到之前释放的内存,那么地址就会变小,也就是说在堆区申请的内存只是从整体概率上来看是从低地址往高地址增长,实际情况是不一定的。并且从地址的跨度非常大也可以推断出,操作系统分配给堆区的内存空间是要比栈区大的(实际上要大很多)。
test4测试的是堆区包含多个变量的变量的地址增长情况,可以发现,其同样是满足越先定义的变量的地址越小,越后定义的变量的地址越大,和栈区中的情况类似。
上方测试的是变量整体在内存中的存储情况,下面在来进行细分,看看单个变量的每个字节在内存中是怎么存储的。
首先说明一下,只要变量占用的内存大小大于一字节,那么其每一个字节在内存中就会有存储的顺序(只占用一字节的变量是没有这个顺序的),这个顺序叫做大小端字节序,在不同平台下,这个顺序可能不同,先来介绍一下它的具体规则:
以int:0x11 22 33 44为例(0x表示是十六进制,后面每两个数字占用1字节,左边是高位,右边是低位)
低地址-------------------------------------------------------------------------------------高地址
大端字节序存储: 11 22 33 44 把一个数据的高位字节存放到低地址处,低位字节存放到高地址处
小端字节序存储: 44 33 22 11 把低位字节存放到低地址处,高位字节存放到高地址处
注:用大端还是小端取决于硬件
也就是说,一个变量的字节在内存中有两种储存规则,下面来用实际的代码进行说明:
int main()
{
int a = 1; //a转为二进制后:00000000 00000000 00000000 00000001
int* pa = &a; // 高位----------------------------低位
char* pc = (char*)pa;
if (*pc == 1)
{
printf("此电脑用的是小端存储\n");
}
else
{
printf("此电脑用的是大端存储");
}
return 0;
}
//低地址-------------------------------------------------------高地址
//如果是大端:00000000 00000000 00000000 00000001
//如果是小端:00000001 00000000 00000000 00000000
首先,在本文最初的说明:对于占用多字节内存的数据,其指针是其首字节的地址中,所谓的首字节就是最靠近低地址那一端的字节,即:一个变量的指针指向的是变量字节中地址最小的那一个字节,因此在上方代码中,关键就是用了char*类型的指针pc指向了int类型a,那么指向的这一个字节就一定是变量a的首字节,并且char*类型的指针在解引用时只能往后访问一字节(往后访问就是从低地址往高地址进行访问),那么如果是大端存储,*pc就会是00000000,如果是小端存储,*pc就会是00000001,因此通过这种方法就可以判断出电脑采用的是哪一种字节序了。
总结一下,内存中的储存规则有三层:
第一层:从最大范围的内存整体的划分,分为栈区,静态区,常量区,堆区(此处只是最常见的区域,还会有更加复杂的其它分区,想了解的话可以去问问AI)
第二层:存放在栈区和堆区中的变量在内存中的存储规则:对于分开定义的多个变量,如果是在栈区中定义的,其对内存的使用是从高地址向低地址增长,如果是在堆区中定义的,其对内存的使用一般是从低地址向高地址增长。但是如果定义的是类似于数组和结构体这种本身内部就包含变量的变量,那么其内部的单个变量在内存中的存储不管是在栈区还是堆区都从低地址到高地址的。
第三层:一个变量中的每一个字节的存储规则:采用大小端字节序进行存储,具体采用哪种由硬件决定,大端存储就是把一个变量的高位字节存放到低地址处,低位字节存放到高地址处,小端存储就是把低位字节存放到低地址处,高位字节存放到高地址处。但是无论是大端还是小端,变量的首字节都是最靠近低地址那一端的字节,而指针指向的永远是变量首字节的地址。
总之,不管是什么类型的变量(数组和结构体也一样),其指针变量的值一定等于变量所占字节中地址最小的那一个,指针指向的字节就称为变量的首字节。由此也容易得知:对指针进行解引用或是加法操作时,指针一定是往高地址的方向走的。
struct obj
{
int a;
int b;
int c;
int d;
};
int main()
{
struct obj o = { 1, 2, 3, 4 };
struct obj* po = &o;
return 0;
}好了,饶了一大圈,现在让我们回到最初的问题:结构体的指针指向结构体中的哪一个字节?利用上面的知识进行分析,首先,结构体变量也是变量,而一个变量的指针指向的就是变量字节中地址最小的那一个字节,那么我们只需要找到结构体中地址最小的那一个字节就可以了,又因为:类似于数组和结构体这种本身内部就包含变量的变量,那么其内部的变量在内存中的存储不管是在栈区还是堆区都从低地址到高地址的。因此可以判断出来,最先定义在结构体中的变量的地址是最小的,也就是变量a的地址是最小的,然后再来对变量a的每一个字节进行具体的判断,因为:无论是大端还是小端,变量的首字节都是最靠近低地址那一端的字节,而指针指向的永远是变量首字节的地址。因此这个问题与大小端无关,变量a的首字节一定是最小的,那么结构体指针po指向的就是结构体变量中变量a的首字节地址,下面来证明一下:
struct obj
{
int a;
int b;
int c;
int d;
};
int main()
{
struct obj o = { 1, 2, 3, 4 };
struct obj* po = &o;
printf("po:%p &o.a:%p", po, &o.a);
return 0;
}
可以看到,推断是正确的,结构体的指针po确实就是指向了结构体中变量a的首字节地址,但是要注意的是,po和&o.a仅仅只是值相等,但是其含义是完全不同的。下面用一张图来说明一下结构体o在内存中的具体结构:
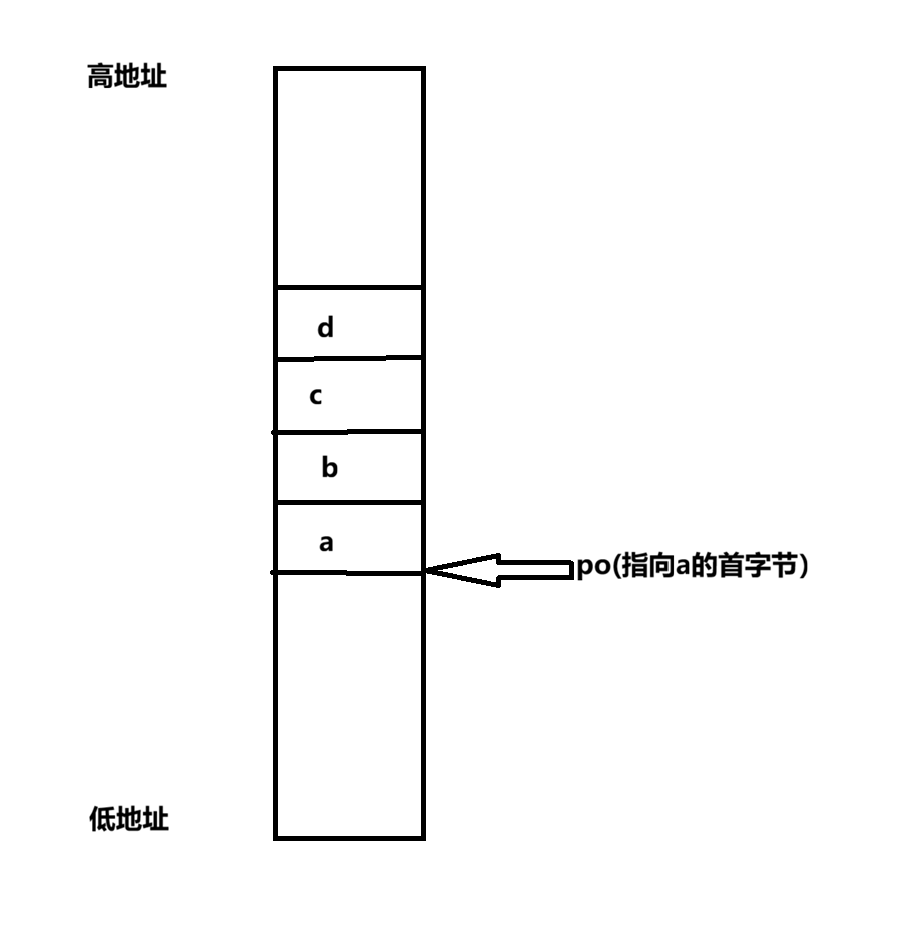
现在我们已经知道了结构体中的变量在内存中具体是怎么存储的了,那么如果此时我们只知道结构体变量中某一个变量的具体地址,要怎么根据这一个变量的地址来计算出整个结构体变量的地址呢?(即:实现一个offsetof),还是以上方的结构体为例:
struct obj
{
int a;
int b;
int c;
int d;
};
int main()
{
struct obj o = { 1, 2, 3, 4 };
int* pc = &o.c;
return 0;
}
也就是说,我们现在只知道pc的地址,需要通过这个来求出结构体o的地址,分析一下:由于结构体中的变量在内存中是连续存储的,并且结构体o的地址在值上等于其中变量a的地址,那么我们就只需要算出变量a的地址就可以求出结构体变量地址的值了,为此首先要算出变量c相对于变量a地址的变化值,然后再用变量c的地址减去这个相对值就可以算出变量a的地址了(相当于:c-(c-a)=a),那么首先我们就先来算出这个相对的差值,具体代码如下:
&(((struct obj*)0)->c); //算出相对值代码只有一行,但是比较不好理解,下面就来解释一下:先看里面的(struct obj*)0,很明显这是一个强制类型转换,把整形0转换成了struct obj*类型,此时就相当于有了一个结构体指针指向了0地址处,然后再加上外层 &(((struct obj*)0)->c),很明显是先用结构体的指针找到其中的变量c,再把c的地址取出来,由于此时这个结构体指针是指向0地址处的,而结构体的指针指向的是结构体中最先定义的变量的首字节地址,也就是变量a的地址,那么就相当于a的地址此时就是0,然后再取出变量c的地址,这个地址直接就是我们要求的相对值了(&c-&a=&c-0=相对值)
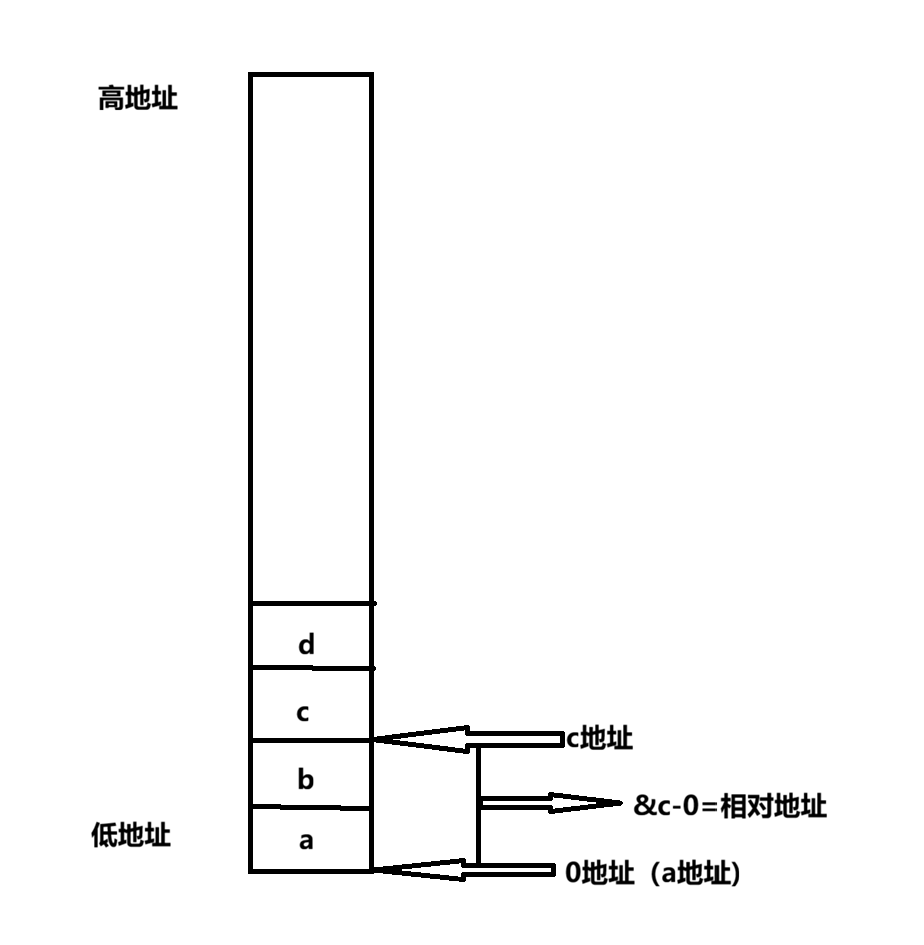
好了,相对地址已经求出了,然后就非常的简单了,由于相对地址是不变的,因此只需要直接用c的地址减去相对地址就可以求出结构体的地址了:
struct obj
{
int a;
int b;
int c;
int d;
};
int main()
{
struct obj o = { 1, 2, 3, 4 };
int* pc = &o.c;
struct obj* po = (struct obj*)((char*)pc - (char*)(&(((struct obj*)0)->c)));
printf("a=%d b=%d c=%d d=%d\n", po->a, po->b, po->c, po->d);
return 0;
}
需要注意的就是类型转换,由于指针直接相减会算出指针直接相差的元素个数,而且一个int*类型的指针和struct obj*类型的指针显然是无法相减的,因此必须进行类型转换。而且最好转换为char*类型,这样既可以避免出现空指针解引用的问题,又可以算出正确的结果(因为指针相减算出的是指针之间元素的个数,而char*类型的指针进行相减算出的正好就是相差的字节了),最后我们可以把这种方法封装成一个宏,那么就可以实现一个简单的offsetof了:
#define my_offsetof(Address, Struct_class, Variable) (Struct_class*)((char*)Address - (char*)(&(((Struct_class*)0)->Variable)))
struct obj
{
int a;
int b;
int c;
int d;
};
int main()
{
struct obj o = { 1, 2, 3, 4 };
int* pc = &o.c;
struct obj* po = my_offsetof(pc, struct obj, c);
printf("a=%d b=%d c=%d d=%d\n", po->a, po->b, po->c, po->d);
return 0;
}
先简单的介绍一下宏,宏的本质是替换,并且由于宏会在使用处直接展开,不会像函数一样开辟栈帧,因此对于短小而又常用的函数,把它实现成宏可以提高代码的效率,对于上方的宏,我们只需要把Address替换为pc,把Struct_class替换为struct obj,把Variable替换为c,然后再带入后方宏中的具体代码,就可以非常轻松的理解了。
这是一个非常有用的操作,在链表等链式的数据结构中可以实现非常骚的操作(相当于可以把链条和具体的数据解耦),在linux操作系统中采用的就是这种数据结构进行管理,具体原理比较复杂,本人会在之后有关linux操作系统的文章中进行专门的讲解。
3.一些有关指针的恶心题目(大部分来自实际的笔试/面试题)
好了,你已经学会怎么写鱼了,下面来试试看:鱽、鲕、鲼、鲰、鲞、鳈、鳉、鳢、鱇、鱊、鱥、鱧、鱡、鱠、䲢、䱵、鱞、鱣、鱤、鱩、鱪。
第一题:
int main()
{
int a[] = { 1, 2, 3, 4 };
printf("%d\n", sizeof(a)); //1
printf("%d\n", sizeof(a + 0)); //2
printf("%d\n", sizeof(*a)); //3
printf("%d\n", sizeof(a + 1)); //4
printf("%d\n", sizeof(a[1])); //5
printf("%d\n", sizeof(&a)); //6
printf("%d\n", sizeof(*&a)); //7
printf("%d\n", sizeof(&a + 1)); //8
printf("%d\n", sizeof(&a[0])); //9
printf("%d\n", sizeof(&a[0] + 1)); //10
return 0;
}先来进行一些分析(如果读者是在64位系统下进行测试,会得出不同的结果,具体原因在上文已有说明):
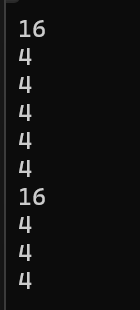
第一个printf非常的简单,sizeof(数组名)时,数组名代表整个数组,因此答案是16;
第二个printf中虽然arr+0看似还是等于arr,但是在sizeof中的已经不是纯粹的数组名了,抽象一下就变为sizeof(数组名+数字),此时数组名不再被视为整个数组,而是数组首元素的地址,而地址的大小取决于操作系统的具体位数,本人在32为系统下运行的代码,因此答案是4
第三个printf中,先*数组名,此时数组名显然是数组首元素的地址,因此会解引用出一个int类型,因此答案是4(要时刻牢记,除了sizeof(数组名)和&数组名外,任何地方的数组名都代表首元素的地址)
第四个printf和第二个printf类似,答案显然是4
第五个printf非常的简单,a[1]会访问到数组的第二个元素,是int类型,因此答案是4(数组中首元素的下标是0)
第六个printf中,先进行&a,此时取出了整个数组的地址,得到一个数组指针,但是在开篇就提过,指针的大小由操作系统决定,这里再说的明确一些:无论任何类型的指针,其大小都由操作系统的具体位数决定。而此处是sizeof(数组指针),数组指针也是指针,因此答案是4
第七个printf中,先&数组名,取出一个数组指针在对数组指针进行解引用,找到的就是整个数组,也可以理解为*和&相互抵消了,因此就变为了sizeof(数组名),因此答案是16
第八个printf中,先&arr,取出了一个数组指针,然后再对其加1,难道指针加1后就不再是指针了吗?因此答案显然是4
第九个printf中,先a[0],访问到了数组的第一个元素,然后在取这个元素的地址,取出的是一个int类型的指针,因此答案是4
第十个printf中,相当于对第九个指针加了1,得出的还是指针,因此答案是4
来看看实际情况(32位系统下):
第二题:
int main()
{
int a[3][4] = { 0 };
printf("%zu\n", sizeof(a)); //1
printf("%zu\n", sizeof(a[0][0])); //2
printf("%zu\n", sizeof(a[0])); //3
printf("%zu\n", sizeof(a[0] + 1)); //4
printf("%zu\n", sizeof(*(a[0]+1))); //5
printf("%zu\n", sizeof(a+1)); //6
printf("%zu\n", sizeof(*(a+1))); //7
printf("%zu\n", sizeof(&a[0]+1)); //8
printf("%zu\n", sizeof(*(&a[0]+1))); //9
printf("%zu\n", sizeof(*a)); //10
printf("%zu\n", sizeof(a[3])); //11
return 0;
}
一维数组的情况还是比较简单的,而二维数组就比较恶心了,来看看具体的分析:
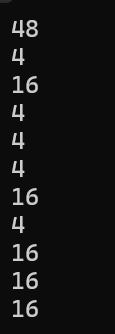
第一个printf中,直接在sizeof中传入了二维数组的数组名,此时数组名表示整个数组,因此计算出的就是整个二维数组的大小,因此答案是48
第二个printf中,显然a[0][0]会访问到一个二维数组中的具体元素,由于元素是int类型因此答案是4
第三个printf中,a[0]是二维数组的首元素,而二维数组的首元素是一个一维数组,而数组名可以代表一个数组,那么就相当于sizeof(一维数组名),因此答案是16(注意:1.二维数组中一维数组元素的个数=二维数组的列数)
第四个printf中,结合第三个printf中的分析,可以把sizeof(a[0]+1)变为sizeof(一维数组名+1),只有纯粹的sizeof(数组名)时,数组名可以被视为整个数组,因此此时数组名是首元素地址,而地址的大小取决于操作系统,本人在32位系统下进行的测试,因此答案是4
第五个printf中,先看里面的a[0]+1,a[0]是二维数组的首元素,相当于一个一维数组的数组名,是二维数组中的一维数组首元素的地址,因此a[0]+1就是一个int*类型的指针,然后再进行解引用,得到一个int,因此答案是4
第六个printf中,此时数组名a不能被视为整个数组,而是数组首元素的地址,是一个一维数组指针,而+1不会改变其类型,本质还是一个指针,因此答案是4
第七个printf中,结合第六个printf的分析,就是对一个一维数组指针进行了解引用,找到的就是一个一维数组的数组名,而sizeof(数组名)时数组名代表整个数组,因此答案是16
第八个printf中,把&a[0]+1,拆分,a[0]相当于一个一维数组名,而&a[0]就取出了一个数组指针,而+1显然不能改变其指针的本质,因此答案是4
第九个printf中,结合第八个printf,&a[0]+1是一个数组指针,解引用后可以找到一个一维数组,因此就相当于sizeof(一维数组名),因此答案是16
第十个printf中,a此时是首元素的地址,是一个一维数组指针,然后对一维数组指针解引用,就相当于sizeof(一维数组名),因此答案是16
第十一个printf中a[3]与a[0]的情况没什么区别,因此答案是16
下面看看实际情况:
要注意分
1.清楚sizeof(数组指针)和sizeof(数组名)
2.对于二维数组(比如arr[数字][数字]),arr[数字]相当于一维数组名,&arr[数字]是一维数组指针
就算是现在本人同样也做错了一题,这种题做多了就容易头昏,看漏一个细节就会错,确实恶心,不过别担心,后面的更恶心(快给我写吐了)。
第三题:
int main()
{
char* p = "abcdef";
printf("%zu\n", sizeof(p)); //1
printf("%zu\n", sizeof(p + 1)); //2
printf("%zu\n", sizeof(*p)); //3
printf("%zu\n", sizeof(p[0])); //4
printf("%zu\n", sizeof(&p)); //5
printf("%zu\n", sizeof(&p + 1)); //6
printf("%zu\n", sizeof(&p[0] + 1)); //7
printf("%zu\n", strlen(p)); //8
printf("%zu\n", strlen(p + 1)); //9
printf("%zu\n", strlen(*p)); //10
printf("%zu\n", strlen(p[0])); //11
printf("%zu\n", strlen(&p)); //12
printf("%zu\n", strlen(&p + 1)); //13
printf("%zu\n", strlen(&p[0] + 1)); //14
return 0;
}先来了解一些前置知识:
1.strlen是用于计算字符串长度的,关注的是\0前出现了几个字符(不计入\0),是库函数,只能对字符串使用,并且其以\0作为结束标志
2.sizeof是用于计算所占内存空间的大小的,只关注所占用的内存(单位是字节),与数据的类型(不在乎内存中存放的是什么)无关,是操作符(计入\0),不存在结束标志这个概念
好了,先看看第一个printf:首先明确p不是一个字符数组,而是一个char*类型的指针,因此答案是4
第二个printf: +1显然不会改变p是指针的本质,因此答案是4
第三个printf: p是指向首字符a的指针,因此对p解引用就可以找到字符a,因此答案是1
第四个printf: p[0]等价于*(p+0),即*p,因此答案是1
第五个printf: &p可以得到一个二级指针,因此答案是4
第六个printf: +1不会改变其是二级指针的本质,因此答案是4
第七个printf: 先看前半部分,&p[0],可以变为&*(p+0),&和*互相抵消了,因此&p[0]就相当于p,p是一个char*类型的指针,+1不会改变其类型,因此答案是4
第八个printf: strlen不会计入\0,因此答案是6
第九个printf: p+1后走到了字符b,因此答案是5
第十个printf: *p相当于字符a,但是strlen是不能直接接收非指针类型的,因此程序会崩溃
第十一个printf: 与第十个printf同理,程序会崩溃
第十二个printf: strlen接收了一个二级指针,是可以的,但是这个指针指向的内容没有\0作为结束标志,因此会打印出随机值
第十三个printf: 和第十二个printf同理,会打印出随机值
第十四个printf: 上面已经说过&p[0]就相当于p,而p+1同样在上面说过,答案是5
来看看实际情况(先去掉10和11):
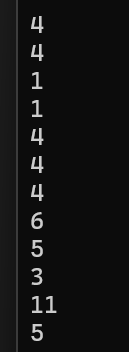
再来单独看看10:

然后是11:

退出时不是0就说明程序崩溃了。
第四题:
int main()
{
char arr[] = { 'a', 'b', 'c', 'd', 'e', 'f' };
printf("%zu\n", sizeof(arr)); //1
printf("%zu\n", sizeof(arr + 0)); //2
printf("%zu\n", sizeof(*arr)); //3
printf("%zu\n", sizeof(arr[1])); //4
printf("%zu\n", sizeof(&arr)); //5
printf("%zu\n", sizeof(&arr + 1)); //6
printf("%zu\n", sizeof(&arr[0] + 1)); //7
printf("%zu\n", sizeof(arr[0] + 1)); //8
printf("%zu\n", strlen(arr)); //9
printf("%zu\n", strlen(arr + 0)); //10
printf("%zu\n", strlen(*arr)); //11
printf("%zu\n", strlen(arr[1])); //12
printf("%zu\n", strlen(&arr)); //13
printf("%zu\n", strlen(&arr + 1)); //14
printf("%zu\n", strlen(&arr[0] + 1)); //15
return 0;
}首先明确:在使用{}创建字符串时,编译器是不会默认在末尾加上\0的(上文有比较详细的说明了,这里不再赘述)
第一个printf: 显然计算的是整个数组的大小,因此答案是6
第二个printf: sizeof中不是纯粹的数组名了,此时arr表示首元素地址,因此答案是4
第三个printf: *arr显然会找到字符a,因此答案是1
第四个printf: 显然访问到了字符b,因此答案是1
第五个printf: &arr会取出一个数组指针,但是数组指针也是指针,因此答案是4
第六个printf: +1不会改变其是指针的本质,因此答案是4
第七个printf: &arr[0]可以变为&*(arr+0),&和*抵消,因此最终就变为了arr+1,因此答案是4
第八个printf: arr[0]可以取出字符a,然后就变为了'a'+1,一个char类型和int类型进行运算,会发生整形提升(简单的说明一下:就是占用内存少的类型在和占用内存多的类型进行运算时,会把占用内存少的扩大到与占用内存多一样的内存大小,而不是截断占用内存多的,这样可以避免数据丢失,注:int和size_t运算时,int会被视为size_t类型),发生整形提升后,运算的结果就变为了int类型,因此答案是4
第九个printf: arr此时是首元素地址,是char*类型,strlen可以接收,但是由于数组arr中没有\0作为结束标志,因此答案是随机值
第十个printf中: 与第九个printf类似,会打印出随机值,并且这个随机值会和第九个printf相同
第十一个printf中:*arr会找到字符a,而strlen不能接受非指针类型,因此程序会崩溃
第十二个printf中: 和十一类似,程序会崩溃
第十三个printf中: &arr可以得到一个数组指针,strlen可以接收,但是同样由于没有结束标志,因此答案是随机值
第十四个printf中: 与十三类似,答案是随机值
第十五个printf中: &arr[0]相当于arr,因此答案是随机值
下面来看看实际情况(先去掉十一和十二):
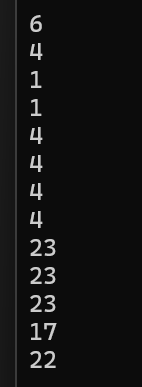
再来看看十一:

最后是十二:

上面这类题只要掌握了指针的基本知识,还是比较容易的,下面来看看与野指针有关的题目
第五题:
void GetMemory(char* p)
{
p = (char*)malloc(100);
}
void Test(void)
{
char* str = NULL;
GetMemory(str);
strcpy(str, "hello world");
printf(str);
}
int main()
{
Test();
return 0;
}
//上方代码的运行结果是什么?
//编译报错 运行崩溃 正常打印先了解一些前置知识:编译报错是语法错误,而运行时崩溃是语法没错,但是出现了对空指针解引用, 程序的逻辑出现了问题.....(问题多种多样)
好了现在来分析一些题目:先从main函数入手,发现其调用了Test函数,然后就将视线转移到Test函数中,首先其中定义了一个空指针str,然后将str传入了函数GetMemory,注意,GetMemory中的形参p就变为了str的临时拷贝,在函数中让p接收了动态开辟的char*类型的内存,然后在Test函数中str就接收到了内存吗?第一个错误出现了,str和p半毛钱关都没有,因此在从GetMemory函数返回Test函数后,指针p被销毁了,但是指针p动态开辟的内存还没有释放,出现了内存泄漏,不过此时程序还可以继续运行(内存泄漏编译器不会报错),因此继续分析,先明确此时str还是一个char*类型的空指针,然后就将str传入了strcpy,如果你并不了解库函数strcpy的内部实现也没关系,可以进行一些猜测,从名字上来看,strcpy应该是进行字符串拷贝的,不管是从哪里拷贝到哪里,在拷贝字符串时肯定对两个指针都要进行解引用,因此在strcpy内部肯定就对空指针进行了解引用,程序就会崩溃。总结一下,这个程序最终会崩溃,并且还出现了内存泄漏,下面来看看实际情况:
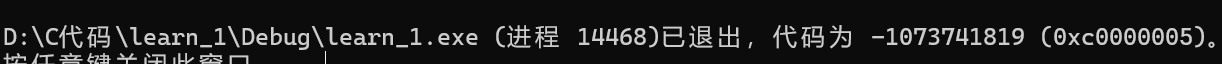
对于这种题,除了一点点分析也没什么好方法了(如果你厉害到可以一眼看出的话,那就当我没说)。
第六题:
char* GetMemory()
{
char* p = (char*)malloc(100);
return p;
}
void Test(void)
{
char* str = NULL;
str = GetMemory();
if (str == NULL)
{
return;
}
strcpy(str, "hello world");
printf(str);
free(str);
}
int main()
{
Test();
return 0;
}
//上方代码的运行结果是什么?
//编译报错 运行崩溃 正常打印同上题的分析,先从main函数入手,发现其调用了Test函数,然后就将视线转移到Test函数中,首先定义了一个char*类型的空指针str,注意,然后让str接收了GetMemory的返回值,虽然局部变量p在出GetMemory函数后同样会被销毁,但是此时p的接力棒已经传到了str的手中(p指向动态开辟的内存的地址拷贝给了str),str就指向了被动态开辟的内存空间,因此没有出现内存泄漏,并且str也变为了指向了有效内存的指针,然后是一个判空(这是使用指针的好习惯),如果库函数melloc成功开辟了内存的话(一般都会成功),那么str就不会是空指针,因此在strcpy中也可以正常的进行拷贝,printf也可以正常进行打印,并且最终也释放了动态开辟的内存,唯一一点瑕疵就是在释放内存后没有将str置空,但是程序总体上来看还是可以正常运行的,会打印出hello world,下面看看实际情况:

第七题:
int* f1(void) {
int x = 0;
return (&x);
}
int* f2(void) {
int* ptr;
*ptr = 10;
return ptr;
}
int* f3(void){
static int a = 10;
return &a;
}先分析一下函数f1:参数处的void是明确的指出该函数不用传参,其内部定义了一个变量x,并且返回了x的地址,但是x在出f1函数后就会被销毁,因此返回了一个野指针,程序可以运行,但是会非常危险。

然后是f2: 首先定义了一个int*类型的指针ptr,此时ptr指向的内容不明确,是一个野指针,那么下一行代码中对ptr的解引用就是对野指针的解引用,程序已经出问题了,并且会报错:

最后是f3,发现其中定义的是一个静态变量,而静态变量是不会存放在栈区的,而是存放在静态区(类似于全局变量),因此函数f3调用结束后无法销毁a,程序可以正常运行,在接收时使用int*类型接收返回值。
第八题:
char* GetMemory(void)
{
char p[] = "hello world";
return p;
}
void Test(void)
{
char* str = NULL;
str = GetMemory();
printf(str);
}
int main()
{
Test();
return 0;
}同样从main函数入手,发现其调用了Test函数,然后就将视线转移到Test函数中,首先定义了一个char*类型的空指针str,之后让str接收了函数GetMemory的返回值,分析一下GetMemory函数,其中定义了一个字符数组,没有动态申请内存,而函数中的字符数组显然是定义在栈区的,不像动态开辟的内存是开辟在堆区的,因此在GetMemory函数调用结束后,该字符数组会被销毁,返回值p就变成了一个野指针,而str就接收了一个野指针,在之后对其进行打印(对于char*类型,printf函数会打印其指向的内容,而不是打印指针本身,对于其它指针类型不会有这种行为),因此在printf函数内部肯定需要对str进行解引用,那么就出现了对野指针解引用,程序已经出问题了,但是由于这个解引用仅仅只是读数据,而没有写入数据,编译器对于这种行为的判定是不明确的,在VS2022中可以正常打印,不过由于内容已经被销毁,因此会打印出奇怪的东西:

第九题:
void GetMemory(char** p, int num)
{
*p = (char*)malloc(num);
}
void Test(void)
{
char* str = NULL;
GetMemory(&str, 100);
strcpy(str, "hello");
printf(str);
}
int main()
{
Test();
return 0;
}
同样从main函数入手,发现其调用了Test函数,然后就将视线转移到Test函数中,首先定义了一个char*类型的空指针str,之后将str的地址传入了GetMemory函数,即传入了一个二级指针给形参p,那么此时在GetMemory函数中*p就可以改变str本身(在2.4中有较为详细的讲解,这里不再赘述),那么在GetMemory函数中就成功的为str申请到了内存,此时str就不再是空指针了,而是指向了有效的内存空间,因此strcpy可以正常的进行拷贝,printf也可以正常的打印出hello:
第十题:
void Test(void)
{
char* str = (char*)malloc(100);
strcpy(str, "hello");
free(str);
if (str != NULL)
{
strcpy(str, "world");
printf(str);
}
}
int main()
{
Test();
return 0;
}同样从main函数入手,发现其调用了Test函数,然后就将视线转移到Test函数中,首先定义了一个char*类型的指针str并为其申请了内存,在之后没有进行str的判空,是一个小瑕疵(在实际项目开发中在动态申请内存后最好进行判空),然后strcpy就可以正常的进行拷贝(malloc一般不会失败),之后直接free掉了str动态开辟的内存,相当于其指向的内容被销毁了,str就变为了一个野指针,并且由于free并不会将str置空,因此if语句判定为真,那么在strcpy函数中就出现了对野指针的解引用,不同于在第五题中的对空指针的解引用一定会导致程序崩溃,对于野指针编译器也是没什么办法的,会出现各种各样的行为,一般是下面三者之一:
- 程序崩溃:操作系统检测到非法内存访问,强制终止程序。
- 数据损坏:如果这块内存已经被系统分配给其他变量使用,写入 "world" 会覆盖其他数据,导致程序逻辑混乱。
- 看似正常:在某些情况下,这块内存可能暂时没有被重新分配,程序能打印出 "world",但这完全是运气问题,代码依然是错误的。
来看看VS2022的行为:
看完这些于野指针相关的题目后,相信你更能体会到野指针的恐怖了,它完全是不可预测的,并且编译器在不是情况下还会让出现了野指针的出现正常运行,这就导致了野指针非常难发现,总之在使用指针时一定要谨慎。
这里分享一些笔者学习编程的技巧,尽管笔者现在还只算是一个刚入门的菜鸡,但是在学习时已经深深的体会到编程中的知识点是非常的多且杂的(尤其是操作系统),因此最好先梳理出一条主线,比如在C语言中,指针就是一条贯穿始终的线,在C++中类和对象就是一条贯穿始终的线,而在操作系统中,进程就是一条贯穿始终的线,先把主线梳理出来,在补充语法上的细枝末节,这样至少不会迷失在编程知识的海洋中,本人在写这篇文章时也是在进行梳理,因此篇幅较长,希望这个技巧可以给读者提供一些帮助。
这篇文章到这里就差不多结束了,篇幅较长,可能会出现一些纰漏,本人尽可能多的介绍了指针的知识,但是这些知识只是指针的一些比较基础的说明,仅仅只是杯水车薪,在真正的项目中还会出现指针更多的情况,当几万行代码摆在你眼前时,指针的错误就会变得非常难以发现。希望这篇文章可以给读者提供一些帮助。(如有错误,还请指出)

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 38
38 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)