【Linux】进程之冯诺依曼体系结构,操作系统,以及进程的基本概念
一.冯诺依曼体系结构
1.概念
我们常⻅的计算机,如笔记本。还有不常⻅的计算机,如服务器,⼤部分都遵守冯诺依曼体系。
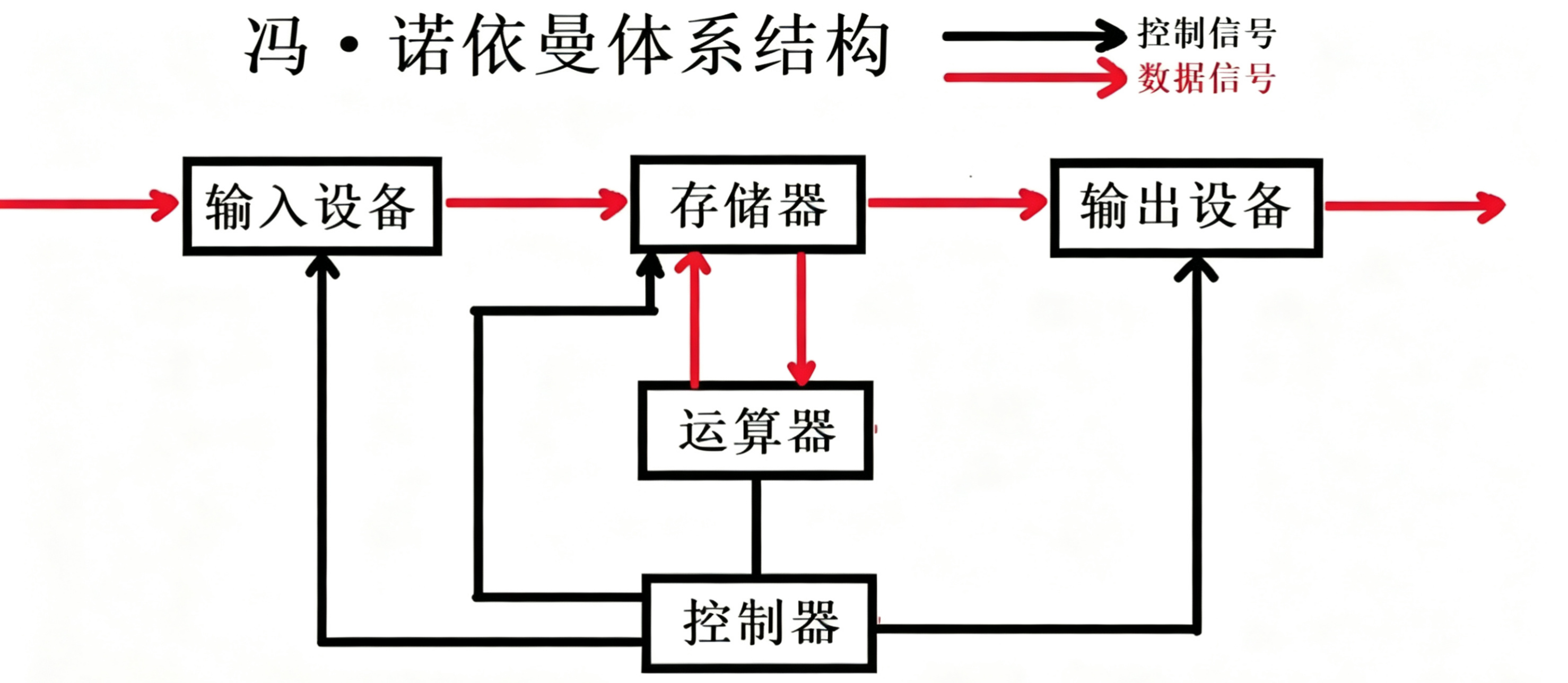
目前,我们所认识的计算机,都是由⼀个个的硬件组件组成
- 输⼊单元:包括键盘, ⿏标,扫描仪, 写板等
- 中央处理器(CPU):含有运算器和控制器等
- 输出单元:显⽰器,打印机等
(1)什么是冯诺依曼体系结构?
冯·诺依曼体系结构由运算器、控制器、存储器、输入设备、输出设备五部分组成。其核心思想是存储程序:将程序指令和数据用二进制形式存放在同一个存储器中,计算机自动从存储器中逐条取出指令并执行。
(2)在冯诺依曼体系下计算机是如何工作的?
输入设备输入数据,数据线先进入存储器,因为存储器本身没有计算的能力,这时候CPU会通过一些方式读取存储器的数据,通过运算器和控制器对数据进行处理然后将数据通过某种方式返回到存储器,最后输出设备再读取存储器当中的信息
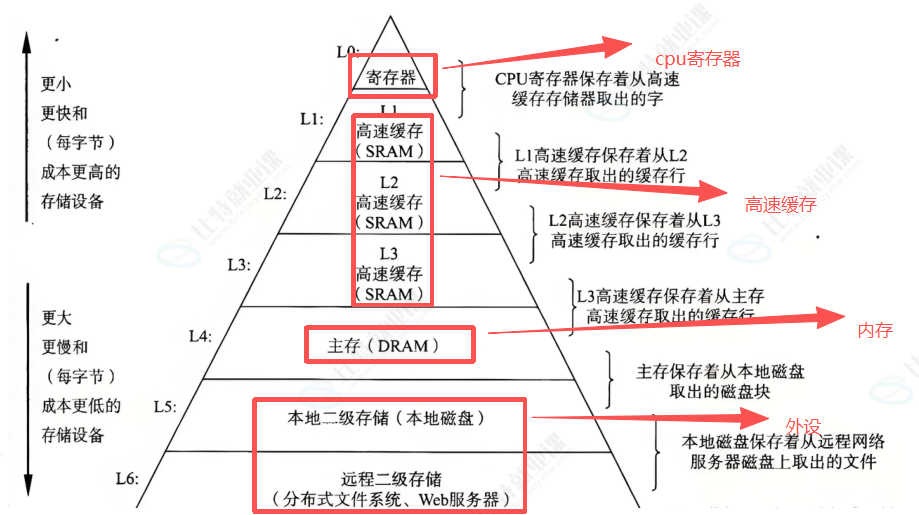
分析这张图:存储器的层次结构中,越往上速度越快,外设最慢 < 主存其次< 高速缓存< CPU寄存器,可以看到,CPU 离寄存器最近,离高速缓存也很近,主存(存储器)次之,所以 CPU 间接从主存中访问数据,效率更高。而让 CPU 直接访问外设(输入/输出设备)肯定效率不高,因为 CPU 特别快,但输入输出设备运行速度特别慢,所以导致效率低。
总结的话就是,当一个快的设备和一个慢的设备在一起同时合作运行的时候,肯定按照慢设备的工作效率为主也就类似于木桶效应
木桶效应
寄存器是长板:
CPU运算速度极快,大部分指令在1个时钟周期内就能完成。
只要数据已经在寄存器里,CPU就能飞速处理。这是个“长板”。
内存是短板:
如果数据不在寄存器里,必须去内存里取。内存访问延迟大约是100-300个时钟周期。
此时,CPU只能空转等待(Stall)。这个漫长的等待时间就是“短板”,它决定了这条指令最终完成的总时间。
结论:一个程序的执行速度,不取决于CPU运算有多快(寄存器多),而取决于它等待从内存拿数据等了多久(内存延迟这个短板)。
(3)在软件中运行可执行程序(文件),运行时必须加载到内存里里面,这是为什么呢?(软件运行前中的可执行程序(文件)在磁盘里)
因为冯诺依曼的体系结构规定,可执行程序时二进制程序,cpu获取并执行这些指令,必须先将磁盘中的可执行程序加载到内存里面,CPU才能执行访问这些命令
2.硬件层面的数据流动
(4)在互联网的世界中,在软件上面的数据的传输如何进行呢?
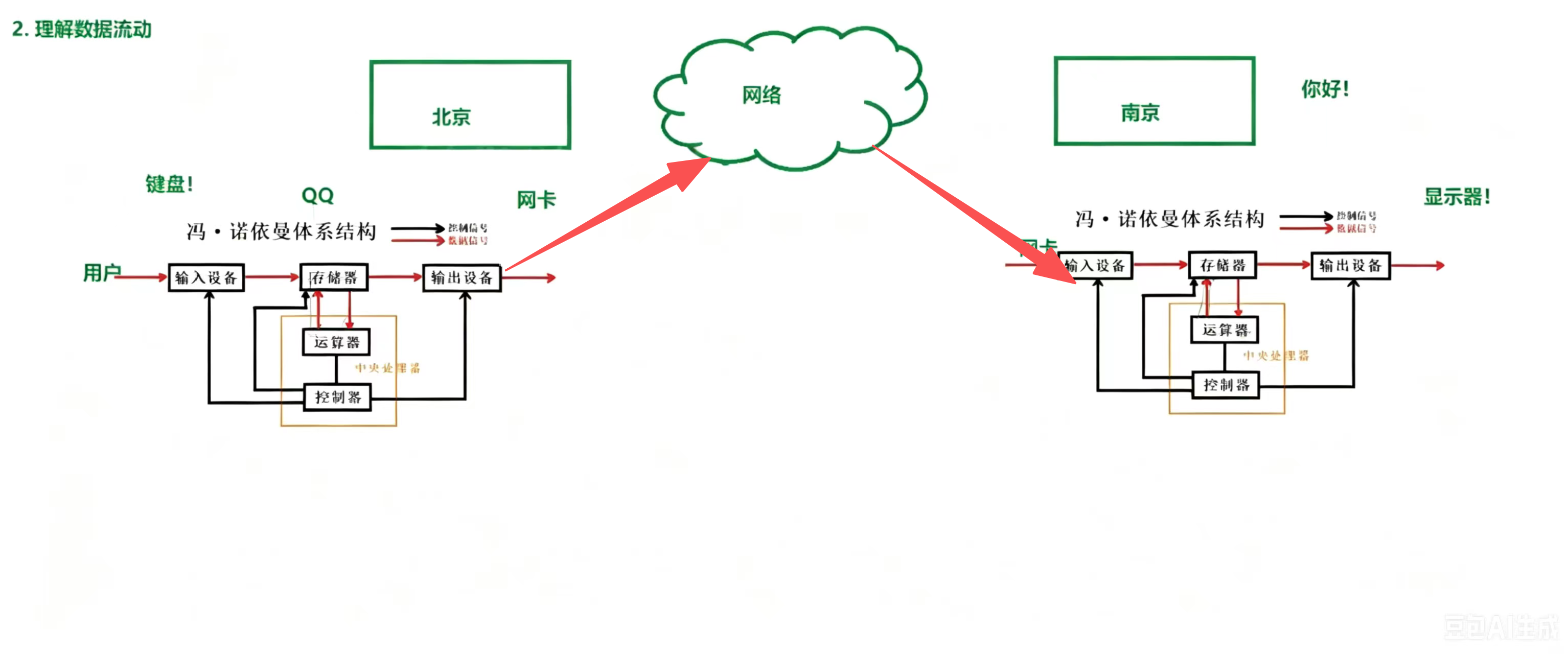
解释:在 QQ 上发送消息,数据的流动过程:电脑联网后,我用键盘敲下要发送的消息:“在吗?”,此时输入设备是键盘,键盘将该消息写入到内存中,CPU 间接从内存中读取到消息。对其进行运算处理后,再写回内存,此时输出设备网卡从内存中读取消息,并经过网络发送到对方的网卡,同时输出设备显示器从内存中读取消息并刷新出来,显示在我的电脑上。 我朋友的电脑的输入设备是网卡,接收到消息后,网卡将该消息写入到内存中,CPU 间接从内存中读取到消息,对其进行运算处理后,再写回内存,此时输出设备显示器从内存中读取消息并刷新出来,显示在我朋友的电脑上。
3.关于冯诺依曼,知识点强调
- 这⾥的存储器指的是内存
- 不考虑缓存情况,这⾥的CPU能且只能对内存进⾏读写,不能访问外设(输⼊或输出设备
- 在数据层面上,CPU 不和外设(输入/输出设备)打交道,外设只和存储器打交道。(可以将存储器理解为是 CPU 和所有外设的缓存)(而在硬件层面上,外设是可以直接给 CPU 发中断的)
- 外设(输⼊或输出设备)要输⼊或者输出数据,也只能写⼊内存或者从内存中读取。
- 也就是说,所有设备都只能直接和内存打交道。
4.CPU的工作原理
CPU里只有“有电”和“没电”
高电平 = 有电 = 1
低电平 = 没电 = 0
指令、数字、地址……统统是“有电/没电”的组合
计算就是让电“流”过一堆门
电从入口流进去,经过一堆门(与门、或门……),从出口流出来
流出来的电是什么样,由门和流进去的电决定
没有“算”的动作,就是电在走
记住东西就是“把电关住”
触发器像个“电的捕鼠夹”
时钟边沿来时,把输入端的电平“夹住”
输出端一直输出被夹住的那个电平,直到下次再夹
4.CPU工作的五个阶段
- 取指令(IF,instruction fetch),即将一条指令从主存储器中取到指令寄存器(用于暂存当前正在执行的指令)的过程。程序计数器中的数值,用来指示当前指令在主存中的位置。当 一条指令被取出后,程序计数器(PC、用于存放下一条指令所在单元的地址的地方)中的数值将根据指令字长度自动递增。
- 指令译码阶段(ID,instruction decode),取出指令后,指令译码器按照预定的指令格式,对取回的指令进行拆分和解释,识别区分出不同的指令类 别以及各种获取操作数的方法。现代CISC处理器会将拆分已提高并行率和效率。
- 执行指令阶段(EX,execute),具体实现指令的功能。CPU 的不同部分被连接起来,以执行所需的操作。
- 访存取数阶段(MEM,memory),根据指令需要访问主存、读取操作数,CPU 得到操作数在主存中的地址,并从主存中读取该操作数用于运算。部分指令不需要访问主存,则可以跳过该阶段。
- 结果写回阶段(WB,write back),作为最后一个阶段,结果写回阶段把执行指令阶段的运行结果数据 “写回” 到某种存储形式。结果数据一般会被写到 CPU 的内部寄存器中,以便被后续的指令快速地存取;许多指令还会改变程序状态字寄存器中标志位的状态,这些标志位标识着不同的操作结果,可被用来影响程序的动作。
备注:引用课本定义
二.操作系统(Operator system)
赋予计算机哲学的美誉
2.1 概念
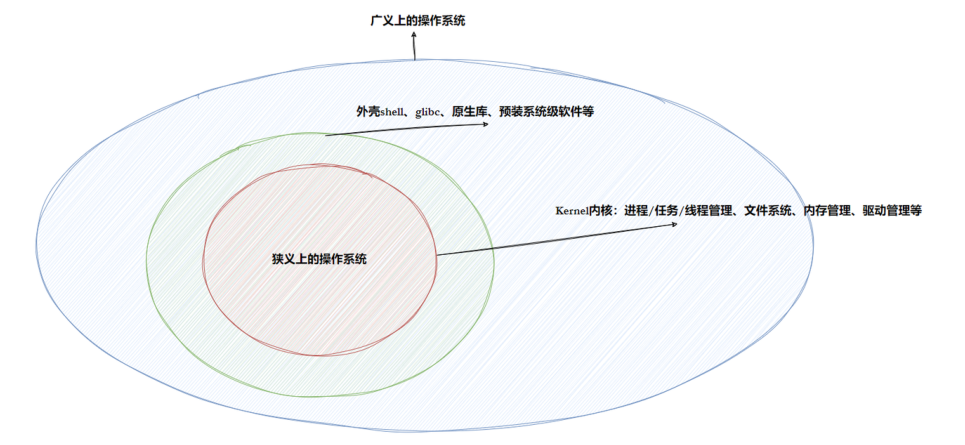
任何计算机系统都包含⼀个基本的程序集合,称为操作系统(OS)。笼统的理解,操作系统包括:
• 内核(进程管理,内存管理,⽂件管理,驱动管理)
• 其他程序(例如函数库,shell程序等等)强调:它是一款软硬件管理的软件
广义上的操作系统:
2-2 设计OS的目的
首先回答几个问题?
问题一:
(1)操作系统是什么?
是一款管理软硬件资源管理的软件
问题二:
(2)为什么会存在操作系统?设计操作系统的目的是啥?
- 原因:方便用户使用,减少用户的使用计算成本
- 目的:(1) 对下,与硬件交互,管理所有的软硬件资源 (2) 对上,为⽤⼾程序应⽤程序提供⼀个良好的执⾏环境.
2-3 核心功能
• 在整个计算机软硬件架构中,操作系统的定位是:⼀款纯正的“搞管理”的软件
2-4 如何理解 "管理"
想想:既然操作系统是一款搞管理的软件,那他是如何进行管理的?究竟管理的是什么呢?
在这个世界管理主要分三种人:决策者;执行者;被管理者,人主要做两件事:决策和执行
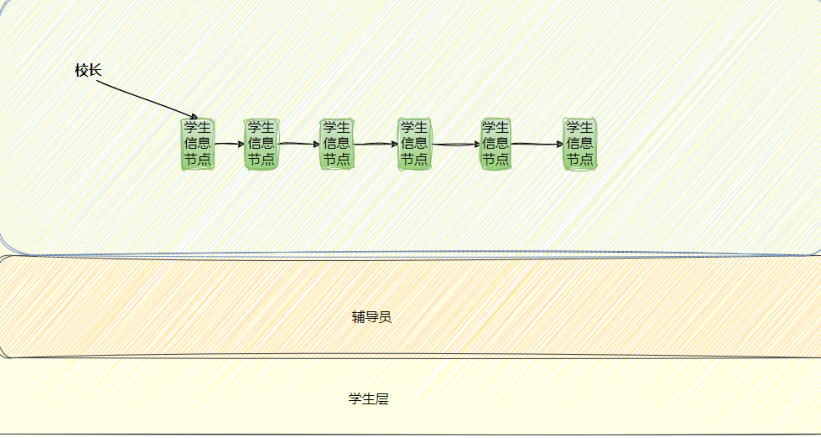
• 管理的例⼦ - 学⽣,辅导员,校⻓他们三人有不同的身份

在平常我们会发现管理者和被管理者是很少见面,二者是不直接打交道的。
那问题来了二者不直接打交道,也不见面,那这个命令是怎样执行的?校长又是怎么知道学生的情况的呢?
答案是:学生的个人信息在学校的系统当中,校长可以调用系统,说明你是这个学校的学生,同时也方便管理学生
比如 24级计科专业有 90 名学生,我们想要给其中特定的几名优秀学生发奖学金,那是否需要校长跑到该专业学生的宿舍里面挨个询问同学们的各科成绩和学分绩点是多少呢?肯定不是的,当他想要做发奖学金这个决策时,他只需要通过学校的教务系统,抽取 24 级计科专业 90 名学生的名单,按照学分绩点来进行排名,在排名后再根据其它的一些要求,综合数据来做出一个决策:给前几名同学发奖学金。当校长做完决策后,通知计科专业的辅导员过来,让他开个表彰大会奖励下这几名优秀同学。辅导员说:“好的,校长。”,此时辅导员就开始做执行这个决策。
这就是一个简单的管理过程
管理学生就要抽取信息,这个抽取信息的过程就叫做“描述学生”。
因为操作系统是用c语言写的,那么c语言是如何管理学生的?
是用struct结构体,比方管理学校几万人,就要有几万个结构体,每个结构体变量都保存着学生的信息。
// 描述学生
struct student
{
char name[10]; //名字
char sex; //性别
int age; //年龄
double score; //分数
char addr[100]; //家庭住址
// ...
};假如,我们想找出成绩最好的同学,只需要将其每个同学的成绩拿出来进行比较即可。但如果每个结构体变量之间没有任何关联的话,是不方便进行管理的,也很难快速找到成绩最好的同学。这个时候就需要将这些结构体变量链接起来,就可以在 struct 中包含一些指针信息,将所有的结构体变量链接起来,此时就形成了一个双链表。
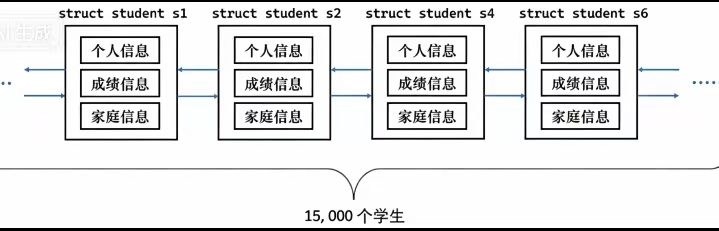
校长进行管理学生,只要双链表的头指针就行。如果校长想要重新奖章某位学生,只需要遍历双链表,再将该学生所属的节点从双链表中查找即可;假设有新生报到,只需要将该学生所属节点插入到双链表中即可。所以校长并不是单独对一个人进行管理的,而是将学生的个人信息组织起来,对双链表数据结构进行管理。
通过双链表对学生进行增删查改的操作,也就是所谓的管理学生
总结:
对学生管理就是先描述,再组织;管理的本质就是对数据结构进行操作
- 描述起来,用 struct 结构体。
- 组织起来,用双链表或其他高效的数据结构(不同的数据结构决定了不同的增删查改的特征和效率,也决定了不同的组织和管理方式)
类比,在计算机中,校长通常指的是操作系统,辅导员可以称为驱动板块,学生可以称为软硬件版板块。
操作系统不会直接和硬件(比如磁盘,网卡,鼠标底层硬件)打交道,而是通过驱动程序和硬件打交道,那问题来了操作系统怎么去管理硬件呢?
- 先描述,再组织。所以操作系统先要描述底层的硬件,然后形成符合被管理者的数据结构,对底层硬件的管理,最后变成了对数据结构的管理。
- 举例:操作系统要管理磁盘,那得要有一个描述硬盘的 struct 结构体,就是先描述一个事物,通常描述是事物的属性,比如磁盘的大小、磁盘的型号等等;假如操作系统卸载一个硬件,并不是要把这个硬件从电脑中拆走,而是直接把这个硬件对应的描述信息给删除掉。所以操作系统为了管理好被管理对象,在系统内部运用了大量的数据结构。
2-5计算机的层次结构
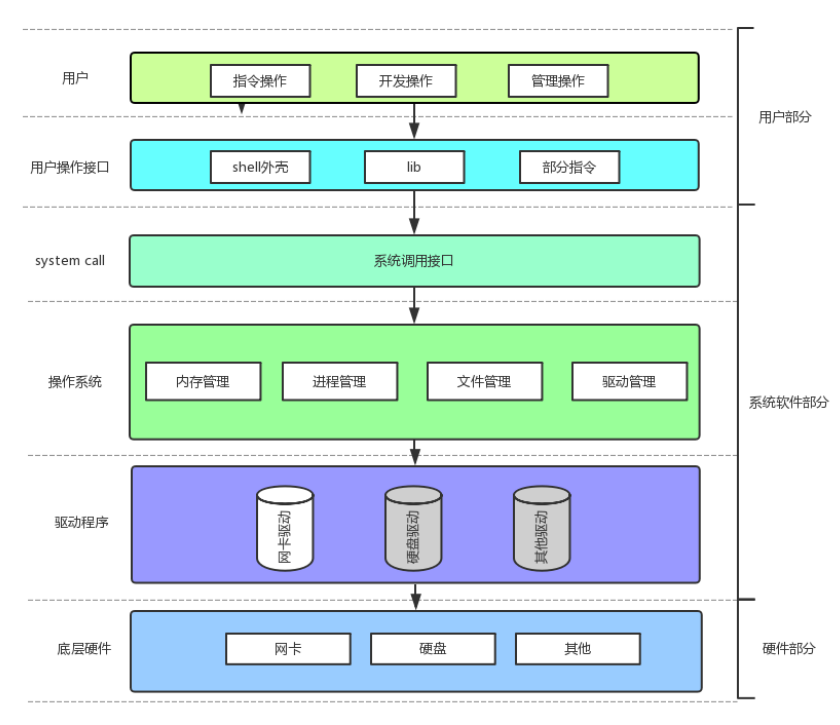
(1)底层硬件
冯诺依曼体系结构。
(2)驱动程序
操作系统中默认会有一部分驱动.如果有新外设,就需要单独安装驱动程序,该驱动程序会通过某种方式将该硬件的信息上报给操作系统,告诉操作系统,多了这个硬件。(驱动程序更多是一种执行者的角色)
(3)操作系统
最重要的四个功能:进程管理、内存管理、文件管理、驱动管理。
(4)系统调用接口
- 操作系统是不信任何用户的,任何对硬件或者系统软件的访问,都必须通过操作系统的手(好比银行是不信任任何用户的,但还是得给用户提供服务,用户想要取钱存钱,都必须经过银行的手),所以用户对操作系统中资源的访问,都必须调用对应的系统接口。(比如:在 Linux 中执行命令,或运行一个 C 程序,就要用到C函数,底层都用到了系统接口)。
- 系统调用接口,本质是操作系统为了方便用户使用操作系统中的资源,给用户提供的一些调用接口。但是,系统调用接口用起来也不是特别方便。所以一般我们会在系统调用接口上再封装一层(比如:shell 外壳,lib库,部分指令,这些的底层一般都是封装的系统调用接口)。
- 不断的封装的目的,也是为了让用户用起来更简单。比如:安装 C/C++ 环境时,系统会默认带上 C/C++ 标准库,这些库提供给用户的接口是一样的,但是底层可能不一样,在 Windows 中调用的就是 Windows 的系统接口,在 Linux 中调用的就是 Linux 的系统接口。
(5)用户操作接口
底层大都是封装的系统调用接口。
2-6库函数和系统调用
- 库函数:语言或者第三方库给我们提供的接口。(实际上我们使用的函数,底层一般就两种情况,要么调用了系统接口,比如 printf/scanf/vector/list/deque等;要么没有调用系统接口,比如自己写的 sum 函数,自己写的循环,判断语句等)。
- 系统调用:操作系统提供的接口,本质就是用户和操作系统之间进行数据的交互
- 系统调用被封装成库函数;判断是否发生系统调用,不能等同于是否访问硬件,因为很多系统调用只在内核里操作数据结构,不涉及硬件。
在开发的角度,操作系统对外会表现成一个整体,但还是会暴露自己的部分接口,供上层开发使用,这部分由操作系统提供的接口,叫做系统调用。
系统调用在使用上,功能比较基础,对用户的要求相对也比较高,所以,有心的开发者可以对部分系统调用进行适度封装,从而形成库,有了库,就很有利于更上层用户或者开发者进行二次开发。
理解就是:
操作系统是整体(黑盒,管理硬件)
系统调用是接口(暴露出来的、基础的、门槛高的功能)
库是封装(把基础功能包装得更好用,方便上层开发)
三.进程(Process)
这个是window任务管理器当中的进程与其意思相同
问题:操作系统如何进行进程的管理
答案:先描述,再组织
操作系统可以一次运行好多个程序吗?
答案是可以。运行的程序有很多,所以OS要将这些程序管理起来,这些正在运行的程序称为进程
如何管理进程呢?
答案是:先描述,再管理
- 操作系统为了方便管理,会创建一个描述和控制该进程的结构体,这个结构体被称为PCB(进程控制块),这里面包含了进程的所有信息,通过这个PCB就可以找到里面的代码和数据信息
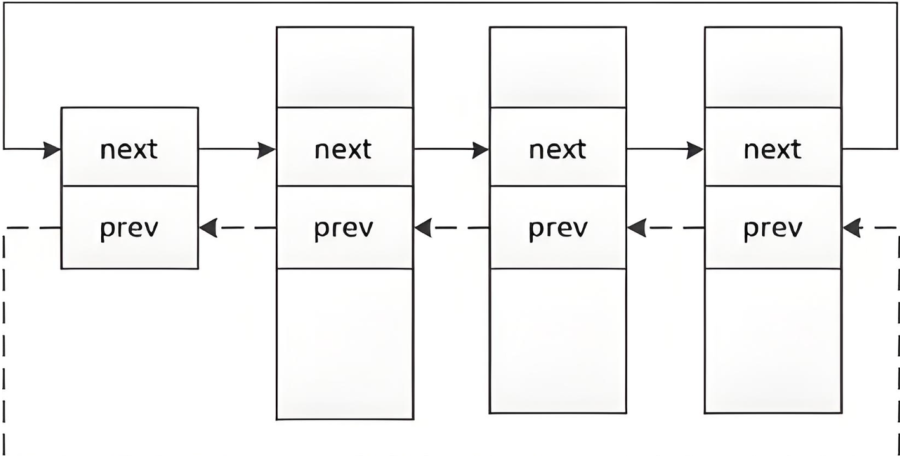
- 在Linux操作系统中,struct_task结构体就是进程控制块,描述号所有信息之后,接着用PCB将所有信息组织起来,因为PCB当中有指针可以通过指针将各个结构体链接起来,也就是双链表的头指针,就可以查找完成PCB所有结构体
- OS把对进程的管理,转换为对数据结构中PCB的管理,也就是双链表的增删查改。
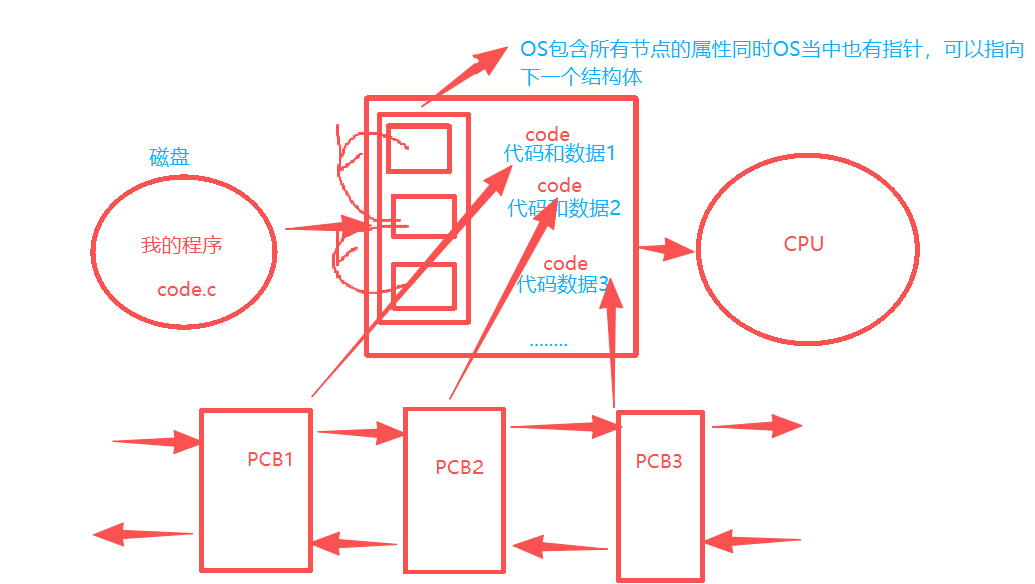
在磁盘里有我的code.c文件,当运行./code操作系统就会发生以上的流程,磁盘加载到内存当中,为它创建相应的进程,申请PCB
这里的PCB指向数据和代码,然后code.c文件指向code
这里面我们要存PCB的原因是OS要对进程进行管理
目前对进程的理解:进程 = 代码 + 数据 + 与该进程对应的数据结构(PCB)。
3-1 基本概念与基本操作.
- 概念:在Linux操作系统当中,每次程序的⼀个执⾏实例,正在执⾏的程序等,同时每一个进程的执行都配上一个ID,一般咱们在写的时候用的PID(进程号)
- 内核观点:担当分配系统资源(CPU时间,内存)的实体
3-2 描述进程-PCB
基本概念
- 进程信息被放在⼀个叫做进程控制块的数据结构中,可以理解为进程属性的集合。
- 课本上称之为PCB(process control block), Linux 操作系统下的 PCB 是: task_struct
task_struct-PCB的⼀种
- 在 Linux 中描述进程的结构体叫做 task_struct ,它是进程实体的一部分,是操作系统中最重要的记录性数据结构,它是进程管理和控制的最重要的数据结构。每一个进程均有自己的PCB,在创建进程时,必须建立 PCB,伴随进程的生命周期,直到进程终止时,PCB 将被删除。
- task_struct 是 Linux 内核的⼀种数据结构类型,它会被装载到RAM(内存)⾥并且包含着进程的信息。
补充:小知识:
人类认识事物是通过事物的属性,而计算机是通过进程的属性去描述和认识进程。然而计算机通过数据结构把要描述的属性,组织起来,交给操作系统,方便管理,所以操作系统中充斥着大量的数据结构
也就印证了,为什么说操作系统是计算机的哲学这个含义
3-3 task_ struct
PCB如何管理进程,答案是进程的属性进行管理
内容分类(进程属性)
- 标⽰符: 描述本进程的唯⼀标⽰符,⽤来区别其他进程。
- 状态: 任务状态,退出代码,退出信号等。
- 优先级: 相对于其他进程的优先级。
- 程序计数器: 程序中即将被执⾏的下⼀条指令的地址。
- 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
- 上下⽂数据: 进程执⾏时处理器的寄存器中的数据[休学例⼦,要加图CPU,寄存器]。
- I/O状态信息: 包括显⽰的I/O请求,分配给进程的I∕O设备和被进程使⽤的⽂件列表。
- 记账信息: 可能包括处理器时间总和,使⽤的时钟数总和,时间限制,记账号等。
理解几个重点概念:
优先级:
比如大家去食堂吃饭,排队情况就相当于确定了优先级,那插队就代表改变优先级
程序计数器:
程序计数器(PC,Program Counter)是一个CPU内部的寄存器,它永远存着下一条要执行的指令在内存中的地址。
进程在运行,实际上是 CPU 在执行该进程的代码,那 CPU 如何得知应该取进程中的哪行指令呢?在 CPU 中有一个寄存器叫做 EIP,这个寄存器通常被称为 PC 指针,保存着当前正在执行指令的下一条指令的地址。如果说后续不想运行了,可以把这个EIP保存在PCB方便后续恢复访问。
内存指针
CPU 只认识 PCB,不认识程序代码和数据。可以通过 PCB 结构体中中的内存指针,可以帮我们找到该进程对应的代码和数据。
上下文数据:
CPU寄存器中的数据称为进程的硬件上下文
记账信息:
操作系统给这个进程记的考勤表 + 绩效表。干了多少活、等了多久、犯了几次错,全记在PCB里。一般默认操作系统去执行默认信息
假如有两个优先级相同的进程,但一个进程运行50s,一个进程运行10s,那下次运行一般运行短的进程
注意:PCB里记着这个进程干了多少活(记账) 和有没有插队权(优先级)。操作系统靠这两样东西来公平+高效地调度。
可以在内核源代码⾥找到它。所有运⾏在系统⾥的进程都以 task_struct 双链表的形式存在内核⾥。
3-5查看进程
1.进程信息可以使⽤top和ps这些⽤⼾级⼯具来获取
命令:ps ajx
- a:显⽰⼀个终端所有的进程,包括其他⽤⼾的进程。
- x:显⽰没有控制终端的进程,例如后台运⾏的守护进程。
- j:显⽰进程归属的进程组ID、会话ID、⽗进程ID,以及与作业控制相关的信息
- u:以⽤⼾为中⼼的格式显⽰进程信息,提供进程的详细信息,如⽤⼾、CPU和内存使⽤情况等
ps ajx | head - l && ps ajx | grep myprocess,其中 ps ajx | head - 1 是把 ps ajx 输出的信息中的第一行信息(属性)列出。一般咱们查看信息的话搭配管道使用

- 使用 top 命令实时显示进程(process)的动态。
- 通过 /proc 系统文件目录查看。
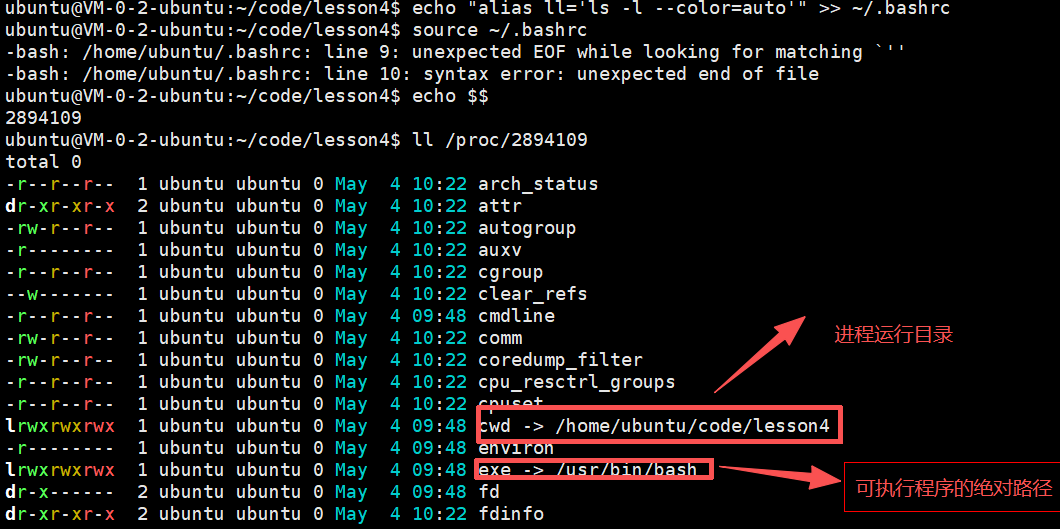
cwd -> /home/ubuntu/code/lesson4 :前终端的进程运行的目录
exe -> /usr/bin/bash :bash 程序的绝对路径
CentOS 里直接用 ll ,Ubuntu 里需要手动配置别名,不然只能用 ls -l
这里的echo $$是直接显示我们用户正在运行的进程ID,因为ubuntu管理严格,有些权限普通用户不可执行,就要用sudo提权,但centos部分指令默认普通用户也可以执行
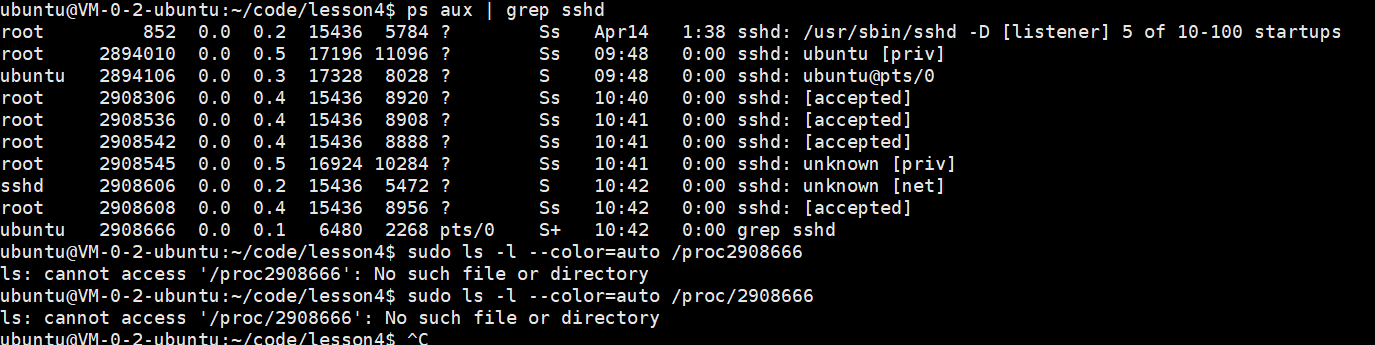
ps aux | grep sshd = 列出系统里所有进程 ,只留下名字带sshd的进程
注意:2908666 是 grep sshd 命令的临时进程,执行完瞬间就退出了,不管在CentOS还是Ubuntu,这个目录都会消失,报同样的错。
所以问题来了,既然临时的不能显示,那如何找长期的?
方法一:看图
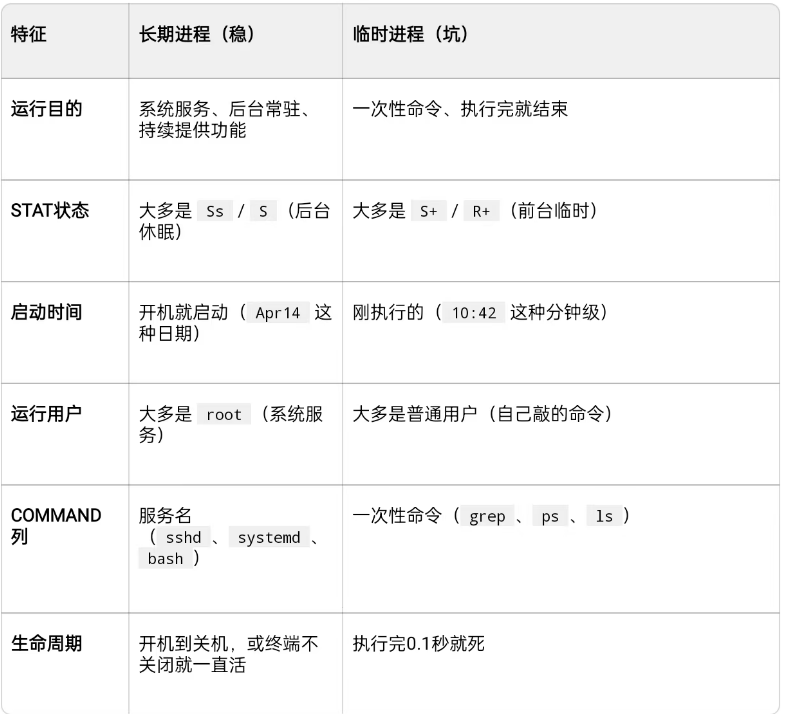
方法二:
1.号进程 systemd (所有Linux系统的根进程)
sudo ls -l /proc/1
这是系统第一个进程,开机就启动,关机才退出,是Linux里最稳的PID
2. sshd 主进程(远程服务,永远活着)
精准提取sshd主进程PID(过滤掉临时进程)
ps aux | grep sshd | grep -v grep | head -1
第一行的PID(比如你的 852 ),就是sshd主进程,开机就运行,永远不退出查它的信息:
sudo ls -l /proc/852
3. 你自己的 bash 进程(普通用户长期用的,终端不关闭就永远活着)
直接拿到当前bash的PID
echo $$
直接查,不用sudo提权
ll /proc/$$
只要你不关闭这个终端窗口,这个PID就永远存在
4. 其他系统级长期服务(随便选)
用这个命令,一键列出所有系统级长期进程:
ps aux | grep root | grep Ss | head -10
这些 输出的全是root用户(要提权)运行的、后台休眠的系统服务,全是长期进程,随便选一个PID查就行
查询1号进程不是临时的,长期存在的,如果是临时的在我们输入ID的时候就已经文件不存在了
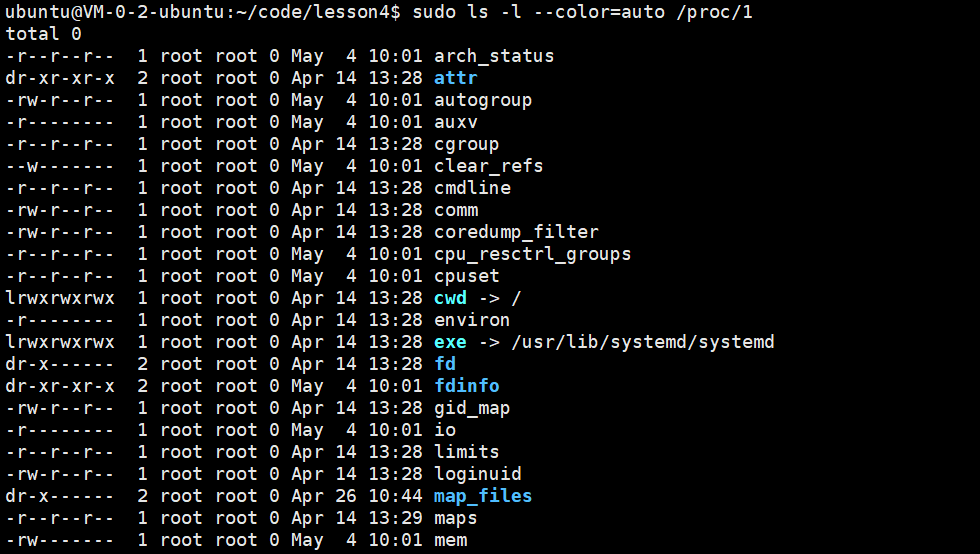
3-6系统调用获取进程标示符
- 子进程 ID(PID)
- 父进程 ID(PPID)
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
printf("pid: %d\n", getpid());
printf("ppid: %d\n", getppid());
return 0;
}
我圈的数就是运行的结果,pit_d是无符号的整数
补充:
shell 是对所有外壳程序的统称,而 bash 是某一个具体的 shell(命令行解释器)。bash 也是许多 Linux 发行版的默认 shell。在执行命令的时候,一般情况下,往往不是由 bash 来解释和执行,而是由 bash 创建子进程,让子进程去执行。
- 运⾏ man fork 认识fork
- fork有两个返回值
- ⽗⼦进程代码共享,数据各⾃开辟空间,私有⼀份(采⽤写时拷⻉),复制进程创建一个新的进程
#include <stdio.h>
#include <sys/types.h> // getpid, getppid
#include <unistd.h> // getpid, getppid, fork, sleep
int main()
{
printf("I am a father: %u\n", getpid());
fork();
while(1)
{
printf("I am a process, pid: %u, ppid: %u\n", getpid(), getppid());
sleep(1);
}
return 0;
}fork 的两种理解:
站在开发者的角度:
父子进程共享用户代码(代码是只读的,不可写),而用户数据各自私有一份(为了不让进程互相干扰,因为二者具有独立性的),采用写时拷贝技术。
就好比,打开 Windows 的任务管理器,可以看到有很多进程,假如我把微信进程关掉,会不会影响到 QQ,抖音,QQ音乐 进程呢?答案是不会
总结:
操作系统中,所有进程是互相独立的。为了不让进程互相干扰。
注意:fork 之后子进程会被创建成功,然后父子进程都会继续运行,但谁先运行是不确定的,由系统调度优先级决定。
站在操作系统内核的角度:
fork 之后,站在操作系统的角度,系统多了一个进程?是的。fork 创建子进程,通常以父进程为模板,其中子进程默认使用的是父进程的代码和数据(写时拷贝)。既然多了一个进程,OS 就会为子进程创建新的 PCB,并把父进程 PCB 中的部分内容拷贝过来。
fork 的用法
fork 在使用的时候通常要用 if 进行分流,让父子进程执行不同的代码,实现一个并行的效果。(比如父进程播放音乐,子进程下载文件)通过 fork 的两个返回值来进行分流:如果 fork 执行成功,在父进程中返回子进程的 pid,在子进程中返回 0。
如果 fork 执行失败,在父进程中返回 -1,不创建子进程,并适当地设置 errno。
#include <stdio.h>
#include <sys/types.h> // getpid, getppid
#include <unistd.h> // getpid, getppid, fork
int main()
{
printf("我是父进程: %u\n", getpid());
pid_t ret = fork();
if (ret == 0)
{
//子进程
while (1)
{
printf("子进程, pid:%u, ppid:%u\n", getpid(), getppid());
sleep(1);
}
}
else if (ret > 0)
{
//父进程
while (1)
{
printf("父进程, pid:%u, ppid:%u\n", getpid(), getppid());
sleep(1);
}
}
else
{
perror("fork");
return 1;
}
return 0;
}理解fork的返回值
fork 为什么会有两个返回值?
1 fork()是一个函数,它的return ret;是用户代码(属于代码段)
2 fork()在执行return之前,子进程已经被创建完成,并且放入了调度队列
3 父子进程在fork()之后共享代码段(只读)
4 所以return ret;这行代码的机器指令,父子进程都能看到、都能执行
5 父进程执行return ret; → 返回子进程的PID
6 子进程被调度后,也从fork()函数返回,执行同一行return ret; → 返回0
如果 fork 执行成功,为什么在父进程中返回子进程的 pid,在子进程中返回的是 0 呢?
每个小孩只有一个亲生父亲,而父亲可以有多个孩子。所以儿子找父亲是特别简单的,是唯只有一个的,而父亲为了更好的找孩子,需要给每个孩子起个名字,并且记住他。所以在父进程中需要返回子进程的 pid,因为得让父进程知道自己的子进程是谁。
如何创建多个子进程?
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int main() {
int i;
int n = 3; // 想创建3个子进程
for (i = 0; i < n; i++) {
pid_t pid = fork();
if (pid < 0) {
perror("fork");
return 1;
}
else if (pid == 0) {
// 子进程
printf("我是子进程 %d, PID=%d, 父进程=%d\n", i+1, getpid(), getppid());
return 0; // 子进程执行完就退出,不再继续fork
}
// 父进程继续循环
}
// 父进程等待所有子进程结束
for (i = 0; i < n; i++) {
wait(NULL);
}
printf("父进程结束, PID=%d\n", getpid());
return 0;
}结果演示:
我是子进程 1, PID=1234, 父进程=1233
我是子进程 2, PID=1235, 父进程=1233
我是子进程 3, PID=1236, 父进程=1233
父进程结束, PID=1233
openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 33
33 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)