高德具身智能技术深度解析:从地图导航到机器人物理世界模型
高德地图推出的ABot全栈具身技术体系在具身智能领域取得重大突破,其三层架构设计构建了完整技术闭环:底层ABot-World可交互世界模型提供数字孪生环境,中层ABot-N导航和ABot-M执行双基座模型分别处理路径规划与动作控制,顶层ABot-Claw机器人操作系统提供标准化接口。核心创新在于采用可微分物理引擎范式,通过140亿参数的Diffusion Transformer模型将物理规律嵌入生
0. 引言
当我们谈论具身智能时,脑海中浮现的往往是波士顿动力的机器狗、特斯拉的人形机器人,或是各类工业机械臂。然而,一个国民级导航应用高德地图,却在这个赛道上取得了令人瞩目的成绩。高德推出的 ABot 全栈具身技术体系,不仅在 CVPR 2026 Video World Model Workshop 国际挑战赛中超越谷歌和英伟达,更在 WorldArena 全球排行榜上夺得第一名,横扫具身智能领域 15 项 SOTA 指标。
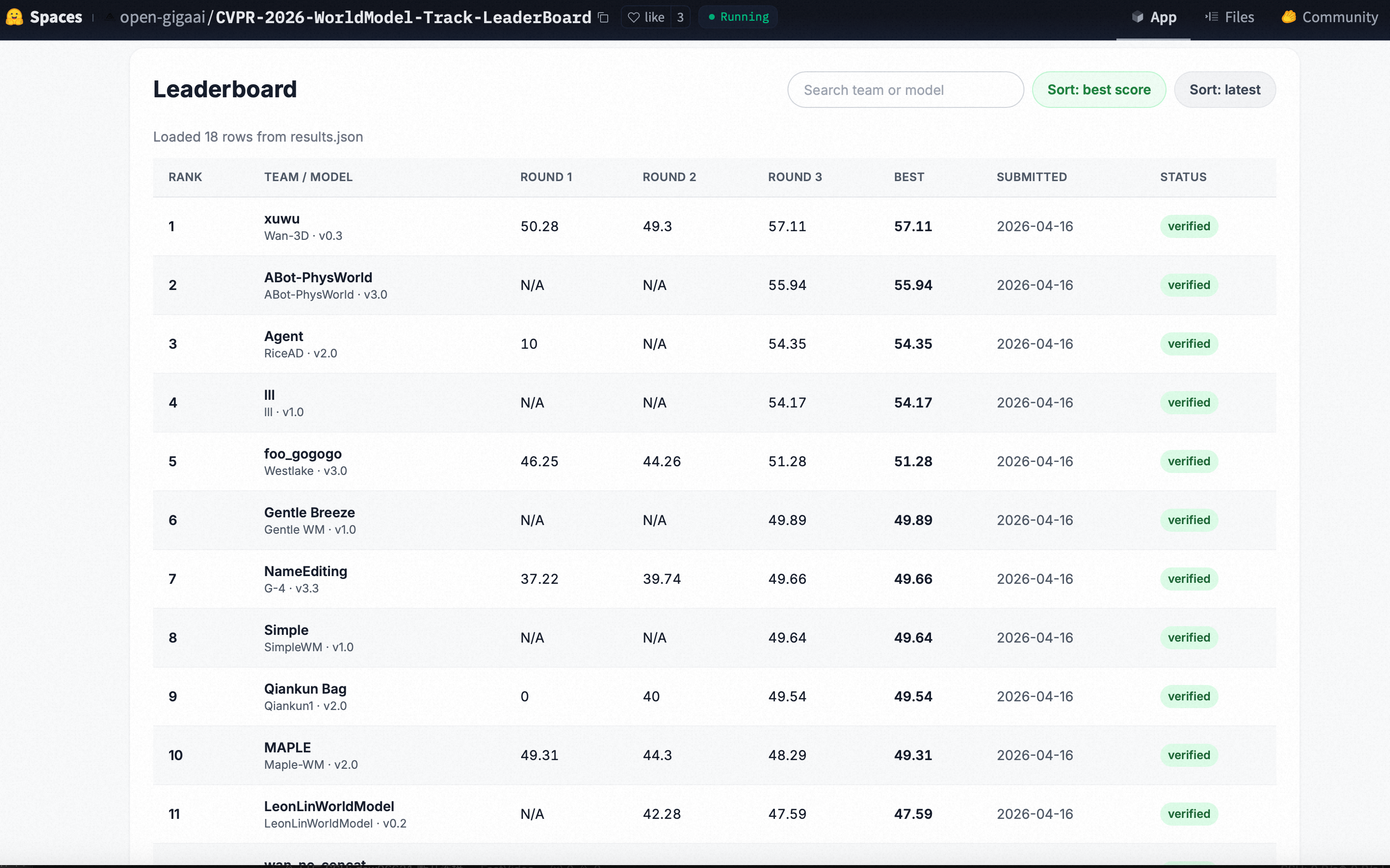
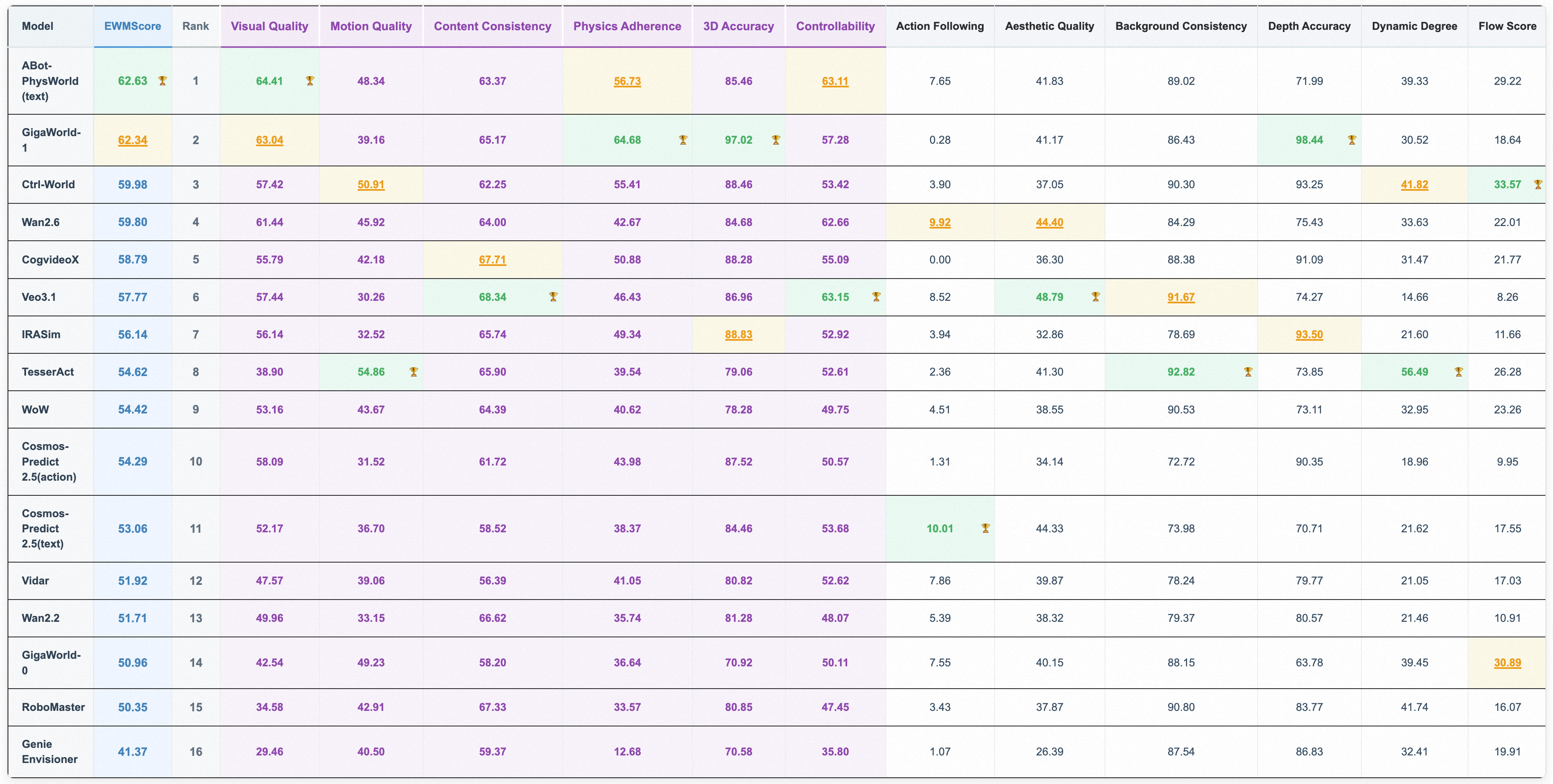
这并非偶然的跨界尝试,而是一次深思熟虑的技术升维。高德从"为人类导航"升级到"为机器人构建物理世界操作系统",其背后的技术逻辑值得深入剖析。本文将从数据基础、模型架构、训练方法到实际应用,全面解读高德如何利用地图时代积累的核心能力,在具身智能领域实现技术突破。

1. 技术体系概览:三层架构构建完整闭环
高德 ABot 采用了从底层到应用层的全栈技术架构,这种设计理念确保了从数据生产到实际部署的完整闭环。整个体系分为三个核心层次,形成了一个自洽的技术生态系统。
1.1 数据层:ABot-World 可交互世界模型
这是整个体系的基石,包含两大核心引擎。ABot-3DGS 作为"数字孪生工厂",负责将真实世界的物理空间转化为可编程的训练环境;ABot-PhysWorld 作为"物理思维引擎",确保生成的数据符合真实物理规律。这一层解决的是具身智能最根本的问题:如何让机器人理解真实物理世界的运作规律。
数据层的核心价值在于构建了一个可交互、可验证、可扩展的虚拟物理世界。与传统的静态数据集不同,ABot-World 能够根据机器人的动作实时生成反馈,形成闭环的交互式学习环境。这种动态数据生成能力,使得模型能够在无限多样的场景中进行训练,而不受真实世界数据采集成本的限制。
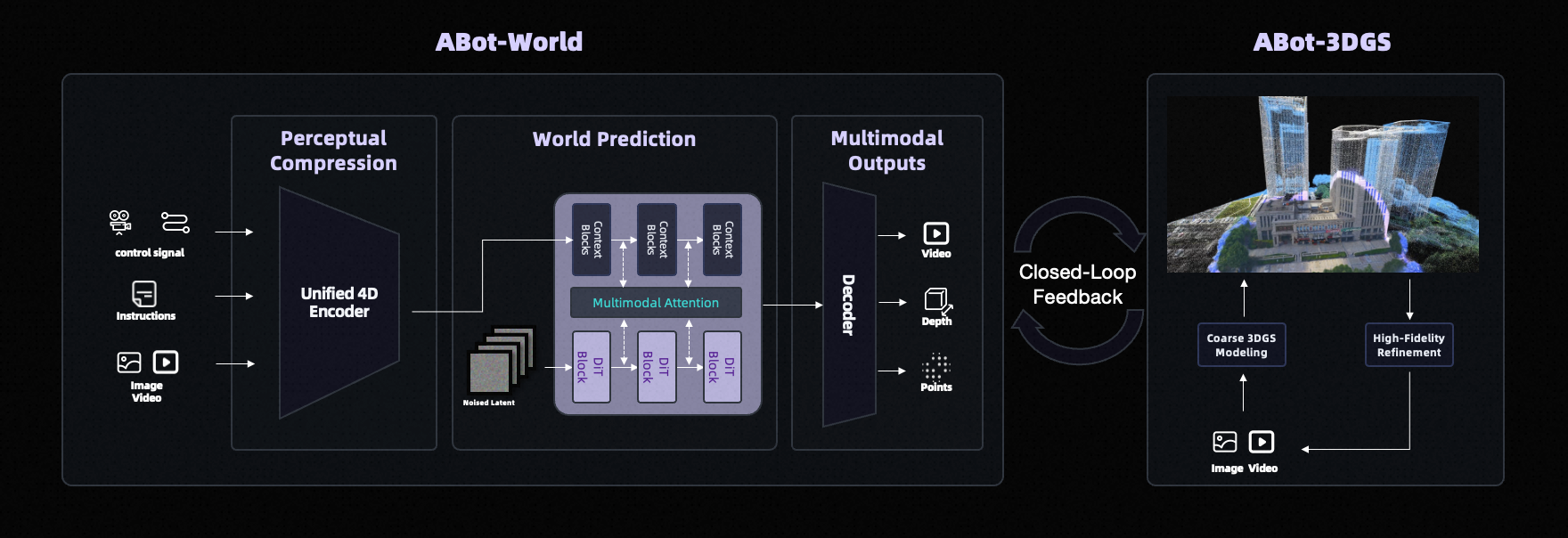
1.2 模型层:导航与执行双基座模型
在数据层之上,高德构建了两个专门化的基座模型。ABot-N 导航基座模型专注于路径规划和空间理解,能够处理从室外到室内的跨场景导航任务;ABot-M 执行基座模型则负责具体的动作生成和控制,将高层指令转化为精确的关节控制信号。这种分工明确的设计,使得系统能够同时处理宏观的导航决策和微观的动作执行,避免了端到端模型在复杂任务中的性能瓶颈。
双基座模型的设计理念源于人类认知系统的分层处理机制。导航模型类似于人类的空间认知系统,负责"去哪里"的决策;执行模型类似于运动控制系统,负责"怎么去"的实现。这种分层设计不仅提高了模型的可解释性,也使得系统能够更灵活地适应不同的机器人平台和任务需求。
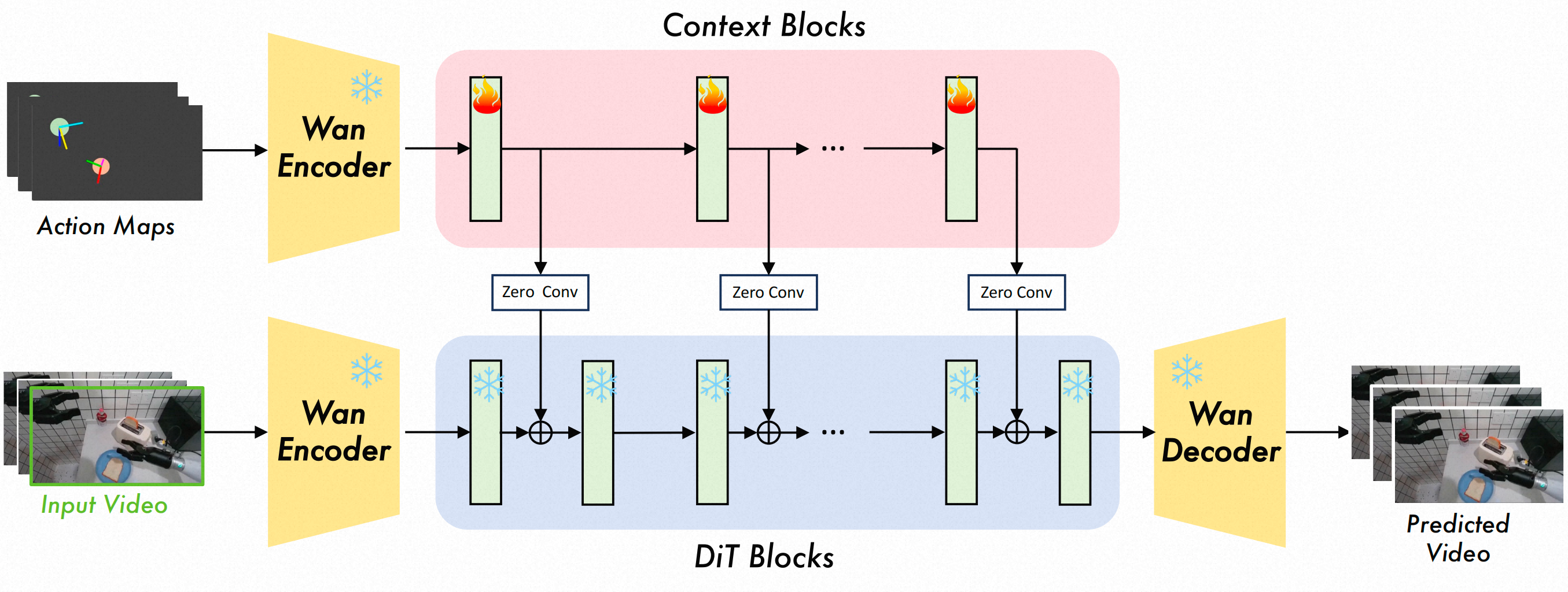
1.3 应用层:ABot-Claw 机器人操作系统
最上层是面向实际应用的操作系统,它将底层的模型能力封装成易于调用的接口,支持不同形态的机器人快速接入。ABot-Claw 提供了统一的 API 规范,使得开发者无需深入了解底层模型的实现细节,就能够快速构建具身智能应用。这种设计理念类似于 Android 系统对移动设备的支持,降低了具身智能应用的开发门槛,加速了技术的产业化进程。
2. 核心突破:从视觉渲染到物理推演的范式转变
2.1 传统方法的困境
当前主流的世界模型大多基于视觉渲染范式,其核心目标是生成"看起来像"的视频内容。这些模型通过学习大量视频数据中的像素分布,能够生成视觉上逼真的画面。然而,这种方法存在致命缺陷:它们只关注表面的视觉相似性,而忽略了物理世界的内在规律。
具体表现为三类典型错误:物体穿透现象(机械臂直接穿过桌面)、无接触抓取(夹爪未接触物体就完成了抓取)、反重力运动(物体悬浮在空中)。这些违反物理常识的行为,使得模型生成的数据无法用于训练真实的机器人系统。即使视觉效果再逼真,一旦部署到实际环境中,机器人也会因为学习了错误的物理关系而频繁失败。
传统视觉渲染模型的根本问题在于,它们将视频生成视为一个纯粹的像素预测问题,而非物理状态演化问题。模型学习的是"什么样的像素序列在统计上更可能出现",而不是"物体在物理规律约束下应该如何运动"。这种方法论上的偏差,导致生成的视频虽然在视觉上连贯,但在物理上却是荒谬的。
2.2 高德的解决方案:可微分物理引擎
高德 ABot-PhysWorld 采用了完全不同的技术路线,实现了从"视觉渲染范式"向"可微分物理引擎范式"的根本性迁移。这个 140 亿参数的 Diffusion Transformer 模型,其核心创新在于将物理规律嵌入到生成过程中。
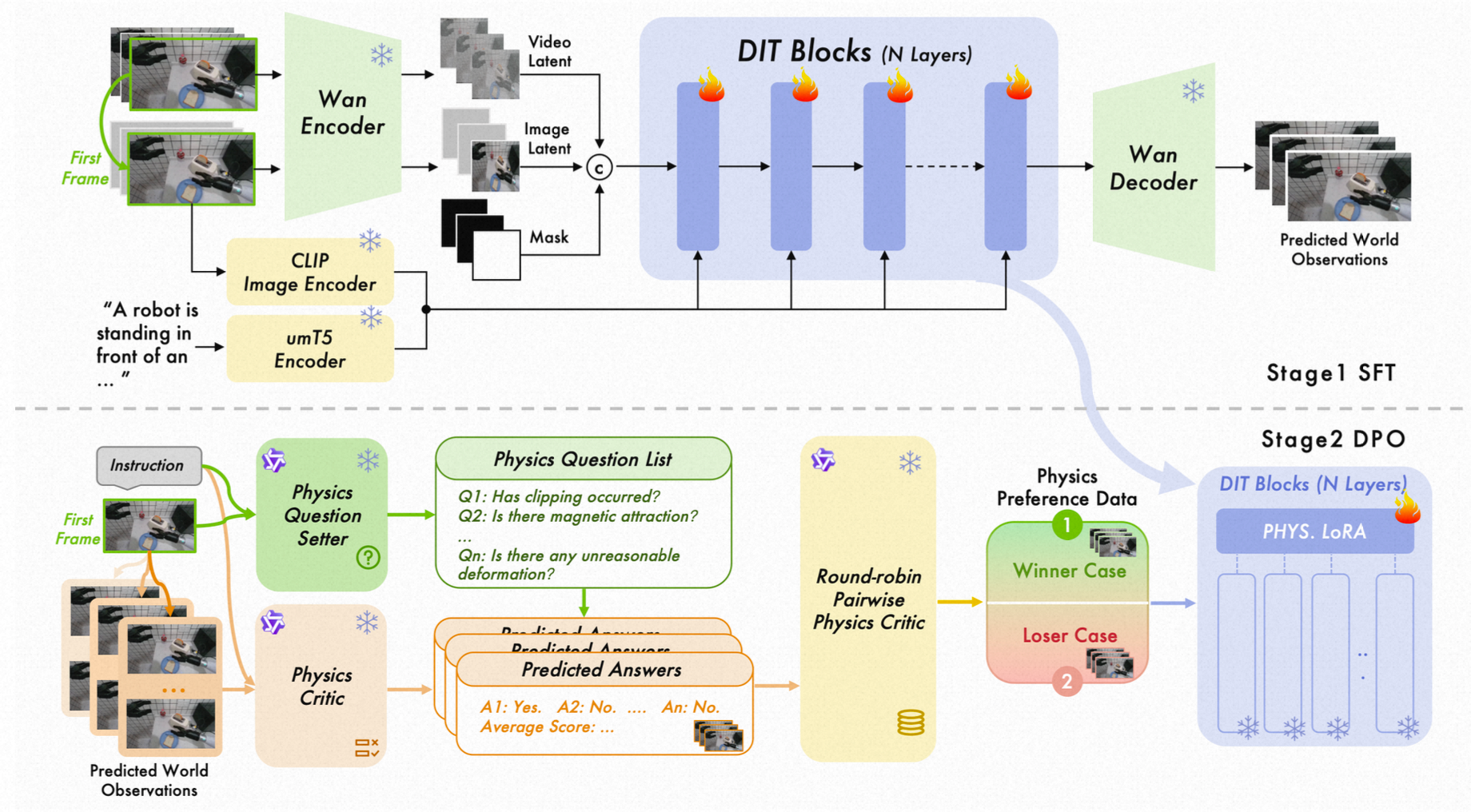
模型的输出不再是简单的像素矩阵,而是包含质量、接触力场、惯性张量的可微分物理状态快照。每一帧画面都对应着一个完整的物理状态描述,包括物体的位置、速度、加速度,以及相互之间的作用力。这种设计使得模型能够进行真正的物理推演,而不是表面的视觉模拟。
以下是 ABot-PhysWorld 的实际推理代码,展示了如何加载模型并生成物理一致的视频:
#!/usr/bin/env python3
"""
ABot-PhysWorld 推理脚本
基于 Wan2.1-I2V-14B-480P 模型的图像到视频生成
"""
import torch
from PIL import Image
from diffsynth import save_video
from diffsynth.pipelines.wan_video_new import WanVideoPipeline, ModelConfig
from diffsynth.models.utils import load_state_dict
# ModelScope 模型标识
MODELSCOPE_MODEL_ID = "amap_cvlab/Abot-PhysWorld"
CHECKPOINT_FILENAME = "step-2400.safetensors"
def load_pipeline(device="cuda"):
"""加载 Wan2.1-I2V-14B-480P 基础流水线"""
print("正在加载 Wan2.1-I2V-14B-480P 基础模型...")
pipe = WanVideoPipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device=device,
model_configs=[
# DiT 扩散模型(140亿参数)
ModelConfig(
model_id="Wan-AI/Wan2.1-I2V-14B-480P",
origin_file_pattern="diffusion_pytorch_model*.safetensors",
offload_device="cpu",
),
# T5 文本编码器
ModelConfig(
model_id="Wan-AI/Wan2.1-I2V-14B-480P",
origin_file_pattern="models_t5_umt5-xxl-enc-bf16.pth",
offload_device="cpu",
),
# VAE 视频编码器
ModelConfig(
model_id="Wan-AI/Wan2.1-I2V-14B-480P",
origin_file_pattern="Wan2.1_VAE.pth",
offload_device="cpu",
),
# CLIP 图像编码器
ModelConfig(
model_id="Wan-AI/Wan2.1-I2V-14B-480P",
origin_file_pattern="models_clip_open-clip-xlm-roberta-large-vit-huge-14.pth",
offload_device="cpu",
),
],
)
return pipe
def load_checkpoint(pipe, checkpoint_path):
"""加载 ABot-PhysWorld 微调检查点"""
print(f"正在加载 ABot-PhysWorld 检查点: {checkpoint_path}")
checkpoint_state_dict = load_state_dict(checkpoint_path)
print(f" 检查点包含 {len(checkpoint_state_dict)} 个参数键")
# 加载到 DiT 模型中
missing_keys, unexpected_keys = pipe.dit.load_state_dict(
checkpoint_state_dict, strict=False
)
print(f" 已加载 - 缺失键: {len(missing_keys)}, 意外键: {len(unexpected_keys)}")
def generate_video(
pipe,
input_image,
prompt,
negative_prompt="静态,细节模糊不清,最差质量,低质量,畸形的",
height=480,
width=832,
num_frames=81,
num_inference_steps=50,
cfg_scale=5.0,
seed=0,
tiled=True,
):
"""从输入图像和文本提示生成视频"""
if input_image.size != (width, height):
input_image = input_image.resize((width, height), Image.Resampling.LANCZOS)
# 调用流水线生成视频
video = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
input_image=input_image,
height=height,
width=width,
num_frames=num_frames,
num_inference_steps=num_inference_steps,
cfg_scale=cfg_scale,
seed=seed,
tiled=tiled,
)
return video
这段代码展示了 ABot-PhysWorld 的核心架构:140 亿参数的 DiT(Diffusion Transformer)模型作为物理推理引擎,配合 T5 文本编码器理解任务指令,VAE 编码器处理视频特征,CLIP 图像编码器提取视觉语义。整个流水线使用 bfloat16 混合精度训练,支持 CPU offload 机制以优化显存使用。
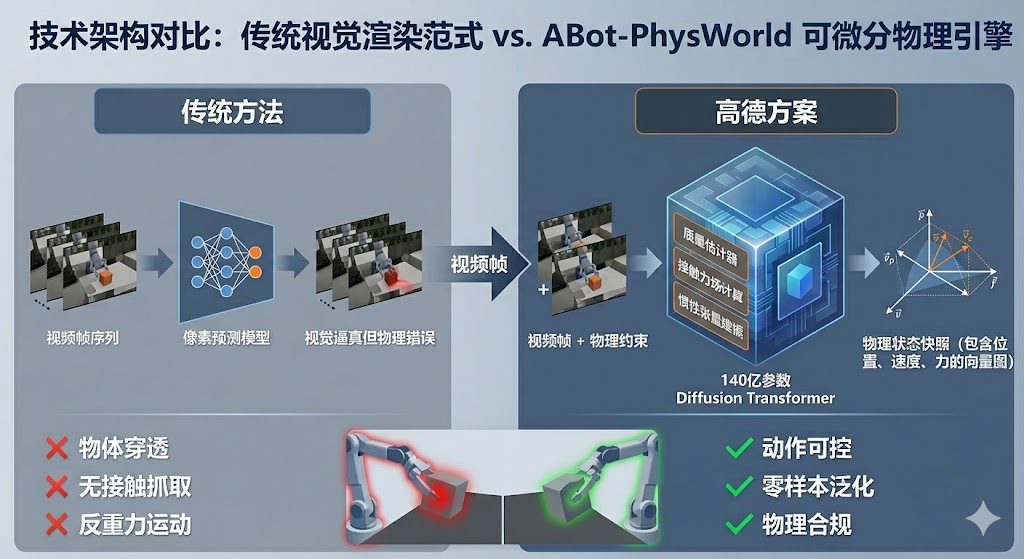
这种物理优先的设计带来了三个关键优势。首先是动作可控性,给定一个动作指令(如"下降 5 厘米、夹爪闭合"),模型能够精准计算出接下来会发生什么,而不是依靠"猜测"。其次是零样本泛化能力,即使遇到从未见过的物体或机器人,模型也能根据质量、摩擦、惯性等通用物理规律做出合理判断。最后是物理合规性,生成的每一帧都严格遵守牛顿力学定律,杜绝了低级物理错误。
3. 数据生产:从真实世界到训练材料的完整流程
3.1 ABot-3DGS:可编程的数字孪生工厂
传统的机器人训练数据采集方式面临三大困境:成本高昂(需要大量人力和设备)、效率低下(采集速度远跟不上需求)、覆盖不全(难以覆盖长尾场景)。高德通过 ABot-3DGS 系统性地解决了这些问题。
该系统以高德积累的厘米级城市、道路、室内空间数据为基础,结合前沿的 3D Gaussian Splatting 技术,构建可编程的数字孪生空间。关键在于"可编程"三个字,这意味着数据生产不再受制于物理世界的采集条件。任意视角、光照条件、遮挡状态都可以通过编程直接生成,机器人形态也能灵活切换,不同执行体之间的差异被系统性抹平。

更重要的是,这套体系能够系统性补齐长尾交互场景。通过大规模组合与仿真,那些机器人容易"翻车"的极端情况、突发干扰都能提前构造出来,最终将场景覆盖率推到 99%。这意味着模型在训练阶段就已经"见过"并"练过"了绝大多数可能出现的情况,大幅降低了实际部署时的失败率。
数据生产的三步流程:
第一步是"翻译",将原始数据转换成机器可读的多模态 Clip。以骑车经过路口为例,高德记录的不只是一张静态图片,而是一整套结构化信息:路口的视觉外观(图像)、红绿灯的空间位置(坐标)、当前的交通状态(红灯或绿灯)、行为意图(直行或转弯),以及周围的动态元素(行人、车辆)。所有信息打包形成一个完整的 Clip,而高德手中拥有千万级规模的此类数据。
第二步是"重建",利用这些多模态 Clip 重建三维场景。ABot-3DGS 能够将路口、街道、商场等地方重建成万级规模的 3D 真实场景。由于前一步获取的信息自带物理规则和空间逻辑,重建出的数字场景也都是"活"的,每个物体都被赋予了质量、摩擦系数等物理属性,从一开始就构成一个可计算、可干预的物理环境。
第三步是"Run",将机器人放入重建的场景中实际运行。通过编程改变参数(如调整物体质量、地面摩擦系数),可以模拟各种不同的物理条件。机器人在这些场景中走一遍、做一遍,千万级训练轨迹数据就这样批量生成。这种方法的效率远超传统的人工采集,且数据质量更高、覆盖面更广。
3.2 ABot-PhysWorld:物理思维引擎的训练策略
有了大规模的场景数据,下一个挑战是如何让模型真正"懂物理"。ABot-PhysWorld 基于 140 亿参数的 Diffusion Transformer 架构,通过三个维度的创新实现了物理对齐。
以下是 ABot-PhysWorld 的实际训练代码,展示了如何进行全参数微调:
#!/usr/bin/env python3
"""
ABot-PhysWorld 训练脚本
全参数 SFT 训练 Wan2.1-I2V-14B-480P 模型
"""
import torch
from diffsynth import load_state_dict
from diffsynth.pipelines.wan_video_new import WanVideoPipeline, ModelConfig
from diffsynth.trainers.utils import DiffusionTrainingModule
class WanTrainingModule(DiffusionTrainingModule):
"""Wan2.1-I2V-14B 视频生成模型的训练模块"""
def __init__(
self,
model_paths=None,
trainable_models=None,
use_gradient_checkpointing=True,
save_encoded_cache=False,
encoded_cache_dir=None,
skip_vae=False,
skip_text_encoder=False,
realtime_text_encode=False,
max_timestep_boundary=1.0,
min_timestep_boundary=0.0,
):
super().__init__()
# 实时文本编码模式:保持文本编码器加载
if realtime_text_encode and skip_text_encoder:
print("=" * 60)
print("警告: realtime_text_encode=True 但 skip_text_encoder=True")
print(" 实时文本编码需要文本编码器,禁用 skip_text_encoder")
print("=" * 60)
skip_text_encoder = False
# 解析模型配置
model_configs = self.parse_model_configs(
model_paths, enable_fp8_training=False
)
# 过滤掉需要跳过的模型(用于缓存训练)
if skip_vae or skip_text_encoder:
filtered_configs = []
skipped_models = []
for config in model_configs:
pattern = config.origin_file_pattern if hasattr(config, 'origin_file_pattern') else ""
if skip_vae and "VAE" in pattern:
skipped_models.append(f"VAE ({pattern})")
continue
if skip_text_encoder and ("t5" in pattern.lower() or "text" in pattern.lower()):
skipped_models.append(f"TextEncoder ({pattern})")
continue
filtered_configs.append(config)
if skipped_models:
print("=" * 60)
print("[缓存训练模式] 跳过以下模型以节省显存:")
for model in skipped_models:
print(f" - {model}")
print("=" * 60)
model_configs = filtered_configs
# 加载模型
self.pipe = WanVideoPipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cpu",
model_configs=model_configs,
)
# 设置训练模式
self.switch_pipe_to_training_mode(
self.pipe,
trainable_models,
enable_fp8_training=False,
)
# 存储配置
self.use_gradient_checkpointing = use_gradient_checkpointing
self.max_timestep_boundary = max_timestep_boundary
self.min_timestep_boundary = min_timestep_boundary
# 编码缓存配置
self.save_encoded_cache = save_encoded_cache
self.encoded_cache_dir = encoded_cache_dir
self.cache_index = {}
if self.save_encoded_cache and self.encoded_cache_dir:
from pathlib import Path
Path(self.encoded_cache_dir).mkdir(parents=True, exist_ok=True)
print(f"编码缓存模式已启用,保存目录: {self.encoded_cache_dir}")
self.skip_vae = skip_vae
self.skip_text_encoder = skip_text_encoder
self.realtime_text_encode = realtime_text_encode
if self.realtime_text_encode:
print("=" * 60)
print("[实时文本编码模式] 已启用:")
print(" - 使用缓存的视频特征 (input_latents, y, clip_feature)")
print(" - 从 JSONL 读取新提示词并实时编码文本")
print(" - 使用场景: 视频不变,但标注重新标注")
print("=" * 60)
这段代码展示了 ABot-PhysWorld 训练的核心特性:
-
全参数微调(Full-parameter SFT):不同于 LoRA 等参数高效方法,ABot-PhysWorld 对 140 亿参数进行全量训练,确保模型能够深度学习物理规律。
-
DeepSpeed ZeRO-2 分布式训练:通过 Accelerate 框架集成 DeepSpeed,支持多 GPU 并行训练,优化显存使用。
-
编码特征缓存:支持保存和加载 VAE、T5、CLIP 的编码结果,大幅加速训练过程。对于视频不变但标注更新的场景,可以跳过视频编码,只重新编码文本。
-
实时文本编码模式:当视频特征已缓存时,可以动态读取新的文本提示词并实时编码,适用于数据标注迭代优化的场景。
-
梯度检查点(Gradient Checkpointing):通过重计算中间激活值来节省显存,使得在有限的硬件资源下也能训练大模型。
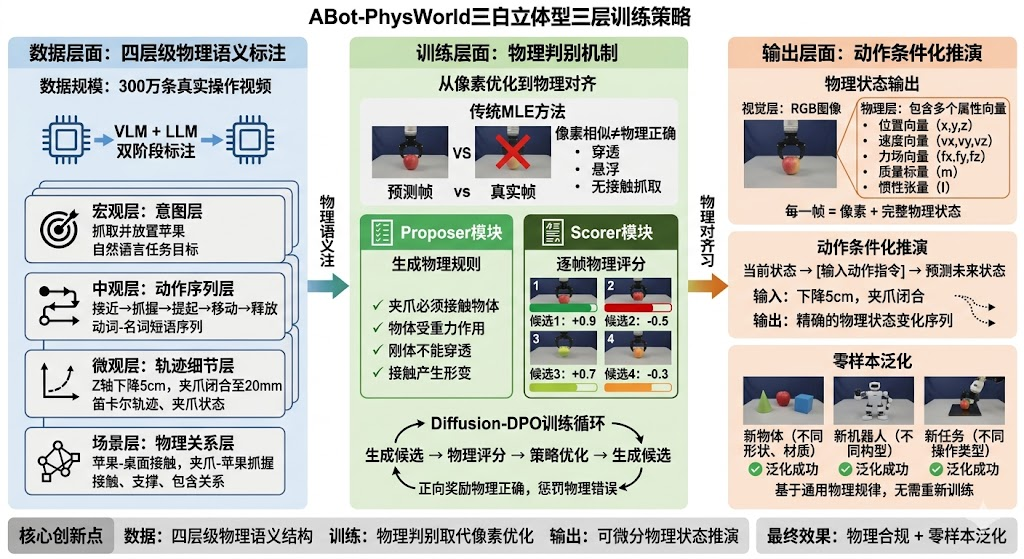
数据层面:四层级物理语义结构
高德精选了 300 万条真实操作视频,采用 VLM(视觉语言模型)和 LLM(大语言模型)双阶段标注,构建了四层级物理语义结构。这种标注方式不仅告诉模型"发生了什么",更重要的是解释"为什么发生"。
**宏观层(意图)**使用自然语言描述整体任务目标,如"抓取并放置苹果"。这一层提供了任务的高层语义理解,帮助模型建立目标导向的认知。通过理解任务意图,模型能够在执行过程中保持目标一致性,避免出现动作正确但目标偏离的情况。
**中观层(动作序列)**采用动词-名词短语序列表示,如"接近→抓握→提起→移动→释放"。这种结构化表示将复杂任务分解为可执行的原子动作,便于模型学习动作之间的因果关系。每个动作都有明确的前置条件和后置效果,形成了一个完整的动作链。
**微观层(轨迹细节)**记录笛卡尔轨迹、相对运动、夹爪状态等精确信息,如"末端沿 Z 轴下降 5cm,夹爪闭合至 20mm"。这一层提供了动作执行的具体参数,确保模型能够生成精确的控制指令。这些精确的数值信息是实现高精度操作的关键。
**场景层(物理关系)**描述接触、支撑、包含关系及任务结果,如"苹果与桌面接触,被夹爪稳固抓握,成功放置于袋中"。这一层明确了物体之间的物理交互关系,是物理推理的关键。通过学习这些物理关系,模型能够理解动作如何改变物体的状态。
# 四层级物理语义标注示例
annotation = {
'macro': {
'intent': '抓取并放置苹果',
'goal': '将苹果从桌面移动到袋子中'
},
'meso': {
'action_sequence': [
{'action': 'approach', 'target': 'apple'},
{'action': 'grasp', 'target': 'apple'},
{'action': 'lift', 'height': 0.1},
{'action': 'move', 'destination': 'bag'},
{'action': 'release', 'target': 'apple'}
]
},
'micro': {
'trajectory': [
{'time': 0.0, 'position': [0.3, 0.2, 0.5], 'gripper': 'open'},
{'time': 1.0, 'position': [0.3, 0.2, 0.45], 'gripper': 'closing'},
{'time': 2.0, 'position': [0.3, 0.2, 0.45], 'gripper': 'closed'},
{'time': 3.0, 'position': [0.3, 0.2, 0.55], 'gripper': 'closed'},
# ... 更多轨迹点
]
},
'scene': {
'physical_relations': [
{'type': 'contact', 'objects': ['apple', 'table'], 'time': 0.0},
{'type': 'grasp', 'objects': ['gripper', 'apple'], 'time': 2.0},
{'type': 'support', 'objects': ['gripper', 'apple'], 'time': 3.0},
{'type': 'contain', 'objects': ['bag', 'apple'], 'time': 5.0}
],
'task_result': 'success'
}
}
训练层面:物理判别机制取代像素优化
传统的**最大似然估计(MLE)**方法只关心"画面对不对",通过最小化预测帧与真实帧之间的像素差异来优化模型。这种方法的问题在于,像素相似并不等于物理正确。一个物体可能在视觉上看起来很真实,但其运动轨迹却违反了物理定律。
高德引入了物理判别机制,将优化目标从"像素相似度"转向"物理一致性"。该机制包含两个核心组件:
Proposer 模块负责根据当前任务生成物理规则清单。对于抓取任务,它会列出"夹爪必须接触物体才能抓取"、“物体受重力作用会下落”、"刚体不能相互穿透"等规则。这些规则来自物理学的基本定律,是不可违反的硬约束。Proposer 的设计基于物理引擎的约束求解器,能够自动推导出任务相关的物理约束。
Scorer 模块对模型生成的多个候选结果逐帧打分。它会检查每一帧是否违反了 Proposer 列出的物理规则,物理正确的帧获得高分,违反物理的帧被扣分。这种评分机制确保了模型学习的是真实的物理规律,而不是表面的视觉模式。Scorer 使用可微分的物理仿真器来计算物理一致性得分。
在此基础上,高德采用 Diffusion-DPO(Direct Preference Optimization)强化学习方法,将物理判别的结果作为奖励信号。物理正确的生成结果获得正向奖励,物理错误的结果受到惩罚。经过反复训练,模型自然学会了"什么动作不违反物理",从根源上消除了低级物理错误。这种方法避免了传统强化学习中的值函数估计问题,直接优化策略的偏好排序。
# 物理判别机制实现示例
class PhysicsDiscriminator:
def __init__(self):
self.proposer = PhysicsProposer() # 生成物理规则
self.scorer = PhysicsScorer() # 评分模块
def generate_physics_checklist(self, task_description):
"""Proposer:生成物理规则清单"""
checklist = []
if 'grasp' in task_description:
checklist.append({
'rule': 'contact_before_grasp',
'description': '夹爪必须接触物体才能抓取',
'check': lambda frame: self.check_contact(frame, 'gripper', 'object')
})
checklist.append({
'rule': 'no_penetration',
'description': '夹爪不能穿透物体',
'check': lambda frame: not self.check_penetration(frame)
})
if 'lift' in task_description:
checklist.append({
'rule': 'gravity_effect',
'description': '物体受重力作用',
'check': lambda frame: self.check_gravity(frame)
})
return checklist
def score_generated_video(self, video_frames, checklist):
"""Scorer:对生成的视频评分"""
scores = []
for frame in video_frames:
frame_score = 0
for rule in checklist:
if rule['check'](frame):
frame_score += 1.0 # 符合物理规则
else:
frame_score -= 1.0 # 违反物理规则
scores.append(frame_score)
return np.mean(scores)
# Diffusion-DPO 训练流程
def train_with_physics_dpo(model, dataset):
for batch in dataset:
# 生成多个候选结果
candidates = model.generate_multiple(batch, num_candidates=4)
# 物理判别评分
checklist = discriminator.generate_physics_checklist(batch['task'])
scores = [discriminator.score_generated_video(c, checklist)
for c in candidates]
# 选择最佳和最差候选
best_idx = np.argmax(scores)
worst_idx = np.argmin(scores)
# DPO 损失:增大最佳候选概率,降低最差候选概率
loss = -log_prob(candidates[best_idx]) + log_prob(candidates[worst_idx])
loss.backward()
optimizer.step()
输出层面:可微分物理状态与动作条件化推演
ABot-PhysWorld 的每一帧输出不仅包含像素信息,更重要的是包含完整的物理状态描述。这种设计支持"动作条件化推演",即给定一个动作指令,模型能够精准计算出未来的物理状态变化。
这种能力带来了零样本泛化的可能。当遇到从未见过的物体或机器人时,模型不需要重新训练,而是根据物体的质量、摩擦系数、惯性等通用物理属性,直接推演出合理的交互结果。这是因为物理定律是普适的,不依赖于具体的物体形态。
3.3 闭环进化:从预测到执行的自我修正
ABot-World 不是一个静态模型,而是具备自我修正能力的认知基座。它支持完整的 VLA(Vision-Language-Action)闭环:预测→执行→反馈→自我修正。
具体工作流程如下:机器人根据 ABot-World 的推演结果生成动作计划,在真实环境中执行该计划,传感器记录实际执行结果,将预测与实际的误差回传给模型。模型根据这个误差信号自动调整内部参数,使得下次预测更加精准。
举例来说,机器人根据模型推演去抓取一个杯子,预测显示夹爪闭合到 15mm 就能稳固抓取。但实际执行中,由于杯子表面比预期更光滑,夹爪在 15mm 时发生了滑脱。这个失败信号立即回传给 ABot-PhysWorld,模型识别出是摩擦系数估计偏高,自动调整该类表面的摩擦参数。下次遇到类似光滑表面时,模型会预测需要更大的夹持力或更小的夹爪开度。
这种自生长、自修正、自适应的能力,意味着机器人不再完全依赖人类演示,而是能够在真实环境中持续进化。随着交互次数的增加,模型对物理世界的理解会越来越准确,这正是 AGI 时代机器人应有的"操作系统级"能力。
# VLA 闭环自我修正机制
class VLAClosedLoop:
def __init__(self, world_model, robot):
self.world_model = world_model
self.robot = robot
self.experience_buffer = []
def execute_with_feedback(self, task):
# 1. 预测阶段
predicted_trajectory = self.world_model.predict(
current_observation=self.robot.get_observation(),
task_description=task
)
# 2. 执行阶段
actual_trajectory = self.robot.execute(predicted_trajectory)
# 3. 反馈阶段
execution_result = self.robot.get_execution_result()
prediction_error = self.compute_error(
predicted_trajectory,
actual_trajectory
)
# 4. 自我修正阶段
if execution_result['success'] == False:
# 分析失败原因
failure_analysis = self.analyze_failure(
predicted_trajectory,
actual_trajectory,
execution_result
)
# 更新物理参数
if failure_analysis['type'] == 'friction_mismatch':
self.world_model.update_friction_model(
object_type=execution_result['object'],
new_friction=failure_analysis['estimated_friction']
)
elif failure_analysis['type'] == 'mass_mismatch':
self.world_model.update_mass_model(
object_type=execution_result['object'],
new_mass=failure_analysis['estimated_mass']
)
# 存储经验用于后续学习
self.experience_buffer.append({
'prediction': predicted_trajectory,
'actual': actual_trajectory,
'error': prediction_error,
'correction': failure_analysis
})
return execution_result
def continuous_improvement(self):
"""基于累积经验持续改进模型"""
if len(self.experience_buffer) >= batch_size:
batch = sample(self.experience_buffer, batch_size)
self.world_model.fine_tune(batch)
self.experience_buffer.clear()
4. 实际应用:从实验室到真实世界
4.1 导盲机器狗:精准导航的实战验证
在北京亦庄机器人半马活动中,高德展示了搭载 ABot 系统的四足机器狗,它能够帮助盲人朋友走出家门,实现精准导航。这个应用场景完美体现了高德技术的实用价值,也是具身智能从实验室走向真实世界的重要里程碑。
导盲任务对导航精度要求极高。机器狗不仅要规划出一条可行路径,还要实时感知环境变化(行人、车辆、障碍物),做出安全决策。更重要的是,它要理解城市环境的语义信息:人行横道在哪里、红绿灯状态如何、哪里有台阶需要提醒。这些看似简单的任务,对机器人来说却是巨大的挑战。
高德的 POI 数据和语义地图在这里发挥了关键作用。机器狗知道"前方 20 米是人行横道,当前红灯,需要等待",而不是简单地"前方有障碍物,停止"。这种语义理解能力,使得机器狗的行为更符合人类的预期,用户体验也更好。导盲机器狗的成功部署,证明了 ABot 系统在复杂真实环境中的可靠性和实用性。
4.2 室内外无缝衔接:BridgeNav 解决最后一公里
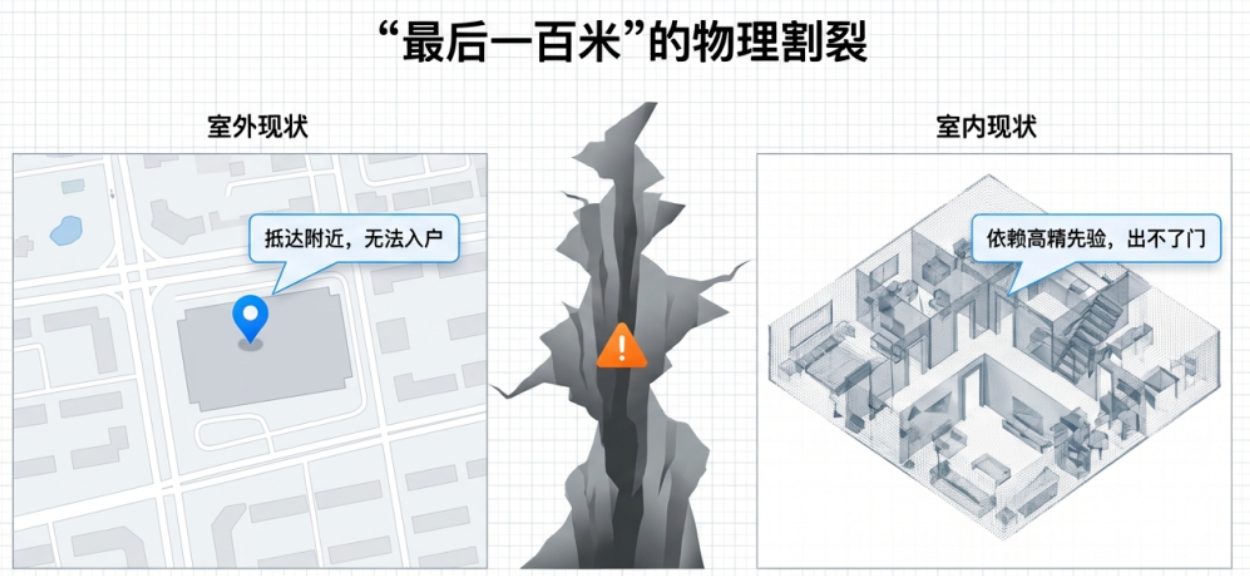
高德还推出了 BridgeNav 框架,专门解决从室外到室内的"最后一公里"导航问题。这是一个长期被忽视但极其重要的场景:外卖配送、快递投递、机器人接待等应用,都需要机器人从室外街道精确进入建筑物内部。
传统方法依赖精确的 GPS 坐标或预先构建的语义地图,但这些信息在实际场景中往往不可用或不准确。GPS 精度通常只能到 5-10 米,无法指导机器人找到具体的入口。而预先构建语义地图成本高昂,且难以应对环境变化。每次建筑物装修、店铺更换,地图就需要重新采集,维护成本极高。
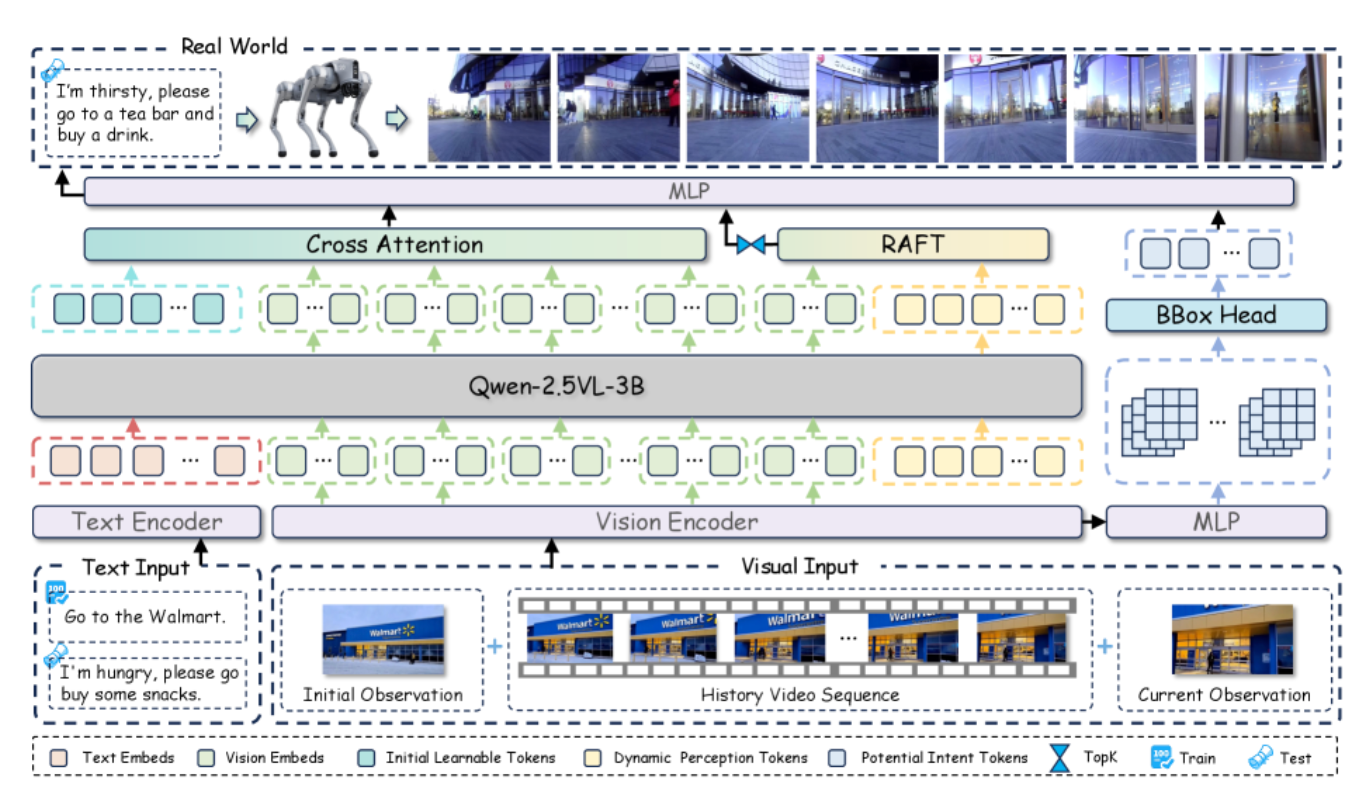
BridgeNav 采用纯视觉驱动的方法,机器人只需要自车视角的观测图像和简单的文字指令(如"去星巴克"),就能完成从室外到室内的导航。系统包含三个核心模块:
潜在意图推断模块(Latent Intention Inference):根据机器人与目标的距离,动态调整注意力焦点。远距离时关注全局图像与指令的匹配,判断目标是否在视野内;中距离时锁定显眼的标志物(如招牌),确定行进方向;近距离时精确定位入口或门,避免"临门找不到门"的尴尬。这种分层注意力机制模拟了人类导航的认知过程。
光流引导的动态感知模块(Optical Flow Guided Perception):让机器人理解"自己动一下,眼前的画面会怎么变"。通过轻量级光流估计网络 RAFT 计算连续帧之间的密集光流场,筛选出受运动影响最大的区域进行重点学习。这种"想象未来"的能力,帮助机器人提前预判,减少导航偏差。动态感知使得机器人能够在移动中持续优化路径。
轨迹条件视频生成(Trajectory-Conditioned Video Generation):为了解决训练数据噪声大的问题,BridgeNav 采用生成式扩散模型合成物理对齐的数据。先用单目几何估计构建局部占用网格,用 A 算法*规划无障碍路径,再用扩散模型生成符合物理约束的视频序列。这种方法生成的数据质量高、覆盖面广,有效补充了真实数据的不足。
# BridgeNav 核心模块实现
class BridgeNav:
def __init__(self):
self.intention_module = LatentIntentionInference()
self.perception_module = OpticalFlowGuidedPerception()
self.multimodal_llm = Qwen2_5_VL_3B()
def navigate(self, observation, instruction):
"""执行导航决策"""
# 1. 潜在意图推断:确定当前应该关注什么
salient_regions = self.intention_module.infer(
observation,
instruction,
distance_to_target=self.estimate_distance(observation, instruction)
)
# 2. 动态感知:预测运动对视觉的影响
future_changes = self.perception_module.predict_changes(
current_observation=observation,
candidate_actions=self.generate_candidate_actions()
)
# 3. 多模态融合:整合视觉、语言、动作信息
decision = self.multimodal_llm.decide(
visual_tokens=self.encode_visual(observation, salient_regions),
language_tokens=self.encode_language(instruction),
dynamic_tokens=future_changes
)
return decision['waypoints']
def estimate_distance(self, observation, instruction):
"""估计与目标的距离,用于调整注意力策略"""
target_in_view = self.detect_target(observation, instruction)
if not target_in_view:
return 'far' # 目标不在视野内
target_size = target_in_view['bbox_area'] / observation.size
if target_size > 0.3:
return 'near' # 目标占据大部分视野
elif target_size > 0.1:
return 'medium' # 目标清晰可见
else:
return 'far' # 目标较小
class LatentIntentionInference:
def infer(self, observation, instruction, distance_to_target):
"""根据距离动态调整注意力"""
if distance_to_target == 'far':
# 远距离:关注全局匹配
return self.global_matching(observation, instruction)
elif distance_to_target == 'medium':
# 中距离:关注标志物(招牌)
return self.detect_signage(observation, instruction)
else:
# 近距离:关注入口
return self.detect_entrance(observation, instruction)
在 BridgeNav 数据集上的实验表明,该方法在成功率和路径效率上都显著优于现有基线方法。更重要的是,它不依赖任何外部先验信息,具有很强的实用性。
4.3 跨机器人平台泛化:真正的零样本能力
ABot-PhysWorld 最令人印象深刻的能力是跨机器人平台的零样本泛化。在 EZS-Bench 基准测试中,模型面对的是完全未见过的机器人形态、任务类型和场景组合。
例如,模型在训练时只见过单臂 Franka 机器人抓取刚性物体,但在测试时需要控制双臂机器人折叠毛巾。这涉及到完全不同的运动学结构(单臂 vs 双臂)、物体属性(刚性 vs 柔性)和任务逻辑(抓取 vs 折叠)。传统方法在这种情况下几乎完全失效,因为它们学习的是特定机器人-任务组合的模式,而不是通用的物理规律。
ABot-PhysWorld 却能够生成物理合理的折叠动作序列:两个机械臂协调运动,避免碰撞;毛巾在抓取点产生真实的形变;折叠过程中保持接触,没有穿透或悬浮。这是因为模型理解了布料的柔性力学、双臂协调的约束条件、以及折叠任务的物理本质。
类似的零样本能力在多个场景中得到验证:
可变形物体操作:双臂折叠毛巾,布料形变真实,双臂运动协调流畅。模型理解了柔性材料的应力-应变关系,能够预测布料在不同抓取点的形变模式。
精细操作:堆叠杯子、搭建积木、放置刀具,不同形状、重量、摩擦系数的物体都能正确处理。模型能够根据物体的物理属性调整抓取力度和放置策略。
铰接物体交互:打开柜门,正确施加旋转力矩,运动遵循铰链约束。模型理解了旋转关节的运动学约束,能够生成符合约束的轨迹。
流体交互:双臂倒水,倾斜角度和时机控制准确,液体转移过程视觉连贯。虽然流体模拟极其复杂,但模型学会了液体流动的基本规律。
清洁任务:擦拭污渍,保持工具与表面接触,系统性覆盖目标区域。模型理解了接触力的维持和路径规划的策略。
多场景泛化:在不同背景、光照、物体变化下,稳定完成水果分拣任务。模型的物理推理能力不受视觉外观变化的干扰。
这些能力的实现,依赖于模型对物理规律的深刻理解。它不是记忆训练数据中的具体案例,而是学会了质量、惯性、摩擦、弹性等物理属性如何影响物体的运动。这种通用的物理知识,可以迁移到任何新的机器人-任务-场景组合中,这才是真正的智能。
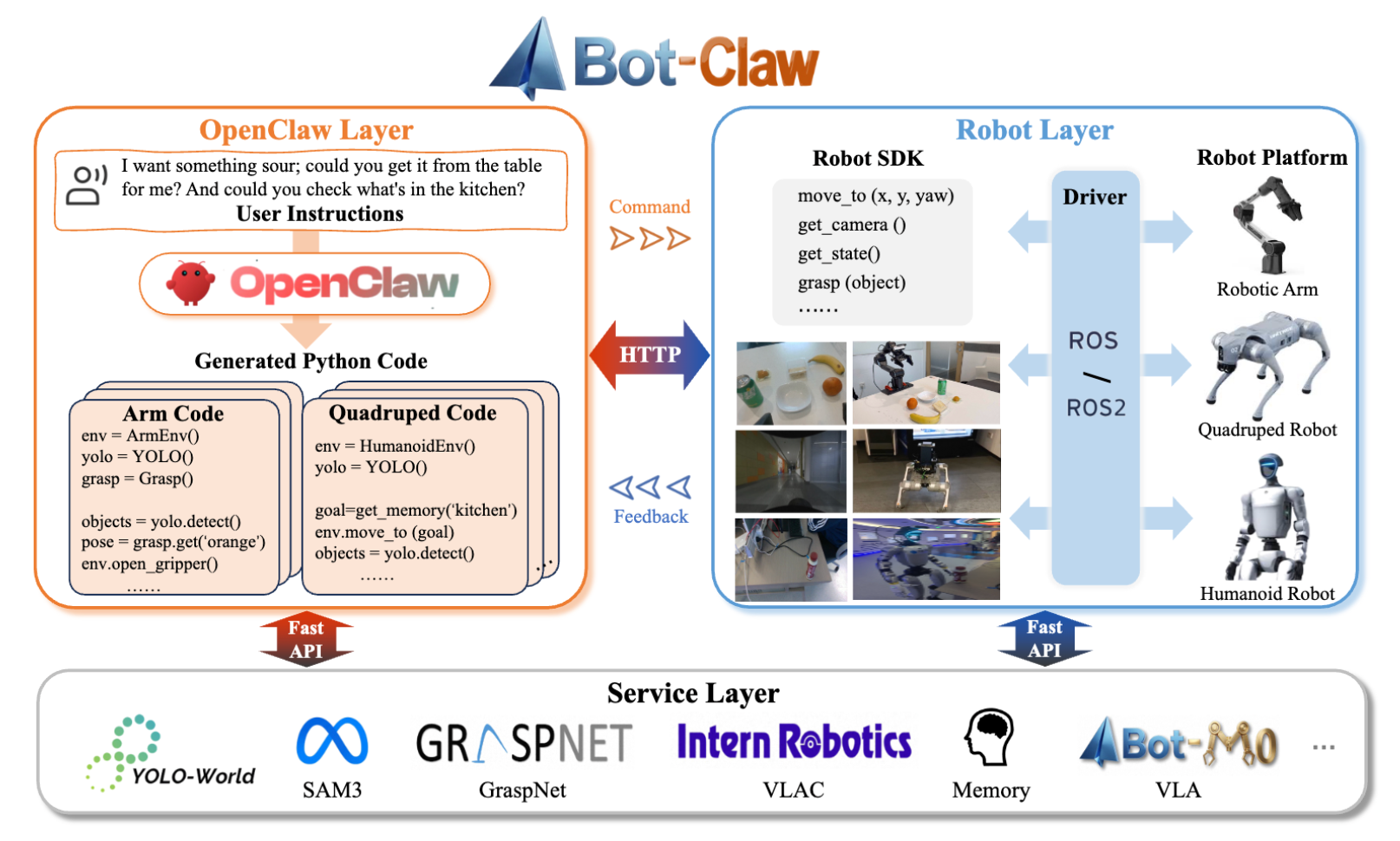
5. ABot-Claw:统一的机器人操作系统
当前具身智能系统面临一个结构性断层:VLA(视觉-语言-动作)架构赋予机器人强大的感知与直觉响应能力,但其开环特性与长期记忆建模的缺失,使其难以应对复杂长程任务。引入 System 2 认知机制的代理框架虽能改进规划与推理,却多运行于封闭沙箱,依赖预定义工具集,缺乏对真实系统的直接控制。
阿里巴巴 AMAP CV Lab 推出的 ABot-Claw,以 OpenClaw 本地化运行时为基础执行核心,通过三项关键技术整合,构建从高层意图到低层动作的端到端闭环,形成可在开放动态环境中持续学习、适应与进化的具身智能框架。
…详情请参照古月居

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)