计算机操作系统
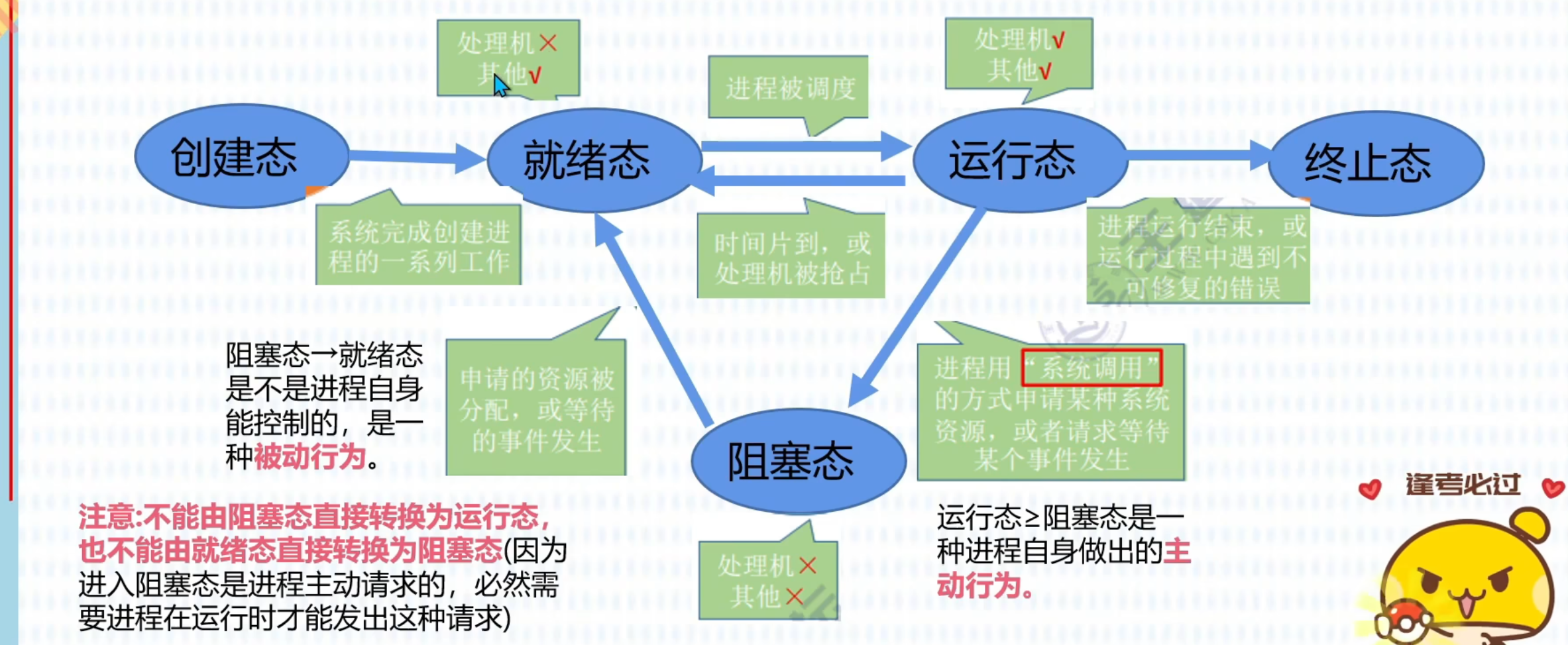
进程管理-状态转换图

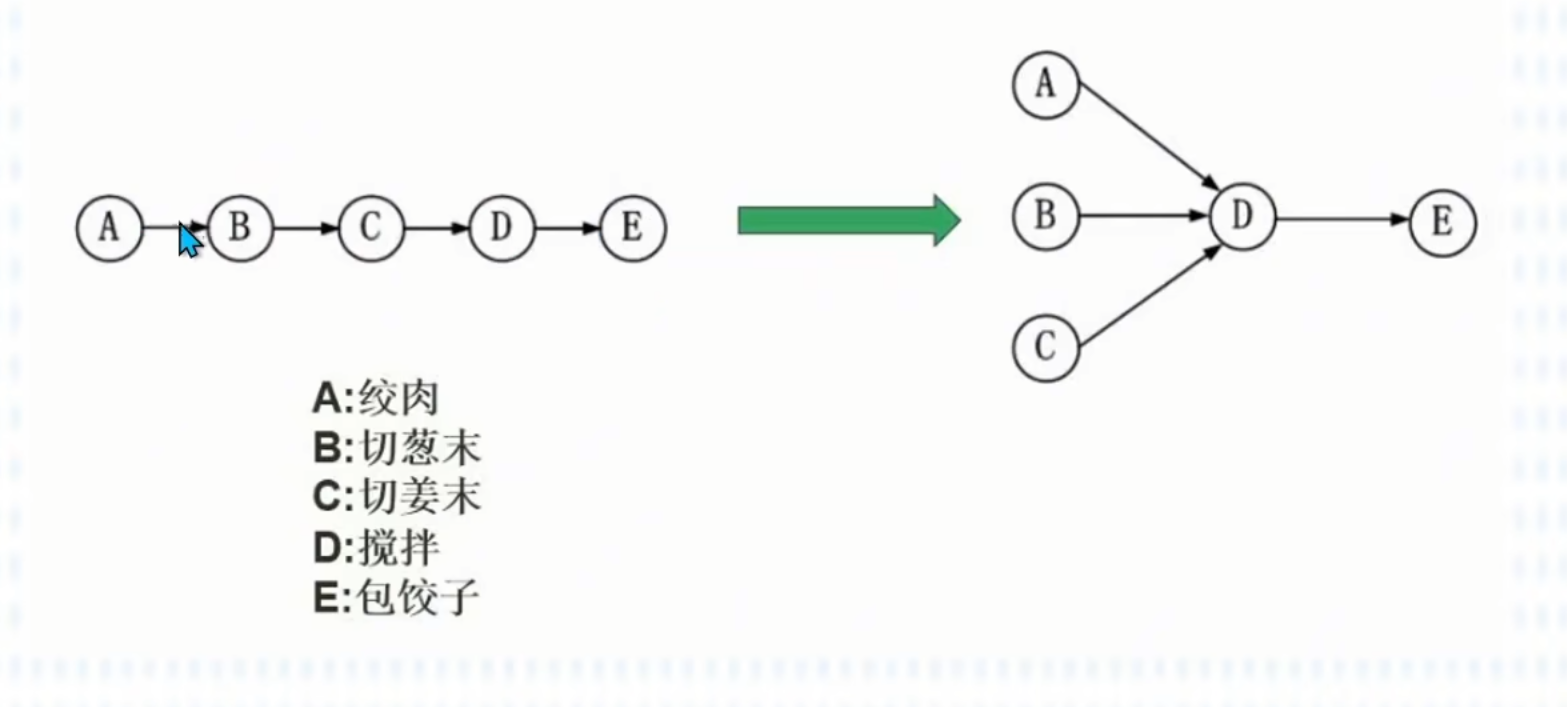
前驱图
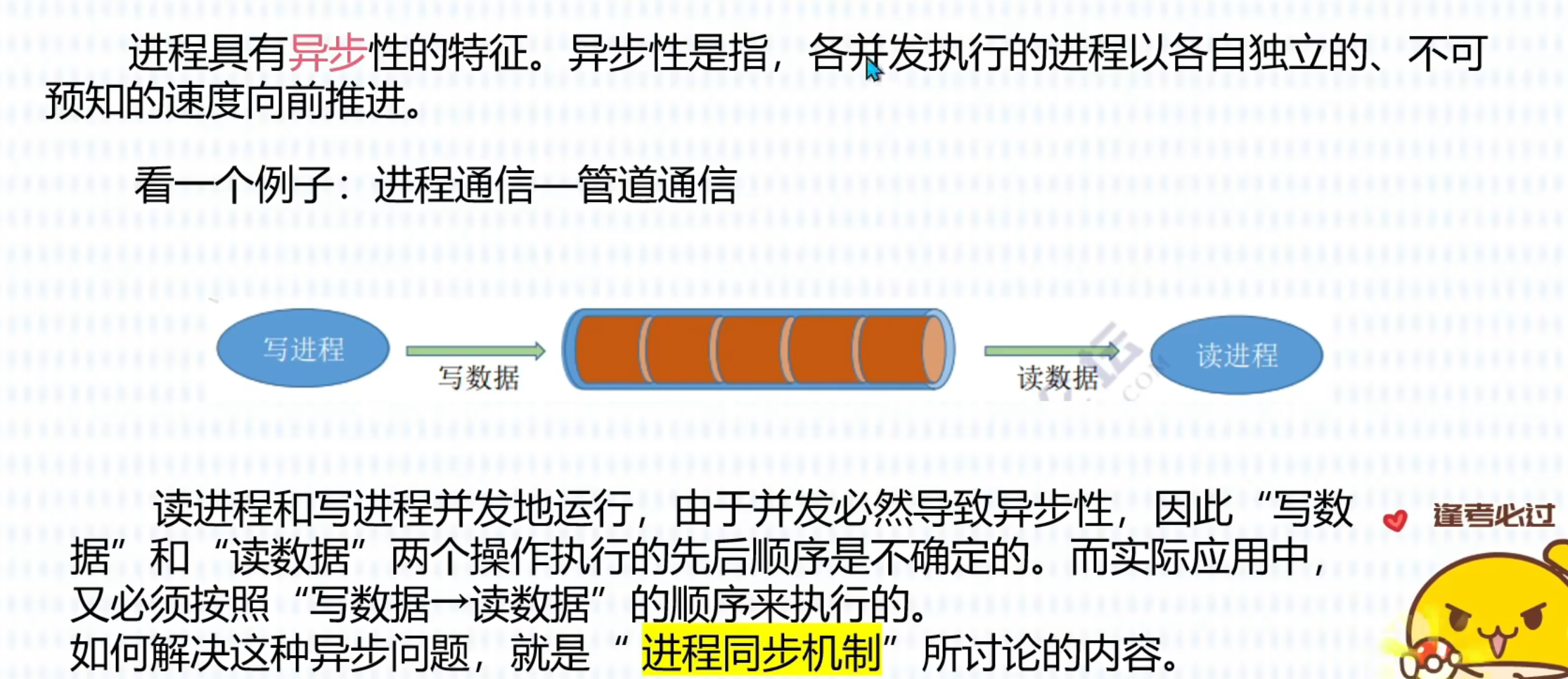
进程同步机制

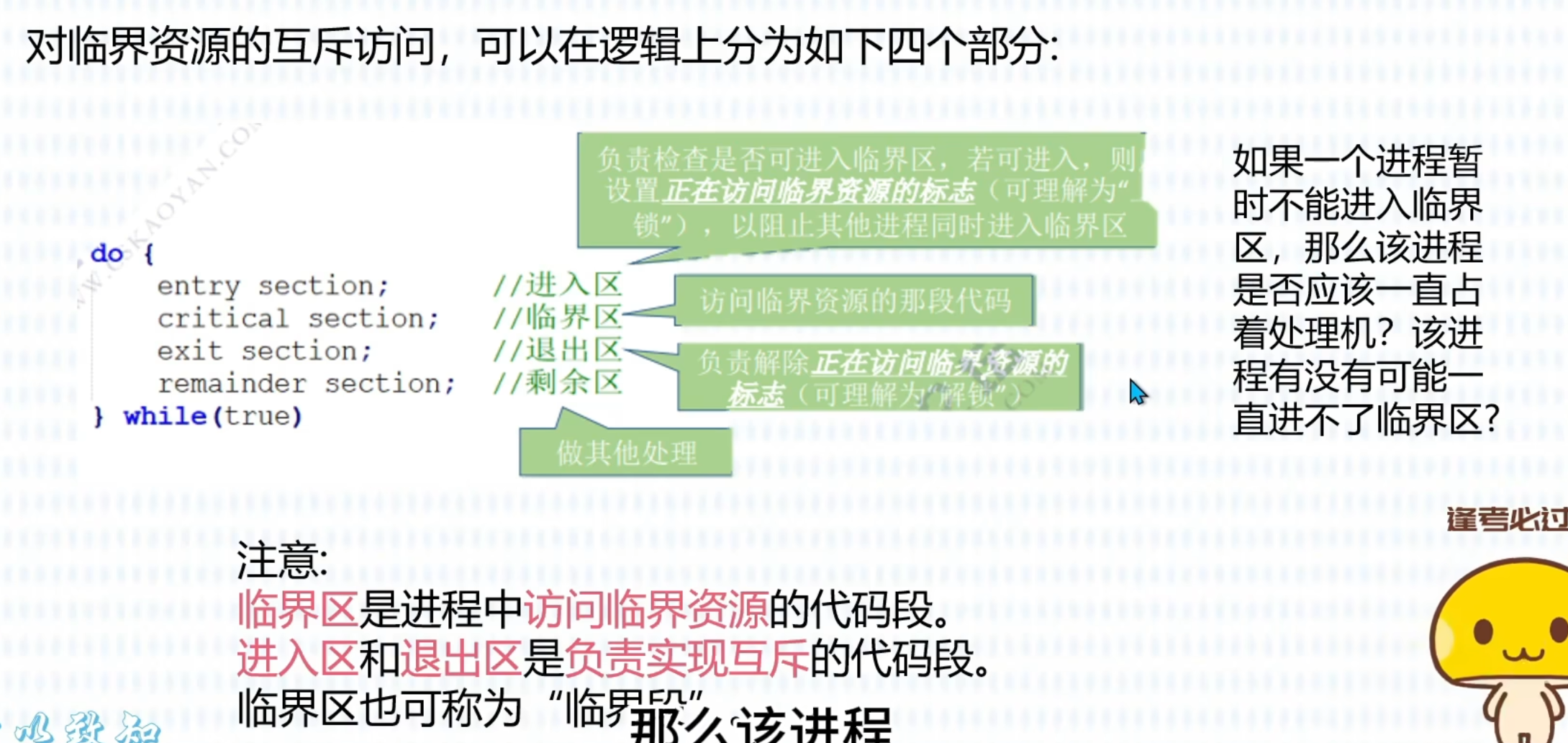
进程互斥机制


信号量机制


PV操作实现前驱操作

死锁产生的必要条件

死锁的处理策略

银行家算法

存储管理

内存的分配与回收
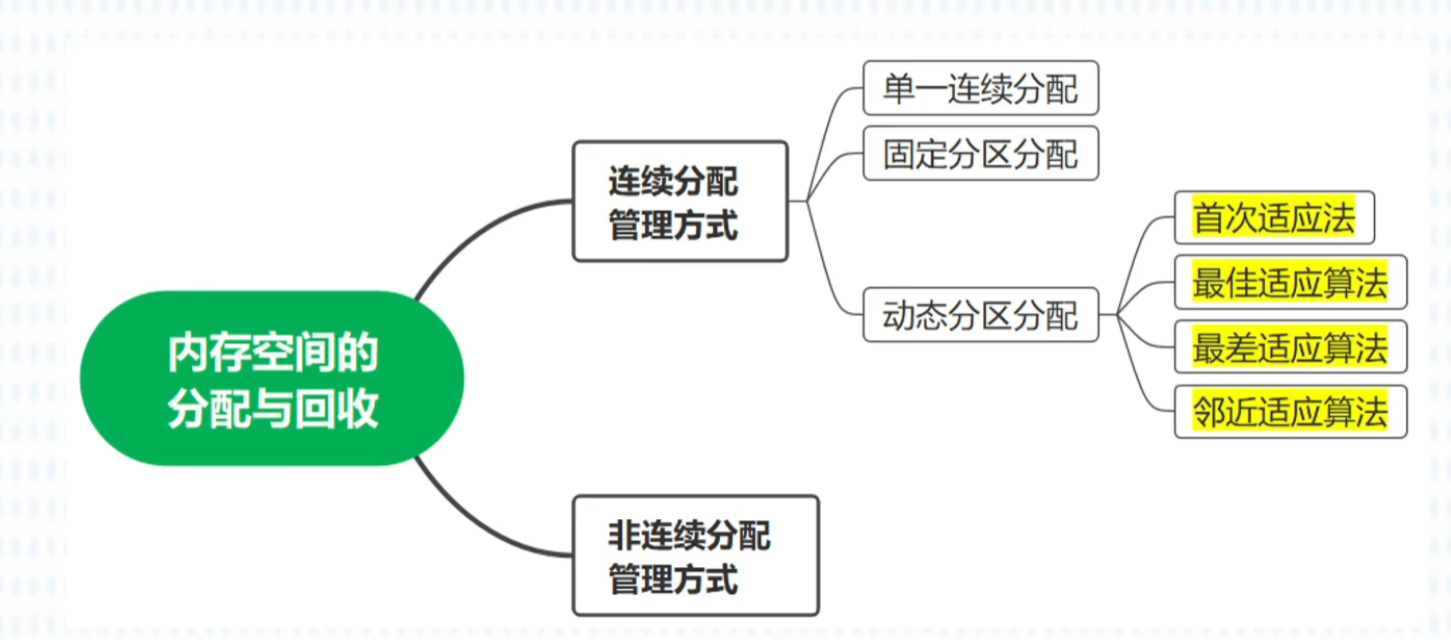
首次适应算法

最佳适应性算法

最差适应性算法

邻近适应性算法(更加均匀)
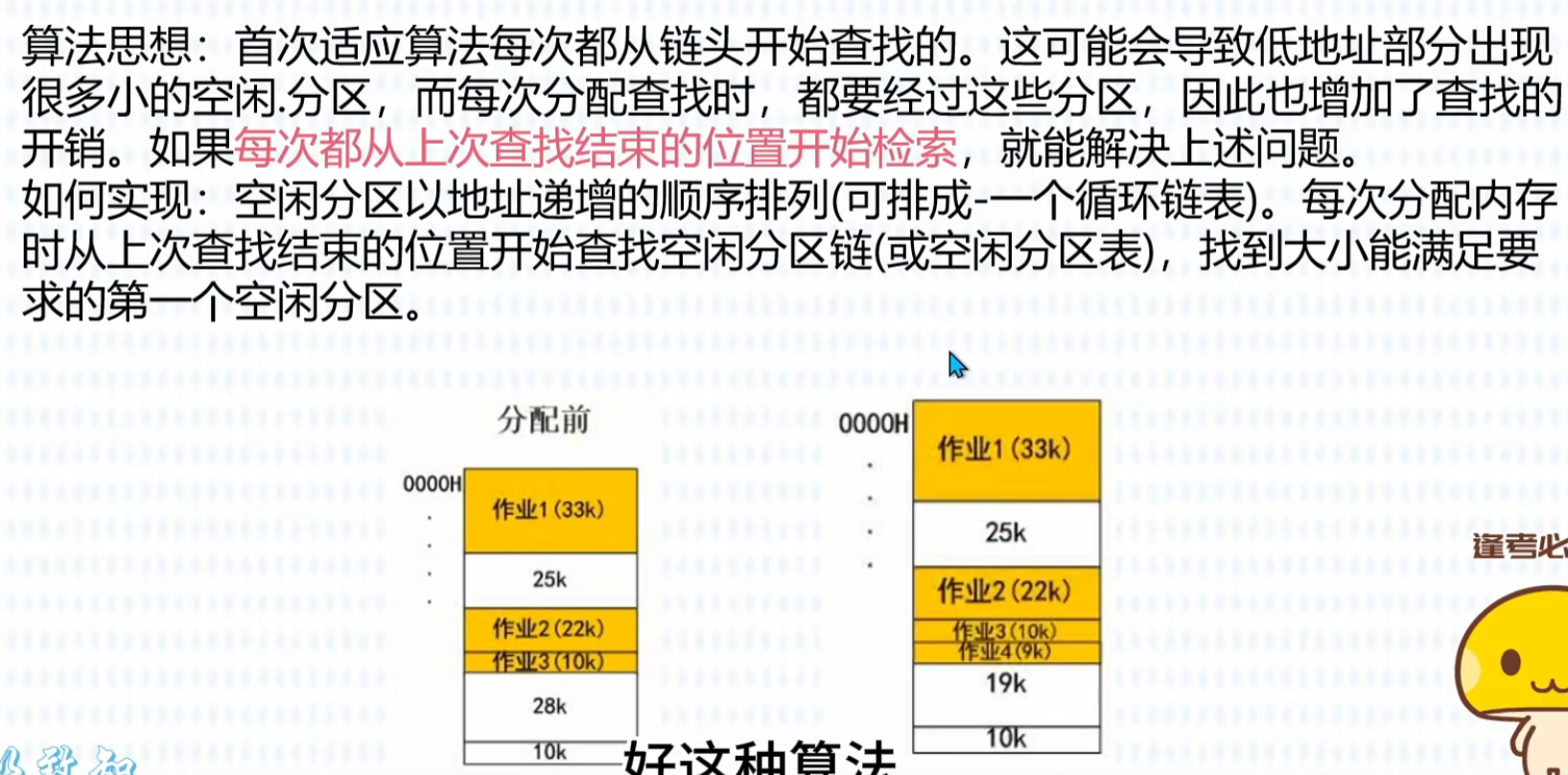
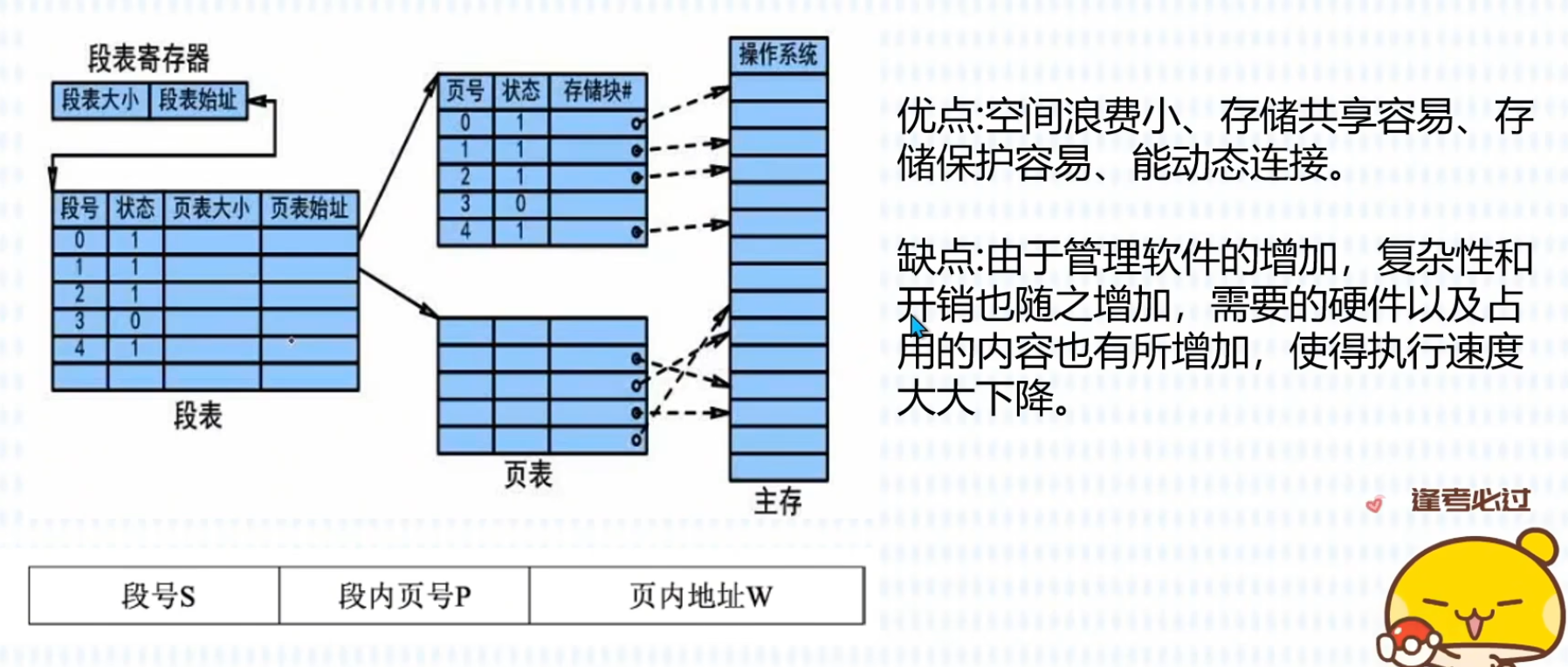
分页存储管理
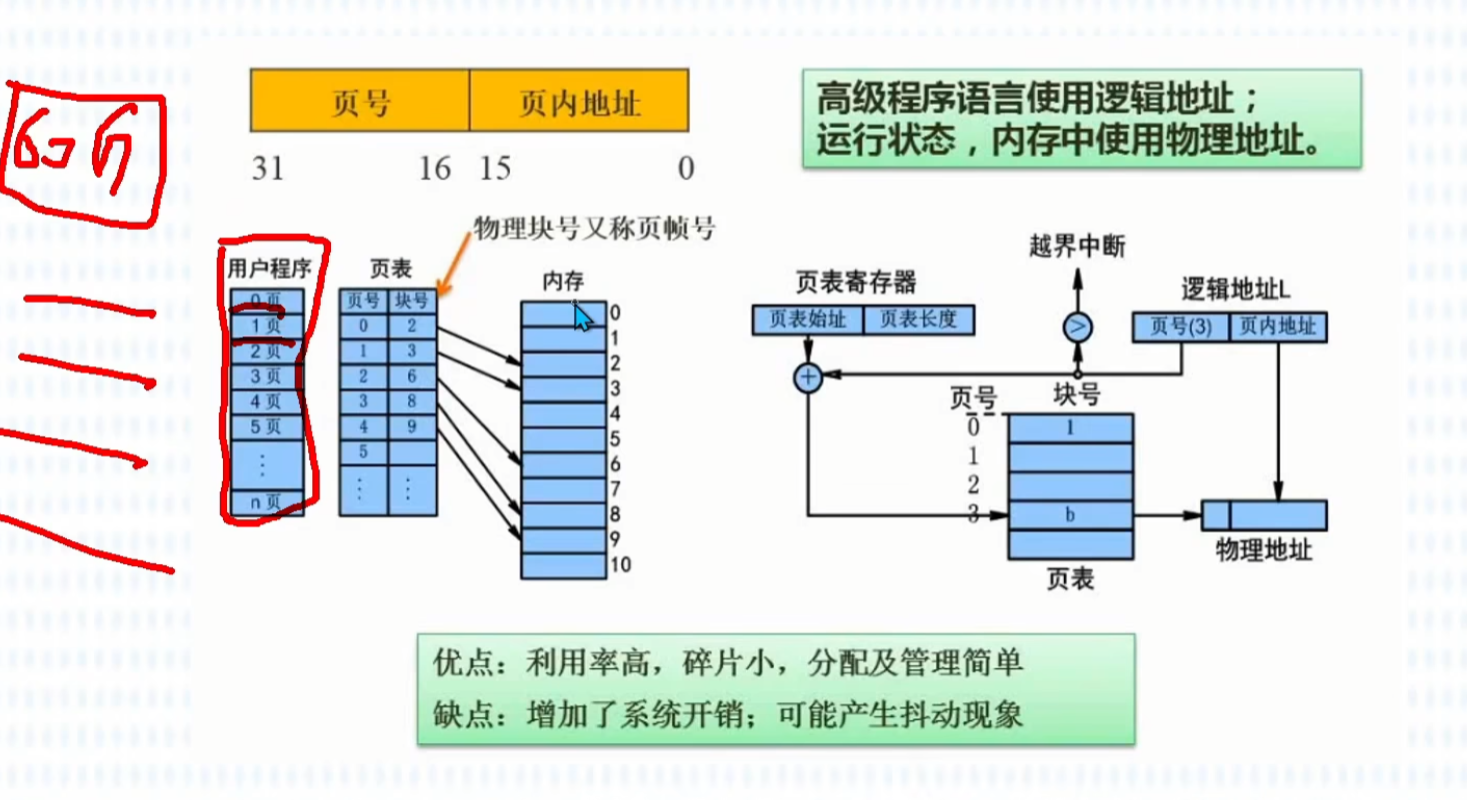

分段存储管理
一、先搞懂:分段是啥?
分页是硬件视角的划分,把内存切成固定大小的 “页框”,程序也跟着切成等大的 “页”,完全不关心程序的逻辑结构。
而分段是软件视角的划分,它完全跟着程序的逻辑结构走:
- 一个程序天然就由多个逻辑部分组成:比如主程序段、数据段、栈段、代码段、共享库段……
- 分段存储管理,就是把这些逻辑上独立的部分,各自作为一个独立的 “段” 来管理,每个段的大小可以不一样,由它本身的逻辑大小决定。
举个生活化的例子:
- 分页就像把一本小说强行按固定页数裁成一张张纸,不管你是章节开头还是结尾,一刀切。
- 分段就像把小说按 “章节”“附录”“注释” 分开装订,每一部分是一个独立的段,长短由内容决定。
二、分段的地址转换逻辑
和分页类似,分段的逻辑地址也被分成两部分,但含义完全不同:逻辑地址 = 段号(S) + 段内地址(偏移量d)
- 段号 (S):标识这个地址属于哪个逻辑段(比如第 0 段是代码段,第 1 段是数据段)。
- 段内偏移量 (d):在这个段内部,距离段起始位置的字节数(和分页的 “页内偏移量” 作用类似,但它的上限是当前段的长度,不是固定的页大小)。
转换过程:
- 先根据段号
S,查进程的段表(每个进程一张,记录每个段的基地址、长度、权限等)。 - 检查段内偏移量
d是否超过该段的长度:- 若超过 → 越界错误,触发中断。
- 若合法 → 取出该段的基地址(物理起始地址)。
- 物理地址 = 段的基地址 + 段内偏移量
d。
三、分段 vs 分页:核心区别对比
表格
| 对比维度 | 分页存储管理 | 分段存储管理 |
|---|---|---|
| 划分依据 | 硬件视角,按固定大小划分,和程序逻辑无关 | 软件 / 用户视角,按程序的逻辑模块划分 |
| 块 / 段大小 | 固定(比如 4KB),所有页 / 页框大小相同 | 不固定,由段本身的逻辑大小决定 |
| 地址结构 | 页号 + 页内偏移量(偏移量上限固定) | 段号 + 段内偏移量(偏移量上限由段长决定) |
| 碎片问题 | 只有页内碎片(每个页最后剩下的空间,最大为页大小 - 1),无外部碎片 | 有外部碎片(内存被不同大小的段分割后,中间留下的零散空间无法被利用),无内部碎片 |
| 共享与保护 | 共享和保护的粒度是 “页”,不够灵活,无法按逻辑模块单独控制 | 共享和保护的粒度是 “段”,天然支持按逻辑模块控制(比如代码段只读、数据段可读写) |
| 用户可见性 | 页对用户透明,用户不需要知道分页的存在 | 段对用户可见,用户 / 编译器需要明确划分段 |
四、一句话总结区别
- 分页是 “为了内存利用率”,强行把程序和内存切成固定大小的块,解决外部碎片问题,但破坏了程序的逻辑结构。
- 分段是 “为了程序逻辑”,按模块把程序分成大小不一的段,方便共享、保护和模块化管理,但会产生外部碎片。
段页式存储管理
先分段、后分页先按程序逻辑分成若干段(像分段),再把每一个段内部,再切成固定大小的页(像分页)。兼顾分段的逻辑优点 + 分页无外部碎片的优点。
一、地址结构(逻辑地址分成 3 部分)
逻辑地址 = 段号 S + 页号 P + 页内偏移 W
- 段号:属于哪个逻辑段(代码段、数据段、栈段)
- 页号:在这个段里面的第几页
- 页内偏移 W:页内部第几个字节(和分页完全一样)
二、怎么转换地址(两步查表)
- 查段表用段号 S 查段表,得到:
- 该段的页表起始地址
- 段长、权限、越界检查
-
查页表用段内页号 P 去该段对应的页表,查出物理页框号
-
拼接物理地址物理地址 = 页框号 × 页大小 + 页内偏移 W
特点:每个段,都有自己独立的一张页表
三、三者极简对比(分页 / 分段 / 段页式)
表格
| 方式 | 划分方式 | 地址结构 | 有无外部碎片 | 逻辑结构 |
|---|---|---|---|---|
| 分页 | 系统硬性等分,跟程序逻辑无关 | 页号 + 页内偏移 | 无外部碎片,只有页内碎片 | 不尊重程序逻辑 |
| 分段 | 按程序逻辑分,段大小不等 | 段号 + 段内偏移 | 有外部碎片 | 完全贴合程序模块 |
| 段页式 | 先逻辑分段,每段再分页 | 段号 + 页号 + 页内偏移 | 无外部碎片 | 贴合程序逻辑 |
四、段页式解决了什么问题
- 保留分段好处:
- 按逻辑模块划分(代码、数据、栈分离)
- 方便按段共享、按段权限保护
- 保留分页好处:
- 内存不用连续,无外部碎片
- 内存利用率高
- 代价:
- 地址转换要查两次表(段表→页表),速度慢一点
- 硬件 MMU 更复杂
五、超通俗大白话版
- 分页:把整本书一刀切,切成一样大的纸,不管章节。
- 分段:把书按章节拆开,每章长短不一样,放书架要占连续位置。
- 段页式:先按章节拆开(分段),再把每一章单独裁成一样大的小纸片(分页)既能按章节管理,又不用连续书架位置,还没零碎空位浪费。
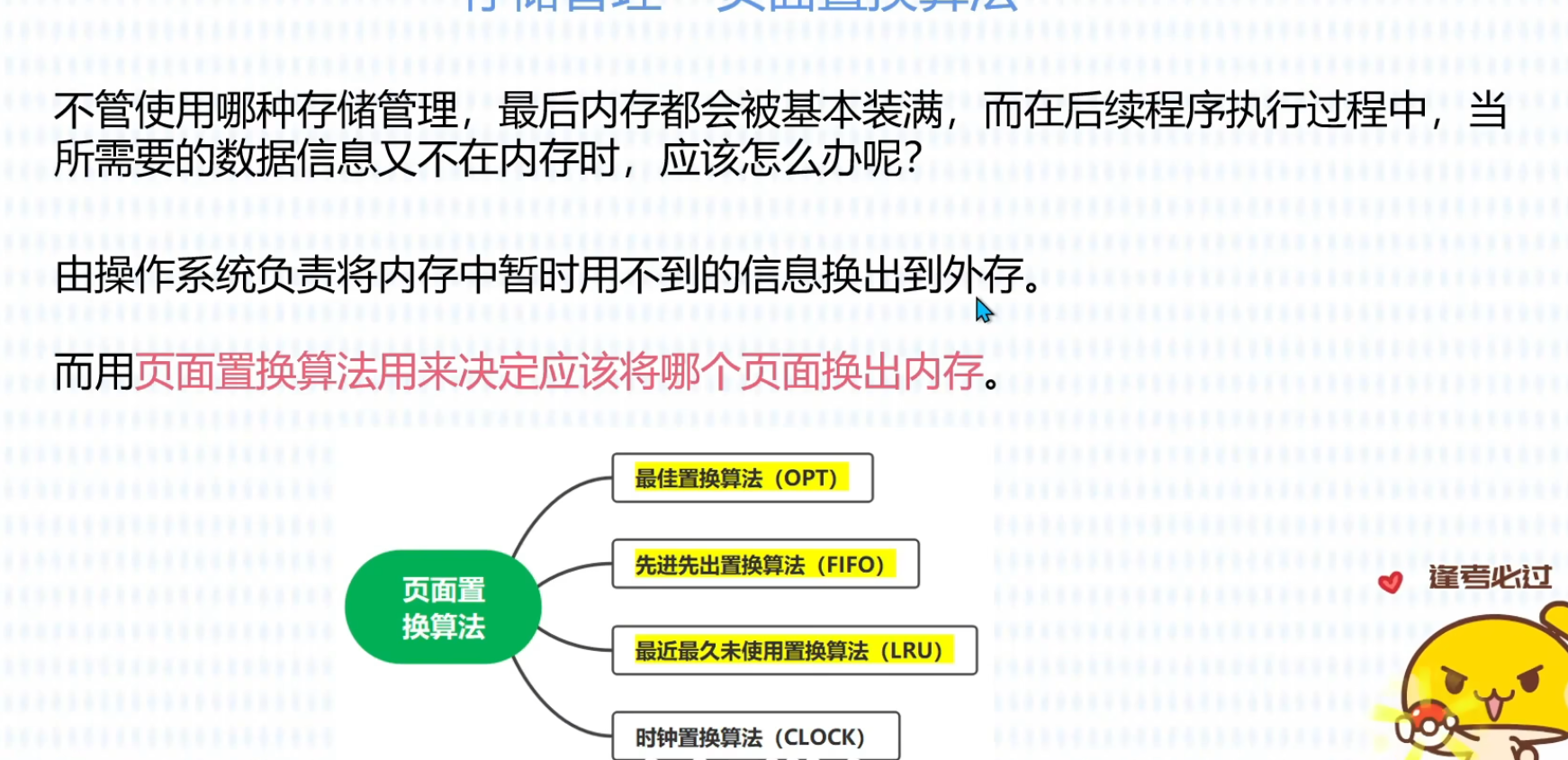
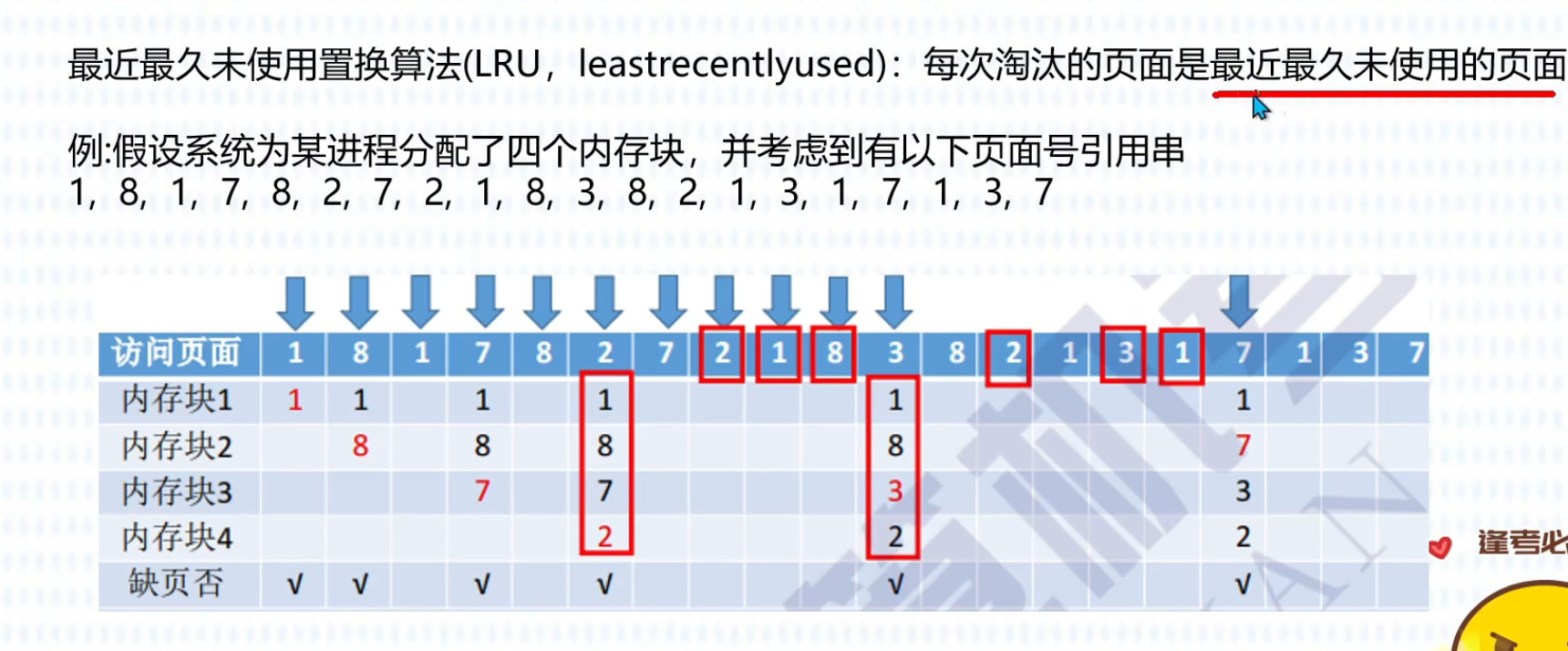
页面置换算法
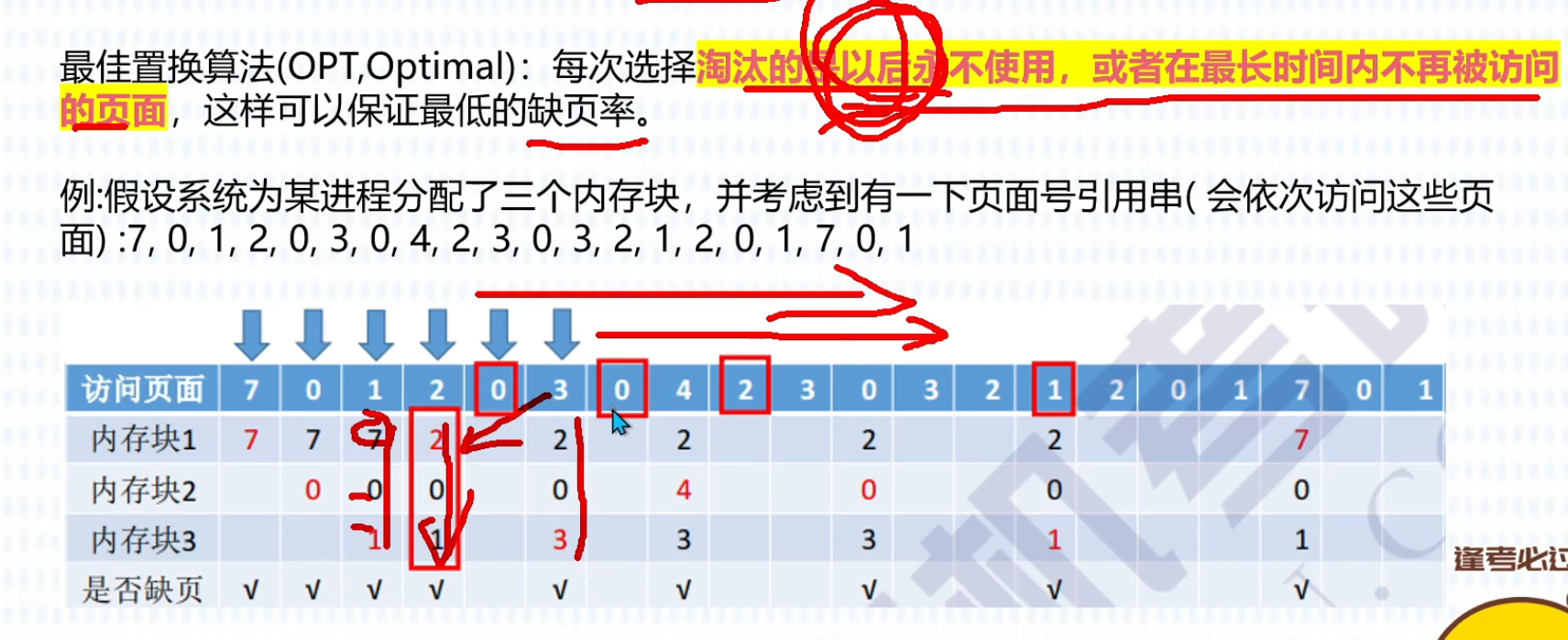
(最佳OPT)
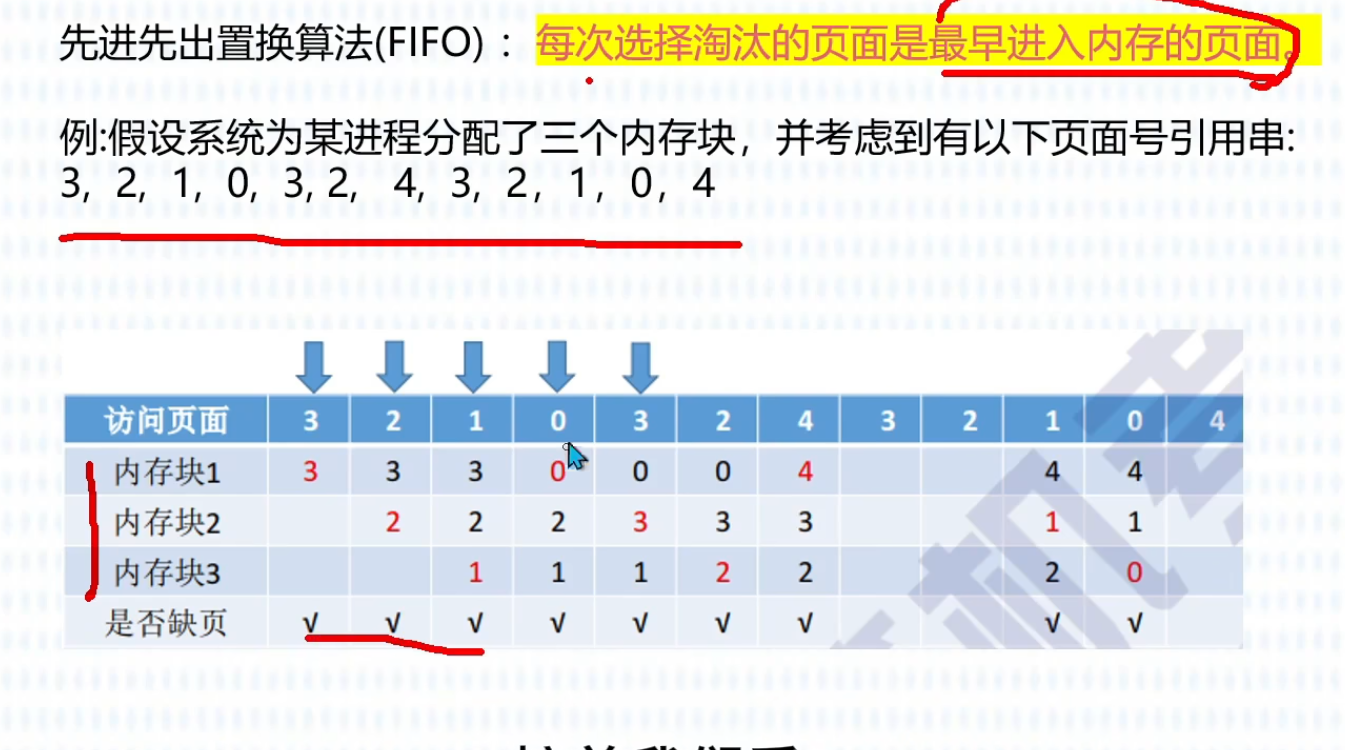
(先进先出FIFO)
(最近最久未使用LRU)
补充
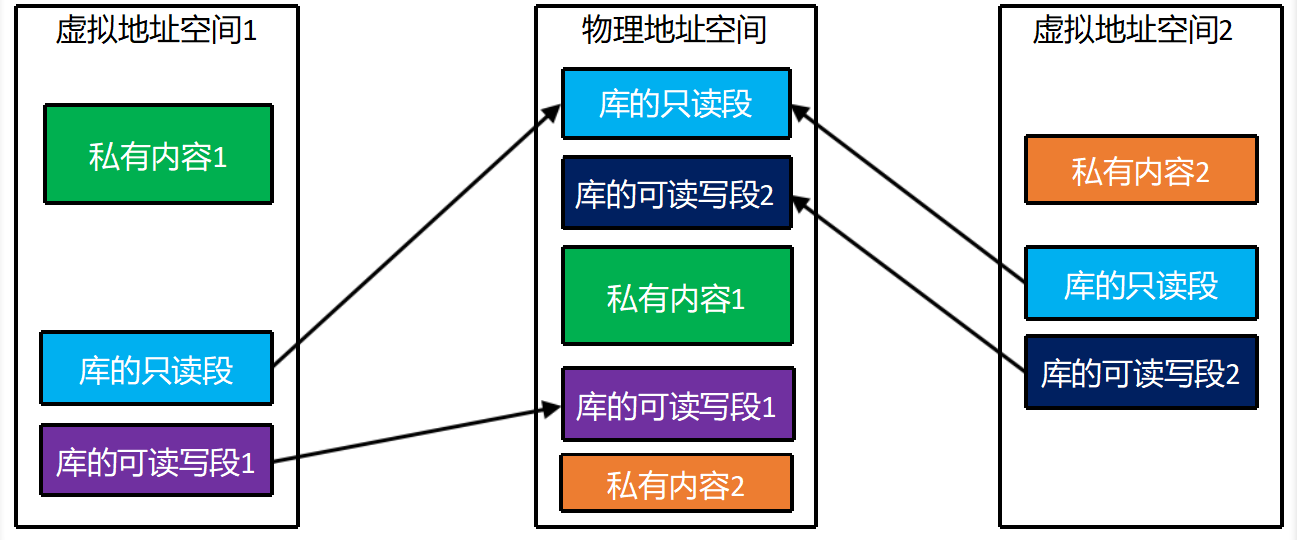
1. 普通分段 为什么有外部碎片?
纯分段:程序分好几个逻辑段(代码段、数据段、栈段)👉 每一个段,必须在物理内存里占一整块连续空间
比如:代码段要 20KB、数据段要 30KB系统必须给它找连续 20KB、连续 30KB 的整块空闲内存。
久而久之内存被切得零零碎碎:总空闲内存够,但没有一块连续大空间放一个完整段👉 这就是外部碎片,没法利用零散小空闲块。
2. 段页式 做了什么关键改变?
段页式流程:
- 先按逻辑分 段(代码段、数据段… 跟普通分段一样)
- 但是:这个段不需要物理上连续!
- 把这个段内部切成固定大小的页
- 每一个页,可以放到内存任意一个零散的页框里
重点一句话:✅ 段只是逻辑上的整体,物理上拆成一堆离散的页,散落放在内存各个角落
3. 为什么就能利用零散碎片?
内存里有很多零散、不连续的小空闲块(比如很多个 4KB 空位):
- 纯分段:不行,放不下任何一个完整段,浪费
- 段页式:我不用给你整个段分配连续空间我只需要一个一个页,随便往这些零散 4KB 空位里塞就行
👉 把大的逻辑段,拆成无数小页,吃掉所有零散碎片这就彻底消灭了外部碎片
只剩下页内碎片(每页最后一点点浪费),很小、可控。
4. 用大白话举例秒懂
假设:你要存一本「小说」(整个程序)里面分 3 章(3 个逻辑段)每一章内容很多。
-
纯分段:每一章必须整块连在一起放书架只剩很多零散小格子,放不下一整章 → 空间浪费
-
段页式:先分成第 1 章、第 2 章、第 3 章(分段)再把每一章撕成一张张同样大小的纸(分页)然后一张纸随便塞书架任意一个空小格子

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐


 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)