爬虫相关操作
获取响应的文本内容,即网页的 HTML 源码,结果返回给result。拿到的只是网站服务器直接返回的 “原始 HTML”,很多动态内容(比如通过 JS 加载的评论、数据、列表)还没被渲染出来,所以这些内容在原始代码里是看不到的。使用 XPath 语法,提取当前 p 标签下 a 标签内 img 标签的 src 属性值,拼接图片的完整 URL,补全网站域名,得到可直接访问的图片地址。使用 XPath
一、etree
etree.parse () 方法:读取并解析本地 html 文件
![]()
使用绝对路径 xpath 语法,提取 html 页面标题标签内的文本内容和body 下指定 div 标签内的 p 标签文本
![]()
xpath 下标索引定位节点,提取页面第 1 个 div 标签下 p 标签的文本.
xpath 节点计数从 1 开始 xpath 下标索引定位节点,提取页面第 2 个 div 标签下 p 标签的文本
多层嵌套下标定位,提取第 2 个 div 下、第 2 个 p 标签里第 2 个子节点的文本

按 class 属性精准匹配节点,提取 class 为 song 的 div 下指定 p 标签文本
![]()
//xpath 语法:跨层级全局搜索文档内所有对应节点,不用写完整绝对路径
![]()
/text () 语法:只获取当前标签直系子节点的文本内容
//text () 语法:获取当前标签下所有嵌套子孙节点的全部文本内容
![]()
@属性名 语法:提取标签指定属性的值,比如图片 src、链接 href 地址
![]()
二、爬取图片
导入 os 库,用于创建文件夹、处理文件路径,实现本地文件操作
![]()
定义全局变量 n,作为图片的序号计数器,给下载的图片自动命名

检查当前目录下是否存在名为 Picture 的文件夹,如果文件夹不存在,则创建该文件夹,用于存储爬取到的图片
![]()
定义请求头字典,用于模拟浏览器请求,使用 fake_useragent 随机生成一个 User-Agent,伪装成真实浏览器的请求。这需要导入 fake_useragent 库,用于随机生成不同的 User-Agent,模拟浏览器请求,降低被反爬机制识别的概率

拼接壁纸网站的分页 URL,实现批量爬取多页数据,其中i为页
![]()
向目标 URL 发送 GET 请求,携带请求头,获取网页响应
![]()
获取响应的文本内容,即网页的 HTML 源码,结果返回给result。使用 etree.HTML() 方法解析 HTML 源码,生成文档树对象,用于后续 XPath 提取
![]()
使用 XPath 语法,提取 id 为 pics-list 的 div 标签下所有的 p 标签,得到图片节点列表
![]()
遍历上一步提取到的所有 p 标签节点,逐个处理图片链接。
使用 XPath 语法,提取当前 p 标签下 a 标签内 img 标签的 src 属性值,拼接图片的完整 URL,补全网站域名,得到可直接访问的图片地址

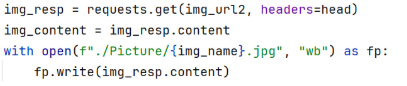
向图片的完整 URL 发送 GET 请求,获取图片的二进制数据。
获取响应的 content 属性,即图片的二进制内容
以二进制写入模式(wb)打开 Picture 文件夹下的图片文件,文件名为自增的序号,格式为 .jpg
将图片的二进制数据写入本地文件,完成图片的下载保存
三、打开网页
导入 selenium 库中的 webdriver 模块,它是驱动浏览器的核心组件,用于控制浏览器执行各种自动化操作。
![]()
导入 Edge 浏览器的 Options 类,通过它可以配置浏览器的启动参数,如指定浏览器路径、设置无头模式、禁用弹窗等。
![]()
创建一个 Options 实例对象,用于存放后续配置的 Edge 浏览器启动选项。
![]()
指定 Edge 浏览器的可执行文件路径,让 WebDriver 知道要启动哪个浏览器程序,确保能正确找到并打开本地安装的 Edge 浏览器。
![]()
使用之前配置好的 Options 实例初始化 Edge 浏览器驱动,创建一个浏览器实例对象,后续所有操作都通过这个对象来执行。
![]()
调用 get () 方法,让浏览器打开指定的 URL 地址
![]()
打开多个网页
使用 execute_script () 方法,在浏览器中执行 JavaScript 代码,调用 window.open 函数,在新标签页中打开网页。

获取渲染后的网页代码
在 Selenium 爬虫里,“渲染后的网页代码”,就是浏览器执行完所有 JavaScript 脚本、把页面完全加载出来之后,最终呈现在用户眼前的完整 HTML 代码。
我们平时用requests.get()拿到的只是网站服务器直接返回的 “原始 HTML”,很多动态内容(比如通过 JS 加载的评论、数据、列表)还没被渲染出来,所以这些内容在原始代码里是看不到的。
![]()

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)