学【Agent】越学越感觉在重新学【操作系统】
这篇文章不是要做一个简单的"OS 概念 → Agent 概念"对照表——网上已经有很多了。我想做的是从操作系统设计者的视角重新审视 Agent 系统,看看哪些问题是 OS 早就解决过的,哪些是 Agent 独有的新挑战,以及为什么"重新发明轮子"这件事在 Agent 领域不仅是必然的,甚至可能是必要的。
学【Agent】越学越感觉在重新学【操作系统】

写在前面:三个月前我开始系统学习 Agent 框架——LangGraph、CrewAI、AutoGen、OpenAI Assistants API——写第一个多 Agent 系统的时候,我觉得自己在写业务逻辑。写第二个的时候,我觉得自己在搭微服务。写到第五个的时候,我猛然意识到一件事:我好像在重新学操作系统。进程调度、内存管理、进程间通信、中断处理、文件系统、虚拟内存……这些在本科 OS 课上让我昏昏欲睡的概念,如今换了一身衣服,站在我面前,而我居然花了这么久才认出它们。更讽刺的是,2026 年学术界已经不满足于"像"了——arXiv 上出现了论文《The Missing Memory Hierarchy: Demand Paging for LLM Context》,直接论证了 LLM 上下文管理在结构上(而非仅仅隐喻上)等价于虚拟内存;AgenticOS 2026 研讨会明确提出了"为 Agent 设计操作系统"的命题;一篇题为《Agent Skills Are Just Header Files (And Virtual Memory, And Unix Pipes)》的文章更是把类比推到了极致。
这篇文章不是要做一个简单的"OS 概念 → Agent 概念"对照表——网上已经有很多了。我想做的是从操作系统设计者的视角重新审视 Agent 系统,看看哪些问题是 OS 早就解决过的,哪些是 Agent 独有的新挑战,以及为什么"重新发明轮子"这件事在 Agent 领域不仅是必然的,甚至可能是必要的。
📑 文章目录
- 📌 一、那个让人脊背发凉的瞬间
- 🧠 二、Context Window = 虚拟内存:最精确的类比
- 🔄 三、State Management = 进程间通信:Channel、Reducer 与信号量
- ⏱️ 四、Agent Orchestration = 进程调度:从轮转到优先级
- 🛡️ 五、Human-in-the-Loop = 中断与信号:谁来掌握控制权?
- 💾 六、Tool Calling = 系统调用:Agent 如何与外部世界交互
- 📂 七、Memory System = 存储层次:从寄存器到磁盘
- 🔒 八、Isolation & Sandbox = 进程隔离与权限控制
- 🔍 九、Observability = 系统监控:dmesg、strace 与 LangSmith
- 🤔 十、为什么 Agent 必须"重新发明"OS?
- 🎁 速查对照表
📌 一、那个让人脊背发凉的瞬间
1.1 一段 LangGraph 代码

事情要从一段代码说起。这是我在 LangGraph 里写的一个多 Agent 协作系统:
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
from typing import Annotated
import operator
class AgentState(TypedDict):
messages: Annotated[list, add_messages]
research_result: str
draft: str
review_notes: str
final_output: str
graph = StateGraph(AgentState)
# 并行执行:研究员和搜索器同时工作
graph.add_node("researcher", researcher_node)
graph.add_node("searcher", searcher_node)
# 顺序执行:写作者依赖研究员的结果
graph.add_node("writer", writer_node)
graph.add_node("reviewer", reviewer_node)
graph.add_edge(START, "researcher")
graph.add_edge(START, "searcher") # 并行分支
graph.add_edge("researcher", "writer")
graph.add_edge("searcher", "writer")
graph.add_edge("writer", "reviewer")
graph.add_conditional_edges("reviewer", should_revise, {
"revise": "writer", # 打回重写
"approve": END
})
checkpointer = MemorySaver()
app = graph.compile(checkpointer=checkpointer, interrupt_before=["reviewer"])
写完这段代码的那天晚上,我躺在床上,脑子里突然冒出一个念头:
这不就是一个带检查点(checkpoint)的、可中断的、有条件分支的、支持并行执行的进程调度器吗?
StateGraph是进程控制块(PCB)的集合add_messagesReducer 是进程间消息队列MemorySaver是文件系统里的检查点/快照interrupt_before是中断向量表add_conditional_edges是条件跳转指令- 并行分支是 fork()
我翻了个身,睡不着了。
1.2 不是我一个人有这种感觉
第二天我去搜了一下,发现这种感觉远不止我一个人有。2026 年 3 月,arXiv 上出现了一篇论文——《The Missing Memory Hierarchy: Demand Paging for LLM Context》——作者直接论证了 LLM 上下文管理在结构上(structurally,而非仅仅隐喻上 metaphorically)等价于操作系统的虚拟内存系统。论文指出,OS 内存层次结构中的缓存替换策略、工作集理论、缺页中断处理,可以直接映射到 LLM 的上下文管理上。他们实现了一个 demand paging 系统,将上下文使用量削减了 93%。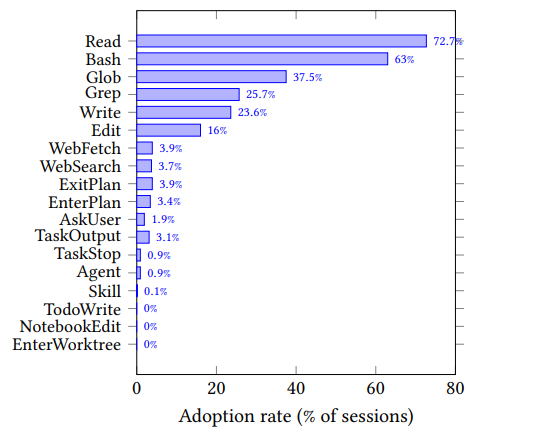
2026 年 5 月 1 日,dev.to 上有一篇文章标题直接就是:《Agent Skills Are Just Header Files (And Virtual Memory, And Unix Pipes)》。作者论证了 Agent 的技能加载机制本质上就是虚拟内存的分页机制——你有 500 个可用技能,但上下文窗口只能装下 20 个,所以你做和 OS 1960 年代以来一直在做的事情一模一样:把活跃的部分放在"内存"里,不活跃的"换出"到磁盘。
更早之前,2025 年 9 月的一篇预印本**《Agent Operating Systems (Agent-OS): A Blueprint Architecture》**已经明确提出了 Agent-OS 的概念,指出当前的 Agent 系统"仍然是临时拼凑的管道(ad-hoc pipelines),缺乏操作系统级别的调度、内存、实时响应和端到端安全保证"。
2026 年,甚至出现了一个专门的研讨会——AgenticOS 2026——其目标就是"定义构建 Agent 操作系统所需的原语(primitives)、隔离模型(isolation models)、调度技术(scheduling techniques)和可观测性机制(observability mechanisms)"。
所以,学 Agent 越学越像在学操作系统,这不是错觉——因为 Agent 系统正在收敛到操作系统的设计模式上。区别只在于,Agent 系统面对的是一种全新的"硬件"——大语言模型——它的特性(概率性、上下文窗口、token 化)让很多经典 OS 问题有了新的变体。
🧠 二、Context Window = 虚拟内存:最精确的类比
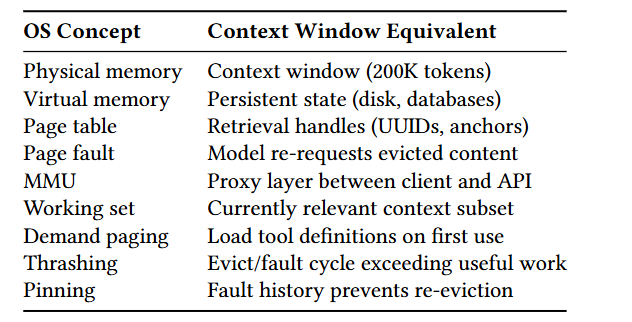
2.1 从一个具体问题说起
假设你在构建一个客服 Agent,它需要:
- 用户的对话历史(最近 50 轮)
- 产品知识库(约 20000 条 FAQ)
- 公司政策文档(约 500 页)
- 用户的个人信息和订单历史
- 当前对话的实时上下文
全部塞进上下文窗口?GPT-4o 的 128K token 听起来很多,但 20000 条 FAQ 光索引就吃掉一半了。Claude 的 200K 稍微宽裕一点,但成本是另一个问题——输入 200K token 的价格是输入 10K 的 20 倍。
你面临的选择和 OS 设计者 60 年前面临的选择完全一样:
| OS 问题 | Agent 问题 |
|---|---|
| 物理内存不够装所有进程的地址空间 | 上下文窗口不够装所有需要的知识 |
| 怎么决定哪些页面留在内存? | 怎么决定哪些信息留在上下文? |
| 页面置换算法(LRU/LFU/Clock) | 上下文淘汰策略(最近最少使用/最不相关) |
| 缺页中断(Page Fault) | 上下文缺失时的检索(RAG) |
| 工作集(Working Set) | 当前任务真正需要的上下文 |
| 预取(Prefetching) | 预测性上下文加载 |
| TLB(Translation Lookaside Buffer) | 语义缓存(Semantic Cache) |
2.2 Demand Paging for LLM Context
前面提到的那篇 arXiv 论文《The Missing Memory Hierarchy》做了一个非常漂亮的实验。他们的核心观察是:
LLM 上下文管理在结构上映射到虚拟内存,OS 内存层次结构的全部内容——从缓存替换策略到工作集理论——可以直接应用。
具体来说,他们发现:
- 21.8% 的 LLM 上下文被浪费在从未被引用的内容上——这和 OS 中"加载了但从未访问的页面"是同一个问题
- 通过实现一个 demand paging 系统(只在需要时加载上下文块),上下文使用量削减了 93%
- LRU(Least Recently Used)策略在上下文管理中同样有效——最近没被 LLM "关注"过的上下文块,大概率接下来也不会被关注
这不仅仅是类比。论文的论点是:这是同一类数学问题。上下文窗口是"物理内存",你想要访问的全部知识是"虚拟地址空间",RAG 检索就是"缺页中断处理程序"。
2.3 Skill Loading 就是 Page In/Page Out
dev.to 上那篇文章《Agent Skills Are Just Header Files》举了一个非常直观的例子:
你有 500 个可用技能(Skills)。你不可能把它们全部塞进上下文窗口。所以你做和 OS 1960 年代以来一直在做的事情一模一样:分页(Paging)。在虚拟内存中,程序"看到"的内存比物理存在的更多。OS 把活跃使用的部分放在快速 RAM 中,把不活跃的部分换出到磁盘。Agent 系统做的是同一件事:把当前任务需要的技能描述放在上下文窗口中,其余的留在向量数据库里,需要时再加载。
这个类比可以继续深入:
| 虚拟内存概念 | Agent 技能管理 |
|---|---|
| 页面(Page) | 技能描述(Skill Description) |
| 页框(Frame) | 上下文窗口中的 token 槽位 |
| 页表(Page Table) | 技能注册表 / 路由索引 |
| 缺页中断(Page Fault) | 技能未加载 → 触发检索 |
| 页面换入(Page In) | 从知识库加载技能描述到上下文 |
| 页面换出(Page Out) | 从上下文中移除不活跃的技能 |
| 抖动(Thrashing) | 频繁切换任务导致反复加载/卸载技能 |
| 工作集(Working Set) | 当前 Agent 任务真正需要的技能子集 |
| 预取(Prefetching) | 根据对话趋势预加载可能需要的技能 |
2.4 为什么这个类比如此精确?
因为两者的根本约束是同构的:
- 有限的"物理容量":物理内存是有限的,上下文窗口也是有限的(token 数)
- 无限的"逻辑需求":进程的虚拟地址空间可以很大,Agent 需要的知识也可以很大
- 访问的局部性:程序在一段时间内倾向于访问内存的某个局部区域(时间局部性 + 空间局部性),Agent 在一个任务中也倾向于使用某几个技能/知识片段
- 加载的代价不对称:从磁盘加载页面比从内存读取慢几个数量级,从向量库检索知识也比从上下文中"回忆"慢得多(需要额外的 API 调用)
当两个系统的约束条件同构时,它们的解决方案也会趋同。这不是巧合,这是数学。
🔄 三、State Management = 进程间通信:Channel、Reducer 与信号量
3.1 回到 LangGraph 的 Channel
在上一篇《LangGraph 源码剖析(二)》中,我们深入分析了 LangGraph 的七种 Channel。现在用 OS 的视角重新审视它们,你会发现每一对映射都严丝合缝:
| LangGraph Channel | OS 对应概念 | 核心相似点 |
|---|---|---|
LastValue |
共享变量 + 互斥锁 | 每次只有一个写入者能修改,后写覆盖先写 |
BinaryOperatorAggregate |
消息队列 + 累加器 | 多个写入者的输出通过 Reducer 合并 |
Topic |
发布-订阅(Pub/Sub) | 多个写入者发布,多个读取者订阅 |
EphemeralValue |
信号(Signal) | 传递一次就消失,不持久化 |
NamedBarrierValue |
屏障(Barrier) | 等待所有并行分支都写入后才继续 |
UntrackedValue |
无锁变量 | 不触发重算的辅助状态 |
3.2 Reducer = 信号量 + 合并策略
在 OS 中,当多个进程同时写一个共享变量时,你需要:
- 互斥(Mutual Exclusion):保证同一时刻只有一个进程在写
- 合并策略:如果允许并发写,怎么合并结果?
LangGraph 的 Reducer 本质上就是合并策略的声明式定义。你在定义 State 的时候就决定了合并策略,而不是在运行时手忙脚乱地加锁:
# OS 思维:这是一个受保护的共享变量,写入策略是"追加"
messages: Annotated[list, operator.add]
# OS 思维:这是一个互斥变量,写入策略是"覆盖"
current_step: str
# OS 思维:这是一个消息队列,写入策略是"按 ID 增删改"
messages: Annotated[list, add_messages]
这和 OS 中"在定义数据结构时就确定同步策略"的思想是一脉相承的。不同的是,OS 用锁和信号量在运行时保证同步,而 LangGraph 用 Reducer 在编译时(图定义时)就消除了冲突的可能性。
3.3 并行节点的状态冲突 = 竞态条件
考虑这个 LangGraph 图:
graph.add_edge(START, "node_a")
graph.add_edge(START, "node_b") # 并行执行
graph.add_edge("node_a", "merge")
graph.add_edge("node_b", "merge")
node_a 和 node_b 并行执行,都要写 state["result"]。如果没有 Reducer,这就是经典的竞态条件(Race Condition)——谁最后写完,谁的结果就留下,另一个被覆盖。
在 OS 中,你用锁解决这个问题:
pthread_mutex_lock(&mutex);
shared_var = new_value;
pthread_mutex_unlock(&mutex);
在 LangGraph 中,你用 Reducer 解决:
result: Annotated[list, operator.add] # 两个节点的结果会合并,而不是覆盖
Reducer 是声明式的锁——你不需要在运行时管理同步,而是在定义时声明合并策略。这是一个更高层次的抽象,但解决的是同一个问题。
3.4 NamedBarrierValue = pthread_barrier
LangGraph 的 NamedBarrierValue 可能是最"OS"的 Channel 了。它的行为和 POSIX 线程库中的 pthread_barrier_t 几乎一模一样:
// OS: 等待所有线程到达屏障后才继续
pthread_barrier_wait(&barrier);
# LangGraph: 等待所有并行分支都写入后才继续
state = {
"barrier": NamedBarrierValue(expect=["node_a", "node_b", "node_c"])
}
在 OS 中,屏障同步用于并行算法中的"汇合点"——所有工作线程完成当前阶段后,再一起进入下一阶段。在 Agent 系统中,同样的模式出现在"多个信息收集 Agent 都返回结果后,汇总 Agent 才开始工作"的场景中。
⏱️ 四、Agent Orchestration = 进程调度:从轮转到优先级
4.1 调度问题的本质
操作系统的进程调度器要回答的问题是:在任意时刻,应该运行哪个进程?
Agent 编排系统要回答的问题是:在任意时刻,应该执行哪个 Agent/节点?
这两个问题的结构完全相同:
| OS 调度维度 | Agent 编排维度 |
|---|---|
| CPU 时间片 | API 调用配额 / Token 预算 |
| 进程优先级 | Agent/任务优先级 |
| I/O 等待 vs CPU 密集 | LLM 推理等待 vs 工具调用 |
| 抢占式 vs 协作式 | 中断驱动 vs 顺序执行 |
| 实时调度(Deadline) | SLA / 响应时间要求 |
| 公平性(Fairness) | 多租户 Agent 资源分配 |
4.2 LangGraph 的调度模型
LangGraph 的图执行引擎本质上是一个非抢占式调度器(Cooperative Scheduler)。节点(Agent)按照图的拓扑排序执行,每个节点主动让出控制权(通过 return),下一个节点才能开始。这和 OS 中的协作式多任务(Cooperative Multitasking)是同一个模型——早期 Mac OS 和 Windows 3.1 用的就是这种模型。
# LangGraph 的调度逻辑(简化)
while not done:
next_nodes = get_next_nodes(current_state, graph_structure)
for node in next_nodes:
if can_run_in_parallel(node, running_nodes):
spawn(node) # 类似 fork()
else:
wait(node) # 类似 waitpid()
current_state = merge_results(next_nodes)
这和 OS 调度器的伪代码惊人地相似:
// OS 调度器(简化)
while (1) {
next_process = pick_next_process(ready_queue, priority);
if (next_process == NULL) continue;
context_switch_to(next_process);
// 进程主动或被动让出 CPU
}
4.3 CrewAI 的优先级调度
CrewAI 引入了更接近优先级调度的模型。你可以给不同的 Agent 设置不同的优先级和执行顺序:
researcher = Agent(role="Researcher", priority=1)
writer = Agent(role="Writer", priority=2)
reviewer = Agent(role="Reviewer", priority=3)
crew = Crew(
agents=[researcher, writer, reviewer],
process=Process.hierarchical, # 层级式调度
manager_llm=llm
)
这类似于 OS 中的多级反馈队列调度(Multilevel Feedback Queue)——不同优先级的进程在不同的队列中等待,高优先级的先执行。
4.4 实时调度:Agent 的 Deadline 问题
OS 实时调度(如 Rate-Monotonic Scheduling、Earliest Deadline First)要保证任务在截止时间前完成。Agent 系统也有类似的需求:
- 客服 Agent:必须在 3 秒内响应,否则用户流失
- 交易 Agent:必须在 100ms 内完成决策,否则市场变化
- 监控 Agent:必须在检测到异常后 1 秒内告警
这些需求和 OS 实时系统的硬实时(Hard Real-Time)约束是同构的。区别在于,OS 的 Deadline 是确定性的(CPU 周期是可预测的),而 Agent 的 Deadline 是概率性的(LLM 推理时间波动很大)。这使得 Agent 的实时调度比 OS 更难——你面对的不是确定性系统,而是一个延迟不确定的计算单元。
🛡️ 五、Human-in-the-Loop = 中断与信号:谁来掌握控制权?
5.1 中断:OS 的灵魂
如果你只能选一个概念来理解操作系统,选中断(Interrupt)。中断是 OS 的灵魂——没有中断,就没有多任务,没有实时响应,没有用户交互。CPU 只是一个快速但笨的计算器,中断让它变成了一个"能响应外部事件"的智能系统。
中断的分类:
| 中断类型 | 触发源 | OS 行为 |
|---|---|---|
| 硬件中断 | 外设(键盘、网卡、磁盘) | 暂停当前进程,处理中断,恢复 |
| 软件中断 | 系统调用(int 0x80) | 用户态 → 内核态切换 |
| 异常 | 除零、缺页、非法指令 | 触发异常处理程序 |
| 信号(Signal) | 其他进程(kill -9) | 异步通知目标进程 |
5.2 Human-in-the-Loop:Agent 的中断
Agent 系统中的 Human-in-the-Loop(HITL)机制,在结构上完全等价于 OS 的中断系统:
| OS 中断 | Agent HITL | 示例 |
|---|---|---|
| 硬件中断 | 用户主动介入 | 用户在审批节点拒绝 Agent 的决策 |
| 软件中断 | Agent 请求人类帮助 | Agent 遇到不确定的情况,请求人类确认 |
| 异常 | Agent 执行出错 | 工具调用失败,触发错误处理流程 |
| 信号 | 外部事件通知 | 收到新消息 / 数据库更新 / API 变更 |
LangGraph 的 interrupt_before 和 interrupt_after 本质上就是设置中断断点:
# 在 reviewer 节点之前设置中断断点
app = graph.compile(
checkpointer=checkpointer,
interrupt_before=["reviewer"] # 类似设置断点调试
)
# 执行到断点时暂停,等待人类输入
result = app.invoke(input, config={"configurable": {"thread_id": "1"}})
# 此时执行暂停,状态被保存到 checkpointer
# 人类审核后,提供输入,恢复执行
result = app.invoke(
Command(resume=human_feedback),
config={"configurable": {"thread_id": "1"}}
)
这和 OS 中断处理的流程一模一样:
- 保存现场(Context Save):当前状态保存到 checkpointer / 进程状态保存到 PCB
- 暂停执行(Halt):Agent 暂停 / CPU 暂停当前进程
- 处理中断(Handle):人类审核 / 中断服务程序执行
- 恢复执行(Resume):从断点继续 / 从中断返回
5.3 中断的优先级
OS 中,中断有优先级——时钟中断可以被键盘中断抢占,但键盘中断不能被磁盘中断抢占(通常)。Agent 系统也需要类似的中断优先级:
- 紧急中断(高优先级):安全相关的人类否决、系统错误
- 普通中断(中优先级):常规审核、参数调整
- 可延迟中断(低优先级):建议性反馈、非阻塞通知
目前大多数 Agent 框架还没有实现中断优先级,但随着 Agent 系统复杂度的增加,这将成为一个必须解决的问题。
💾 六、Tool Calling = 系统调用:Agent 如何与外部世界交互
6.1 系统调用:用户态与内核态的桥梁
在 OS 中,应用程序不能直接访问硬件——你不能在用户态代码里直接读写磁盘、操作网卡。所有对硬件的访问都必须通过系统调用(System Call),由内核代为执行。系统调用是用户态和内核态之间的受控接口。
用户程序 → syscall() → 内核 → 硬件
← 返回结果 ←
6.2 Tool Calling:Agent 与外部世界的桥梁
Agent 不能直接访问外部世界——它不能直接查数据库、发邮件、调用 API。所有对外部世界的访问都必须通过工具调用(Tool Calling),由运行时代为执行。Tool Calling 是 Agent 的"推理态"和"执行态"之间的受控接口。
Agent (LLM) → tool_call() → 运行时 → 外部世界(API/DB/文件系统)
← 返回结果 ←
这个类比可以继续深入:
| OS 系统调用 | Agent Tool Calling | 共同点 |
|---|---|---|
open() / read() / write() |
搜索工具 / 读取文件 / 写入数据 | 对资源的受控访问 |
fork() / exec() |
创建子 Agent / 执行任务 | 创建新的执行单元 |
kill() / signal() |
终止 Agent / 发送通知 | 进程间控制 |
socket() / connect() |
HTTP 请求工具 / API 调用 | 网络通信 |
ioctl() |
自定义工具 / 特殊操作 | 非标准操作的扩展接口 |
| 权限检查(rwx) | 工具权限控制 | 访问控制 |
| 参数验证 | 工具参数 schema | 接口契约 |
| 返回值 + errno | 返回结果 + 错误信息 | 错误处理 |
6.3 Tool 的权限控制 = 文件系统权限
在 OS 中,每个文件都有权限(rwx),每个进程有用户/组身份。进程尝试访问文件时,内核检查权限——有权限就执行,没权限就返回 EACCES。
Agent 系统也需要类似的权限控制:
# OpenAI Assistants API 的工具权限控制
assistant = client.beta.assistants.create(
model="gpt-4o",
tools=[
{"type": "code_interpreter"}, # 允许执行代码
{"type": "file_search", "file_ids": ["file-abc"]}, # 只能搜索特定文件
{
"type": "function",
"function": {
"name": "send_email",
"parameters": {...},
# 但没有 "allowed_recipients" 字段——权限控制还不够细
}
}
]
)
目前 Agent 框架的权限控制还远不如 OS 的文件系统权限精细。但随着 Agent 系统处理越来越敏感的操作(转账、删除数据、发送邮件),细粒度的工具权限控制将成为必需品。
6.4 Tool 执行的沙箱 = chroot / namespace
OS 用 chroot、namespace、cgroup 等机制隔离进程的执行环境。Agent 系统也需要类似的沙箱机制——特别是当 Agent 可以执行代码(Code Interpreter)时:
| OS 沙箱 | Agent 沙箱 | 作用 |
|---|---|---|
| chroot | 限制文件系统访问 | Agent 只能访问特定目录 |
| namespace | 隔离网络/进程/IPC | Agent 之间互相不可见 |
| cgroup | 限制 CPU/内存 | 限制 Agent 的资源使用 |
| seccomp | 限制系统调用 | 限制 Agent 可执行的操作 |
| Docker | 完整容器隔离 | Agent 在独立容器中运行 |
📂 七、Memory System = 存储层次:从寄存器到磁盘
7.1 OS 的存储层次
OS 的存储层次是计算机科学中最优雅的设计之一:
寄存器 (1 cycle) → L1 Cache (1-3 cycles) → L2 Cache (10 cycles) →
L3 Cache (40 cycles) → 内存 (100 cycles) → SSD (10μs) → HDD (10ms)
每一层都比上一层慢,但容量更大、成本更低。OS 的内存管理器负责在层次之间移动数据,让程序"感觉"自己拥有无限快的无限内存。
7.2 Agent 的存储层次
Agent 系统也有一个清晰的存储层次:
当前推理上下文 (0ms) → 会话历史 (0ms) → 向量数据库检索 (50-200ms) →
知识图谱查询 (100-500ms) → 全文搜索 (200ms-1s) → 互联网搜索 (1-5s)
| Agent 存储层 | 对应 OS 层 | 访问延迟 | 容量 | 成本 |
|---|---|---|---|---|
| 当前上下文窗口 | 寄存器 + L1 Cache | 0ms(已加载) | 128K-200K token | 极高(每 token 都计费) |
| 会话历史(checkpointer) | 内存(RAM) | ~0ms | 取决于存储 | 中等 |
| 向量数据库 | SSD | 50-200ms | 几乎无限 | 低 |
| 知识图谱 | SSD + 索引 | 100-500ms | 大 | 低 |
| 互联网搜索 | 网络(远程磁盘) | 1-5s | 无限 | 极低 |
7.3 缓存替换策略的迁移
OS 中经典的缓存替换策略在 Agent 系统中找到了新的用武之地:
- LRU(Least Recently Used):淘汰最久没被引用的上下文。适用于对话历史管理——如果某个话题已经 10 轮没被提及了,它的上下文可以被换出。
- LFU(Least Frequently Used):淘汰引用频率最低的上下文。适用于知识缓存——如果某个 FAQ 从来没被检索过,它的缓存可以被淘汰。
- ARC(Adaptive Replacement Cache):自适应地在 LRU 和 LFU 之间切换。适用于混合工作负载的 Agent。
- Working Set Model:保持当前任务"工作集"内的所有上下文在窗口中。适用于有明确任务边界的 Agent。
7.4 Colony 的 Virtual Context Memory
有一个叫 Colony 的开源项目已经实现了Virtual Context Memory——直接把 OS 虚拟内存的概念搬到了 Agent 系统中。他们的核心思想是:
在 OS 虚拟内存中,空间局部性(Spatial Locality)意味着如果一个程序访问了某个内存地址,它很可能很快访问附近的地址。这就是为什么内存以页面为单位管理——利用局部性来最小化昂贵的缺页中断。Agent 系统中也有类似的局部性:如果 Agent 在讨论某个话题,它很可能继续讨论相关的话题。所以上下文也应该以"语义页面"为单位管理。
🔒 八、Isolation & Sandbox = 进程隔离与权限控制
8.1 为什么 Agent 需要进程隔离?
在 OS 中,进程隔离解决了两个核心问题:
- 安全性:进程 A 不能读写进程 B 的内存
- 可靠性:进程 A 崩溃不会影响进程 B
Agent 系统面临完全相同的问题:
- 安全性:Agent A 不能访问 Agent B 的对话历史/工具权限
- 可靠性:Agent A 的 LLM 幻觉/工具调用失败不应该影响 Agent B
8.2 当前的隔离现状
| 隔离维度 | OS 成熟度 | Agent 成熟度 |
|---|---|---|
| 内存隔离 | 成熟(MMU + 页表) | 初步(独立 State) |
| 文件系统隔离 | 成熟(namespace/chroot) | 初步(工具权限) |
| 网络隔离 | 成熟(network namespace) | 几乎没有 |
| 身份隔离 | 成熟(UID/GID) | 几乎没有 |
| 资源隔离 | 成熟(cgroup) | 初步(rate limit) |
| 审计日志 | 成熟(auditd) | 初步(LangSmith) |
Agent 框架在隔离方面还有很长的路要走。目前大多数多 Agent 系统的"隔离"仅仅是"各自有独立的 State 字典"——这在 OS 术语中相当于"所有进程共享同一个地址空间,只是用不同的变量名"。一旦 Agent 系统开始处理敏感数据(医疗、金融、法律),真正的进程级隔离将成为刚需。
🔍 九、Observability = 系统监控:dmesg、strace 与 LangSmith
9.1 OS 的可观测性工具
OS 有一套成熟的可观测性工具链:
| 工具 | 功能 | 输出 |
|---|---|---|
dmesg |
内核日志 | 系统事件流 |
strace |
系统调用追踪 | 每一次 syscall 的参数和返回值 |
top / htop |
实时资源监控 | CPU/内存/进程状态 |
perf |
性能分析 | 函数级耗时统计 |
tcpdump |
网络抓包 | 每一个网络包 |
auditd |
安全审计 | 安全相关事件的日志 |
9.2 Agent 的可观测性工具
Agent 系统正在建立类似的工具链:
| Agent 工具 | OS 对应 | 功能 |
|---|---|---|
| LangSmith | strace + perf |
追踪每一次 LLM 调用、工具调用、token 使用 |
| Langfuse | dmesg + auditd |
开源的 Agent 可观测性平台 |
| Weave | top + htop |
实时监控 Agent 执行状态 |
| Promptfoo | 单元测试 | 对 Agent 的输入/输出进行回归测试 |
| Braintrust | perf |
Agent 性能评估和优化 |
9.3 strace 思维:追踪每一次 Tool Call
strace 的强大之处在于它记录了进程的每一次系统调用——包括参数和返回值。Agent 系统的可观测性也应该做到同样的粒度:
# OS: 追踪一个进程的所有系统调用
$ strace -f -e trace=network,read,write ./my_app
# Agent: 追踪一个 Agent 的所有工具调用(理想状态)
$ agent-trace -f -e trace=tool_call,llm_invoke,token_usage ./my_agent
目前 LangSmith 已经接近了这个目标——它可以记录每一次 LLM 调用的 prompt/completion、每一次工具调用的输入/输出、token 使用量和延迟。但和 strace 相比,Agent 可观测性还缺少:
- 零侵入:
strace不需要修改目标程序的代码,但 LangSmith 需要你手动埋点 - 实时流式:
strace可以实时输出,Agent 追踪通常是事后查看 - 标准化:
strace的输出格式是统一的,Agent 追踪工具各有各的格式
🤔 十、为什么 Agent 必须"重新发明"OS?
10.1 不是重新发明,是重新发现
读到这里,你可能会问:既然 Agent 系统和 OS 这么像,为什么不直接用 OS 的方案?为什么要"重新发明轮子"?
答案是:因为"硬件"不同了。
OS 的设计是围绕确定性硬件的——CPU 指令是确定性的,内存访问是确定性的,磁盘 I/O 虽然慢但是可预测的。而 Agent 系统的核心计算单元——LLM——是概率性的:
| 维度 | OS(确定性) | Agent(概率性) |
|---|---|---|
| 计算结果 | 相同输入 → 相同输出 | 相同输入 → 不同输出 |
| 执行时间 | 可预测(指令周期) | 不可预测(推理时间波动大) |
| 错误模式 | 确定性错误(bug) | 非确定性错误(幻觉) |
| 资源消耗 | 可精确计算 | 不可精确计算(token 数取决于输出) |
| 测试 | 单元测试即可 | 需要统计性评估 |
这些差异意味着 OS 的很多方案不能直接搬过来,需要适配甚至重新设计。比如:
- 调度器:OS 假设每个任务的时间是可预测的,Agent 调度器必须处理时间不确定的任务
- 内存管理:OS 的页面置换基于确定性访问模式,Agent 的上下文管理必须处理概率性的"注意力分布"
- 中断:OS 的中断是精确的(在指令级别暂停),Agent 的中断是模糊的(在"推理步骤"级别暂停)
- 隔离:OS 用硬件(MMU)实现隔离,Agent 需要用软件实现"语义隔离"
10.2 Agent 独有的新挑战
除了适配经典 OS 问题,Agent 系统还面临一些 OS 从未遇到过的新挑战:
挑战一:推理成本
OS 不需要关心"执行一条指令要花多少钱"。但 Agent 系统必须关心——每调用一次 LLM,就是真金白银。这使得 Agent 的"调度"不仅要考虑时间和优先级,还要考虑成本。OS 调度器优化的是吞吐量和延迟,Agent 调度器需要同时优化吞吐量、延迟和成本的三元权衡。
挑战二:非确定性调试
OS 的 bug 是可复现的——同样的输入,同样的执行路径,同样的错误。Agent 的 bug 是概率性的——同一个 prompt,LLM 有时候返回正确结果,有时候返回错误结果。这使得传统的调试方法(断点、单步执行、日志)在 Agent 系统中效果大打折扣。
挑战三:信任边界
OS 的信任边界是清晰的——内核信任自己,不信任用户态程序。Agent 的信任边界是模糊的——LLM 是"内核"还是"用户态程序"?工具调用是"系统调用"还是"用户操作"?人类审核是"中断"还是"管理员登录"?这些边界的模糊性给安全设计带来了全新的挑战。
挑战四:状态爆炸
OS 的进程状态是有限的——寄存器、栈、堆、打开的文件描述符。Agent 的状态可以是无限的——对话历史可以无限增长,工具调用的返回值可以是任意大的 JSON,知识库的检索结果可以是无限多的文档。如何在无限状态空间中做检查点、恢复和垃圾回收,是 OS 从未面对过的问题。
10.3 AgenticOS:下一个前沿
这也是为什么 AgenticOS 2026 研讨会的命题如此重要。他们提出的四个研究方向——原语(Primitives)、隔离模型(Isolation Models)、调度技术(Scheduling Techniques)、可观测性机制(Observability Mechanisms)——恰好对应了 OS 的四个核心子系统。但 Agent-OS 不是简单地把 OS 搬过来,而是要在概率性计算的约束下重新设计这些子系统。
🎁 速查对照表
Agent 概念 vs OS 概念
| Agent 概念 | OS 概念 | 核心相似点 | 关键差异 |
|---|---|---|---|
| Context Window | 虚拟内存 | 有限的"物理容量"承载无限的"逻辑需求" | OS 是确定性的,Agent 是概率性的 |
| State / Channel | 进程间通信(IPC) | 多个执行单元之间的数据共享 | OS 用锁,Agent 用 Reducer |
| Reducer | 信号量 + 合并策略 | 声明式冲突解决 | Reducer 是编译时的,锁是运行时的 |
| Graph Execution | 进程调度 | 决定"下一步执行谁" | Agent 调度要考虑成本 |
| Human-in-the-Loop | 中断(Interrupt) | 暂停 → 处理 → 恢复 | Agent 中断是语义级的,不是指令级的 |
| Tool Calling | 系统调用(Syscall) | 受控的外部世界访问 | Agent 的"外部世界"更复杂 |
| RAG | 缺页中断处理 | 按需加载不在"内存"中的数据 | RAG 是语义检索,不是地址映射 |
| Checkpointer | 文件系统快照 | 保存/恢复执行状态 | Agent 状态可以是无限的 |
| LangSmith | strace + perf | 追踪执行过程 | Agent 追踪需要处理非确定性 |
| Tool Permission | 文件权限(rwx) | 访问控制 | Agent 权限控制还不够成熟 |
| Agent Sandbox | chroot / namespace | 执行环境隔离 | Agent 隔离需要"语义隔离" |
| Skill Loading | 页面换入/换出 | 按需加载到"内存" | 技能是语义单元,不是固定大小的页面 |
经典 OS 课程 → Agent 框架映射
| 你在 OS 课上学到的 | 你在 Agent 框架里遇到的 |
|---|---|
| 进程控制块(PCB) | LangGraph 的 State |
| 进程调度算法 | LangGraph 的图执行引擎 |
| 信号量(Semaphore) | Channel 的 Reducer |
| 管道(Pipe) | Agent 之间的消息传递 |
| 共享内存 | 共享 State + Reducer |
| 消息队列 | Channel / Topic |
| 中断处理 | Human-in-the-Loop |
| 系统调用 | Tool Calling |
| 虚拟内存 + 分页 | Context Window + RAG |
| 缓存替换(LRU/LFU) | 上下文淘汰策略 |
| 进程隔离(namespace) | Agent Sandbox |
| 检查点(Checkpoint) | LangGraph Checkpointer |
| dmesg / strace | LangSmith / Langfuse |
| chroot / cgroup | Tool 权限控制 |
| pthread_barrier | NamedBarrierValue |
| fork() / exec() | 创建子 Agent |
一句话总结
学 Agent 越学越像在学操作系统,因为 Agent 系统正在收敛到操作系统的设计模式上——进程调度变成了 Agent 编排,虚拟内存变成了上下文管理,系统调用变成了工具调用,中断变成了 Human-in-the-Loop。但 LLM 的概率性本质让这些经典问题有了新的变体:调度需要考虑成本,调试需要处理非确定性,隔离需要"语义隔离",状态空间可以是无限的。Agent 系统不是在重新发明 OS,而是在概率性计算的约束下重新发现 OS 的设计智慧——并且在这个过程中,创造出一门全新的"AgentOS"工程学科。
参考链接:
- The Missing Memory Hierarchy: Demand Paging for LLM Context (arXiv)
- Agent Skills Are Just Header Files (dev.to)
- Agent Operating Systems (Agent-OS): A Blueprint Architecture
- AgenticOS 2026: Operating Systems Design for AI Agents
- Colony: Virtual Context Memory
- Your LLM Needs Virtual Memory (aeshift)
- AI Operating Systems & Agentic OS Explained (Fluid.ai)
- LangGraph State Management in Practice (eastondev)
- LangGraph Multi-Agent Workflows: Production Patterns (inductivee)

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 25
25 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)