AMD Instinct MI350P 深度解析:PCIe AI 推理 GPU,正在重新进入企业级数据中心
AMD推出Instinct MI350P PCIe AI加速器,主打企业级AI推理场景。该产品采用标准PCIe形态,配备144GB HBM3E显存,支持风冷部署,强调在现有数据中心内的低成本部署能力。相比专注于训练的高密度方案,MI350P更关注推理效率、显存容量和实际交付性能,支持RAG、Agent等企业AI应用。其核心价值在于让大显存AI推理回归标准服务器架构,降低企业部署复杂度。该产品反映出
前言
过去两年,AI 基础设施的发展方向,几乎都在向更高密度、更大规模演进。AMD 和 NVIDIA 的精力几乎都集中在高密度模块化方案上——MI300X、MI350X 以及 H100、H200、B200 等旗舰产品均采用专用接口形态,本质上都在围绕“训练”展开:更大的模型、更高的带宽、更密集的 GPU 互连。
但对于大多数企业而言,实际面临的问题并不是“如何训练万亿模型”,而是如何在现有数据中心内部署 AI 推理能力,如何控制供电、散热与整体 TCO,以及如何兼容现有服务器架构并长期稳定运行。
尤其是在 RAG、Agent、企业知识库、本地化大模型部署逐渐进入生产环境之后,企业开始重新关注一种更现实的路线:
在标准 PCIe 服务器体系内构建 AI 推理能力。
AMD 最新发布的 AMD Instinct MI350P,正是在这一背景下出现的产品。相比强调极限训练性能的 OAM 平台,MI350P 更关注企业 AI 推理场景中的实际部署问题:如何以更低的数据中心改造成本,在标准服务器架构中部署当前 generation 的 AI 推理能力。
什么是 AMD Instinct MI350P?
AMD Instinct MI350P 是 AMD 基于 CDNA4 架构推出的企业级 PCIe AI 加速器,主要面向企业级 AI 推理、私有化大模型部署、Agent 工作负载以及 RAG 检索增强等场景。相比 MI350X 等 OAM 形态产品,MI350P 更强调标准 PCIe 服务器兼容性、风冷部署能力以及渐进式 GPU 扩展能力。
从规格来看,MI350P 采用 FHFL 双槽 PCIe 形态,配备 144GB HBM3E 显存与 4TB/s 显存带宽,支持 PCIe Gen5 x16 接口,TBP 为 600W,同时支持 450W 模式。GPU 本身采用单 IOD + 4 XCD 的 chiplet 组合设计,完整支持 FP16、BF16、FP8、MXFP4 等低精度格式。
它的定位并不是构建超大规模训练集群,而是在标准 PCIe 形态下,为企业提供高显存、高带宽的 AI 推理能力。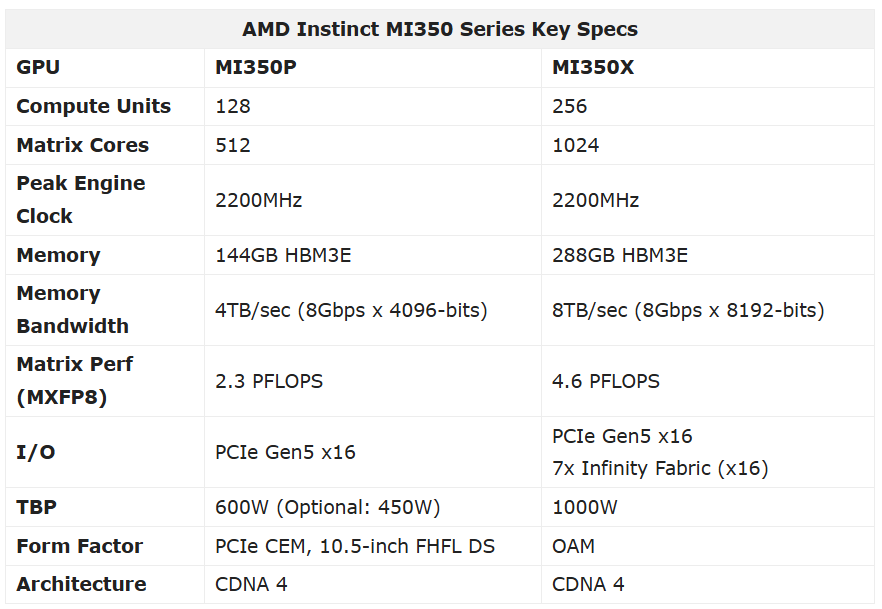
这次 AMD 在 MI350P 上,除了公布理论峰值外,还首次同步给出了更接近真实推理场景的 Delivered Performance(实际交付性能)。
达成率存在差异的原因在于,600W 的功耗预算无法让所有晶体管同时跑在极限频率上。电气限制和内存带宽瓶颈共同作用,导致低精度格式的理论利用率反而偏低——MXFP4 的达成率约为 50%,而 FP8/BF16 的达成率则在 60% 以上。
横向对比的话,MI350P 在 FP16 和 FP8 的理论峰值上比 NVIDIA H200 NVL 高出约 40%。不过需要提醒的是,实际推理性能不只取决于 FLOPS,还受内存带宽、模型规模、精度格式、框架优化程度等多重因素影响,简单的 FLOPS 对标只能作为初步参考,Delivered Performance 对企业更有参考价值。
为什么企业开始重新关注 PCIe AI GPU?
这是 MI350P 背后最值得关注的行业变化。过去几年,高端 AI GPU 逐渐向 OAM、SXM、液冷以及 GPU Pod 方向演进,但现实情况是,并不是所有企业都具备重构 AI 数据中心的条件。
很多企业当前真正需要的,其实是在现有机房内部署 AI,在标准服务器内增加 GPU 能力,并支持多业务并发推理与渐进式扩容。尤其在企业 AI 推理场景中,训练并不是长期核心负载,真正持续运行的往往是企业知识库、AI 搜索、RAG、Agent、Copilot 以及推理 API 服务。
这些场景相比超大规模训练,更关注:
● 单节点显存容量
● 推理吞吐
● 稳定性
● 部署复杂度
● 长期 TCO
而 PCIe GPU 的价值,也开始重新体现。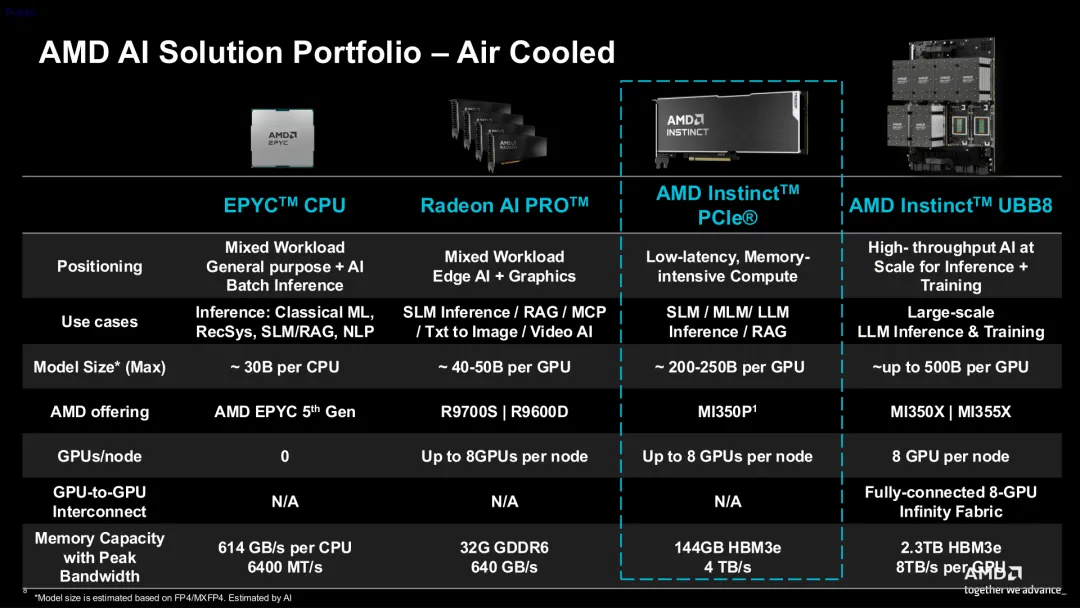
MI350P 的核心价值:高显存 AI 推理回归标准服务器
MI350P 最大的特点,并不是单纯的理论 FLOPS,而是在标准 PCIe 形态下,提供当前代 AI GPU 的推理能力。
AMD 官方披露,MI350P 支持双槽 PCIe 风冷部署、PCIe Gen5 x16 接口以及标准机架服务器环境,最高可部署于 8 GPU 节点。这意味着,很多已经部署 EPYC 双路服务器的平台,可以直接扩展 AI 推理能力,而不需要重新建设专用 GPU 集群。
对于企业 IT 基础设施团队而言,这种部署方式更加接近传统服务器运维逻辑:
● 电力体系更容易兼容
● 风冷机房可直接适配
● 扩容节奏更灵活
● 维护复杂度更低
这也是 MI350P 与 OAM GPU 最大的差异之一。
为什么 144GB HBM3E 很重要?
在当前 AI 推理场景中,很多企业真正遇到的瓶颈已经不是纯计算能力,而是显存容量。尤其是长上下文、多用户并发、Agent Workflow、KV Cache 以及多模型同时运行等场景,都会明显增加显存压力。
MI350P 配备 144GB HBM3E 与 4TB/s 显存带宽,相比传统 PCIe GPU,更适合承载大参数量模型、长上下文推理以及多模型服务。它的价值不只是“参数更高”,而是能够减少张量切分、CPU 回退、跨卡通信以及频繁 KV Cache 交换,从而影响整体推理延迟、系统稳定性以及 GPU 利用率。
对于企业来说,这类大显存 PCIe GPU 的价值,正在逐渐从“性能提升”转向“部署复杂度优化”。
CDNA4 的重点,已经开始转向 AI 推理效率
从 MI350 系列的设计方向可以看到,AMD 正在强化 FP8、MXFP4、MXFP6 等低精度推理能力。MXFP(Microscaling Floating Point)是 OCP 推动的新型低精度格式,其特点是更低显存占用、更高推理吞吐以及更适合大模型推理。
对于 AI 基础设施而言,这意味着 GPU 的核心指标,正在从传统 HPC 时代的 FP64、科学计算能力,逐渐转向:
● Token 吞吐
● 推理效率
● Token/W
● Token/$
这也是当前企业 AI 基础设施演进的重要方向。
企业部署 MI350P 时,需要关注什么?
相比消费级 GPU,企业 AI 推理平台真正复杂的部分,往往不只是 GPU 本身。在实际部署中,更需要关注服务器平台兼容性、PCIe Gen5 拓扑、CPU NUMA 结构、GPU P2P、电源冗余以及风道散热设计。
此外,ROCm 与推理框架兼容性同样值得重点验证,例如:
● vLLM
● SGLang
● PyTorch
● Kubernetes
● TGI
不同模型、不同推理框架,对 ROCm 的适配成熟度仍然存在差异,因此企业在正式上线前,通常需要进行实际业务 PoC 测试。
需要注意的是,MI350P 更适合推理、微调以及多模型服务场景,而不是大规模分布式训练。由于其主要通过 PCIe Gen5 通信,并未像 OAM 平台一样提供高带宽 GPU Scale-Up 互连,因此如果企业核心目标是超大规模训练,MI350X 等 OAM 架构仍然更适合。
MI350P 释放出的行业信号
MI350P 的意义,并不只是 AMD 发布了一块新的 GPU,更重要的是,它反映出 AI 基础设施正在进入新的阶段。
过去行业更多关注:
● 谁的参数更大
● 谁的训练规模更高
● 谁的 GPU 更贵
但进入企业生产环境后,真正重要的问题开始变成:
● 如何稳定运行
● 如何长期扩展
● 如何控制 TCO
● 如何兼容现有数据中心
● 如何真正进入业务系统
而这类 PCIe AI GPU 的重新出现,也说明企业 AI 推理,正在从“实验室阶段”逐渐进入“标准化基础设施阶段”。
FAQ:企业部署 AMD Instinct MI350P 前,需要了解什么?
Q1:MI350P 与 MI350X 的核心区别是什么?
两者都基于 CDNA4 架构,但定位不同。MI350X 更偏向超大规模训练与 HPC 场景,采用 OAM 形态并支持更高带宽 GPU 互连;MI350P 则采用 PCIe 形态,更适合企业级 AI 推理、本地化部署以及标准服务器环境。
Q2:MI350P 是否可以直接部署在现有服务器中?
需要视服务器平台而定。理论上,支持 PCIe Gen5、具备足够供电与散热能力的双路服务器平台即可部署,但实际仍需重点验证:
● 单卡 600W 功耗支持
● 风道设计
● GPU 间距
● PCIe 拓扑结构
● 电源冗余能力
Q3:MI350P 更适合训练还是推理?
更适合推理。尤其适用于:
● RAG
● Agent
● Copilot
● 私有化大模型部署
● 多模型服务
如果企业目标是超大规模分布式训练,OAM 平台仍然更合适。
Q4:144GB HBM3E 的实际价值是什么?
相比传统 PCIe GPU,更大的显存意味着:
● 更适合长上下文
● 更适合多用户并发
● 更容易承载大参数模型
● 可减少跨卡通信与 CPU 回退
对于企业 AI 推理系统而言,大显存往往直接影响整体部署复杂度。
Q5:MI350P 与 NVIDIA H200 NVL 怎么选?
两者处于同一功率区间。MI350P 在 FP16/FP8 理论峰值上高出约 40%,且显存容量更大(144GB vs 141GB)。实际选择需综合考虑软件生态(ROCm vs CUDA)、模型兼容性以及供应商支持能力。若更关注大显存、PCIe AI 推理、开放生态、推理性价比等,可以考虑MI350P。
赋能科技,智创未来
从 MI300 系列到 MI350P,可以明显看到 AMD AI 路线正在发生变化:不仅关注极限训练性能,也开始覆盖企业级 AI 推理、标准 PCIe GPU 部署以及开放 AI 软件生态。
对于企业而言,未来 AI 平台建设的重点,也会逐渐从“单卡性能”转向:
● 架构可扩展性
● 推理效率
● 资源利用率
● 长周期运营能力
在实际项目中,企业真正需要的,往往也不只是 GPU 本身,而是如何构建稳定的 AI 算力底座,如何兼容不同模型路线,以及如何让 AI 能真正进入生产系统。
这也是当前企业级 AI 基础设施建设正在发生的变化。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)