< 8 > Linux 进程:冯诺依曼体系结构 + 操作系统OS + 进程
本文摘要: 冯诺依曼体系结构是现代计算机的基础架构,由CPU、存储器(内存)和外部设备(输入/输出设备)组成。其核心特点是CPU不直接访问外设,而是通过内存作为中介进行数据交互,解决了CPU与外设速度差异导致的效率问题。操作系统通过进程管理(PCB结构体)实现软硬件资源管理,采用"先描述再组织"的方式。进程运行涉及虚拟地址空间机制,父子进程通过写时拷贝实现数据隔离,同时共享代码
1.2 存储器(内存)—— 外设与CPU数据流的中介 & fflush的原因
1.3 为什么CPU 不向 外设 直接读写数据?—— 读写速度量级差异!
1.4 为什么 CPU 和 外设 差异极大? —— 存储分级原理
2.2 为什么要有操作系统?—— 管理软硬件,稳定 安全 高效
2.3 操作系统如何管理软硬件资源?—— 结构体+数据结构+分层级管理
3.22 运行程序时,先在OS创建PCB,再加载代码、数据进入内存
3.23 存在多个进程,就存在多个PCB,每个独立,即便父子进程
3.34 ls /proc/数字pid -l —— 查看指定pid进程的内部信息
3.38 chdir("指定路径") —— 修改cwd、缺省路径
3.39 getcwd(字符数组,字符数组大小) —— 获取 当前路径cwd
3.41 ps [axj] | head -1 —— 提取第一行,表头。用于查看进程类型
3.43 命令行解释器 直接运行的 程序,其父进程是命令行解释器
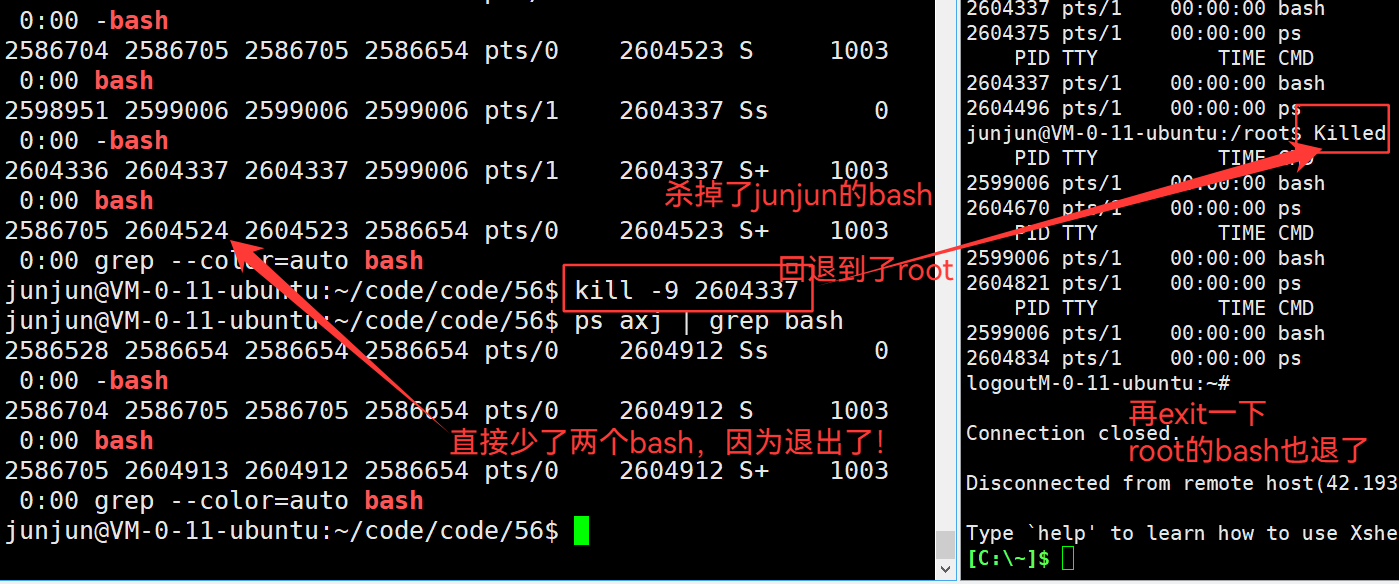
3.45 kill [-9] [bash的pid] —— 关掉 bash 命令行解释器
3.43 fork 有 两个返回值 —— 导致 if else 都会执行
3.44 为什么父进程得到子进程pid返回值? —— 需要唯一值,标识不同子进程
3.45 所以为什么会有两个返回值?—— 子进程一旦被创建就开始共享代码
3.46 为什么一个id,有两个值? —— 代码共享、数据拷贝
1. 冯诺依曼体系结构
1.1 冯诺依曼体系结构是什么?如何定义外设
如果有人问你,你的电脑的体系结构是什么?你可以回答:
英特尔,ARM
如果有人问你,你的计算机的体系结构是什么?就要回答:
冯诺依曼体系结构。
计算机,笔记本电脑,服务器,所有的智能电子设备绝大部分都遵守 冯诺依曼体系结构
原因是它是目前最兼具效率与性价比的方案,极大程度推动了互联网的发展(后面讲)
计算机的 所有上层行为,都会被转化为计算问题,交给CPU,算出对应的二进制表达式
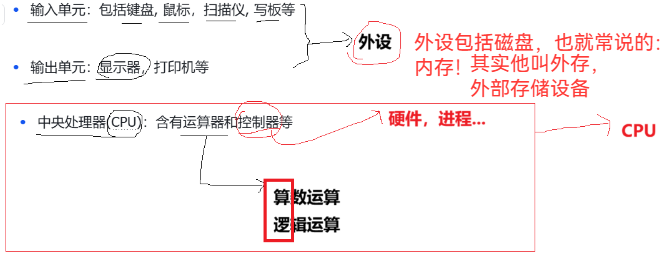
在冯诺依曼体系结构中,只有三个概念:外部设备,内存,CPU
外部设备又分为:输入设备,输出设备,英文就是:input,output,简称IO流!
外部设备的磁盘是重点:它不是内存,习惯上称之为内存,但其实是:外存,外部存储设备
并且磁盘可读可写,所以是输入设备,也是输出设备!
1.2 存储器(内存)—— 外设与CPU数据流的中介 & fflush的原因
从软件层面上,存储器,内存,就是缓存。它批量化存储外设的数据,最后批量化返回结果。这也是为什么进度条项目需要刷新缓冲区,其实他们存在内存中了,还没结束,CPU不返回。
主动刷新才会一次性返回,不然就会攒够再返回
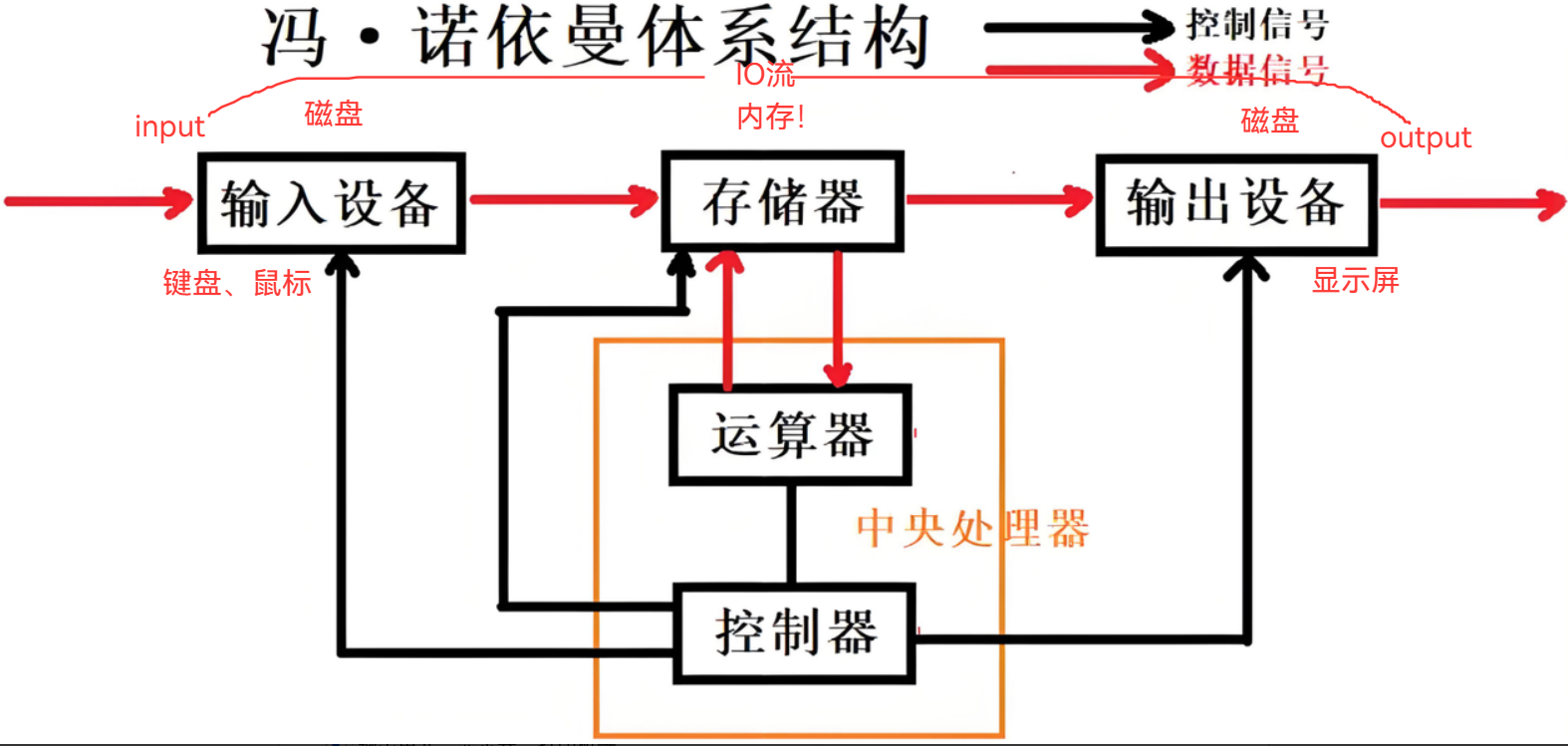
冯诺依曼体系结构中,存储器就是内存
不考虑缓存,CPU不会直接和外设进行访问、数据交换! 只能控制行为(暂时不考虑)
CPU只能和存储器——内存,进行读写操作
外设也只能和存储器——内存,读取或写入
他们层次分明,CPU <-> 存储器 <-> 外设
CPU和外设:只会向内存 读写数据!
1.3 为什么CPU 不向 外设 直接读写数据?—— 读写速度量级差异!
没有冯诺依曼体系结构时:没有存储器,外设就是直接与CPU读写数据
结果:运行缓慢!延迟很大。发送信息延迟极大,体验极差。
原因:CPU精度很高,计算速度是纳秒级别,内存极小。外设精度低:毫秒级,内存稍大,早期没有内存缓冲的概念,外设与CPU只能一个个数据传递,每个数据读写延迟都很大,1000个数据,
效率就是1000 * 延迟
他们读写数据存在量级差异! CPU读写完1000遍,外设可能还没响应!
冯引入存储器。虽然存储器的速度居中,但是存量大,并且因为有内存缓冲,它可批量读取外设的临近数据,而不是一个个读写。批量地与CPU进行交互,最后批量地返回结果给外设,运行速度量级提升。1000个数据,只需要一次延迟,效率差距悬殊。
有了这个中介,运行速度和延迟得到极大的改善,存储器的引入,性价比极高,买得起的人也多,促使了互联网的兴盛
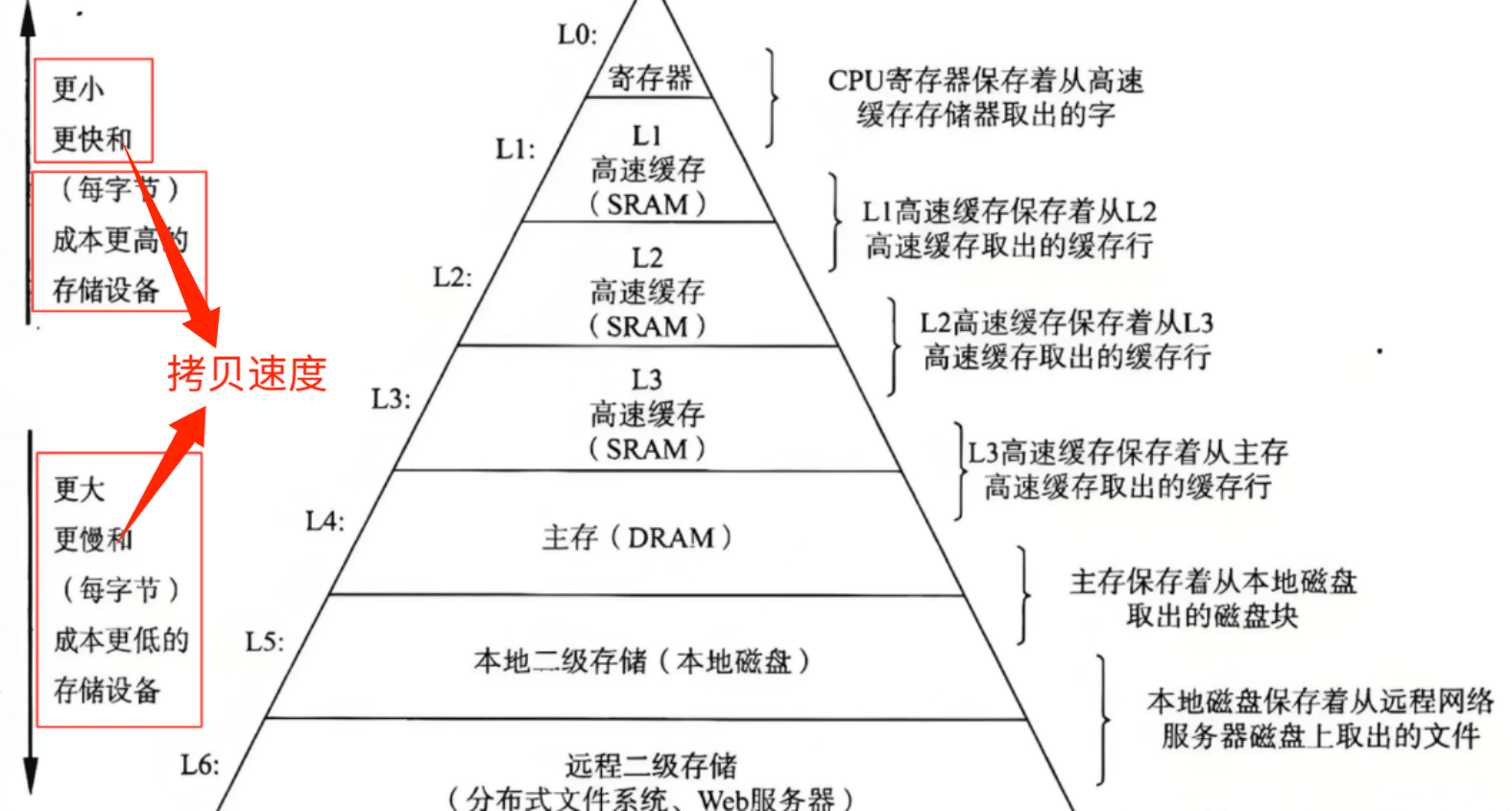
1.4 为什么 CPU 和 外设 差异极大? —— 存储分级原理
寄存器,高速缓存速度极快,内存极小,造价很贵,CPU速度快的核心
高速缓存在CPU内部,可批量读写数据,
这是早期外设只能逐个数据读写的根本原因。造价也贵
主存,其实是存储器,能提取磁盘块,利用了缓存机制,可批量化读写数据给CPU,极大幅度减少延迟,提升效率
再往下,就是外设级别的设备,逐个读取数据。虽然现代的外设多少有缓存机制,但与上面的仍是天壤之别。
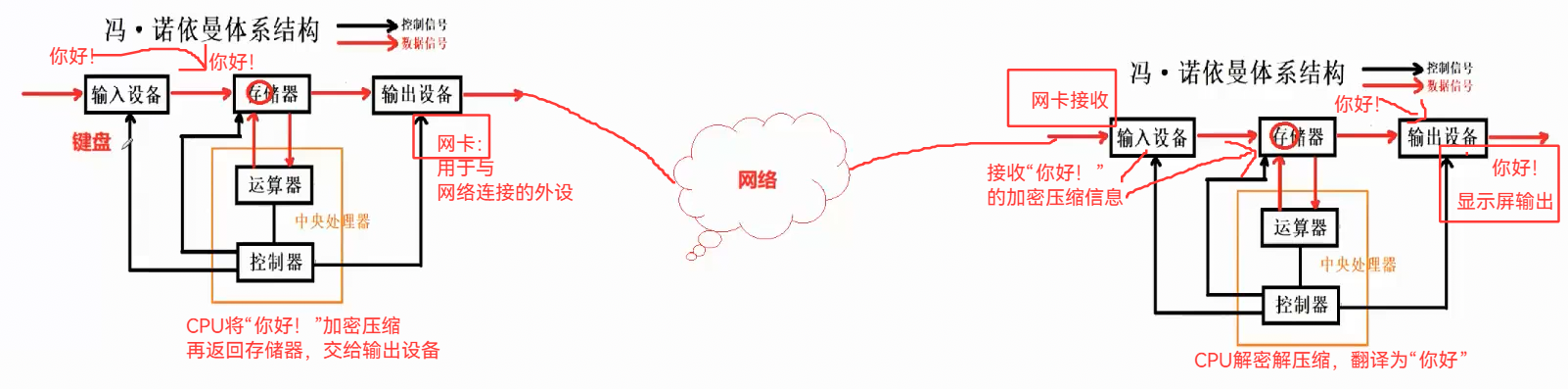
1.5 模拟 冯诺依曼体系结构 下 的 运行原理
如果是发送文件,那也一样,不同的是:信息是从键盘读取,文件是从磁盘读取,存储在磁盘
文件会被加密压缩,再通过网络发送到另一台设备接收。
本地存储器是会保留的,信息也一样,会还给外设(磁盘),所以聊天记录,文件等,都可以在本地磁盘搜索到,对方设备也一样
2. 操作系统(Operator System)
2.1 操作系统概念
任何计算机系统都包含一个基本的程序集合,称为操作系统(OS)
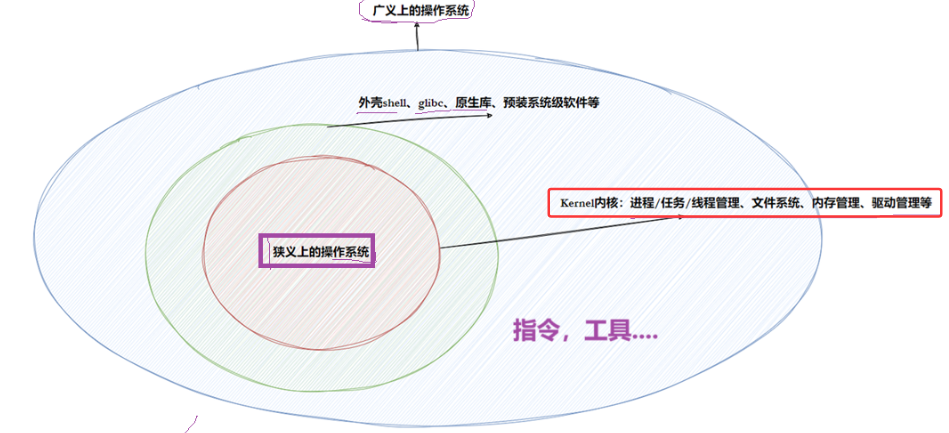
广义操作系统:Linux 操作系统内核 + Shell命令行 + 指令 + 核心应用软件,比如刚买的手机
狭义操作系统:Linux 操作系统内核 -> 作用:文件管理,进程管理,内存管理,驱动与设备管理
2.2 为什么要有操作系统?—— 管理软硬件,稳定 安全 高效
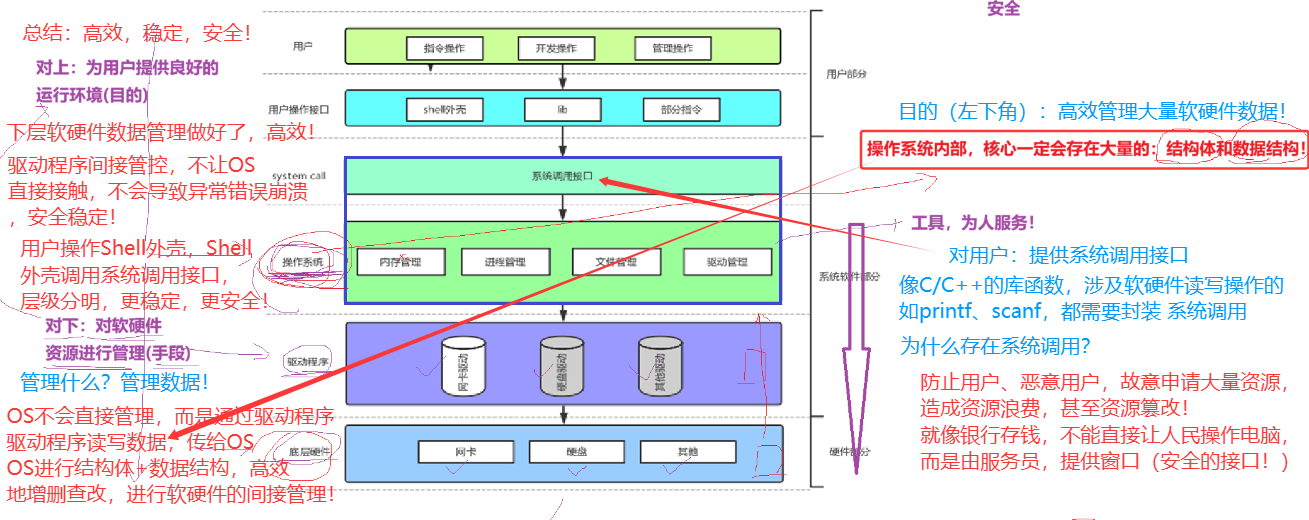
1.作用: 与硬件交互,管理所有软硬件资源
2.目的: 为用户提供稳定、安全、高效的运行环境、计算机
2.3 操作系统如何管理软硬件资源?—— 结构体+数据结构+分层级管理
现实中,写项目也是,任何东西用计算机语言进行管理时,都是:
先描述,再组织 -> 搞清楚需求,再编写代码
操作系统管理软硬件,就是管理他们的数据!
数据怎么管理?链表,数组,批量化管理,
问题转变为 结构体/类 + 数据结构 -> 写项目也是,都是结构体/类 + 数据结构!
总结:计算机世界,一切皆数据!管理数据,需要数据结构。
工程项目,面向对象,那就需要结构体、类进行安全封装,方便使用!
3. 进程
3.1 进程概念
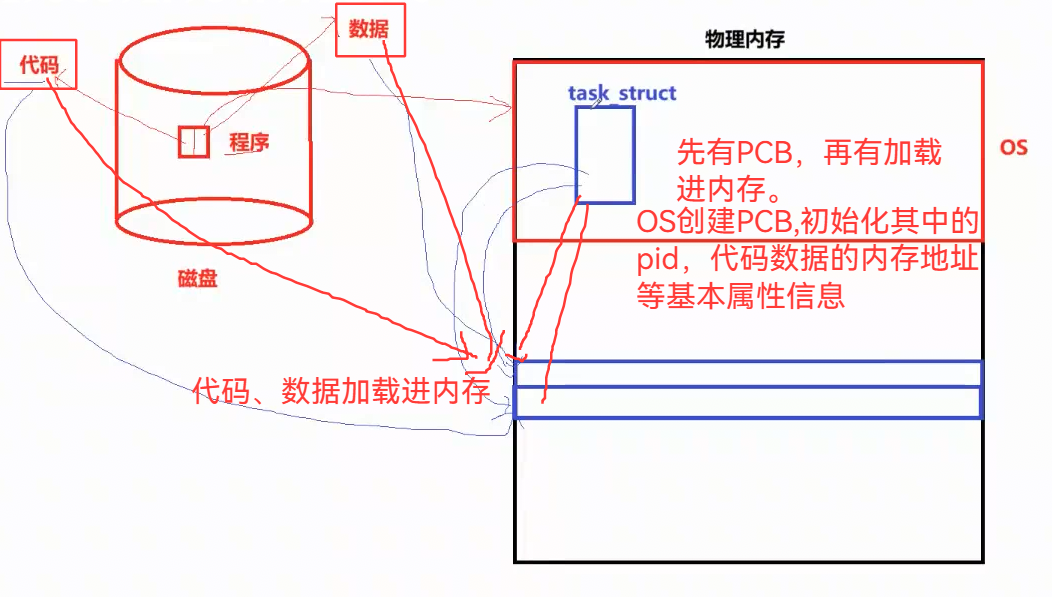
进程(task、任务):正在运行的程序 是 进程,加载进内存中的程序 是 进程
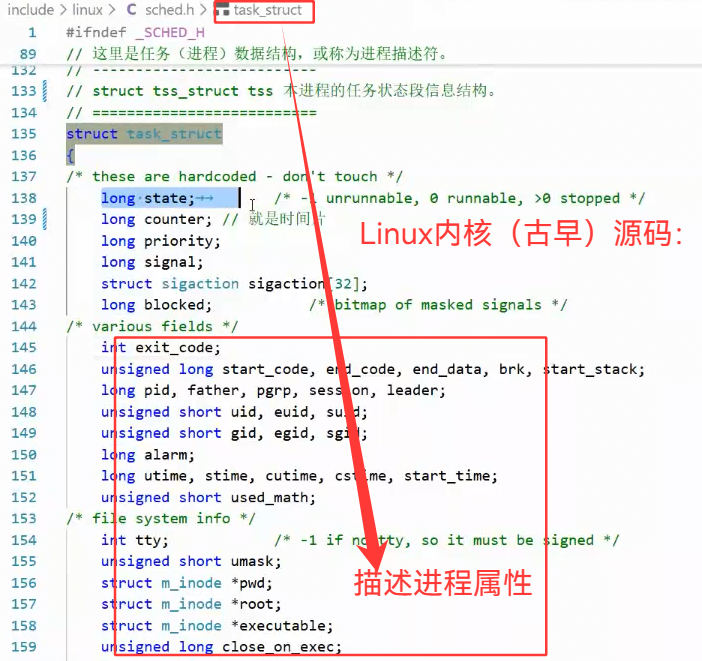
进程本质:操作系统内核的PCB结构体 + 加载进内存的程序代码和数据
PCB:(Process Control Block,进程控制块),具体如Linux:struct task_struct
,里面存放的是具体进程的属性数据。多个不同的进程有多个不同的PCB
PCB具体源码样例:
所有启动的程序,都会转化为进程,被操作系统运行
程序包括各种shell指令,系统工具,应用软件,二进制可执行程序

3.2 进程原理
操作系统OS可同时执行多个进程,比如windows电脑,它底层就是Linux操作系统。
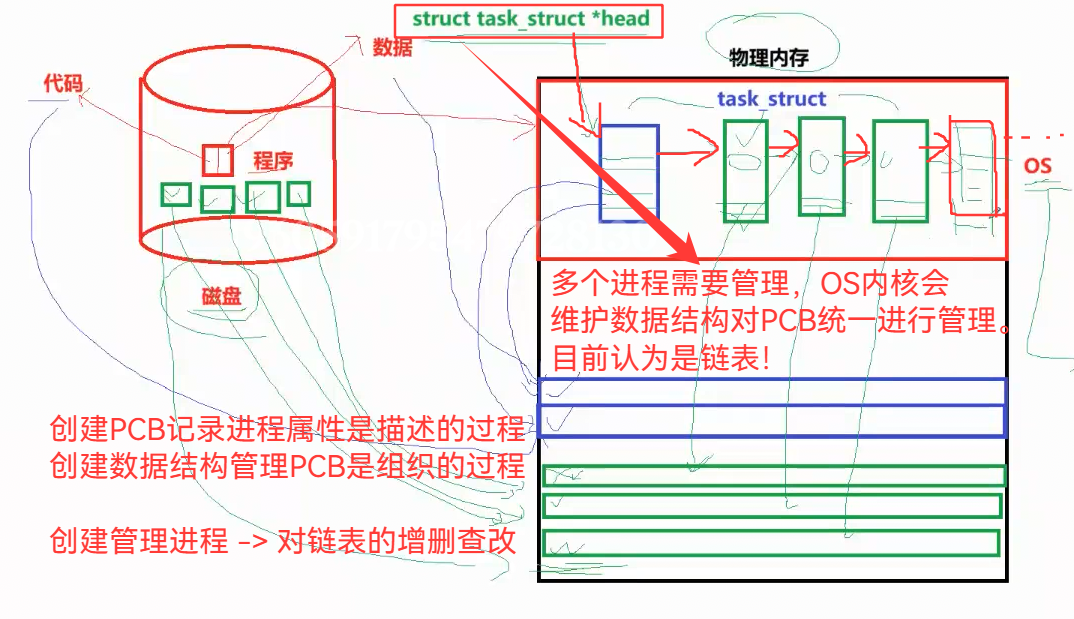
既然有多个进程,那操作系统肯定要对进程进行管理。如何管理?
就回到了上面的知识——
先描述,再组织:利用结构体+数据结构,将管理进程简化为:对数据结构的增删查改
这说明:必然在内核中,存在结构体,对进程进行描述。(PCB)
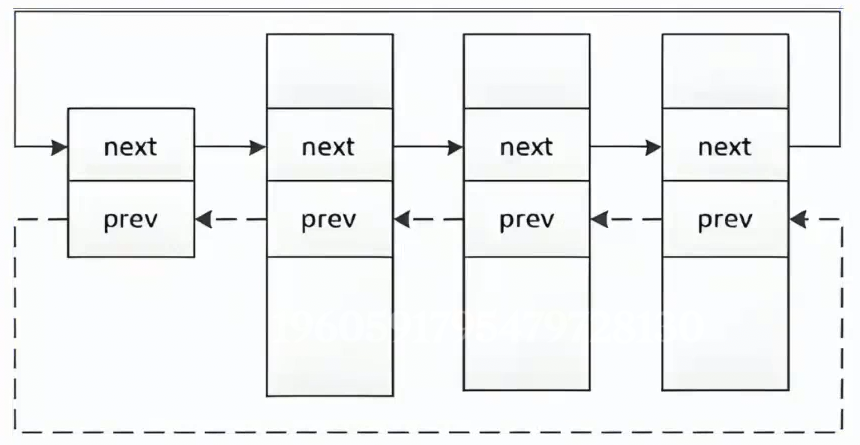
必然在内核中,存在数据结构,对多个进程,进行增删查改的管理,组织(链表)
下面看看进程的原理:

3.21 电子设备启动,会先加载操作系统到内存中
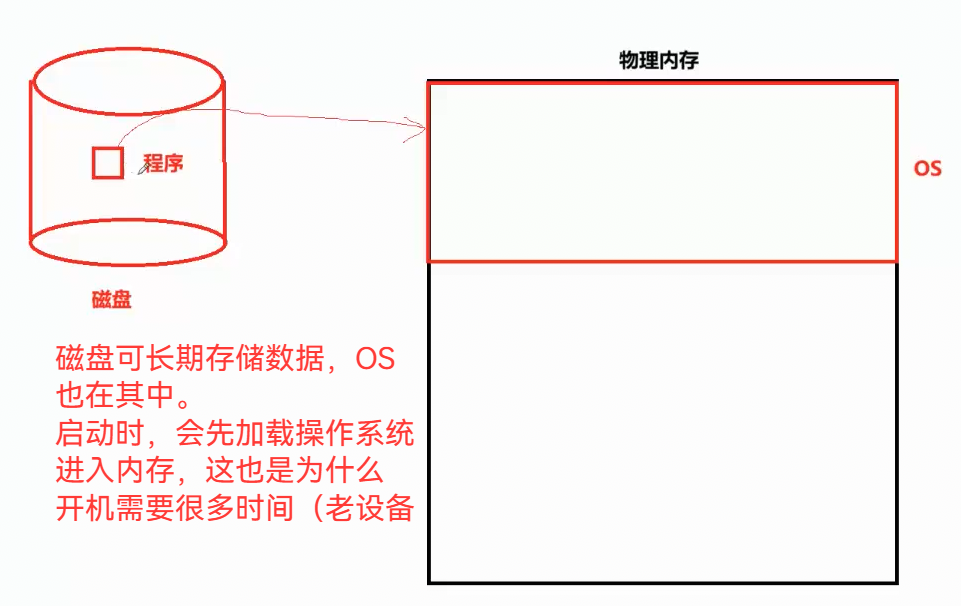
3.22 运行程序时,先在OS创建PCB,再加载代码、数据进入内存
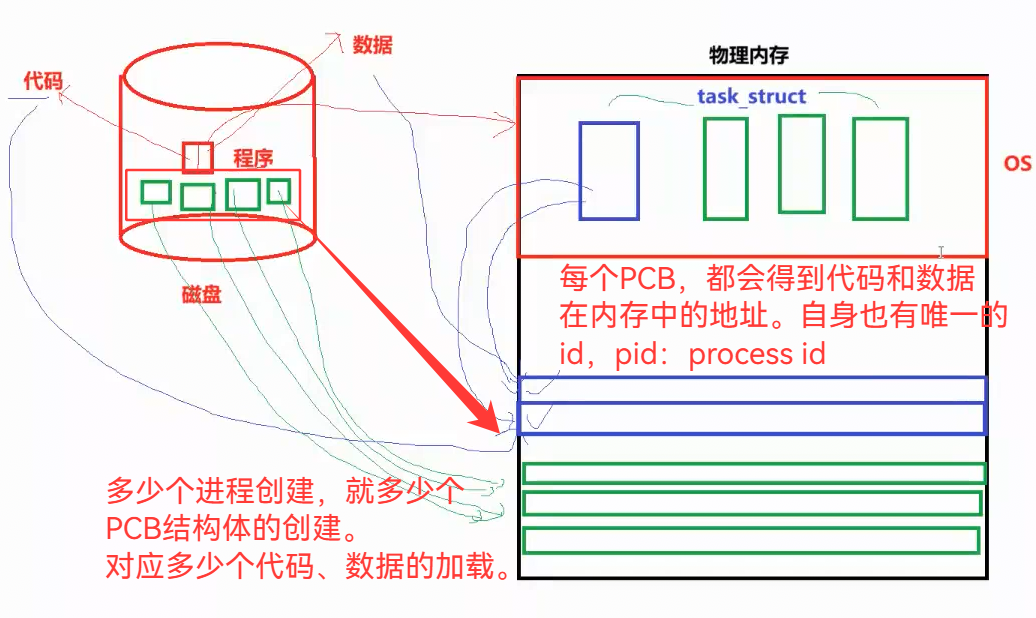
3.23 存在多个进程,就存在多个PCB,每个独立,即便父子进程
不过,多个进程执行同一段代码(如父子进程),代码是会共享的
数据不会共享,会重新拷贝一份数据。他们地址表面一样,实则是虚拟地址
3.24 CPU只会去OS内核的PCB中寻找进程
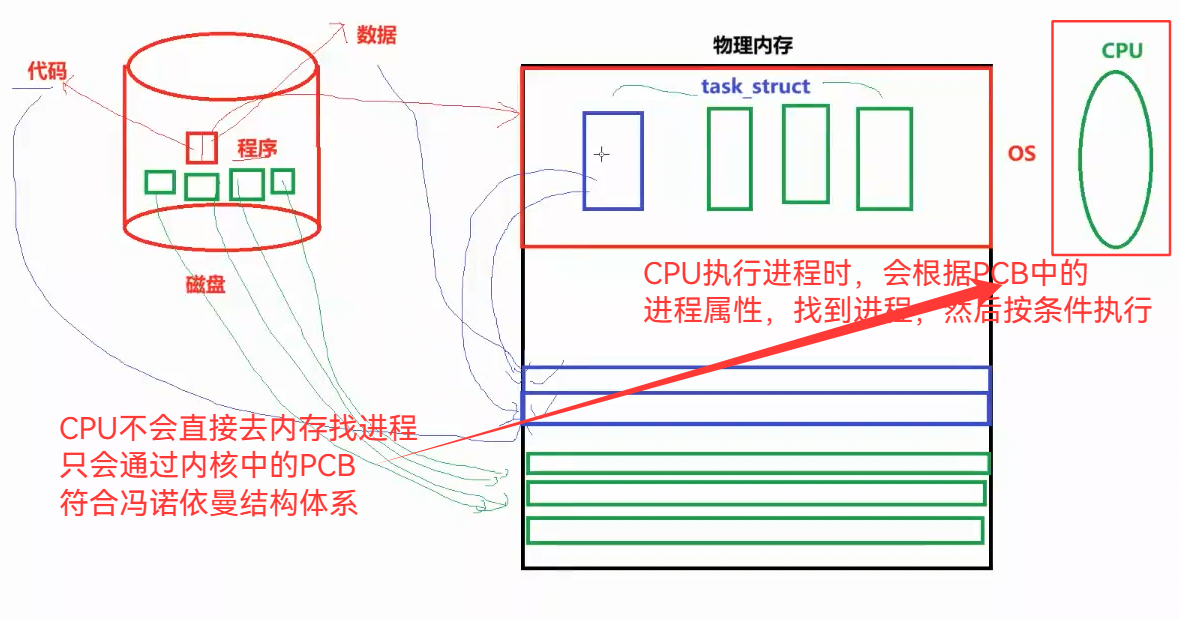
3.25 描述组织 -> 增删查改
3.3 查看进程信息 以及 阐述概念
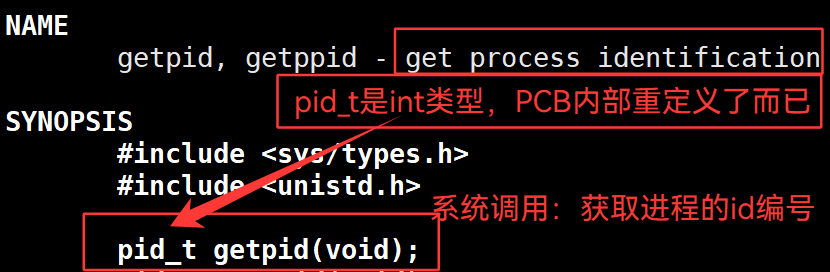
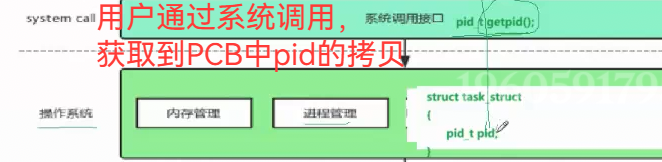
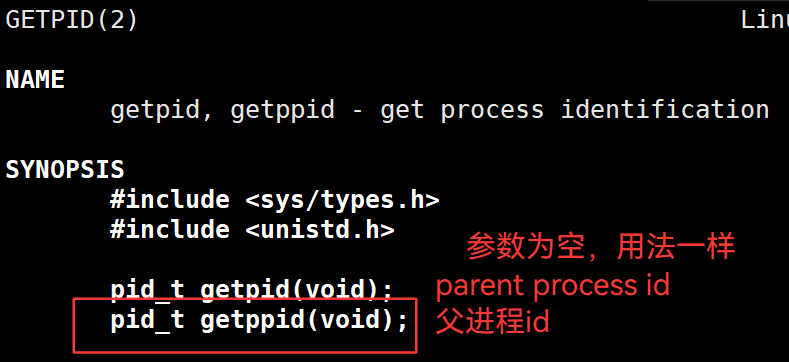
3.31 getpid()—— 获取进程 id
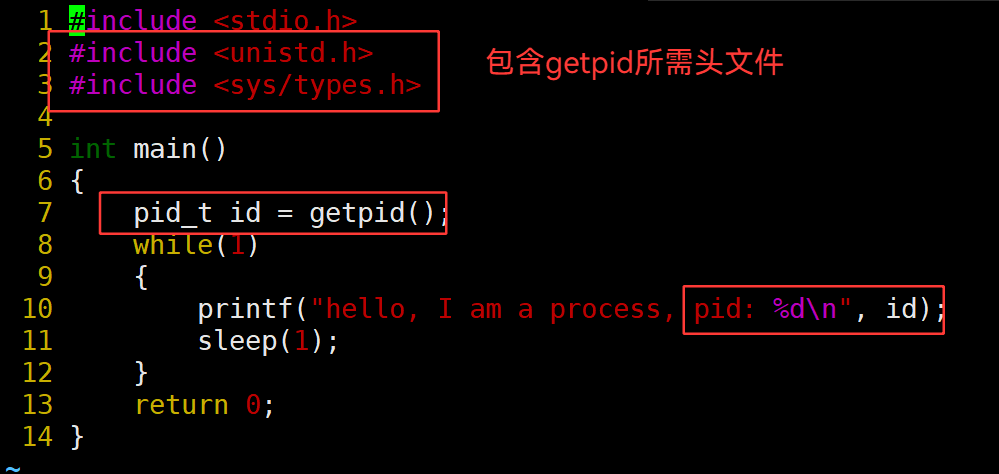
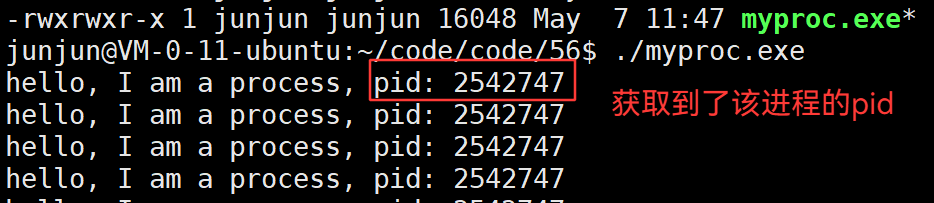
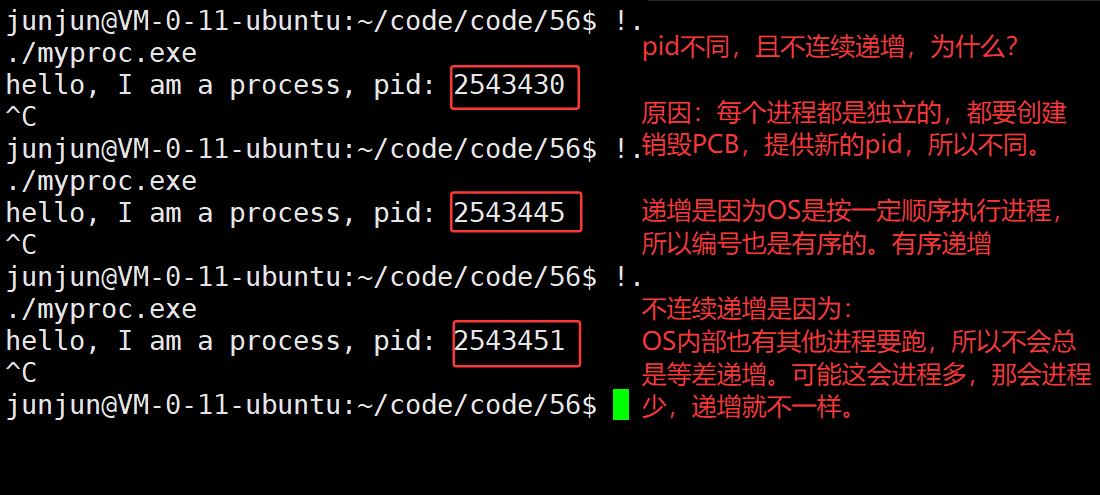
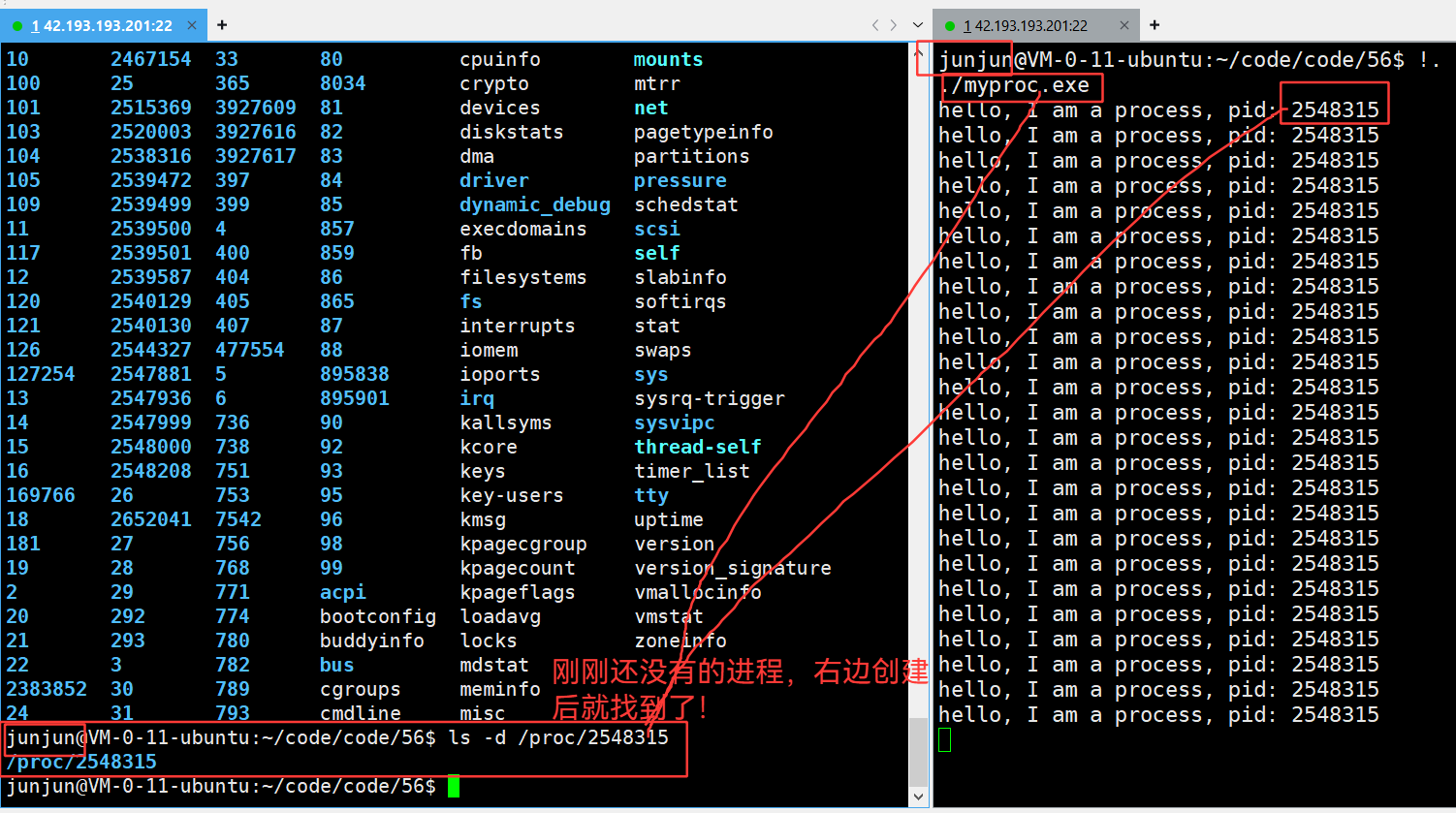
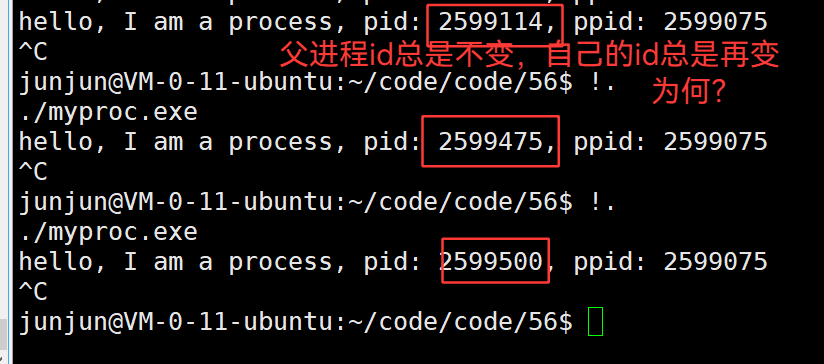
3.32 新建进程,pid为什么总是不同,且不等差递增?
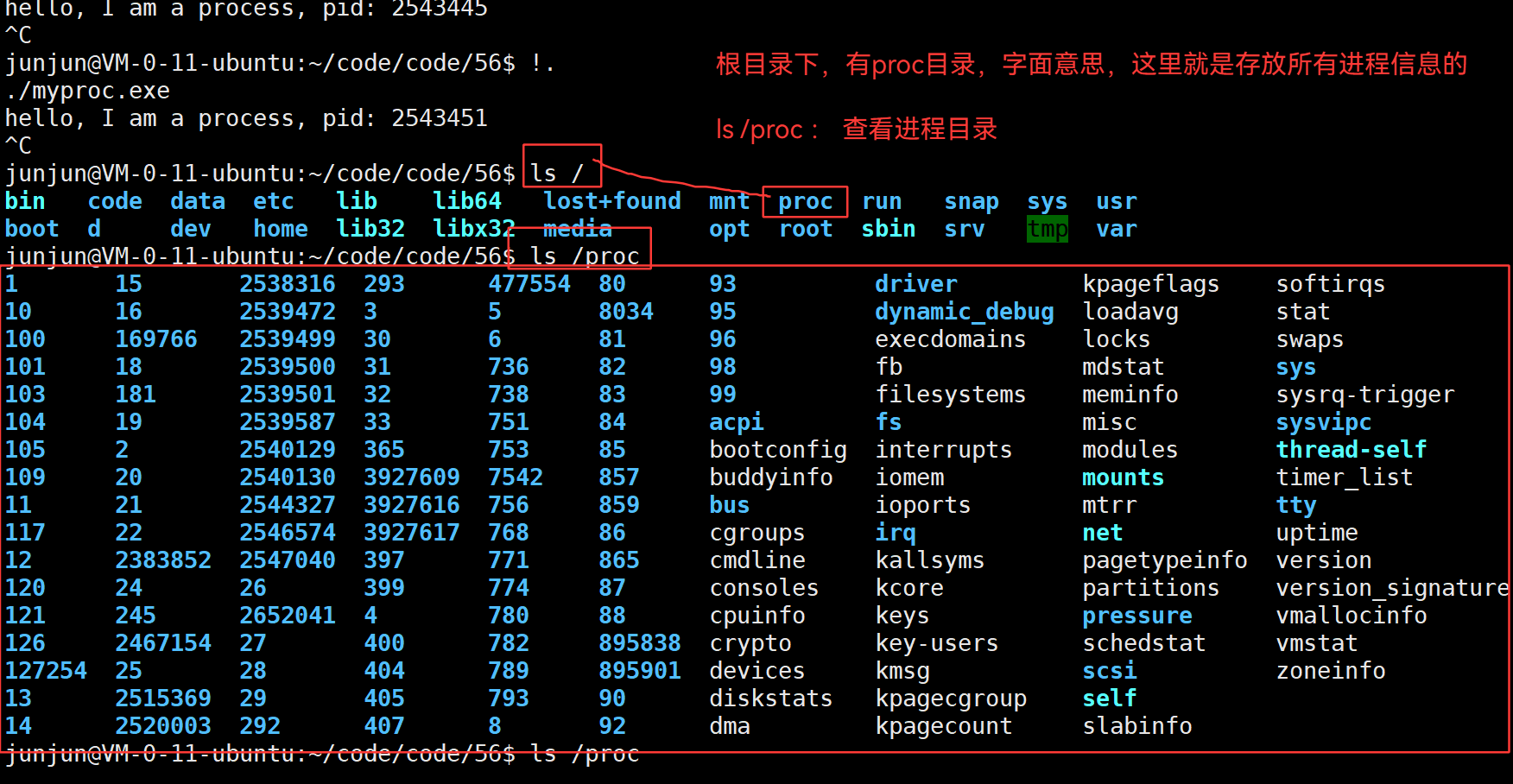
3.33 ls /proc —— 查看进程目录
那些非数字的,都是系统级信息,不需要了解。
而那些数字命名的目录,都是:pid!
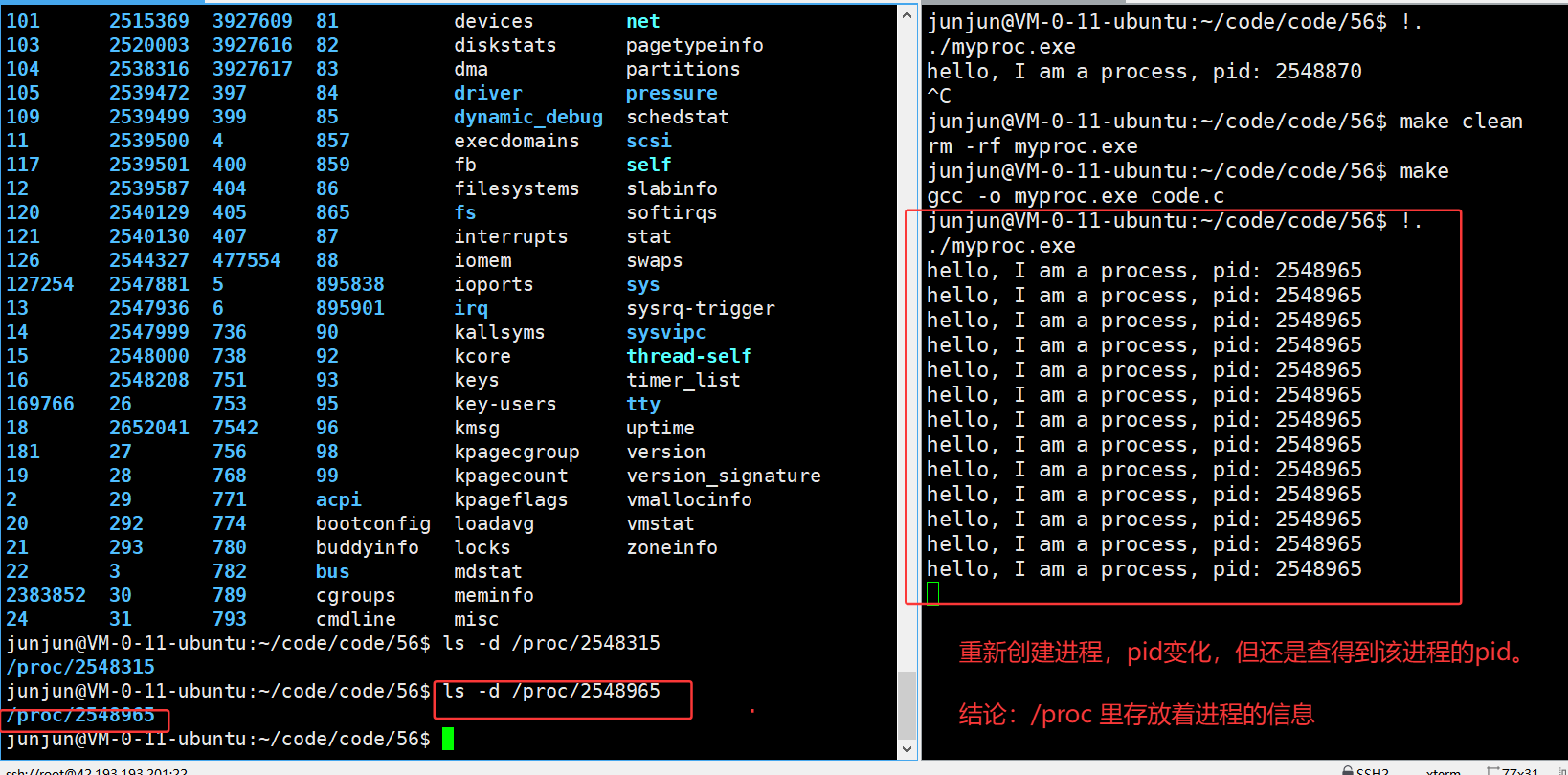
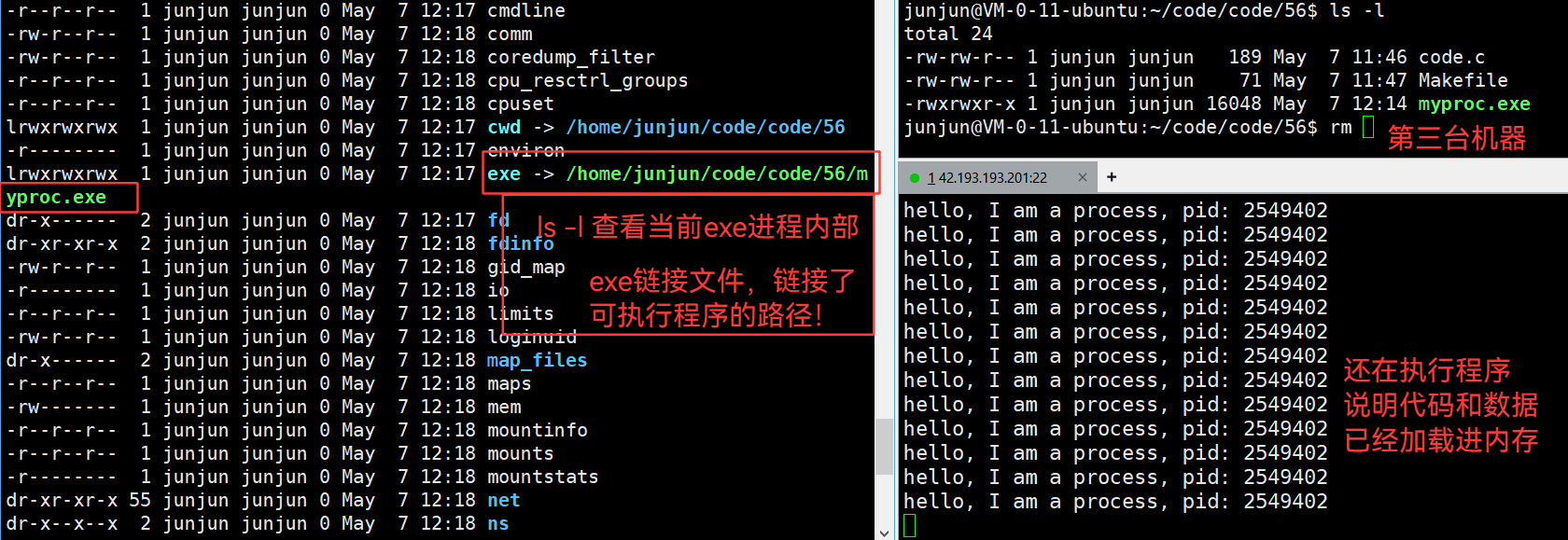
3.34 ls /proc/数字pid -l —— 查看指定pid进程的内部信息
3.35 进程 与 程序 的独立性验证
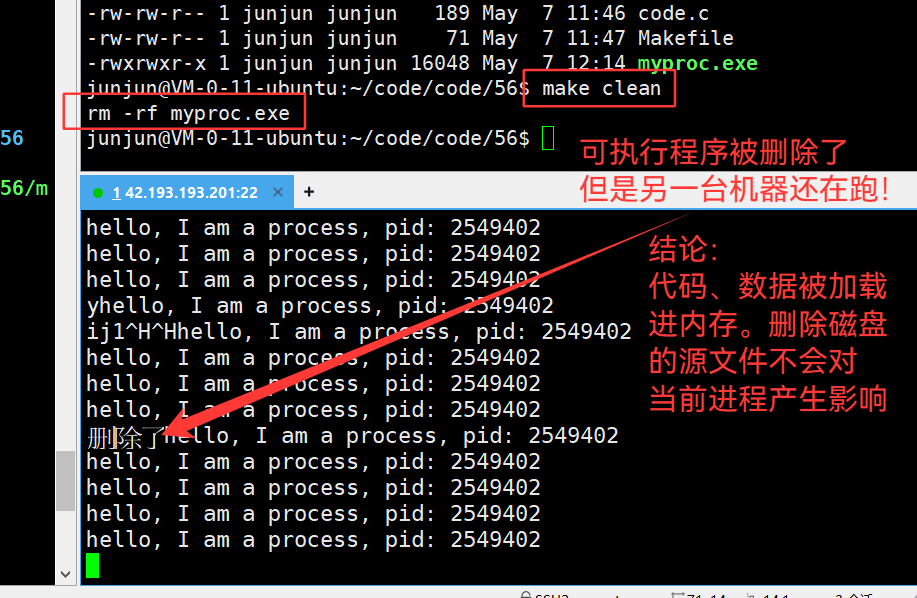
但是左侧机器重新输入 ls /proc/2549402 -l 时:
变红了,并且标明了删除:说明链接文件丢失了,因为原路径的exe被标记删除!
进程还在运行,但是磁盘文件被删除了。
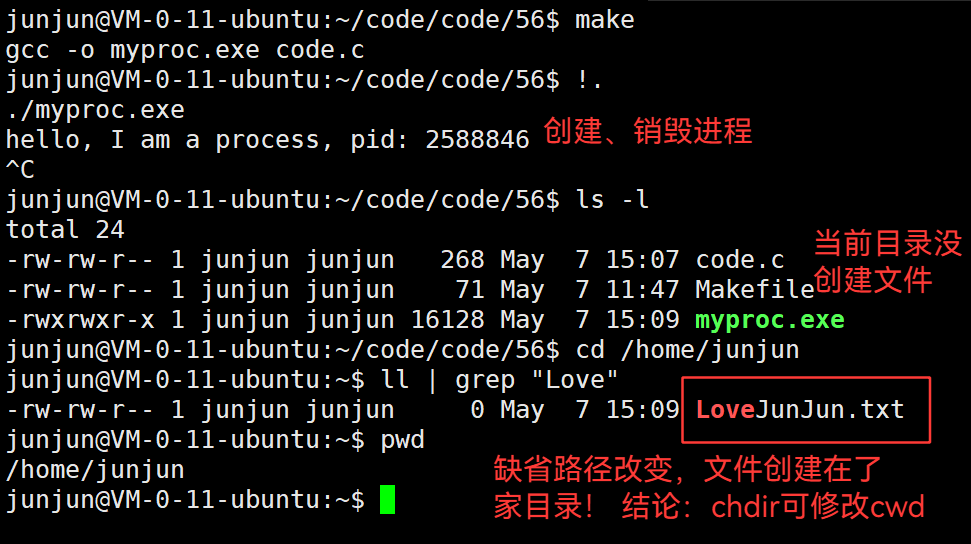
只要停下运行,它就再也无法恢复。


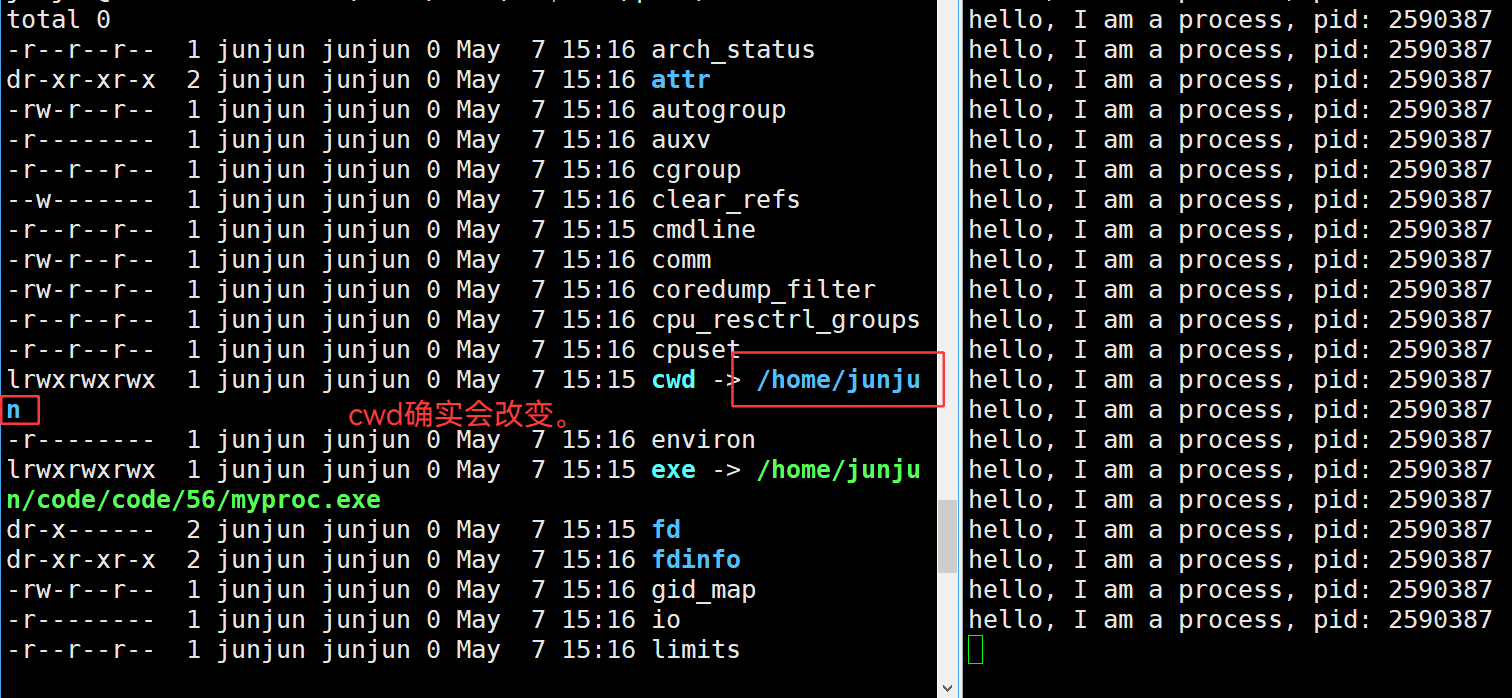
3.36 cwd —— 当前工作目录,当前路径,是缺省路径

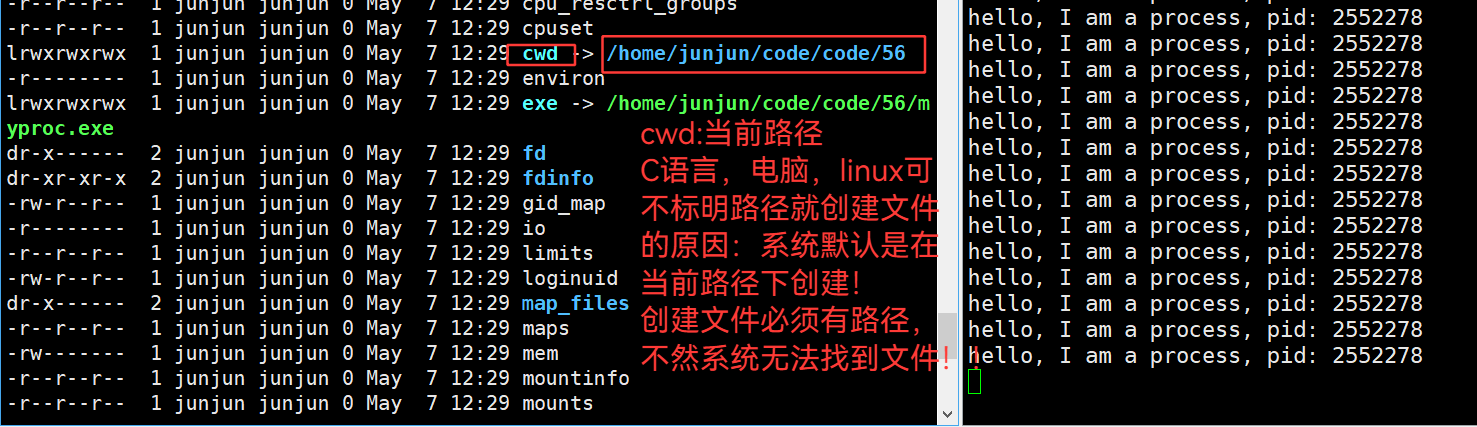
3.37 验证:缺省路径就是当前路径cwd
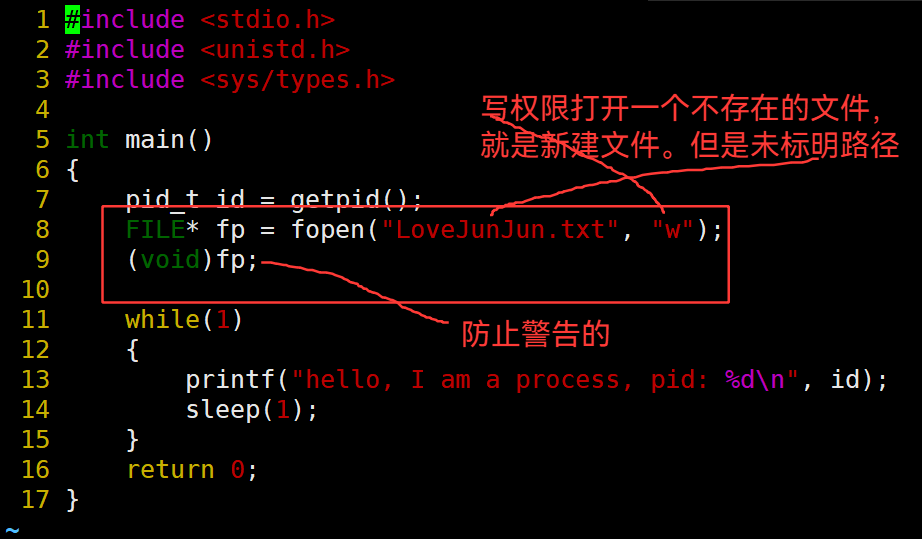
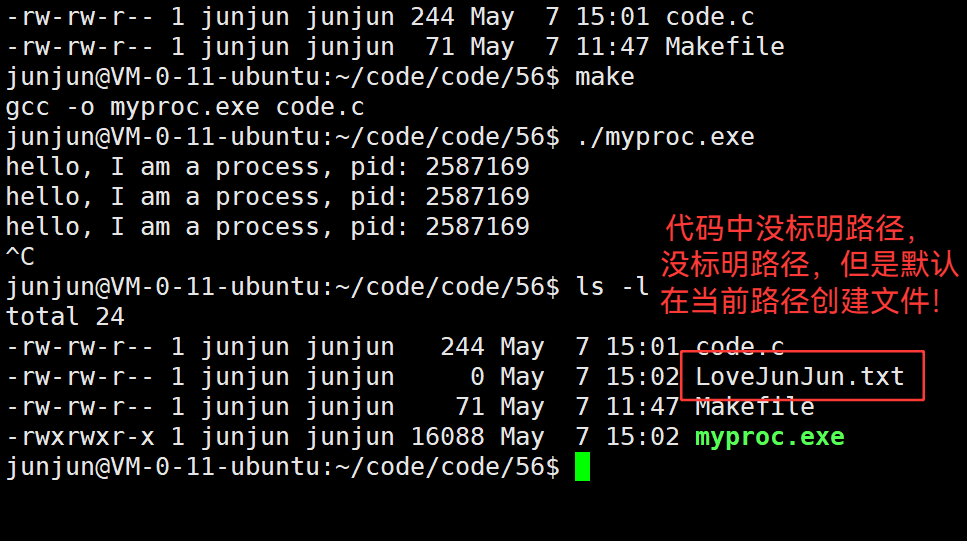
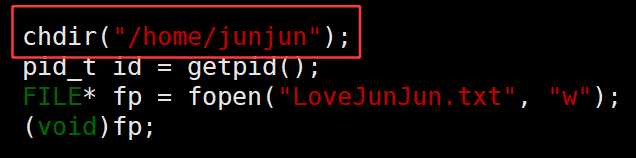
3.38 chdir("指定路径") —— 修改cwd、缺省路径
修改cwd、缺省路径
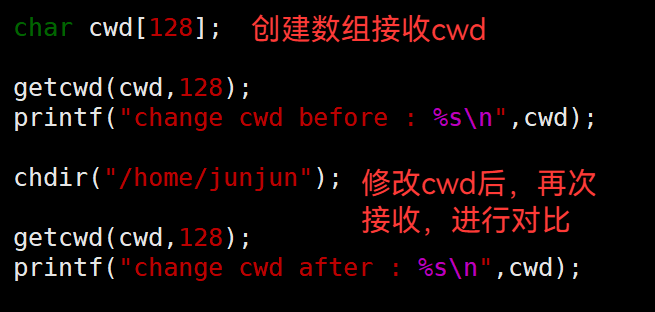
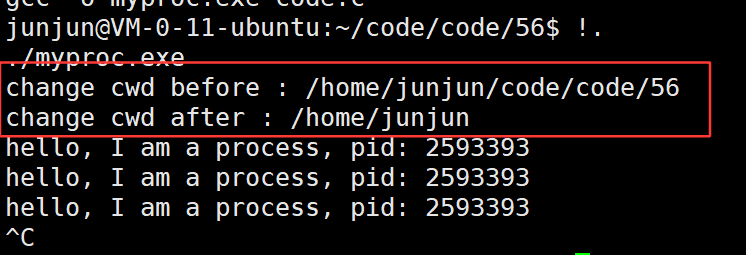
3.39 getcwd(字符数组,字符数组大小) —— 获取 当前路径cwd
3.40 ps [axj] —— 查看进程、所有进程

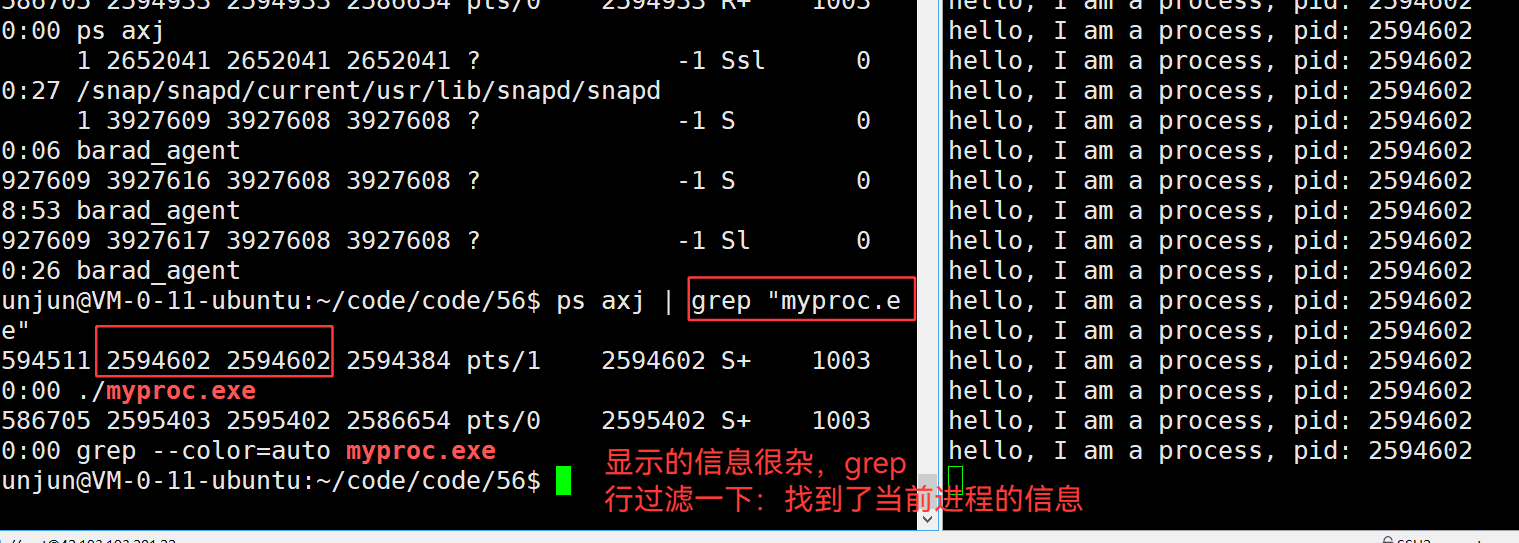
3.41 ps [axj] | head -1 —— 提取第一行,表头。用于查看进程类型

3.42 getppid() —— 获取父进程的 id
3.43 命令行解释器 直接运行的 程序,其父进程是命令行解释器
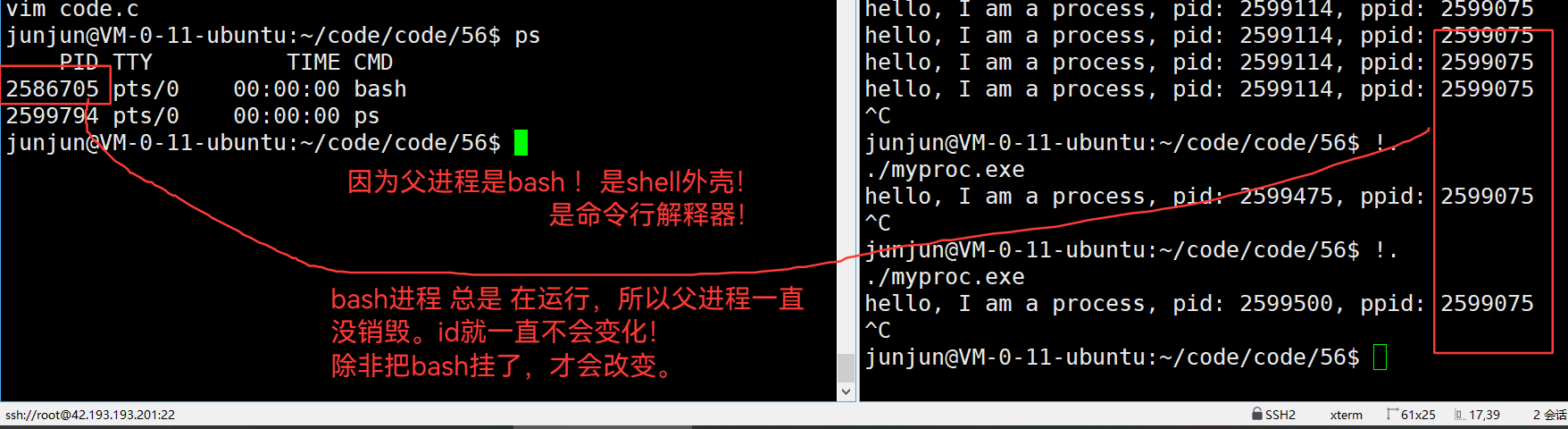
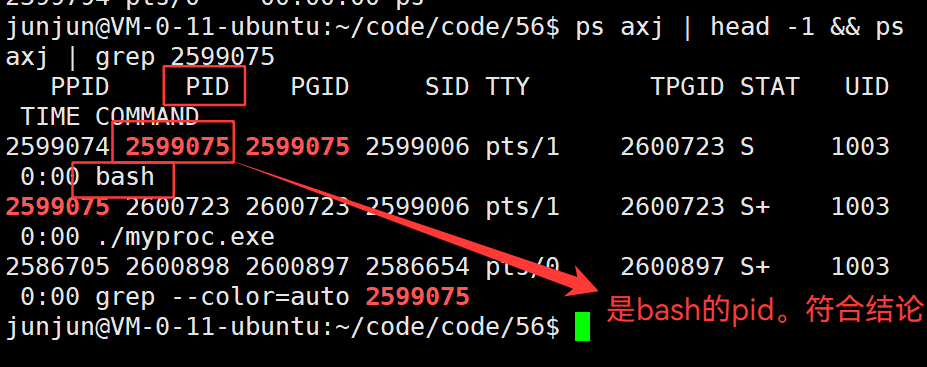
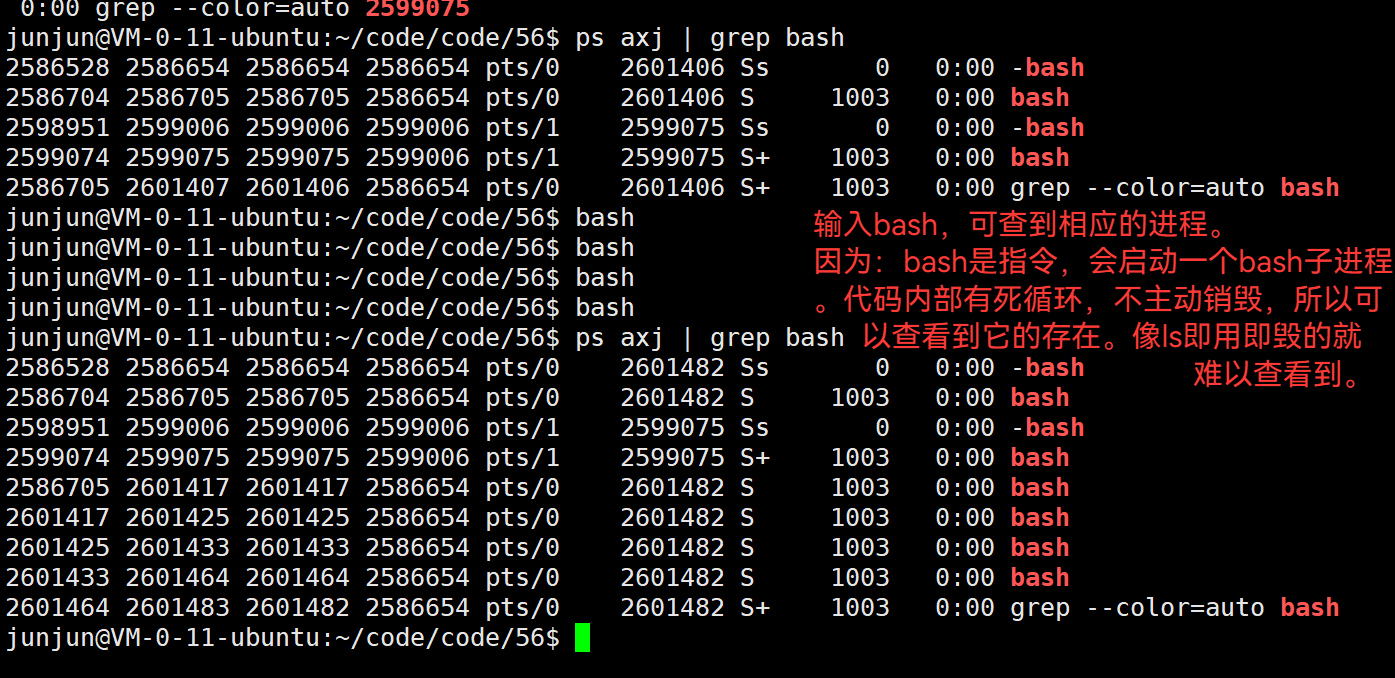
3.44 bash 是 一个内部有死循环,不主动销毁的程序
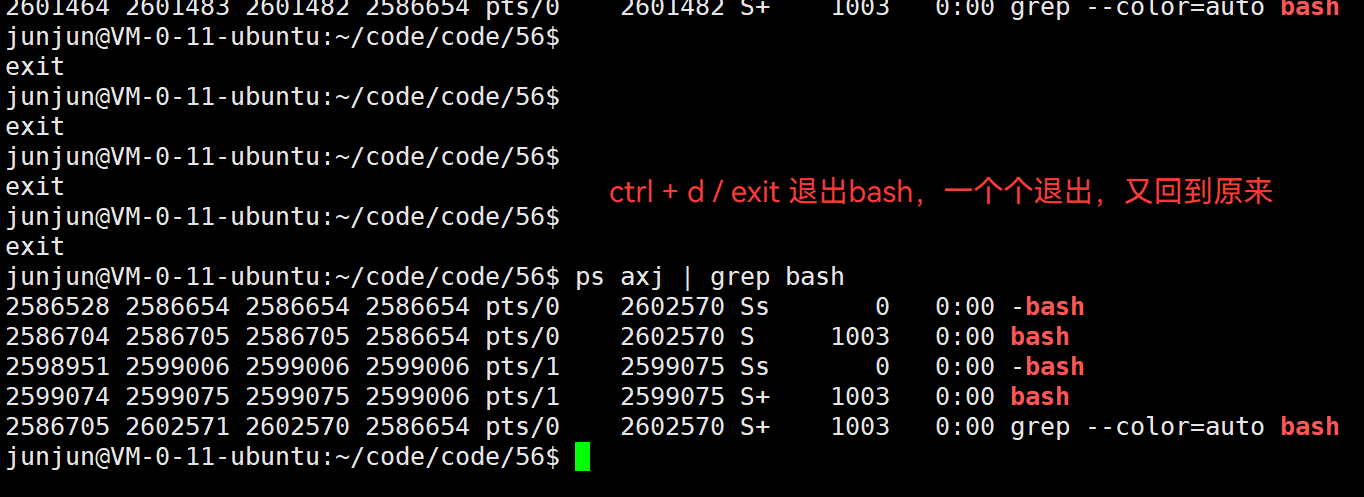
3.45 kill [-9] [bash的pid] —— 关掉 bash 命令行解释器
3.4 创建子进程
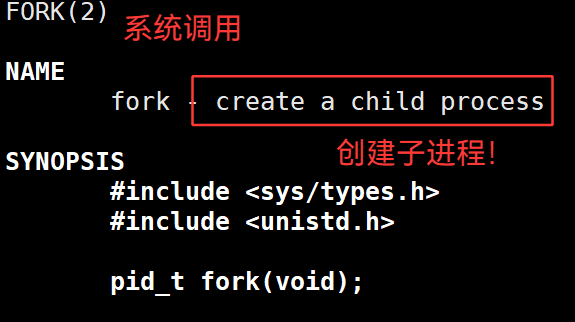
3.41 fork() —— 创建子进程
对比一下fork前后:
-

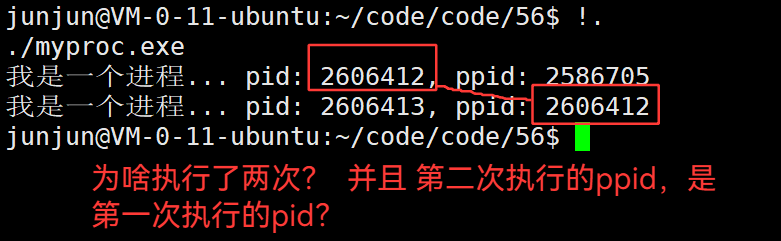
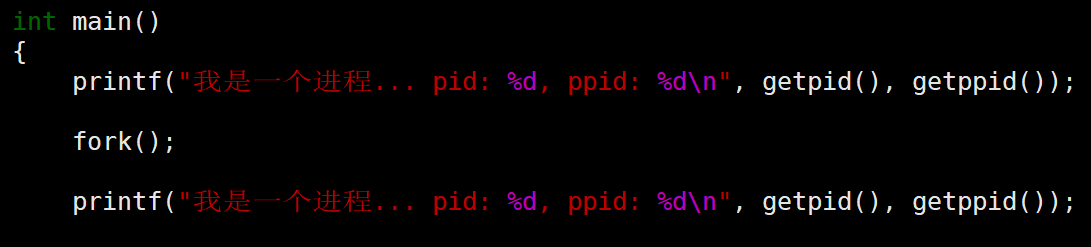
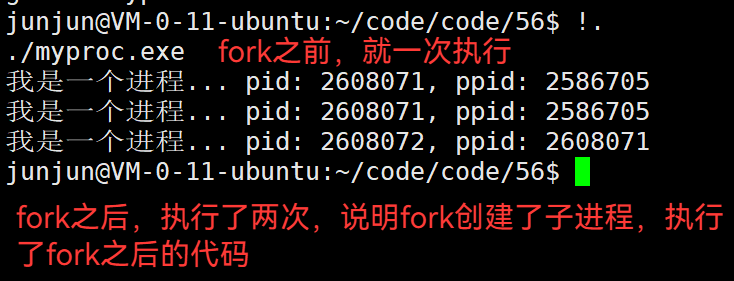
3.42 子进程会共享未执行的代码
结论:fork 创建子进程后,会立刻共享未执行完的代码。导致一句printf执行了2次。
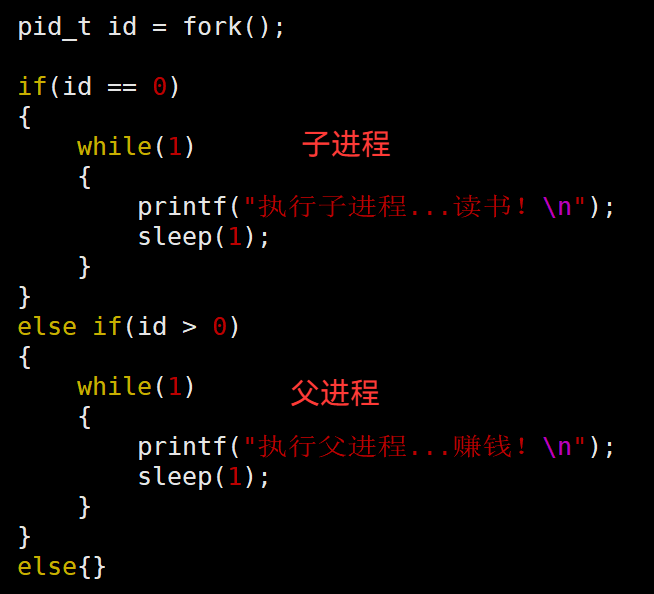
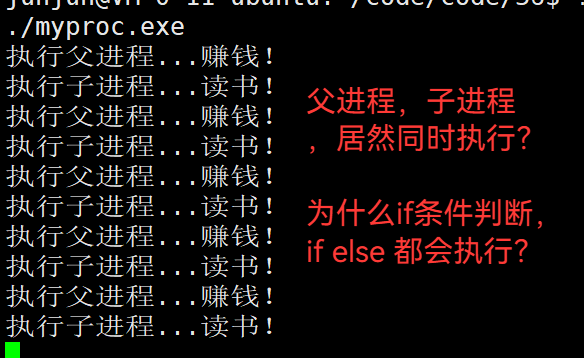
3.43 fork 有 两个返回值 —— 导致 if else 都会执行
翻译:
创建子进程成功,会返回子进程的pid给父进程,然后 0 返回给 子进程。
创建子进程失败,会返回 -1 给父进程,然后设置对应的错误码errno
原因是:父子进程同时都在执行,父子进程接收的返回值不一样,导致各自执行的指令不一样。

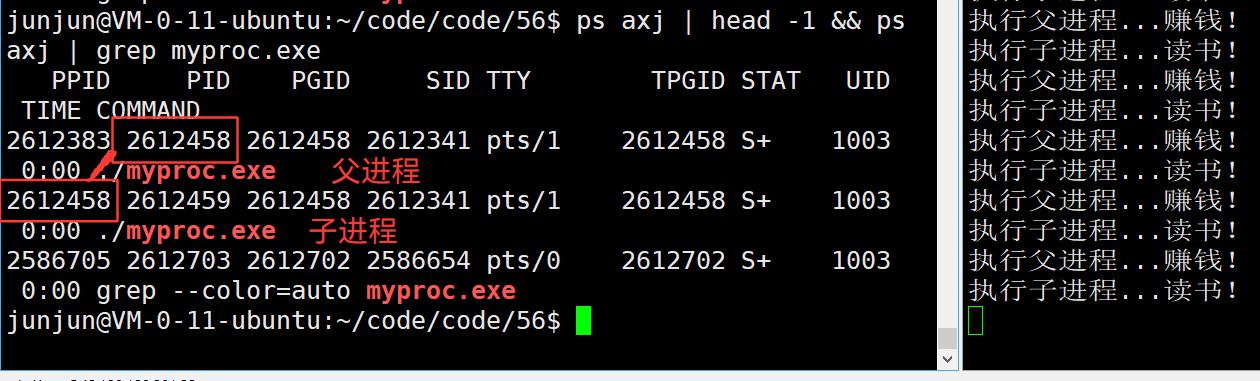
3.44 为什么父进程得到子进程pid返回值? —— 需要唯一值,标识不同子进程
父进程 是 唯一的,子进程 是 无限多的,他们是 1 :n
有了子进程,其目的归父进程管控。但是如何知道谁是谁?
最方便的:获取他们的pid!
由于子进程创建后,父子独立性很强,所以fork直接返回子的pid,很方便。
3.45 所以为什么会有两个返回值?—— 子进程一旦被创建就开始共享代码
fork:创建子进程,这是外层的理解。进入fork内部看,fork内部肯定有一段代码是用于创建子进程,然后最后会获取其pid,最后返回
那么:当子进程在fork内部被创建时,其实它就已经是子进程了!它会直接共享接下来的代码:也就是说:从fork内部从 子进程被创建开始,子进程就开始共享代码了。
表面看是fork函数返回了两次,实则:子进程和父进程是独立的两个程序,他们都执行了fork。只不过:父进程是从头执行到尾,子进程从fork内部创建位置开始执行!
这直接导致了,父进程返回一次后,子进程接着返回一次。
本质上,C/C++的函数就是只有一个返回值。fork极其特殊
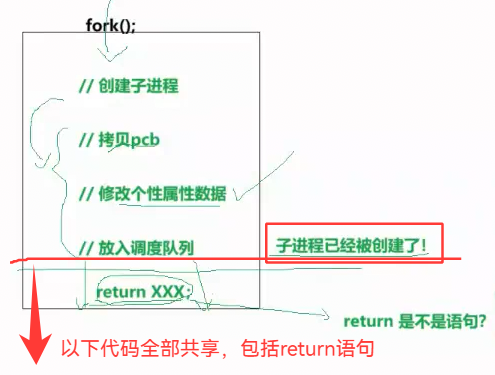
3.46 为什么一个id,有两个值? —— 代码共享、数据拷贝
fork后,循环被反复执行。那为什么,明明id已经不再被返回了,id还是保持两个值?
还是能无限循环地if else 两个分支?
原因:有两个 id !id作为数据,不会因为 浅拷贝的指针 而 直接共享:
这会导致父子都能修改同个数据,数据安全无法保障。
数据是重新拷贝一份的。这和代码不同,代码是指针共享,数据是完整拷贝。
他们的数据同名,地址不同、完全独立!
子进程 会 几乎完整拷贝 一份 父进程 的 PCB 。
它以父进程的PCB为模板,修改几个核心属性:pid、ppid等,其余完整拷贝。
这也导致一个问题:
父子 PCB 的内存指针是浅拷贝,所以父指向的代码,子也会指向,这就是共享代码的原理
原则上,整个代码都是共享的,但是因为fork后才存在子进程,所以默认:子进程只会执行后续的代码,不考虑已经执行的
本质是因为代码是只读,所以可共享。数据是可写,混用不安全,不可共享。
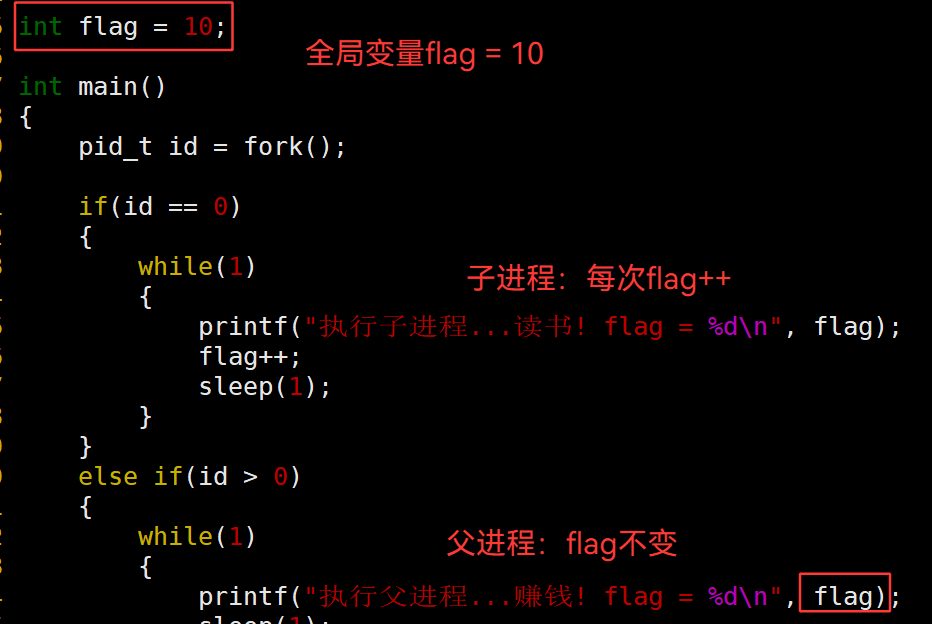
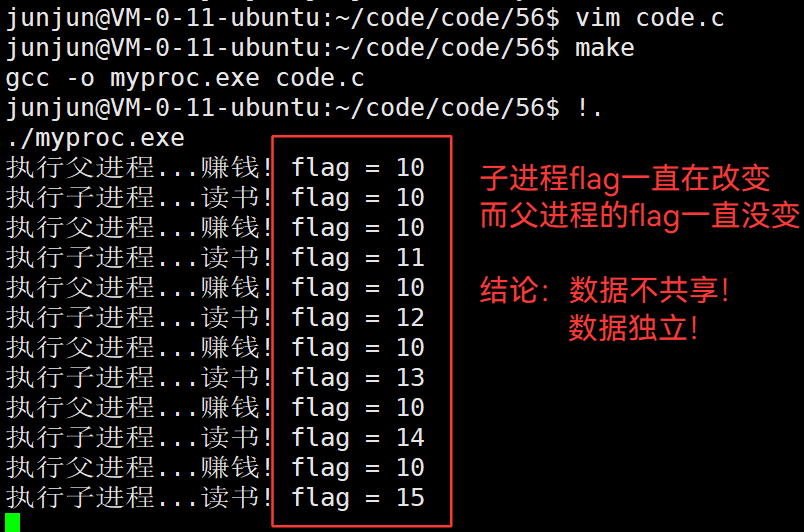
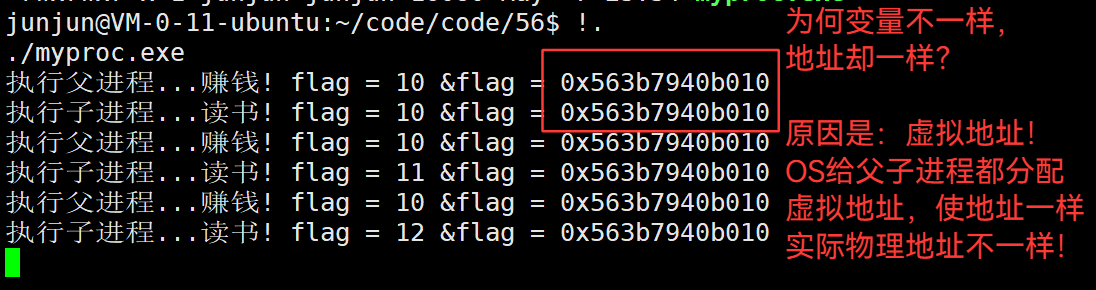
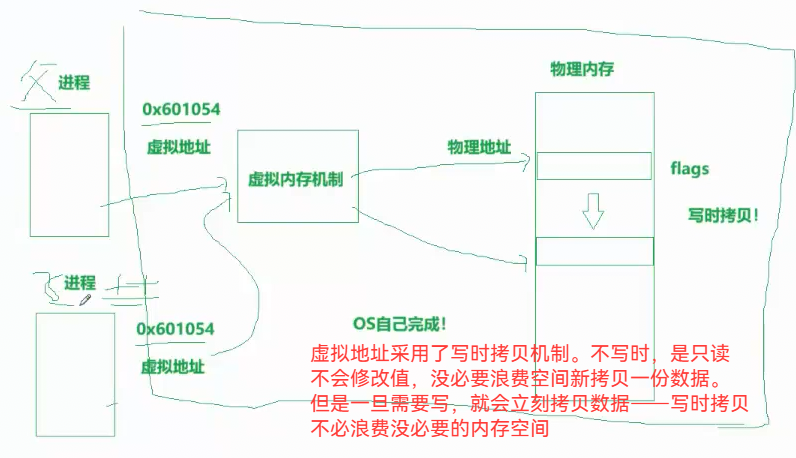
3.47 虚拟地址空间机制 —— 所有 进程 的根基
虚拟地址空间 是 专门为 进程 提供的 。只要有进程,就必须有虚拟地址空间机制。
因为每个进程都需要独立的地址。而物理地址有限,而且存储了很多杂乱的,不好预分配和规划。
有了虚拟地址,可以先分配虚拟的地址。转换到物理内存时,发现冲突,就切换地址
3.48 虚拟地址 与 写时拷贝

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)