Linux内存管理系列:3.页表的实现细节
这个认识是没错的,是对页表的一个功能性和概念性认识,读者在阅读下方的页表具体技术细节时也应该要时刻明确页表的作用本质上就是哈希映射。但是这个认识太浅了,页表作为虚拟地址空间中一个重要的模块,其实是一个非常复杂的东西,涉及到了权限,操作系统管理内存的方式和单个虚拟地址的划分等知识,下面就来进行讲解(先进行原理的说明,再分析源代码的具体实现)。
如果读者是从系列之初开始看的,那么目前我们对于页表的认识就停留在:页表是用于把虚拟地址映射到物理地址的,这个认识是没错的,是对页表的一个功能性和概念性认识,读者在阅读下方的页表具体技术细节时也应该要时刻明确页表的作用本质上就是哈希映射。但是这个认识太浅了,页表作为虚拟地址空间中一个重要的模块,其实是一个非常复杂的东西,涉及到了权限,操作系统管理内存的方式和单个虚拟地址的划分等知识,下面就来进行讲解(先进行原理的说明,再分析源代码的具体实现)。
1.物理空间(内存条上的内存)的管理
先提出几个问题:操作系统要管理物理空间吗?操作系统是怎么管理物理空间的?首先操作系统是绝对要管理物理空间,毕竟物理空间(内存条)才是真正存放数据的地方,必须要对物理空间进行准确,精细,高效的管理,从技术发展的流程来说,是先有了成熟的物理空间管理方案后才诞生了虚拟地址空间的,也就是说物理空间的管理是实现虚拟地址空间的基础。
然后来回答第二个问题,我们先不谈操作系统具体是怎么管理的,想想看如果是你,你会怎么管理物理空间,有了对于虚拟地址空间的了解后,应该不难想到首先要对物理地址进行划分,也就是把整个物理空间分成多个小段,然后给每个段其一个名字,比如物理栈区,物理堆区....,停!前半段的思路是正确的,也就是把物理空间分成多个小段,但是后面就有问题了,对于操作系统来说,物理空间上的每一个字节都是等效的,内存条的制造厂商是不会在内存条上设置权限的,也就是说对于操作系统来说,物理空间纯粹就是个存放数据的地方,没有什么弯弯绕绕的,不会有什么栈区,堆区之类的概念,具体来说就是会把物理空间分成多个等大的小段,每个段都完全相同,每个段的大小都是4kb(4096字节),我们把物理空间中的一个段称为一个页框(也就是一个4kb,页框也叫做页帧),以一个4GB的内存条为例子(后文也是),该内存条可以被分为1048576个页框,这1048576个页框都是连续的(因为物理地址是连续的),大小固定与连续意味着什么?这意味着我们可以使用编程界的核武器"数组"来管理所有的页框了,该数组中的每一个元素都是一个页框,此时一个内存条就被抽象成一个数组了,也就是说对物理空间的管理就变为了对一维数组的管理,那就是我们程序员的领域了。最后要说明的是,上方的那种以一维数组管理物理内存的方式叫平坦内存模式,在现代的64位内核中会使用更加复杂的管理模式,也就是稀疏内存模式,本篇blog分析的是经典老内核,使用的是平坦内存模式,笔者分析的也是该模式,读者如果对稀疏内存模式感兴趣的话可以去问问AI。
数组最大的优势就是可以使用天生自带的下标来快速定位指定元素,在物理空间中我们需要的是使用数组的下标定位到一个页框,更准确的说是定位到一个页框的起始物理地址,见下图:
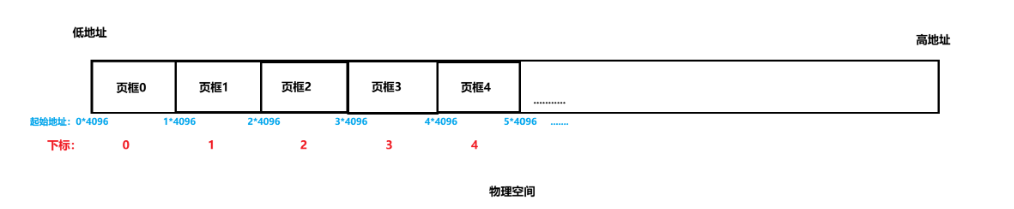
可以看到页框在页框数组中的下标和页框的起始物理地址是有对应关系的,也就是:页框下标*4096=页框起始物理地址,还可以反过来,使用整数除法就可以确认任意一个物理地址是属于哪一个页框的,比如现在已知物理地址80801,那么就可以得出该物理地址所属页框的下标是:80801/ 4096 = 19(取整,直接舍去小数),这个些都不难,只是小学的乘除法,最终的结论就是:我们可以通过页框的下标找到页框的起始物理地址,也可以通过任意物理地址确定该物理地址属于的页框的下标,这个简单的关系是虚拟地址和物理地址之间进行对应的核心,希望读者牢记。在源代码中,会使用结构体struct page来描述一个页框,使用数组mem_map来管理所有的页框,具体来说这个mem_map就是这样的:struct page mem_map[1048576],具体源代码的分析会在介绍完页表的所有原理后统一进行。
2.页表的全貌
不知道读者在学习指针时有没有想过一个问题:既然我们会给内存中的每一个字节都分配一个地址,而一个地址的大小在32位平台下是4字节,在64位平台下是8字节,那内存存储的地址不会把内存撑爆吗?而且这似乎还是个无解的问题,当内存条的存储空间变大了,需要的地址也会增多,也就是说无论如何也无法存储所有的地址,并且内存不是用来存储地址的,是要用来跑进程的,如果存储的地址都把内存空间给耗尽了,那么进程要放在哪里呢?这个问题在笔者学习编程语言时就困扰着笔者,而且无论在语言中怎么找,都找不到答案,直到学习完操作系统后,笔者才明白了答案其实是在虚拟地址空间中的,而且还和硬件有关,如果只是学习编程语言,你想一辈子都不会想明白这个问题,从这个角度来看,学习操作系统也是必须的,因此笔者在此处强烈的推荐读者去系统的学习一下操作系统,操作系统才是计算机的根,编程语言只是根上的叶子,或者说其实所有的计算机软件(比如AI,网络通信,游戏引擎,数据库...)都是这个根上的叶子,无根之木是活不长的,希望读者能打牢自己的根(学好操作系统)。
废话不多说,下面来回答上方提出来的问题,首先我们要把地址分为两类,其一是虚拟地址,其二是物理地址,物理地址是不会占用实际内存的,以一台理想的32位计算机为例子,该计算机的内存条是4GB的,而内存条上每一字节的物理地址不是记录在内存中的,而是会给该计算机连32根地址线,可以想象成32根电线,每一根电线都可以发送高低电平,高电平表示1,低电平表示0,那么就会产生2^32个组合,这些组合出来的数字就是所谓的物理地址了,而高低电平显然是不需要占用实际物理内存的,然后是虚拟地址,虚拟地址可不会有什么虚拟电线,虚拟地址是真的会占用物理内存的,这意味着虚拟地址和物理地址绝不是简单的一一对应关系(否则内存条就被撑爆了),而是会采用某种更加精妙的设计,这个精妙的设计就是页表的核心所在了,下面就来详细说说(会涉及到较多计算)。
要注意的是页框是一个偏向硬件的概念,页框划分了物理空间,是可以直接往页框中存放数据的,而页表是一个纯软件概念,并且页表和页框有一定的对应关系(下文介绍)。
我们先假设有一个32位的计算机,该计算机的内存条是4GB的,此时在该计算机上运行着一个进程,该进程使用了所有的物理内存空间,即4GB(实际上是不可能的),以该进程为对象,来分析该进程的页表是什么样子的,首先并不会直接使用一个页表直接进行4GB的映射,而是会使用多张页表,每一张页表的大小是4kb(正好是一个页框的大小),我们把页表中的一个4字节大小的块称为页表的一个条目,也就是这样的:
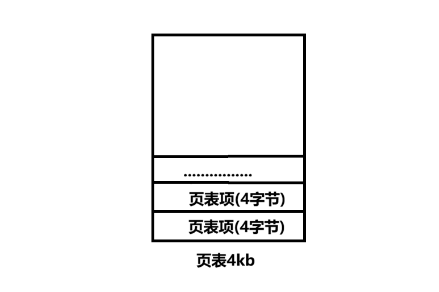
简单的计算一下,一张页表中会存在4096/4=1024个页表项,在页表项中填的是一个页框的起始物理地址(实际上不完全是,先这么理解,后文修正),要注意的是此处的物理地址是要被记录的数据,不是由高低电平的组合产生的,也就是说会占用4字节内存空间。在上文已经计算过4GB的内存空间可以被划分成1048576个页框,每一个页表项能够记录一个页框的起始地址,而一个页表中存在1024个页表项,那么一个页表就能够记录1024个页框的起始地址,那么就可得总共需要:1048576/1024=1024个页表就可以记录所有页框的起始物理地址,也就是说这个超级大的进程会使用1024个页表来进行虚拟地址到物理地址的映射。
有读者可能会问了,这也没有涉及到虚拟地址啊,而且只记录了页框的起始物理地址,页框中的物理地址要怎么办呢?这个问题比较复杂,笔者在下文会详细说明,此处先让我们搭建起页表体系的全貌(由于假设的进程占满了所有内存空间,所以它的页表体系就是页表的全貌)。现在已知该进程会使用1024张页表,那么就又出现了一个问题,我们要怎么找到在1024个页表中定位到一张具体的页表呢?毕竟这是定位页框的第一步,是要进行遍历吗,遍历当然是可以的,但是效率太低了(定位页表是一个非常常用的操作,因此就算页表的总量少,在大量的遍历时也会很影响效率)。这1024张页表就像是一本1024页的书,我们在看书时如果想要快速的定位到某一页,首先当然是要去查看目录的,因此内核的设计者就借鉴了这个概念,在页表体系中加入了一个页目录,一个页目录同样会占用4kb的内存,其中每4字节也叫一个页表项,那么一个页目录就会有1024个页表项,正好等于总页表的数量,页目录中的每一个页表项就记录着一张页表的起始物理地址(一张页表是4kb,正好可以占满一个页框),也就是这样的:
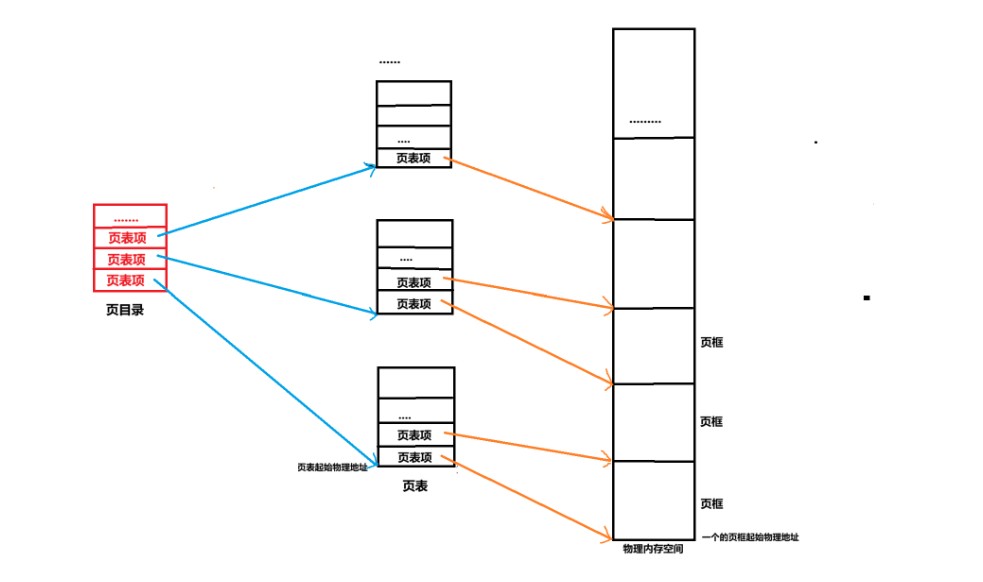
这张图就是页表的全貌了,总计有1024张页表,一个页目录,页目录中的每一个页表项记录着一张页表的起始物理地址,页表中的每一个页表项记录着物理内存中一个页框的起始地址,现在还存在很多问题,比如虚拟地址在哪里?怎么使用虚拟地址找到物理地址?虚拟地址到物理地址的转换是谁做的?....但是我们已经明确了一点:使用页目录+页表的结构,可以快速定位到一个页框的起始物理地址。
下面来补充第一个细节,一个虚拟地址要如何定位一个物理地址(注意,此处使用的是定位,而不是映射,这是一个概念的修正),首先我们已知,在32位平台下,一个虚拟地址的大小是4字节,也就是32bit位,把这32个bit位分为3部分,即:10bit 10bit 12bit,分别称为高10位bit位,中间10位bit位和低12位bit位,在使用一个虚拟地址定位物理地址时,首先使用高10位bit位来找到页目录中的一个页表项,此时2^10正好等于1024,和页表项的总数是相同的,因此10个bit位能够找到页目录中的任意一个页表项,然后通过页目录中页表项记录的信息,就可以找到一张页表的起始物理地址,也就是找到一张页表,之后我们使用中间10位bit位找到该页表中的一个页表项,同理,2^10=1024,那么就可以找到一张页表中的任意一个页表项,然后再根据页表的页表项中记录的信息就可以找到物理内存空间中一个页框的起始物理地址,也就是定位到了一个页框,最后再使用低12位进行页内偏移(简单来说就是找到页框中间具体的一个字节),一个页框的大小是4kb,也就是2^12字节,那么正好就可以使用低12位找到页框中的任意一字节了。是不是非常神奇,一切都是如此的巧合,这就是页表中设计的一个精妙的地方了,哪有什么巧合,一切都是别人精心设计的结果(此处涉及到的计算比较多,如果没看懂的话可以去让AI生成几个例子)。
现在我们已经可以使用一个虚拟地址定位到物理内存空间中的任意一字节的内存了,虚拟地址的主要功能已经实现,那么此时最大的问题就是:这个虚拟地址是存放在哪里的呢?这个问题涉及到了不少硬件的知识(比如下文要谈的CPU和MMU),还涉及到编译器编码和可执行文件的存储,在此处笔者尽量简化,先只做一个概念上的说明,让读者逻辑自洽:编译器在编译代码时就会为每一句指令带上虚拟地址(不是每一行代码,而是每一句汇编指令),然后生成的可执行文件中的每一句指令就会自带虚拟地址,此后可执行文件就会被存放到磁盘中,也就是说在程序未执行时,一个程序的虚拟地址是和程序一起存放在磁盘中的,在该程序被执行后,该程序就会被加载到内存中,然后操作系统就会把该进程(程序运行起来后变为进程)中的指令喂给CPU,由于每一句指令都是自带虚拟地址的,因此CPU使用虚拟地址定位到每一句指令的物理地址,那么就可以正确的执行实际数据了。要说明的时虚拟地址到物理地址的转换是由MMU完成的,并且还涉及到CPU上的寄存器和缓冲区,会在下文进行概念的修正。
来说点题外话,看到这里读者也应该发现了,笔者在文章之初提出的概念多少都是有点毛病的,在后文才进行了修正,这一方面是为了降低理解的难度,另一方面就是在计算机中概念的修正是很常见的,毕竟计算机的发展速度是非常恐怖的(从计算机诞生到现在的AI连80年都没有用到),和基础学科不同(比如物理和数学公式都是定死的),计算机中几乎没什么定死的东西,因此在学习计算机时,一定是会不断的进行概念修正的,也就是说一定不要使用老眼光看待新技术,士别三日在计算机中体现的尤为明显,笔者在本篇blog介绍的也仅仅只是虚拟地址空间中比较核心的知识,当前新内核中的虚拟地址一定是大不相同的并且更加复杂的,在技术实现上的差别虽然会有,不过实现时逻辑是一样的,理解了老的,再去看新的,就不需要从0开始了,只需要进行概念修正便可。
回到正题,在文章之初还提到过在页表中是可以设置权限位的,比如读权限,写权限等,那这些权限要设置在哪里呢?毕竟页表的每一个字节都被使用了,答案很简单,字节被使用了不代表字节中的每一个bit位都会被使用,权限位就是使用bit位来表示的(内存的极致使用)。我们现在已知一张页表中的一个页表项记录的是一个页框的起始物理地址,这个物理地址是不会占满32个bit位的,具体来说就是它的低12位都是0,实际有效的只有高20位,来举几个例子来证明一下:8号页框,90号页框,891号页框和1048575号页框(号数指struct page mem_map[1048576]中的下标,上文有介绍下标到页框起始物理地址的转换方式):
| 8号 | 起始物理地址:4096*8 | 二进制:1000 0000 0000 0000 |
| 90号 | 起始物理地址:4096*90 | 二进制:0101 1010 0000 0000 0000 |
| 891号 | 起始物理地址:4096*891 | 二进制:0011 0111 1011 0000 0000 0000 |
| 1048575号 | 起始物理地址:4096*1048575 | 二进制:1111 1111 1111 1111 1111 0 |
这可真是太神奇了,低12位真的就正好都为0,其实这是一个简单的数学问题,核心就在于页框的大小正好为4kb,4kb等于4096字节,而4096等于2^12,那么所有页框的起始地址就必然是2^12的倍数,而2^12的二进制表示为1 0000 0000 0000,低12位为0,0的倍数都是0,因此所有页框的起始物理地址的低12位就都是0了。那么在实际使用可以把页表中记录一个页框的起始物理地址分为高20位和低12位,高20位记录页框起始物理地址的有效值,低12位记录该页表项定位到的页框的权限,在查找时只需要提取出高20位然后使用:高20位<<12的操作就可以得出页框的起始物理地址了,举个例子:现在在一个页表的页表项中记录的信息是:0010 1111 0111 0011 0011 0101 0010 0100,高20位是0010 1111 0111 0011 0011,低10位是0010 0100,我们使用位运算操作把高20位右移12位,得出0010 1111 0111 0011 0011 0000 0000 0000,该值就是页框的起始物理地址,转换为十进制就变为了:796078080 = 194355 * 4096,也就是说该页框是194355号页框,后10位0010 0100就表示权限位了,具体表示什么权限在此处不做介绍,读者感兴趣的话可以去问问AI(其中有一个bit位是表缺页异常的,非常重要)。
最后让我们来看看一套完整的页表体系(定位满所有的页框)在内存空间中要占用多少内存,这部分内存占用就是一个虚拟地址空间所占用内存的大头了,我们同样以4GB的内存条为例子,在上文已经计算过总共需要1024张页表和一个页目录,页表和页目录的大小都是4kb,那么总占用大小就是(1024+1)*4kb = 4mb + 4kb(理论最大值),这个大小是可以接受的,并且实际上页表是按需分配的,一个进程一般最多就会使用几张页表,因此实际占用就更小了,而编译器在编译时为每一句指令编码的虚拟地址是4字节,就算一个大型项目有几万条指令,虚拟地址的总大小撑死了也就几mb,和虚拟地址空间带来的好处相比,这点微不足道的代价是完全可以接受的,整套页表体系节省内存消耗的关键就是在页表项中记录的不是物理内存中每一字节的物理地址,而是通过记录页框起始物理+虚拟地址后12位页内偏移的方式定位到所有的物理地址。
3.页表相关源代码分析
页表的全貌已经搭建完毕,之后就是了解具体的技术实现细节了,也就是源代码分析,让我们继续前进(页表体系涉及到的结构体比较多,本节只挑重点介绍)。
3.1struct page
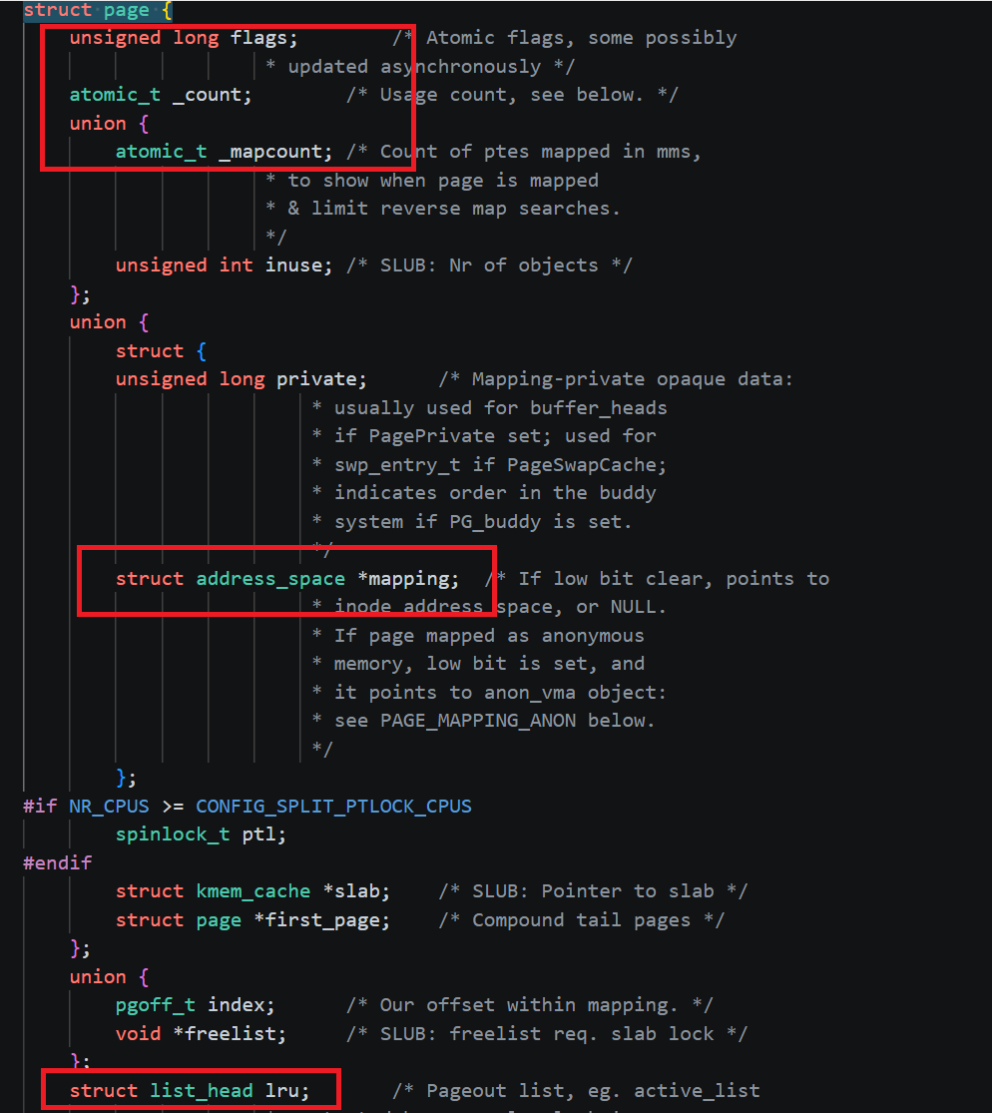
在本章之初就提到过一个页框在操作系统内核中就是使用struct page进行描述的,这个结构体是虚拟地址空间的基石,也是管理物理内存空间的基石,由于它在物理内存中会大量存在(4GB时有1048576个),这就意味着该结构体对象不能占用太多内存,因此在其中使用了联合体(union),指针和位图来节省空间占用,并且其字段比较少,要说明的是:尽管字段较少,但是该结构体非常复杂,涉及到的知识非常多(伙伴系统,页框分类,引用计数...),很多东西笔者也是第一次见,也是边学边写的,如果有错误,还请指出,下面就来看看这个struct page是个什么东西:
在正式讲解前,先来简单复习一下联合体(毕竟这个东西确实比较少见),联合体主要用于对内存空间要求非常苛刻的情景,比如操作系统开发,嵌入式开发和网络通信等,其语法和结构体差不多(就是把struct改成union),重点是联合体中的所有成员共用同一块空间,比如在一个联合体中定义了int a,和int b,那么整个联合体就只会占用4字节空间,a和b共用这4字节空间,这就意味着a和b会互相影响,比如a=10时就算没有给b赋值,b的值也会变为10,通过b也可以改变a,数据互相影响,这本身就意味着联合体的使用的比较困难的,具体来说可以遵循使用联合体时只给其中的一个成员赋值,当该成员没有用了后再给另一个成员赋值的原则,这样就可以避免互相影响了,如果你学习过共享内存,理解联合体就没什么成本了,原理是类似的,并且在共享内存中也会出现类似的问题。联合体的大小计算也存在对齐规则,其大小必须是最大对齐数的整数倍,最大对齐数=max(联合体中占用内存最大的那个类型,编译器默认对齐数),要注意的是只有部分编译器会有默认对齐数,最后来举个例子计算一下:
union lh{
char arr[12];
int i;
double b;
};假设编译器没有默认对齐数(有的话一般是4),联合体中占用内存最大的类型是double,占用8字节空间,而该联合体至少也需要12字节的空间(为了放下arr),因此要向上对齐,该联合体最终的大小就是2*8=16;

联合体不是本文的重点,因此仅作简单介绍,如果没看懂的话就去问问AI吧,下面回到正题,开始struct page的字段分析:
| flags |
该字段是一个位图,用于表示页框属性信息,unsigned long的大小是4字节,共32个bit位,也就是说可以表示32种只存在两态的属性,此处挑出几个重点进行介绍: PG_locked:表示该页框中的内存正在进行IO操作(比如向磁盘读写数据),此时该页框不能被打扰(不能被移动,释放,进程读写...),对该页框的任何操作都必须在其IO完毕后(正在吵架的人是无法被打断的)。 PG_dirty:表示该页框是脏页,说人话就是该页框中的数据被动过了(比如被进程写入了),但是数据还没有写入长期存储设备(比如磁盘),因此在释放该页框中的内存前必须进行一次数据同步。 具体的标志位还有很多,笔者认为在如今的AI时代,介绍这些没什么逻辑性的东西是没什么意义的(不如直接问AI),因此不再进行说明。 |
| _count |
其类型是atomic_t,意味着对_count的操作是原子的,简单来说可以认为原子操纵的意思就是该操纵只有一条汇编指令(无锁的情况下),而CPU是以汇编指令为单位进行执行的(不太恰当,但好理解),也就是说有原子性就意味着该操作要么执行完,要么不执行,不会存在执行到一半就被中断的情况,本质上来看_count的类型就是一个加了锁的int类型(有关锁的概念比较复杂,笔者将在之后对于多线程的讲解blog进行介绍)。 该字段在struct page中非常重要,本质上_count是一个引用计数器,实时统计了有多少东西使用(引用)了本页框,注意此处的东西不止进程,比如磁盘/网卡/键盘等带有IO功能的外设在向内存中写数据时都会使用页框,此时被使用页框的_count就会++,可以认为只要是计算机中的任何东西,只要使用了一个页框,都会导致对应页框的_count++。 对于操作系统来说,只要一个页框被计算机中的任何东西使用了(_count不为0),都意味着该页框处于被使用的状态,不能释放其中的数据,也不能把页框对应的struct page对象链入伙伴系统(下文详细介绍,可以先简单的认为伙伴系统就是用来存放空闲(未被使用)页框的struct page对象的),简单来说可以认为_count决定了页框的"生命周期",只要有任何东西使用了页框,被使用页框的_count就不为0,该页框就"还活着"。 最后要说明的是,在老内核中,_count的值为-1才表示页框的空闲的(没有任何东西使用该页框),而0是一个瞬间的状态,举个例子:此时磁盘正在使用5号页框进行数据输入,那么5号页框的_count就为1(假设只有磁盘在使用该页框),等到磁盘写完数据并且操作系统也处理完了写入到5号页框中的数据后,_count就会--,即变为0,此时操作系统立刻识别到5号页框的_count变为0了,就会立刻把5号页框链入伙伴系统,然后把5号页框的_count置为-1,表示该页框空闲,也就是说实际上当_count变为0时就代表5号页框已经空闲了,不过这个0是告诉操作系统可以把该页框链入伙伴系统了(可回收),操作系统把5号页框链入伙伴系统后会把_count的值置为-1,明确的表示"我"已经知道该页框处于空闲状态了,在5号页框下一次被使用时,操作系统会先把5号页框从伙伴系统中取出来,在取出来的一瞬间5号页框的_conunt会变为0,然后立刻变为1,也就是说0是一个在非空闲和空闲之间过渡的瞬间状态,在新内核中,采用了更加复杂的管理机制(没有-1了),不过核心逻辑是一样的,都是_count的值为0时就表示页框空闲。 最后的最后要说明的是,上文采用"使用"一词其实是不太恰当的,正确来说应该是"引用",但是引用这个词又太过于抽象了,没有实感,为了便于读者理解,笔者才采用了使用一词。在此处统一区分一下使用和引用的含义,使用代表着对象正在用,而引用代表着对象记录下来了页框的起始地址,不一定真的使用了,比如此时网卡和磁盘同时要向5号页框中输入数据,但是显然是不能让两者同时输入的,我们假设磁盘先输入,那么对5号页框来说磁盘就处于使用的状态,而网卡只记录着5号页框的起始地址,没有实际输入数据,网卡就处于引用的状态,此时5号页框的_count就为2,等到磁盘输入完毕后,磁盘就不用改页框了,_count--变为1,然后就轮到网卡使用5号页框输入数据(注:引用计数的引用和语言中的引用不是同一个东西,也没什么关系)。 也就是说使用者永远只有一个,而引用者可以有多个,_count = 使用者(1) + 引用者(n),这是笔者的理解方法,也有部分人会把使用当成引用的一部分,这也可以,不过笔者更喜欢把概念区分开,更加生动的理解是...嗯..使用者就是直接上手操作的,引用者就是排在后面看的,区分使用和引用的关键就是是否进行了实际的操作(比如数据的拷贝)。 |
| _mapcount |
这个字段的类型同样是atomic_t的,也就是说对该字段的操作也是原子的,此处不再对类型进行过多解释,直接分析字段的作用:该字段也是一个引用计数器,和_count最大的区别是,该字段统计是一个页框被多少个页表中的页表项引用了,具体来说就是有多少个页表项中填写了该页框的起始物理地址,这个还是非常好理解的,要注意的是_count是包含_mapcount的,举个例子,比如5号页框此时正在被磁盘使用,同时还有网卡和6个页表项引用了5号页框,那么_count = 使用者 + 引用者 = 1 + 7 = 8;而_mapcount就只等于5(下文说明为什么不是6),也就是说_count的范围是比_mapcount大的。 该字段乍一看似乎和_count的效果重叠了,但其实不然,首先要明确使用页框的对象是分为不同的类型的,大体上分为两类,第一类是进程,具体表现就是在页表项中填写页框的起始物理地址,第二类就是拥有IO设备的外设,一般来说它们在向页框中写入数据时不需要使用页表(具体做法比较复杂,不做展开),而_mapcount统计的就是一个页框被多少个第一类对象使用了,可以明显发现,这两类对象使用页框的方法是完全不同的(还有其它类型,但大体上就分为这两类),因此必须要作区分,所以_mapcount就是必须的了。 在共享内存,动态库使用和写实拷贝等操作时,该字段的值就会发生变化,当该字段的值为-1时,意味着页框的起始物理地址没有被填写到任何一个页表项中,为0时意味着有一个页表项中填入了该页框的起始物理地址.....为N时就意味着有N+1个页表项中填写了该页框的起始物理地址,所以当一个页框被6个页表项引用时_mapcount的值是5。 最后要补充的是,如果页框中的数据是只读的,那么是可以多个进程同时使用该页框的,也就是此时多个进程的页表项中都填了该页框的起始物理地址,但是它们只是读取该页框中的数据,不会进行修改,那么多个进程是可以同时读取的,不过如果此时有任意一个进程要修改该页框中的内容,就会触发写实拷贝(下文详细介绍) |
| mapping |
该字段是一个结构体指针类型,指向的那个结构体非常复杂,这里不做介绍,仅介绍该字段的作用,简单来说这是一个用于反向查找的指针,正向查找是使用页表项中记录的起始地址找到页框,而反向查找就是通过页框找到具体有哪些进程在使用该页框,具体的流程就是通过页框的起始物理地址/4096确定下标,在struct page mem_map[1048576]定位到该页框对应的struct page对象 ,然后通过mapping指针找到所有使用该页框的进程。 在内存空间不足时,操作系统就必须回收一些不重要的页框,这些页框可能还被进程使用着,那么在回收前,操作系统就必须断开这些进程与页框的连接(清空对应的页表项,处理VMA...),此时操作系统就可以使用mapping快速定位到所有使用该页框的进程了。 要说明的是该字段是能够回指向两类使用页框的对象的,其一就是进程,就如同上文介绍过的进程的虚拟地址空间(比如堆,栈...)可以通过页表映射到实际的内存空间,被映射了这部分空间的页框叫做匿名页,其二是进程打开的文件,文件被进程打开后,其内容就会被加载到内存的页框中,为了让进程能够使用页表体系找到文件内容,也会使用页表映射这部分内容所处的页框,被映射了文件内容的页框叫做文件映射页,mapping可以回指向在两类使用了页框的对象,即进程和进程打开的文件。 |
| lru | 该字段和伙伴系统强相关,在介绍伙伴系统时会详细说明(在此处先埋个伏笔) |
4.小结
上方仅仅只是最简单的介绍,实际上设计到的技术细节还有非常非常非常多,而且其它字段其实也挺重要的,并且不同于mm_struct和vm_area_struct,很难给struct page建立具体的模型(画出图),这就比较难受了(或者也是笔者的水平不够),分析这种无法建模的对象确实是复杂很多,笔者也是边学边写的,尽可能写的生动了,希望读者可以理解,不过在struct page中的伙伴系统概念是很好建模的,并且伙伴系统也是一个理解内存管理和struct page的关键,因此在下一篇文件就来介绍一下伙伴系统。要说明的是伙伴系统小节和虚拟地址空间并没有很强的联系,其主要作用是管理空闲的页框,笔者在该篇中采用了自己进行数据结构选型,策略设计等操作,从0开始设计伙伴系统和slap分配器,因此篇幅较长。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)