C++内存管理、进程和线程
本文摘要:文章系统介绍了操作系统中的进程与线程概念,以及并发多线程编程的关键技术。首先阐述了进程作为资源分配单位、线程作为调度单位的特点及区别。然后重点讲解了自动驾驶领域常用的多线程技术:1)四种线程创建方式;2)互斥锁和条件变量的使用方法;3)死锁产生的四个必要条件及避免策略;4)原子变量的作用及适用场景。文章通过实例说明这些概念在实际编程中的应用,并对比了不同同步机制的优缺点,为多线程编程提供
目录
1. malloc /free 用法与特点【容易忘记free和delete是导致动态内存的内存泄漏】
2. 互斥锁 mutex、条件变量 condition_variable
一、内存管理
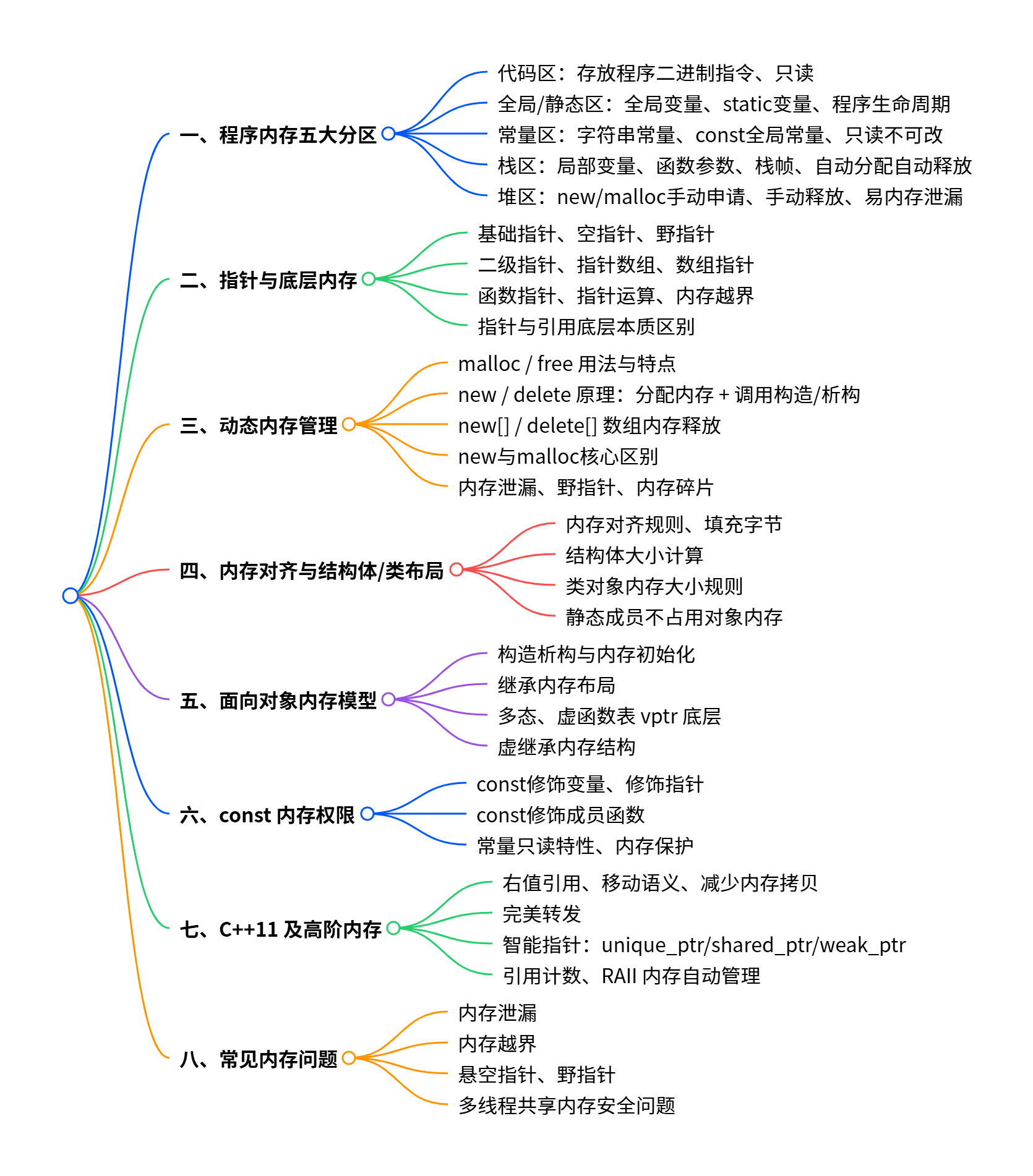
二、C++ 内存管理完全指南
内存管理是 C++ 的核心重难点,直接影响程序的性能、稳定性和安全性。本文基于内存管理思维导图,从基础分区到高阶特性,全面解析 C++ 内存管理的核心知识。
一、程序内存五大分区
C++ 程序运行时,内存会被划分为五大独立区域,各区域的存储内容、分配方式和生命周期均不同,是理解内存管理的基础。
1. 代码区(Code Segment)
- 存储内容:存放程序编译后的二进制机器指令(如函数执行逻辑、运算指令等)。
- 核心特性:
- 只读属性:防止程序运行时意外修改指令,保障安全性;
- 编译时分配:程序编译阶段就确定内存大小,运行时直接加载到内存;
- 生命周期:从程序启动到程序终止,全程存在。
2. 全局 / 静态区(Data Segment)
- 存储内容:全局变量(定义在函数外部的变量)、static 修饰的静态变量(包括全局静态变量和局部静态变量)。
- 核心特性:
- 编译时分配内存:变量的内存空间在程序编译阶段就已确定,而非运行时;
- 默认初始化:未显式赋值的变量会被默认初始化为 0(全局变量)或对应类型的默认值(静态变量);
- 生命周期:程序启动时分配内存,程序终止时才释放,全程贯穿程序运行;
- 共享性:全局变量可被整个程序的所有文件访问(需配合 extern 声明),静态变量仅在其定义的作用域内访问。
3. 常量区(Constant Segment)
- 存储内容:字符串常量(如 "hello world")、const 修饰的全局常量(const 修饰的局部常量可能存于栈区,取决于编译器优化)。
- 核心特性:
- 只读属性:不可通过指针或直接赋值修改,强行修改会导致程序崩溃(未定义行为);
- 编译时分配:内存大小在编译阶段确定,运行时加载;
- 生命周期:同程序生命周期,程序终止后释放;
- 字符串常量池优化:相同的字符串常量会被合并存储,避免重复占用内存(如 const char* s1 = "abc"; const char* s2 = "abc"; 中 s1 和 s2 指向同一块内存)。
4. 栈区(Stack)
- 存储内容:局部变量(函数内部定义的变量)、函数参数(形参)、函数调用时的栈帧(包含返回地址、寄存器状态等)。
- 核心特性:
- 自动分配与释放:变量随作用域创建(如进入函数时),随作用域结束(如函数返回时)自动释放,无需手动管理;
- 内存空间小:栈的大小通常固定(Windows 下默认约 1MB,Linux 下默认约 8MB),超出会导致栈溢出(Stack Overflow);
- 分配效率高:栈内存的分配通过 “栈指针移动” 实现,无需复杂的内存分配算法,速度快于堆区;
- 存储顺序:遵循 “先进后出(FILO)” 原则,新变量压入栈顶,释放时从栈顶弹出;
- 未初始化随机值:局部变量若未显式赋值,其值为随机垃圾值(不默认初始化)。
5. 堆区(Heap)
- 存储内容:程序运行时手动申请的动态内存(通过 new/malloc 申请的内存块)。
- 核心特性:
- 动态分配:内存大小可在程序运行时根据需求确定,灵活度高;
- 手动管理:需通过 delete/free 手动释放,若未释放会导致内存泄漏(程序运行期间内存持续占用,直至程序终止);
- 内存空间大:堆区是程序可使用的最大内存区域(取决于系统物理内存和虚拟内存配置);
- 分配效率低:堆内存分配需通过内存管理算法查找空闲内存块,速度慢于栈区;
- 未初始化随机值:申请的堆内存若未显式初始化,其值为随机垃圾值。
二、指针与底层内存
指针是 C++ 操作内存的核心工具,本质是存储内存地址的变量。理解指针的底层逻辑,是掌握内存管理的关键。
1. 基础指针概念
- 定义:指针变量存储的是目标变量的内存地址,通过指针可间接访问或修改目标变量的值。
- 核心类型:
- 空指针(nullptr):C++11 引入的标准空指针,指向 “无有效地址” 的位置,用于避免野指针(推荐使用,替代旧版 NULL);
- 野指针:未初始化、已释放或越界的指针,指向不确定的内存区域,访问野指针会导致程序崩溃(未定义行为)。
2. 复杂指针类型
- 二级指针:指向指针的指针,用于存储指针变量的内存地址(如 int a = 10; int* p = &a; int** pp = &p;),常用于函数参数中修改指针的值;
- 指针数组:数组的每个元素都是指针(如 int* arr[3];),数组大小固定,元素是指针类型;
- 数组指针:指向数组的指针(如 int (*p)[3];),指针指向整个数组,而非数组元素,常用于多维数组操作;
- 函数指针:指向函数的指针,存储函数的入口地址(如 int (*func)(int, int);),常用于回调函数、函数表等场景。
3. 指针核心操作
- 指针运算:
- 算术运算:指针 + n 表示指向当前地址后第 n 个元素的地址(步长为指针指向类型的大小,如 int* p 中 p+1 偏移 4 字节);
- 关系运算:指针可比较大小(基于内存地址的高低),常用于数组遍历边界判断;
- 内存越界:指针访问超出其指向内存区域的地址(如数组下标越界、堆内存越界),会导致内存污染或程序崩溃;
- 指针与引用的底层区别:
- 内存占用:指针变量本身占用内存(32 位系统 4 字节,64 位系统 8 字节),引用本质是指针的 “别名”,不占用额外内存;
- 初始化:指针可初始化为空指针,引用必须初始化且绑定到有效变量;
- 可修改性:指针可重新指向其他变量,引用一旦绑定无法更改绑定对象;
- 安全性:引用比指针更安全,避免野指针问题,但灵活性低于指针。
三、动态内存管理
C++ 提供两种动态内存管理方式:C 语言兼容的 malloc/free 和 C++ 专属的 new/delete,核心用于堆区内存的申请与释放。
1. malloc /free 用法与特点【容易忘记free和delete是导致动态内存的内存泄漏】
- malloc:
- 函数原型:void* malloc(size_t size);,接收内存大小(字节数),返回指向申请内存的 void* 指针;
- 核心特点:仅分配内存,不初始化内存(内存值为随机垃圾值),不调用构造函数;
- 注意事项:需显式转换指针类型(如 int* p = (int*)malloc(4);),申请失败返回 NULL。
- free:
- 函数原型:void free(void* ptr);,接收 malloc 申请的指针,释放对应的堆内存;
- 核心特点:仅释放内存,不调用析构函数,释放后指针变为野指针(需手动置为 nullptr);
- 注意事项:不可重复释放同一指针,不可释放非 malloc 申请的指针(如栈指针、常量区指针)。
2. new /delete 原理与用法
- new:
- 核心流程:先调用 operator new 函数分配堆内存,再调用目标类型的构造函数初始化对象;
- 用法示例:
- 注意事项:申请失败时抛出 std::bad_alloc 异常(而非返回 NULL),无需显式类型转换。
- 数组对象:int* arr = new int[3]{1,2,3};(分配 12 字节内存,初始化数组元素);
- 单个对象:int* p = new int(10);(分配 4 字节内存,初始化值为 10);
- delete:
- 核心流程:先调用目标类型的析构函数销毁对象,再调用 operator delete 函数释放堆内存;
- 用法示例:
- 单个对象:delete p;(调用析构函数 + 释放内存);
- 数组对象:delete[] arr;(必须用 delete[],否则仅销毁第一个元素,导致内存泄漏);
- 注意事项:释放后指针变为野指针,需手动置为 nullptr,不可重复释放。
3. new 与 malloc 核心区别
|
对比维度 |
new |
malloc |
|
本质 |
C++ 运算符,支持对象初始化 |
C 语言函数,仅分配内存 |
|
类型转换 |
无需显式转换 |
需显式转换为目标类型指针 |
|
构造 / 析构 |
自动调用构造函数 / 析构函数 |
不调用,仅分配 / 释放内存 |
|
申请失败处理 |
抛出 std::bad_alloc 异常 |
返回 NULL |
|
数组支持 |
支持 new[] 分配数组 |
需手动计算数组总字节数 |
|
重载扩展 |
可重载 operator new 自定义分配 |
不可重载,功能固定 |
4. 常见动态内存问题
- 内存泄漏:堆内存申请后未释放,导致内存持续占用,程序运行时间越长,占用内存越多,最终可能导致系统内存耗尽;
- 典型场景:函数中 new 申请内存后,未在返回前 delete;异常抛出导致 delete 语句未执行;
- 避免方式:使用智能指针(RAII 机制)自动管理内存;养成 “申请即释放” 的习惯;使用内存检测工具(如 Valgrind)。
- 野指针:指针未初始化、已释放或越界,指向不确定内存区域;
- 避免方式:指针初始化时置为 nullptr;释放后再次置为 nullptr;不访问已释放的指针。
- 内存碎片:频繁申请和释放大小不一的堆内存,导致内存中存在大量零散的空闲内存块(无法被有效利用),降低内存使用效率;
- 缓解方式:使用内存池(预先分配大块内存,按需拆分使用);尽量申请连续的大块内存;避免频繁申请 / 释放小块内存。
四、内存对齐与结构体 / 类布局
内存对齐是编译器为了提高程序运行效率,对结构体、类的成员变量存储地址进行的规则化排列,本质是 “空间换时间”。
1. 内存对齐规则
- 基础规则:
- 结构体 / 类的第一个成员变量的偏移量(相对于结构体起始地址的距离)为 0;
- 后续每个成员变量的偏移量,必须是该成员变量大小的整数倍(若有编译器指定的对齐系数,则取成员大小和对齐系数的较小值的整数倍);
- 结构体 / 类的总大小,必须是所有成员变量大小的最大公约数的整数倍(或对齐系数的整数倍,取两者较大值)。
- 对齐系数:编译器默认对齐系数(如 GCC 默认 4 字节,VS 默认 8 字节),可通过 #pragma pack(n) 手动指定(n 为 2 的幂,如 1、2、4、8)。
2. 结构体大小计算示例
// 示例1:默认对齐(GCC,对齐系数4)
struct A {
char c; // 大小1,偏移0(0是1的整数倍)
int i; // 大小4,偏移需是4的整数倍 → 偏移4(填充3字节)
short s; // 大小2,偏移需是2的整数倍 → 偏移8(4+4=8)
};
// 总大小:8+2=10,需是最大成员大小(4)的整数倍 → 12字节(填充2字节)
// 示例2:指定对齐系数2(#pragma pack(2))
struct B {
char c; // 偏移0
int i; // 偏移需是2的整数倍 → 偏移2(填充1字节)
short s; // 偏移2+4=6(6是2的整数倍)
};
// 总大小:6+2=8,是最大成员大小(4)和对齐系数(2)的较大值(4)的整数倍 → 8字节3. 类对象内存大小规则
- 类对象的内存大小 = 所有非静态成员变量的大小之和 + 内存对齐填充字节 + 虚函数表指针大小(若类含虚函数);
- 核心注意点:
- 静态成员变量不占用类对象内存(存于全局 / 静态区);
- 成员函数(普通函数、静态函数、虚函数)不占用类对象内存(函数指令存于代码区);
- 虚函数表指针(vptr):若类含虚函数,编译器会为类对象添加一个指针(32 位 4 字节,64 位 8 字节),指向虚函数表(vtable),用于实现多态。
五、面向对象内存模型
C++ 面向对象的核心特性(封装、继承、多态),其底层实现依赖内存布局的设计。
1. 构造析构与内存初始化
- 构造函数:对象创建时自动调用,用于初始化对象的非静态成员变量,分配对象所需的资源(如堆内存、文件句柄);
- 内存层面:构造函数执行时,对象的内存已分配(栈区或堆区),构造函数的作用是填充该内存区域的成员变量值;
- 默认构造函数:无参数的构造函数,若未显式定义,编译器会自动生成(但在某些场景下会被抑制,如定义了带参数的构造函数)。
- 析构函数:对象销毁时自动调用,用于释放对象占用的资源(如堆内存、文件句柄);
- 内存层面:析构函数执行后,对象的内存才会被释放(栈区自动释放,堆区需手动 delete);
- 虚析构函数:若类作为基类,需将析构函数声明为 virtual,否则删除基类指针指向的派生类对象时,仅调用基类析构函数,导致派生类资源泄漏。
2. 继承内存布局
- 单继承:派生类对象的内存 = 基类成员变量 + 派生类成员变量,按继承顺序排列,遵循内存对齐规则;
- 示例:
class Base { int a; };
class Derived : public Base { int b; };
// Derived对象内存布局:a(偏移0)→ b(偏移4),总大小8字节(对齐后)- 多继承:派生类对象的内存 = 第一个基类成员 + 第二个基类成员 + ... + 派生类成员,可能存在内存冗余(如多个基类有相同成员);
- 虚继承:用于解决多继承中的菱形继承问题(多个派生类继承自同一基类,再被一个类多重继承),通过 “虚基类表” 优化内存,确保基类成员仅存储一次;
- 内存层面:虚继承的派生类会添加一个虚基类表指针,指向虚基类表,用于定位虚基类成员的地址。
3. 多态与虚函数表底层
- 虚函数表(vtable):每个含虚函数的类(或其派生类)会有一个全局唯一的虚函数表,存储该类所有虚函数的入口地址;
- 虚函数表指针(vptr):每个含虚函数的类对象,会在内存布局的起始位置(或固定位置)添加一个 vptr,指向该类的 vtable;
- 多态实现原理:
- 基类指针指向派生类对象时,指针访问虚函数时,会通过对象的 vptr 找到派生类的 vtable,调用对应的派生类虚函数;
- 非虚函数直接通过类名定位函数地址,不经过 vtable,无法实现多态。
六、const 内存权限
const 关键字用于限制变量的修改权限,其底层实现与内存分区、编译器优化密切相关。
1. const 修饰变量
- const 全局变量:存于常量区,只读属性,不可修改;
- const 局部变量:
- 栈区存储(未被编译器优化时):可通过指针间接修改(但属于未定义行为,可能导致程序异常);
- 编译器优化为常量(如 const int a = 10;):可能直接嵌入指令,不占用栈内存,修改指针无效。
2. const 修饰指针
- const 修饰指针指向的内容(const int* p):指针指向的变量不可修改,指针本身可重新指向其他地址;
- const 修饰指针本身(int* const p):指针本身不可重新指向其他地址,指针指向的变量可修改;
- const 同时修饰两者(const int* const p):指针本身和指向的变量均不可修改。
3. const 修饰成员函数
- 声明格式:void func() const;,表示该成员函数不会修改类对象的非静态成员变量;
- 底层实现:const 成员函数的 this 指针是 const 类名* 类型,限制了对成员变量的修改;
- 注意事项:const 成员函数可访问 const 成员变量和非 const 成员变量,但不可修改;非 const 成员函数可调用 const 成员函数,const 成员函数不可调用非 const 成员函数。
七、C++11 及高阶内存
C++11 引入了一系列内存优化特性,解决传统动态内存管理的痛点(如内存泄漏、拷贝开销大)。
1. 右值引用与移动语义
- 右值引用:用 && 声明,专门绑定到右值(临时对象、字面量等),如 int&& a = 10;;
- 移动语义:通过移动构造函数和移动赋值运算符,将一个对象的资源(如堆内存)“转移” 到另一个对象,而非拷贝,减少内存拷贝开销;
-
- 移动构造函数原型:类名(类名&& other);,通常会将 other 的资源指针置为 nullptr,避免释放时重复释放;
-
- 适用场景:函数返回局部对象、容器扩容时元素转移等。
2. 完美转发
- 核心目的:在模板函数中,将参数原封不动地转发给其他函数,保留参数的左值 / 右值属性;
- 实现方式:通过 std::forward 函数配合右值引用模板,如 template <typename T> void func(T&& args) { other_func(std::forward<T>(args)); }。
3. 智能指针
智能指针是基于 RAII(资源获取即初始化)思想的类模板,自动管理堆内存,避免内存泄漏。
(1)unique_ptr
- 核心特性:独占式所有权,同一时间仅一个 unique_ptr 指向堆内存,不可拷贝,仅可移动;
- 用法示例:
std::unique_ptr<int> p1 = std::make_unique<int>(10);
std::unique_ptr<int> p2 = std::move(p1); // 移动所有权,p1变为nullptr
// p1 = p2; 错误,不可拷贝- 适用场景:单个对象的独占式管理,无需共享所有权。
(2)shared_ptr
- 核心特性:共享式所有权,多个 shared_ptr 可指向同一堆内存,通过引用计数管理生命周期;
- 引用计数:每个 shared_ptr 指向的堆内存会维护一个引用计数,新增一个 shared_ptr 时计数 + 1,销毁一个时计数 - 1,计数为 0 时自动释放内存;
- 用法示例:
std::shared_ptr<int> p1 = std::make_shared<int>(10);
std::shared_ptr<int> p2 = p1; // 引用计数变为2- 注意事项:避免循环引用(如 A 的 shared_ptr 指向 B,B 的 shared_ptr 指向 A),导致引用计数无法归零,内存泄漏(需用 weak_ptr 解决)。
(3)weak_ptr
- 核心特性:弱引用,不占引用计数,用于解决 shared_ptr 的循环引用问题;
- 用法:通过 shared_ptr 构造 weak_ptr,需通过 lock() 方法获取 shared_ptr 后才能访问对象(避免对象已释放);
- 示例:
std::shared_ptr<int> p = std::make_shared<int>(10);
std::weak_ptr<int> wp = p; // 不增加引用计数
if (auto sp = wp.lock()) { // 若对象存在,sp是shared_ptr,计数+1
std::cout << *sp << std::endl;
}4. RAII 内存自动管理
RAII 是一种编程范式,核心思想是 “资源获取时初始化对象,对象销毁时释放资源”;
- 智能指针是 RAII 的典型应用,此外还可自定义 RAII 类管理其他资源(如文件句柄、锁);
- 示例:
class FileRAII {
private:
FILE* file;
public:
FileRAII(const char* path) { file = fopen(path, "r"); }
~FileRAII() { if (file) fclose(file); } // 自动关闭文件
};八、常见内存问题与解决方案
1. 内存泄漏
- 原因:堆内存申请后未释放,如 new 后未 delete、malloc 后未 free、智能指针循环引用等;
- 解决方案:
-
- 优先使用智能指针(unique_ptr/shared_ptr)自动管理内存;
-
- 避免手动管理大块堆内存,使用 STL 容器(如 vector)替代;
-
- 使用内存检测工具(Valgrind、Visual Studio 内存诊断)排查泄漏点;
-
- 遵循 “谁申请谁释放” 的原则,明确内存释放责任。
2. 内存越界
- 原因:指针访问超出其指向的内存区域,如数组下标越界、堆内存越界写入;
- 解决方案:
- 数组遍历使用迭代器或范围 for 循环,避免手动计算下标;
- 堆内存操作时,严格控制写入大小,不超过申请的内存;
- 使用边界检查工具(如 GCC 的 -fsanitize=address 编译选项)检测越界。
3. 悬空指针 / 野指针
- 原因:指针未初始化、已释放后未置空、指针指向的对象已销毁;
- 解决方案:
-
- 指针初始化时默认置为 nullptr;
-
- 释放指针后(delete/free),立即置为 nullptr;
-
- 避免返回局部变量的指针或引用;
-
- 使用前检查指针是否为 nullptr。
4. 多线程共享内存安全
- 原因:多个线程同时读写共享内存,导致数据竞争(未定义行为);
- 解决方案:
- 使用互斥锁(std::mutex)保护共享内存,确保同一时间仅一个线程访问;
- 使用原子类型(std::atomic)替代普通变量,避免数据竞争;
- 减少共享内存的使用,采用消息传递(如队列)实现线程间通信。
三、操作系统:进程和线程
进程(Process)和线程(Thread),是操作系统里非常重要的两个概念。
进程是资源分配的基本单位。进程的创建、终止、调度、同步以及进程间的通信,都是由操作系统负责的。应用程序的运行,包括操作系统本身核心功能的运行,都是以进程的形式存在。
每个进程都包括程序的代码、数据、状态,以及操作系统为该程序分配的资源(如内存空间、文件句柄、网络端口等)。操作系统通过进程管理,来确保各个进程能够高效、安全地共享CPU时间。
我们使用“Ctrl+Alt+Del”快捷键调出Windows的任务管理器,就可以看到很多的进程:
任务管理器
线程,则是操作系统进行运算调度的最小单位。
线程比进程更低一级,是进程内的一个可以独立调度和指派的执行单元。
一个进程中可以有多个线程,共享相同的内存空间和资源,可以更容易地进行通信和数据共享。
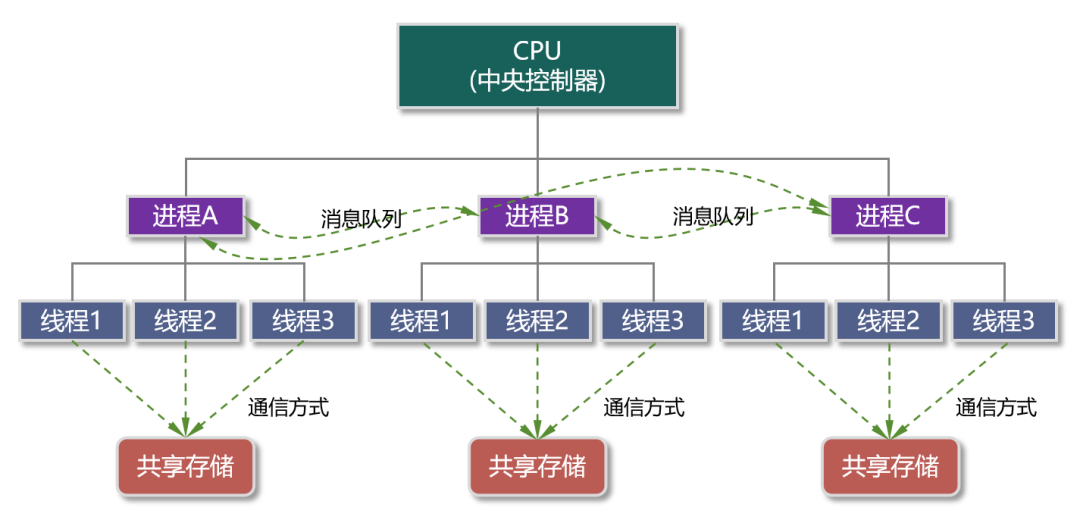
进程与线程
例如你启动了一个浏览器程序,那么,操作系统就会开启一个相应的进程。这个进程里面,又会有多个线程,如HTTP请求线程、事件响应线程、渲染线程等。
如果你关闭这个浏览器程序,从任务管理器可以看到,这个进程和对应的线程都没有了。当然,你也可以在任务管理器里,直接右键关闭某个进程,程序也就强制退出了。Linux里干掉一个进程,用的命令就是“kill(杀掉)”。
线程是操作系统发展到后期才引入的。它进一步提供了程序执行的并发性,提高了系统的效率。
进程和线程,都可以包括执行态、就绪态、阻塞态等状态。对进程和线程进行管理,本质上是为了实现对CPU资源的分配调度。
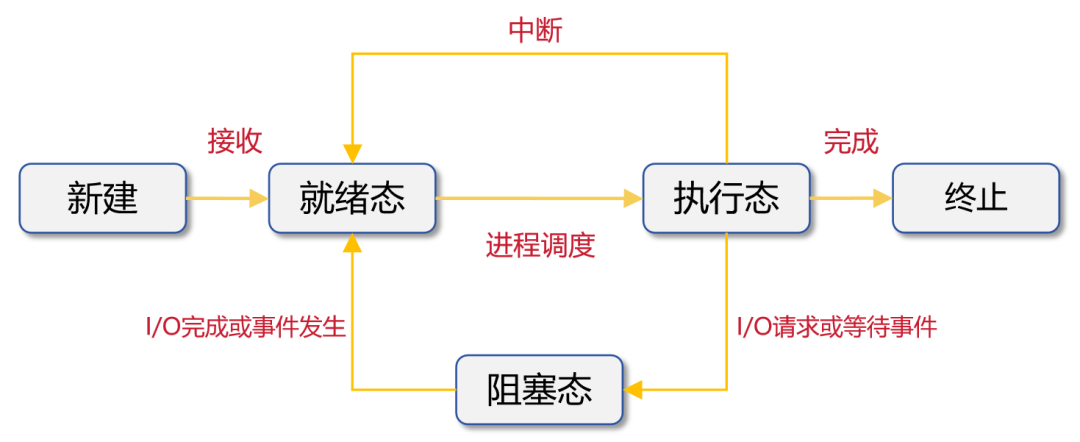
进程的状态变化
需要注意的是,一个程序可以对应一个或多个进程。而一个进程同样可以对应一个或多个程序(虽然比较罕见)。
其次,是内存管理。
以前我们多次提到过冯·诺依曼架构。程序要从硬盘到内存,才能够被运算器(CPU)处理。每个程序都有足够的内存空间,才能够确保正常运行。
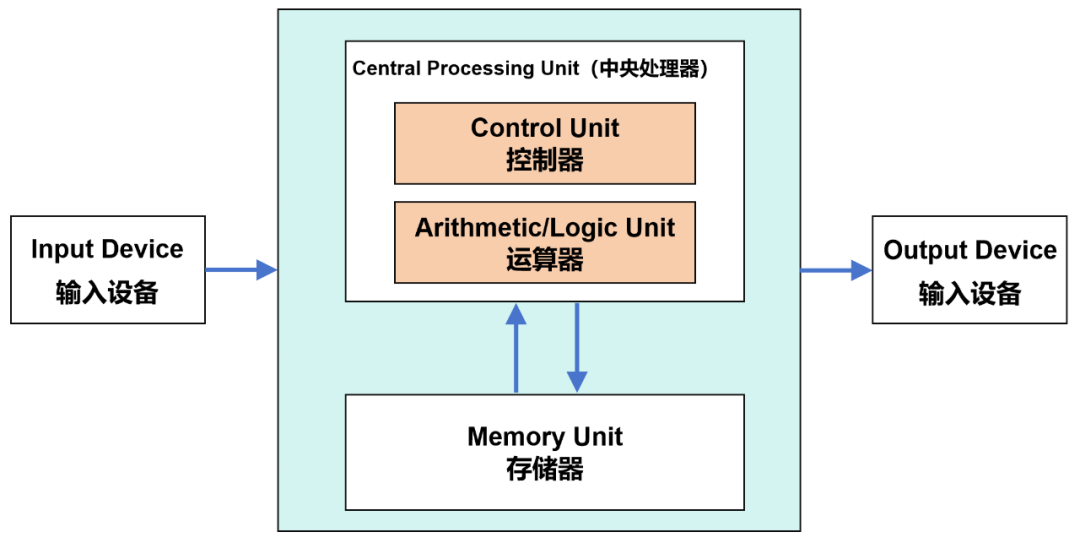
冯·诺依曼架构
运行之后,内存也需要被及时释放,才能让别的程序能够继续占用。
内存的分配和回收,也是操作系统负责的。
除了内存分配之外,操作系统还要负责进行内存保护(确保每道程序都只在自己的内存区中运行,进程间不会互相干扰)、地址映射(将程序装入内存运行时,需要将逻辑地址转化成内存单元所限定的物理地址)、内存扩充(借助于虚拟存储技术,从逻辑上去扩充内存容量)等工作。

四、并发多线程(自动驾驶常问)
1. 线程创建方式
标准答案:C++11后常用4种,重点记前3种:
-
用函数指针:std::thread t(func, 参数); (func是线程要执行的函数)。
-
用lambda表达式:std::thread t([](){ /* 线程执行逻辑 */ });
-
用类的成员函数:std::thread t(&类名::成员函数, &对象, 参数);
-
用可调用对象(如函数对象):自定义类,重载()运算符,传入thread。
补充:线程创建后,需调用join()(等待线程结束)或detach()(分离线程,线程独立运行),否则程序会崩溃。
2. 互斥锁 mutex、条件变量 condition_variable
标准答案:
-
互斥锁 mutex:用于保护多线程共享资源,避免竞争条件(多个线程同时读写共享资源);用法:std::mutex mtx; mtx.lock(); (临界区代码); mtx.unlock(); 推荐用std::lock_guard(自动上锁、解锁,避免忘记unlock)。
-
条件变量 condition_variable:用于线程间通信,实现线程的等待和唤醒;常与互斥锁配合使用,如线程A等待某个条件满足,线程B满足条件后唤醒线程A;常用接口:wait()(等待)、notify_one()(唤醒一个线程)、notify_all()(唤醒所有线程)。
3. 死锁产生四个必要条件、怎么避免死锁
标准答案:
死锁四个必要条件(必须同时满足才会产生):① 互斥条件:资源只能被一个线程占用;② 请求与保持条件:线程持有一个资源,又请求另一个资源;③ 不可剥夺条件:资源不能被强制剥夺;④ 循环等待条件:多个线程互相等待对方的资源。
避免死锁方法:① 按固定顺序获取资源(如所有线程都先获取锁A,再获取锁B);② 避免长时间持有锁,获取锁后尽快释放;③ 用std::lock()同时获取多个锁,避免循环等待;④ 用try_lock()尝试获取锁,失败则释放已持有锁。
4. 原子变量 atomic 作用
标准答案:用于多线程共享变量的原子操作,保证操作的不可分割性(不会被其他线程打断),避免竞争条件,无需手动加锁;常用类型:std::atomic<int>、std::atomic<bool>;适用场景:多线程计数、标志位判断(如自动驾驶中,多线程更新目标计数)。
补充:atomic比mutex效率高,适合简单的读写操作,复杂操作仍需用mutex。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)