ElasticSearch与Kibana
ElasticSearch(简称ES): 是一个基于Lucene构建的开源、分布式、RESTful的全文本搜索引擎;它还是一个分布式实时文档存储, 其中每个field均是被索引的数据且可被搜索;也是一个带实时分析功能的分布式搜索引擎, 并且能够扩展至数以百计的服务器存储及处理PB级的数据。主机IP内存 / CPU安装软件磁盘node14G/2sdanode24G/2sdanode34G/2sda服
1.ELK实战概述
1.概述
ELK 是一套开源免费且功能强大的日志分析管理系统,由 Elasticsearch、Logstash、Kibana 三部分组成,简称 ELK。
ELK 可以将系统日志、网站日志、应用系统日志等各种日志进行收集、过滤、清洗,然后进行集中存放并可用于检索、分析。
这三款软件都是开源软件,通常是配合使用,且归于 Elastic.co 公司名下,所以被简称为 ELK Stack。
2.系统架构
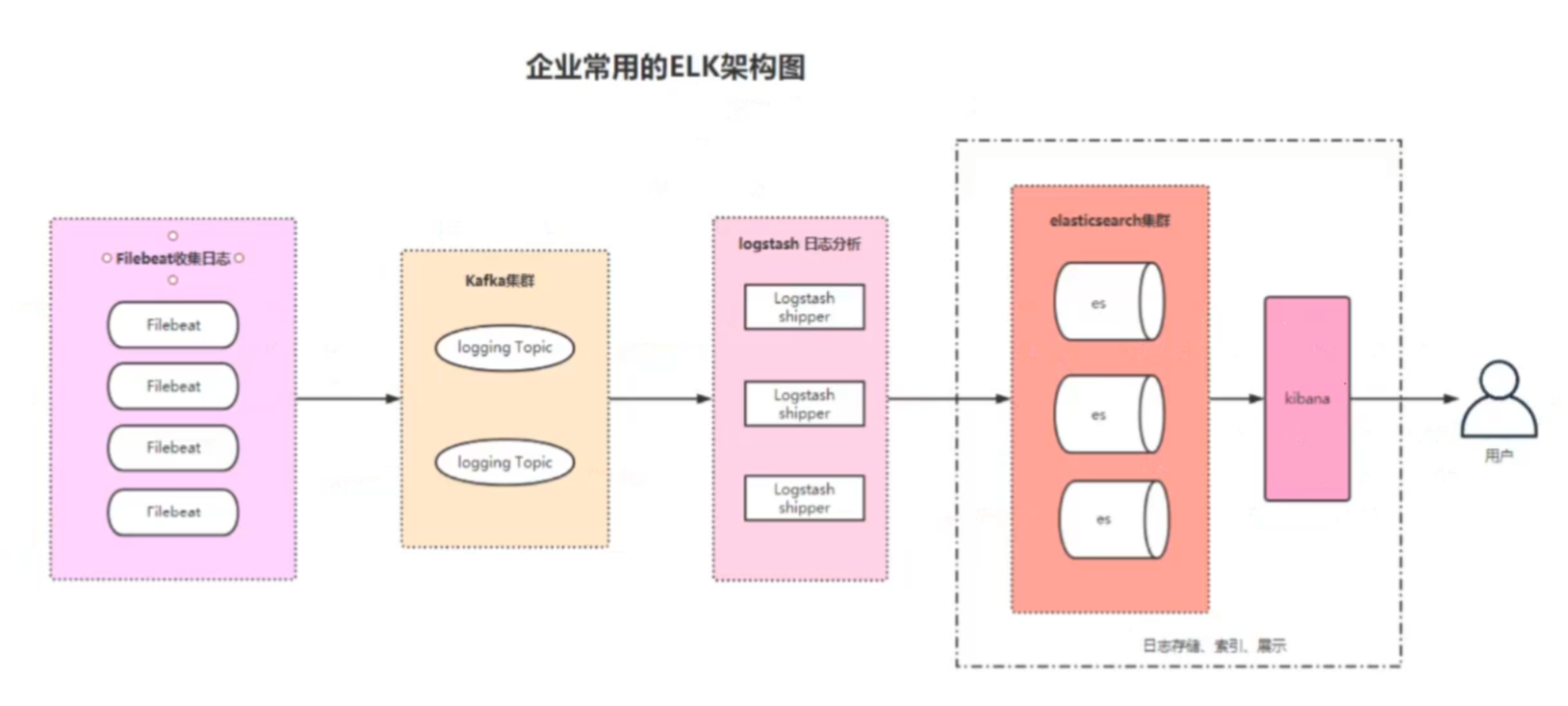
其中每个架构有什作用
第一部分:收集日志的部分Filebaet收集日志,就是将所有的日志收集到一起,比如nginx,tomcat,mysql等日志收集到一起
第二部分:Kafka集群,用于存储收集日志数据,因为收集数据是非常快的,但是在第三部分的日志分析却又是异常缓慢的,因此就需要有一个缓冲的部分也就是Kafka集群
第三部分:对日志数据进行分析,格式化
第四部分:其中有两个部分第一个部分elasticsearch用于存储日志,增加索引以达到增加其搜索效率的目的,第二个部分就是kibana就是用于展示日志用图形化的界面
2.ES概述
1.概述
ElasticSearch(简称ES): 是一个基于Lucene构建的开源、分布式、RESTful的全文本搜索引擎; 它还是一个分布式实时文档存储, 其中每个field均是被索引的数据且可被搜索; 也是一个带实时分析功能的分布式搜索引擎, 并且能够扩展至数以百计的服务器存储及处理PB级的数据。
2.核心概念
1.全文检索
全文检索就是对一篇文章进行索引,可以根据关键字搜索,类似于mysql里的like语句。 全文索引就是把内容根据词的意义进行分词,然后分别创建索引,例如“接下来听我给大家讲解ES的基本使用与深层原理”可能会被分词成:“接下来”,“大家”,“学会”,“基本”,“原理”等词条,这样当你搜索“你们”或者“原理”都会把这句搜出来。
2.近实时查询
Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒以内)
3.倒排索引
倒排索引(反向索引):倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。 由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字所对应的所有文档,所以效率高于正排表。在全文检索中,检索的快速响应是一个最为关键的性能,而索引建立由于在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率。
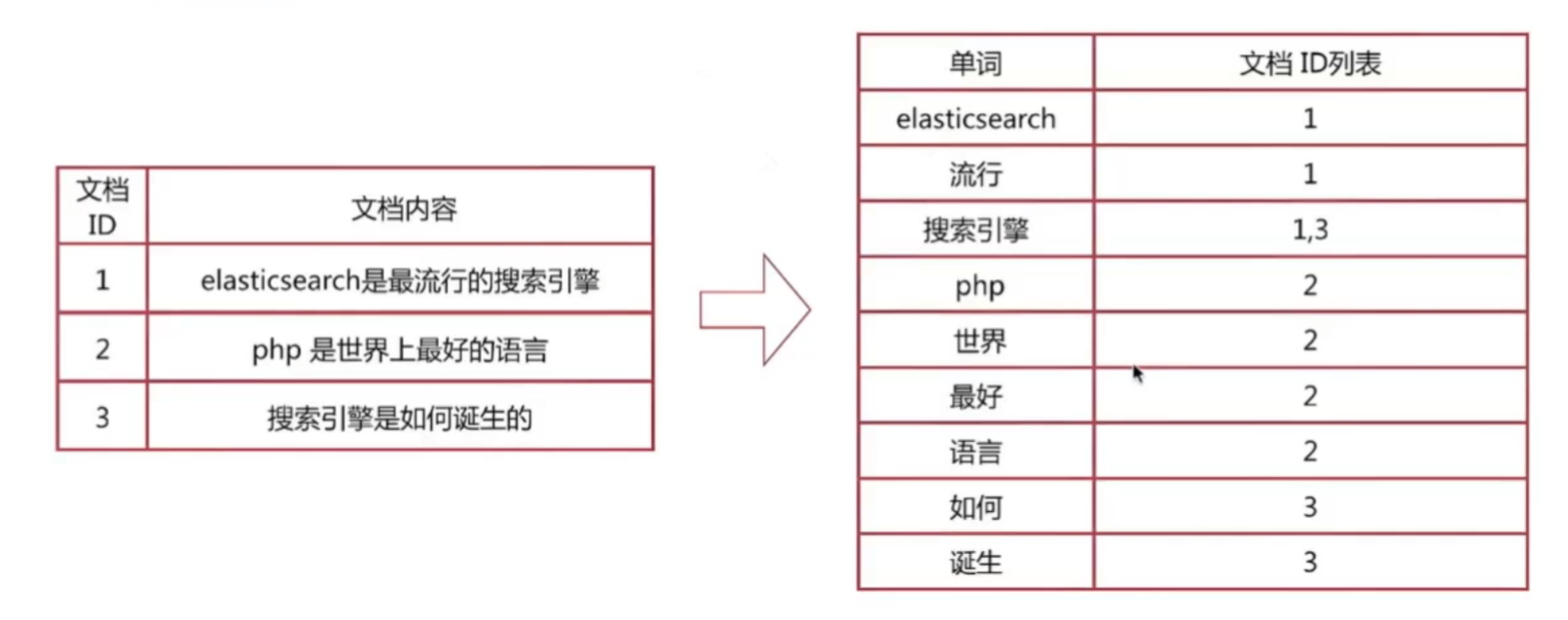
先通过关键字在倒排索引查询到文档ID,在通过ID查询正排索引返回内容
4.集群
ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群
5.节点
形成集群的每个服务器称为节点
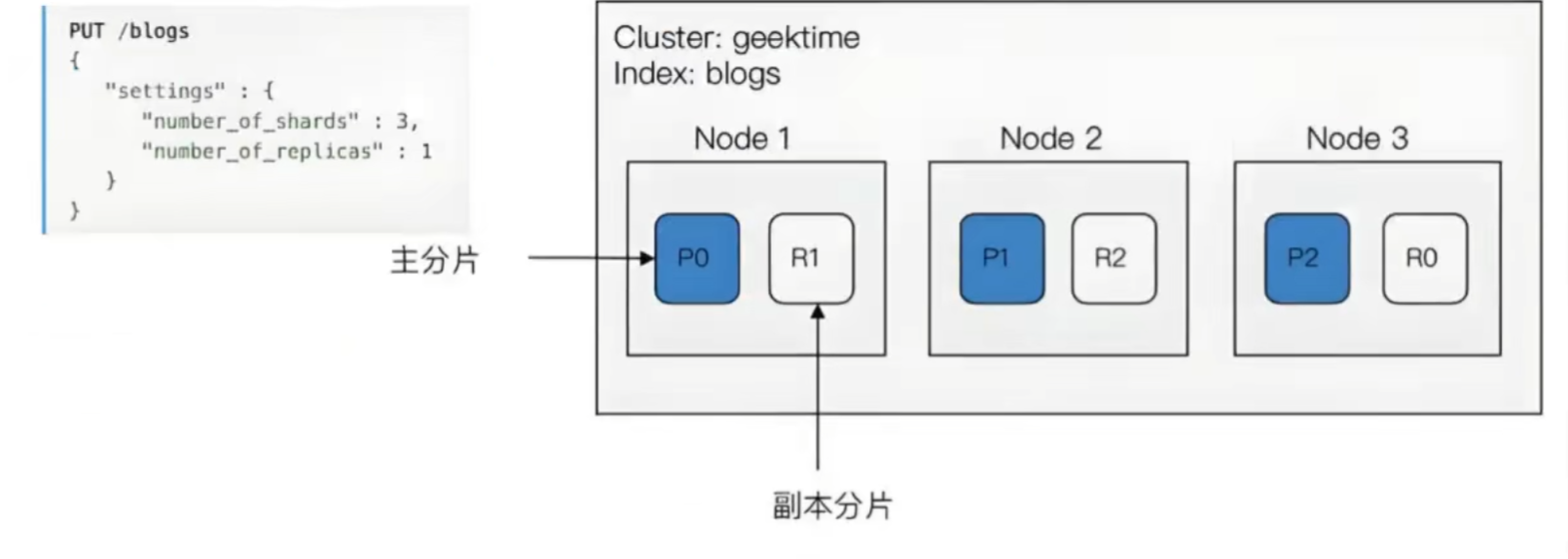
6.分片
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上 至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
7.副本
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。 复制之所以重要,有两个主要原因:在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行。总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。 默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。
3.ES与MySQL对比
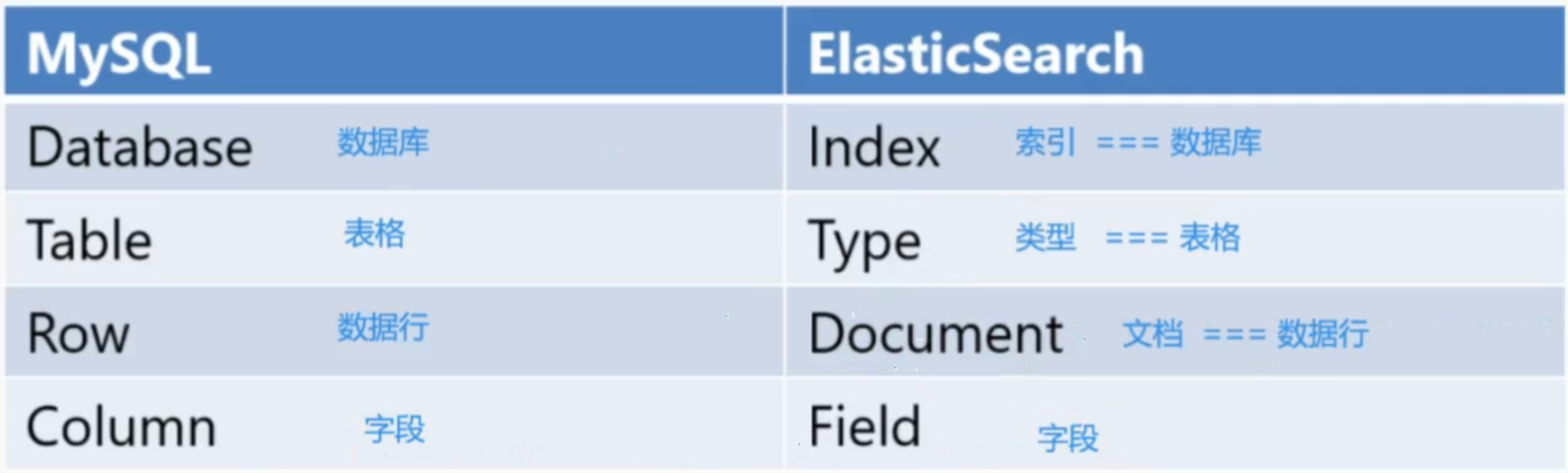
两者都差不多基本就是一一对应的
3.ES集群搭建
1.环境概述
| 主机 | IP | 内存 / CPU | 安装软件 | 磁盘 |
|---|---|---|---|---|
| node1 | 192.168.217.155 | 4G/2 | elasticsearch、kibana、filebeat | sda |
| node2 | 192.168.217.156 | 4G/2 | elasticsearch、logstash | sda |
| node3 | 192.168.217.157 | 4G/2 | elasticsearch、kafka | sda |
服务器初始化脚本
#!/bin/bash
# 1. 设置主机名
hostnamectl set-hostname $1
# 2. 修改hosts文件
echo 192.168.22.151 node1 >> /etc/hosts
echo 192.168.22.147 node2 >> /etc/hosts
echo 192.168.22.148 node3 >> /etc/hosts
# 3. 关闭防火墙
systemctl stop firewalld && systemctl disable firewalld
setenforce 0
sed -i "s/SELINUX=enforcing/SELINUX=disabled/" /etc/selinux/config
# 4. 配置yum源
cd /etc/yum.repos.d
rm -rf *
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
yum clean all
yum makecache
yum install epel-release -y
# 5. 安装必要软件
yum install vim -y
yum install net-tools -y
yum install wget -y
yum install yum-utils -y
yum install ntp -y
# 6. 时间同步
systemctl enable ntpd --now
# 7. 重启
reboot
2.安装
1.上传资源
jdk-8u371-linux-x64.tar.gz
elasticsearch-7.13.2-x86_64.rpm这里直接yum安装java吧
yum list java*
yum install java-1.8.0-openjdk.x86_64 -yelasticsearch-7.13.2-x86_64.rpm这里直接源码安装下面下载链接
Elasticsearch 7.13.2 | Elastic
下载好之后看下面一篇文章吧,非常详细
Linux环境下安装Elasticsearch,史上最详细的教程来啦~_linux elasticsearch-CSDN博客
vim /etc/elasticsearch/config/elasticsearch.yml
# 下面有的就修改没有的就添加
cluster.name: elk
node.name: node1
node.data: true
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts:
- node1 #下面三个都按格式添加
- 192.168.22.147:9300
- 192.168.22.148
cluster.initial_master_nodes: ["node1", "node2", "node3"]2.测试
#ES测试直直接访问看是否启动
http://192.168.22.151:9200/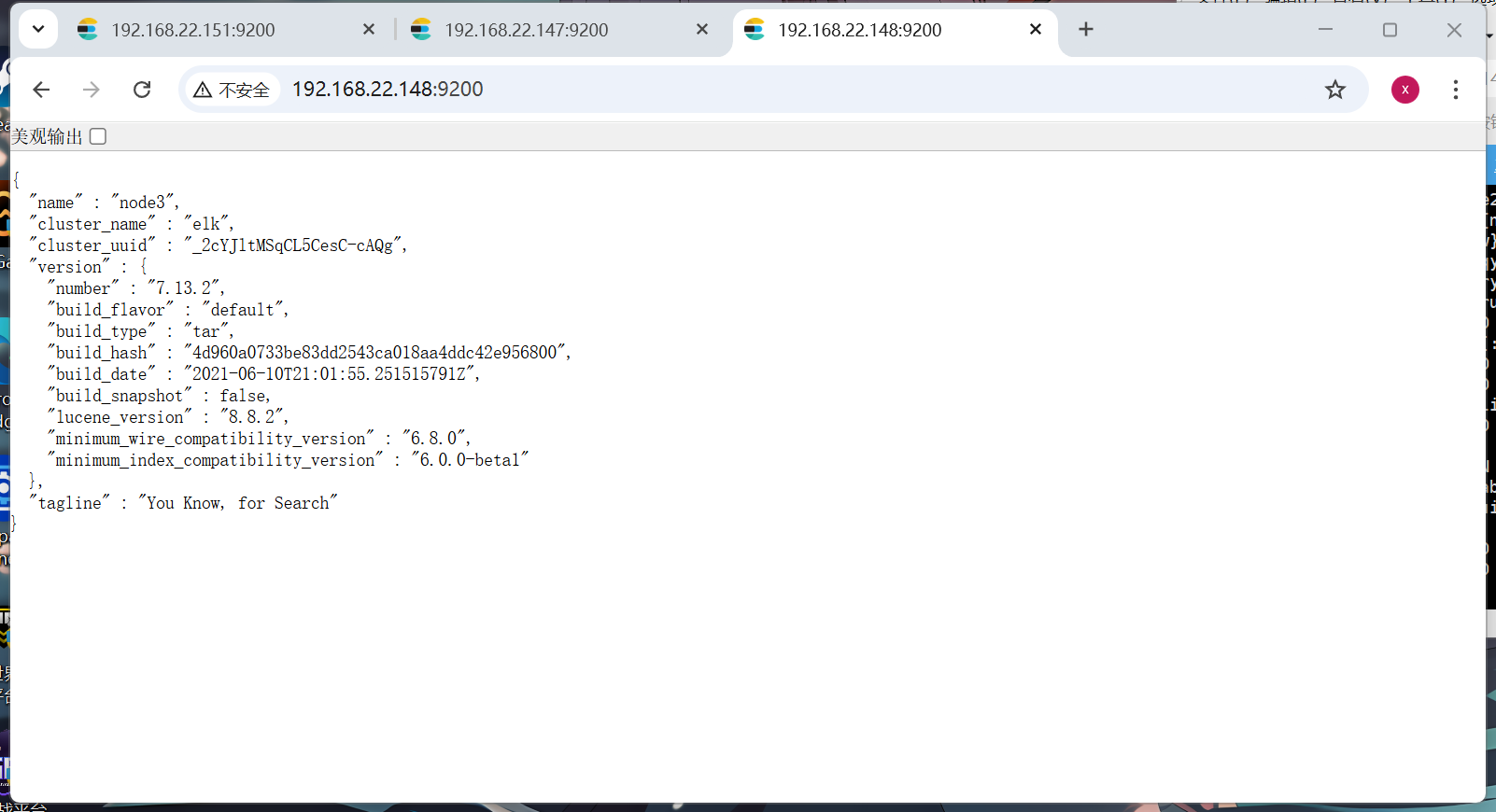
这里我三台都正常启动了
ES集群测试
http://192.168.22.151:9200/_cat/health?v
ES节点测试

都是正常连接到了
4.分词器
1.概述
IKAnalyzer 是一个开源的,基于 Java 语言开发的轻量级的中文分词工具包。从 2006 年 12 月推出 1.0 版开始,IKAnalyzer 已经推出了 3 个大版本。最初,它是以开源项目 Lucene 为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的 IKAnalyzer3.0 则发展为面向 Java 的公用分词组件,独立于 Lucene 项目,同时提供了对 Lucene 的默认优化实现。
IK 分词器 3.0 的特性如下:
- 采用了特有的 “正向迭代最细粒度切分算法”,具有 60 万字 / 秒的高速处理能力。
- 采用了多子处理器分析模式,支持:英文字母(IP 地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。
- 对中英联合支持不是很好,在这方面的处理比较麻烦,需再做一次查询,同时支持个人词条的优化的词典存储,更小的内存占用。
- 支持用户词典扩展定义。
- 针对 Lucene 全文检索优化的查询分析器 IKQueryParser;采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高 Lucene 检索的命中率。
2.安装
# 下载地址
https://get.infini.cloud/elasticsearch/analysis-ik/7.13.2
# 上传到系统中
elasticsearch-analysis-ik-7.13.2.zip
# 解压到指定目录
mkdir /usr/share/elasticsearch-7.13.2/plugins/ik
unzip elasticsearch-analysis-ik-7.13.2.zip -d /usr/local/elasticsearch-7.13.2/plugins/ik/
# 重启ES下载好之后我们用接口测试工具来测试一下他的分词效果
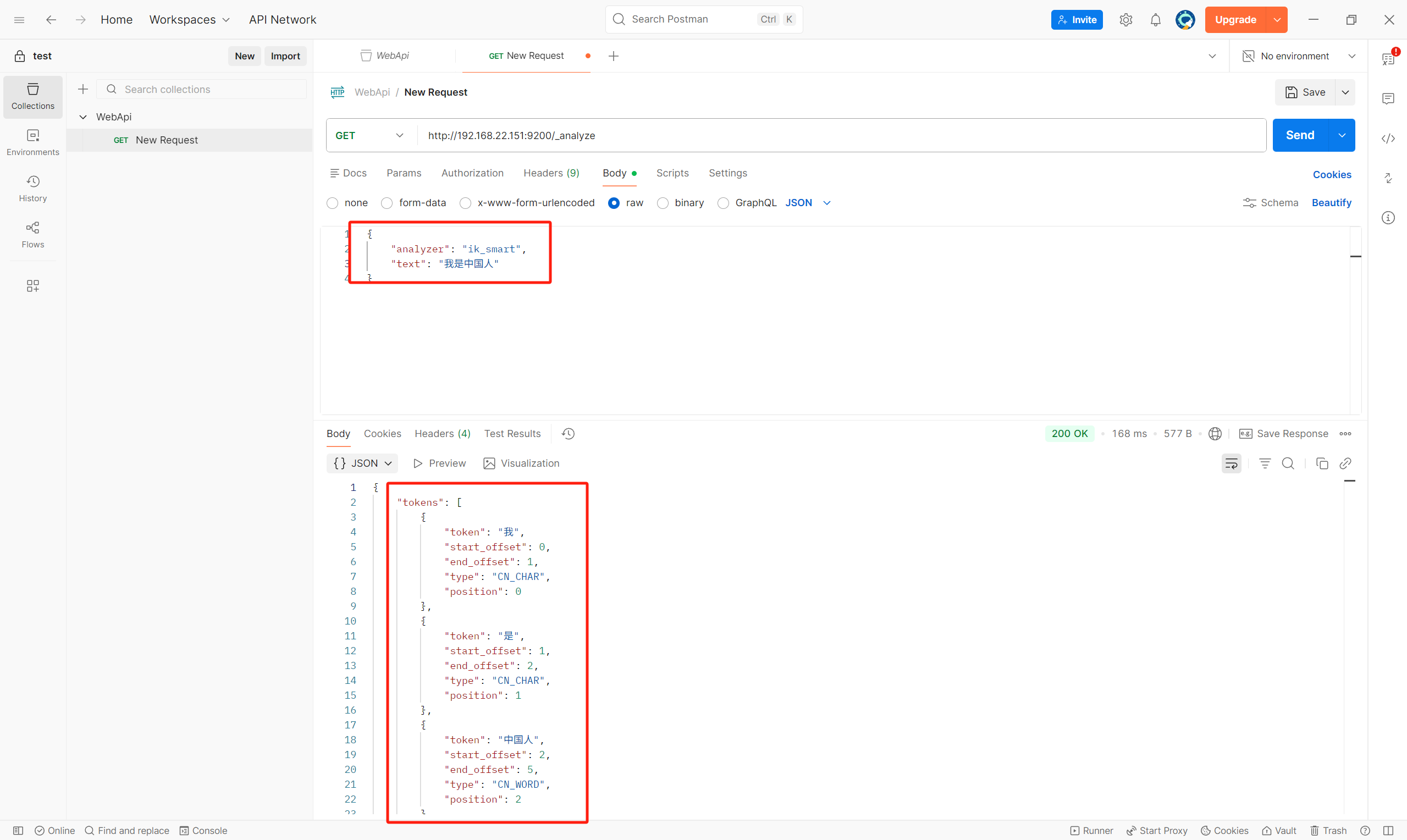
# json的数据格式发送
# ik_smart 智能分词 ik_max_word最大智能分词
{
"analyzer": "ik_smart",
"text": "我是中国人"
}智能分词效果
最大智能分词效果
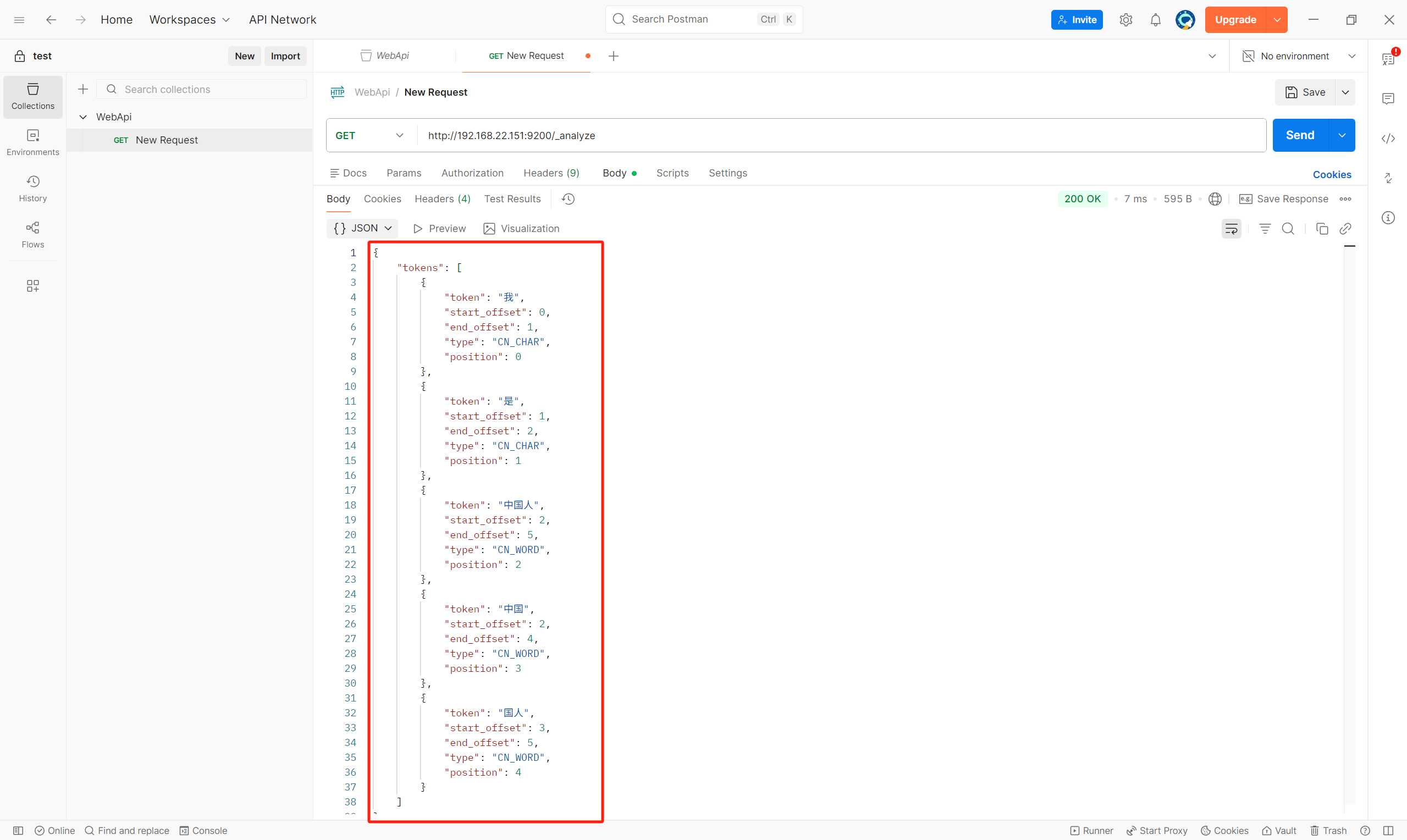
分出来的更多
5.kibana安装配置
1、概述
Kibana 是一个开源的数据分析和可视化平台,它是 Elastic Stack(包括 Elasticsearch、Logstash、Kibana 和 Beats)的一部分,用于对 Elasticsearch 中的数据进行搜索、查看、交互操作。
Kibana 的主要功能和用途包括:
- 数据可视化:Kibana 提供了丰富的数据可视化选项,如柱状图、线图、饼图、地图等,帮助用户以图形化的方式理解数据。
- 数据探索:Kibana 提供了强大的数据探索功能,用户可以使用 Elasticsearch 的查询语言进行数据查询,也可以通过 Kibana 进行数据筛选和排序。
- 仪表盘:用户可以将多个可视化组件组合在一起,创建交互式的仪表盘,用于实时监控数据。
- 机器学习:Kibana 还集成了 Elasticsearch 的机器学习功能,可以用于异常检测、预测等任务。
- 定制和扩展:Kibana 提供了丰富的 API 和插件系统,用户可以根据自己的需求定制和扩展 Kibana。
总的来说,Kibana 是一个强大的数据分析和可视化工具,它可以帮助用户更好地理解和探索他们的数据。
2.安装
1.上传资料文件(其中一台机器就可以了,比如就上传到 node1 服务器)
kibana-7.13.2-linux-x86_64.tar.gz
2.解压缩
tar -xf kibana-7.13.2-linux-x86_64.tar.gz -C /usr/local3.修改配置文件
vim /usr/local/kibana-7.13.2-linux-x86_64/config/kibana.yml
###########################
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://node1:9200"]
logging.dest: /var/log/kibana.log
i18n.locale: "zh-CN"4.root用户来运行kibana
nohup /usr/local/kibana-7.13.2-1inux-x86_64/bin/kibana --allow-root &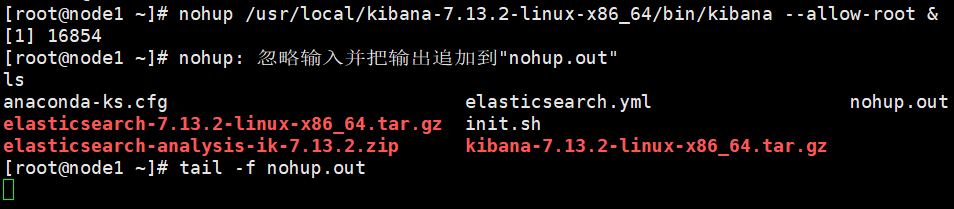
这里启动成功,里面有一个开发工具,可以测试接口
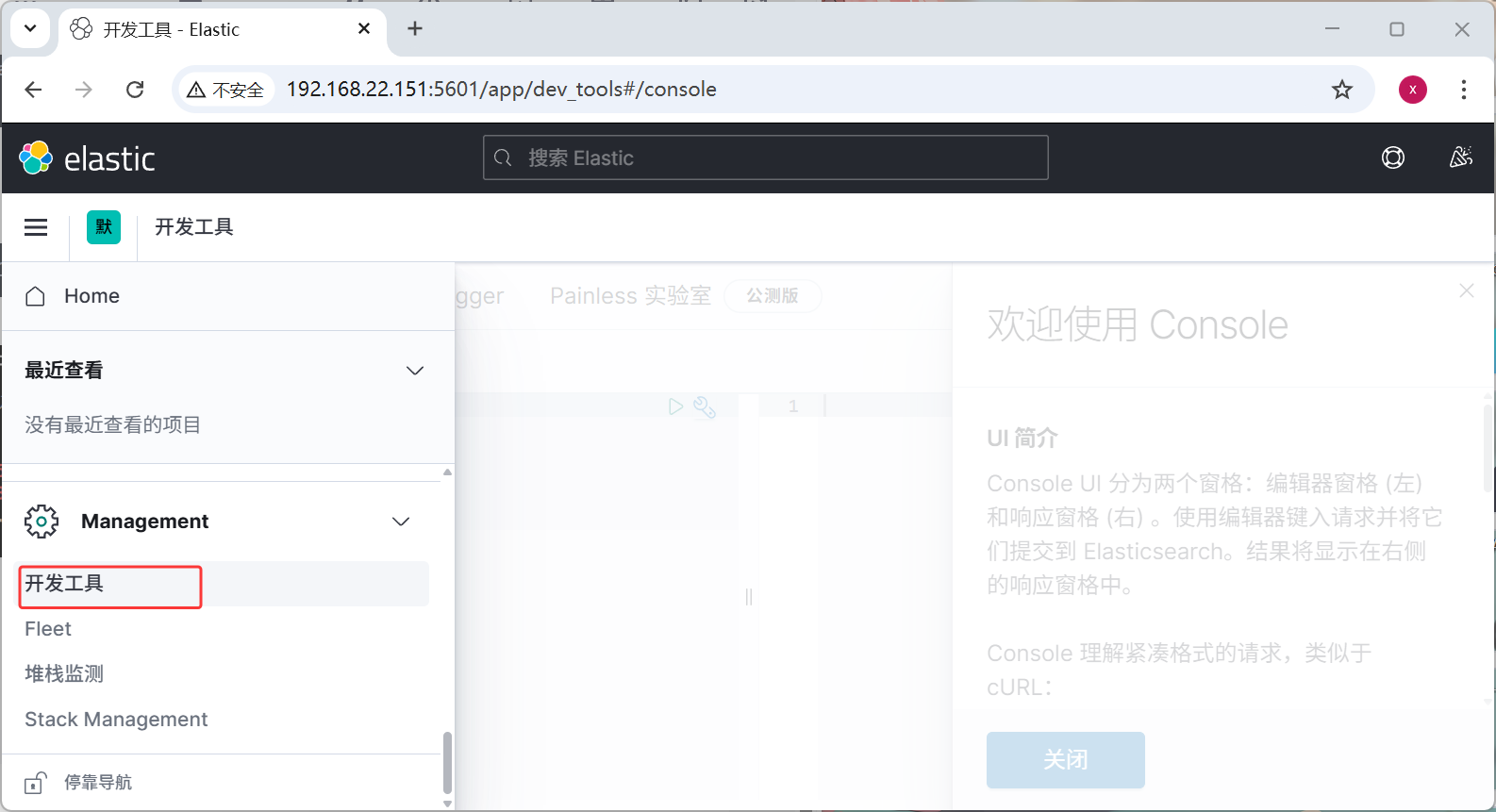
这里就测试上面的分词器接口
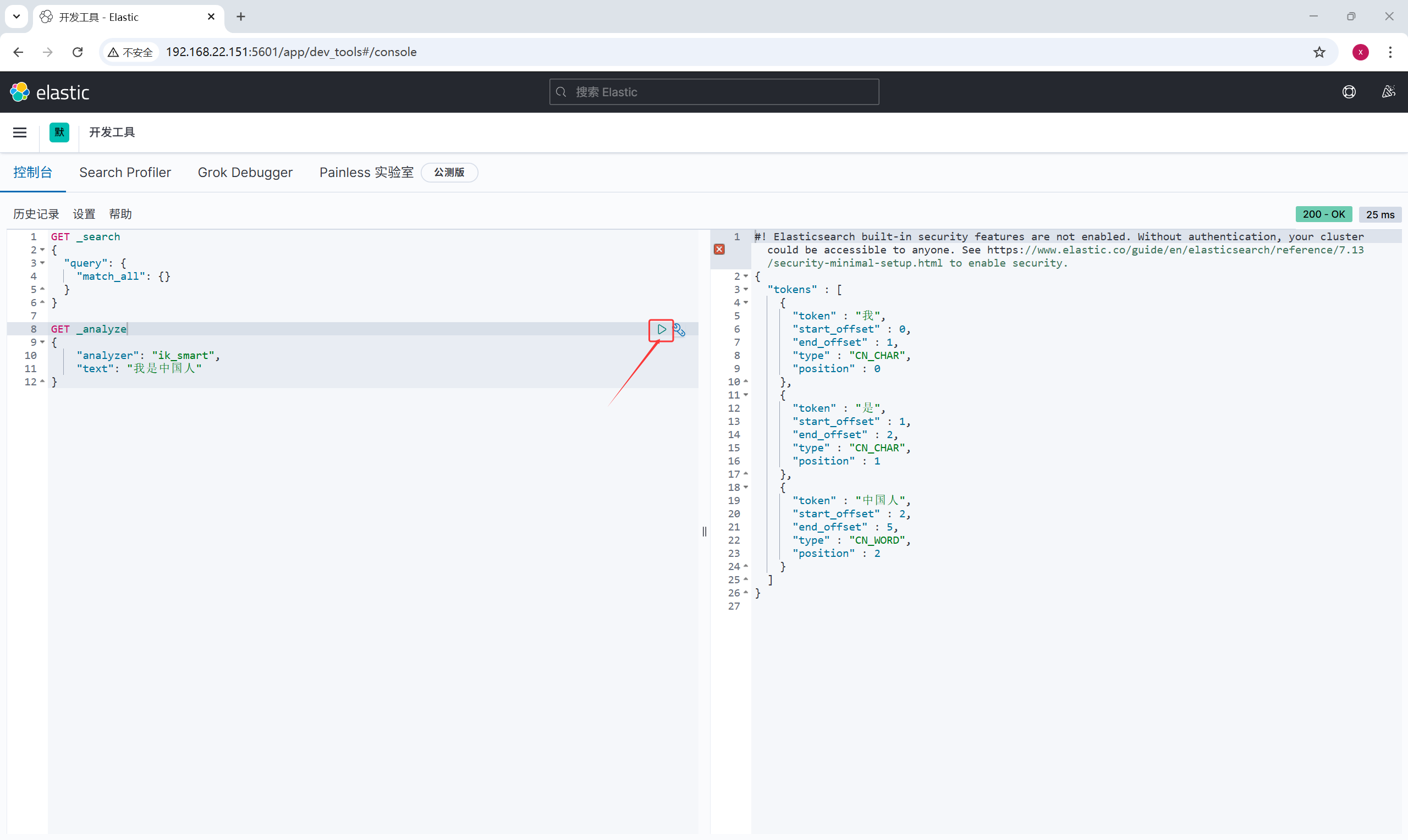 点击发送之后就可以看到效果
点击发送之后就可以看到效果
6.Filebeat安装与使用
1、概述
1.概述
Filebeat 是一个轻量级的日志托运工具,用于转发和集中日志数据。Filebeat 作为代理安装在服务器上,监控指定的日志文件或目录,收集日志事件,并将它们转发到 Elasticsearch 或 Logstash 进行索引。
Filebeat 是用于 “转发” 和 “集中日志数据” 的 “轻量型数据采集器”,用 go 语言开发,相比 Logstash 来说轻便。
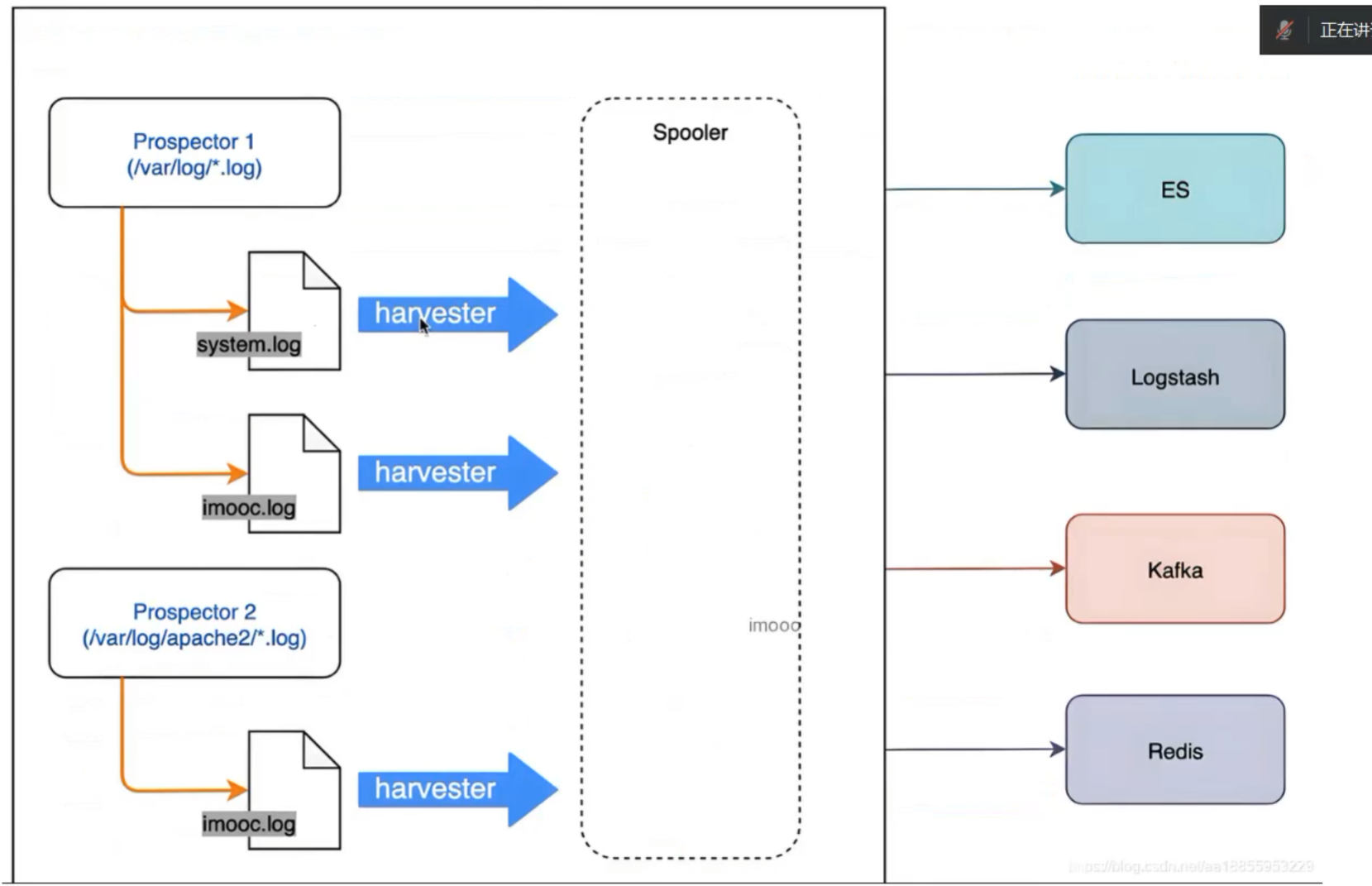
2.组件
Filebeat 包含两个主要组件,输入和收割机,两个组件协同工作将文件尾部最新数据发送出去
- 输入 Input:输入负责管理收割机从哪个路径查找所有可读取的资源。
- 收割机 Harvester:负责逐行读取单个文件的内容,然后将内容发送到输出。
3.原理
当 filebeat 启动后,filebeat 通过 Input 读取指定的日志路径,然后为该日志启动一个收割进程 harvester,每一个收割进程读取一个日志文件的新内容,并发送这些新的日志数据到处理程序 spooler,处理程序会集合这些事件,最后 filebeat 会发送集合的数据到你指定的位置。
2.安装
1.上传压缩包(需要收集日志的机器都要安装 Filebeat,此处我们以 node1 为例,将 Filebeat 安装在 node1 机器上)
filebeat-7.13.2-linux-x86_64.tar.gz2.解压缩
tar -xf filebeat-7.13.2-linux-x86_64.tar.gz -C /usr/local3.配置 Filebeat 为系统服务
vim /usr/lib/systemd/system/filebeat.service
############################################
[Unit]
Description=Filebeat sends log files to Logstash or directly to Elasticsearch.
Wants=network-online.target
After=network-online.target
[Service]
User=root
Group=root
Environment="BEAT_CONFIG_OPTS=-c /usr/local/filebeat-7.13.2-linux-x86_64/filebeat.yml"
ExecStart=/usr/local/filebeat-7.13.2-linux-x86_64/filebeat $BEAT_CONFIG_OPTS
Restart=always
[Install]
WantedBy=multi-user.target
#重新加载配置文件
systemctl daemon-reload4.修改配置文件
vim /usr/local/filebeat-7.13.2-linux-x86_64/filebeat.yml
##########################################################
filebeat.inputs:
- type: log
enabled: true
paths:
- /tmp/*.log # 指定需要收集日志的路径,支持通配符可以写多个
filebeat.config.modules: # 内置的收集日志的模块配置文件的存放路径
path: ${path.config}/modules.d/*.yml
reload.enabled: false # 当模块的配置文件有更新时,此程序是否要自动加载,false不加载,true 加载
setup.template.settings:
index.number_of_shards: 1
output.console: #添加 输出到终端即屏幕上
pretty: true
processors: #改
- add_host_metadata: # 添加此主机的源数据信息到输出数据中,比如 IP MAC OS 等信息
when.not.contains.tags: forwarded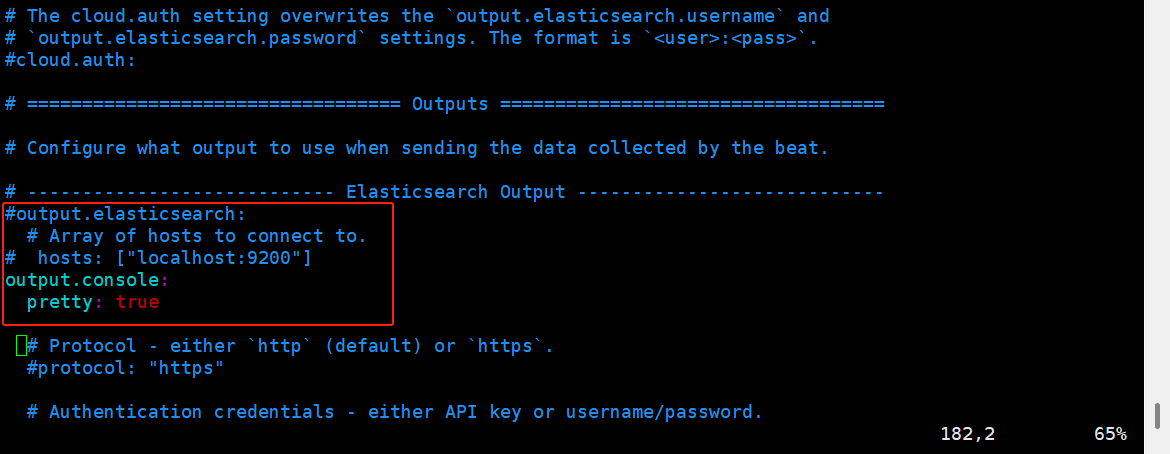
3.测试
我们先收集nginx目录下的日志
1.先安装nginx
vim /etc/yum.repos.d/nginx.repo
###################################################
[nginx-stable]
name=nginx stable repo
baseurl=https://nginx.org/packages/centos/$releasever/$basearch/
gpgcheck=1
enabled=1
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
[nginx-mainline]
name=nginx mainline repo
baseurl=https://nginx.org/packages/mainline/centos/$releasever/$basearch/
gpgcheck=1
enabled=0
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true2.修改 nginx 日志模块配置文件,(如果 nginx 的日志文件在默认位置,则不需要修改)
vim nginx.yml.disabled3.启动nginx日志模块
/usr/local/filebeat-7.13.2-linux-x86_64/filebeat -c /usr/local/filebeat-7.13.2-linux-x86_64/filebeat.yml modules enable nginx启动完成之后后面的disable不见了
4.启动filebeat
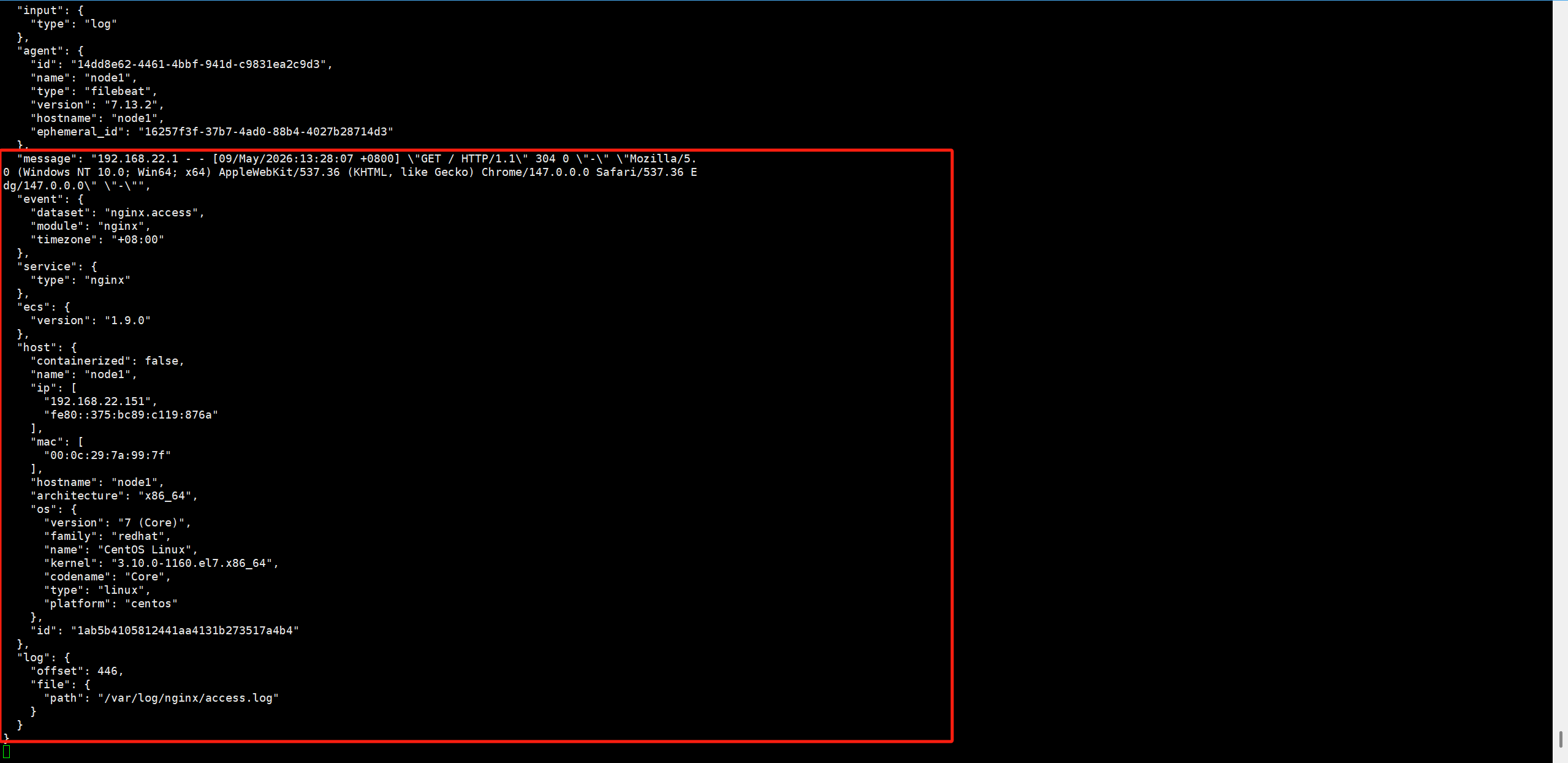
./filebeat -c filebeat.yml访问nginx产生日志文件,每刷新一次就产生下面的类似一个日志
7.ES的基本用法
1.ES索引操作
put goods1.删除索引
delete goods2.查询索引
get goods
get goods/_cat/indices?v3.创建索引指定映射关系
PUT goods
{
"mappings": {
"properties": {
"id": {
"type": "long",
"index": false
},
"title": {
"type": "text",
"index": true
},
"brand_name": {
"type": "keyword",
"index": true
}
}
}
}就类似于数据库,数据库里面有id,titile,brand_name字段
2.ES 文档操作与查询命令
1.添加文档
POST goods/_doc/1001
{
"id": 1001,
"title": "mate40",
"brand_name": "华为"
}
POST goods/_doc/1002
{
"id": 1002,
"title": "mate50",
"brand_name": "华为"
}2.删除文档
# 删除文档
DELETE goods/_doc/10013.修改文档
# 全量修改(会覆盖原文档所有字段)
PUT goods/_doc/1001
{
"id": 1001
}
PUT goods/_doc/1001
{
"price": 4999
}
# 局部修改(仅更新指定字段,保留其他字段)
POST goods/_update/1001
{
"doc": {
"price": 5999
}
}4.查询文档
# 查询单条文档
GET goods/_doc/1001
# 查询索引所有文档
GET goods/_search5.term查询说明
term 主要用于分词精确匹配,如字符串、数值、日期等(不适合情况:1. 列中除英文字符外有其它值;2. 字符串值中有冒号或自带属性如_version)
# term查询示例1:查询brand_name为“华为”的文档
GET goods/_search
{
"query": {
"term": {
"brand_name": {
"value": "华为"
}
}
}
}
# term查询示例2:查询title中包含“mate”的文档
GET goods/_search
{
"query": {
"term": {
"title": {
"value": "mate"
}
}
}
}6.match 查询说明
match 查询是标准查询,全文本 / 精确查询场景都适用。使用 match 查询全文本字段时,会在查询前用分析器先处理查询词,再进行匹配。
# match查询示例1:查询brand_name为“华为”的文档
GET goods/_search
{
"query": {
"match": {
"brand_name": "华为"
}
}
}
# match查询示例2:查询title中包含“mate”的文档
GET goods/_search
{
"query": {
"match": {
"title": "mate"
}
}
}文档操作就相当于给数据库里面添加值

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)