项目2|内存池|版本2|高并发内存池
内存分配器本质上是操作系统和应用程序之间的一个‘中间件’。没有内存分配器时,程序通过brk或mmap函数申请内存,brk或mmap函数申请的是一整页的。brk(int),只需要4B,也会申请8KB,巨大的内部碎片。释放后,还给os。有了内存分配器malloc,malloc(4B),程序通过brk或mmap函数申请8KB,它会在上面切一小块。如果不用了,会放在freelist上。有了定长内存池。me
什么是内存分配器
内存分配器本质上是操作系统和应用程序之间的一个‘中间件’。
没有内存分配器时,程序通过brk或mmap函数申请内存,brk或mmap函数申请的是一整页的。brk(int),只需要4B,也会申请8KB,巨大的内部碎片。释放后,还给os。
有了内存分配器malloc,malloc(4B),程序通过brk或mmap函数申请8KB,它会在上面切一小块。如果不用了,会放在freelist上。
有了定长内存池。memoryPoolMalloc(4B),程序通过brk或mmap函数申请8KB,它会在上面切一小块。如果不用了,会放在freelist上。
malloc和定长内存池
他们俩都是内存分配器,思想也非常像。malloc是一个各种类型通用的分配器,定长内存池则是只分配某一钟类型。
malloc是一个通用的内存池,而定长内存池是专门针对申请定长对象而设计的,因此在这种特殊场景下定长内存池的效率更高,正所谓“尺有所短,寸有所长”。
普通new和内存池的区别
- new先调用malloc开辟一块空间。再用定位new,在这片空间上构造对象
- 内存池。使用brk或mmap函数向堆里申请一大块内存。在大内存块上移动char型指针。再用定位new
定长内存池的实现
直接使用brk或mmap函数向堆里申请一大块内存。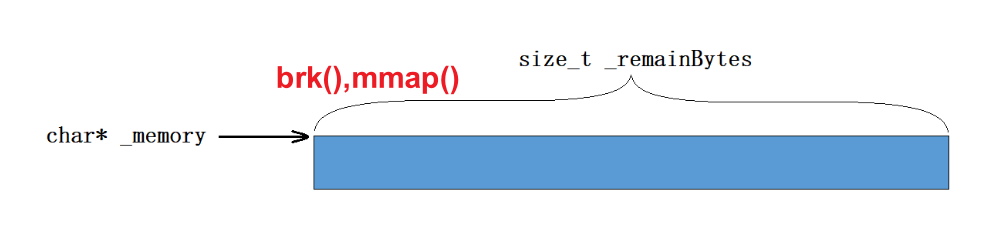
申请完,释放放到freeLIst中

阶梯式内存对齐优化
tc支持的最大容量是256KB
- 如果完全不对齐(每种字节大小建一个桶):要建 262,144 个哈希桶!
- 如果全部按 8 字节对齐:262,144 / 8 = 32,768 个桶
- 阶梯式对齐策略:

图
tc
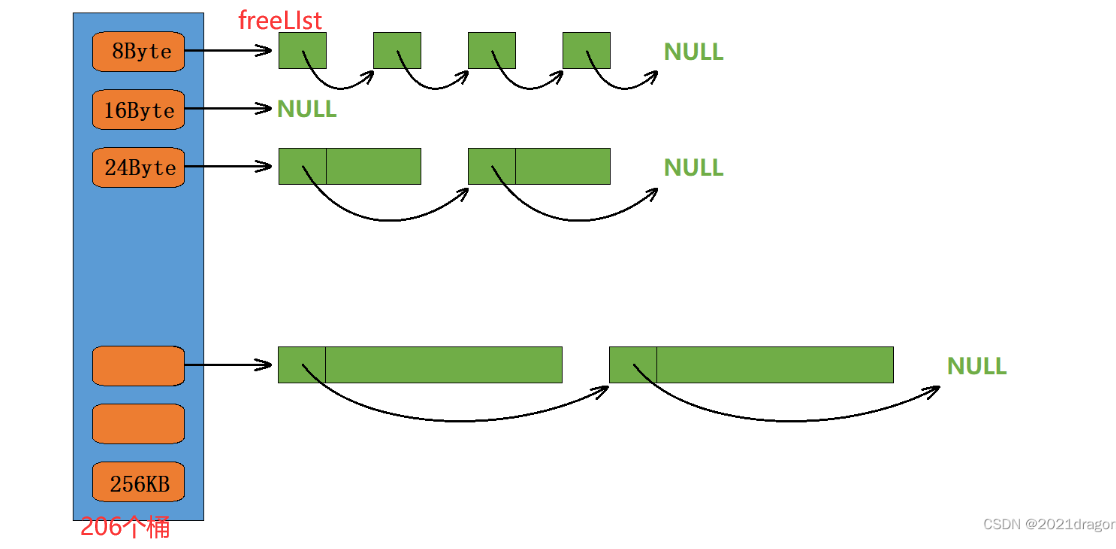
cc
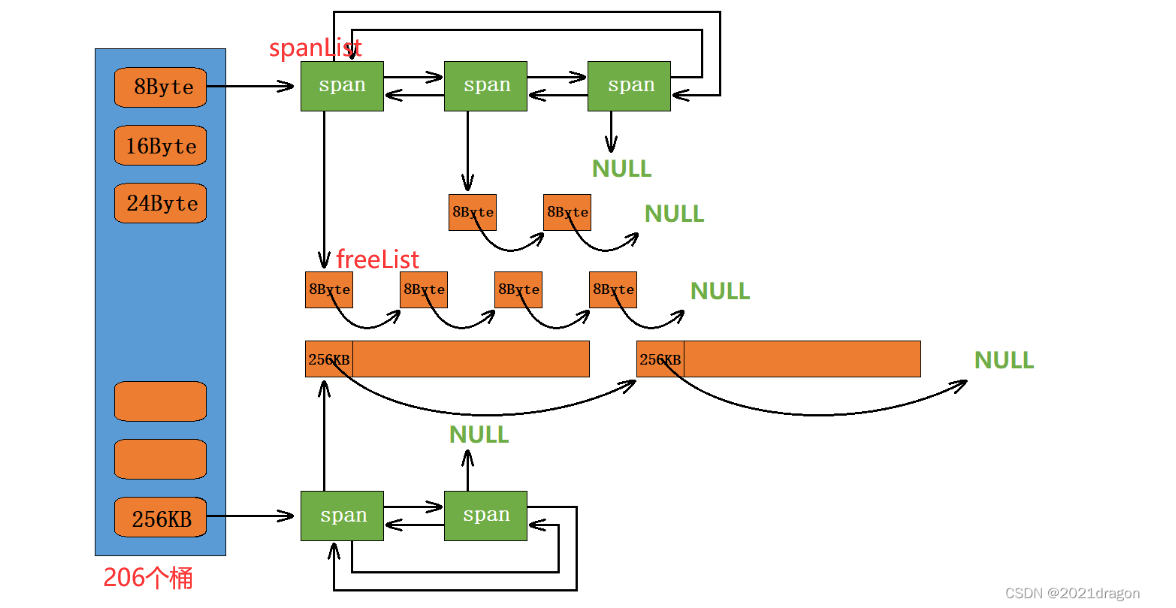
pc
哪些地方需要把new换成定长内存池
- 在pc中向os申请一个span,要把new换成从spanpool中拿
- 在cc还给pc span时,若有连续span,应合并成一个。free
- pc,cc中的spanlist的头结点创建时,需要从new换成定长内存池
- threadCache需要从定长内存池创建,
pTLSThreadCache = new ThreadCache; - pc,cc因为时单例模式,在静态区,不用换。
访问定长内存池时需要加锁吗?
- spanpool池不用加锁,因为这个span的申请是在pc的大锁中,只准一个线程访问。
- spanlist的头结点span,也不用,要么在cc的桶锁中,要么在pc的大锁里
- threadcachePool需要加锁。不然线程竞态,线程A申请时char* memory会乱。
自旋锁+自定义退避策略

项目中有用过那些锁吗?
- tc使用了TLS,避免了线程竞争。
- cc使用的是spanlist锁(桶锁),最终把桶锁改成自旋锁
- pc使用的是将整个pc都锁起来的锁。spanlists大锁
- 用
基数树代替unorderedmap做页面与span的映射。 - 定长内存池中用锁,锁threadCachePool。
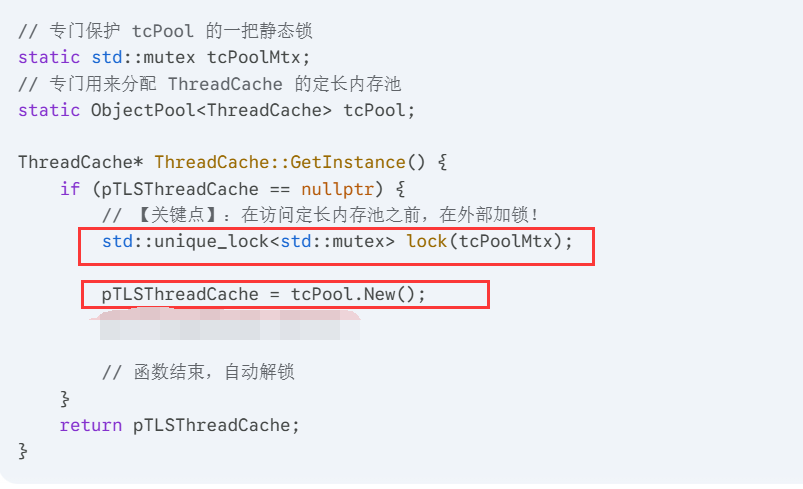
基数树的结构
基数树和页表一模一样。数据结构就是一个数组,【0】就代表0号页,放的是指向0号页的span。每次我们向os拿出内存页时,就会在基数树里记录。(页表就是每次拿内存页,就把虚拟页号物理页号记录下来)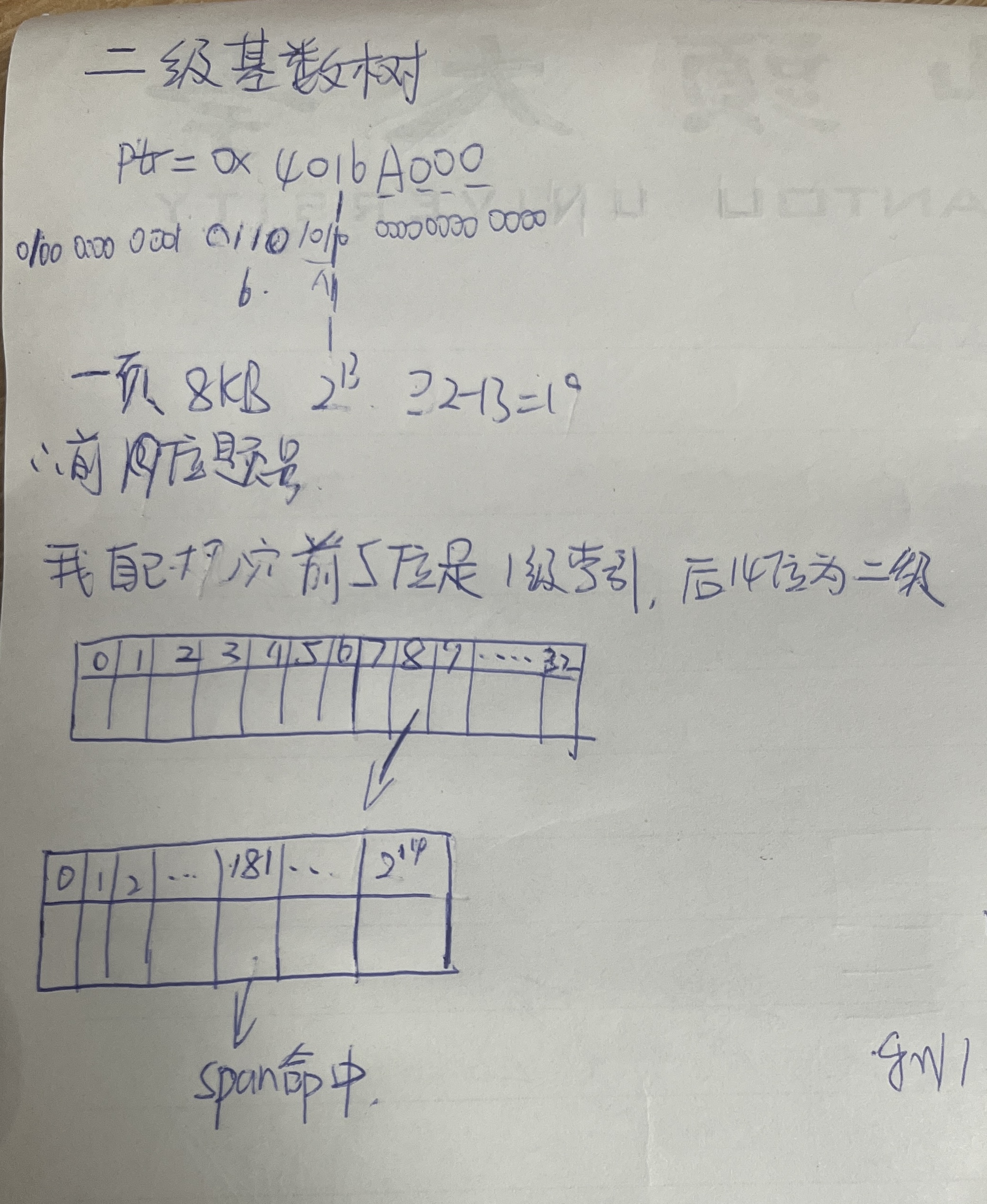
基数树在哪里起作用
- 在我们
free(ptr)时,得把释放的内存还给tc吧,那就得知道放到哪一个freelist上(8字节?16字节?还是256KB?)。
所以我们得ptr=》页号=》查基数树,得到span=》知道是哪一个freelist。 - 同样也是在释放操作时,tc见自己的freelist数据太多,要退回一点给cc。这样导致cc中的span可能要合并。
假设我现在有一个包含 3 个页的 Span(页号是 100、101、102)被还回来了。我怎么知道页号 99 和页号 103 的状态?它们是空闲的吗?
就是查基数树表。
项目介绍
这个高并发内存池项有四个核心模块。
第一个线程缓存模块,它的结构是哈希桶+自由链表。每一个桶的大小不同,是阶梯式内存对齐。还使用了tls无锁化设计。
第二个是中心缓存。结构是哈希桶+跨度链表+自由链表了。为了减少tc向cc借内存的开销,使用了自定义退避策略的自旋锁。还有慢开始反馈算法。
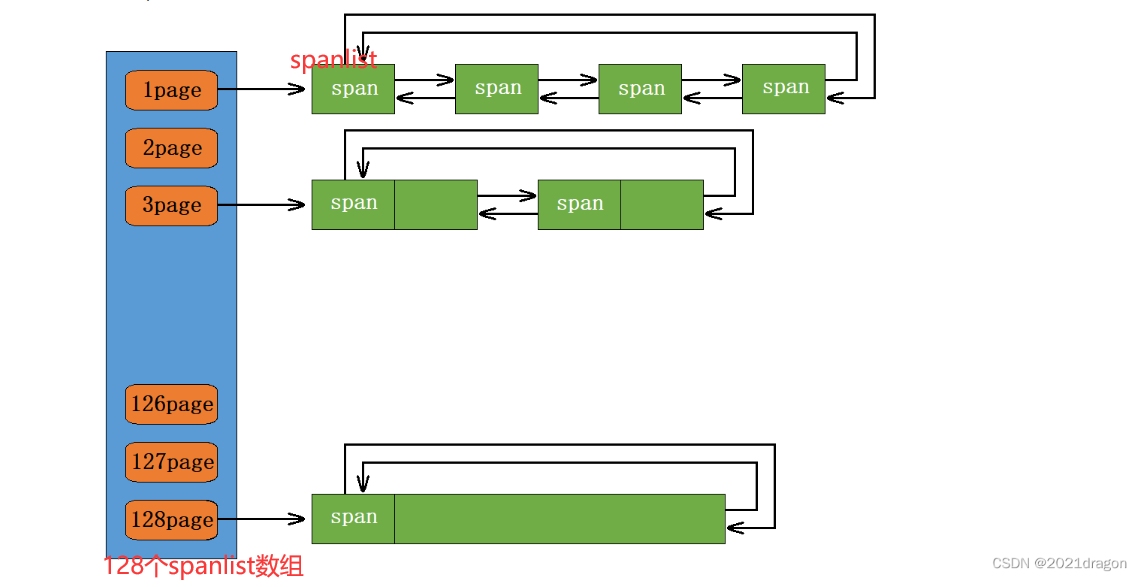
第三个是page缓存。其中有一个基数树 记录 页号与span之间的映射。主要用在释放内存时。
第四块,是一个定长内存池。用来分配ThreadCache 对象和 Span 节点。cc,pc用的是单例模式。
申请内存的工作流
是由tc,cc,pc+一个定长内存池组成的三层架构的多线程高并发内存池。
申请内存工作流。
- ConcurrentAlloc(15),字节对齐到16字节。直接去 1 号(_freeLists[1])里拿。
- 如果桶里有,直接结束。如果没有,去cc进货。
- 根据“慢开始”算法,加spanlist锁找非空span,找到结束。找不到,去pc进货。
- pc诺没有,使用mmap/VirtualAlloc找os进货。把进的page放入pc,填写基数树()。**进货要写借条。**写好基数树,后面释放时才好用(因为span都是在这一步从os调入堆区的)
释放内存的工作流
- Free(ptr),通过 ptr 算出页号,通过基数树查页号对应的 Span,span结构体中有记录槽的大小。直接把内存槽挂回 ThreadCache 的 1 号桶。
- 如果,这串多余的对象还给 CentralCache。快回收(第一次是有一个就回收,第二次是有两个)
- 如果这个span切出去的所有slot都回来了,cc则拿回到pc中。
- 查基数树,看有没有能合并的span。pc中span合并。
慢开始反馈借内存算法/快回收

我写的不是内存池吗?为什么threadcache要叫线程缓存?
缓存(Cache)的核心语义是:为了弥补速度差异。我先从os堆中去一部分内存出来,这个内存用作缓存,给各个线程。
有用过哪些智能指针?
并没有使用任何智能指针。因为智能指针的构造和析构都默认使用了new/delete。
其次我们“徒手实现”智能指针的思想。Span 结构体里面那个极其关键的变量 _useCount,它的作用和 shared_ptr 的引用计数一模一样!
- 当 CentralCache 把一个小块内存切出去给 ThreadCache 时,Span->_useCount++。
- 当 ThreadCache 把小块内存还回来时,Span->_useCount–。
- 当 _useCount == 0 时,说明这个大块内存派发出去的所有碎片都回家了。此时触发回收机制,把这个完整的 Span 向上交还给 PageCache。
哪里使用了lambda函数
性能测试的时候,创建匿名线程。
进行了单元测试
测试案例一:定长内存池
断言查看。
核心目的是验证:我们的 ObjectPool 能不能正常分配和释放,且从Freelist拿出来的内存地址正常不?
#include <iostream>
#include <cassert>
// 引入你的定长内存池头文件
struct TreeNode {
int _val;
TreeNode* _left;
TreeNode* _right;
};
void TestObjectPool() {
ObjectPool<TreeNode> pool;
// 1. 测试基础分配
TreeNode* t1 = pool.New();
TreeNode* t2 = pool.New();
assert(t1 != nullptr);
assert(t2 != nullptr);
assert(t1 != t2); // 地址绝对不能一样
// 2. 测试回收机制
pool.Delete(t1);
// 3. 测试复用机制(关键断言)
// t1 刚被 Delete,挂入了空闲链表。此时再次 New,
// 按照机制,应该直接把刚才的 t1 拿出来复用!
TreeNode* t3 = pool.New();
assert(t3 == t1); // 如果不等于,说明复用逻辑写错了!
std::cout << "ObjectPool 单元测试通过!" << std::endl;
}
测试案例二:Span 合并测试

性能测试
使用Lambda表达式,创建匿名线程用于测试。
测试的原理是,主线程创建很多子线程,子线程对vector进行pushback(malloc(15)),然后再free。再将数据汇总到主线程。
为了使这个项目跨平台,做出的工作
第一,面对不同的OS,我通过 条件 宏(#ifdef _WIN32)将 Windows 的 VirtualAlloc 和 Linux/macOS 的 mmap封装成了统一的 SystemAlloc 接口
第二,在硬件架构上。在freelist的指针上,我抛弃了固定字节的强转,采用 (void*) 的二级指针解引用技巧,使得代码能够自动兼容 32 位和 64 位系统架构,避免了指针截断问题。
模拟面试
什么是内存池?就是解释一下池化技术是什么?
没有内存池前,程序**”零售“的找os申请内存。用malloc
有了后,”批发“**一次性申请一大堆放在内存池中,当需要资源时直接从“池”中获取。
内存池最底层用的什么函数?还是malloc吗?
不是,用的是virtualAlloc。直接申请一整页空间。
内存池主要解决什么问题?
- 效率问题。以前是”零售“,现在是批发,不用一直切换内核态,用户态。
- 内部碎片。tc会用一个合适的槽,来装数据。
- 外部碎片。pagecache会合页。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)