三、进程概念(操作系统与进程(4))
本文探讨了32位Linux系统中进程地址空间的设计原理与实现机制。通过实验验证了虚拟地址空间的区域分布,包括栈向下生长、堆向上生长的设计,以及中间共享区域的动态分配特性。研究发现: 虚拟地址空间通过页表映射实现物理内存隔离,同一虚拟地址可对应不同物理内存(如父子进程的写时复制机制); 进程地址空间由mm_struct管理,包含代码段、数据段、堆栈等VMA区域,通过页表实现虚拟到物理地址转换; 虚拟
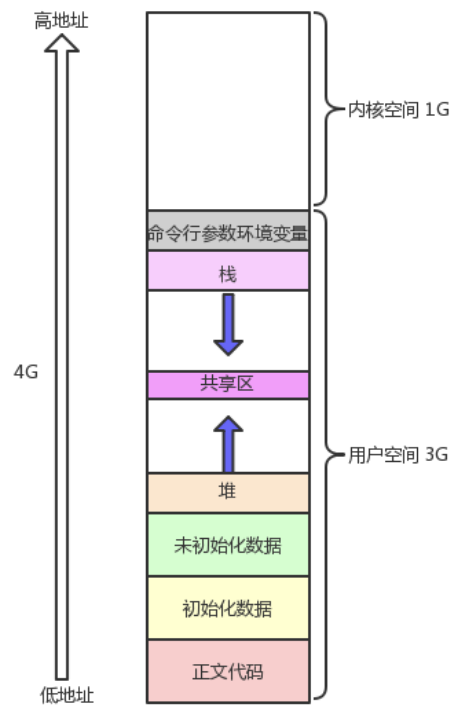
5. 程序地址空间
经典 32 位 Linux 虚拟地址空间图
我们对该图并不理解!可以先对其进行各区域分布验证:
栈和堆为什么相向生长
设计用意——中间那片空白是共享的: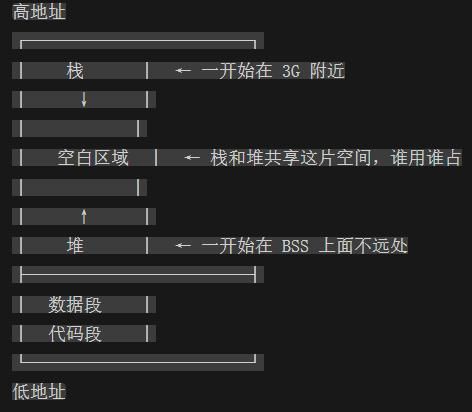
- 栈向下生长,堆向上生长 → 两者从两端往中间挤
- 中间空白区域很大(几G),正常程序不会碰到对方
- 如果碰到了 → 栈溢出 或 OOM(内存耗尽)
好处: 不用事先决定"栈多大、堆多大",它们共用同一片空闲空间,动态分配。栈用得多堆就少用点,反过来也一样。内存利用率最大化。
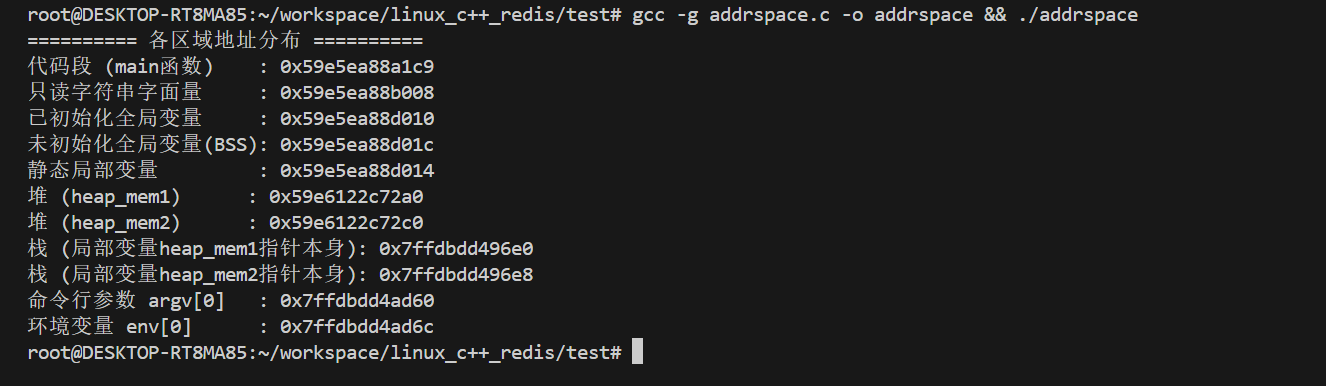
实验一:各区域地址分布
vim addrspace.c
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_unval; // 未初始化全局变量
int g_val = 100; // 已初始化全局变量
int main(int argc, char *argv[], char *env[])
{
const char *str = "helloworld"; // 字符串字面量(只读)
static int test = 10; // 静态局部变量
char *heap_mem1 = (char*)malloc(10);
char *heap_mem2 = (char*)malloc(10);
printf("========== 各区域地址分布 ==========\n");
printf("代码段 (main函数) : %p\n", main);
printf("只读字符串字面量 : %p\n", str);
printf("已初始化全局变量 : %p\n", &g_val);
printf("未初始化全局变量(BSS): %p\n", &g_unval);
printf("静态局部变量 : %p\n", &test);
printf("堆 (heap_mem1) : %p\n", heap_mem1);
printf("堆 (heap_mem2) : %p\n", heap_mem2);
printf("栈 (局部变量heap_mem1指针本身): %p\n", &heap_mem1);
printf("栈 (局部变量heap_mem2指针本身): %p\n", &heap_mem2);
printf("命令行参数 argv[0] : %p\n", argv[0]);
printf("环境变量 env[0] : %p\n", env[0]);
free(heap_mem1);
free(heap_mem2);
return 0;
}
实验二:虚拟地址——父子进程同一地址不同值
vim forkaddr.c
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/wait.h>
int g_val = 0;
int main()
{
pid_t id = fork();
if(id < 0) {
perror("fork");
return 1;
}
else if(id == 0) {
// 子进程
g_val = 100;
printf("子进程[%d]: g_val=%d, &g_val=%p\n", getpid(), g_val, &g_val);
}
else {
// 父进程:等子进程改完再读
wait(NULL);
printf("父进程[%d]: g_val=%d, &g_val=%p\n", getpid(), g_val, &g_val);
}
return 0;
}
5-2 / 5-3 程序地址空间 & 虚拟地址
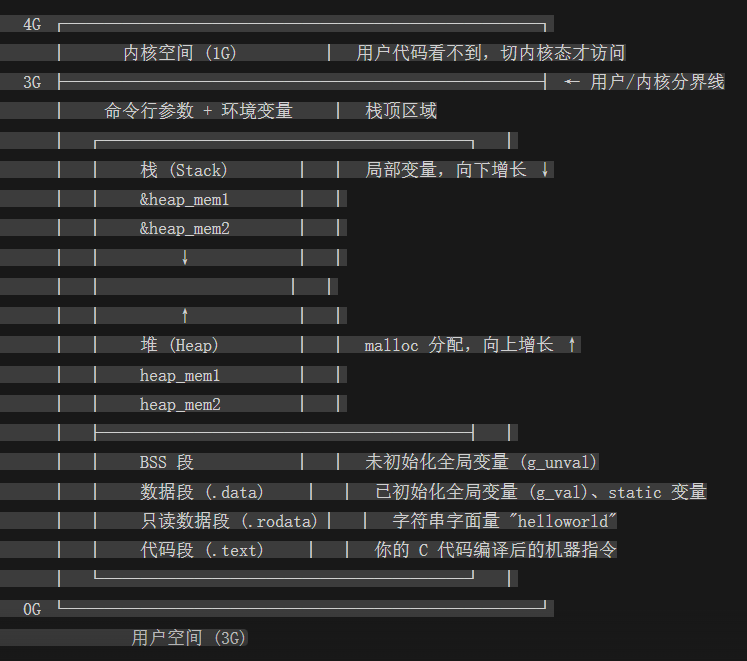
实验一的结果,按地址从低到高排
把刚才跑出来的地址逐项对上号:
高地址(大数值)
0x7ffc83b8f65f 环境变量 —— 在栈的顶部,最高
0x7ffc83b8f653 命令行参数
0x7ffc83b8eb78 栈(局部变量 heap_mem2 指针本身) ← 栈向下生长
0x7ffc83b8eb70 栈(局部变量 heap_mem1 指针本身)
↑ 栈向下长,地址递减 ↑
│ 中间有大片空白(共享区、mmap等) │
↓ 堆向上长,地址递增 ↓
0x5bc881f6d2c0 堆(heap_mem2)
0x5bc881f6d2a0 堆(heap_mem1)
0x5bc87cc2601c BSS段(未初始化全局变量 g_unval)
0x5bc87cc26014 已初始化数据段(静态局部变量 test)
0x5bc87cc26010 已初始化数据段(全局变量 g_val)
0x5bc87cc24008 只读数据段(字符串字面量 "helloworld")
0x5bc87cc231c9 代码段(main 函数)
低地址(小数值)
实验二的结果分析——虚拟地址的核心证据
子进程[128251]: g_val=100, &g_val=0x587d3a19a014
父进程[128250]: g_val=0, &g_val=0x587d3a19a014
↑ 值不同 ↑ 地址完全相同
同一地址,不同值 —— 说明这个地址绝对不是物理地址。
物理地址只能对应一块真实的物理内存单元,不可能存两个不同的值。之所以父子进程看到同一个地址,是因为:
物理内存
┌──────────────────┐
│ 物理页 A │ ← 父进程的 g_val,值 = 0
│ 物理页 B │ ← 子进程的 g_val,值 = 100
└──────────────────┘
↑ ↑
页表映射 页表映射
↑ ↑
父进程页表 子进程页表
↑ ↑
虚拟地址相同:0x587d3a19a014
父子进程的虚拟地址相同,但 OS 通过各自的页表把这个虚拟地址映射到了不同的物理内存。
这就是虚拟地址的本质:你写的 C 代码里所有的 &变量、%p 看到的地址,全是假的——是 OS 给你画的一张"地图"。真正存数据的地方在哪个物理内存条上、第几个芯片颗粒,你永远看不到,全由 OS 通过页表暗中管理。
总结
| 结论 | 解释 |
|---|---|
| C/C++ 看到的地址全是虚拟地址 | 物理地址用户态看不到 |
| 同一虚拟地址可以对应不同物理内存 | 每个进程有自己的页表 |
| 父子进程 fork 后地址相同值不同 | 写时拷贝 + 页表各自映射 |
| 栈向下、堆向上 | 共享中间空闲空间,利用率最大化 |
| 32 位系统用户空间 3G | 最高 1G 留给内核,切换内核态用 |
5-4 进程地址空间
所以之前说‘程序的地址空间’是不准确的,准确的应该说成 进程地址空间 ,那该如何理解呢?
看 图: 分页&虚拟地址空间
同一个变量,地址相同,其实是虚拟地址相同,内容不同其实是被映 射到了不同的物理地址!
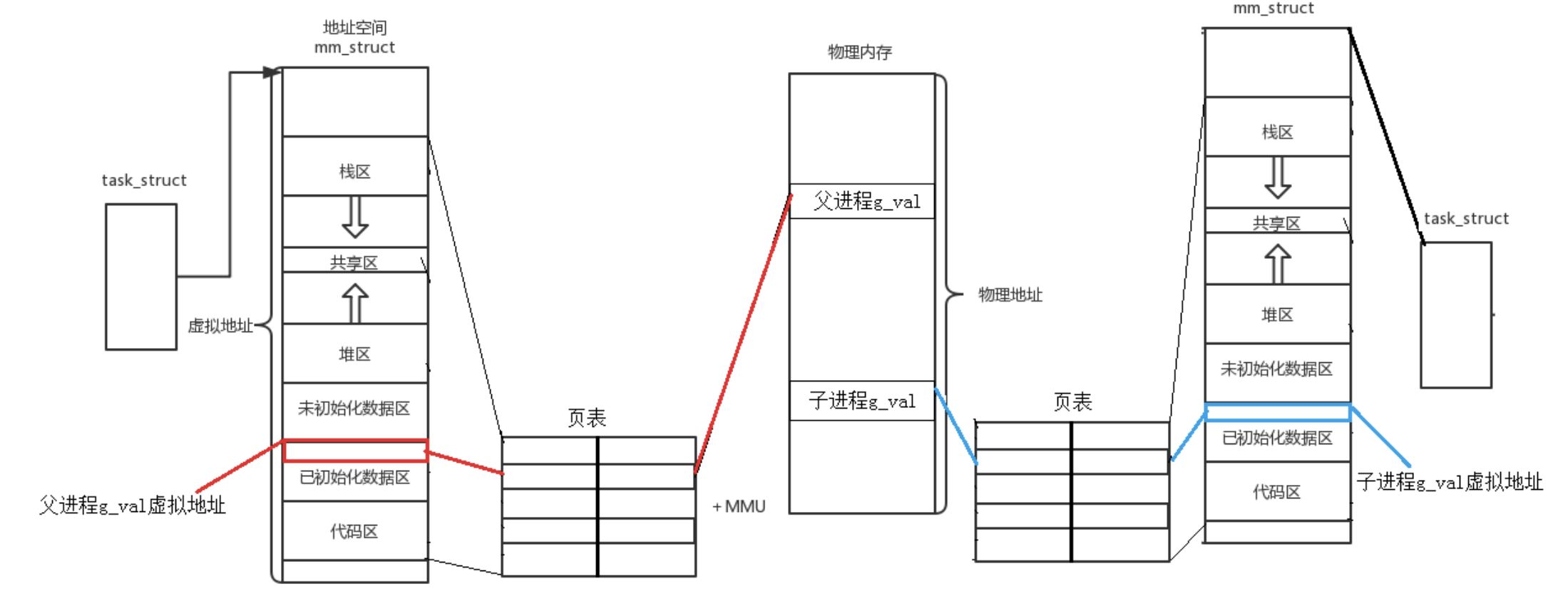
5-4 进程地址空间
为什么叫"进程地址空间"不叫"程序地址空间"
程序 = 躺在磁盘上的 .exe / elf 文件,是死的。 进程 = 程序被加载到内存跑起来之后的活体,有自己的地址空间。
同一个程序可以同时跑多个进程(你开三个终端就是三个 bash 进程),每个进程都有自己独立的一套地址空间,互不影响。
磁盘上的 bash 程序(一份) 内存中(多份)
┌─────────────┐ ┌──────────────┐
│ /bin/bash │ │ 进程 bash #1 │ ← 地址空间 A
│ (死的) │ ── 启动三次 → │ 进程 bash #2 │ ← 地址空间 B
└─────────────┘ │ 进程 bash #3 │ ← 地址空间 C
└──────────────┘
每个进程一张自己的"地图"(地址空间),OS 给每张地图指到不同的物理内存区域。 这就是"进程地址空间"的含义。
地址空间是怎么实现的——三个核心结构
task_struct(PCB)
│
└── mm_struct(内存描述符) ← 这张进程的完整"地图"
│
├── start_code → 代码段起点
├── end_code → 代码段终点
├── start_data → 数据段起点
├── end_data → 数据段终点
├── start_brk → 堆起点
├── brk → 堆当前边界
├── start_stack → 栈起点
├── mmap_base → 共享区起点
└── pgd → 页表(虚拟→物理映射表)
task_struct 是进程的身份证,mm_struct 是进程的地图,页表是地图上每条街道对应到真实物理位置的对照表。
父子进程 fork 后的 COW(写时复制)
用之前跑出来的实验数据讲:
子进程: g_val=100, &g_val=0x587d3a19a014
父进程: g_val=0, &g_val=0x587d3a19a014
fork 刚完成时:
父进程 子进程
┌──────────┐ ┌──────────┐
│task_struct│ │task_struct│
│ mm_struct │ │ mm_struct │ ← 新 mm_struct,但页表指向同一物理页
│ 页表────┼───────┐ ┌───┤ 页表 │
└──────────┘ │ │ └──────────┘
↓ ↓
同一块物理内存
┌──────────────┐
│ g_val = 0 │ ← 父子共享同一页,页表标记为只读
└──────────────┘
子进程执行 g_val = 100 时——COW 触发:
1. 子进程写 g_val
2. MMU 发现这个页是只读的 → 触发缺页异常
3. OS 捕获异常:
- 在物理内存中分配一页新的
- 把原页内容拷贝到新页(g_val=0)
- 把子进程的页表指向新页
- 把父子页表都改回可写
4. 子进程在新页上写入 100
父进程 子进程
页表→ ┌────────┐ 页表→ ┌────────┐
│ g_val=0 │ │ g_val=100│
└────────┘ └────────┘
原物理页 新分配的物理页
虚拟地址一样 (0x587d3a19a014),但各自页表指向了不同的物理内存。
COW 的精髓:fork 时不真复制内存页,只复制页表,父子共享物理页。谁先写,就复制谁的那一页。省内存,还快。
回答两个核心问题
如何理解虚拟地址空间?
虚拟地址空间 = OS 给每个进程画的一张私人地图。每张地图的格局都一样(代码段从这开始、栈从这开始),但每张地图通过自己的页表指向不同的物理内存。
地图是虚拟的,但地图上每个坐标最终对应的物理地址由页表决定。你在 C 里看到的 %p 永远是地图上的坐标,不是真实物理位置。
如何理解区域划分?
高地址
┌──────────┐
│ 栈 │ ← 局部变量、函数调用栈帧。向下增长(函数调用越深,栈地址越低)
│ ↓ │
│ ... │ ← 中间留空,栈和堆共享,各自从两端往中间挤
│ ↑ │
│ 堆 │ ← malloc 分配的内存。向上增长
├──────────┤
│ BSS │ ← 未初始化全局变量(g_unval),初值为0,不占文件空间
│ .data │ ← 已初始化全局/静态变量(g_val, static test),初始值写死在可执行文件里
│ .rodata │ ← 只读数据("helloworld"这种字符串常量),写它→段错误
│ .text │ ← 代码(main 函数的机器指令),只读,不可写
└──────────┘
低地址
不同区域放不同类型的数据,权限不同:
| 区域 | 放什么 | 读写权限 | 生长方向 |
|---|---|---|---|
| .text | 机器指令 | 只读不可写 | 固定 |
| .rodata | 字符串字面量 | 只读不可写 | 固定 |
| .data | 初始化过的全局/静态变量 | 可读可写 | 固定 |
| .bss | 未初始化的全局变量 | 可读可写 | 固定 |
| heap | malloc 出来的 | 可读可写 | 向上 ↑ |
| stack | 局部变量 | 可读可写 | 向下 ↓ |
总结串起来
fork() 创建子进程
│
├── 新建 task_struct
├── 新建 mm_struct(地图格局复制父进程,所以虚拟地址一模一样)
├── 页表复制父进程的,但标记为只读(为 COW 做准备)
└── 不复制物理内存页,父子共享
│
├── 只读 → 大家共享,不额外占用物理内存
├── 写了 → COW 触发,OS 分配新物理页,各自独立
│
└── 这保证了"同一虚拟地址不同物理内存"的可能性
虚拟地址空间 = 地图。mm_struct = 地图的数据结构。页表 = 地图坐标 → 物理内存的对照表。COW = 谁写谁复制,不写白共享。
5-5 虚拟内存管理——mm_struct
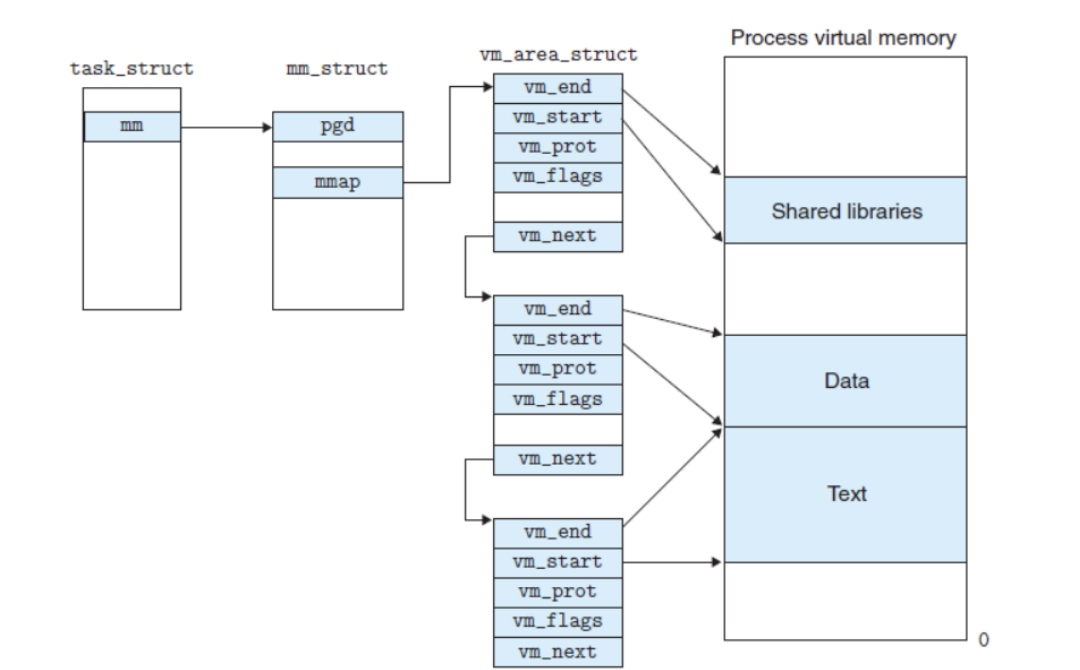
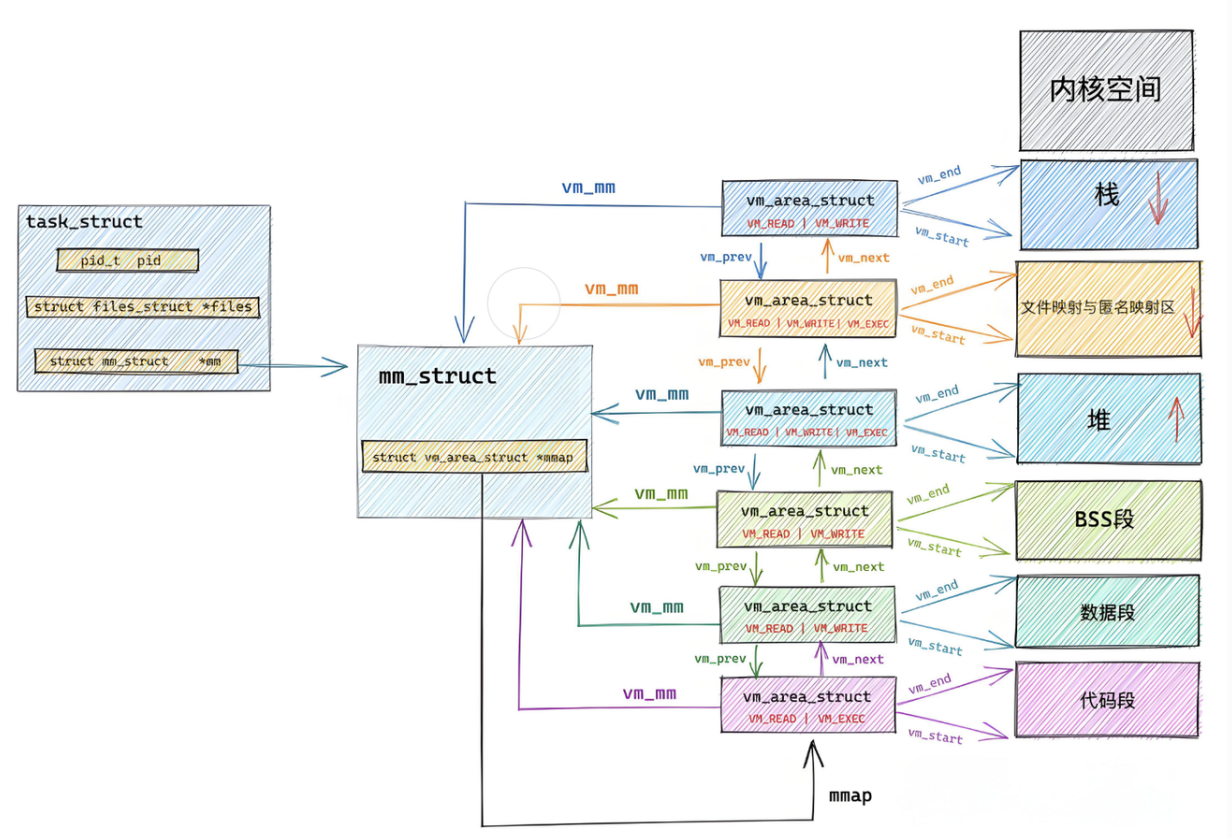
从 task_struct 到 mm_struct
每个进程一张地图,这张"地图"的数据结构就是 mm_struct:
task_struct(进程控制块)
┌─────────────────────────┐
│ pid = 42 │
│ state = RUN │
│ priority = 120 │
│ │
│ struct mm_struct *mm │ ← 指向虚拟地址空间的完整描述(用户进程用)
│ struct mm_struct *active_mm │ ← 内核线程用(mm为NULL时借用别人的)
│ │
└─────────┬───────────────┘
│ 指向
▼
mm_struct(内存描述符)
┌─────────────────────────┐
│ start_code = 0x400000 │ ← 代码段起点
│ end_code = 0x401000 │ ← 代码段终点
│ │
│ start_data = 0x600000 │ ← 数据段起点
│ end_data = 0x601000 │ ← 数据段终点
│ │
│ start_brk = 0x800000 │ ← 堆起点
│ brk = 0x820000 │ ← 堆当前边界(malloc 后上移)
│ │
│ start_stack = 0x7000000│ ← 栈起点
│ │
│ mmap_base = 0x5000000│ ← 共享区(动态库映射、mmap映射)
│ │
│ pgd = 页表地址 │ ← 虚拟→物理 映射表
│ │
│ map_count = 15 │ ← 有多少个 VMA(区域块)
│ │
│ struct vm_area_struct *mmap │ ← 指向 VMA 链表
└─────────┬───────────────────┘
│ 指向
▼
VMA 链表(每个区域一块)
为什么要有两个指针:mm 和 active_mm
struct task_struct {
struct mm_struct *mm; // 用户进程:指向自己的完整地址空间
struct mm_struct *active_mm; // 内核线程:借用别人的 mm_struct
};
| 情况 | mm 的值 |
active_mm 的值 |
|---|---|---|
| 普通用户进程(mycmd、bash) | 指向自己的 mm_struct | 指向自己的 mm_struct |
| 内核线程 | NULL(自己没有) | 借上一个进程的 mm_struct |
为什么内核线程可以没有自己的 mm_struct? 因为所有进程的内核空间部分是共享的(3G-4G 那 1G)。内核线程只跑在内核态,只需要访问那 1G 共享空间,不需要自己的用户空间映射。所以直接借用别人已有的页表对付一下就行。
mm_struct 怎么描述用户空间——VMA 链表
一个地址空间不是一整块"铁板",而是被切成很多虚拟内存区域(VMA = vm_area_struct):
mm_struct VMA 链表
┌──────────────┐ ┌──────────────────┐
│ mmap ────────┼────────────────→│ vm_start=0x400000 │ ← 代码段
│ map_count=4 │ │ vm_end =0x401000 │
└──────────────┘ │ vm_flags=读+执行 │
│ vm_file→mycmd.elf │
├──────────────────┤
│ vm_start=0x600000 │ ← 数据段
│ vm_end =0x601000 │
│ vm_flags=读+写 │
├──────────────────┤
│ vm_start=0x800000 │ ← 堆
│ vm_end =0x820000 │
│ vm_flags=读+写 │
│ vm_file=NULL │ ← 匿名映射
├──────────────────┤
│ vm_start=0x6000000│ ← 栈
│ vm_end =0x7000000│
│ vm_flags=读+写 │
│ vm_file=NULL │ ← 匿名映射
└──────────────────┘
每个 VMA 就是一个矩形块(起始地址 + 结束地址 + 权限),用链表串起来。遍历这个链表就知道:代码段从哪到哪、能不能写、堆现在多大了、栈边界在哪。
完整的地址空间分布图
3G ┌───────────────────────────┐ ← 用户空间顶部
│ 命令行参数 + 环境变量 │
├───────────────────────────┤
│ 栈 (Stack) │ start_stack 记录起点
│ ↓ 向下增长 │ brk/sp 随运行变化
│ ... │
├───────────────────────────┤
│ 共享区 (mmap) │ mmap_base 记录起点
│ 动态库 libc.so、文件映射 │
│ ... │
├───────────────────────────┤
│ 堆 (Heap) │ brk 记录当前边界
│ ↑ 向上增长 │ malloc 后 brk 上移
│ start_brk 记录起点 │
├───────────────────────────┤
│ BSS 段 (未初始化全局变量) │ start_data / end_data
│ .data 段 (已初始化全局变量) │ 描述数据段整体范围
├───────────────────────────┤
│ .rodata (只读数据) │
│ .text (代码) │ start_code / end_code
└───────────────────────────┘ ← 用户空间底部
mm_struct 里的 start_code、end_data、start_brk、start_stack 就是这张图的坐标。VMA 链表把被使用的每个区域按块描述清楚。页表 pgd 把每个虚拟坐标转成物理地址。
总结
| 结构体 | 作用 |
|---|---|
task_struct |
进程的总档案 |
mm_struct |
进程的完整地址空间地图 |
vm_area_struct(VMA) |
地图里的一个区域块(代码区、堆区、栈区各是一个 VMA) |
页表 pgd |
地图坐标 → 物理地址的对照表 |
task_struct.mm → mm_struct → VMA 链表 + 页表,就是"进程地址空间"的全部秘密。
5-6 为什么要有虚拟地址空间
核心问题:如果程序直接操作物理内存,会出什么事?
一、早期的直接物理内存分配
物理内存 128M
┌──────────────┐
│ 程序 A │ 0M ~ 10M
│ (10M) │
├──────────────┤
│ │
│ 程序 B │ 10M ~ 120M
│ (110M) │
│ │
├──────────────┤
│ 空闲 │ 120M ~ 128M
└──────────────┘
简单粗暴:A 来了给前 10M,B 来了接着给 110M。能用,但问题一堆。
二、直接操作物理内存的三大问题
问题 1:安全风险——任意进程可以读写任意内存
进程 C 是一个恶意程序
物理内存
┌──────────────┐
│ 进程 A │ ← C 可以直接读写这里(偷数据)
├──────────────┤
│ 进程 B │ ← C 可以直接写这里(搞破坏)
├──────────────┤
│ 内核数据 │ ← C 甚至能碰到内核(系统瘫痪)
└──────────────┘
没有墙,任何进程能碰任何内存。一个木马就能让整个系统挂掉。
问题 2:地址不确定——每次运行时程序的加载位置都不一样
第一次运行 a.out:物理内存全空,加载到 0x00000000
第二次运行 a.out:已经有 10 个进程占着,只能加载到 0x05000000
编程的时候怎么写?不知道哪个地址能用!
编译时没法确定程序的代码、全局变量要放在哪个物理地址。整个编译模型失效。
问题 3:效率低下——换入换出必须整块搬
物理内存不够用,想把暂不用的进程 A 先挪磁盘:
虚拟内存有页表:
只把进程 A 不怎么用的那几页换出去(4KB × 几页)
经常用的还留内存里
物理内存直接操作:
整个进程 A 10M 全部搬出去 → 10M 的磁盘读写,极慢
而且进程 A 必须连续存放,找 10M 连续空间本身就够呛
三、虚拟地址空间怎么解决这三个问题
解决 1:地址空间 + 页表 → OS 全权监管,物理数据安全
进程 A 进程 B
虚拟: "我写地址 0x1000" 虚拟: "我读地址 0x1000"
│ │
A的页表 B的页表
│ │
▼ ▼
┌──────────┐ ┌──────────┐
│ 物理页 X │ │ 物理页 Y │ ← 完全隔离!谁碰不到谁
└──────────┘ └──────────┘
如果 A 尝试访问不属于它的虚拟地址:
→ 页表里根本没有映射 → MMU 直接拒绝 → 段错误(Segfault)
→ 根本到不了物理内存,物理数据天然安全
任何内存访问必须过页表翻译,页表归 OS 管,OS 不给你映射的物理地址你永远碰不到。
解决 2:解耦 —— 进程管理和内存管理彻底分离
没有虚拟内存时:
加载器得搞清楚物理内存哪里有空闲
必须找连续区域
进程和物理内存紧耦合
有了虚拟内存后:
进程管理模块 内存管理模块
┌──────────────┐ ┌──────────────┐
│"我要 10M 空间"│ │ 管理物理页 │
│ │ ── OS 调度 ──→ │ 任意位置分配 │
│ 看到的是 │ │ 可以不连续 │
│ 连续的虚拟地址 │ │ 页表串起来 │
└──────────────┘ └──────────────┘
两个模块各管各的,互不依赖 ← 解耦
物理内存可以任意位置加载,页表把虚拟地址映射过去就行。进程看到的是连续的,物理上可以碎片化,O(1) 调度和内存分配各回各家。
解决 3:延迟分配 —— malloc 时可以不真给物理内存
你在代码里:
char *p = malloc(100MB); // 申请 100M
→ 返回一个虚拟地址
→ mm_struct 里 VMA 记录了"这块区域归你"
→ 物理内存:一个字节都没分!
稍后你第一次用:
p[0] = 'a'; // 第一次真正访问
→ MMU 去找页表 → 发现没映射 → 缺页异常
→ OS 收到异常:哦这块 VMA 是合法的,现在才真分配一页物理内存
→ 写页表映射 → 返回重新执行刚才的指令
→ 物理内存:只分了 4KB(一页)
malloc 100M,只分了一页(4KB)。剩下的继续延迟,用到才分。这就是你 C 代码里 malloc 不报错、物理内存却没少的原因。
总结对照表
| 直接操作物理内存 | 有虚拟地址空间 | |
|---|---|---|
| 安全 | 谁都能碰谁 | 页表隔离,越界就段错误 |
| 地址确定 | 每次加载位置不同 | 每个进程都从固定的虚拟地址起步 |
| 换入换出 | 整块搬,极慢 | 按页搬(4KB),按需换 |
| 内存分配 | 必须预先连续分配 | 延迟分配 + 碎片化分配 |
| 进程/内存关系 | 紧耦合 | 解耦,两大模块独立运行 |
虚拟地址空间 = 给每个进程一间私人影棚。进去全是绿幕,OS 帮你把绿幕换成真实背景,外人看你的画面光鲜亮丽,但你永远进不去别人的影棚。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 10
10 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)