云计算Linux——Nginx 常见问题、Nginx 的优化、常见的排查命令(十三)
一、CPU 相关专业:实时查看系统进程、CPU 整体负载、各进程占用情况大白话:系统任务管理器重点关注:load average 1 分钟、5 分钟、15 分钟负载% Cpu 空闲率、用户态、系统态占用哪个进程 CPU 占满2. mpstat专业:查看每颗 CPU 核心的使用率重点关注:是否单核打满、多核不均衡3. uptime专业:快速查看系统负载平均值、开机时长重点关注:负载是否大于 CPU
一、Nginx 常见问题
Nginx 常见问题现象:
以下是HTTP状态码分类及说明的表格整理:
HTTP状态码分类表
| 类别 | 状态码 | 名称 | 说明 |
|---|---|---|---|
| 2xx 正常访问 | 200 | OK | 请求成功,服务器已返回所需数据。 |
| 3xx 重定向 | 301 | Moved Permanently | 永久重定向,浏览器会缓存新地址,后续直接访问新URL(如HTTP跳转HTTPS)。 |
| 302 | Found | 临时重定向,用于维护或升级场景,维护结束后可恢复原URL。 | |
| 4xx 客户端错误 | 403 | Forbidden | 权限不足,服务器理解请求但拒绝执行(如无文件访问权限)。 |
| 404 | Not Found | 请求的资源不存在,通常由URL路径错误或文件缺失导致。 | |
| 5xx 服务端错误 | 502 | Bad Gateway | 网关错误,后端服务异常或无响应(如反向代理的后端服务关闭)。 |
| 503 | Service Unavailable | 服务不可用,通常因服务器过载或维护中(如高并发导致系统崩溃)。 | |
| 504 | Gateway Timeout | 网关超时,后端服务未在约定时间内响应(如网络拥堵或处理超时)。 |
关键场景示例
- 301:域名更换后旧域名跳转至新域名。
- 302:临时将首页跳转到维护公告页。
- 502:Nginx反向代理的Apache服务崩溃时触发。
- 504:后端数据库查询耗时过长,超过Nginx的
proxy_read_timeout设置。
表格内容可直接用于技术文档或故障排查参考。
二、Nginx 的优化
观测命令:
1. top(动态的进程信息)
htop ps aux|elf(查看的静态进程信息)
1.top 命令详解
top 命令的动态监控功能,重点解读了 PID、USER、%CPU、%MEM 等关键字段,以及 Tasks 区域显示的进程状态(Running、Sleeping、Zombie)。
htop 增强工具:推荐安装 htop 作为更友好的交互式系统监控工具,以替代系统自带的 top 命令。
#top 动态查看进程信息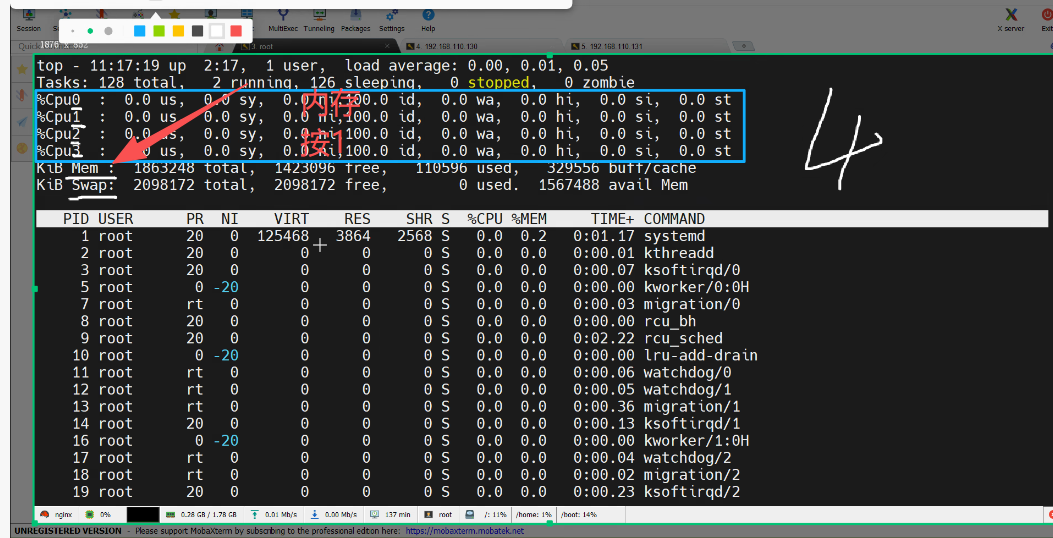
Load Average(平均负载)这一核心指标,用于判断系统压力趋势:
load average: 0.00, 0.01, 0.05
load average: 1min 5min 15min 之前的CPU平局负载值/压力情况
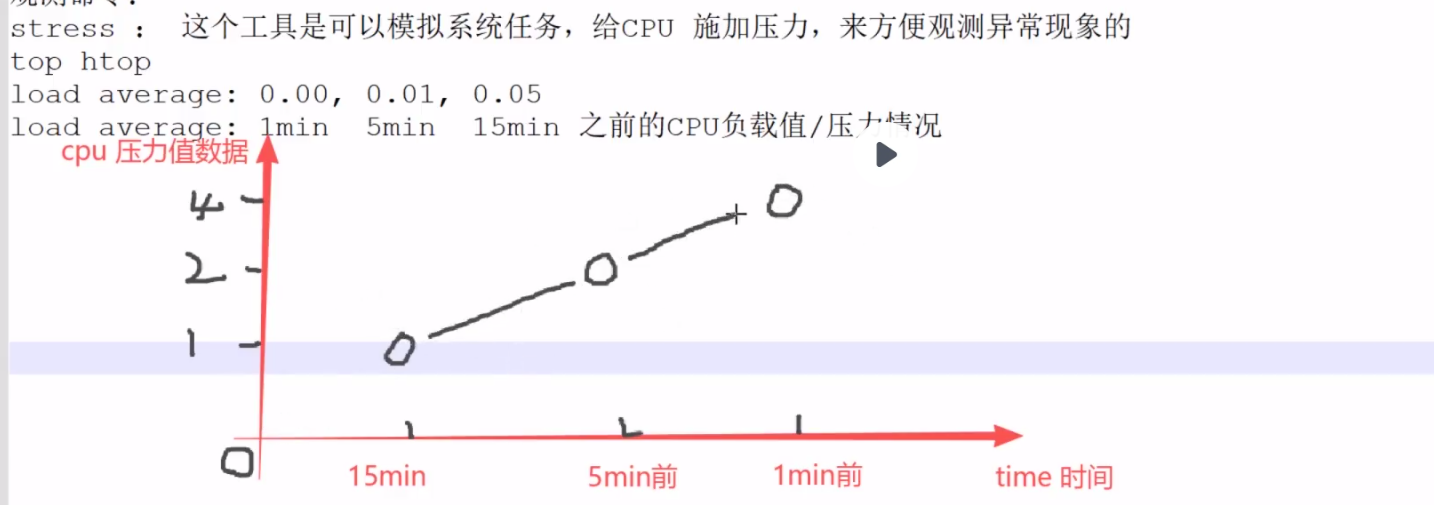
根据我们CPU核心数来判断的 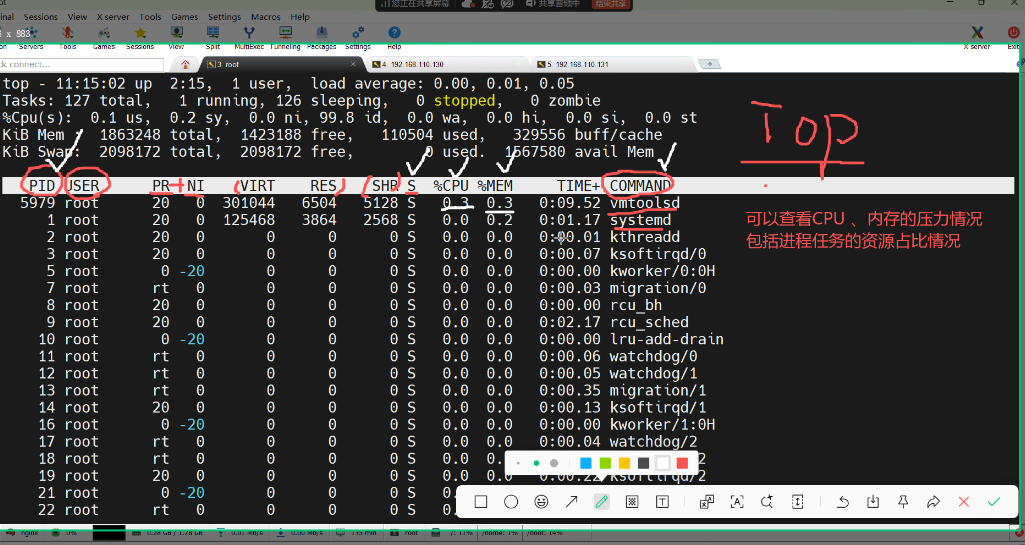
假设当前CPU 核心数为 2
CPU空闲: 数字<2
CPU繁忙: 数字=2左右
CPU高负载:数字=cpu核心数的*2=4
CPU随时死给你看:数字>cpu核心数*3+
tasks 进程任务的数量 常用的进程状态
CPU使用率
内存/swap的使用信息统计
pid S %cpu %mem time command(cmd)
2. stress 命令
这个工具是可以模拟系统任务,给CPU 施加压力,来方便观测异常现象的
通过 stress 工具模拟高并发场景,演示了从发现问题到解决问题的完整流程:
2.1 压力模拟与观测
stress -c 2 模拟2个cpu满负载工作,来观测系统的top命令查看的现象
load average: 1.50, 0.50, 0.21
`stress -c 4` 模拟 4 核 CPU 满负载,观察 Load Average 数值迅速飙升并超过 CPU 核心数,验证了系统在高负载下的表现。(超负载模拟)
2.2 异常进程处理
进程定位:利用 top 或 ps aux 命令找出占用 CPU 资源过高的异常进程(如 stress 进程)。
进程终止:通过 kill 命令强制终止异常进程,观察系统负载恢复正常。
3. ps 静态进程信息查看
进程资源快照:使用 `ps aux` 命令查看进程的PID、CPU与内存占比、占用时间及状态;使用 `ps -elf` 重点关注进程的父进程ID(PPID),以识别进程间的派生关系。
父子关系识别:`ps -elf` 可清晰展示进程的父子层级,帮助判断进程是否由特定主进程(如Nginx Master)创建。
区别
ps 命令查看的是静态的进程信息
top/htop 查看的是动态的进程信息
uptime :单独查看load average 1min 5min 15min 之前CPU的平均负载值
4.free -m -g / vmstat 查看内存的信息
基础内存监控:使用 `free -m`(MB单位)或 `free -g`(GB单位)命令查看内存总量、已使用量及剩余量。
详细内存统计:推荐使用 `vmstat` 命令查看虚拟内存统计信息,包括进程、内存、SWAP、IO及CPU的详细数据。
5.磁盘分区检查命令
分区信息查看:使用 `fdisk -l` 或 `lsblk` 命令查看磁盘分区情况。
空间使用率查看:使用 `df -h` 命令查看各分区的已用空间、可用空间及挂载点。
6.1. IO 性能监控与磁盘读写分析
iostat / iotop
IO 状态监控命令:iostat 命令用于查看磁盘读写速率及分区信息,`iotop` 命令用于动态监控进程级别的磁盘读写消耗。
静态与动态观测区分:明确 `iostat` 侧重于静态输出,而 `top` 和 `iotop` 侧重于动态实时观测。
补充:
网络流量抓包工具: `tcpdump` 工具,抓取特定网卡(如 ens33)和端口(如 80)的流量信息。
网络数据管理工具:`nethogs` 工具,用于监控进程级别的网络带宽占用情况,要求学员掌握其使用方法及关注的关键数据。
(cpu、mem、io、disk、network )
三、Nginx 性能与安全优化
1. 安全防护:隐藏版本信息
配置文件隐藏:通过在 `nginx.conf` 的 http 区域添加 `server_tokens off;` 指令,可隐藏 Nginx 版本号,防止黑客利用特定版本漏洞进行攻击。
源码级伪装:通过修改源码 `src/core/nginx.h` 文件中的 `NGINX_VERSION` 和 `NGINX_VER`,可自定义服务名称,彻底隐藏服务类型。
2. 权限与性能优化
用户组管理:将运行用户从 `nobody` 改为 `nginx`,提升服务管理权限,便于文件下载等操作。
缓存时间配置:利用 `expires` 指令设置静态资源缓存时间(如 `1d`),减少重复请求,提升访问速度。
缓存机制风险:指出缓存虽能提速,但会占用大量内存空间,需根据业务需求合理设置缓存时长(如半小时或一小时)。
总结
一、CPU 相关
1. top /htop
专业:实时查看系统进程、CPU 整体负载、各进程占用情况
大白话:系统任务管理器
重点关注:
load average 1 分钟、5 分钟、15 分钟负载
% Cpu 空闲率、用户态、系统态占用
哪个进程 CPU 占满
2. mpstat
专业:查看每颗 CPU 核心的使用率
重点关注:是否单核打满、多核不均衡
3. uptime
专业:快速查看系统负载平均值、开机时长
重点关注:负载是否大于 CPU 核心数,判断是否 CPU 瓶颈
二、内存 相关
1. free -h
专业:查看总内存、已用、空闲、缓存、交换分区使用
重点关注:
物理内存是否耗尽
缓存占用是否过高
Swap 交换分区是否大量使用(一用就说明内存不够)
2. top fdisk -l ls
专业:进程级内存占用
重点关注:哪个进程吃内存最多,是否内存泄漏
三、磁盘 使用率
1. df -h
专业:查看各分区磁盘使用率、剩余空间、挂载点
重点关注:磁盘使用率是否接近 100%,满盘会直接导致服务 503、卡顿
2. du -sh 目录
专业:查看单个文件夹占用磁盘大小
重点关注:定位哪个日志 / 文件夹占用磁盘过大
四、磁盘 IO 读写性能
1. iostat
专业:监控磁盘读写速度、IO 等待、繁忙百分比
重点关注:
% util 接近 100%:磁盘 IO 打满
await 等待时间过大:磁盘卡顿、响应慢
2. pidstat -d
专业:看每个进程的磁盘读写情况
重点关注:哪个进程疯狂读写拖垮服务器
五、网络 相关
1. ifconfig / ip addr
专业:查看网卡 IP、MAC、网卡状态
重点关注:IP 是否配置正常、网卡是否宕机
2. ss -tulnp
专业:替代 netstat,查看监听端口、已建立连接、进程对应端口
重点关注:端口是否监听、连接数是否暴增、是否有异常端口
3. netstat -anpt
专业:查看所有网络连接状态
重点关注:ESTABLISHED 正常连接、TIME_WAIT、CLOSE_WAIT 是否堆积过多
4. ping、curl
专业:测试网络连通性、端口通不通
重点关注:延迟、丢包、接口能否正常访问
5. dstat / sar tcpdump netstat
专业:综合监控网络流量、IO、CPU 实时走势
重点关注:网卡出入流量是否跑满、带宽瓶颈
总结:排查故障时我优先看的顺序
uptime/top 先看 CPU 负载
free -h 看内存够不够、有没有用 Swap
df -h 先查磁盘有没有满
iostat 看是不是磁盘 IO 卡死
ss -tulnp / netstat 看端口、连接数、网络异常
openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐


 6
6 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)