Java内存模型JMM和volatile底层原理
本文先阐述JVM内存模型、硬件(CPU、GPU)、OS(操作系统)内存区域架构、Java多线程原理以及Java内存模型(JMM)之间的关联后,再对Java内存模型进一步剖析JavaJMMJVM。
概述
本文先阐述JVM内存模型、硬件(CPU、GPU)、OS(操作系统)内存区域架构、Java多线程原理以及Java内存模型(JMM)之间的关联后,再对Java内存模型进一步剖析
注意:一定不要混淆Java内存模型(JMM)和JVM内存模型
理解JVM内存模型和Java内存模型JMM的区别
JVM内存模型-JVM内存区域是如何划分的,分别有什么功能
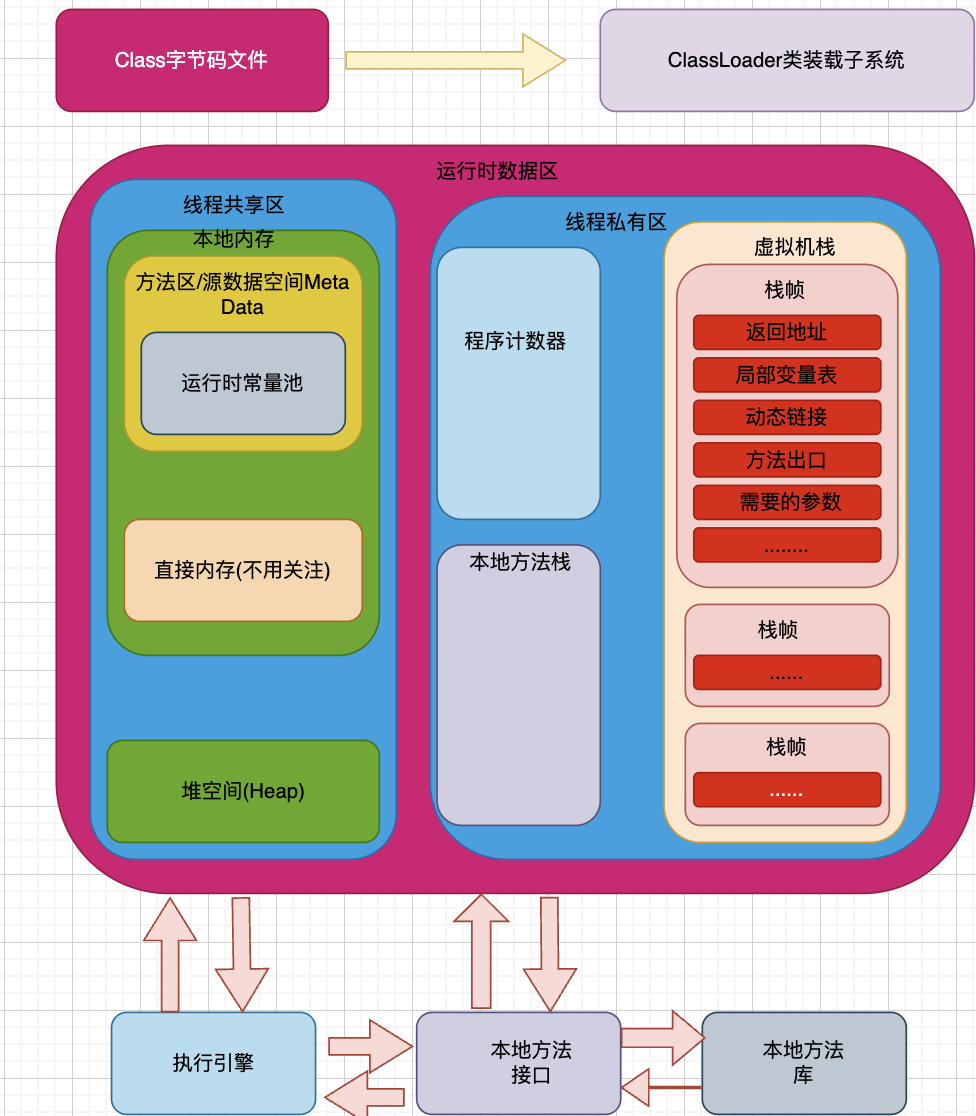
Java通过JVM虚拟机实现跨平台运行的功能,只需要把源文件(.Java文件)通过?方式编译后成为字节码文件(.class文件)后就可以在不同的操作系统下运行字节码文件
JVM在运行期间,会把自己管理的内存划分为上图所示区域:运行时数据区,在Java程序运行的时候每个区域都对应着不同的功能,发挥着不同的作用。 JVM运行时数据区主要分为:线程共享区、线程私有区。
线程共享区
方法区Method Area
在Java8之后修改为了源数据空间,该区域在线程共享区,该区域也叫非堆内存Non-Heap,因为在线程共享区还有一个堆内存,主要用于存储已经被虚拟机加载后的类信息、常量、静态变量、JIT编译后的代码缓存等数据。
注意 在方法区中还有一个运行时常量池Runtime Constant Pool的区域,主要用来存放编译器生成的各种字面量和符号引用,这些数据在虚拟机完成类加载之后就会载入到运行时常量池中,方便后续程序运行时使用
在方法区中很可能会导致
OOM异常Out Of Memory。根据
Java虚拟机规范的规范,如果方法区无法满足内存分配需求时,将会抛出Out Of Memory Error异常
堆空间-Java Heap-JVM堆
JVM堆是属于线程共享区域中的内存区域,只要虚拟机启动就会创建JVM堆,就是只要进行加载过程就会创建堆空间,给它分配内存空间。
JVM堆是JVM所管理的内存中最大的一块,主要用来存放对象实例,几乎所有新建(new)的对象都会在JVM堆中分配内存,但是还有少部分不是在JVM堆中分配内存
线程私有区
程序计数器Program Counter Register
程序计数器在线程私有区中,是一块较小的内存空间,主要作为线程执行的行号指示器。
JVM字节码解析器(就是对.class字节码文件进行解析)工作时,通过改变程序计数器的数值来决定.class文件下一条需要执行的字节码指令,是分支、循环还是跳转、还是异常处理、线程恢复等基础功能,都需要通过程序计数器来完成
其实就是因为CPU时间片在调度线程工作时,会中断某个线程,让另外一个线程开始工作,如果CPU想要重新调度这个被中断的线程区工作,就要通过程序计数器来得知上次执行到哪一行代码了,找到对应的位置
虚拟机栈Java Virtual Machine Stacks
虚拟机栈属于线程私有区,也叫做:线程栈,当操作系统OS在创建线程时就会创建线程栈,为其分配内存空间,虚拟机栈的总数和线程栈的总数是对应的,主要在执行Java方法时,作为临时内存区域来使用
当线程开始执行一个方法时,会先创建一个栈帧来存储这个方法对应的变量表、操作数栈、动态链接、返回值、返回地址等信息。那么直到这个方法执行结束/调用结束时,这个栈帧就会有一个出栈的过程,如下图:
在虚拟机栈中会有多个栈帧,因为不止一个线程,会同时执行多个方法
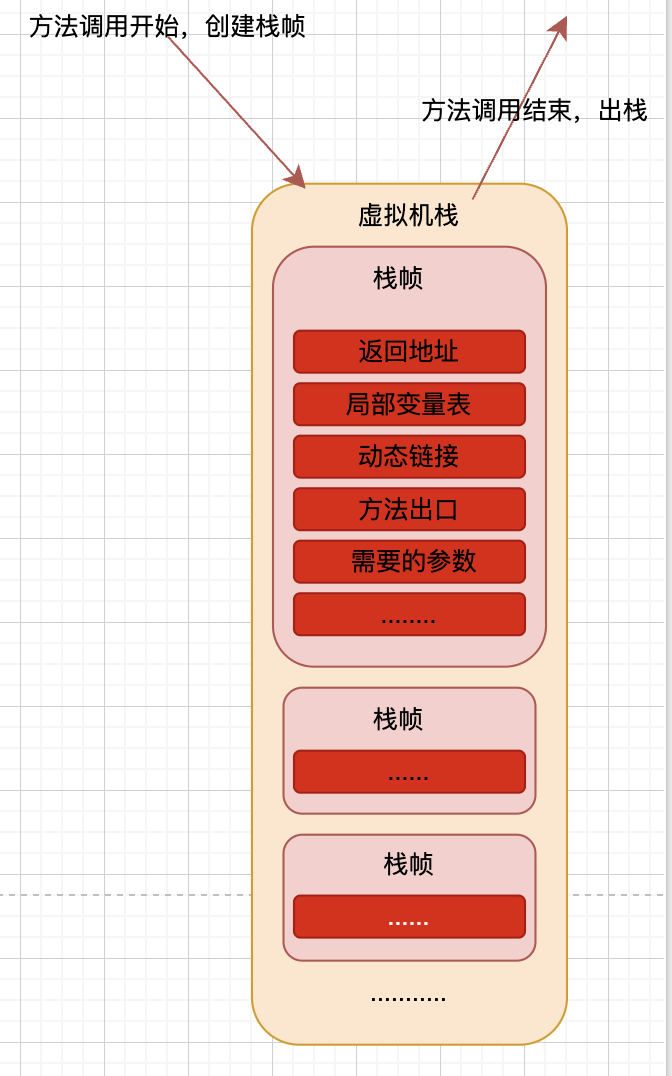
CPU调度线程去执行一个方法时,方法的调用开始直到调用结束表示栈帧入栈和出栈的过程
本地方法栈Native Method Stacks
本地方法栈也是属于私有线程区,这个区域跟C语言编写的Native方法相关,JVM会在本地方法栈中维护一张本地方法登记表,当有线程需要去调用本地Native方法时就会在本地方法栈维护的登记表栈去记录哪个线程调用了哪个本地方法/接口,是不会直接在本地方法栈中去直接调用方法/接口的,仅仅用于登记处理,真正是需要通过本地方法接口去调用本地方法库中C语言编写的函数
而一般情况下我们是不会关心这个区域的,因为热点HotSpot虚拟机中和虚拟栈已经合成一起了
还需要提醒一句:
JVM内存模型和JMM内存模型是完全不一样的
JVM内存模型是Java程序在运行期间的数据区域,对于操作系统而言本质就是存在内存中
JMM是Java和OS硬件架构层面的概念,JMM并不存在具体的代码,只是一种规范,不是技术实现,我感觉有点像Harness和Hermes的区别,但是不知道这么理解是否正确,欢迎大家指正。
Java内存模型(JMM)
Java memory model(简称:JMM),是一个规范,不是真实存在的,也不是技术实现手段。规定Java程序中各个变量(实利字段、静态字段、构成数组对象的元素)的访问方式。
JVM运行程序的实体是线程,每个线程在创建的时候JVM都要给它分配工作内存,用来存储线程私有数据。在Java内存模型中规定所有的变量都要存储在主内存中,主内存是共享内存区域的,所有的线程都可以访问。当线程想对一个变量进行赋值/运算操作时就要把对应的数据拷贝到工作内存中
所以,当一个线程想要去操作变量的时候,首先要从主内存中把变量拷贝到该线程的工作内存中,然后再在工作内存中对该变量进行操作,在工作内存中操作完成后再将变更后的值刷回主内存中,即:线程不能直接在主内存中操作变量,避免造成数据污染问题,必须将主内存中的变量拷贝到工作内存中进行操作
注意
Java中线程在操作一个对象时,对象实例是存放在JVM的堆内存中的,而栈空间是存放该对象实例的引用地址的。当一个线程去操作一个对象时,会先根据栈中的地址去主内存中的真实对象,然后将对象拷贝到自己对应的线程的工作内存中再进行操作,但是如果被操作的对象较大时,就不会完全拷贝整个对象,只会讲需要操作的部分成员拷贝过来
工作内存是每一个线程的私有数据区域,不同线程间的工作内存是无法访问的,线程间的通信就要靠主内存来完成的,如图:
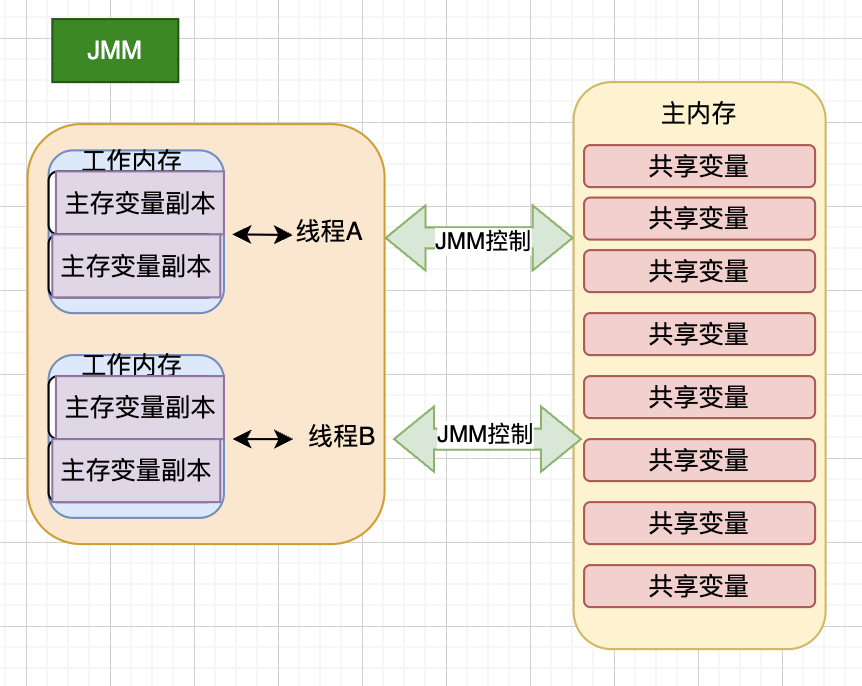
JMM内存模型和JVM的唯一区别就是:都存在共享数据区域和私有数据区域
主内存
在JMM中主内存属于共享内存区域,从某个角度上看可以认为主内存包含:方法区和堆
主内存主要存储共享数据,类的成员变量、方法的局部变量、共享的类信息、常量、静态变量等数据,还有所有线程创建的实例对象,栈内存中分配的对象除外
注意:因为主内存是线程共享区域,所以多个线程有可能对同一个数据同时进行操作,即非原子性操作,就会导致线程竞争,多线程安全问题的出现
工作内存
工作内存属于线程私有区,从某个角度看,可以认为包含:线程计数器、本地方法栈、虚拟机栈
工作内存主要存储的是当前方法所有的本地变量信息,每个线程的工作内存对其他线程是不可见的,例如线程T1的工作内存中,存储着主内存中拷贝回来的某个共享变量副本,线程T2是不可见的
即使这两个线程执行的是主内存中的同一段代码、同一个方法,都会在其工作内存中,创建属于当前线程的本地变量、字节码行号指示器、相关Native方法等信息,两者不会共用一块内存的数据
存储在工作内存中的数据没有线程安全问题 因为工作内存是每个线程的私有数据,线程间无法相互访问对方的工作内存,线程之间的通讯是需要依赖主内存来进行的
工作内存和主内存的关系
首先了解一下工作内存和主内存的数据存储类型和操作方式
根据虚拟机规范,对于一个实例对象的成员方法而言,如果方法中包含的本地变量(局部变量)是八大基本数据类型boolean、byte、char、int、long、float、double,就直接存储在工作内存的栈帧结构的局部变量表中
因为工作内存是线程私有区域,从某个角度看工作内存是包含虚拟机栈的,所以就直接存储在栈帧中
如果本地变量(局部变量)是引用数据类型:
-
该对象在内存中的具体引用地址会被存储到工作内存的栈帧结构的局部变量表中
-
具体的实例对象会被存储到主内存(堆中,跟上面工作内存的理解方式一样)
但对于实例对象的成员字段(全局变量)不管是基本数据类型、引用数据类型、包装类都会被存储到堆中(小部分在栈中分配的除外)
static静态变量以及类本身相关信息将会被存储到主内存中
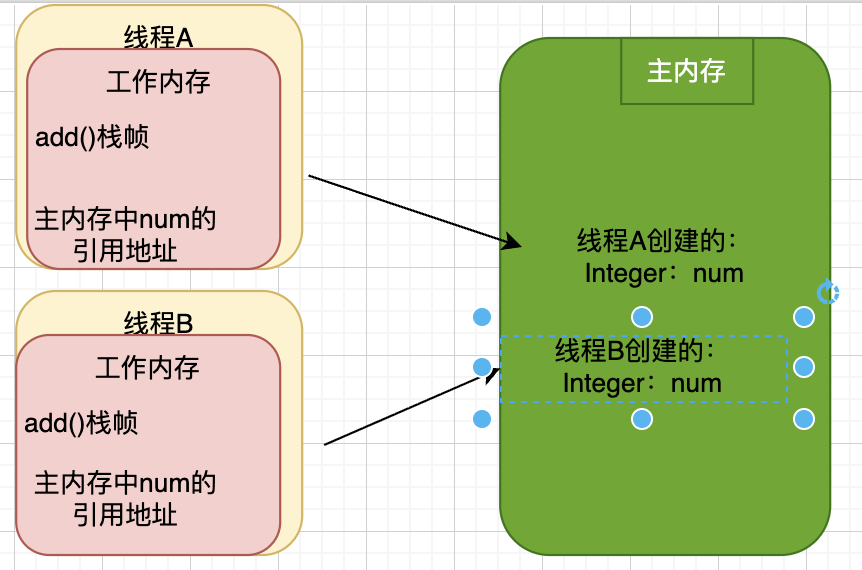
注意: 主内存是线程共享区,主内存中的实例对象是可以被多条线程同时共享的,如果这两条线程同时调用同一个类的、同一个方法,那么这两条线程需要将操作的数据拷贝一份到自己的工作内存中,在工作内存操作完之后才刷新到主内存中
如图:
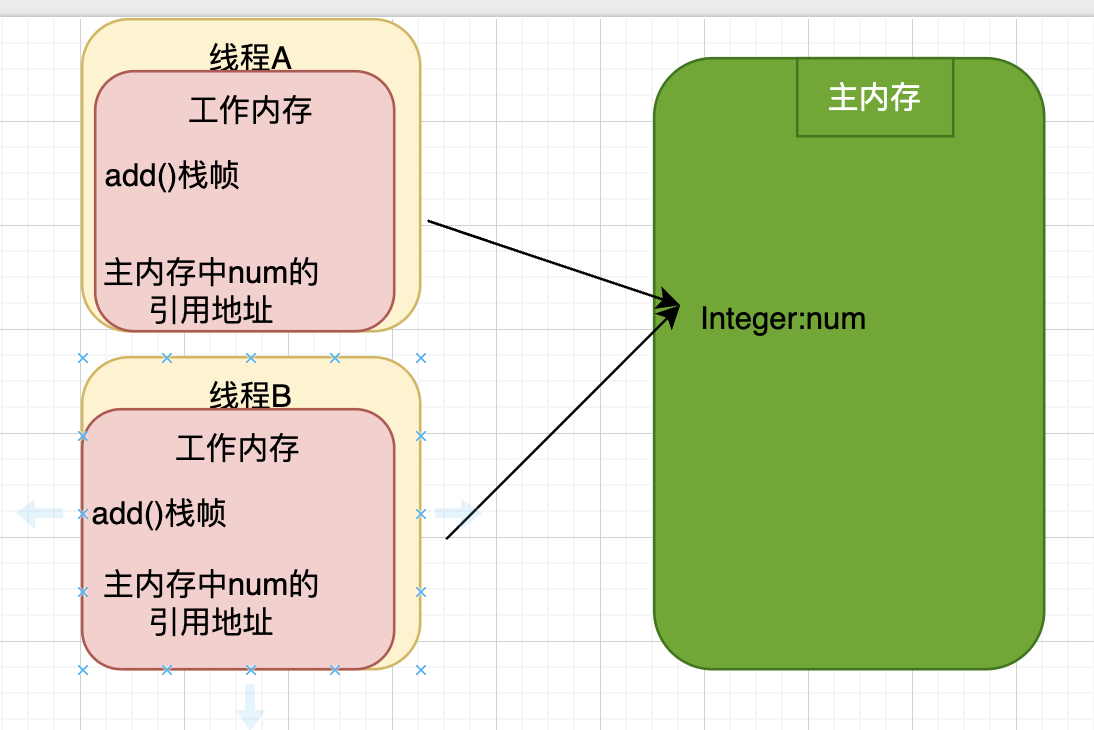
//假设此时主内存中有一个数据
//是一个全局变量而且是引用数据类型
Integer num = new Integer(100);
//有两个线程A和B都调用这个方法
public void add(){
num++;
}
那如果这个变量是局部变量呢? 局部变量的话一个线程就会对应一个值
public void add(){
Integer num = new Integer(200);
num++;
}
硬件内存架构、OS操作系统、Java多线程实现原理及JMM
计算机硬件内存架构
先画一副简易的CPU和内存操作的简易图:
一般对于一台计算机而言,会有多个CPU,一个CPU会有多个核心,多核是指在一枚处理器中,集成了多个完整的核心(计算引擎),那么这样就可以支持多任务并发执行。从多线程的角度看,每个线程都会映射到各个CPU核心上并行执行
在CPU内部有一组CPU寄存器,寄存器存储CPU直接访问和处理的数据,也就是一个临时存放数据的空间
一般情况下CPU都会先从内存中获取数据,然后把数据存放到寄存器中,然后对数据进行处理,但是内存的处理速度远低于CPU,导致CPU在处理指令时需要花很多时间在等待内存准备数据上。那么为了解决这个问题就在CPU和内存之间添加了CPU高速缓存,该缓存区域空间比较小,但是访问速度比内存快很多。高速缓存就可以把从内存提取的数据暂时保存起来,如果寄存器要取内存中同一位置的数据,可以直接从缓存中提取,不需要再去内存中获取,效率高很多,有点像MySQL和Redis的关系,内存就是MySQL中获取数据,高速缓存就是从Redis中获取数据,寄存器就相当于是请求,例如查询语句,修改语句等等。
但是只有当寄存器要取的数据在缓存中有才能取得到,如果不是同一个内存地址的数据那么寄存器就得绕过CPU高速缓存从内存中去获取对应的数据,,这种想象在学习Redis的时候也讲过,就是缓存命中率,可以从缓存中获取就是命中,从内存中获取就是没有命中,那么命中率越高CPU执行性能越高
总结: 当CPU需要访问内存数据时,首先从内存中读取一部分数据到CPU高速缓存中存放,然后把读取缓存数据到寄存器中,当CPU需要写数据时会先刷寄存器中的数据到CPU缓存中,然后再把数据刷回内存中
Redis就是CPU高速缓存,CPU寄存器就是Java程序,内存就是MySQL
OS和JVM线程关系、Java线程实现原理
在Java中线程是基于一对一模型实现的,所谓的一对一模型,就是在语言级别的层面,去间接调用系统内核的线程模型,如我们在使用Java线程时:
new Thread(Runnable).start();
JVM最终会调用当前操作系统的内核线程,来执行当前的Runnable任务
内核线程
Kernel-Level Thread, KLT,它是操作系统内核Kernel支持的线程,这种线程由操作系统进行控制,内核通过操作调度器完成对线程的执行调度,并将线程的任务映射到各个处理器上。每个线程可以视为内核的一个分身,那么多线程就有多个分身,所以操作系统就可以同时处理多个任务
但是我们编写的多线程程序是基于语言层面的多线程,一般是无法直接调用/创建内核线程,所以就出现了一种轻量级进程Light Weight Process,这也是通常意义上的线程。每个轻量级进程都会映射一个内核线程,所以可以通过轻量级进程来调用内核线程,进而由操作系统内核将内核线程的任务映射到各个处理器,这种轻量级进程与内核线程是一对一的关系,就称为Java线程和OS内核线程的一对一模型,如图:
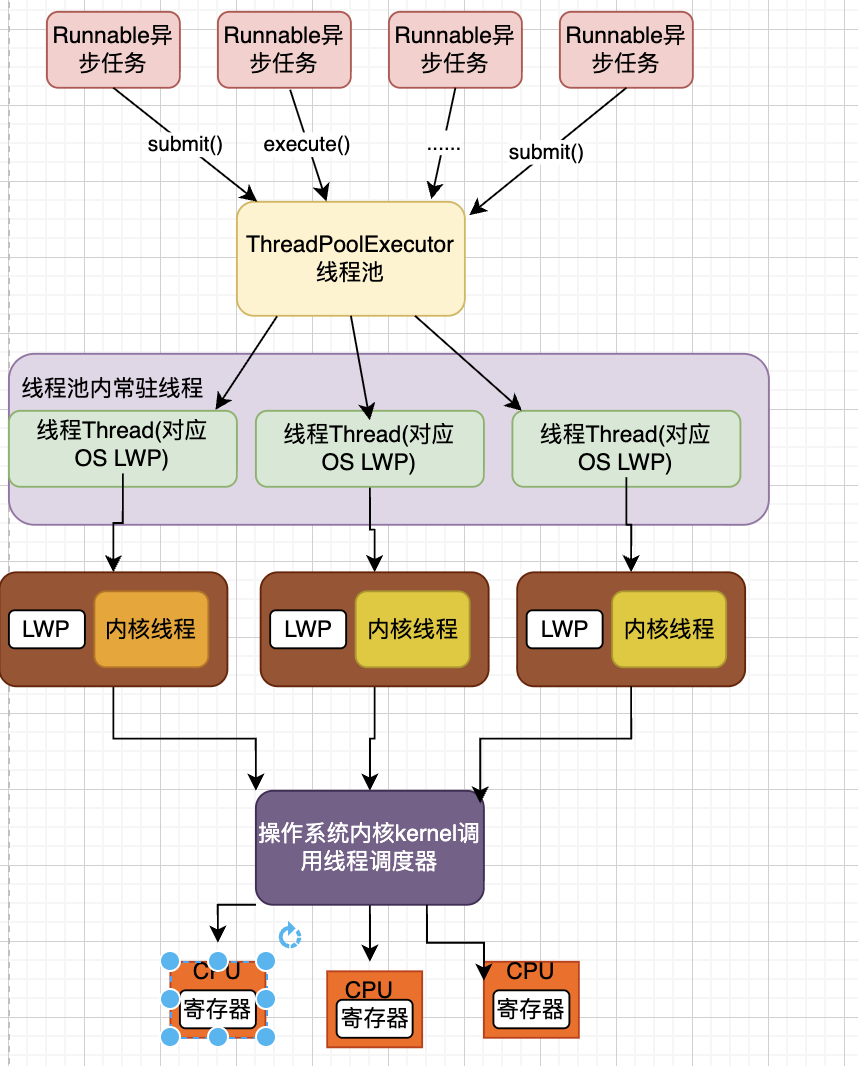
Java中的每个线程都会经过操作系统内核,通过操作系统内核调用线程调度器把每一个线程对应的任务映射到CPU中进行处理,如果CPU是多核的,那么一个CPU可以同时并行调度执行多个线程,执行多个任务
JMM与硬件内存架构的关系
Java内存模型(JMM)和硬件内存架构是不一样的
对于硬件内存架构而言,只有:主内存、CPU高速缓存、寄存器,没有工作内存(线程私有区)和主内存(线程共享区)之分,JMM的内存划分对硬件内存架构是没有任何影响的,因为JMM只是一种理论,并非实际的技术,所以在JMM中的数据不管是在工作内存还是在主内存中,都有可能存储在计算机主内存、CPU高速缓存、寄存器中其中的一个区域中
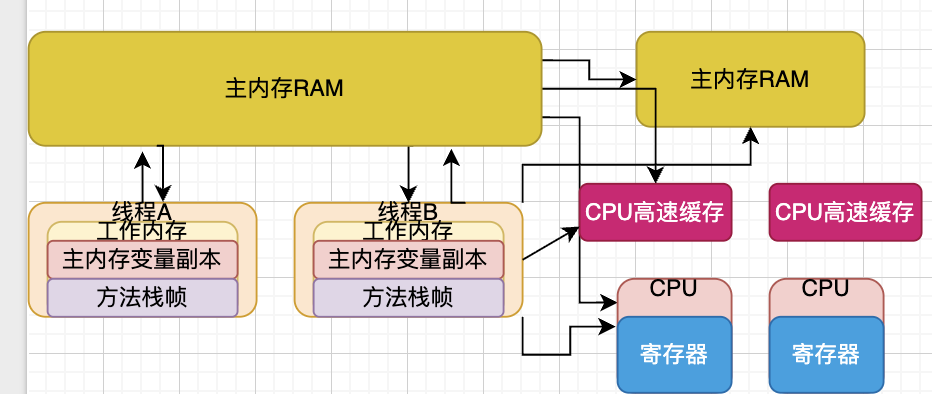
为什么需要有JMM内存模型的存在?
由于线程是操作系统的最小调度单位,所以的程序运行时的实体都是一条线程,运行在操作系统上的Java程序也不例外。每条线程在创建时,JVM都会为其创建一个工作内存,可以理解为虚拟机栈,用于存储线程私有的数据,线程如果想要操作主内存中的某个变量,必须通过工作内存间接完成
主要过程: 将变量从主内存拷贝到线程自己的工作内存中,然后在工作内存中对变量进行操作,操作完成后再将修改后的变量刷回到主内存中,如果存在多个线程同时对主内存中的同一个实例对象/变量操作时可能会导致线程安全问题出现
举个例子:假设主内存中有一个共享变量:int i = 0,然后他们调用的方法是对i = i + 1
public void add(){
i++;
}
有如下两种情况
第一种情况
有两个线程,分别是线程A和线程B,分别对变量i进行奥做,线程A和线程B各自分别把主内存中的变量i拷贝一份到自己的工作内存中,然后在工作内存中对变量i进行i=i+1的操作,然后A和B进行完操作之后就刷回主内存中,i=1
当A对i完成自增操作后变成了1,但是B是看不见的,还是基于i=0来进行操作的,所以最终在主内存中的值是1
但是理想情况下应该是i=2,所以这个时候就出现了线程安全问题
第二张情况
假设现在A线程想要把i的值修改为2,而B线程却想要读取i的值,那么B线程读取到的值,是A线程更新后的i=2这个值,还是更新前的i=1这个值呢?答案是不确定,即B线程有可能读取到A线程更新前的1,也有可能读取到A线程更新后的2。
这是因为工作内存属于每个线程的私有数据区域,而线程A修改变量i时,首先是将变量从主内存拷贝到自己的工作内存中,然后对变量进行操作,操作完成后再将变量i写回主内存。对于B线程的也是类似的,这样就有可能造成主内存与工作内存间数据存在一致性问题。
假如A线程修改完后,正在将数据写回主内存,而B线程此时正在读取主内存的i,也就是将i=1拷贝到自己的工作内存中,这样B线程读取到的值就是i=1。但如果A线程已将i=2写回主内存后,B线程才开始读取的话,那么此时B线程读到的就是2,但到底是哪种情况先发生呢?这是不确定的。
所以如上两种情况,对于程序来说是不应该的,假设把这个变量i换成淘宝双十一的商品库存数,A、B线程换成参加双十一的用户,这时就会导致超卖、重复卖等问题的出现,这会由于技术问题造成业务经济受损,尤其是是在类似于淘宝双十一此类的大促活动中,此类问题如果不控制好,出现问题的风险会成倍增长,其实这也就是所谓的线程安全问题。
为了解决上述两类问题,JVM定义了一组规则,通过这组规则来决定:一个线程对共享变量的写入何时对另一个线程可见,这组规则也称为Java内存模型(JMM),JMM整体是围绕着程序执行的原子性、有序性、可见性展开的,下面我们看看这三个特性。
未完待续

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)