告别Agent开发痛点!用MCP协议让工具调用标准化,5分钟上手,生产环境避坑指南
本文介绍了MCP协议在AI Agent开发中的应用,该协议通过标准化工具调用解决了跨模型兼容性问题。文章首先分析了传统工具调用的痛点,指出MCP已成为行业事实标准。随后详细说明了MCP的三层架构(主机、客户端、服务器)及其工作原理,并提供了5分钟快速上手的代码示例。最后给出生产环境中的关键建议:确保工具描述精准、实施分级错误处理机制(区分限流、参数错误等类型)、设置超时保护。作者建议新项目直接采用
本文介绍了MCP(Model Context Protocol)协议,旨在解决AI Agent开发中工具调用不标准、跨模型复用难、生产环境不稳定等问题。文章详细阐述了MCP的工作原理、快速上手步骤,并提供了生产环境中的3个避坑指南(工具描述精准、错误分级处理、超时保护)。最后,对比了MCP与Function Calling的适用场景,建议新项目直接采用MCP协议,以提升开发效率和稳定性。
如果你做过AI Agent开发,一定遇到过这种情况:好不容易接好的工具调用,线上跑着跑着就报错了。API参数改了、返回格式变了、或者干脆就没响应——然后你就开始漫长的debug之旅。
说实话,我早期做Agent的时候,光是处理各种Function Calling的兼容性问题,就花了好几周。直到我开始用MCP(Model Context Protocol),整个开发体验才有了质的飞跃。
今天这篇文章,就是从我踩过的坑出发,聊聊MCP到底是什么、怎么用,以及生产环境中要注意什么。
一、为什么需要MCP?
在MCP出现之前,给大模型接入外部工具是个头疼事。每个模型有自己的一套逻辑:
- OpenAI用Function Calling
- Claude有自己的工具定义格式
- 国产模型又是另一套
结果就是:你给OpenAI写的工具代码,换到Claude就得重写一遍。换个模型?继续重写。我曾经维护过一套同时支持3个模型的代码,那酸爽,现在想起来都后怕。
MCP的出现,就是为了解决这个问题。它的核心理念很简单:让工具调用标准化,就像USB-C接口统一了充电和数据传输一样。
2026年的数据更能说明问题:
- MCP月SDK下载量超过9700万次
- 超过10000个生产级服务器在运行MCP
- Anthropic、OpenAI、Google、微软、AWS全部支持MCP
换句话说,MCP已经成为Agent工具调用的事实标准。
二、MCP的工作原理
MCP的架构分为三个核心部分:
1. 主机(Host)
主机是发起请求的应用,比如你的AI聊天应用或者Agent框架。它负责:
- 管理与MCP服务器的连接
- 向服务器请求可用工具列表
- 调用工具并处理返回结果
2. 客户端(Client)
每个MCP服务器对应一个客户端,负责:
- 维护与服务器的通信
- 处理请求和响应的序列化
- 管理连接状态
3. 服务器(Server)
服务器是你的工具提供者,它:
- 声明自己能提供哪些工具
- 接收并执行工具调用
- 返回执行结果
┌─────────────┐ ┌─────────────┐ ┌─────────────┐│ 主机应用 │ ←──→ │ MCP客户端 │ ←──→ │ MCP服务器 ││ (Agent) │ │ (连接管理) │ │ (工具提供者) │└─────────────┘ └─────────────┘ └─────────────┘
这个架构的好处是:你只需要实现一次工具,就能被任何支持MCP的应用使用。
三、5分钟快速上手
说了这么多,来点实际的。下面是MCP的最小可用示例:
第一步:安装SDK
pip install mcp
第二步:创建MCP服务器
from mcp.server import Serverfrom mcp.types import Tool, TextContentfrom mcp.server.stdio import stdio_server# 创建服务器实例app = Server("my-tools")# 声明可用工具@app.list_tools()asyncdef list_tools() -> list[Tool]: return [ Tool( name="get_weather", description="获取指定城市的天气信息", inputSchema={ "type": "object", "properties": { "city": { "type": "string", "description": "城市名称,如:北京、上海" } }, "required": ["city"] } ) ]# 处理工具调用@app.call_tool()asyncdef call_tool( name: str, arguments: dict) -> list[TextContent]: if name == "get_weather": city = arguments["city"] # 这里调用真实的天气API weather = fetch_weather(city) return [TextContent(type="text", text=f"{city}今天天气:{weather}")] raise ValueError(f"Unknown tool: {name}")# 启动服务asyncdef main(): asyncwith stdio_server() as (read, write): await app.run(read, write, app.create_initialization_options())if __name__ == "__main__": import asyncio asyncio.run(main())
第三步:在Agent中调用
from mcp.client import ClientSessionfrom mcp.client.stdio import stdio_clientasyncdef main(): asyncwith stdio_client("./weather_server.py") as (read, write): asyncwith ClientSession(read, write) as session: # 初始化连接 await session.initialize() # 获取可用工具列表 tools = await session.list_tools() print("可用工具:", [t.name for t in tools]) # 调用工具 result = await session.call_tool("get_weather", {"city": "北京"}) print(result.content[0].text)asyncio.run(main())
就这么简单。你的Agent现在可以通过MCP调用天气工具了。
四、生产环境中的3个避坑指南
上面的例子能跑通,但放到生产环境,还有几个坑需要避开。
坑1:工具描述要精准
MCP的工具描述是模型决定是否调用的关键。描述模糊或参数定义不清,会导致模型乱调用工具。
错误示例:
Tool( name="search", description="搜索功能")
正确做法:
Tool( name="search_documents", description="在公司知识库中搜索文档,返回与查询最相关的文档列表和摘要", inputSchema={ "type": "object", "properties": { "query": { "type": "string", "description": "搜索关键词,建议使用2-5个核心词,过长的查询会被自动分词" }, "limit": { "type": "integer", "description": "返回结果数量上限,范围1-20,默认5", "default": 5 } }, "required": ["query"] })
我的经验是:描述要包含"返回值是什么",参数要说明"默认值和有效范围"。这样模型才能准确判断何时该调用、传入什么参数。
坑2:错误处理要分级
工具调用失败是常态,不是意外。你需要区分错误类型并处理:
@app.call_tool()asyncdef call_tool(name: str, arguments: dict) -> list[TextContent]: try: if name == "get_weather": result = fetch_weather(arguments["city"]) return [TextContent(type="text", text=result)] except APIRateLimitError: # 限流错误:可以重试 return [TextContent( type="text", text="服务暂时繁忙,请在30秒后重试", is_error=True )] except InvalidParameterError as e: # 参数错误:返回修正建议 return [TextContent( type="text", text=f"参数错误:{e.message},请检查city参数", is_error=True )] except Exception as e: # 未知错误:记录日志,返回友好提示 logger.error(f"工具调用失败: {name}, {arguments}, {e}") return [TextContent( type="text", text="服务暂时不可用,请稍后重试", is_error=True )]
关键点:用is_error=True标记错误,这样Agent能正确理解工具执行失败了,而不是把错误信息当作正常结果处理。
坑3:考虑工具超时
生产环境中,一次工具调用可能涉及数据库查询、外部API调用等,耗时会很长。你需要设置合理的超时:
# 全局超时配置TIMEOUT_SECONDS = 30@app.call_tool()asyncdef call_tool(name: str, arguments: dict) -> list[TextContent]: try: result = await asyncio.wait_for( execute_tool(name, arguments), timeout=TIMEOUT_SECONDS ) return result except asyncio.TimeoutError: return [TextContent( type="text", text=f"工具执行超时(>{TIMEOUT_SECONDS}秒),请减少查询范围或稍后重试", is_error=True )]
五、MCP vs Function Calling:选哪个?
既然MCP是后来者,肯定有人问:我之前用Function Calling好好的,为什么要换?
我的看法是:看场景。
| 对比维度 | Function Calling | MCP |
|---|---|---|
| 适用场景 | 单模型、单工具简单调用 | 多模型、多工具复杂协作 |
| 生态支持 | 厂商私有协议 | 开放标准,跨厂商通用 |
| 开发成本 | 低(单个模型) | 中(标准化实现) |
| 维护成本 | 高(多模型需要适配层) | 低(一次实现,多处复用) |
建议:
- 如果你的Agent只用一个模型,Function Calling够用
- 如果你要做多Agent协作,或者需要跨模型复用工具,MCP是更好的选择
- 新项目建议直接上MCP,因为这是行业趋势
六、总结
MCP协议解决的不是什么高深的技术难题,而是实实在在的工程问题:工具调用标准化、跨模型复用、生产级稳定性。
用好MCP的关键:
- 工具描述精准:模型才能准确判断何时调用
- 错误分级处理:区分可重试和不可重试的错误
- 超时保护:防止单个慢查询拖垮整个Agent
目前MCP的生态正在快速成熟,主流模型和框架都在支持。如果你还没开始用,建议从今天开始,把新项目的工具调用都迁移到MCP上。
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

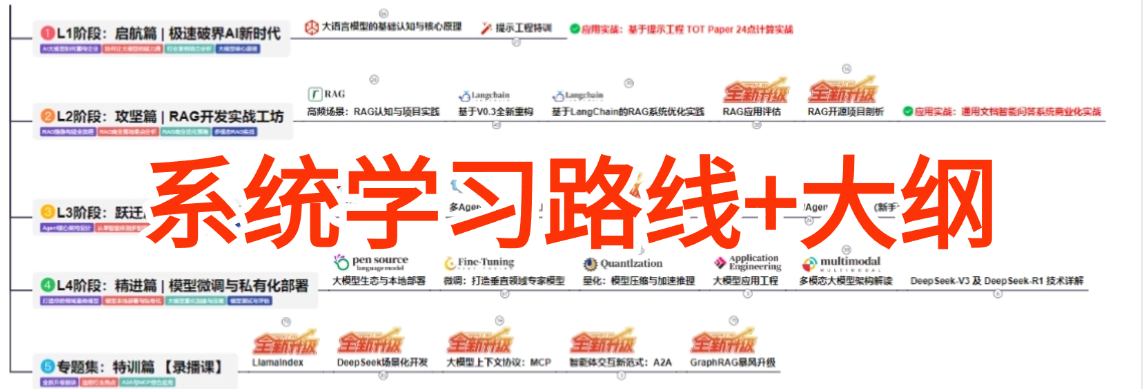
② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)