DPDK 实战:从 Linux 内核协议栈到用户态高速转发的架构设计
DPDK 是当前高性能网络开发领域的重要基础技术,广泛应用于虚拟交换机、网络安全设备、云计算数据平面等场景。本文从工程实践角度出发,分析 Linux 传统内核协议栈在高并发场景下的性能瓶颈,介绍 DPDK 绕过内核协议栈、用户态轮询收发包的核心设计思想,并深入解析其高性能实现机制,包括零拷贝、大页内存、CPU 亲和性、NUMA 优化及批量处理等关键技术。同时结合实际项目经验,给出典型 DPDK 转
在高性能网络开发领域,尤其是数通设备、虚拟交换机、边缘网关和安全设备中,传统 Linux 内核协议栈在高并发场景下常常成为性能瓶颈。
这也是为什么越来越多的数据平面系统开始采用 DPDK 进行用户态高速报文处理。
本文从工程实践角度,分析 DPDK 的核心设计思想,以及在实际项目中如何构建一个高性能转发框架。
一、为什么 Linux 内核协议栈性能会受限
传统网络收发路径如下:
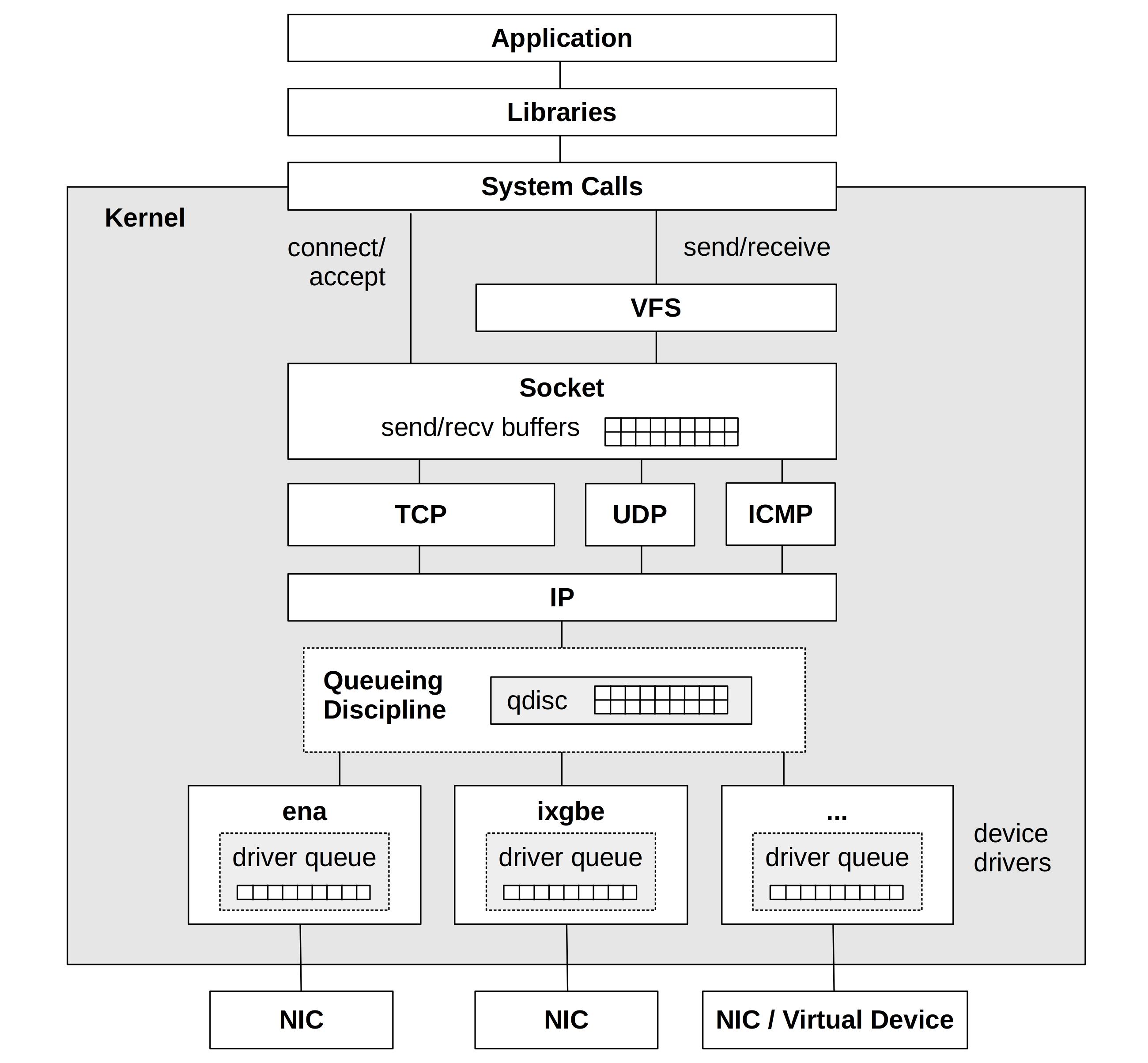
NIC → DMA → Ring Buffer → 中断 → 内核协议栈 → socket → 用户进程这个过程中存在几个典型性能问题:
1. 中断开销巨大
每个报文到达都会触发中断:
- 中断上下文切换
- CPU cache 失效
- scheduler 参与调度
在百万 PPS 场景下,这种模式不可接受。
2. 多次内存拷贝
报文从网卡到应用层可能经历:
- DMA 到内核缓冲区
- 内核协议栈处理
- socket copy 到用户态
大量 copy 直接消耗内存带宽。
3. 系统调用开销
recv/send 本质上都依赖系统调用:
- 用户态 ↔ 内核态切换
- TLB flush
- 上下文切换成本
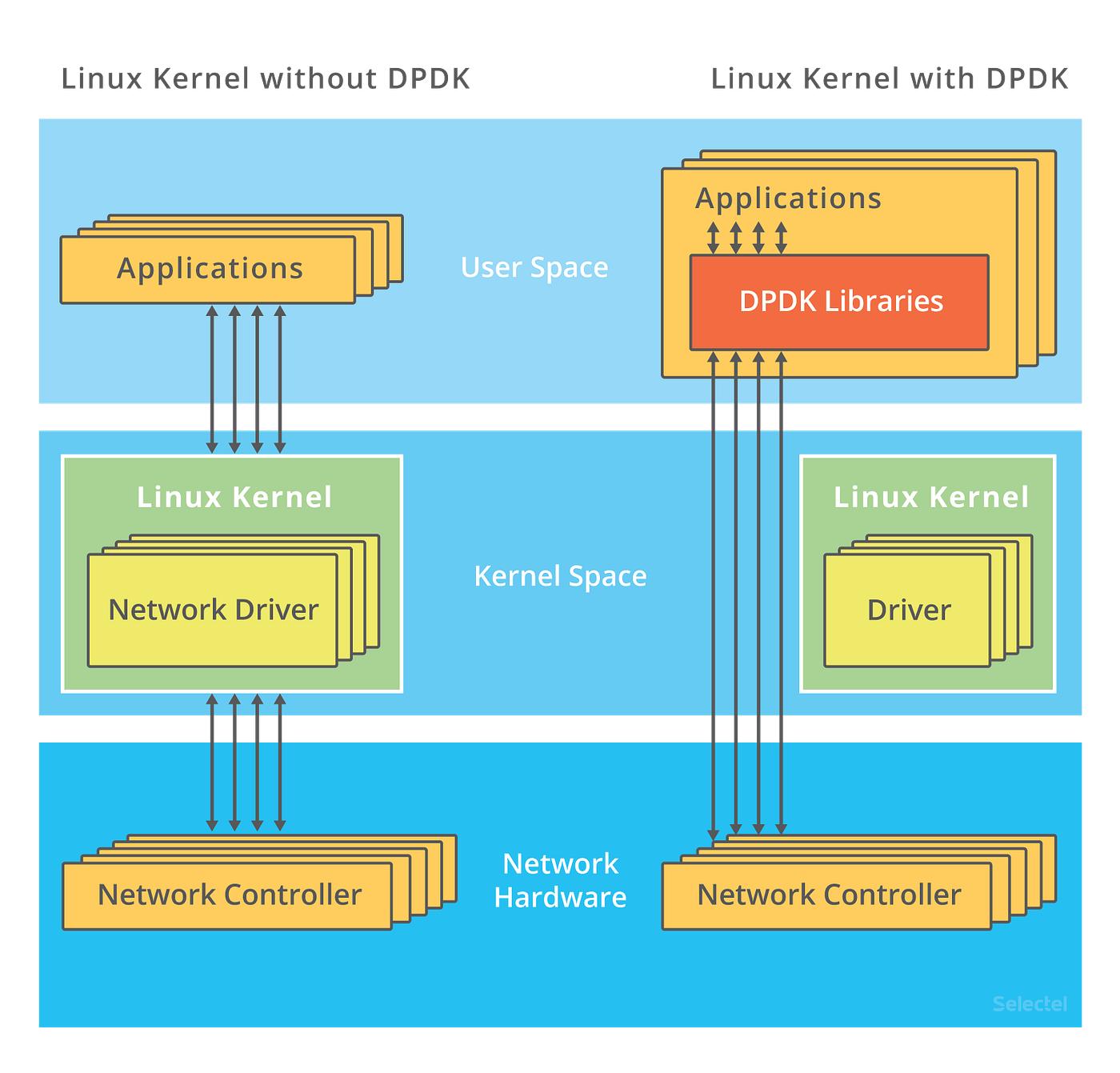
二、DPDK 的核心思想
DPDK 的设计非常直接:绕过内核协议栈,直接在用户态轮询网卡。
路径变为:
NIC → DMA → Hugepage Memory → User Space Polling核心原则:
Poll Mode Driver(PMD)
PMD 是 DPDK 的核心。
它放弃中断机制,采用:
- busy polling
- lockless ring
- burst I/O
即:
while (1) {
rte_eth_rx_burst(...);
process_packets();
rte_eth_tx_burst(...);
}这也是 DPDK 高性能的根本。
三、DPDK 为什么快
从体系结构来看,主要有 5 个原因。
1. 零拷贝
DPDK 中 mbuf 直接位于 hugepage 中:
NIC DMA → hugepage → user app避免:
- skb 分配
- socket copy
- 内核缓存迁移
2. 大页内存
使用 hugepage:
常见:
- 2MB
- 1GB
优点:
- 减少 TLB miss
- 提升 DMA 效率
初始化:
echo 1024 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages3. CPU 亲和绑定
通常一个 lcore 对应一个 RX queue:
queue0 -> core2
queue1 -> core3
queue2 -> core4避免跨核 cache 抖动。
4. NUMA 感知
多路服务器中:
- 网卡在 NUMA0
- CPU core 也绑定 NUMA0
- 内存从 NUMA0 分配
避免跨 socket 内存访问。
5. 批量处理
DPDK 所有接口都是 burst 模型:
nb_rx = rte_eth_rx_burst(port, queue, pkts, 32);不是一次一个包,而是一次 32 个。
这样:
- 减少函数调用次数
- 提高 cache locality
- SIMD 更友好
四、一个实际工程中的转发框架设计
我在项目中常用的 DPDK 架构如下:
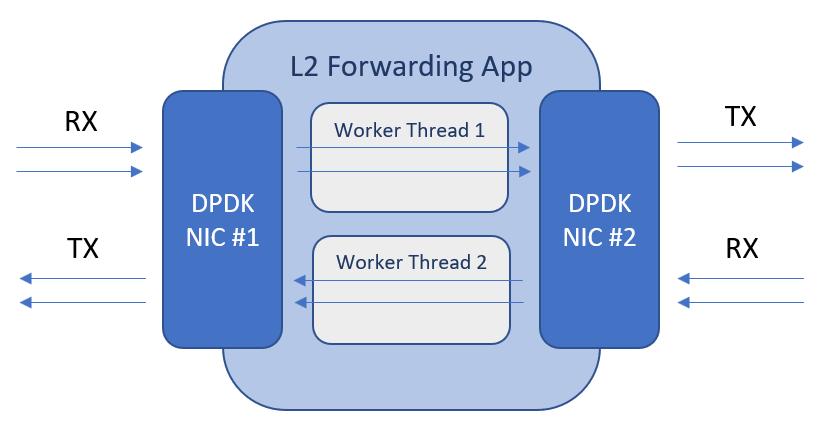
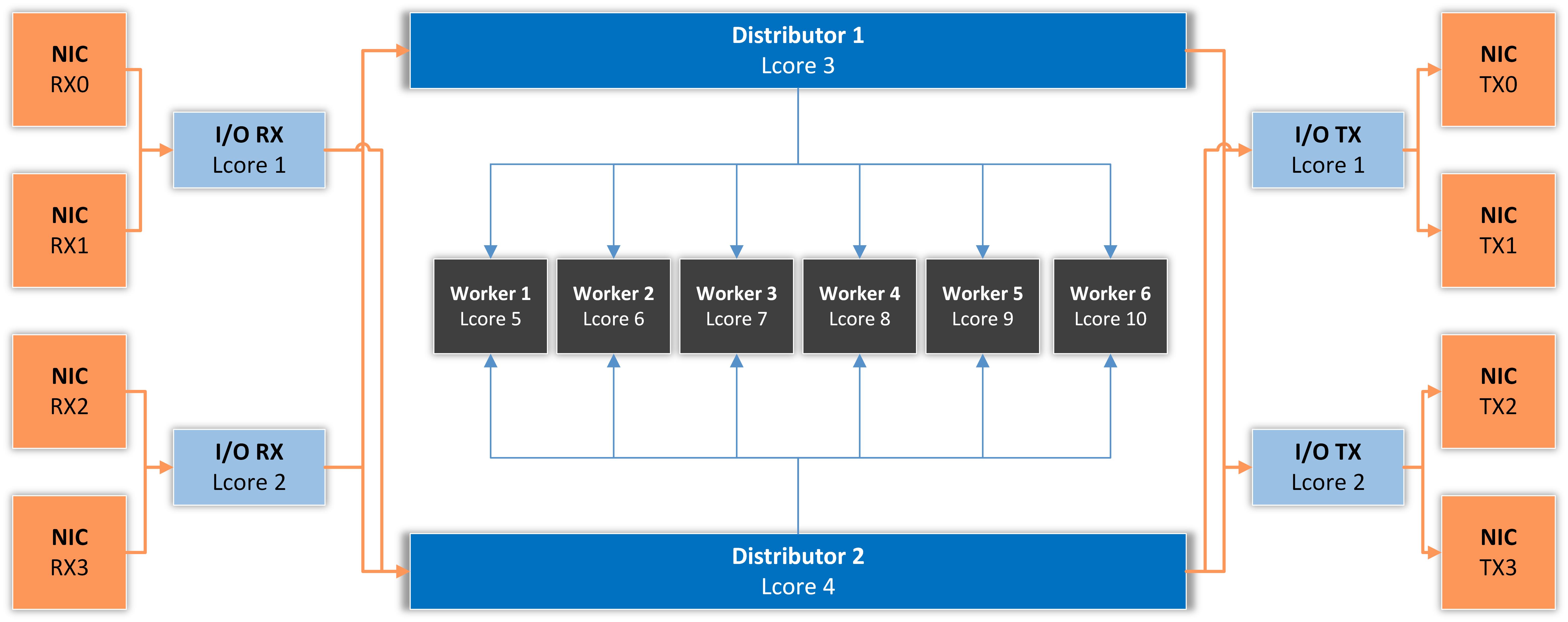
这种架构的优势:
1. 解耦业务逻辑
RX/TX 不处理业务:
只负责:
- 收包
- 发包
业务由 worker 完成。
2. 利于扩展
可扩展:
- ACL
- NAT
- DPI
- IPSec
- GRE/VXLAN
3. 易于无锁设计
通过:
DPDK Ring
实现 core 间通信:
rte_ring_enqueue()
rte_ring_dequeue()无需 mutex。
五、工程中最容易踩坑的地方
1. mbuf 泄漏
非常常见。
例如:
if (drop)
return;如果忘记:
rte_pktmbuf_free(m);运行一段时间后:
- mempool 耗尽
- 收包停止
2. cache line false sharing
多个核访问共享结构:
struct stats {
uint64_t rx;
uint64_t tx;
};会导致 cache line ping-pong。
正确做法:
struct stats {
uint64_t rx;
uint64_t tx;
} __rte_cache_aligned;3. NUMA 错误绑定
例如:
- 网卡在 socket0
- lcore 在 socket1
性能可能下降 40%。
必须检查:
cat /sys/class/net/eth0/device/numa_node4. burst 参数不合理
burst值并非越大越好。
我总结的经验值:
| burst | 建议 |
|---|---|
| 16 | 延迟优先 |
| 32 | 平衡 |
| 64 | 吞吐优先 |
后记
如果你是从事:
- Linux 网络开发
- 虚拟交换机
- SDN
- 云网络
- 安全网关
- 高性能代理
建议一定深入理解 DPDK。
因为它已经不仅仅是一个库,而是现代数据平面的基础设施。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)