Python 进阶:如何在 Python 应用中实现缓存
我们正在用 Python 构建一个应用程序,它将向终端用户展示产品列表。每天将有超过 100 个用户多次访问此应用程序。该应用程序将托管在应用程序服务器上,并可在互联网上访问。产品的资料将存储在数据库服务器中。因此应用程序服务器将查询数据库以获取相关记录。下图展示了我们的目标应用程序是如何配置的:上图说明了应用程序服务器如何从数据库服务器获取数据。
我将概述以下三个关键点:
- 什么是缓存以及为什么我们需要实现缓存?
- 缓存的规则是什么?
- 如何实现缓存?
我将首先解释什么是缓存,为什么我们需要在我们的应用程序中引入缓存,以及如何实现缓存。
1. 什么是缓存以及为什么我们需要实现缓存?
要想了解缓存是什么以及我们为什么需要缓存,试考虑以下场景:
- 我们正在用 Python 构建一个应用程序,它将向终端用户展示产品列表。
- 每天将有超过 100 个用户多次访问此应用程序。
- 该应用程序将托管在应用程序服务器上,并可在互联网上访问。
- 产品的资料将存储在数据库服务器中。
- 因此应用程序服务器将查询数据库以获取相关记录。
下图展示了我们的目标应用程序是如何配置的:
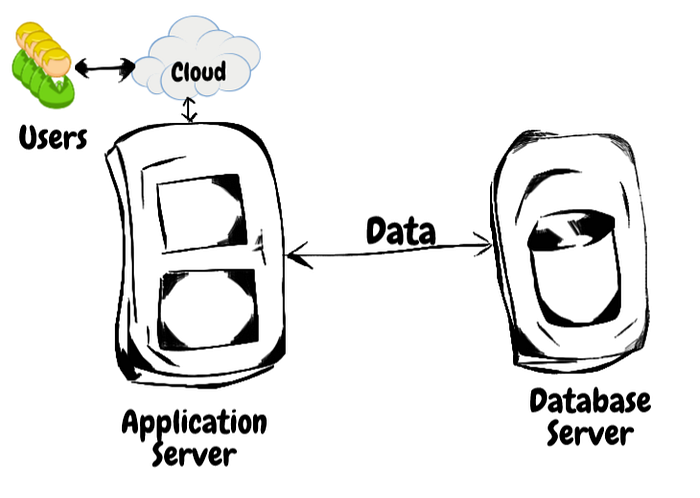
上图说明了应用程序服务器如何从数据库服务器获取数据。
问题
从数据库中获取数据是一个 I/O 密集型的操作。因此,它本质上是缓慢的。如果服务端需要频繁地发送请求但服务器响应跟不上请求的速度,那么我们可以将响应缓存在应用程序的内存中。
与其每次都查询数据库,我们可以将结果缓存,如下所示:
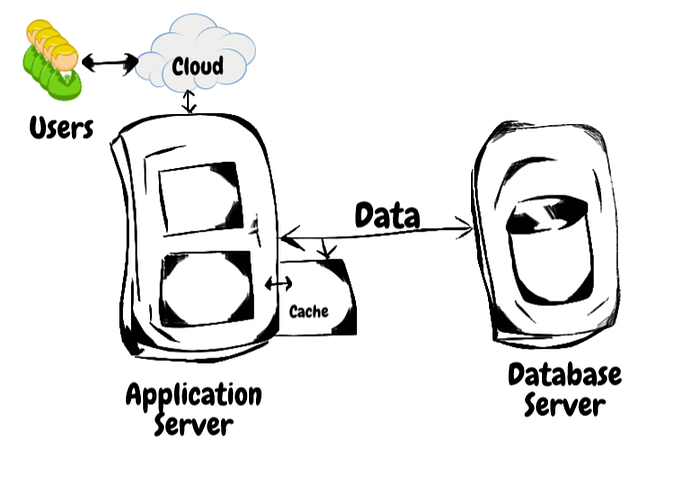
获取数据的请求必须通过网线,响应也必须通过网线返回。
这本质上是缓慢的。因此,我们引入了缓存。
我们可以缓存结果以减少运算时间并节省计算机资源。
缓存是一个临时存储位置。它以惰性载入的方式工作。
一开始,缓存是空的。当应用程序服务器从数据库服务器获取数据时,数据集将填充缓存。从那以后,后续的请求便能直接从缓存中获取数据。
我们还需要及时使缓存失效,以确保我们向终端用户显示最新信息。
本文的下一部分:缓存规则。
2. 缓存规则
在我看来,缓存有三个规则。
在启用缓存之前,我们需要执行一个关键步骤 —— 分析应用程序。
因此,在应用程序中引入缓存之前的第一步是分析应用程序。
只有这样我们才能了解每个函数需要执行多长时间以及它被调用了多少次。
我在这篇文章中解释了分析的艺术,我强烈将它推荐给大家。
分析完成后,我们需要确定需要缓存的内容。
我们需要一种能将输入链接到函数的输出的机制,并将它们存储在内存中。这就是缓存的第一条规则。
2.1. 第一条规则:
第一条规则是确保目标函数确实需要很长时间才能返回输出,且它会频繁被执行但输出的更动不大。
我们不想为不需要很长时间才能完成的函数,或几乎不会在应用程序中调用的函数,或那些返回结果在源中频繁更改的函数引入缓存。
请牢记这条重要的规则。
适合缓存的候选 = 经常调用的函数,输出不经常变化并且需要很长时间执行。
举例来说,如果一个函数被执行了 100 次,且该函数需要很长时间才能返回结果,并且它为给定的输入返回相同的结果,那么我们可以缓存它。
相反,如果函数返回的值在源中每秒更新一次,但我们每分钟才收到一个执行该函数的请求,那么我们得明白是否需要缓存这样的结果。这非常重要,因为这可能导致应用发送过时的数据给用户。这个例子可以帮助我们明白是否需要缓存,是否需要不同的通信通道、数据结构或序列化机制来更快地检索数据,例如通过 socket 使用二进制序列化器还是通过 HTTP 的 XML 序列化发送数据。
此外,知道何时使缓存失效并重新加载新数据到缓存也是非常重要的。
2.2. 第二条规则:
第二条规则是确保从缓存中获取数据的速度比执行目标函数的速度更快。
如果实践缓存后对检索结果所需的时间有正面的影响,我们才应该引入缓存。
缓存应该比从当前数据源获取数据更快。
因此,选择合适的数据结构(例如字典或 LRU 缓存)作为缓存的实例至关重要。
2.3. 第三条规则:
第三个重要规则是关于内存占用,这很常被忽略。你执行的是 I/O 操作(例如查询数据库、网络服务),还是执行 CPU 密集型操作(例如处理数字和执行内存内计算)?
当我们缓存数据时,应用程序的内存占用会增加,因此选择合适的数据结构并且只缓存需要缓存的数据是至关重要的。
有时侯,我们得查询多个表来创建一个类的对象。然而,我们只需要在我们的应用程序中缓存基本属性。
缓存对内存占用有影响。
例如,假设我们构建了一个报告面板,用于查询数据库并检索订单列表。为了让你有个大致的画面,我们假设面板上仅显示订单名称。
因此,我们可以只缓存每个订单的名称,而不是缓存整个订单对象。通常,架构师建议创建一个具有 __slots__ 属性的「瘦身版」数据传输对象(DTO)以减少内存占用。命名元组或 dataclass 类也有同样的效果。(dataclass 类是 Python 3.7 中新增的功能。)
本文的最后一部分:概述实现缓存的细节。
3. 如何实现缓存?
有多种方法可以实现缓存。
我们可以在 Python 进程中创建本地数据结构来构建缓存,或将缓存作为服务器充当代理并为请求提供服务。
Python 中有相应的内置工具,例如 functools 库中的 cached_property 装饰器。我将通过它来介绍缓存的实现。(仅适用于 Python 3.8 及更高版本。)
下面的代码段说明了 cached_property 如何运作:
python
体验AI代码助手
代码解读
复制代码
from functools import cached_property class FinTech: @cached_property def run(self): return list(range(1, 100))
因此,现在 FinTech().run 已被缓存,并且 list(range(1,100)) 将只生成一次。但是,在实际场景中,我们几乎不需要缓存属性。
让我们看看其他方法。
3.1. 字典方法
对于简单的用例,我们可以创建/使用映射数据结构(例如字典),将数据保存在内存中并使其使其可在全局范围内访问。
实现方式有多种,最简单的方法是创建一个单例模块,例如:config.py。
在 config.py 中,我们可以创建一个字典类型的字段,该字段在开始时被填充一次。
以后我们便可以使用字典的字段来获取结果。
举例来说,看看下方的代码。
config.py 带有 cache 属性:
python
体验AI代码助手
代码解读
复制代码
cache = {}
试想一下,我们的应用程序将通过 get_prices(symbol, start_date, end_date) 函数查询雅虎财经的网络服务以获取公司的历史价格。
历史价格不会改变,因此我们不需要每次需要历史价格时都查询网络服务。我们可以在内存中缓存价格。
在内部实践中,函数 get_prices(symbol, start_date, end_date) 可以在尝试返回结果之前检查数据是否在缓存中。
让我通过代码解释该策略。
下面的 get_prices 函数接受一个名为 companies 的参数。
- 首先,该函数创建一个开始和结束日期的变量,其中开始日期设为昨天,结束日期设为 12 天前。
- 然后它创建一个名为
target_key的元组类型变量。它的值唯一,由模块、函数、开始和结束日期组成。 - 该函数首先在
config.cache中查找键。如果它找到了,则检查cache是否包含目标公司名称。 - 如果缓存中包含公司名称,它会从缓存中返回价格。
- 如果
target_key不在缓存中,那么它通过雅虎财经检索所有公司,并将价格保存在缓存中以备将来调用,最后返回价格。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐


 0
0 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)