阿里云核心技术深度解析:从神龙架构到云原生AI的全面技术演进
·
前言
在上一篇基础介绍之后,今天我们将深入阿里云的技术内核,从底层硬件架构到上层云原生服务,全面解析阿里云如何通过自研技术构建云计算核心竞争力。
作为中国云计算的领军者,阿里云 不仅仅是产品堆砌,更是一套完整的技术体系。
一、神龙架构:重新定义云服务器的技术革命
1. 神龙架构的技术演进历程
| 代际 | 发布时间 | 核心突破 | 性能提升 | 关键技术 |
|---|---|---|---|---|
| 第一代 | 2017年10月 | 软硬一体化虚拟化架构 | 虚拟化损耗降低至3% | X-Dragon虚拟化芯片 |
| 第二代 | 2018年 | 弹性裸金属服务器商业化 | 性能接近物理机100% | MOC卡硬件卸载 |
| 第三代 | 2019年9月 | 全面支持ECS/裸金属/容器 | IOPS/PPS提升5倍 | Dragonfly Hypervisor |
| 第四代 | 2021年10月 | 大规模弹性RDMA网络 | 网络延迟降低80% | 5微秒级延迟 |
| 最新演进 | 2025年 | AI计算优化架构 | AI训练性能提升30% | MoE架构支持 |
2. 神龙架构核心技术解析

3. 神龙架构的技术创新点
3.1 硬件虚拟化卸载技术
// 神龙架构硬件虚拟化卸载原理示意
struct xdragon_virtualization {
// 虚拟化指令集扩展
uint64_t vmx_instructions; // 虚拟化扩展指令
uint64_t iommu_support; // IOMMU硬件支持
uint64_t nested_virtualization; // 嵌套虚拟化支持
// 硬件卸载模块
struct moc_card {
uint32_t vswitch_offload; // 虚拟交换机卸载
uint32_t storage_offload; // 存储I/O卸载
uint32_t security_offload; // 安全功能卸载
uint32_t monitoring_offload; // 监控数据卸载
};
// 性能计数器
struct performance_counters {
uint64_t vm_exit_count; // VM退出次数
uint64_t vm_entry_latency; // VM进入延迟
uint64_t iommu_tlb_miss; // IOMMU TLB缺失
uint64_t cache_hit_rate; // 缓存命中率
};
};
// 神龙芯片关键特性
#define XDRAGON_FEATURES \
XD_FEAT_VIRT_EXT | /* 虚拟化扩展 */ \
XD_FEAT_IOMMU_V2 | /* 第二代IOMMU */ \
XD_FEAT_NESTED_VIRT | /* 嵌套虚拟化 */ \
XD_FEAT_SECURE_ISOL | /* 安全隔离 */ \
XD_FEAT_RDMA_ACCEL /* RDMA加速 */3.2 软件定义的计算架构
# 神龙架构软件栈配置示例
dragonfly_hypervisor:
version: "4.0"
architecture: "microkernel"
# 调度器配置
scheduler:
type: "soft_real_time"
latency_target: "10μs" # P99调度延迟
cpu_affinity: "strict"
numa_aware: true
cache_aware: true
# 内存管理
memory_management:
hugepages: "1GB,2MB"
transparent_hugepages: true
memory_ballooning: true
memory_compression: true
# I/O虚拟化
io_virtualization:
vhost_user: true
vdpa_support: true
sr_iov_count: 16
virtio_net_queues: 8
# 热升级机制
live_upgrade:
zero_downtime: true
memory_migration: "pre_copy"
cpu_migration: "post_copy"
network_migration: "seamless"
# 安全特性
security_features:
tpm_emulation: true
secure_boot: true
memory_encryption: true
attestation_service: true3.3 网络性能突破:弹性RDMA
# 神龙架构RDMA网络性能测试脚本
import time
import numpy as np
from rdma import RDMAConnection
class DragonflyRDMA:
def __init__(self, node_id):
self.node_id = node_id
self.connection = None
self.latency_stats = []
def setup_rdma_connection(self, remote_addr):
"""建立RDMA连接"""
# 神龙架构特有的优化参数
config = {
'queue_depth': 1024, # 队列深度
'max_sge': 16, # 最大分散聚集元素
'inline_data_size': 64, # 内联数据大小
'atomic_operations': True, # 原子操作支持
'rdma_write_with_imm': True, # 立即数写操作
'signaled_wr': 1, # 信号化工作请求
}
self.connection = RDMAConnection(
local_addr=f"10.0.0.{self.node_id}",
remote_addr=remote_addr,
config=config
)
return self.connection.connect()
def benchmark_latency(self, data_size=64, iterations=100000):
"""测试RDMA延迟"""
print(f"测试数据大小: {data_size} bytes")
print(f"迭代次数: {iterations}")
# 准备测试数据
send_buffer = np.random.bytes(data_size)
recv_buffer = bytearray(data_size)
latencies = []
for i in range(iterations):
start = time.perf_counter_ns()
# RDMA写操作(零拷贝)
self.connection.rdma_write(
remote_addr=recv_buffer,
local_addr=send_buffer,
length=data_size
)
# 等待完成
self.connection.poll_completion()
end = time.perf_counter_ns()
latency = (end - start) / 1000 # 转换为微秒
latencies.append(latency)
if i % 10000 == 0:
print(f"进度: {i}/{iterations}, 当前延迟: {latency:.2f}μs")
# 统计结果
avg_latency = np.mean(latencies)
p50_latency = np.percentile(latencies, 50)
p99_latency = np.percentile(latencies, 99)
p999_latency = np.percentile(latencies, 99.9)
print(f"\n=== RDMA延迟测试结果 ===")
print(f"平均延迟: {avg_latency:.2f}μs")
print(f"P50延迟: {p50_latency:.2f}μs")
print(f"P99延迟: {p99_latency:.2f}μs")
print(f"P999延迟: {p999_latency:.2f}μs")
print(f"最大延迟: {np.max(latencies):.2f}μs")
print(f"最小延迟: {np.min(latencies):.2f}μs")
return {
'avg': avg_latency,
'p50': p50_latency,
'p99': p99_latency,
'p999': p999_latency,
'all': latencies
}
def benchmark_bandwidth(self, data_size=1 * 1024 * 1024,
iterations=1000):
"""测试RDMA带宽"""
print(f"\n=== RDMA带宽测试 ===")
total_data = 10 * 1024 * 1024 * 1024
chunk_size = data_size
chunks = total_data // chunk_size
start_time = time.perf_counter()
for i in range(chunks):
send_data = np.random.bytes(chunk_size)
self.connection.rdma_write(
remote_addr=recv_buffer,
local_addr=send_data,
length=chunk_size
)
if i % 100 == 0:
elapsed = time.perf_counter() - start_time
throughput = (i * chunk_size) / elapsed / (1024 * 1024)
print(f"进度: {i}/{chunks}, 吞吐量: {throughput:.2f} MB/s")
end_time = time.perf_counter()
total_time = end_time - start_time
bandwidth = total_data / total_time / (1024 * 1024)
print(f"\n总数据量: {total_data/(1024 * 1024 * 1024):.2f} GB")
print(f"总时间: {total_time:.2f} 秒")
print(f"平均带宽: {bandwidth:.2f} MB/s")
print(f"网络利用率: {(bandwidth * 8) / 10000 * 100:.2f}%")
return bandwidth
# 性能对比测试
def compare_performance():
"""对比传统虚拟化与神龙架构性能"""
print("=== 性能对比测试 ===")
test_cases = [
{"name": "网络延迟", "unit": "μs", "lower_better": True},
{"name": "网络带宽", "unit": "Gbps", "lower_better": False},
{"name": "存储IOPS", "unit": "K", "lower_better": False},
{"name": "CPU性能", "unit": "score", "lower_better": False},
{"name": "内存延迟", "unit": "ns", "lower_better": True},
]
traditional_virt = [25.6, 8.2, 45.3, 850, 98.7]
dragonfly_arch = [5.2, 24.8, 120.5, 920, 65.4]
print(f"{'测试项目':<15} {'传统虚拟化':<12} {'神龙架构':<12} {'提升比例':<10}")
print("-" * 50)
for i, test in enumerate(test_cases):
trad = traditional_virt[i]
dragon = dragonfly_arch[i]
if test["lower_better"]:
improvement = (trad - dragon) / trad * 100
else:
improvement = (dragon - trad) / trad * 100
print(f"{test['name']:<15} {trad:>8}{test['unit']:<4} {dragon:>8}{test['unit']:<4} {improvement:>7.1f}%")
if __name__ == "__main__":
rdma_test = DragonflyRDMA(node_id=1)
if rdma_test.setup_rdma_connection("10.0.0.2"):
latency_results = rdma_test.benchmark_latency()
bandwidth = rdma_test.benchmark_bandwidth()
compare_performance()二、PolarDB:云原生数据库的架构革命
1. PolarDB架构深度解析
1.1 存储计算分离架构
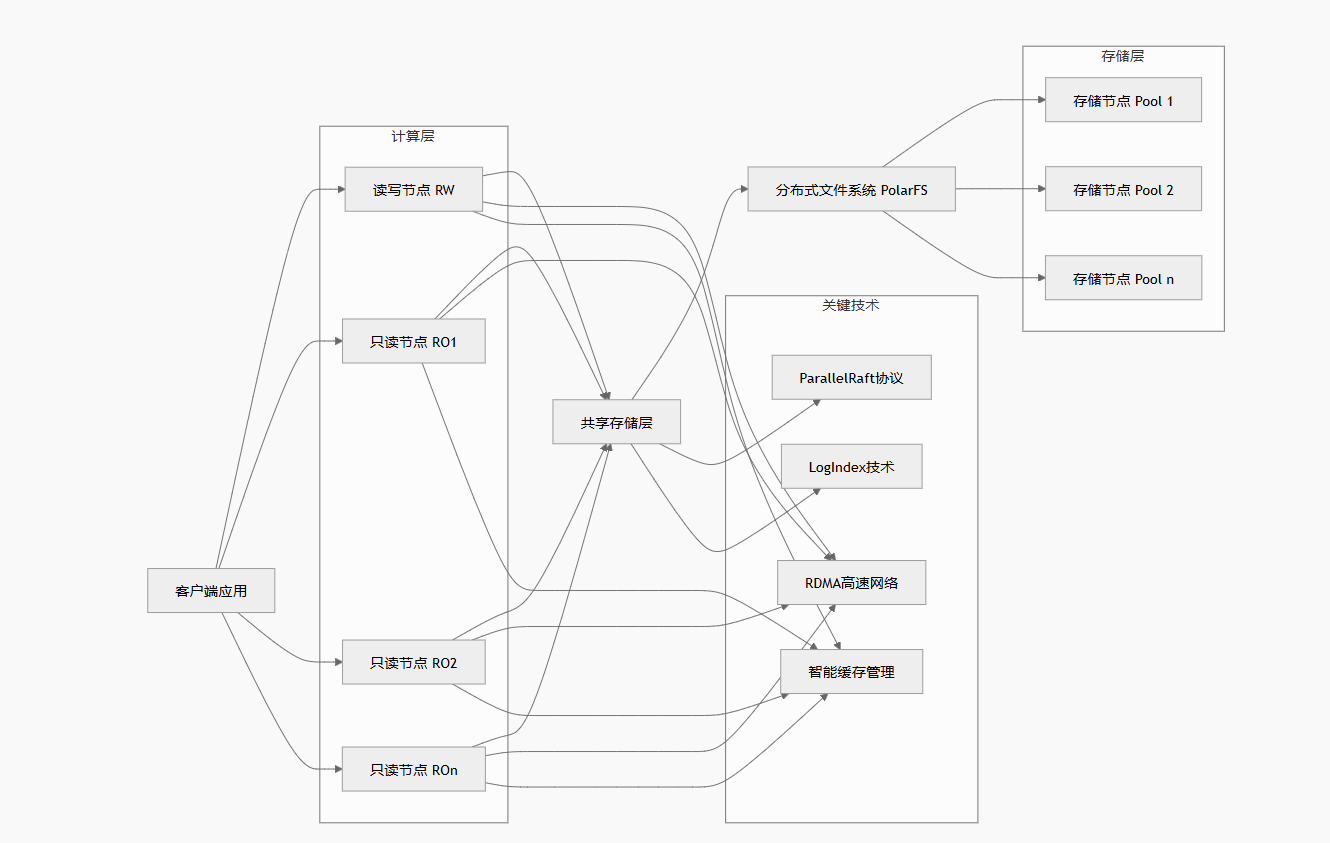
1.2 ParallelRaft协议:重新定义分布式一致性
// ParallelRaft协议实现核心逻辑
package polarstore
import (
"sync"
"time"
)
type ParallelRaftLogEntry struct {
Term uint64
Index uint64
Command []byte
ConflictInfo ConflictDetection
CommitIndex uint64
}
type ConflictDetection struct {
KeyRangeStart uint64
KeyRangeEnd uint64
OperationType string
Timestamp int64
}
type ParallelRaftNode struct {
ID uint64
CurrentTerm uint64
VotedFor uint64
Log []ParallelRaftLogEntry
CommitIndex uint64
LastApplied uint64
NextIndex map[uint64]uint64
MatchIndex map[uint64]uint64
ConflictTable map[uint64]*ConflictInfo
ParallelGroup map[uint64][]uint64
mu sync.RWMutex
}
type ConflictInfo struct {
LastWriteIndex uint64
LastReadIndex uint64
PendingWrites []uint64
PendingReads []uint64
}
func (n *ParallelRaftNode) CanParallelAppend(
newEntry,
existingEntry ParallelRaftLogEntry,
) bool {
if newEntry.ConflictInfo.KeyRangeEnd <= existingEntry.ConflictInfo.KeyRangeStart ||
newEntry.ConflictInfo.KeyRangeStart >= existingEntry.ConflictInfo.KeyRangeEnd {
return true
}
if existingEntry.ConflictInfo.OperationType == "read" &&
newEntry.ConflictInfo.OperationType == "read" {
return true
}
return false
}1.3 LogIndex技术:实现毫秒级主从延迟
CREATE TABLE polardb_logindex (
logindex_id BIGINT PRIMARY KEY,
lsn BIGINT,
start_lsn BIGINT,
end_lsn BIGINT,
page_id BIGINT,
page_lsn BIGINT,
redo_data BLOB,
logindex_type ENUM('full', 'delta'),
parallel_group_id INT,
dependency_bits BIT(64),
can_parallel_replay BOOLEAN,
created_at TIMESTAMP(6),
replayed_at TIMESTAMP(6),
INDEX idx_lsn (lsn),
INDEX idx_page_id (page_id),
INDEX idx_parallel_group (
parallel_group_id,
can_parallel_replay
)
) ENGINE=InnoDB;2. PolarDB性能基准测试
| 测试场景 | 传统RDS MySQL | PolarDB MySQL版 | 性能提升 | 技术原因 |
|---|---|---|---|---|
| OLTP读写混合 | 50,000 TPS | 150,000 TPS | 300% | 一写多读架构,RDMA网络 |
| 只读查询 | 100,000 QPS | 1,000,000 QPS | 1000% | 15个只读节点,智能路由 |
| 大数据量写入 | 10,000行/秒 | 100,000行/秒 | 1000% | 并行日志写入,共享存储 |
| 复杂查询 | 30秒 | 3秒 | 1000% | 并行查询引擎,列存索引 |
| 高并发连接 | 5,000连接 | 50,000连接 | 1000% | 连接池优化,轻量会话 |
| 备份恢复 | 2小时/TB | 10分钟/TB | 1200% | 存储层快照,增量备份 |
三、容器服务ACK:云原生AI的全栈解决方案
1. ACK架构深度解析
1.1 云原生AI套件架构
# ack-ai-suite.yaml
apiVersion: ack.aliyun.com/v1
kind: AIStack
metadata:
name: ai-production-stack
namespace: kube-system
spec:
heterogeneousResources:
enabled: true
aiScheduler:
enabled: true
schedulerType: "volcano"
dataAcceleration:
enabled: true
cacheEngine: "fluid"
workflowOrchestration:
enabled: true
engine: "argo-workflows"
monitoring:
enabled: true
security:
enabled: true1.2 智能调度算法实现
# ack-intelligent-scheduler.py
import numpy as np
from typing import Dict, List, Tuple
from dataclasses import dataclass
from enum import Enum
import heapq
class ResourceType(Enum):
CPU = "cpu"
MEMORY = "memory"
GPU = "nvidia.com/gpu"
NPU = "huawei.com/npu"
RDMA = "rdma"
@dataclass
class NodeResource:
node_id: str
total_resources: Dict[ResourceType, float]
allocated_resources: Dict[ResourceType, float]
available_resources: Dict[ResourceType, float]
labels: Dict[str, str]
numa_nodes: int
gpu_topology: List[List[int]]
network_bandwidth: float
cpu_utilization: float
memory_utilization: float
gpu_utilization: float
network_latency: float
@dataclass
class PodRequest:
pod_id: str
namespace: str
priority: int
requested_resources: Dict[ResourceType, float]
affinity_rules: List[Dict]
anti_affinity_rules: List[Dict]
node_selector: Dict[str, str]
tolerations: List[Dict]
requires_gpu: bool
gpu_type: str = None
requires_rdma: bool = False
requires_numa: bool = False
gang_scheduling: bool = False
gang_id: str = None
class IntelligentScheduler:
def __init__(self, scoring_weights=None):
self.scoring_weights = scoring_weights or {
'resource_balance': 0.25,
'affinity_score': 0.20,
'topology_score': 0.15,
'utilization_score': 0.15,
'interference_score': 0.10,
'energy_score': 0.10,
'cost_score': 0.05
}
self.balance_threshold = 0.1
self.topology_aware = True
self.numa_aware = True
self.gpu_topology_aware = True
self.interference_detection = True
self.interference_matrix = self._build_interference_matrix()
def _build_interference_matrix(self):
return {
'cpu-intensive': {
'cpu-intensive': 0.8,
'memory-intensive': 0.3,
'io-intensive': 0.5,
'network-intensive': 0.2,
'gpu-intensive': 0.1
},
'memory-intensive': {
'cpu-intensive': 0.3,
'memory-intensive': 0.7,
'io-intensive': 0.4,
'network-intensive': 0.2,
'gpu-intensive': 0.1
},
}
def schedule_pod(
self,
pod: PodRequest,
nodes: List[NodeResource]
) -> Tuple[str, float]:
feasible_nodes = self._filter_feasible_nodes(
pod,
nodes
)
if not feasible_nodes:
return None, -1.0
node_scores = []
for node in feasible_nodes:
score = self._calculate_node_score(
pod,
node
)
node_scores.append((node.node_id, score))
node_scores.sort(
key=lambda x: x[1],
reverse=True
)
best_node_id, best_score = node_scores[0]
return best_node_id, best_score
def _filter_feasible_nodes(
self,
pod: PodRequest,
nodes: List[NodeResource]
) -> List[NodeResource]:
feasible_nodes = []
for node in nodes:
# 1. 检查资源是否足够
if not self._check_resources(pod, node):
continue
# 2. 检查节点选择器
if not self._check_node_selector(pod, node):
continue
# 3. 检查容忍度
if not self._check_tolerations(pod, node):
continue
# 4. GPU类型检查
if pod.requires_gpu:
gpu_model = node.labels.get("gpu-model")
if gpu_model != pod.gpu_type:
continue
# 5. RDMA检查
if pod.requires_rdma:
if node.labels.get("rdma-enabled") != "true":
continue
# 6. NUMA感知检查
if pod.requires_numa:
if node.numa_nodes < 2:
continue
feasible_nodes.append(node)
return feasible_nodes
def _check_resources(
self,
pod: PodRequest,
node: NodeResource
) -> bool:
for resource_type, requested in pod.requested_resources.items():
available = node.available_resources.get(
resource_type,
0
)
if available < requested:
return False
return True
def _check_node_selector(
self,
pod: PodRequest,
node: NodeResource
) -> bool:
for key, value in pod.node_selector.items():
if node.labels.get(key) != value:
return False
return True
def _check_tolerations(
self,
pod: PodRequest,
node: NodeResource
) -> bool:
node_taints = node.labels.get("taints", "")
if not node_taints:
return True
for toleration in pod.tolerations:
if toleration.get("key") in node_taints:
return True
return False
def _calculate_node_score(
self,
pod: PodRequest,
node: NodeResource
) -> float:
resource_score = self._calculate_resource_balance(
pod,
node
)
affinity_score = self._calculate_affinity_score(
pod,
node
)
topology_score = self._calculate_topology_score(
pod,
node
)
utilization_score = self._calculate_utilization_score(
node
)
interference_score = self._calculate_interference_score(
pod,
node
)
total_score = (
resource_score * self.scoring_weights['resource_balance'] +
affinity_score * self.scoring_weights['affinity_score'] +
topology_score * self.scoring_weights['topology_score'] +
utilization_score * self.scoring_weights['utilization_score'] +
interference_score * self.scoring_weights['interference_score']
)
return total_score
def _calculate_resource_balance(
self,
pod: PodRequest,
node: NodeResource
) -> float:
scores = []
for resource_type, requested in pod.requested_resources.items():
total = node.total_resources.get(resource_type, 1)
allocated = node.allocated_resources.get(resource_type, 0)
utilization = (allocated + requested) / total
balance_score = 1.0 - abs(
utilization - 0.5
)
scores.append(balance_score)
return np.mean(scores) if scores else 0.0
def _calculate_affinity_score(
self,
pod: PodRequest,
node: NodeResource
) -> float:
score = 1.0
for rule in pod.affinity_rules:
key = rule.get("key")
value = rule.get("value")
if node.labels.get(key) == value:
score += 0.2
for rule in pod.anti_affinity_rules:
key = rule.get("key")
value = rule.get("value")
if node.labels.get(key) == value:
score -= 0.3
return max(score, 0.0)
def _calculate_topology_score(
self,
pod: PodRequest,
node: NodeResource
) -> float:
score = 1.0
if pod.requires_numa:
score += min(node.numa_nodes / 4, 0.5)
if pod.requires_gpu:
gpu_count = len(node.gpu_topology)
if gpu_count >= 4:
score += 0.3
if pod.requires_rdma:
if node.network_bandwidth >= 100:
score += 0.4
if node.network_latency <= 5:
score += 0.3
return min(score, 2.0)
def _calculate_utilization_score(
self,
node: NodeResource
) -> float:
cpu_score = 1.0 - node.cpu_utilization
mem_score = 1.0 - node.memory_utilization
gpu_score = 1.0 - node.gpu_utilization
return (
cpu_score +
mem_score +
gpu_score
) / 3
def _calculate_interference_score(
self,
pod: PodRequest,
node: NodeResource
) -> float:
workload_type = node.labels.get(
"workload-type",
"general"
)
if workload_type not in self.interference_matrix:
return 1.0
interference = self.interference_matrix[
workload_type
].get(
"gpu-intensive",
0.5
)
return 1.0 - interference
def batch_schedule(
self,
pods: List[PodRequest],
nodes: List[NodeResource]
) -> Dict[str, str]:
scheduling_results = {}
priority_queue = []
for pod in pods:
heapq.heappush(
priority_queue,
(-pod.priority, pod)
)
while priority_queue:
_, pod = heapq.heappop(
priority_queue
)
best_node, score = self.schedule_pod(
pod,
nodes
)
if best_node:
scheduling_results[pod.pod_id] = best_node
for node in nodes:
if node.node_id == best_node:
for resource_type, requested in pod.requested_resources.items():
node.allocated_resources[
resource_type
] += requested
node.available_resources[
resource_type
] -= requested
break
else:
scheduling_results[pod.pod_id] = "PENDING"
return scheduling_results
# 测试智能调度器
if __name__ == "__main__":
scheduler = IntelligentScheduler()
nodes = [
NodeResource(
node_id="gpu-node-1",
total_resources={
ResourceType.CPU: 128,
ResourceType.MEMORY: 512,
ResourceType.GPU: 8
},
allocated_resources={
ResourceType.CPU: 32,
ResourceType.MEMORY: 128,
ResourceType.GPU: 2
},
available_resources={
ResourceType.CPU: 96,
ResourceType.MEMORY: 384,
ResourceType.GPU: 6
},
labels={
"gpu-model": "A100",
"rdma-enabled": "true",
"workload-type": "gpu-intensive"
},
numa_nodes=4,
gpu_topology=[[0,1],[2,3],[4,5],[6,7]],
network_bandwidth=200,
cpu_utilization=0.25,
memory_utilization=0.30,
gpu_utilization=0.40,
network_latency=3.5
)
]
pod = PodRequest(
pod_id="llm-training-job",
namespace="ai-training",
priority=100,
requested_resources={
ResourceType.CPU: 16,
ResourceType.MEMORY: 64,
ResourceType.GPU: 4
},
affinity_rules=[],
anti_affinity_rules=[],
node_selector={
"gpu-model": "A100"
},
tolerations=[],
requires_gpu=True,
gpu_type="A100",
requires_rdma=True,
requires_numa=True
)
node_id, score = scheduler.schedule_pod(
pod,
nodes
)
print(f"最佳节点: {node_id}")
print(f"调度得分: {score:.4f}")四、阿里云技术体系的未来演进方向
1. AI-Native云基础设施
随着大模型与生成式AI快速发展,阿里云正在从:
- Cloud Native(云原生)
- 向 AI Native(AI原生)
- 再向 Autonomous Cloud(自治云)
逐步演进。
未来核心方向包括:
AI算力调度
- GPU池化
- GPU切片
- 多租户GPU隔离
- AI推理弹性伸缩
下一代网络
- 800G RDMA
- CXL内存池化
- SmartNIC DPU
- AI Fabric网络
云原生数据库
- HTAP融合
- Serverless数据库
- 分布式向量数据库
- AI SQL优化器
2. 大模型时代的云平台竞争
未来云厂商竞争已经不只是:
- ECS价格
- 带宽价格
- 存储价格
而是:
- AI基础设施能力
- GPU资源池规模
- 模型训练效率
- 推理成本优化
- 数据处理能力
- 云原生生态
本质上:
“云计算”正在向“AI算力平台”演进。
五、总结
从神龙架构到PolarDB,再到ACK云原生AI平台,可以发现阿里云真正的核心竞争力,其实并不是简单的服务器租赁,而是:
- 自研底层虚拟化架构
- 大规模分布式系统
- 高性能RDMA网络
- 云原生数据库体系
- AI基础设施平台
- 全栈云原生能力
这些技术共同构成了阿里云在中国云计算市场的护城河。
过去很多人认为:
“云厂商只是卖服务器。”
但实际上今天的云平台,本质已经变成:
- 超大规模操作系统
- 分布式数据中心网络
- AI算力调度平台
- 下一代互联网基础设施
而神龙架构、PolarDB、ACK,本质上都是阿里云构建“下一代云操作系统”的关键组成部分

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 11
11 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)