HTTP协议:初识
HTTP协议核心要点摘要 HTTP协议是客户端与服务器通信的基础,定义了请求响应机制和数据传输格式。核心特点包括无连接、无状态、基于TCP协议。URL作为资源标识符,包含协议、地址、路径等组件,对应服务器上的文件资源。HTTP请求由请求行、请求头、空行和请求体组成,通过空行分隔报头与有效载荷,Content-Length确定数据长度。URL编码(urldecode/urlencode)处理特殊字符
一个前端与后端开发者都必须掌握的核心协议
前言:为什么需要HTTP协议?
在网络通信的世界里,我们编写的所有网络程序本质上都是在进行数据交换。无论是刷短视频、看网页,还是上传照片,我们的行为只有两种:从远端下载数据 或 将本地数据上传到远端。
那么问题来了:这些数据以什么形式存在呢?答案是——文件。
这些文件存放在哪里?它们静静地躺在Linux服务器的某个路径下。而我们与这些文件交互的桥梁,就是HTTP协议。
一、HTTP协议概述
1.1 什么是HTTP?
HTTP(HyperText Transfer Protocol,超文本传输协议) 是互联网中客户端(如浏览器)与服务器之间通信的基石。
简单来说,HTTP协议定义了:
-
客户端如何向服务器发送请求
-
服务器如何响应客户端的请求
-
数据以什么格式进行传输
1.2 HTTP的核心特点
| 特点 | 说明 |
|---|---|
| 无连接 | 每次请求都需要建立新的连接,请求完成后断开 |
| 无状态 | 服务器不会保存客户端的状态信息,每个请求都是独立的 |
| 简单灵活 | 报文结构简单,易于理解和扩展 |
| 基于TCP | HTTP依赖TCP协议提供可靠的传输 |
1.3 端口号与协议
-
HTTP默认端口:80
-
HTTPS默认端口:443
虽然标准端口是80,但这只是惯例,HTTP服务器完全可以使用其他端口(如9090)。
二、URL详解
2.1 什么是URL?
URL(Uniform Resource Locator),就是我们俗称的“网址”。它是互联网上资源的唯一标识符。
2.2 URL的结构

| 组成部分 | 说明 | 示例 |
|---|---|---|
| 协议 | 通信方式 | http / https |
| 登录认证 | 可选的认证信息(不推荐明文使用) | user:pass@ |
| 服务器地址 | 域名或IP地址 | www.example.jp |
| 端口号 | 服务器的服务端口 | :80 |
| 文件路径 | 服务器上资源的路径 | /dir/index.htm |
| 查询字符串 | 动态请求的参数 | ?id=1 |
| 片段标识符 | 页面内的锚点 | #ch1 |
2.3 真正理解“资源”
在HTTP协议的角度:
-
资源 = 文件
-
文件存在于Linux服务器的特定路径下
举个例子:访问 https://news.qq.com/rain/a/20250418A05TE500.html,实际上是在请求腾讯新闻服务器上某个特定路径下的一个文件。

三、urlencode 和 urldecode
3.1 为什么需要转义?
像?、&、=、:、/等字符,在URL中被赋予了特殊含义。如果某个参数值中本来就要包含这些特殊字符(比如搜索关键词中包含:),就会导致URL解析错误。
3.2 转义规则
urlencode规则:
-
将需要转码的字符转为16进制
-
从右到左,取4位(不足4位直接处理)
-
每2位做一位,前面加上
%,编码成%XY格式
示例:
-
原本:
C++→ 转义后:C%2B%2B -
+被转义成了%2B
urldecode 就是反向操作,将%XY还原为原始字符。
💡 实践注意:浏览器会自动对URL中的特殊字符进行编码(urlencode),而服务器收到请求后会自动进行解码(urldecode)。
四、HTTP请求(HTTP Request)
4.1 请求的格式
HTTP请求是一个结构化的字符串,可以按行划分。它的格式如下:
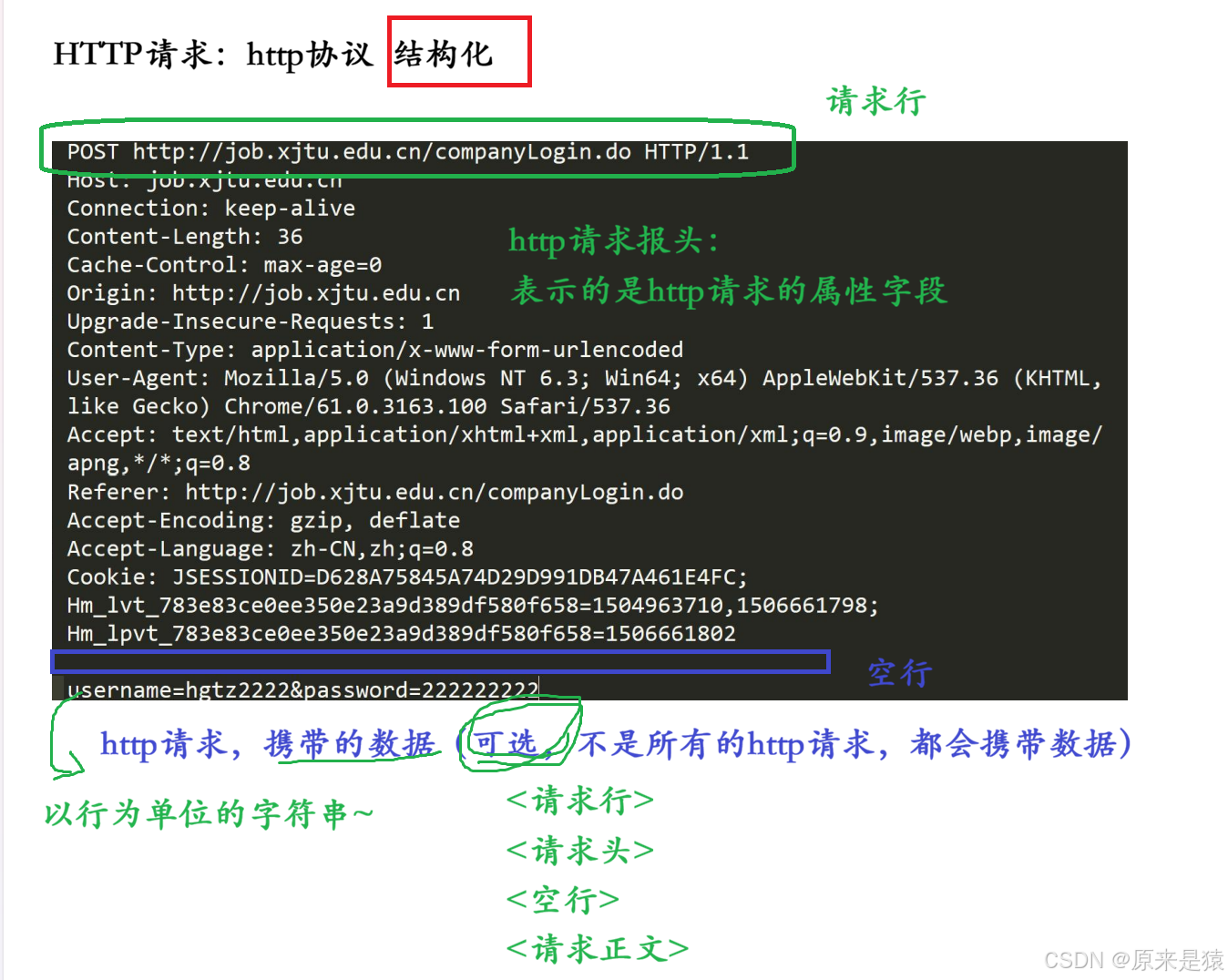
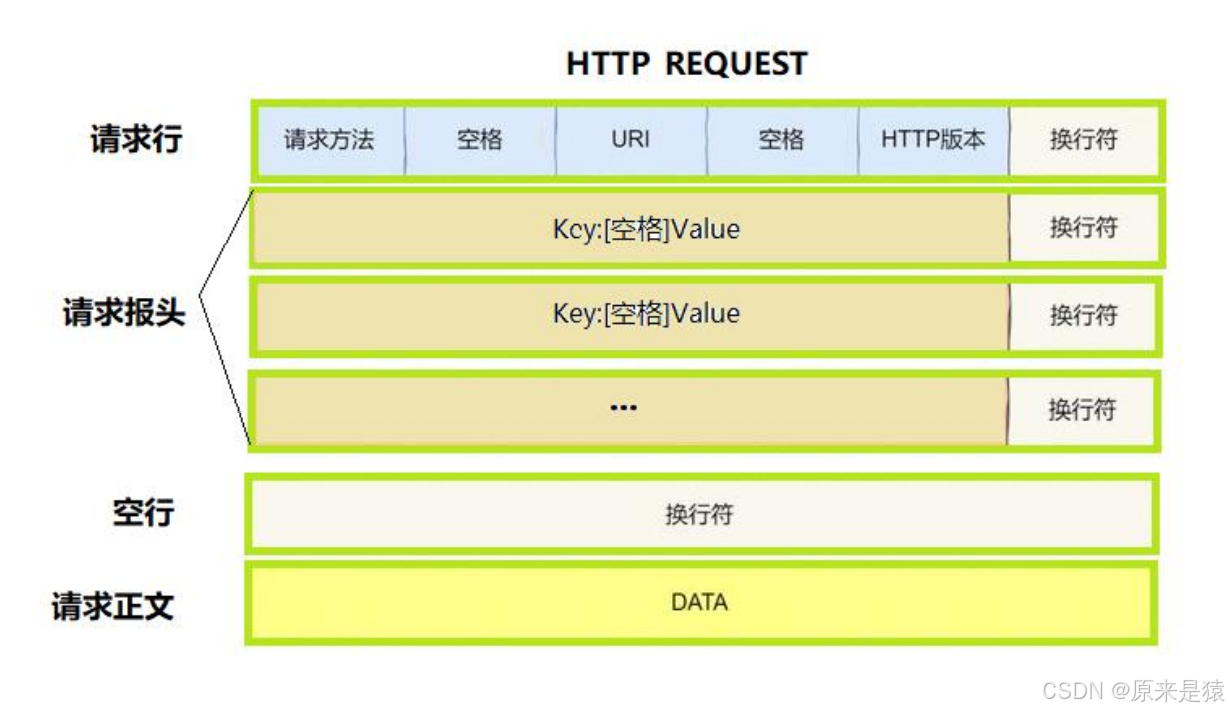
第一部分:请求行(Request Line)
格式:
<方法> <URL> <版本号>
| 元素 | 示例 | 说明 |
|---|---|---|
| 方法 | POST | 请求的动作 |
| URL | /xxxx | 请求的资源路径 |
| 版本 | HTTP/1.1 | HTTP协议版本号 |
第二部分:请求头(Headers)
格式:
<键>: <值>,每对之间用\r\n分隔。
常见请求头:
| Header | 含义 | 示例 |
|---|---|---|
| Host | 请求的主机名和端口 | job.xjtu.edu.cn |
| User-Agent | 客户端软件环境 | 浏览器类型/版本 |
| Referer | 当前页面从哪跳转而来 | 防盗链、来源统计 |
| Content-Type | 请求体的数据类型 | application/json |
| Content-Length | 请求体的字节大小 | 36 |
| Cookie | 携带的会话信息 | session_id=xxx |
| Accept | 客户端接受的数据类型 | text/html, */* |
| Connection | 连接管理 | keep-alive / close |
第三部分:空行
一个单独的
\r\n,用于分隔报头和有效载荷。
⭐ 核心设计思想:HTTP协议通过空行来分离报头和正文。这是HTTP能够正确解析数据的关键!
第四部分:请求正文(Body)
可选部分,存放实际数据。如果存在,Head中必须有Content-Length标明长度。
4.2 HTTP如何处理报头和有效载荷的分离?
这是理解HTTP协议的关键问题:
-
报头与有效载荷的分离:通过空行(
\r\n\r\n)来区分 -
有效载荷的读取:通过
Content-Length知道需要读取多少字节 -
序列化与反序列化:将结构化的字符串转换为数据结构,反之亦然
// 思想演示(伪代码)
class HttpRequest {
string method; // GET/POST...
string url; // 请求路径
string version; // HTTP/1.1
map<string, string> headers; // 请求头
string body; // 请求正文
};
openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 21
21 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)