vmstat详解
text如果 us 高 → 业务代码要优化如果 sy 高 + cs 高 → 线程太多了(或锁竞争)如果 wa 高 → 磁盘太慢如果 si/so > 0 → 内存不够如果 r 很大,id=0 → CPU 不够用了vmstat 1看生产服务器性能看deepseek给出的解释正常Java应用:cs < 5,000高并发应用:cs 5,000-15,000你的应用:cs 24,000-27,000← 异常
·
vmstat(Virtual Memory Statistics)是 Linux/Unix 上最经典的系统性能监控工具,它能一次性报告服务器的 CPU、内存、IO、进程等关键指标。
可以用来排查我们之前提到的 “CPU 上下文切换过高” 和 “CPU 是否打满” 这两个瓶颈。
1 基本用法:
# 每 2 秒输出一次,共输出 5 次 vmstat 2 5 # 常用:每秒一次,持续观察(按 Ctrl+C 停止) vmstat 1
2 输出&详解
执行 vmstat 1 后,你会看到类似这样的输出:
text
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 2 0 0 512400 78900 1023400 0 0 10 20 200 500 15 3 80 2 0 5 1 0 501200 79000 1025000 0 0 0 100 350 1200 25 8 65 2 0 8 0 0 498000 79000 1026000 0 0 0 50 400 2000 40 12 45 3 0
procs(进程)
| 列 | 含义 | 你的关注点 |
|---|---|---|
| r | 运行队列:正在运行或等待 CPU 的进程数。 | ⚠️ 重点关注:如果 r 长期 > CPU 核数(如 16 核机器上 r > 20),说明 CPU 不够用。 |
| b | 阻塞队列:等待 IO(磁盘/网络)的进程数。 | 如果 b 持续 > 0 且很大,说明磁盘或网络是瓶颈。 |
🧠 memory(内存)
| 列 | 含义 | 你的关注点 |
|---|---|---|
| swpd | 已使用的虚拟内存大小(KB)。 | 如果数值大且持续增长,说明物理内存不足。 |
| free | 空闲物理内存(KB)。 | 接近 0 时需警惕。 |
| buff | 用于块设备(如磁盘)的缓冲区大小。 | 正常值。 |
| cache | 用于文件系统的页缓存大小。 | Linux 会自动用空闲内存做缓存,数值大是好事。 |
💾 swap(交换分区)
| 列 | 含义 | 你的关注点 |
|---|---|---|
| si | 每秒从磁盘交换到内存的数据量(KB)。 | ⚠️ 重点关注:如果 si 和 so 长期 > 0,说明内存严重不足,性能会骤降。 |
| so | 每秒从内存交换到磁盘的数据量(KB)。 | 同上。 |
📀 io(磁盘读写)
| 列 | 含义 | 你的关注点 |
|---|---|---|
| bi | 每秒从块设备(磁盘)读入的数据量(块/秒,通常 1 块=1KB)。 | 高 bi 表示大量读磁盘。 |
| bo | 每秒写入块设备的数据量(块/秒)。 | 高 bo 表示大量写磁盘(如 RocketMQ 刷盘、数据库写入)。 |
⚙️ system(系统)
| 列 | 含义 | 你的关注点 |
|---|---|---|
| in | 每秒中断次数(interrupts),包括时钟、网卡、磁盘等。 | 如果异常高(如 > 50000),可能有硬件中断风暴。 |
| cs | 每秒上下文切换次数(context switches)。 | ⚠️ 核心关注点:对你之前的场景(90 个消费者线程)至关重要。如果 cs 远高于 in(如 in=500, cs=20000),说明线程切换过于频繁,通常是因为线程数过多或锁竞争激烈。 |
💻 cpu(CPU 使用率)
这些列加起来是 100%。
| 列 | 含义 | 你的关注点 |
|---|---|---|
| us | 用户态 CPU 占比。 | 你的业务代码(消费逻辑)在这里。如果持续 > 80%,说明业务代码是瓶颈。 |
| sy | 内核态 CPU 占比。 | 系统调用、锁操作、上下文切换在这里。如果 sy > 20-30%,通常伴随高 cs,说明内核开销过大(线程太多)。 |
| id | 空闲 CPU。 | 如果接近 0,说明 CPU 已打满。 |
| wa | 等待 IO 的 CPU 占比。 | ⚠️ 重点关注:如果 wa 持续 > 10-20%,说明磁盘太慢(如下游数据库写盘慢)。 |
| st | 被虚拟机偷走的 CPU(仅虚拟机环境)。 | 如果 > 5-10%,说明云主机超卖严重,找云服务商。 |
总结:一图看懂 vmstat
text
如果 us 高 → 业务代码要优化 如果 sy 高 + cs 高 → 线程太多了(或锁竞争) 如果 wa 高 → 磁盘太慢 如果 si/so > 0 → 内存不够 如果 r 很大,id=0 → CPU 不够用了
vmstat 1看生产服务器性能
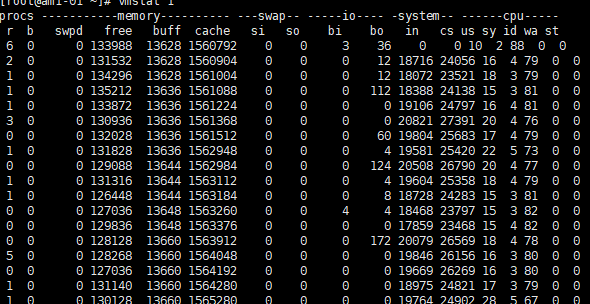
看deepseek给出的解释
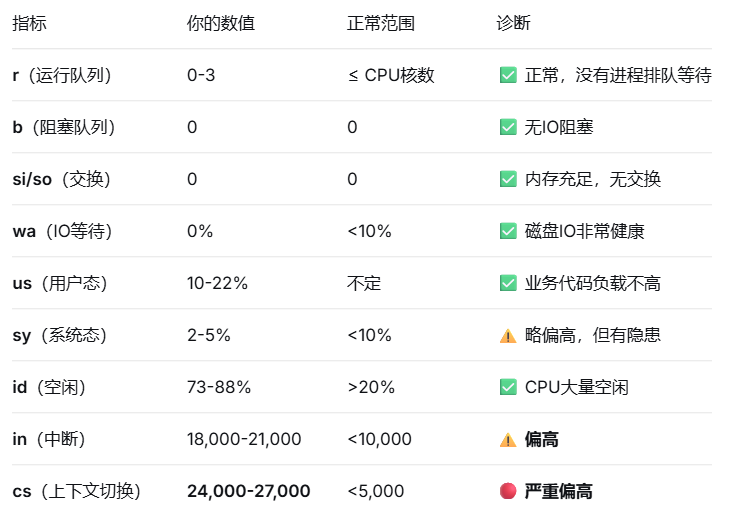
正常Java应用:cs < 5,000 高并发应用:cs 5,000-15,000 你的应用:cs 24,000-27,000 ← 异常区间
nproc查看cpu核数,如果线程数远远大于核数,就存在上下文切换频繁的问题
2. 查看哪个进程导致的
bash
# 查看上下文切换最高的进程 pidstat -w 1 3
输出中看 cswch/s(自愿切换)和 nvswch/s(非自愿切换):
-
非自愿切换高 → CPU 核数不够,线程被强制抢占
-
自愿切换高 → 线程在等锁、IO、或主动让出CPU
# 查看该进程的线程数(确认是否真的有15个消费者线程) ps -eLf | grep <PID> | wc -l 生产am有366个

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)