OS23.【Linux】初识进程地址空间
目录
1.知识回顾:C/C++的内存区域划分
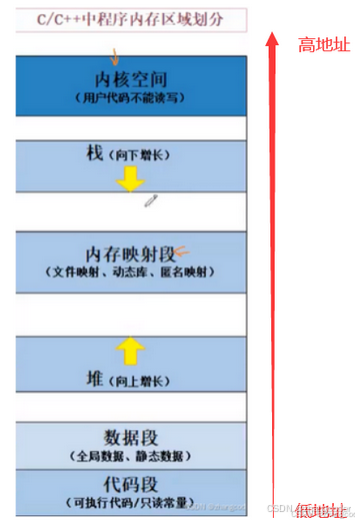
上方提到的空间布局图其实准确来说叫进程地址空间
2.验证进程地址空间各个区域的划分
#include <stdio.h>
#include <stdlib.h>
int global_val_1; // 未初始化全局变量
int global_val_2 = 100; // 已初始化全局变量
int main()
{
printf("code addr: %p\n", main); // 代码段地址
const char* str = "Hello World!";
printf("read only string addr: %p\n", str); // 只读字符串常量地址
printf("init global value addr: %p\n", &global_val_2 ); // 已初始化全局变量地址
printf("uninit global value addr: %p\n", &global_val_1); // 未初始化全局变量地址
char* mem = (char *)malloc(100); // 申请堆空间
printf("heap addr: %p\n", mem); // 堆地址
printf("stack addr: %p\n", &str); // 栈地址(变量 str 本身在栈上)
free(mem);
return 0;
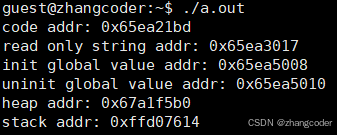
}Linux下执行:
先安装32位工具链:
sudo apt-get install gcc-multilib生成32位可执行文件:
g++ test.c -m32运行结果:从上往下看,地址依次增加
VS:Debug+x86环境运行结果:
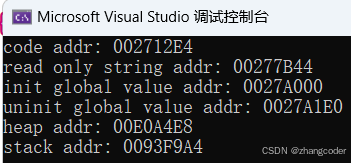
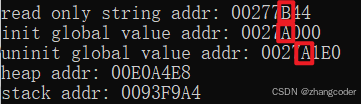
发现从上往下看,地址不是依次增加的,说明进程地址空间依赖于操作系统
验证栈区向下增长
以函数的嵌套调用为例:
#include <stdio.h>
void test3()
{
int val;
printf("test3's val addr: %p\n", &val);
return;
}
void test2()
{
int val;
printf("test2's val addr: %p\n", &val);
test3();
}
void test1()
{
int val;
printf("test1's val addr: %p\n", &val);
test2();
}
int main()
{
int val;
printf("main's val addr: %p\n", &val);
test1();
return 0;
}注意要打印函数内部局部变量的地址,不能打印函数的地址,因为函数在代码段的地址是通过这个地址去调用这个函数的,并不是它压栈之后的函数栈帧的地址
运行结果:压栈顺序:main→ test1→ test2→ test3,因此地址大小&main>&test1>&test2>&test3
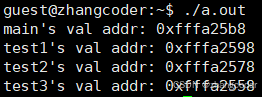
验证堆向上增长
#include <stdio.h>
#include <stdlib.h>
int main()
{
int* p1 = (int*)malloc(sizeof(int));
char* p2 = (char*)malloc(sizeof(char));
float* p3 = (float*)malloc(sizeof(float));;
printf("p1: %p\n", p1);
printf("p2: %p\n", p2);
printf("p3: %p\n", p3);
free(p1);
free(p2);
free(p3);
return 0;
}运行结果:初始化顺序: p1→p2→p3,因此地址大小:p1<p2<p3
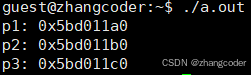
验证全局数据区的变量
注:全局数据区包含未初始化的全局变量、已初始化的全局变量和字符串常量区
验证static修饰的变量生命周期与程序运行周期相同,函数退出后不会销毁
#include <stdio.h>
int* func()
{
static int val = 1;
return &val;
}
int main()
{
int* p_val=func();
int stack_val;
printf("val = %d,val addr = %p\n", *p_val,p_val);
printf("stack_val addr = %p\n", &stack_val);
getchar();
return 0;
}可以使用pmap查看进程地址空间布局:
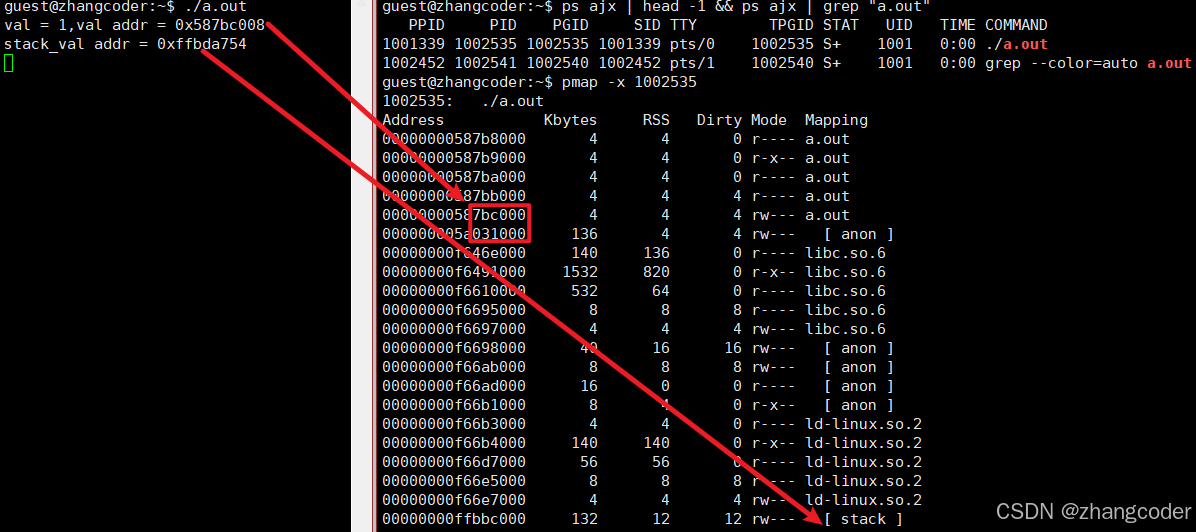
可以看到被static修饰的变量,在编译的时候已经被编译到全局数据区
3.几种地址类型
1.线性地址(也称虚拟地址): 32位平台下,该种地址的范围是0x00000000~0xFFFFFFFF,是平坦(flat)的,相当于只有一个段(unsegmented)
2.物理地址(也称绝对内存地址): 为内存芯片单元中的内存单元(memory cells)的编址,可以理解为内存条
3.逻辑地址
狭隘来说,指8086下的段地址:偏移地址的形式
宽泛来说,指逻辑段地址:偏移地址的访问形式
《Intel® 64 and IA-32 Architectures Software Developer's Manual, Volume 3A System Programming Guide, Part 1》描述的逻辑地址和线性地址:

上面提到了逻辑地址由16位的段选择子和32位偏移量组成,段选择子确定1字节数据所处的段,偏移量确定1字节数据在指定段的位置

线性地址空间包含
《Understanding.The.Linux.kernel.3rd.Edition》描述的三种地址:
Programmers casually refer to a memory address as the way to access the contents of
a memory cell. But when dealing with 80 × 86 microprocessors, we have to distinguish
three kinds of addresses:
Logical address
Included in the machine language instructions to specify the address of an operand
or of an instruction. This type of address embodies the well-known 80 × 86
segmented architecture that forces MS-DOS and Windows programmers to
divide their programs into segments. Each logical address consists of a segment
and an offset (or displacement) that denotes the distance from the start of the segment
to the actual address.Linear address (also known as virtual address)
A single 32-bit unsigned integer that can be used to address up to 4 GB—that is,
up to 4,294,967,296 memory cells. Linear addresses are usually represented in
hexadecimal notation; their values range from 0x00000000 to 0xffffffff.
Physical address
Used to address memory cells in memory chips. They correspond to the electrical
signals sent along the address pins of the microprocessor to the memory bus.
Physical addresses are represented as 32-bit or 36-bit unsigned integers.
3.回顾遗留的问题
在OS18.【Linux】进程基础知识(2)文章提到了一个没有解决的问题:对于pid_t ret_id=fork(),变量ret_id为什么会有两个不同的值?
虽然两个进程打印各自ret_id的地址是一样的,而且这两个ret_id的值不同,所以这两个地址绝对不可能是物理地址,只可能是线性地址
→C/C++指针存储的值都不是物理地址
其实"虽然两个进程打印各自ret_id的地址是一样的,而且这两个ret_id的值不同"的现象是因为分页
页功能未开启,线性地址==物理地址;页功能开启,线性地址!=物理地址
可推测: 进程地址空间需要映射物理地址上→两个ret_id的地址需要映射到不同物理地址上,而MMU(Memory Management Unit)将地址从虚拟地址空间映射到物理地址空间
可以看看《x86汇编语言:从实模式到保护模式 第二版》对此的描述:

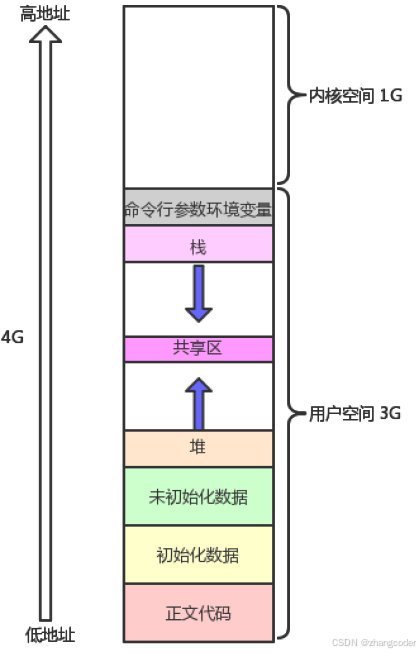
4.进程地址空间
进程地址空间又称为虚拟地址空间(Virtual Address Space)、线性地址空间(Linear Address Space)、虚拟内存(Virtual Memory)
32位下进程地址空间分为两部分:1G内核空间和3G用户空间
1.每个进程都有自己的PCB、进程地址空间和页表,因此当父进程创建子进程时,子进程也有自己的PCB、进程地址空间和页表
2.进程在被创建的时候,先创建内核数据结构,后加载对应的可执行程序
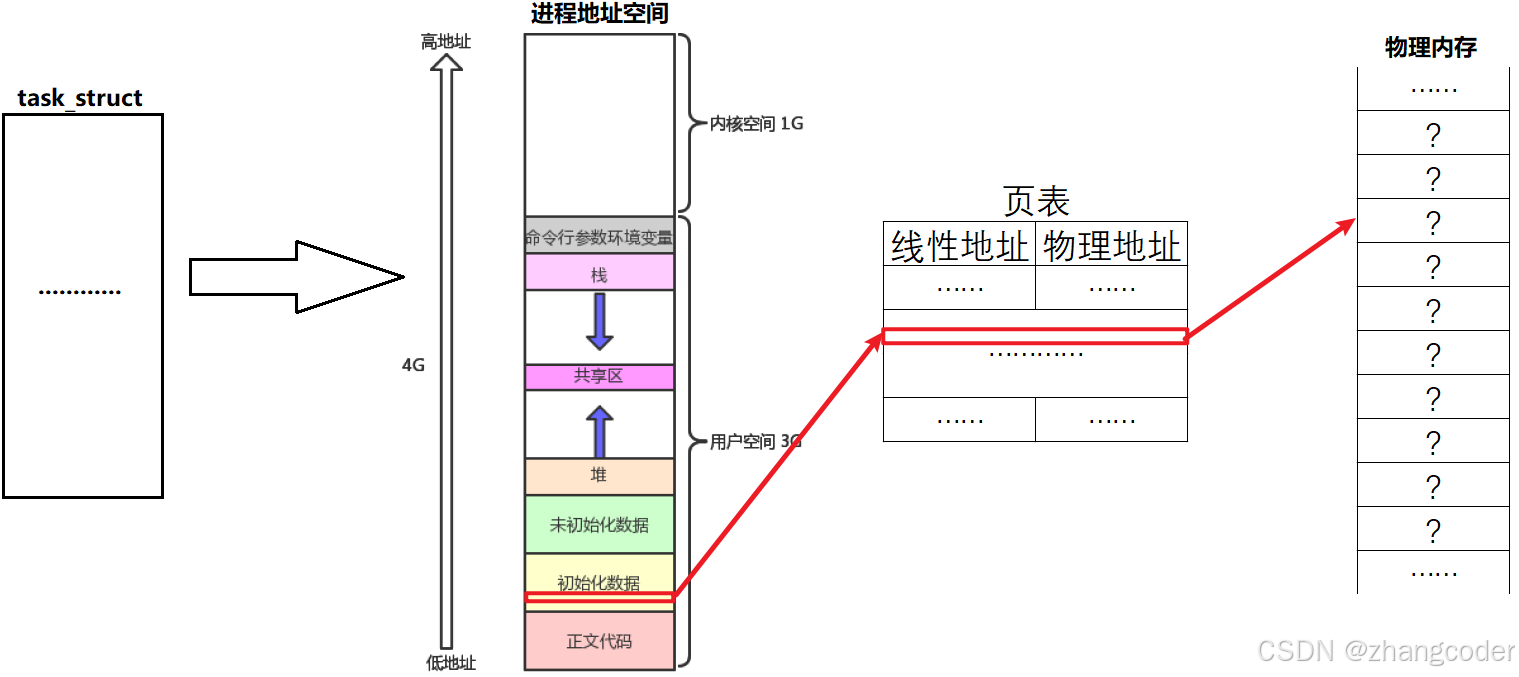
页表
进程地址空间的的地址是虚拟地址,虚拟地址转换到物理地址还需要页表(简单理解为KV映射)的帮忙
每个进程都有属于自己的页表
下面是简化的页表的示意图:
遗留问题中的"虽然两个进程打印各自ret_id的地址是一样的,但是这两个ret_id的值不同"可画图表示为:
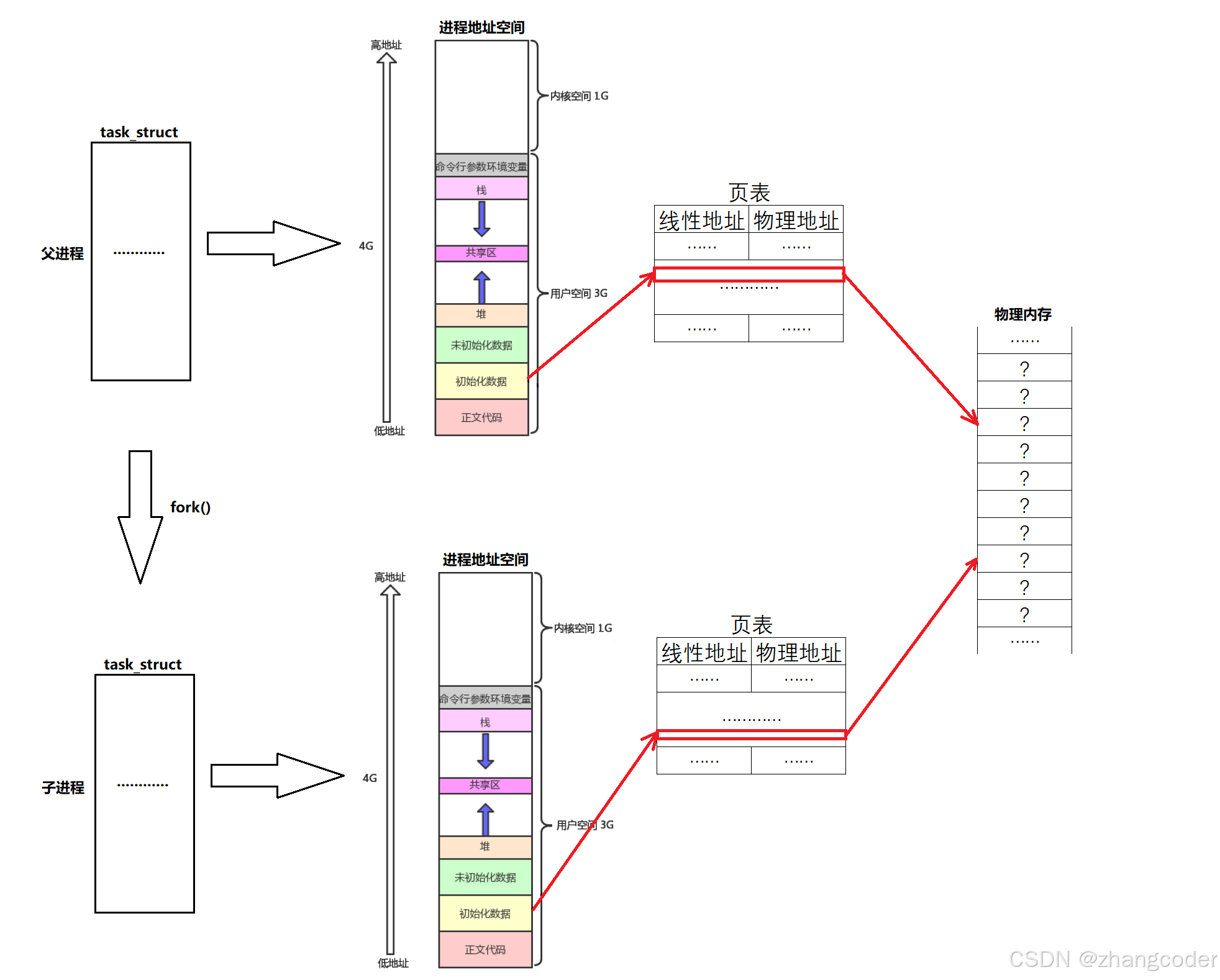
父进程创建子进程时,父进程的页表会拷贝一份给子进程,供子进程修改后使用
写时拷贝和页表的关系
之前在OS18.【Linux】进程基础知识(2)文章讲过:用fork()创建子进程时,父子进程共用同一份代码,数据以写时拷贝的方式各自私有
一开始父子进程的代码段是共享的,此时它们页表的对数据段映射的都是同一块物理内存,如果发生写时拷贝,那么子进程的页表中对数据段映射的物理内存会发生修改.该步骤由操作系统完成,进程无需负责
可以看出:修改的实际上是虚拟地址到物理地址的映射关系,虚拟地址是不用修改的(即虚拟地址是0感知的),进程可以继续使用
CR3寄存器
Intel CPU中有一个CR3寄存器记录当前进程的页表地址(从进程的PCB中取得). 当进程切换时,CR3寄存器的内容也会变
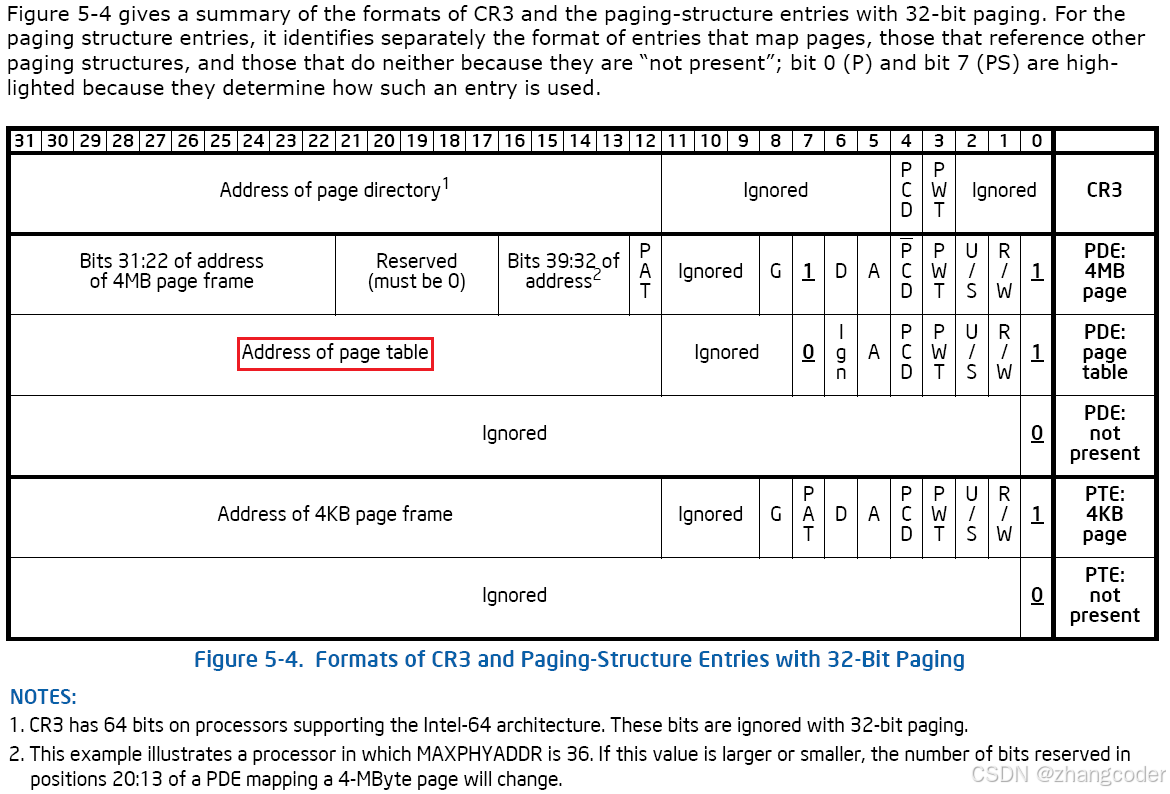
(摘自《Intel® 64 and IA-32 Architectures Software Developer's Manual, Volume 3A: System Programming Guide, Part 1》的第119页)
如何确认物理内存的读写权限
虽然物理内存本身可读可写,但是物理内存的读写权限由页表规定,在Intel开发手册中是有描述的
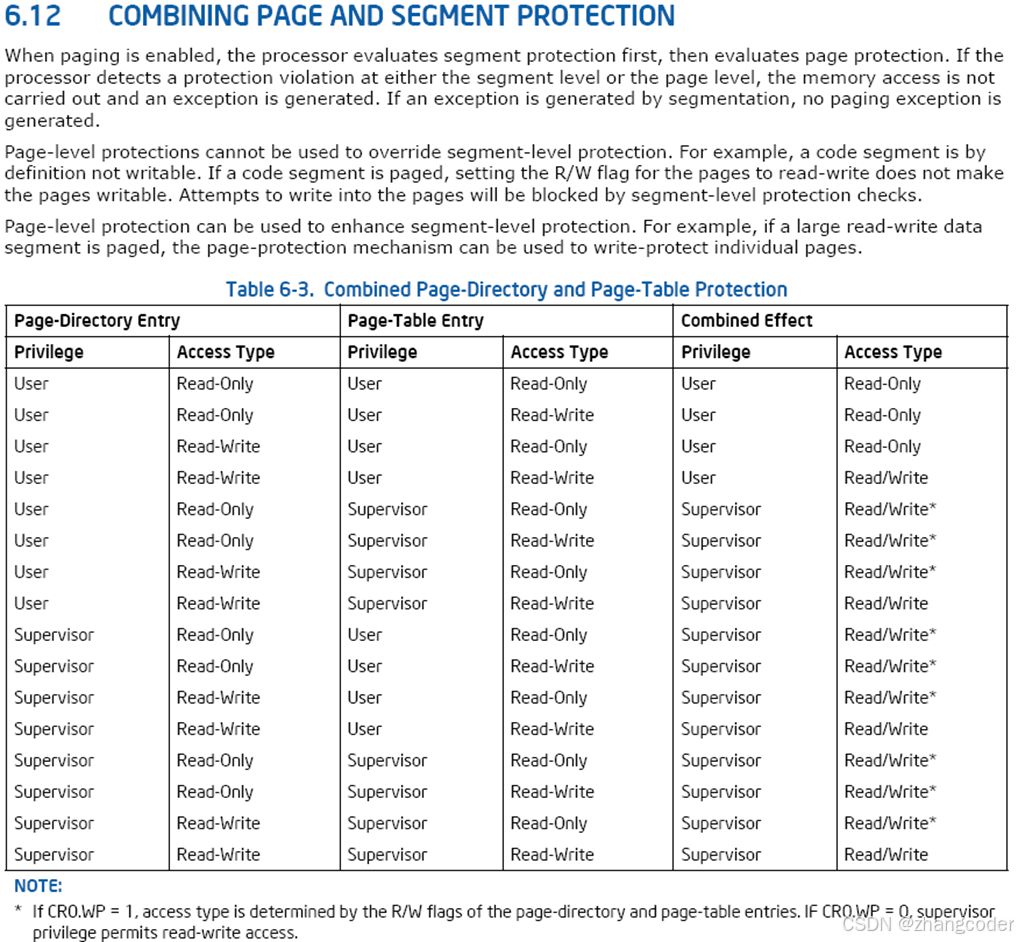
添加读写权限的简化版的页表的构成:

注:缺页中断的简单理解在本文的最后
实验: Linux系统下验证页表的读写权限
例如以下代码:
#include <stdio.h>
int main()
{
char* str = "Hello World!";
*str = 'A';
return 0;
}运行结果:修改常量字符串会报段错误
![]()
修改代码,查看字符串地址在页表中的位置:
#include <stdio.h>
#include <unistd.h>
int main()
{
char* str = "Hello World!";
printf("PID=%d\n",getpid());
printf("字符串的地址: %p\n",str);
getchar();//防止进程退出
return 0;
}gcc带m32选项生成32位可执行文件后运行,去该进程的/proc/[pid]/maps文件查看权限,反映了页表中该虚拟内存区域的访问权限
可以看到访问权限是r--p,p表示私有映射,进程对它的写操作不会直接修改原文件, 需要写时拷贝单独复制一份内存页
编译器将字符串放到只读数据段
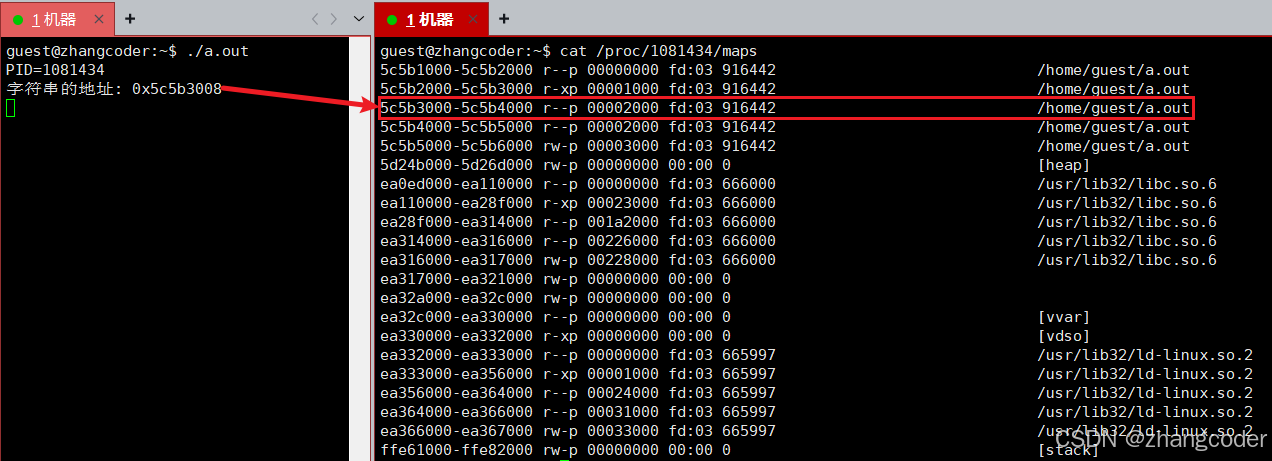
如果读者仔细看的话,可以看到字符串所处的页是从0x5c5b3000-0x5c5b4000的,正好是4KB的页大小!
![]()
进程地址空间的本质
进程地址空间指的是地址总线排列组合形成地址范围,32位下这个范围是,即0x000000000~0xFFFFFFFF,这个范围是极端范围,最大为4GB的虚拟空间
连续的空间中,每一个最小单位(memory cell)都可以有地址,例如下图的0x7b的虚拟地址是0x00AFF985

进程地址空间是空间上的区域划分,描述进程的可视范围大小,因此地址空间本质是内核的一个数据结构对象,如下图32位的区域划分为:
区域划分可以使用结构体,定义起始和结束,那么空间区域的调整(变大或变小)指的是修改空间区域的范围,可以修改边界值
例如原空间区域的范围是[a,b],经过调整,空间区域的范围变成[x,y]
附64位的进程地址空间
图来自Oracle公司的docs.oracle.com/cd/E19253-01/816-5138/fcowb/index.html的Address Space Layout for amd64 Applications图
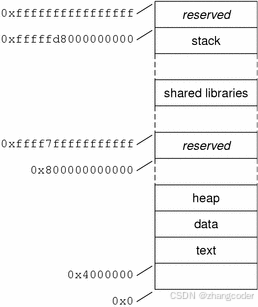
栈从地址空间的顶部向下增长,而堆则从底部向上扩展数据段
注意: 上图中的reserved区域,详见李忠老师的《x86汇编语言:编写64位多处理器多线程操作系统》书的第2章 x64架构的基本执行环境 2.7.2 扩高(Canonical)地址
管理进程地址空间
地址空间本质是内核的一个数据结构对象,类似PCB,地址空间也是要被操作系统管理: 先描述,再组织,
可以用结构体描述进程地址空间,每个进程的PCB中会有一个指针指向进程地址空间的结构体,例如:
struct Process_Address_Space
{
//......
char* code_area_start;
char* code_area_end;
char* data_area_start;
char* data_area_end;
char* stack_area_start;
char* stack_area_end;
char* heap_area_start;
char* heap_area_end;
//.......
};在Linux下,task_struct存储着进程地址空间的结构体mm_struct的指针:
struct task_struct
{
//......
#ifdef CONFIG_SMP
struct plist_node pushable_tasks;
struct rb_node pushable_dl_tasks;
#endif
struct mm_struct *mm;
struct mm_struct *active_mm;
struct address_space *faults_disabled_mapping;
int exit_state;
int exit_code;
int exit_signal;
//......
} __attribute__ ((aligned (64)));(task_struct的完整源码参见OS17.【Linux】进程基础知识(1)文章结尾,这里只截取了一部分)
mm_struct定义在Linux内核源代码的include/linux/mm_types.h中,这里全部给出来,方便查阅:
struct mm_struct {
struct {
/*
* Fields which are often written to are placed in a separate
* cache line.
*/
struct {
/**
* @mm_count: The number of references to &struct
* mm_struct (@mm_users count as 1).
*
* Use mmgrab()/mmdrop() to modify. When this drops to
* 0, the &struct mm_struct is freed.
*/
atomic_t mm_count;
} ____cacheline_aligned_in_smp;
struct maple_tree mm_mt;
unsigned long mmap_base; /* base of mmap area */
unsigned long mmap_legacy_base; /* base of mmap area in bottom-up allocations */
#ifdef CONFIG_HAVE_ARCH_COMPAT_MMAP_BASES
/* Base addresses for compatible mmap() */
unsigned long mmap_compat_base;
unsigned long mmap_compat_legacy_base;
#endif
unsigned long task_size; /* size of task vm space */
pgd_t * pgd;
#ifdef CONFIG_MEMBARRIER
/**
* @membarrier_state: Flags controlling membarrier behavior.
*
* This field is close to @pgd to hopefully fit in the same
* cache-line, which needs to be touched by switch_mm().
*/
atomic_t membarrier_state;
#endif
/**
* @mm_users: The number of users including userspace.
*
* Use mmget()/mmget_not_zero()/mmput() to modify. When this
* drops to 0 (i.e. when the task exits and there are no other
* temporary reference holders), we also release a reference on
* @mm_count (which may then free the &struct mm_struct if
* @mm_count also drops to 0).
*/
atomic_t mm_users;
#ifdef CONFIG_SCHED_MM_CID
/**
* @pcpu_cid: Per-cpu current cid.
*
* Keep track of the currently allocated mm_cid for each cpu.
* The per-cpu mm_cid values are serialized by their respective
* runqueue locks.
*/
struct mm_cid __percpu *pcpu_cid;
/*
* @mm_cid_next_scan: Next mm_cid scan (in jiffies).
*
* When the next mm_cid scan is due (in jiffies).
*/
unsigned long mm_cid_next_scan;
/**
* @nr_cpus_allowed: Number of CPUs allowed for mm.
*
* Number of CPUs allowed in the union of all mm's
* threads allowed CPUs.
*/
unsigned int nr_cpus_allowed;
/**
* @max_nr_cid: Maximum number of allowed concurrency
* IDs allocated.
*
* Track the highest number of allowed concurrency IDs
* allocated for the mm.
*/
atomic_t max_nr_cid;
/**
* @cpus_allowed_lock: Lock protecting mm cpus_allowed.
*
* Provide mutual exclusion for mm cpus_allowed and
* mm nr_cpus_allowed updates.
*/
raw_spinlock_t cpus_allowed_lock;
#endif
#ifdef CONFIG_MMU
atomic_long_t pgtables_bytes; /* size of all page tables */
#endif
int map_count; /* number of VMAs */
spinlock_t page_table_lock; /* Protects page tables and some
* counters
*/
/*
* With some kernel config, the current mmap_lock's offset
* inside 'mm_struct' is at 0x120, which is very optimal, as
* its two hot fields 'count' and 'owner' sit in 2 different
* cachelines, and when mmap_lock is highly contended, both
* of the 2 fields will be accessed frequently, current layout
* will help to reduce cache bouncing.
*
* So please be careful with adding new fields before
* mmap_lock, which can easily push the 2 fields into one
* cacheline.
*/
struct rw_semaphore mmap_lock;
struct list_head mmlist; /* List of maybe swapped mm's. These
* are globally strung together off
* init_mm.mmlist, and are protected
* by mmlist_lock
*/
#ifdef CONFIG_PER_VMA_LOCK
struct rcuwait vma_writer_wait;
/*
* This field has lock-like semantics, meaning it is sometimes
* accessed with ACQUIRE/RELEASE semantics.
* Roughly speaking, incrementing the sequence number is
* equivalent to releasing locks on VMAs; reading the sequence
* number can be part of taking a read lock on a VMA.
* Incremented every time mmap_lock is write-locked/unlocked.
* Initialized to 0, therefore odd values indicate mmap_lock
* is write-locked and even values that it's released.
*
* Can be modified under write mmap_lock using RELEASE
* semantics.
* Can be read with no other protection when holding write
* mmap_lock.
* Can be read with ACQUIRE semantics if not holding write
* mmap_lock.
*/
seqcount_t mm_lock_seq;
#endif
#ifdef CONFIG_FUTEX_PRIVATE_HASH
struct mutex futex_hash_lock;
struct futex_private_hash __rcu *futex_phash;
struct futex_private_hash *futex_phash_new;
/* futex-ref */
unsigned long futex_batches;
struct rcu_head futex_rcu;
atomic_long_t futex_atomic;
unsigned int __percpu *futex_ref;
#endif
unsigned long hiwater_rss; /* High-watermark of RSS usage */
unsigned long hiwater_vm; /* High-water virtual memory usage */
unsigned long total_vm; /* Total pages mapped */
unsigned long locked_vm; /* Pages that have PG_mlocked set */
atomic64_t pinned_vm; /* Refcount permanently increased */
unsigned long data_vm; /* VM_WRITE & ~VM_SHARED & ~VM_STACK */
unsigned long exec_vm; /* VM_EXEC & ~VM_WRITE & ~VM_STACK */
unsigned long stack_vm; /* VM_STACK */
vm_flags_t def_flags;
/**
* @write_protect_seq: Locked when any thread is write
* protecting pages mapped by this mm to enforce a later COW,
* for instance during page table copying for fork().
*/
seqcount_t write_protect_seq;
spinlock_t arg_lock; /* protect the below fields */
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv */
struct percpu_counter rss_stat[NR_MM_COUNTERS];
struct linux_binfmt *binfmt;
/* Architecture-specific MM context */
mm_context_t context;
unsigned long flags; /* Must use atomic bitops to access */
#ifdef CONFIG_AIO
spinlock_t ioctx_lock;
struct kioctx_table __rcu *ioctx_table;
#endif
#ifdef CONFIG_MEMCG
/*
* "owner" points to a task that is regarded as the canonical
* user/owner of this mm. All of the following must be true in
* order for it to be changed:
*
* current == mm->owner
* current->mm != mm
* new_owner->mm == mm
* new_owner->alloc_lock is held
*/
struct task_struct __rcu *owner;
#endif
struct user_namespace *user_ns;
/* store ref to file /proc/<pid>/exe symlink points to */
struct file __rcu *exe_file;
#ifdef CONFIG_MMU_NOTIFIER
struct mmu_notifier_subscriptions *notifier_subscriptions;
#endif
#if defined(CONFIG_TRANSPARENT_HUGEPAGE) && !defined(CONFIG_SPLIT_PMD_PTLOCKS)
pgtable_t pmd_huge_pte; /* protected by page_table_lock */
#endif
#ifdef CONFIG_NUMA_BALANCING
/*
* numa_next_scan is the next time that PTEs will be remapped
* PROT_NONE to trigger NUMA hinting faults; such faults gather
* statistics and migrate pages to new nodes if necessary.
*/
unsigned long numa_next_scan;
/* Restart point for scanning and remapping PTEs. */
unsigned long numa_scan_offset;
/* numa_scan_seq prevents two threads remapping PTEs. */
int numa_scan_seq;
#endif
/*
* An operation with batched TLB flushing is going on. Anything
* that can move process memory needs to flush the TLB when
* moving a PROT_NONE mapped page.
*/
atomic_t tlb_flush_pending;
#ifdef CONFIG_ARCH_WANT_BATCHED_UNMAP_TLB_FLUSH
/* See flush_tlb_batched_pending() */
atomic_t tlb_flush_batched;
#endif
struct uprobes_state uprobes_state;
#ifdef CONFIG_PREEMPT_RT
struct rcu_head delayed_drop;
#endif
#ifdef CONFIG_HUGETLB_PAGE
atomic_long_t hugetlb_usage;
#endif
struct work_struct async_put_work;
#ifdef CONFIG_IOMMU_MM_DATA
struct iommu_mm_data *iommu_mm;
#endif
#ifdef CONFIG_KSM
/*
* Represent how many pages of this process are involved in KSM
* merging (not including ksm_zero_pages).
*/
unsigned long ksm_merging_pages;
/*
* Represent how many pages are checked for ksm merging
* including merged and not merged.
*/
unsigned long ksm_rmap_items;
/*
* Represent how many empty pages are merged with kernel zero
* pages when enabling KSM use_zero_pages.
*/
atomic_long_t ksm_zero_pages;
#endif /* CONFIG_KSM */
#ifdef CONFIG_LRU_GEN_WALKS_MMU
struct {
/* this mm_struct is on lru_gen_mm_list */
struct list_head list;
/*
* Set when switching to this mm_struct, as a hint of
* whether it has been used since the last time per-node
* page table walkers cleared the corresponding bits.
*/
unsigned long bitmap;
#ifdef CONFIG_MEMCG
/* points to the memcg of "owner" above */
struct mem_cgroup *memcg;
#endif
} lru_gen;
#endif /* CONFIG_LRU_GEN_WALKS_MMU */
#ifdef CONFIG_MM_ID
mm_id_t mm_id;
#endif /* CONFIG_MM_ID */
} __randomize_layout;
/*
* The mm_cpumask needs to be at the end of mm_struct, because it
* is dynamically sized based on nr_cpu_ids.
*/
unsigned long cpu_bitmap[];
};会发现里面定义了各个段的起始和结束位置:
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;进程地址空间存在的意义
意义:能让进程以统一的视角看待内存,方便操作系统管理进程,可以设想如果程序直接访问物理内存,那么会越界,影响其他进程
在早期的MS-DOS系统下,进程能任意访问物理内存,这其实是不安全的,可以看看《x86汇编语言:从实模式到保护模式 第二版》的描述:
一般来说,操作系统负责整个计算机软、硬件的管理,它做任何事情都是可以的。但是,用户程序却应当有所限制,只允许它访问属于自己的数据,即使是转移,也只允许在自己的各个代码段之间进行。
问题在于,在实模式下,用户程序对内存的访问非常自由,没有任何限制,随随便便就可以修改任何一个内存单元。比如以下代码片段,这个程序首先将段地址设置到0xb800,传统上,这是文本模式下的显存。所以,它通过指令向显存写入一个字符H。然后,它又将段地址切换到0x8000,向这个段内偏移地址为6 的地方写入一字节0xc7。紧接着,又将段地址切换到0,向段内偏移地址为0x30 的地方写入一字节0。事实上我们知道,段地址为0 的这1KB 内存是中断向量表,它这样做实际上是破坏了中断向量表的内容,但是它这样做是不受限制的,没有人可以阻止。最后,它又向端口0x60 发送一字节的数据,用来控制设备。mov ax, 0xb800 mov ds, ax mov byte [0xb0], 'H' mov ax, 0x8000 mov ds, ax mov byte [0x06], 0xc7 mov ax, 0 mov ds, ax mov byte [0x30], 0 mov al, 0 out 0x60, al通过这一段程序可以看出,在实模式下,程序是可以“为所欲为”的。它想访问内存的哪
一部分,都可以很轻松地通过设置段地址和偏移地址来办到。
很显然,即使某个内存位置不属于当前程序,它照样可以切换到那里,并随意修改其中的内容。最恐怖的是,如果那个地方是操作系统或其他用户程序的“地盘”,那将带来不可预料
的后果。通过这个例子,你就知道为什么很多人能通过修改内存中的数据来提升游戏人物的法力和生命值,并获得各种道具。
在多用户、多任务时代,内存中会有多个用户(应用)程序在同时运行。为了使它们彼此隔离,防止因某个程序的编写错误或者崩溃而影响到操作系统和其他用户程序,使用保护模式是非常有必要的。
结论:1.增加进程地址空间可以让进程访问内存的时,增加一个转换的过程,在这个转化的过程中,可以对进程的寻址请求进行审查,一旦异常访问,操作系统会直接拦截,该请求不会到达物理内存,保护物理内存 2.有地址空间和页表的存在,进程管理模块和内存管理模块可以解耦合
★进程地址空间不等于内存
理解操作系统为进程"画大饼"这个说法:
1.32位下,每个进程都认为自己有4GB的内存空间,但实际上这是操作系统为进程画的大饼,实际上4GB的内存空间是虚拟的
2.4GB的内存空间,实际上每个进程用不了这么多
3.证明4GB的内存空间是虚拟的
有些计算机的内存条的大小是4GB的,但依然能够运行32位甚至是64位的操作系统
例如博主的物理机子上的内存条的大小只有4GB,但依然能运行大量进程,显然每个进程都分到实打实的4GB内存空间是不现实的
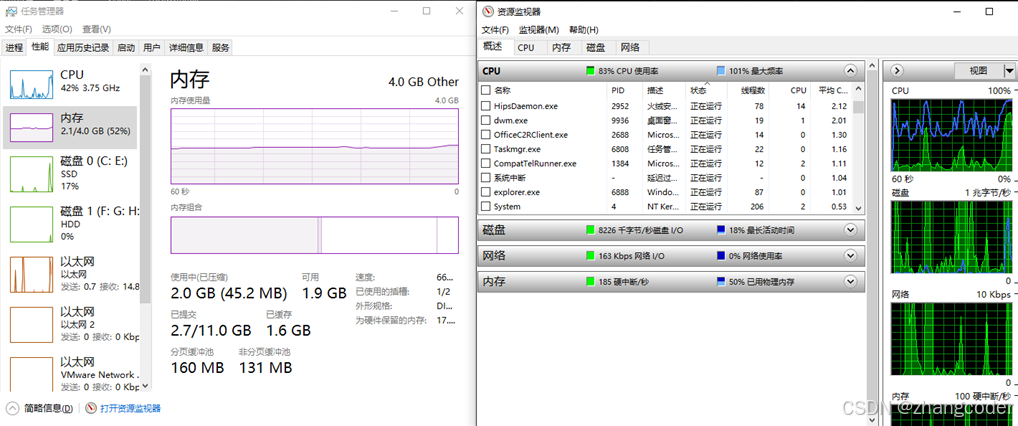
因此进程地址空间是内存分布情况,是虚拟内存空间,不是真正的内存
得出结论
用户程序申请内存时,系统首先会分配虚拟内存给用户,由于物理内存十分宝贵,那么只有用户需要真正使用内存时才会分配物理内存,也就是说虚拟内存映射至物理内存有一定的滞后性,这其实是操作系统的懒加载(惰性加载)机制
5.操作系统的懒加载(惰性加载)机制
操作系统是如何加载少则几百MB多则十几GB的可执行程序呢?
内存条的空间不够,操作系统会考虑让大型程序分段加载(即懒加载、惰性加载)
操作系统承诺每个进程有4GB的空间,但是操作系统实际在运行进程时不会加载那么多,这样节省空间
缺页中断的简单理解
操作系统为了节省空间,某些情况下,虽然操作系统会给了虚拟地址,但是不会立刻分配物理内存
只有当进程访问,操作系统查页表的时,看页表存在标志位后发现虚拟地址到物理地址的映射关系不存在,然后触发缺页中断,此时才会把数据加载到内存,即懒加载机制: 边使用边加载
→写时拷贝也是缺页中断导致的
malloc 和mmap 函数在内存分配时只是建立了进程的虚拟地址,并没有分配虚拟地址对应的物理内存,当进程访问这些没有建立映射关系的虚拟内存时,处理器自动触发一个缺页异常,引发缺页中断,此时操作系统会根据页表中的外存地址在外存中找到所缺的一页,将其调入内存
6.进程=内核数据结构+代码段和数据段
对OS17.【Linux】进程基础知识(1)文章讲过的进程的组成公式进行更新:
进程=内核数据结构(task_struct、mm_struct和页表)+代码段和数据段
那么进程切换只需要切换上下文就自动切换了内核数据结构(PCB、mm_struct和页表)
7.再次理解进程的独立性
1.进程的独立性指的是每个进程都有独立的内核数据结构
2.让页表映射到不同的物理地址,进程之间相互不干扰

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 31
31 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)