Linux开发专属工具
1.1什么是软件包软件包(Software Package)是将已编译的程序、依赖库、配置文件、文档、资源文件等,按标准化格式打包而成的单一分发单元,是现代操作系统与开发环境中软件交付、安装、管理的基本单位。我们简化一下:它相当于 “预组装好的软件成品”,用户无需手动编译源码、处理依赖,直接安装即可使用。软件包的核心构成,类型,格式,怎么打包就不一一介绍了,有兴趣可以查查。1.2Linux软件生态
目录
一.软件包管理器的介绍和使用
1.软件包和软件包管理器介绍(了解)
1.1什么是软件包
软件包(Software Package)是将已编译的程序、依赖库、配置文件、文档、资源文件等,按标准化格式打包而成的单一分发单元,是现代操作系统与开发环境中软件交付、安装、管理的基本单位。
我们简化一下:它相当于 “预组装好的软件成品”,用户无需手动编译源码、处理依赖,直接安装即可使用。
软件包的核心构成,类型,格式,怎么打包就不一一介绍了,有兴趣可以查查。
1.2Linux软件生态(了解)
我们肯定要询问:我们下载的软件来源于哪里?为什么会形成这个来源(利益动机是什么)?我们需要翻墙去搜寻这个软件生态吗?
问题一:
所有 Linux 软件,统一来自 官方软件仓库(软件源)。
这个到底是什么?Linux操作系统生态的一部分
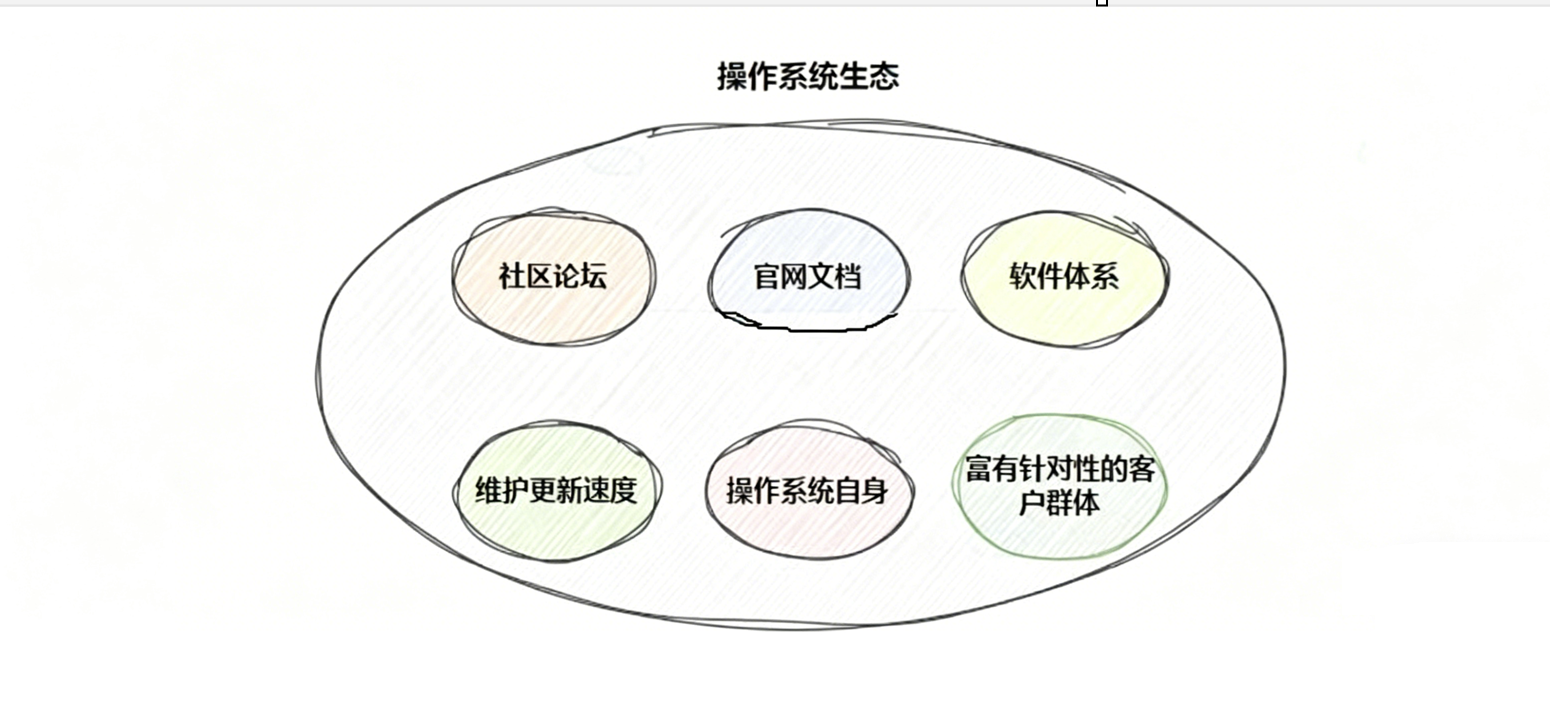
简单了解一下Linux生态:Linux 生态 = 系统本体 + 官方软件仓库
相当于window上的应用商店,是系统官方 / 官方授权搭建的远程集中服务器,统一存放、管理、分发全部合规软件包的
问题二:
从不同角度分析:
1.用户角度:
不用百度乱找安装包、不用拷贝别人文件、不用手动编译。输一条命令,直接从仓库下载、自动装依赖。既方便又便宜,软件还先进。2. 开发者角度:
软件写好后,直接上传到官方仓库,所有人都能下载,不用自己到处发安装包。有渠道大幅度提高自身知名度。
3. 系统角度:
统一管控,软件安全无病毒,版本统一,系统不容易崩。安全
4.社区维护者角度:
不仅可以低成本掌握大量工程师资源,还可以接受大量依赖公司的赞助。
问题三:
我们知道Linux操作系统生态是在外网,如果我们需要搜寻软件源来安装,是不是需要翻越到外网。这个可能会有点违法并且麻烦。所以解决办法是镜像——拷贝国外的软件源并且修改下载链接就可以了。
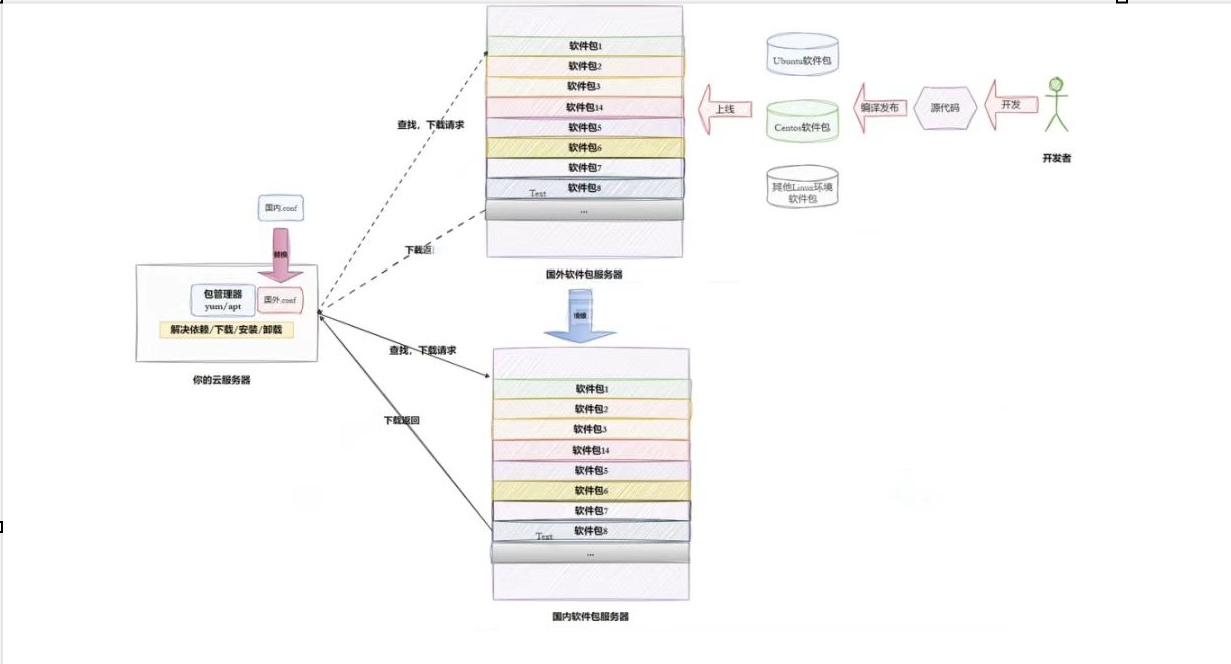
1.3什么是软件包管理器
顾名思义,软件包管理器就是专门对软件包进行管理的工具。我们现在有几个问题。
问题一,为什么我们需要创造专门的管理器对软件包进行管理呢?
我们先看软件的构成:
软件由几个软件包构成分别为:
主程序 → 单独一个包
依赖库、公共组件 → 拆分成独立小包
配置文件、帮助文档、资源文件 → 各自分包
再对比一下软件的下载操作:
1.源码安装:
直接拷贝别人的代码,再自己编译,链接成可执行程序。评价就是太麻烦,而且还有丢失的风险,依赖无法自动处理(缺了什么库还得自己慢慢安装),会非常难受。
2.手动软件包安装
把别人编译好的软件安装包拿过来安装,但是安装包有几十几百。。。。评价就是文件零散存放,没有统一登记管理,极易丢失、损坏,同时无法自动处理依赖问题。
3.软件包管理器安装
只要一键下载安装、统一管理、自动补全依赖。完全不用自己操心。
问题二:内部构成是什么?(核心(现在不重要))
1.软件源解析模块
对接远程仓库,获取所有软件包索引、列表。
2.依赖解析模块
计算软件包之间依赖、冲突关系,自动补齐所需包。
3.安装部署模块
解压软件包,将程序、库、配置文件安装到系统对应目录。
4.本地数据库
记录已安装软件包、版本、文件位置,用于管理和卸载。
5.安全校验模块
校验安装包完整性、签名,防止篡改、病毒。
问题三:主要有什么操作?
1.安装:下载软件包,自动安装 + 补全依赖
下载之前先联网(链接软件源(国内的镜像))
sudo apt install 软件名
2.卸载:删除软件,可保留或清除配置
sudo apt purge 软件名
3.更新:同步软件源索引、升级软件版本
sudo apt update
4.查询:搜索软件、查看已安装包、依赖信息
apt show 软件名
5.清理:删除缓存、无用依赖包,释放空间
sudo apt autoremove
总结:软件包管理器可以成体系完整地管理软件包。
二.文件编辑器——vim
1.概念
Vim = Linux 系统里最常用的命令行文本编辑器
作用:
写代码
修改配置文件
查看、编辑文本
2.vim的模式介绍并且使用
为什么vim的使用要模式来实现?
因为Vim 是命令行编辑器
它运行在 终端(黑窗口) 里
没有封装好的图形界面
所有操作全靠键盘 + 命令(来完成输入和其它相关的操作)
vim的模式非常多,而每个模式的功能都不同首先我们先介绍vim的最核心,最常使用的三大模式,然后介绍一些其它可能有用的模式。
(1)命令模式
vim进去就是
![]()
1.1光标移动
vim可以直接用键盘上的光标来上下左右移动
“h”、“j"、"k"、''l'',分别控制光标左、下、上、右移⼀格
gg:光标快速定位到起始位置。
shift + g:光标切换到结尾位置。
n + shift + g:黄标定位到第 n 行。
shift + 4:光标定位到当前行的最右边。
shift + 6:光标定位到当前行的最左边。
w:光标自动向右跳过一个字符串。
b:光标自动向左跳过一个字符串。
1.2文本快速编辑(删除,复制,替换)
yy:复制光标所在行。
p:粘贴到下一行。
u:撤销历史命令。
Ctrl + r:撤销 u 操作。\n\ndd:剪切当前行,可充当删除作用。
x:删除光标所在位置元素。\n\nshift + x:删除光标左侧的元素。
r + 字符:将光标所在位置的字符替换为你输入的字符。
n + r + 字符:将光标所在位置后面的n 个字符全部替换为你输入的字符(限当前行)。
注意:
1.以上指令中 p ,dd,x ,shift + x命令前面加上 n(表示数字)。即可批量化操作。
2.x 和shift + x 删除的元素可以通过 p 粘贴回来。
1.3切换模式
1.“ i ”:自动切换到插入模式:可以直接文本编辑
2.“shift+:”:切换到底行模式:所有保存、退出、设置、查找、替换、操作文件都在这。后面详细介绍。
3."ctrl + v":切换到视图模式:区域选择
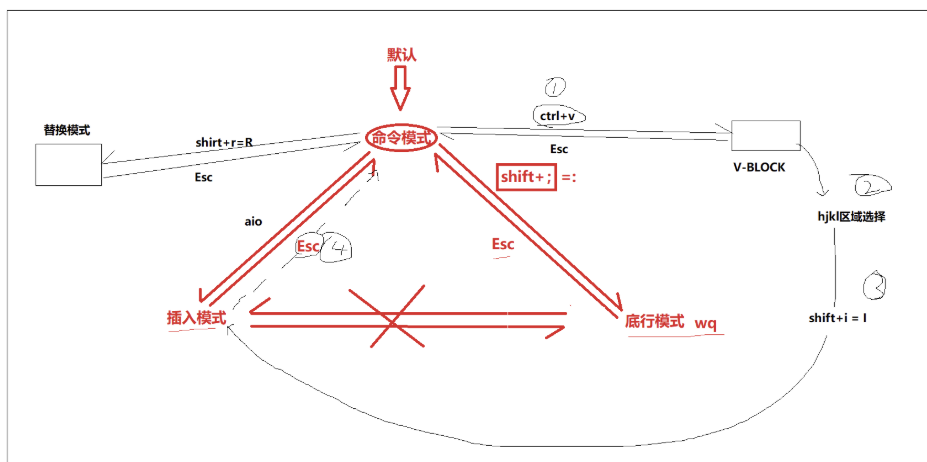
(2)底行模式
2.1.保存/退出
:w 只保存,不退出
:q 正常退出(没修改才能退)
:wq 保存并退出
:q! 不保存,强制退出
:wq! 强制保存并退出
2.2.配置设置(临时生效)
后面有永久配置
比如
:set number 显示行号
:set nonumber 关闭行号
:set hlsearch 搜索高亮
2.3.查找替换
/ + 关键词 向下搜索关键词
? + 关键词 向上搜索关键词
2.4.跳转行
:10 跳到第10行
:$ 跳到最后一行
2.5.新建 / 读取文件
2.5.1.此文件内部内容操作
同一块缓冲区
:new 新建窗口
还有更多操作,就不展开了
2.5.2.对其它文件
在原文件上,对不同的多个文件操作
:e 文件名 打开另一个文件
也不展开了
3.vim配置
3.1是什么
是一个隐藏文本文件,里面写一堆设置命令(set命令)
注意:
.vimrc 是用户级别的自定义配置文件,它的作用是保存你对 Vim 的个性化设置。
Linux 系统默认安装的 Vim,只会提供一套通用的默认配置(比如在 /etc/vim/vimrc 里),而不会为每个用户自动创建一个 .vimrc需要就自己创建一个
文件名:.vimrc
位置:家目录下 ~/.vimrc
功能:
每次启动 Vim,自动读取这个文件,帮你把设置全部开好
3.2设置方式
Vim 有两种设置:
临时设置:底行模式输
:set number,只当前窗口有效,关掉就没了配置文件
.vimrc:写进去永久生效,每次打开都有
3.3常规设置
syntax enable语法高亮(代码变彩色)
set number显示行号
set autoindent自动缩进(回车自动对齐)
set tabstop=4按一下 Tab = 4 个空格
set shiftwidth=4缩进宽度 4
set expandtab把 Tab 换成空格
set hlsearch搜索内容高亮
set encoding=utf-8编码 UTF-8(不乱码)
文本里写好之后直接:shift+:wq保存退出就行。
三.自动化构建——Makefile
1.Makefile是什么
首先回顾一下程序编译过程
gcc 把 .c 变成可执行文件,一共分 4 个步骤
源代码 .c
↓ 1. 预处理
预处理文件 .i
↓ 2. 编译
汇编文件 .s
↓ 3. 汇编
目标文件 .o
↓ 4. 链接
可执行文件.exe
操作演示:
1.源码
![]()
2.预处理

3.编译

4.汇编

5.链接
![]()
然后就可以运行了。
补充一个知识:gcc是动态库的代码
我们看到了从原代码编译到可执行代码的步骤是非常麻烦的,那有没有可以一键生成的方式呢?
有的,包有的,就是Makefile
我们来正式介绍一下:
Makefile 是一个定义编译规则的脚本文件,
通过记录文件依赖关系和编译命令,
使用 make 工具自动完成程序的编译、链接、清理等构建工作,
实现项目的自动化构建。
简单来说就是:Makefile里写好命令过程,make命令一键生成可执行文件
2.怎么构建Makefile
2.1.简单创建一个
先写一个源代码文件file4.c
再写Makefile的自动执行的指令
1 file4:file4.c #依赖关系
2 gcc -o file4 file4.c #依赖方法!!!
3 PHONY:clean
4 clean: #依赖关系
5 rm -f file4 #依赖方法
注意:前面的不是普通空格,而是Tab键
编译:make

运行:

清理:

2.2解释Makefile
依赖关系和依赖方法是什么东西
我们通过观察可以发现依赖关系的依赖文件是我们写指令中需要使用的文件
比如:file4.c
依赖方法就是我们完成这个指令需要使用的命令
而file4就是我们需要生成的目标文件
所以格式就是
目标 : 依赖1 依赖2 ...
方法(必须 TAB 开头)十分重要!!!!!!
那么clean是什么?
我们没有看到任何生成相应的文件
下面会解释
2.3总被执行和三时间
我们尝试make两次
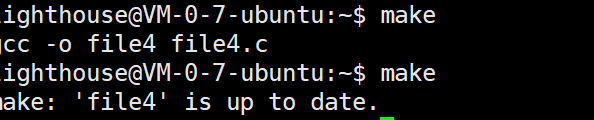
结果是并不可以,会有提示这个目标文件已经是最新的。
这个是根据文件的三个时间属性的Modify

我们执行两次clean

居然可以反复删除
因为clean是伪目标(普通目标会生成目标文件,而clean只会执行命令,只是一个命令集,并不会生成目标文件),所以clean可以反复执行。
那么PHONY是什么?
我们先来简单解释make命令的工作逻辑
是什么:
make是自动执行器,执行依赖方法,生成目标文件
工作逻辑:(习惯偷懒)
检查依赖关系:对比目标文件(比如 file4)和依赖文件(比如 file4.c)的修改时间。
按需执行命令:如果依赖文件比目标文件新(说明代码改了),就重新执行编译命令;如果没改,就直接提示 is up to date,不做重复工作。
make使用格式:make+目标文件名
注意:不加目标文件名就是默认执行第一个
如果当前目录下有一个同名的clean不就完蛋了
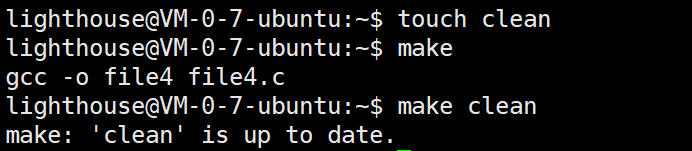
所以为了避免这种情况就有了PHONY一直提醒make:clean是个伪目标,一定要执行。
3.多文件编译
先介绍几个新东西
3.1变量
#定义变量
BIN=file4
SRC=file4.c
CC=gcc
RM=rm -f
FLAGS=-o
$(BIN):$(SRC)
$(CC) $(SRC) $(FLAGS) $(BIN)
PHONY:clean
clean:
$(RM) $(BIN)使用变量给文件,指令等等来代替
使用变量时需要加一个$
3.2 @和^
偷懒用的
$@:冒号 左边 的名字 代表目标文件
$^:冒号 右边 代表所有依赖文件
#定义变量
BIN=file4
SRC=file4.c
CC=gcc
RM=rm -f
FLAGS=-o
$(BIN):$(SRC)
$(CC) $(FLAGS) $@ $^ #$@:BIN——file4,$^:SRC——file.c
PHONY:clean
clean:
$(RM) $(BIN)3.3 @
如果不想要make时将使用的命令打印到屏幕就可以在前面加一个@
3.4多文件编译
多文件编译逻辑:
先把每个 .c 编译成 .o 目标文件
再把所有 .o 链接成最终可执行文件
方式1:每个文件都手搓
# 最终可执行文件
main: main.o fun.o
gcc main.o fun.o -o main #需要main.o,往下寻找
# 逐个编译成 .o
main.o: main.c fun.h
gcc -c main.c -o main.o #需要 .c ,往下寻找
fun.o: fun.c fun.h
gcc -c fun.c -o fun.o #完成,往上返回
# 伪目标清理
.PHONY: clean
clean:
rm -f main *.o将最终想要的指令放在首位,按需求的文件往下写(会自己找)
方式2:
借助我们刚刚提到的新东西
1 BIN=file4
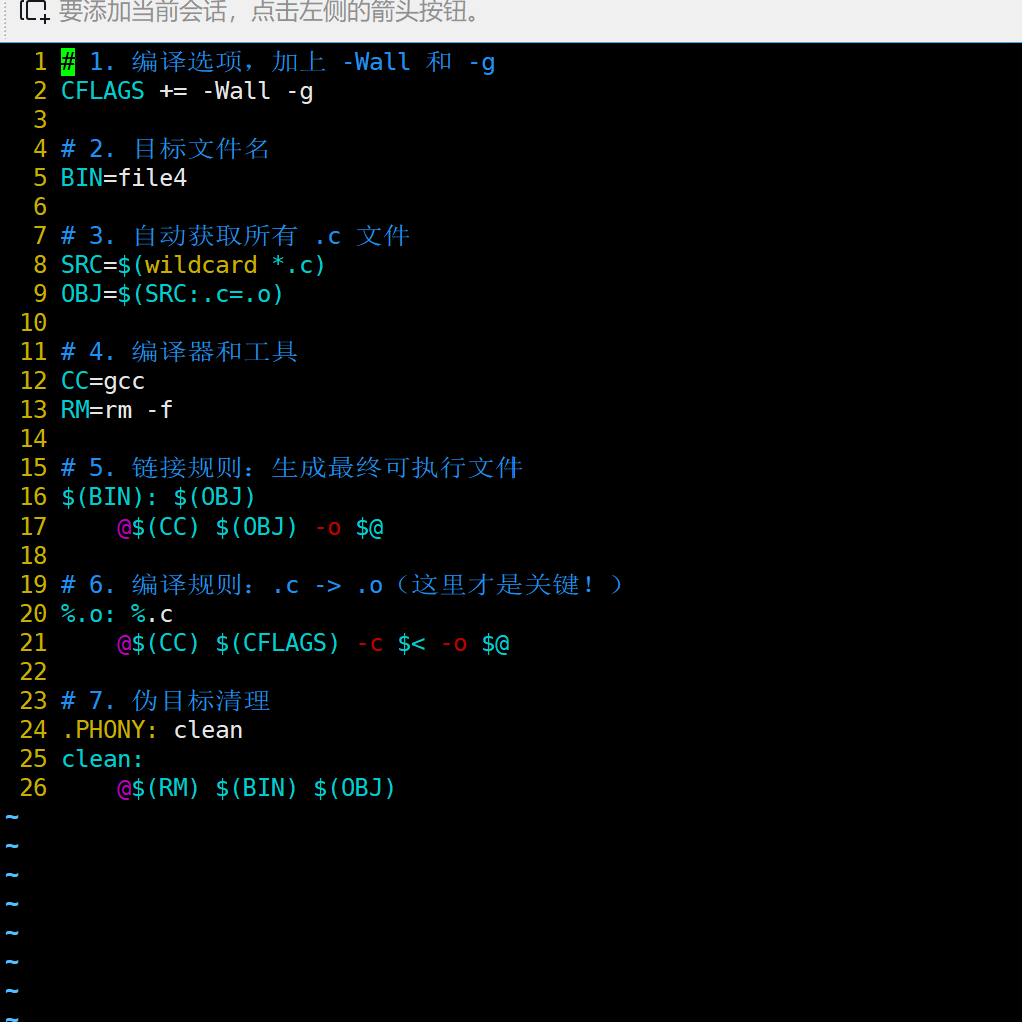
2 SRC=$(wildcard *.c)
3 OBJ=$(SRC:.c=.o)
4 CC=gcc
5 LFLAGS=-o
6 FLAGS=-c
7 RM=rm -f
8
9 $(BIN):$(OBJ)
10 @$(CC) $(LFLAGS) $@ $^ #$@:BIN,$^:OBJ
11
12 %.o:%.c
13 @$(CC) $(FLAGS) $<
14
15 PHONY:clean
16 clean:
17 @$(RM) $(BIN) $(OBJ)
%.o:%.c:展开当前路径的所有.o与.c文件
$<:代指源文件
4.实现项目——进度条
4.1设计想法:
我们可以将一串字符串不断就行反复覆盖来实现视觉中的进度条的增长
功能支持:回车操作——支持从头开始覆盖
功能暂时到这里,我们先来个数字刷新的程序来试试水
1 #include<stdio.h>
2 #include<unistd.h>
3 int main()
4 {
5 int a=0;
6 for(a=0;a<=10;a++)
7 {
8 printf("%-2d\r",a);#记得要左对齐,否则就默认右对齐,这样覆盖会有问题
9 sleep(1);
10 }
11 printf("\n");
12 return 0;
13 }
结果:没有数字覆盖刷新,只有最后10出现

所以问题是怎么使数字刷新出来
这时就要用到fflush刷新缓冲区来达到目的。

功能准备完毕。
4.2进度条
功能内容:1.字符串不断打印覆盖,实现动态增长
2.数字显示进度
3.光标旋转
代码:
1 #include"process.h"
2 #define N 101 #进度条长度,有一个作为\0
3 #define H '#' #作为进度条符号
4
5 void process()
6 {
7 char buffer[N];#进度条字符串
8 memset(buffer,0,sizeof(buffer));#初始化为0
9
10 char label[]={"-/|\\"};#光标字符串
11 int labelLen=strlen(label);
12
13 int count=0;#进度数字
14 while(count<N)
15 {
16
17 printf("%-100s[%d%%]%c\r",buffer,count,label[count % labelLen]);#打印进度条
18 fflush(stdout);#及时刷新
19 buffer[count]=H;#增长
20 count++;
21 usleep(100000);#100微秒
22
23
24 }
25 printf("\n");#刷新最后一个进度条并换行
26
27 }
效果:
![]()
![]()
4.3进阶版——与下载操作绑定
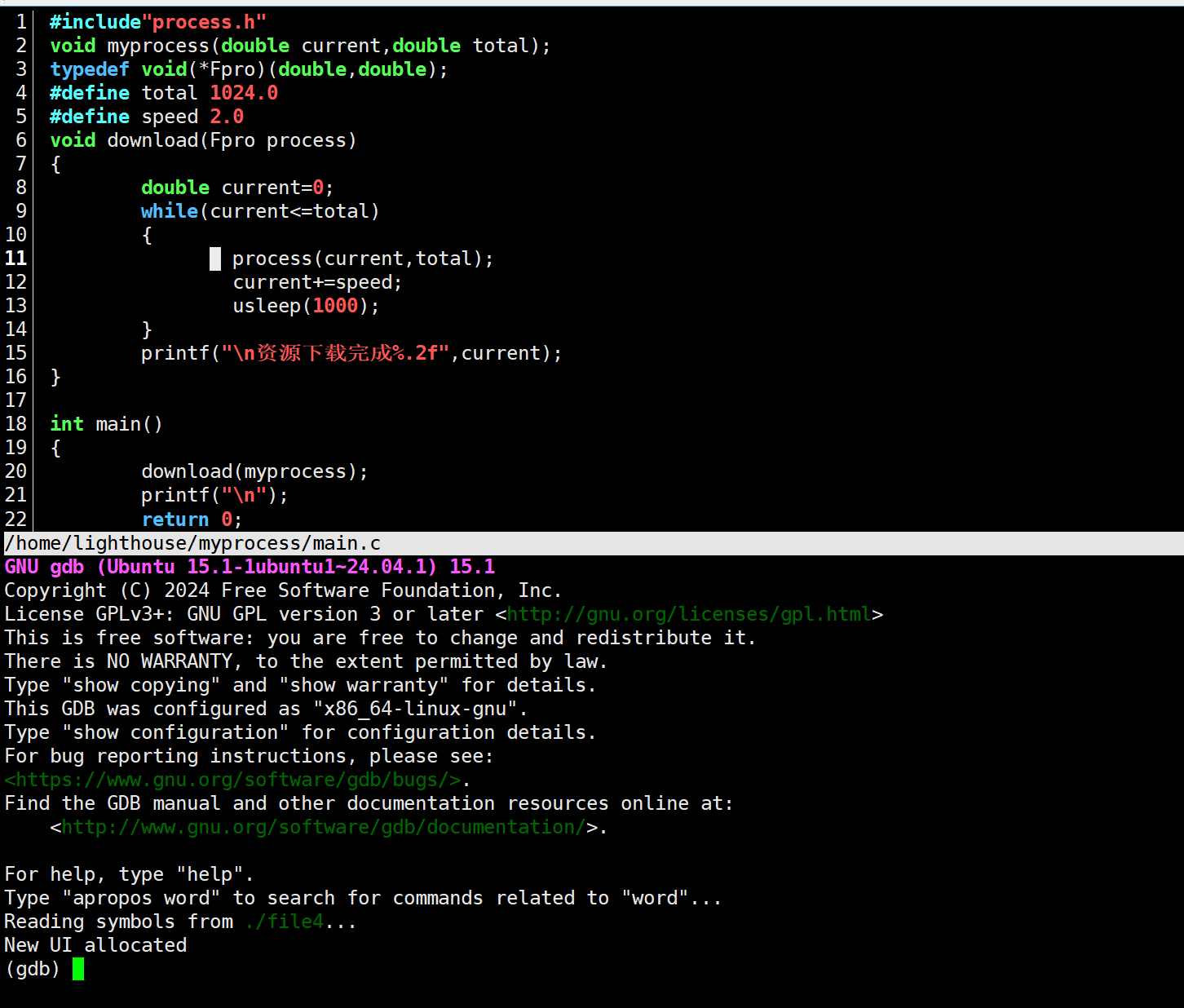
main.c
1 #include"process.h"
2 void myprocess(double current,double total); #函数声明
3 typedef void(*Fpro)(double,double); #函数指针
4 #define total 1024.0 #资源总量
5 #define speed 2.0 #下载速度
6 void download(Fpro process)
7 {
8 double current=0;
9 while(current<=total)
10 {
11 process(current,total);
12 current+=speed;
13 usleep(2000); #模拟下载速度
14 }
15 printf("\n资源下载完成%.2f",current);
16 }
17
18 int main()
19 {
20 download(myprocess);
21 printf("\n");
22 return 0;
23 }
process.h
1 #include<stdio.h>
2 #include<string.h>
3 #include<unistd.h>
~ process.c
1 #include"process.h"
2 #define N 101
3 #define H '#'
4
5 void myprocess(double current,double total)
6 {
7 char buffer[N];
8 memset(buffer,0,sizeof(buffer));
9
10 char label[]={"-/|\\"};
11 int labelLen=strlen(label);
12
13 int count=(int)(current*100/total);
14 for(int i=0;i<=count;i++) #完成一个当前进度条
15 {
16 buffer[i]=H;
17 }
18 static int labelcount=0; #为label转换准备的变量
19 double rate=current*100/total; #进度
20 printf("%-100s[%.2f%%]%c\r",buffer,rate,label[labelcount % labelLen]);
21 labelcount++;#++改变
22 fflush(stdout);
23
24 }
25
![]()
四.git的了解和使用(浅度)
1.git是什么?有什么用?
不知道你⼯作或学习时,有没有遇到这样的情况:我们在编写各种文档时,为了防止文档丢失,更改失误,失误后能恢复到原来的版本,不得不复制出⼀个副本,比如:
“报告-v1”
“报告-v2”
“报告-v3”
“报告-确定版”
“报告-最终版”
“报告-究极进化版”
...
每个版本有各自的内容,但最终会只有⼀份报告需要被我们使用。
但在此之前的工作都需要这些不同版本的报告,于是每次都是复制粘贴副本,产出的文件就越来越
多,文件多不是问题,问题是:随着版本数量的不断增多,你还记得这些版本各自都是修改了什么
吗?
文档如此,我们写的项目代码,也是存在这个问题的!!
对于原来普通文件系统能不能满足呢?
我们来对比一下:
原生文件系统:只存当前最新文件,改了直接覆盖,历史直接丢失 (没有)
Git 内置文件系统:1.每次提交生成完整快照,任意时间点一键还原,删错、改错随时回滚
2.极致省空间,自动内容去重
3.秒建分支,零成本并行开发
4. 精准追溯,全链路日志,精准定位问题来源
5.本地自带完整全套版本库,可同步云端,多端全量备份,不怕数据丢失
6.高效多人协作:规范合并机制,自动比对差异,轻松整合多人代码,统一项目版本
对应git的功能,我们也可以将其叫作一个版本控制器。这样看是不是git优势就大多了。
2.git的结构组成和功能组成
2.1物理结构组成:
_1. 四大工作区域
1. 工作区:日常编写代码的项目文件夹,存放当前正在编辑文件
2. 暂存区(索引区):临时存放待提交修改,缓存改动,用来筛选提交内容
3. 本地仓库(.git 目录):本地磁盘存储所有版本快照,核心数据库,存所有历史
4. 远程仓库:云端服务器仓库,仅做代码同步、共享、备份
_2.管理层
HEAD:指向当前所在分支
index:暂存区文件
objects:对象库(存所有 blob、tree、commit)
refs:存放分支、标签指针
config:仓库配置信息
hooks:提交前后自动执行脚本
等等
组成管理系统:文件存储管理系统和版本时序管理系统
组成层级管理关系:上,中,低
专门负责统筹、调度、存储、管控 Git 所有内部数据与运行规则。就不过多解释了。
_3.三层对象存储结构(核心层级)
Commit(提交)→ Tree(目录)→ Blob(文件内容)
• Commit:版本节点,记录提交信息、父版本
• Tree:记录文件夹结构、文件名、权限
• Blob:只纯存文件内容,自动去重
2.2、功能组成(逻辑功能)
1. 基础版本控制功能
2. 版本回溯功能
3. 分支管理功能
4. 远程协作功能
5. 高效辅助功能
每个功能都有相应的操作命令和操作流程。这里就不过多叙述了。
3.创建和推送到远端仓库的操作流程
3.1安装git(完成配置)
apt install git
配置:
git config --global user.name "你的名字"
git config --global user.email "你的邮箱"
检查有没有配置好
git config --list
3.2创建仓库
1.创建项目目录并进入
2.初始化本地仓库
git init
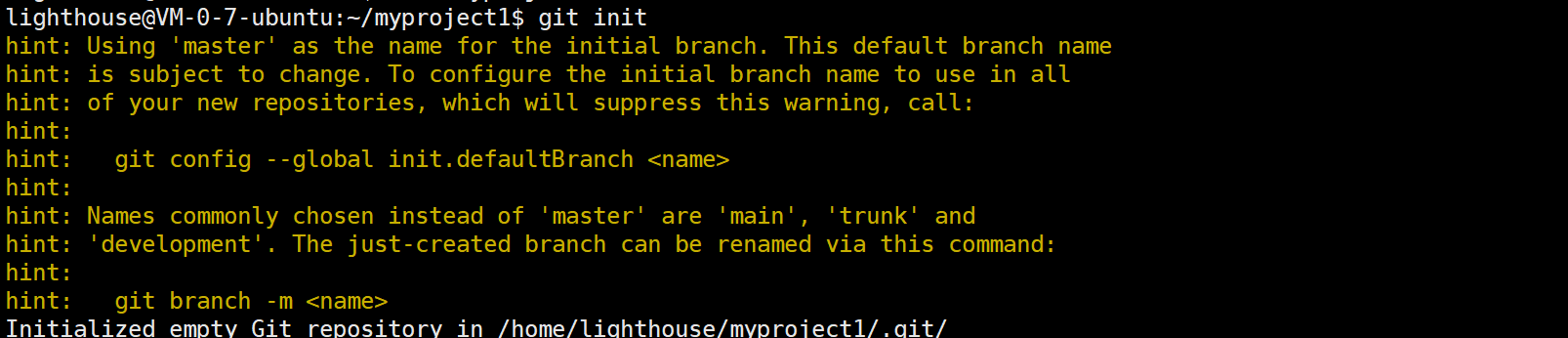
查看:是否生成隐藏文件.git

3. 添加所有文件到暂存区
git add .
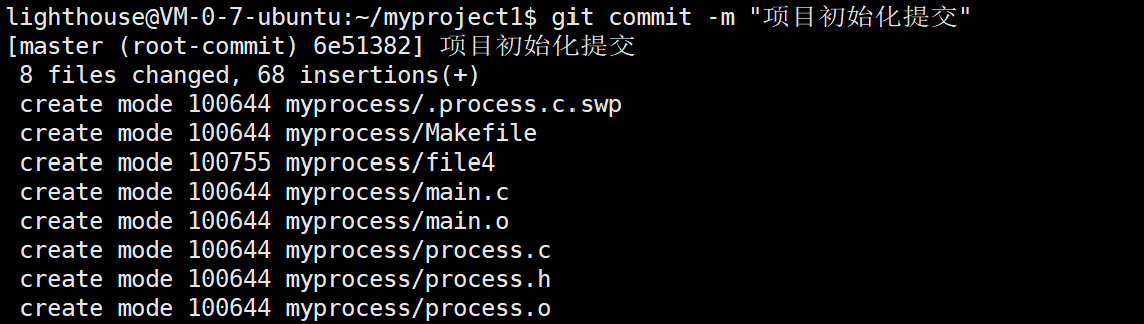
4. 提交到本地仓库
git commit -m "项目初始化提交"
5.在 GitHub/Gitee/GitLab 上创建空远程仓库
得到一个仓库地址
6.本地仓库绑定远程仓库
git remote add origin+仓库地址

7.把本地代码推送到远程
git push
五.gdb和cgdb的介绍和使用
gdb和cgdb是对可执行程序进行的。
准备阶段(准备debug模式)
程序的发布方式有两种, debug 模式和 release 模式, Linux gcc/g++ 出来的⼆进制程
序,默认是 release 模式。
要使用gdb调试,必须在源代码生成二进制程序的时候, 加上 -g 选项,如果没有添加,程序无法被编译
比如在Makefile上
1.gdb的使用
1.1.启动 GDB
gdb ./file4
退出:Ctrl + d或者quit 指令
我们可以看到gdb调试的时候是无法看到源代码的,所以推荐使用cgdb。
cgdb的指令和gdb指令相同,接下来以cgdb讲解指令
2.cgdb
2.1安装
sudo apt install cgdb
2.2启动调试:
cgdb ./file4
3.常见的调试指令:
1.运行
run # r 运行程序
2.打断点
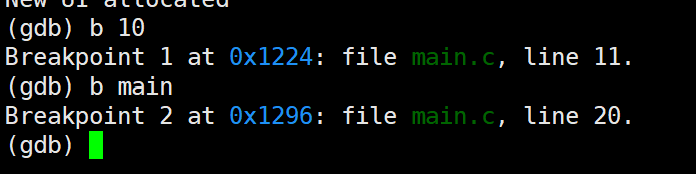
b 行号 # 打断点 b 10
b 函数名 # 打断点 b main
info b # 查看所有断点
delete/d 断点号 # 删除断点
delete/d break # 删除所有断点
打断点
查看断点

删除断点

3.单步调试
n # next 下一步(不进函数)
s # step 进入函数
finish # 跳出当前函数
u # 运行到当前行下面(跳出循环)
4.查看变量 / 内存
p 变量名 # 打印变量
display 变量 # 每步自动显示
undisplay # 取消自动显示
bt # 查看函数调用栈
info local #查看当前调用栈的变量值
watch#监视变量
5.继续和停止
c # continue 继续运行到下一个断点
Ctrl + C # 停止程序运行
6.set var
在调试过程中,强行改变某个变量的值
set var 变量名 = 新值

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)