MySQL运维篇
自己补充:不管是 cmd 里执行的 SQL,还是 Python 程序执行的 SQL,只要是 MySQL 服务器出错,都会统一记录在同一个错误日志里!如果看不懂日志,可以找AI帮分析。
第一节 日志
P02 错误日志
windows系统常见的日志路径:
C:\ProgramData\MySQL\MySQL Server X.X\Data\主机名.err比如自己电脑中错误日志的路径为:
C:\ProgramData\MySQL\MySQL Server 9.6\Data\LAPTOP-TQ4U85RH.err自己补充:
不管是 cmd 里执行的 SQL,还是 Python 程序执行的 SQL,只要是 MySQL 服务器出错,都会统一记录在同一个错误日志里!
如果看不懂日志,可以找AI帮分析。
mysql自带的错误日志,没办法代替程序自身开发的错误日志系统,因为程序自身的错误日志,可以定位到错误日志是哪个源码产生的,什么时间产生的,哪个用户产生的,同样的错误出现了多少次,这些都是可以定位的。
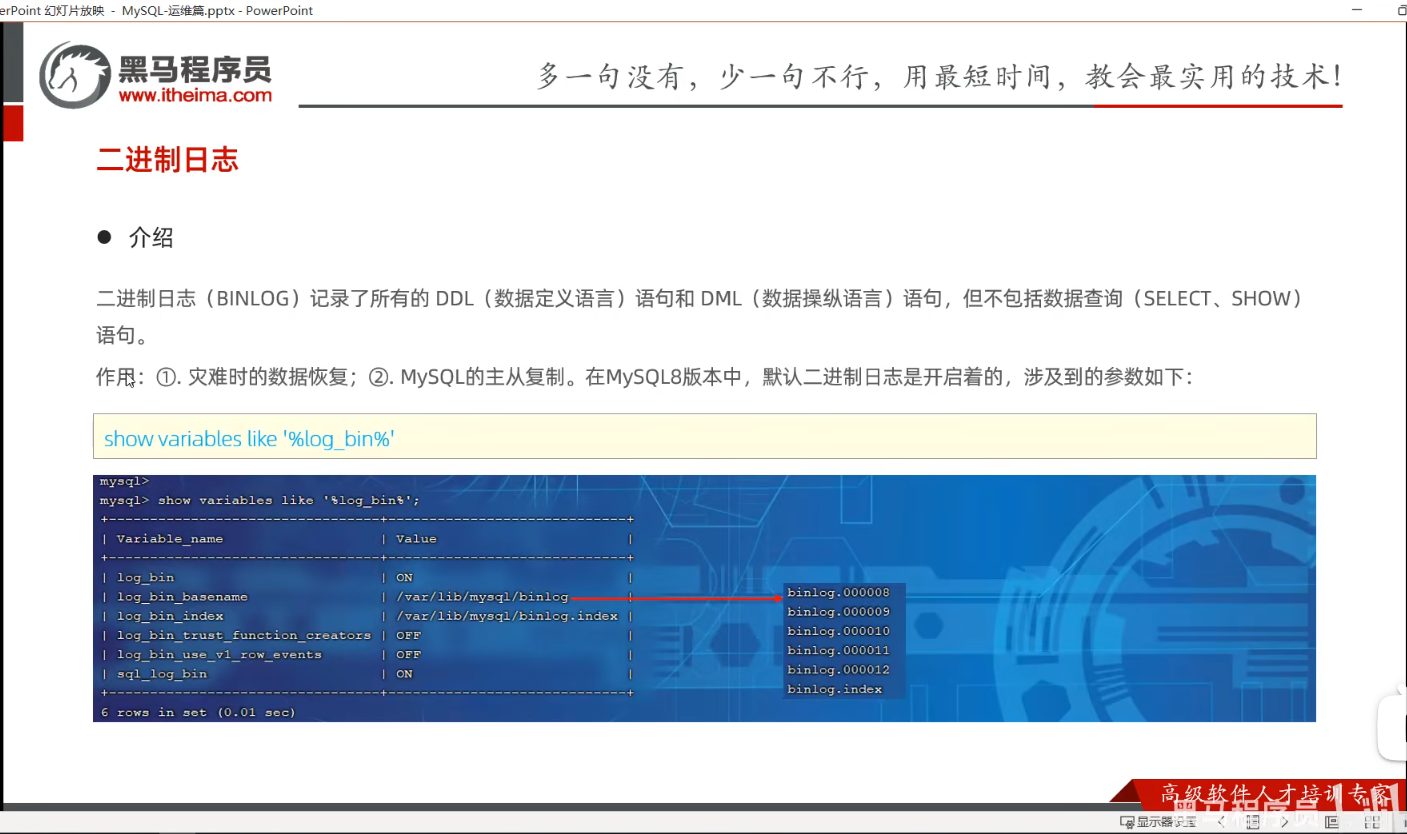
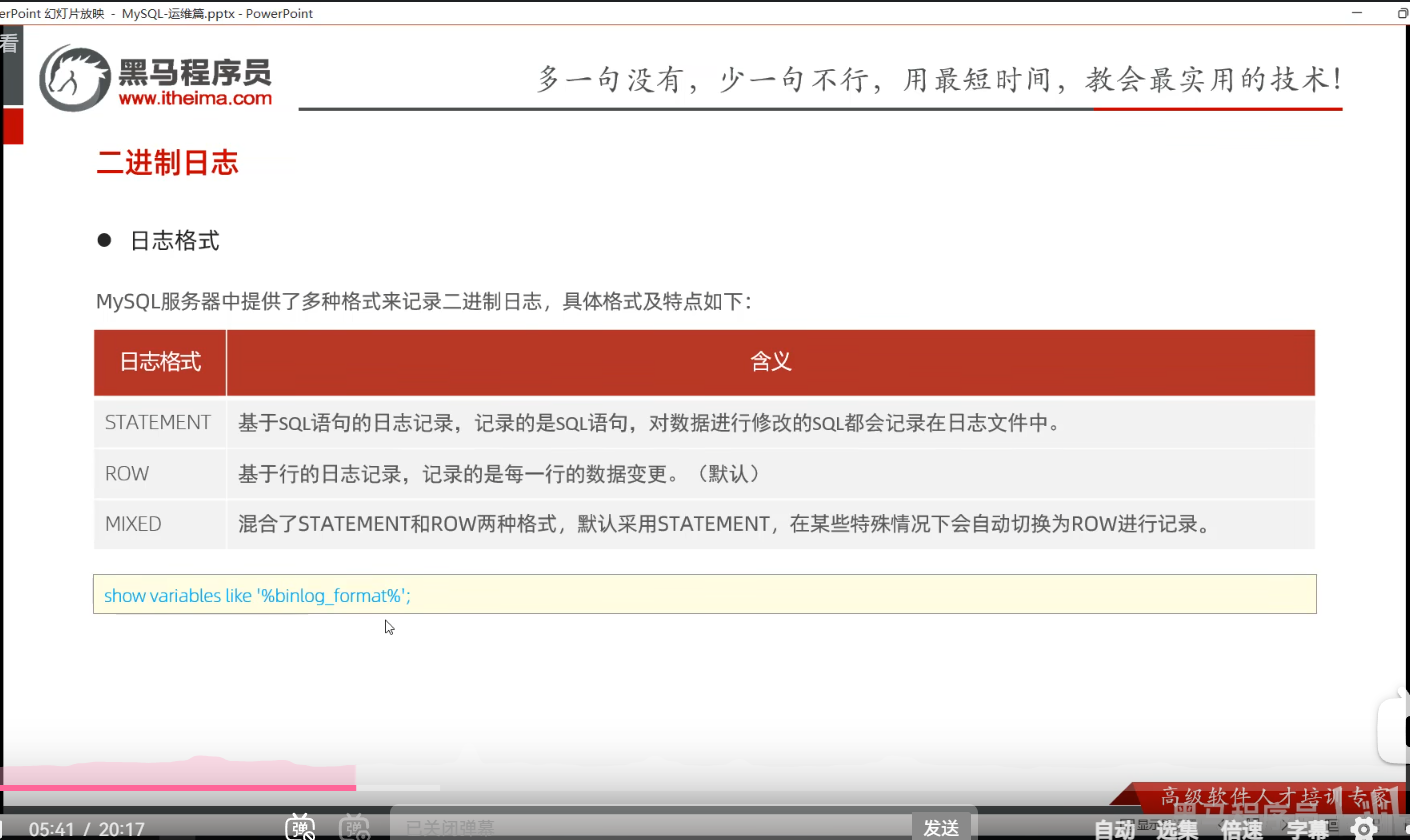
P03 二进制日志
一、课堂内容
个人感悟:
二进制日志的路径是:
C:\ProgramData\MySQL\MySQL Server 9.6\Data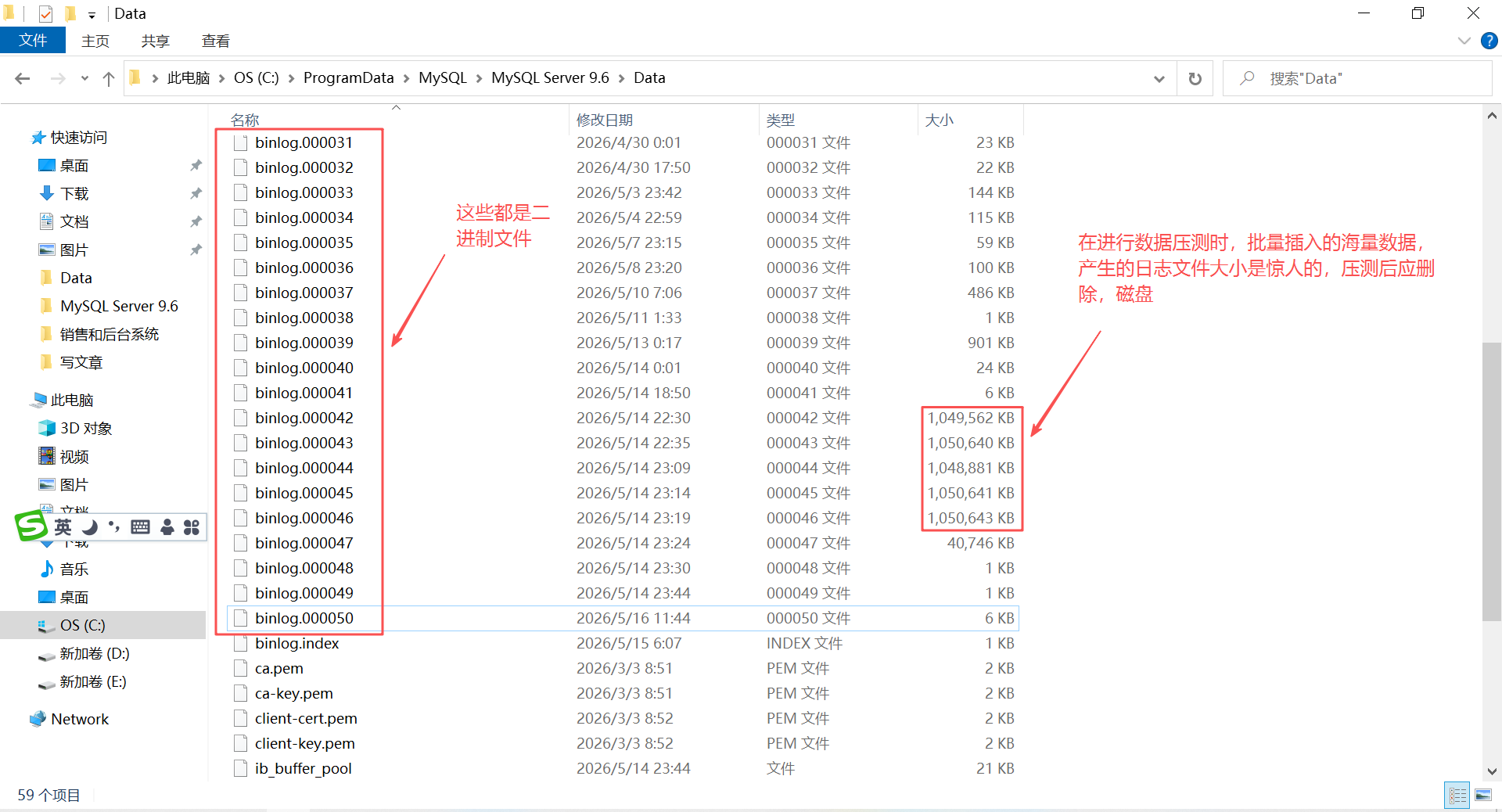
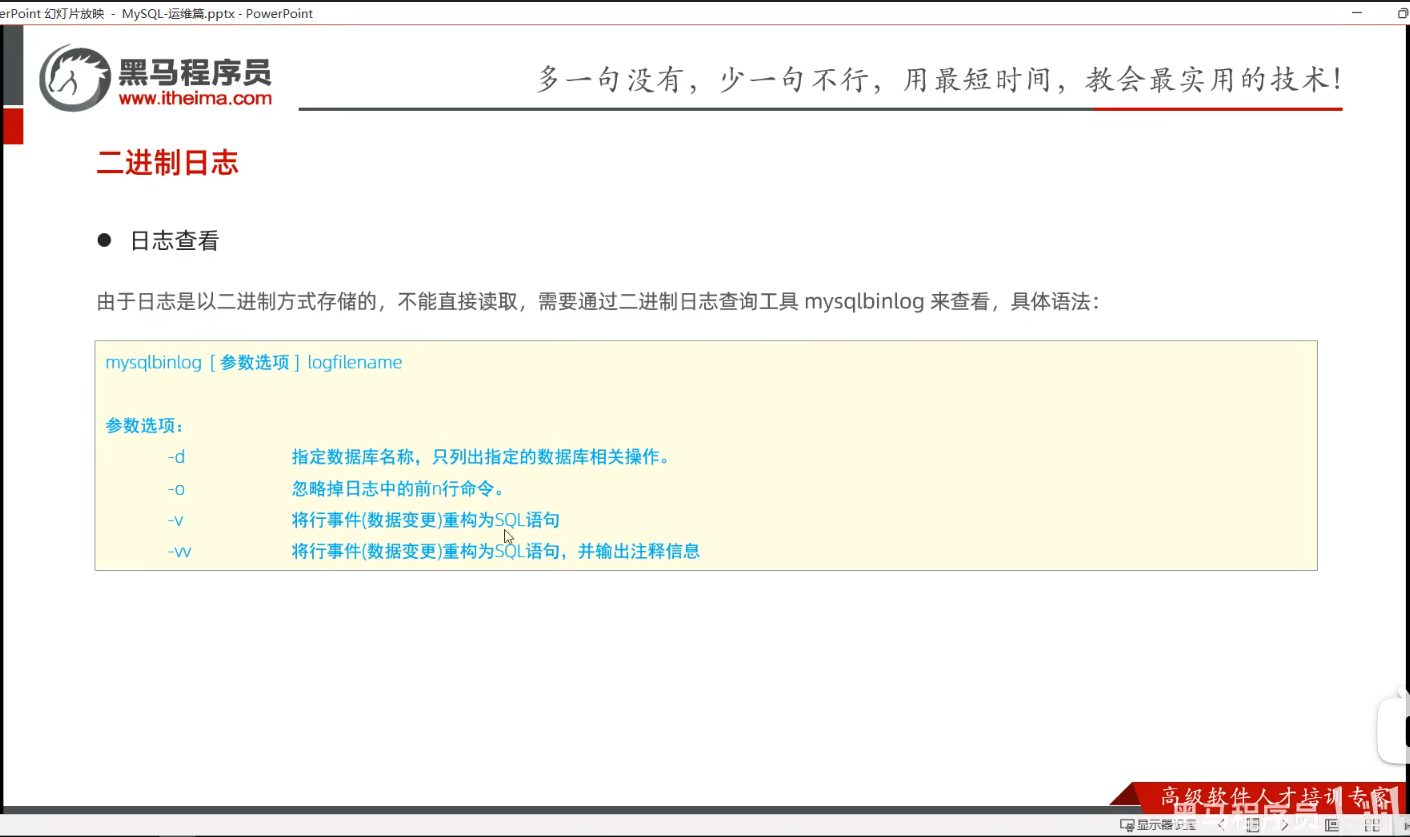
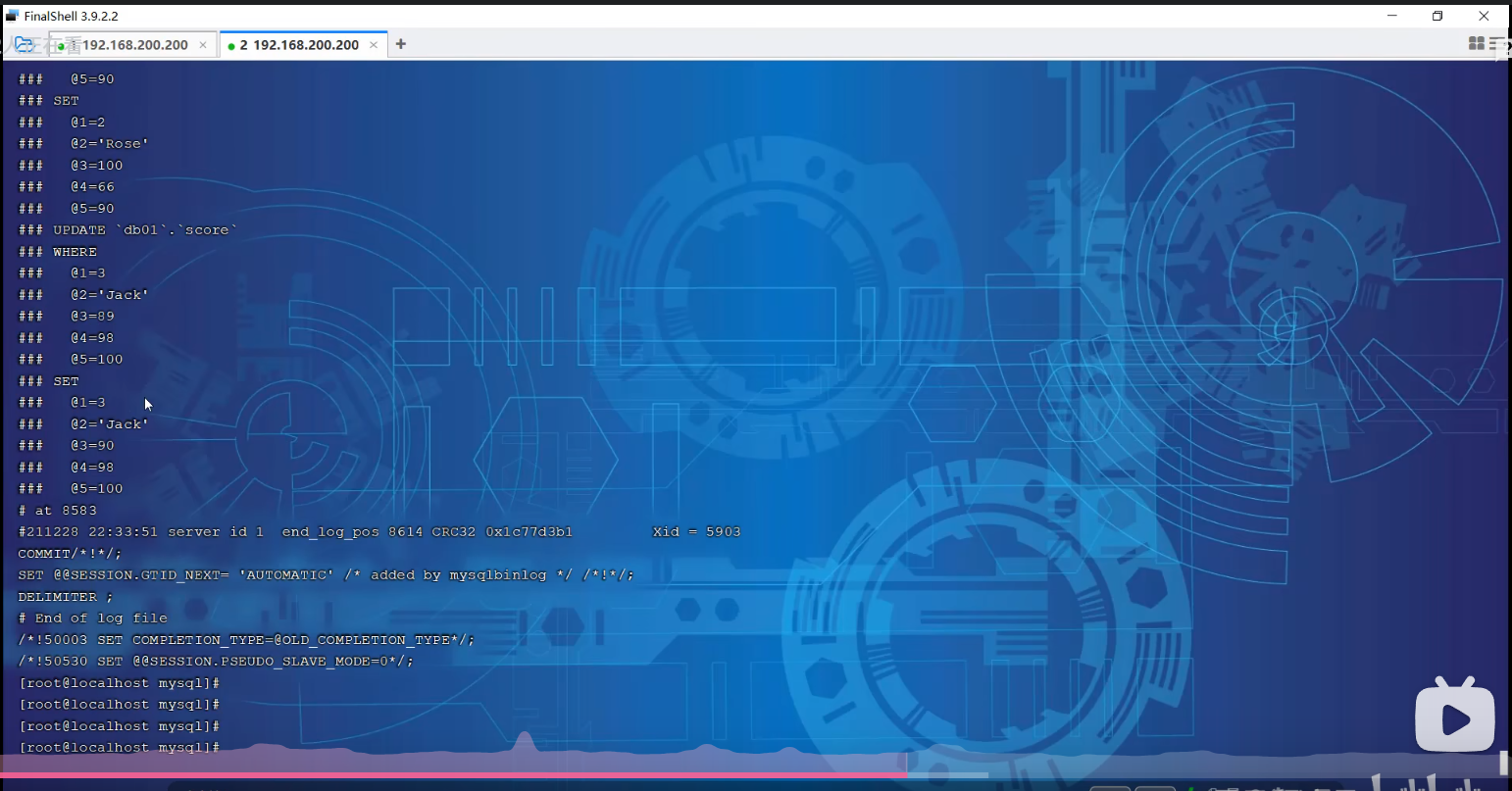
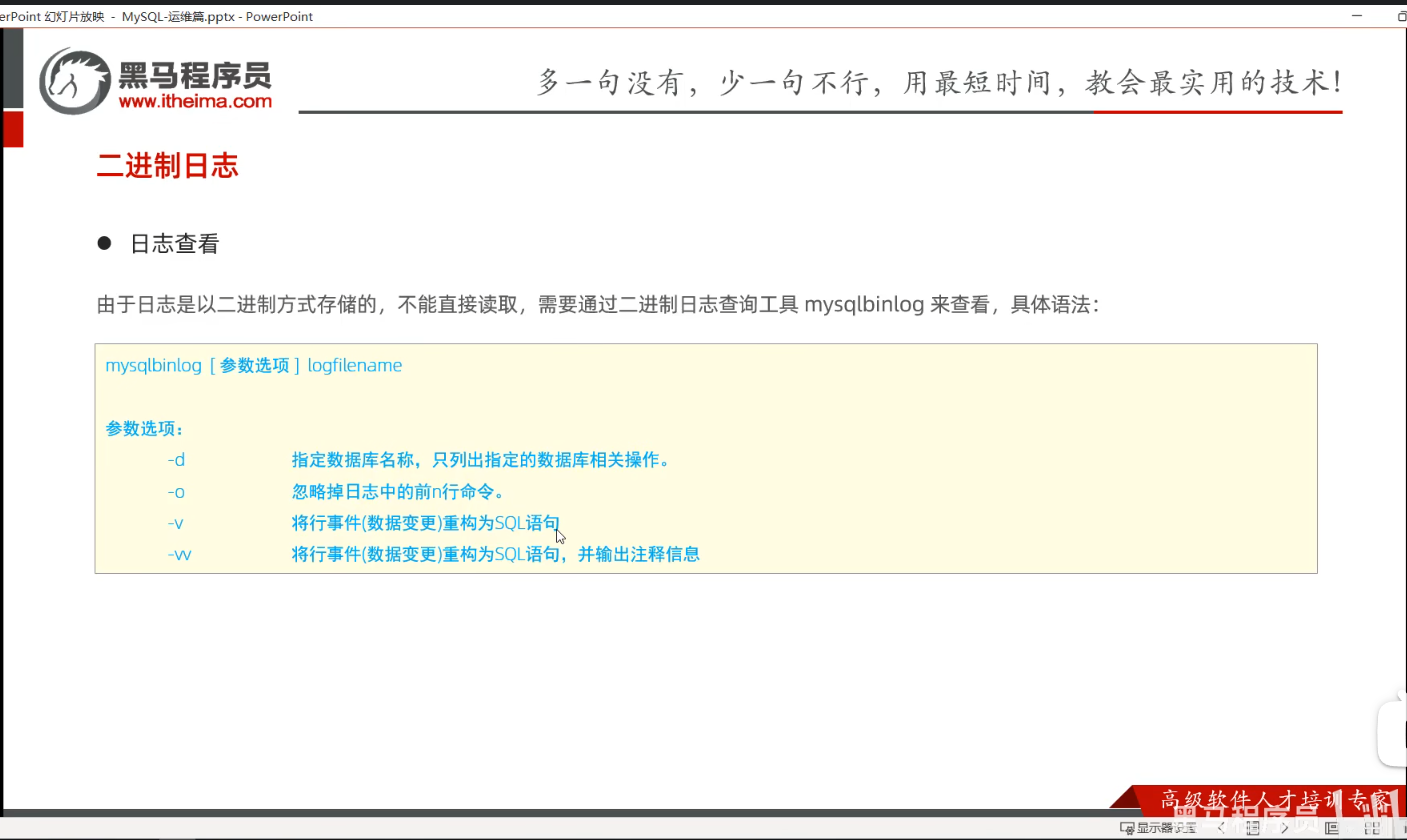
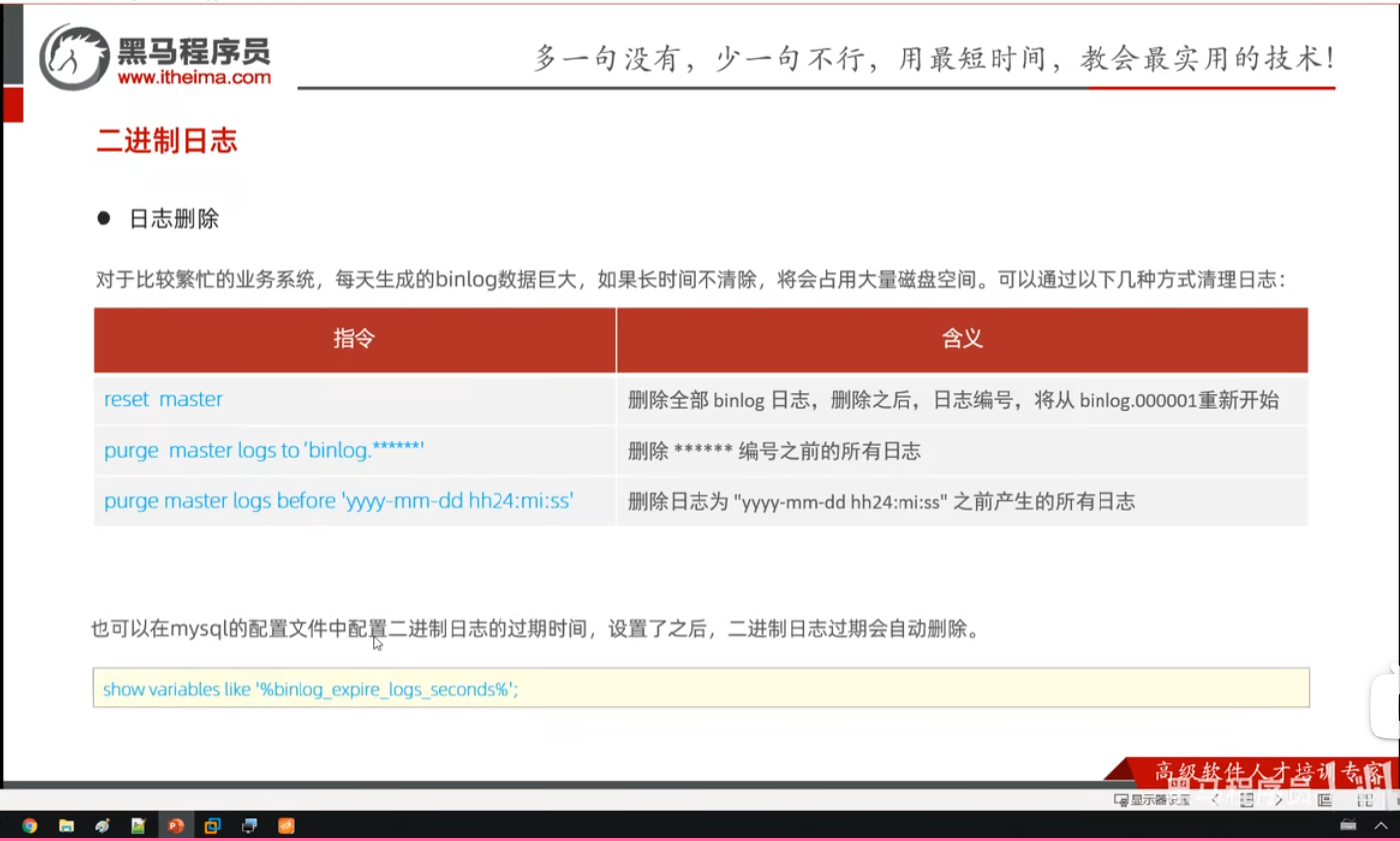
二进制日志默认保存的时候单位为秒,默认保存时间是30天。
个人感悟:
这一切的核心是弄明白,二进制查看的命令。
二、自己补充:mysql中的二进制日志,我怎么知道哪个表的日志在哪个文件中
(一)先理解核心前提
Binlog 是按时间顺序写入的,每个文件记录了一段时间内所有库表的操作,并不是 “按表分文件” 的。所以你需要通过解析 binlog 文件内容,反向找出哪些文件包含了目标表的操作。
(二)方法 1:用 SQL 命令直接查(不用导出文件)
在 MySQL 命令行里,直接查看 binlog 文件里的事件,这是最方便的方式。
1. 先查看当前有哪些 binlog 文件
-- 查看所有 binlog 文件列表
SHOW BINARY LOGS;
你会看到类似 binlog.000023、binlog.000037 这样的文件名,和你截图里的文件对应上。
2. 查看某个 binlog 文件里的事件(含表信息)
-- 替换成你要查的 binlog 文件名
SHOW BINLOG EVENTS IN 'binlog.000037';
输出里的 Table_map 事件,会直接告诉你:
- 哪个数据库(库名)
- 哪个表(表名)
- 被映射成了什么
table_id - 后续的
Write_rows/Update_rows/Delete_rows事件,都是针对这个table_id的操作
比如你会看到类似这样的行:
plaintext
| binlog.000037 | 1234 | Table_map | 1 | 456 | table_id: 789 (bai_study.test_table) |
这就说明 bai_study.test_table 这张表的操作,记录在 binlog.000037 这个文件里。
(三)方法 2:用 mysqlbinlog 工具解析(适合批量 / 导出分析)
MySQL 自带 mysqlbinlog 工具,可以把二进制日志解析成可读文本,还能直接过滤目标表。
1. 基础解析命令(查看所有事件)
在 Windows 上,打开 CMD / 终端,进入你的 MySQL Server 9.6 的 bin 目录(比如 C:\Program Files\MySQL\MySQL Server 9.6\bin),执行:
# 解析单个 binlog 文件
mysqlbinlog "C:\ProgramData\MySQL\MySQL Server 9.6\Data\binlog.000037" > binlog_000037.txt
生成的 binlog_000037.txt 文件里,所有 Table_map 事件都会明确写出表名,你可以直接搜索表名,快速定位哪些文件里有它的操作。
2. 直接过滤出目标表的所有操作(推荐)
如果你的 binlog 是 ROW 格式(生产环境默认推荐),可以直接用 --database 和 --table 参数过滤:
# 只解析 bai_study 库中 test_table 表的操作
mysqlbinlog --database=bai_study --table=test_table "C:\ProgramData\MySQL\MySQL Server 9.6\Data\binlog.000037" > test_table_operations.txt
如果文件里没有这个表的任何操作,生成的文件就会是空的,这样你就能快速判断这个 binlog 文件是否包含目标表的日志。
(四)补充:怎么批量检查所有 binlog 文件?
如果你的 binlog 文件很多,想一次性找出所有包含目标表的文件,可以用 for 循环批量处理(Windows 终端):
# 进入 binlog 目录
cd "C:\ProgramData\MySQL\MySQL Server 9.6\Data"
# 遍历所有 binlog 文件,筛选包含目标表的文件
for %f in (binlog.*) do @(
mysqlbinlog "%f" | findstr "bai_study.test_table" > nul && echo "%f contains test_table operations"
)
执行后,终端会直接输出哪些文件里有目标表的操作。
(五)关键注意事项
- binlog 格式限制:
--table参数只对ROW格式的 binlog 生效,如果你的 binlog 是STATEMENT格式,只能用文本搜索表名。 - 权限问题:
ProgramData目录是隐藏且受保护的,解析时如果报错权限不足,需要用管理员身份打开终端。 - 文件大小:大的 binlog 文件解析会很慢,建议优先用
SHOW BINLOG EVENTS快速查看关键文件。
P04 查询日志
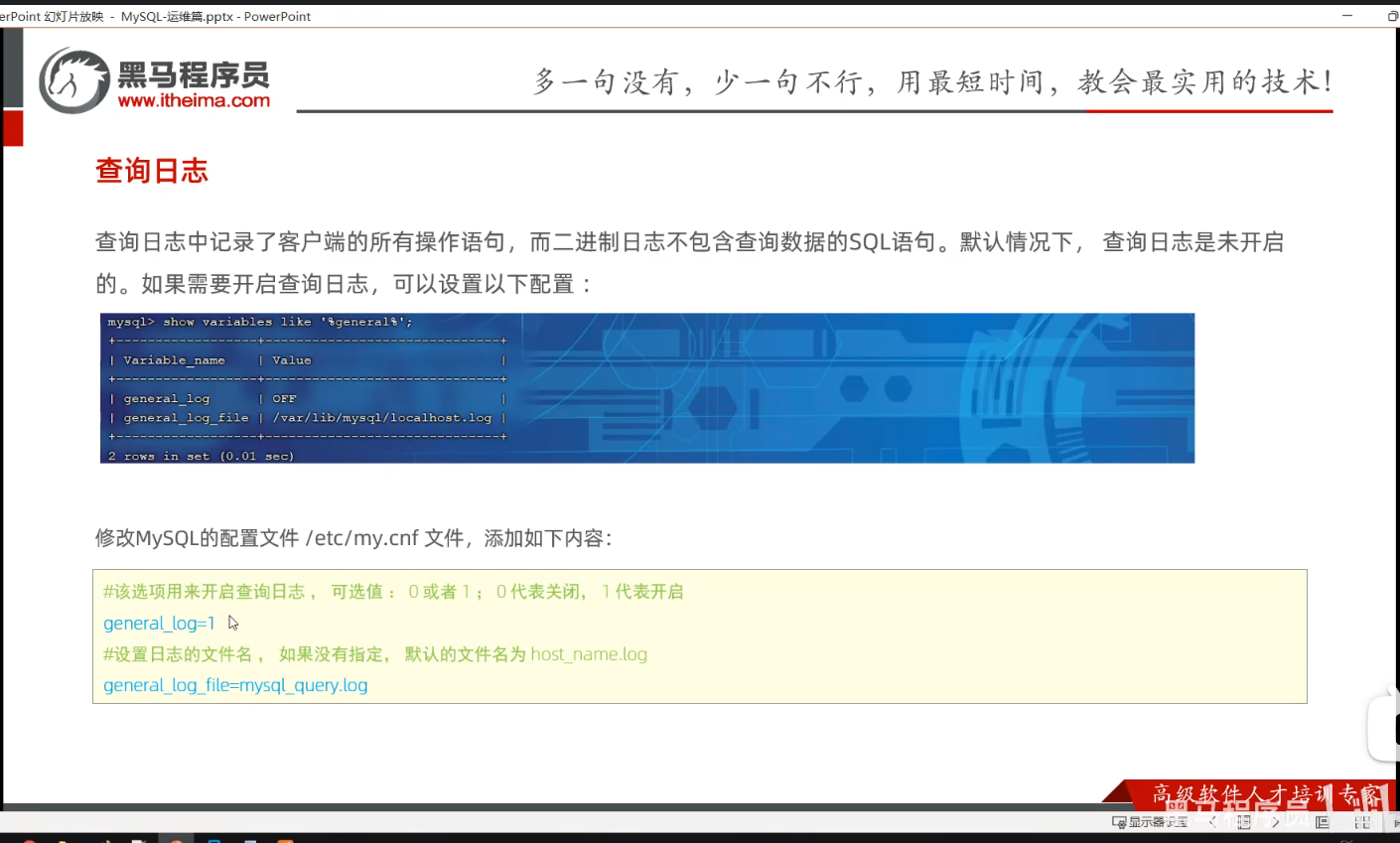
如果平时用不到查询日志,可以把这个文件关掉,因为这个文件在运行过程中,是很大的。
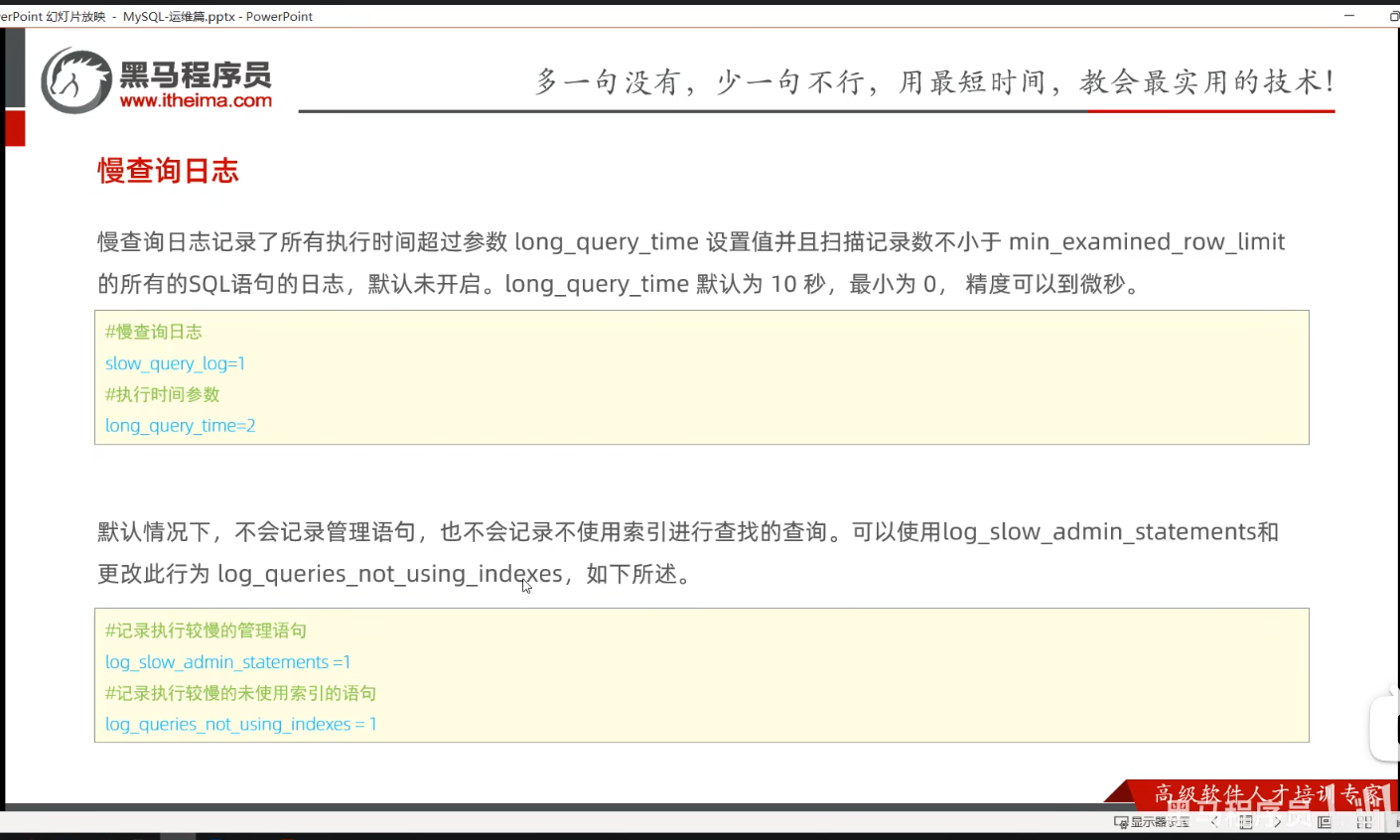
P05 慢查询日志

第二节 主从复制
P06 概述


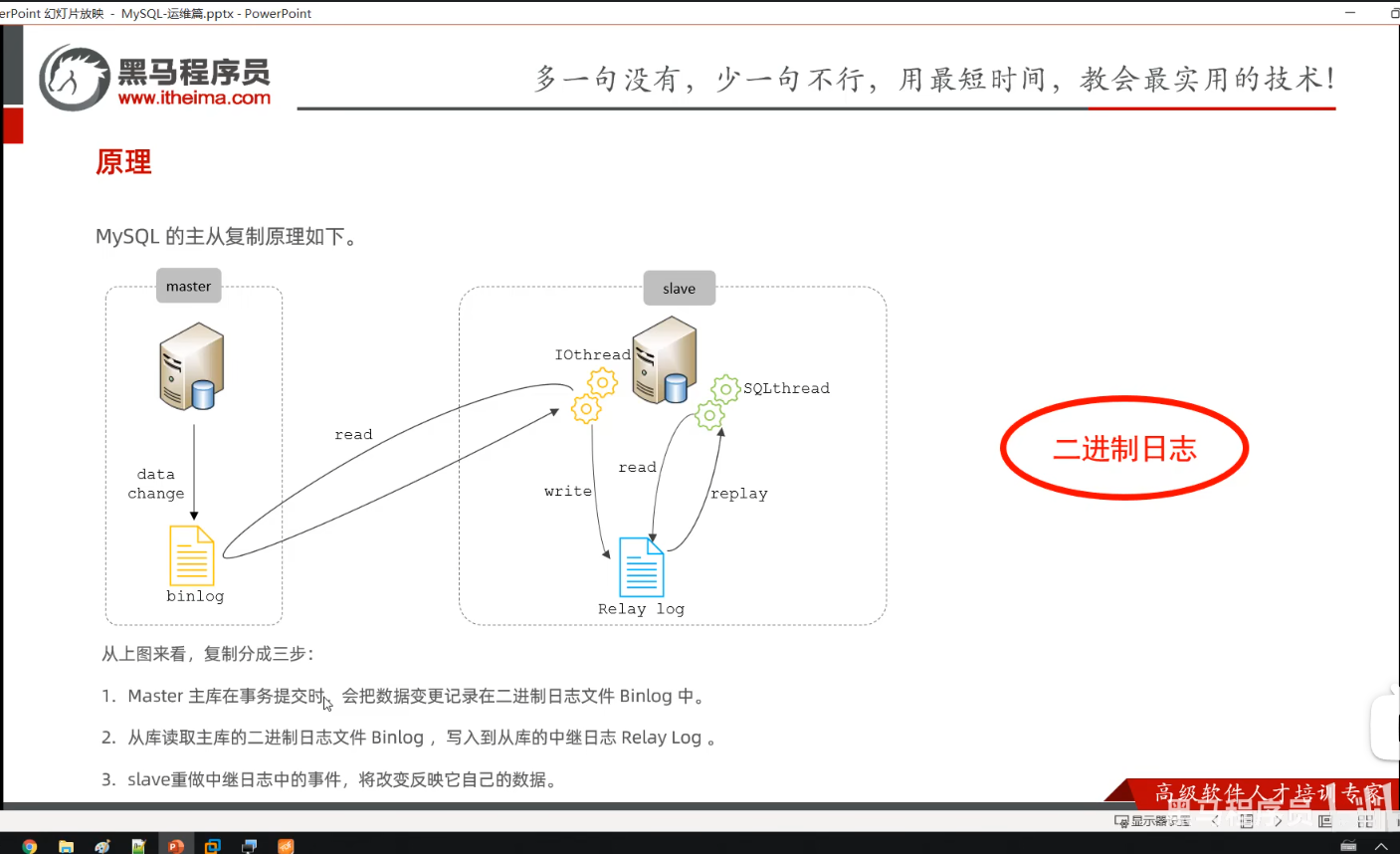
P07 原理
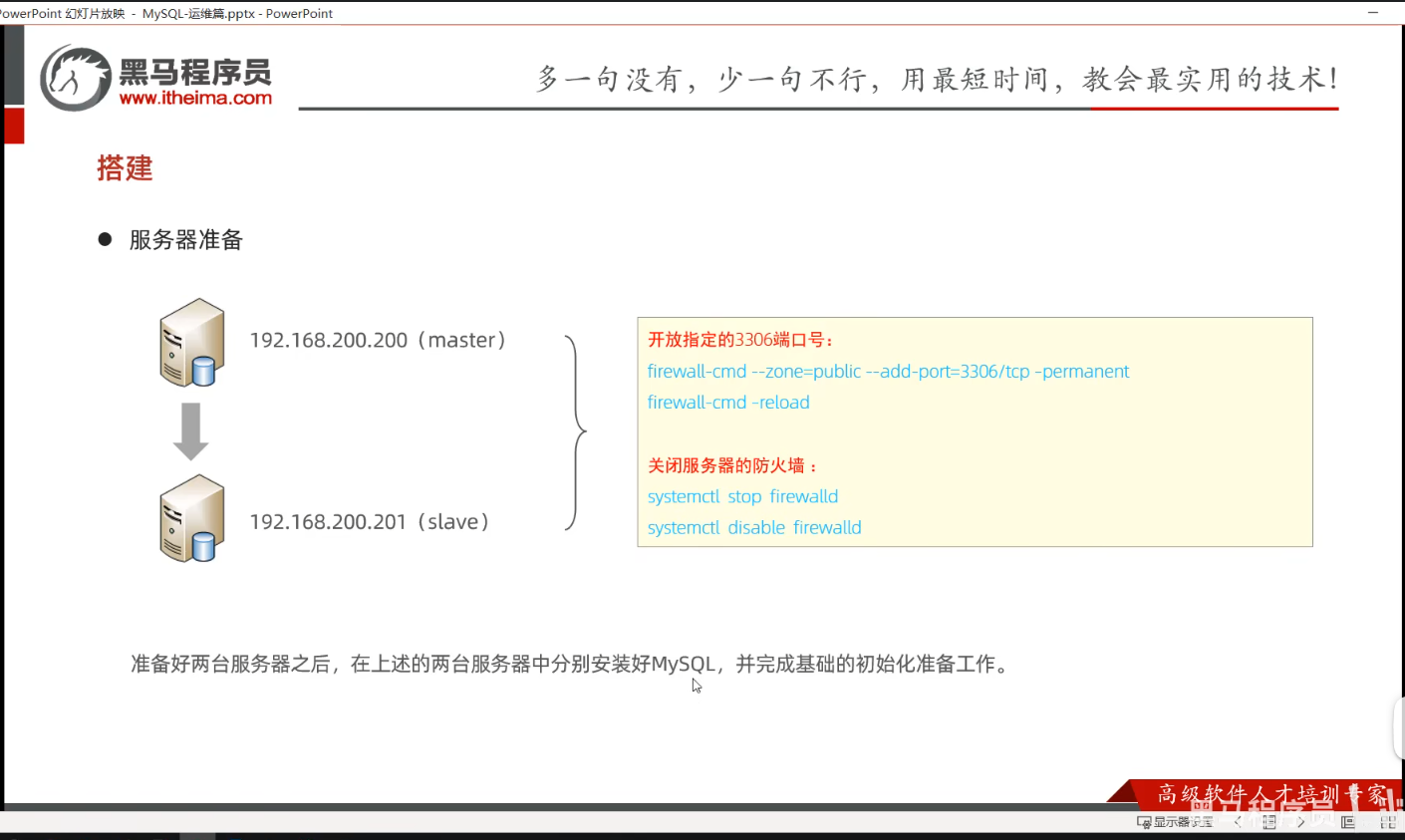
P08 主库配置
一、课堂笔记
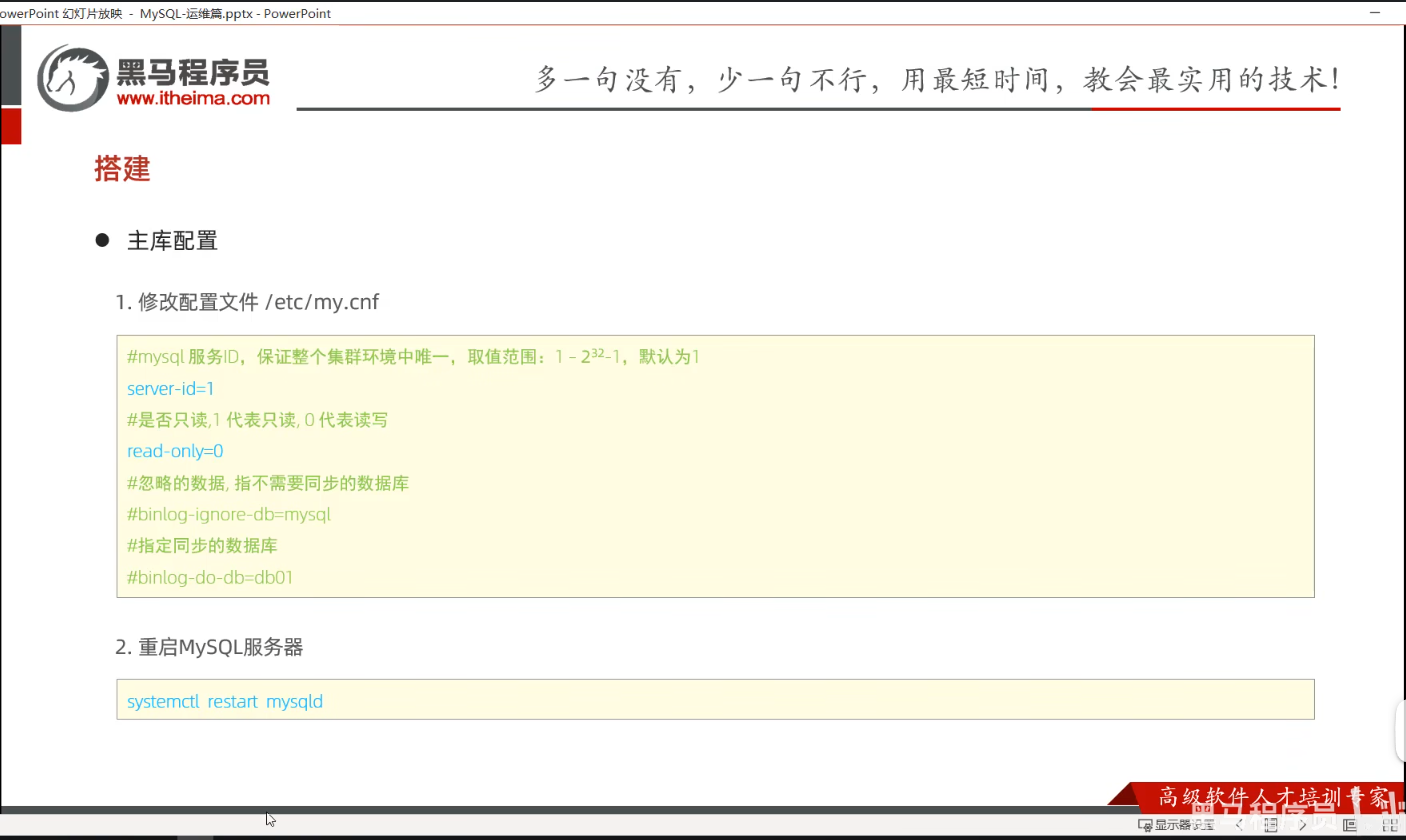
# 在执行下面命令前必须先开启二进制日志
log-bin=binlog
# 9.xx系列命令
SHOW BINARY LOG STATUS;
# 需要将bind-address注释掉或改为如下,否则执行show replica status时会报错
bind-address = 0.0.0.0二、windows系统中操作防火墙的命令
1. 最简查看状态
netsh advfirewall show allprofiles
看这行:状态 = 开启 / 关闭
2. 直接看总开关
netsh advfirewall get state
3. 关闭防火墙
netsh advfirewall set allprofiles state off
4. 开启防火墙
netsh advfirewall set allprofiles state on
5. Win10/11 新版命令
Get-NetFirewallProfile三、read-only及额外加的命令来源
(一)先讲透:read-only 到底是什么意思?
1. 一句话人话解释
read-only = 数据库是不是 “只读模式”
read-only=0:可读、可写(正常干活,能增删改查)read-only=1:只能查、不能改(只能读数据,不能新增、删除、修改数据)
2. 再结合「主从复制」场景,你瞬间就懂
主从架构里:
- 主库(Master):负责写数据(用户新增、修改、删除都往主库来)→ 所以主库必须是
read-only=0(能写),默认就是 0,不写这行也没事 - 从库(Slave):只负责同步主库的数据,给用户查,不允许任何人手动改从库数据→ 所以从库要手动加
read-only=1(锁住,不让改,防止数据和主库不一致)
3. 补充一个关键细节(黑马课没讲全)
read-only=1 只限制普通账号不能改;root 超级管理员,就算设了 read-only=1,照样能增删改。它的作用是:防止开发、普通用户误操作改坏从库数据,不是锁死 root。
(二)第二个问题:这些配置从哪来?能不能乱加?
1. 核心结论
所有配置都来自 MySQL 官方文档,不是老师瞎编、也不能乱加默认 my.ini 只给你装了「最基础的几十项」;剩下几千个配置参数,官方全有文档,按需自己加,不是乱加。
2. 通俗类比(一下就懂)
把 MySQL 想象成一台出厂汽车:
- 默认
my.ini= 汽车出厂基础配置(方向盘、油门、刹车、车灯,够用能开) server-id/read-only/binlog这些 = 额外加装配件(导航、定速巡航、胎压监测)- 你不需要(单机用),就不装(不写进配置)
- 你需要(搭主从、调性能),就自己手动加装(手动写进 my.ini)
3. 这些配置在哪能查到?(给你最靠谱的 2 个渠道)
- MySQL 官方文档(最权威,一点不掺水)所有参数、取值范围、默认值、作用,官方全写死了;比如
read-only,官方明确:- 取值:0/1
- 默认值:0
- 作用:控制普通用户是否只读
- 正规教程(黑马、尚硅谷这些)老师讲的,全是从官方文档里摘出来的高频实用参数,挑干活讲,不扯没用的。
4. 能不能乱加?
- 参数名字不能瞎写:官方没这个参数,你乱写一行,MySQL 直接启动报错;
- 参数值不能瞎填:比如
server-id只能填 1~2^32-1,你填个 0、10000000000,直接报错; - 没用到的配置,不用加:你不做主从,就没必要加
server-id、read-only,加了也没用。
(三)给你一个最简单的实操判断标准(你以后自己就能判断)
- 单机自己用、自己学习:90% 高级配置都不用加,默认
my.ini完全够用; - 搭主从、做集群、调性能、开日志:需要啥功能,就去查官方 / 正规教程,只加对应的那几行配置;
- 看不懂的配置,绝不乱加,先搞懂作用再加。
最后一句总结
read-only 就是:控制普通账号能不能改数据的开关;所有这些额外配置,全是 MySQL 官方规定好的 “高级功能开关”,默认不打开,你需要哪个功能,就手动加哪一行,不是乱加。
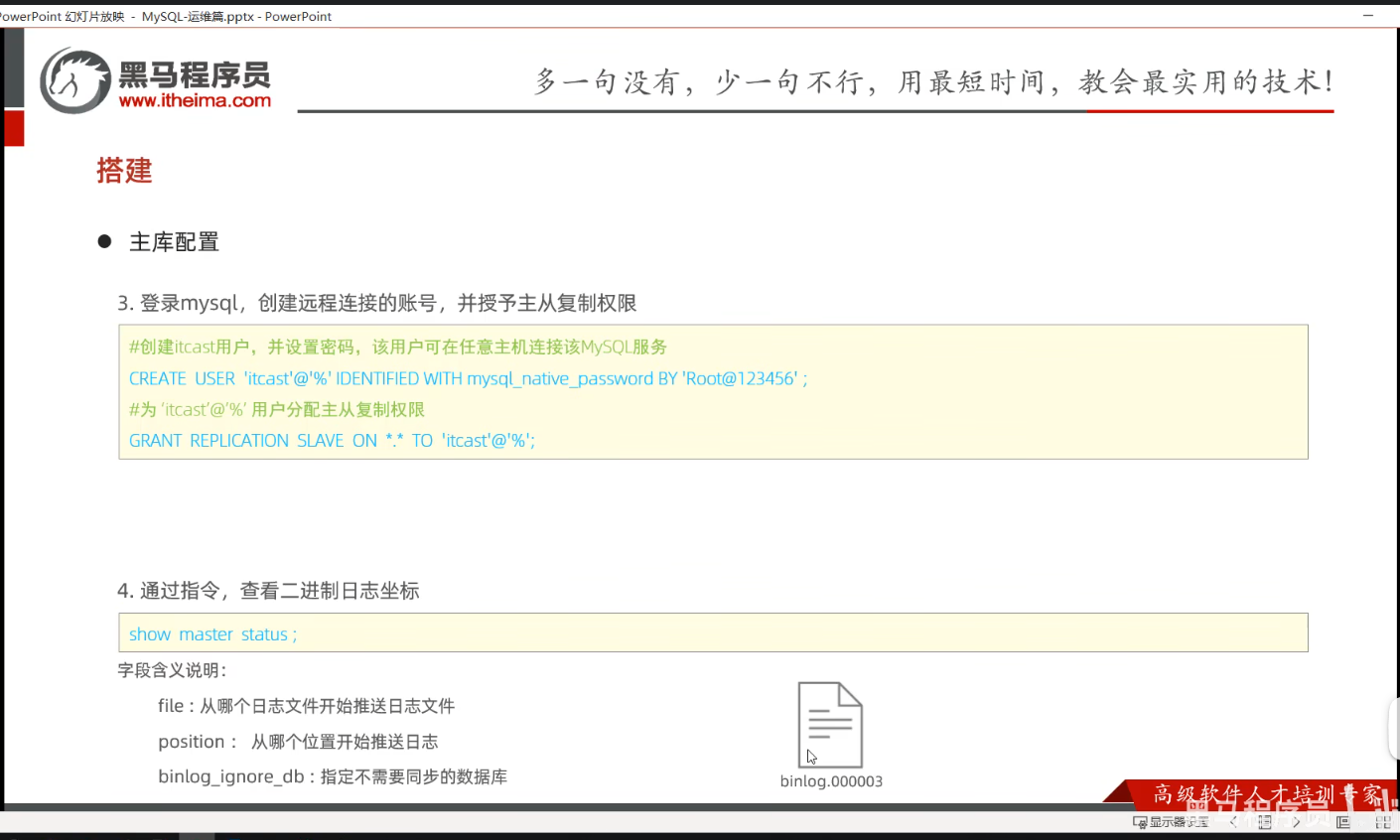
四、创建远程连接账号中IDENTIFIED WITH mysql_native_password BY是什么
1. 红框里的 IDENTIFIED WITH mysql_native_password BY 'xxx' 到底是什么?
它的作用,一句话人话解释:给用户指定「密码加密方式」,让这个账号用 mysql_native_password 这种老算法来验证密码。
它不是主从复制的专属功能,任何普通账号都可以用。
2. 为什么平时创建用户看不到这行?
因为:
- MySQL 5.7 及之前:默认加密方式就是
mysql_native_password,所以创建用户时不用写,默认就是它; - MySQL 8.0 及之后:默认改成了
caching_sha2_password这种新算法,所以创建用户时,如果你想让它兼容老客户端 / 老连接方式,就需要手动加上这行,强制指定用老算法。
你平时看到的简化写法:
CREATE USER 'itcast'@'%' IDENTIFIED BY 'Root@123456';
在 MySQL 8.0 里,等价于:
CREATE USER 'itcast'@'%' IDENTIFIED WITH caching_sha2_password BY 'Root@123456';
而你截图里的写法,是强制指定用老算法:
CREATE USER 'itcast'@'%' IDENTIFIED WITH mysql_native_password BY 'Root@123456';
3. 为什么主从复制的场景,老师要特意加这行?
核心原因是:兼容性。很多老版本的 MySQL 从库、或者老客户端,不支持新的 caching_sha2_password 加密方式,用这种账号连不上主库。所以老师特意加上这行,强制让主从复制的账号用老算法,保证从库能正常连接。
4. 总结一下关键点
- 这行不是主从复制特有的,普通账号也能加;
- 它的作用是指定密码加密方式,不是主从权限;
- 主从复制真正的权限,是下面这行:
GRANT REPLICATION SLAVE ON *.* TO 'itcast'@'%'; - 你平时看不到它,是因为 MySQL 5.7 默认就是这个算法,不用写出来;8.0 之后默认换了,才需要手动指定。
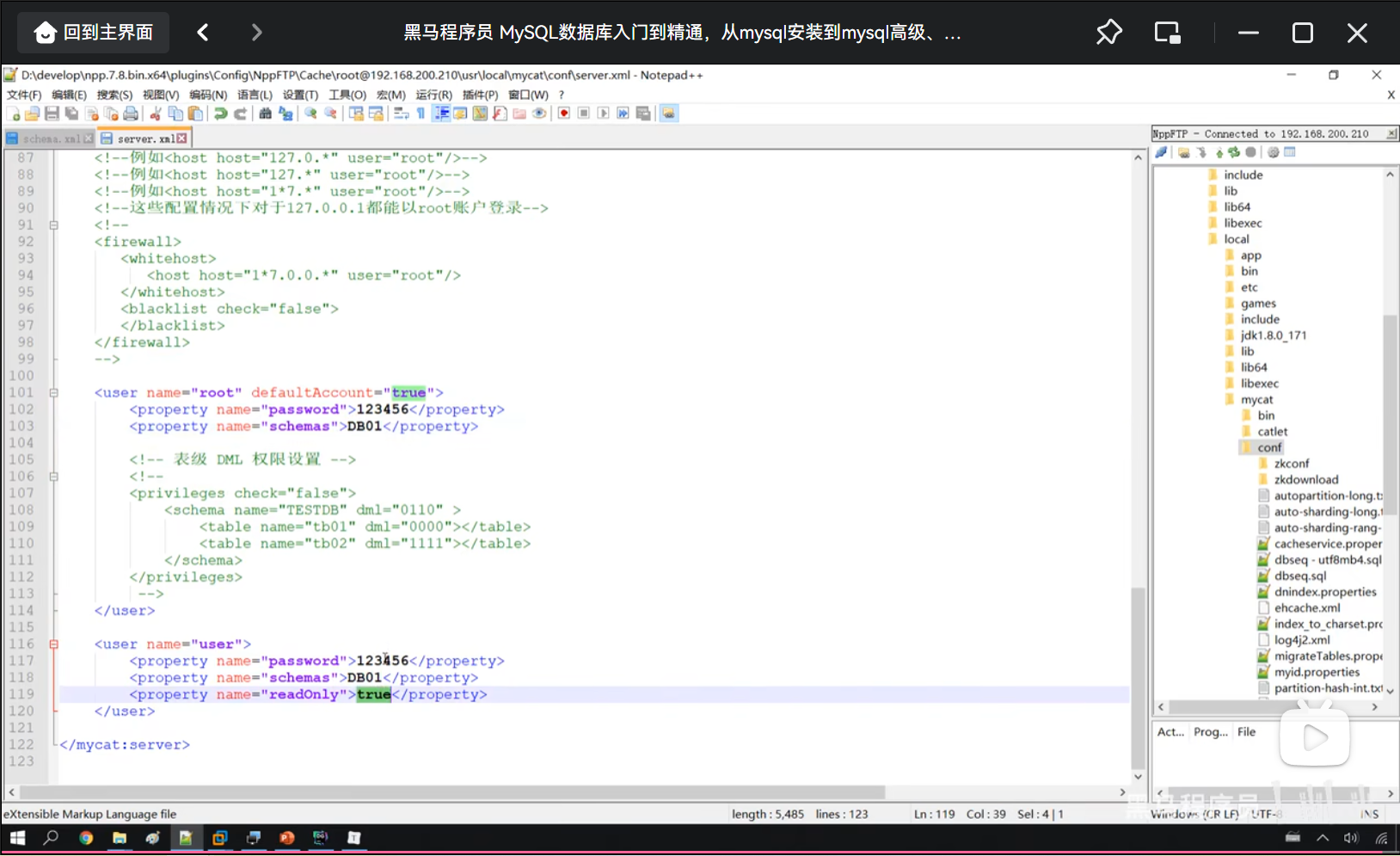
P09 从库配置
一、课堂内容
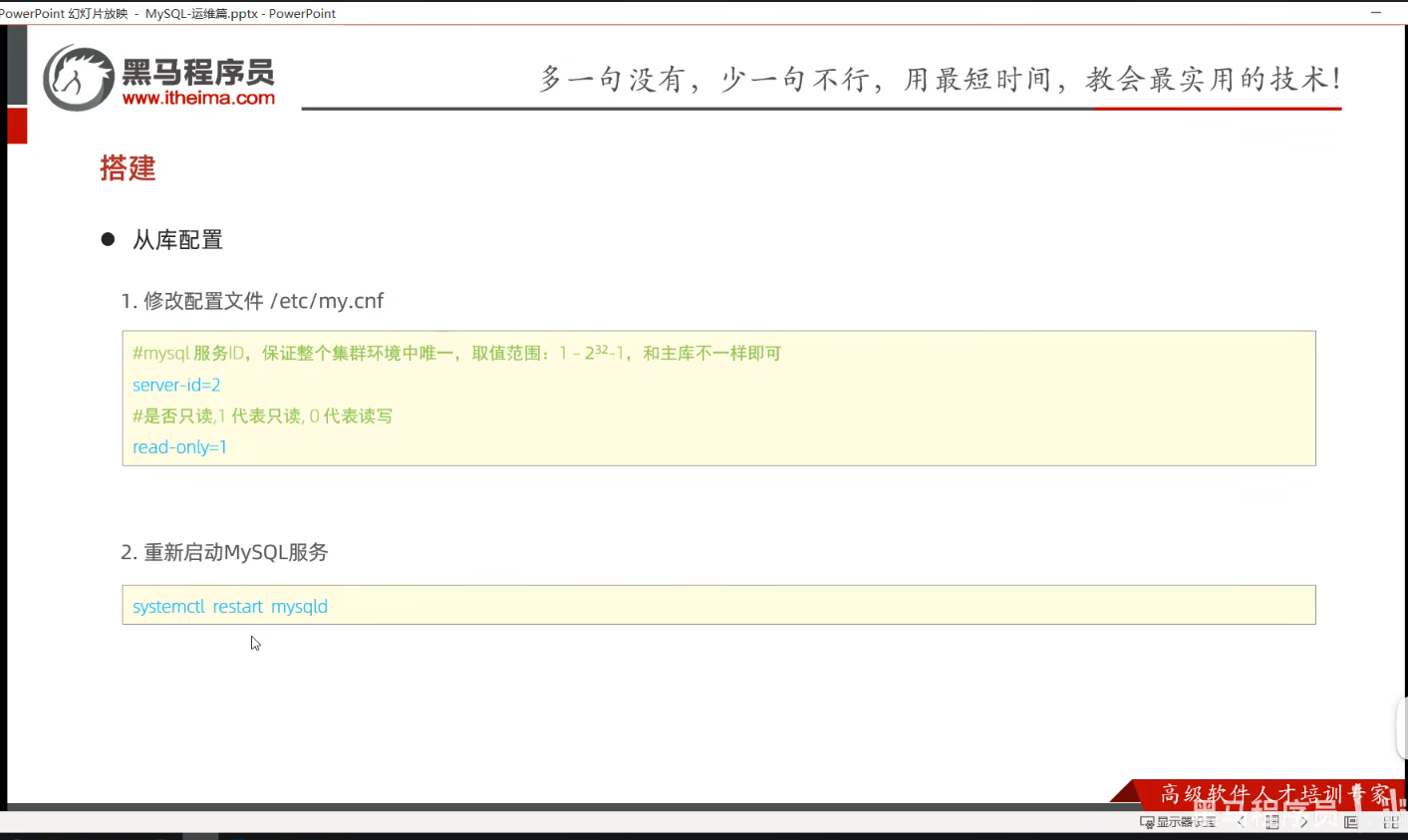
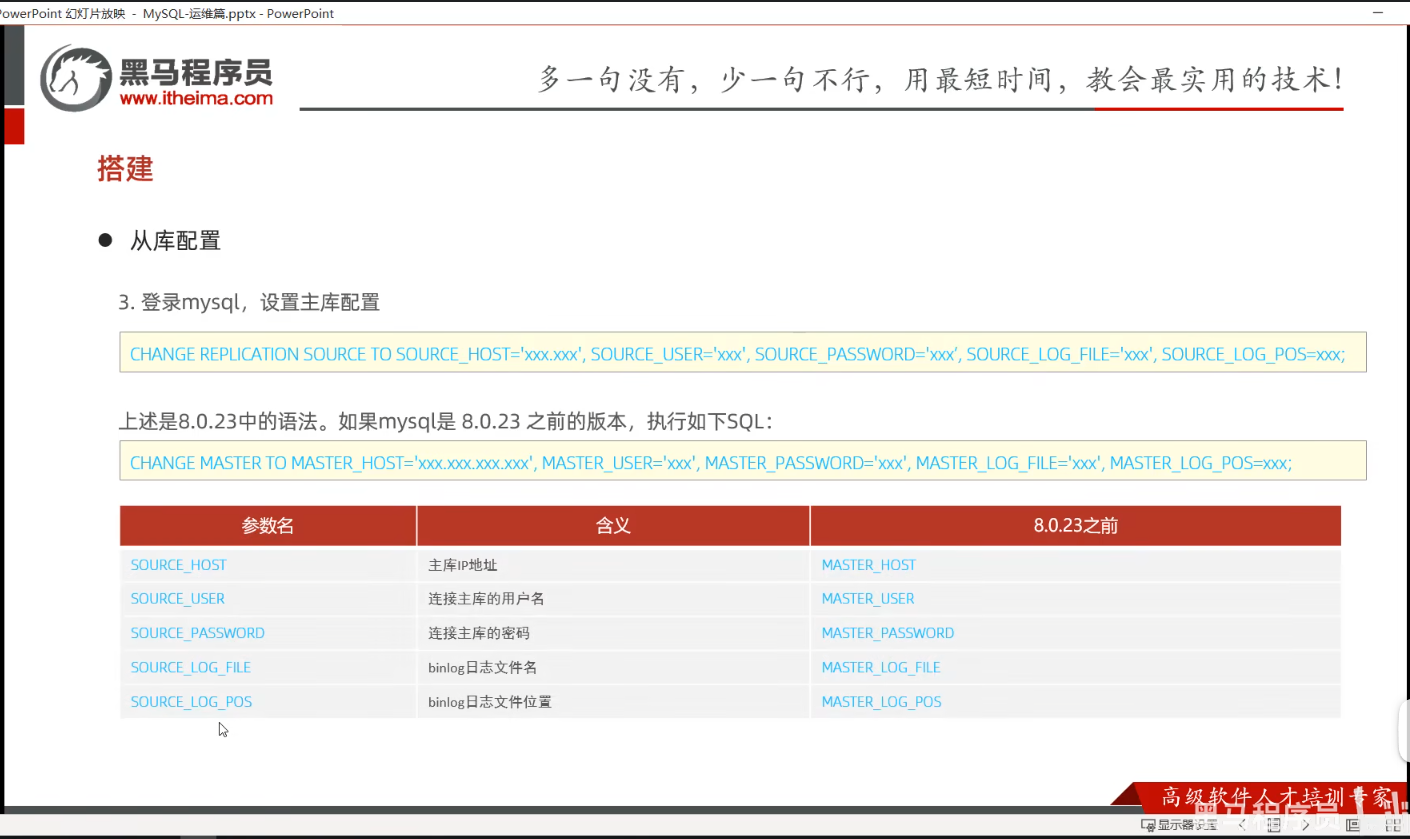
# 必须在从库中登录root账号,执行配置主库语句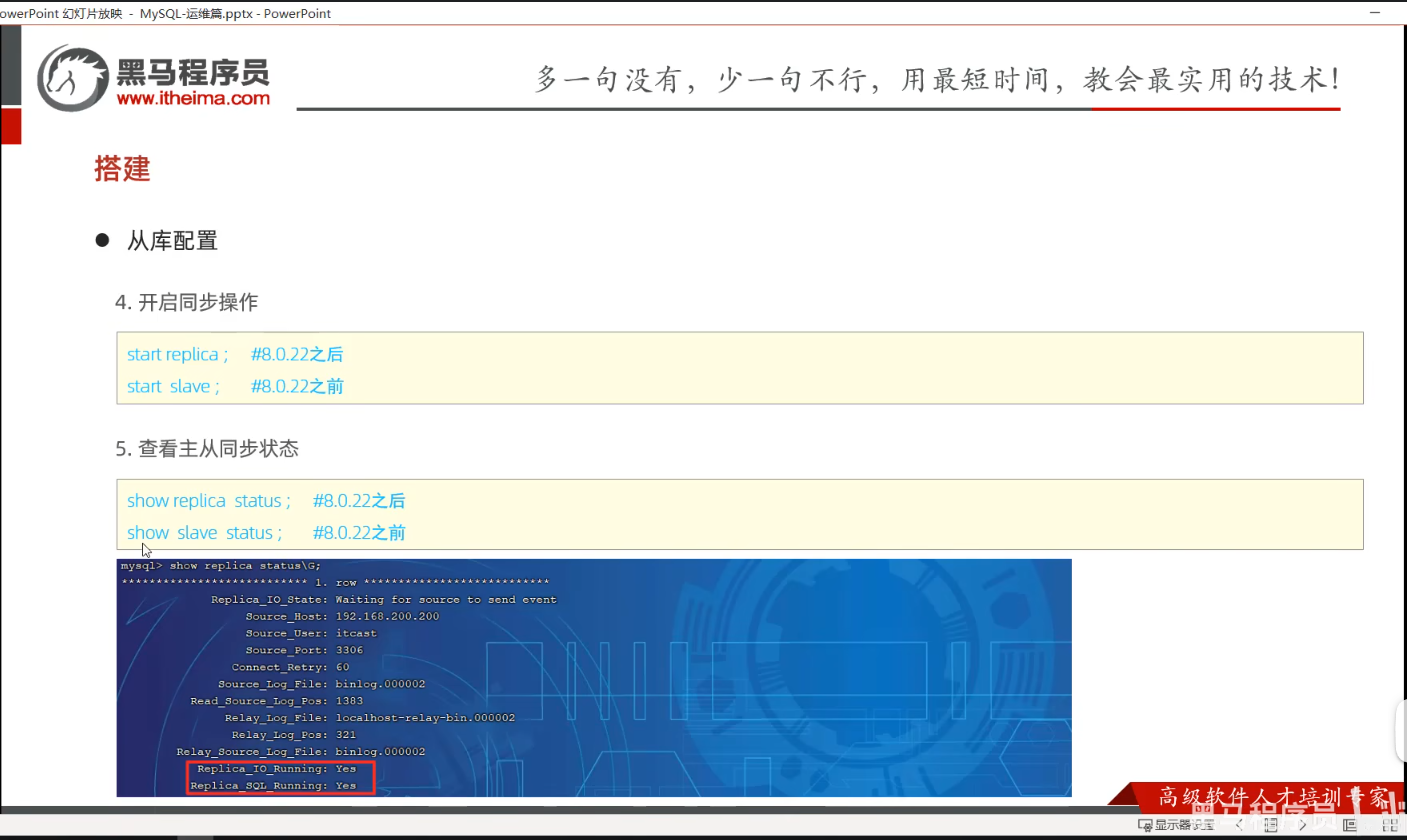
二、File+Position:复制起始位说明

(一)核心大白话解释
File: binlog.000058 + Position: 198= 告诉从库:你只同步「这个文件里、198 这个位置之后」的所有新操作,198 位置之前的所有历史数据,一概不管、一概不复制。
- binlog.000058:就是主库的二进制日志文件,主库所有增、删、改操作,全按顺序记在这个文件里;
- Position: 198:就是这个日志文件里的「字节位置」,相当于看书的页码;
- 198 之前的页码:旧数据,从库不复制;
- 198 之后的页码:新产生的所有操作,从库实时同步。
(二)举个最直白的例子
- 你现在配置完主从这一刻,相当于在这本书的 198 页夹了个书签;
- 主库以后新增的数据(新建表、插数据、改数据),都会写在 198 页后面;
- 从库只同步 198 页之后的内容,198 页之前的历史数据,从库完全不碰;
- 所以:配置之前主库已有的老数据,不会自动同步;配置之后新产生的数据,才会实时同步。
(三)如果你想把「主库所有历史老数据」也同步到从库
必须多一步:
- 先把主库现有所有数据库,手动导出成 SQL 备份;
- 再把这个备份,手动导入到从库;
- 再配置上面的
CHANGE REPLICATION SOURCE TO;这样:老数据手动导入,新数据自动同步,主从就完全一模一样了。
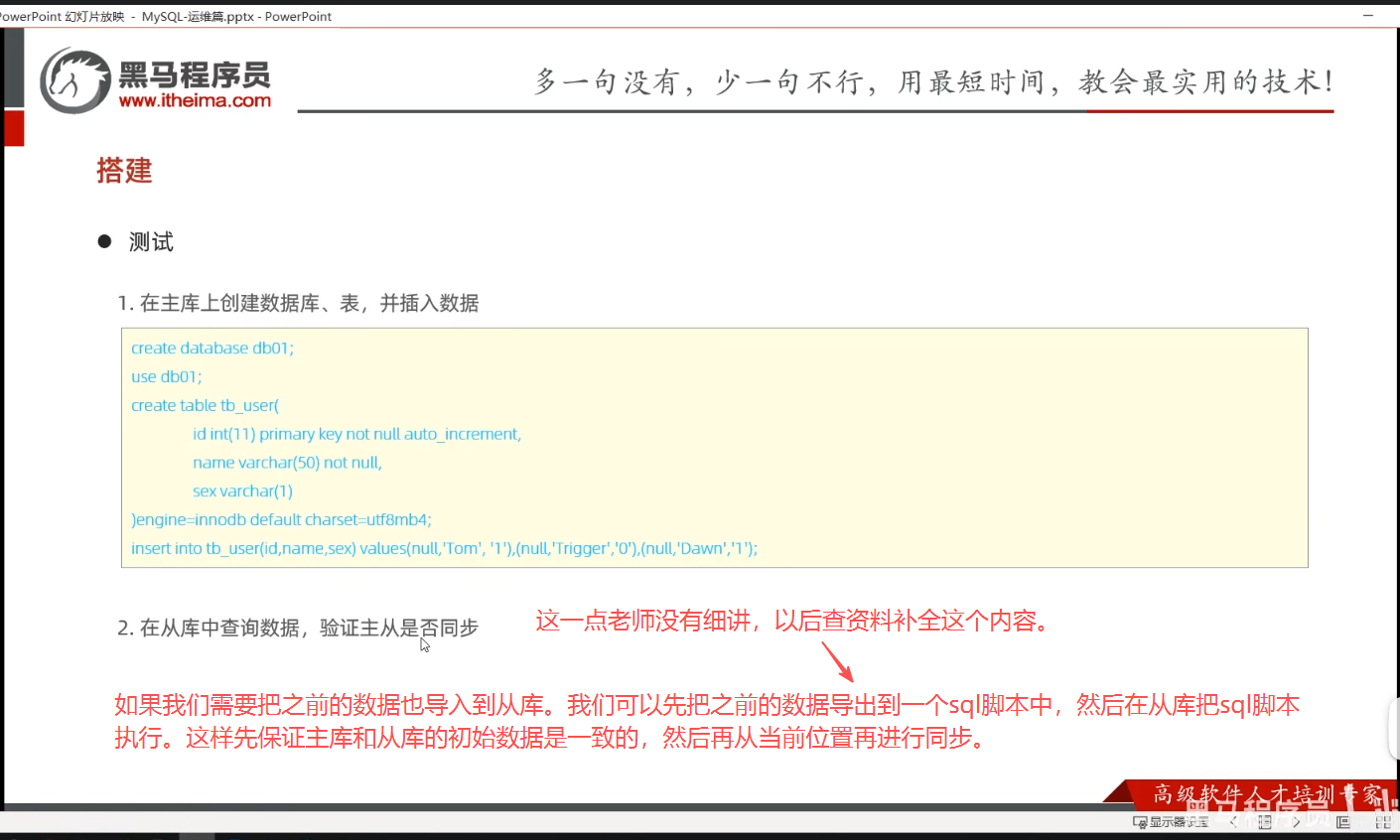
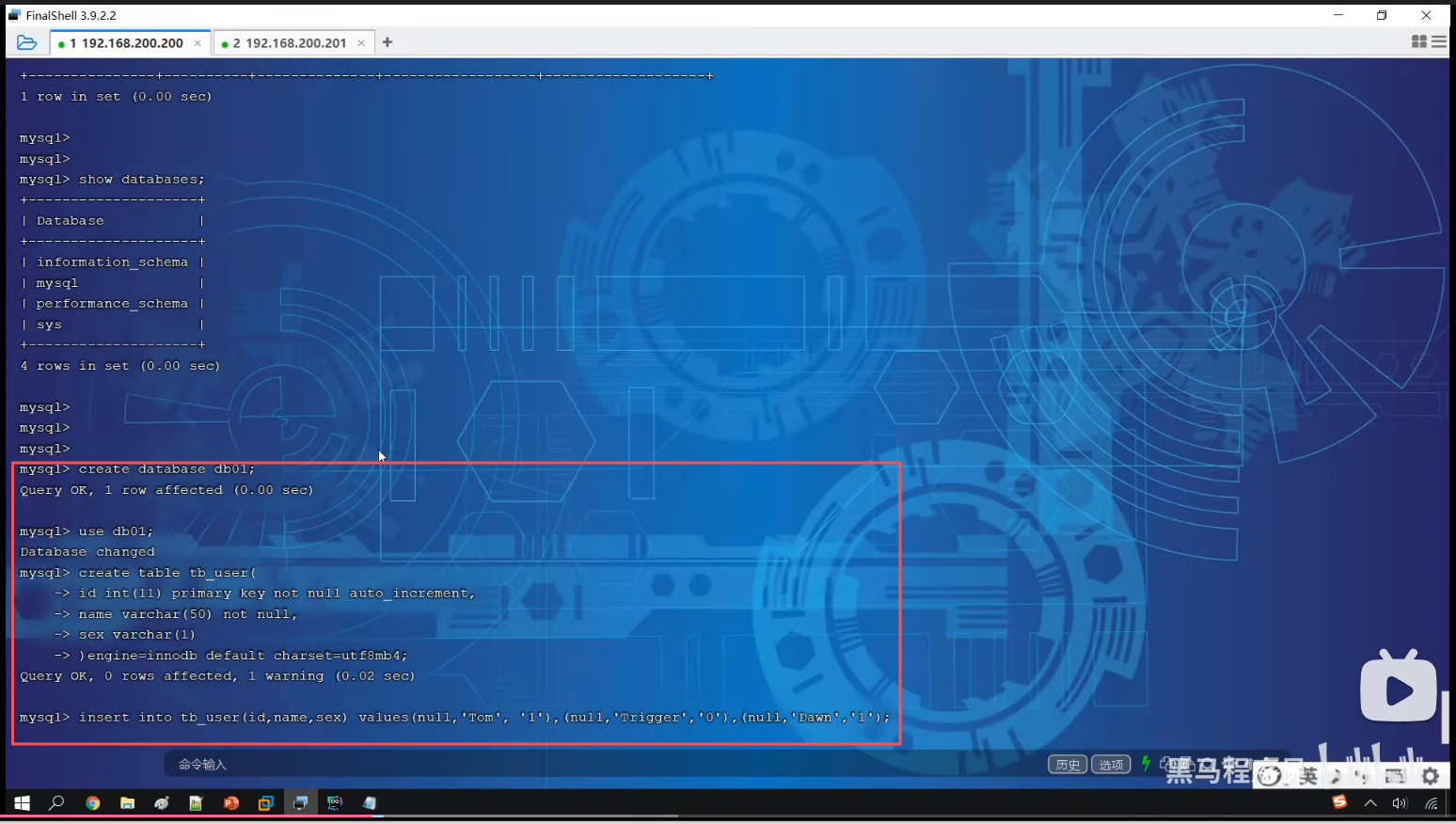
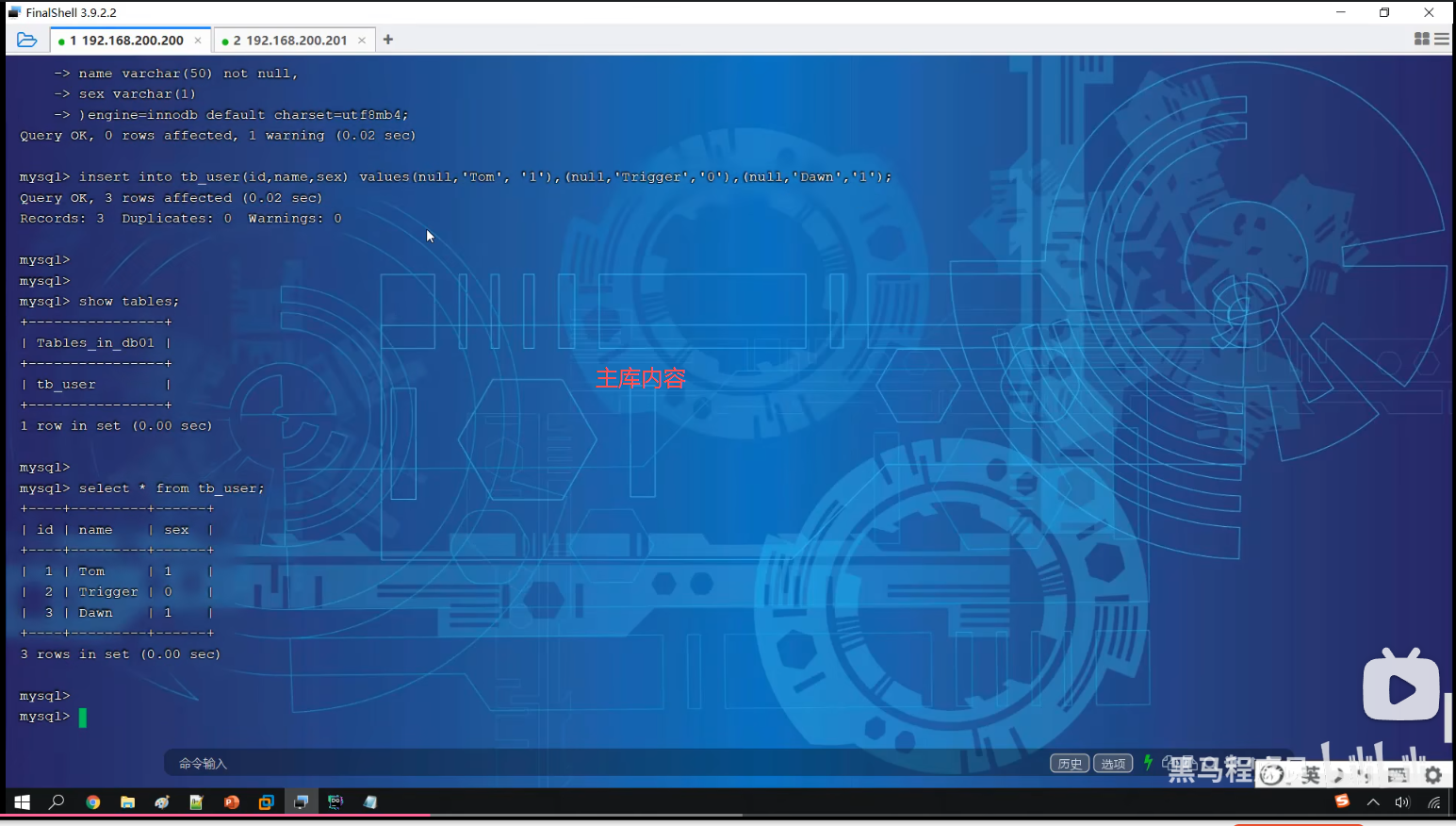
P10 测试
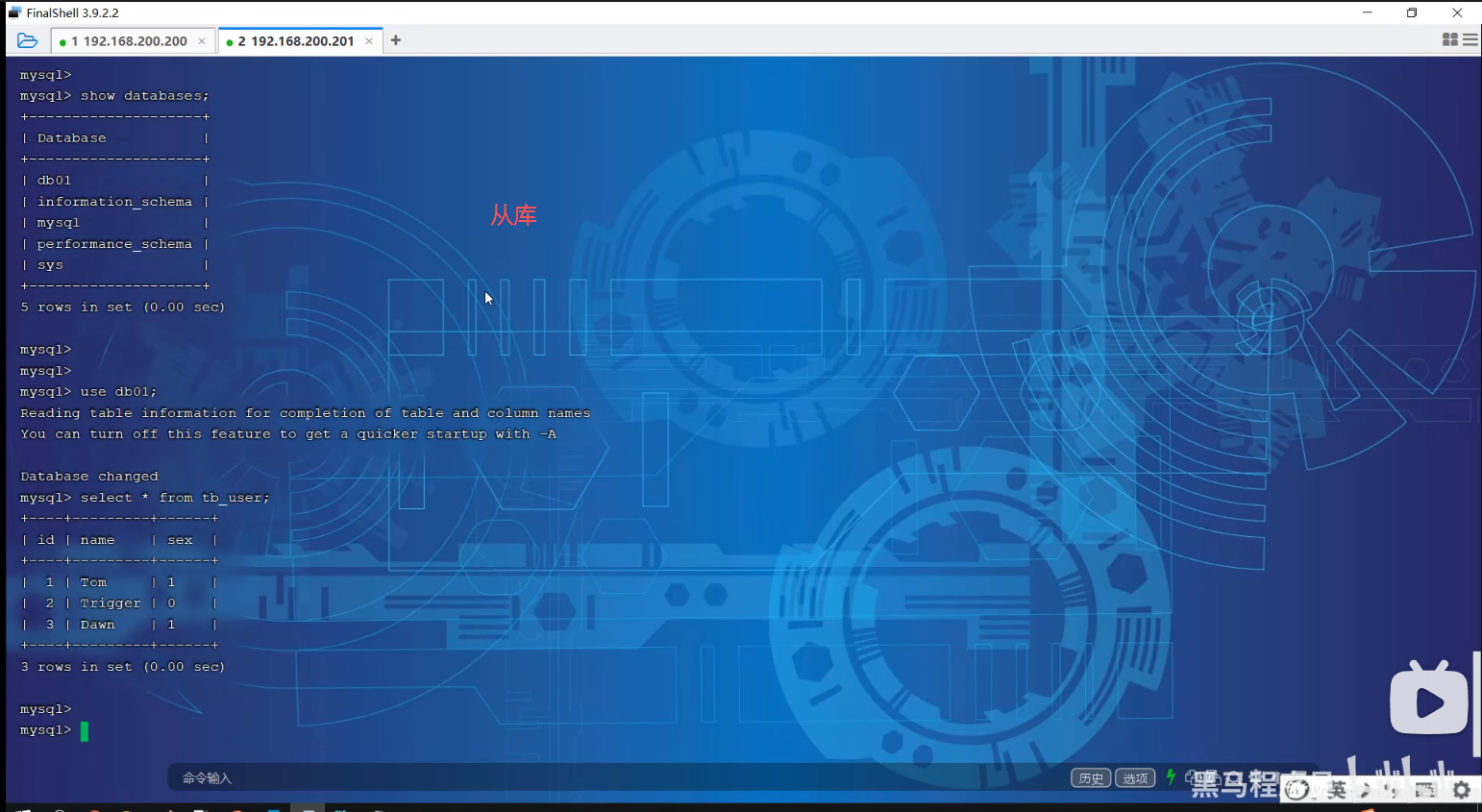
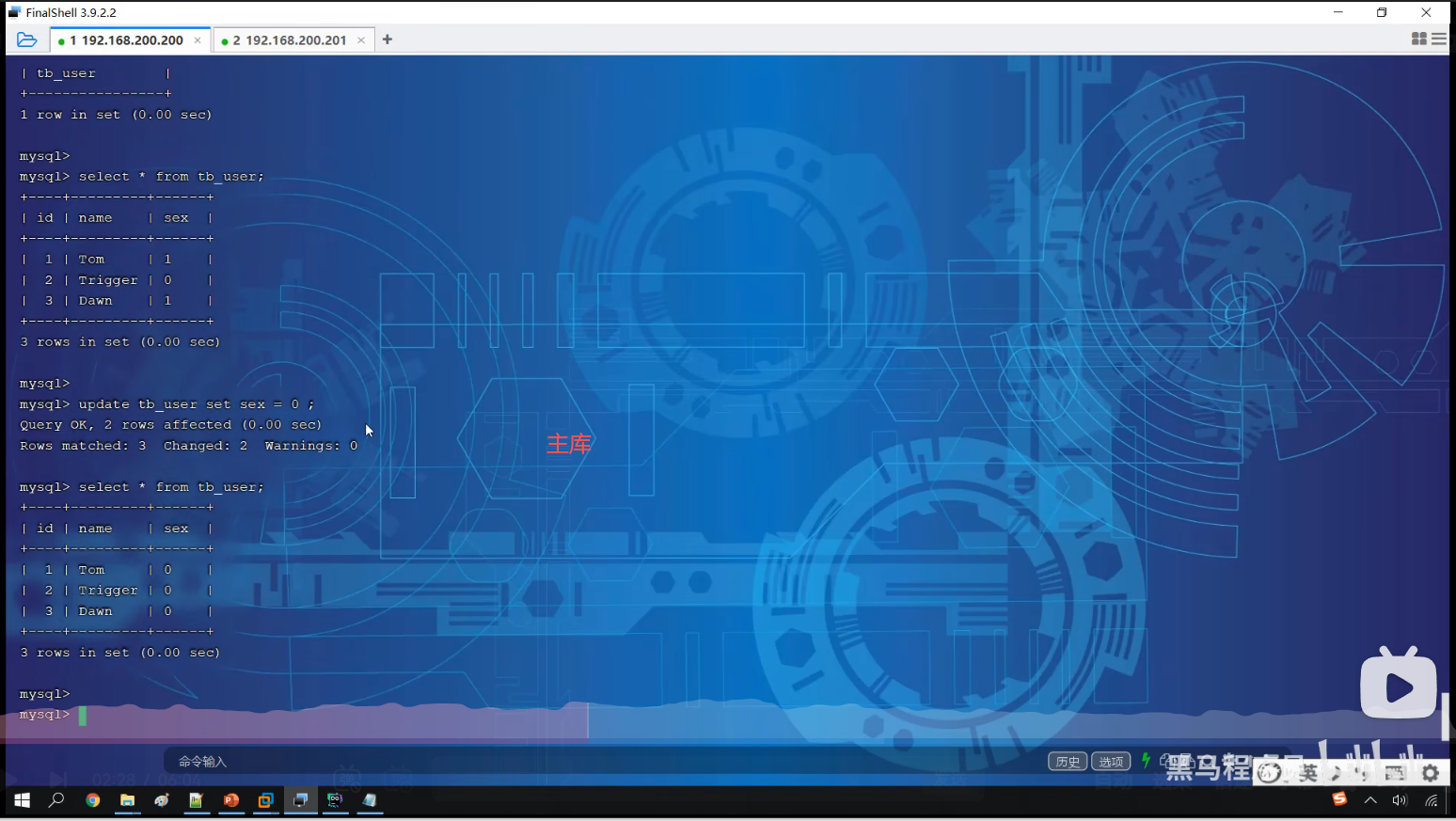
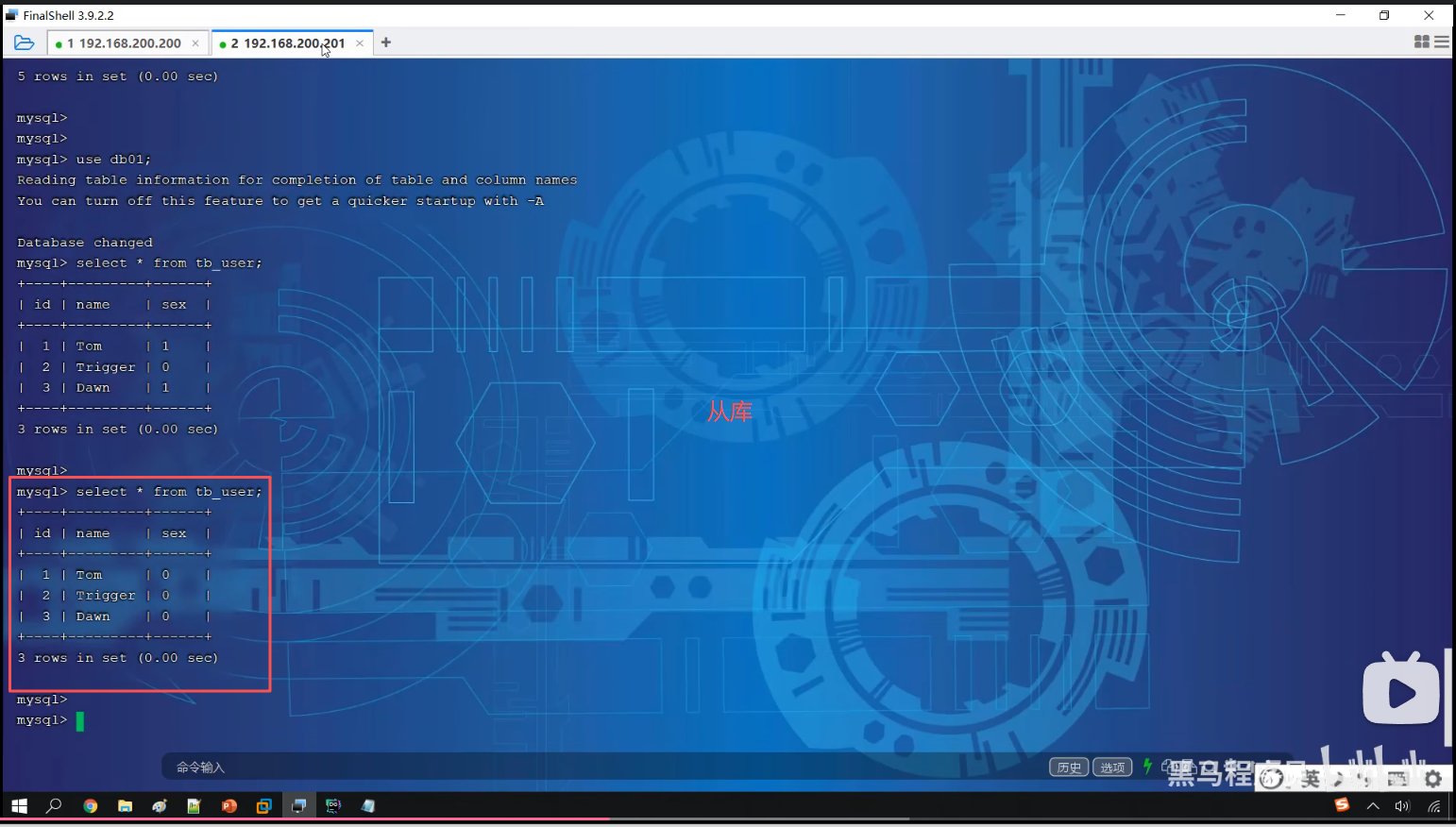

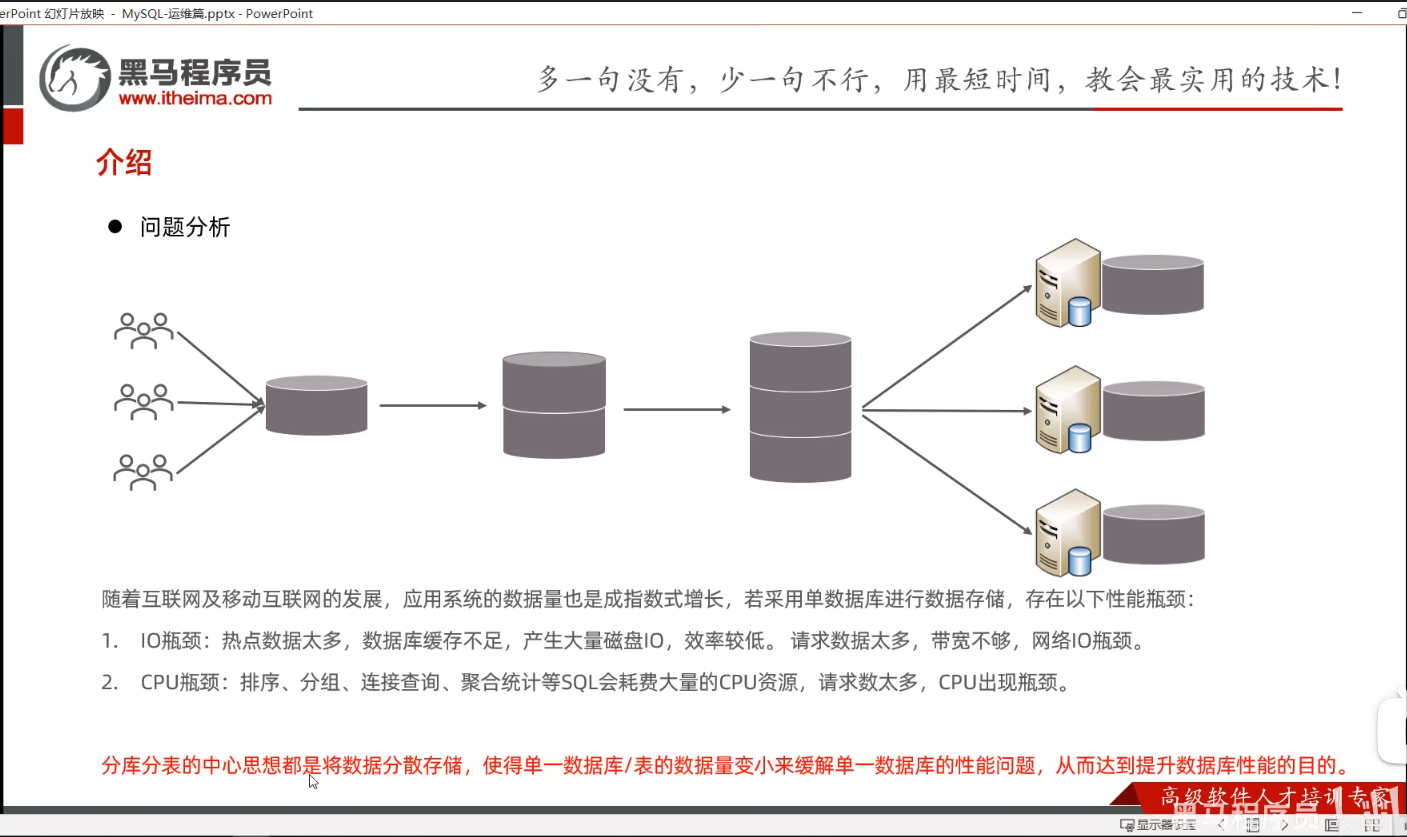
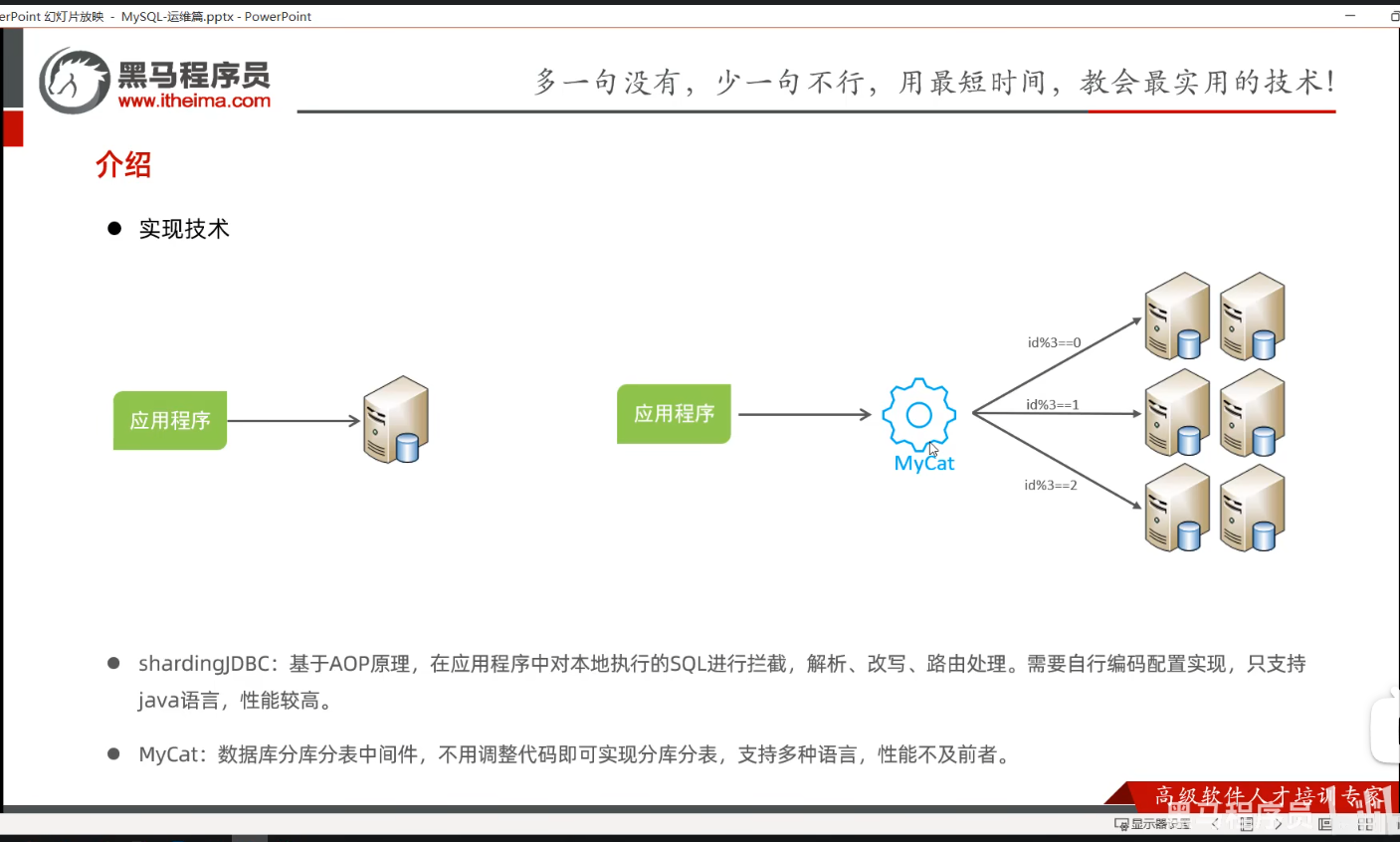
第三节分库分表
P11 介绍
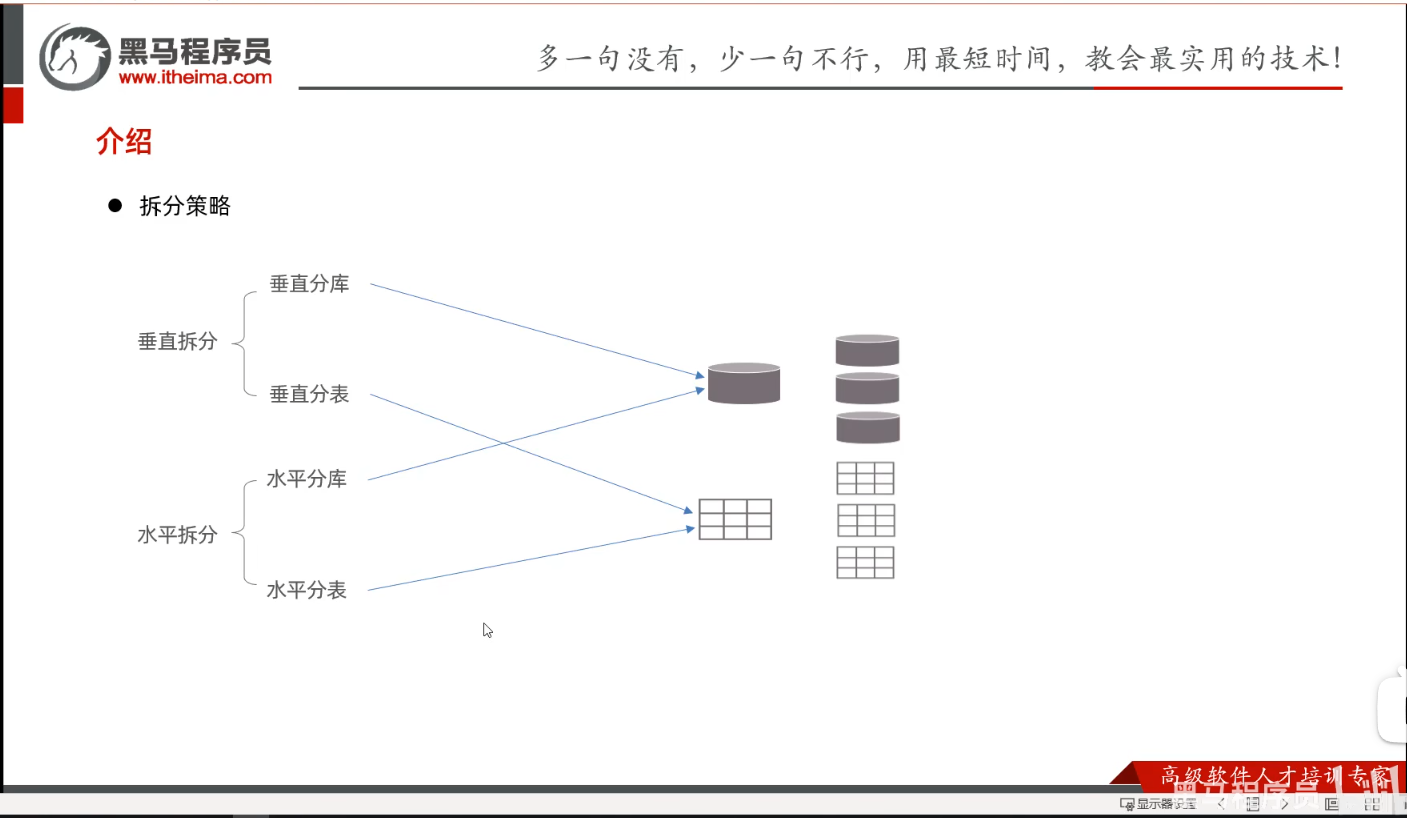
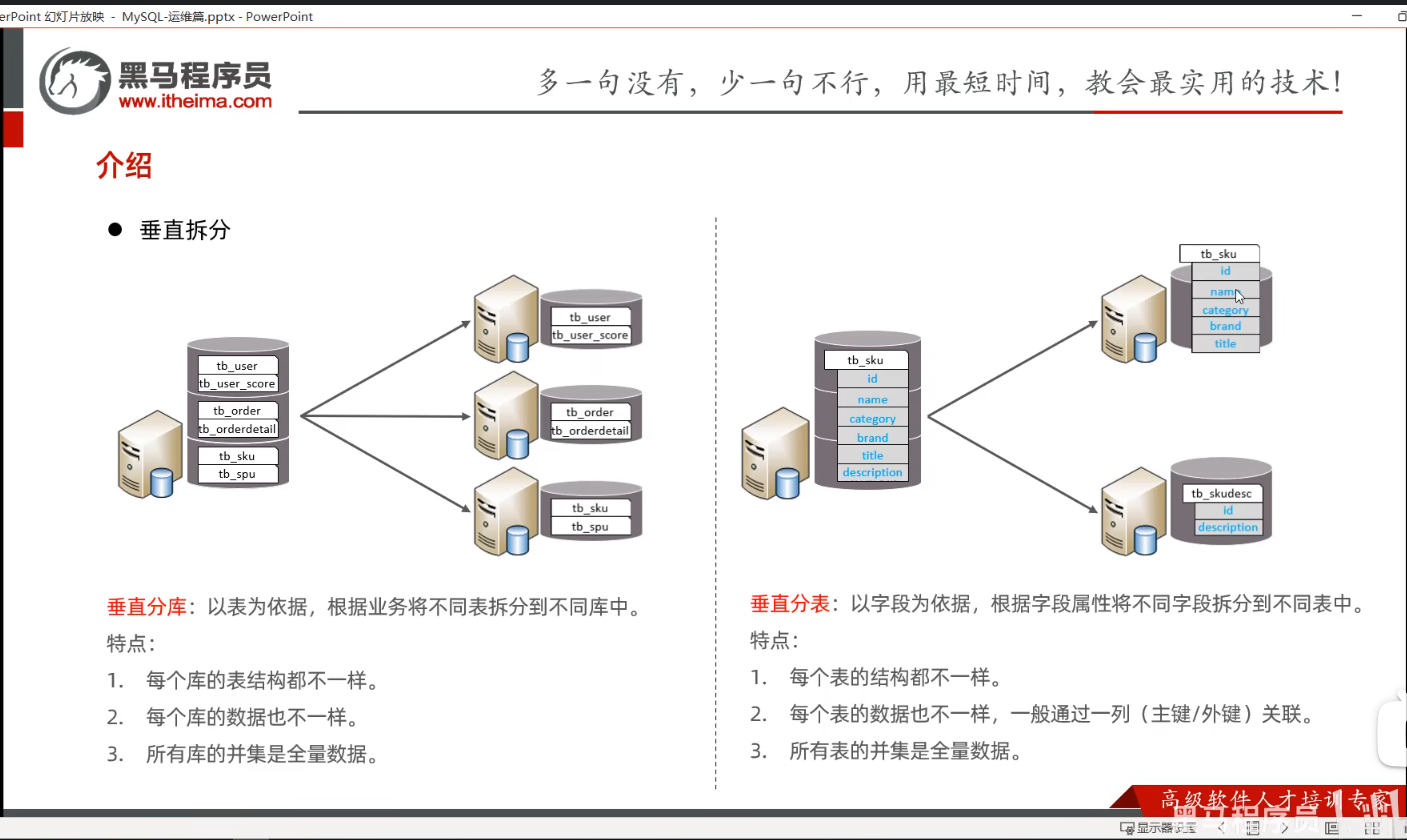
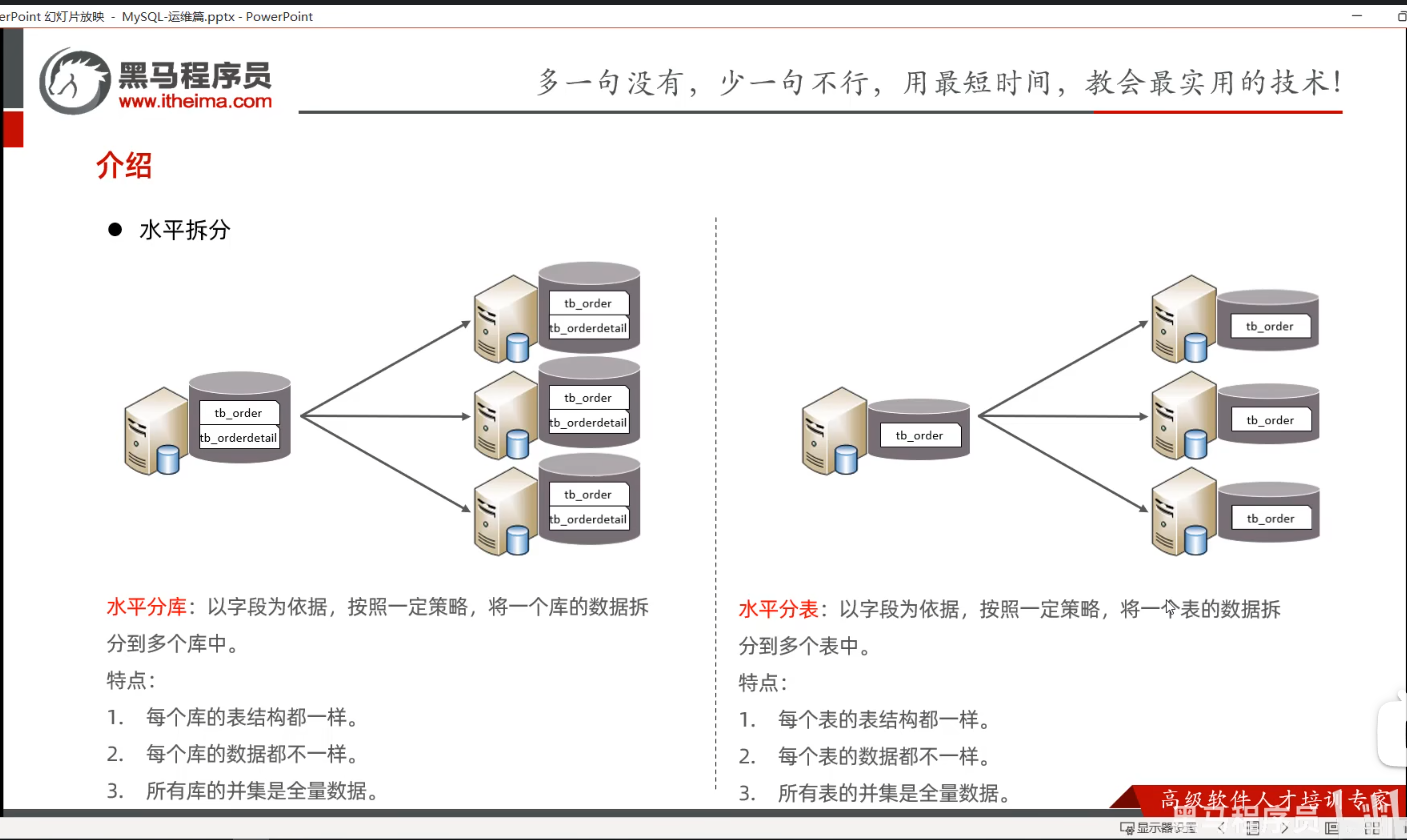
P12介绍-拆分方式
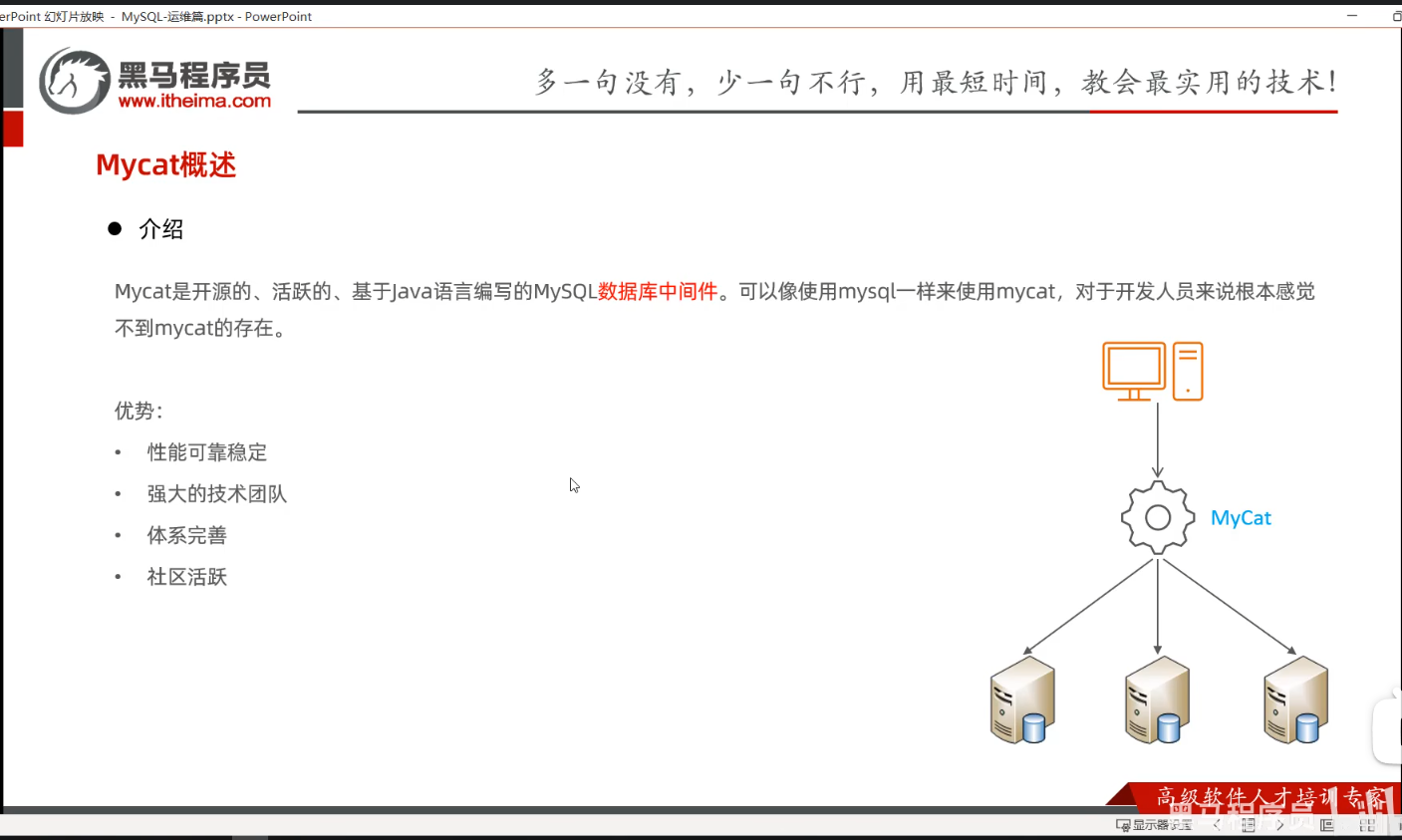
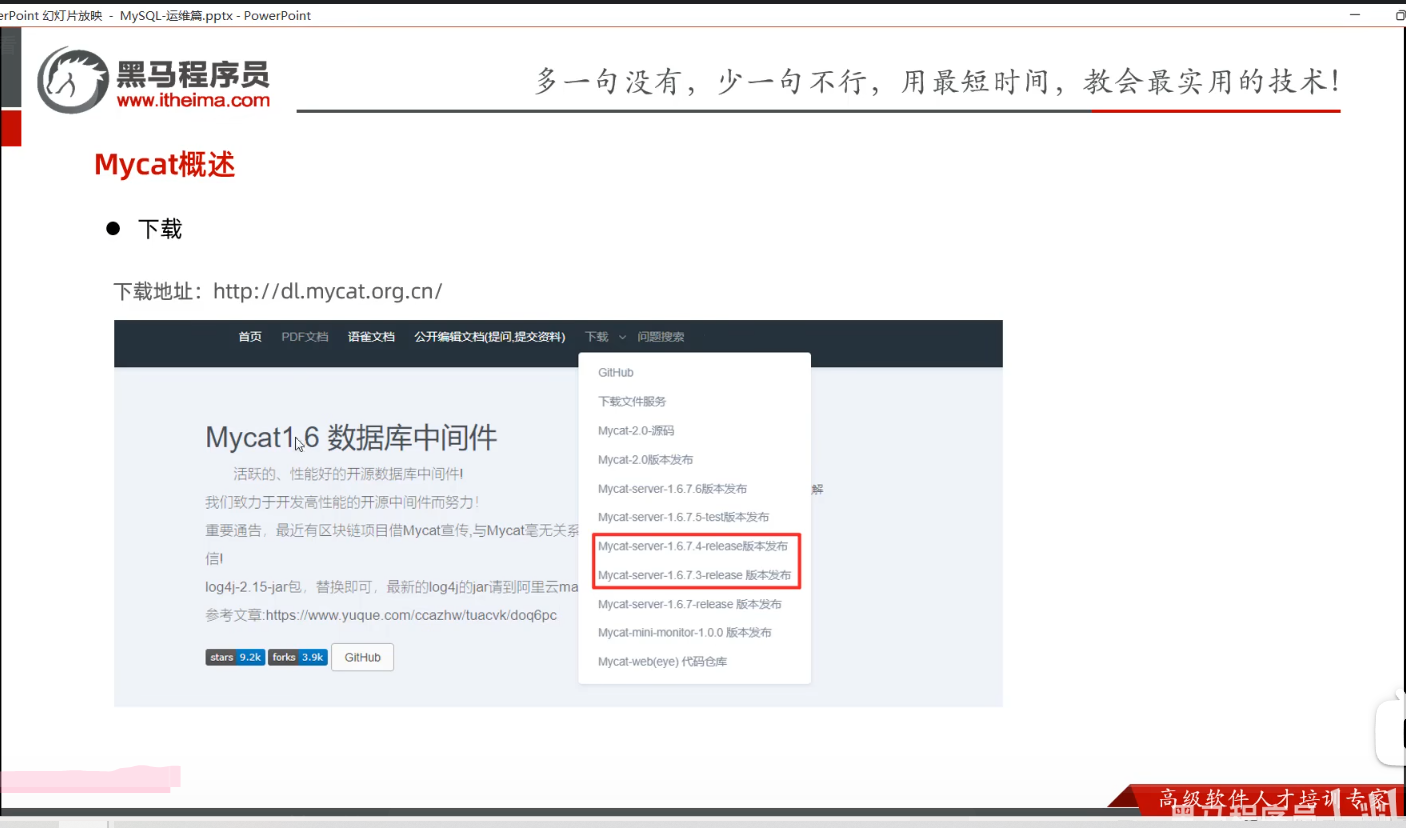
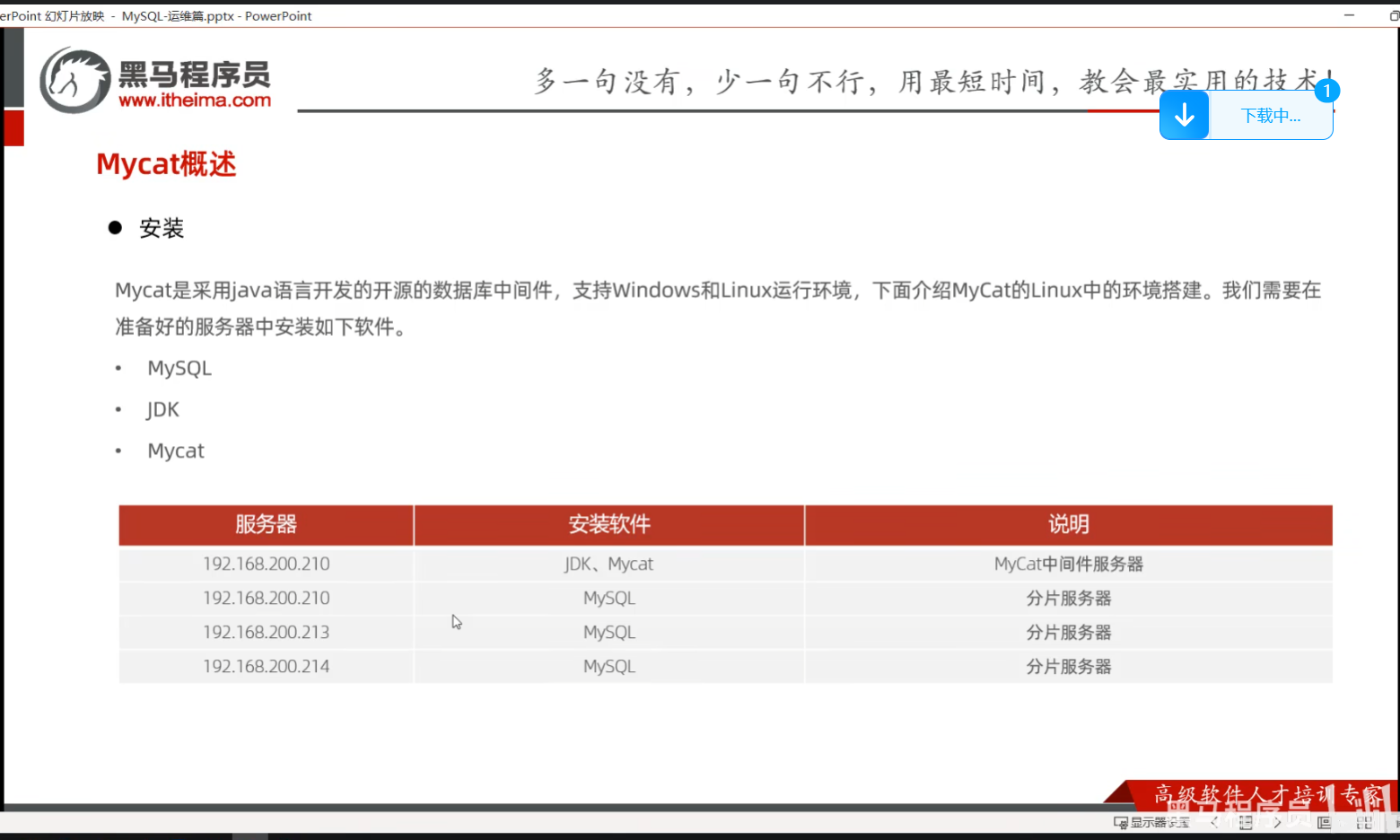
P13 MyCat概述-安装
一、课堂内容
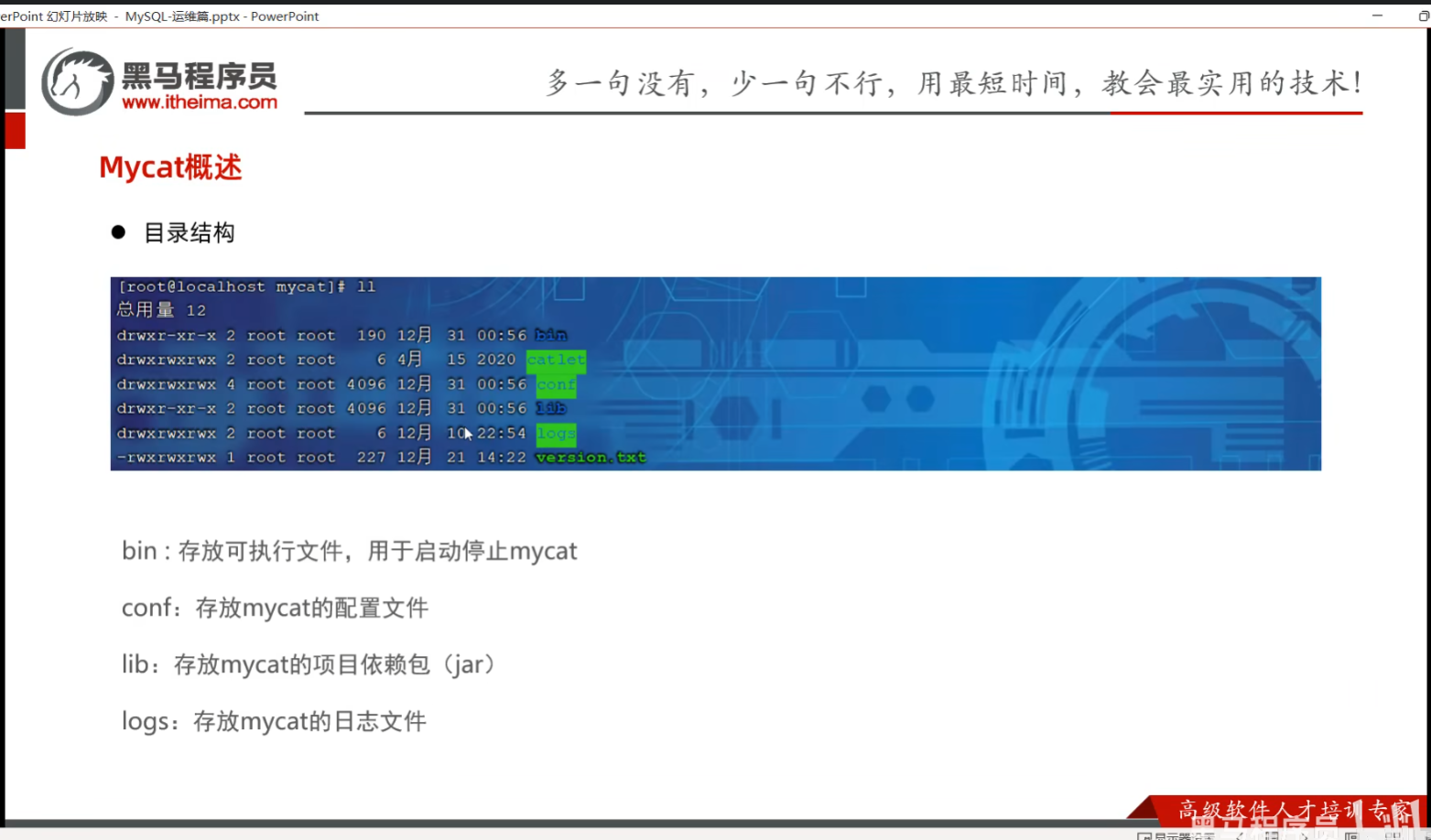
二、环境变量
(一)什么是环境变量
我再给你用最糙的人话,把环境变量扒到底,一句话给你钉死:
环境变量 = 你提前告诉电脑几个固定地址,以后你在电脑任何地方敲命令,电脑都能自动去这些地址里找程序,不用你自己跑过去。
就这么简单。你直接跑到文件夹里开 CMD 敲命令,就是手动跑过去;配置环境变量,就是让电脑帮你记住地址,你不用跑了。
它没有任何技术含量,就是一个纯纯的路径快捷方式。
(二)通用配置步骤(以 MySQL 为例,所有软件都照抄)
步骤 1:先找到软件的「核心目录」
- 目标:找到包含
.exe程序的bin文件夹。 - 比如 MySQL:
C:\Program Files\MySQL\MySQL Server 9.6\bin - 比如 JDK:
D:\Java\jdk1.8.0_171\bin(先找 JDK 根目录,再找里面的 bin)
步骤 2:新建「系统变量」(给地址起个名字)
- 打开「环境变量」窗口:右键此电脑 → 属性 → 关于(界面拉到底)→ 相关设置→ 高级系统设置 → 环境变量。
- 在系统变量区域,点「新建」(必须是系统变量,用户变量只对当前用户生效)。
- 填写信息:
- 变量名:自定义(比如
MYSQL_BAI),但要记死,后面引用要一字不差。 - 变量值:软件的
bin文件夹路径(比如C:\Program Files\MySQL\MySQL Server 9.6\bin)。
- 变量名:自定义(比如
- 点「确定」保存。
补充:如果是 JDK 这类软件,变量值建议写根目录(比如
D:\Java\jdk1.8.0_171),变量名必须用软件规定的(比如JAVA_HOME),因为第三方软件会读这个固定名字。
步骤 3:把变量加到「Path」里(关键一步,之前你绕晕的就是这里)
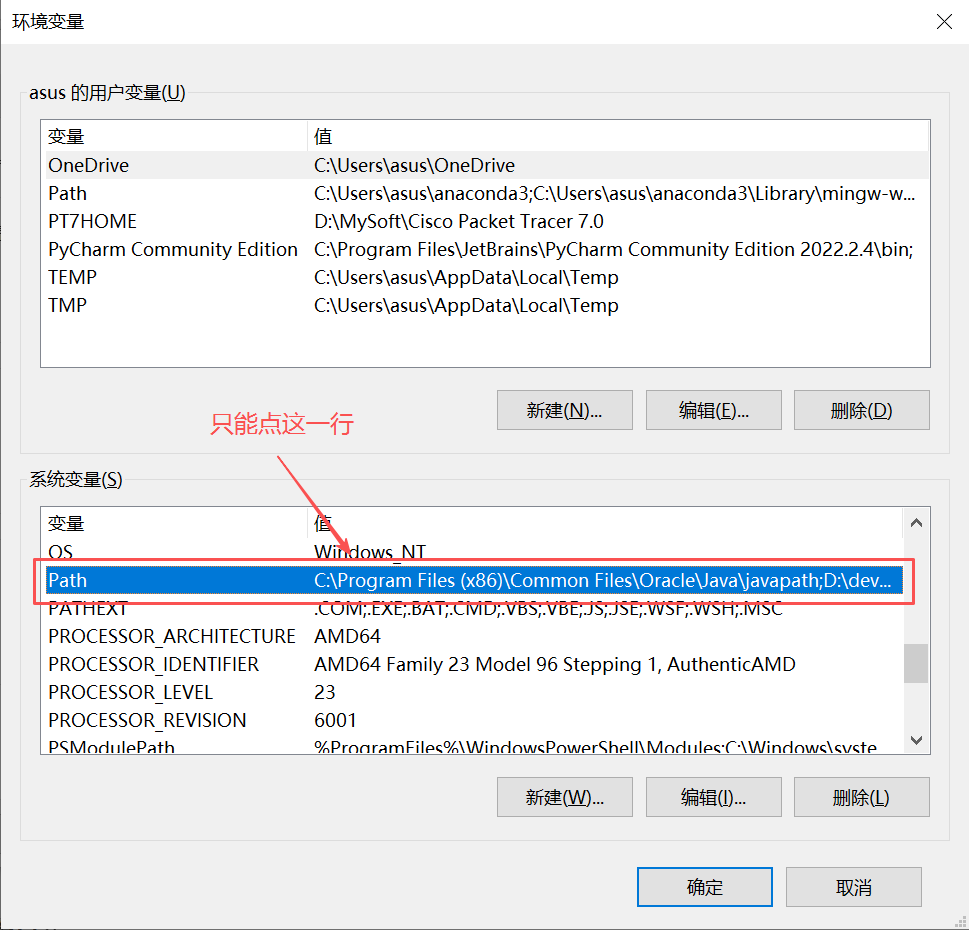
- 在系统变量列表里,找到Path这一行,选中它。
- 点下面的「编辑」按钮,弹出「编辑环境变量」窗口。
- 点「新建」,输入:
%变量名%(比如%MYSQL_BAI%)。- 这里的
%是「引用变量」的语法,系统会自动把它解析成你之前存的 bin 路径。
- 这里的
- 一路点「确定」,把所有窗口都关掉(必须全关,配置才会生效)。
步骤 4:验证配置是否成功(必须做,避免白忙活)
- 关闭所有已打开的 CMD 窗口,重新打开一个新的 CMD(旧窗口不读新配置)。
- 输入软件的命令验证:
- MySQL:
mysql -V(显示版本号就是成功) - JDK:
java -version - Python:
python --version
- MySQL:
- 能显示版本号 = 配置成功;提示 “不是内部命令” = 配置失败,回去检查。
(三)你踩过的坑 + 避坑指南(重点!)
1. 最容易搞混的两个操作:别选错行!
- ❌ 错误:选中自己建的变量(比如
MYSQL_BAI),点「编辑」。👉 这只会修改变量本身,跟 “让系统能找到命令” 没关系。 - ✅ 正确:选中系统变量里的 Path 这一行,再点「编辑」,把变量加进去。
2. 变量值别写错路径!
- ❌ 错误:变量值写到
.exe文件(比如C:\...\bin\mysql.exe)。👉 环境变量只认文件夹,不认单个文件,写文件会直接失效。 - ✅ 正确:变量值写到
bin文件夹这一层(比如C:\...\bin)。
3. 变量名必须前后一致!
- 变量名里的大小写、下划线、字母,必须和
Path里引用的完全一样。 - 比如变量名是
MYSQL_BAI,引用时必须写%MYSQL_BAI%,少一个字母、多一个下划线都不行。
4. 配置完必须关窗口重开!
- 旧的 CMD 窗口不会读取新的环境变量配置,不重开就会一直报错。
- 必须把所有环境变量窗口、CMD 窗口都关掉,再新开一个测试。
5. 第三方软件(如 JDK)别瞎改变量名!
- 像 JDK、Tomcat、MyCat 这类软件,会自动读取固定的变量名(比如
JAVA_HOME)。 - 变量名必须严格按照软件要求写,不能自己随便起名,否则软件找不到环境会直接闪退。
(四)一句话总结(所有软件通用)
建变量存地址 → 加到 Path 里引用 → 重开 CMD 验证
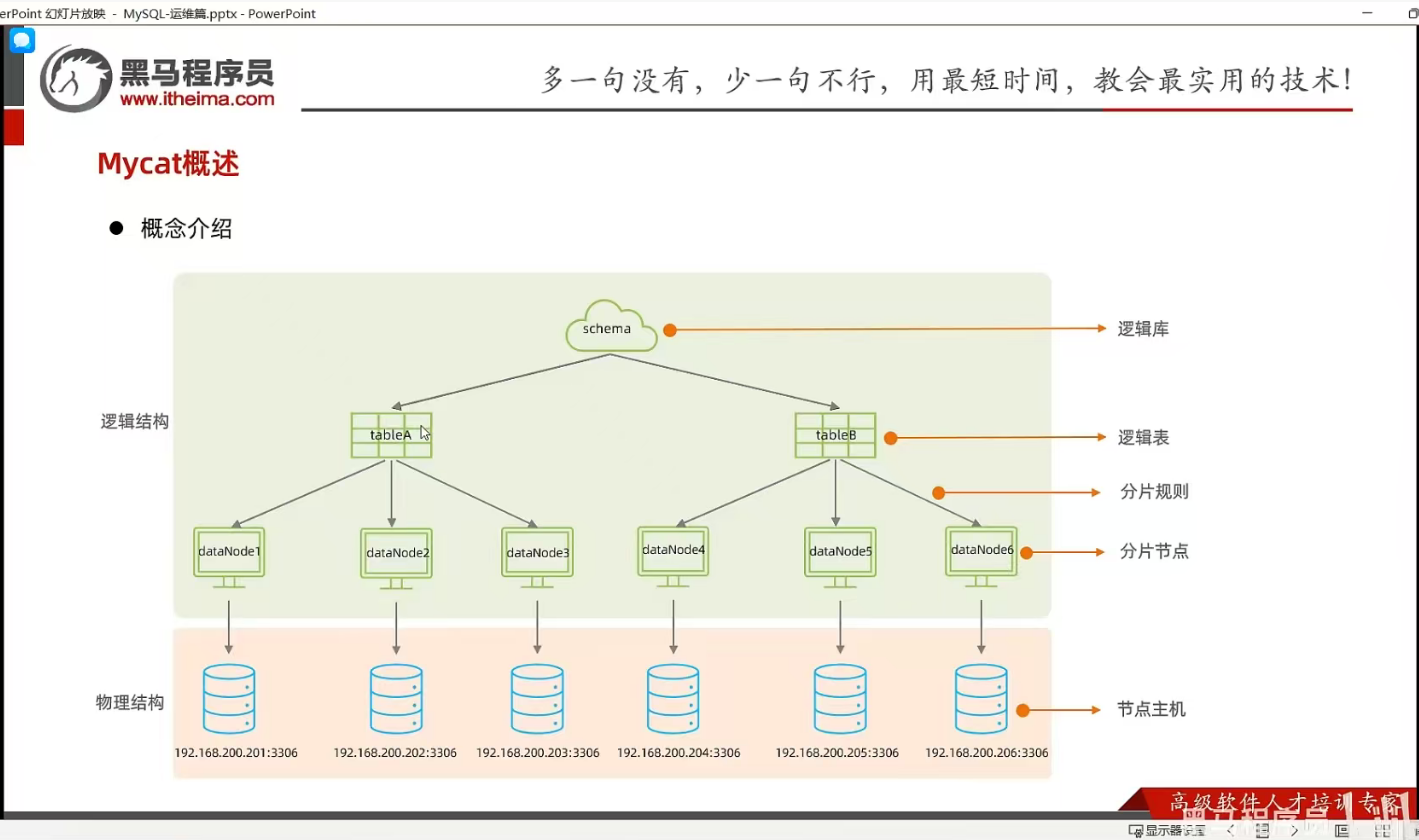
P14 MyCat概述-核心概念
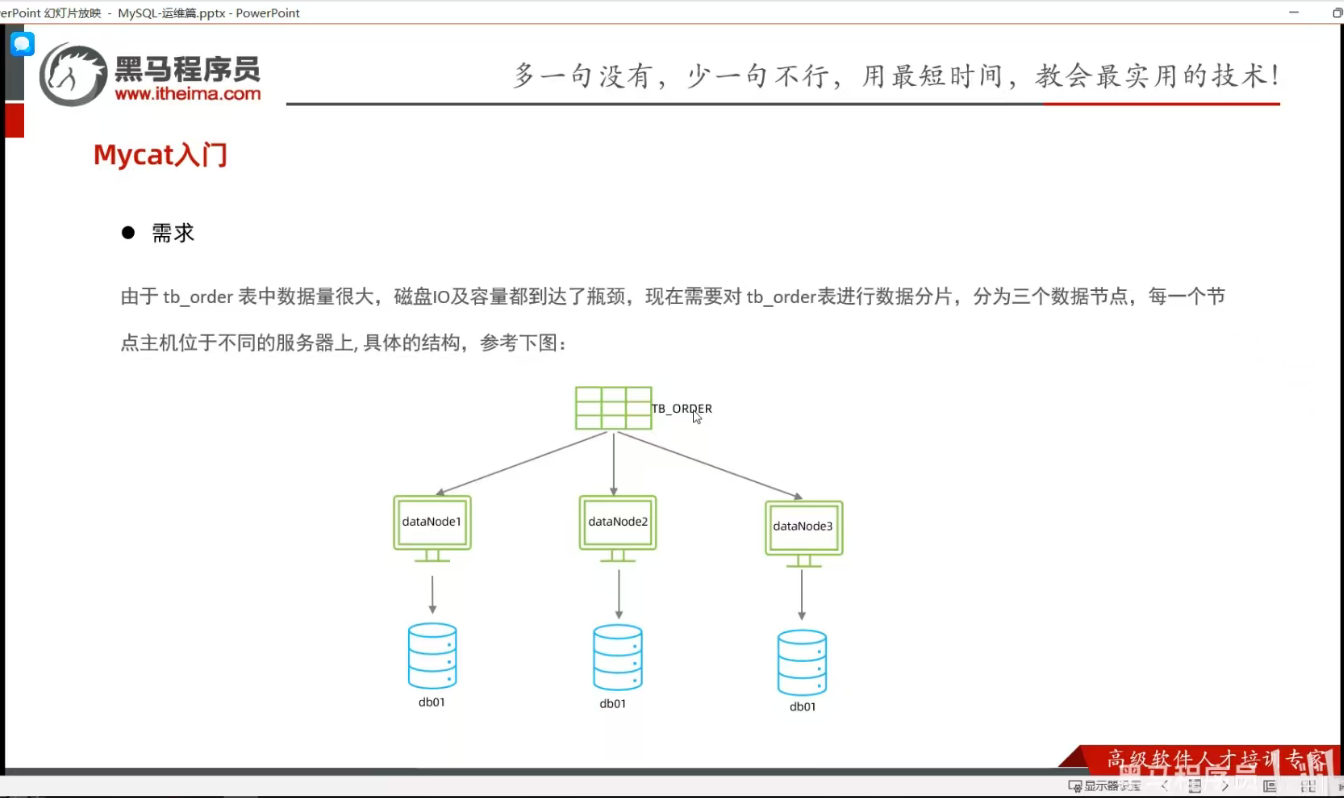
P15 MyCat入门
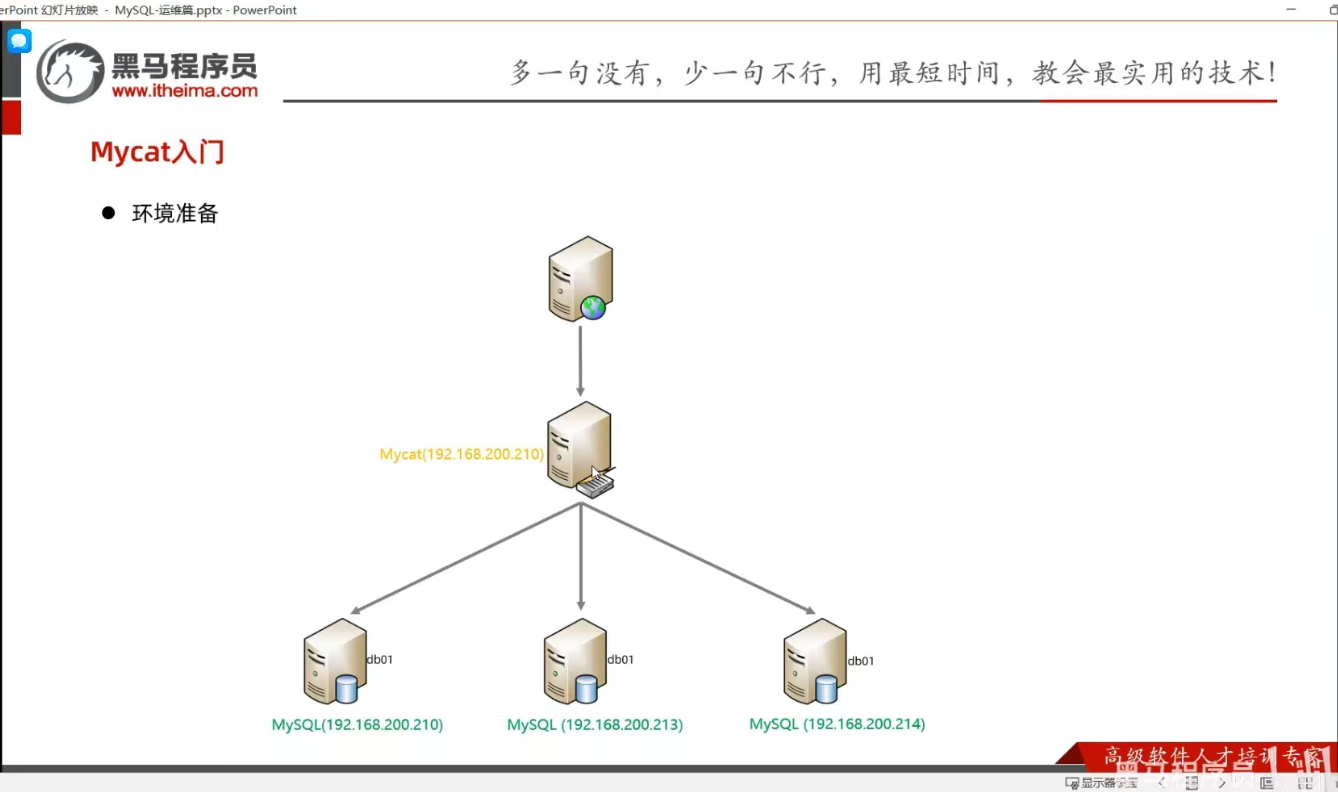
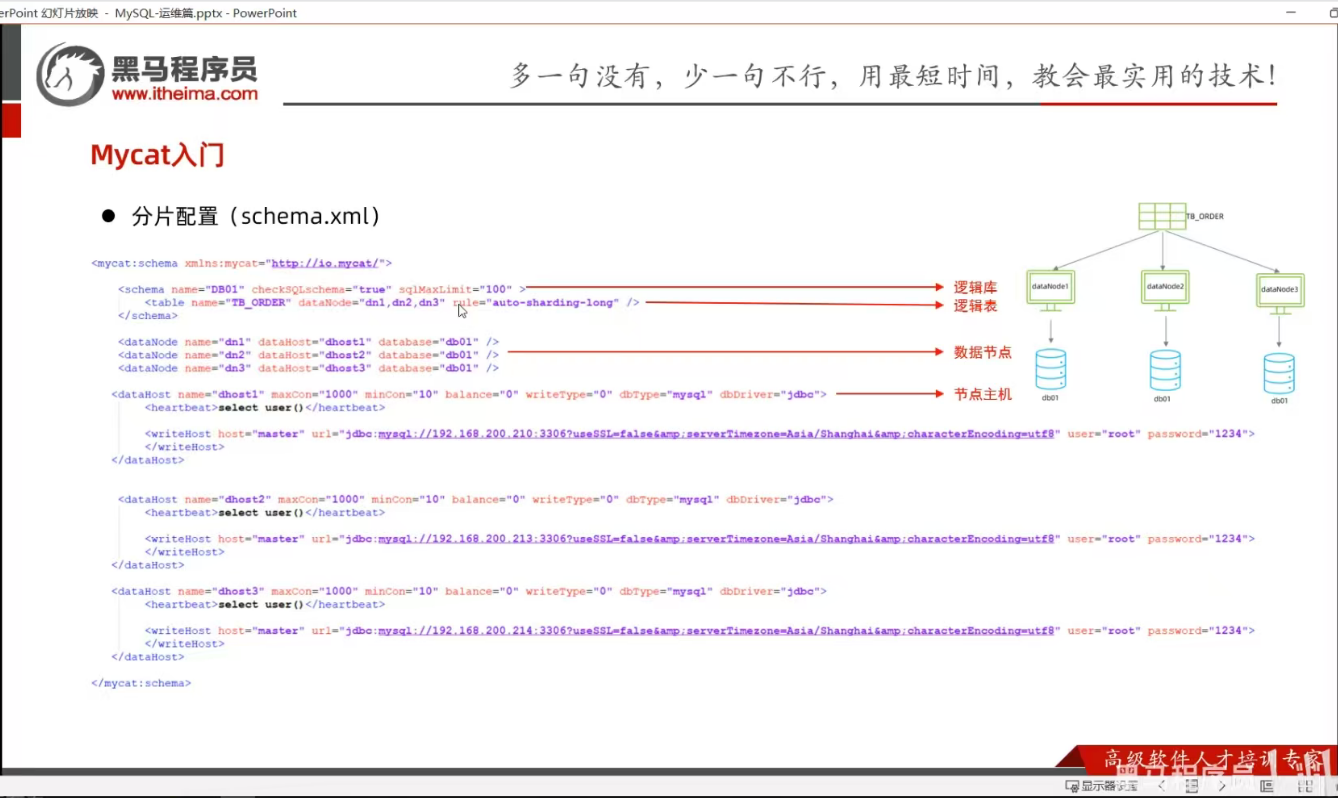
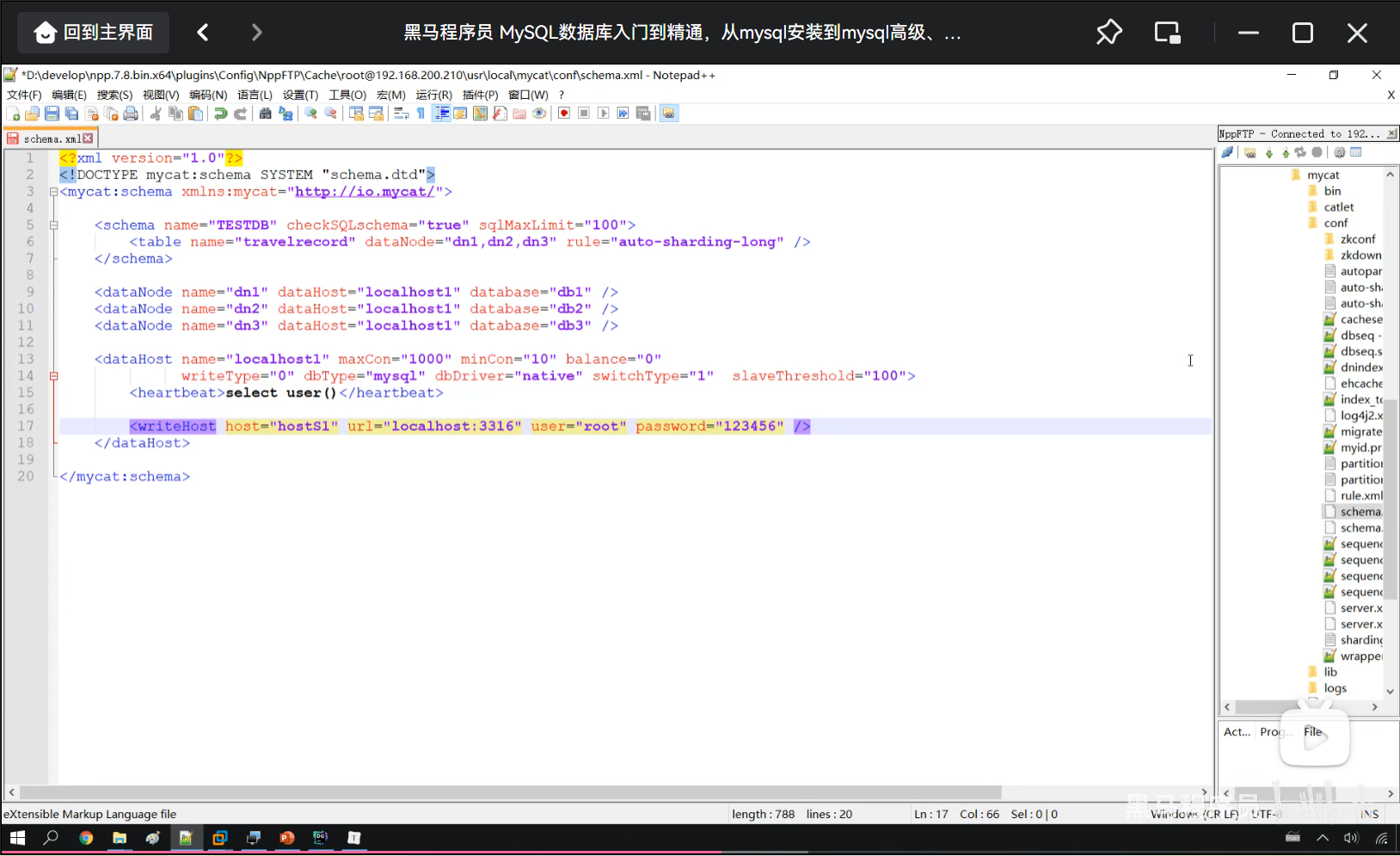
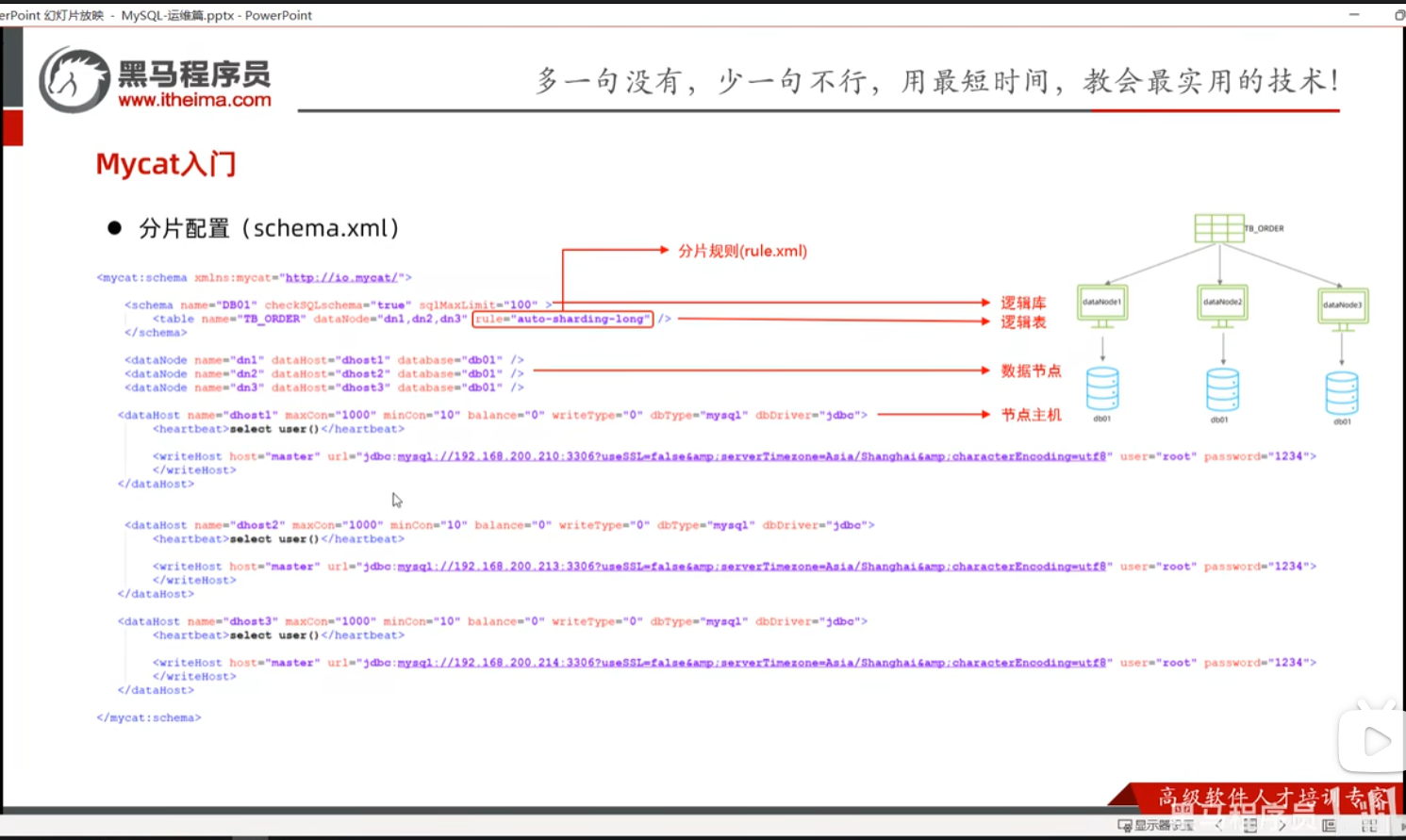
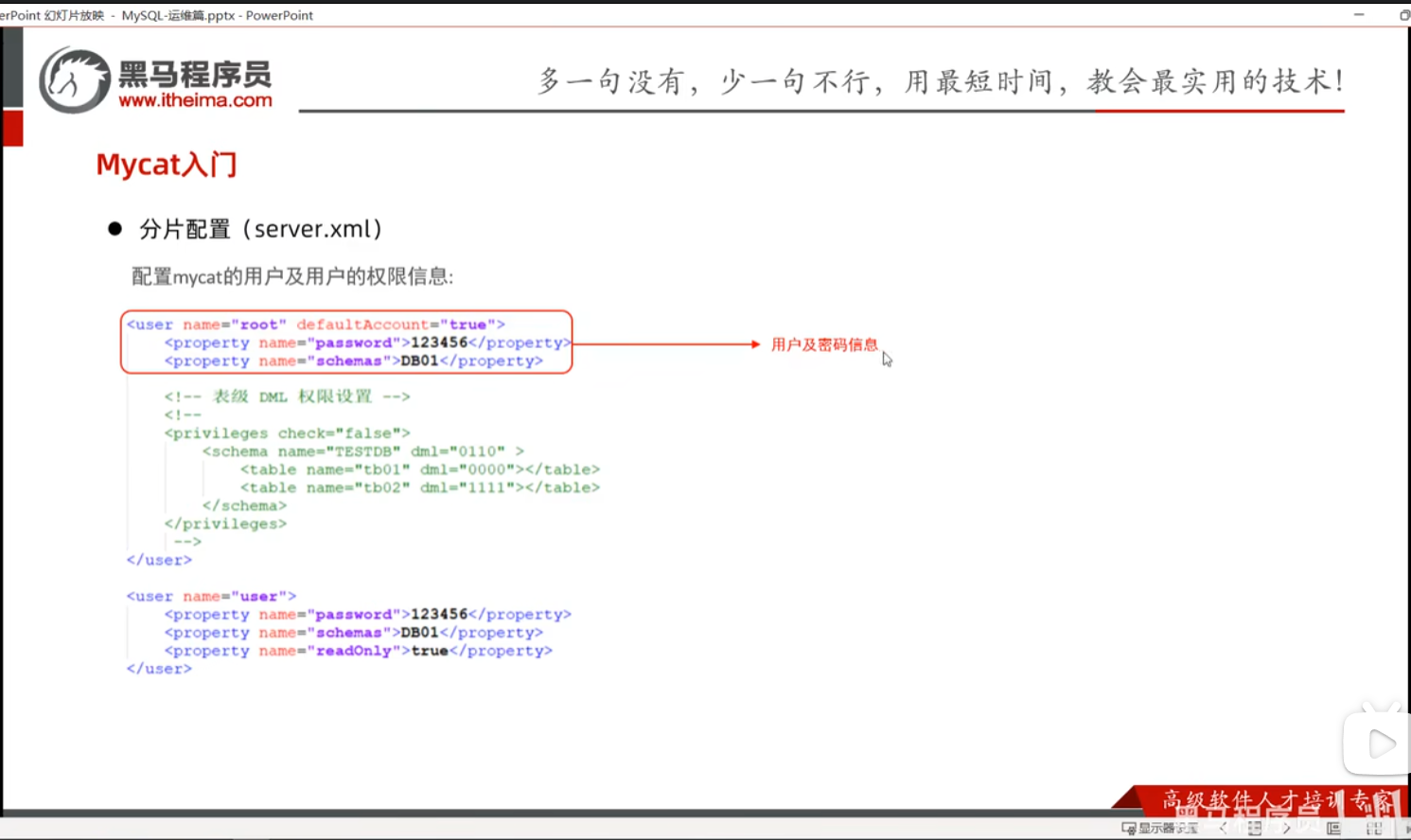
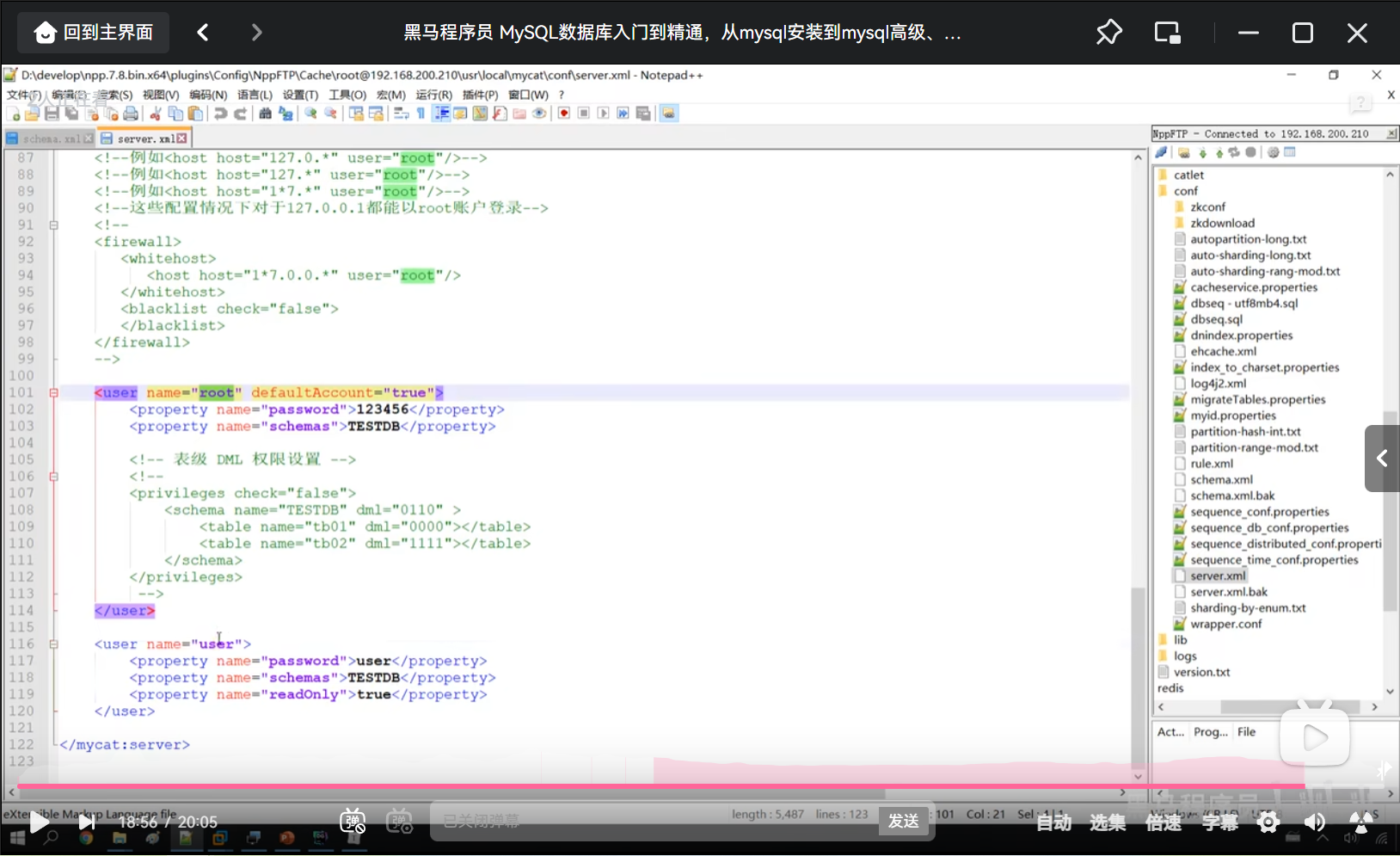
P16 MyCat入门-测试
MyCat配置1
MyCat配置2
Mycat分片-垂直分库
Mycat分片-垂直分库-测试
Mycat分片-水平分表
分片规则-范围分片
分片规则-取模分片
分片规则-一致性hash算法
分片规则-枚举分片
分片规则-应用指定算法
分片规则-固定hash算法
分片规则-字符串has解析
分片规则-按天分片
分片规则-按自然月分片
Mycat管理与监控-原理
Mycat管理工具
MyCat监控1
MyCat监控2
总结
第四节 读写分离
P36 介绍
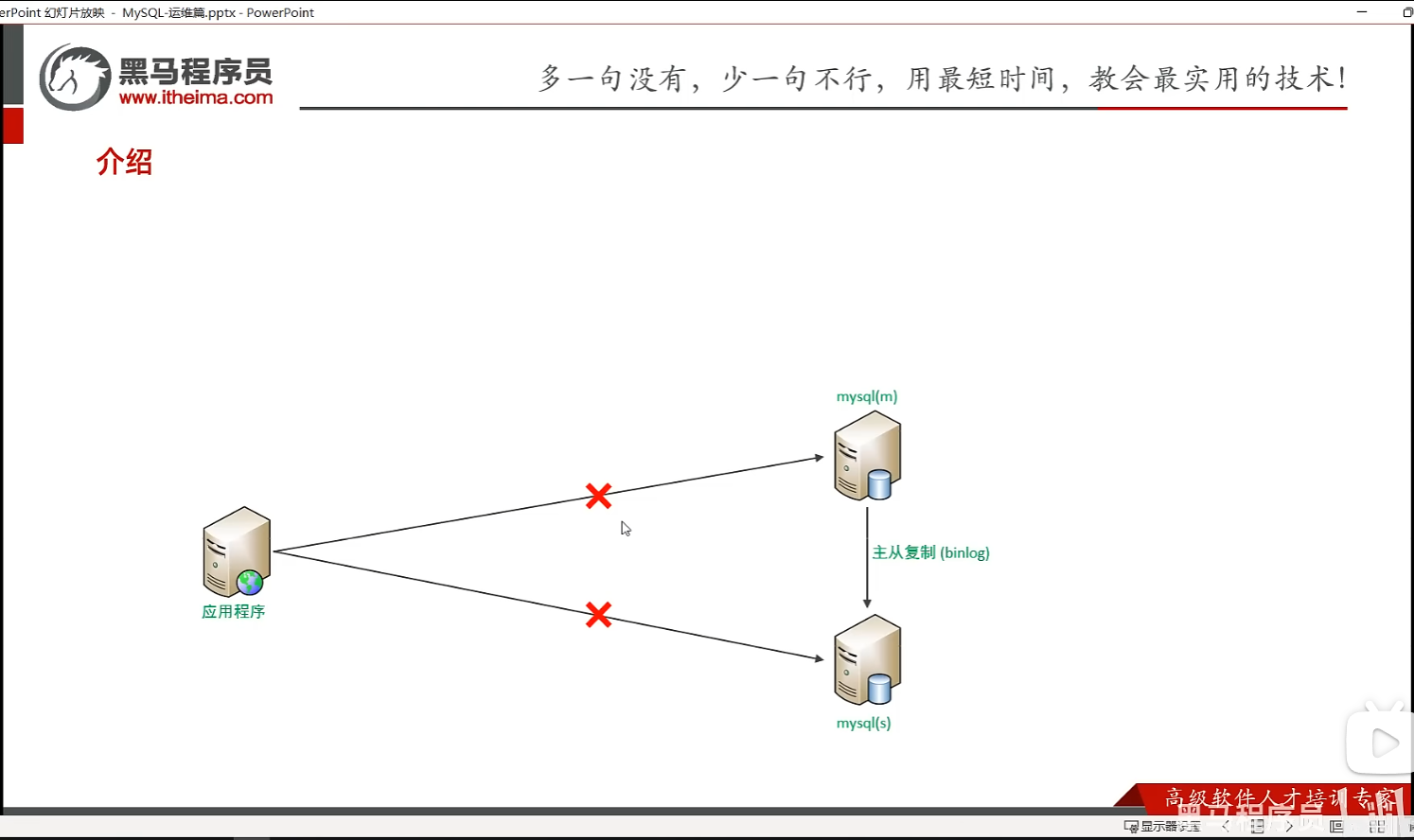
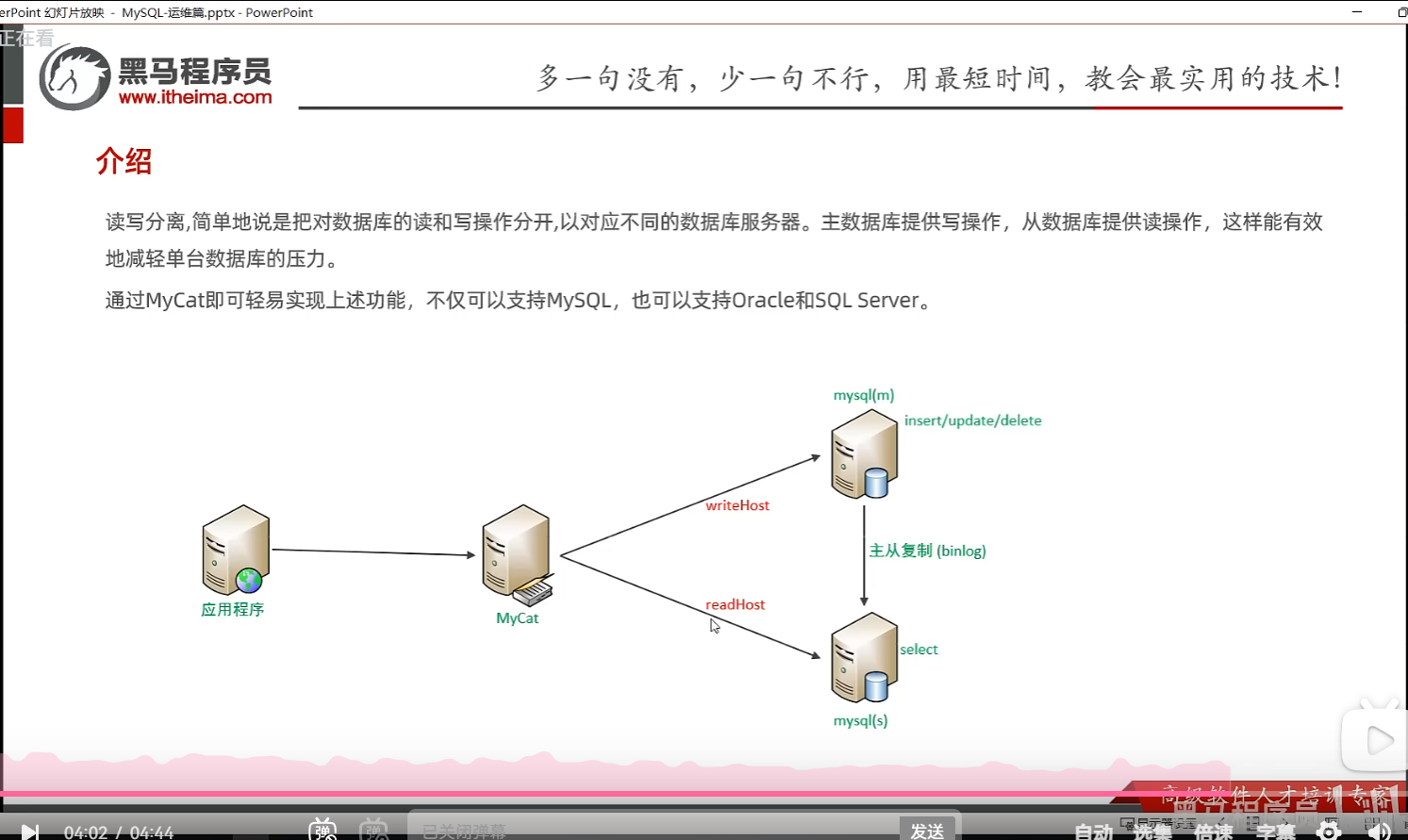
P37 一主一从
P38 一主一从读写分离
P39 双主双从
P40 双主双从读写分离
P41 总结

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)