爬虫学习笔记
解释1:通过一个程序,根据网页进行爬取网页,获取有效信息;·解释2:使用程序模拟浏览器,去向服务器发送请求,来获取响应信息;
1.什么是爬虫
·解释1:通过一个程序,根据网页进行爬取网页,获取有效信息;
·解释2:使用程序模拟浏览器,去向服务器发送请求,来获取响应信息;
2.爬虫核心:
(1)爬取网页:爬取整个网页,包含了网页中所有的内容;
(2)解析数据:将网页中得到的数据,进行解析;
(3)难点:爬虫与反爬虫之间的博弈;
【反爬虫:网站用来阻止爬虫程序自动抓取数据的技术】
3.爬虫的用途:
(1)数据分析/人工数据集
(2)社交软件冷启动
(3)舆情监控(企业/机构)
(4)竞争对手监控(电商,出行等行业)
4.爬虫分类:
(1)通用爬虫:
·实例:百度,360,搜狗等搜索引擎
·核心流程:访问页面-抓取数据-数据存储-数据处理-提供检索服务
·缺点:数据无用,不能根据用户的需求来精准获取数据
(2)聚焦爬虫:
·功能:根据你的需求编写爬虫程序,只抓取你需要的目标数据,精准高效。
·设计思路:
确定要爬取的URL:找到目标网站的地址/接口
发送HTTP请求,获取HTML代码:模拟浏览器向服务器发送请求,拿到网页的原始内容(所有内容)
解析HTML字符串:按照规则从网页里提取你需要的数据
5.反爬手段
(1)User-Agent(UA):
·作用:服务器通过UA识别客户端信息(操作系统,浏览器版本等),判断是否为正常浏览器访问
(2)代理IP:
·作用:隐藏真实IP,防止被网站封禁
·三种代理的区别
|
代理类型 |
网站是否知道你用了代理 |
网站是否知道你的真实IP |
|
透明代理 |
是 |
是 |
|
匿名代理 |
是 |
否 |
|
高匿代理 |
否 |
否 |
(3)验证码访问
(4)动态加载网页:
网站返回的是JS数据,不是网页的真实数据
(5)数据加密:
·原理:请求参数或返回数据被JS加密,无法直接解析
·应对方法:分析JS数据
6.urllib库使用:
(1)基本使用:
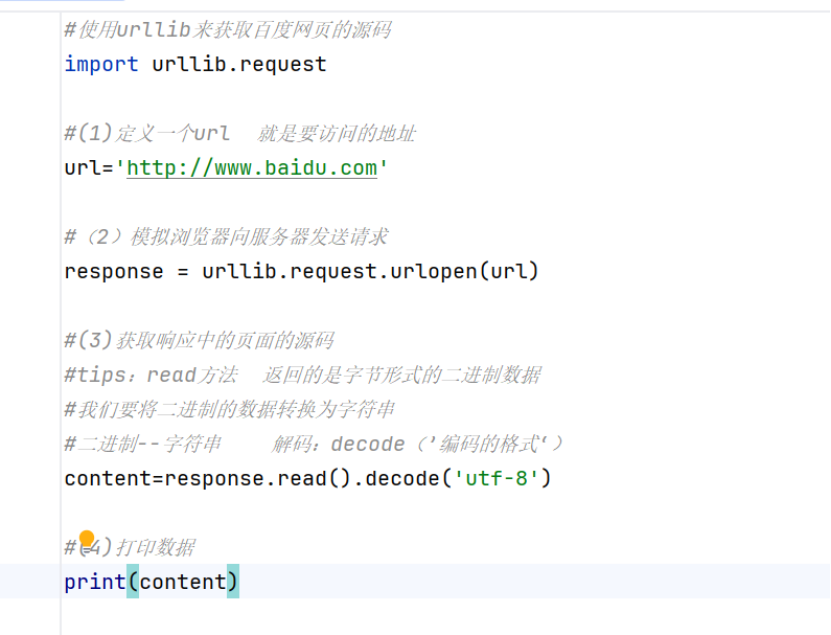
·urlopen:python标准库urllib.request模块里的一个核心函数
功能:完成“连接服务器——发送请求——接收响应”的流程
·read()方法:读取服务器返回的响应内容
直接调用read()返回的是字节类型,要用decode()方法解码成字符串
·decode()方法:把二进制的字节数据转换成字符串
常见编码格式:utf-8:通用编码,支持几乎所以语言;
gbk :中文常用编码,主要在Windows系统中使用。
(2)1个类型和6个方法:
a .read( ) :读取响应体,返回字节类型(一个字节 一个字节的读)
content=response.read()
b .read(n) : 读取前n个字节
content=response.read(100)
c .readline( ) : 读取1行内容
line=response.readline()
d .readlines( ) 按行读取所以内容,返回列表list
lines=response.readlines()
e .getcode( ) 获取HTTP状态码
print(response.getcode())
·常见HttP状态码:
200——正常拿到网页
403——被反爬拦住了
404——网站写错了
500——网站服务器炸了
f .geturl( ) 获取最终返回url地址
print(response.geturl())
g .getheaders( ) 获取一个状态信息
print(response.getheaders()
(3)下载:
A.网络请求模块(不需要额外安装第三方库)
·核心用途:发送HTTP请求,获取网页内容,下载网络文件
·导入方式:Import urllib.request
B.核心函数(urlretrieve)
·导入方式:urllib.request.urlretrieve(url,filename=None,reporthook=None,date=None)
url:要下载的网路资源地址(网页/图片/视频的URL)
filename:保存到本地的文件名
·函数特点: 1.它会自动发送请求,把远程资源下载到本地,无需手动处理请求和响应
2.支持的文件格式:网页,图片,视频等几乎所有的网络资源
C.代码展示用法
·下载网页

·下载图片

·下载视频
![]()
7.请求对象的定制:
(1)为什么要【请求对象的定制】
直接用urllib.request.urlopen(url)访问网站,会遇到这些问题
- 403 Forbidden:网站识别出你是爬虫,拒绝访问
- 没有浏览器标识:默认请求头没有User-Agent,服务器一看就知道不是正常用户
- 无法带自定义信息:不能直接传递headers,data,method等参数
所以我们要用Request对象来伪装成浏览器,绕过基础反爬
(2)基础语法
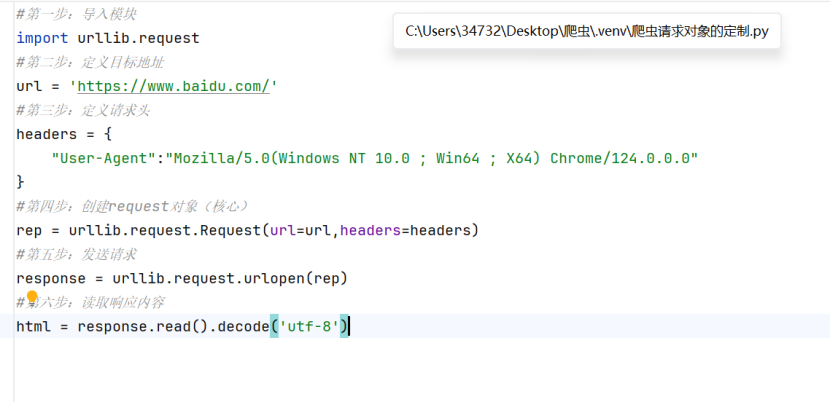 A. import urllib.request
A. import urllib.request
·作用:导入Python自带的网络请求模块,写的所有urllib代码,都必须导入它
B. url=”https://www.baidu.com”
·作用:定义你要访问的目标地址(url)
C. Headers={“User-Agent”:”XXX”}
·作用:定义请求头,模拟浏览器的身份信息
·User-Agent:它是浏览器的“身份证”
·格式:是一个python字典(键值对),键是请求头名称,值是具体内容
D. rep=urllib.request.Request(url=url,headers=headers)语法核心
- urllib.request.Request:
·它是一个类,专门用来创建“请求对象”
·作用:把url/ headers/data 这些信息打包成一个完整的请求包,方便发送
- 参数url=url:
·把你定义的目标地址传给Request对象
- 参数headers=headers:
·把你的请求头传给Request对象
- 执行完代表什么
·python会创建一个Request实例对象,里面装好了地址url/浏览器身份headers
·这个对象就是后面urlopen要发送的请求包
E. Response=urllib.request.urlopen(rep)
·作用:把Request对象发送给服务器,并接受服务器返回的响应
·细节:Urlopen只能接受两种参数:纯url字符串/Request对象
执行完这一行,服务器会返回一个“响应对象”,存在response里
F. html=response.read().decode(“utf-8”)
·response.read():读取响应里的原始内容(二进制数据)
·decode(“utf-8”):把二进制数据解码成正常的字符串
(3)url的组成
a.协议:
·写在最前面,用://结尾
·常见:http:// https://(加密,更安全)
·作用:告诉程序用什么规则访问资源
b.主机名:
·就是域名/IP地址
·作用:找到目标服务器在哪
c.端口名:
·格式:主机名:端口
·http默认80 https默认443(平时可以省略)
d.路径:
·主机名后面,问号前面的部分
·作用:定位服务器上具体哪个文件/页面
e.查询参数:
·以?开头,键=值格式,多个用&连接
·作用:给服务器传参数(搜索关键词,页码,筛选条件)
f.锚点:
·以#开头
·作用:跳到页面内某个位置
g.例子:
https://www.bilibili.com/video/BV123456/?p=2#reply
·协议:https
·主机:www.bilibili.com
·路径:/video/BV123456/
·查询参数:p=2
·锚点:#reply
8.编解码(get请求+post请求):
(1)为什么要使用编解码:
·URL只能包含字母,数字,少数符号,不能直接出现中文,空格,特殊字符
·直接把中文放进URL会报错or乱码,所有必须编码转义
(2)get请求的quote方式:【单个字符串】
·导入模块:import urllib.parse
a. urllib.parse.quote (字符串)
作用:对单个独立字符串完成 URL 编码
b. urllib.parse.unquote (编码字符串)
作用:URL 解码,将%xx格式还原为正常中文
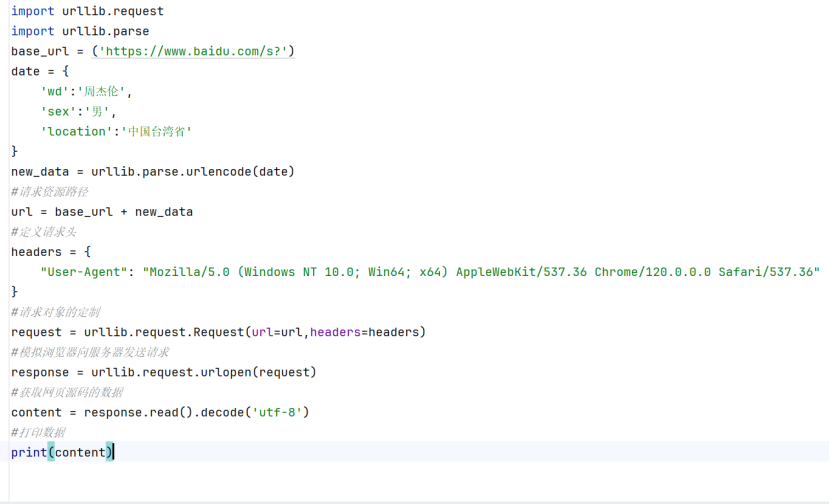
(3)get请求的urlencode方式:【多个参数】
a. 归属导入:import urllib.parse
b. 核心作用:·把字典参数转为url格式
·Key1=value1&key2=value2
·自动编码中文/特殊符号,解决get请求乱码报错
c. 基础语法:

d. 整个流程:
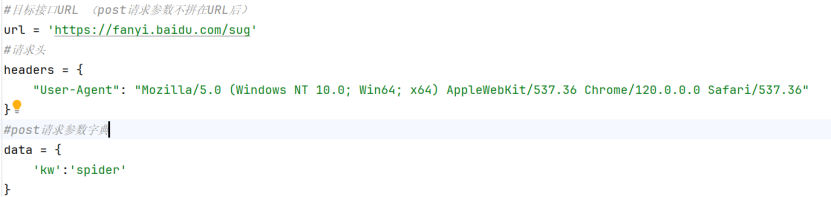
(4)post请求:
a. 模块导入:

·urllib.request: 负责发送网络请求,创建请求对象,获取响应
·urllib.parse: 负责URL编码,处理请求参数
b. 基础配置
c. post参数核心编码

·第一步urlencode(data):将python字典转为key = value&key2=value2格式的URL字符串,自动编码中文/特殊符号
·第二步.encode(‘utf_8’):将字符串转为bytes字节流
·核心结论:post参数必须两步编码,缺一不可
d. 创建请求对象

·data参数:传入编码后的bytes参数,post专属,GET请求不需要传data
·headers参数:挂载请求头,必须传入Request,不能直接传给urlopen
e. 发送请求与响应处理

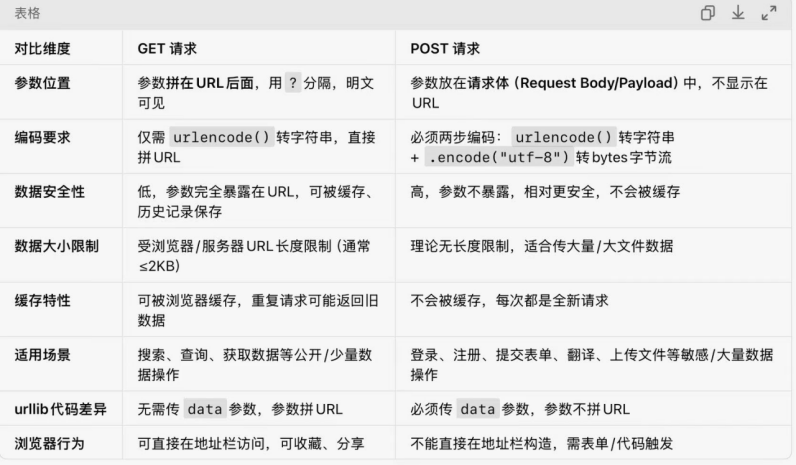
(5)get请求和post请求的区别:

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)