【GO语言开发实践】二 GO 并发快速上手
上一篇主要学习了基础语法和进阶的一些语法 【GO语言开发实践】一 GO 语法快速上手,这一篇主要学习一下Go的核心并发,深入理解下Go一直以来比较有优势的点:协程。还是使用「对比总结+带完整注释对照代码」模式学习完,主要学习内容:Goroutine协程、sync.WaitGroup等待组、sync.Mutex互斥锁、Channel通道、并发实战
GO 协程的设计思想
以下内容整理自与DeepSeek多轮对话:
1. 什么是 Goroutine:Go 的轻量级协程
Goroutine 是 Go 语言中实现并发的核心单元,是一种用户态的轻量级协程。与传统操作系统线程相比,它的创建成本极低(初始栈仅 2KB 且可动态伸缩),由 Go 运行时自行调度,而不是由操作系统内核管理。
一个典型的 goroutine 创建只需在函数前加上 go 关键字:
go myFunction()
这行代码会创建一个独立的、并发执行的“任务”,它会在某个可用的操作系统线程上被调度执行。
2. Goroutine 底层是如何实现的:GMP 调度模型
Go 的调度器实现了著名的 GMP 模型,完全在用户态运行,不依赖操作系统内核的线程调度。
2.1 GMP 中的三个核心角色
-
G(Goroutine)
代表一个 goroutine,包含栈、指令指针、寄存器等信息。每个 G 有独立的状态(如就绪、运行、等待等)。 -
M(Machine)
代表一个操作系统线程(内核线程)。M 负责真正执行 G 的代码。M 的数量由 Go 运行时控制,通常等于 CPU 核心数(GOMAXPROCS),但在阻塞系统调用时会临时增加。 -
P(Processor)
代表一个逻辑处理器,是 M 的“调度助理”。每个 P 维护一个本地 goroutine 任务队列。P 的数量默认等于GOMAXPROCS。M 必须绑定一个 P 才能执行 G。
2.2 调度流程的时间线图(GMP 视角)
下面用 Mermaid 序列图展示一个典型的调度流程,包含创建、执行、阻塞、唤醒、结束等阶段:
该图清晰展示了:同一个 M 可以在不同 G 之间快速切换,而切换过程完全在用户态完成(除了真正的阻塞系统调用)。
3. Goroutine 的生命周期与核心状态
Goroutine 拥有与线程类似的状态机,定义在 runtime/runtime2.go 中。
3.1 Goroutine 核心状态说明
| 状态 | 含义 | 典型转换 |
|---|---|---|
| _Grunnable | 就绪,等待被调度执行 | 新建的 G 或从等待中唤醒的 G 进入此状态 |
| _Grunning | 正在某个 M 上执行 | 调度器从队列中取出 G 后运行 |
| _Gwaiting | 等待某条件(如 channel、锁、time.Sleep) | 执行阻塞操作时进入;条件满足后转为 _Grunnable |
| _Gsyscall | 正在执行阻塞的系统调用 | 发起系统调用时进入;完成后转为 _Grunnable |
| _Gdead | 已结束 | 执行完毕或从未被使用 |
对于网络 I/O,Go 使用非阻塞 socket + netpoller(epoll/kqueue),当数据未就绪时,goroutine 被挂起,线程不会进入内核阻塞态,而是去执行其他 goroutine。这里并没有“线程进入内核态等待”,只有 epoll 等待系统调用会短暂进入内核,但线程本身不阻塞。
对于真正的阻塞系统调用(如文件 I/O、time.Sleep),线程会进入内核阻塞态,此时 Go 会临时新建线程来替代。
3.2 Goroutine 状态切换图
调度器使用协作式+抢占式混合调度:goroutine 会主动让出(如 channel 操作),但长时间运行的 G 也会被异步抢占(Go 1.14 起),防止“饿死”其他 G。
4. 协程的本质:操作系统看不到的执行单元
一个关键的本质问题:操作系统在物理/内核层面根本没有“协程”这个概念。协程完全是用户态的运行时(语言、库、或虚拟机)自己模拟出来的轻量级执行流。
4.1 操作系统只知道内核线程
操作系统(Linux、Windows 等)的最小调度单元是内核线程(或进程)。每个线程拥有独立的寄存器上下文、栈,切换必须通过系统调用陷入内核,由内核调度器完成。
4.2 协程是如何“活”起来的?
协程只存在于用户态,其核心机制是:
- 保存/恢复寄存器:每个协程维护一组寄存器快照(PC、SP、通用寄存器等)。
- 用户态切换:从一个协程切换到另一个时,运行时执行一段汇编代码,将当前寄存器保存到旧协程的上下文中,再从新协程的上下文中恢复寄存器,然后跳转到新协程的代码继续执行。
- 完全不需要操作系统参与,就像一次函数调用 + 切换栈。
因此,一个内核线程可以在用户态时分复用成千上万个协程。不是把线程“拆碎”,而是让同一个线程不断换活干。
4.3 临时增多的内核线程是怎么回事?
虽然 Go 通常保持内核线程数 ≈ GOMAXPROCS,但当 goroutine 执行阻塞的系统调用(如读文件)时,该线程会陷入内核阻塞,Go 运行时会临时新建一个内核线程来接管被释放的 P,继续执行其他 G。系统调用返回后,临时线程会被回收或休眠。
这些临时线程的阻塞和唤醒机制与 Java 传统线程完全一样(都是内核线程)。区别在于:
- Java 中每个任务往往独占一个线程 → 阻塞成本高,且数量受限。
- Go 中临时线程极少出现(只发生在真正阻塞的系统调用),且不影响用户创建百万级 goroutine 的能力。
4.4 为什么操作系统不直接支持协程?
这是一个非常深刻的底层问题。答案的核心是:操作系统的最小调度单元是内核线程,协程完全是用户态模拟出来的概念,操作系统“看不到”也“不需要”看到协程。
4.4.1 操作系统的设计边界
操作系统的核心职责是管理物理资源:CPU 时间、内存、磁盘、网络等。为了公平且安全地分配 CPU 时间,内核必须能够强制抢占执行中的程序。这个抢占的单位就是内核线程(或进程)。内核线程拥有:
- 独立的硬件上下文(寄存器、栈指针、PC)
- 内核栈和用户栈
- 属于某个进程,享有独立的地址空间
操作系统提供了线程的创建、销毁、切换、同步等系统调用,但它不关心用户态程序如何在单个线程内实现“多任务”。这就像高速公路管理者只关心车道和车辆(线程),不关心一辆车里坐了多少人(协程)。
4.4.2 如果操作系统支持协程会怎样?
理论上,内核也可以提供类似 clone(CLONE_VM | CLONE_SYSCALL) 的轻量级执行单元,称为“用户线程”或“协程”。但实际上,这样做会带来几个严重问题:
-
调度复杂性爆炸 内核既要调度线程,又要调度协程,调度器复杂度骤增。而且协程的切换成本极低,如果每次切换都要陷入内核,这个优势就荡然无存了。所以协程必须在用户态完成切换才快。
-
阻塞语义混乱 如果内核知道协程的存在,那么当一个协程做阻塞 I/O 时,内核应该阻塞整个线程还是只阻塞这个协程?如果只阻塞协程而让同线程的其他协程继续跑,那就需要内核支持可增长的栈、用户态上下文保存等,这基本等于把整个 Go 运行时的功能搬到内核里,违背了“内核保持精简”的设计哲学。
-
可移植性问题 不同的操作系统对协程的支持程度不同(比如 Windows 的纤程 Fibers 一直半死不活,Linux 的
ucontext已被标记为废弃)。如果语言依赖内核提供的协程,就会失去跨平台一致性。
4.4.3 正确的关系
操作系统提供内核线程;用户态运行时(如 Go、Java 虚拟线程、Rust tokio)在内核线程之上模拟出协程/虚拟线程。
协程的调度在用户态完成,只有涉及真实的 I/O 阻塞或时间片耗尽时,才需要内核介入(而且介入的粒度是线程,不是协程)。
5. Go Goroutine vs. Redis 单线程 AIO 模型
Go 的 goroutine 是否像 Redis 的单线程事件循环?答案是:底层机制有本质不同,但在“用少量线程支撑大量并发任务”这个目标上殊途同归。
5.1 Redis 模型:单线程 + 非阻塞 I/O + 事件循环
- 单线程:整个 Redis 服务器只有一个主线程处理所有网络请求。
- 非阻塞 I/O:socket 设置为非阻塞,使用
epoll(Linux)/kqueue(BSD)同时监听大量文件描述符。 - 事件循环:主线程循环调用
epoll_wait,一旦有事件就绪,依次执行对应的命令处理函数(如get、set)。 - 禁止阻塞:任何阻塞操作(如
sleep、磁盘 I/O)都会卡住整个 Redis。
5.2 Go Goroutine 模型:多线程 + 阻塞式编程 + 用户态调度
- 多线程:默认有
GOMAXPROCS个内核线程(M),每个线程都可以执行 goroutine。 - 阻塞式编程:开发者可以用同步风格写网络 I/O(如
conn.Read),看起来像阻塞,实际由 netpoller 转化为非阻塞。 - 用户态调度:当 goroutine 阻塞时,调度器自动挂起它,让同线程的其他 goroutine 继续跑。
- 可混合阻塞:真正的系统调用(如文件 I/O)会临时增加 M,但不会阻塞所有 goroutine。
5.3 Redis 单线程模型 与 Go Goroutine 模型对比
| 维度 | Redis 单线程模型 | Go Goroutine 模型 |
|---|---|---|
| 线程数量 | 1 个(严格单线程) | 多个(默认 = CPU 核心数) |
| 编程模型 | 异步/回调(或响应式) | 同步阻塞风格(但自动切换) |
| 阻塞操作容忍度 | 零容忍(任何阻塞都会挂起整个服务) | 高容忍(调度器自动切换,或临时加线程) |
| 上下文切换成本 | 无(单线程,顺序执行) | 极低(用户态切换,纳秒级) |
| 底层 I/O 多路复用 | 是,使用 epoll/kqueue | 是,netpoller 封装了 epoll/kqueue/IOCP |
| 是否支持 CPU 密集型任务 | 不适合(会阻塞事件循环) | 适合(多线程并行执行) |
- 相同点:都依赖 I/O 多路复用(epoll/kqueue)来高效管理大量网络连接,都试图用有限的线程处理海量连接。
- 不同点:Redis 是“单线程 + 显式非阻塞”,开发者必须避免任何阻塞;Go 是“多线程 + 隐式非阻塞”,开发者写同步代码,运行时自动做异步切换。
Go 的 netpoller + 调度器本质上是一个“多线程版的 Redis 事件循环”,但每个 goroutine 对开发者来说是一个独立的任务。
6. Java 为什么不用 Go 这种协程模型?
这是由历史包袱、设计哲学和演进路径共同决定的。
6.1 历史原因:Java 的线程模型早已固化
Java 1.0(1995 年)就选择了 1:1 映射到操作系统线程 的模型。这个选择在当时很合理:跨平台、简单可靠。随后 20 多年里,整个 Java 生态(应用服务器、JDBC、事务管理器、各种框架)都深度绑定在这个模型上。要彻底改成用户态协程,相当于要推倒重来,代价不可接受。
6.2 设计哲学:显式控制 vs. 隐式托管
- Go 倾向于提供“一体化”的并发方案:运行时自动调度 goroutine,开发者写同步代码即可,不需要关心底层线程数量。
- Java 偏向提供“可组合的底层构件”:
Thread、ExecutorService、Lock、BlockingQueue等,允许开发者精细控制并发行为。内置一个固定的调度器可能会限制灵活性。
6.3 时代变了:Java 也引入了虚拟线程
从 JDK 21 开始,Java 正式推出了虚拟线程(Virtual Threads)。它是一种用户态轻量级线程,由 JVM 调度,挂在少量平台线程(载体线程)上运行。虚拟线程与 Go goroutine 在核心思想上殊途同归:
- 创建成本极低,可以创建数百万个
- 阻塞操作(如
Thread.sleep、锁、网络 I/O)会自动挂起虚拟线程,释放底层平台线程 - 编程模型依然是同步风格,无需学习异步 API
两者的差异在于实现细节(例如虚拟线程基于 Continuation,goroutine 基于内置调度器),但已不再是“Java 没有协程”的格局。
6.4 Goroutine vs. Java 线程模型:核心区别一览
| 特性 | Java 平台线程 (pre-JDK21) | Go Goroutine | Java 虚拟线程 (JDK21+) |
|---|---|---|---|
| 映射模型 | 1:1(Java 线程 = 内核线程) | M:N(多个 G 跑在少量 M 上) | M:N(多个虚拟线程跑在少量平台线程上) |
| 创建/切换成本 | 高(内核态切换,微秒级) | 极低(用户态切换,纳秒级) | 极低(用户态切换,纳秒级) |
| 初始栈大小 | ~1MB(固定) | ~2KB(动态伸缩) | ~KB 级别(由 JVM 实现决定) |
| 阻塞处理 | 阻塞内核线程,造成资源浪费 | 挂起 G,释放 M 去运行其他 G | 挂起虚拟线程,释放载体线程 |
| 并发能力 | 数千 ~ 数万个 | 数百万个 | 数百万个 |
| 调度者 | 操作系统内核 | Go 运行时 | JVM(用户态) |
Go 的 goroutine 之所以快,是因为它绕开了操作系统内核的线程调度,在用户态完成几乎所有并发控制,让一个内核线程可以复用给海量任务。Java 传统线程模型受限于 1:1 映射,但并没有坐以待毙——虚拟线程的引入标志着两套模型在核心思想上走向趋同进化。
GO 并发的相关操作
了解了Go 协程相关的概念后,接下来继续探索Go的协程在并发中的使用
知识点1:Goroutine 协程
Java 底层是操作系统原生线程,占用资源大、创建成本高、并发数量受限,关于Java的线程和操作系统线程映射的导致CPU和内存资源浪费的可以参照之前写的一篇【系统架构设计 服务高性能设计】从内核态到锁升级,一篇文章深入理解计算机高性能关键;Go 的 Goroutine 是用户态轻量级协程,由Go运行时调度,占用内存极小,创建成本极低,轻松支持数十万级并发,仅需go关键字即可快速启动执行。
package main
import (
"fmt"
"time"
)
// 自定义执行任务
func runTask(num int) {
fmt.Printf("当前执行协程任务:%d\n", num)
// 模拟业务耗时操作
time.Sleep(500 * time.Millisecond)
}
func main() {
// 普通函数调用:串行顺序执行
// runTask(1)
// runTask(2)
// go 关键字启动Goroutine协程,异步并发执行
go runTask(1)
go runTask(2)
/*
Java对应:new Thread().start() 开启线程
区别:
1. Java线程依赖系统内核,数量上限低;Goroutine轻量,并发量级大
2. Go启动协程语法极简,仅加go关键字,无需创建线程对象
3. 主线程执行完毕会直接退出,不会等待子协程执行完成
*/
// 主线程休眠,等待子协程执行完成
time.Sleep(1 * time.Second)
fmt.Println("主程序执行结束")
}
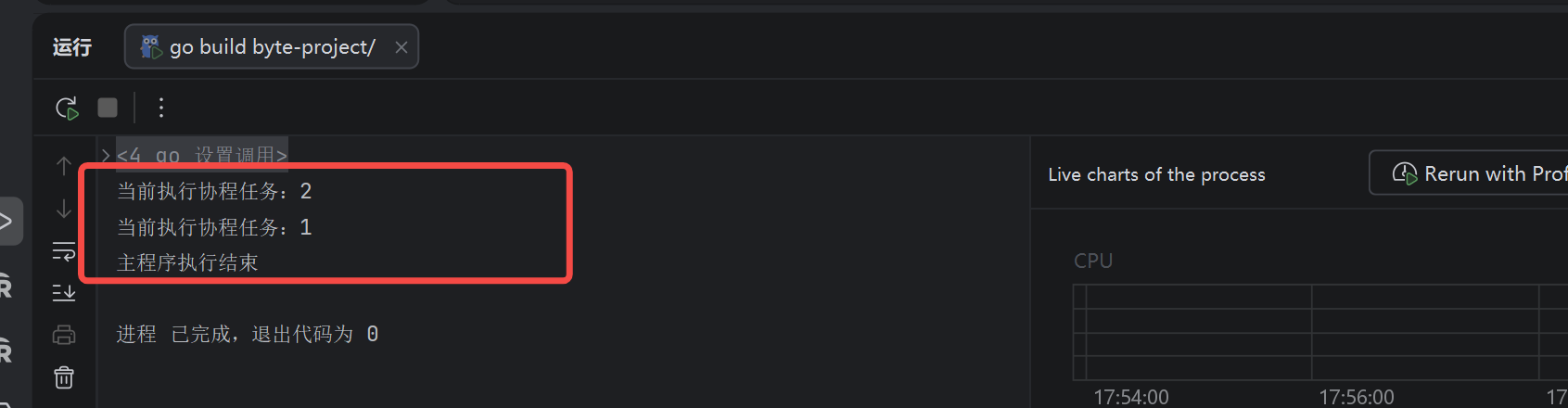
执行的顺序也是争用的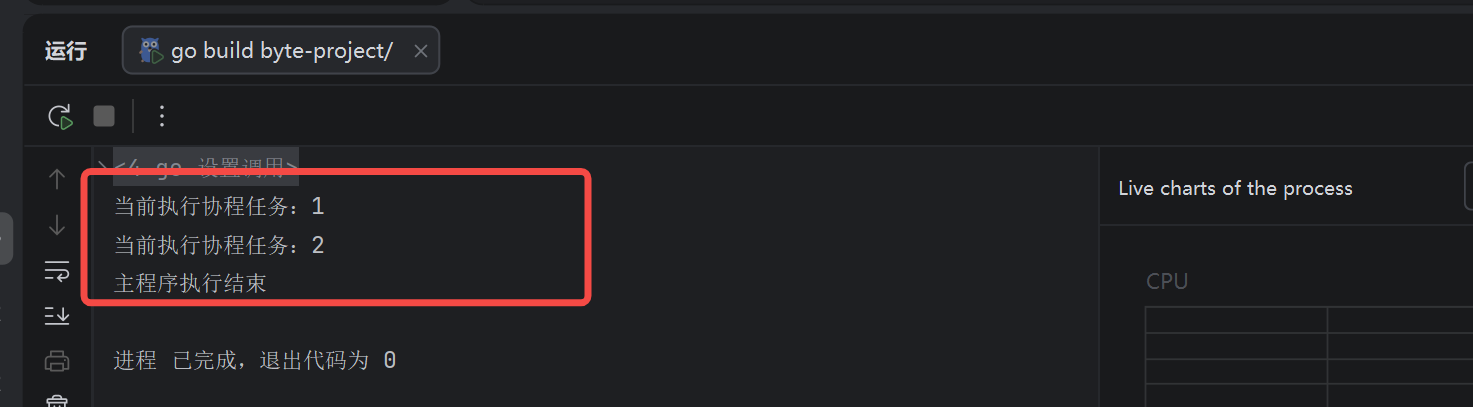
知识点2:sync.WaitGroup 等待组
Java 实现线程等待常用CountDownLatch,Go中sync.WaitGroup作用完全一致,专门用于让主线程等待所有子协程全部执行完毕后,再结束程序,替代休眠等待,代码更加严谨规范。
package main
import (
"fmt"
"sync"
"time"
)
// 定义全局等待组
var wg sync.WaitGroup
func task(index int) {
// 协程执行完毕,计数器减一
defer wg.Done()
fmt.Printf("协程 %d 开始执行\n", index)
time.Sleep(600 * time.Millisecond)
fmt.Printf("协程 %d 执行完成\n", index)
}
func main() {
// 设置等待协程数量,计数器累加
wg.Add(3)
// 批量启动协程
for i := 1; i <= 3; i++ {
go task(i)
}
// 阻塞主线程,等待所有协程计数器归零
wg.Wait()
/*
Java等价:CountDownLatch.await()
核心用法:
1. Add(n):确定需要等待的协程数量
2. Done():单个协程结束,计数-1
3. Wait():阻塞等待全部完成
*/
fmt.Println("所有协程全部执行完毕")
}
Java中的实现是通过信号量来实现的,本质上是锁来实现的,go的sync.WaitGroup内置实现了这个功能
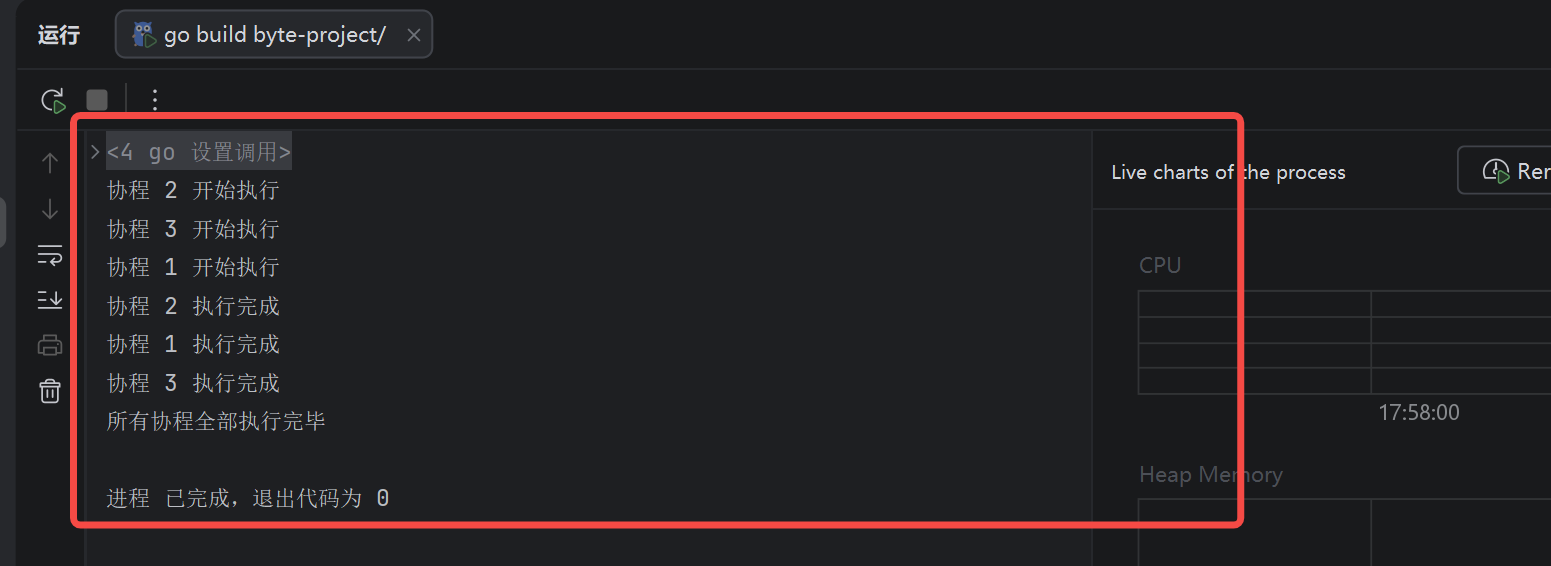
知识点3:sync.Mutex 互斥锁
多协程同时操作同一个共享变量时,会出现数据竞争、数据错乱问题;Java使用synchronized、ReentrantLock解决,Go使用sync.Mutex互斥锁,通过加锁、解锁保证同一时间仅有一个协程操作共享数据,保障并发数据安全。
package main
import (
"fmt"
"sync"
)
// 共享全局变量
var totalNum int
// 定义互斥锁
var mutex sync.Mutex
var wg sync.WaitGroup
// 累加任务
func addNum() {
defer wg.Done()
// 上锁:锁住共享资源
mutex.Lock()
totalNum++
// 解锁:释放资源
mutex.Unlock()
/*
Java对应:synchronized 代码块 / 手动锁
区别:Go锁语法更简洁,手动控制加锁解锁范围,精准控制临界区
*/
}
func main() {
wg.Add(1000)
// 启动1000个协程累加
for i := 0; i < 1000; i++ {
go addNum()
}
wg.Wait()
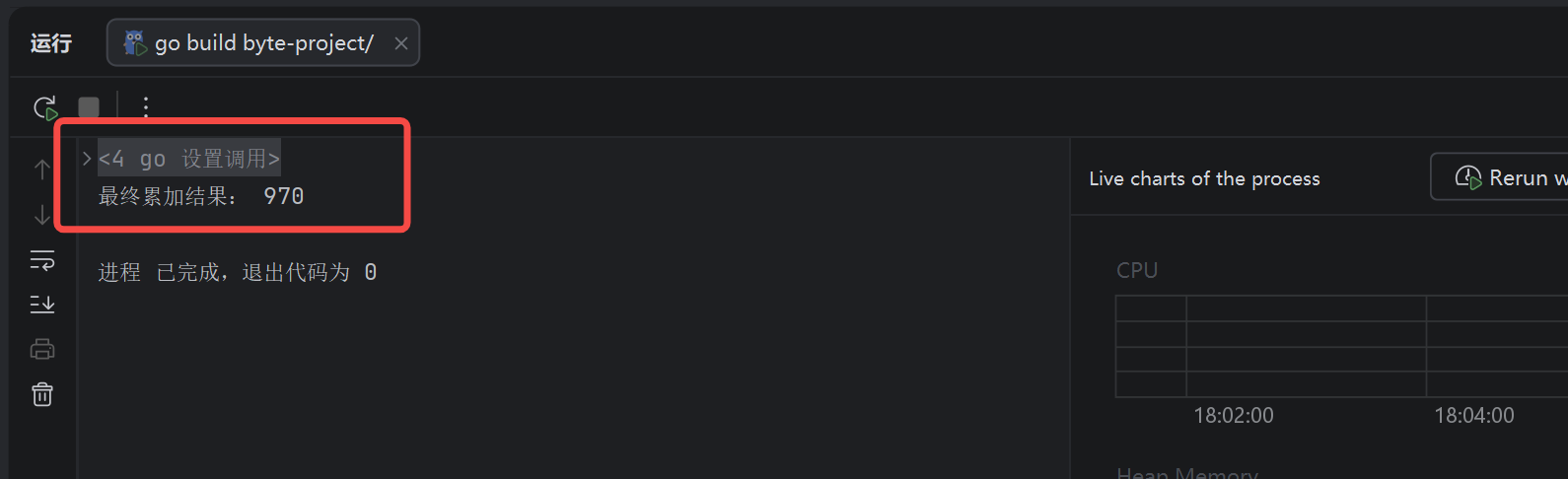
// 加锁后结果固定为1000,无锁会出现数据错乱
fmt.Println("最终累加结果:", totalNum)
}
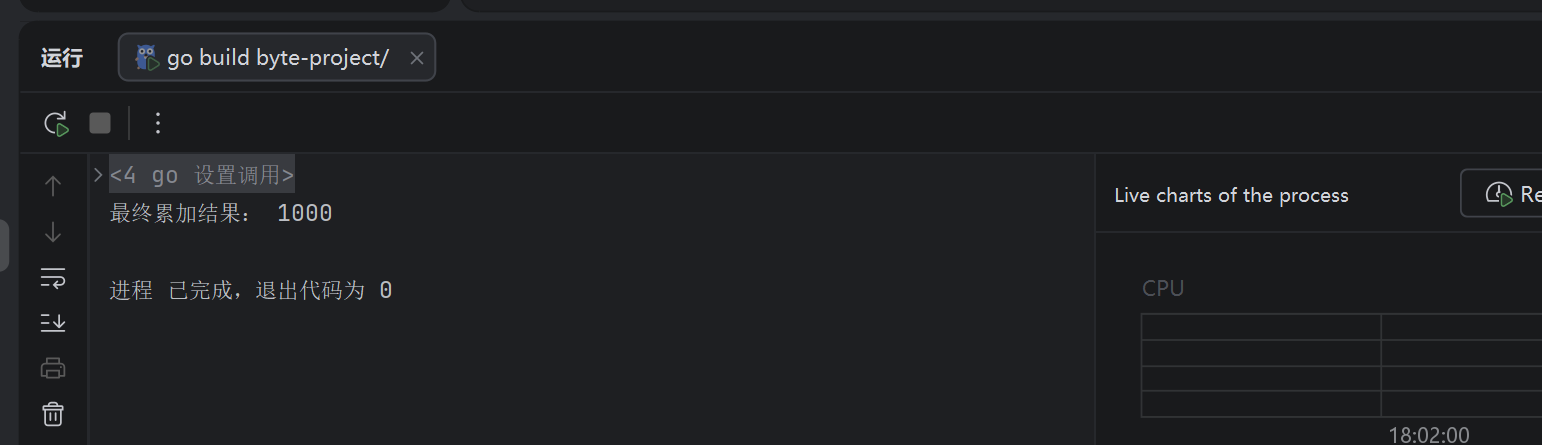
如果这里没有锁,那么累加会出现共享变量的争用,例如注销掉锁的调用
// 累加任务
func addNum() {
defer wg.Done()
// 上锁:锁住共享资源
//mutex.Lock()
totalNum++
// 解锁:释放资源
// mutex.Unlock()
/*
Java对应:synchronized 代码块 / 手动锁
区别:Go锁语法更简洁,手动控制加锁解锁范围,精准控制临界区
*/
}
知识点4:Channel 通道
Go并发设计理念:不要通过共享内存通信,要通过通信实现数据共享。Channel是协程之间专用的数据通信管道,替代Java共享变量+锁的通信方式,实现协程间安全数据传输,分为无缓冲通道、有缓冲通道。
package main
import "fmt"
func main() {
// 1. 创建无缓冲通道,用于传输int类型数据
msgChan := make(chan int)
// 启动发送数据协程
go func() {
// 向通道写入数据
msgChan <- 666
fmt.Println("数据已发送至通道")
}()
// 从通道读取数据,主线程接收
res := <-msgChan
fmt.Printf("从通道接收数据:%d\n", res)
/*
无缓冲通道特性:
1. 必须同时存在发送和接收操作,否则程序阻塞
2. 数据收发一一对应,同步执行
Java无原生对等组件,需手动封装队列实现协程通信
*/
// 2. 有缓冲通道,指定缓冲区容量
bufChan := make(chan string, 2)
// 可先存入数据,无需立即接收,缓冲区满后才阻塞
bufChan <- "Go并发"
bufChan <- "Channel通道"
fmt.Println(<-bufChan)
fmt.Println(<-bufChan)
}
关闭通道 + 遍历通道
通道使用完成后需要手动关闭,避免协程一直阻塞等待;可通过for range自动遍历通道内所有数据,数据读取完毕自动退出遍历,简化批量数据接收逻辑。
package main
import "fmt"
func sendData(ch chan<- int) {
// 单向通道:只允许发送数据
for i := 1; i <= 5; i++ {
ch <- i
}
// 数据发送完成,关闭通道
close(ch)
}
func main() {
// 创建双向通道
ch := make(chan int, 3)
go sendData(ch)
// range遍历通道,通道关闭后自动结束遍历
for val := range ch {
fmt.Println("读取通道数据:", val)
}
fmt.Println("通道数据读取完毕,通道已关闭")
}
知识点6:并发实战:生产者消费者模型
后端开发高频经典并发模型,Java通过线程+队列实现,Go依托协程+Channel实现更加简洁高效,分工明确,生产者负责生产数据,消费者负责处理数据,完美解耦。
package main
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
// 生产者:生产数据写入通道
func producer(ch chan<- int) {
defer wg.Done()
for i := 1; i <= 5; i++ {
ch <- i
fmt.Printf("生产者生产数据:%d\n", i)
time.Sleep(300 * time.Millisecond)
}
close(ch)
}
// 消费者:读取通道数据并处理
func consumer(ch <-chan int) {
defer wg.Done()
for data := range ch {
fmt.Printf("消费者处理数据:%d\n", data)
time.Sleep(500 * time.Millisecond)
}
}
func main() {
dataChan := make(chan int, 2)
wg.Add(2)
go producer(dataChan)
go consumer(dataChan)
wg.Wait()
fmt.Println("生产者消费者模型执行结束")
}
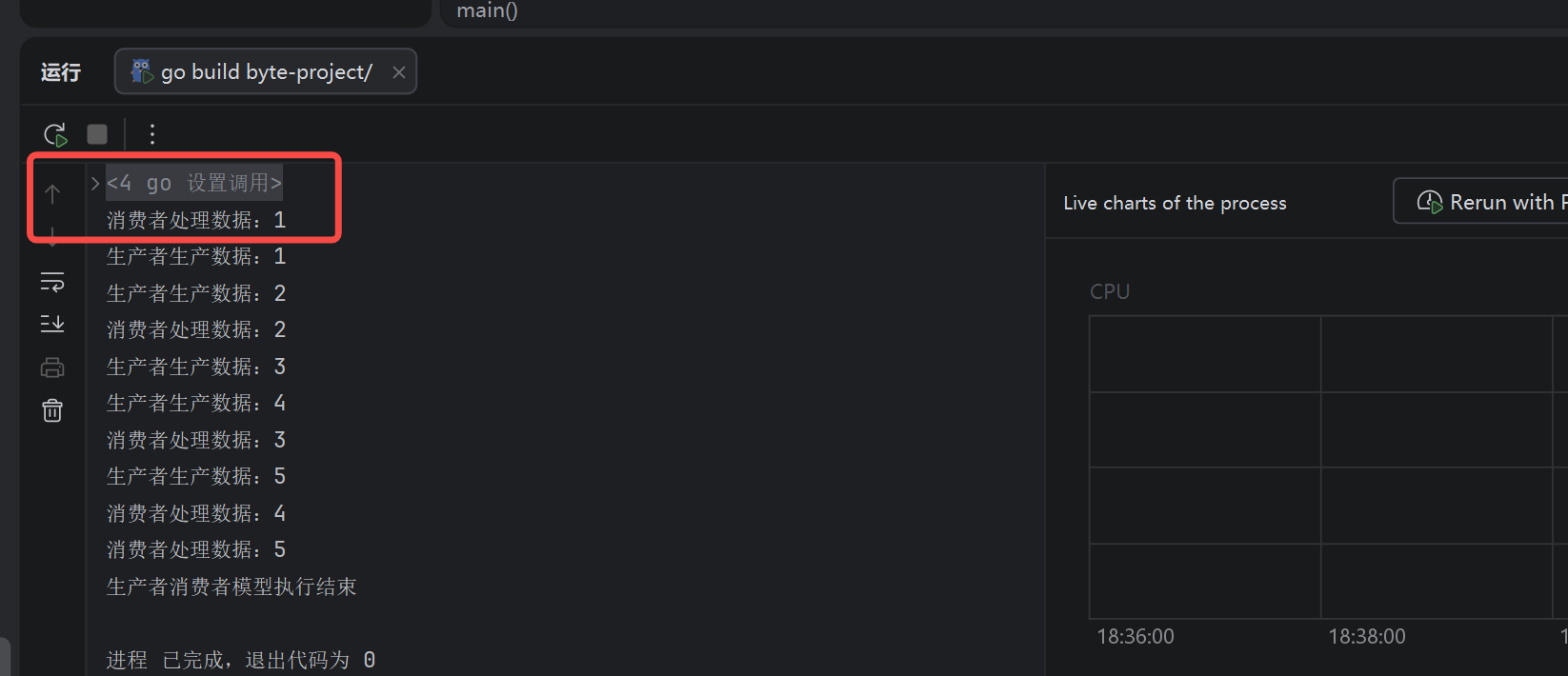
消费者不是提前消费,是刚拿到数据就立刻输出了!只是输出比生产者快一点点。现在看到顺序混乱,只是并发协程调度抢占 CPU导致打印先后错位,业务逻辑完全安全。可以改下代码,让生产逻辑的打印睡眠时间短于消费逻辑
package main
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
// 生产者:生产数据写入通道
func producer(ch chan<- int) {
defer wg.Done()
for i := 1; i <= 5; i++ {
ch <- i // 先往通道塞数据
fmt.Printf("【生产者】生产数据:%d\n", i)
time.Sleep(300 * time.Millisecond)
}
close(ch)
fmt.Println("【生产者】全部生产完毕,关闭通道")
}
// 消费者:读取通道数据并处理
func consumer(ch <-chan int) {
defer wg.Done()
fmt.Println("【消费者】已启动,通道暂无数据,进入阻塞等待...")
// 通道为空时,直接阻塞在这里,不会执行循环体
for data := range ch {
fmt.Printf("【消费者】成功拿到数据开始处理:%d\n", data)
time.Sleep(500 * time.Millisecond)
}
fmt.Println("【消费者】通道关闭,无新数据,消费结束")
}
func main() {
// 缓冲区大小2
dataChan := make(chan int, 2)
wg.Add(2)
go producer(dataChan)
go consumer(dataChan)
wg.Wait()
fmt.Println("生产者消费者模型执行结束")
}
这样看到的结果就是顺序的了
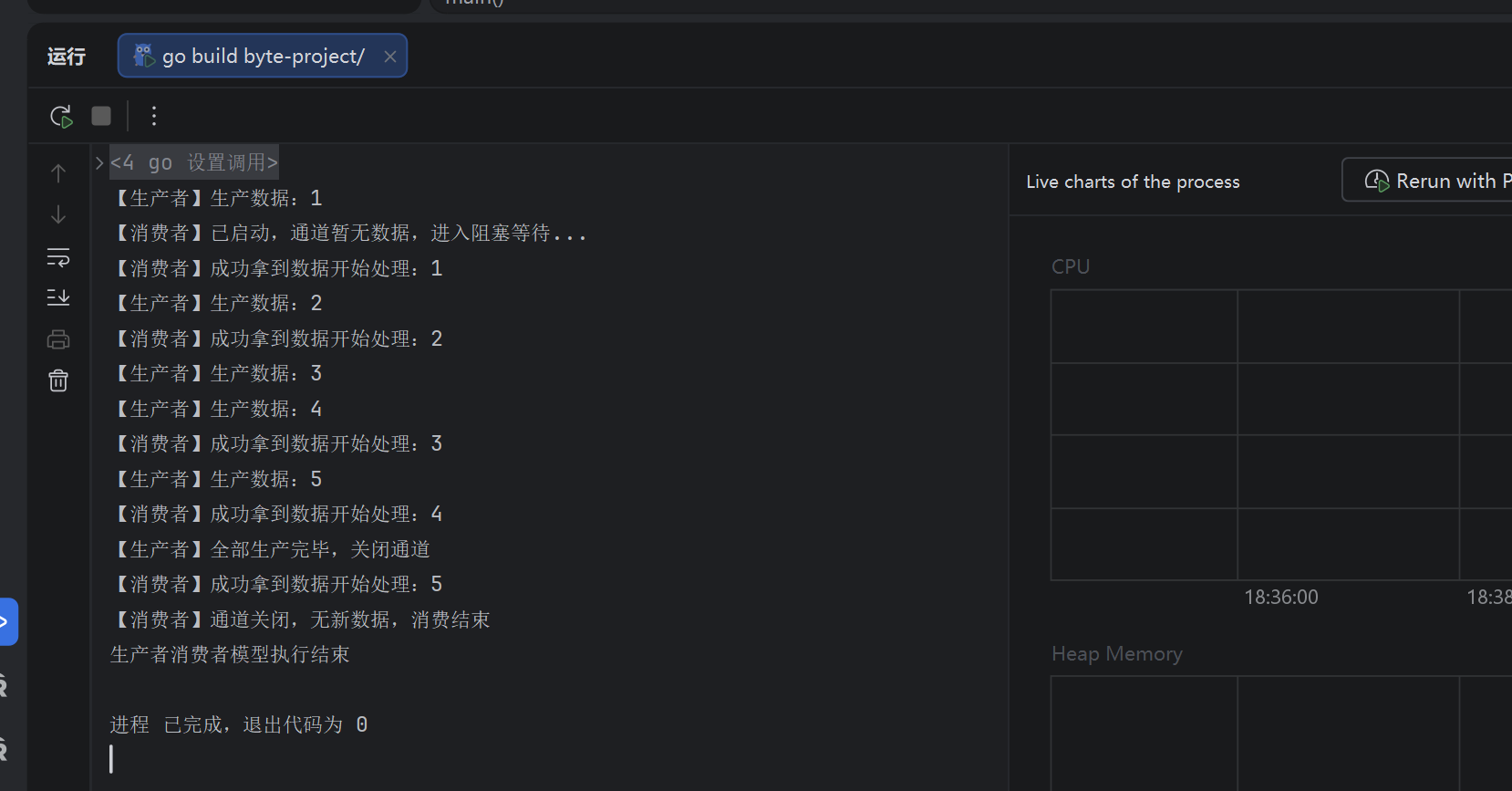
总结一下
Go原生对并发的支持确实会比Java好,核心原因是内置 GMP 调度模型,可以在用户态自主完成多数协程调度切换,摆脱对操作系统原生内核线程的强依赖,减少内核态与用户态切换产生的 CPU、内存资源损耗(仅当发生真正的阻塞系统调用或 I/O 时才会进入内核态)
Go 协程与 Java 线程的生命周期状态逻辑相近,但 Java 受限于历史线程模型(1:1 映射内核线程),只能通过线程池、虚拟线程等方式优化开销,无法从底层彻底抛弃内核线程调度架构(即使想实现类似 GMP 的模型,历史替换成本也极高)。
此外Go 语言面向云原生高并发场景做了深度优化,原生封装等待组、互斥锁、通道等常用并发组件,可以快速实现生产者消费者等经典并发模型(这些在Java里都需要自己去搭配相关类库和自己去组合实现),Go锁的使用也更加简洁,将底层的复杂逻辑(原子操作、信号量、goroutine 阻塞/唤醒、排队等)隐性封装在运行时中
总的来说在并发这件事上,Java 大而全,并发开发需要开发者自行整合工具、把控线程池细节;Go 小而美,让开发者更聚焦业务逻辑,并发调度逻辑以隐式方式可靠运行。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)