他让 AI 自己组了一个编辑部:导演、配音、动画、质检全自动跑
今天这个不一样。一个开发者把自己搭建的 AI 视频制作流水线完整拆给你看。不是概念图,不是 PPT,是真实跑在生产服务器上的东西。看完你会发现:真正用 AI 做视频的人,根本不是在一键生成,而是在搭生产线。
你有没有刷到过那种视频——号称"AI 一键成片",点进去发现就是在卖课。
今天这个不一样。
一个开发者把自己搭建的 AI 视频制作流水线完整拆给你看。不是概念图,不是 PPT,是真实跑在生产服务器上的东西。
看完你会发现:真正用 AI 做视频的人,根本不是在一键生成,而是在搭生产线。
AI 视频的真相:不是一键成片,是流水线
普通人以为的 AI 创作:输入一句话 → AI 啪一下生成成片 → 完事。
但实际情况呢?这个开发者直接展示了他的后台。
一台叫 10.20.3.200 的 Linux 服务器,54G 内存。上面跑着:
• FFmpeg 8.1 版本,负责所有视频编解码
• CosyVoice3 模型,负责原声生成
• faster-whisper,负责语音识别
• edge_tts,文本转语音备选方案
这不是概念图,是可登录的生产环境。
真正的剪辑,就发生在这台机器上。
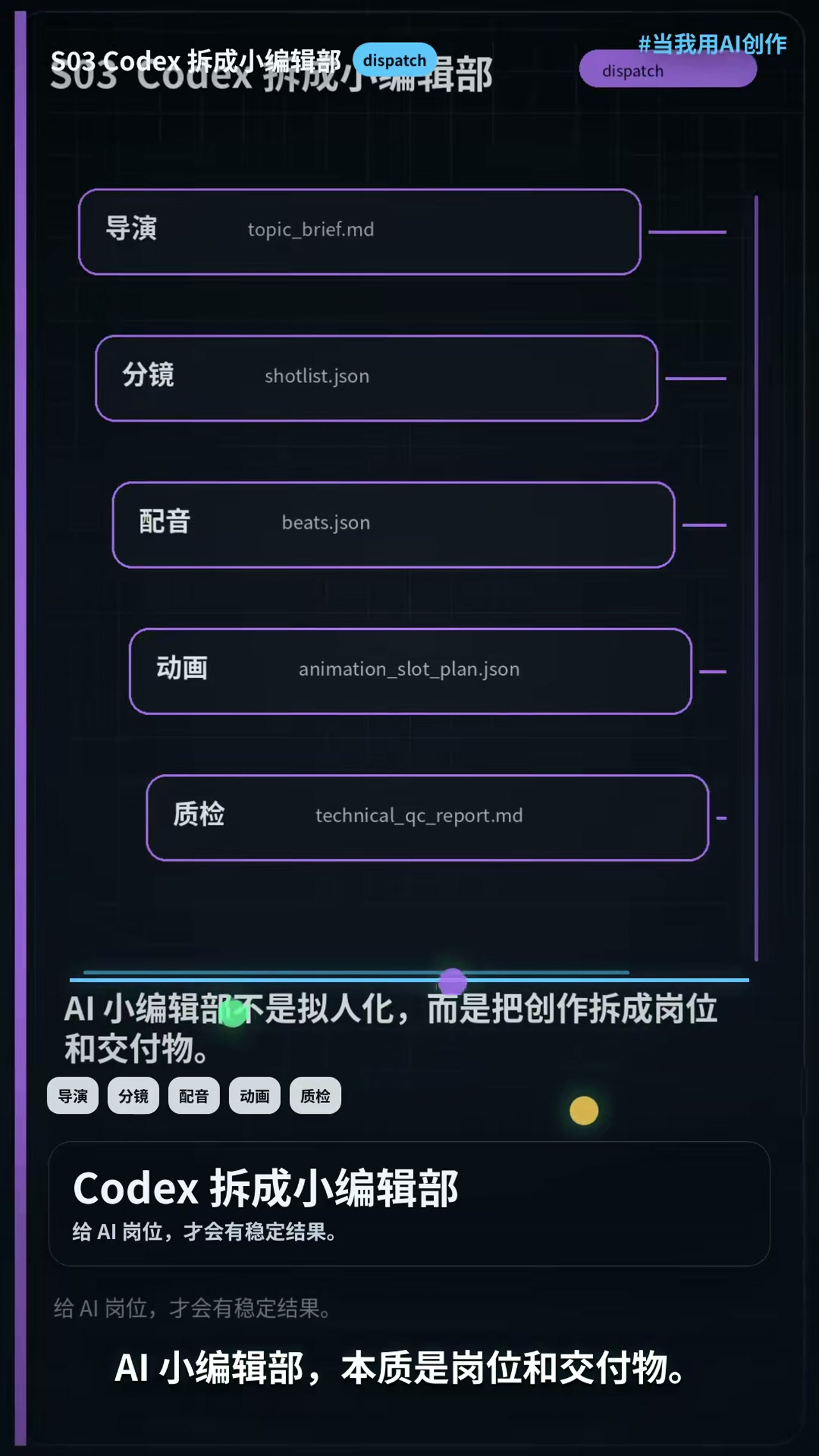
把创作拆成岗位:AI 小编辑部
最妙的设计在这里。
他没把 AI 当成一个"万能创作者",而是把视频制作的每个环节拆成了岗位和交付物:
| 岗位 | 负责什么 | 交付物 |
|------|---------|--------|
| 导演 | 理解选题,出分镜方案 | topic_brief.md |
| 分镜 | 把方案转成镜头列表 | shotlist.json |
| 配音 | 生成原声,决定节奏 | beats.json |
| 动画 | 设计动效方案 | animation_slot_plan.json |
| 质检 | 检查技术指标 | technical_qc_report.md |
给 AI 明确的岗位和交付物,才会有稳定的结果。
这比"帮我做一个视频"那种模糊指令,效果好十倍。
先拦 PPT 风险,再让服务器渲染
他提了一个很尖锐的观点:AI 做动画最容易翻车的地方,是做得像 PPT。
怎么解决?
他让"动画导演"这个 AI 角色先做一件事——检查分镜 layout 是不是像"同一模板重复"。如果是,直接拦住,重新设计。
动效不是装饰,是服务镜头职责的。每一个 motion 要有动机,每一个转场要对应节奏 beat。
拦住 PPT 风险之后,才交给 FFmpeg 渲染。
这一步很多人会跳过,但恰恰是这一步,决定了成品是"看着还行"还是"真能发"。
先生成原声,再量时间线
另一个反直觉的操作:不是先做画面再配音,而是反过来。
CosyVoice3 先生成原声 → 再用 ffprobe 测量每一段声音的真实时长 → 然后画面按声音的时间线来剪。
声音不是装饰,它决定节奏。
这跟传统剪辑的工作方式一模一样。专业的剪辑师也是先铺音轨,再对画面。
验收只看最终 MP4
最后一步是质检。他用的方式很硬核:
• ffprobe 检查视频流、音频流是否正常
• blackdetect 检测是否有黑场
• silencedetect 检测是否有静音
• 随机抽帧,检查画面质量
只看编码后的 MP4,不看 HTML 快照。渲染成功不算完,最终文件要过完整的 QC 清单。
启示:AI 创作的关键,是可检查的生产线
这个开发者的核心理念是:AI 真正厉害的,不是帮你按一个按钮,而是把灵感变成可检查的生产线。
灵感进来 → Codex 拆任务 → 分镜 → 配音 → 动画 → 渲染 → QC → 成品 + 证据一起交付。
每一步都有岗位、有交付物、有验收标准。
这条流水线搭好之后,不是一个视频,是以后每一个视频都能这样跑。
这才是 AI 做内容的正确姿势:不是替代人,而是把人的创作流程标准化、自动化。
你花时间搭一次生产线,后面就是批量化生产。
如果你也在用 AI 做内容创作,或者想了解怎么搭自己的 AI 工作流,欢迎点个「在看」。
我会持续拆解更多真正在跑的 AI 实操案例,不讲虚的,只拆给你看。关注我,一起把 AI 用出真东西。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)