理解文件和缓冲区
本文系统阐述了文件操作的核心概念与技术实现。首先解析了文件的本质,指出文件由内容数据和元数据组成,强调文件操作实质是进程通过内核进行的系统调用。详细介绍了C语言和系统层面的文件操作接口,包括fopen/open、fread/write等函数的使用方法及参数说明。深入剖析了文件描述符机制,通过实验验证了其分配规则,并解释了重定向的实现原理。重点阐述了"Linux一切皆文件"的设计
理解文件
文件 = 文件内容 + 文件属性(元数据)
文件内容:用户写入的实际数据
文件属性(元数据):描述文件的信息,不包含用户数据。例如:文件名,文件大小,访问,修改,改变时间,权限,文件类型,存储位置等。
1.对于文件内容 0KB 的空文件是占用磁盘空间的,占用的是元数据(inode)的空间,不是数据区的空间。
2.文件操作的本质,是对文件的内容操作和对文件属性操作。
3.对文件的操作的本质,是进程通过内核对文件的操作。
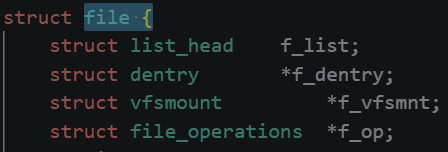
4.文件本身是磁盘上的静态数据,只有被进程打开后,才会在内核中生成动态的文件对象(struct file),进程对文件的操作本质是对这个内核文件对象的操作。
5.文件是在磁盘上存储的,且磁盘是永久性存储介质,因此文件在磁盘上的存储是非易失性的。
6.磁盘的管理者是操作系统,文件的读写底层本质不是通过C/C++的库函数来操作的(这些库函数只是为用户提供方便),而是通过文件相关的系统调用接口来实现的。
IO:磁盘是外设(即是输出设备,也是输入设备),对文件的所有操作,都是对外设的输入和输出,这种行为被简称IO。 IO 分为 “用户态缓冲区 -> 内核态缓冲区” 和 “内核态缓冲区 -> 磁盘”两个阶段。
对文件 IO 性能的优化,大部分优化的是用户态和内核态之间的缓冲区策略,而不是直接操作磁盘(磁盘本身的物理 IO 速度很慢)。
C语言下的文件操作
fopen ---- 打开文件

1 #include <stdio.h>
2 #include <stdlib.h>
3
4 int main()
5 {
6 FILE* fp = fopen("log.txt", "w");
7 if(fp == NULL)
8 {
9 perror("fopen fail");
10 exit(1);
11 }
12
13 fclose(fp);
14 return 0;
15 } 打开文件本质是,进程要打开文件,那么进程是怎么知道文件在哪里的呢?
通过 ls /proc/[进程id] -l 命令可以查看当前正在运行的进程的相关信息:
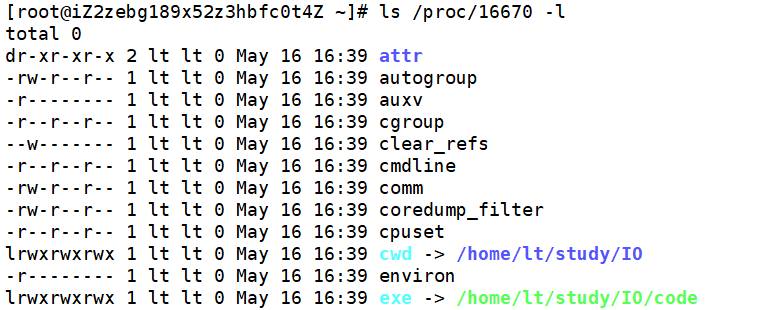
cwd:指向当前进程运行目录的一个软连接文件。
exe:指向启动当前进程的可执行文件的一个软连接文件
通过 cwd 就可以知道当前进程处于哪个目录下,所以即便打开文件不带路径,进程会默认在当前目录下打开或新建文件。
fopen的第二个参数 ---- 文件的打开模式
| 模式 | 读写权限 | 文件不存在 | 文件存在 | 文件偏移 | 补充说明 |
|---|---|---|---|---|---|
r |
只读 | 打开失败 | 直接打开 | 开头 | 最安全的只读模式 |
r+ |
可读可写 | 打开失败 | 直接打开 | 开头 | 不会清空文件,可覆盖已有内容 |
w |
只写 | 创建新文件 | 清空内容 | 开头 | 危险模式,会直接清空旧文件 |
w+ |
可读可写 | 创建新文件 | 清空内容 | 开头 | 先清空再打开,读写都可 |
a |
只写 | 创建新文件 | 追加打开 | 末尾 | 写操作只能在末尾,偏移无效 |
a+ |
可读可写 | 创建新文件 | 追加打开 | 读在开头,写在末尾 | 读操作可调整偏移,写操作强制到末尾 |
fread fwrite fclose fflush fseek ftell rewind等文件操作函数,这里不再论述。
系统下的文件操作
对于语言层面上的文件操作,基本都封装了系统调用,接下来让我们认识一些系统调用的接口。
open

参数1:要打开或创建的目标文件路径,支持绝对路径和相对路径
参数2:文件的打开方式
打开方式,必须包含一下三类之一:
| 基础模式 | 含义 | 对应 fopen 模式 |
|---|---|---|
O_RDONLY |
只读 | r |
O_WRONLY |
只写 | w/a |
O_RDWR |
读写 | r+/w+/a+ |
| 附加模式 | 作用 |
|---|---|
O_CREAT |
文件不存在时创建,创建的文件需要被设置权限,此时需要使用到第三个参数 |
O_TRUNC |
文件存在时清空内容 |
O_APPEND |
写操作强制追加到末尾 |
这些宏均为常量,可以用一个或多个宏进行按位或运算,构成flags(文件的打开方式)
参数3:创建文件时,文件的权限
返回值:
成功:被打开文件的文件描述符
失败:-1
int fd = open("log.txt", O_RDONLY); // 只读方式打开 对应C语言下的 r
int fd = open("log.txt",O_WRONLY | O_CREAT | O_TRUNC, 0664); // 以写方式打开 -> w
int fd = open("log.txt",O_WRONLY | O_APPEND | O_CREAT, 0664) // 以追加方式打开 -> a
if(fd < 0)
{perror("open fail");
exit(1);
}// 文件操作
close(fd);
注意:mode_t mode 一般以八进制形式传参,来表示文件的目标权限,但它不是文件的最终权限
文件的最终权限 :mode & (~umask)
所以要是想不受 umask 的影响,可以在 open 调用前,添加一行代码 :
umask(0);
write

参数1:文件描述符,必须是已打开的文件
参数2:要写入的数据的首地址,可以是任意类型的数据,因为这是按字节来写入
参数3:期望写入多少字节的数据。注意:'\0' 不要写入到文件中,因为'\0' 是C语言规定的,如果写入了'\0',系统会将它作为数据来处理,由于系统调用和其他语言再次读取文件的时候就需要对其做特殊处理,就会导致很麻烦,还浪费空间。况且C语言库函数向文件写入时,也不会写入'\0'。
返回值:
成功:实际写了多少字节数据
失败:-1(如fd无效,权限不够)
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <sys/types.h>
4 #include <sys/stat.h>
5 #include <fcntl.h>
6 #include <unistd.h>
7 #include <string.h>
8
9 int main()
10 {
11
12 umask(0);
13 int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
14
15 if(fd < 0)
16 {
17 perror("open fail");
18 exit(1);
19 }
20
21 char* buf = "hello world\n";
22
23 write(fd, buf, strlen(buf));
24
25 close(fd);
26
27 return 0;
28 }
read
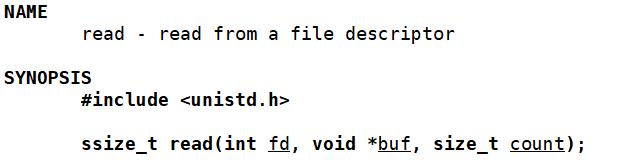
read 的参数和返回值与 write 的参数和返回值一致,不再过多论述
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <sys/types.h>
4 #include <sys/stat.h>
5 #include <fcntl.h>
6 #include <unistd.h>
7 #include <string.h>
8
9 int main()
10 {
11
12 umask(0);
13 int fd = open("log.txt", O_RDONLY);
14
15 if(fd < 0)
16 {
17 perror("open fail");
18 exit(1);
19 }
20
21 char buf[128];
22
23 while(1)
24 {
25 ssize_t sz = read(fd, buf, sizeof(buf) - 1);
26 if(sz == 0)
27 {
28 break;
29 }
30 buf[sz] = 0;
31 printf("%s", buf);
32 }
33
34 close(fd);
35 return 0;
36 }
close
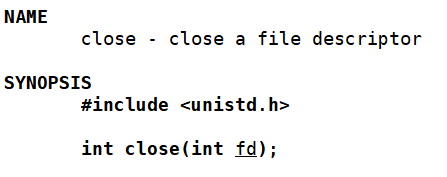
参数:文件描述符
返回值:成功关闭文件返回 0 ,失败返回 -1
文件描述符
文件描述符:通过对open函数的学习,文件描述符就是一个整数,它就相当于文件的id,但它的本质是进程文件表的下标
对于我们写的可执行程序,加载到内存中形成进程。进程默认情况下会打开3个文件,并分配文件描述符,分别是标准输入0,标准输出1,标准错误2。
0,1,2对应的物理设备一般是:键盘,显示器,显示器
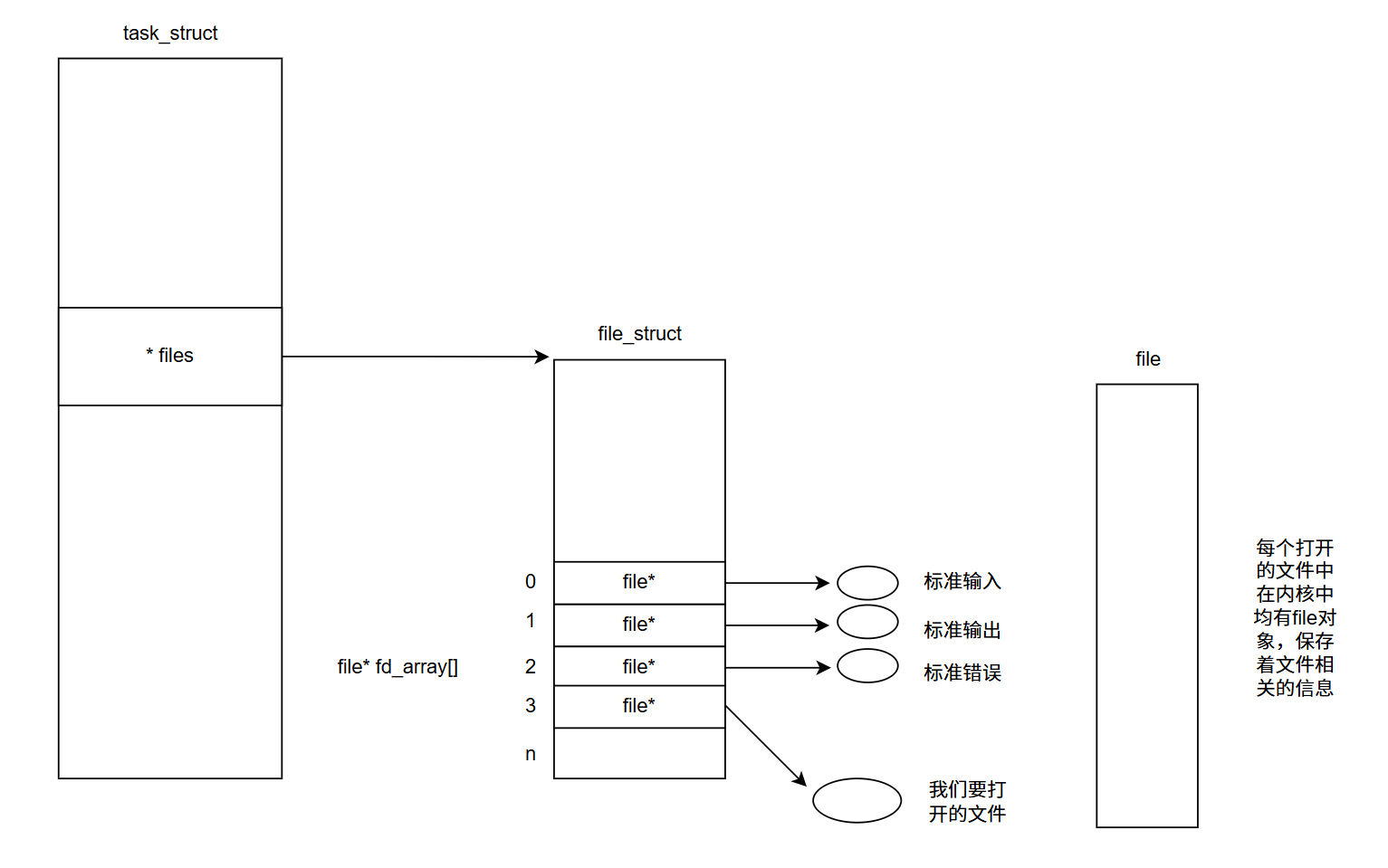
文件描述符就是从0开始的整数,但我们打开一个文件时,操作系统在内存中要创建相应的数据结构来描述目标文件。于是就有了file结构体,表示一个已经打开的文件对象。而进程执行open系统调用,所以就必须让进程和文件关联起来。每个进程都有一个指针*files,指向一张表files_struct,该表最重要的部分就是包含一个指针数组,每个元素都是一个指向打开文件的指针,所以,本质上,文件描述符就是该数组的下标,进程拿着文件表中的文件描述符就能找到对应的文件。
task_struct 中指向文件表的指针

文件表中结构,里面有一个指针数组,每个元素指向一个打开的文件的指针
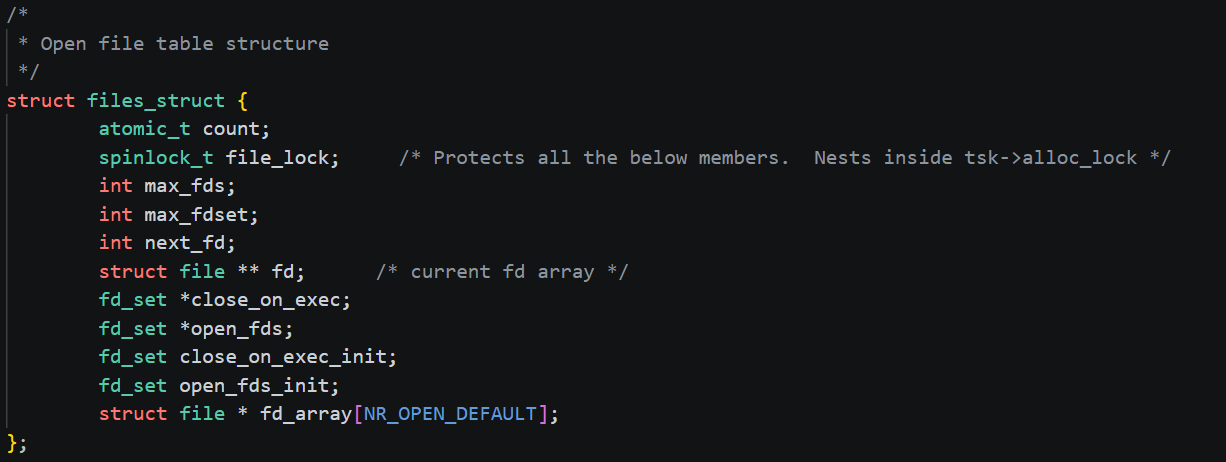
文件的结构
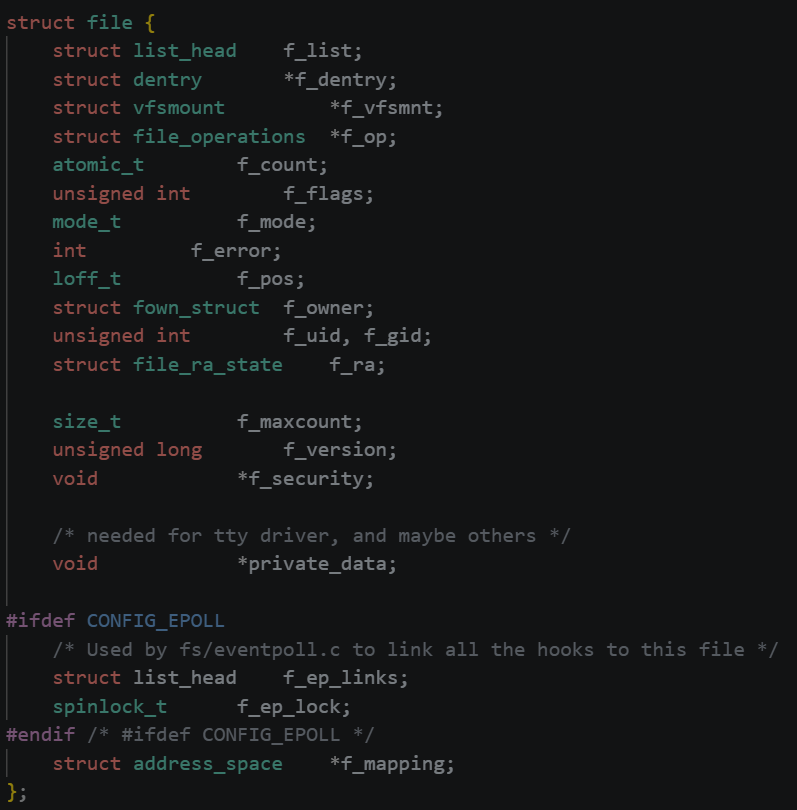
文件描述符的分配规则
文件描述符的分配规则:在files_struct指针数组中,找到当前没有被使用的最小的一个下标,作为新的文件描述符。
1 #include <stdio.h>
2 #include <sys/types.h>
3 #include <sys/stat.h>
4 #include <fcntl.h>
5 #include <unistd.h>
6
7 int main()
8 {
9 int fd = open("log.txt", O_RDONLY);
10 if(fd < 0)
11 {
12 perror("open fail");
13 return 1;
14 }
15 printf("fd:%d\n", fd);
16 close(fd);
17 return 0;
18 }
输出结果是 fd:3
验证了进程默认会打开3个文件
1 #include <stdio.h>
2 #include <sys/types.h>
3 #include <sys/stat.h>
4 #include <fcntl.h>
5 #include <unistd.h>
6
7 int main()
8 {
9 close(0);
10 int fd = open("log.txt", O_RDONLY);
11 if(fd < 0)
12 {
13 perror("open fail");
14 return 1;
15 }
16 printf("fd:%d\n", fd);
17 close(fd);
18 return 0;
19 }
输出结果是: fd:0
验证了文件描述符的分配规则
理解重定向
1 #include <stdio.h>
2 #include <sys/types.h>
3 #include <sys/stat.h>
4 #include <fcntl.h>
5 #include <unistd.h>
6
7 int main()
8 {
9 umask(0);
10 close(1);
11 int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0664);
12 if(fd < 0)
13 {
14 perror("open fail");
15 return 1;
16 }
17 printf("fd:%d\n", fd);
18 fflush(stdout);
19 close(fd);
20 return 0;
21 }

关闭1,此时我们发现,本来应该输出到显示器上的内容,输出到了文件 log.txt 中,其中 fd = 1。
这种现象叫做输出重定向。常见的重定向:> >> <
重定向的本质:修改进程文件描述符指向的文件,不改变库函数(printf,scanf)的逻辑。
因为库函数只认 0 作为标准输入, 1 作为标准输出, 2 作为标准错误。但不管0 ,1,2究竟指向了什么文件,俗称 “狸猫换太子” ,欺骗了库函数。
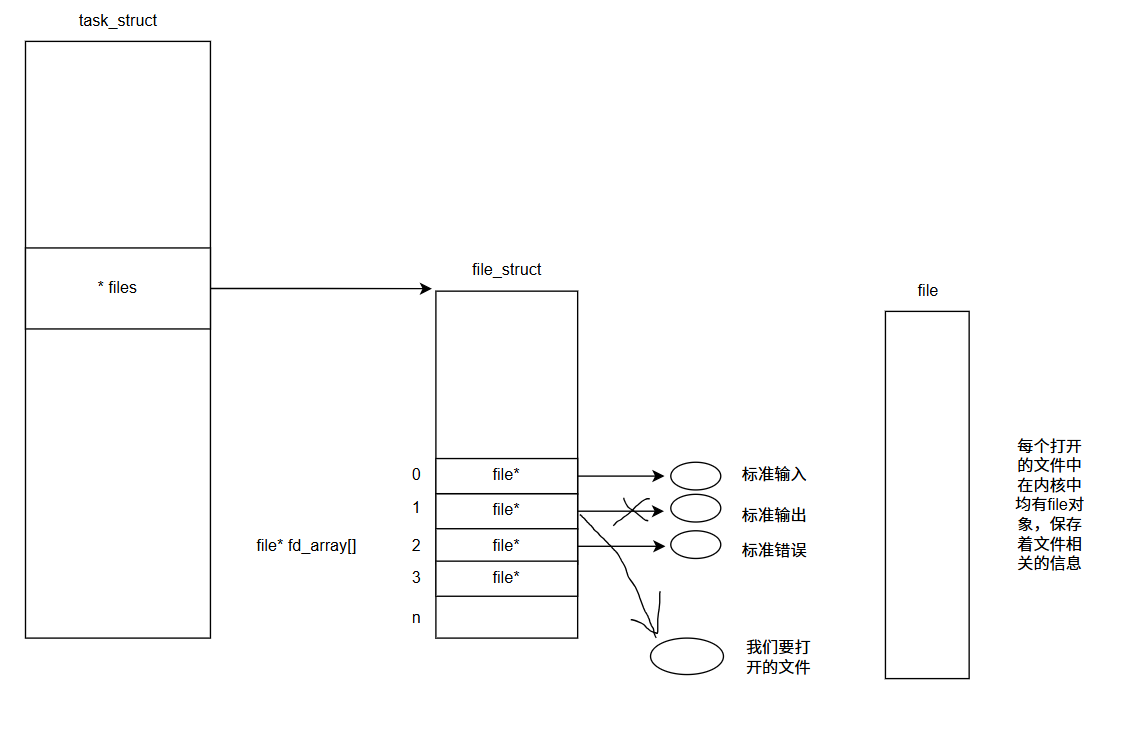
dup 系统调用
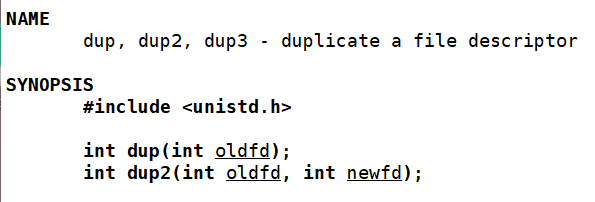
dup2(oldfd, newfd)先关闭newfd原本指向的指针,然后将newfd 与 oldfd 指向同一个内核文件对象,两者共享文件偏移、状态标志和引用计数。
1 #include <stdio.h>
2 #include <sys/types.h>
3 #include <sys/stat.h>
4 #include <fcntl.h>
5 #include <unistd.h>
6
7 int main()
8 {
9 umask(0);
10 int fd = open("log.txt", O_WRONLY | O_TRUNC | O_CREAT, 0664);
11 if(fd < 0)
12 {
13 perror("open fail");
14 return 1;
15 }
16
17 dup2(fd, 1);
18
19 printf("fd:%d\n", fd);
20
21 close(fd);
22
23 return 0;
24 }
dup2(fd, 1); // 执行它的流程
1. 先关闭原本指向终端的 1 号文件描述符
2. 让 1 号文件描述符指向 fd 对应的log.txt
3. 此时 fd 和 1 都指向同一个文件
理解 “Linux一切皆文件”
Linux一切皆文件:在Linux系统中,除了磁盘上的文件,一些硬件设备也被抽象成了文件,进程可以通过使用访问文件的方式来访问硬件设备。
通过这样的方式来处理硬件设备,开发者仅需要使用一套API和开发工具,即可调动Linux下的绝大部分资源。例如 Linux 中几乎所有读的操作都可以用 read 函数来进行,几乎所有写的操作都可以用 write 函数来进行。
所以,站在进程的角度上,它只管在文件表中为“文件”分配文件描述符,调用 read 和 write 等函数对“文件” 进行读写等操作,它并不知道 文件是什么。所以操作系统通过统一的文件抽象接口,让进程只需关注文件描述符和read/write调用,而无需关心底层是磁盘文件、设备还是管道,以此方式欺骗进程。所以Linux一切皆文件,是站在了进程的角度上来说的,相对应的是,欺骗了进程,也就欺骗了用户,所以在用户层面上,也就有了Linux一切皆文件的说法。
让我们来见识一下,read 和 write 对于不同类型的“文件”是如何做到不同读写操作的

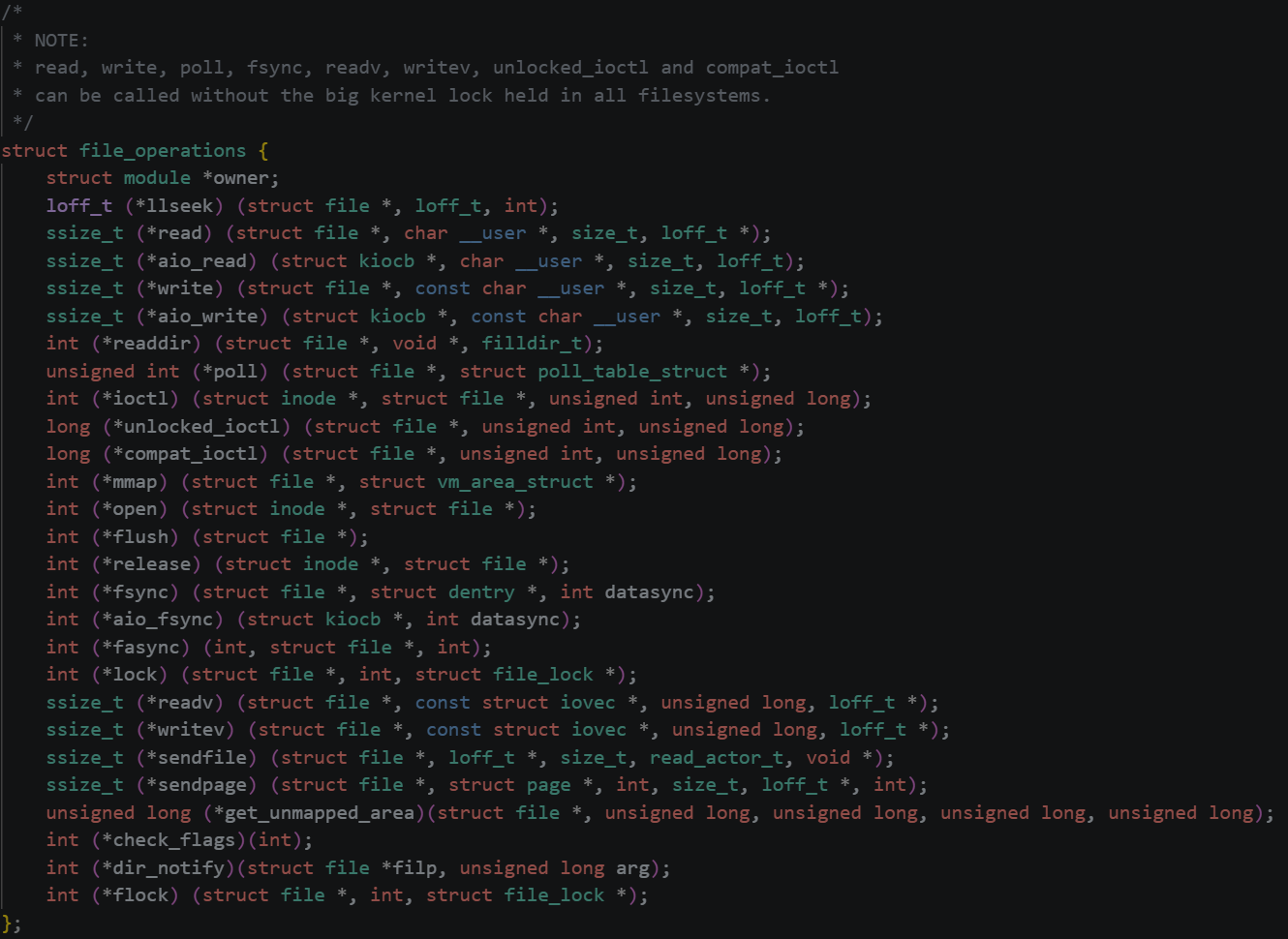
当打开一个文件时,操作系统为了管理所打开的文件,都会为这个文件创建一个file结构体,file结构体中存在着一个 *f_op 指针指向了一个 file_operations 结构体,这个结构体中的存在许多函数指针,这些函数指针就指向了不同的文件操作。
file_operations 就是把系统调用和驱动程序关联起来的数据结构,这个结构的每一个成员都对应着一个系统调用。读取file_operations 中相应的函数指针,接着把控制权交给函数,从而完成了对硬件设备的操作。
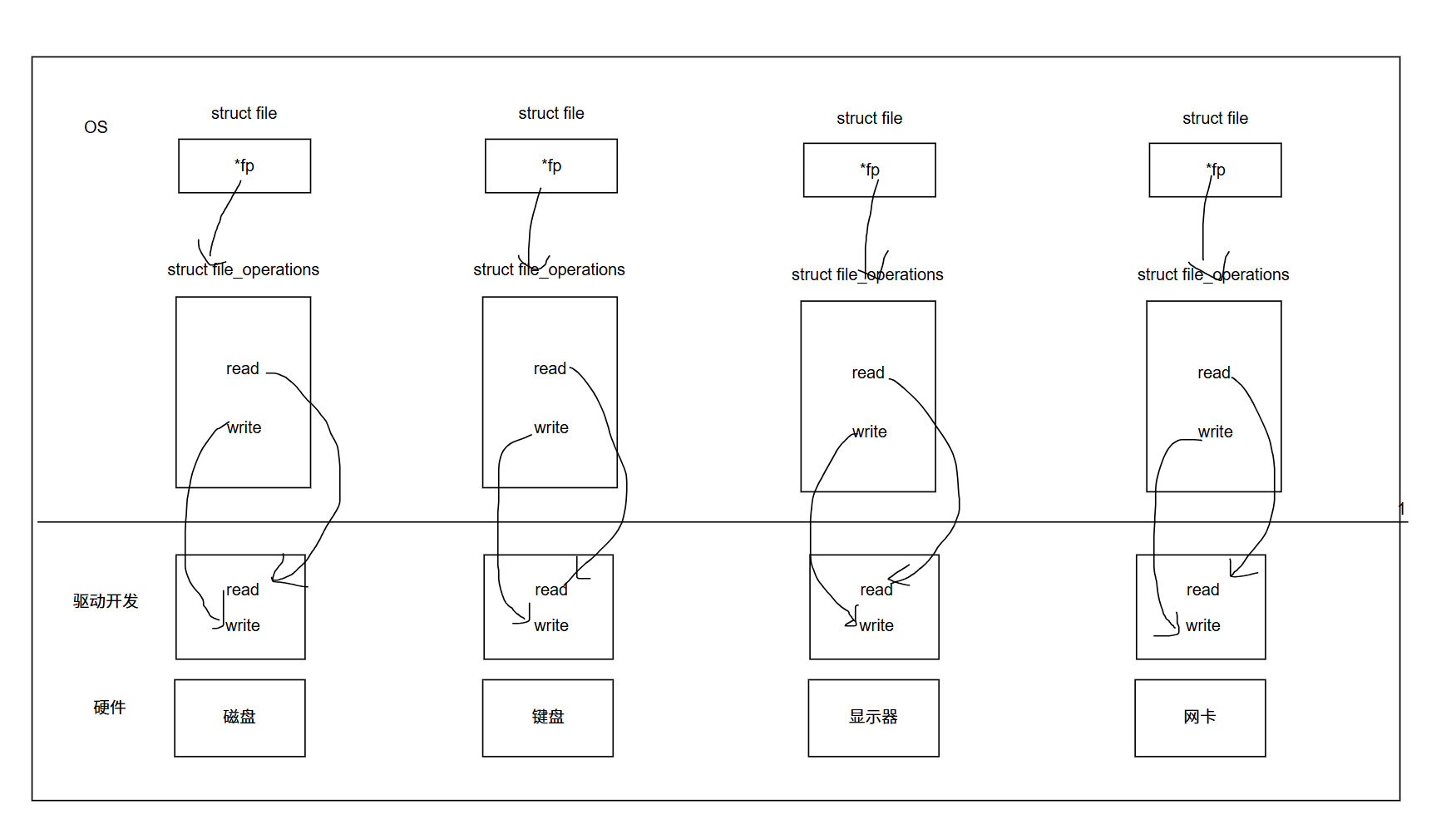
上图中的外设,每个设备都可以有自己的 read、write,但一定对应着不同操作方法,所以对于开发者来讲,只用file便可调度Linux系统中绝大部分资源,这便是“Linux一切皆文件”的核心理解
缓冲区
什么是缓冲区
缓冲区是内存空间的一部分空间。在内存空间中预留了一定的存储空间来缓冲输入和输出的数据,这部分用来缓冲输入和输出的数据的空间就叫做缓冲区。
缓冲区的分类
缓冲区分为:用户态缓冲区(语言级缓冲区)和内核态缓冲区
缓冲区根据外设的不同又可以细分为两种,对应输入设备的是输入缓冲区,对应输出设备的是输出缓冲区。
用户级缓冲区的刷新策略
| 刷新策略 | 触发条件 | 典型场景 | 补充细节 |
|---|---|---|---|
| 全缓冲 | 缓冲区满、程序退出、调用 fflush |
普通文件(fopen 打开的文件) |
重定向 stdout 到文件时,会自动切换为全缓冲模式 |
| 行缓冲 | 遇到 \n、缓冲区满、程序退出、调用 fflush |
终端设备(stdout 默认指向终端) |
默认行缓冲区的大小为1024字节 |
| 无缓冲 | 直接调用系统调用,无用户态缓存 | stderr、stdprn |
错误信息必须实时输出,所以默认无缓冲 |
注意:
1.进程fork()时,父进程的用户态缓冲区会被复制到子进程,导致输出重复(解决方法:fork前调用fflush(stdout))。
2.fflush(stdout) 的作用:强制刷新stdout的用户态缓冲区,将数据写入内核态缓冲区,不影响内核态缓冲区的刷盘行为。
3.printf 重定向的缓冲区行为
当stdout 指向终端时,是行缓冲模式。
当stdout被重定向到文件时,会自动切换为全缓冲。
内核态缓冲区的刷新策略
对于内核态缓冲区的刷新策略,没有特定的标准,只要用户把数据交到了内核态缓冲区,由内核在合适实际(如内核态缓冲区满、定时刷盘、调用fsync)批量写入磁盘。
注意:内核不会每次write都刷盘,而是将数据暂存到内核态缓冲区,只有调用fsync,才会强制将内核缓冲区的数据刷新到磁盘。
数据流动的完整路径
用户态程序 → 用户态缓冲区(C库) → 内核态缓冲区(页缓存) → 磁盘/设备
缓冲区存在的意义
读写文件时,如果没有缓冲区,就需要直接通过系统调用对磁盘进行操作,那么每一次对文件的操作,都需要通过系统调用来处理,即需要执行一次系统调用,执行一次系统调用将要涉及CPU状态的切换,即从用户空间切换到内核空间,实现进程上下文的切换,这将损耗一定的CPU时间,频繁的磁盘访问对程序的执行效率造成很大的影响。
为了减少系统调用的次数来提高效率,就可以采用缓冲区机制来实现。例如我们从磁盘里读取数据,可以一次从文件中读出大量的数据到缓冲区,以后对这部分的数据的访问就不需要使用系统调用了,等缓冲区的数据读取完,再从磁盘上读取,这样就可以减少磁盘的读写次数,再加上OS对缓冲区的操作远大于对磁盘的操作,这样就可以大大提高了程序的运行速度。又比如,我们使用打印机打印文档,由于打印机的打印速度相对较慢,我们先把文档输出到打印机相应的缓冲区,打印机再自行逐步打印,这时我们的CPU可以处理别的事情。可以看出,缓冲区就是一块内存空间,它用在输入输出设备和CPU之间,用来缓存数据。它使得低速的输入输出设备和高速的CPU能够协调工作,避免低速的输入输出设备占用CPU,解放出CPU,使其能够高效率工作。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)