Redis集群:从单点故障到高可用的进阶之路
Redis高可用架构演进 单点问题 单点部署存在可用性和性能瓶颈,服务器宕机导致服务不可用,硬件资源限制并发处理能力。 主从模式 主节点处理写请求,从节点复制数据并处理读请求 提升读性能和数据冗余,但主节点仍是单点 哨兵模式 引入哨兵进程监控节点状态 实现自动故障转移,主节点宕机时自动选举新主 但仍存在单点写瓶颈和存储限制 集群模式 采用哈希槽分区算法(16384个槽位) 数据分片存储在多个主节点
背景
单点问题:如果一个服务只部署在一台物理服务器上,那这台服务器就是整个服务的 “唯一入口”。一旦它宕机、网络中断或硬件故障,整个服务就会彻底不可用,同时性能也受单机硬件的限制。
单点问题的两大核心痛点:
可用性(Availability)问题
单机挂了 → 服务直接中断,没有任何冗余备份。
对于线上业务,这意味着用户无法访问、交易中断,甚至造成严重的经济损失。
性能与并发瓶颈
单机的 CPU、内存、网络带宽都是有限的,能支撑的并发请求数和吞吐量有明确上限。
当业务量增长到单机无法承载时,就会出现响应延迟飙升、服务雪崩等问题。
为什么要引入分布式系统?
引入分布式系统(多节点部署)的核心目标,就是解决单点问题:
通过多台服务器共同提供服务,避免 “一台机器挂了全服务挂掉” 的风险。
通过负载均衡,将请求分散到多台机器,突破单机性能瓶颈,提升并发处理能力。
Redis 作为核心的缓存 / 存储组件,如果只部署在单台服务器上,就会成为整个分布式系统的单点瓶颈:
- 如果 Redis 挂了,所有依赖它的业务服务(如缓存穿透、会话存储)都会受到影响。
- 单机 Redis 的 QPS 上限(约 10w/s)在高并发场景下很快就会被打满。
因此,我们需要将 Redis 部署成多节点集群,让它为整个分布式系统提供:
- 更高的可用性:一台节点挂了,其他节点可以顶上。
- 更高的性能:请求可以分散到多个节点,提升整体吞吐量。
- 更大的存储容量:数据可以分片存储在多个节点,突破单机内存 / 磁盘限制。
redis经典集群部署方案
1. 主从模式(Master-Slave)
这是 Redis 最基础的高可用部署模式,核心是数据冗余 + 读写分离。
核心架构:
一个主节点(Master):负责处理所有写请求,并将数据同步到从节点。
多个从节点(Slave):负责复制主节点的数据,处理读请求。
解决的问题:
可用性:主节点挂了,从节点可以手动提升为主节点,继续提供服务。
性能:读请求可以负载均衡到多个从节点,分担主节点的读压力。
存在的问题:
主节点仍是单点:写操作只能在主节点进行,主节点挂了需要人工干预切换,无法自动故障转移。
数据一致性:主从复制是异步的,可能出现短暂的 “读旧数据”(最终一致性)。
2. 主从 + 哨兵模式(Master-Slave + Sentinel)
在主从模式的基础上,引入了哨兵(Sentinel) 进程,解决了 “主节点挂了需要人工干预” 的问题,实现了自动故障转移。
核心架构:
哨兵是独立的监控进程,通常部署 3 个或以上,监控所有主从节点的健康状态。
当哨兵检测到主节点宕机时,会自动从从节点中选举一个新的主节点,并更新其他节点的配置。
解决的问题:
自动故障转移:主节点挂了,哨兵会自动完成主从切换,无需人工介入,大大提升了可用性。
配置中心:客户端可以连接哨兵,获取当前主节点的地址,实现自动路由。
存在的问题:
写瓶颈依然存在:写操作仍然只能在一个主节点上进行,无法水平扩展写能力。
存储容量受限:所有节点存储的都是全量数据,无法分片,存储容量受限于单台服务器的最大内存。
3. Redis 集群模式(Redis Cluster)
这是 Redis 官方提供的分布式解决方案,彻底解决了主从 + 哨兵模式的瓶颈,实现了数据分片 + 高可用。
核心架构:
数据被分成 16384 个哈希槽(slot),分布在多个主节点上。
每个主节点都有自己的从节点,用于故障转移。
客户端可以直接连接任意节点,根据 key 的哈希值路由到对应的 slot 所在节点。
解决的问题:
水平扩展:可以通过增加主节点来线性提升写性能和存储容量。
高可用:内置了故障转移机制,主节点挂了,从节点会自动提升为主节点。
分布式路由:客户端可以自动感知集群拓扑,将请求路由到正确的节点。
从单点 Redis 到 Redis 集群,是一个逐步解决问题的过程:
- 单点问题:单机挂了服务就没了,性能也上不去。
- 主从模式:解决了读性能和数据冗余问题,但主节点仍是单点,故障需要人工处理。
- 主从 + 哨兵:解决了主节点故障的自动切换问题,但写性能和存储容量仍是瓶颈。
- Redis 集群:彻底实现了分布式,解决了写性能、存储容量和高可用的所有问题。
主从模式
设计初衷:主从模式是为了 “备份” 和 “读扩展”,不是为了 “多活写入”。
主节点专注写,从节点分担读压力(如查询、统计),这是主从模式的核心价值
28定律:百分之80都是为了读,百分之20为了写,所以主从模式更好的是设立一主多从,并且数据传输是单向的,只能是主到从,设计初衷就是为了读扩展的
- 数据一致性:所有变更都来自一个源头,避免了多节点同时写导致的数据冲突(比如从节点 A 和从节点 B 同时修改同一个 key,谁对谁错?)。
- 实现简单:主节点只需要把自己的写操作广播出去,从节点只需要执行,不需要处理复杂的 “冲突解决” 和 “双向同步” 逻辑。
本身的设计里面就只能是主节点给从节点传输数据,这里有个复制缓冲区,只能是主写给从
从节点的数据跟随主节点变化,和主节点保持一致
从节点挂掉:重启后确实能自动从主节点 / 其他从节点重新同步数据,几乎无需人工干预;
主节点挂掉:纯主从模式下(无哨兵 / 集群),需要手动切换从节点为主节点,否则整个集群无法处理写操作 —— 这也是纯主从模式最大的痛点。
主节点挂掉需要手动把某个从节点提升为主节点,或者增加哨兵(后面讲)
简单来说,主从模式大大提高了读的并发量和可用性和数据安全性(有多个读节点备份)
对于写不能设立多个主节点,否则主节点之间的数据同步又是一个问题
所以没有解决单点问题中的写,没有解决主节点自动故障转移
配置主从模式
前提:由于没有多台服务器,只有一台,我们需要开多个进程,然后端口号不同
redis-server启动方式
1:临时命令行直接启动
# 启动Redis,指定端口为6380(替换成你想要的端口即可) redis-server --port 6380 # 后台启动Redis,指定端口6380 redis-server --port 6380 --daemonize yes2:通过配置文件redis.conf进行修改端口
下次启动的时候指定配置文件即可
要注意区分你启动服务器时的操作是临时的还是永久的,通过配置文件修改就是永久的


搭建主从结构
注意:5.0之前老版本使用slaveof,之后新版本使用replicaof和slaveof都行(建议使用replicaof)
1:直接通过命令指定主节点是谁
# Redis < 5.0 redis-server --port 6380 --slaveof 127.0.0.1 6379 --daemonize yes # Redis ≥ 5.0(推荐) redis-server --port 6380 --replicaof 127.0.0.1 6379 --daemonize yes2:通过配置文件修改
3:客户端命令
# Redis < 5.0 127.0.0.1:6380> SLAVEOF 127.0.0.1 6379 OK # Redis ≥ 5.0(推荐) 127.0.0.1:6380> REPLICAOF 127.0.0.1 6379 OK断开所有的主从关系
slaveof no one replicaof no one
- 主节点没有 “断开从节点” 的命令:主节点只能被动接受从节点的连接 / 断开,无法主动踢掉从节点,也不能命令从节点升级为主节点;
- 从节点是主从关系的 “主导方”:只有从节点主动执行
REPLICAOF NO ONE,才能断开和主节点的关系并升级为主节点;- 主节点仅能 “感知” 从节点断开:当从节点主动断开后,主节点的
connected_slaves数量会减少,但主节点本身的角色(master)和数据都不变。从节点执行断开之后主动变为主节点,数据不会变,但是不会更新之前主节点的数据了
查询当前节点的信息
info replicationNagle算法
由于redis是tcp连接,tcp协议当中有一个nagel算法
Nagle 算法的核心目的是 减少小数据包的网络传输次数(俗称 “粘包”),通过延迟发送小数据包、凑够一定大小 / 等待确认后再发送,降低网络拥塞;但在 Redis 这类 “低延迟、小数据包频繁传输” 的场景中,Nagle 算法反而会增加延迟,所以 Redis 会默认关闭它。
关闭nagel算法会增加带宽,降低延迟
打开nagel算法会降低带宽,增大延迟

实操演示
三个进程已经启动了,并且都是通过命令配置好了主从关系
前面三个是6379、6380、6381,这三个是进程
由于我们同属于一台服务器,从节点与主节点之间相当于客户端与服务器的通信,从节点需要作为客户端的一个端口与服务器的6379进行连接
图中可以看出是38576和38572两个端口,并且状态时established


当从节点进行set数据的时候根本不允许,因为从节点只能读
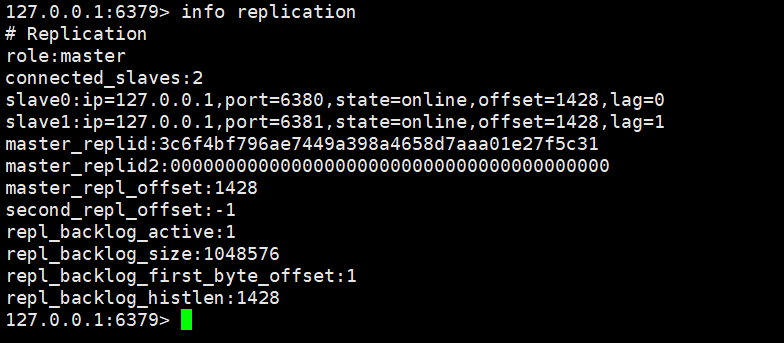
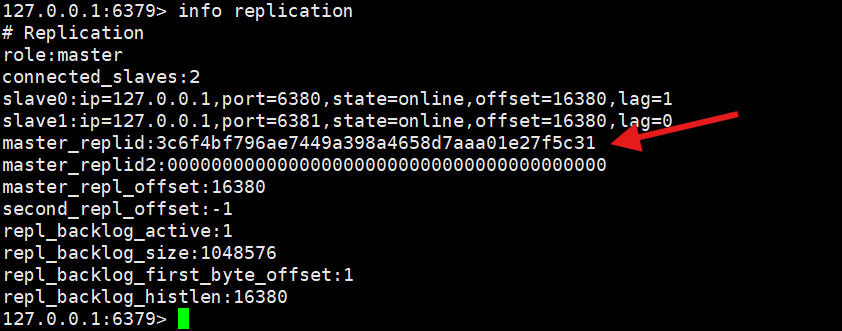
主节点的主从信息
role的信息是master,那就是主节点
connected_salve:那就是有两个从节点
offset=1428:这个是复制偏移量,代表主节点和从节点之间数据同步的进度。主从节点都维护这个值,用来判断数据是否同步完成。
lag=表示从节点最后一次向主节点发送确认消息的时间间隔(秒),这里是 0和1秒,说明主从同步很及时。
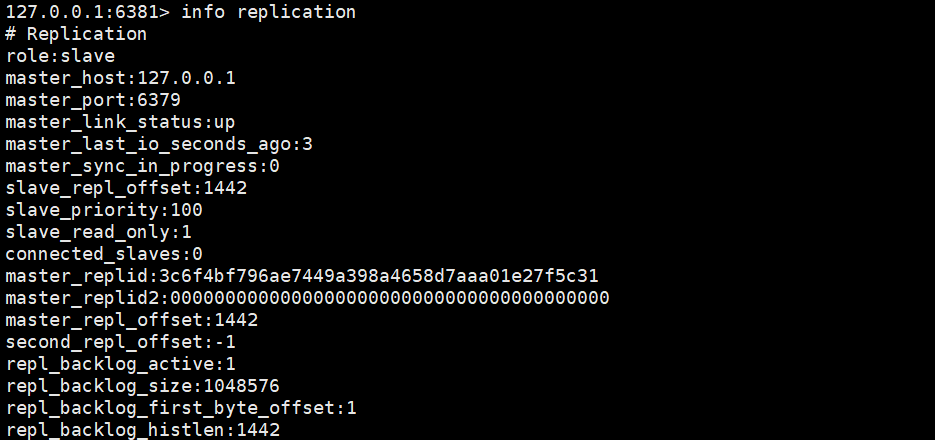
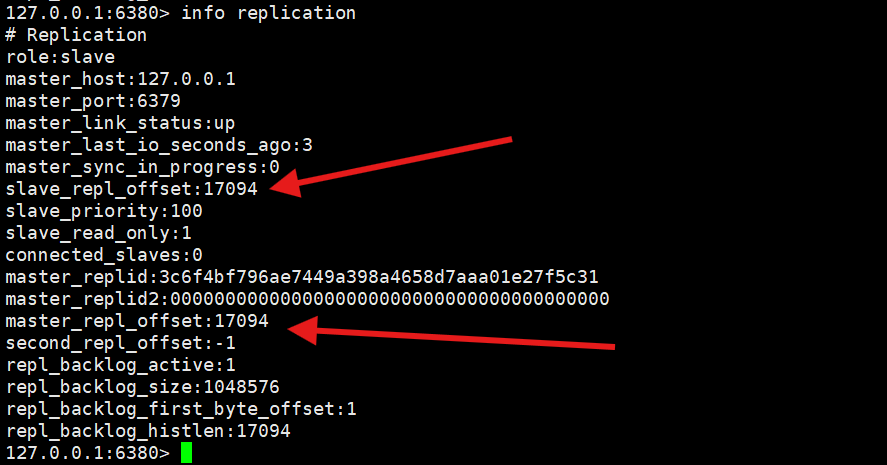
从节点的主从信息
可以看到role的信息是slave,那就是从节点

主从架构分析
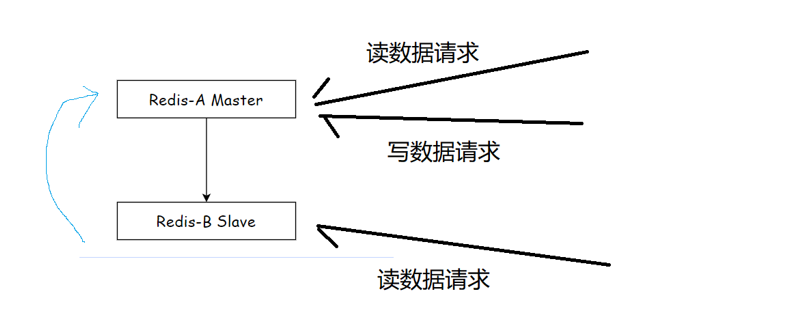
一主一从
对于写请求只能发给主节点
读请求可以发给主节点,也可以发给从节点
可以通过关闭主节点的AOF来缓解一下,因为从节点就是主节点的复制
但是重启的时候不能让主节点直接重启(AOF当中没有数据),否则进一步主从同步的时候,导致从节点的数据也没了
应该把从节点的aof文件拷贝过来,然后让主节点通过这个aof文件重启
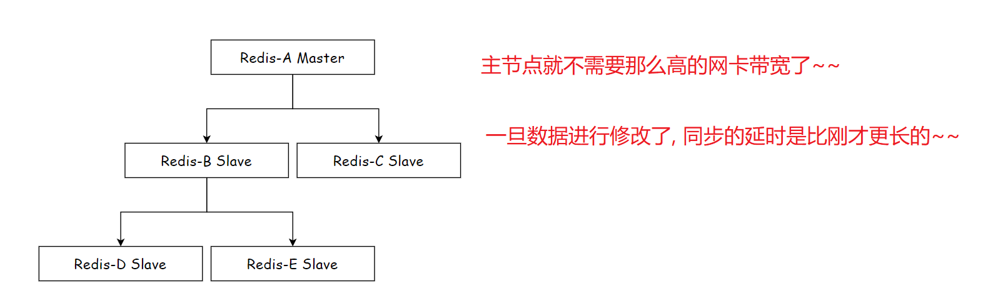
一主多从
- 主节点每修改一条数据,就要把这条数据同时发给所有从节点
- 从节点越多,主节点的网络带宽压力越大,同步延迟也越长
比较时候从节点<=3的时候
主-从-主
数据同步的链路变长,主从之间的延迟会更大

主从如何实现的???

保存主节点信息
- 你执行
REPLICAOF后,Redis 会把主节点的 IP 和端口保存到内部变量(也会写入redis.conf持久化)。- 下次重启时,从节点会自动读取这些信息,再次尝试连接主节点。
主从建立连接
- 从节点会主动作为 TCP 客户端,向主节点发起三次握手,建立长连接。
- 这个连接就是后续所有复制数据的传输通道。
发送 PING 命令
- 连接建立后,从节点会主动发送
PING给主节点。- 目的是验证主节点是否存活、是否能正常响应,避免在一个不可用的节点上浪费时间。
权限验证
- 如果主节点设置了密码(
requirepass),从节点会自动发送AUTH命令进行身份验证。验证失败的话,复制流程会直接终止。当主节点设置了密码(
requirepass 123456),任何客户端(包括从节点)想要和它通信,都必须先执行AUTH 123456验证身份,否则主节点会拒绝所有请求。在主从复制流程中:
1:从节点会自动尝试发送
AUTH命令,但它需要知道密码是什么;2:如果从节点没有配置密码,或者配置的密码和主节点不一致,验证就会失败;
3:验证失败后,主节点会断开连接,复制流程直接终止,从节点无法同步数据。
同步数据集
- 这是最核心的一步,Redis 会根据情况选择:
- 全量同步:首次连接或数据差异过大时,主节点生成 RDB 文件,发给从节点加载。
- 增量同步:网络闪断重连时,只同步断开期间的新命令。
- 整个过程完全自动,不需要你手动生成或传输文件。
命令持续复制
- 初始同步完成后,主节点会把后续所有写操作,实时通过之前建立的 TCP 连接发给从节点。
- 从节点收到后,按顺序重放这些命令,保证和主节点的数据一致。
redis提供了一个psync命令,完成数据同步的过程
在完成主从关系的建立之后,从节点自动执行psync命令,不需要我们手动执行,自动向主节点拉取数据
PSYNC是 Redis 为解决「重连后全量同步效率低」设计的增量同步机制,核心原理是:通过唯一标识(RunID)确认主节点身份,通过复制偏移量(offset)定位数据缺口,通过复制积压缓冲区(backlog)缓存增量数据,优先增量同步,仅在必要时触发全量同步。runID(replid):每个节点启动的时候都会自动生成,只要节点重启就会重新生成
当关系建立好了之后,就需要获取主节点的id
一般来说id2是不用的,但是主和从通信过程当中出现抖动,从会认为主挂掉了,然后把自己升为主节点,然后此时就可以用id2来记录之前的主节点,然后id1自己生成一个,后续如果通信好了又会变回去,这个需要手动干预,但是哨兵模式不需要,哨兵自动完成
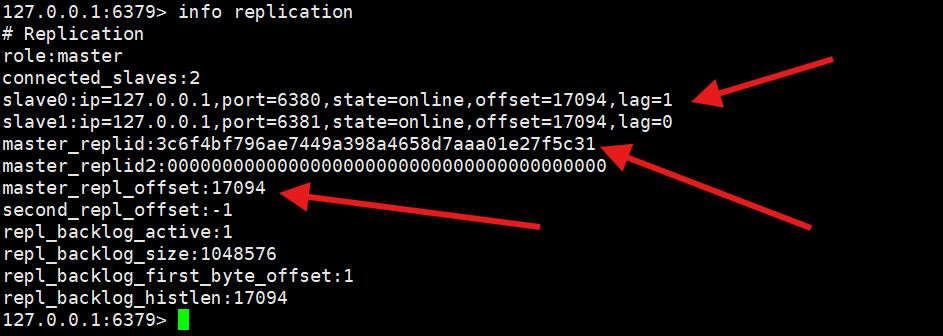
字段 含义 repl_backlog_active:1表示 backlog 缓冲区已启用(1 为启用,0 为关闭) repl_backlog_size:1048576缓冲区的总大小,这里是 1MB(1048576 字节),可通过 repl-backlog-size配置repl_backlog_first_byte_offset:1缓冲区中最早数据的起始偏移量,用于判断从节点的 offset 是否还在缓冲区范围内 repl_backlog_histlen:16380缓冲区中当前已缓存的数据长度(字节数),这里是 16380 字节 这个backlog缓冲区是为了验证offset还是不是在合理范围
- 主节点每给从节点发 100 字节的复制数据,
offset从 1000 → 1100;- 从节点收到后,
offset也从 1000 → 1100;- 主节点同时把这 100 字节写入
backlog;- 若网络断了,主节点继续写数据,
offset涨到 1500,而从节点还停在 1100 → 缺口是 1100~1500。offset:偏移量,主节点和从节点各自维护一个整数
offset。主节点:记录它总共向从节点发送了多少字节的修改命令。每处理一个写操作,这个数字就会累加
从节点:记录它已经从主节点同步到了哪个位置。
这是主节点自己的总偏移量
然后从节点0要每s上报偏移量给主节点
字段 含义 slave_repl_offset:17094从节点当前的复制偏移量,表示它已经同步到了第 17094 字节的位置。 master_repl_offset:17094从节点从主节点那里获取到的、主节点当前的偏移量。 master_replid从节点当前从属的主节点的 RunID(身份标识)。
- 数据集合:
replication id+offset共同描述了一个唯一的 “数据快照”。- 判断逻辑:如果两个 Redis 节点的
replication id相同,并且offset也相同,那么可以认为它们存储的数据是完全一样的。这里解释的就是唯一性,一般来说id已经唯一了,在加上一个offset更唯一
replication id是 “身份”,用来确认是不是同一个数据源;offset是 “进度”,用来确认数据同步到了哪一步;- 两者结合,
PSYNC就能聪明地决定是 “断点续传”(增量同步)还是 “重新下载”(全量同步)。流程再度解析
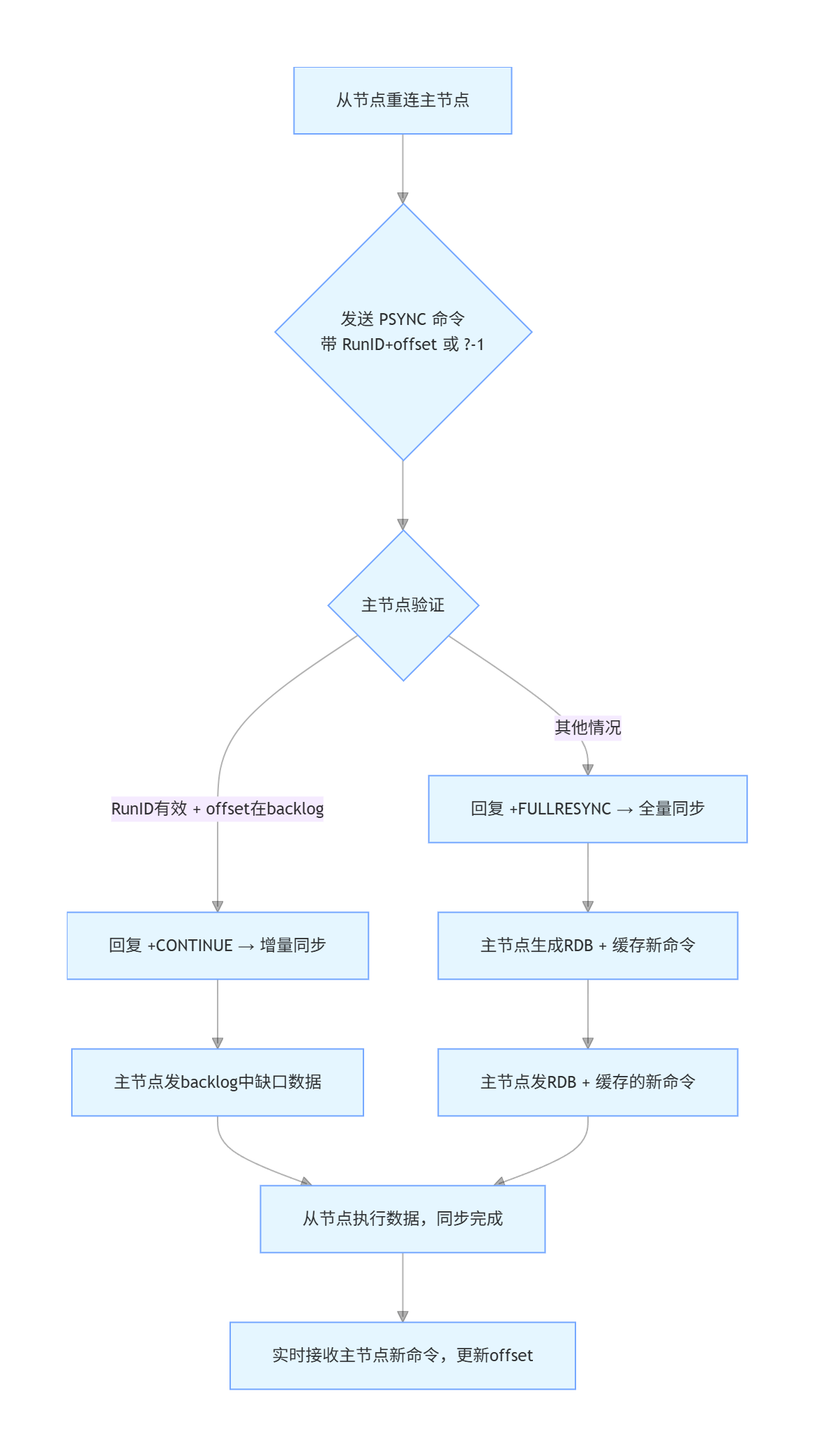
建立好连接之后发送psync命令,根据自身情况发送
如果之前没有链接过主节点,就会发送psync ? -1(?表示无主节点id,-1表示offset)
如果链接过主节点,就会发送psync RunID offset(根据之前的记录发送)
主节点收到之后,进行验证,首先RunID对不对,offset还在不在合理返回(这个通过backlog验证,缺口数据是不是还在backlog当中)
- 从节点发送
PSYNC <主节点RunID> <从节点当前offset>给主节点;- 主节点验证 RunID 有效,且
offset在backlog中 → 回复+CONTINUE;- 主节点从
backlog中读取offset之后的所有数据,发给从节点;- 从节点接收并执行这些增量数据,同步完成后,继续实时接收主节点的新命令。
如果无id/offset或者id不对(主节点重启)或者offset超出backlog范围(断开太久,缓冲区被覆盖)
- 从节点发送
PSYNC ? -1(? 表示无 RunID,-1 表示无 offset)给主节点;- 主节点回复
+FULLRESYNC <新RunID> <主节点当前offset>,并开始生成 RDB 文件;- 主节点生成 RDB 期间,把新收到的写命令写入「复制缓冲区」(避免丢失);
- 主节点发送 RDB 文件给从节点 → 从节点清空本地数据,加载 RDB;
- 从节点加载完 RDB 后,主节点把「复制缓冲区」中的新命令发给从节点;
- 从节点执行这些命令,完成全量同步,后续进入实时增量同步。
注意主节点会fork一个进程,进程去生成RDB,不会写入磁盘,而是以网络形式直接往网络当中写,传给从节点,避免了一系列读硬盘和写硬盘的操作
网络抖动详解
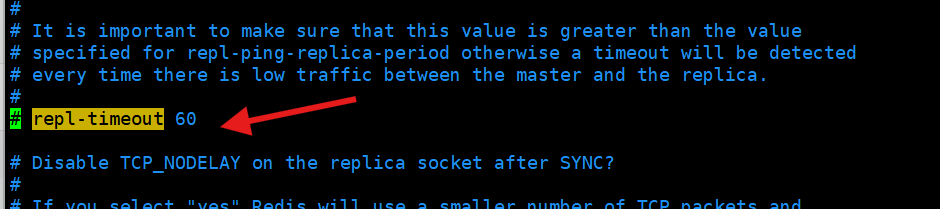
repl-timeout这个就是超时断开
这个是从节点发ping的时间间隔,也就是心跳检测
1. 主节点视角(监控从节点)
主节点会给每个从节点维护一个 “最后交互时间戳”:
每次给从节点发命令、收到从节点的 PONG 响应,都会更新这个时间戳;
如果某个从节点的 “当前时间 - 最后交互时间戳” >
repl-timeout,主节点会:
标记该从节点状态为
down;断开与该从节点的 TCP 复制连接;
在日志中打印
Replica xxx:xxx timed out, closing connection。2. 从节点视角(监控主节点)
从节点也会监控与主节点的交互:
从节点会定期给主节点发 PING(默认每 10 秒一次),并等待主节点的响应;
如果从节点超过
repl-timeout秒没收到主节点的任何数据(包括 PONG 响应、复制命令),会:
标记主节点状态为
down;断开与主节点的 TCP 连接;
尝试重新连接主节点(默认会无限重试,间隔由
replica-retry-timeout控制);日志中打印
Master xxx:xxx timed out, reconnecting...。需要打开才能使用,否则主从之间感受不到对方的失联,就会占用资源,并且哨兵模式也用不了
当主节点挂掉,就会导致写操作无法进行,主从也会随之断开,因为超过了60s无响应
- 从节点检测到主节点失联(触发
repl-timeout),会断开连接并反复重试重连主节点(默认无限重试,间隔由replica-retry-timeout控制,默认 60 秒);- 从节点始终保持 “从节点身份”,不会主动切换为 “主节点”,依然是只读状态;
- 此时整个集群:写操作完全中断(主节点失联),读操作只能用从节点的旧数据。
# 1. 进入从节点的客户端 redis-cli -p 6380 # 2. 断开与旧主节点的复制关系,升级为主节点 127.0.0.1:6380> REPLICAOF NO ONE OK # 3. (可选)让其他从节点(如果有)切换到新主节点 redis-cli -p 6381 REPLICAOF 127.0.0.1 6380
纯主从架构下(无哨兵/无集群),从节点不会自动升主,必须手动操作;只有搭配哨兵(Sentinel)或 Redis Cluster 时,才会自动触发主从切换。


注意:这里有一个小知识点
一般来说Linux有多用户,不要使用root去运行进程,因为root的权限最高,运行进程,就会导致被攻击时,别人能使用redis这个进程去读写任何文件
一般使用别的用户去运行,比如这里redis下载好了之后会自动装一个redis用户
vim /etc/passwad
redis:用户名;x:密码占位符(密码存在/etc/shadow);983:983:UID(用户 ID)和 GID(组 ID);Redis Database Server:用户描述;/var/lib/redis:用户的家目录;/sbin/nologin:登录 shell(禁止登录)。用专用的
redis用户运行,它只能访问 Redis 数据目录、日志目录,就算被攻击,危害也被限制在极小范围内。也就是降低你的权限
哨兵模式
背景:主要解决主节点挂了 / 网络断了 → 自动把从节点提升为主节点,让服务继续可用
对于主从模式,当主节点挂了,整个集群就无法写入,此时需要人工手动干预
并且主从模式下,主节点故障后,你都不知道,没有感知到故障,哨兵能够解决24小时监控
还能解决主恢复后,旧主和新主的问题
- 监控:主节点活着吗?
- 自动选主:主死了,从里面选一个最好的从节点升为主
- 自动配置:通知其他从节点同步新主,旧主变从
通过自动化的方式,解决主节点挂机问题,弥补主从模式缺陷(人工操作)
哨兵(Sentinel)进程就是 Redis 官方原生提供的核心组件


基础原理
对于后端开发,很多服务器都需要监控,保证高可用,不可能是人工24小时监控,所以写一个进程来监控,第一时间发现异常就会报警
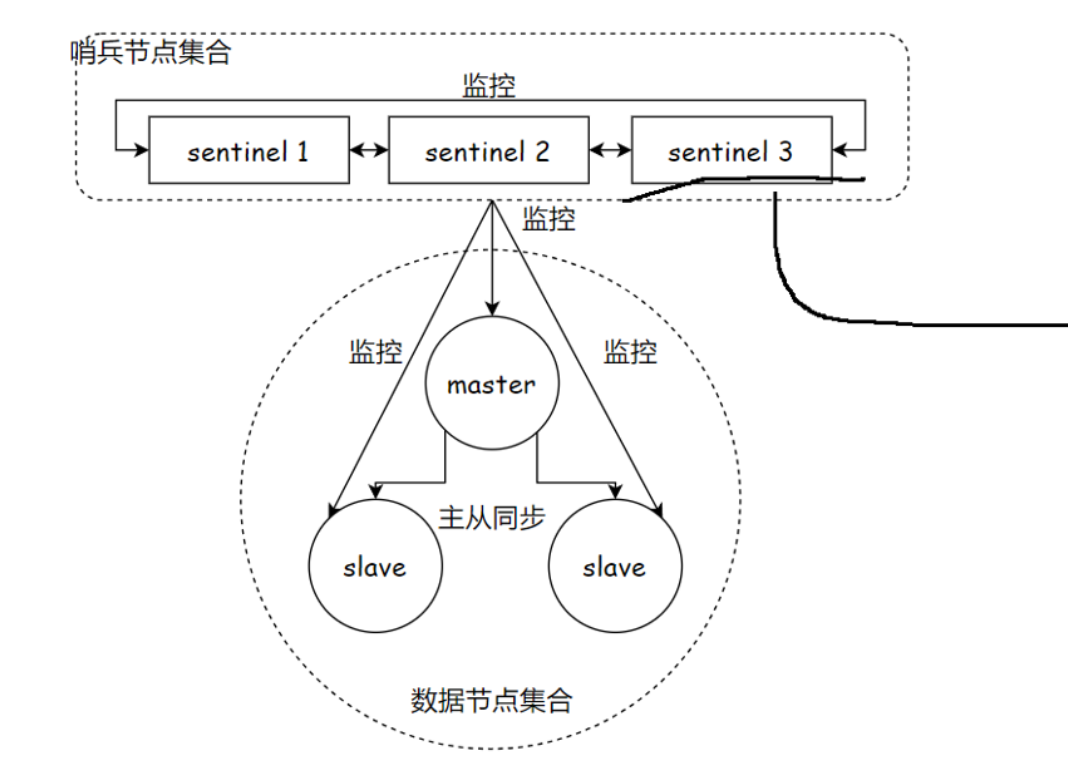
redis提供了多个sentinel哨兵,这些都是单独的进程,每个sentinel都去监控数据节点
注意是一个哨兵监控其他哨兵和所有的数据节点(主节点和从节点),每个哨兵都是这样
当从节点挂了,其实没关系
1:当主节点挂了,哨兵检测到了,需要结合其他多个哨兵,防止出现误判
2:当很多哨兵都认为主节点挂了,那就会在哨兵当中推举出一个leader,然后这个leader负责从现有的从节点当中,挑选一个作为新的主节点
3:挑选出的主节点之后,哨兵节点,就会自动控制被选中的节点,执行replicaof no one,并且控制其他从节点,修改replicaof 到新的主节点上
4:哨兵节点会自动的通知客户端程序,告知新的主节点是谁,并且后续客户端在进行写操作,就会针对新的主节点进行操作了
哨兵节点的配置:
基本原则:避免单点问题,最好配置奇数个
本质来说一个哨兵节点也可以完成
但是会增加误判概率,并且可能哨兵也会挂掉,所以应当配置一定数量的哨兵节点
所以,通过以上来看,哨兵具备以下功能
1:监控
2:自动的故障转移
3:通知
配置哨兵模式
一般来说,这些节点需要配在不同的服务器当中,否则一台服务器挂掉,直接全部挂掉,这是不现实的,当前我们的配置又不具备
但是可以进行配置试试,但由于每个配置文件都在一台服务器,很繁琐
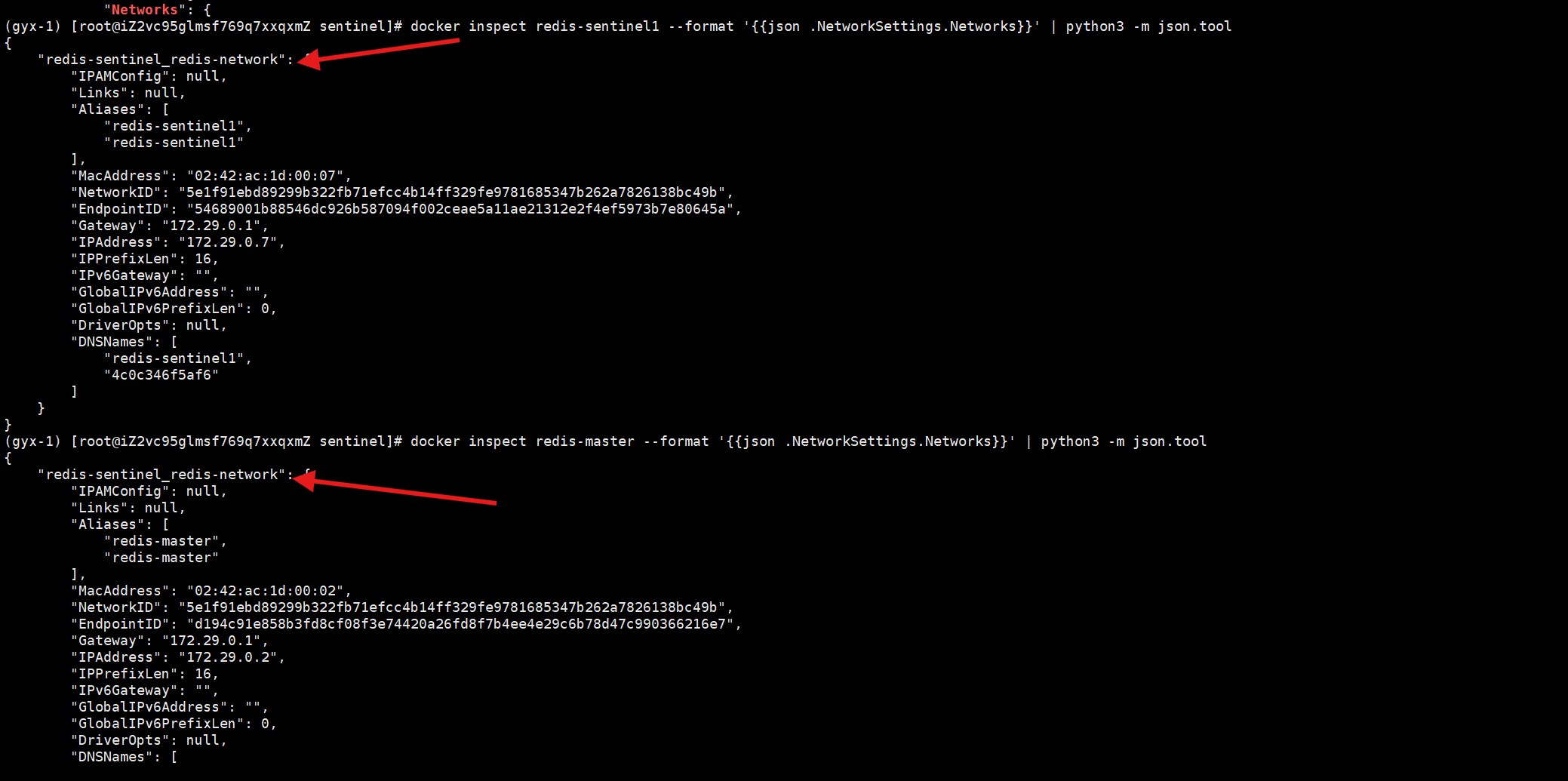
所以可以使用docker,详细的docker操作请看这篇文章
https://blog.csdn.net/Laydya/article/details/152094224
这里已经全部停掉redis服务,接下来采用docker来配置哨兵模式
docker pull拉取镜像
查看本地镜像,看看有没有拉取成功
配置yml,后续docker启动的时候可以根据配置文件一键启动
告诉 Docker 如何创建网络、拉取 Redis 镜像、启动主节点 / 从节点 / 哨兵容器,并配置容器的网络、端口、数据持久化和启动规则,最终一键搭建出可运行的 Redis 哨兵集群。
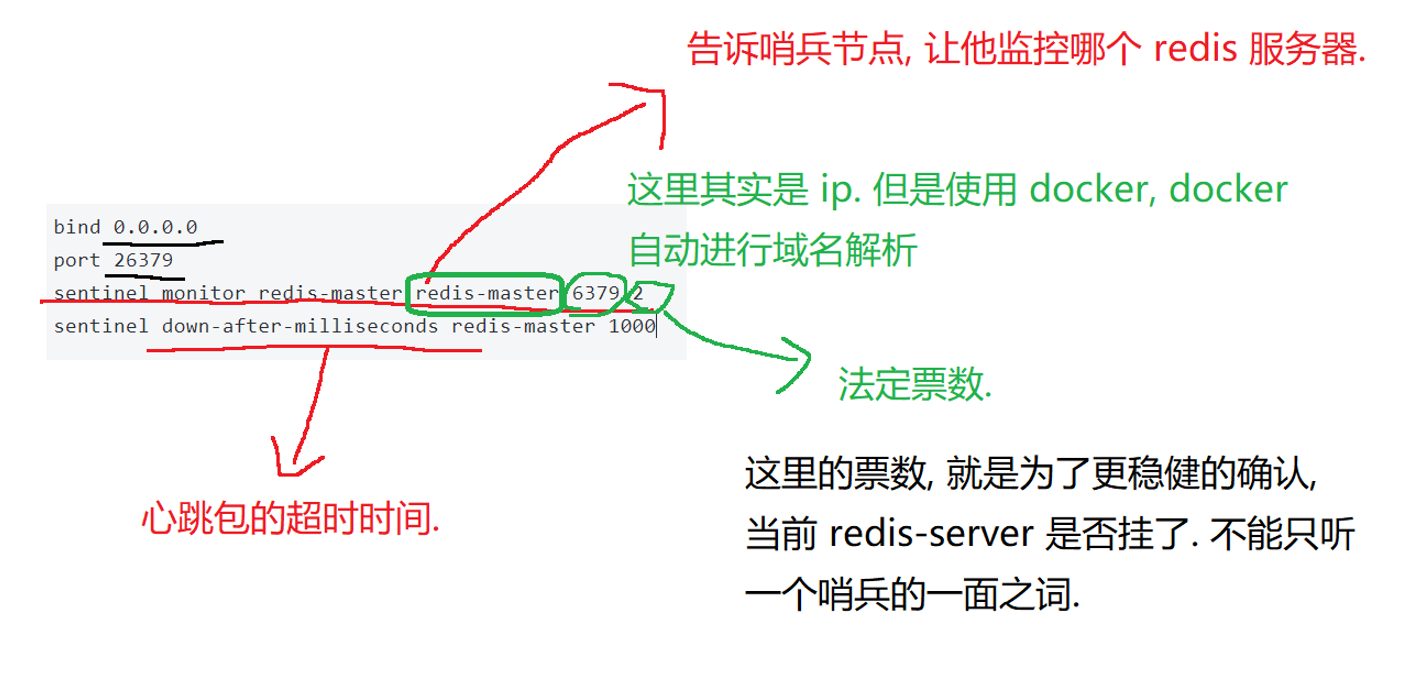
redis.conf按照之前的主从模式进行好配置,记得打开心跳
yml文件也要根据路径具体配置docker的启动
哨兵配置
注意有两种心跳包,一个是在redis.conf中的,这是主节点和从节点之间的心跳,目的是维持主从复制关系,和哨兵无关
还有一个是在哨兵配置当中的,这是哨兵对主节点 / 从节点 / 其他哨兵的检测心跳,目的是判断节点是否存活,是哨兵触发故障转移的核心
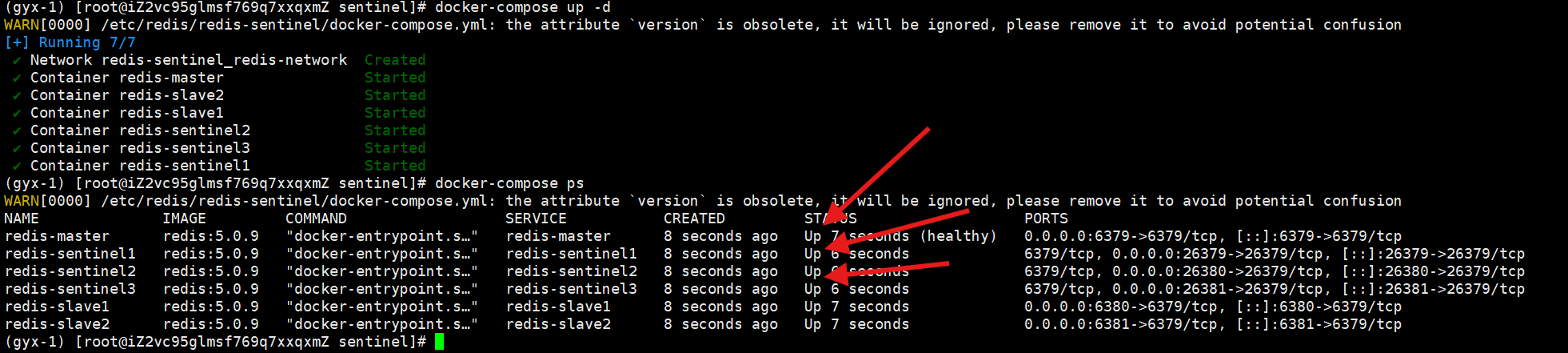
在docker-compose.yml下启动
可以看到全都启动起来了
如果起不起来,可能是版本之间,yml配置问题,需要根据docker日志一步步排查
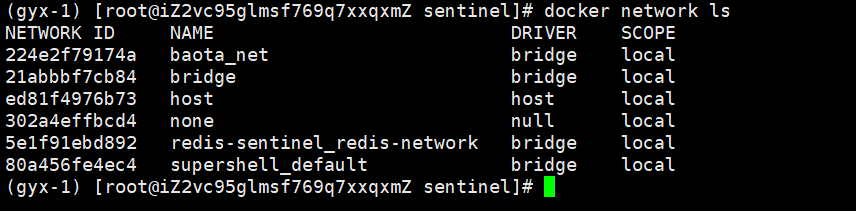
看一下是否处于同一个局域网
检查完毕,同属于一个局域网
测试哨兵模式
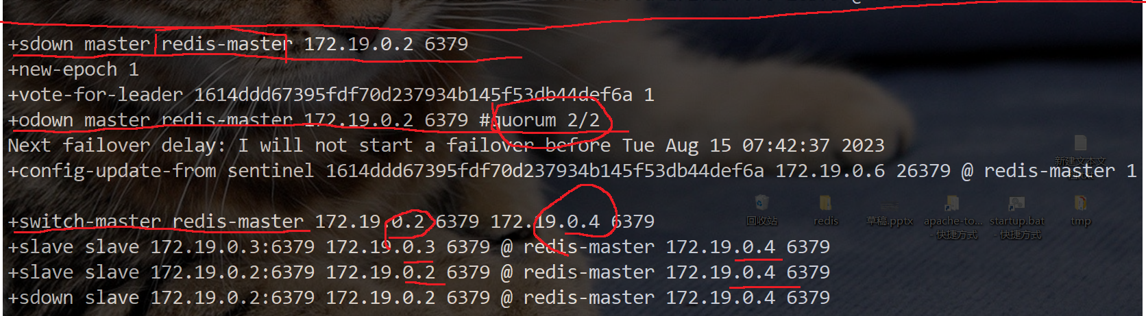
左屏幕一直打印哨兵日志,右屏幕让主节点挂掉
sdown是主观下线,本哨兵节点认为主节点下线
odown是客观下线,好几个哨兵节点认为主节点下线,达到了法定票数,也就是2
此时就需要选举一个新的节点作为主节点
流程
哨兵节点一直通过心跳包监控,判定redis服务器是否正常工作
如果心跳包没有如约而至,说明节点挂掉了
从节点挂掉后,哨兵只会做 “标记 + 记录”,但不会触发任何故障转移(选举新主),只有主节点挂掉才会触发 odown 和故障转移
主节点挂掉后,此时是主观下线,为sdown,可能因为网络抖动、主节点短暂卡顿导致,所以不会直接触发选举。会向集群内其他哨兵发 “投票请求”:“我觉得主节点挂了,你们觉得呢?”;
当同意的数量大于等于你配置文件中的法定票数之后,标记为odown客观下线
这是集群级别的共识判断,是触发故障转移(选举新主)的核心前提!
注意:当然也可能是服务器没有挂掉,因为网络抖动很严重导致所有的哨兵都接收不到心跳包,但是哨兵都接收不到,客户端也接收不到了,这样来说服务器也可以认为挂掉了
挂不一定是进程挂掉,只要无法正常访问
接下来就是投票选举新的主节点
当主节点被标记为
odown(客观下线)后,所有监控该主节点的哨兵都会尝试成为领导者,来执行故障转移。选举规则(Raft 算法简化版)
发起投票:每个哨兵都会给自己投一票,并向其他哨兵发送请求:“请选我当领导者”。
投票规则:一个哨兵在一轮选举周期内,只会给第一个向它发起请求的哨兵投票。
当选条件:一个哨兵如果获得了超过半数(
N/2 + 1)的哨兵选票,它就会成为领导者。
例如:3 个哨兵,获得 2 票即可当选;5 个哨兵,获得 3 票即可当选。
超时重试:如果一轮选举超时(默认 10 秒)没有产生领导者,所有哨兵会等待一段随机时间后,发起新一轮选举,避免冲突。
领导者的任务
当选的哨兵领导者,就是这次故障转移的 “总指挥”,它负责:
从所有从节点中,挑选出最合适的一个作为新主。
向其他节点(从节点、客户端)发布新主的信息。
注意投票时先投给自己,如果别人的请求先到时还未投给自己(自己还没发现主节点挂掉),那此时投给别人,极端情况就是所有都投给自己,那会超时重试,那所有的哨兵都会
随机等待一段时间,此时就会出现别的请求先来,避免死局
领导者确定后,就开始从所有健康的从节点里,按以下优先级进行筛选和排序:
1. 第一轮筛选:排除不合格的从节点
领导者会先排除掉那些不适合当主的从节点:
已经标记为
sdown(主观下线)的从节点。与旧主节点断开连接时间超过
down-after-milliseconds5 倍的从节点(认为数据太旧)。2. 第二轮排序:按优先级打分
对于剩下的合格从节点,领导者会按以下优先级进行排序,得分最高的就是新主:
优先级(replica-priority):
每个从节点都有一个优先级配置(
replica-priority,默认 100)。优先级数字越小,优先级越高。这是最高权重的考量。如果你想指定某个从节点优先成为新主,可以把它的优先级设得比其他节点低。
复制偏移量(replication offset):
如果优先级相同,就比较复制偏移量。偏移量越大,说明这个从节点同步的数据越新,越接近旧主节点。
这是为了保证数据丢失最少。
运行 ID(Run ID):
如果优先级和偏移量都相同,就比较从节点的 Run ID。字典序较小的那个会被选中。
这一步纯粹是为了打破平局,保证选举结果的确定性。
3. 执行切换
新主确定后,领导者会执行以下操作:
向被选中的从节点发送
SLAVEOF NO ONE命令,让它脱离旧主,升级为独立的主节点。向其他所有从节点发送
SLAVEOF <新主IP> <新主端口>命令,让它们去同步新主。更新自己的配置,并通过
__sentinel__:hello频道向其他哨兵和客户端广播新主的地址。
数据容量这里的意思:假设你的内存只有100g,但是你存储的数据有200g怎么办?因为redis是内存型的数据库,所有的数据都在内存,所以这里需要解决容量问题,redis集群就可以
还有单点写问题,你是提高了高可用,但是没有根本的解决单点写的性能瓶颈
很明显,解决方案就是加入多个写节点,这样数据容量也上来了


源码分析
// 哨兵启动入口(替代普通 redis-server 的 main 函数) int sentinelMain(int argc, char **argv) { // 1. 切换运行模式为哨兵(设置 server.sentinel_mode = 1) server.sentinel_mode = 1; // 2. 加载哨兵配置文件(sentinel.conf),解析监控的主节点配置 loadSentinelConfigFile(server.configfile); // 3. 初始化定时任务:核心是 3 个定时事件 aeCreateTimeEvent(server.el, 1000, sentinelTimerProc, NULL, NULL); // 1秒检测主节点心跳 aeCreateTimeEvent(server.el, 10000, sentinelReconfiguratorTimer, NULL, NULL); // 10秒同步从节点/哨兵状态 aeCreateTimeEvent(server.el, 1000, sentinelHelloTimer, NULL, NULL); // 1秒往 __sentinel__:hello 发广播 // 4. 启动事件循环(和普通 Redis 一致) aeMain(server.el); return 0; }核心逻辑:哨兵本质是特殊模式的 Redis 服务器,启动后会初始化 3 个核心定时任务,这是所有监控 / 发现 / 选举的基础。
// 1秒执行一次:检测主节点存活状态 void sentinelTimerProc(aeEventLoop *el, long long id, void *clientData) { sentinelCheckMasterDownState(); // 核心:判定主节点是否 sdown } // 判定主观下线的核心逻辑 void sentinelCheckMasterDownState(sentinelRedisInstance *mi) { // 1. 计算主节点无响应时间(当前时间 - 最后一次收到 PONG 的时间) mstime_t delay = mstime() - mi->last_pong_time; // 2. 对比 down-after-milliseconds 配置(你设置的 30000ms) if (delay > mi->down_after_period) { // 3. 标记为主观下线(sdown=1) mi->s_down = 1; } else { mi->s_down = 0; } }核心逻辑:每秒检测主节点最后一次响应时间,超过阈值则标记
s_down=1(主观下线),这是故障转移的起点。// 1秒执行一次:往主节点的 __sentinel__:hello 频道发广播 void sentinelHelloTimer(aeEventLoop *el, long long id, void *clientData) { // 1. 构造广播消息:包含哨兵IP、端口、运行ID、监控的主节点信息 robj *hello = createHelloMessage(mi); // 2. 发布到主节点的 __sentinel__:hello 频道 redisAsyncCommand(..., "PUBLISH __sentinel__:hello %s", hello->ptr); // 3. 订阅该频道,接收其他哨兵的广播 redisAsyncCommand(..., "SUBSCRIBE __sentinel__:hello", ...); } // 收到其他哨兵广播后的处理逻辑 void sentinelHelloMessageCallback(redisAsyncContext *c, void *reply, void *privdata) { // 解析广播中的哨兵信息,添加到自己的哨兵列表 sentinelAddSentinel(mi, ip, port, runid); // 更新 num-other-sentinels 计数 mi->num_other_sentinels = listLength(mi->sentinels) - 1; }核心逻辑:哨兵通过主节点的 Pub/Sub 机制广播自身信息,同时订阅频道接收其他哨兵的信息,自动完成集群发现 —— 这也是你之前
num-other-sentinels=0的根源:该频道的消息收发失败,哨兵无法解析彼此的信息。注意1:这个频道本质就是所有的哨兵跟主节点进行tcp连接,主节点进行转发消息,比如
# 哨兵1 发布的消息(RESP 格式) PUBLISH __sentinel__:hello "192.168.32.6,26379,5f987a6b...,redis-master,192.168.32.2,6379,0"然后主节点就会转发这个哨兵1的消息到频道里面(也就是把这个消息转发给其他哨兵),这样哨兵之间就能够通信,这样能够减少tcp连接的条数,否则所有的哨兵都要与别的哨兵tcp连接,这样的设计的好处就是避免网状连接的复杂度,当连接过多管理成本就过大
注意2:哨兵先和主节点建立tcp连接,然后订阅频道,然后info replication获取与主节点连接的从节点,然后哨兵和从节点tcp连接,去监测从节点
// 判定客观下线:统计认为主节点 sdown 的哨兵数量 int sentinelCheckObjectivelyDown(sentinelRedisInstance *mi) { int count = 0; // 遍历所有哨兵,统计 s_down=1 的数量 listIter li; listNode *ln; listRewind(mi->sentinels, &li); while((ln = listNext(&li))) { sentinelRedisInstance *si = ln->value; if (si->flags & SRI_MASTER_LINK_DOWN) count++; } // 数量 ≥ quorum(你配置的 2),则标记 odown=1 return count >= mi->quorum; } // 领导者选举核心:先自我锁票,再拉票 int sentinelElectLeader(sentinelRedisInstance *mi) { // 1. 自我锁票:给自己投一票 mi->leader_runid = server.runid; mi->leader_epoch = mi->current_epoch; // 2. 向其他哨兵发送拉票请求 sentinelRequestVote(mi); // 3. 统计票数,超过半数则当选 return mi->votes >= (listLength(mi->sentinels)/2 + 1); }核心逻辑:客观下线需要满足
sdown 哨兵数 ≥ quorum;选举采用 Raft 简化算法,先自我锁票,再拉票,超过半数即当选。// 故障转移状态机:选新主 → 切换从节点 → 更新配置 void sentinelFailoverStateMachine(sentinelRedisInstance *mi) { switch(mi->failover_state) { case SENTINEL_FAILOVER_STATE_SELECT_SLAVE: // 选新主:按优先级 → 偏移量 → RunID 排序 sentinelSelectSlave(mi); break; case SENTINEL_FAILOVER_STATE_PROMOTE_SLAVE: // 提升从节点为新主:发送 SLAVEOF NO ONE sentinelPromoteSlave(mi); break; case SENTINEL_FAILOVER_STATE_RECONF_SLAVES: // 让其他从节点同步新主:发送 SLAVEOF 新主IP 端口 sentinelReconfigureSlaves(mi); break; } }核心逻辑:故障转移分 3 步,严格按优先级选新主,确保数据丢失最少。
- 解决的问题:核心解决了主从架构 “人工故障转移” 的问题,实现了主节点的高可用;
- 未解决的问题:
- 核心:主节点单点写问题仍存在,写压力无法分担;
- 其他:数据一致性风险、脑裂、无分片能力、扩容复杂等。
集群模式
广义的集群:只要是多个机器构成的分布式系统,都可以说是集群,前面的主从,哨兵都是
狭义的集群:redis提供的集群模式
Redis Cluster(Redis 集群)是 Redis 官方提供的分布式解决方案,它的核心目标就是解决哨兵模式(主从 + 哨兵)的核心缺陷 —— 尤其是 “单点写” 和 “单节点存储瓶颈” 问题。
| 架构模式 | 核心能力 | 核心缺陷 |
|---|---|---|
| 单机 Redis | 基础读写、存储 | 单点故障、单点写、存储上限受限 |
| 主从 Redis | 数据备份、读负载分担 | 主节点单点写、故障需人工切换 |
| 主从 + 哨兵 | 主节点高可用(自动切换) | 主节点单点写、无分片、存储上限受限 |
| Redis Cluster | 分布式分片 + 多主高可用 | 不支持强一致性、部分命令受限 |
基础原理
集群模式中:每个主节点对应多个从节点,也就是从节点是专属于某个主节点的
那此时就需要想一想:主节点是写,是数据的来源?那数据应该如何分配?是主节点之间同步?还是每个主节点存储的不一样的数据
如果采用主节点之间同步数据,那每一时刻也只能有一个主节点写,因为如果同时写就会导致数据冲突,那这样就会回到单点写问题,而且写完之后同步又浪费io资源,而且存储数据的内存大小还是没变
综上,采用数据分片,每个主节点存储不同的数据
主节点采用分片,一个主节点有多片
方案一:哈希求余
当key存储的时候,借助hash函数(md5)%N(片数),存储到不同的主节点当中
缺陷:当扩容的时候,每次引入新的主节点的时候,会导致原来数据计算出不在原来的片位,此时就会导致大量的数据需要重新计算,此时消耗的成本也很高
方案二:一致性哈希算法
直接一开始%一个很大的数字
缺陷:数据不均匀
方案三:哈希槽分区算法
槽位号 = CRC16(key) % 16384
- CRC16:是一种轻量的哈希算法,输出 16 位整数(0~65535),计算速度极快(适配 Redis 单线程高性能需求);
- % 16384:把 CRC16 的结果限定在 0~16383 范围内,确保每个 key 都能映射到唯一的槽位。
首先划分为16384个槽位,这个是固定不变的,不随着主节点的增加而增加
redis还会维护一张槽位-节点的映射表
- 槽位 0~5460 → 主节点 A;
- 槽位 5461~10922 → 主节点 B;
- 槽位 10923~16383 → 主节点 C;
// Redis 源码中 clusterNode 结构体的核心字段 typedef struct clusterNode { // 16384位的位图,每一位对应一个槽位(0~16383) // 位值=1 → 该槽位归当前节点管理;位值=0 → 不归当前节点管理 unsigned char slots[16384/8]; // 16384位 = 2048字节(仅2KB) int numslots; // 当前节点负责的槽位总数 } clusterNode;每个主节点都有一个这样的slots位图,拥有哪个槽位,位图就是1
注意槽位也可以离散管理,节点可以拥有离散的槽位
这样的好处就是key-槽位-节点,把key和节点的映射关系进行解耦,也就是解决了方案一和方案二的缺陷,当数据迁移的时候,仅仅需要修改槽位和节点的映射关系,无需修改key的计算,然后进行部分数据搬运即可,并且分配也很均匀,每个节点基本槽位一样,你如果使用一致性hash,一开始分配可能是畸形的
问题一:集群最多有16384片吗?
Redis 官方明确不建议把集群节点数做到 16384 个,核心原因有 3 点:
- 集群元数据同步开销:每个节点需要维护「槽位 - 节点」映射表(2KB),但节点间通过 Gossip 协议同步状态时,消息量随节点数呈线性增长(1000 个节点的 Gossip 消息量已是 3 个节点的 300 倍),会占用大量网络 / CPU 资源;
- 运维复杂度:16384 个节点的集群几乎无法运维(故障排查、扩缩容、监控都不可行);
- 性能瓶颈:Redis Cluster 的优势是 “分片 + 高可用”,而非 “海量节点”—— 节点数过多会导致路由延迟增加(客户端需缓存更多「槽位 - 节点」映射),反而降低性能。
场景 主节点数建议 每个节点槽位数 核心目的 小型集群(测试 / 单机) 3 个 5461/5461/5462 最小高可用集群 中型集群(生产) 8~32 个 500~2000 个 / 节点 平衡性能与扩展性 大型集群(超大规模) ≤100 个 ≥163 个 / 节点 避免 Gossip 协议过载 问题二:为什么是16384个槽位?
Cluster 里主节点 ↔ 主节点 的 Gossip 心跳→ 只为集群状态同步(谁活着、槽位在哪、谁宕机)
16384是2kb,主节点之间的心跳需要传给对方,如果是8kb,看起来不多,但是心跳需要一直发,长时间来看也吃网络带宽资源的,元数据的内存 + 网络开销极致小
并且hash计算槽位的时候非常快
配置集群模式
记得清除redis容器
3主3从
Docker 容器内的文件默认是临时的,需要把配置 / 数据挂载到宿主机目录,避免容器删除后数据丢失;按节点分目录更清晰。
# 创建总目录,后续每个节点的配置/数据都放在这里 mkdir -p /usr/local/redis-cluster/{node1,node2,node3,node4,node5,node6} cd /usr/local/redis-clusterRedis Cluster 启动必须配置集群相关参数,且每个节点需要唯一的端口 / IP 标识。
每个都需要编写一个redis.conf文件,编辑
node1/redis.conf文件:# 基础网络配置 port 6379 # 节点端口(容器内端口,可统一用6379,宿主机映射不同端口) bind 0.0.0.0 # 允许所有IP访问,容器内必须配置,否则集群节点无法通信 protected-mode no # 关闭保护模式,否则外部无法连接 daemonize no # 禁止后台运行(Docker容器内必须关闭,否则容器启动后会立即退出) # 持久化配置(可选但建议开启,避免集群重启数据丢失) appendonly yes # 开启AOF持久化 appendfsync everysec # 每秒刷盘,平衡性能和数据安全 # 集群核心配置(必须开启) cluster-enabled yes # 开启集群模式(核心开关,没有这个就是普通Redis) cluster-config-file nodes.conf # 集群元数据文件(自动生成,记录槽位/节点信息) cluster-node-timeout 5000 # 节点超时时间(5秒),超时未响应则判定节点下线 cluster-announce-ip 172.17.0.2 # 容器IP(后续启动容器时固定分配,关键!) cluster-announce-port 6379 # 客户端连接端口 cluster-announce-bus-port 16379 # 集群总线端口(Gossip协议通信,端口=服务端口+10000)# 复制配置到node2-node6,仅修改cluster-announce-ip(后续容器IP依次为172.17.0.3~172.17.0.7) sed 's/172.17.0.2/172.17.0.3/' node1/redis.conf > node2/redis.conf sed 's/172.17.0.2/172.17.0.4/' node1/redis.conf > node3/redis.conf sed 's/172.17.0.2/172.17.0.5/' node1/redis.conf > node4/redis.conf sed 's/172.17.0.2/172.17.0.6/' node1/redis.conf > node5/redis.conf sed 's/172.17.0.2/172.17.0.7/' node1/redis.conf > node6/redis.conf
cluster-enabled yes:开启集群模式,Redis 进程会加载集群相关逻辑(槽位管理、Gossip 协议等);cluster-announce-ip:容器内的 IP 地址,集群节点间通过这个 IP 通信(Docker 默认网桥网段是 172.17.0.0/16,后续启动容器时手动分配这个 IP,避免自动分配导致 IP 变化);cluster-announce-bus-port:集群节点间通信的总线端口,用于 Gossip 心跳、槽位迁移等,必须和服务端口错开且唯一。Docker 默认的桥接网络会随机分配 IP,为了让
cluster-announce-ip固定,需要创建自定义网络:# 创建自定义网桥,指定网段(和配置文件中的IP匹配) docker network create --subnet=172.17.0.0/16 redis-cluster-net自定义网络可以手动指定容器 IP,确保配置文件中的
cluster-announce-ip和容器实际 IP 一致,否则集群节点间无法通信。依次启动每个节点的容器,挂载宿主机配置 / 数据目录,指定固定 IP:
docker run -d \ --name redis-node1 \ --net redis-cluster-net \ --ip 172.17.0.2 \ -v /usr/local/redis-cluster/node1/redis.conf:/etc/redis/redis.conf \ -v /usr/local/redis-cluster/node1/data:/data \ -p 6379:6379 -p 16379:16379 \ redis:5.0.9 \ redis-server /etc/redis/redis.conf# node2(主节点2,IP=172.17.0.3) docker run -d --name redis-node2 --net redis-cluster-net --ip 172.17.0.3 -v /usr/local/redis-cluster/node2/redis.conf:/etc/redis/redis.conf -v /usr/local/redis-cluster/node2/data:/data -p 6380:6379 -p 16380:16379 redis:5.0.9 redis-server /etc/redis/redis.conf # node3(主节点3,IP=172.17.0.4) docker run -d --name redis-node3 --net redis-cluster-net --ip 172.17.0.4 -v /usr/local/redis-cluster/node3/redis.conf:/etc/redis/redis.conf -v /usr/local/redis-cluster/node3/data:/data -p 6381:6379 -p 16381:16379 redis:5.0.9 redis-server /etc/redis/redis.conf # node4(从节点1,IP=172.17.0.5) docker run -d --name redis-node4 --net redis-cluster-net --ip 172.17.0.5 -v /usr/local/redis-cluster/node4/redis.conf:/etc/redis/redis.conf -v /usr/local/redis-cluster/node4/data:/data -p 6382:6379 -p 16382:16379 redis:5.0.9 redis-server /etc/redis/redis.conf # node5(从节点2,IP=172.17.0.6) docker run -d --name redis-node5 --net redis-cluster-net --ip 172.17.0.6 -v /usr/local/redis-cluster/node5/redis.conf:/etc/redis/redis.conf -v /usr/local/redis-cluster/node5/data:/data -p 6383:6379 -p 16383:16379 redis:5.0.9 redis-server /etc/redis/redis.conf # node6(从节点3,IP=172.17.0.7) docker run -d --name redis-node6 --net redis-cluster-net --ip 172.17.0.7 -v /usr/local/redis-cluster/node6/redis.conf:/etc/redis/redis.conf -v /usr/local/redis-cluster/node6/data:/data -p 6384:6379 -p 16384:16379 redis:5.0.9 redis-server /etc/redis/redis.conf
--net redis-cluster-net:指定容器使用自定义网络,确保 IP 固定;--ip 172.17.0.X:手动分配 IP,和配置文件中的cluster-announce-ip一致;-v 宿主机目录:容器目录:挂载配置文件和数据目录,确保配置持久化、数据不丢失;-p 宿主机端口:容器端口:映射端口(容器内都是 6379/16379,宿主机用不同端口避免冲突);redis:5.0.9:指定 Redis 版本,和你的环境一致;redis-server /etc/redis/redis.conf:启动 Redis 并加载自定义配置(默认启动是无集群配置的普通 Redis)。docker ps # 查看6个容器是否都是Up状态有时候可能是配置的网段被占用了,需要更换成别的网段
Redis 5.0+ 内置了
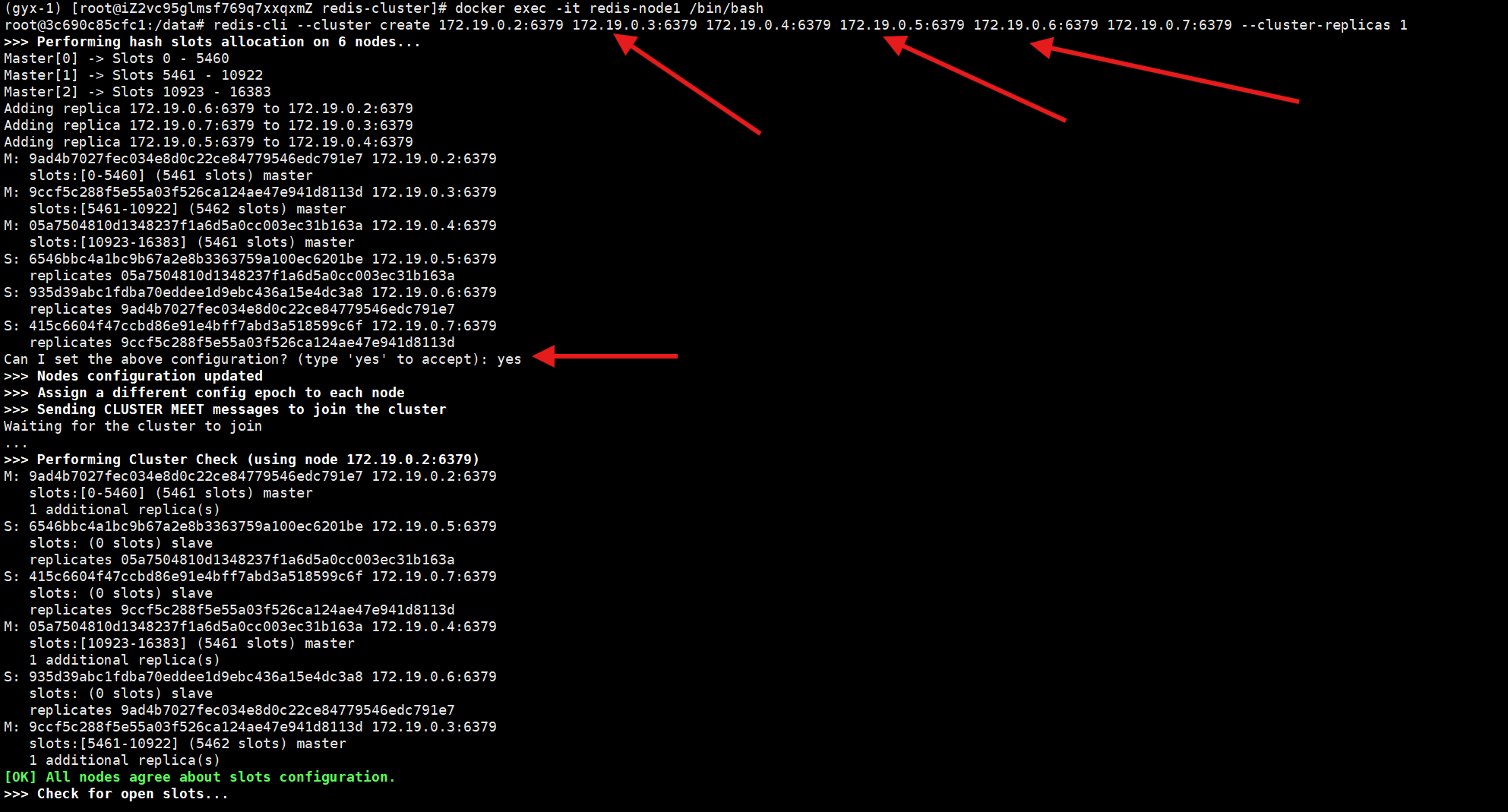
redis-cli --cluster命令(5.0 之前需要用redis-trib.rb,依赖 Ruby,更复杂),直接用这个命令初始化集群。进入任意一个节点
docker exec -it redis-node1 /bin/bashredis-cli --cluster create \ 172.17.0.2:6379 172.17.0.3:6379 172.17.0.4:6379 \ # 3个主节点 172.17.0.5:6379 172.17.0.6:6379 172.17.0.7:6379 \ # 3个从节点 --cluster-replicas 1 # 每个主节点分配1个从节点
配置的时候就发现网段被占用了,所以进行了更换
- 终端会输出集群规划(比如 node1/node2/node3 是主节点,分别负责 0-5460、5461-10922、10923-16383 槽位;node4 是 node1 的从节点,node5 是 node2 的从节点,node6 是 node3 的从节点);
- 输入
yes确认集群规划,等待初始化完成。接下来验证集群
# 进入容器后,连接集群(-c表示集群模式,自动路由槽位) redis-cli -c -h 172.17.0.2 -p 6379 # 查看集群节点信息 172.17.0.2:6379> CLUSTER NODES# 写入一个key,Redis会自动路由到对应槽位的主节点 172.17.0.2:6379> SET testkey testvalue -> Redirected to slot [5798] located at 172.17.0.3:6379 # 自动路由到node2 OK # 读取key(无论连接哪个节点,都能读到) 172.17.0.2:6379> GET testkey "testvalue" # 查看key所属槽位 172.17.0.2:6379> CLUSTER KEYSLOT testkey (integer) 5798此时你如果使用-c就是连接集群,那此时就是一个整体,无论你连接哪个节点都是一样的,会进行路由
Redis Cluster 实现了智能路由,整个过程分 3 步(你不用手动干预,Redis 自动完成):
1. 客户端连接任意节点后,会先获取「槽位 - 节点」映射表
当你用
redis-cli -c连接某个节点时,该节点会把集群的「16384 个槽位分别对应哪个主节点」的映射表,返回给客户端并缓存;2. 客户端计算 key 所属槽位,自动路由到对应主节点
比如你执行
SET testkey 123:
客户端先计算
testkey的槽位:CRC16(testkey) % 16384 = 5798;客户端查缓存的映射表,发现槽位 5798 属于 node2(172.19.0.3);
客户端自动把请求转发到 node2 执行,你会看到终端输出
-> Redirected to slot [5798] located at 172.19.0.3:6379;3. 读操作同理,写操作只到主节点,读操作可到从节点(默认读主)
写操作(SET/DEL/HSET 等):必须路由到 key 所属槽位的主节点执行(保证数据一致性);
读操作(GET/HGET 等):默认路由到主节点,也可通过
READONLY命令让客户端优先读从节点(分担主节点压力)。Redis Cluster 能成为 “整体”,核心靠 2 类通信:
1. 主节点之间的 Gossip 通信(集群状态同步)
每个主节点每秒随机给几个同伴发 Gossip 包,内容包括:✅ 自己的状态(活 / 死);✅ 槽位分配情况;✅ 其他节点的状态(比如检测到某个节点失联);
作用:确保所有主节点都知道 “整个集群的拓扑结构”,比如 node1 知道 node2 负责 5461-10922 槽位,node3 知道 node1 的从节点是 node4。
2. 主从节点之间的复制通信(数据同步)
每个主节点的从节点(比如 node1 的从节点是 node4),会和主节点建立 “复制连接”;
主节点有数据变更(比如 SET/DEL),会实时把变更同步给从节点;
作用:主节点宕机后,从节点能立即升级为主节点,数据不丢失。
注意点
1. 必须加
-c参数才能自动路由如果连接时没加
-c(比如redis-cli -h 172.19.0.2 -p 6379),客户端不会自动路由,执行跨槽位操作会报错MOVED 5798 172.19.0.3:6379,需要你手动连接目标节点;2. 写操作只能到主节点,从节点默认只读
从节点(比如 node4、node5、node6)默认拒绝写操作,执行
SET会报错READONLY You can't write against a read only replica.,这是为了避免数据不一致。
由于先发生路由错误,所以先报了moved
如果采用了-c,那就会重定向给主节点


集群深度刨析
当从节点挂了,没事
当主节点挂了,因为主节点才能写,从不能写
此时所做的工作就和之前的哨兵一样,下线主节点,选一个新的主节点出来(故障转移)
假设集群是 3 主 3 从:
node1(主,172.19.0.2)→node4(从,172.19.0.5)、node2(主)→node5(从)、node3(主)→node6(从)在宕机之前正常通信,gossip协议,不止是简单的心跳,还包含了集群的快照信息
包类型 发送时机 核心作用 PING 每个节点每秒随机发给几个节点 1. 检测对方是否存活;2. 携带自己的节点状态 + 集群信息 PONG 收到 PING 包的节点立即回复 1. 告诉对方 “我还活着”;2. 回传自己的最新集群信息 PFAIL 节点判定其他节点 “主观下线” 时发送 通知集群:“我认为 XX 节点挂了(主观下线)” FAIL 集群判定节点 “客观下线” 时发送 通知集群:“XX 节点已被多数主节点确认下线(客观下线)” 每种类型的包都有特殊的字段,这个可以自行查资料学习
假设现在
node1宕机:步骤 1:节点失联,触发「主观下线(PFAIL)」
集群内所有主节点每秒通过 Gossip 协议互发心跳包;(每s不是都发,是挑一些发,否则这样全发的成本太高,保底是太久没联系必发)
当
node2/node3超过cluster-node-timeout(5 秒)没收到node1的心跳响应,就会把node1标记为「主观下线」(PFAIL,即 “我认为它挂了”);👉 大白话:
node2心里想 “node1 5 秒没回我消息,我觉得它挂了”,但不会立刻行动(避免单节点误判)。步骤 2:Gossip 传播,触发「客观下线(FAIL)」
node2/node3会把 “node1 主观下线” 的信息,通过 Gossip 包同步给集群所有节点;当超过半数主节点(这里是≥2 个:node2+node3)都认为
node1下线,node1会被标记为「客观下线(FAIL)」(即 “大家都认为它挂了”);👉 大白话:集群达成共识 “node1 真的宕机了,必须处理”。
如果是从节点挂掉,那不会进行故障转移
如果是主节点挂掉,那需要进行故障转移,寻找宕机的主节点的从节点进行故障转移
步骤 3:从节点竞选 “新主节点”
node1的从节点node4发现主节点被标记为客观下线,会发起 “竞选投票”;集群内所有主节点(node2、node3)会给
node4投票:
只有「持有槽位的主节点」有投票权;
每个主节点只能投 1 票,超过半数(≥2 票)则竞选成功;
👉 大白话:node4 举手 “我要当新主”,node2、node3 都同意,node4 竞选成功(如果有多个从节点,会按「复制偏移量(数据同步进度)+ 运行时长」排序,数据最新的优先)。
竞选这里注意:
如果有多个从节点,那会进行休眠,休眠时间 = 500ms + 随机值(0 ~ 500ms) + (从节点优先级 × 1000ms)
休眠时间最短 → 复制偏移量最高 → 运行时长最长 → 节点 ID 字典序小;
其他主节点投票时,早就判断哪个offset最好,就只投给它
休眠时间 = 避免冲突
offset = 决定谁能赢
步骤 4:从节点升级为主节点,接管槽位
node4成功当选后,会执行 3 个关键操作:
把自己的角色从「slave」改为「master」;
接管原主节点
node1的所有槽位(0-5460);通过 Gossip 协议向集群广播:“我现在是新主,槽位 0-5460 归我管”;
👉 大白话:node4 官宣 “以后我就是新主,node1 的活我全包了”。
步骤 5:客户端自动路由,故障转移完成
集群所有节点更新槽位映射表(槽位 0-5460 现在对应
node4);客户端再操作槽位 0-5460 的 key 时,会自动路由到
node4;如果原主节点
node1后续重启,会自动变成node4的从节点,同步新主的数据;👉 大白话:业务无感知,读写请求正常路由到新主,集群恢复正常。
注意:集群内所有节点(包括主节点和从节点)都会收到这个 “node1 主观下线” 的 Gossip 包 —— 但只有主节点会参与「客观下线判定」和「投票选举」,从节点只做 “信息同步”,不参与决策。
Gossip包就是主和主、主和从、从和从,每个节点之间都建立tcp连接,每个节点都监听服务端口+10000的端口总线
主从复制是主和从之间通过服务端口进行
可以从以上学到,什么时候出现集群宕机
1:当主节点挂掉,却没有从节点进行故障转移
2:某个分片的主从全都挂掉
3:超过半数的master挂掉
无论是集群什么节点,一旦挂掉,都需要尽快的处理好
配置集群2.0
加入新的节点
- 加主节点:redis-cli --cluster add-node 新节点IP:端口 任意旧节点IP:端口
- 加从节点:redis-cli --cluster add-node 新节点IP:端口 任意旧节点IP:端口 \ --cluster-slave --cluster-master-id 主节点ID
这里注意,跟之前一样配置好node7和node8,然后docker启动起来
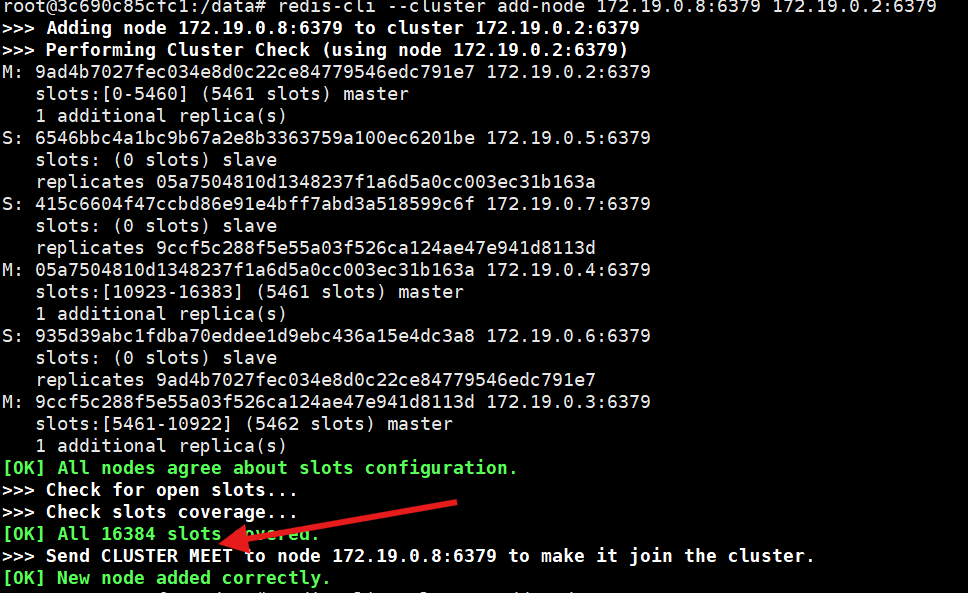
docker exec -it redis-node1 /bin/bash redis-cli --cluster add-node 172.19.0.8:6379 172.19.0.2:6379这里需要说明新增加的节点是谁:172.19.0.8:6379
然后后面跟集群即可,因为某个节点就代表了某个集群
这里先检查你指定的节点代表的集群的信息,以上检查说明没问题,然后向新节点发送
CLUSTER MEET命令(让新节点加入集群),最终提示:新节点添加成功!能和集群其他节点通信,但不会处理任何业务请求(因为没有槽位,客户端路由时不会指向它);
# 进入任意旧主节点,执行槽位重分配 docker exec -it redis-node1 redis-cli --cluster reshard 172.19.0.2:6379
- 输入要迁移的槽位数:比如
1000(从原主节点挪 1000 个槽位给新节点);- 输入新节点的 ID(先执行
docker exec redis-node7 redis-cli CLUSTER MYID获取);- 输入
all(表示从所有主节点均匀迁移槽位);- 输入
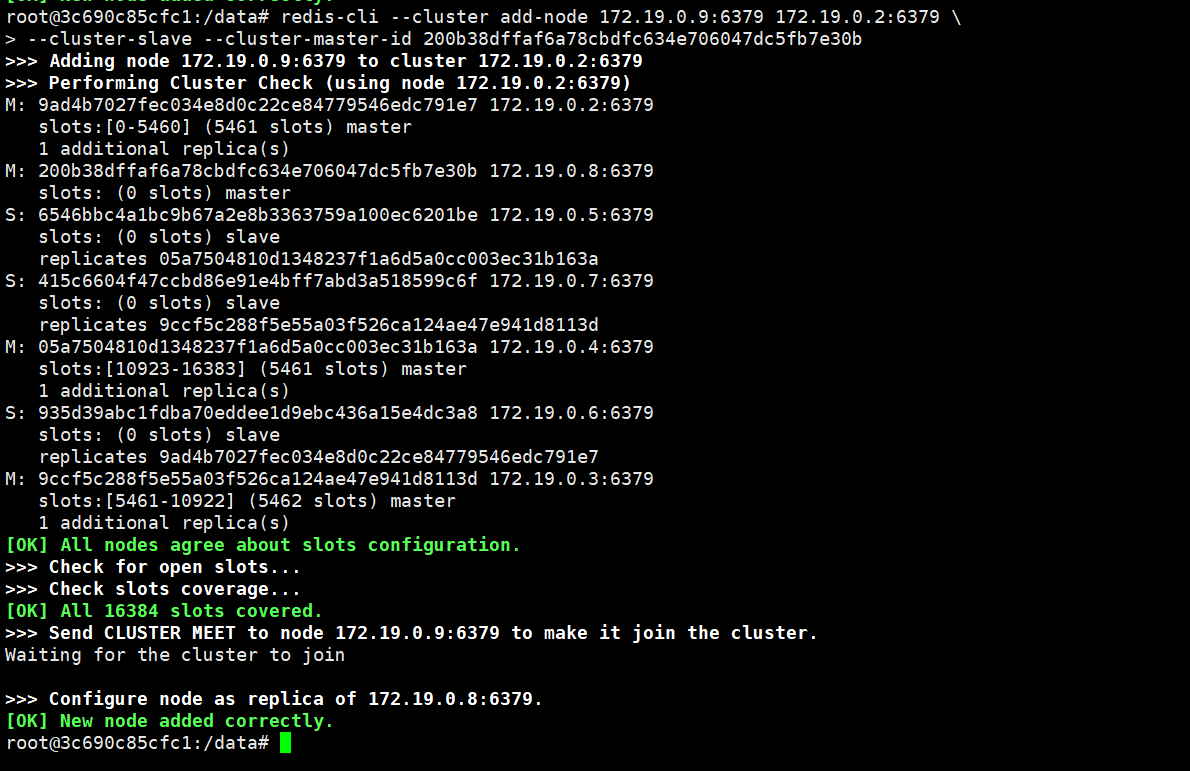
yes确认迁移。//这一步是获取node7的ID docker exec redis-node7 redis-cli CLUSTER MYID //注意这一步需要把xxxx换成node7的ID docker exec -it redis-node1 \ redis-cli --cluster add-node 172.19.0.9:6379 172.19.0.2:6379 \ --cluster-slave --cluster-master-id XXXXX
检查主从是否对
可以看到172.19.0.9是slave,它的master是172.19.0.8
也就是我们刚刚加入的主从节点
- C++ 客户端只需配置任意一个集群节点的 6379 端口(比如 172.19.0.2:6379)作为 “初始连接点”;(这需要客户端具备路由功能)
- 客户端连接后,会立即发送
CLUSTER NODES命令,从该节点获取整个集群的节点拓扑、槽位映射表;- 后续客户端会根据 key 的槽位,直接访问对应的节点(无需经过初始节点);
- 若集群节点变化(如故障转移、槽位迁移),客户端会自动更新本地拓扑表,保持路由正确。



openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 30
30 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)