别被 Linux 缓存骗了!你的云服务器内存根本没 “炸”
Linux内存管理常见误区:缓存高≠内存泄漏。Linux会利用空闲内存作为磁盘缓存(buff/cache)提升性能,这部分内存可随时回收。正确查看内存应关注"available"而非"free"列,只有当available持续很低且出现OOM错误时才需警惕。手动清理缓存(echo 3 > /proc/sys/vm/drop_caches)会降低系统性能
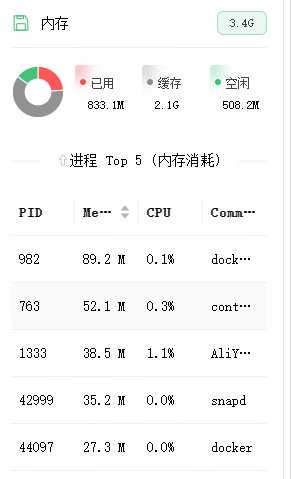
今天登录我的 Ubuntu 云服务器后台,一眼就看到内存监控吓了一跳:总内存 3.4G,空闲只剩 508M,而缓存居然占了 2.1G!我当时第一反应是:完了,哪个进程在偷偷吃内存?难道被挖矿了?
一顿排查下来才发现,是我对 Linux 内存管理的误解闹了乌龙 —— 这根本不是内存泄漏,反而是 Linux 高效利用内存的表现!(原谅我很少做运维的活)

一、新手必踩坑:别把「缓存」当成「占用」
很多人看内存只看 “已用” 和 “空闲”,看到free列的数值低就慌了,比如我这次的情况:
- 总内存:3.4G
- 已用:833.1M(进程实际占用)
- 缓存:2.1G
- 空闲:508.2M
光看 “空闲” 的话,确实只剩不到 1G 了,感觉马上就要爆了。但这是完全错误的理解!
在 Linux 里,内存的使用分为三类,很多人搞混了它们的区别:
| 类型 | 含义 | 是否可回收 |
|---|---|---|
| 应用实际占用(Used) | 进程正在运行的内存(比如 Java 应用、Docker 容器) | ❌ 不可回收,进程退出前一直占用 |
| 缓存 / 缓冲(Cached/Buffers) | 系统把暂时不用的内存,借过来存磁盘上的常用文件数据(也就是页缓存) | ✅ 完全可回收,应用需要时立刻释放 |
| 空闲(Free) | 完全没被用到的 “纯闲置” 内存 | ✅ 可直接使用 |
也就是说,缓存不是 “被占用的内存”,而是 “被系统借去加速磁盘 IO 的闲置内存”。你可以把它理解成:系统把暂时没人用的内存,拿来当磁盘的 “高速缓存”,让你的读写操作更快,而不是让它白白空着浪费资源。
二、为什么 Linux 要这么做?空着的内存才是浪费!
我们都知道,磁盘(哪怕是 SSD)的读写速度,和内存比起来差了几个数量级:机械硬盘的随机 IOPS 大概是 100 左右,SSD 也就几千,而内存的 IOPS 能到几十万甚至上百万。
Linux 的设计哲学里,空着不用的内存就是浪费。与其让内存闲着,不如把它用来存常用的文件数据,这样下次应用读同一个文件的时候,直接从内存里拿就行,不用再跑一趟慢得要死的磁盘,性能直接起飞。
举个例子:你打开一个 100M 的日志文件,第一次打开的时候,系统会把这个文件读到内存的缓存里,花了 1 秒;第二次再打开的时候,直接从缓存读,只需要 0.1 秒,体验差了 10 倍。这就是缓存的作用。
而且这个过程是完全透明的,你不用手动管。当应用需要更多内存的时候,系统会自动把缓存里不常用的数据清掉,把内存还给应用,完全不用你手动干预。所以缓存高,不仅不是坏事,反而是 Linux 内存利用高效的表现。
三、怎么正确看 Linux 内存?别再只看free了!
很多人用free命令的时候,只看第一行的free列,其实要看第二行的available列!
举个例子,free -h的输出:
$ free -h
total used free shared buff/cache available
Mem: 3.4G 833M 508M 100M 2.1G 2.5G
Swap: 1.0G 0B 1.0G 这里的available列,才是真正可以给应用用的内存!它的值是free + buff/cache里可回收的部分,也就是 2.5G,完全够用来跑应用的,根本不存在内存不够的问题。
几个实用的内存查看命令:
free -h:最常用,直接看available列就行,不用管buff/cache。top/htop:打开后按M按内存排序,看哪个进程实际占用高,而不是看整体的内存使用率。cat /proc/meminfo:看更详细的内存信息,比如MemAvailable、Cached、Buffers这些。
四、什么时候才需要担心内存问题?
很多人看到缓存高就慌了,其实真正的内存不足,不是看缓存,而是看这几个信号:
available内存持续很低,同时应用开始报 OOM(内存不足)错误,或者被系统 OOM Killer 杀掉了。swap分区被大量使用,甚至频繁发生 swap in/out,这时候磁盘 IO 会很高,系统也会变卡,这才是真的内存不够了。- 用
top看进程,发现某个进程的VIRT/RES占用异常高,而且持续上涨,可能有内存泄漏(比如我的进程列表里的 Docker 容器,要是它的内存持续涨,才需要排查)。
而单纯的buff/cache高,完全不用管,更不用手动清理!
五、手动清理缓存?不推荐,但给你方法
很多教程会教你用echo 3 > /proc/sys/vm/drop_caches来清缓存,这里必须说清楚:
- 原理:这个命令会让系统把所有可回收的缓存都清掉,还给
free内存。 - 副作用:清完之后,
free内存是变高了,但缓存也没了,接下来的磁盘读写都要重新从磁盘加载,性能会直接下降,相当于把系统辛辛苦苦给你搭的高速缓存拆了。 - 什么时候可以用?:只有在测试的时候(比如测磁盘 IO 性能,需要清空缓存再测),或者你确定接下来没有频繁的磁盘读写操作的时候,平时完全不用清,清了反而有害。
给几个drop_caches的选项(需要 root 权限):
# 清理pagecache(页缓存)
echo 1 > /proc/sys/vm/drop_caches
# 清理slab对象(dentries和inodes)
echo 2 > /proc/sys/vm/drop_caches
# 清理pagecache、dentries和inodes(最常用)
echo 3 > /proc/sys/vm/drop_caches注意:这个操作是一次性的,系统会继续往缓存里写数据,过一会缓存又会涨回去,治标不治本。
六、Linux 内存管理的其他 “反常识” 特点
除了缓存,Linux 还有几个设计,新手也很容易误解:
- Swap 分区不是洪水猛兽:很多人觉得用 swap 就是内存不够了,其实 Linux 会把不常用的内存数据放到 swap 里,把物理内存留给常用的进程用,只要不是频繁的 swap in/out,少量使用 swap 是正常的。
- OOM Killer 的存在:当系统真的内存不够的时候,会触发 OOM Killer,杀掉占用内存最高的进程,防止整个系统崩溃,而不是让系统直接卡死。(好像很多团队是会关闭这个功能,因为我已经遇到好几次开发环境的redis和MQ崩掉了)
- Overcommit 机制:Linux 允许进程申请超过物理内存的地址空间,因为很多进程申请了内存但不会立刻用,这样可以提高内存的利用率,避免浪费。
七、给新手的内存管理建议
- 别慌!缓存高不是内存泄漏,是好事:只要
available内存够,应用没报错,就不用管缓存。 - 别乱清缓存:除非你有特殊需求,不然清缓存只会让系统变慢,没有任何好处。
- 看内存要看
available,别只看free:free内存低,不代表系统内存不够,要看available。 - 关注应用实际占用:如果真的担心内存,用
top看进程的实际占用,而不是看整体的内存使用率。 - 云服务器内存不够的话,加内存才是根本解决办法:缓存是系统优化,不能当内存不够的解决方案,真的不够了还是得升级配置。
结尾
这次的乌龙事件也给我上了一课:很多时候我们觉得的 “问题”,其实是对系统设计的误解。Linux 的内存管理比我们想象的要聪明得多,它会自动帮你平衡性能和资源利用,不用我们手动瞎操心。
下次再看到内存缓存高,别再慌了,先看看available内存够不够,应用有没有报错,再决定要不要排查问题。毕竟,让内存闲着,才是对资源的浪费啊!
如果觉得这份基础知识点总结清晰,别忘了动动小手点个赞👍,再关注一下呀~ 后续还会分享更多有关开发问题的干货技巧,同时一起解锁更多好用的功能,少踩坑多提效!🥰 你的支持就是我更新的最大动力,咱们下次分享再见呀~🌟

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)