【冯诺依曼体系与操作系统:计算机的“骨架”与“大脑”】
冯诺依曼体系决定程序必须加载到内存才能运行,操作系统是资源大管家。一篇讲透计算机两大基石。

为什么程序必须先加载到内存?操作系统到底在管什么?一篇讲透计算机核心架构
前言
你有没有想过这些问题?
- 为什么你双击一个程序,它要先“加载”才能运行?
- CPU 那么快,为什么不直接从硬盘读取数据?
- 操作系统到底在忙什么?
如果你对这些问题的答案模模糊糊,那这篇文章就是为你准备的。
我们把 冯诺依曼体系结构(计算机的骨架)和 操作系统(计算机的大脑)这两个计算机基石,一次性讲清楚。
🏛️ 比喻:冯诺依曼体系结构就像工厂的流水线设计,操作系统就像工厂的管理层。
第一部分:冯诺依曼体系结构 —— 计算机的骨架
一、什么是冯诺依曼体系结构?
冯诺依曼体系结构是现代计算机的基本设计蓝图,由数学家冯·诺依曼在 1945 年提出。几乎所有的通用计算机都遵循这个结构。
1.1 核心组成部分
| 部件 | 作用 | 比喻 |
|---|---|---|
| 运算器 | 做数学运算(加减乘除、与或非) | 工厂里的工人 |
| 控制器 | 指挥协调各个部件工作 | 工厂里的车间主任 |
| 存储器 | 存储数据和指令(就是内存) | 工厂里的工作台 |
| 输入设备 | 把数据送进计算机(键盘、鼠标) | 工厂的原材料入口 |
| 输出设备 | 把结果展示出来(显示器、打印机) | 工厂的成品出口 |
💡 CPU = 运算器 + 控制器(工人 + 车间主任)
1.2 体系结构图
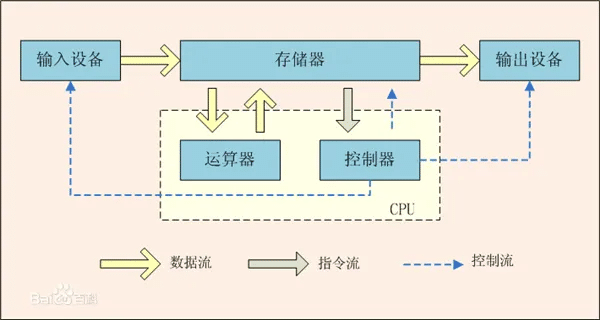
这里的存储器就是内存
二、核心规则:CPU 只能和内存打交道
2.1 为什么程序必须先加载到内存?
规则:CPU 获取指令、读写数据,只能从内存中进行,不能直接从硬盘、键盘、网卡读取。
| 你以为是 | 实际是 |
|---|---|
| CPU 直接从硬盘读文件 | ❌ 不行 |
| CPU 直接从键盘读输入 | ❌ 不行 |
| CPU 从内存读取 | ✅ 对的 |
所以:一个程序要想运行,必须先被加载到内存中。
🍔 比喻:CPU 像一个只认工作台的厨师。食材(数据)必须先放到工作台(内存)上,厨师才能处理。你不可能把菜直接扔给厨师,让他边切边炒。
2.2 数据流动的本质
数据在计算机里流动,本质上是从一个设备拷贝到另一个设备。
| 场景 | 数据流动路径 | 拷贝次数 |
|---|---|---|
| 键盘打字 | 键盘 → 内存 → CPU → 内存 → 显示器 | 多次 |
| 读取文件 | 硬盘 → 内存 → CPU → 内存 | 多次 |
| 网络下载 | 网卡 → 内存 → CPU → 内存 → 硬盘 | 多次 |
🚗 比喻:数据流动就像快递运输。每经过一个节点,就是一次“拷贝”。整个系统的效率,取决于最慢的那段“运输”。
2.3 外设只和内存打交道
| 设备 | 直接和谁打交道 | 说明 |
|---|---|---|
| 硬盘 | 内存 | 硬盘把数据读到内存,CPU 再从内存取 |
| 键盘 | 内存 | 键盘输入存到内存,CPU 再从内存读 |
| 网卡 | 内存 | 网卡收到数据放到内存,CPU 再处理 |
💡 结论:CPU 和外设之间不直接通信,全部通过内存中转。内存是整个系统的数据交换中心。
三、体系结构的效率瓶颈
3.1 木桶效应
整个计算机的效率,不取决于最快的部件(CPU),而取决于最慢的部件。
| 部件 | 速度级别 | 比喻 |
|---|---|---|
| CPU 缓存 | 纳秒级 | 超级跑车 |
| 内存 | 纳秒-微秒级 | 小轿车 |
| 固态硬盘 SSD | 微秒级 | 自行车 |
| 机械硬盘 HDD | 毫秒级 | 步行 |
| 网络 | 毫秒-秒级 | 蜗牛 |
就像一队人走路,最快的人跑得再快,也要等最慢的人。
3.2 为什么要有缓存?
| 存储层级 | 速度 | 容量 |
|---|---|---|
| CPU 寄存器 | 0.3 纳秒 | 几十字节 |
| L1 缓存 | 1 纳秒 | 几十 KB |
| L2 缓存 | 3-5 纳秒 | 几百 KB |
| L3 缓存 | 10-20 纳秒 | 几 MB |
| 内存(RAM) | 50-100 纳秒 | 几 GB |
| 硬盘 | 几毫秒 | 几百 GB |
问题:CPU 太快,内存太慢。CPU 等数据的时间,足够做几百次运算。
🏃 比喻:CPU 是博尔特,内存是普通人。让博尔特等普通人,是巨大浪费。
解决方案:在 CPU 和内存之间加一层更小但更快的存储器——缓存。
3.2 缓存的核心思想:局部性原理
| 类型 | 含义 | 例子 |
|---|---|---|
| 时间局部性 | 刚用过的数据,很可能马上再用 | 循环计数器 i |
| 空间局部性 | 用了一个数据,旁边的也可能被用 | 数组遍历 |
📖 比喻:你看书会把当前页和附近几页放在手边,不用每次翻页都去书架找。
3.3 缓存的工作流程
CPU 想读数据
│
▼
1. 先查 L1 缓存
├─ 命中 → 直接返回(最快)
└─ 未命中 → 去 L2
│
▼
2. 查 L2 缓存
├─ 命中 → 返回
└─ 未命中 → 去 L3
│
▼
3. 查 L3 缓存
├─ 命中 → 返回
└─ 未命中 → 去内存
│
▼
4. 从内存读取(慢几十倍)
并把数据加载到 L3→L2→L1
一个生活比喻
| 层级 | 比喻 |
|---|---|
| L1 缓存 | 你手里的书(当前页) |
| L2 缓存 | 桌面上的书 |
| L3 缓存 | 书包里的书 |
| 内存 | 家里的书架 |
| 硬盘 | 图书馆 |
找书逻辑:先看手里 → 再看桌面 → 翻书包 → 回家找 → 去图书馆
🎯 越靠近 CPU,越快但越小;越远离,越慢但越大。
3.4 缓存一致性(多核 CPU)
问题:核1 改了缓存里的数据,核2 的缓存里还是旧的。
解决方案:MESI 协议
| 状态 | 含义 |
|---|---|
| M | 已修改,和内存不一致 |
| E | 独占,和内存一致 |
| S | 共享,多个核心只读 |
| I | 无效 |
3.5 按行遍历 VS按列遍历
3.5.1 了解数组在内存中的存储方式
在 C/C++ 中,二维数组是按行优先存储的:
int arr[3][4] = {
{1, 2, 3, 4}, // 第0行
{5, 6, 7, 8}, // 第1行
{9, 10, 11, 12} // 第2行
};
数组在内存中的实际排列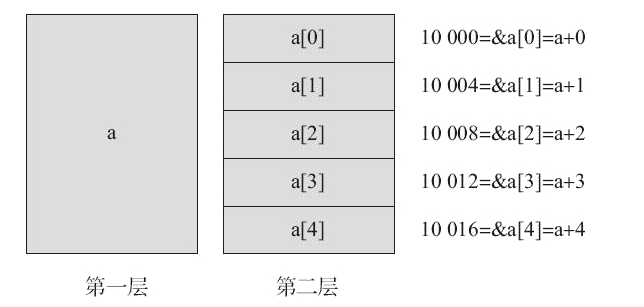
🎯 关键:同一行的元素在内存中是连续挨着的。不同行之间也是连续的,行与行是首尾相接。
3.5.2 缓存的工作方式
CPU 从内存读数据时,不是只读一个变量,而是一次读一整块(叫缓存行,Cache Line,通常是 64 字节)。
假设一个 int 是 4 字节,一个缓存行 64 字节,一次能装下 16 个 int。
| 你只想要 | CPU 实际读入 |
|---|---|
arr[0][0] |
arr[0][0] 到 arr[0][15](整整 16 个元素) |
🚌 比喻:就像学校的校车,接送一个学生需要跑一趟,接送一车的学生也需要跑一趟,那就还不如每次都接送一车的学生,这样可以减少总的趟数,更加高效。
3.5.3 结合具体场景来看
场景一:按行遍历(缓存友好)
for (int i = 0; i < N; i++)
for (int j = 0; j < N; j++)
sum += arr[i][j];
访问顺序:arr[0][0] → arr[0][1] → arr[0][2] → arr[0][3] …
内存访问模式:
访问 arr[0][0]:CPU 把 arr[0][0]~arr[0][15] 加载到缓存
↓ 接着访问 arr[0][1]
✔ 已经在缓存里了(命中!)
↓ 接着访问 arr[0][2]
✔ 已经在缓存里了(命中!)
↓ ... 一直到 arr[0][15]
✔ 全部命中!
↓ 访问 arr[0][16]
✘ 缓存没命中 → 加载下一批 arr[0][16]~arr[0][31]
操作 缓存命中率
第 1 次访问(加载整行) 未命中
后面 15 次访问 命中
命中率 ≈ 93.75% 极高
🚀 结论:一次缓存未命中,换来 15 次命中,效率极高。
场景二:按列遍历(缓存不友好)
for (int j = 0; j < N; j++) // 列在外层
for (int i = 0; i < N; i++) // 行在内层
sum += arr[i][j];
访问顺序:arr[0][0] → arr[1][0] → arr[2][0] → arr[3][0] …
内存访问模式(假设 N 很大,一列元素不在同一个缓存行里):
访问 arr[0][0]:CPU 把 arr[0][0]~arr[0][15] 加载到缓存
↓ 接着访问 arr[1][0]
✘ arr[1][0] 不在刚才的缓存行里!(因为它在第1行,相隔很远)
→ 又加载 arr[1][0]~arr[1][15] 到缓存
↓ 接着访问 arr[2][0]
✘ 又不在!加载 arr[2][0]~arr[2][15]
↓ ... 每次访问都是未命中!
操作 缓存命中率
访问 arr[0][0] 未命中
访问 arr[1][0] 未命中
访问 arr[2][0] 未命中
访问 arr[3][0] 未命中
命中率 ≈ 0% 极低
🐌 结论:每次访问一个元素,都要重新从内存加载,缓存完全没用上。
一个直观类比
| 遍历方式 | 比喻 |
|---|---|
| 按行遍历 | 你站在一排货架前,从左往右拿货,一次拿一排。手边的货拿完,旁边就是下一排。 |
| 按列遍历 | 你拿完第一排的第 1 个,然后跑到第二排的第 1 个,再跑到第三排的第 1 个…每次都要跑到不同位置,永远拿不到"附近的货" |
🎯 一句话:缓存利用的是空间局部性——访问了某个地址,它旁边的地址很可能也会被访问。按列遍历完全破坏了这种连续性。
3.5.4 总结
| 问题 | 答案 |
|---|---|
| 数组怎么存的? | 按行优先,同一行连续 |
| 缓存怎么读的? | 一次读一整行(64 字节) |
| 按行为什么快? | 访问 arr[i][j] 后,arr[i][j+1] 已经在缓存里了 |
| 按列为什么慢? | 访问 arr[i][j] 后,arr[i+1][j] 在内存中相隔很远,缓存里没有 |
| 本质原因 | 按列遍历破坏了空间局部性 |
🎯 一句话记住:因为数组是按行存的,所以按行遍历更充分利用缓存。按列遍历等于每次都访问“远房亲戚”,缓存帮不上忙。
第二部分:操作系统 —— 计算机的大脑
一、操作系统是什么?
| 概念 | 说明 |
|---|---|
| 操作系统 | 一款纯正的“搞管理”的软件 |
| 内核 | 操作系统的核心部分 |
| 其他程序 | 图形界面、驱动程序、系统工具等 |
🏢 比喻:操作系统就像一家公司的管理层:
- 管理层不直接搬砖(不直接处理硬件)
- 管理层负责管理资源(CPU、内存、硬盘、进程)
- 管理层给员工提供工作规范(系统调用)
1.1 操作系统的定位
操作系统的核心职责:
| 职责 | 说明 | 比喻 |
|---|---|---|
| 管理 CPU | 决定哪个进程用 CPU | 排班经理 |
| 管理内存 | 分配、回收内存 | 仓库管理员 |
| 管理文件 | 读写、权限控制 | 档案管理员 |
| 管理设备 | 驱动、输入输出 | 设备调度员 |
| 管理进程 | 创建、销毁、调度 | 人事经理 |
二、管理的本质:先描述,再组织
2.1 管理者不需要和被管理者见面
💡 这是一个非常重要的思想:管理者和被管理者不需要见面,管理者根据数据进行管理,数据由中间层获取。
| 现实例子 | 管理者 | 数据 | 被管理者 |
|---|---|---|---|
| 学校管理学生 | 教务处 | 学籍档案、成绩单 | 学生 |
| 公司管理员工 | HR | 员工档案、考勤记录 | 员工 |
| 操作系统管理进程 | 操作系统 | PCB(进程控制块) | 进程 |
🎯 核心:管理就是基于数据做决策。操作系统不需要“看到”进程,只需要看进程的“档案”(PCB)。
2.2 先描述,再组织
操作系统管理资源的方法:
- 描述:用数据结构描述一个资源(比如用
struct task_struct描述一个进程) - 组织:把这些数据结构用链表、队列等方式组织起来
// 操作系统眼中的“进程”就是一个结构体
struct task_struct {
int pid; // 进程ID
int state; // 进程状态
int priority; // 优先级
// ... 还有很多字段
};
// 所有进程的组织:一个链表
struct list_head task_list;
🍔 比喻:就像学校的学生管理系统。每个学生有一张档案卡(描述),所有档案卡放在一个柜子里(组织)。教务处不需要见学生本人,看档案卡就行。
三、系统调用 —— 访问操作系统的唯一入口
3.1 什么是系统调用?
系统调用是操作系统提供的函数接口,用户程序通过它来请求操作系统提供服务。
| 服务 | 系统调用示例 | 作用 |
|---|---|---|
| 文件操作 | open()、read()、write() |
读写文件 |
| 进程管理 | fork()、exec()、wait() |
创建、执行进程 |
| 内存管理 | malloc()、free()、mmap() |
分配、释放内存 |
| 设备管理 | ioctl()、read()、write() |
操作设备 |
🏦 比喻:操作系统就像一个银行。你不能直接进金库拿钱(不能直接访问硬件)。你必须通过柜台窗口(系统调用)来办理业务。银行不相信任何人,必须走正规流程。
3.2 为什么不能直接访问硬件?
| 原因 | 说明 |
|---|---|
| 安全性 | 防止用户程序破坏系统 |
| 稳定性 | 防止程序崩溃导致整个系统崩溃 |
| 抽象性 | 用户不需要知道硬件细节 |
| 公平性 | 操作系统可以调度、分配资源 |
🔒 核心原则:操作系统不相信任何用户。所有对硬件的访问,必须经过操作系统。
3.3 软硬件体系结构层次图
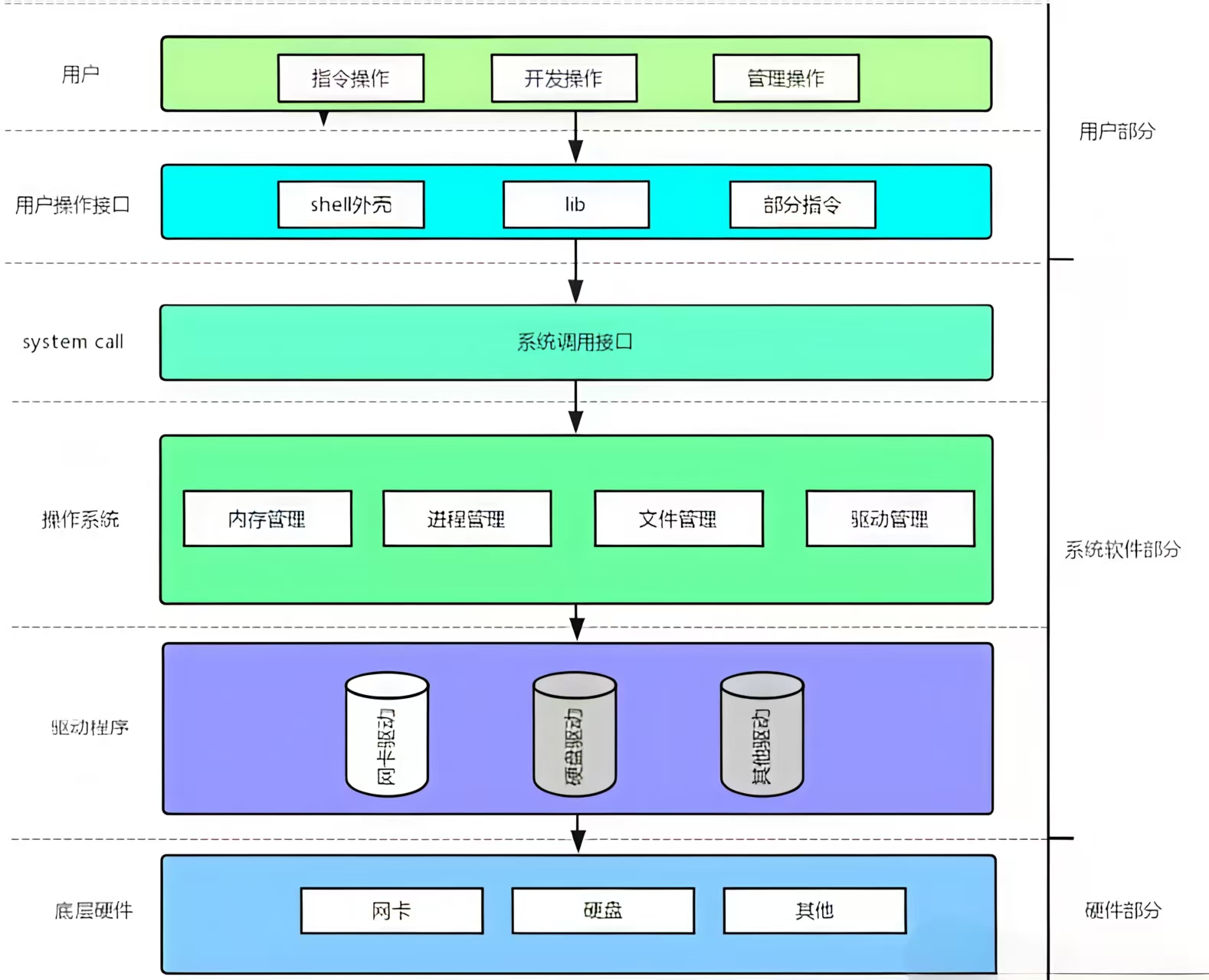
四、重要结论
4.1 访问硬件必须贯穿整个体系
任何程序,只要访问硬件,它的请求必须贯穿整个软硬件体系结构。
例如:你在程序中调用 printf(“hello”):
printf()
→ 库函数
→ 系统调用(write)
→ 操作系统内核
→ 显卡/显示器驱动
→ 硬件(显示器)
4.2 库函数底层封装了系统调用
我们常用的库函数,很多在底层封装了系统调用:
| 库函数 | 底层系统调用 | 说明 |
|---|---|---|
printf() |
write() |
输出到屏幕 |
scanf() |
read() |
从键盘读取 |
fopen() |
open() |
打开文件 |
malloc() |
brk()、mmap() |
分配内存 |
💡 所以:库函数提供了更方便的接口,但底层还是操作系统在干活。
4.3 操作系统是“搞管理”的软件
操作系统不直接“干活”(不直接算 1+1,不直接显示像素),它的工作是:
· 分配:谁用 CPU、谁用内存
· 调度:谁先运行、谁后运行
· 保护:不让程序互相干扰
· 抽象:让程序员不用关心硬件细节
🎯 一句话:操作系统是资源的管理者,不是资源的使用者。
五、总结速查表
| 知识点 | 核心内容 |
|---|---|
| 冯诺依曼体系 | CPU、内存、输入、输出四大部件 |
| CPU 只和内存打交道 | 程序必须先加载到内存才能运行 |
| 数据流动本质 | 从一个设备拷贝到另一个设备 |
| 效率瓶颈 | 由最慢的部件决定(木桶效应) |
| 操作系统 | 一款"搞管理"的软件 |
| 管理本质 | 先描述(数据结构),再组织(链表等) |
| 系统调用 | 访问操作系统的唯一入口 |
| 操作系统不相信用户 | 所有硬件访问必须经过操作系统 |
| 库函数 | 底层可能封装了系统调用 |
最后
冯诺依曼体系结构给了计算机骨架,操作系统给了计算机灵魂。
理解这两者,你就理解了:
· 为什么程序要“加载”
· 为什么电脑会“卡”
· 为什么程序崩溃不会让整个系统崩溃
· 为什么写代码时不能直接访问硬盘
这是计算机科学的基石,值得你反复品味。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)