Linux:进程间通信 和 简单进程池
Visual Studio Code,简称VS Code,是微软推出的免费、跨平台、轻量级代码编辑器,支持 Windows、macOS、Linux 全系统,目前是全球最主流的开发工具之一,尤其适合学生、后端、前端、嵌入式、操作系统学习使用。它和我们之前学习C/C++使用的最多的 Visual Studio 开发软件都是微软公司开发的。Visual Studio Code - 开源的 AI 代码编辑
1.进程间通信介绍
我们以前学习进程的时候,进程之间的独立性都很强,即使对于父子进程来说,虽然父进程的数据可以给子进程共享,但是子进程也无法修改父进程的数据,并且因为写时拷贝,子进程也无法给父进程共享自己的数据。但是如果我们就是想要让进程与进程之间能够协同工作呢?这就需要进程间通信的知识。
1.1 基本概念
进程间通信(IPC,Inter‑Process Communication),是指操作系统提供的、允许不同进程之间进行数据交换、信息传递、状态同步、资源协调的一系列机制与接口。由于每个进程拥有独立的虚拟地址空间,进程之间天然相互隔离,无法直接访问对方内存,因此必须依靠操作系统内核提供的特殊方式,实现跨进程的数据交互与协作。
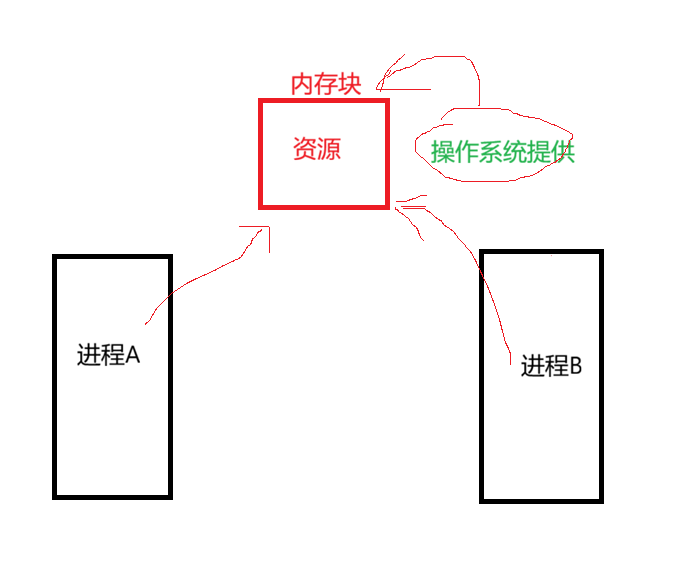
因此我们可以说,进程间通信的本质, 就是让不同的进程能看到同一份资源,而这个资源大家姑且可以粗暴的认为就是内存块,而这个内存块是由操作系统通过系统调用提供的。
1.2 进程间通信的目的
1. 数据传输:一个进程将数据发送给另一个进程,完成信息传递;
2. 资源共享:多个进程共享同一部分资源,避免重复创建、节约系统开销;
3. 进程控制:一个进程控制另一个进程的执行,如暂停、唤醒、终止,或处理异常事件;
4. 通知事件:进程间互相发送信号,告知对方某类事件发生;
5. 同步互斥:协调多个进程的执行顺序,避免同时争抢临界资源,防止数据错乱、竞态条件。
2. 管道
管道是 Unix 中最古老的进程间通信的形式。 我们把从一个进程连接到另一个进程的一个数据流称为一个 "管道"。它是 Linux 最基础的进程间通信(IPC)方式,本质是内核维护的一块环形缓冲区,用于实现有亲缘关系进程间的单向数据传输。 管道分为匿名管道和命名管道(FIFO)。
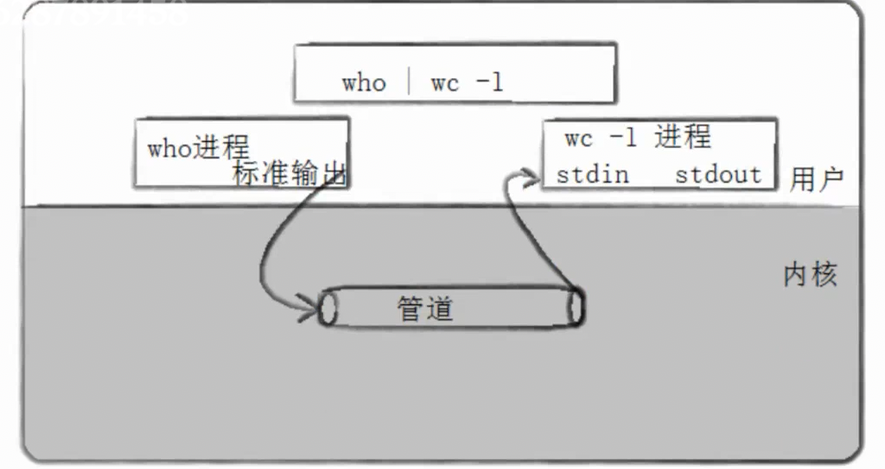
在我们讲解父子进程的时候,其实有一个场景就涉及了管道的知识:
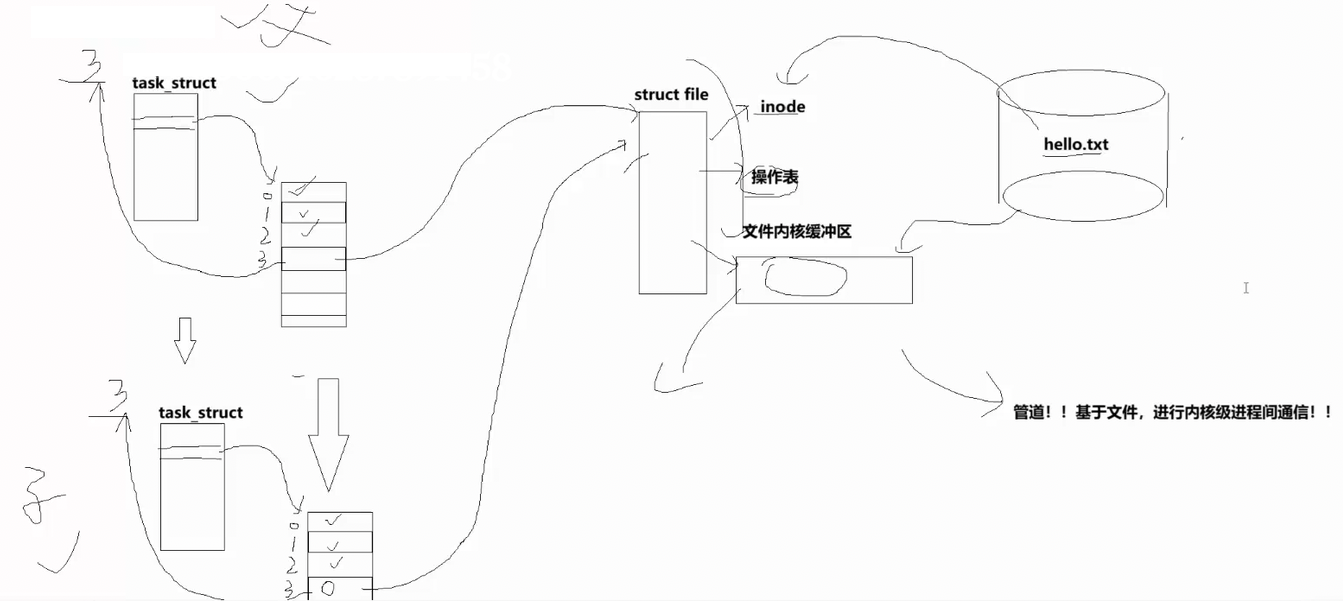
这幅图中,父进程打开磁盘中的文件hello.txt,打开文件时内核会生成一个struct file结构体,该结构体通过inode记录文件属性,通过文件操作表提供读写接口,并将文件内容加载到文件内核缓冲区;父进程会在自身文件描述符表中记录该struct file的地址,对外返回文件描述符下标。当父进程创建子进程时,子进程会拷贝父进程的 PCB 及文件描述符表,子进程的文件描述符表同样指向同一个struct file结构体,内核不会为子进程新建该结构体,因此父子进程可共享该内核资源,父进程向文件内核缓冲区写入数据,子进程可从中读取,至此父子进程之间具备了进程间通信的条件。
这种基于文件系统、依靠内核缓冲区实现的通信方式,和管道底层原理完全一致。因此管道的本质是基于文件系统,进行内核级的进程间通信。
3. 匿名管道
3.1 基本概念
我们上面的讲解对于管道的底层原理,还是基于磁盘去做的,但是真正的对于真正的管道,我们先讨论匿名管道,实际上是完全不用依赖磁盘的,而是直接使用系统调用。
匿名管道是 Linux 中最基础的半双工、有亲缘关系进程间通信方式,通过 pipe() 系统调用创建,依托 Linux 文件系统架构实现,本质是内核开辟的一块环形内存缓冲区。
因为匿名管道是只存在内核内存里,不在磁盘、不在文件系统,只能靠 pipe() 创建,只能靠文件描述符访问。只有父子 / 亲缘进程能继承 fd 使用,外部进程完全找不到、用不了。那也就不需要文件名和文件的路径信息,因此才叫做匿名管道。
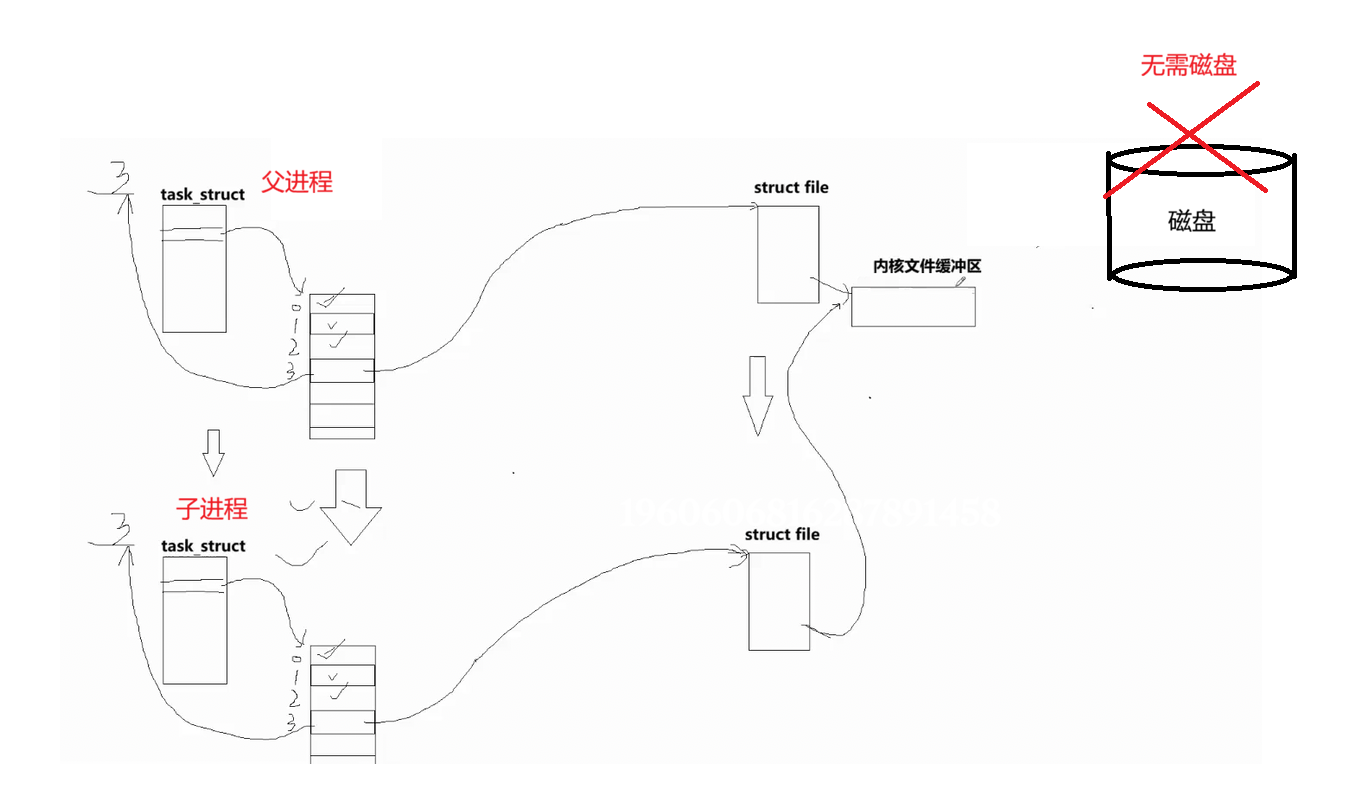
匿名管道通过 pipe 系统调用,在内核中创建内存级临时 inode、struct file 结构体与专属内核缓冲区,全程无需磁盘参与。父进程创建管道后调用 fork 生成子进程,子进程拷贝父进程的 PCB 与文件描述符表,父子进程通过文件描述符指向同一个内核缓冲区,并且要注意的是,此时子进程也会拷贝一份struct file ;父进程向内核缓冲区写入数据,子进程从缓冲区读取数据,依靠文件系统模型完成内核级、单向的父子进程间通信,这就是匿名管道。
3.1.1 pipe 系统调用
pipe 是 Linux 系统中用于创建匿名管道的核心系统调用,是实现亲缘进程(父子 / 兄弟进程)间内核级通信的基础机制。该调用由内核直接提供,全程基于内存缓冲区完成数据交互,不依赖磁盘文件,因此也被称为无名管道。
#include <unistd.h>
int pipe(int fd[2]); 调用成功时返回 0,失败时返回 -1。参数 fd 是一个长度为 2 的整型数组,用于接收内核分配的两个文件描述符,其中:
fd[0]固定作为管道读端,只能从管道中读取数据;fd[1]固定作为管道写端,只能向管道中写入数据。
当进程执行 pipe 调用时,内核会在内核空间中创建一块环形内存缓冲区,同时构建对应的管道管理结构,将读端与写端文件描述符关联到同一缓冲区。这两个文件描述符会被添加到调用进程的文件描述符表中,使进程具备对管道的读写能力。
3.2 通用通信分类概念
通用通信方式分为单工、半双工、全双工三类。
1. 单工通信(Simplex)
信息只能沿一个固定方向传输,永远不能反向。就好比说是老师对于学生,在上课的时候是老师单向对学生进行信息输出,此时信息传输的方向是固定的。
2. 半双工通信(Half‑duplex)
同一时刻只能单向传输,但方向可以切换。就好比是我们日常沟通交流,都是你一句我一句这样来回切换信息输出方向。
3. 全双工通信(Full‑duplex)
两个方向可以同时收发数据。这就好比如说是在吵架的时候,大家都在互相问候,谁也听不进去谁的,都在声嘶力竭的给对方输出。
我们所提到的匿名管道实际就是半双工的通信模式的。
3.3 文件描述符角度理解管道
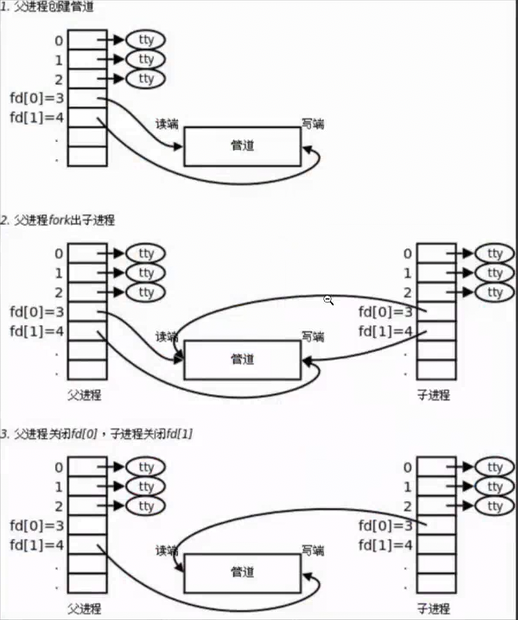
这张图就演示了 匿名管道 和 fork 结合的场景:
第一步,父进程创建匿名管道。父进程调用 pipe( ) 系统调用,由内核在内存中创建匿名管道缓冲区,同时在父进程的文件描述符表中分配两个专用文件描述符:fd[0]=3为管道读端,fd[1]=4为管道写端,分别对应管道的读取与写入接口;0、1、2 号文件描述符默认绑定标准输入、标准输出、标准错误终端设备,此时管道仅能被父进程访问。
第二步,父进程通过fork()创建子进程。子进程完整拷贝父进程的文件描述符表,因此子进程同样拥有管道读端fd[0]=3与写端fd[1]=4;父子进程共享内核中唯一的管道缓冲区,实现对同一通信资源的访问,为进程间数据交互奠定基础。此时父子进程均可对管道进行读写操作。
第三步,关闭冗余端口,建立单向半双工通信。父进程关闭自身管道读端fd[0],仅保留写端用于向管道写入数据;子进程关闭自身管道写端fd[1],仅保留读端用于读取管道数据。最终形成父进程写入、子进程读取的固定单向传输模式,完成父子进程间的匿名管道通信。
之所以在这里父子进程要各自关闭一个读端一个写端,是因为:首先,匿名管道为半双工通信,数据仅能从写端流向读端。父进程关闭读端、子进程关闭写端,可强制固定父进程写入、子进程读取的单向传输方向,避免父子进程双向读写产生数据错乱、覆盖的问题,保障数据有序交互。
其次,为规避进程永久阻塞。因为管道存在读写阻塞机制,当管道无数据时读端会阻塞等待;若存在任意打开的写端,读端将持续阻塞。子进程关闭自身写端后,所有管道写端将随父进程写入完成而全部关闭,子进程读取完毕后可正常结束,避免进程卡死。
同时,文件描述符属于内核有限资源,关闭冗余端口能够及时释放闲置句柄,减少系统资源占用,防止资源泄漏。最后,匿名管道生命周期依赖所有持有端口的进程关闭后才会销毁,规范关闭多余端口可精准管控管道生命周期,通信结束后内核可正常释放管道缓冲区内存。
3.4 内核角度理解管道
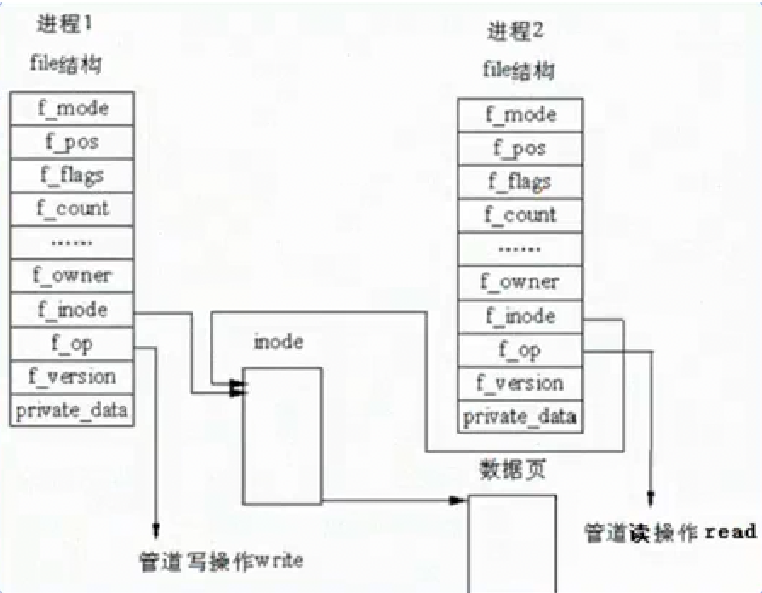
该图从Linux 内核底层视角,展示了匿名管道实现进程间通信的核心结构与数据交互逻辑,清晰呈现了进程、文件结构、索引节点(inode)与管道数据缓冲区的关联关系。
进程 1 与进程 2 分别维护各自独立的file文件结构,结构体包含访问模式f_mode、文件偏移f_pos、标志位f_flags、引用计数f_count、索引节点指针f_inode、操作函数集f_op等内核成员。两个进程的file结构通过f_inode指针,指向内核中同一个管道专属的 inode 索引节点,inode 节点再关联管道的数据页缓冲区,由此实现两个进程对同一管道资源的共享。
其中,进程 1 通过自身file结构发起管道写操作 write,将数据写入共享的数据页缓冲区;进程 2 通过自身file结构执行管道读操作 read,从同一数据页中读取数据。两个进程虽拥有独立的文件描述信息,但依托唯一的 inode 节点与公共数据缓冲区,完成数据的单向传递。
3.5 管道样例
接下来乃至以后,为了方便我们的文章中的代码编写以及日常练习,我们就要逐渐从 vim编辑器 转向 VScode了,下面对VScode做一个介绍。
3.5.1 VScode介绍
为了保证文章的连贯性,我将文章用链接的形式展示:
3.5.2 代码样例 1
首先我们来验证一下 pipe 系统调用:
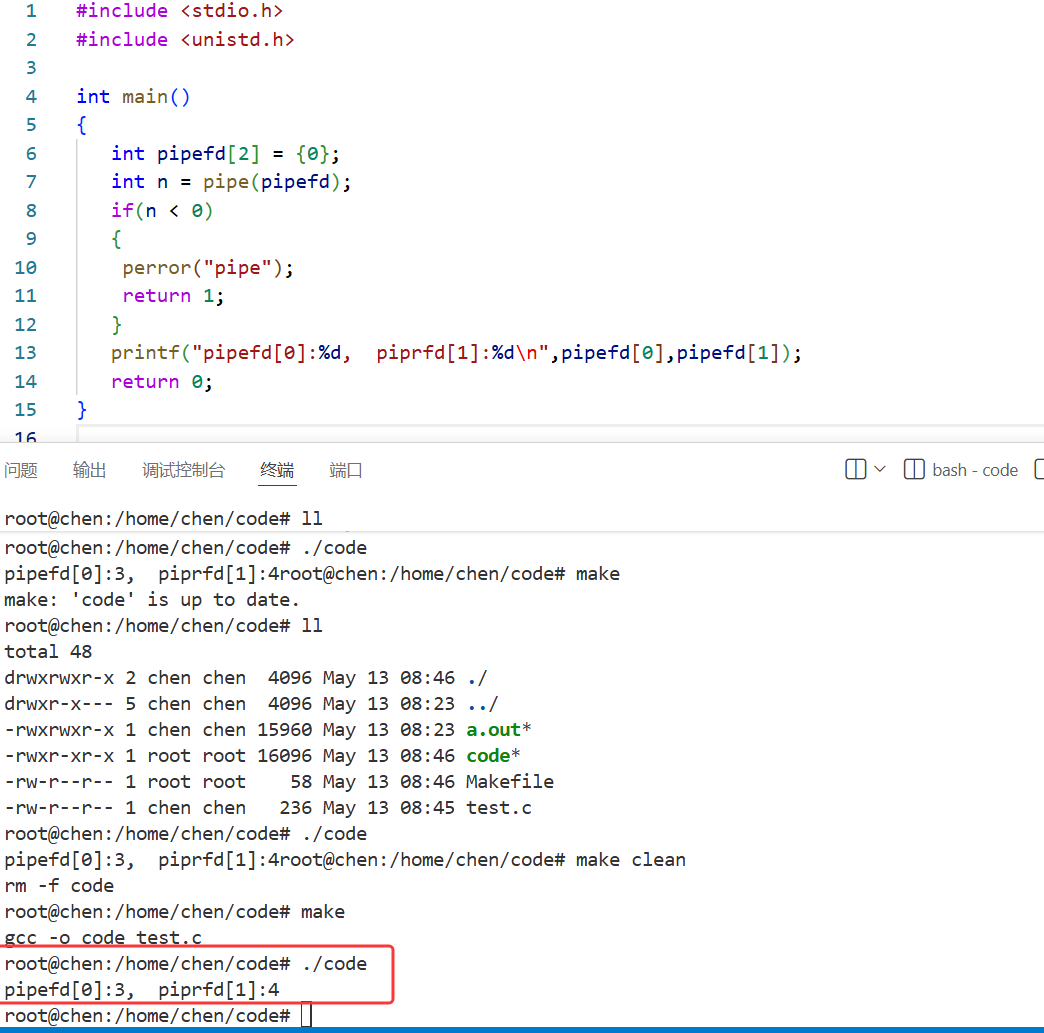
我们先创建一个容量为 2 的数组用于传参,用于接收内核分配的两个文件描述符。接着使用 n 接收 pipe系统调用的返回值, 调用成功时返回 0,失败时返回 -1。然后我们看到,果然 pipefd[0] 和 pipefd[1] 接收到的是对应文件描述符表中的下标 3 和 4 。
当管道创建好了之后,我们fork创建子进程,再关闭父子进程各自对应的管道:
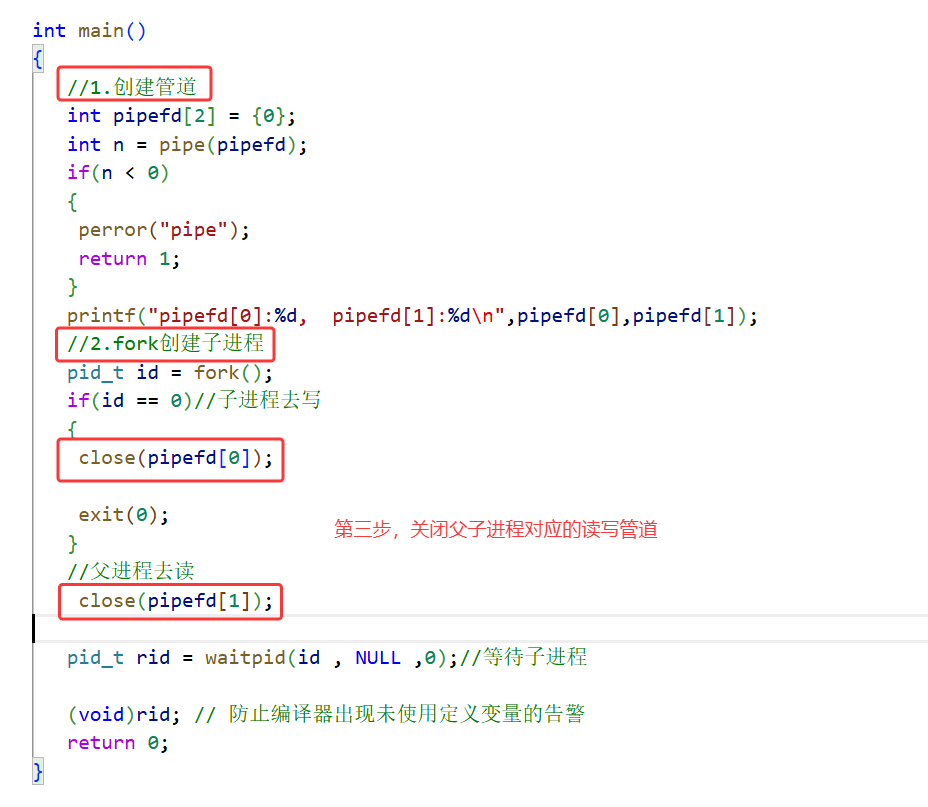
接下来直接展示后半段完整代码:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <string.h>
int main()
{
//1.创建管道
int pipefd[2] = {0};
int n = pipe(pipefd);
if(n < 0)
{
perror("pipe");
return 1;
}
printf("pipefd[0]:%d, pipefd[1]:%d\n",pipefd[0],pipefd[1]);
//sleep(1);
//2.fork创建子进程
pid_t id = fork();
if(id == 0)//子进程去写
{
close(pipefd[0]);
char *msg = "hello world!";
int cnt = 10;
char outbuffer[1024];
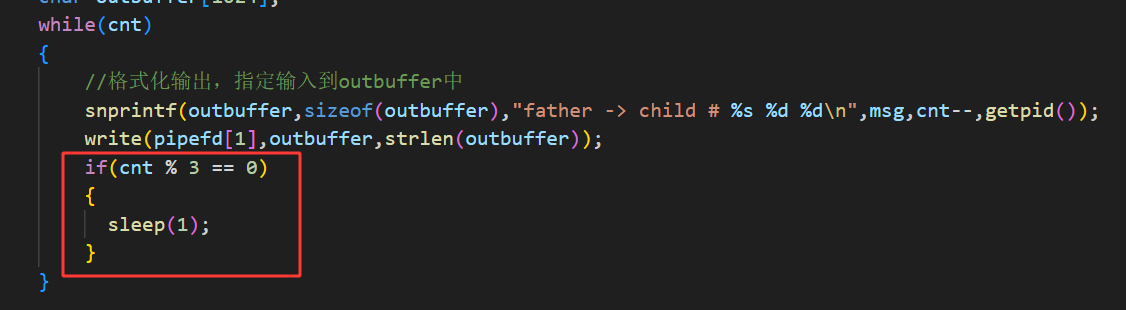
while(cnt)
{
//格式化输出,指定输入到outbuffer中
snprintf(outbuffer,sizeof(outbuffer),"father -> child # %s %d %d\n",msg,cnt--,getpid());
write(pipefd[1],outbuffer,strlen(outbuffer));
sleep(1);
}
exit(0);
}
//父进程去读
close(pipefd[1]);
char buffer[1024];
char inbuffer[1024];
while(1)
{
ssize_t n = read(pipefd[0],inbuffer,sizeof(inbuffer)-1);
if(n > 0)//说明读取到了有效信息
{
inbuffer[n] = 0;//让数组中最后一位有效数字的后一位为 \0
printf("%s",inbuffer);
}
else if(n == 0)
{
//读到末尾,对方关闭写端
printf("打印完毕,子进程已退出,管道关闭 \n");
break;
}
else
{
perror("read");
break;
}
}
pid_t rid = waitpid(id , NULL ,0);//等待子进程
(void)rid; // 防止编译器出现未使用定义变量的告警
return 0;
} 首先调用pipe()创建匿名管道,得到读端文件描述符pipefd[0]、写端文件描述符pipefd[1];随后通过fork()创建子进程,父子进程共享该管道。子进程作为写入端,主动关闭管道读端,通过snprintf拼接包含自定义文本、计数与进程 ID 的字符串,循环 10 次、每次间隔 1 秒将数据写入管道;父进程作为读取端,主动关闭管道写端,循环调用read系统调用阻塞读取管道数据,读到有效数据则格式化输出,当管道写端全部关闭时结束读取,最终调用waitpid()回收子进程资源,避免产生僵尸进程。
其中snprintf是 C 语言标准格式化输出函数,函数原型为
//标准定义
#include <stdio.h>
int snprintf(char *str, size_t size, const char *format, ...);
//对应代码中的语句是
snprintf(outbuffer, sizeof(outbuffer), "father -> child # %s %d %d\n", msg, cnt, pid); 第一个参数str为格式化后字符串的存储缓冲区,第二个参数size限制缓冲区最大写入字节数,避免内存溢出,第三个参数format为格式化模板字符串,后续可变参数用于填充模板内占位符。本代码中该函数将文本、递减计数、进程 ID 拼接为完整字符串,同时在末尾添加换行符,使后续printf可自动刷新缓冲区实时输出内容。
read是 Linux 系统调用,原型为:
//标准定义
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
//代码中对应的语句是
ssize_t n = read(pipefd[0], inbuffer, sizeof(inbuffer)-1); 用于从指定文件描述符读取数据到缓冲区,fd为读取对象的文件描述符,本代码中为管道读端pipefd[0];buf为接收数据的缓冲区;count为单次最大读取字节数。
其返回值n的变化直接对应管道通信状态,
1. > 0:实际读到的字节数
2. = 0:遇到 EOF(文件结束 / 管道写端关闭)
3. = -1:读取失败,错误码保存在 errno
当管道内存在子进程写入的数据时,read读取到有效字节,n为大于 0 的实际读取字节数;子进程完成 10 次写入后执行exit(0)退出,操作系统自动关闭子进程持有的管道写端,而父进程早已关闭自身的管道写端,此时管道所有写端全部关闭,read读取不到任何数据,返回值n变为 0;若读取过程中出现文件描述符异常、权限错误等问题,n会返回 - 1,代表读取失败。正是基于n从大于 0 逐步变为 0 的状态变化,父进程可判断数据读取完成,退出读取循环,完整实现父子进程的单向数据通信。
最后执行的结果就如下图所示:
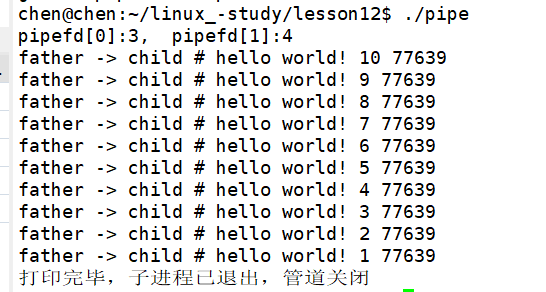
3.5.2.1 样例 1 总结
刚刚的代码中,我们对匿名管道做了一个小小的印证,从子进程中写数据,父进程确实是能通过管道看到子进程写入的数据,实现内容交互的场景,接下来我们就要对匿名管道做一点阶段性总结:
1. 管道是只能单向通信,即单工通信。
2. 匿名管道只能用来进行父子进程间的通信,因为是通过子进程能继承父进程的内核资源来实现的,也就是说管道通信是文件的功劳,但真正能让父子进程能够看到对方的数据,其实还是fork的功劳。
3. 像我们平时在Xshell上直接输入的命令,其实也是兄弟进程之间通过匿名管道进行信息交互:

我们可以看到调用的三个 sleep 命令的父进程的 PID 都是一样的。
4. 管道是面向字节流的。这句话的意思是说:管道只认一堆连续的字节,不管你发的是整数、字符串、结构体,它只管按顺序收发二进制字节,不自带消息边界。它传输连续无边界的字节序列,不区分消息,不自带数据格式,读写按字节顺序进行,需要用户自己划分消息边界。
具体是什么意思,我们可以用这段代码来说明:
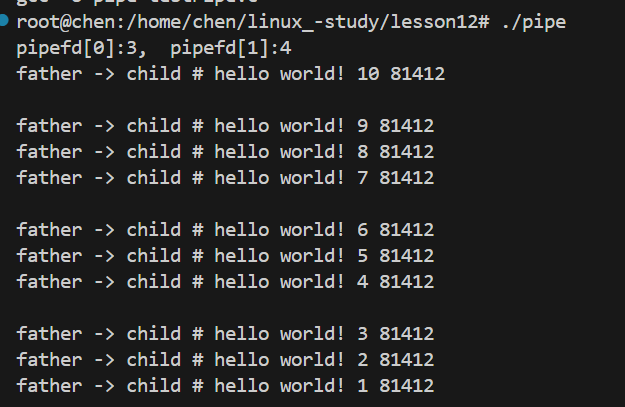
我们可以看到,当在打印的时候让 cnt 逢三就睡眠一秒钟,父进程打印的结果就是三条三条打印,而不是像我们之前看到的一条一条打印的过程,但是对于子进程来说,写入的过程是一条一条写入的,只不过当 cnt = 3 的时候会睡眠一秒而已。这就说明了,如果没有用户自动设置边界,管道的读取就是一次性读完的,而不是根据写入的多少来调整。
用一个生活化的例子说明就是:假如我买了很多快递,收件地址都是菜鸟驿站。第一天快递员往菜鸟驿站入库了一件快递,第二天一次性入库了两件,第三天一次性入库了三件。虽然在三天里面入库的快递件数都不一样,但是我可以在第四天集中把它们统一都取出来。也就是说在这个过程里面,我不管快递员往菜鸟驿站里放了多少件快递,或者说以怎样的数量放入的,我只要在我需要的时候,就可以把快递所有一次性全部取出来。
在这段关系中,菜鸟驿站 = 管道缓冲区; 快递员往驿站放快递 = 进程 write 写管道; 去取快递 = 进程 read 读管道 ; 每一件快递 = 一个字节 ; 字节流 = 一堆连续快递,驿站根本不管你是分几次放的、每次放几件。
5. 如果开启管道之后,父子进程都已经结束了,但是并没有手动关闭管道,那么此时管道就会被操作系统自动回收。
这是因为,调用 pipe() 创建管道时,内核会为管道的读端、写端分别创建对应的 struct file 文件对象,每个对象内部维护引用计数成员 f_count(部分内核版本命名为 ref_count),用于记录当前持有该文件对象的进程数量。
当父进程通过 fork() 创建子进程时,子进程会完整复制父进程的文件描述符表,父子进程的文件描述符将指向同一个管道对应的 struct file 对象,每一次复制都会使对应文件对象的引用计数 f_count ++ 。
进程正常或异常终止时,操作系统会自动执行进程退出清理逻辑:遍历该进程打开的所有文件描述符,对每个文件描述符关联的 struct file 对象,将其引用计数 f_count 递减。
对于管道场景,若父子进程均已结束,即便代码中未手动调用 close() 关闭管道文件描述符,内核也会通过进程退出隐式关闭所有管道 fd,使管道读端、写端对应的 struct file 引用计数全部归零。当引用计数为 0 时,内核判定当前无任何进程持有管道资源,会自动释放管道内核缓冲区、销毁管道 inode 与文件对象,完成管道资源的回收。
6. 如果子进程写入的速度比较慢,那父进程就会阻塞等待,直到管道中有了有效数据,父进程才能继续读。
7. 子进程如果写入的速度远远快于父进程,那写入的内容就会在管道中堆积,一旦管道被写满,子进程就会进入阻塞状态。
8. 读端在持续读取,但是写端直接关闭,当读端读完管道中的剩余数据,再读就只能读取到空内容,那么 read 的返回值就一直是 0 ,表明该管道读到文件结尾。
9. 如果写端一直在写,但是读端直接关闭,因为只写不读这是没有意义的,那么操作系统就会直接杀掉写端进程。
4. 进程池
因为前面提到了匿名管道,这里为了让大家能更好的熟悉和理解,所以需要讲解进程池的知识,但是其内容也不少,因此为了不影响文章的连贯性,我把进程池的内容放到了另外一篇文章,这是文章链接:
大家可以看完之后再接着看下面的内容。
5. 命名管道
5.1 基本概念
命名管道也叫 FIFO,是 Linux 下一种半双工、面向字节流、持久化、可用于任意进程间通信的特殊文件类型。 它和前面提到的 匿名管道(pipe) 是亲兄弟,它的通信规则、阻塞逻辑与匿名管道完全一致,但突破了血缘限制,能力更强。
匿名管道只能用于有血缘关系的父子、兄弟进程之间通信,必须通过fork继承文件描述符使用,生命周期是临时的,进程退出后便随之消失,没有实体名称,仅存在于内存中;命名管道则支持任意无血缘的无关进程间通信,无需依赖fork,通过文件名即可完成打开通信,以特殊文件的形式持久存在于文件系统中,具备标识名称,任意知晓该名称的进程都能使用,简单来说,匿名管道是临时专用通道,命名管道则相当于公共电话亭。
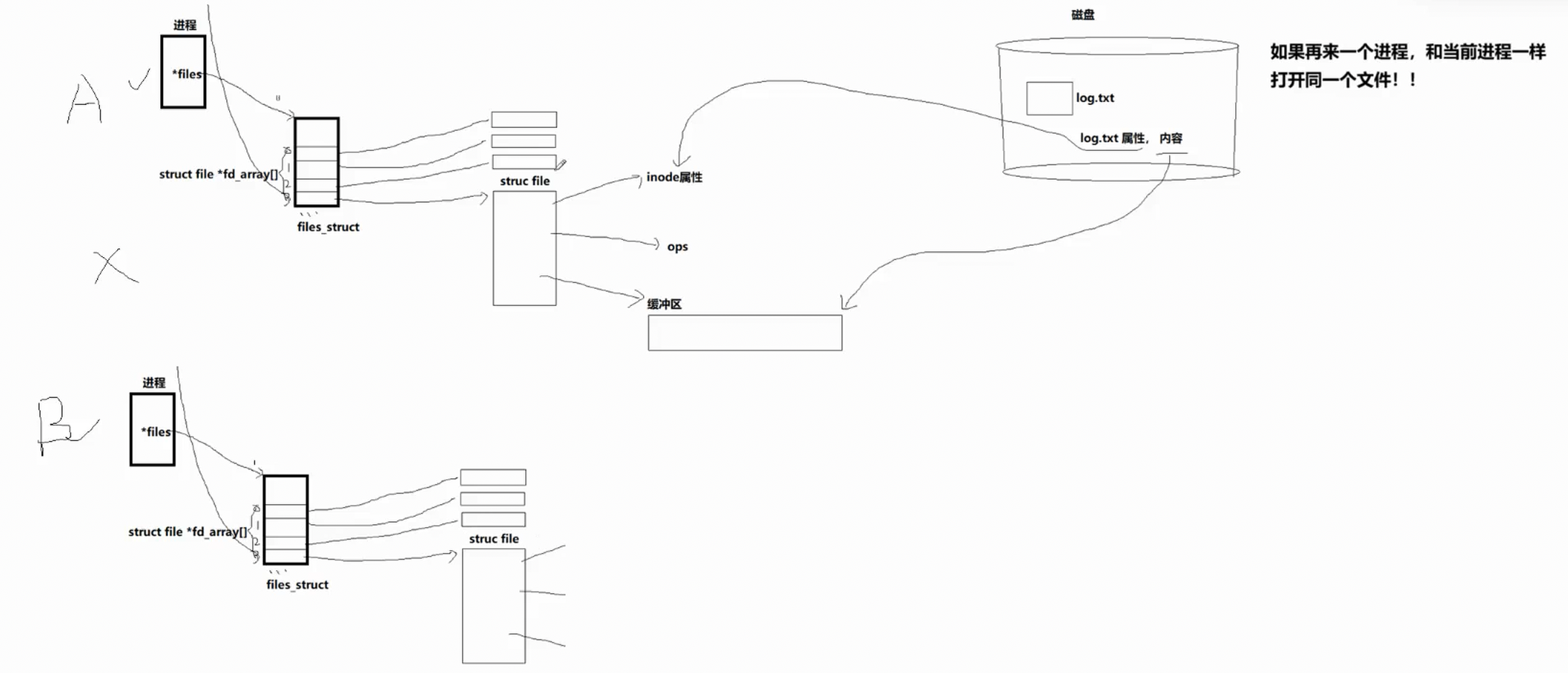
如图所示当一个进程想要打开磁盘上的一个文件时,操作系统会为这个文件分配一个struct file结构体,用来存储文件的属性和代码数据。但是当多个进程要打开同一份文件时,每个进程调用一次 open,内核就新建一个独立的 struct file,这个结构体只维护该进程自己的读写偏移量、打开模式、标志位,不保存文件内容。文件内容、权限、大小、时间等属性,存在磁盘 inode 里,内核只会把它加载到内存中一份 inode 缓存,所有进程共享这一份,不会重复加载。
那这也就相当于,让多个进程,看到同一份资源,这就是管道的底层逻辑。那么说是多个进程打开同一份文件,怎么保证这几个进程打开的确实是同一份文件呢?只要打开文件的时候,用的是相同的路径+文件名,就能保证是同一个文件。既然需要路径+文件名,所以叫做命名管道。
创建方式有在命令行中创建和在程序中创建两种:
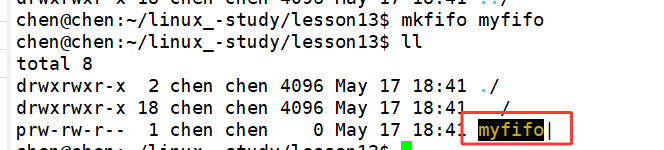
// 在命令行中创建
mkfifo [选项] 管道文件名 执行后会在当前目录生成名为 myfifo 的管道文件,通过 ls -l 查看,文件权限首位为 p,代表命名管道。该命令本质是底层调用 mkfifo 系统调用实现创建。
我们用两台机器来演示一下:

下面是程序中的 mkfifo 函数:
#include <sys/stat.h>
#include <sys/types.h>
int mkfifo(const char *pathname, mode_t mode); mkfifo 是 POSIX 标准的系统调用函数,用于在 C/C++ 程序中动态创建命名管道,需要包含指定头文件,是进程间通信编程的标准接口。pathname:要创建的命名管道文件路径 + 名称;mode:管道文件的访问权限,例如 0666(可读可写),权限会受系统权限掩码 umask 影响。
创建成功:返回 0;创建失败:返回 -1(例如文件已存在时会报错)。作用是:在指定路径创建一个命名管道文件,不占用磁盘空间,仅作为进程间通信的标识,使用方式与普通文件一致,通过 open/close/read/write 操作。
而命名管道的本质,就是用 mkfifo 创建一个专门用于进程间传输信息的特殊文件。它看起来像文件、有文件名、能在磁盘看到,但不存真实数据、不占磁盘空间, 只作为 “通信通道标识”,让无关进程通过它传递数据。
5.2 使用命名管道
在这里我们选择将对管道的管理封装成类的形式,因为管道的操作不是孤立的,它是围绕一个“资源实体”展开的,这个资源就是管道文件描述符。把这个文件描述符、路径、权限以及围绕它的一系列操作(增删查改)都封装在一个类里,把状态和行为绑在一起,代码逻辑会更内聚,用起来也更像在操作一个“管道对象”,而不是散落的一堆函数调用。
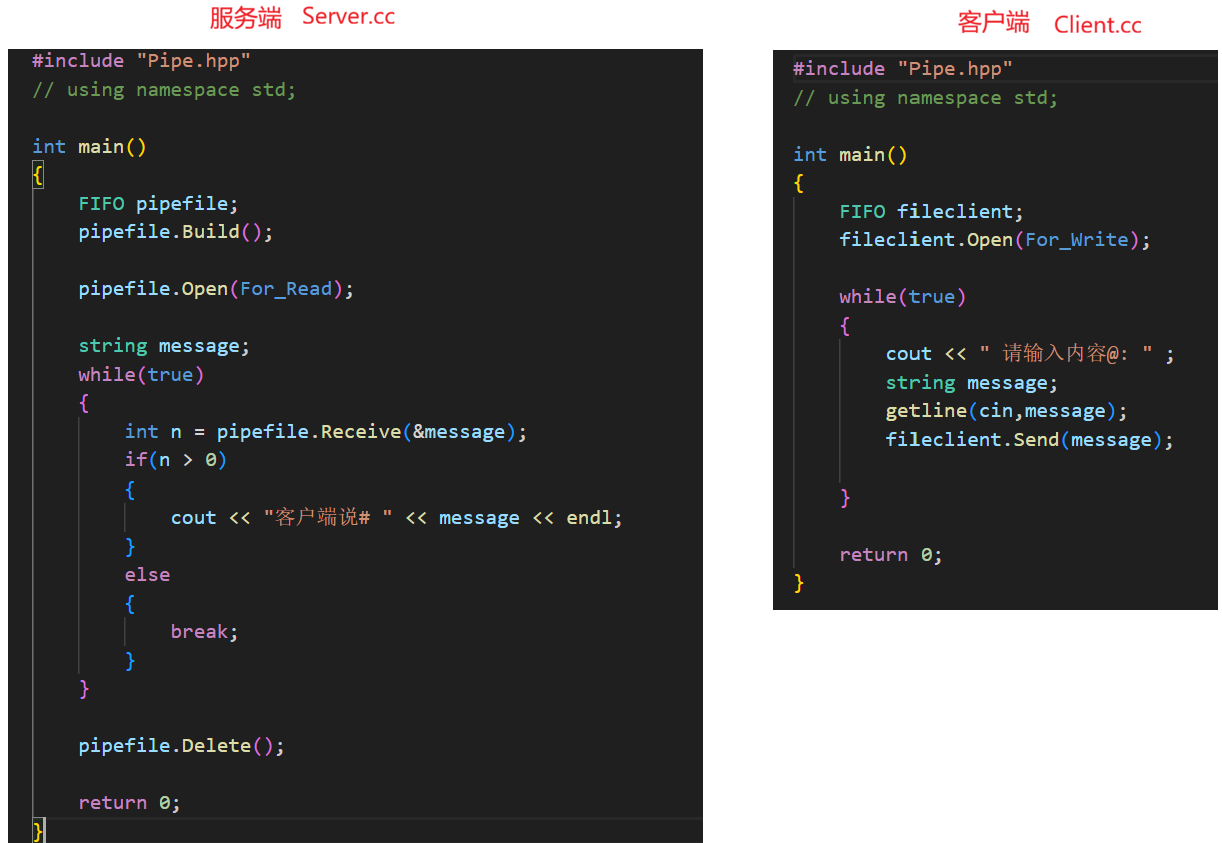
另外,我们创建了两个文件去模拟客户端和服务端,一个是 Client ,另一个是 Server。其中通过命名管道来实现信息交互。我们让服务端去创建管道,而服务端不必且不能创建管道,因为这样的话就会存在两个管道,完全没必要。我们的目的,是要让客户端向管道内输入内容,服务端通过管道去获取客户端输入的信息。
首先看构造函数。我们初始化了三个成员:管道文件的路径 _commfile,默认就是 "./fifo";权限模式 _mode,默认 0666;文件描述符 _fd,先置成 -1。这个 _fd 很关键,后续的读写全靠它。
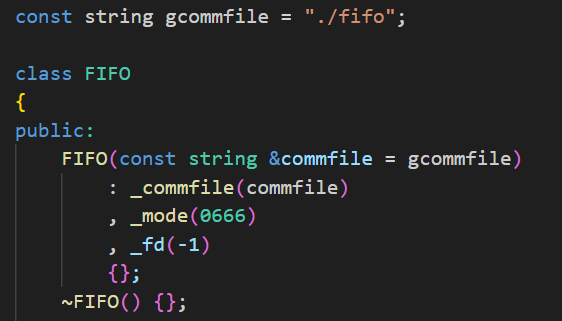
然后是 Build(),负责创建管道文件。它没有直接调 mkfifo,而是先调用 IsExists() 判断文件是否已存在。
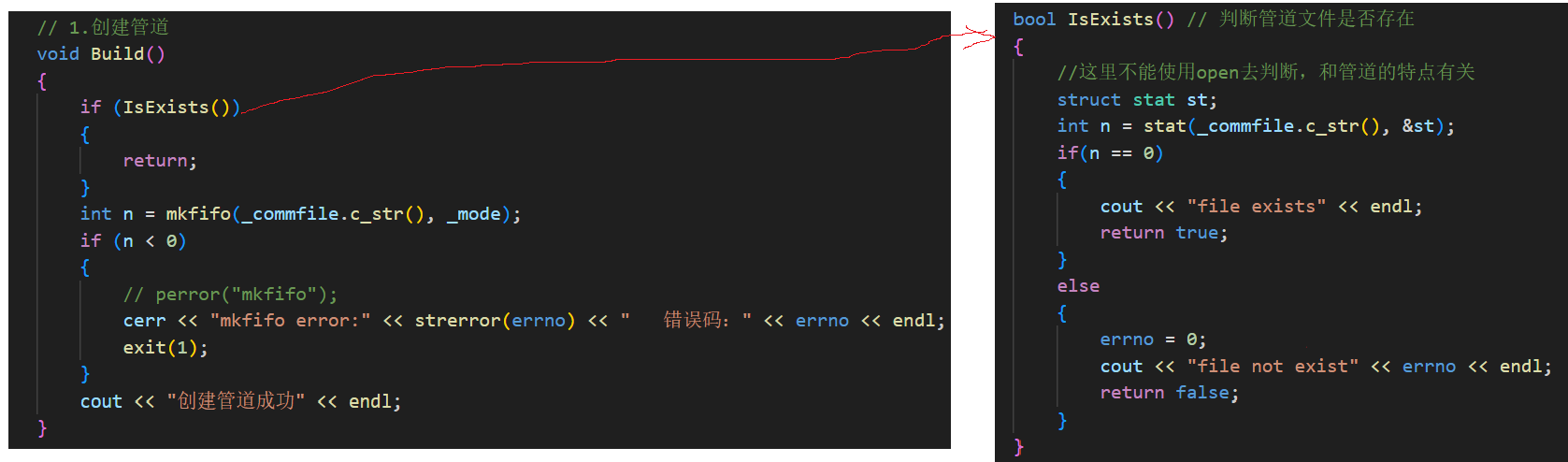
IsExists() 用 stat 系统调用来检查,没有直接用 open,因为命名管道用 open 打开时会阻塞,因为当你用 open 打开命名管道时,如果另一端还没有进程打开,open 会卡住不动,一直等,直到另一端也打开,才会继续往下执行,所以不适合用来做存在性判断。
这里的 stat 系统调用是 Linux 下非常重要的系统调用,作用是:不打开文件,直接获取文件的元信息(属性),比如文件大小、类型、权限、创建时间、修改时间等等。
#include <sys/stat.h>
#include <sys/types.h>
#include <unistd.h>
int stat(const char *pathname, struct stat *statbuf);如果获取成功:返回 0。如果获取失败:返回 -1。这也可以让 stat 系统调用实现一个非常重要的功能:查看文件是否存在。
所以此时,如果 stat 返回 0,说明管道文件已经在那儿了,就直接返回;否则就调用 mkfifo 创建,权限用的就是构造时给的 0666,创建失败直接退出。这样一来,Build() 可以安全地重复调用,不会因为管道已存在而出错。
要注意的是这里IsExists函数内部的else语句分支里面,有一个非常重要的 errno = 0 的语句,之所以这么干,是因为 errno 是一个个全局变量,它不会自己重置。stat 在检查文件不存在时,虽然返回 -1 表示出错,但它同时会把 errno 设置为 ENOENT(通常值为 2)。如果放着不管,这个 errno 的值就会一直留在那里,成为过时的错误信息。
这个类的其他部分(比如 Build 里 mkfifo 失败后)会依赖 errno 去打印错误原因。如果不清理,万一后续某个操作成功了但没修改 errno,或者调试时看到了这个残留的 errno,就会误以为刚刚发生了错误,造成逻辑干扰。显式清 0 就是在告诉程序:我知道文件不存在,这不是异常,别把这次的“错误”记在账上。
然后是打开管道 Open(int mode)。这里根据传入的模式,决定是以只读(For_Read 对应 O_RDONLY)还是只写(For_Write 对应 O_WRONLY)方式打开管道文件,然后把拿到的文件描述符存到 _fd 里。如果打开失败,打印错误信息并退出。这个设计意味着一个 FIFO 对象只能以一种模式打开,要么读要么写,符合管道半双工的特点。
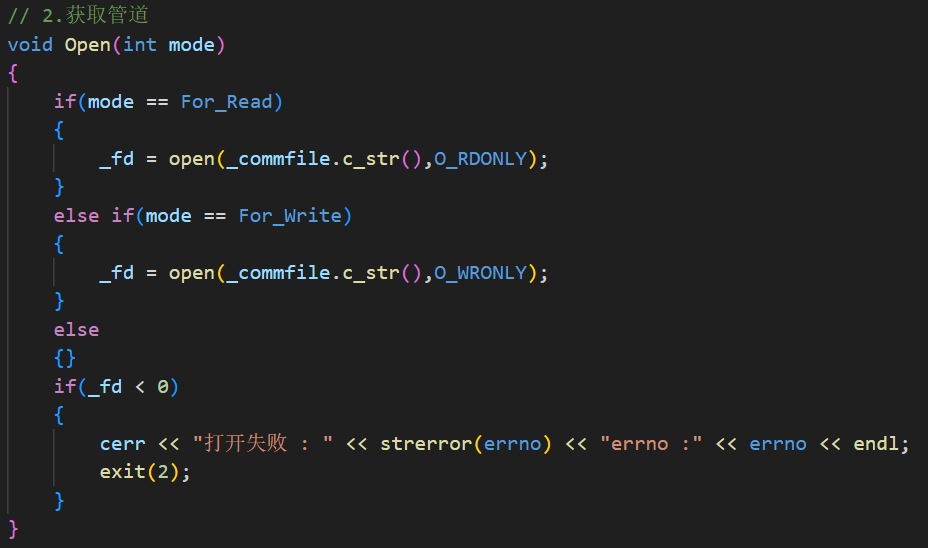
根据收发信息的部分,Send 和 Receive 分别对应 write 和 read。Send 接收一个 string 引用,直接把字符串的 c_str() 和数据长度 size() 写进 _fd,没有处理返回值(用 (void)n 忽略了),这是简明写法,避免VScode因为没有使用这个 n 而去做未使用的告警。
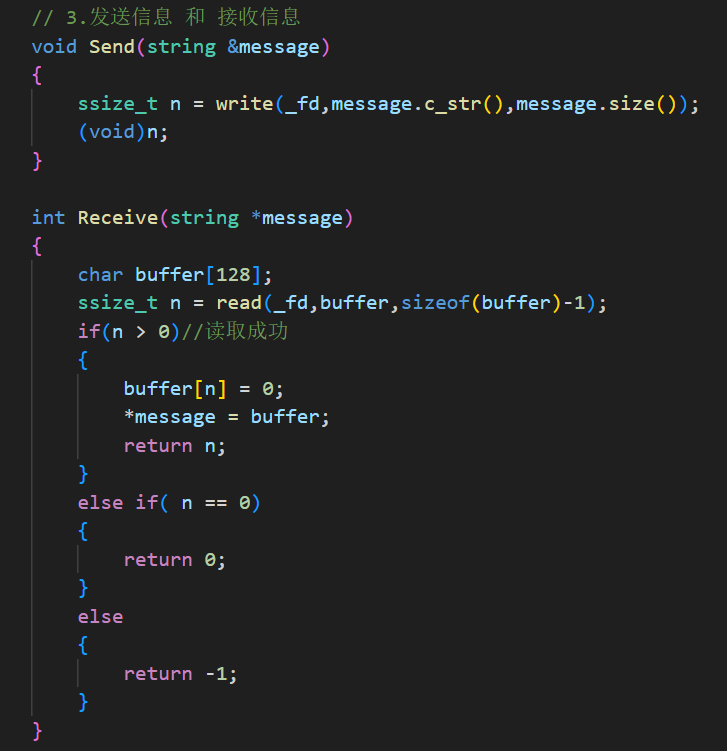
Receive 中先定义一个 128 字节的临时缓冲区,read 的时候故意留出一个字节,读取成功后手动在末尾补 \0,然后把缓冲区内容赋给传进来的 string 指针,同时返回实际读到的字节数。这里返回值的语义做了区分:读成功返回正数,对端关闭时 read 返回 0 它也返回 0,出错返回 -1,便于外部判断状态。
最后是 Delete(),调用的就是 unlink 删除命名管道文件。同样先检查是否存在,存在才删,不会盲目操作。
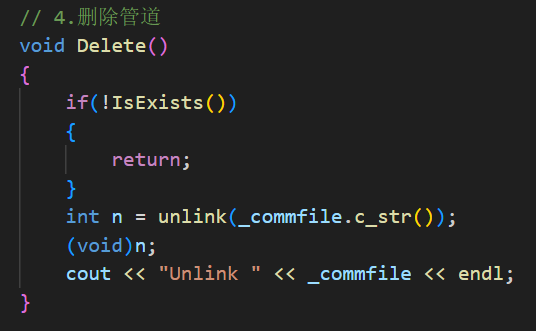
这里的 unlink 系统调用是 Linux 系统调用,作用是删除文件(包括命名管道文件),功能和命令行的 rm 几乎一样。
#include <unistd.h>
int unlink(const char *pathname);它的作用是删除文件系统中的文件(普通文件、命名管道文件都可以删),本质是将文件的硬链接计数减 1,当计数变为 0 时,文件真正被删除。
最后是服务端和客户端的代码展示:
最后我们来看看测试效果:

最终我们实现了客户端通过管道向服务端写入信息的场景。
本文到此结束,感谢各位读者的阅读,如果有讲解的不到位或者错误的地方,欢迎各位读者的批评和指正。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)