超节点文章2:从 Scale-Out 到 Scale-Up:大模型训练为什么需要新的算力组织方式?
摘要: 超节点技术通过融合Scale-Up(纵向扩展)和Scale-Out(横向扩展)解决大模型训练的通信瓶颈。传统数据中心依赖Scale-Out堆叠服务器,但大模型训练需要高频协同计算,跨节点通信时延和带宽成为瓶颈。超节点通过构建高带宽域(HBD),将更多加速芯片紧密互联,减少跨服务器通信开销,同时保留Scale-Out的集群扩展能力。行业趋势显示,超节点正推动协议融合与拓扑创新(如CLOS、D

目录
本文基于以下三份报告进行汇总、解释和二次整理:
- 华为《超节点发展报告
- 中兴《超节点技术白皮书
- H3C《超节点技术白皮书》
上一篇文章里,我们把 超节点 理解为一种新的 AI 算力组织方式:它不是简单把更多 GPU/NPU 堆在一起,而是通过高速互联、统一内存编址、资源池化和软硬件协同,让更多加速芯片像一个整体一样协同工作。
这篇文章继续往下拆:为什么传统数据中心常用的横向扩展方式,也就是 Scale-Out,在大模型训练里开始显得不够用了?为什么行业会越来越重视 Scale-Up?以及,超节点到底是在重新划分什么边界?
一、传统数据中心为什么偏向 Scale-Out
在很长一段时间里,数据中心的主流扩展方式都是横向扩展。
一台服务器不够,就加更多服务器;一个机柜不够,就加更多机柜;一个集群不够,就继续扩大集群规模。
这种方式的好处很明显:
- 架构通用,适合大多数互联网和云计算业务。
- 服务器可以标准化采购、部署和替换。
- 扩容方式直接,容量不够就增加节点。
- 故障隔离相对清楚,单台服务器坏了可以从集群里摘掉。
这就是 Scale-Out 的基本逻辑。
对于 Web 服务、微服务、离线批处理、通用存储、传统大数据平台来说,这套逻辑非常有效。因为很多任务本身就是松耦合的,节点之间不需要每一步都高速同步。
但大模型训练不一样。
大模型训练不是把很多独立任务分给很多机器这么简单。一个模型往往会被切成很多份,分布在多张卡、多台服务器上同时计算。每一步训练中,各个计算单元都可能需要交换参数、梯度、激活值或者专家路由结果。
也就是说,大模型训练对集群的要求不是“能不能横向堆大”,而是“堆大之后还能不能高效协同”。
二、大模型训练为什么让通信变成核心问题
要理解这个变化,先看大模型训练里常见的几类并行方式。
| 并行方式 | 主要作用 | 对通信的影响 |
|---|---|---|
| 数据并行 | 多份模型处理不同数据,再同步梯度 | 需要梯度同步,常见 All-Reduce |
| 张量并行 | 把单层矩阵计算切到多张卡上 | 通信频繁,对时延和带宽敏感 |
| 流水线并行 | 把模型不同层放到不同设备上 | 需要跨阶段传递激活值 |
| 专家并行 | MoE 模型中把不同专家放到不同设备上 | 会产生大量 All-to-All |
| 序列并行 | 按序列维度拆分长上下文计算 | 长上下文下通信压力上升 |
其中,张量并行 和 专家并行 特别容易触发通信瓶颈。
张量并行要求多张卡一起完成一个层内计算。它不是训练结束后同步一次,而是在模型前向、反向过程中反复通信。
专家并行常见于 MoE 模型。每个 token 会被路由到不同专家,专家分布在不同设备上,就会产生大量分发和聚合通信。专家越多,并发越高,通信越重。
华为《超节点发展报告》提到
随着模型参数和集群规模继续扩大,传统服务器集群会面对通信墙、功耗散热墙和复杂度墙。通信墙是最直接的一堵墙:集群中卡越多,通信路径越复杂,等待同步的时间就越容易吞掉算力收益。
H3C《超节点技术白皮书》也提到
传统“1 机 8 卡”架构中,机内互联和机间互联存在明显断层。机内 GPU 可以通过高速互联通信,但跨服务器后往往依赖 RDMA 网络。集群规模越大,多级交换、拥塞和长尾时延越难忽略。
所以,大模型训练并不是简单的“卡越多越快”。如果通信跟不上,更多卡只会带来更多等待。
三、Scale-Out 的边界在哪里
Scale-Out 的问题不是不能扩展,而是扩展到大模型训练场景后,效率会受到通信和调度的限制。
可以从三个角度理解。
第一,通信路径变长。
单机内部通信路径短,带宽高,时延低。跨服务器后,数据要经过网卡、交换机、协议栈和多级网络。大规模集群里,一次同步可能跨越多个网络层级。
第二,通信模式更复杂。
传统云计算业务里,很多节点之间是请求-响应式通信,或者批处理式数据交换。大模型训练里的集合通信更密集,All-Reduce、All-to-All、Broadcast、Reduce-Scatter 都会频繁出现。
第三,故障和抖动更容易放大。
当任务分布在成千上万张卡上,一条链路抖动、一个光模块异常、一台交换机拥塞,都可能影响整个训练任务的步长。长周期训练里,这些小概率事件会变成常态。
这也是为什么华为报告会强调 RAS 和自动化运维。到了万级处理器规模,系统能力不只是性能问题,也是稳定性问题。
四、Scale-Up 的本质是什么
如果说 Scale-Out 是“向外扩”,那么 Scale-Up 就是“向内聚”。
它的目标不是把更多服务器松散连起来,而是把更多加速芯片组织进一个更紧密的高性能计算单元里。
在超节点语境下,Scale-Up 的核心目标包括:
- 扩大高带宽通信范围。
- 降低高频通信路径长度。
- 减少跨服务器通信带来的协议和转发开销。
- 支持更直接的内存访问方式。
- 让更多 GPU/NPU 在逻辑上表现得更像一个整体。
中兴《超节点技术白皮书》把超节点定义为通过高速互联协议和专用交换芯片构建的高带宽域,也就是 HBD。这个定义很关键,因为它点出了超节点的核心不是“机柜外观”,而是“高带宽域”。
换句话说,超节点首先要回答的问题是:哪些计算单元应该被放进同一个高速协同域里?
对于大模型来说,答案通常是:那些需要频繁交换数据、对通信极其敏感的计算单元。
例如:
- 张量并行域尽量放在高带宽域里。
- 专家并行通信尽量减少跨慢速网络。
- KV Cache 传输尽量走更短路径。
- 对延迟敏感的推理阶段尽量靠近高带宽内存和互联。
这就是 Scale-Up 的价值。
它不是取代所有网络,而是把最敏感、最频繁、最影响效率的通信,放进更快的域里。
五、HBD 高带宽域:超节点里的关键边界
HBD 是 High-Bandwidth Domain,也就是高带宽域。
在普通集群里,我们常把服务器作为基本计算边界。一台服务器内部是一组高速互联的 GPU,服务器之间通过网络互联。
超节点则试图把这个边界扩大。
原来“高速互联”的范围可能只在单机内部,现在希望扩展到整机柜,甚至跨机柜。这样,更多 GPU/NPU 可以处在同一个高带宽、低时延通信域里。
中兴报告中提到,超节点内任意 GPU 间的互联带宽原则上应明显高于机间互联,有助于降低通信开销、提高 MFU。这个判断背后的逻辑很直接:如果并行计算的核心通信都落在低速网络上,算力利用率就很难上去。
H3C 报告在部署实践中也把网络分成三类:
| 网络类型 | 作用 | 典型承载流量 |
|---|---|---|
| Scale-Up 网络 | 构建超节点内部高带宽域 | 张量并行、专家并行 |
| Scale-Out 网络 | 跨 HBD 域扩展集群 | 数据并行、流水线并行、全局梯度同步 |
| Frontend 网络 | 业务、管理和存储访问 | 数据加载、Checkpoint、控制面 |
这个划分非常适合理解超节点:不是所有流量都需要走同一种网络,不同类型的通信需要不同的基础设施承载。
下面这张图展示了超节点架构中 Scale-Up 和 Scale-Out 融合设计的思路。
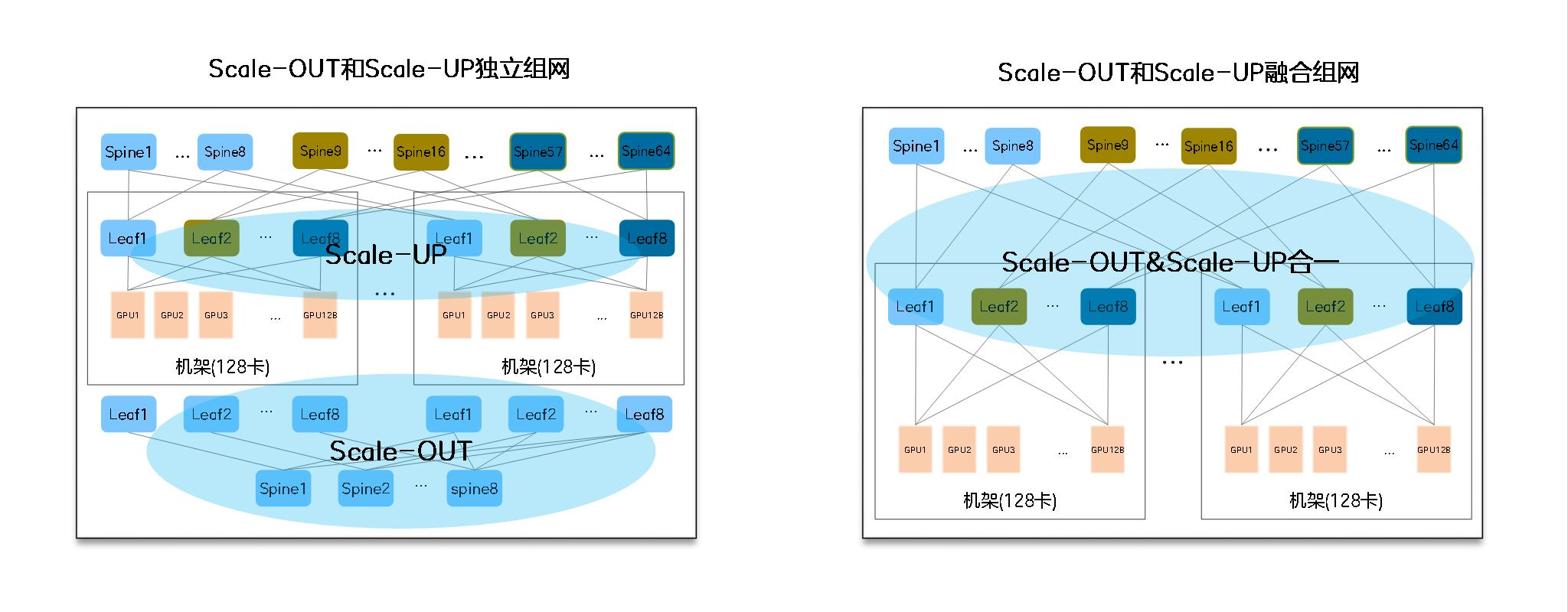
图源:中兴《超节点技术白皮书》第 25 页,图 2-3。
六、Scale-Up 和 Scale-Out 不是二选一
很多人第一次接触超节点,容易误以为 Scale-Up 会取代 Scale-Out。
其实不是。
这两者解决的是不同层次的问题。
Scale-Up 负责把一个算力单元内部做得更紧、更快、更像一个整体。它适合承载张量并行、专家并行、细粒度同步、远端内存访问等强耦合通信。
Scale-Out 负责把多个算力单元继续扩展成更大集群。它适合承载数据并行、流水线并行、跨超节点同步、存储访问和更大规模调度。
用一个不太严谨但好理解的类比:
- Scale-Up 像是在一个房间里安排高频协作团队,大家面对面沟通。
- Scale-Out 像是把多个团队、多个楼层、多个园区连成组织体系。
大模型训练需要两者同时存在。
如果只有 Scale-Out,通信路径太长,高频协作效率低。
如果只有 Scale-Up,单个高带宽域也有物理、功耗、散热、成本上限。
所以更现实的方向是:在一个合理大小的高带宽域内做 Scale-Up,再通过 Scale-Out 把多个高带宽域组织成更大集群。
七、为什么两者会走向融合
中兴报告提出一个重要趋势:在 Matrix 集群超节点中,Scale-Up 和 Scale-Out 的边界会逐渐模糊。
原因很简单:模型越来越大,高频通信的范围也可能超过单机柜。
当张量并行、专家并行需要跨越多个单体超节点时,如果仍然把 Scale-Up 和 Scale-Out 完全分成两套网络,系统会面临几个问题:
- 网络重复建设,成本上升。
- 数据跨域时需要协议转换,增加复杂度。
- 资源调度需要同时理解两套网络,运维难度变大。
- 模型并行策略受到物理边界限制。
因此,行业开始探索 Scale-Up/Scale-Out 融合网络。
H3C 报告在未来趋势中也提到,协议融合正在成为超节点技术创新方向。例如一些协议尝试复用以太网生态,把 Scale-Up 事务封装到更通用的网络基础设施之上,以降低部署成本和迁移成本。
这并不意味着所有网络都会完全统一,而是意味着超节点的内部高速互联和外部集群互联会越来越协同。
八、不同拓扑背后的取舍
当我们谈 Scale-Up 和 Scale-Out 时,背后一定会涉及拓扑。
常见拓扑包括:
- CLOS
- Fat-Tree
- 3D Torus
- DragonFly
- Mesh
- 厂商自研拓扑
这些拓扑没有绝对好坏,核心是取舍。
例如,CLOS/Fat-Tree 更强调无阻塞或低收敛比,适合大规模数据中心网络,但交换层级和光模块数量可能带来成本压力。
3D Torus 可以减少部分全局互联成本,但对通信模式和业务调度更挑剔。
DragonFly 通过组内高带宽和组间连接降低全局链路数量,但也需要更复杂的路由和拥塞控制。
H3C 报告中整理了多种典型拓扑,包括 GB200 NVL576、Google TPU v4、DragonFly、Huawei UB-Mesh 等。这些图的共同价值在于说明一件事:超节点不是单一标准答案,而是一组围绕带宽、时延、成本、可靠性、部署复杂度做出的系统设计选择。
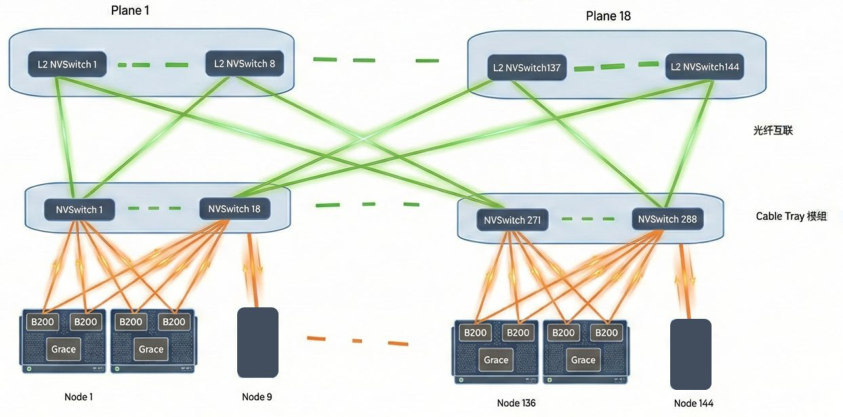
图源:H3C《超节点技术白皮书》第 44 页,图 19, GB200 NVL576 组网拓扑示意图。
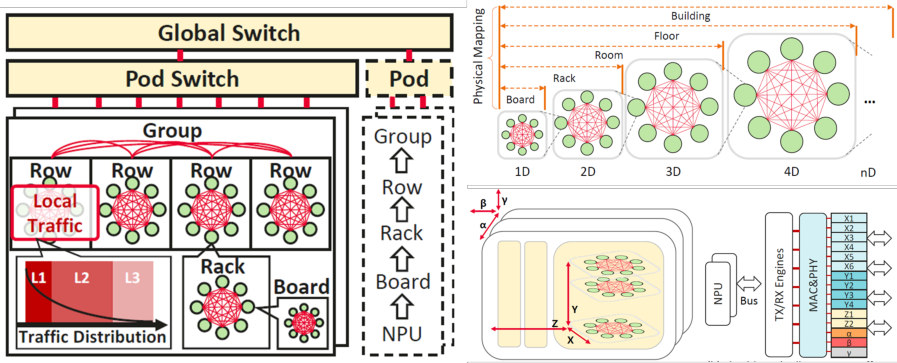
图源:H3C《超节点技术白皮书》第 49 页,图 26, Huawei UB-Mesh 架构组网拓扑示意图。
九、超节点是在重新定义“节点”
传统数据中心里,“节点”通常指一台服务器。
但在 AI 基础设施里,这个边界正在变化。
如果一个大模型的高频通信已经跨出了单台服务器,而系统又希望这些通信仍然保持接近本地互联的效率,那么“节点”的边界就不能再简单停留在服务器级。
超节点的出现,本质上就是把“节点”从服务器级扩大到机柜级,甚至更大的高带宽域级。
这也是为什么华为报告会说,超节点将成为 AI 时代的核心计算单元。
这里的“核心计算单元”不是指它一定替代所有服务器,而是指在大模型训练和推理中,系统调度、资源组织、故障管理和性能优化的基本边界正在从单台服务器上移。
以前我们问:这个任务需要多少台服务器?
现在更应该问:这个任务需要多大的高带宽域?需要多少个超节点?超节点之间如何连接?
这个问题的变化,就是 AI 基础设施范式变化的核心。
十、总结
从 Scale-Out 到 Scale-Up,不是一句架构口号,而是大模型训练把基础设施逼到新阶段之后的自然结果。
传统 Scale-Out 擅长把系统做大,但大模型训练要求的不只是规模,还有通信效率、内存访问效率、资源调度效率和长周期稳定性。
Scale-Up 的价值在于:把高频、强耦合、低时延敏感的通信,尽可能放进高带宽域里,让更多 GPU/NPU 像一个整体一样协同。
但 Scale-Up 也不是万能的。它有功耗、散热、成本和物理扩展上限。因此,未来更现实的方向不是二选一,而是:
- 用 Scale-Up 构建高带宽域。
- 用 Scale-Out 连接多个高带宽域。
- 在更大规模上探索两者融合。
超节点正是在这个方向上出现的。
它不是传统 GPU 集群的简单放大,而是 AI 时代对“节点”“网络”和“算力边界”的重新定义。
下一篇文章,我们会继续深入超节点内部,拆解它背后的核心技术:高速互联、统一内存编址、Load/Store 语义,以及在网计算。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)