一次奇怪的性能抖动,让我彻底理解 DPDK 中的 NUMA
在 DPDK 开发中,程序吞吐稳定但周期性出现性能抖动,是一个较难定位的问题。本文通过真实案例分析,排查过程中发现问题根源并非代码逻辑,而是双路服务器下的 NUMA 架构导致的跨节点内存访问。文章结合实际工程场景,介绍 NUMA、hugepage、rte_mbuf、DPDK Mempool 和 DPDK Ring 的节点绑定关系,说明在高性能数据面程序中,CPU 核心、网卡和内存布局对性能的关键影
在我最开始做DPDK开发时,我曾遇到一个非常诡异的问题:
程序运行正常,吞吐也不错,但每隔几秒钟就会出现一次明显性能下降:
- PPS 突然掉一半
- 时延明显增加
- 几百毫秒后又恢复正常
这种现象不是持续性的,而是周期性抖动。
更奇怪的是:
- CPU 没打满
- 网卡无丢包
- 代码没有锁竞争
- 流量模型也很稳定
最后定位下来,问题根源只有两个字:NUMA
而理解这个问题的过程,也让我真正理解了 DPDK 高性能架构中最容易被忽视的一层。
一、问题现场
测试环境:服务器配置
双路 Xeon
2 个 CPU socket
64 核
双口 25G 网卡程序架构:
- 4 个 RX 核
- 4 个 worker 核
- 2 个 TX 核
理论上非常正常。
实际现象:压测时:平均 12 Mpps
但每隔几秒:掉到6 Mpps
持续约:300~500 ms 然后恢复。
这种抖动在网络设备里很危险。
二、第一反应:是不是代码有锁?
很多人遇到性能抖动,第一反应是:某处锁竞争。
检查:
- spinlock
- rte_ring
- stats
- timer
结果:没有明显问题。
三、第二反应:是不是 cache miss
继续 perf 分析:
发现:偶尔会出现大量:
LLC miss
remote access这里开始有线索。
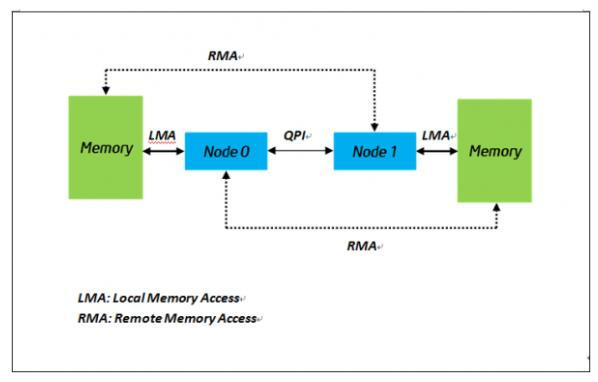
四、NUMA 是什么
NUMA 全称:Non-Uniform Memory Access
即:非一致性内存访问架构。
在双路服务器中:每颗 CPU 都有自己的本地内存控制器。
结构类似:
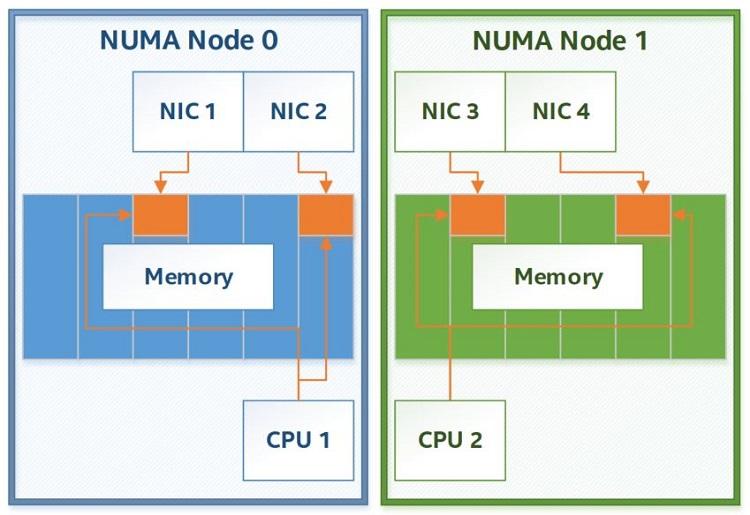
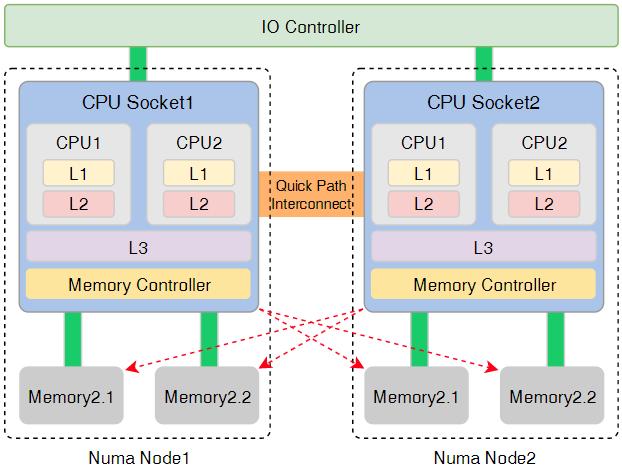
socket0 ---> local memory0
socket1 ---> local memory1每颗 CPU 访问自己的内存更快。访问另一颗 CPU 的内存更慢。
五、为什么会影响 DPDK
DPDK 大量依赖:
- hugepage
- mempool
- mbuf
这些对象都在内存中。
如果:网卡在 socket0,但 worker 跑在 socket1,
就会出现:
NIC -> socket0 memory -> socket1 CPU跨 NUMA 访问。
六、为什么会“抖动”,不是一直慢?
这是最迷惑人的地方。
原因在于:缓存掩盖了问题。
正常阶段
当热点数据仍在 cache 中:访问快。
某个时刻
cache line 被淘汰:CPU 需要重新访问远端内存。
于是:延迟突增,表现为抖动。
七、如何确认 NUMA 问题
先查看网卡在哪个 NUMA 节点。
命令:
cat /sys/class/net/eth0/device/numa_node输出:
0说明网卡在:socket0。
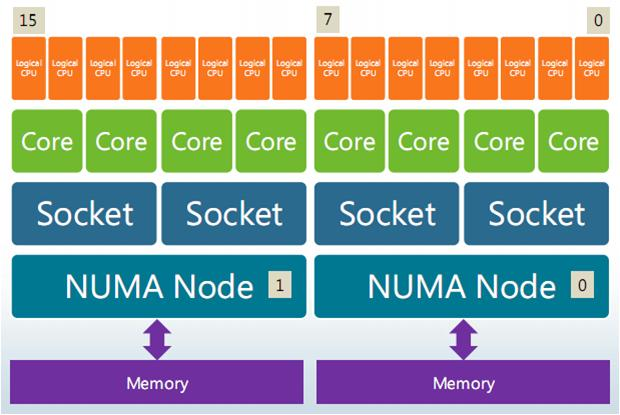
再看线程绑核:
lscpu -e发现:
worker 被绑在:
socket1问题找到了。
八、一个关键知识:hugepage 也有 NUMA 属性
很多人只知道 hugepage。
但忽略了:hugepage 是分 NUMA 节点的。
例如:
cat /sys/devices/system/node/node0/hugepages/...
cat /sys/devices/system/node/node1/hugepages/...每个 node 独立。
如果分配不当:即使线程在本地,内存也可能在远端。
九、mempool 为什么更敏感
每个包对应一个:rte_mbuf
来自:DPDK Mempool
如果 mempool 在远端:每个收包都跨节点。代价非常高。
十、真实错误配置
当时代码:
mbuf_pool = rte_pktmbuf_pool_create(...);没有指定 socket:
默认:
SOCKET_ID_ANY于是:可能分配在错误节点。
十一、正确做法
应该:
rte_socket_id()或者明确:
socket_id = rte_lcore_to_socket_id(lcore_id);然后:
rte_pktmbuf_pool_create(..., socket_id);保证本地分配。
十二、另一个隐藏坑:ring 也有 NUMA
不仅 mbuf。
连:DPDK Ring 也有 NUMA 属性。
创建时:
rte_ring_create(...)如果 socket 配错:跨核通信同样变慢。
十三、优化后结果
调整:
1. 网卡对应核绑定
全部绑到:socket0。
2. mempool 本地分配
按 lcore 创建。
3. ring 本地创建
同 socket。
优化后:
性能
从:12 Mpps 波动 变成:16 Mpps 稳定
并且:抖动消失。
十四、为什么 NUMA 在 DPDK 中格外重要
因为 DPDK 是:内存带宽型程序
大量操作:
- mbuf
- descriptor
- ring
- flow table
一旦远端访问:代价会被放大。
十五、如何避免 NUMA 问题
工程建议非常明确。
1. 网卡和核心同节点
必须。
2. hugepage 按节点预留
例如:
echo 1024 > node0/hugepages/...3. per-socket mempool
推荐。
4. per-socket ring
推荐。
5. 不跨 socket 传递热点对象
尤其:mbuf。
十六、一个经验法则
如果是双路服务器:
最佳实践:socket0 处理 port0。socket1 处理 port1。
不要跨节点。
即:
port0 -> socket0
port1 -> socket1最优。
十七、总结
这次问题看似只是:周期性性能抖动
但本质暴露了高性能系统最重要的一点:内存位置比代码本身更重要。
通过这个问题,我们理解了 DPDK 中几个非常关键的概念:
包括
- NUMA
- hugepage
- mempool
- mbuf
- ring
- remote memory access
很多时候,性能瓶颈并不是算法。
而是:数据放错了地方。
这也是高性能数据面开发和普通应用开发最大的区别之一。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)