超节点技术深度篇一:超节点的 Scale-Up 互联到底解决了什么?从 HBD、拓扑到带宽墙

目录
本文基于以下三份报告进行汇总、解释和二次整理:
- 华为《超节点发展报告
- 中兴《超节点技术白皮书
- H3C《超节点技术白皮书》
本文你会看懂什么
- 为什么传统
Scale-Out集群可以扩规模,但不适合承载所有高频训练通信。 HBD高带宽域到底是什么,以及它和超节点、Scale-Up 互联之间的关系。- 评估一个超节点互联方案时,为什么不能只看卡数和总带宽,还要看拓扑、时延、收敛比和软件感知。
前面 6 篇综述版文章里,我们已经讲过超节点是什么、为什么 AI 时代需要它,以及三家报告的不同侧重点。
从这篇开始,我们进入技术深度版。
这一篇讨论一个问题:超节点里的 Scale-Up 互联到底解决了什么?
很多人第一次听到超节点,会自然把它理解成“更多 GPU/NPU 放在一起”。这个理解不算错,但还不够技术化。真正要理解超节点,必须先理解一个现象:大模型训练和推理里,并不是所有通信都适合走传统横向扩展网络。
传统 Scale-Out 集群擅长把更多服务器连起来,扩展规模。但当某些通信变得极其高频、低时延敏感、强同步时,跨服务器网络就会成为瓶颈。
超节点的 Scale-Up 互联,本质上是在重新划分 AI 集群里的通信边界:把最敏感、最频繁、最影响训练效率的通信,尽量放进一个更高带宽、更低时延、更紧耦合的高带宽域里。
中兴报告把这个域称为 HBD,也就是 High-Bandwidth Domain。
一、先从单机 8 卡的边界说起
传统 AI 服务器最常见的形态之一,是单机多卡。例如一台服务器里放 8 张 GPU/NPU,服务器内部通过 PCIe、NVLink 或其他专用互联连接,服务器之间再通过 RoCE、InfiniBand 或以太网集群互联。
这个架构有一个隐含边界:机内通信和机间通信不是一个量级。
机内互联通常带宽更高、时延更低、路径更短;机间通信虽然也可以通过 RDMA、RoCE、IB 等技术优化,但毕竟要经过网卡、交换机、网络协议栈、拓扑路径和拥塞控制。
对很多通用分布式任务来说,这个差异可以接受。因为任务之间通信不那么频繁,或者通信可以异步、批量、延迟处理。
但大模型训练不同。
张量并行、专家并行、序列并行、上下文并行,会让多卡之间在每个 step、甚至每一层里不断交换中间结果。通信不是偶尔发生,而是训练过程的一部分。
华为报告在通信范式演变部分强调
AI 基础设施正在从传统节点架构向超节点架构演进。背后的核心逻辑,就是单台服务器的计算边界已经无法承载更大模型和更复杂并行策略。
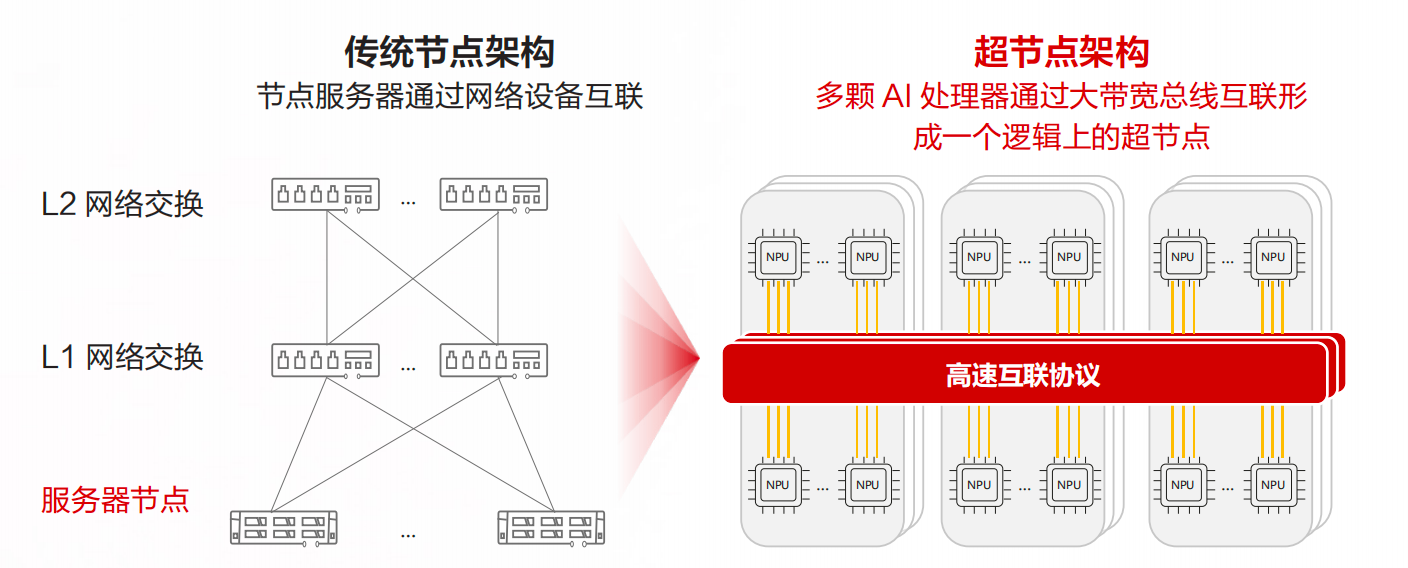
图源:华为《超节点发展报告》第 13 页,图 3.1。
这张图适合理解一个关键变化:过去我们习惯把服务器看作基本计算单元,服务器之间通过网络组成集群;而超节点试图把计算单元放大到机柜级、整柜级甚至更大的紧耦合系统。
这个变化不是为了“看起来更大”,而是为了缓解机内和机间之间的带宽断层。
H3C 报告也明确指出,传统“1 机 8 卡”架构存在机内 TB 级互联与机间 Gbps 级网络之间的带宽断层。这个断层一旦被高频通信打穿,训练效率就会明显下降。
二、Scale-Out 为什么不够用
Scale-Out 的思路很自然:一台服务器不够,就加更多服务器;一个机柜不够,就加更多机柜;一个集群不够,就继续扩展网络规模。
这套方式在云计算、存储、大数据和很多分布式系统里都非常成功。
但大模型训练会暴露 Scale-Out 的一个弱点:它擅长扩规模,但不一定擅长处理强耦合通信。
可以把训练通信分成两类。
| 通信类型 | 特征 | 对网络的要求 | 更适合的位置 |
|---|---|---|---|
| 松耦合通信 | 频率较低、可以批量、对时延不极端敏感 | 吞吐和稳定性更重要 | Scale-Out 网络 |
| 强耦合通信 | 高频、同步、每步都发生、等待会阻塞计算 | 高带宽、低时延、低抖动 | Scale-Up 高带宽域 |
问题在于,大模型中的一些并行模式天然属于强耦合通信。
例如 TP,也就是张量并行。模型某一层的矩阵计算被切到多张卡上,计算过程中需要频繁交换中间结果。如果这类通信跨越普通机间网络,等待时间就会直接进入每一层的关键路径。
再例如 EP,也就是专家并行。MoE 模型中 token 被路由到不同专家,专家可能分布在不同加速卡上,这会产生大量 All-to-All、Dispatch 和 Combine 流量。如果专家分发跨越较慢网络,就会拖慢整个 step。
所以 Scale-Out 不是没用,而是不能把所有通信都交给 Scale-Out。
更合理的做法是分层:
Scale-Up负责高频、低时延、强耦合通信。Scale-Out负责跨超节点、跨机柜、跨集群的大规模扩展。Frontend或管理网络负责存储、管理、业务访问等流量。
中兴报告在 Scale-Up 和 Scale-Out 融合部分,正是从这个角度解释超节点集群的网络分工。
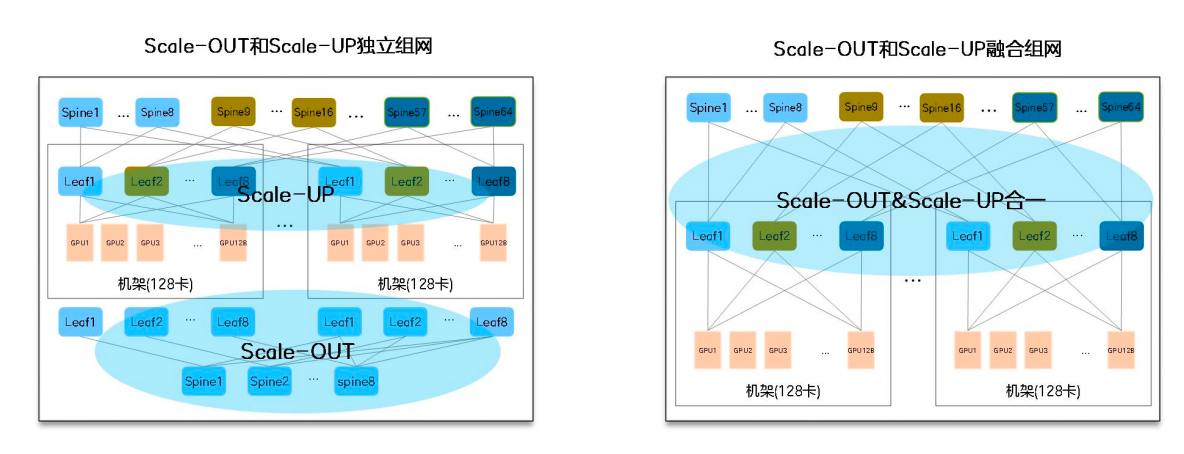
图源:中兴《超节点技术白皮书》第 24 页,图 2-3。
这张图的重点不是“哪张网更高级”,而是说明不同网络层承载不同通信流量。对 AI 集群来说,流量分类比单纯堆带宽更重要。
三、HBD 高带宽域到底是什么
中兴报告把超节点定义为由高速互联协议和专用交换芯片构建的 HBD 高带宽域。
这个定义非常关键。
如果只说“超节点是很多 GPU/NPU 互联”,很容易停留在硬件数量上。但 HBD 这个词把重点拉回到通信域:哪些设备之间处在一个高带宽、低时延、统一语义的协同范围内?
可以把 HBD 理解成 AI 集群里的“高频通信保护区”。
在这个域内,系统希望做到:
- 单卡到其他卡的可用带宽更高。
- P2P 时延更低。
- 集合通信跳数更少。
- 高频通信尽量不跨越普通机间网络。
- 拓扑更可控,拥塞更可预测。
- 软件栈能够感知域内拓扑并做并行策略映射。
中兴报告提到,超节点内 GPU 间互联需要数百 GB/s 到 TB/s 级带宽能力,用于承载 TP、EP 等并行计算流量。报告还指出,PCIe 5.0 x16 双向带宽约 128GB/s,难以满足超节点对 TB 级带宽的需求;以太网 SerDes 技术迭代更快,112Gbps 已成为主流,224Gbps 也已经进入商用阶段。
这些数字说明一个问题:HBD 不是简单把几台服务器插到更快交换机上,而是需要从物理链路、交换芯片、拓扑、协议和软件栈一起设计。
四、OEX 互联:为什么物理结构也重要
很多网络文章会重点讲协议,但超节点里物理结构同样重要。
高带宽互联不是抽象的“带宽数字”。它要落到真实的高速信号链路上,包括连接器、背板、线缆、SerDes、交换芯片和板级布局。
中兴报告提出 OEX 正交无背板互联架构,关注点正是减少信号路径、提升连接密度和可维护性。
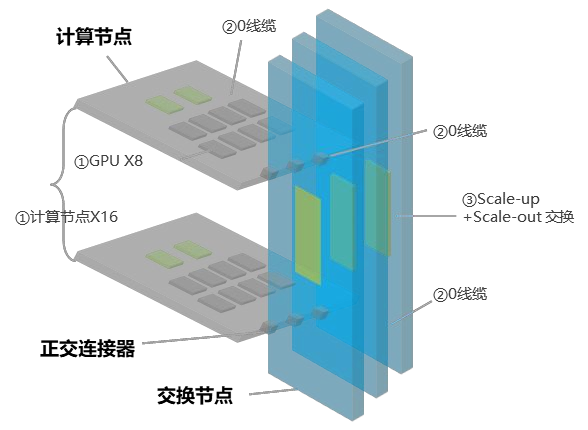
图源:中兴《超节点技术白皮书》第 14 页,图 2-1。
从工程角度看,OEX 这类设计想解决几个问题。
第一,缩短信号链路。
高速 SerDes 对链路长度、插损、串扰非常敏感。链路越长、连接点越多,信号完整性越难保证。
第二,减少线缆复杂度。
传统 Cable Tray 方案在高密度互联下会带来大量线缆,布线、维护、风道和可靠性都会变复杂。
第三,提升互联密度。
超节点需要在有限机柜空间里连接更多 GPU/NPU 和交换模块,物理结构必须服务于拓扑。
第四,提升可维护性。
高密度系统一旦出问题,能不能快速定位和替换模块,会直接影响运维效率。
所以,Scale-Up 互联不是纯软件问题,也不是纯网络协议问题。它从一开始就是硬件结构、信号链路和系统工程问题。
五、看 Scale-Up 互联,不能只看“总带宽”
很多方案喜欢宣传总带宽,比如某个超节点内部互联总带宽达到多少 TB/s。
总带宽当然重要,但它不是唯一指标。真正评估 Scale-Up 互联,至少要看下面这些维度。
| 指标 | 要问的问题 | 为什么重要 |
|---|---|---|
| 单卡可用带宽 | 每张 GPU/NPU 实际能用多少带宽 | 决定单卡通信瓶颈 |
| P2P 时延 | 两张卡之间点对点访问延迟是多少 | 影响小包和同步通信 |
| 双向带宽 | 是否能同时高效收发 | 影响 All-to-All 和集合通信 |
| 拓扑跳数 | 任意两卡通信需要经过几跳 | 跳数越多,时延和拥塞风险越高 |
| 收敛比 | 下行带宽和上行带宽是否收敛 | 收敛会影响满负载通信 |
| 阻塞特性 | 多通信流同时发生时是否互相争抢 | 影响训练尾时延 |
| 故障域 | 单个链路或交换模块故障影响多大 | 影响可用性和恢复 |
| 软件可见性 | 调度器和通信库是否知道真实拓扑 | 决定硬件能力能否被用起来 |
这里面最容易被忽略的是拓扑和软件可见性。
同样是高总带宽,如果拓扑设计不合理,高频通信可能仍然撞到热点路径。反过来,如果软件栈不知道哪些卡之间通信更快,也可能把张量并行或专家并行放到不合适的设备组合上。
所以,HBD 不是“带宽越大越好”的简单问题,而是高带宽、低时延、拓扑可控和软件协同的组合问题。
六、典型拓扑:CLOS、NVL576、DragonFly、UB-Mesh
H3C 报告对多种 Scale-Up/Scale-Out 相关拓扑做了梳理。这里不展开每一种协议细节,只解释它们为什么重要。
拓扑决定了设备之间怎么连接,也决定了通信的路径长度、带宽分布、容错能力和扩展方式。
下面这张图展示了 UBB 互联拓扑示意。
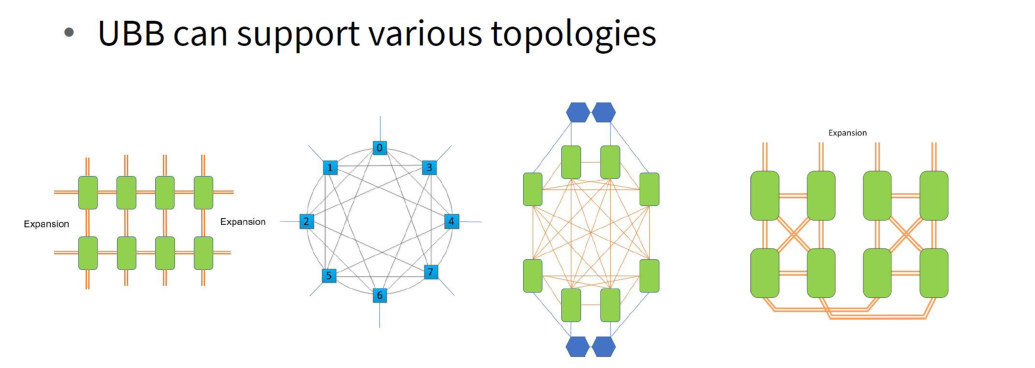
图源:H3C《超节点技术白皮书》第 31 页,图 12。
在超节点里,拓扑不是画给人看的结构图,而是会直接影响并行策略。
例如张量并行组最好放在互联更紧密、时延更低的设备之间;专家并行组则需要考虑 All-to-All 流量和专家负载;流水线并行要考虑阶段之间的数据传递路径。
H3C 报告还展示了 GB200 NVL576 组网拓扑示意。
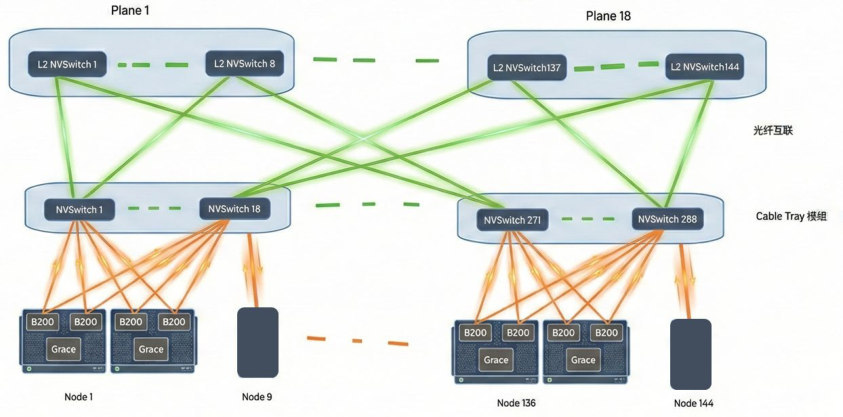
图源:H3C《超节点技术白皮书》第 44 页,图 19。
NVL576 这类拓扑的技术意义,是把更多 GPU 放进一个高带宽、低时延的互联域里,让更大规模的并行通信能够留在紧耦合范围内。
但规模扩大后,拓扑设计难度也会提高。如何减少跳数、降低阻塞、控制成本、保证可靠性,是这类系统必须面对的问题。
DragonFly 拓扑则更强调大规模互联中的全局连接效率。
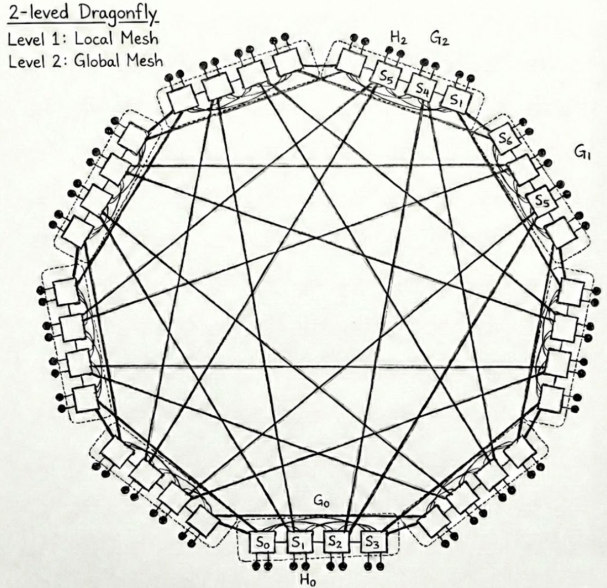
图源:H3C《超节点技术白皮书》第 48 页,图 25。
DragonFly 的思路可以粗略理解为:先在局部组内做高密连接,再通过全局链路连接不同组,以减少大规模系统中的网络直径。
这类拓扑适合思考一个问题:当超节点继续扩大,系统不可能让所有设备都完全直连,那么如何在成本和性能之间取平衡?
H3C 报告还列出了 Huawei UB-Mesh 架构组网拓扑示意。
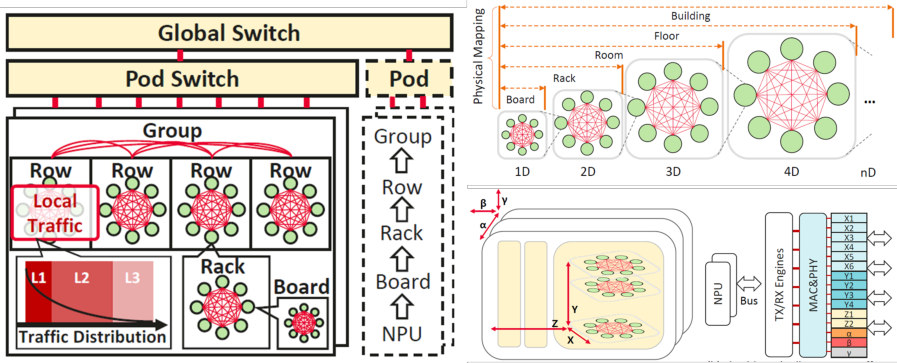
图源:H3C《超节点技术白皮书》第 49 页,图 26。
这些拓扑图放在一起看,可以得到一个结论:超节点的互联路线不会只有一种答案。不同厂商、不同芯片、不同机柜形态、不同集群规模,会采用不同拓扑。
对技术人员来说,更重要的不是背拓扑名字,而是理解每种拓扑背后的取舍:
- 是更重视低时延,还是更重视扩展性?
- 是更重视全互联能力,还是更重视成本和可部署性?
- 是更适合 TP,还是更适合 EP 和 All-to-All?
- 故障发生后,是否还能保持足够带宽?
- 软件栈能不能感知拓扑并做调度?
七、Scale-Up 和 Scale-Out 不是替代关系
讲到这里,很容易产生一个误解:既然 Scale-Up 这么重要,那未来是不是 Scale-Out 不重要了?
不是。
超节点真正的架构方向,是 Scale-Up 和 Scale-Out 分工协同。
华为报告里的超节点集群组网架构,可以用来理解这个分层。
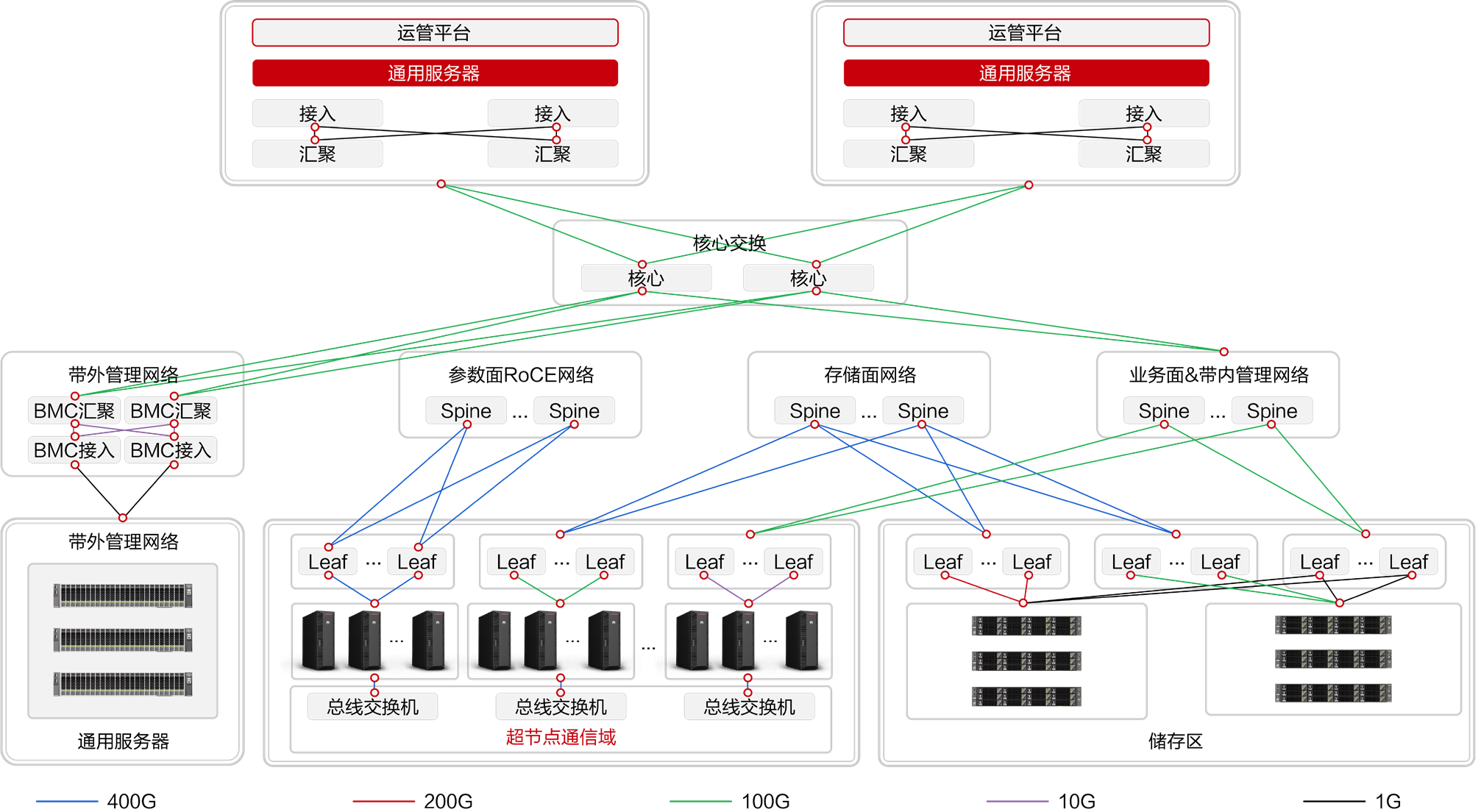
图源:华为《超节点发展报告》第 17 页,图 4.1。
一个简单的理解方式是:
- 超节点内部,用 Scale-Up 承载高频通信。
- 超节点之间,用 Scale-Out 承载更大规模扩展。
- 管理、存储、业务访问等流量,走 Frontend 或其他网络。
这就像把一个大模型训练任务拆成不同通信层级。
最紧密的计算协同,尽量放到超节点内部。跨超节点通信仍然存在,但应该让它承担更适合的并行流量,比如数据并行、流水线并行的阶段通信,或者跨超节点的扩展流量。
H3C 报告也把超节点部署网络划分为 Scale-Up、Scale-Out 和 Frontend 三类,分别承载不同业务流量。这说明未来 AI 集群不是一张网打天下,而是多层网络共同工作。
八、HBD 也有边界:不是越大越一定越好
既然 HBD 能减少跨机通信,那是不是 HBD 越大越好?
不一定。
高带宽域扩大,会带来收益,也会带来成本。
收益包括:
- 更多高频通信留在低时延域内。
- 更大的 TP/EP 并行组可以减少跨域通信。
- 更大的显存/内存资源可以被更统一地组织。
- 对 MoE、长上下文、复杂推理更友好。
成本也很明显:
- 交换芯片和高速链路成本上升。
- 线缆、背板、连接器和信号完整性更复杂。
- 功耗和散热压力增加。
- 拓扑调度更复杂。
- 故障域可能扩大。
- 边际收益可能下降。
中兴报告在 Qwen3-235B 仿真分析中也提示,随着超节点形态增大,单卡训练性能逐渐提升,但收益存在边际效应。
这点很重要。
超节点不是无限放大的“巨型服务器”。它更像是在特定工程约束下,找到一个合适的高带宽域大小,让通信收益、硬件成本、部署复杂度和软件调度能力达到平衡。
九、工程判断清单:怎样看一个 Scale-Up 方案是否扎实
如果要评估一个超节点 Scale-Up 互联方案,不建议只看“多少卡”和“总带宽”。
可以按下面这张清单看。
| 判断维度 | 需要追问的问题 |
|---|---|
| 高带宽域边界 | 多少 GPU/NPU 处在同一个 HBD 内?域内通信和跨域通信差异多大? |
| 单卡带宽 | 每张卡可用的双向通信带宽是多少?是否能支撑 TP/EP? |
| P2P 时延 | 任意两卡 P2P 时延是多少?小包通信表现如何? |
| 拓扑跳数 | 任意两卡之间需要几跳?是否存在明显热点路径? |
| 收敛与阻塞 | 满负载 All-to-All 或 All-Reduce 时是否会收敛?收敛比例是多少? |
| 交换能力 | 交换芯片支持哪些通信模式?是否支持在网计算或组播/归约优化? |
| 物理链路 | SerDes、线缆、背板、连接器、插损和可维护性如何? |
| 软件感知 | 通信库、调度器、训练框架是否能识别拓扑? |
| 故障处理 | 单链路、单交换模块故障后是否能降级运行?影响范围多大? |
| 工程落地 | 功耗、液冷、整柜交付、机房承重和运维是否匹配? |
这张表背后的思路是:超节点不是单一参数竞赛,而是端到端系统能力。
有些方案硬件参数很漂亮,但如果软件栈无法感知拓扑,训练任务仍然可能放错卡。有些方案总带宽很高,但如果 All-to-All 时出现严重热点,MoE 训练仍然会被尾时延拖住。有些方案互联很强,但供电、液冷和运维跟不上,也无法稳定交付。
真正扎实的 Scale-Up 方案,应该同时回答“能连多快”“怎么连”“谁来用”“坏了怎么办”这四类问题。
十、总结
超节点的 Scale-Up 互联,本质上解决的是 AI 集群里的通信边界问题。
传统 Scale-Out 集群可以扩展规模,但大模型训练和推理里有大量高频、低时延、强同步通信。把这些通信全部交给跨服务器网络,会让 GPU/NPU 等待网络,降低有效算力利用率。
HBD 高带宽域的意义,就是把最敏感的通信放进更紧耦合的范围里,用更高带宽、更低时延、更可控的拓扑支撑 TP、EP、MoE、长上下文和复杂推理。
但 Scale-Up 不是替代 Scale-Out。未来更合理的架构是:
- Scale-Up 负责超节点内部强耦合通信。
- Scale-Out 负责跨超节点大规模扩展。
- Frontend 负责管理、存储和业务访问。
从工程角度看,评估超节点互联不能只看卡数和总带宽,还要看单卡可用带宽、P2P 时延、拓扑跳数、收敛比、物理链路、软件感知和故障处理。
也就是说,超节点不是把更多卡塞进一个机柜,而是在重新设计 AI 集群的通信组织方式。
核心术语表
| 术语 | 含义 |
|---|---|
Scale-Up |
在一个更紧耦合的系统或高带宽域内扩展多颗 GPU/NPU,让强同步通信尽量留在低时延范围内。 |
Scale-Out |
通过增加服务器、机柜或集群规模进行横向扩展,适合更大范围的分布式扩展。 |
HBD |
High-Bandwidth Domain,高带宽域,中兴报告中用于描述超节点内高速、低时延、紧耦合通信范围。 |
P2P 时延 |
两个加速设备之间点对点通信的延迟,直接影响小包、高频和同步通信。 |
收敛比 |
网络上行和下行带宽之间的比例关系,收敛越明显,满负载通信越容易出现争抢。 |
OEX |
中兴报告提出的正交无背板互联架构,用于降低高速互联链路复杂度并提升维护性。 |
下一篇我们继续往下走,讨论超节点的另一个关键能力:统一内存编址。它会把问题从“网络能不能更快搬数据”,推进到“设备之间能不能更像访问统一内存空间”。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)