操作系统之文件系统
本文章是基于《操作系统导论》的总结,如果大家想深入了解,很建议阅读这本书。
引言
本文章是基于《操作系统导论》的总结,如果大家想深入了解,很建议阅读这本书。
文件和目录
我们的电脑存储数据的地方有很多,但是主要的就两个,一个是内存,一个是磁盘。
内存离CPU比较近,那么自然而然;每一次访问数据肯定更加的方便,而磁盘离CPU比较的远,自然而然,串起门来就不这么方便。
但是因为内存有一个很大的缺点,一断电,里面的数据全部消失(就像你和她的聊天记录,可能一夜之间一无所有)。但是磁盘就不一样,无论你断不断电,写在磁盘里的数据永远在那里(就像别人的女朋友一样),所以,如果很重要的数据,我们都要放在磁盘里面,而访问的时候,所有的数据都在内存之中。
那么,这些在磁盘中的数据,操作系统需要特别的关心,因为每个用户都离不开它们。
随着时间的推移,存储虚拟化形成了两个关键的抽象。
文件
文件类型
第一个是文件。文件就是一个线性字节数组,每个字节都可以读入或者写入。
对于文件的命名,每个文件都有着它的一个自己的低级名称,就是inode(某一数字),但是作为用户,我们通常不知道inode。
在大多数操作系统之中,操作系统不太了解文件的结构(是图片还是文档)。而文件系统的任务仅仅是把数据存储到磁盘上,确保你下一次请求数据的时候,还可以访问到。所以如果一个.c 的文件,我们趁别人不注意,改成.img文件,其实从原理上来说也是可以运行的。
文件一般分为两类,一类是常规文件,这也是我们接触到最多的文件,图片,可执行文件。。。
文件的访问
早期的操作系统,文件的访问是顺序访问,而在现在,我们更多采用的是随机访问文件。
文件的属性
简单来说就是文件的信息。所以,大家要注意!!!!如果你直接把别人的作业copy过来,一定要有所更改,不然如果发现你们的文件最后一次更改时间一摸一样,内容也一样,那可坏事了。
目录
第二个是目录,目录里面存的就是文件,而一般的目录,都是树形结构的
一级目录系统
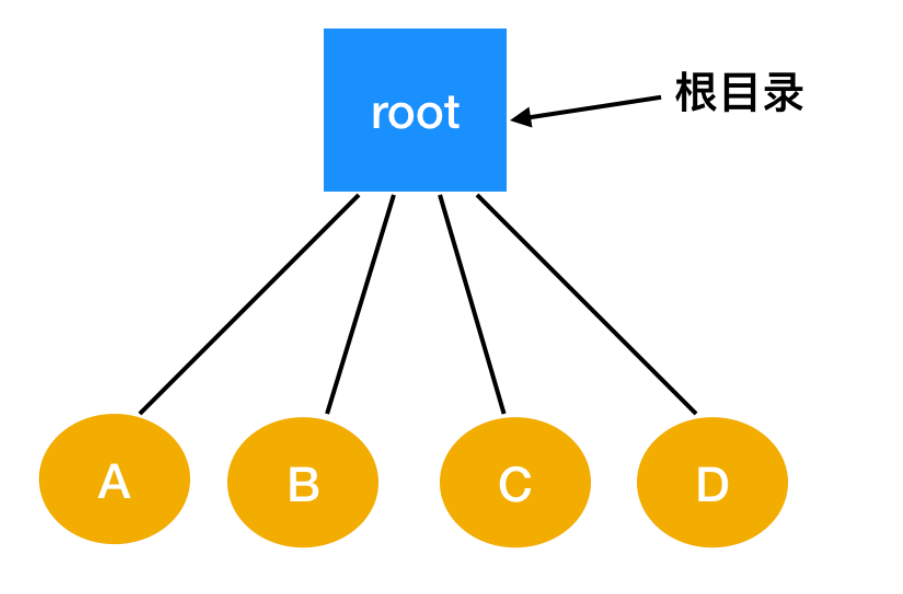
优势就是简洁高效,但是缺点也很明显,文件数量的增加导致查找特定文件十分的困难。
层次目录系统
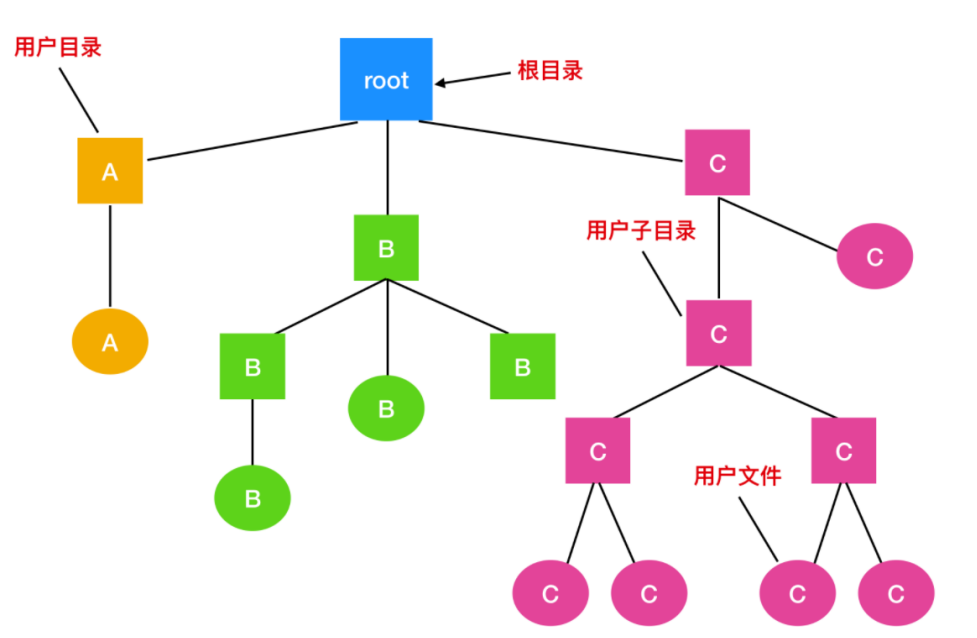
可以用多个目录对于文件进行分类,让用户的查找更加的方便。现代的文件系统一般都是这种形式。
路径名
绝对路径和相对路径,前者是从root开始找,后者是从当前位置开始找。
目录操作
这里主要讲两个的区别
1、删除目录(rmdir)
如果这个目录是空的,那么可以直接删除,否则不行。
2、删除链接(unlink)
硬连接和软连接
软链接就是windows的快捷方式,软连接本身就是一个单独的小文件,里面存的是源文件的路径,点击这个文件,会通过路径打开源文件。
所以删除软链接的文件是没有用的,要删除源文件。下一次卸载软件可不要直接把图标丢进垃圾桶了哟。
硬链接相当于给文件起别名(自始自终都只有一个文件),如果你只删除了一个文件,无论是哪一个文件,文件依然存在,只有当把所有文件删除,让引用计数为0的时候,才真正删除了文件。
文件系统
文件系统是纯软件,所以我们有必要理解它的工作原理。但是在我们讲述原理的时候,会忽略一些东西,当然,这些东西马上也会被提起。
第一个就是文件系统的数据结构。
文件系统被存储在磁盘里面。磁盘通常可以划分成多个区域,这些区域被称为磁盘分区,每个分区都有着自己独立的文件系统,并且这些文件系统的类型可以不相同。
先不管那么多,我们可以想象一下,为了构建文件系统,这些文件肯定是一个一个块组成的,文件里面存的就是数据,那么,一个很自然的想法就是,我们把磁盘分成块,块的大小一般是4KB,然后这些块里面就存数据。这个就是数据区域。
但是存了数据没有用,我们真正需要的是找到这些数据,所以我们在磁盘里,还要有一片区域来记录这些文件在磁盘分区里的位置。所以文件系统必须要记录下每个文件的信息,该信息是元数据的关键部分,比如文件大小,访问权限,修改时间等。。。为了存储这些信息,文件系统里面有一个inode的数据结构,至于什么是inode,我们稍后来聊。所以为了存放inode,磁盘必须要留一部分空间,来存inode。假设有64块,我们56块存数据,5块存inode,那么4*5KB=20KB,一个inode假设256字节,20KB/256B = 80个inode,说明在这64块里面,我们可以建立80个文件。但是,信息是有了,那我们总不能说每一次要访问信息了,每次都是遍历整个inode,看看哪些是有空位的,哪些是有人的。所以我们还需要用位图的方式记录inode和数据区的空闲情况,这里假设各分配一个块去存储inode和数据区的位图,也就是4KB * 8 = 32 KB,可以记录32KB的对象是否分配。最后,整个文件系统还有一块,这里存放的是超级块,超级块包含了这个分区文件系统的信息,比如有多少个inode和数据块。
因此,在挂载文件系统(让操作系统可以访问)的时候,操作系统首先读取的是超级块,初始化各种参数,然后将该卷添加到文件系统树中,当卷中的文件被访问到的时候,操作系统就知道在磁盘的哪里去寻找。
inode数据结构
inode里面存的就是文件的信息,这个不是我们的重点。假设我们读取32号inode,那么先计算inode区域的偏移量(32 * 4 KB),再加上inode在磁盘上的位置,就得到了32inode的位置。
我们把所有关于文件的数据称为元数据,在设计inode的时候,最重要的就是如何引用数据块鹅位置。一个最简单的方法就是inode里面有一个或者多个指针,每个指针指向一个数据块。假设我们有12个指针,那么文件的最大大小就是(12 * 4 KB = 48 KB)。
当我们看到这个数的时候,就知道问题出现了,文件太小了,我要是搞个大项目,怎么办。所以我们推出了多级索引
多级索引
这是一个很巧妙的想法,我们为了扩大文件的大小,我们inode块里面不再存指向含用户数据的块的指针,而是存指向一个包含更多数据块的指针,当然,这些块是在数据区,只不过存的是指针罢了。假设只分配一个块存更多的指针,一个块是4KB,一个指针的大小是4字节,那么一个块就可以增加1024个指针,文件就可以增加(12 + 1024 )* 4 KB = 4144KB字节。如果还要更多,可以分配更多的块存指针。
目录组织
目录只是“存储名->inode”映射特定类型的文件
目录存在哪里,这是一个好问题。通常目录是一个特殊的文件(dir),但至始至终,目录也是一个文件,所以目录有一个inode,也在inode表中的某处,所以我们的磁盘结构不需要改变。
空闲空间管理
文件系统必须要记录哪些inode和数据块是空闲的,哪些不是,这样可以更快速的分配文件。我们一般解决办法有两个:一个是位图,一个是链表。
在分配空间的时候,为了减少磁盘寻道时间,尽量把一个文件安排在一起。
数据的写入
写入数据一直都是一件非常非常糟糕的事情,首先文件必须打开,其次要更新,最后要关闭,并且运气不好的话,还要分配新的块。
看上去这个过程没啥特别的。别急,我们慢慢来。
假设我们需要一个新的块
首先我们要I/O读取数据位图,(用来更新标记新分配的块被使用),然后I/O写入位图(将新的状态存入磁盘),然后I/O读取inode,I/O写入inode,最后I/O写入数据本身。
前后有5次磁盘I/O,饿啊~
那么如何降低成本呢。这些操作似乎不可以避免,那么我们就尽量减少这些操作的次数,所以我们引入了缓存和缓冲,这两个老熟人也不必介绍了。
不过呢,有些人就是不喜欢弯弯绕绕的,所以系统也提供了一个函数fsync(),这个可以避免缓冲直接I/O。
局部性和快速文件系统
快速文件系统是一个非常古老的文件系统,但是我们很有必要了解一下,方便我们之后的学习。
之前性能不好主要是:数据到处都是,相关的文件没安在一起,寻道浪费时间;有碎片。
为了解决这个问题快速文件系统(FFS)保证了相关文件放在一起。其操作就是分块组,一个块组的内容寻道基本不会耗时。大文件除外,大文件分开放,因为如果放在了一起,那么就妨碍了相关文件放置在该块里面,而分开放可以腾出更多的空间。但是有人可能觉得分开放那不是性能低了很多,其实有这种想法不错,但是大文件其实主要时间都是在读取和写入,所以寻道的时间可以忽略了。
FFS的其他几件事情
引入子块(512K)和缓冲区形成配合,避免碎片
优化扇区布局,保证发出一个请求块0并读取完之后,如果发出第二个请求,那么下一个扇区就是块1。所以磁盘的块号是跳跃的(根据转速)
日志
这一方面我们仅仅简单的提及一下。
假设我们要更新磁盘的结构A和结构B,但是如果刚更新完A,啪一下,断电了,那完了,B还没更新,那电脑怎么知道开机之后要继续更新B呢。
所以我们就引入了日志,每一次在更新磁盘的时候,现在磁盘的一个众所周知的地方写下一点小注释,描述我要做的事情,然后断电之后,要恢复内容或者继续覆写,通过注释可以想起往日的事迹。
这也就是日志的主要任务了!
日志结构文件系统(LFS)
这个就比较关键了。当时面临了很多的问题:
1、内存大小不断地增加,所以缓存可以有更多的数据了。所以磁盘更多的开销就放在了写入操作,因为读操作的小助手缓存已经很强大了。所以文件系统的性能很大程度上取决于写入的性能。
2、随机I/O的性能远远低于顺序I/O的性能
3、虽然相同的文件放在了一起,但是会导致短寻道和旋转延迟,性能低(10次1毫米的短寻道,其总耗时远大于1次10厘米的长寻道,在碎片化的小文件读取中,每个文件都要重新等一圈)
所以我们解决方案首先第一个,让所有的写入变成顺序写入。不知道大家还记不记得文章前面我们的inode存放在哪里,存放在文件系统的开头那一部分,位置是固定的,也就是我们每一次写入的时候,要寻道找inode,又要寻道找数据区,很麻烦。
所以我们这一次写入数据的时候把inode一起写进去,这个inode就指向的是对应的块。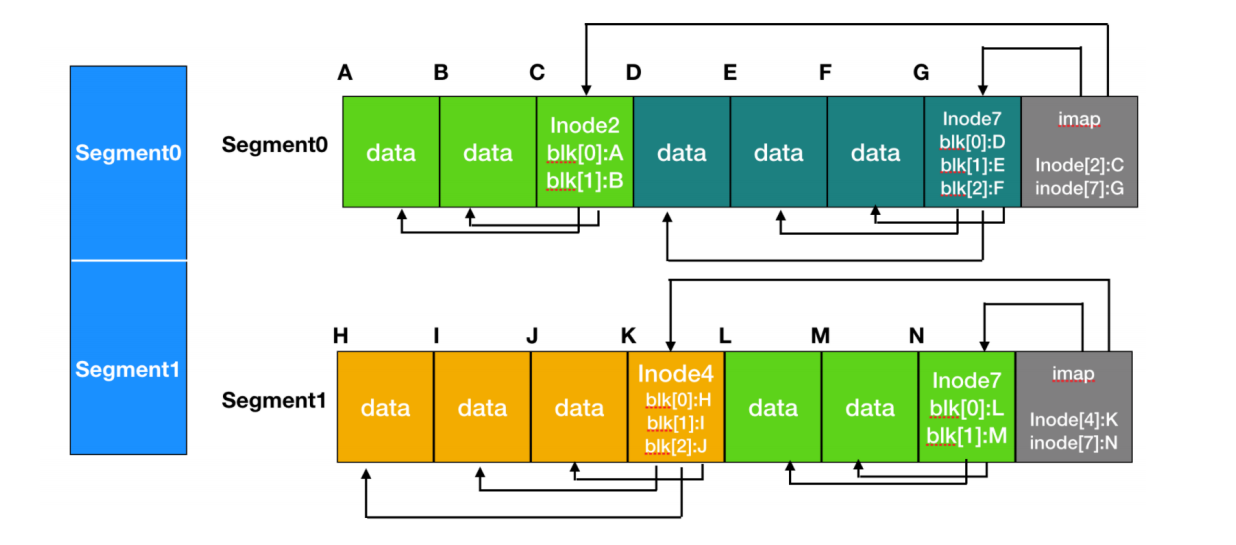
我们把一次性写入的所有数据称为段。
从图中我们也可以发现,如果一次写入占用了两个块,那么对应的inode就会存两个块的位置,即使可能这两个块根本不是同一个文件,也没有关系,因为inode不是负责这一部分的,它只负责找到块的位置。
不过可能这个图片看上去inode和块的大小一样,但是实际上inode要小很多,一般都是128B。
不过怎么找到inode呢?
图里面已经告诉我们答案了,imap。
imap记录了最新版本的inode的位置,至于为什么是最新的。当然是每一次更新数据的时候都会更新imap的数据啊~ 亲~
遗憾的是,imap需要保持持久的访问,必须要写入磁盘。
当然了, 亲~ ,imap可以写在一个固定的位置,但是这个位置每次更新的时候都要寻道,所以性能并不高。
所以, 亲~ , 我们的imap也是随着数据一起写入到磁盘的,它的位置也一直在变动,但是至少保证了一个点,顺序写入。
那既然是顺序写入,那这个磁盘上会有很多的imap,确实,但是一旦imap被重新写入,也就是更新,那么原来的imap就没有作用了,我们不会再读取原来的imap。
检查点区域
说了这么多,我知道你心中的疑惑依然存在,就是imap也在动,如果数据更新了,inode也在动,那我怎么找到我想要的数据呢?LFS在磁盘上只有这么一个固定的位置,称为检查点区域(CR)。检查点包含了指向最新的inode映射片段的指针(即地址)。
所以我们的读取数据的过程很明显了:
通过CR找到imap,把imap缓存到内存之中,通过imap找到inode,通过inode找到数据区。
目录
那我们怎么找到目录呢?
目录也是文件,也有inode号,既然如此,那也很简单了,目录的inode号也存在在imap里面。
okok,说了这么多,我们模拟一个比较复杂的场景,我们需要找到目录下面的foo文件
先找到imap,存到内存里,然后通过目录的特殊标记(dir)找到目录的inode,然后进入目录的地址,目录里面存的是名称->inode,所以我们找到foo对应的inode(数字),然后回到imap,找到对应inode的地址,最后通过inode找到foo文件。
其实在不知不觉中,imap还帮了我们一个大忙,对于一个不会原地更改的文件系统,而是把新数据写入到新的位置,如果更改一个inode而且还没有imap,我们就要更改父目录,因为父目录记录了inode的位置,父目录一改,位置也变了,又要更新父父目录,一直往上递归,全毁了。
但是我们有imap,inode的信息无论怎么变化,inumber是不变的,而目录的作用就是找到名称对应的inode,根本不记录inode的位置,记录inode的位置的是imap,而imap一直是被顺序写入的,并不影响。
垃圾收集
LFS的特点就是不断地写,管你是什么,顺序写入的开销小,那就不断地写,不止是imap,如果你更新一个文件,也会重新的写入。但是问题就是我们怎么知道那是旧块的。
先解决第一个问题,每个数据段头部都有一个地方存储额外信息,里面就有数据块对应的inode和块的地址。假设一个数据块的原来地址是A,更新了之后数据块的地址是B,我只需要拿着这个inode跑到imap那查看一下inode的地址,然后再跑到inode那个地方看一下这个inode到底指向哪里,如果是地址A,和之前一模一样,那就说明没啥问题,如果指向的是地址B,不是地址A,那你就是垃圾,一边去。
那既然知道这个是垃圾了,怎么处理呢?
这里有个很简单的方法,就是把LFS定期读一般文件数据,把那些垃圾释放掉,让那些块变成空闲,但同时为了避免外部碎片,把那些旧的段重新读到缓存里面,积累到一定程度,重新写入,组成一个新的段,然后把原来的段全部释放。
高速缓存
CPU读取内存的速率其实也不是很快,所以为了加快速度,高速缓存横空出世。它的容量不大,但是效率是内存读取的10倍,一般我们会把内存读取的数据放到高速缓存上面,并且提前读取一段,所以为什么说遍历数组最好一行一行的遍历,其实原因就在这里,因为每次遍历一行的开头,其实高速缓存里面已经存储了这一行的所有数据,没必要再读取内存了,这个效率就很高。
emmmm ,最后,也到了和操作系统短暂告别的时候了~~ 操作系统的所有内容就到这里结束了。
从操作系统内存到操作系统文件系统,操作系统的故事就到这里结束了。大家如果有兴趣可以阅读我博客的其他内容。
感谢大家的阅读!!!!

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 17
17 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)