AMD Ryzen AI Strix Halo架构处理器:如何在笔记本上跑通原本属于服务器的模型?
本文将系统地介绍一下如何在 Strix Halo 平台上部署服务器级 AI 大模型。先画一张整体架构图,再详细展开。
本文将系统地介绍一下如何在 Strix Halo 平台上部署服务器级 AI 大模型。先画一张整体架构图,再详细展开。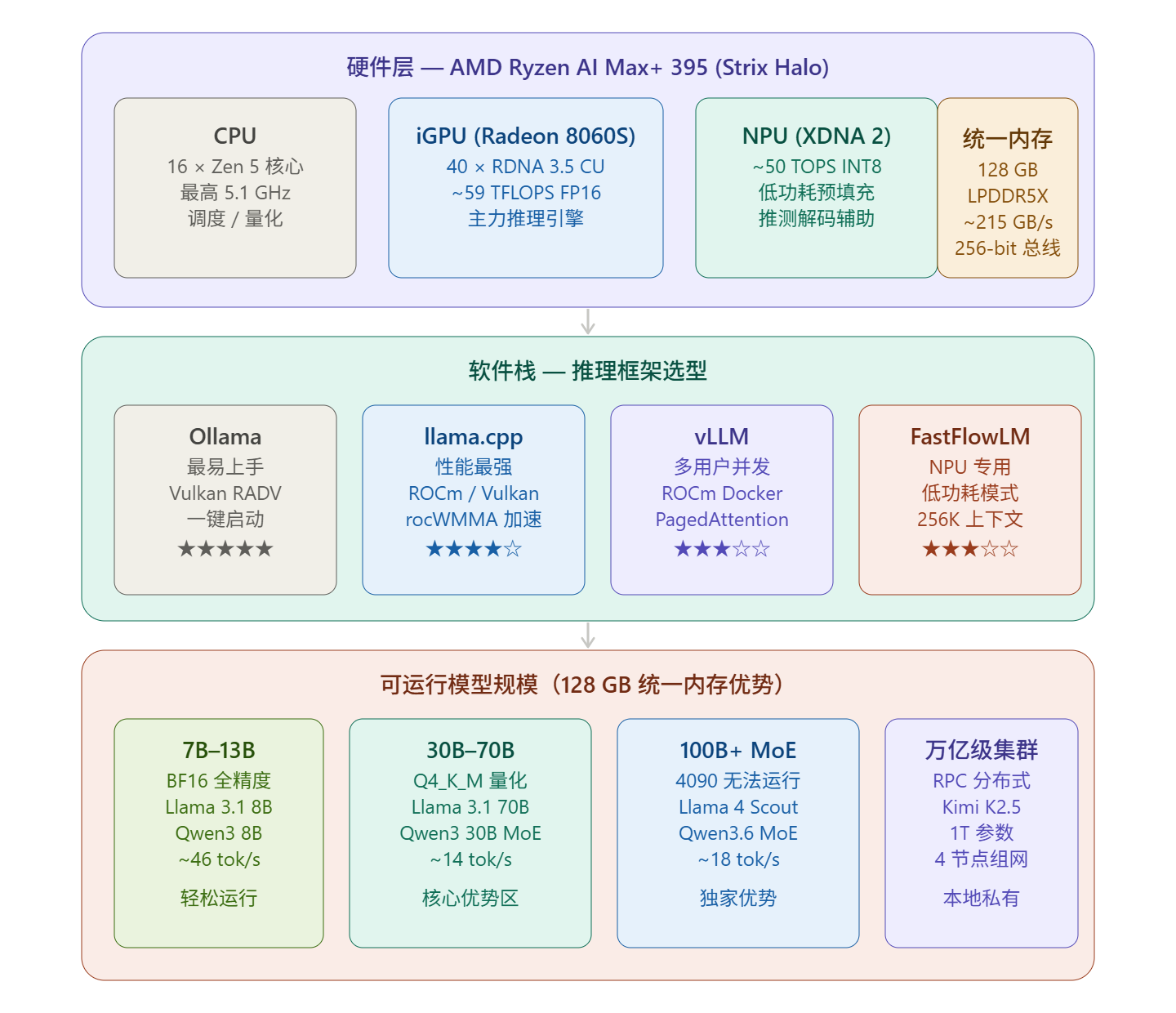
一、为什么 Strix Halo 能跑服务器级大模型?
核心优势:统一大内存突破显存瓶颈
传统消费级 GPU(RTX 4090)最多只有 24 GB 独立显存,无法在单卡上运行 70B 参数模型。Strix Halo(Ryzen AI Max+ 395)最多支持 128 GB LPDDR5X-8000 统一内存,CPU 和 iGPU 共享这块内存,因此可以完整加载 Llama 3.1 70B 的 BF16 全精度权重,而没有任何消费级 NVIDIA 显卡能做到这一点。
与独立显卡的专用 VRAM 不同,Ryzen AI Max 采用统一内存架构,通过 GTT(图形转换表)让 GPU 访问系统内存,配置后约有 96 GB 可用于 LLM 推理,可以加载原本需要多块高端 GPU 才能运行的模型。
二、系统准备:BIOS 与内核配置(Linux 最优)
BIOS 关键配置:
- UMA(统一内存架构)分配:将 GPU 专用显存分区设为 96 GB(或尽量大),这直接决定 GPU 可见的显存池大小。
- TDP 功耗配置:建议设为 85 W,这是性能/效率的最优平衡点;24 小时推理服务器可在 65–90 W 区间运行。
- IOMMU:禁用,避免内存访问被限制。
Linux 内核要求:
需要内核 6.16.9 或更高版本才能获得完整的内存访问支持。如果系统内核较旧,可通过 mainline 工具安装新内核:
sudo add-apt-repository ppa:cappelikan/ppa -y
sudo apt update
sudo apt install mainline -y
sudo mainline --install 6.16.9
三、驱动层:Vulkan RADV vs ROCm,如何选择?
AMDVLK(AMD 以前的开源 Vulkan 驱动)已于 2025 年 4 月停止更新,RADV 现在是 AMD 唯一支持的开源 Vulkan 驱动。RADV 在提示词处理(pp)上比 AMDVLK 快 63%,且解码速度也更快。特别注意:即使不主动使用 AMDVLK,其 ICD 配置文件仍会静默劫持 Vulkan,将提示词处理速度减半——应彻底卸载。
实际选择建议:
| 场景 | 推荐后端 |
|---|---|
| 日常 LLM 推理(短上下文) | Vulkan RADV |
| 需要 vLLM 兼容 | ROCm HIP |
| MoE 大模型 | Vulkan + Flash Attention |
使用 ROCm HIP 时需要设置环境变量 HSA_OVERRIDE_GFX_VERSION=11.5.1,Ollama 0.20+ 已修复此问题。
四、推理框架详细部署
方案 A:Ollama(最快上手)
# 安装 Ollama
curl -fsSL https://ollama.com/install.sh | sh
# 启用 Flash Attention(关键优化)
export OLLAMA_FLASH_ATTENTION=1
# 直接拉取运行 70B 模型
ollama run llama3.1:70b
ollama run qwen3:30b-a3b # MoE 结构,速度更快
启用 Flash Attention 是对 Strix Halo 最重要的单项优化;Ollama 0.21 版本开始默认启用。
方案 B:llama.cpp + ROCm(性能最强)
AMD 官方提供了面向 gfx1151(Strix Halo GPU 代号)的预编译二进制:
# 使用 Lemonade SDK 预编译包(免去自行编译)
wget https://github.com/lemonade-sdk/llamacpp-rocm/releases/latest/download/\
llama-bXXXX-ubuntu-rocm-gfx1151-x64.zip
unzip llama-bXXXX-ubuntu-rocm-gfx1151-x64.zip
chmod +x llama-cli llama-server
# 验证 GPU 识别
./llama-cli --list-devices
# 应输出: Device 0: AMD Radeon Graphics, gfx1151
# 运行 70B 模型,开启 Flash Attention
./llama-server \
-m Llama-3.1-70B-Instruct-Q4_K_M.gguf \
--n-gpu-layers 999 \ # 全部层卸载到 GPU
-fa \ # Flash Attention
--ctx-size 32768 \
--host 0.0.0.0 --port 8080
Lemonade SDK 提供了内置 ROCm 7 加速的 llama.cpp 夜间构建版本,专门针对 gfx1151(Strix Halo / Ryzen AI Max+ 395)优化。
rocWMMA 加速(针对 BF16/FP16 大幅提速):
rocWMMA 标记的构建版本利用了 AMD 的 rocWMMA 库,解锁了通过波形矩阵乘累加(WMMA)指令加速的矩阵乘法流水线,可显著提升 BF16/FP16 工作负载的性能。
方案 C:NPU 加速(FastFlowLM)
FastFlowLM 是专为 AMD Ryzen AI NPU 设计的推理运行时,无需 GPU 即可运行。它类似 Ollama,但专门针对 NPU 优化,支持高达 256,000 tokens 的超长上下文,提供 CLI、REST 和 OpenAI 兼容 API 接口,运行时仅约 14 MB。
# 安装 FastFlowLM(通过 Lemonade Server)
flm pull qwen3:1.7b
flm run qwen3:1.7b
在 Windows 下用 NPU 运行 Mistral 7B,解码速度约 4–5 tok/s,而纯 GPU 路径约 40 tok/s。AMD 正在推进"分解推理"概念——计算密集的提示词处理由 NPU 承担,内存带宽密集的解码阶段由 GPU 处理,这对功耗受限的笔记本电脑意义重大。
五、量化策略:模型精度与内存权衡
| 量化格式 | 内存占用(70B) | 速度 | 质量 | 推荐场景 |
|---|---|---|---|---|
| BF16 全精度 | ~140 GB | 最慢 | 最优 | 评估/微调 |
| Q8_0 | ~70 GB | 较快 | 极佳 | 高质量推理 |
| Q4_K_M | ~40 GB | 快 | 良好 | 日常推理★ |
| Q3_K_M | ~30 GB | 最快 | 一般 | 超大模型 |
| IQ4_XS | ~35 GB | 快 | 较好 | MoE 模型★ |
MoE 模型是 Strix Halo 的隐藏王牌——MoE 架构(如 Qwen3 30B-A3B)虽然总参数量大,但每次推理只激活少量参数,在内存带宽受限的 APU 上速度反而远超同等参数的密集模型。
六、实测性能基准
基于 Vulkan RADV 后端的实测数据(Beelink GTR9 Pro,Ryzen AI Max+ 395,128 GB):
- Gemma 4 26B-A4B:解码 48.5 tok/s
- Llama 4 Scout 109B:解码 18.3 tok/s(RTX 4090 根本无法加载此模型)
- Qwen3.6 MoE:约 50.5 tok/s
七、多机集群:突破单机限制
当单台机器内存不够跑万亿参数模型时,可通过 llama.cpp 的 RPC 机制组网:
利用 llama.cpp RPC 引擎,一台主机负责 tokenization、调度和编排,其余机器运行轻量级 RPC server 暴露本地 GPU 内存和算力。模型从主机视角看就像运行在一块超大加速器上,RPC 在幕后处理张量传输与同步——整个框架完美匹配 Ryzen AI Max+ 的统一内存架构,可实现对 Kimi K2.5 万亿参数模型的本地推理。
# 从节点(每台机器执行)
./rpc-server --host 0.0.0.0 --port 50052
# 主节点(分片加载模型)
./llama-server \
-m kimi-k2.5-Q4_K_M.gguf \
--rpc 192.168.1.2:50052,192.168.1.3:50052,192.168.1.4:50052 \
-fa --ctx-size 16384
八、关键调优清单
- 始终保持 llama.cpp 最新版:对 MoE 模型而言,更新 llama.cpp 带来的性能提升(+25%)超过了所有内核参数调优、批次大小调整和驱动对比的总和。
- 启用 Flash Attention:
-fa 1或OLLAMA_FLASH_ATTENTION=1 - 卸载 AMDVLK:防止静默劫持 Vulkan
- 使用
tuned性能守护进程:accelerator-performance配置文件可带来 +5–8% 的 LLM 速度提升。 - ROCm 环境变量:
HSA_OVERRIDE_GFX_VERSION=11.5.1(使用 ROCm 路径时)
总体而言,Strix Halo 的核心竞争力在于:用笔记本/迷你 PC 的功耗(65–120 W)和价格(约 ¥14,000 起),实现原本需要服务器级多卡配置才能支撑的 70B+ 模型本地推理,且数据完全不出本地,满足隐私和合规需求。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)