【Linux网络】Linux 网络编程:HTTP(三)HTTP 协议原理
本文通过从零实现一个 C++ HTTP 服务器的过程,深入讲解了 HTTP 协议的核心原理。我们从最基础的请求响应报文结构开始,一步步实现了静态资源的读取与返回、状态码的处理、重定向功能,最终实现了支持 GET 和 POST 方法的动态交互服务器。通过本文的学习,我们应该掌握以下重点内容:1、HTTP 报文结构:HTTP 请求和响应都由四部分组成:请求行 / 状态行、报头、空行和正文。所有的通信都

《Linux操作系统编程详解》《笔试/面试常见算法:从基础到进阶》《Python干货分享》
🎬 艾莉丝的简介:

文章目录

本文大纲
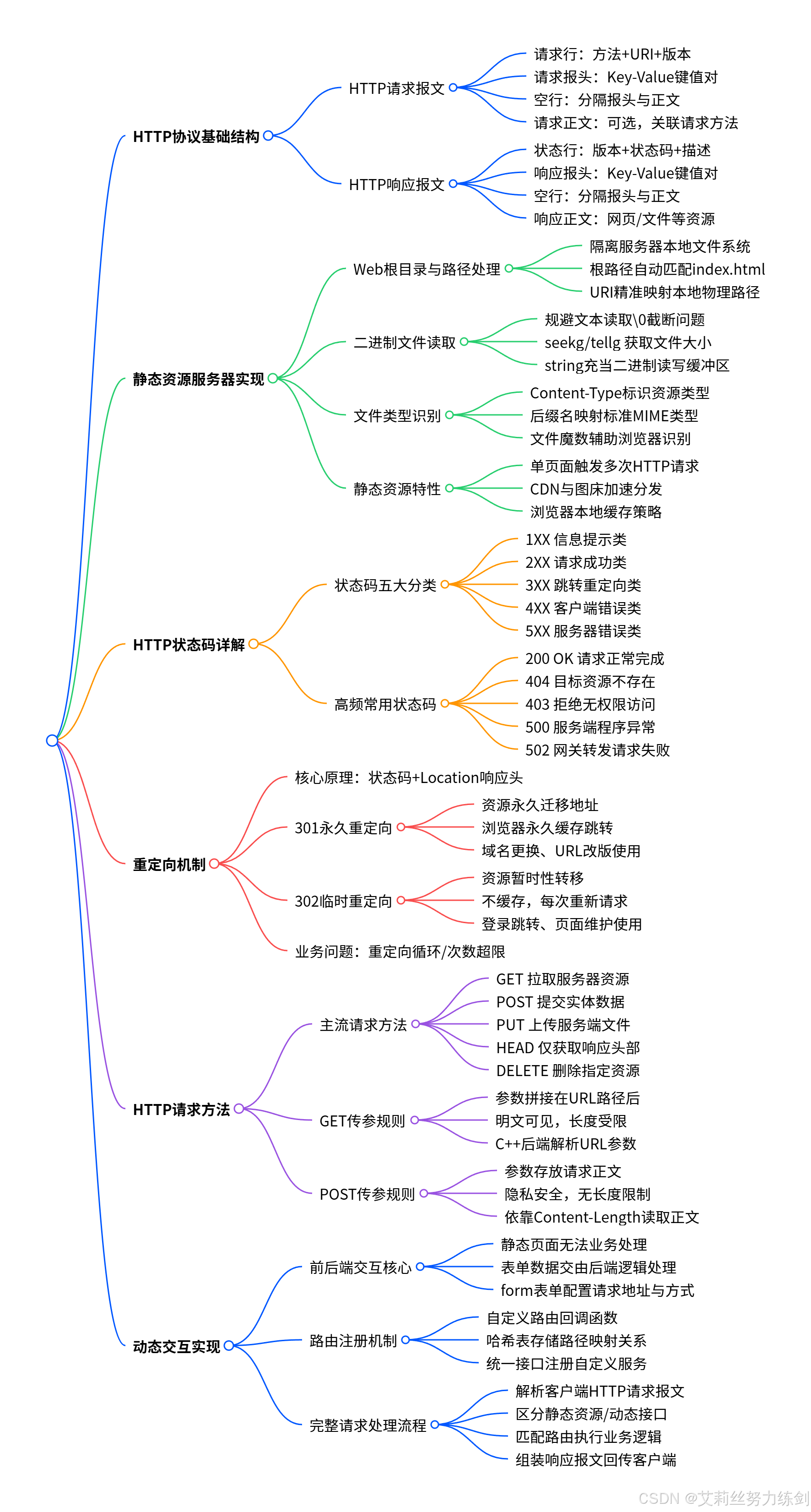
HTTP协议原理与C++实现
├─ HTTP协议基础结构
│ ├─ HTTP请求报文
│ │ ├─ 请求行(方法+URI+版本)
│ │ ├─ 请求报头(Key-Value键值对)
│ │ ├─ 空行(分隔报头与正文)
│ │ └─ 请求正文(可选,与方法相关)
│ └─ HTTP响应报文
│ ├─ 状态行(版本+状态码+描述)
│ ├─ 响应报头(Key-Value键值对)
│ ├─ 空行(分隔报头与正文)
│ └─ 响应正文(资源内容)
├─ 静态资源服务器实现
│ ├─ Web根目录与路径处理
│ │ ├─ Web根目录概念(隔离服务器文件系统)
│ │ ├─ 根目录请求处理(自动拼接index.html)
│ │ └─ URI到本地路径的映射
│ ├─ 二进制文件读取
│ │ ├─ 文本读取的问题(\0截断)
│ │ ├─ seekg/tellg获取文件大小
│ │ └─ string作为二进制缓冲区
│ ├─ 文件类型识别
│ │ ├─ Content-Type报头作用
│ │ ├─ 文件后缀映射MIME类型
│ │ └─ 魔数与浏览器自动识别
│ └─ 静态资源特性
│ ├─ 一个网页对应多个HTTP请求
│ ├─ 图床与CDN的作用
│ └─ 浏览器缓存机制
├─ HTTP状态码详解
│ ├─ 状态码分类
│ │ ├─ 1XX:信息性状态码
│ │ ├─ 2XX:成功状态码
│ │ ├─ 3XX:重定向状态码
│ │ ├─ 4XX:客户端错误状态码
│ │ └─ 5XX:服务器错误状态码
│ └─ 常见状态码详解
│ ├─ 200 OK:请求成功
│ ├─ 404 Not Found:资源不存在
│ ├─ 403 Forbidden:无权限访问
│ ├─ 500 Internal Server Error:服务器内部错误
│ └─ 502 Bad Gateway:网关错误
├─ 重定向机制
│ ├─ 重定向本质:状态码+Location报头
│ ├─ 301永久重定向
│ │ ├─ 含义:资源永久移动
│ │ ├─ 特性:浏览器/搜索引擎缓存
│ │ └─ 场景:域名变更、URL重构
│ ├─ 302临时重定向
│ │ ├─ 含义:资源临时移动
│ │ ├─ 特性:每次请求原地址
│ │ └─ 场景:登录跳转、临时维护
│ └─ 常见问题:重定向次数过多
├─ HTTP请求方法
│ ├─ 常见方法概览
│ │ ├─ GET:获取资源
│ │ ├─ POST:传输实体主体
│ │ ├─ PUT:传输文件
│ │ ├─ HEAD:获取报文首部
│ │ └─ DELETE:删除文件
│ ├─ GET方法传参
│ │ ├─ 参数拼接在URI中(?key=value&key2=value2)
│ │ ├─ 参数可见,长度有限制
│ │ └─ 服务器端参数解析实现
│ └─ POST方法传参
│ ├─ 参数放在请求正文中
│ ├─ 参数不可见,长度无限制
│ └─ Content-Length与正文读取
└─ 动态交互实现
├─ 前后端交互本质
│ ├─ 静态HTML无法处理数据
│ ├─ 数据提交给后端程序处理
│ └─ form表单的action与method属性
├─ 服务注册与路由机制
│ ├─ 定义路由处理函数类型
│ ├─ 用unordered_map存储路由映射
│ └─ Register接口注册服务
└─ 完整请求处理流程
├─ 反序列化HTTP请求
├─ 判断是否为动态路由
├─ 调用对应处理函数
└─ 序列化HTTP响应返回
导入语
HTTP(超文本传输协议)是互联网上应用最广泛的应用层协议,是整个 Web 世界的基石。我们每天浏览网页、看视频、刷社交媒体,背后都离不开 HTTP 协议的工作。很多uu学习 HTTP 时只是死记硬背概念,比如请求方法、状态码,但却不理解它们在实际代码中是如何实现的。本文中,艾莉丝将通过用 C++ 编写一个完整的 HTTP 服务器的过程,带你深入理解 HTTP 协议的核心原理。我们会从最基础的请求响应报文结构讲起,一步步实现静态资源的读取与返回、状态码的处理、重定向功能,最终实现支持 GET 和 POST 方法的动态交互服务器。通过代码层面的实现,我们将真正明白为什么 HTTP 报文是那样设计的,每个字段有什么作用,以及前后端是如何通过 HTTP 协议进行交互的。
1 ~> HTTP 协议基础结构
HTTP 是一个基于请求 - 响应模式的无状态协议,所有的通信都由客户端发起请求,服务器返回响应。无论是请求还是响应,都遵循严格的报文格式,以行为单位进行解析。
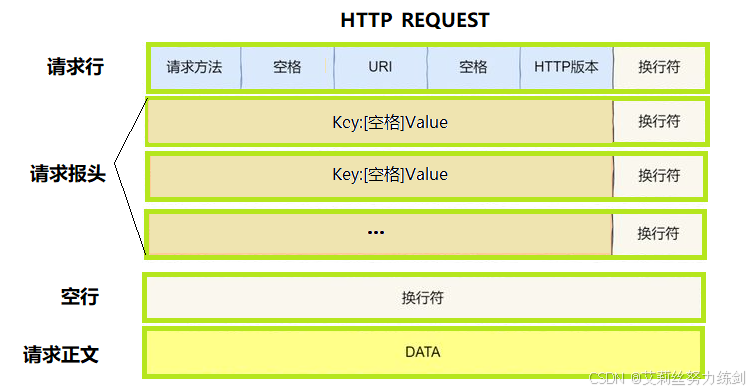
1.1 HTTP 请求报文结构
HTTP 请求报文由四部分组成:请求行、请求报头、空行和请求正文。
- 请求行:是请求报文的第一行,包含三个字段,用空格分隔:请求方法、URI(统一资源标识符)和 HTTP 版本。例如
GET /index.html HTTP/1.1表示使用 GET 方法请求服务器上的/index.html资源,使用 HTTP/1.1 版本协议。 - 请求报头:由多行 Key-Value 键值对组成,每行格式为
Key: Value,用于传递请求的附加信息,比如客户端的浏览器类型、支持的编码方式、连接状态等。常见的请求报头有Host(指定服务器的主机名和端口)、User-Agent(客户端标识)、Accept(客户端能接收的媒体类型)等。 - 空行:是一个单独的换行符,用于分隔请求报头和请求正文,告诉服务器报头已经结束。
- 请求正文:可选部分,用于向服务器提交数据,是否存在与请求方法有关。例如 GET 方法通常没有请求正文,而 POST 方法会把提交的数据放在正文中。
1.2 HTTP 响应报文结构
HTTP 响应报文也由四部分组成:状态行、响应报头、空行和响应正文。
- 状态行:是响应报文的第一行,包含三个字段,用空格分隔:HTTP 版本、状态码和状态码描述。例如
HTTP/1.1 200 OK表示服务器使用 HTTP/1.1 版本协议,请求成功处理。 - 响应报头:同样由多行 Key-Value 键值对组成,用于传递响应的附加信息,比如响应正文的长度、类型、服务器信息等。常见的响应报头有
Content-Length(响应正文的字节数)、Content-Type(响应正文的媒体类型)、Server(服务器软件标识)等。 - 空行:分隔响应报头和响应正文。
- 响应正文:服务器返回的资源内容,可以是 HTML 文本、图片、视频、JSON 数据等任何类型的字节流。

2 ~> 静态资源服务器实现
静态资源服务器是 HTTP 服务器最基础的功能,它的作用是将服务器上的文件(如 HTML、CSS、JS、图片、视频等)返回给客户端。实现一个静态资源服务器需要解决路径处理、文件读取、内容类型识别等核心问题。
2.1 Web 根目录与路径处理
HTTP 协议的核心是传输资源,这些资源在服务器上以文件的形式存在。为了安全起见,我们不能让客户端访问服务器上的任意文件,因此需要设置一个Web 根目录(通常命名为wwwroot或webroot,不过命名这个自拟即可,艾莉丝演示的时候使用的是tuturoot),所有客户端能访问的资源都必须放在这个目录下。
客户端请求中的 URI 会被映射到 Web 根目录下的对应路径。例如,当客户端请求/index.html时,服务器会去读取wwwroot/index.html(或者tuturoot/index.html,这个Web根目录的名字无所谓,自己定就行)文件的内容。需要特别处理根目录请求(即 URI 为/根目录),此时服务器应该返回网站的首页,通常是index.html,因此需要将路径拼接为wwwroot/index.html(或者tuturoot/index.html)。
2.2 二进制文件读取实现
服务器需要读取各种类型的文件,包括文本文件(HTML、CSS、JS)和二进制文件(图片、视频、音频)。如果使用普通的文本方式读取文件,会遇到一个严重的问题:二进制文件中可能包含\0字符,而 C++ 的字符串默认以\0作为结束标志,这会导致文件内容被截断。
因此,必须使用二进制方式读取文件。具体实现步骤如下:
1、使用std::ifstream以
std::ios::binary模式打开文件。
2、使用seekg(0,std::ios::end)将文件指针移动到文件末尾。
3、使用tellg()获取当前文件指针的位置,也就是文件的大小。
4、使用seekg(0, std::ios::beg)将文件指针移动回文件开头。
5、创建一个大小等于文件大小的std::string作为缓冲区。
6、使用read()方法将文件内容一次性读取到缓冲区中。
7、关闭文件并返回缓冲区内容。
这种方式可以保证无论是文本文件还是二进制文件,都能被完整地读取,不会出现内容丢失的问题。
2.3 Content-Type 与文件类型识别(魔数)
当服务器返回资源给客户端时,需要告诉客户端资源的类型,这样客户端才能正确地处理和显示资源。这个信息通过Content-Type响应报头传递,它的值是一个 MIME 类型(Multipurpose Internet Mail Extensions)。
服务器可以通过请求资源的文件后缀名来判断资源类型,并映射到对应的 MIME 类型。例如:
.html和.htm对应text/html.css对应text/css.js对应application/javascript.jpg和.jpeg对应image/jpeg.png对应image/png
我们可以在服务器中维护一个后缀名到 MIME 类型的映射表,当处理请求时,提取资源路径的后缀名,然后查找映射表得到对应的Content-Type值,添加到响应报头中。
现代浏览器为了兼容不规范的服务器,会通过读取文件开头的魔数(Magic Number)来自动识别文件类型。魔数是文件开头的特定字节序列,用于唯一标识文件格式。例如 JPEG 文件的魔数是FF D8 FF,PNG 文件的魔数是89 50 4E 47。但为了保证兼容性,服务器仍然应该正确设置Content-Type报头。
2.4 静态资源的多请求特性
很多人会误以为一个网页对应一个 HTTP 请求,实际上并非如此。一个 HTML 网页中通常会包含图片、CSS 文件、JS 文件、视频等多个外部资源,浏览器在解析 HTML 时,会自动为每个外部资源发起一个单独的 HTTP 请求。
例如,当我们访问一个包含两张图片的网页时,浏览器会先发起一个请求获取 HTML 文件,然后解析 HTML 发现有两个<img>标签,再分别发起两个请求获取这两张图片。因此,一个简单的网页可能会对应十几个甚至几十个 HTTP 请求。
为了减轻服务器的带宽压力,我们可以使用图床来存储图片资源。图床是专门用于存储和提供图片访问的服务,我们只需要在 HTML 中使用图床提供的图片链接,浏览器就会直接从图床服务器获取图片,而不需要经过我们自己的服务器。
更通用的解决方案是使用CDN(内容分发网络)。CDN 通过在全球部署大量的服务器节点,将网站的静态资源缓存到离用户最近的节点上,用户访问时直接从最近的节点获取资源,从而大幅提升访问速度,同时减轻源服务器的压力。
3 ~> HTTP 状态码详解
HTTP 状态码是服务器在响应报文中返回的一个 3 位数字,用于告诉客户端请求的处理结果。状态码的第一位数字定义了响应的类别,后两位数字没有分类作用,用于表示具体的状态。
3.1 状态码分类与作用
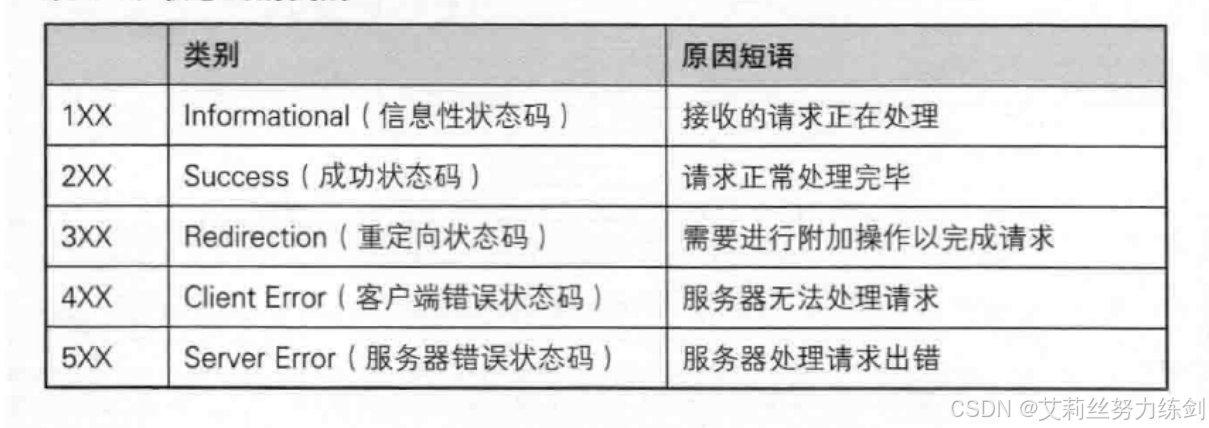
HTTP 状态码分为五大类:
- 1XX(信息性状态码):表示服务器已经接收到请求,正在处理。这类状态码比较少见,例如 100 Continue 表示客户端可以继续发送请求正文。
- 2XX(成功状态码):表示请求已经被成功接收、理解和处理。最常见的是 200 OK,表示请求成功,服务器返回了请求的资源。
- 3XX(重定向状态码):表示需要客户端进行附加操作才能完成请求,通常是跳转到另一个 URL。
- 4XX(客户端错误状态码):表示客户端发送的请求有错误,服务器无法处理。最常见的是 404 Not Found,表示请求的资源不存在。
- 5XX(服务器错误状态码):表示服务器在处理请求时发生了错误。最常见的是 500 Internal Server Error,表示服务器内部发生了未预期的错误。
状态码和状态码描述是一一对应的,状态码是给浏览器看的,用于自动处理响应;状态码描述是给人看的,方便开发者调试。
3.2 常见状态码详解
- 200 OK:请求成功,服务器返回了请求的资源。这是最常见的状态码,当我们成功访问一个网页时,服务器就会返回 200 状态码。
- 201 Created:请求成功,并且服务器创建了一个新的资源。通常用于 POST 请求提交数据后,服务器创建了新的记录。
- 204 No Content:请求成功,但服务器没有返回任何响应正文。通常用于 DELETE 请求删除资源后,不需要返回任何内容。
- 400 Bad Request:请求格式错误,服务器无法理解。通常是客户端提交的参数格式不正确。
- 401 Unauthorized:请求需要用户认证。如果用户未登录,服务器会返回 401 状态码,要求用户登录。
- 403 Forbidden:服务器拒绝请求,客户端没有权限访问该资源。即使登录了也无法访问。
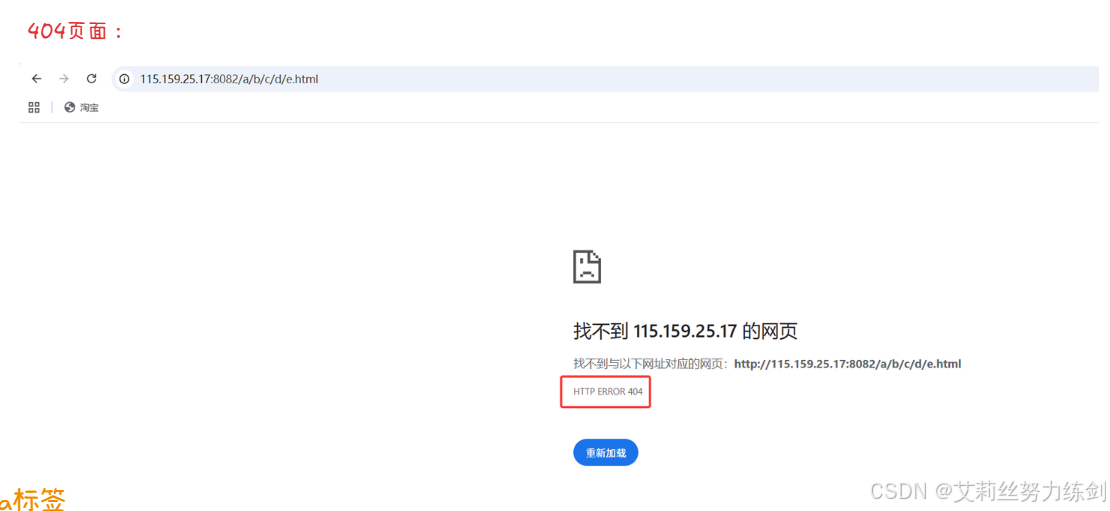
- 404 Not Found:请求的资源不存在。这是最常见的错误状态码,当我们输入了一个错误的 URL 时,服务器就会返回 404。
- 500 Internal Server Error:服务器内部错误。通常是服务器代码有 bug,或者数据库连接失败等原因导致的。
- 502 Bad Gateway:网关错误。当服务器作为代理或网关时,无法从上游服务器获取有效的响应。
- 503 Service Unavailable:服务器暂时无法处理请求。通常是服务器过载或者正在维护。
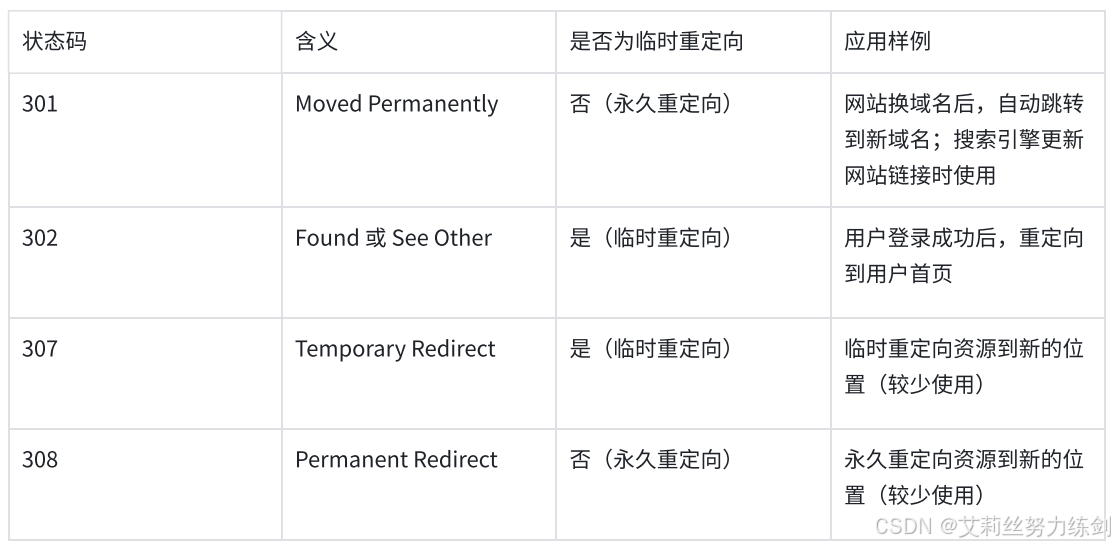
3.3 仅包含重定向相关的状态码
308比较少用。
4 ~> 重定向机制
重定向是 HTTP 协议中一个非常重要的功能,它允许服务器告诉客户端:“你请求的资源不在这个地址,请到另一个地址去获取”。客户端收到重定向响应后,会自动向新的地址发起请求。
4.1 重定向的本质与实现
重定向的实现非常简单,只需要两个条件:
1、返回一个 3XX 系列的状态码;
2、在响应报头中添加一个Location字段,指定新的 URL 地址。
例如,要将所有请求重定向到腾讯网,只需要在响应中设置状态码为 302,并添加Location: https://www.qq.com/报头即可。客户端收到这个响应后,会自动跳转到腾讯网。
重定向可以分为站内重定向和站外重定向。站内重定向是指跳转到同一个网站的其他页面,例如将不存在的页面重定向到 404 页面;站外重定向是指跳转到其他网站的页面。
4.2 301 永久重定向与 302 临时重定向的区别
最常用的重定向状态码是 301 和 302,它们的核心区别在于语义和缓存行为:
-
301 Moved Permanently(永久重定向):表示请求的资源已经被永久移动到了新的 URL 地址。浏览器和搜索引擎会缓存这个重定向结果,下次再访问原地址时,会直接跳转到新地址,而不会再向原地址发起请求。301 重定向适用于网站域名变更、页面 URL 重构等场景,它可以将原地址的搜索引擎权重转移到新地址。
-
302 Found(临时重定向):表示请求的资源暂时被移动到了新的 URL 地址。客户端下次再访问原地址时,仍然会向原地址发起请求,服务器再决定是否重定向。302 重定向适用于用户登录成功后跳转到首页、网站临时维护等场景。
4.2.1 小故事理解
我们可以用一个生活中的例子来理解这个区别:
临时重定向就像你去一家火锅店吃饭,发现门口贴了个通知:“因施工临时搬到西门”。你这次会去西门吃饭,但下次还是会先去东门看看,如果通知还在,再去西门。
永久重定向就像火锅店门口贴了个通知:“因生意更好,永久搬到西门”。你下次就会直接去西门吃饭,不会再去东门了。
在实现重定向时,需要注意一个常见的问题:重定向次数过多。如果重定向的目标地址又会重定向回原地址,就会形成一个无限循环,浏览器会在重定向一定次数后(通常是 20 次)自动停止,并显示错误页面。
5 ~> HTTP 请求方法
HTTP 请求方法定义了客户端对服务器上的资源执行的操作类型。HTTP/1.1 协议定义了多种请求方法,但在实际开发中,99% 的场景都只使用 GET 和 POST 方法。
5.1 常见 HTTP 方法概览
- GET:获取资源。这是最常用的方法,用于从服务器获取指定的资源。GET 方法应该是安全的和幂等的,即多次执行相同的 GET 请求,结果应该是一样的,并且不会对服务器上的资源产生任何修改。
- POST:传输实体主体。用于向服务器提交数据,通常用于创建新的资源或者提交表单数据。POST 方法不是安全的,也不是幂等的,多次执行相同的 POST 请求可能会产生不同的结果。
- PUT:传输文件。用于将请求正文中的文件保存到指定的 URL 位置。由于安全原因,大多数服务器都不会开启 PUT 方法。
- HEAD:获得报文首部。与 GET 方法类似,但服务器只返回响应报头,不返回响应正文。用于确认 URL 的有效性以及资源的更新时间等信息。
- DELETE:删除文件。用于删除指定 URL 位置的资源。同样由于安全原因,大多数服务器都不会开启 DELETE 方法。
- OPTIONS:询问支持的方法。用于查询服务器对指定资源支持的 HTTP 方法。
补充:除了GET和POST方法,其它的我们大概率用不到。
5.2 GET 方法与 URI 传参
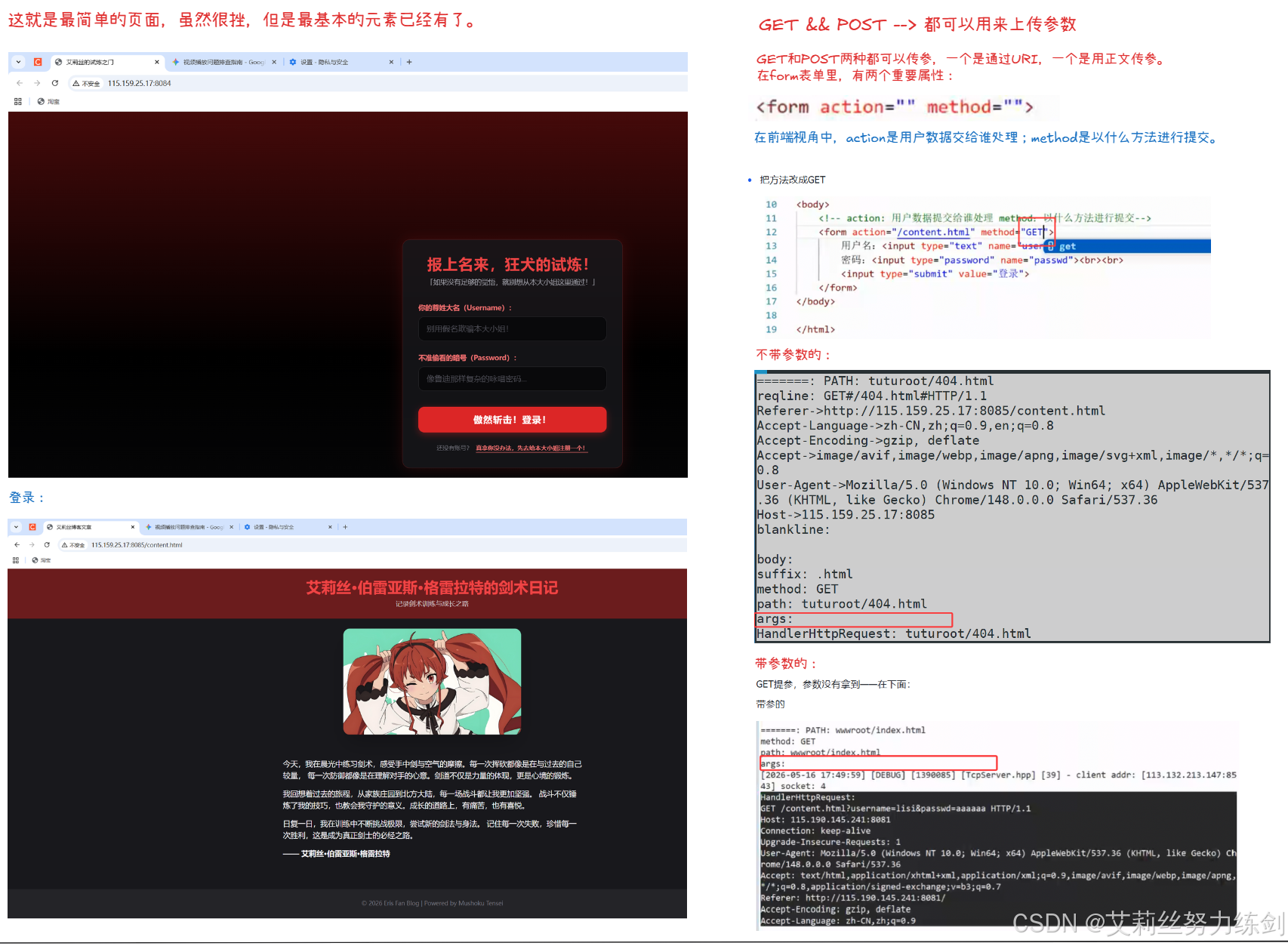
GET 方法不仅可以用于获取资源,还可以向服务器传递参数。GET 方法的参数是拼接在 URI 中的,格式为?key1=value1&key2=value2。例如/login?username=zhangsan&passwd=123456表示向/login地址提交了两个参数:username的值为zhangsan,passwd的值为123456。
服务器端需要解析 URI 中的参数。具体实现步骤如下:
1、在解析请求行时,检查 URI 中是否包含?字符。
2、如果包含?,则将?左边的部分作为资源路径,右边的部分作为参数字符串。
3、将参数字符串按照&分割成多个键值对。
4、将每个键值对按照=分割成键和值,存储起来供后续处理使用。
GET 方法传参的优点是简单、方便,缺点是参数会暴露在 URL 中,不安全,并且 URL 的长度有限制(不同浏览器的限制不同,通常在 2KB 到 8KB 之间),不适合传递大量数据。
5.3 POST 方法与正文传参
POST 方法将参数放在请求正文中传递,而不是拼接在 URI 中。POST 方法的参数格式与 GET 方法类似,也是key1=value1&key2=value2,但需要在请求报头中设置Content-Type: application/x-www-form-urlencoded,告诉服务器请求正文的格式。
服务器端需要读取请求正文来获取参数。具体实现步骤如下:
1、检查请求报头中是否包含Content-Length字段,该字段的值表示请求正文的字节数。
2、如果包含Content-Length字段,则从请求报文中读取对应字节数的内容作为请求正文。
3、将请求正文按照&分割成多个键值对。
4、将每个键值对按照=分割成键和值,存储起来供后续处理使用。
POST 方法传参的优点是参数不会暴露在 URL 中,相对安全,并且没有长度限制,可以传递大量数据。缺点是实现稍微复杂一些。
6 ~> 动态交互实现
前面实现的静态资源服务器只能返回服务器上已经存在的文件,无法处理用户提交的数据,也无法实现动态内容。要实现动态交互,我们需要让服务器能够根据用户提交的数据执行相应的逻辑,并返回动态生成的内容。
6.1 前后端交互的本质
很多初学者会误以为前端提交的数据是交给 HTML 页面处理的,这是一个常见的误解。静态的 HTML 文件只是一个文本文件,它没有能力处理数据,也无法与数据库交互。
真正处理用户数据的是运行在服务器上的后端程序。前端通过 form 表单将数据提交给后端程序,后端程序接收到数据后,进行验证、处理、与数据库交互等操作,然后将处理结果返回给前端。
我们可以用寄快递的例子来理解这个过程:
- form 表单就像是一个信封
- input 标签中的数据就像是信件的内容
- action 属性就像是收件人的地址
- 真正的收件人是后端程序,而不是 HTML 页面
在实际开发中,action 属性通常填写的是一个后端接口的地址,例如/login、/api/v1/auth等,而不是一个 HTML 文件的地址。
6.2 服务注册与路由机制
为了实现动态交互,我们需要在服务器中实现一个服务注册与路由机制。这个机制的核心思想是:将不同的 URL 路径映射到不同的处理函数,当客户端请求某个路径时,服务器自动调用对应的处理函数来处理请求。
具体实现步骤如下:
1、定义一个路由处理函数的类型,该函数接收两个参数:一个 HttpRequest 对象(包含请求的所有信息)和一个 HttpResponse 对象(用于构建响应)。
2、在 HttpServer 类中添加一个 unordered_map 成员变量,用于存储 URL 路径到处理函数的映射关系。
3、提供一个 Register 接口,允许上层代码将处理函数注册到指定的 URL 路径。
4、在处理请求时,先检查请求的路径是否已经注册了处理函数。如果已经注册,则调用对应的处理函数;如果没有注册,则按照静态资源的方式处理。
这种机制的优点是非常灵活,我们可以很方便地添加新的功能,只需要编写一个处理函数,然后注册到对应的 URL 路径即可,不需要修改服务器的核心代码。
6.3 完整的请求处理流程
现在,我们可以总结出一个完整的 HTTP 请求处理流程:
1、服务器接收到客户端发送的 HTTP 请求报文。
2、对请求报文进行反序列化,解析出请求行、请求报头和请求正文,构建一个 HttpRequest 对象。
检查请求的路径是否已经注册了处理函数:
3、如果已经注册,则调用对应的处理函数,将 HttpRequest 对象和一个空的 HttpResponse 对象传递给处理函数。处理函数执行相应的业务逻辑,填充 HttpResponse 对象的内容。
- 如果没有注册,则按照静态资源的方式处理:读取对应路径的文件内容,如果文件存在,则构建一个 200 OK 的响应,将文件内容作为响应正文;
- 如果文件不存在,则构建一个 404 Not Found 的响应,或者重定向到 404 页面。
4、对 HttpResponse 对象进行序列化,生成 HTTP 响应报文。
5、将响应报文发送给客户端。
7 ~> 实验与测试:理论与实践相结合
写代码不是目的,实践才是目的。
7.1 HttpProtocol.hpp
#ifndef __HTTP_PROTOCOL_HPP
#define __HTTP_PROTOCOL_HPP
#include <iostream>
#include <string>
#include <unordered_map> // key_value
#include <sstream>
// 日志
#include "Logger.hpp"
// 怎么提取?分隔符 --> 我要把分隔符暴露出来
const std::string linesep = "\r\n"; // 空行
// 我需要一个报头的分隔符
const std::string headersep = ": ";
// tuturoot
const std::string webroot = "tuturoot";
// 家目录
const std::string homepage = "index.html";
// 版本号
const std::string gdefault_version = "HTTP/1.0"; // 这个也可以配置文件化
// 如何把一个应答序列化?来一个空格描述符
const std::string gspace = " ";
// 资源后缀的分隔符
const std::string suffixsep = ".";
// GET请求参数分隔符 --> 在Request里面,把参数和方法分开
const std::string argsep = "?";
// 命名空间
using namespace LogModule;
// 示例:协议格式
// 前3行:带长度前缀的自定义协议格式("长度"\r\nJSON内容)
// "40"\r\n{"float":3.14, "int": 100, "s1": "helloworld", "s2": "hello bit"}
// "40"\r\n{"float":3.14, "int": 100, "s1": "helloworld", "s2": "hello bit"}
// "40"\r\n{"float":3.14, "int": 100, "s1": "helloworld", "s2": "hello bit"}
// 最后1行:纯JSON格式,没有长度前缀
// {"float":3.14, "int": 100, "s1": "helloworld", "s2": "hello bit"}
// HTTP协议底层就是TCP协议
// 也需要请求和应答
class HttpRequest
{
private:
// 把请求行读出来
int ReadOneLine(std::string &streamstr,std::string *line) // \r\n
{
// 1. 在输入字节流中查找行分隔符 "\r\n" 的位置
auto pos = streamstr.find(linesep);
// 2. 如果没找到行分隔符,说明数据不完整,返回空字符串
if(pos == std::string::npos) // 整个字符串里没有分隔符
// return std::string(); // 返回值字符串是空串
return -1; // 参数要匹配
// 3. 从字节流开头截取到分隔符之前,得到一行完整内容
*line = streamstr.substr(0,pos); // 截止到pos位置
// 4. 从字节流中删除已经读取的这一行(包括 "\r\n" 分隔符),
// 方便下次调用时读取下一行
streamstr.erase(0,pos + linesep.size()); // 删的时候删到换行符
// // 5. 返回读取到的这一行
// return line;
return line->size(); // >=(表示截取成功;等于0的时候说明读到空串)
}
// 把stringstream以文件的形式写到网络
void ParseReqLine(std::string &status_line)
{
std::stringstream ss(status_line);
ss >> _method >> _uri >> _http_version;
// 比如说资源是:/a/b/c.html or /
// 这个资源会被拼接到http当中
if(_uri == "/") // 请求根目录就返回一个首页
{
_path = webroot + _uri + homepage; // tuturoot + / + index.html
}
else
{
_path = webroot + _uri; // tuturoot/a/b/c.html _uri = / + index.html(Web自己设置的根目录)
}
// /content.html?username=zhangsan&passwd=123456
// 把method统一转大写什么的也可以,这里就直接大小写都写了
if(_method == "GET" || _method == "get")
{
// ?:就是argsep,?右边就是我要的参数(带参了)
// URI提取出来,我用的是path,直接在path里面找
auto pos = _path.find(argsep);
if(pos != std::string::npos) // 双重否定表肯定,这里就是带?
{
// 参数和请求分开了
_args = _path.substr(pos + argsep.size());
_path = _path.substr(0, pos); // 这样_path只是单纯保存了我需要的路径
}
}
// 分析请求的资源的后缀! // tuturoot + / + index.html tuturoot/image/Alice.png tuturoot/css/XXX.css
// .是资源后缀分隔符
// 字符串里要倒着查找,从右向左找
auto pos = _path.rfind(suffixsep);
if(pos == std::string::npos) // 等于npos说明没找到
_suffix = ".html";
else // 找到了。截取
_suffix = _path.substr(pos); // .css .html .jpg --> 得到后缀
// 出问题了,登录页面一直404,打印检查一下 --> 有可能是没保存Login.html
std::cout << "=======: PATH: " << _path << std::endl;
}
// 打印
void PrintDebug()
{
std::cout << "reqline: " << _method << "#" << _uri << "#" << _http_version << std::endl;
// 遍历headerkv
for(auto &item : _header_kv)
{
std::cout << item.first << "->" << item.second << std::endl;
}
// 把空行打印出来
std::cout << "blankline: " << _blankline << std::endl; // 空行这里再加个换行
// 我的body现在没什么东西,加点东西
std::cout << "body: " << _body << std::endl;
// 打印资源后缀名
std::cout << "suffix: " << _suffix << std::endl;
}
// 单独设计一个分割字符串的接口
void SplitString(std::string &line,std::string *key,std::string *value,std::string sep = headersep)
{
// headersep设置为“:”,就是以:为分隔符
auto pos = line.find(sep);
if(pos == std::string::npos) // 没有返回空串
return;
*key = line.substr(0,pos);
*value = line.substr(pos + sep.size());
}
public:
HttpRequest()
{}
// 提供一个反序列化的接口
void Deserialize(std::string &streamstr)
{
// 从网络当中传递一个字节流信息,然后转换成结构化信息
// 1.读取第一行
std::string status_line;
int n = ReadOneLine(streamstr,&status_line);
(void)n;
// GET /a/b/c/d/e.html HTTP/1.1
// GET / HTTP/1.1
// 2.解析请求行
ParseReqLine(status_line);
// PrintDebug();
// 3.提取请求报头
n = 0; // 第一行已经被移除了
do
{
std::string line;
n = ReadOneLine(streamstr,&line);
if(n > 0)
{
std::string key,value;
SplitString(line,&key,&value,headersep);
// 都不为空说明取到了合法的key_value值
if(!key.empty() && !value.empty())
{
_header_kv[key] = value;
}
}
else if(n == 0)
{
_blankline = "\r\n";
break;
}
else
{
LOG(LogLevel::DEBUG) << "bug???";
break;
}
}while(n > 0);
// 请求的正文是否存在
if(_header_kv.find("Content-Length") != _header_kv.end())
{
// 不存在就什么都不做
int len = std::stoi(_header_kv["Content-Length"]);
// 前面都已经去掉了,这里就读到body了
_body = streamstr.substr(0,len);
// 请求只要有body,必然是参数 --> 稳妥一点,考虑大小写
if(_method == "POST" || _method == "post")
{
_args = _body;
}
// _body = streamstr;
}
PrintDebug();
}
// 在Request里面做一个运算符重载(只读),重载一个中括号,因为原来获取URI的方式不太优雅
// 这里引用不能引用常量字符串,把const和&去掉
std::string operator [](const std::string &key) const // 未来提供一个key就行
{
// 把一堆GET方法,封装从接口,以只读方式访问
if(key == "method")
return _method;
else if(key == "uri")
return _uri;
else if(key == "httpversion")
return _http_version;
else if(key == "body")
return _body;
// else if(key == "uri")
// return _uri;
// 不要请求uri了,在当前代码中还存在像/a/b/c.html这样的特殊情况
else if(key == "path")
return _path;
else if(key == "suffix")
return _suffix;
// 经过序列化之后
else if(key == "args")
return _args;
else
{
auto iter = _header_kv.find(key);
if(iter != _header_kv.end())
return iter->second;
}
return std::string(); // 返回一个空串
}
~HttpRequest()
{}
private:
// 请求方法、URI、HTTP版本、Key:[空格]Value,还有空行
std::string _method;
std::string _uri; // /a/b/c.html /(特殊情况)
std::string _http_version;
std::unordered_map<std::string,std::string> _header_kv;
std::string _blankline;
// 除了请求还要有一个请求的正文
std::string _body;
private:
std::string _path;
std::string _args;
std::string _suffix;
};
// 处理请求,构建应答
class HttpResponse
{
public:
HttpResponse() : _http_version(gdefault_version),_blankline(linesep) // 版本和空行都有了
{}
~HttpResponse() {}
void Serialize(std::string *outstr)
{
// 状态行:空格为分隔符
std::string status_line = _http_version + gspace + std::to_string(_status_code) + gspace + _status_code_desc + linesep;
// 响应报头
std::string headers;
for(auto &item : _resp_headerkv)
{
std::string header = item.first + headersep + item.second + linesep;
headers += header;
}
*outstr = status_line + headers + _blankline + _body; // 状态行 + 响应报头 + 空行 + 正文
}
// 把正文内容拿进来
void SetBody(const std::string &content)
{
_body = content;
}
// 状态码
void SetCode(int code)
{
_status_code = code;
// code和描述是一对一的
_status_code_desc = Code2Desc(code);
// // 文件长度字段可以不放在外面,因为添加_body的时候就可以这样
// SetHeader("Content-Length"); // -->这里我还是放在外面吧
}
// 我需要一个设置报头的接口
void SetHeader(const std::string &key, int value)
{
_resp_headerkv[key] = std::to_string(value);
}
// 报头当中的字段如果想去外部加可以这样
void SetHeader(const std::string &key, const std::string &value)
{
_resp_headerkv[key] = value;
}
private:
std::string Code2Desc(int code)
{
switch(code)
{
// 直接映射
// case 200:
// return "OK";
// 1xx: 信息响应
case 100:
return "Continue";
case 101:
return "Switching Protocols";
case 102:
return "Processing"; // WebDAV
case 103:
return "Early Hints";
// 2xx: 成功
case 200:
return "OK";
case 201:
return "Created";
case 202:
return "Accepted";
case 203:
return "Non-Authoritative Information";
case 204:
return "No Content";
case 205:
return "Reset Content";
case 206:
return "Partial Content";
case 207:
return "Multi-Status"; // WebDAV
case 208:
return "Already Reported";
case 226:
return "IM Used";
// 3xx: 重定向
case 300:
return "Multiple Choices";
case 301:
return "Moved Permanently";
case 302:
return "Found"; // 如果是302,就会自动拼接这个
case 303:
return "See Other";
case 304:
return "Not Modified";
case 305:
return "Use Proxy";
case 306:
return "Switch Proxy"; // 已废弃,但仍保留
case 307:
return "Temporary Redirect";
case 308:
return "Permanent Redirect";
// 4xx: 客户端错误
case 400:
return "Bad Request";
case 401:
return "Unauthorized";
case 402:
return "Payment Required";
case 403:
return "Forbidden";
case 404:
return "Not Found";
case 405:
return "Method Not Allowed";
case 406:
return "Not Acceptable";
case 407:
return "Proxy Authentication Required";
case 408:
return "Request Timeout";
case 409:
return "Conflict";
case 410:
return "Gone";
case 411:
return "Length Required";
case 412:
return "Precondition Failed";
case 413:
return "Payload Too Large";
case 414:
return "URI Too Long";
case 415:
return "Unsupported Media Type";
case 416:
return "Range Not Satisfiable";
case 417:
return "Expectation Failed";
case 418:
return "I'm a teapot"; // 愚人节笑话,但常被实现
case 421:
return "Misdirected Request";
case 422:
return "Unprocessable Entity"; // WebDAV
case 423:
return "Locked";
case 424:
return "Failed Dependency";
case 425:
return "Too Early";
case 426:
return "Upgrade Required";
case 428:
return "Precondition Required";
case 429:
return "Too Many Requests";
case 431:
return "Request Header Fields Too Large";
case 451:
return "Unavailable For Legal Reasons";
// 5xx: 服务端错误
case 500:
return "Internal Server Error";
case 501:
return "Not Implemented";
case 502:
return "Bad Gateway";
case 503:
return "Service Unavailable";
case 504:
return "Gateway Timeout";
case 505:
return "HTTP Version Not Supported";
case 506:
return "Variant Also Negotiates";
case 507:
return "Insufficient Storage"; // WebDAV
case 508:
return "Loop Detected";
case 510:
return "Not Extended";
case 511:
return "Network Authentication Required";
// 未知状态码
default:
return "Unknown";
}
}
private:
// 结构化字段
std::string _http_version; // HTTP协议版本,如 "HTTP/1.1"
int _status_code; // 状态码,如 200(成功)、404(未找到)、500(服务器错误)
std::string _status_code_desc; // 状态码描述,如 "OK"、"Not Found"、"Internal Server Error"
std::unordered_map<std::string,std::string> _resp_headerkv; // 响应头键值对,如 Content-Type、Content-Length
std::string _blankline; // 空行,用于分隔响应头和响应体
std::string _body; // 正文:响应体,如网页内容、JSON数据等
};
#endif
7.2 HttpServer.hpp
#ifndef __HTTPSERVER_HPP
#define __HTTPSERVER_HPP
// Http就不用写客户端了,因为是和浏览器连接,浏览器就是客户端
#include <iostream>
#include <string>
#include <memory>
#include <fstream>
#include <functional>
#include <unordered_map>
#include "TcpServer.hpp"
#include "Logger.hpp"
#include "HttpProtocol.hpp"
// 命名空间包一下
using namespace LogModule;
using route_t = std::function<void(const HttpRequest &req,HttpResponse &resp)>;
class HttpServer
{
public:
// ===== 原来的代码(已注释)=====
HttpServer(uint16_t port)
: _port(port),
_tsvr(std::make_unique<TcpServer>(port))
{}
// 不想这样写就在类里面写这样一个接口
std::string HandlerHttpRequest(std::string &streamstr)
{
// 1.报文完整性这里不管啦,不是不存在粘包问题,粘包问题是个小概率事件,这里先不考虑,默认报文是完整的
// 2.反序列化
HttpRequest httpreq; // 服务端接收到的是一个请求
httpreq.Deserialize(streamstr);
// 3. 处理请求,构建应答:httpreq --> httpresp
HttpResponse httpresp;
if(NeedHandler(httpreq["uri"])) // NeedHandler -> 处理了动态资源,用uri匹配路由!
{
_route[httpreq["uri"]](httpreq,httpresp); // 用原始uri做路由key!
}
else
{
// 处理静态资源请求,构建应答:httpreq --> httpresp
std::string filecontent = GetFileContentHelper(httpreq["path"]);
std::string suffix = httpreq["suffix"]; // 得到请求资源的后缀
if(filecontent.empty())
{
// httpresp.SetCode(302);
// httpresp.SetHeader("Location", "/404.html"); // 要从根目录开始请求
}
else
{
httpresp.SetCode(200);
httpresp.SetHeader("Content-Length",filecontent.size()); // 长度就是文件内容的大小
httpresp.SetHeader("Content-Type",Suffix2Type(suffix)); // 资源后缀转成type
httpresp.SetBody(filecontent);
}
}
// 4.应答序列化:把结构化的字段变成字符串
std::string httprespstr;
httpresp.Serialize(&httprespstr);
// 5.返回:返回应答的序列化字段
return httprespstr;
}
// 回调有了
void Run()
{
// _tsvr->Run();
// 写一个lambda
_tsvr->Run([this](std::string &streamstr)->std::string{
return this->HandlerHttpRequest(streamstr);
});
}
// route_t:方法路由
void Register(std::string key,route_t handler)
{
_route[key] = handler;
}
~HttpServer()
{}
private:
bool NeedHandler(const std::string &key)
{
return _route.find(key) != _route.end();
}
std::string GetFileContentHelper(const std::string &filename)
{
std::ifstream in(filename);
if(!in.is_open())
{
return std::string();
}
in.seekg(0,in.end);
int filesize = in.tellg();
in.seekg(0,in.beg);
std::string content;
content.resize(filesize);
in.read((char*)content.c_str(),filesize);
in.close();
return content;
}
// suffix: .html
// return: text/html
std::string Suffix2Type(const std::string &suffix) // 可以设置到内部,但是暴露出来比较有仪式感
{
// if(suffix == ".html")
// return "text/html";
// 使用静态映射表提高效率,避免每次调用都重新创建
// static静态成员,只会初始化一次
static const std::unordered_map<std::string, std::string> mime_map = {
// 一样才冲突,不一样不冲突
// 文本类型
{".html", "text/html"},
{".htm", "text/html"},
{".css", "text/css"},
{".js", "application/javascript"},
{".mjs", "application/javascript"},
{".json", "application/json"},
{".xml", "application/xml"},
{".txt", "text/plain"},
{".csv", "text/csv"},
{".md", "text/markdown"},
// 图片类型
{".jpg", "image/jpeg"},
{".jpeg", "image/jpeg"},
{".png", "image/png"},
{".gif", "image/gif"},
{".bmp", "image/bmp"},
{".webp", "image/webp"},
{".svg", "image/svg+xml"},
{".ico", "image/x-icon"},
{".tiff", "image/tiff"},
{".tif", "image/tiff"},
// 字体类型
{".woff", "font/woff"},
{".woff2", "font/woff2"},
{".ttf", "font/ttf"},
{".otf", "font/otf"},
// 视频类型
{".mp4", "video/mp4"},
{".webm", "video/webm"},
{".ogv", "video/ogg"},
{".avi", "video/x-msvideo"},
{".mov", "video/quicktime"},
{".mpeg", "video/mpeg"},
{".mpg", "video/mpeg"},
// 音频类型
{".mp3", "audio/mpeg"},
{".wav", "audio/wav"},
{".ogg", "audio/ogg"},
{".flac", "audio/flac"},
{".m4a", "audio/mp4"},
{".aac", "audio/aac"},
// 应用类型
{".pdf", "application/pdf"},
{".zip", "application/zip"},
{".rar", "application/vnd.rar"},
{".7z", "application/x-7z-compressed"},
{".tar", "application/x-tar"},
{".gz", "application/gzip"},
{".exe", "application/vnd.microsoft.portable-executable"},
{".dll", "application/x-msdownload"},
{".msi", "application/x-msi"},
{".doc", "application/msword"},
{".docx", "application/vnd.openxmlformats-officedocument.wordprocessingml.document"},
{".xls", "application/vnd.ms-excel"},
{".xlsx", "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet"},
{".ppt", "application/vnd.ms-powerpoint"},
{".pptx", "application/vnd.openxmlformats-officedocument.presentationml.presentation"},
{".wasm", "application/wasm"},
// 其他常见类型
{".jsonld", "application/ld+json"},
{".rss", "application/rss+xml"},
{".atom", "application/atom+xml"},
{".manifest", "text/cache-manifest"},
{".map", "application/json"}, // source maps
{".ts", "video/mp2t"}, // MPEG transport stream
{".m3u8", "application/vnd.apple.mpegurl"}
};
auto it = mime_map.find(suffix);
if (it != mime_map.end())
{
return it->second;
}
// 默认返回二进制流,或根据需求返回其他默认值
return "application/octet-stream";
}
private:
// 端口号
uint16_t _port;
// 这里要有一个协议字段
// std::unique_ptr<HttpProtocol> _protocol; // 不想这样写就在类里面写一个接口
std::unique_ptr<TcpServer> _tsvr;
// 注册服务
std::unordered_map<std::string, route_t> _route; // 注册服务的容器
};
#endif
7.3 目录结构
7.4 效果演示
7.4.1 个人博客网站首页
7.4.2 404页面
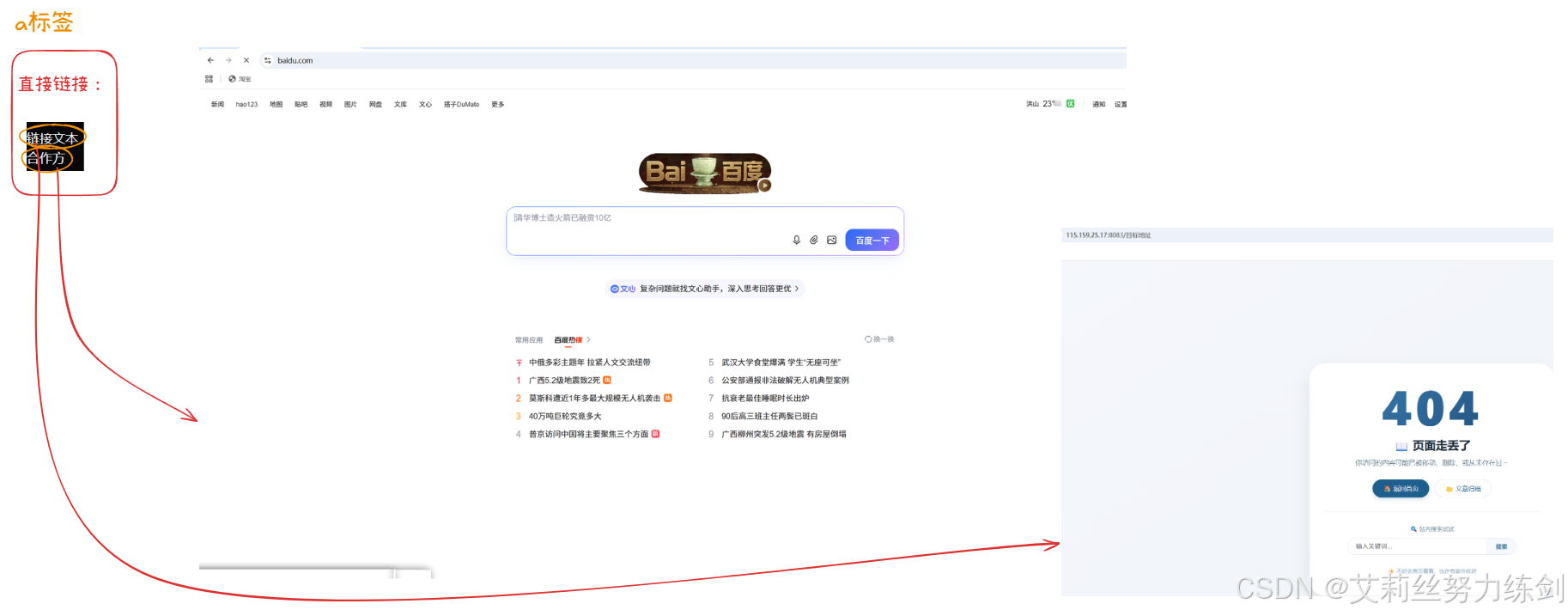
7.4.3 a标签
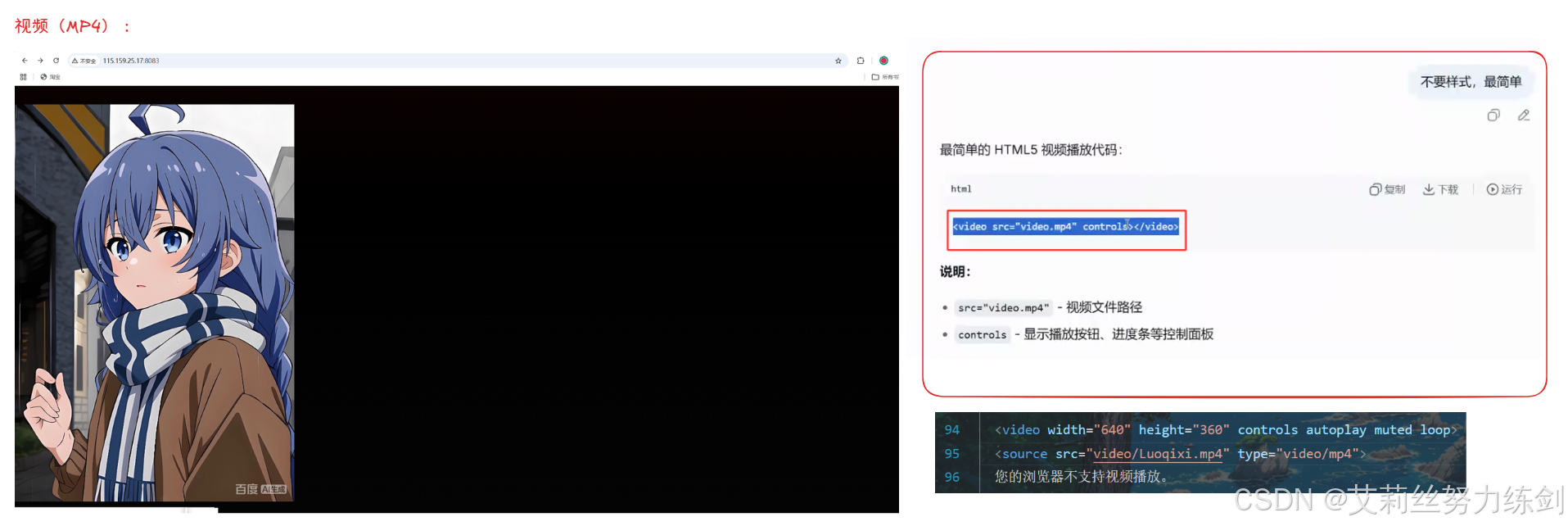
7.4.4 视频(MP4格式)
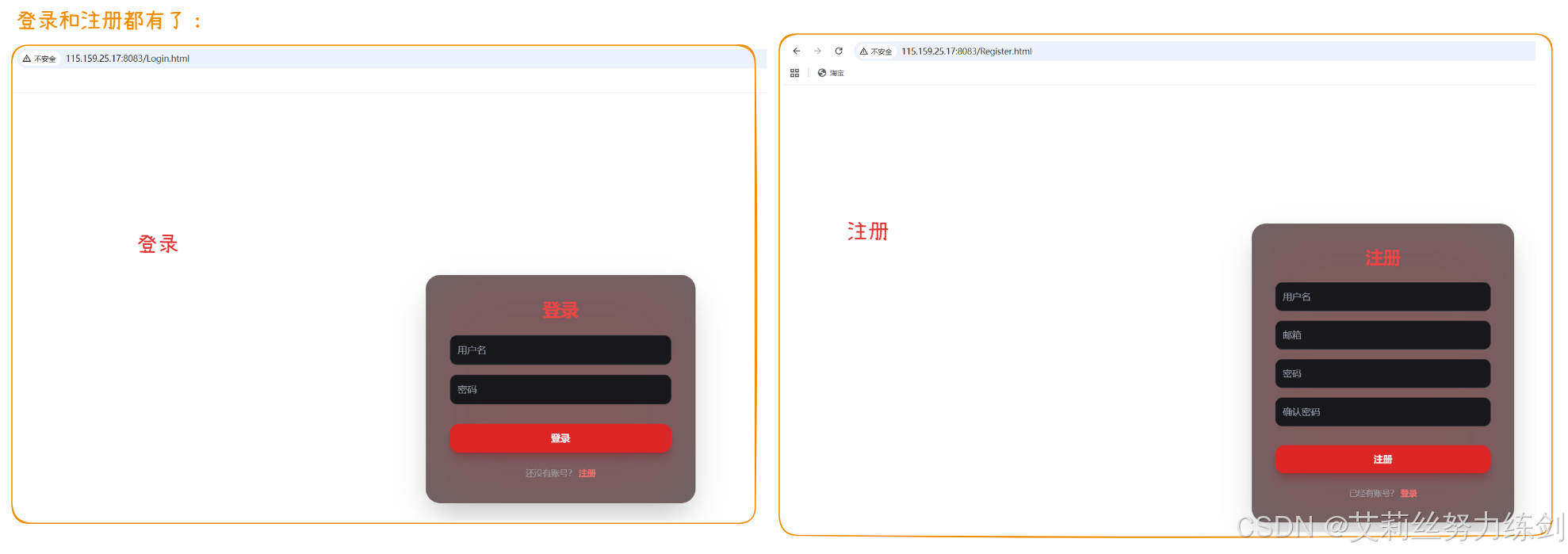
7.4.5 登录和注册
总结
本文通过从零实现一个 C++ HTTP 服务器的过程,深入讲解了 HTTP 协议的核心原理。我们从最基础的请求响应报文结构开始,一步步实现了静态资源的读取与返回、状态码的处理、重定向功能,最终实现了支持 GET 和 POST 方法的动态交互服务器。
通过本文的学习,我们应该掌握以下重点内容:
1、HTTP 报文结构:HTTP 请求和响应都由四部分组成:请求行 / 状态行、报头、空行和正文。所有的通信都遵循这个严格的格式。
2、静态资源处理:Web 根目录用于隔离服务器文件系统,保证安全;必须使用二进制方式读取文件,避免内容被截断;通过文件后缀名映射 MIME 类型,设置正确的 Content-Type 报头;一个网页对应多个 HTTP 请求,可以使用图床和 CDN 减轻服务器压力。
3、HTTP 状态码:状态码分为五大类,分别表示不同的处理结果。常见的状态码有 200(成功)、404(资源不存在)、500(服务器内部错误)等。状态码和状态码描述是一一对应的。
4、重定向机制:重定向通过 3XX 状态码 + Location 报头实现。301 是永久重定向,会被浏览器和搜索引擎缓存;302 是临时重定向,每次都会请求原地址。
5、HTTP 请求方法:GET 方法通过 URI 传参,参数可见,长度有限制;POST 方法通过正文传参,参数不可见,长度无限制。99% 的 Web 场景都只使用这两个方法。
6、动态交互实现:静态 HTML 无法处理数据,真正处理数据的是后端程序。通过服务注册与路由机制,可以将不同的 URL 路径映射到不同的处理函数,实现灵活的动态交互功能。
HTTP 协议是 Web 开发的基础,只有深入理解了 HTTP 协议的工作原理,才能写出高质量的 Web 应用。本文实现的 HTTP 服务器虽然简单,但已经涵盖了 HTTP 协议的核心功能,你可以在此基础上继续扩展,例如添加 Cookie 和 Session 支持、HTTPS 支持、并发处理等功能,进一步加深对 HTTP 协议的理解。
结尾
uu们,本文的内容到这里就全部结束了,艾莉丝在这里再次感谢您的阅读!
|

结语:希望对学习Linux相关内容的uu有所帮助,不要忘记给博主“一键四连”哦!
往期回顾:
【Linux网络】Linux 网络编程:HTTP(二)HTTP协议请求应答宏观格式(附代码演示)
🗡博主在这里放了一只小狗,大家看完了摸摸小狗放松一下吧!🗡 ૮₍ ˶ ˊ ᴥ ˋ˶₎ა


openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 15
15 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)