【Linux网络】Linux 网络编程:HTTP(四)从手写服务器到生产级 Nginx 与 cpp-httplib 实战
底层实现:HTTP基于TCP协议,通过字节流解析、资源分发(静态/动态)、路由注册实现服务。手写HTTP服务器帮助理解协议本质,掌握报文解析、回调函数、前后端联动等核心技能。报文与报头:HTTP报文由起始行、头部、空行、体部组成。核心报头包括Host(虚拟主机/代理)、User-Agent(客户端标识/反爬)、Referer(防盗链/CSRF)、Location(重定向)、Connection(连

《Linux操作系统编程详解》《笔试/面试常见算法:从基础到进阶》《Python干货分享》
🎬 艾莉丝的简介:

文章目录

大纲

HTTP协议核心详解
├─ 1 HTTP服务底层实现
│ ├─ 1.1 整体架构与核心文件
│ ├─ 1.2 核心处理流程
│ ├─ 1.3 静态资源处理
│ ├─ 1.4 动态资源处理与路由注册
│ │ ├─ 1.4.1 路由表实现
│ │ ├─ 1.4.2 业务服务注册示例
│ │ └─ 1.4.3 前后端表单联动
│ └─ 1.5 RESTful接口设计规范
├─ 2 HTTP报文与核心报头
│ ├─ 2.1 报文通用结构
│ ├─ 2.2 核心请求头详解
│ │ ├─ 2.2.1 Host
│ │ ├─ 2.2.2 User-Agent
│ │ ├─ 2.2.3 Referer
│ │ ├─ 2.2.4 Location
│ │ └─ 2.2.5 Connection
│ └─ 2.3 常见Content-Type类型
├─ 3 HTTP连接管理:长连接与短连接
│ ├─ 3.1 短连接(HTTP/1.0默认)
│ ├─ 3.2 长连接(HTTP/1.1默认)
│ └─ 3.3 版本差异对比
├─ 4 HTTP请求方法全解
│ ├─ 4.1 核心方法:GET vs POST
│ ├─ 4.2 其他常用方法
│ │ ├─ 4.2.1 HEAD
│ │ ├─ 4.2.2 PUT
│ │ ├─ 4.2.3 DELETE
│ │ └─ 4.2.4 OPTIONS
│ └─ 4.3 curl工具调试方法
├─ 5 Nginx生产级HTTP服务器
│ ├─ 5.1 Nginx核心特性
│ ├─ 5.2 安装与基础操作
│ ├─ 5.3 核心文件路径(Ubuntu apt安装)
│ └─ 5.4 静态资源部署实战
├─ 6 C++ HTTP开源库:cpp-httplib
│ ├─ 6.1 库特性
│ ├─ 6.2 基础服务器搭建
│ └─ 6.3 静态资源托管
├─ 7 完整工程结构与依赖说明
│ ├─ 7.1 手写HTTP服务器完整工程
│ └─ 7.2 cpp-httplib工程结构
└─ 8 代码编译运行说明与常见问题排查
├─ 8.1 通用编译环境要求
├─ 8.2 手写HTTP服务器常见问题
├─ 8.3 Nginx常见问题
└─ 8.4 cpp-httplib常见问题
导入语
HTTP(超文本传输协议)是互联网的基石,从浏览器打开网页、手机APP加载数据到后端服务间的调用,几乎所有网络交互都基于HTTP。很多人只知道HTTP是"请求-响应"模式,但不清楚它如何基于TCP实现字节流到结构化数据的转换,如何区分静态资源和动态服务,生产环境中又用什么工具替代手写的简陋服务器。
本文将从底层代码实现出发,带你手写一个完整的HTTP服务器,理解静态资源返回、动态路由注册、前后端表单联动的核心逻辑;然后深入协议细节,拆解HTTP报文结构和每个核心报头的作用,搞懂长连接为什么能提升性能;接着介绍生产级工具Nginx,学习如何部署静态网站和配置基础服务;最后引入开源库cpp-httplib,展示如何快速搭建工业级HTTP服务。全程结合代码示例和实验现象,让你不仅"知其然",更"知其所以然"。
1 HTTP服务底层实现
HTTP本质上是基于TCP的应用层协议,它定义了客户端和服务器之间交换数据的格式。我们手写的HTTP服务器,核心就是在TcpServer的基础上,对TCP传输的字节流进行解析、处理和封装。
1.1 整体架构与核心文件
我们的HTTP服务器采用分层设计,底层依赖TcpServer处理TCP连接和字节流传输,上层由HttpServer实现HTTP协议的解析和业务逻辑分发。核心文件包括:
TcpServer.hpp:封装TCP服务器,负责监听端口、接受连接、接收和发送字节流HttpServer.hpp:实现HTTP协议核心逻辑,包括报文解析、资源分发、路由注册HttpProtocol.hpp:定义HttpRequest和HttpResponse结构化数据,提供序列化/反序列化方法InetAddr.hpp:封装网络地址(IP+端口)操作Socket.hpp:封装Socket系统调用Logger.hpp:日志模块,支持控制台和文件输出Main.cc:程序入口,注册业务服务并启动服务器
1.2 核心处理流程
当客户端发起HTTP请求时,服务器的处理流程如下:
- 字节流接收:TcpServer调用
Recv方法从socket读取字节流到缓冲区 - 报文完整性校验:检查缓冲区中是否包含完整的HTTP报文(空行
\r\n\r\n分隔头部和体部,结合Content-Length判断体部长度) - 反序列化:将字节流解析为结构化的
HttpRequest对象,提取请求方法、路径、参数、头部等信息 - 资源分发:
- 如果请求路径在路由表中存在,调用对应的回调函数处理动态资源
- 如果不存在,尝试读取本地文件返回静态资源
- 响应构造:根据处理结果生成
HttpResponse对象,设置状态码、头部和体部 - 序列化与发送:将
HttpResponse序列化为字节流,通过socket发送给客户端 - 连接管理:根据Connection头部决定是否关闭连接(短连接直接关闭,长连接等待下一个请求)
核心代码逻辑如下:
// HttpServer.hpp 核心处理函数
std::string HandlerHttpRequest(std::string &streamstr) {
// 1. 报文完整性校验(需实现:按\r\n\r\n分割头部,根据Content-Length读取体部)
// 2. 反序列化字节流为HttpRequest对象
HttpRequest httpreq;
httpreq.Deserialize(streamstr);
HttpResponse httpresp;
// 3. 资源分发:判断是否为动态路由
if (IsNeedRoute(httpreq["path"])) {
// 调用注册的业务回调函数
_route[httpreq["path"]](httpreq, httpresp);
} else {
// 处理静态资源:读取本地文件
std::string filecontent = GetFileContentHelper(httpreq["path"]);
std::string suffix = httpreq["suffix"];
if (filecontent.empty()) {
// 资源不存在:301重定向到404页面
httpresp.SetCode(301);
httpresp.SetHeader("Location", "/404.html");
} else {
// 资源存在:构造200响应
httpresp.SetCode(200);
httpresp.SetHeader("Content-Length", std::to_string(filecontent.size()));
httpresp.SetHeader("Content-Type", Suffix2Type(suffix));
httpresp.SetBody(filecontent);
}
}
// 4. 序列化HttpResponse为字节流并返回
return httpresp.Serialize();
}
1.3 静态资源处理
静态资源是指服务器上预先存在的文件,如HTML页面、CSS样式表、JavaScript脚本、图片、视频等。这些资源不需要服务器进行业务处理,直接读取文件内容返回即可。
静态资源处理的核心逻辑:
- 根据请求路径拼接本地文件系统路径(如
/index.html映射到wwwroot/index.html) - 尝试读取文件内容,如果读取失败(文件不存在或权限不足),返回301重定向到404页面
- 如果读取成功,根据文件后缀名设置对应的
Content-Type头部(如.html对应text/html,.jpg对应image/jpeg) - 设置
Content-Length头部为文件内容的长度,确保客户端能正确解析响应体 - 将文件内容作为响应体返回
1.4 动态资源处理与路由注册
动态资源是指需要服务器根据请求参数进行业务处理后生成的内容,如登录验证、用户注册、搜索结果等。动态资源处理通过路由注册机制实现:服务器维护一个路由表,将URI路径与对应的处理函数关联起来。
1.4.1 路由表实现
路由表使用std::unordered_map<std::string, route_t>存储,其中key是URI路径,value是处理函数(回调函数)。处理函数的签名为void(const HttpRequest &, HttpResponse &),接收请求对象并填充响应对象。
// HttpServer.hpp 路由相关定义
using route_t = std::function<void(const HttpRequest &, HttpResponse &)>;
private:
std::unordered_map<std::string, route_t> _route; // 路由表:URI -> 处理函数
// 判断路径是否需要路由(是否在路由表中)
bool IsNeedRoute(const std::string &key) {
return _route.find(key) != _route.end();
}
public:
// 注册服务接口:将URI与处理函数绑定
void Register(std::string uri, route_t handler) {
std::string key = webroot + uri; // webroot为静态资源根目录
_route[key] = handler;
}
1.4.2 业务服务注册示例
在Main.cc中,我们可以注册多个业务服务,如登录、注册、搜索、调用大模型等:
// Main.cc 业务服务实现与注册
#include "HttpServer.hpp"
// 登录服务
void Login(const HttpRequest &req, HttpResponse &resp) {
std::string args = req["args"]; // 获取GET请求的查询参数
std::cout << "-----> Login service, args: " << args << std::endl;
// 实际场景:解析args,查询数据库验证用户名密码
resp.SetCode(200);
resp.SetHeader("Content-Type", "text/plain");
resp.SetBody("Login success!\n");
}
// 注册服务
void Register(const HttpRequest &req, HttpResponse &resp) {
std::string args = req["args"];
std::cout << "-----> Register service, args: " << args << std::endl;
resp.SetCode(200);
resp.SetHeader("Content-Type", "text/plain");
resp.SetBody("Register success!\n");
}
// 搜索服务
void Search(const HttpRequest &req, HttpResponse &resp) {
std::string args = req["args"];
std::cout << "-----> Search service, args: " << args << std::endl;
// 实际场景:从数据库查询搜索结果
resp.SetCode(200);
resp.SetHeader("Content-Type", "text/plain");
resp.SetBody("Search results for: " + args + "\n");
}
// 大模型调用服务
void CallBigModel(const HttpRequest &req, HttpResponse &resp) {
std::string args = req["args"];
std::cout << "-----> BigModel service, args: " << args << std::endl;
resp.SetCode(200);
resp.SetHeader("Content-Type", "text/plain");
resp.SetBody("BigModel response for: " + args + "\n");
}
int main(int argc, char *argv[]) {
if (argc != 2) {
std::cerr << "Usage: " << argv[0] << " <port>" << std::endl;
exit(1);
}
ENABLE_CONSOLE_LOG_STRATEGY(); // 启用控制台日志
uint16_t port = std::stoi(argv[1]);
// 创建HTTP服务器实例
std::unique_ptr<HttpServer> hsvr = std::make_unique<HttpServer>(port);
// 注册业务服务
hsvr->Register("/app/login", Login);
hsvr->Register("/app/register", Register);
hsvr->Register("/app/search", Search);
hsvr->Register("/app/model", CallBigModel);
// 启动服务器(阻塞调用)
hsvr->Run();
return 0;
}
1.4.3 前后端表单联动
前端通过HTML表单将用户数据提交给后端服务。表单的action属性指定提交的URI,method属性指定请求方法(GET或POST)。
例如,登录表单的HTML代码(保存为wwwroot/login.html):
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>登录</title>
</head>
<body>
<h1>用户登录</h1>
<!-- action: 提交到后端/login接口 method: 使用GET方法 -->
<form action="/app/login" method="GET">
用户名:<input type="text" name="username"><br><br>
密码:<input type="password" name="passwd"><br><br>
<input type="submit" value="登录">
</form>
</body>
</html>
当用户点击"登录"按钮时,浏览器会将输入框的内容与name属性拼接成查询参数,附加在URI后面发送给服务器:
GET /app/login?username=zhangsan&passwd=111 HTTP/1.1
Host: 115.190.145.241:8080
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/148.0.0.0
...
服务器通过req["args"]获取查询参数,解析后进行登录验证。
1.5 RESTful接口设计规范
RESTful是一种流行的API设计风格,它使用HTTP方法表示操作类型,使用URI表示资源。以下是5个符合RESTful风格的接口设计:
- 用户注册(创建资源)
- HTTP方法:POST
- URL:
/api/users - 请求体(JSON):
{ "username": "zhangsan", "email": "zhangsan@example.com", "password": "123456" }- 成功响应:201 Created
{ "id": 1001, "username": "zhangsan", "email": "zhangsan@example.com", "createdAt": "2026-05-19T10:00:00Z" }- 失败响应:400 Bad Request(用户名已存在、密码格式错误)
- 用户登录(认证)
- HTTP方法:POST
- URL:
/api/auth/login - 请求体(JSON):
{ "username": "zhangsan", "password": "123456" }- 成功响应:200 OK
{ "token": "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...", "expiresIn": 7200 }- 失败响应:401 Unauthorized(用户名或密码错误)
- 站内搜索(查询资源)
- HTTP方法:GET
- URL:
/api/search?q=关键字&page=1&size=10 - 成功响应:200 OK
{ "total": 100, "page": 1, "size": 10, "results": [ {"id": 1, "title": "HTTP协议详解", "url": "/article/1"}, {"id": 2, "title": "Nginx入门教程", "url": "/article/2"} ] }
- 获取用户资料(查询资源)
- HTTP方法:GET
- URL:
/api/users/{id}(如/api/users/1001) - 成功响应:200 OK
{ "id": 1001, "username": "zhangsan", "email": "zhangsan@example.com", "nickname": "张三", "createdAt": "2026-05-19T10:00:00Z" }- 失败响应:404 Not Found(用户不存在)
- 更新用户资料(更新资源)
- HTTP方法:PUT
- URL:
/api/users/{id}(如/api/users/1001) - 请求体(JSON):
{ "email": "new_zhangsan@example.com", "nickname": "新张三" }- 成功响应:200 OK
{ "id": 1001, "username": "zhangsan", "email": "new_zhangsan@example.com", "nickname": "新张三", "updatedAt": "2026-05-19T11:00:00Z" }- 失败响应:403 Forbidden(无权限修改)
2 HTTP报文与核心报头
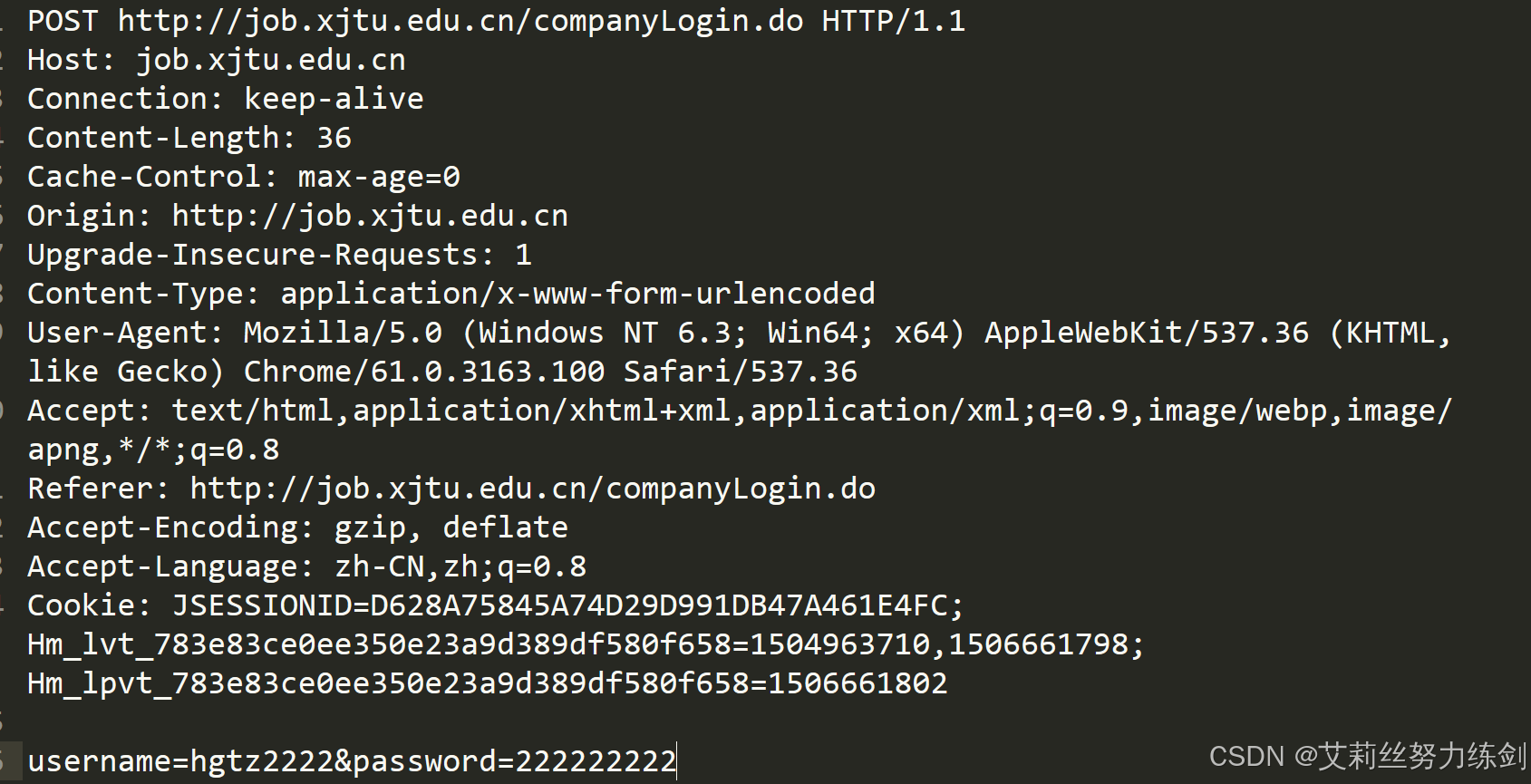
2.1 报文通用结构
HTTP报文分为请求报文和响应报文,两者结构相似,都由四部分组成:
- 起始行:
- 请求报文:
方法 URI HTTP版本(如GET /index.html HTTP/1.1) - 响应报文:
HTTP版本 状态码 状态描述(如HTTP/1.1 200 OK)
- 请求报文:
- 头部字段:由多个键值对组成,每个键值对占一行,用冒号分隔,以
\r\n结尾 - 空行:由
\r\n组成,用于分隔头部和体部 - 响应体:空行后面的内容,允许为空(如HEAD请求的响应体为空)
例如,一个完整的响应报文:
HTTP/1.1 200 OK
Server: nginx/1.24.0
Content-Type: text/html; charset=UTF-8
Content-Length: 615
Connection: keep-alive
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
</head>
<body>
<h1>Welcome to nginx!</h1>
</body>
</html>
2.2 核心请求头详解
2.2.1 Host
Host头部用于指定请求的目标主机和端口,格式为Host: <主机>:<端口>。例如:
Host: 115.190.145.241:8080
Host是HTTP/1.1协议要求必须包含的字段,核心作用:
- 虚拟主机支持:一台物理服务器可以运行多个网站,通过
Host头部区分不同的域名 - 反向代理转发:反向代理服务器通过
Host头部将请求转发到对应的后端应用服务器
2.2.2 User-Agent
User-Agent头部用于标识发起请求的客户端软件信息,包括操作系统、浏览器类型和版本等。标准格式:
User-Agent: Mozilla/5.0 (平台; 加密; 操作系统或CPU; 语言) 浏览器/版本 浏览器内核/版本 其他信息
示例(Chrome浏览器):
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/148.0.0.0 Safari/537.36
主要应用场景:
- 平台适配:服务器根据User-Agent返回PC端或移动端页面
- 反爬虫:拦截非浏览器请求(如wget、curl的默认User-Agent)
- 统计分析:统计用户的浏览器和操作系统分布
注意:User-Agent可以被伪造,爬虫可以通过设置该头部模拟浏览器请求。
2.2.3 Referer
Referer头部用于告诉服务器当前请求是从哪个页面跳转过来的。例如:
Referer: http://115.190.145.241:8080/index.html
核心作用:
- 防盗链:防止其他网站直接引用本站的图片、视频等资源。服务器检查Referer,如果不是本站域名,返回403错误或默认图片
- 访问统计:分析用户的访问来源和跳转路径
- CSRF防护:验证请求是否来自本站合法页面,防止跨站请求伪造攻击
2.2.4 Location
HTTP状态码301(永久重定向)和302(临时重定向)都依赖Location选项。
Location头部与3xx重定向状态码配合使用,告诉客户端接下来要访问的URL。例如:
HTTP/1.1 301 Moved Permanently
Location: /404.html
客户端收到该响应后,会自动向/404.html发起新的GET请求。
2.2.5 Connection
Connection头部用于管理TCP连接的生命周期,两个主要取值:
Connection: close:请求/响应完成后立即关闭TCP连接(短连接)Connection: keep-alive:请求/响应完成后保持TCP连接,以便后续请求复用(长连接)
2.3 常见Content-Type类型
Content-Type头部用于指定请求体或响应体的数据类型,服务器根据该头部正确解析数据。常见类型:
| Content-Type | 说明 |
|---|---|
| text/plain | 纯文本,无格式 |
| text/html | HTML文档 |
| text/css | CSS样式表 |
| text/javascript | JavaScript代码 |
| application/x-www-form-urlencoded | 表单数据(默认格式) |
| application/json | JSON数据 |
| multipart/form-data | 表单数据(支持文件上传) |
| image/jpeg | JPEG图片 |
| image/png | PNG图片 |
| video/mp4 | MP4视频 |
3 HTTP连接管理:长连接与短连接
3.1 短连接(HTTP/1.0默认)
短连接是指客户端和服务器每进行一次HTTP请求-响应,就建立一个新的TCP连接,请求结束后立即关闭连接。
工作流程:
- 客户端发起TCP连接(三次握手)
- 客户端发送HTTP请求
- 服务器处理请求并返回响应
- 关闭TCP连接(四次挥手)
优点:实现简单,不需要管理连接状态 缺点:频繁的三次握手和四次挥手浪费网络资源,当网页包含多个资源时,加载速度慢
3.2 长连接(HTTP/1.1默认)
长连接是指客户端和服务器在一个TCP连接上可以进行多次HTTP请求-响应,直到一方明确要求关闭连接。
工作流程:
- 客户端发起TCP连接(三次握手)
- 客户端发送第一个HTTP请求
- 服务器处理请求并返回响应
- 客户端发送第二个HTTP请求(复用同一个TCP连接)
- 服务器处理请求并返回响应
- …
- 客户端或服务器发送
Connection: close头部,关闭TCP连接
优点:减少TCP连接建立和关闭的次数,显著提升网络性能 缺点:服务器需要维护大量长连接,占用内存资源
3.3 版本差异对比
| 特性 | HTTP/1.0 | HTTP/1.1 |
|---|---|---|
| 默认连接模式 | 短连接 | 长连接 |
| 长连接支持 | 需要显式设置Connection: keep-alive |
默认开启,需显式设置Connection: close关闭 |
| 并发性能 | 低(每个请求一个连接) | 高(复用连接) |
注意:长连接不是永久保持的,服务器通常会设置超时时间(如60秒),超时后主动关闭连接。
4 HTTP请求方法全解
HTTP定义了多种请求方法,用于表示对资源的不同操作类型。最常用的是GET和POST,其他方法在特定场景下使用。
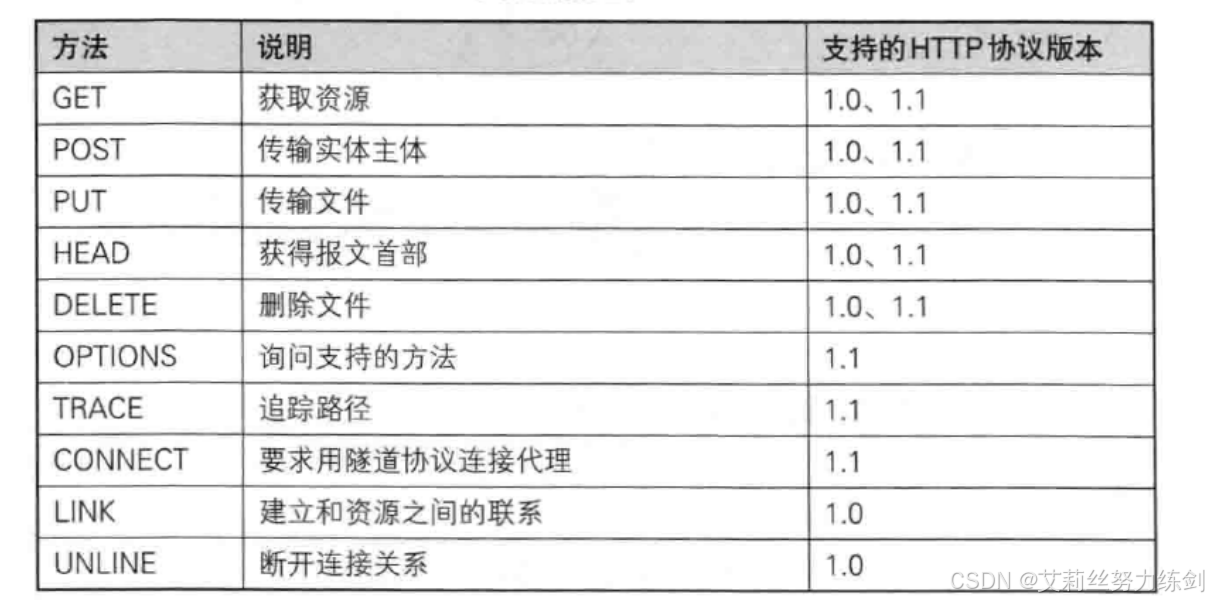
4.1 核心方法:GET vs POST
GET和POST是最常用的两个请求方法,核心区别如下:
| 对比项 | GET | POST |
|---|---|---|
| 参数传递位置 | URI查询串(明文显示) | 请求体(相对隐蔽) |
| 参数长度限制 | 受浏览器/服务器URI长度限制(通常2KB-8KB) | 无严格限制(受服务器配置) |
| 安全性 | 低(参数暴露在地址栏,可被书签保存) | 中(参数不在地址栏,但抓包仍可见) |
| 缓存 | 可被浏览器缓存 | 默认不缓存 |
| 后退/刷新 | 无害 | 会重新提交表单 |
| 适用场景 | 获取资源(浏览网页、搜索) | 提交数据(登录、注册、上传文件) |
重要说明:POST方法不是绝对安全的,HTTP是明文协议,所有数据在网络中都是明文传输。要实现真正的安全传输,必须使用HTTPS协议。
4.2 其他常用方法
4.2.1 HEAD
HEAD方法与GET方法几乎完全相同,唯一区别是服务器只返回响应头,不返回响应体。
主要用途:
- 检查资源是否存在
- 获取资源的元数据(如大小、修改时间)
- 测试服务器是否正常运行
curl命令示例:
# 只获取响应头
curl --head www.baidu.com
4.2.2 PUT
PUT方法用于上传文件,将请求体中的内容保存到请求URI指定的位置。
示例:
PUT /example.html HTTP/1.1
Host: example.com
Content-Length: 123
<html>...</html>
安全风险:允许用户直接修改服务器文件,生产环境默认禁用。
4.2.3 DELETE
DELETE方法用于删除请求URI指定的资源。
示例:
DELETE /example.html HTTP/1.1
Host: example.com
安全风险:允许用户删除服务器文件,生产环境默认禁用。
4.2.4 OPTIONS
OPTIONS方法用于查询服务器对指定资源支持的请求方法。
示例请求:
OPTIONS / HTTP/1.1
Host: example.com
成功响应:
HTTP/1.1 200 OK
Allow: GET, HEAD, POST, OPTIONS
Content-Length: 0
安全考虑:防止攻击者探测服务器配置,生产环境通常禁用,返回405 Not Allowed错误。
4.3 curl工具调试方法
curl是一个强大的命令行HTTP客户端,常用命令:
- 发送GET请求:
curl http://example.com - 查看响应头+响应体:
curl -i http://example.com - 只查看响应头:
curl -I http://example.com - 发送POST表单数据:
curl -X POST -d "username=zhangsan&passwd=111" http://example.com/app/login - 发送JSON数据:
curl -X POST -H "Content-Type: application/json" -d '{"username":"zhangsan","password":"123456"}' http://example.com/api/users - 自定义User-Agent:
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/148.0.0.0" http://example.com - 保存响应到文件:
curl -o output.html http://example.com
5 Nginx生产级HTTP服务器
手写的HTTP服务器仅适用于学习,生产环境中使用成熟的Nginx服务器,它以高性能、高并发、低内存消耗著称。
5.1 Nginx核心特性
- 高并发:异步非阻塞事件驱动架构,单机可处理数十万并发连接
- 低内存:10000个连接仅占用几MB内存
- 静态资源服务:处理HTML/CSS/JS/图片等静态资源性能极高
- 反向代理:将请求分发到后端多个应用服务器
- 负载均衡:支持轮询、最少连接、IP哈希等算法
- HTTPS支持:原生支持SSL/TLS加密传输
5.2 安装与基础操作
Ubuntu系统安装Nginx:
sudo apt update
sudo apt install -y nginx
基础操作命令:
- 启动:
sudo nginx - 停止:
sudo nginx -s stop - 重启(重载配置):
sudo nginx -s reload - 查看进程:
ps ajx | grep nginx - 检查配置文件:
sudo nginx -t
进程模型:Nginx采用master-worker多进程模型,master进程管理配置和worker进程,worker进程处理实际请求。worker进程数通常设置为CPU核心数。
5.3 核心文件路径(Ubuntu apt安装)
- 主配置文件:
/etc/nginx/nginx.conf - 站点配置目录:
/etc/nginx/sites-enabled/ - 默认Web根目录:
/var/www/html/ - 访问日志:
/var/log/nginx/access.log - 错误日志:
/var/log/nginx/error.log - 二进制文件:
/usr/sbin/nginx
5.4 静态资源部署实战
将手写HTTP服务器的静态资源部署到Nginx:
- 复制静态资源到Nginx根目录:
sudo cp -r ~/code/HttpServer/wwwroot/* /var/www/html/
- 备份默认首页:
sudo mv /var/www/html/index.nginx-debian.html /var/www/html/index.nginx-debian-backup.html
- 将自定义首页重命名为默认首页:
sudo mv /var/www/html/index-backup.html /var/www/html/index.nginx-debian.html
- 重载Nginx配置:
sudo nginx -s reload
- 测试:浏览器访问服务器IP,即可看到自定义网站。
6 C++ HTTP开源库:cpp-httplib
cpp-httplib是一个轻量级C++ HTTP库,单头文件、无依赖、接口简洁,适合快速搭建小型HTTP服务。
6.1 库特性
- 单头文件实现:仅需包含
httplib.h - 无第三方依赖:无需安装额外库
- 支持HTTP/1.1
- 同时支持客户端和服务端
- 支持静态资源托管、路由注册、参数解析
6.2 基础服务器搭建
// main.cc
#include <iostream>
#include "httplib.h"
int main() {
httplib::Server server;
// 根路径GET请求
server.Get("/", [](const httplib::Request& req, httplib::Response& res) {
res.set_content("Hello World!", "text/plain");
});
// 带路径参数的GET请求
server.Get("/hello/:name", [](const httplib::Request& req, httplib::Response& res) {
std::string name = req.path_params.at("name");
res.set_content("Hello, " + name + "!", "text/plain");
});
// POST请求:接收JSON并回显
server.Post("/echo", [](const httplib::Request& req, httplib::Response& res) {
res.set_content(req.body, "application/json");
});
// 启动服务器,监听0.0.0.0:8080
std::cout << "Server started at http://localhost:8080" << std::endl;
server.listen("0.0.0.0", 8080);
return 0;
}
6.3 静态资源托管
cpp-httplib提供set_mount_point方法,一键托管静态资源:
// main.cc
#include "httplib.h"
int main() {
httplib::Server svr;
// 将../wwwroot目录挂载到根路径/
// 访问http://localhost:8080/index.html → 返回../wwwroot/index.html
svr.set_mount_point("/", "../wwwroot");
// 注册搜索接口
svr.Get("/search", [](const httplib::Request& req, httplib::Response& res) {
// 获取查询参数q
std::string query = req.get_param_value("q");
if (query.empty()) {
res.set_content(R"({"error":"请提供搜索关键字q"})", "application/json");
return;
}
// 模拟搜索结果
std::string results = R"([
{"title":"关于)" + query + R"(的第一条结果","url":"/page1"},
{"title":"关于)" + query + R"(的第二条结果","url":"/page2"}
])";
res.set_content(results, "application/json");
});
std::cout << "Server started at http://localhost:8080" << std::endl;
svr.listen("0.0.0.0", 8080);
return 0;
}
7 完整工程结构与依赖说明
7.1 手写HTTP服务器完整工程
HttpServer/
├── include/ # 头文件目录
│ ├── TcpServer.hpp # TCP服务器封装(监听、连接、收发数据)
│ ├── HttpServer.hpp # HTTP服务器核心逻辑(报文处理、路由分发)
│ ├── HttpProtocol.hpp # HTTP报文序列化/反序列化(HttpRequest/HttpResponse)
│ ├── InetAddr.hpp # 网络地址封装(IP+端口转换)
│ ├── Socket.hpp # Socket系统调用封装(socket、bind、listen、accept)
│ ├── Logger.hpp # 日志模块(控制台/文件输出、日志级别)
│ └── Mutex.hpp # 互斥锁封装(线程安全)
├── src/
│ └── Main.cc # 程序入口(注册服务、启动服务器)
├── wwwroot/ # 静态资源根目录
│ ├── index.html # 网站首页
│ ├── login.html # 登录页面
│ ├── register.html # 注册页面
│ ├── s.html # 搜索页面
│ ├── 404.html # 404错误页面
│ ├── css/ # CSS样式表目录
│ │ └── main.css
│ ├── js/ # JavaScript脚本目录
│ │ └── main.js
│ ├── image/ # 图片资源目录
│ │ └── logo.png
│ └── video/ # 视频资源目录
└── Makefile # 编译脚本
Makefile示例:
CXX = g++
CXXFLAGS = -std=c++11 -Wall -I./include
LDFLAGS = -lpthread
TARGET = httpserver
SRCS = src/Main.cc
all: $(TARGET)
$(TARGET): $(SRCS)
$(CXX) $(CXXFLAGS) -o $@ $^ $(LDFLAGS)
clean:
rm -f $(TARGET)
7.2 cpp-httplib工程结构
CppHttpServer/
├── include/
│ └── httplib.h # cpp-httplib单头文件
├── src/
│ └── main.cc # 程序入口
├── static/ # 静态资源根目录
│ ├── index.html
│ └── ...
└── Makefile # 编译脚本
Makefile示例:
CXX = g++
CXXFLAGS = -std=c++11 -Wall -I./include
LDFLAGS = -lpthread
TARGET = server
SRCS = src/main.cc
all: $(TARGET)
$(TARGET): $(SRCS)
$(CXX) $(CXXFLAGS) -o $@ $^ $(LDFLAGS)
clean:
rm -f $(TARGET)
8 代码编译运行说明与常见问题排查
8.1 通用编译环境要求
- 编译器:GCC 7.0+ 或 Clang 6.0+(支持C++11及以上标准)
- 操作系统:Linux(推荐Ubuntu 20.04+)
- 依赖:所有示例均无额外第三方依赖,仅需C++标准库和线程库(编译时添加
-lpthread参数)
8.2 手写HTTP服务器常见问题
- 编译错误:undefined reference to pthread_create
- 原因:未链接线程库
- 解决:编译命令末尾添加
-lpthread参数
- 运行错误:bind: Address already in use
- 原因:端口被其他进程占用
- 解决:
# 查看占用8080端口的进程 sudo lsof -i:8080 # 杀死进程(替换<PID>为实际进程号) sudo kill -9 <PID>
- 浏览器无法访问服务器
- 原因:服务器防火墙未开放对应端口
- 解决:
# 开放8080端口 sudo ufw allow 8080 # 重启防火墙使配置生效 sudo ufw reload
- 静态资源404错误
- 原因:文件路径错误或权限不足
- 解决:
- 确保
wwwroot目录与可执行文件在同一目录 - 检查文件权限:
chmod 644 wwwroot/* - 检查请求路径是否与文件名一致(Linux区分大小写)
- 确保
8.3 Nginx常见问题
- Nginx启动失败:Address already in use
- 原因:80端口被Apache等其他服务占用
- 解决:
# 停止Apache服务 sudo systemctl stop apache2 # 禁止Apache开机自启 sudo systemctl disable apache2
- 403 Forbidden错误
- 原因:文件权限不足或Nginx用户无访问权限
- 解决:
# 修改文件权限为755(所有者可读写执行,其他可读执行) sudo chmod -R 755 /var/www/html/ # 修改文件所有者为Nginx运行用户www-data sudo chown -R www-data:www-data /var/www/html/
- 配置修改不生效
- 原因:未重载Nginx配置
- 解决:执行
sudo nginx -s reload(重载配置不中断服务)
8.4 cpp-httplib常见问题
- 编译错误:‘std::function’ was not declared in this scope
- 原因:未启用C++11标准
- 解决:编译时添加
-std=c++11参数
- 静态资源404错误
- 原因:
set_mount_point的路径错误 - 解决:推荐使用绝对路径,例如:
svr.set_mount_point("/", "/home/user/code/wwwroot");
- 原因:
总结
本文从底层原理到生产应用,系统讲解了HTTP协议的核心知识:
- 底层实现:HTTP基于TCP协议,通过字节流解析、资源分发(静态/动态)、路由注册实现服务。手写HTTP服务器帮助理解协议本质,掌握报文解析、回调函数、前后端联动等核心技能。
- 报文与报头:HTTP报文由起始行、头部、空行、体部组成。核心报头包括Host(虚拟主机/代理)、User-Agent(客户端标识/反爬)、Referer(防盗链/CSRF)、Location(重定向)、Connection(连接管理)等,每个报头都有明确的应用场景。
- 连接管理:HTTP/1.0默认短连接,每次请求都要建立和关闭TCP连接,性能低下;HTTP/1.1默认长连接,复用TCP连接处理多个请求,是现代Web性能提升的关键。
- 请求方法:GET用于获取资源,参数在URI中;POST用于提交数据,参数在请求体中。两者在安全性、长度限制、缓存等方面有本质区别。其他方法如HEAD、PUT、DELETE、OPTIONS在特定场景使用,生产环境通常禁用PUT、DELETE等危险方法。
- 生产工具:Nginx是工业级HTTP服务器,擅长静态资源服务、反向代理和负载均衡,是后端部署的必备工具。cpp-httplib是轻量级C++ HTTP库,单头文件无依赖,适合快速开发小型服务和工具。
这些知识是后端开发的核心基础,也是学习HTTPS、WebSocket、HTTP/2等高级协议的前提。掌握HTTP协议,才能真正理解互联网的运行机制。
结尾
uu们,本文的内容到这里就全部结束了,艾莉丝在这里再次感谢您的阅读!
|

结语:希望对学习Linux相关内容的uu有所帮助,不要忘记给博主“一键四连”哦!
往期回顾:
【Linux网络】Linux 网络编程:HTTP(三)HTTP 协议原理
🗡博主在这里放了一只小狗,大家看完了摸摸小狗放松一下吧!🗡 ૮₍ ˶ ˊ ᴥ ˋ˶₎ა


openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)